Руководство по настройке передачи данных в хранилище данных с использованием компонента Архивирование (ARCH)#
Введение#
Компонент Архивирование (ARCH) (далее по документу — ARCH) продукта Platform V Archiving (ARC) обеспечивает передачу данных в хранилище данных.
Можно выделить три составляющих интеграции с ARCH:
Инициализирующая загрузка (далее инициализация) — первичная загрузка данных в хранилище данных.
Репликация данных (далее репликация) — потоковая загрузка в хранилище данных текущих транзакций.
Технический контроль данных (далее ТКД) — контроль факта, что данные в оперативной БД и в хранилище данных синхронны.
Варианты настройки инициализации#
Существует два варианта настройки инициализации, имеющие свои плюсы и минусы:
Инициализация с основной БД с кратковременной недоступностью агрегата на изменение (целевой вариант).
Инициализация с БД StandIn с приостановкой репликации в StandIn.
Инициализация с основной БД с кратковременной недоступностью агрегата на изменение ("безблокировочный init") (целевой вариант)#
Примечание
В типовом случае кратковременная недоступность агрегата не превышает 1 сек.
При большой частоте изменений конкретного агрегата время блокировки на изменения может увеличиться. В этом случае нужно проводить нагрузочное тестирование и по его результатам, анализируя метрики распределения по шагам процесса инициализации, адаптировать параметры инициализации.
Плюсы:
Не требуется наличие репликации в StandIn.
Не требуется полная остановка нагрузки на основную БД на весь период инициализации.
Минусы:
Существует вероятность кратковременной недоступности инициируемого агрегата в момент завершения инициализации по агрегату.
Повышенная нагрузка на основную БД в процессе выполнения инициализации.
Инициализация с БД StandIn с приостановкой репликации в StandIn#
Плюсы: отсутствует вероятность кратковременной недоступности инициируемого агрегата на основной БД.
Минусы:
Требуется наличие репликации в StandIn.
Во время работы инициализации нельзя быстро перейти в StandIn, поскольку репликация в StandIn перед началом инициализации должна быть отключена.
Если во время работы инициализации выполняется включение репликации с последующим переходом в StandIn, результат инициализации будет непредсказуемым.
Алгоритм настройки интеграции#
Необходимо выполнить следующие действия:
Подключение к компоненту Прикладной Журнал (APLJ) (далее — ПЖ):
Подключить ПЖ и StandIn, если они не подключены (см. раздел "Настройка репликации в StandIn при использовании DataSpace" документа "Руководство по установке"). Убедиться, что корректно работает следующая функциональность:
Инициализация BSSI (см. раздел "Методика выполнения BSSI-инициализации и BSSI-сверки в ПЖ" документа "Руководство по установке").
BSSI-сверка (см. раздел "Методика выполнения BSSI-инициализации и BSSI-сверки в ПЖ" документа "Руководство по установке").
Репликация в StandIn (см. раздел "Настройка репликации в StandIn при использовании DataSpace" документа "Руководство по установке").
Плагин ARCH для репликации в хранилище данных (описание настройки см. в документации продукта Platform V Archiving (ARC)).
Если необходимо подключить ПЖ без StandIn, см. раздел "Настройка подключения к ПЖ с отключенной репликацией в StandIn" документа "Руководство по установке". Убедиться, что корректно работает или настроена следующая функциональность:
Формирование векторов типа DataSpace.
Плагин ARCH (для репликации в хранилище данных).
Подключение к Kafka ARCH (описание настройки см. в документации продукта Platform V Archiving (ARC)).
Формирование белого списка атрибутов для передачи в хранилище данных (описание настройки см. в документации продукта Platform V Archiving (ARC)).
Настройку фоновых процессов (компонент Фоновые процессы (BGPX) продукта Platform V Batch Legacy (BGP)) для запуска инициализации и ТКД (описание настройки см. в документации продукта Platform V Archiving (ARC)).
Настройку модуля DataSpace Migration для выполнения инициализации и ТКД (см. раздел "Настройка модуля DataSpace Migration").
Настройка модуля DataSpace Migration#
Установка с помощью Platform V DevOps Tools (CDJE)#
Процесс установки дистрибутива при помощи CDJE описан в разделе "Установка с помощью Deploy tools (CDJE)" документа "Руководство по установке".
В рамках установки при помощи данного инструмента настройка взаимодействия с ARCH производится на основе конфигурирования параметров в файлах (dataspace-cr-migration-service-${modelName}.conf — параметры .pprbod., .all.conf — секции ARCH) в репозитории ФП до непосредственного развертывания на стенд.
Примечание
В случае взаимодействия с HashiCorp Vault все необходимые для подключения параметры, ранее определяемые в Kind: Secret, уже определены в ConfigMap соответствующего сервиса dataspace.
Если же работа с HashiCorp Vault не предполагается, то требуется создание секрета pprbodkafka settings — secret для подключения к серверам ARCH Kafka. В актуальных конфигурациях, поставляемых с архетипом соответствующей релизной версии, предусмотрены шаблоны для автоматического формирования данного секрета во время выполнения развертывания приложения на стенд.
Для формирования необходимой для подключения обвязки Istio в рамках работы с CDJE необходимо ознакомиться с разделом "Конфигурация обвязки Istio для ARCH" документа "Руководство по установке".
Для подключения механизма ротации секретов (Hot Reload) необходимо ознакомиться с разделом "Kafka Archiving Applier" документа "Руководство по установке".
