DataSpace Monitoring#
О документе#
Настоящий документ является руководством по системе мониторинга DataSpace.
DataSpace Monitoring представляет собой набор компонентов, предназначенных для сбора, хранения и отображения различных метрик в виде информационных панелей (графики, таблицы, диаграммы).
Расшифровку основных понятий см. в документе "Термины и определения".
Подходы в формировании метрик#
Любой программный сервис состоит из различных этапов своего развития (требования -> проектирование-> реализация -> тестирование -> эксплуатация и т.п.). Поэтому мы реализовали два подхода в формировании метрик:
Эксплуатационные метрики — предназначены для получения состояния системы в целом за большие промежутки времени (десятки часов и выше) с приемлемой точностью до минут. Данный подход позволяет экономно расходовать инфраструктурные ресурсы, ведь для хранения каждого состояния метрики необходимы дисковые ресурсы для их хранения, а также ресурсы системы отображения для прорисовки или анализа этих данных (например Alarm).
Диагностические метрики — предназначены для кратковременного анализа поведения сервиса во время тестирования, например нагрузочного. Так как нет необходимости долгого хранения данных метрик, мы можем собирать их с более высокой точностью (интервал 1 сек) для более точного анализа во время тестирования.
Для эксплуатационных метрик характерно следующее:
Применяется Pull-модель. Система сбора и хранения метрик Prometheus (см. раздел "Системное программное обеспечение" документа "Руководство по установке") сама опрашивает сервис, который мониторит, при этом проставляет timestamp метрики в момент обращения к сервису DataSpace.
Метрики имеют как правило агрегированный характер (mean, percentile).
DataSpace предоставляет набор метрик в стандартном формате Prometheus, доступных через endpoint http://IP:PORT/actuator/prometheus.
Для Prometheus используется свой DashBoard в системе отображения Grafana.
Для диагностических метрик характерно следующее:
Применяется Push-модель. Сервис DataSpace сам отправляет метрики в InfluxDB (см. раздел "Системное программное обеспечение" документа "Руководство по установке"), группируя их в пакеты. При этом частота сбора регулируется самим сервисом DataSpace и составляет 1 сек. Timestamp метрики проставляется в момент ее формирования. Интервал выбран путем поиска компромисса между подробностью, тяжестью и SLA изучаемых во время нагрузочного тестирования.
Метрики без агрегации, raw.
Для InfluxDB используется свой DashBoard в системе отображения Grafana.
Описание метрик и функциональности#
Весь перечень собираемых метрик в сервисах DataSpace возможно разделить на следующие типы:
Системные метрики. Утилизация контейнера в облачной среде с точки зрения самого контейнера в Pod (cgroup, millicores, throttling, RAM, RSS и т.п.), доступное в Pod.
Метрики JVM (Java Virtual Machine).
Метрики состояния компонентов SpringBoot-приложения (запросы, утилизация пулов).
Метрики приложения с разбиением по типам исполняющихся запросов.
Метрики, связанные с БД с точки зрения сервиса DataSpace.
Метрики модуля DataSpace Subscription — публикации событий в другие сервисы. Описание данных метрик приведено в разделе "Мониторинг" документа "Руководство по работе с сервисом DataSpace Subscription".
Метрики мониторинга процесса Init. Описание данных метрик приведено в разделе "Метрики" документа "Руководство по настройке передачи данных в хранилище данных с использованием компонента Архивирование (ARCH)".
Также имеется дополнительная функциональность для облегчения анализа:
трассировка HTTP-запросов в зависимости от длительности запроса (мс) с выводом содержимого запроса/ответа (JSON) в журнал;
журналирование методов с записью длительности исполнения в журнал;
журналирование SQL-операций с БД в журнал;
трассировка HTTP-запросов и генерация Span в формате OpenTracing и отправка их Zipkin для отображения;
автоматическое снятие ThreadDump JVM в случае превышения порога (мс) для 95 percentile длительности исполнения задач. Порог возможно изменять в Runtime через HTTP-запрос. Используется облегченный метод снятия, практически не влияющие на производительность;
автоматическое снятие ThreadDump JVM в случае накопления очереди в пуле задач;
автоматическое снятие ThreadDump JVM в случае резкого падения нагрузки ("провал");
ручное снятие и получение ThreadDump через HTTP-запрос;
упрощенный просмотр распределения длительности исполнения запросов (гистограмма) через HTTP-вызов;
сжатие файлов с имеющимися ThreadDump выполняется в случае отсутствия интенсивной нагрузки для минимизации влияния на полезную нагрузку;
скрипт анализа производительности Envoy-контейнера (istio-proxy).
Собираемые метрики#
Описание метрик:
Наименование бизнес-операции |
Частота сбора метрик |
Наименование метрики |
Тип метрики |
Описание метрики |
Описание результатов выполнения операции |
|---|---|---|---|---|---|
Operation System |
1раз/10сек |
CPU Utilization |
Метрика |
Статистика утилизации CPU в контейнере |
cpu_limit — лимит, максимальное количество millicores; cpu_usage — потребляемое количество millicores; throttling — процент принудительного ограничения быстродействия CPU |
Operation System |
1раз/10сек |
Container Memory |
Метрика |
Статистика утилизации RAM в контейнере |
limit — лимит/макс RAM; usage — потребляемое количество RAM; VmRSS — количество непосредственно занятого JVM RAM; cache — объем, занимаемый файловым cache; vmswap — объем памяти, занимаемый JVM, который вытеснился в swap (должен быть равен "0"); vmswap — общий объем памяти, вытесненный в swap |
Operation System |
1раз/10сек |
Container Memory activity |
Метрика |
Активность использования RAM в контейнере |
Количество bytes IN/OUT контейнера |
Java Virtual Machine |
1раз/10сек |
JVM Memory Capacity |
Метрика |
Статистика утилизации различных областей памяти JVM (Heap & Non-Heap) |
Количество bytes макс/текущих для различных областей JVM |
Java Virtual Machine |
1раз/10сек |
Code Heap Utilization |
Метрика |
Статистика утилизации Code Heap(JIT) |
Количество bytes макс/текущих для областей Code Heap |
Java Virtual Machine |
1раз/10сек |
Compiler(JIT) |
Метрика |
Статистика Just in Time compiler(JIT) в JVM |
compilerTime — время, затраченное на компиляцию; Succes — количество успешных компиляций; Bailouts, Invalidates — количество различных событий декомпиляции (после прогрева JVM должны быть равны "0") |
Java Virtual Machine |
1раз/10сек |
SafePoints |
Метрика |
Длительность SafePoint (SF), возникающих в JVM |
sf_Time — общая длительность за секунду; sf_count — количество SF за секунду; syncSFTime — время, которое потребовалось для достижения SF всеми потоками |
Java Virtual Machine |
1раз/10сек |
Garbage Collector |
Метрика |
Статистика GC для JVM |
gc_Time — время, занятое на операции GC; YoungGen_count — количество событий очистки в "молодом" поколении; Full_GC_count — количество событий полной очистки JVM Heap (данная метрика должна быть равна "0") |
TomCat |
1раз/10сек |
TomCat Request |
Метрика |
Различная служебная статистика от TomCat по HTTP-вызовам |
requestCount — количество вызовов на сокете byte sent/received; total processing Time (ms) — время исполнения всех запросов |
ThreadPool usage |
1раз/10сек |
Pool utilization |
Метрика |
Статистика утилизации пула |
poolSize — размер пула; activeCount — количество исполняющихся задач; queueSize — количество задач в очереди; taskCount — количество всего исполненных задач; completedTaskCount — количество всего полностью исполненных задач; corePoolSize — core-размер пула; rejectCount — количество отброшенных задач |
ThreadPool execution time histogram |
1раз/10сек |
Task Duration Histogram |
Метрика |
Гистограмма длительности исполнения задач в пуле потоков |
Показывает распределение длительности исполнения запросов(гистограмма) |
DB |
1раз/10сек |
Query Latency |
Метрика |
Длительность исполнения SQL-операций |
Длительность и количество SQL-операций (insert, select, update, batch) |
DB |
1раз/10сек |
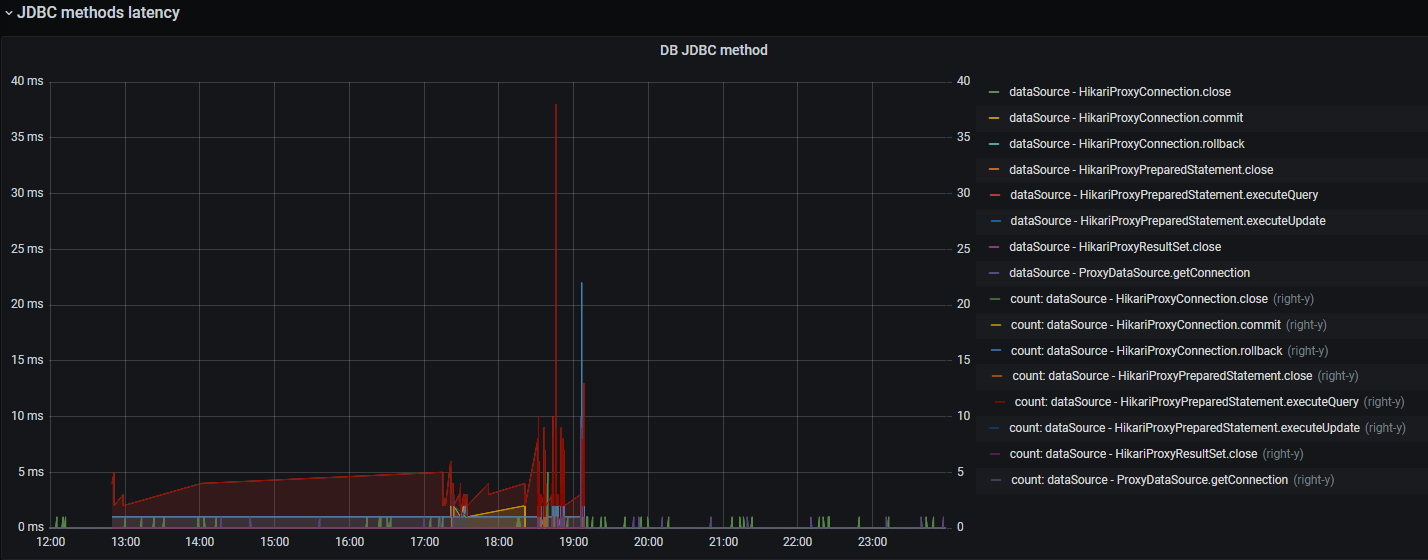
JDBC Latency |
Метрика |
Длительность JDBC-операций |
Длительность и количество JDBC-операций (execute, commit, rollback, close) |
DB |
1раз/10сек |
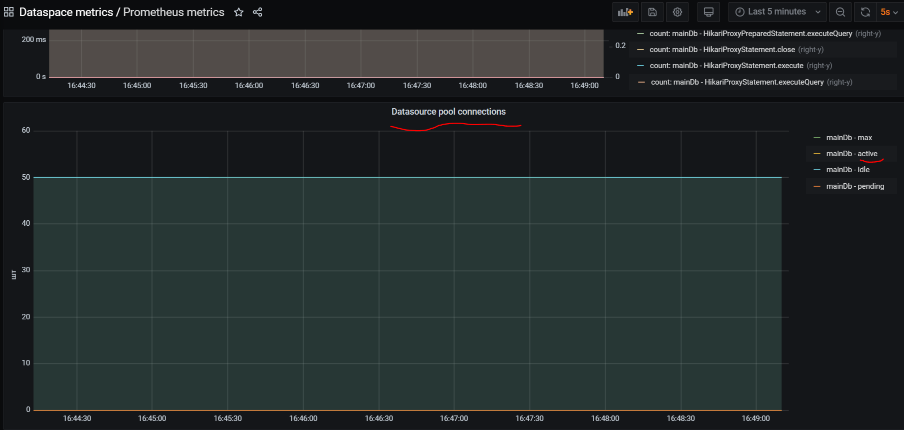
Datasource pool connections |
Метрика |
Статистика Hikari пула |
active — количество активных соединений в пуле, idle — количество idle-соединений в пуле, pending — количество потоков, ожидающих подключения из пула |
DB |
1раз/10сек |
DB Ping |
Метрика |
Задержка сетевой среды до БД |
Длительность задержки (в мс) сетевой среды между приложением JVM и БД |
Application |
1раз/10сек |
Application method |
Метрика |
Метрики приложения с разбиением по типам исполняющихся запросов |
Статистика исполнения методов count, percentile96, mean |
Журналирование методов приложения DataSpace и SQL-запросов#
Компоненты DataSpace Monitoring позволяют получать приближенное представление о временах отклика методов приложения и SQL-запросов на основе логирования без подключения и настройки специальных систем хранения и отображения метрик. Но здесь важно понимать, что логирование оказывает большее влияние на производительность приложения, чем сбор легковесных метрик.
Рассмотрим на примере:
2021-10-08 16:22:04,736 DEBUG [general-pool-thread-3] dataspace.packet.processor — >>
0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process,
args: '[PacketRequest(idempotencePacketId=null, commands=[PacketRequest.Command(id=0, name=create,
params={"type":"Product","code":"code","riskGroup":["1","2","3"],"num":"46","beginDate":"2021-10-08T16:22:04.456"},
aggregateClass=class sbp.dataspace.deals.jpa.Product)], aggregateClass=class sbp.dataspace.deals.jpa.Product,
commandResults={}, commandsResponseMode=ARRAY, softAggregateRestriction=true, aggregateVersion=0,
aggregateVersionMode=NOT_PRESENT, aggregateInstanceByApiCall=null, firstGetCommand=null,
firstGetCommandNeedRemoveAggregateVersionField=false)]'
2021-10-08 16:22:04,760 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:7,
Success:True, Type:Prepared, Batch:True, QuerySize:1, BatchSize:1, Query:["insert into t_product
(chgcnt, sys_isdeleted, sys_lastchangedate, offflag, sys_ownerid, sys_partitionid, sys_recmodelversion, begindate,
code, comment_, description, division_entityid, enddate, endfactdate, name, num, owner_entityid, reason, series,
statusforservice_id, syalactive, syalchangedate, syalreason, syaltimeout, syaltoken, type, object_id) values
(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, 'Product', ?)"],
Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,762 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:0,
Success:True, Type:Prepared, Batch:True, QuerySize:1, BatchSize:1, Query:["insert into t_producthobjectstatus
(chgcnt, sys_isdeleted, sys_lastchangedate, offflag, sys_ownerid, sys_partitionid, sys_recmodelversion,
aggregateroot_id, changereason, changetime, changeuser, owner_id, status_id, object_id)
values (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)"], Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,763 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:0,
Success:True, Type:Prepared, Batch:True, QuerySize:1, BatchSize:1, Query:["update t_product set
sys_lastchangedate=?, statusforservice_id=? where object_id=?"], Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,764 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:0,
Success:True, Type:Prepared, Batch:True, QuerySize:1, BatchSize:3, Query:["insert into lc_product_riskgroup
(product_id, riskgroup) values (?, ?)"], Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,766 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:0,
Success:True, Type:Prepared, Batch:False, QuerySize:1, BatchSize:0, Query:["SELECT migrationstatus, silock, version,
guid FROM T_REPL_AGGLOCK_PRODUCT WHERE rootid = ? FOR UPDATE"], Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,767 INFO [general-pool-thread-3] dataspacecore.SQL — Name:mainDb, Connection:4, Time:0,
Success:True, Type:Prepared, Batch:False, QuerySize:1, BatchSize:0, Query:["INSERT INTO T_REPL_AGGLOCK_PRODUCT
(rootid, version, guid, sys_lastchangedate) VALUES (?, ?, ?, SYSTIMESTAMP)"],
Params:[to show params set log level to 'debug']
2021-10-08 16:22:04,783 INFO [general-pool-thread-3] dataspace.packet.processor — <<
v:0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process, result:
'PacketResponse(commandMap={0="7016685172277575681"}, commandsResponseMode=ARRAY,
aggregateInstance=sbp.dataspace.deals.jpa.Product@fc6b9196, aggregateVersion=null,
idempotenceResponse=false)', 45815us [47410us]
В журнале видим вход в метод, где указывается имя метода с параметром в виде UoW пакета:
2021-10-08 16:22:04,736 DEBUG [general-pool-thread-3] dataspace.packet.processor — >>
0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process,
args: '[PacketRequest(idempotencePacketId=null, commands=[PacketRequest.Command(id=0, name=create,
params={"type":"Product","code":"code","riskGroup":["1","2","3"],"num":"46","beginDate":"2021-10-08T16:22:04.456"},
aggregateClass=class sbp.dataspace.deals.jpa.Product)], aggregateClass=class sbp.dataspace.deals.jpa.Product,
commandResults={}, commandsResponseMode=ARRAY, softAggregateRestriction=true, aggregateVersion=0,
aggregateVersionMode=NOT_PRESENT, aggregateInstanceByApiCall=null, firstGetCommand=null,
firstGetCommandNeedRemoveAggregateVersionField=false)]'
Далее отображается ряд SQL-запросов, где указывается (http://ttddyy.github.io/datasource-proxy/docs/current/user-guide/#query-logging-listener):
Name — имя ProxyDataSource.
Connection — id соединения.
Time — время выполнения запроса в мс.
Success — успешность выполнения запроса.
Type — тип statement (Statement/Prepared/Callable).
Batch — batch execution.
QuerySize — число запросов.
BatchSize — размер batch-запроса.
Далее отображается выход из метода:
2021-10-08 16:22:04,783 INFO [general-pool-thread-3] dataspace.packet.processor — <<
v:0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process, result:
'PacketResponse(commandMap={0="7016685172277575681"}, commandsResponseMode=ARRAY,
aggregateInstance=sbp.dataspace.deals.jpa.Product@fc6b9196, aggregateVersion=null,
idempotenceResponse=false)', 45815us [47410us]
Время выполнения непосредственно метода sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process равно 45815us. Общее время выполнения [47410us] с учетом работы листенеров на before и after этапах, которые обрамляют вызов метода sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process.
Особенности отображения в Grafana#
Для интерактивной визуализации метрик используется Web-приложение Grafana.
Стандартная область DashBoard представлена на рисунке ниже. В верхней части можно выбрать фильтры из выпадающего списка, характерные для данного пространства:
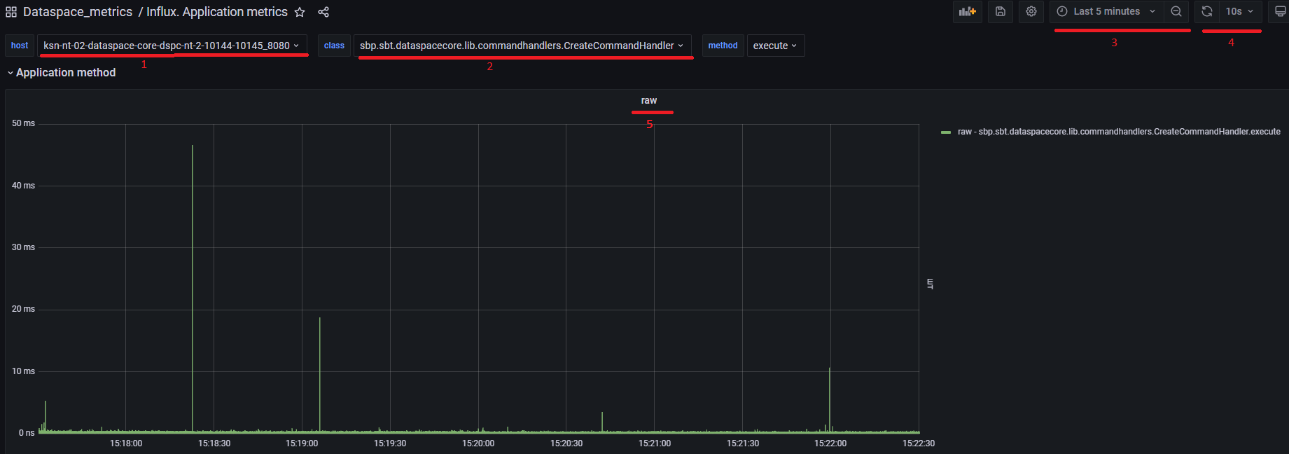
На рисунке:
1 — host-наименование хоста, POD, контейнера, в котором запущен сервис;
2 — фильтры;
3 — временной период, за который отображается статистика (например, за последние 5 минут);
4 — интервал обновления DashBoard (как часто Grafana опрашивает БД с метриками Prometheus/InfluxDB);
5 — наименование панели на DashBoard. Панелей может быть множество.
Стандартная панель, как правило, представляет собой отображение графика с осями X — время и Y — метрика. При наличии метрик, несущих совместный смысл, но различные единицы измерения, применяется две оси Y — левая и правая.
Рассмотрим более подробно типовую панель с метриками. Данная панель отображает статистику исполнения Java-методов.
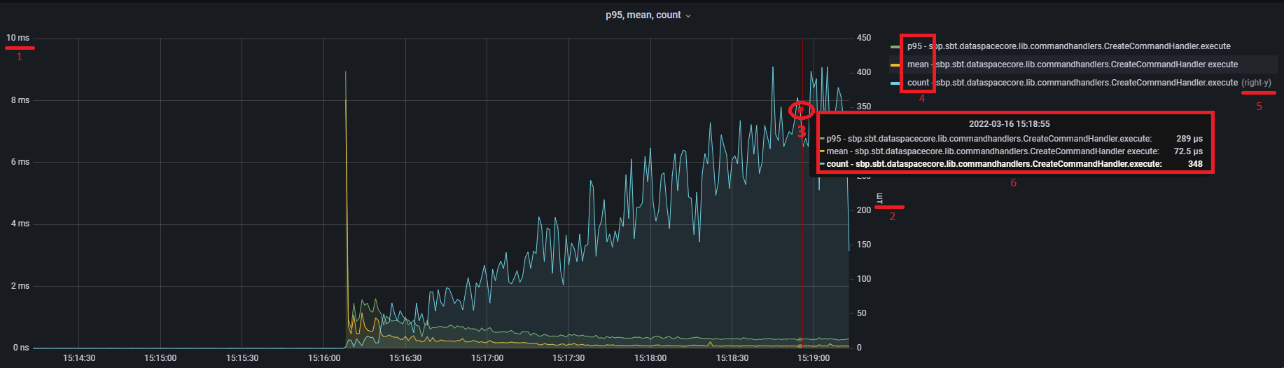
На рисунке:
1 — единицы измерения левой оси Y "milliseconds";
2 — единицы измерения правой оси Y "штук";
3 — если навести курсором мыши на график, появится всплывающая область со значениями в этот период (см. описание под цифрой 6);
4 — постоянная область со значением метрики (см. описание под цифрой 6);
5 — right-y значение метрики отображается по правой шкале Y. В данном случае сколько раз исполнился метод;
6 — всплывающая область:
"2022-03-16 15:18:55" — время фиксации метрики в БД Prometheus/Influx;
"p95" — 95 percentile за период сбора (Influx — 1 сек, Prometheus — 10 сек) исполнения метода CreateCommandHandler.execute() составил 289 мкс;
"mean" — среднее значение за период сбора (Influx — 1 сек, Prometheus — 10 сек) равно 72.5 мкс;
"count" — количество исполнений метода за период сбора (Influx — 1 сек, Prometheus — 10 сек) составило 348 раз.
Системные метрики#
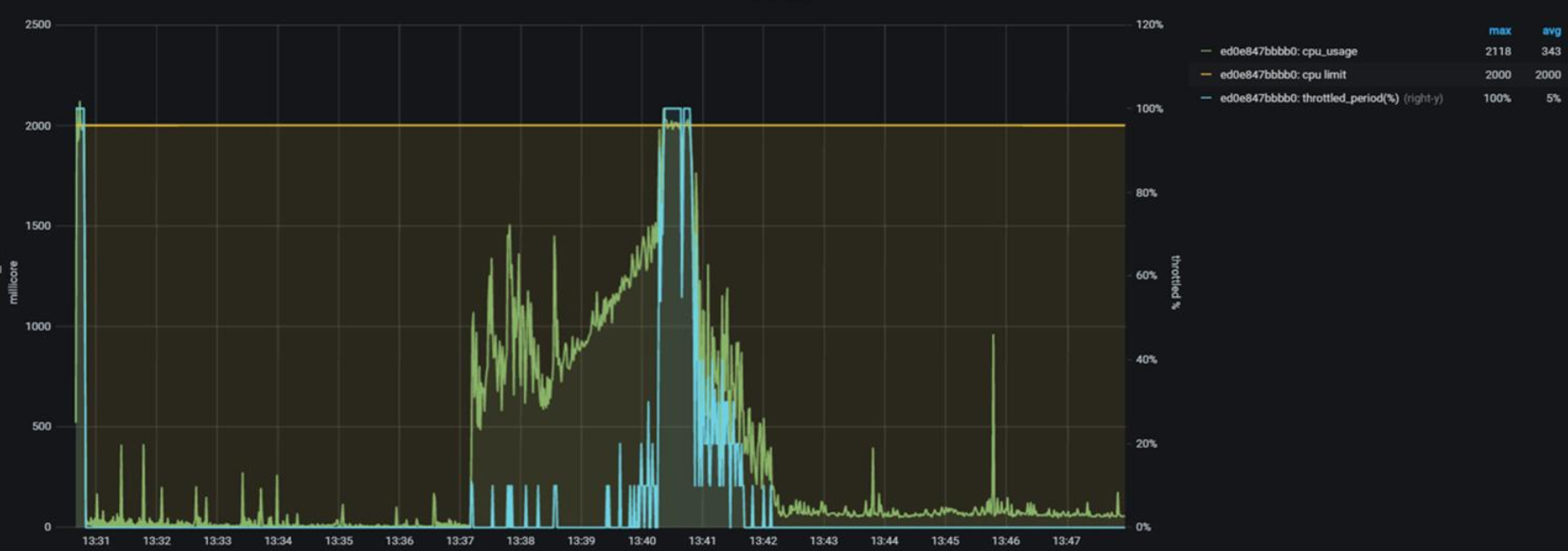
Показатели утилизации CPU Linux Control Group (контейнера с dataspace в Pod):
"cpu_limit" — максимальное ограничение CPU для CGroup (POD Limit millicores);
"cpu_usage" — текущее потребление CPU для CGroup (POD usage millicores);
"cpu_throttling" — % времени CPU, который не был выдан CGroup для работы ("пробуксовка/ожидание CPU").
На рисунке ниже:
"желтым" цветом отображается CPU Limit в 2000 millicores (~ 2 CPU);
"зеленым" цветом отображается утилизация CPU (периодов CGroup);
"синим" цветом отображается throttling "зажимание" CPU при распределении ресурсов ядром ОС Linux для данной cgroup (~POD). Появление данного показателя говорит о наличии проблем при распределении CPU периодов на узле (сервере), где был запущен данный контейнер/POD. Фактически — это нехватка CPU-периодов для CGroup.
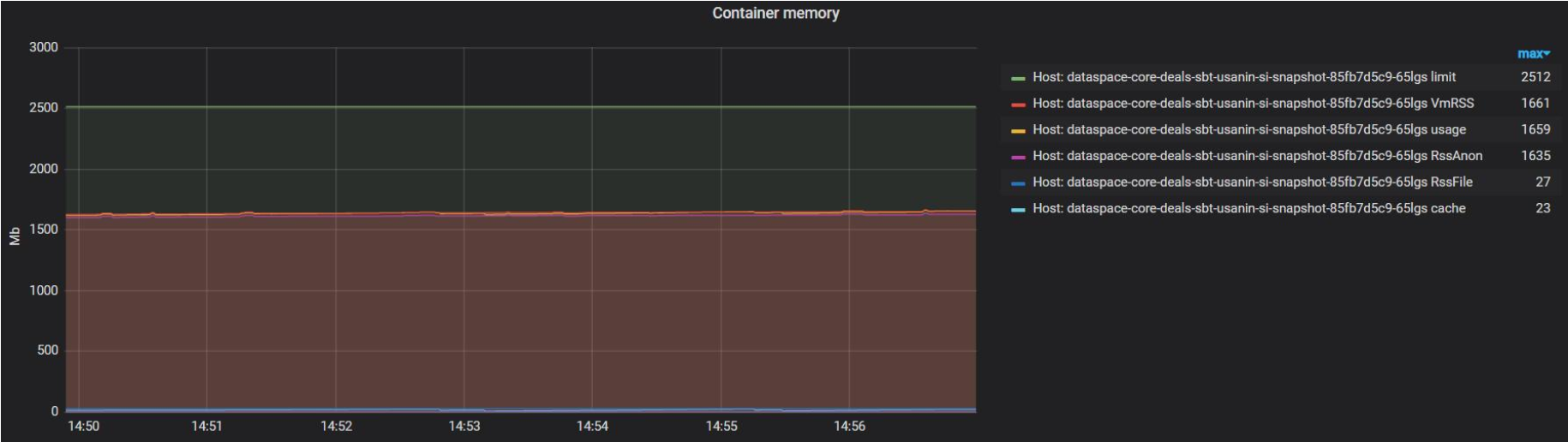
Утилизация Memory для ControlGroup (только для Linux-контейнеров) и полный размер памяти, занимаемой всей JVM (Heap + NonHeap):
"limit" — максимальное ограничение Memory для CGroup (POD Memory Limit);
"usage" — текущее использование Memory для CGroup (POD Memory usage);
"VmRSS" — общий объем используемой процессом JVM физической памяти (Heap + NoneHeap) с точки зрения OS Linux;
"cache" — текущий размер page-cache для данной CGroup;
"VmSwap" — объем памяти процесса JVM, находящегося в swap-е OS Linux.
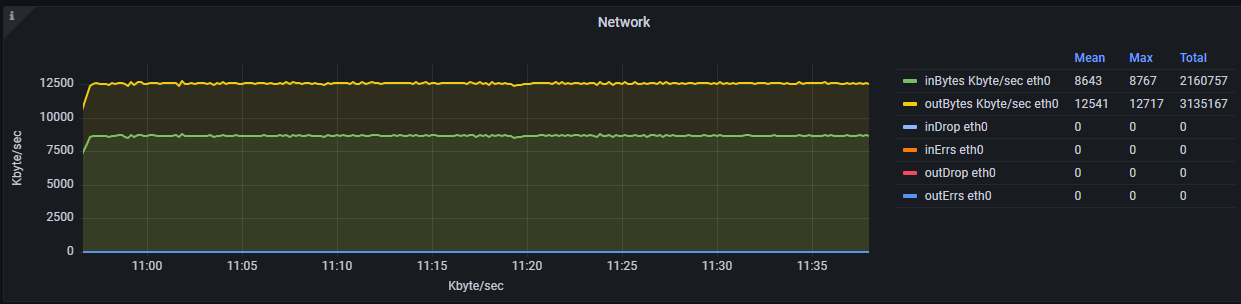
Сетевая активность на интерфейсе:
"inBytes/s" — получено байт в секунду;
"outBytes/s" — отправлено байт в секунду;
"inDrop" — отброшено полученных пакетов;
"outDrop" — отброшено отправленных пакетов;
"inErrs" — полученных пакетов с ошибкой;
"outErrs" — отправлено пакетов с ошибкой.
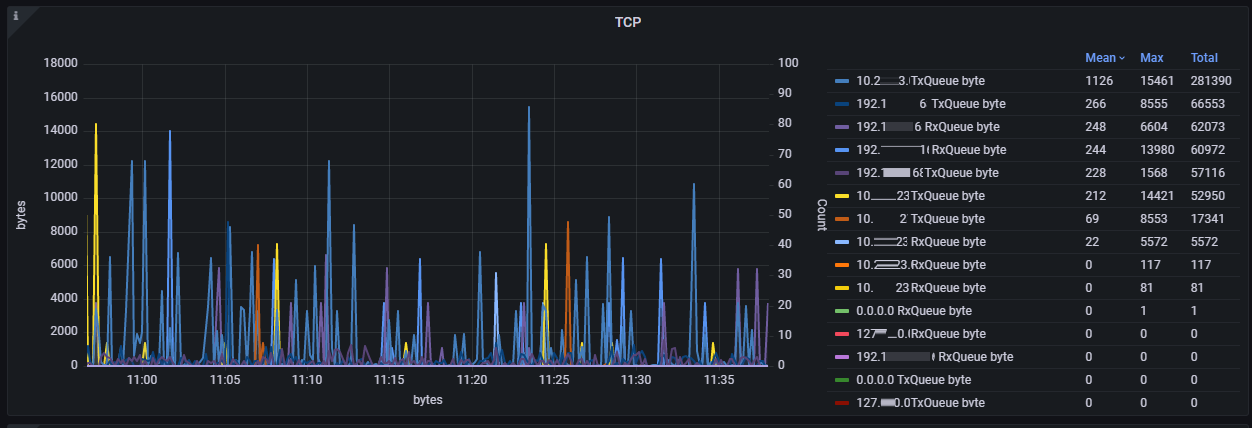
Сетевая очередь и повторные отправки сетевого сокета/соединения:
"TxQueue byte" — байт в очереди сетевого буфера OS Linux на отправку;
"RxQueue byte" — байт в очереди сетевого буфера OS Linux на получение;
"Retransmit" — количество повторных запросов TCP-пакетов.