Конфигурации для подключения к ARCH#
В secret с настройками подключения к ПЖ (обычно это
secret-appjournalsettings) модулей DataSpace необходимо прописать свою мнемонику для заполнения заголовкаsourceInfoжурналов с помощью параметраdataspace.replicator.journal-headers.source-info. Данная мнемоника должна совпадать с тем, что указано вsourceDescription.ymlв качестве значенияname. Пример:dataspace.replicator.journal-headers.source-info=stock_exchanges. Пример файла sourceDescription.yml:###Настройки Platform V Archiving### source_parameters: name: "EEF" description: "Банковское сопровождение инвестиционных проектов и инжиниринговые услуги" modelType: "MAPPER_METAMODEL" verboseKey: "false" dqModuleId: 'eef-main' offDQRequestSenderFactoryMode: "KAFKA_WITH_SAMPLES" ajZones: ift: EEF-IFT psi: EEF-PSI prom: EEF-PROM mmtZones: ift: DEFAULT psi: DEFAULT prom: DEFAULT ajDataTypes: ift: DATASPACE psi: DATASPACE prom: DATASPACE whiteListMode: "ROOT_TYPES" initiator: "eef" nonRootTypeHandlingMode: "SEND_ROOT" nexusArtifactId: "ci00682829_cdm" nexusGroupId: "Nexus_PROD" deserializerName: com.sbt.pprbod.artifacts.mapper.MapperJsonPprbodSourcePlugin modelProviderType: "ANNOTATION"Для конфигурирования файла sourceDescription.yml необходимо ознакомиться с документацией компонента Прикладной журнал (APLJ) продукта Platform V Backend (#BD).
Создать в namespace secret, содержащий параметры подключения к Kafka ARCH. Обычно это key/value secret:
значение key равно pprbodKafka.properties или pprbodKafka.yml (в зависимости от формата настроек);
value — настройки подключения.
Пример pprbodKafka.yml с настройками подключения к Kafka ARCH:
apiVersion: v1
kind: Secret
metadata:
name: pprbodkafkasettings-secret
data:
stringData:
pprbodKafka.properties: |-
pprbod.cloud.transport-kafka-lib.kafka.bootstrapServers=${KAFKA_BOOTSTRAP_SERVERS}
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[partition.assignment.strategy]"=org.apache.kafka.clients.consumer.RoundRobinAssignor
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[security.protocol]"=SSL
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.enabled.protocols]"=TLSv1.2
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.protocol]"=TLSv1.2
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.keystore.type]"=JKS
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.truststore.type]"=JKS
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.truststore.location]"=/opt/keystore/kafka/server.keystore.jks
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.keystore.location]"=/opt/keystore/kafka/server.keystore.jks
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.keystore.password]"=
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.truststore.password]"=
pprbod.cloud.transport-kafka-lib.kafka.producerConfig."[ssl.key.password]"=
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[partition.assignment.strategy]"=org.apache.kafka.clients.consumer.RoundRobinAssignor
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[security.protocol]"=SSL
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.enabled.protocols]"=TLSv1.2
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.protocol]"=TLSv1.2
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.keystore.type]"=JKS
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.truststore.type]"=JKS
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.truststore.location]"=/opt/keystore/kafka/server.keystore.jks
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.keystore.location]"=/opt/keystore/kafka/server.keystore.jks
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.keystore.password]"=
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.truststore.password]"=
pprbod.cloud.transport-kafka-lib.kafka.consumerConfig."[ssl.key.password]"=
Примечание
Механизм указания параметров подключения к Kafka ARCH аналогичен механизму указания параметров подключения к Kafka ПЖ. При использовании для задания настроек формата properties-файла, ресурс должен иметь название pprbodKafka.properties. Можно задать настройки в виде yaml-файла, тогда ресурс должен иметь название pprbodKafka.yml.
Подключение к Kafka ARCH при использовании Helm-конфигурации#
Необходимо выполнить следующие действия:
Изменить конфигурацию values.yaml модуля DataSpace Migration и заполнить обязательные значения соответствующих секретов для Kafka (параметры:
pprbod.kafka.config,appJournal.config,appJournal.kafkaSslSecret). Необходимо добавить значения для секретов для БД(параметры:db.main,db.standin). В секции fluentBit указать необходимый секрет, например:appConfig: pprbod: kafka: config: "pprbod-kafka-secret" customLogback: "" packagesToScan: "sbp.com.sbt.dataspace" appJournal: config: "journal-stub-secret" kafkaSslSecret: "kafkaSslSecret" db: ssl: keystorepath: /deployments/credentials/dbSslKeystore keystoresecret: "optionalChangeIt" # Secret with jks keystore from ssl database connection influx: secret: "optionalChangeIt" # Influx database secret from metrics main: secret: "main-pg-secret" standin: enabled: true secret: "standin-pg-secret" fluentBit: enabled: true image: "" secret: "fluentBitSecret" config: "" mtResourceName: "n/a"Необходимо также указать требуемые и максимальные потребляемые ресурсы pod в секции resources value.yaml:
resources: limits: cpu: 2 memory: 2512Mi requests: cpu: 1 memory: 2512MiДополнительно необходимо прописать следующие параметры для value.yaml в секции overrideProperties (значения необходимо заменить на актуальные!):
overrideProperties: pprbod: cloud: stub: enabled: true client: polygon: "my-polygon" # [обязательный] название полигона; параметр Platform V Archiving: pprbod.cloud.client.polygon zone: "my-zone" # [обязательный] название шарда (при отсутствии шардирования — default); параметр Platform V Archiving: pprbod.cloud.client.zone source: "my-source" # [обязательный] наименование модуля источника; параметр Platform V Archiving: pprbod.cloud.client.source listeningThreadCount: "48" # [по умолчанию — "48"] количество потоков обработки входящих сообщений; параметр Platform V Archiving: pprbod.cloud.client.listeningThreadCount clientResponseTimeout: "40" # [по умолчанию — "40"] тайм-аут в секундах на вызов rpc; параметр Platform V Archiving: pprbod.cloud.client.clientResponseTimeout dataToTsaReplicationConfig: storageType: "PASSIVE" StorageTypeForTkd: "ACTIVE"
Описание параметров#
Имеются следующие параметры:
dataspace.init.v2.enabled— признак включения режима оптимизации (по умолчанию включен — "true").dataspace.init.v2.mode— режим инициализации:ACTIVE— инициализация с активного контура ("безблокировочный init") (значение по умолчанию).PASSIVE— инициализация с пассивного контура с обязательным отключением репликации и обеспечением статичности данных в БД.