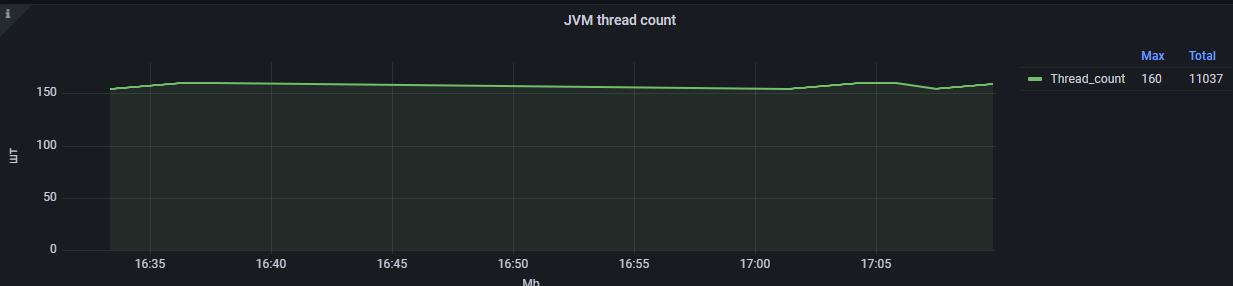
Количество потоков в JVM: "Thread_count" — количество потоков в JVM.
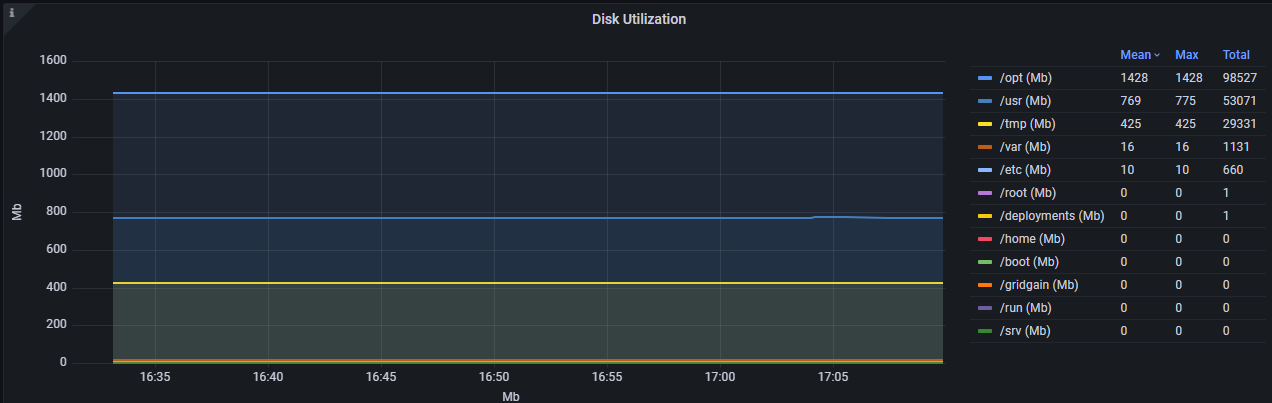
Утилизация дисковой подсистемы: "/usr(Mb) 1428" — директория "/usr" утилизирует 1428 Мб.
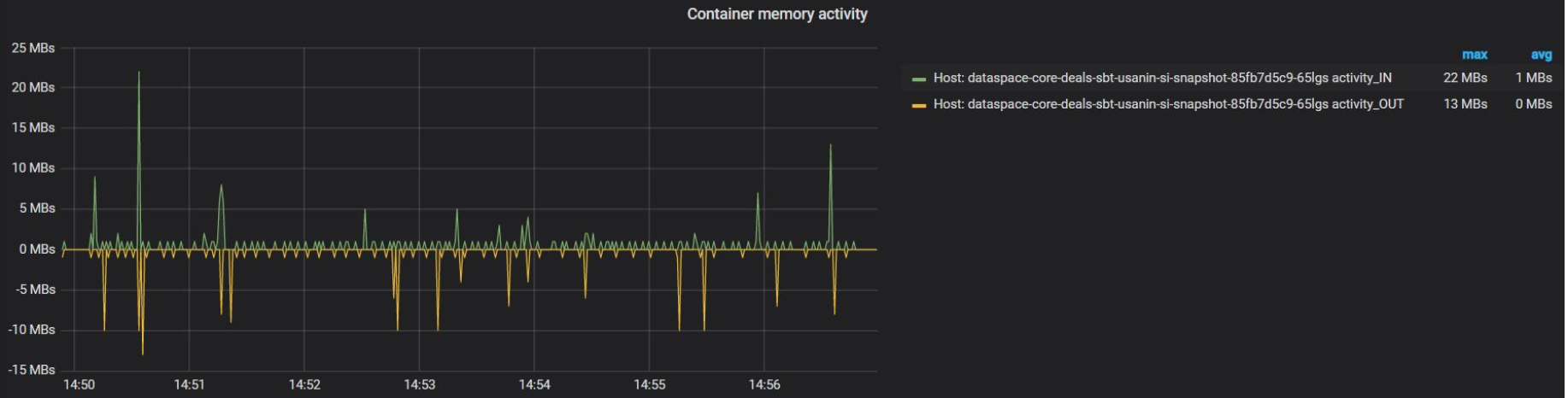
Активность при работе с памятью — "memory CGroup activity" IN/OUT активность памяти CGroup.
Метрики JVM#
Пауза JVM по причине перехода в safe-points. Причиной перехода в Safe-Point может быть Garbage Collector, Just-In-Time Compiler, снятие тред-дампа, внутренние задачи JVM. Присутствуют:
"sf_Time" (mks) — общая длительность пауз (safe points);
"sf_count" (шт.) — количество пауз;
"syncSFtime" (mks) — time_to_safepoint. Время, потраченное на синхронизацию/остановку потоков для достижения SafePoint.

Garbage Collector#
Присутствуют:
"gc_Time" (mks) — общая длительность GC-пауз;
"YoungGen_count" (шт.) — количество пауз YoungGen;
"Full_GC_count" !!! (шт.) — количество Full GC.

Compiler (Jit) statistics#
Присутствуют:
"compileTime" (mks) — общая длительность компиляции;
"Success" (шт.) — количество удачных компиляций;
"Bailouts" (шт.) — количество неудачных компиляций Bailouts;
"Invalidates" (шт.) — количество неудачных компиляций Invalidates.

JVM Memory — утилизация областей памяти (Heap & NON-Heap)#
Присутствуют:
"maxHeap" (Мб) — максимальный размер Хипа;
"eden,s0,s1б old" (Мб) — утилизация областей;
"meta" (Мб) — утилизация NON-Heap области metaSpace;
"compress" (Мб) — утилизация области NON-Heap compressClasses.

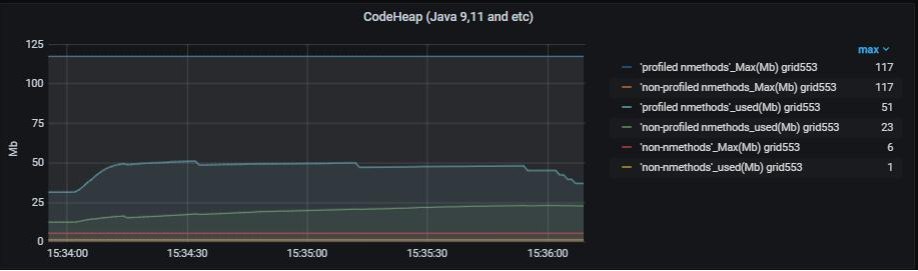
Утилизация JIT CodeCache#
Представлены текущий и максимально возможный размер областей CodeCache компилятора JIT.
Блокировка в случае неудачной попытки получения монитора#
В случае неудачной попытки получения монитора синхронизированного блока/объекта в JVM возникают события:
MONITOR_CONTENDED_ENTER;
MONITOR_CONTENDED_ENTERED.
Метрики:
"count (шт.)" — количество неудачных попыток получения монитора MONITOR_CONTENDED_ENTER;
"time (mks)" — длительность ожидания получения монитора MONITOR_CONTENDED_ENTERED.
По умолчанию функционал отключен.

StackTrace потока с неудачной попыткой получения монитора (MONITOR_CONTENDED_ENTER)#
На данном снимке можно увидеть, что поток "http-nio-28070-ClientPoller" не смог получить монитор 3 раза и его Stack_Trace: [http-nio-28070-ClientPoller] sun.nio.ch.EPollSelectorImpl#clearInterrupt <-sun.nio.ch.EPollSelectorImpl#processEvents <-sun.nio.ch.EPollSelectorImpl#doSelect <-sun.nio.ch.SelectorImpl#lockAndDoSelect <-sun.nio.ch.SelectorImpl#select <-org.apache.tomcat.util.net.NioEndpoint$Poller#run
Собирается максимально 10 фрэймов.

Метрики состояния компонентов SpringBoot-приложения (запросы, утилизация пулов)#
Показатели пула потоков, обрабатывающего HTTP-вызовы Spring Boot-приложения#
В приложении присутствует 2 коннектора и 2 пула потоков (ThreadPoolExecutor), обрабатывающих входящие запросы:
General — для основных HTTP-запросов от потребителей (default tcp socket 8080). В некоторых случаях при распараллеливании используется еще один пул Batch-pool.
Service — для служебных запросов, например, readiness/liveness запросы (default tcp socket 9080).
Статус состояния пула потоков#
Присутствуют:
"poolSize" — размер пула;
"activeCount" — количество исполняющихся задач;
"queueSize" — количество задач в очереди;
"taskCount" — всего исполненных задач;
"completedTaskCount" — всего полностью исполненных задач;
"corePoolSize" — core-размер пула;
"rejectCount" — количество отброшенных задач. Возникает, когда переполнена очередь.
Наиболее значимые метрики — activeCount и queueSize. Например, в случае "тяжелой" работы с задержками по каким-то причинам, количество activeCount может подойти к corePoolSize, в результате чего новые запросы (а соответственно задачи) попадут в очередь queueSize. В случае полной утилизации очереди новые запросы будут отбрасываться (reject).
На представленном рисунке из Grafana видно использование очереди в самом начале подачи нагрузки до 36 (default max 50):
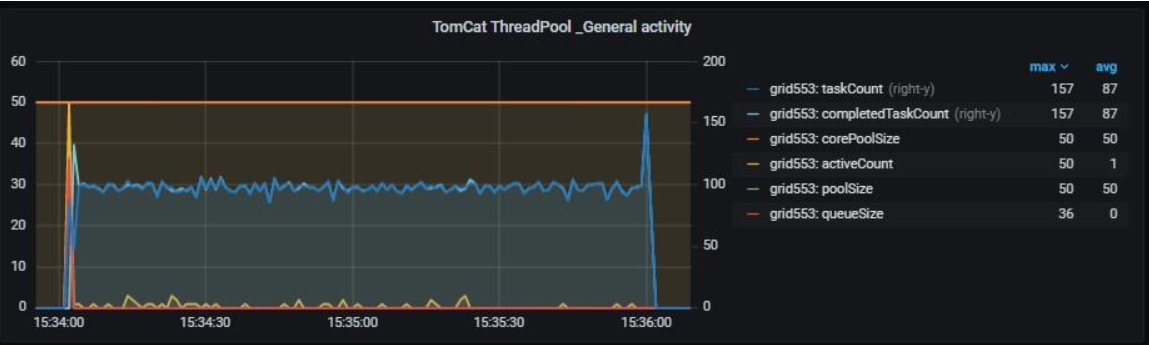
Гистограмма длительности исполнения задач в пуле потоков#
Следующая панель отображает гистограмму распределения длительности вызовов.
На представленной панели видно, что основная масса задач исполнялась в интервале от 2 мс до 5 мс (~5000шт) и т.п.
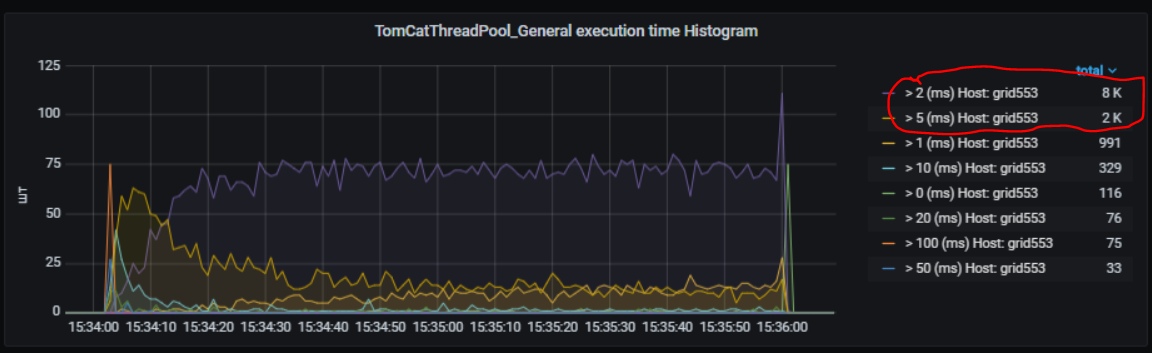
Представлены следующие периоды(buckets): -> 0ms; -> 1ms; -> 2ms; -> 5ms; -> 10ms; -> 20ms; -> 50ms; -> 100ms; -> 1sec; -> 10sec; -> 100sec.
Длительность исполнения задачи (потока)#
Длительность исполнения задачи (потока) в течение одной секунды (поток может использоваться несколько раз разными запросами). Иногда для анализа по журналам удобно понимать, какой поток был наиболее загружен. На рисунке ниже показано, что в 15:35:35 поток general-pool-thread-29 исполнялся в течение 43893 мкс.

На основе метрик утилизации пула потоков (General, Service) присутствует следующая функциональность:
Сбор ThreadDump каждые 200 мс в течение 5 секунд в следующих случаях:
когда размер очереди ThreadPool превысит пороговое значение (по умолчанию 2);
когда резко упала нагрузка (например произошел провал в нагрузке и т.п. (по умолчанию, если старое количество активных потоков было > 15, а новое стало < 4)).
Сжатие сгенерированных файлов ThreadDump, но в момент наименьшей нагрузки (чтобы не потреблять CPU на сжатие в момент нагрузки). По умолчанию, если в течение 2 минут количество активных потоков в TomcatThreadPool < 5, принимается решение об отсутствии загруженности сервиса и возможности выполнения неважных/фоновых задач.
Все пороги настраиваются через опции (см. раздел "Настройка сервиса Dataspace в отношении мониторинга").
Метрики приложения с разбиением по типам исполняющихся запросов#
Метрики приложения предоставляют статистику работы методов приложения, которая включает количество успешных вызовов, среднее время и 95 percentile.
Метрики приложения настраиваются через опции (см. раздел "Настройка сервиса Dataspace в отношении мониторинга").
Рассмотрим метрики приложения на примере модуля dataspace-core, которые подразделяются на две основные группы:
метрики Unit of Work (UoW metrics);
метрики поисковых запросов (Search metrics).
Метрики Unit of Work (UoW metrics)#
На рисунке ниже представлено количество успешных вызовов метода PacketProcessorImpl.process, среднее время и 95 percentile (метод PacketProcessorImpl.process осуществляет обработку десериализованного UoW-пакета).
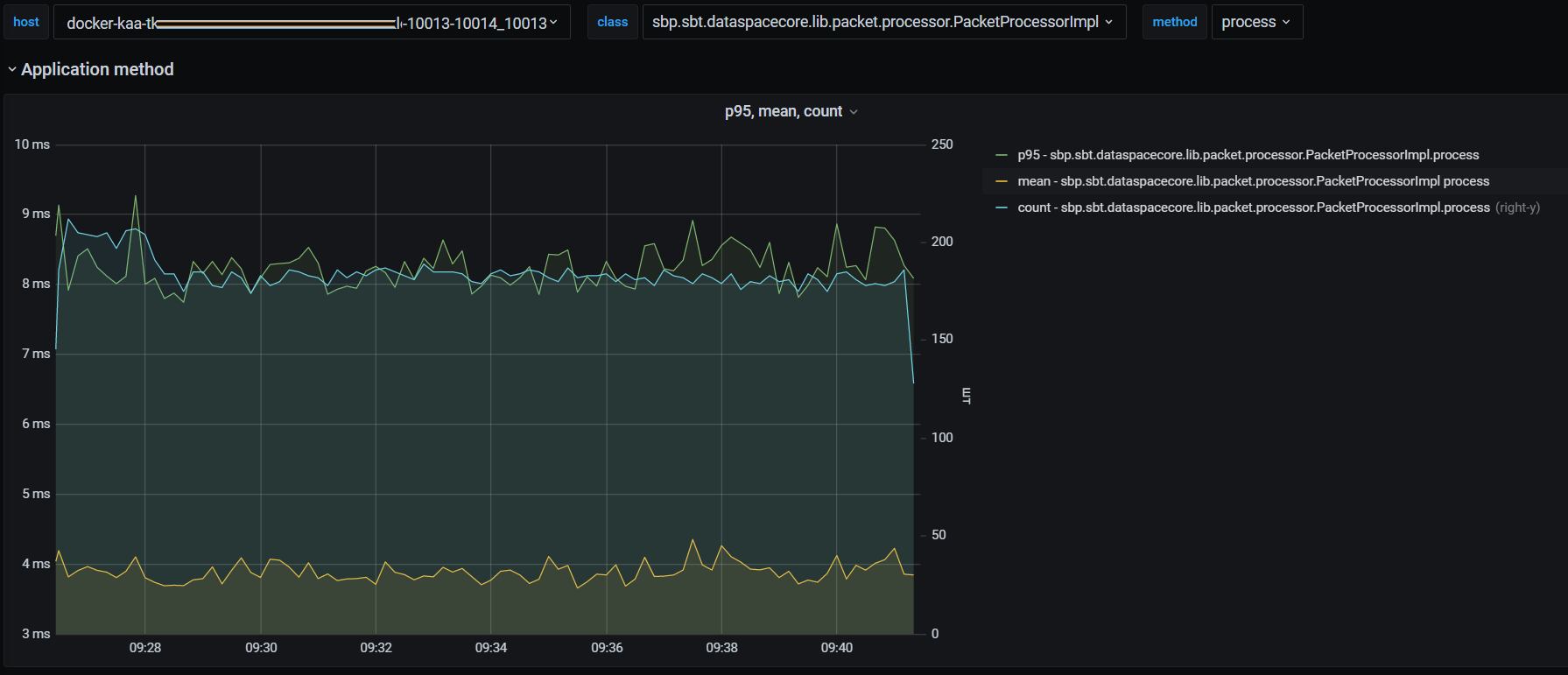
В зависимости от подключенных опций возможно замерять отдельно более низкоуровневые методы приложения:
статистика работы обработчика команды create UoW:
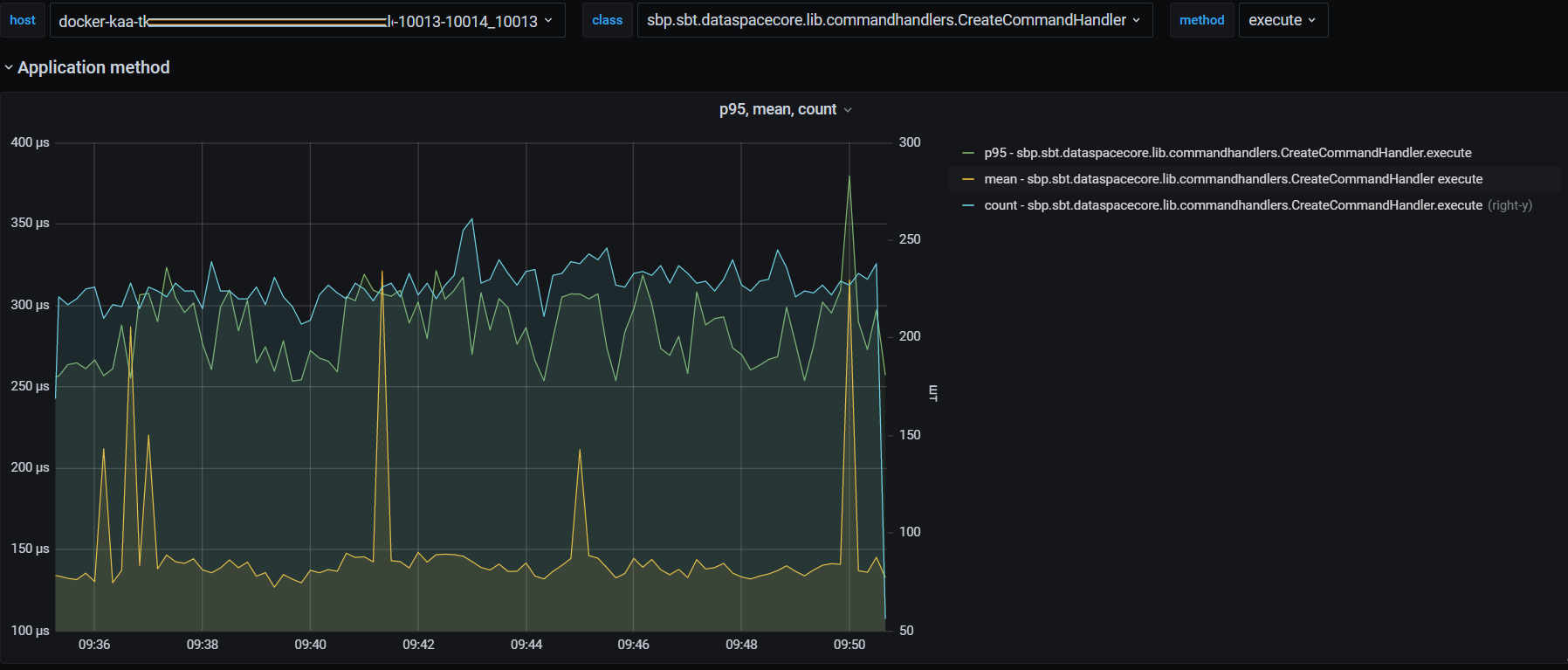
статистика работы обработчика команды update UoW:
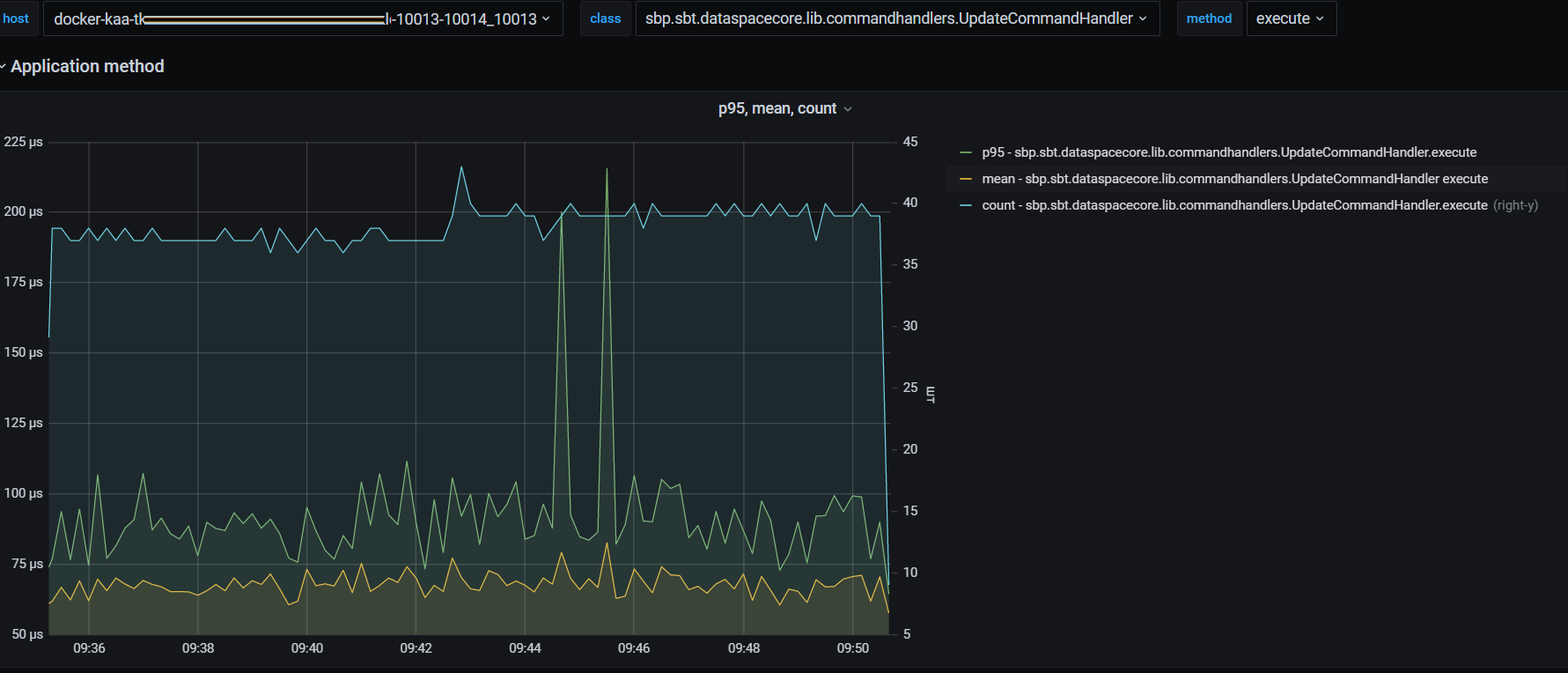
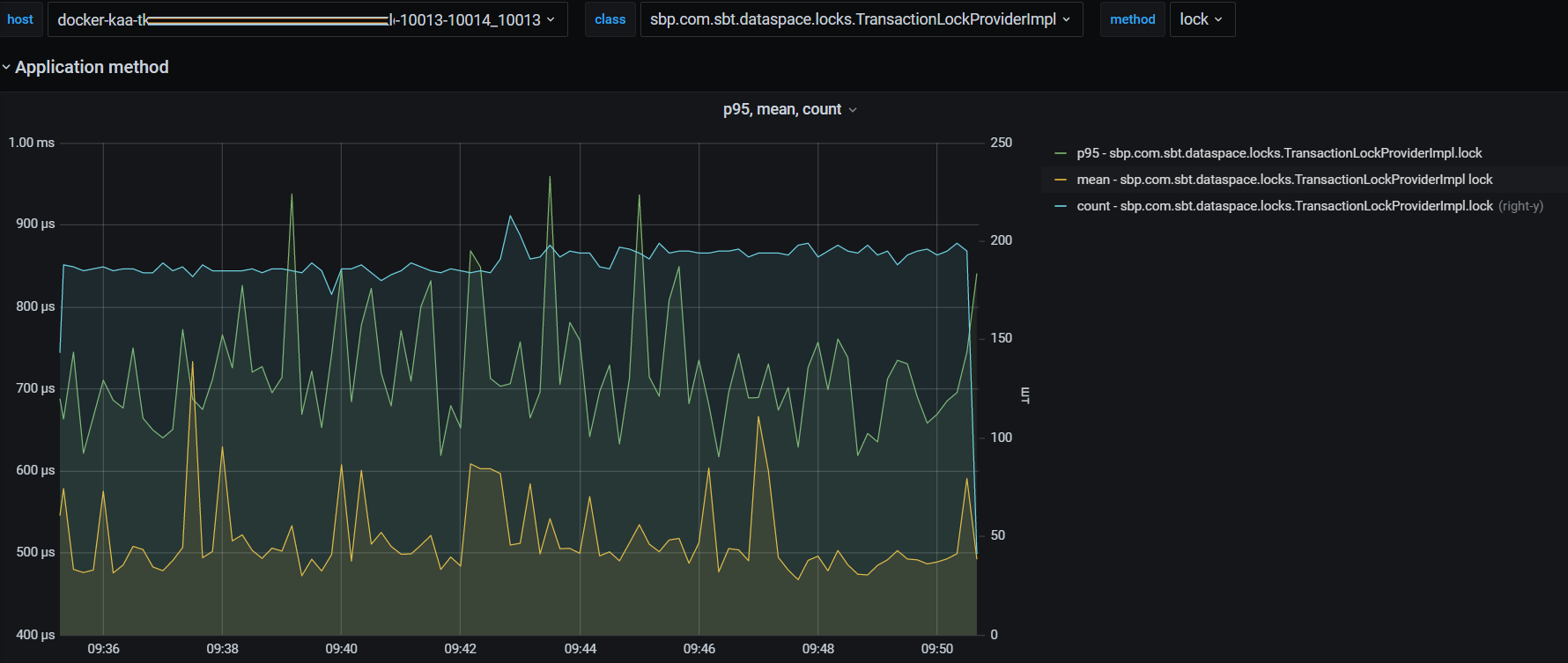
транзакционная блокировка, смысл которой в гарантии того, что агрегат не заблокирован (например, процессом миграции, выгрузкой, переходом в StandIn) :
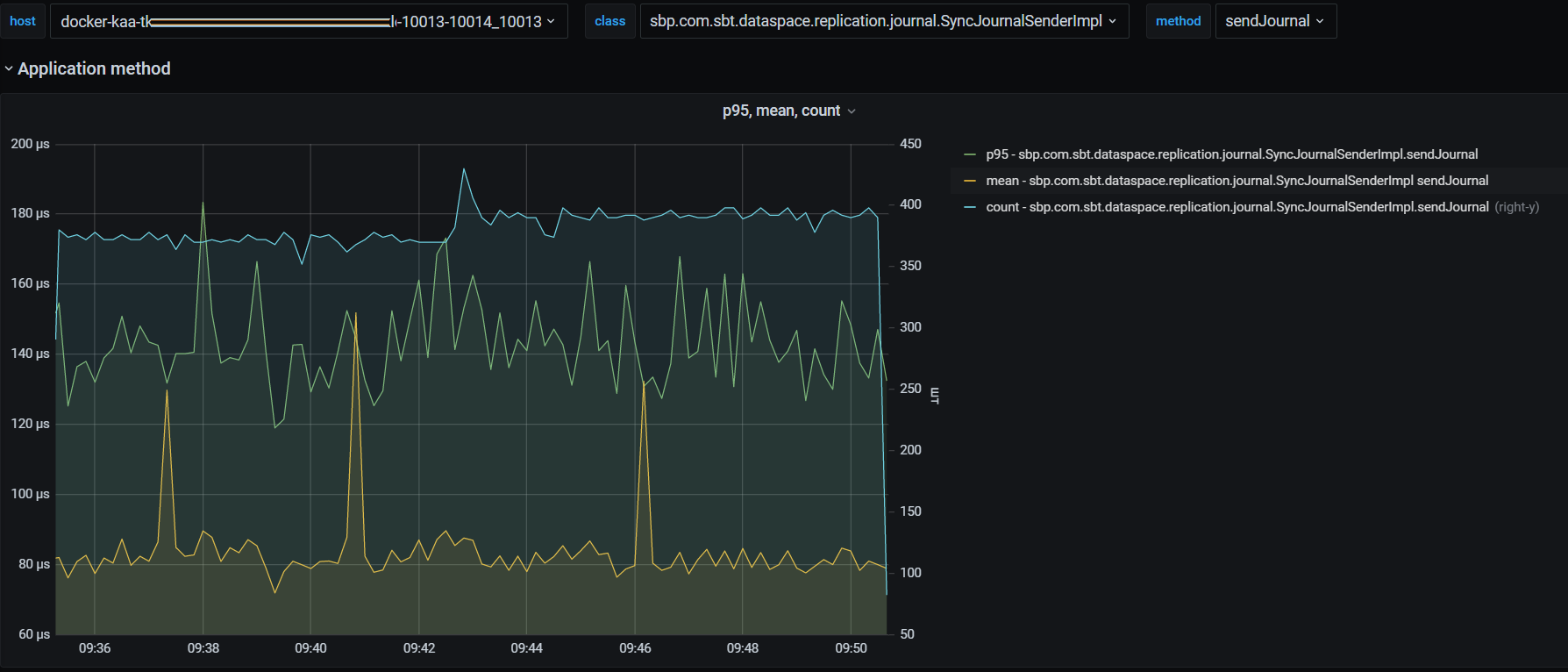
отправка вектора изменений в Прикладной журнал:
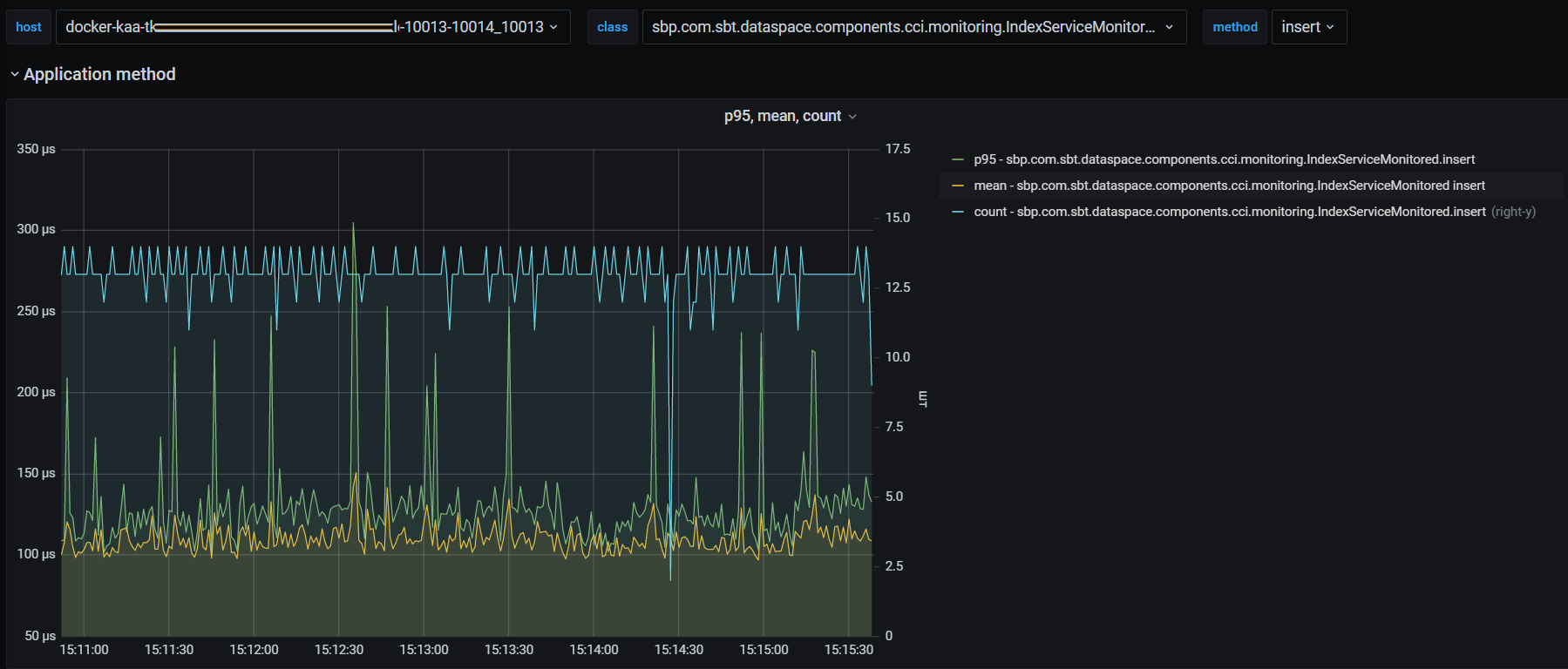
метрики длительности взаимодействия с CCI:
Чтобы включить логирование запросов в CCI, необходимо добавить в application.properties файл категорию:
dataspace.monitoring.watch-log.category.sbp.com.sbt.dataspace.components.cci=all
Аналогичный подход применяется для всех методов приложения, которые находятся под наблюдением. Подробнее см. в разделе "Логирование методов приложения".