dataToTsaReplicationConfig.storageTypeForTkd— режим для проведения ТКД:ACTIVE- ТКД с активного контура (значение по умолчанию).PASSIVE- ТКД с пассивного контура (рекомендуется для первого ТКД сразу же после init с пассивного контура).
dataspace.init.v2.default-aggregates-per-page— количество агрегатов на страницу (по умолчанию — "1").dataspace.init.v2.thread-pool.size— количество потоков в пуле потоков (по умолчанию — "25").dataspace.init.v2.thread-pool.queue-capacity— емкость очереди задач в пуле потоков (по умолчанию — "0"). Если все потоки заняты, то происходит накопление указанного в параметре количества задач прежде чем сообщить, что ресурсов нет.dataspace.init.v2.thread-pool.name— наименование пула потоков (по умолчанию — "init-v2-worker").dataspace.init.v2.chunk-sender.max-size— максимальный размер (эвристический) отправляемых за один раз чанков в байтах (по умолчанию — "524288" или 512 Кбайт).dataspace.init.v2.table-sender.batch-size— количество сущностей, вычитываемых за один раз из базы данных (по умолчанию — "500").dataspace.init.v2.task-lifespan— время жизни задачи в секундах, через которое задачу разрешено удалять (по умолчанию — "864000" или 10 дней).dataspace.init.v2.init-task-cleaner.batch-size— количество задач, вычитываемых за один раз из базы данных для выполнения очистки (по умолчанию — "500").dataspace.init.v2.cleaner.sub-tasks-batch-size— количество подзадач, вычитываемых за один раз из базы данных для выполнения очистки (по умолчанию — "500").dataspace.init.v2.init-task-cleaner.cron— расписание удаления задач (по умолчанию — "0 0 0 */10 * *").dataspace.init.v2.controller— признак включения JSON-RPC-контроллера для работы с инициализацией (по умолчанию — "false").dataspace.init.v2.aggregate-changes-per-batch— количество обрабатываемых изменений(версий) по агрегату в одной пачке (по умолчанию — "1000").dataspace.init.v2.send-changes-iterations-count— количество итераций до миграционной блокировки агрегата (по умолчанию — "2").dataspace.init.v2.tasks-manager.check-tasks-status.cron— расписание сканирования статуса активных задач (по умолчанию — "0 */5 * * * *").dataspace.init.v2.tasks-manager.clean-aborted-tasks.cron— расписание удаления прерванных задач (по умолчанию — "0 0 0 * * *").dataspace.init.v2.task-total-metric.cron— расписание сканирования объема данных задач для метрики "Объем данных задачи" (по умолчанию — "0 * * * * *").dataspace.init.v2.table-sender.retry-count— количество попыток вычитать данные из таблицы (по умолчанию — "5").dataspace.init.v2.tasks-to-clean-batch-size— количество задач, вычитываемых за один раз из базы данных для выполнения очистки при прерывании всех задач (по умолчанию — "500").dataspace.init.v2.tasks-manager.aborted-task-lifespan— время жизни прерванной задачи в секундах, в течении которого процессы могут среагировать на прерывание задачи (по умолчанию — "86400" или 1 день).dataspace.admin.init.controller.enabled— признак включения REST-контроллера для администрирования инициализации (по умолчанию — "true").dataspace.admin.init.controller.port— порт REST-контроллера для администрирования инициализации (по умолчанию — 8090).dataspace.tkd.missing-as-deleted— алгоритм передачи отсутствующей сущности, запрошенной при ТКД:"true" — формируется специальный вектор, сообщающий о том, что сущность удалена (по умолчанию);
"false" — ответ по несуществующей сущности не формируется.
Описание служебных таблиц в терминах PostgreSQL#
table T_DSPC_SYS_INIT_TASK
(
LOADING_ID varchar(254) not null primary key, -- Идентификатор задачи по выполнению инициализации заданного типа агрегата
AGGREGATETYPE varchar(254), -- Тип агрегата
AGGREGATESPERPAGE integer, -- Количество агрегатов на странице
STATUS varchar(254), -- Статус задачи
CREATEDATE timestamp(3), -- Дата и время создания задачи
PAGESCOUNT integer -- Количество страниц
);
table T_DSPC_SYS_INIT_SUBTASK
(
LOADING_ID varchar(254) not null, -- Идентификатор задачи по выполнению инициализации заданного типа агрегата
AGGREGATE_ID varchar(254) not null, -- Идентификатор агрегата
PAGENUMBER integer, -- Номер страницы
STARTVERSION bigint, -- Стартовая версия (агрегата)
primary key (LOADING_ID, AGGREGATE_ID)
);
index
I_DSPC_SYS_INIT_SUBTASK_LOADING_ID on T_DSPC_SYS_INIT_SUBTASK (LOADING_ID, PAGENUMBER);
table T_DSPC_SYS_CHANGE_EVENT
(
AGGREGATETYPE varchar(254) not null, -- Тип агрегата
AGGREGATE_ID varchar(254) not null, -- Идентификатор агрегата
AGGREGATEVERSION bigint not null, -- Версия агрегата
ENTITYTYPE varchar(254) not null, -- Тип сущности
ENTITY_ID varchar(254) not null, -- Идентификатор сущности
EVENTTYPE int2 not null, -- Тип события
PROPERTYNAME varchar(254), -- Наименование свойства
CREATEDATE date not null -- Дата создания (записи)
);
Описание состояний статуса задачи T_DSPC_SYS_INIT_TASK.STATUS:
NEW— новая задача (первоначальный статус);COUNTING— начат процесс расчета количества и состава страниц;COUNTED— успешно завершен расчет количества и состава страниц (конечный статус);ABORTING— начат процесс прерывания задачи, после завершения которого задача будет удалена.
Алгоритм взаимодействия модуля миграции c ARCH#
Описание алгоритма взаимодействия:
ARCH запрашивает запуск инициализации данных по типу агрегата (
AGGREGATETYPE) и указывает необходимое количество агрегатов на странице (AGGREGATESPERPAGE). Если переданное в запросе количество агрегатов на странице равно "0" или "null", то значение берется из параметраdataspace.init.v2.default-aggregates-per-page.Выполняется создание задачи (
T_DSPC_SYS_INIT_TASK) со статусом "NEW" и возвращается в ARCH идентификатор задачи (LOADING_ID).ARCH по идентификатору задачи (
LOADING_ID) выполняет запрос количества страниц и периодически повторяет его, пока не получит результат с вычисленным количеством страниц. При первом запросе количества страниц модуль миграции переводит задачу в статус "COUNTING".При подсчете страниц модуль миграции также создает подзадачи на каждый агрегат, которые группируются по страницам.
После успешного подсчета задача переводится в статус "COUNTED", и в этот момент ARCH на свой очередной запрос получит ответ в виде количества страниц.
Далее ARCH для каждой страницы:
запрашивает идентификаторы агрегатов, привязанных к странице;
запрашивает передачу страницы в ARCH.
В процессе передачи страницы для каждого агрегата происходит следующее:
фиксируется номер первого чанка и эпохи, в ARCH отправляется первый (пустой) чанк;
вычитываются данные агрегата (в режиме ACTIVE — из активного контура, в режиме PASSIVE — из пассивного контура) и отправляются в ARCH в виде последовательности чанков;
отправляется последний чанк в ARCH с пометкой "EOD".
В любой момент ARCH может передать команду "прекратить" (аварийно завершить) инициализацию. Модуль миграции в ответ переведет задачу в статус "ABORTING" и начнет процесс прерывания задачи с последующим ее удалением.
Диаграмма взаимодействий модулей ARCH и dataspace-migration:

Особенности алгоритма для режима ACTIVE ("безблокировочный init")#
Главной особенностью режима ACTIVE ("безблокировочный init") является возможность изменять те самые данные, по которым выполняется инициализация.
Описание алгоритма взаимодействия на примере инициализации одного агрегата:
В момент, когда все готово для инициализации агрегата, по нему устанавливается инициализационная блокировка и происходит фиксация версии агрегата:
все последующие транзакции по агрегату будут иметь признак, что они выполняются параллельно с инициализацией, и векторы, имеющие такой признак, будут проигнорированы ARCH;
с агрегатом возможна штатная работа (чтение и запись);
все последующие транзакции по агрегату будут анализироваться процессом инициализации с целью запоминания информации, какая сущность была затронута в транзакции и каким образом затронута (создана, изменена, удалена).
После инициализации основных данных по агрегату, выполняется анализ списка затронутых сущностей и повторно выполняется инициализация только этих сущностей. Количество затронутых сущностей может быть велико, поэтому в одной итерации оно ограничивается параметром
dataspace.init.v2.aggregate-changes-per-batch.В процессе выполнения п.2 в свою очередь могли быть выполнены новые транзакции по сущностям агрегата, и эти сущности еще раз будут проинициализированы.
Пункт 3 выполняется определенное количество раз, настраиваемое параметром
dataspace.init.v2.send-changes-iterations-count. После этого устанавливается миграционная блокировка:выполняется блокирование агрегата от выполнения изменений по нему (кратковременная недоступность);
выполняется финальный анализ сущностей, затронутых новыми транзакциями, по которым прошли изменения, и они инициализируются повторно;
выполняется фиксация версии агрегата, на которой завершился процесс инициализации.
Выполняется отправка EOD.
Выполняется понижение миграционной блокировки по агрегату до инициализационной, и все последующие транзакции по агрегату будут анализироваться процессом инициализации с целью запоминания информации, какая сущность была удалена в транзакции на случай, если агрегат будет инициализирован повторно (см. п. 8).
Разрешается штатная работа с агрегатом, векторы имеют штатный признак и обрабатываются ARCH в рамках потоковой загрузки. Если используется новый интерфейс ARCH (
com.sbt.pprbod.data.kafka.bgp.InitAggregateBulkAsyncPlusApplicationTask), то ARCH вызывает API разблокировки (postInit), который разблокирует окончательно агрегаты и удаляет служебную информацию из БД.В случае, если происходит повторная инициализация агрегата (перезапуск инициализации страницы), то перед инициализацией основных данных, происходит отправка событий удалений, произошедших с момента запуска первоначальной инициализации(см. п. 1), и затем выполняются повторно пункты с 1 по 7.
BSSI-сверка#
BSSI-сверку (между основной и StandIn БД) в процессе инициализации проводить нельзя — будут наблюдаться расхождения.
Примечание
При программных сбоях могут образоваться расхождения в части типа векторов, миграционной и init-блокировок, маски и токена регистрации изменений.
При штатном завершении инициализации таблицы в основной и StandIn БД будут совпадать.
Внимание!
Инициализацию BSSI в процессе инициализации ARCH проводить запрещено!
Очистка служебных данных после инициализации#
Очистка служебных данных необходима в следующих случаях:
выполняется инициализация по типу векторов, но произошел сбой;
выполняется инициализация по типу векторов, но ее необходимо прервать и запустить новую;
инициализация по типу векторов успешно завершена, и служебные данные больше не нужны.
В случае прерывания инициализации (кроме очистки данных) необходимо также сбросить установленные блокировки.
Примечание
При очистке служебных данных вектора изменений не формируются.
Если используется новый интерфейс ARCH (com.sbt.pprbod.data.kafka.bgp.InitAggregateBulkAsyncPlusApplicationTask), то ARCH вызывает API разблокировки (postInit), который разблокирует окончательно агрегаты и удаляет служебную информацию из БД.