Кроме того, для диагностических метрик доступны следующие возможности:
Получение метрик UoW в разрезе набора команд, из которых состоит пакет UoW:
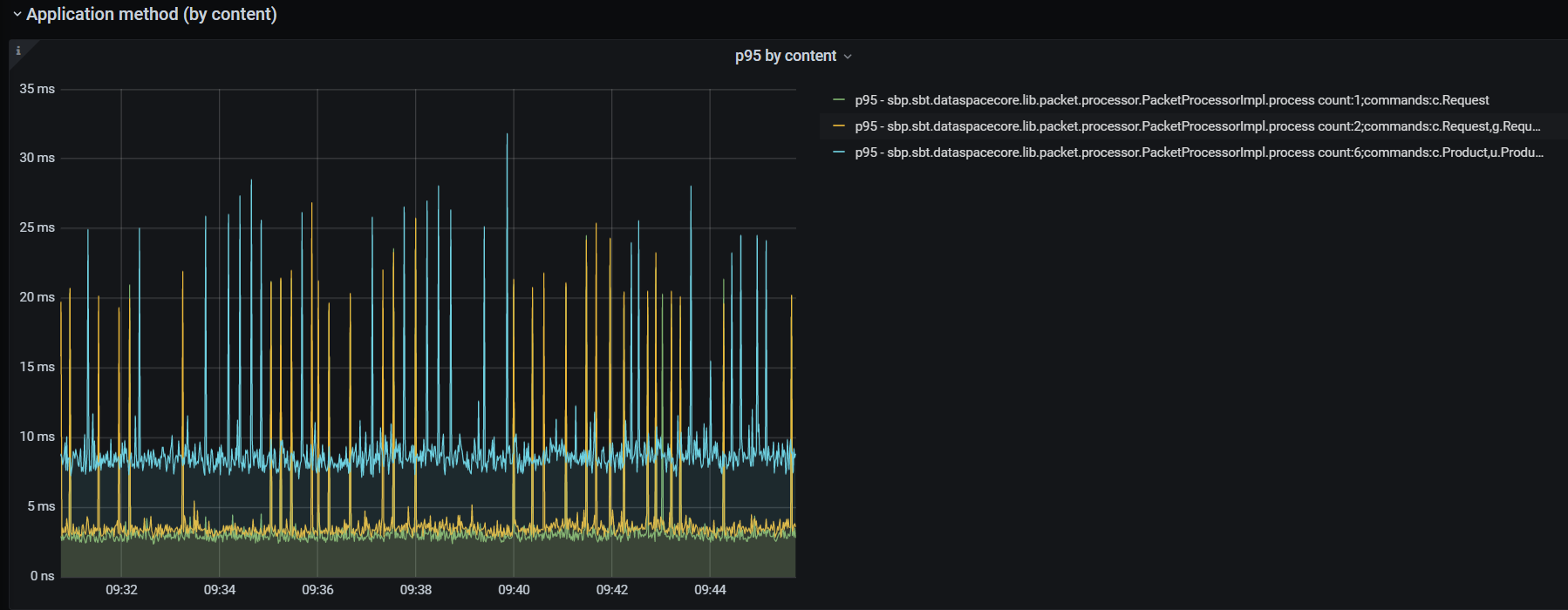
Пример записи из рисунка выше:
p95 — sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process count:2;commands:c.Request,g.Requestгде:
p95 — 95 percentile;
count:2 — количество команд в пакете 2;
sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process — класс и метод;
commands:c.Request,g.Request — разбиение по типам команд (c. — create, u. — update, g. — get, d. — delete) и классам модели (Request).
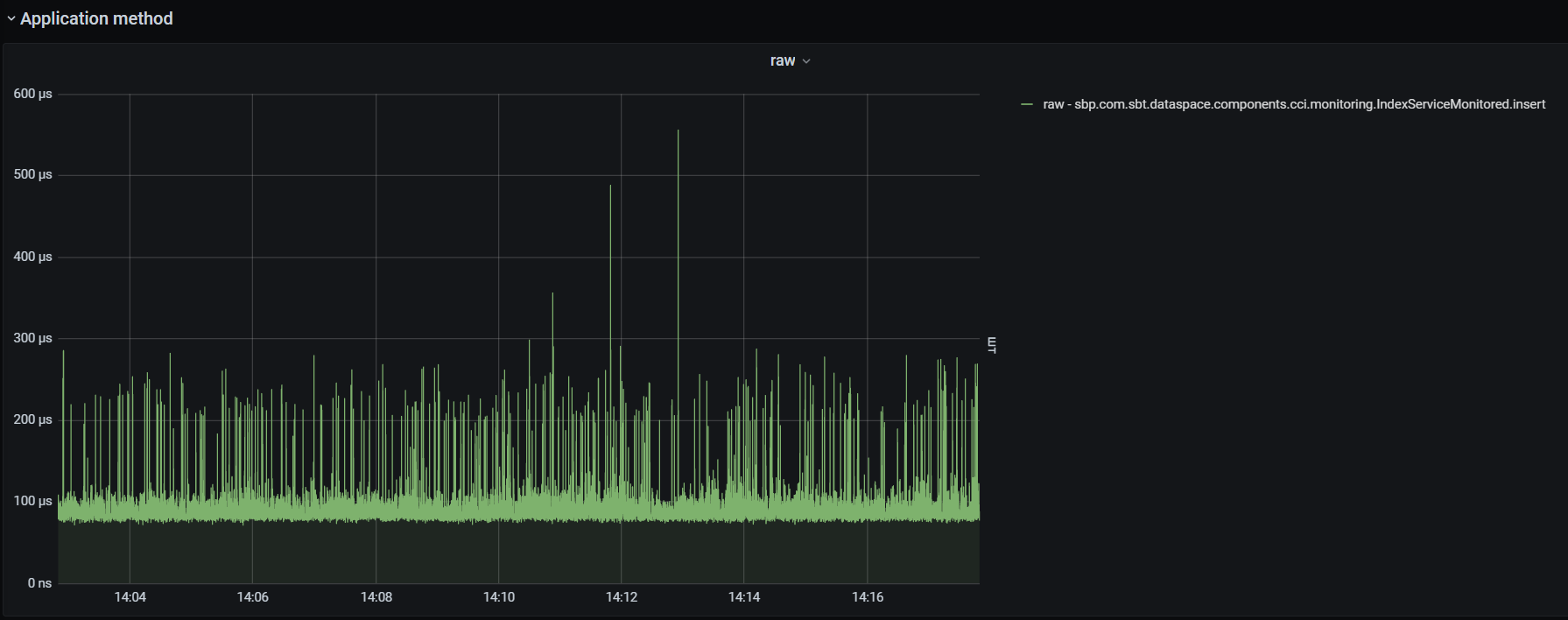
Получение информации о длительности выполнения методов приложения в "сыром" виде. Ниже в качестве примера показана длительность взаимодействия с CCI:
Search metrics#
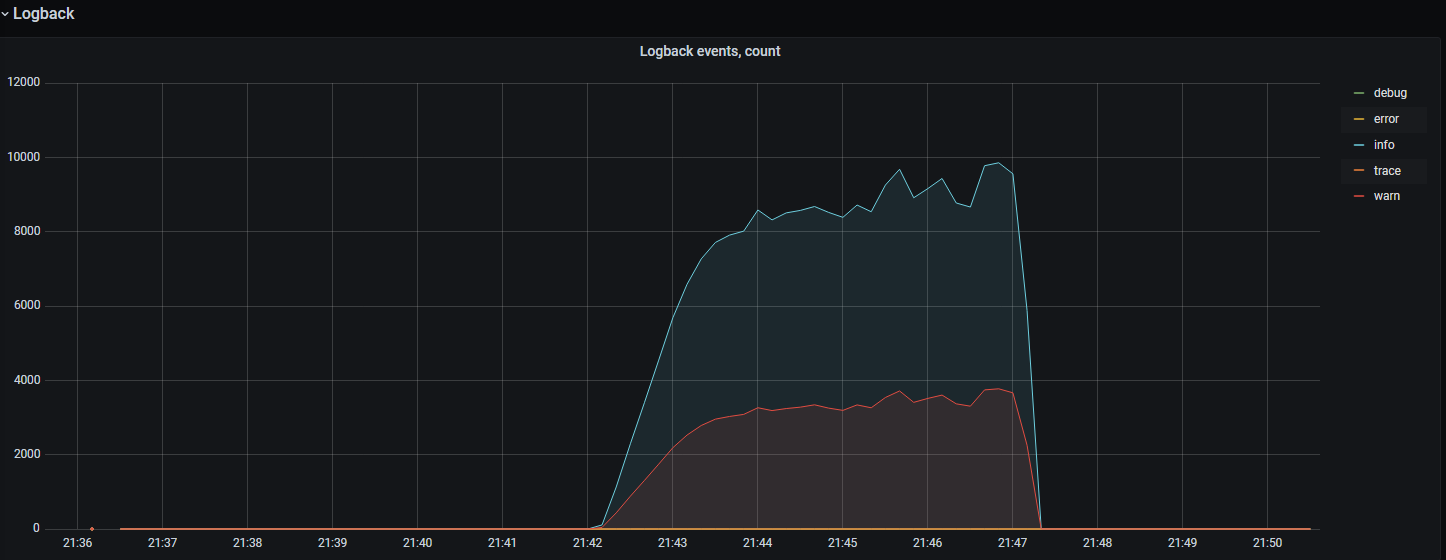
Количество событий журналирования по типам (LOGBACK info, error, warning, trace, debug)#
Метрики, связанные с БД с точки зрения сервиса DataSpace#
Показатели пула подключения к БД (Hikari)#
Основные показатели утилизации пула соединений к БД:
"active" — количество активных соединений в пуле;
"idle" — количество idle-соединений в пуле;
"pending" — количество потоков, ожидающих подключения из пула.
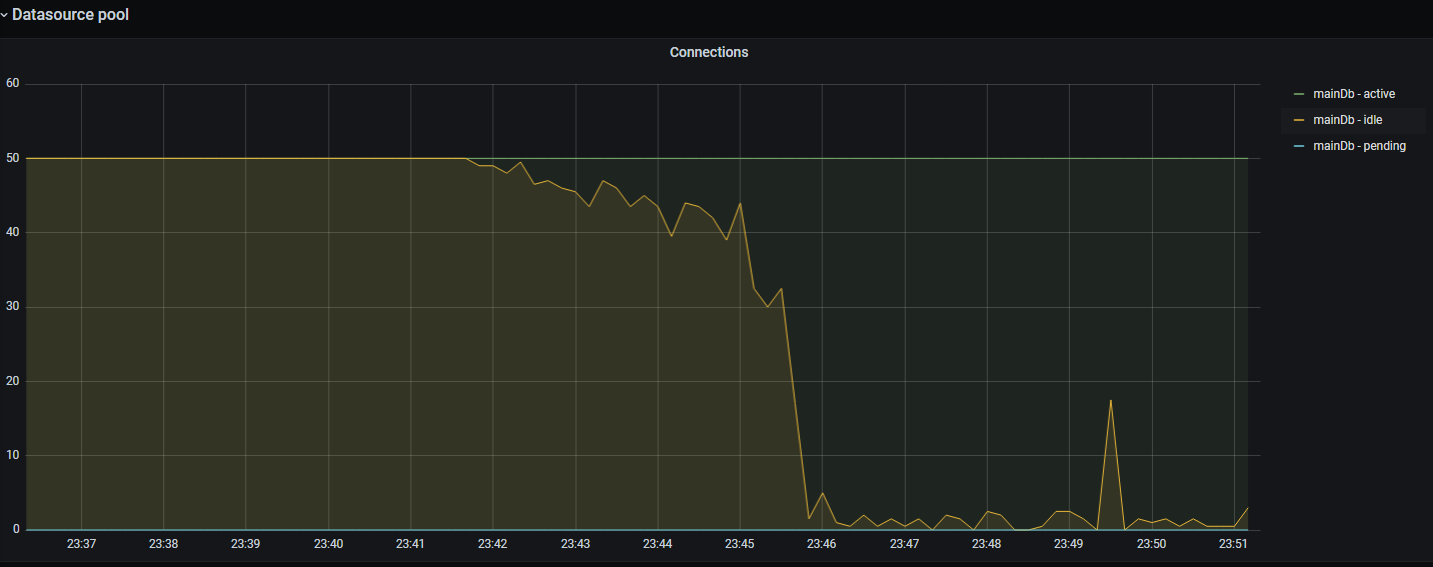
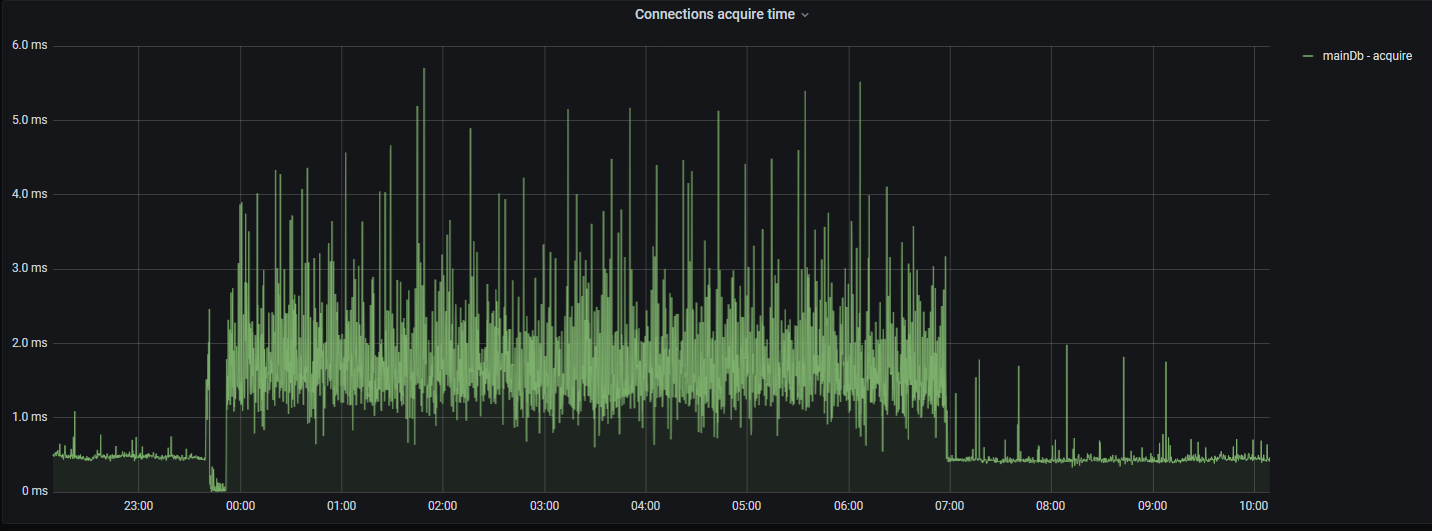
Далее на снимке показывается время, затраченное на получение соединения к БД из пула соединений:
Длительность исполнения SQL-операций в БД#
Чтобы измерять время работы jdbc-методов и SQL-запросов, источник данных (datasource) приложения оборачивается proxy-объектом.
В качестве прокси используется библиотека https://github.com/ttddyy/datasource-proxy.
<dependency>
<groupId>net.ttddyy</groupId>
<artifactId>datasource-proxy</artifactId>
<optional>true</optional>
</dependency>
Время выполнения SQL-запросов и их количество с разделением по типу SQL операций:
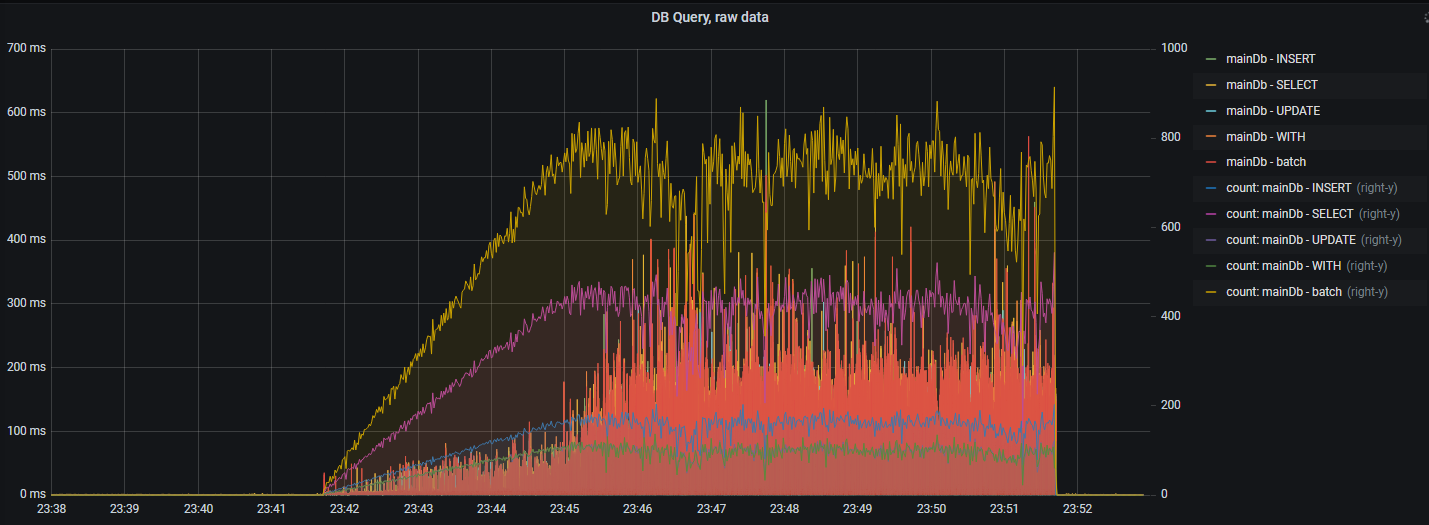
Вышеуказанный график выводит "сырые" данные. Далее представлена статистика SQL-операций (95 percentile, среднее время):
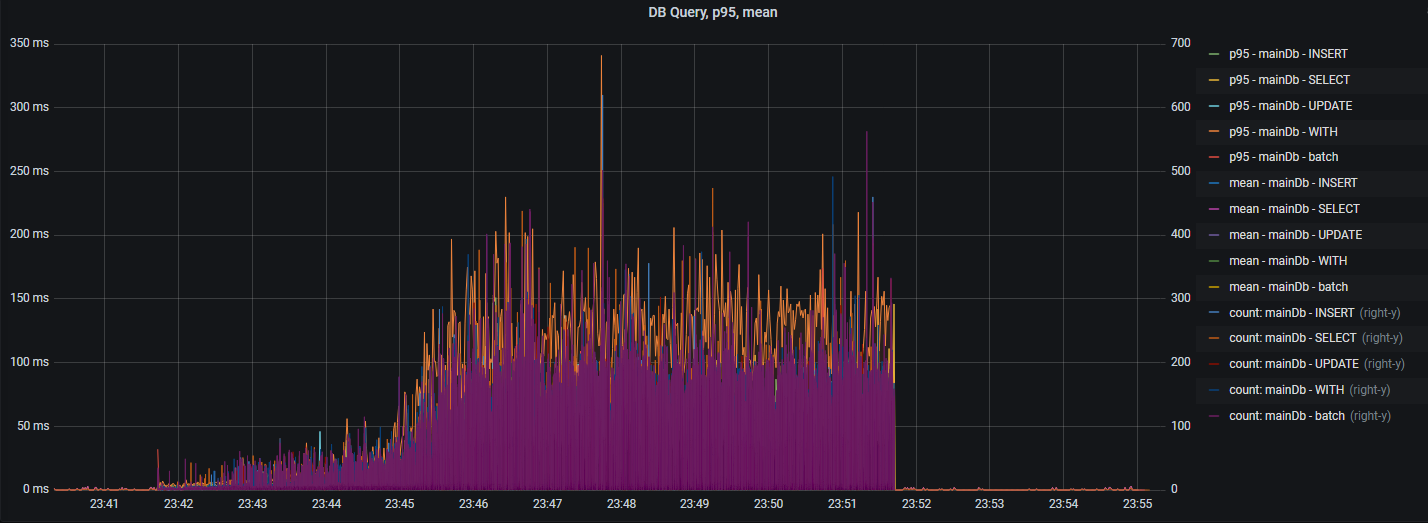
Присутствует опция для вывода времени выполнения jdbc-методов и их количества:
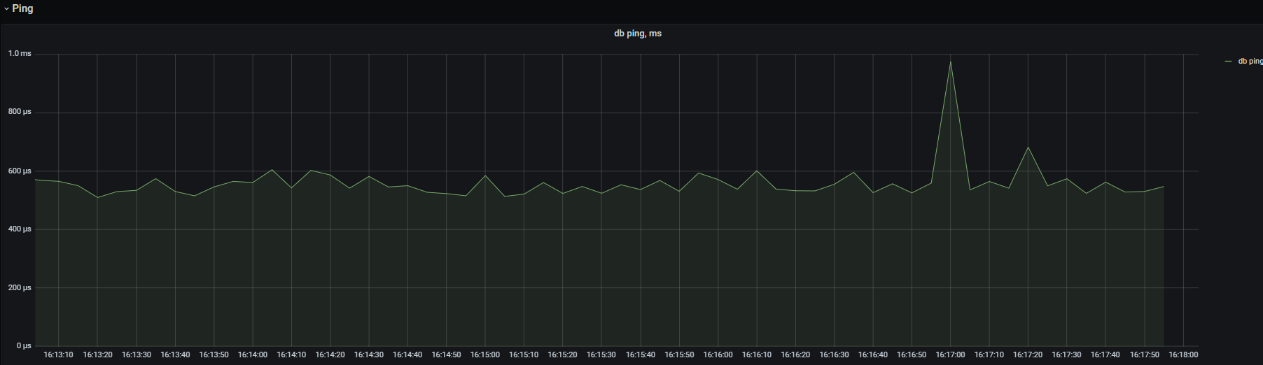
Метрика db ping#
Метрика, показывающая длительность исполнения простейшего запроса в памяти СУБД:
Oracle select 1 from dual;
PostgreSQL select 1.
За счет отсутствия в запросе обращения к дискам БД и т.п., данный показатель хорошо характеризует задержки в сетевой топологии между БД и сервисом DataSpace.
При правильно настроенной облачной среде "db ping" не должен превышать 5 мс.
Метрики буферизации запросов#
Метрики буферизации (накопления и отправки пачками) запросов.
Для просмотра метрик необходимо использовать панель "Buffering Metrics":
bufferQueueSize — количество пакетов в очереди на формировании пачки;
packetsInOneTransactionCount — количество пакетов в пачке;
batchHandlingTime (95prc ms) — 95 percentile времени обработки пачки в мс;
batchHandlingTime (MAX ms) — максимальное значение времени обработки пачки в мс;
commitsByBatchSizeCount — количество завершений формирования пачки по причине BatchSize;
commitsByEmptyQueueCount — количество завершений формирования пачки по причине EmptyQueue;
commitsByTimeWindowCount — количество завершений формирования пачки по причине TimeWindow.
Метрики GraphQL#
GraphQL, используемый в продукте, предоставляет собственные метрики, доступные в формате Prometheus, в общем наборе метрик через endpoint /actuator/prometheus, а так же дополнительную трассировочную информацию в ответе.
Настройка GraphQL-метрик#
Для включения или отключения метрик GraphQL необходимо воспользоваться опцией graphql.servlet.actuator-metrics. В продукте по умолчанию опция активации GraphQL-метрик выключена:
graphql.servlet.actuator-metrics=false
Каждая из метрик GraphQL предоставляется в разрезе операции "parsing", "validation", "execution".
Доступны следующие метрики:
Количество запросов:
graphql_timer_query_seconds_count{application="dataspace-core",namespace="tribe-pf-dev-ds-06",node_name="worker-50.stands-vdc01.solution.sbt",operation="parsing",operationName="m1111",pod="ds-core-2pg-b323-b3-4-s6-rolistov-rolistov-2107-snapshot-cwbg58",} 2.0Суммарное время исполнения:
graphql_timer_query_seconds_sum{application="dataspace-core",namespace="tribe-pf-dev-ds-06",node_name="worker-50.stands-vdc01.solution.sbt",operation="parsing",operationName="m1111",pod="ds-core-2pg-b323-b3-4-s6-rolistov-rolistov-2107-snapshot-cwbg58",} 0.009050253Максимальное время исполнения:
graphql_timer_query_seconds_max{application="dataspace-core",namespace="tribe-pf-dev-ds-06",node_name="worker-50.stands-vdc01.solution.sbt",operation="validation",operationName="m1111",pod="ds-core-2pg-b323-b3-4-s6-rolistov-rolistov-2107-snapshot-cwbg58",} 0.002259523Количество ошибок, возникающих при исполнении GraphQL-запроса:
# HELP graphql_error_counter_total GraphQL Error # TYPE graphql_error_counter_total counter graphql_error_counter_total{application="dataspace-core",error_type="DataFetchingException",namespace="local",node_name="local",pod="ksn-nt-01-dataspace-core-dspc-nt-2-10134-10135_8080",} 2.0 graphql_error_counter_total{application="dataspace-core",error_type="ValidationError",namespace="local",node_name="local",pod="ksn-nt-01-dataspace-core-dspc-nt-2-10134-10135_8080",} 3.0
Настройка GraphQL-трассировки#
Для добавления в ответ трассировочной информации необходимо в настройки добавить опцию graphql.servlet.tracing-enabled.
По умолчанию трассировка отключена.
graphql.servlet.tracing-enabled=true
Для примера, был выполнен запрос с ошибкой в имени полей:
curl -H 'Content-Type: application/json' -d '{"query": "query{searchDeposit{elems{name1,id2}}}"}' -X POST http://POD/graphql
Ответ с трассировочной информацией:
{
"errors": [
{
"message": "Validation error of type FieldUndefined: Field 'name1' in type 'Deposit' is undefined @ 'searchDeposit/elems/name1'",
"locations": [
{
"line": 1,
"column": 27
}
],
"extensions": {
"classification": "ValidationError"
}
},
{
"message": "Validation error of type FieldUndefined: Field 'id2' in type 'Deposit' is undefined @ 'searchDeposit/elems/id2'",
"locations": [
{
"line": 1,
"column": 33
}
],
"extensions": {
"classification": "ValidationError"
}
}
],
"extensions": {
"tracing": {
"version": 1,
"startTime": "2022-11-28T12:58:00.994899Z",
"endTime": "2022-11-28T12:58:00.999210Z",
"duration": 4330876,
"parsing": {
"startOffset": 673300,
"duration": 572359
},
"validation": {
"startOffset": 3521015,
"duration": 2802247
},
"execution": {
"resolvers": []
}
}
},
"data": null
}
В ответе видно, что возникла ошибка проверки запроса ValidationError. Длительность исполнения составляет ~4мс.
Скрипт анализа утилизации ресурсов контейнера (istio-proxy, dataspace и т.п.)#
Пример, когда наблюдается нехватка ресурсов контейнера с Envoy.
Зачастую при подаче значительной нагрузки на сервис DataSpace и постепенном ее увеличении в какой-то момент количество исполняемых запросов перестает расти. В случае отсутствия признаков утилизации ресурсов (CPU, блокировок, БД) со стороны контейнера с DataSpace причиной является недостаточность ресурсов у прокси-сервиса istio-proxy (Envoy), через который проходит весь сетевой трафик любого POD.
Утилизацию ресурсов Envoy возможно посмотреть в системе мониторинга облачной среды в целом, но для быстрого анализа возможно воспользоваться bash-скриптом, который легко выполнить с консоли Envoy-контейнера:
Данный скрипт предназначен для application контейнера в среде Linux Kernel v3 & v4 .
#!/usr/bin/sh
#####
# Designed by Dataspace team
# Show millicore&memory utilization of ControlGroup and send statistics to InfluxDB
# v 1.2 (Kramarev SN)
# If you want send to InfluxDB set SEND_TO_INFLUX=true and type correct INFLUX_URL&INFLUX_DB
# Istio-proxy container has the same hostname as general container. So if you want identify istio-proxy container in Grafan by postfix set HOST_IS_ISTIO=true
#
######
SEND_TO_INFLUX=false
HOST_IS_ISTIO=true
INFLUX_URL="http://IP:7086"
INFLUX_DB="ksn"
HOSTNAME=$(cat /etc/hostname)
if [ "$HOST_IS_ISTIO" == true ]; then
HOSTNAME="$(cat /etc/hostname)-istio"
echo "------------------ $HOSTNAME"
fi
MEASUREMENT_MILLICORE_USAGE="cgroup-millicore-usage"
MEASUREMENT_MEMORY_USAGE="cgroup-mem-usage"
cpu_limit_raw=$(cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us)
cpu_limit=$(expr $cpu_limit_raw / 100)
mem_limit_raw=$( cat /sys/fs/cgroup/memory/memory.limit_in_bytes)
mem_limit=$(expr $mem_limit_raw / 1024)
th_time_raw_before=$(cat /sys/fs/cgroup/cpu/cpu.stat | grep "throttled_time" | awk '{print $2}')
swap_total=$( cat /proc/meminfo | grep SwapTotal | awk '{print $2 $3}')
before=$( cat /sys/fs/cgroup/cpu/cpuacct.usage)
while true
do
sleep 1
after=$(cat /sys/fs/cgroup/cpu/cpuacct.usage)
mem_usage_raw=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
mem_usage=$(expr $mem_usage_raw / 1024)
tmp=$(expr $after - $before)
before=$after
cpu_result=$(expr $tmp / 1000000)
th_time_after=$(cat /sys/fs/cgroup/cpu/cpu.stat | grep "throttled_time" | awk '{print $2}')
th_time_ns=$(expr $th_time_after - $th_time_raw_before )
th_time_raw_before=$th_time_after
th_time_ms=$(expr $th_time_ns / 1000000)
swap_used=$( cat /proc/meminfo | grep SwapCached | awk '{print $2 $3}')
page_cache_used_bytes=$( cat /sys/fs/cgroup/memory/memory.stat | grep "^cache" | awk '{print $2}' )
echo "CPU: "$cpu_result "(millicores)" limit=$cpu_limit Thrl_time=$th_time_ms"(ms)" "Mem:" $mem_usage"(Kb)" limit=$mem_limit"(Kb) swapUsed=$swap_used swapTotal=$swap_total cache(bytes)=$page_cache_used_bytes"
if [ "$SEND_TO_INFLUX" == true ]; then
epoch_ns=$(date +%s%N)
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=usage_mlc,host=$HOSTNAME usg=$cpu_result $epoch_ns"
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=limit_mlc,host=$HOSTNAME usg=$cpu_limit $epoch_ns"
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=thr_ms,host=$HOSTNAME usg=$th_time_ms $epoch_ns"
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MEMORY_USAGE,metric=usage_kb,host=$HOSTNAME usg=$mem_usage $epoch_ns"
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MEMORY_USAGE,metric=limit_kb,host=$HOSTNAME usg=$mem_limit $epoch_ns"
fi
done
Данный скрипт каждую секунду выводит в консоль текущую утилизацию CPU (usage/limit/Throttling) и Memory(Usage/Limit). В случае необходимости можно отправлять данные в InfluxDB. Таким образом, воспользовавшись данным скриптом, можно моментально получить текущую утилизацию системных ресурсов application контейнера.