В противном случае очистка должна быть выполнена вручную (см. Локальный endpoint для API администрирования).
Внимание!
При использовании нового интерфейса ARCH (com.sbt.pprbod.data.kafka.bgp.InitAggregateBulkAsyncPlusApplicationTask) необходимо убедиться, что версия серверной части ARCH поддерживает данный интерфейс.
Повторная отправка в случае сбоя#
В случае сбоя возможна повторная отправка данных, если выполнены соответствующие настройки на стороне ARCH:
Сбой передачи страницы влечет повторный запрос страницы, при этом часть данных уже передана в хранилище данных. Для обеспечения целостности при повторной инициализации необходимо передать информацию по событиям удаления агрегатов, накопленные от начала исходной инициализации.
Сбой инициализации приводит к повторной инициализации. При сбое всей инициализации по типу требуется выполнить ее снова. В этом случае данные в хранилище данных должны быть предварительно очищены.
Гарантия завершения предыдущих процессов до начала выполнения очередного процесса инициализации по типу#
Гарантия последовательного запуска INIT по одному типу обеспечивается алгоритмом инициализации.
Пример:
Выполняется процесс инициализации сущности Product.
Оператор выполняет запуск нового процесса инициализации этой же сущности Product и получает ошибку — Задача инициирующей выгрузки для типа Product уже создана.
Оператор выполняет отмену исходного процесса инициализации сущности Product. При этом автоматически выполняется:
Асинхронная очистка служебных таблиц по отменяемой задаче.
Сброс блокировок.
Оператор следит за прогрессом очистки с помощью метрики
dspc.tsa.init.tasks.total.Оператор выполняет повторно запуск нового процесса инициализации этой же сущности Product.
Локальный endpoint для API администрирования#
Локальный endpoint /admin/init/ необходим для API администрирования.
Включение выполняется параметромdataspace.admin.init.controller.enabled.
Вызывается локально из консоли контейнера dataspace-migration на отдельном порту, определяемому параметром dataspace.admin.init.controller.port.
В составе этого API реализован метод v1/cleanup, выполняющий:
очистку миграционных блокировок;
сброс типа векторов c IC на CV;
сброс маски регистрации изменений в журнале событий по агрегату.
Пример запроса для сброса блокировок и очистки по всем выполняющимся заданиям:
curl -X DELETE http://localhost:8090/admin/init/v1/cleanup
Пример запроса для сброса блокировок и очистки по заданию 123456:
curl -X DELETE http://localhost:8090/admin/init/v1/cleanup?loadingId=123456
Алгоритм очистки задач#
Алгоритм очистки задач следующий:
Осуществляется выборка по заданной задаче пачки подзадач размером
dataspace.init.v2.cleaner.sub-tasks-batch-size.По каждой подзадаче выполняется:
Разблокировка агрегата.
Удаление подзадачи.
Осуществляется повторение п. 2 до тех пор, пока не будут удалены все подзадачи по заданной задаче.
Осуществляется удаление задачи.
Задача удаляется:
При осуществлении вызова API postInit (при использовании нового интерфейса com.sbt.pprbod.data.kafka.bgp.InitAggregateBulkAsyncPlusApplicationTask).
При осуществлении вызова API abort (при использовании нового интерфейса com.sbt.pprbod.data.kafka.bgp.InitAggregateBulkAsyncPlusApplicationTask).
По расписанию
dataspace.init.v2.init-task-cleaner.cron, если задача старше времени в секундахdataspace.init.v2.task-lifespan.Вручную (см. Локальный endpoint для API администрирования).
ТКД#
Выбор контура, с которого производится ТКД, осуществляется по настройке dataToTsaReplicationConfig.storageTypeForTkd.
Внимание!
Важно понимать, что для удачного ТКД с активного контура должны успешно реплицироваться все вектора в КАП по плагину EXPORT_FD4.
При проведении ТКД со стороны КАП приходит запрос на пачки ключей по конкретному типу, размер пачки определяется на стороне КАП. При этом важно, чтобы размер пачки не превышал допустимое количество соединений с БД.
Для этого количество соединений N должно быть больше размера пачки S. Это можно изменить стандартными настройками pool подключений к БД:
Для активного контура —
spring.datasource.hikari.maximum-pool-size=N> S.Для пассивного контура —
standin.datasource.hikari.maximum-pool-size=N> S.
Алгоритм передачи несуществующих сущностей DELETED_IN_SOURCE при ТКД#
Алгоритм включается с помощью параметра dataspace.tkd.missing-as-deleted.
При отсутствии в БД запрашиваемой сущности формируется ответ с deleteEvent для отсутствующей сущности, а запрос в ARCH попадет в topic DELETED_IN_SOURCE.
В этом ответе обязательным к заполнению является поле rootId (ID агрегата).
Поскольку для несуществующих записей rootId определить невозможно, для них в качестве rootId будет возвращаться константа DELETED_IN_SOURCE и "0" в качестве rootVersion.