Запуск скрипта:
Скопируйте один из двух вариантов скрипта (для Application или istio-proxy контейнера) в буфер обмена (Ctr + C).
Подключитесь в терминале POD к необходимому контейнеру.
Вставьте из буфера обмена скрипт в консоль (Ctrl + V).
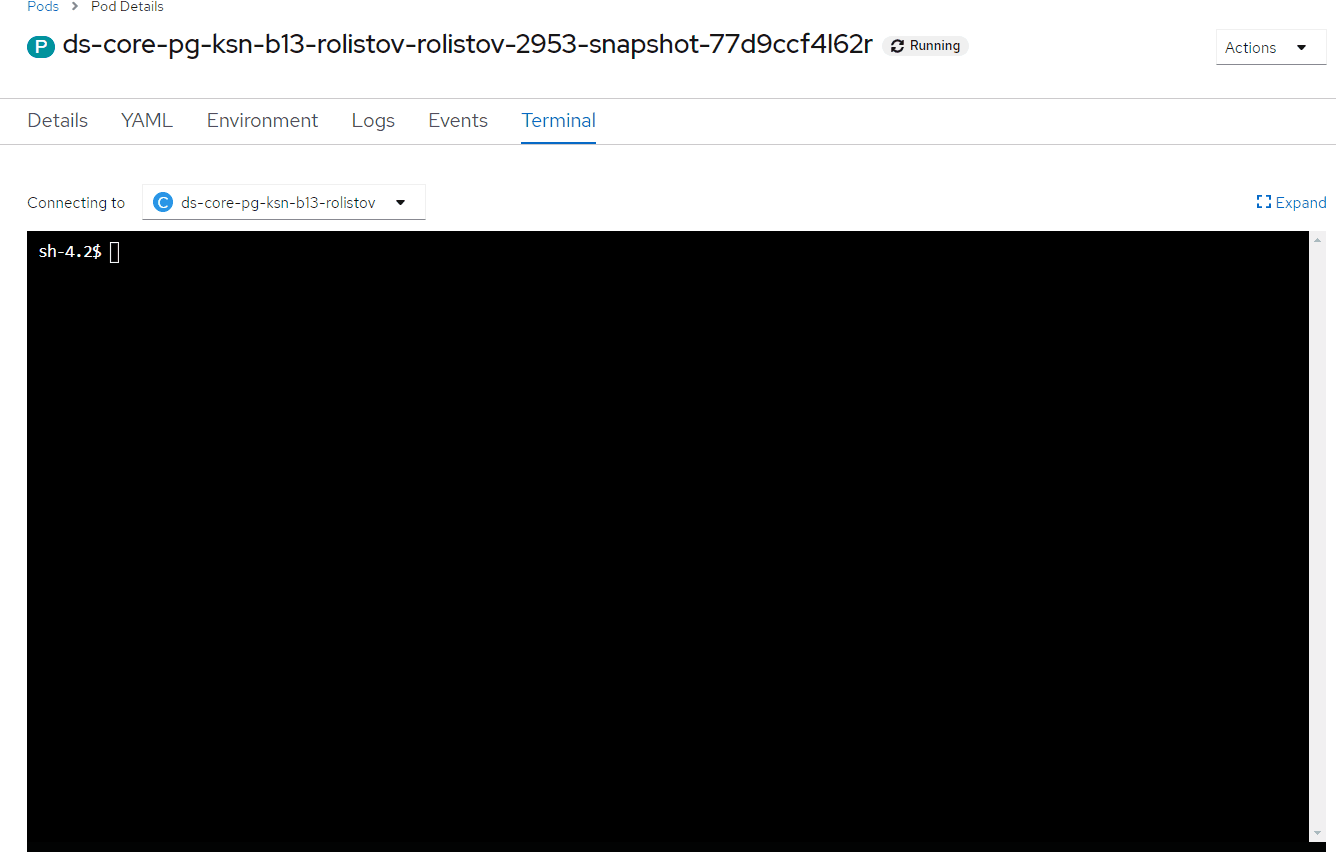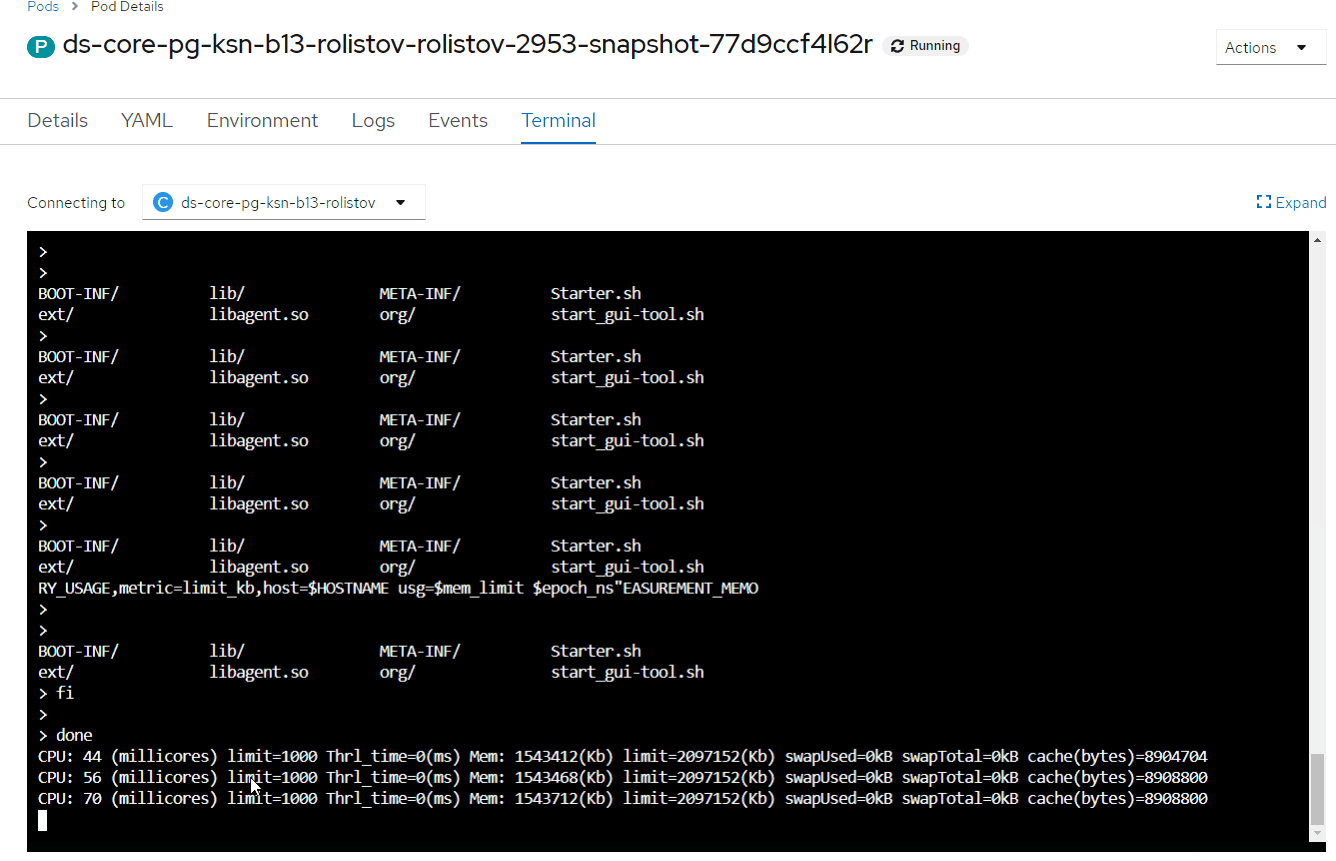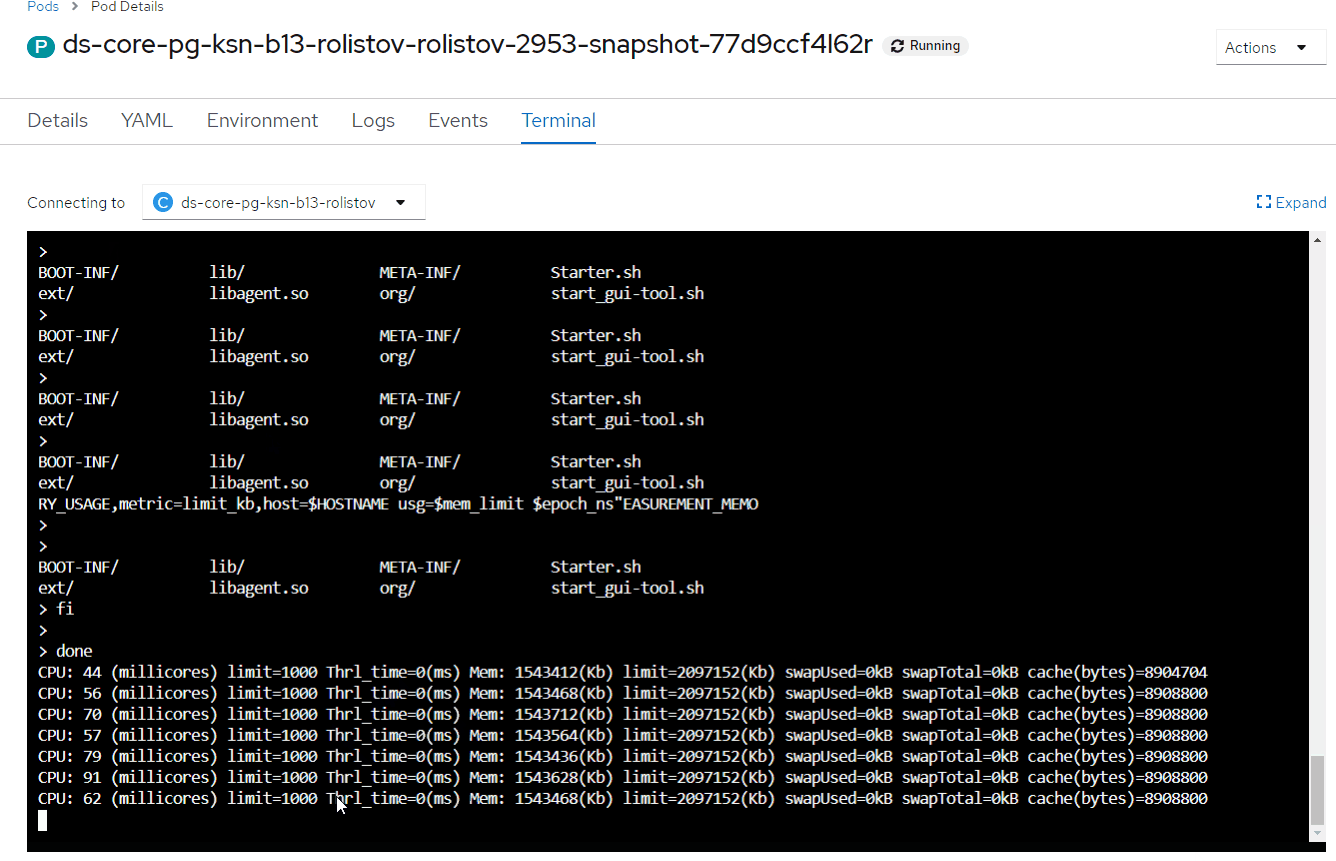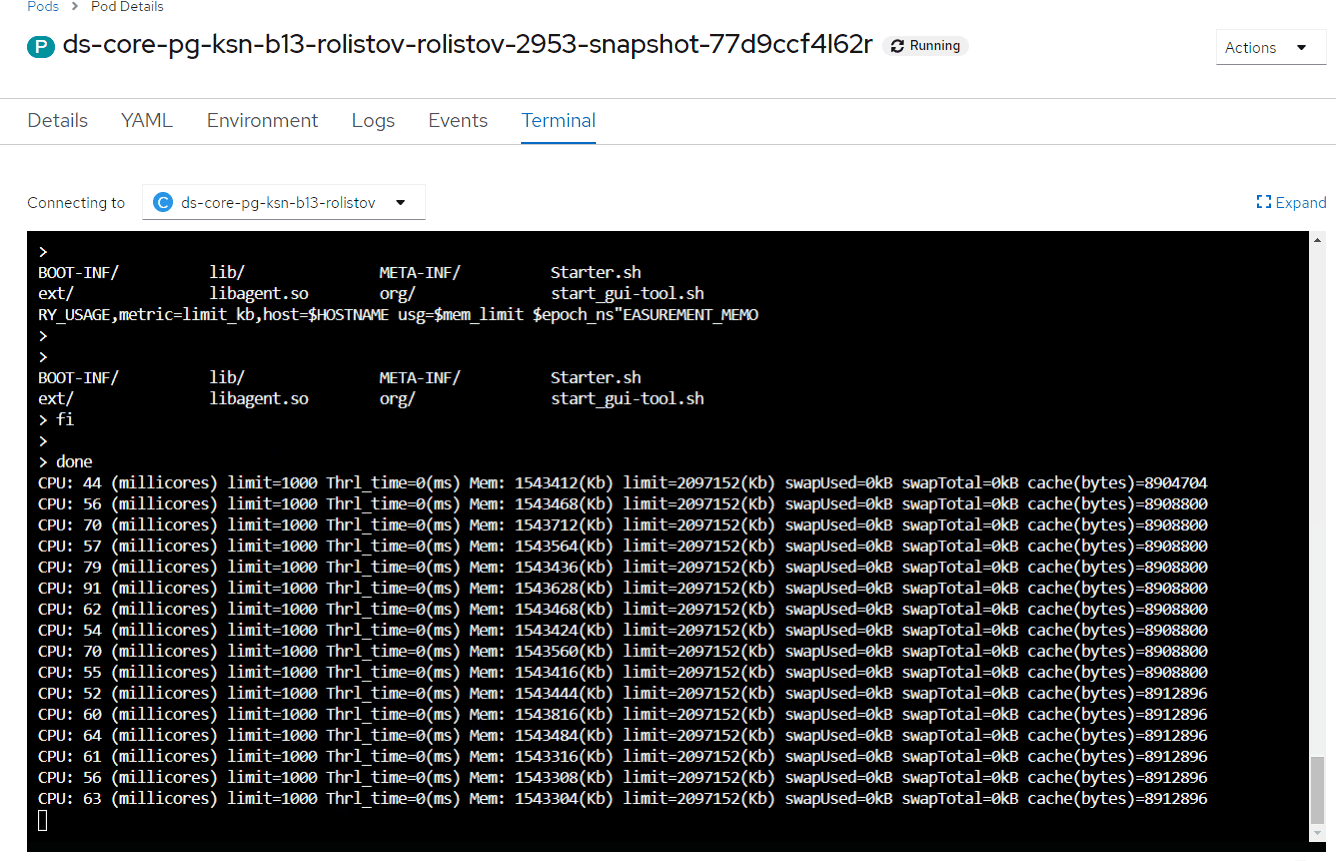
Раздел CPU:
1-й столбец — количество потребляемых millicores;
limit — текущий cpu limit;
Thrl_time — Throttling/нехватка CPU — ключевой показатель, должен быть равен "0" или иногда принимать значения, не превышающие 20-50 мс.
Раздел Mem:
4-й столбец — потребляемый объем памяти;
limit — текущий memory limit;
swapUsed — используемый swap;
cache — используемый cache (PageCache).
Скрипт, представленный ниже, предназначен для istio-proxy контейнера в среде Linux Kernel v3 & v4.