Пример содержимого поля data ответа:
{
"type": "DATASPACE",
"txId": "46edc727-af2f-422e-b3d9-c1006e72c5e3",
"headers": {
"rootClass": "sbp.com.sbt.dataspace.jpa.ProductForTCA",
"rootId": "DELETED_IN_SOURCE",
"rootVersion": 0,
"txTimestamp": 1691054365028
},
"partitions": [
{
"type": "ORM_CV",
"serializer": "change_vector_json",
"format": "JSON",
"payload": {
"serializerInfo": {
"id": "3375153340802439707",
"name": "json_gson",
"format": "JSON"
},
"data": {
"type": "DELTA",
"txId": null,
"partitionId": null,
"changeSets": [
{
"createEvents": [],
"updateEvents": [],
"deleteEvents": [
{
"alias": "sbp.com.sbt.dataspace.jpa.ProductForTCA",
"id": "7199921107129729061A",
"version": null
}
],
"snapshotEvents": []
}
]
}
}
}
]
}
Пример заголовка ответа в topic -response:
{
"zone_id": "",
"data_type": "PprbData_1.0",
"message_id": "2",
"pprbod_client_id": "28117241-4dc9-4e4c-bd33-9154d7e1df51",
"message_timestamp": 1691054365280,
"event_date": "2023-08-03 12:19:25.000270",
"global_key": "DELETED\\_IN\\_SOURCE",
"global_type": "sbp.com.sbt.dataspace.jpa.ProductForTCA",
"global_version": 0,
"data_container": [
{
"key": "7199921107129729061A",
"entry_type": "sbp.com.sbt.dataspace.jpa.ProductForTCA",
"version": 0,
"oper_type": "D",
"upd_attrs": null,
"avro_entry": [
{
"bigd0": null,
"bigd1": null,
"bigd2": null,
"bigd3": null,
"bigd4": null,
"date0": null,
"date1": null,
"date2": null,
"date3": null,
"date4": null,
"decimals": null,
"lastChangeDate": null,
"long0": null,
"long1": null,
"long2": null,
"long3": null,
"long4": null,
"long5": null,
"long6": null,
"long7": null,
"long8": null,
"long9": null,
"name0": null,
"name1": null,
"name2": null,
"name3": null,
"name4": null,
"name5": null,
"name6": null,
"name7": null,
"name8": null,
"name9": null,
"objectId": "7199921107129729061A",
"request": null,
"services": null
}
]
}
],
"cont_hash": "AAAAAAb+VNI="
}
Метрики#
Для мониторинга процесса Init добавлены следующие метрики, которые отбрасываются в Prometheus и могут быть получены в графическом представлении в Grafana:
Наименование метрики |
Тип метрики |
Описание |
|---|---|---|
dspc.tsa.init.start.load.page.total |
Counter |
Счетчик количества вызовов startLoadPage |
dspc.tsa.init.page.load.seconds |
Timer |
Время загрузки страницы (90-ый и 95-ый процентиль) |
dspc.tsa.init.aggregates.per.page.info |
Gauge |
Количество агрегатов на страницу |
dspc.tsa.init.chunks.per.page |
DistributionSummary |
Количество чанков на одну страницу |
dspc.tsa.init.chunks.per.aggregate |
DistributionSummary |
Количество чанков на отдельный агрегат |
dspc.tsa.init.pages.count.seconds |
Timer |
Время подсчета количества страниц (90-ый и 95-ый процентиль) |
dspc.tsa.init.page.identifiers.load.seconds |
Timer |
Время загрузки идентификаторов страницы (90-ый и 95-ый процентиль) |
dspc.tsa.init.chunk.list.send.seconds |
Timer |
Время отправки списка чанков (90-ый и 95-ый процентиль) |
dspc.tsa.init.aggregate.load.seconds |
Timer |
Время загрузки агрегата (90-ый и 95-ый процентиль) |
dspc.tsa.init.loaded.aggregates.total |
Counter |
Счетчик количества загруженных агрегатов |
dspc.tsa.init.chunks.pushed |
DistributionSummary |
Количество чанков отправлено в буфер |
dspc.tsa.init.lock.seconds |
Timer |
Время блокировки агрегата |
dspc.tsa.init.lock.iterations |
DistributionSummary |
Количество итераций отправки в буфер с установленной блокировкой агрегата |
dspc.tsa.init.tasks.total |
Gauge |
Объем данных задачи |
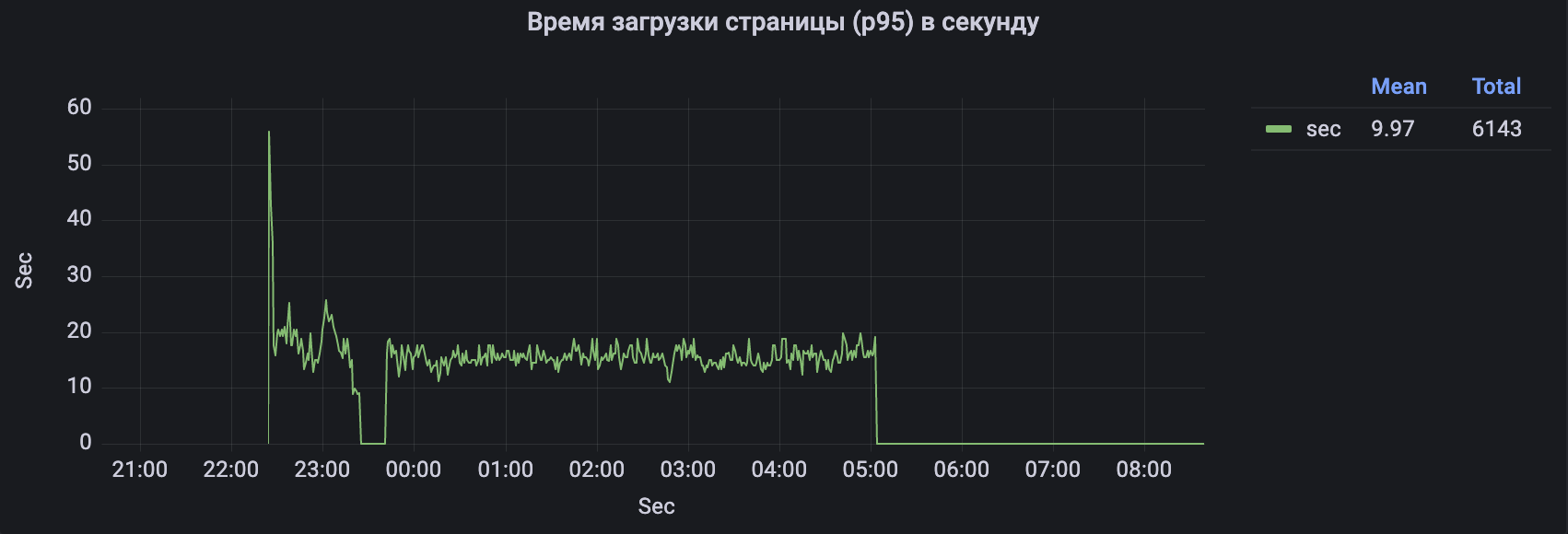
Пример настроенной метрики с отображением в Grafana. На данном графике отображаются изменения времени загрузки каждой страницы агрегатов в секундах:
Порядок выполнения проверки Init и ТКД#
Необходимо выполнить следующие действия:
Выполнить Init.
Выполнить ТКД по максимально возможному количеству сущностей.
Выполнить штатную транзакционную нагрузку с полным набором бизнес-транзакций.
Выполнить ТКД по максимально возможному количеству созданных, измененных и удаленных сущностей в процессе отработки п. 3.
Особенности настроек в шардированной среде#
Внимание!
Параметр
dataspace.tkd.missing-as-deletedдолжен быть установлен в значение "false".
Методика проверки интеграции#
Необходимо выполнить следующие действия:
Обеспечить в оперативной БД максимально полное наполнение данных с точки зрения бизнес-логики приложения.
Полностью снять оперативную нагрузку.
Выполнить инициализацию в хранилище данных посредством ARCH.
Выполнить ТКД и зафиксировать синхронность данных после инициализации при отсутствии оперативной нагрузки.
Организовать максимально полную оперативную нагрузку с точки зрения бизнес-логики приложения.
Зафиксировать, что формируются векторы DataSpace.
Зафиксировать, что происходит репликация в хранилище данных посредством ARCH.
Выполнить ТКД и зафиксировать синхронность данных после репликации.
Выполнить инициализацию в хранилище данных посредством ARCH при наличии оперативной нагрузки.
После окончания инициализации продолжить подачу оперативной нагрузки.
Выполнить ТКД и зафиксировать синхронность данных после инициализации при наличии оперативной нагрузки и репликации в хранилище данных посредством ARCH.
Вопросы и ответы#
Определение успешного запуска модуля migration-service#
Чтобы понять, что модуль успешно стартовал, нужно проверить его лог-записи на наличие двух topics:
v4-ift-kb-eef-main-default-confirm— topic подтверждения;v4-ift-kb-eef-main-default-request— topic запроса.
Topics состоят из:
имя зоны v4-ift-kb,
имя модуля источника eef-main,
название шарда (при отсутствии шардирования — default),
тип topic: confirm — topic подтверждения; request — topic запросов.
2021-09-25 16:34:03,984 [main] [INFO] (com.sbt.pprbod.transport_kafka.impl.AbstractTopicConsumer) [com.sbt.pprbod.transport_kafka.impl.AbstractTopicConsumer::startListening:62] mdc:()| Start listening topic for topic v4-ift-kb-eef-main-default-confirm
2021-09-25 16:34:04,475 [main] [INFO] (com.sbt.pprbod.transport_kafka.impl.AbstractTopicConsumer) [com.sbt.pprbod.transport_kafka.impl.AbstractTopicConsumer::startListening:62] mdc:()| Start listening topic for topic vv4-ift-kb-eef-main-default-request
Инициализирующая загрузка#
Обратите внимание, что инициализирующая загрузка должна проходить только по типам, соответствующим корням агрегатов.
Список сущностей-корней агрегатов приведен в файле с именем <имя модели>-aggregate-list.txt, расположенном в папке /meta/` JPA-артефакта.
Для справочников типом корня агрегата является RootDictionary.
Как выгружать в хранилище данных посредством ARCH локальные справочники DataSpace#
Для начальной загрузки локальных справочников DataSpace необходимо указать в списке типов, по которым проходит init, тип RootDictionary. Именно этот тип будет являться для них корнем агрегата.
Как формировать LDM-модель данных для ARCH#
Для генерации LDM необходимо использовать соответствующий maven-плагин в модуле, содержащем модель данных.
Обязательно нужно сконфигурировать следующие параметры:
basePackage— базовый пакет типов;primitiveWithPackage— если установлено значение "true" (рекомендуется), то для примитивных типов формируются полные имена классов с пакетом;excludeSystemClasses— исключить системные классы (установить "true");excludeSystemAttributes— исключить системные атрибуты (установить "true");includeClassTypeDiscriminator— если установлено значение "false", то из всех классов исключается атрибут (элементproperty) с именемtypeиchangeable="READ_ONLY". Также исключаются все индексы со свойствомtype. По умолчанию установлено значение "false", так как в большинстве случаев служебный атрибутtypeне должен попадать в модель для хранилища данных.
Пример использования плагина:
```xml
<profile>
<id>meta</id>
<build>
<plugins>
<plugin>
<groupId>sbp.com.sbt.dataspace</groupId>
<artifactId>model-api-generator-maven-plugin</artifactId>
<executions>
<execution>
<id>createMeta</id>
<goals>
<goal>generateMeta</goal>
</goals>
<configuration>
<ldmVersion>1.3</ldmVersion>
<basePackage>${modelPackage}</basePackage>
<shortClassNames>false</shortClassNames>
<useModelVersion>true</useModelVersion>
<primitiveWithPackage>true</primitiveWithPackage>
<excludeSystemClasses>true</excludeSystemClasses>
<excludeSystemAttributes>true</excludeSystemAttributes>
<includeClassTypeDiscriminator>false</includeClassTypeDiscriminator>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
```
При выставлении maven-профиля meta и сборке проекта (mvn clean package -P meta) в каталоге target/classes/meta/ появится файл ldm.xml.
Подробнее о генерации LDM-модели данных можно узнать в документе "Руководство по установке" в разделе "Публикация модели DataSpace в META".
Рекомендации по выбору классов и атрибутов модели данных для передачи в хранилище данных (формирование "белого списка")#
Чтобы компонент ARCH сформировал из полученных им данных набор данных для хранилища, требуется вначале определить так называемый "белый список" (далее БС) — явно перечисленных классов и атрибутов, подлежащих передаче в хранилище.
БС создается в отдельной специализированной системе (не представленной среди продуктов Platform V) на основе модели данных DataSpace, сформированной при сборке DataSpace в формате LDM-модели.
В БС включаются сущности (классы) и их поля (атрибуты) в соответствии с целями и задачами потребителя DataSpace.
Примечание
Описание модели данных предметной области приведено в документе "Руководство по ведению модели".
При подготовке БС следует руководствоваться следующими рекомендациями:
Если сущность (класс) должен быть в БС, то необходимо включить в БС его первичный ключ — атрибут
objectId.Служебные классы DataSpace и служебные поля (кроме
objectId,lastChangeDate,ownerIdиisDeleted, а для историцируемых сущностей дополнительноsysHistNumber) остальных классов по умолчанию исключаются из LDM-модели данных предметной области. Нет видимых причин, по которым может потребоваться отменить их исключение.Обычно атрибуты
ownerId,isDeleted,sysHistNumberтакже не используются и их можно исключить.Классы событий (event) также исключаются из LDM-модели, поскольку существуют только для публикации события, а не для хранения бизнес-данных.
Сгенерированные классы хранения истории изменений (историцирования) в большинстве случае не нужны в хранилище данных, поэтому их тоже исключают. DataSpace генерирует для них имя вида
<тип сущности>History.Сгенерированные классы хранения истории изменения статусов с именами вида
<Имя сущности>HObjectStatus, и ссылки на них с именемstatusHistoryтакже скорее всего не представляют интереса в хранилище данных, поэтому и их исключают.Из БС нужно исключать атрибуты, описывающие связь
One-To-Oneчерез обратную ссылку (в LDM-модели для атрибута задано свойствоmapped-by="true").Следует соблюдать следующие правила:
Если в БС включена дочерняя сущность агрегата — в БС также должны быть включены сущность-корень агрегата и все сущности в цепочке от него к дочерней сущности.
Если в БС необходимо включить справочник (класс, помеченный
is-dictionary="true") — необходимо включить в БС классRootDictionary, поскольку он является корнем агрегата для всех справочников.Если включенный в БС класс наследует от другого класса — класс-предок также нужно включить в БС. Для этого необходимо, чтобы в БС был включен как минимум один из его собственных атрибутов.
В том числе, если в БС включен класс-потомок агрегата, который по сути сам является агрегатом — в БС также должен быть включен класс-предок для данного класса.
Если в БС включается поле с типом
embeddable-класса (embeddable="true"— нужно также включить в БС необходимые поляembeddable-класса.Если необходимо включить в БС коллекцию референсов, нужно добавить в БС сгенерированный для элементов такой коллекции класс с именем
Rci<имя класса><имя свойства коллекции>, напримерRciServiceClients— в нем важны поляobjectId,reference,backreference.Для самих
referenceсоздаетсяembeddable-класс<тип ссылки>Reference. В БС включаются атрибутыentityId(идентификатор сущности) и, если есть,rootEntityId(идентификатор корня агрегата сущности).При необходимости выгружать статусы включить в БС:
атрибуты класса с именами
statusFor<имя stakeholder — разреза ведения статусов>Id– идентификатор записи из справочникаStatus;Справочник статусов
Status— для него достаточно атрибутовobjectId,code,name,lastChangeDate,description,initial,stakeholder,statusType;Справочник разрезов статусов (если надо)
Stakeholder, для него достаточно атрибутовobjectId,code,name,lastChangeDate;Справочник переходов статусов (если надо)
StatusGraph— для него достаточно атрибутовobjectId,code,name,lastChangeDate,label,statusFrom,statusTo.
Примечание
Инициализирующая загрузка должна выполняться только по корням агрегатов, входящим в БС.
Полный список корней агрегатов модели при сборке выгружается в файл
<имя модели>-aggregate-list.txtв папке/meta/JPA-артефакта.Также, при необходимости, определить, какие из классов являются корнями агрегатов можно либо по признаку
aggregate-root="true"на классе в LDM-модели версии 1.3 и выше, либо по отсутствию в классе поляaggregateRoot.
Обязательные исключения из белого списка#
Свойства, являющиеся mappedBy-ссылками/коллекциями ссылок#
Внимание!
Из белого списка передаваемых в хранилище данных атрибутов обязательно нужно исключать атрибуты, являющиеся mappedBy-ссылками/коллекциями ссылок.
Пример 1: <property name="leafOne" type="LeafOne" collection="set" mappedBy="rootOne"/> — наличие mappedBy:
<class name="RootOne" >
<property name="name" type="String" label="Наименование"/>
<property name="leafOne" type="LeafOne" collection="set" mappedBy="rootOne"/>
</class>
Пример 2: <property name="subLeafOne" type="SubLeafOne" mappedBy="leafOne"/> — наличие mappedBy:
<class name="LeafOne">
<property name="name" type="String" label="Наименование"/>
<property name="rootOne" type="RootOne" parent="true"/>
<property name="subLeafOne" type="SubLeafOne" mappedBy="leafOne"/>
</class>
Вычисляемые свойства#
Внимание!
Из белого списка передаваемых в хранилище данных атрибутов обязательно нужно исключать атрибуты, являющиеся вычисляемыми свойствами.
Пример: вычисляемое свойство codeCalc:
<class name="AggSmallCalc" lockable="false">
<property name="name" type="String" label="Наименование"/>
<property name="code" type="String" label="Код"/>
<property name="codeCalc" type="String">
CASE WHEN code is not null THEN code
ELSE '' END
</property>
</class>