#!/usr/bin/sh
#####
# Designed by Dataspace team
# Show millicore&memory utilization of ControlGroup and send statistics to InfluxDB
# v 1.1 (Kramarev SN)
# If you want send to InfluxDB set SEND_TO_INFLUX=true and type correct INFLUX_URL&INFLUX_DB
# Istio-proxy container has the same hostname as general container. So if you want identify istio-proxy container in Grafan by postfix set HOST_IS_ISTIO=true
#
######
SEND_TO_INFLUX=false; \
HOST_IS_ISTIO=true; \
INFLUX_URL="http://IP:7086"; \
INFLUX_DB="ksn"; \
HOSTNAME=$(cat /etc/hostname) ; \
if [ "$HOST_IS_ISTIO" == true ]; then \
HOSTNAME="$(cat /etc/hostname)-istio"; \
echo "------------------ $HOSTNAME" ; \
fi; \
MEASUREMENT_MILLICORE_USAGE="cgroup-millicore-usage"; \
MEASUREMENT_MEMORY_USAGE="cgroup-mem-usage"; \
MEASUREMENT_MILLICORE_USAGE="cgroup-millicore-usage"; \
MEASUREMENT_MEMORY_USAGE="cgroup-mem-usage"; \
cpu_limit_raw=$(cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us); \
cpu_limit=$(expr $cpu_limit_raw / 100); \
mem_limit_raw=$( cat /sys/fs/cgroup/memory/memory.limit_in_bytes); \
mem_limit=$(expr $mem_limit_raw / 1024); \
th_time_raw_before=$(cat /sys/fs/cgroup/cpu/cpu.stat | grep "throttled_time" | awk '{print $2}'); \
swap_total=$( cat /proc/meminfo | grep SwapTotal | awk '{print $2 $3}'); \
before=$( cat /sys/fs/cgroup/cpu/cpuacct.usage); \
while true; do
sleep 1;
after=$(cat /sys/fs/cgroup/cpu/cpuacct.usage); \
mem_usage_raw=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes); \
mem_usage=$(($mem_usage_raw / 1024)); \
tmp=$(($after - $before)); \
before=$after; \
cpu_result=$(($tmp / 1000000)); \
th_time_after=$(cat /sys/fs/cgroup/cpu/cpu.stat | grep "throttled_time" | awk '{print $2}'); \
th_time_ns=$(($th_time_after - $th_time_raw_before)); \
th_time_raw_before=$th_time_after; \
th_time_ms=$(($th_time_ns / 1000000)); \
swap_used=$( cat /proc/meminfo | grep SwapCached | awk '{print $2 $3}'); \
echo "CPU: "$cpu_result "(millicores) limit="$cpu_limit "Thrl_time="$th_time_ms"(ms)" "Mem:" $mem_usage"(Kb) limit="$mem_limit"(Kb) swapUsed="$swap_used "swapTotal="$swap_total \
if [ "$SEND_TO_INFLUX" == true ]; then \
epoch_ns=$(date +%s%N); \
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=usage_mlc,host=$HOSTNAME usg=$cpu_result $epoch_ns"; \
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=limit_mlc,host=$HOSTNAME usg=$cpu_limit $epoch_ns"; \
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MILLICORE_USAGE,metric=thr_ms,host=$HOSTNAME usg=$th_time_ms $epoch_ns"; \
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MEMORY_USAGE,metric=usage_kb,host=$HOSTNAME usg=$mem_usage $epoch_ns"; \
curl -XPOST "$INFLUX_URL/write?db=$INFLUX_DB" --data-binary "$MEASUREMENT_MEMORY_USAGE,metric=limit_kb,host=$HOSTNAME usg=$mem_limit $epoch_ns"; \
fi; \
done \
Быстрая диагностика внутри контейнера#
В случае отсутствия мониторинга для быстрой/верхнеуровневой диагностики можно воспользоваться диагностической утилитой внутри контейнера.
Для этого необходимо:
Подключиться терминалом в application контейнер через утилиты oc, kubectl или Web-интерфейс OpenShift.
Запустить скрипт start_gui-tool.sh. Скрипт должен находиться в рабочем каталоге приложения /usr/app, куда терминал попадает автоматически.
В графическом интерфейсе выбрать необходимый раздел:
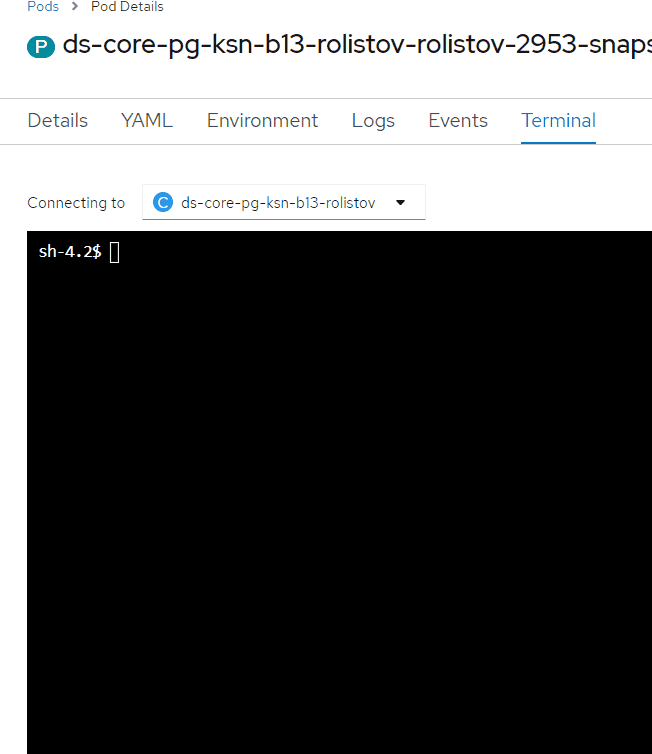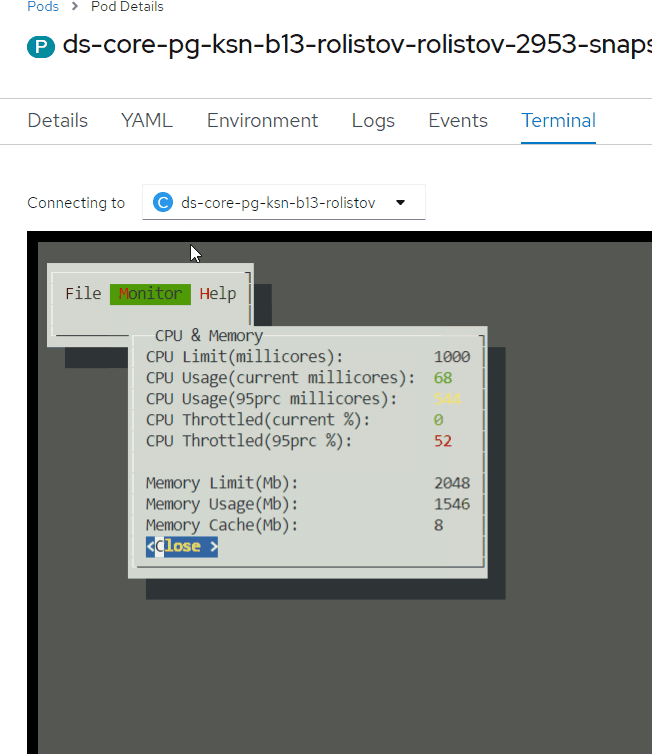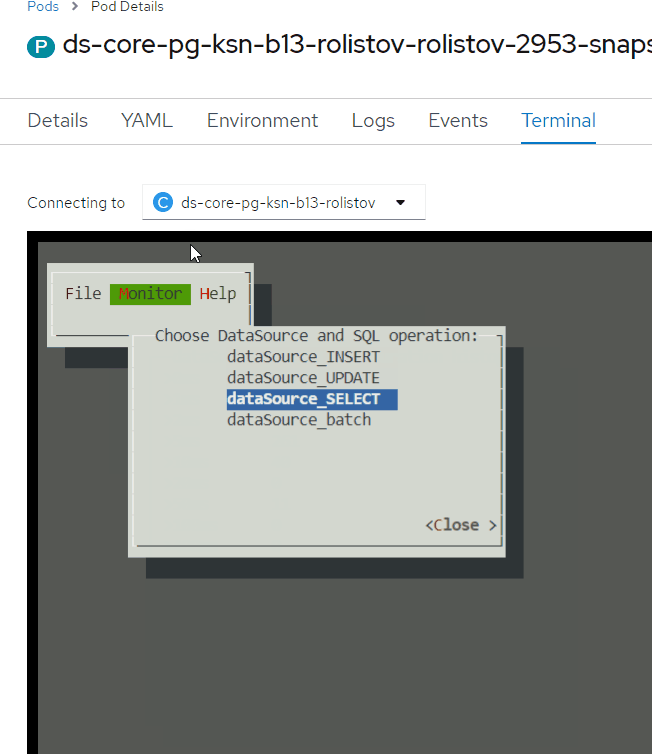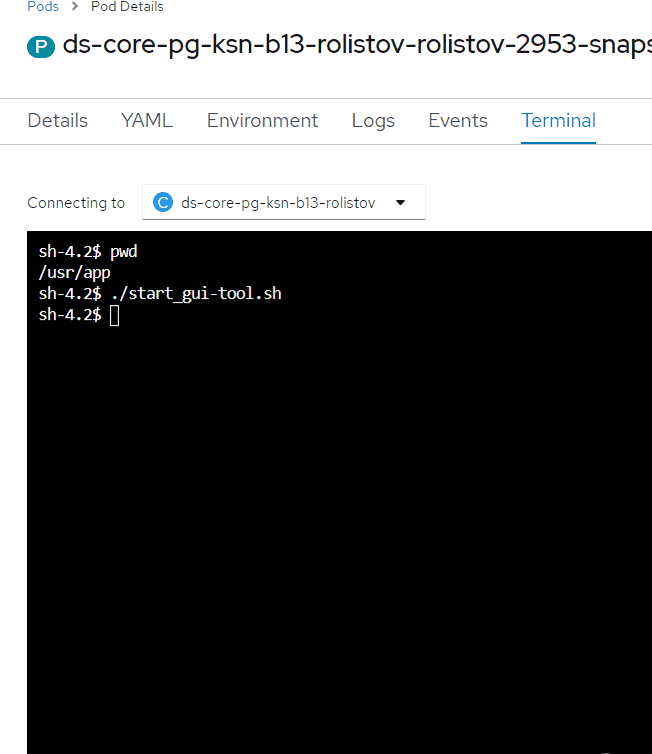
CPU&Memory — информация о потреблении CPU и Memory в контейнере;
Tomcat socket — статистика предоставляемая компонентом Tomcat о входящих подключениях (RPS, Throughput);
PoolGeneral Duration Histogram — гистограмма длительности обработки любого запроса в основном пуле потоков с момента старта приложения;
Method Duration Histogram — гистограмма длительности исполнения некоторых методов;
SQL Duration Histogram — гистограмма длительности исполнения SQL-операций;
JVM Info — статистика JVM; Safepoints — гистограмма длительности операций Safepoint для обслуживания служебных задач внутри JVM (GC, JIT, etc).
Инструкции по настройке мониторинга#
Необходимые компоненты#
В зависимости от типа выбранных метрик (эксплуатационные или диагностические/частые) для их сбора и отображения необходимо наличие следующей функциональности:
Prometheus версии 2.22.2 и выше. Зачастую данный сервис, развернутый в облачной среде в том же пространстве, автоматически находит у всех POD в данном namespace стандартные endpoint /actuator/prometheus. Если по каким-то причинам Prometheus не настроил targets, необходимо обратиться к DevOps-специалисту данного стенда. Также необходимо в настройках Prometheus (yaml) для данного target указать scrape_interval и scrape_timeout равными 10s.
InfluxDB 1.8. Также необходимо обеспечить сетевую доступность из POD. Проверить доступность возможно вызовом из POD, выполнив:
curl -GET http://IP:8086/query?pretty=true --data-urlencode "q=show databases"В ответ вернется JSON хотя бы с одной служебной БД _internal:
{ "results": [ { "statement_id": 0, "series": [ { "name": "databases", "columns": [ "name" ], "values": [ [ "_internal" ] ] } ] } ] }Grafana 7.3 и выше.
Импорт dashboards в Grafana#
DashBoard для Prometheus в виде json-файла Prometheus_metrics.json можно найти по следующему пути внутри дистрибутива: package/sdk/mvn/m2/sbp/com/sbt/dataspace/grafana-dashboard.
Необходимо создать Datasource к нужной БД хранения метрик Configuration->Data Sources->Add data source->, выбрать тип Prometheus или InfluxDB. Указать URL database (если ее нет, при первом старте DataSpace она создается автоматически), при наличии авторизации указать user/password. Также необходимо указать:
для InfluxDB — "Min time interval" 1s;
для Prometheus — "Scrape interval" 10s.
Для импорта нужного dashboard необходимо выбрать в интерфейсе Grafana Dasboards->Manage->Import->Upload JSON file и далее указать файл Prometheus_metrics.json из дистрибутива.
Во время импорта необходимо:
Сменить UID, выбрав Change uid.
Выбрать ранее созданный Datasource.
При необходимости выбрать папку Folder.
Нажать Import (Overwrite).
Настройка сервиса DataSpace в отношении мониторинга#
Подключение компонентов мониторинга в Spring Boot приложение#
Компонент DataSpace Core предоставляет возможности:
конфигурирование мониторинга;
логирование запросов к базе данных;
логирование методов приложения (лог-записи входа/выхода в метод с параметрами, результатом и временем выполнения).
Для включения вышеперечисленной функциональности используется глобальная настройка:
dataspace.monitoring.enabled=true
Внимание!
Глобальное свойство и все далее указанные параметры приведены со значениями по умолчанию!
Параметры можно найти в конфигурационном файле dataspace-core/dataspace-core-module/src/main/resources/application.properties.
Метрики приложения (application metrics)#
Метрики приложения осуществляют измерение времени работы методов и количества вызовов.
Включение/выключение функциональности:
dataspace.monitoring.watch-metrics.enabled=true
Определение способа поиска методов для наблюдения:
Над методом или классом должна быть поставлена аннотация
@EyeOn.Через свойства в
application.propertiesдля конкретного пакета, класса или метода имеется возможность указать необходимость сбора метрик:
dataspace.monitoring.watch-metrics.category.sbp.sbt.dataspacecore.lib.commandhandlers=true
Возможно также указать имя spring-бина, который будет определять дополнительные измерения для метрики, например, prettyCommandPacketProcessorTagsResolver:
dataspace.monitoring.watch-metrics.category.sbp.sbt.dataspacecore.lib.commandhandlers=true
dataspace.monitoring.watch-metrics.category.sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process=true,prettyCommandPacketProcessorTagsResolver
В группе dataspace.monitoring.watch-metrics.category описываются параметры для метрик. Может быть указано полное название класса с методом или какая-то часть из этого, например:
пакет —
com.sbt.ac.test.service;пакет и класс —
com.sbt.ac.test.service.ServiceOne;пакет, класс и метод —
com.sbt.ac.test.service.CompositeService.methodThree.
В параметрах можно указать, включен или выключен конкретный пакет или класс, а также имя spring-бина, который может кастомизировать (tags) измерения для указанного имени. Например, на основании входящих параметров или результата можно добавить измерения. По умолчанию измерения (размерности/tags/label) — это класс, метод и ошибка (имя класса исключения). Для получения дополнительных измерений нужно описать spring-бин, реализующий интерфейс TagsResolver.
Метрики базы данных (db metrics)#
Включение/выключение функциональности:
dataspace.monitoring.datasource.enabled=true
Измерение длительности выполнения и количества SQL-запросов (INSERT, SELECT, BATCH etc.):
dataspace.monitoring.datasource.datasource-proxy.metrics.enable-query=true
Измерение длительности выполнения и количества jdbc-методов:
dataspace.monitoring.datasource.datasource-proxy.metrics.enable-method=true
Перечень jdbc-методов:
dataspace.monitoring.datasource.methods=commit,createStatement,rollback,close,execute,executeQuery,executeUpdate,executeBatch,executeLargeBatch,executeLargeUpdate,getConnection
Измерение длительности ping БД:
dataspace.monitoring.db.ping.enabled=false
Системные метрики (system metrics)#
Набор системных метрик включает в себя метрики jvm и так называемую непосредственную группу системных метрик (cgroup metrics).
В непосредственную группу системных метрик входят:
Показатели пулов потоков, обрабатывающих HTTP-вызовы Spring Boot-приложения.
Показатели утилизации CPU Linux Control Group (POD/контейнера).
Утилизация Memory для ControlGroup (только для Linux-контейнеров) и полный размер памяти, занимаемой всей JVM (Heap + NonHeap).
Утилизация сетевого интерфейса.
TCP очередь и повторные TCP-запросы.
Утилизация дисковой подсистемы.
Количество потоков JVM.
Включение/выключение функциональности:
dataspace.monitoring.cgroup.enabled=false
Включение/выключение сбора гистограммы длительности выполнения Tomcat ThreadPool's tasks для general, batch, service пулов потоков:
server.tomcat.threadstatistics=false
Настройка сетевой статистики:
dataspace.monitoring.network.enabled=true — включение/выключение целиком сетевой статистики
dataspace.monitoring.network.interfaceName=eth0 — имя сетевого интерфейса
dataspace.monitoring.network.procNet=/proc/net — имя псевдо-файла OS для получения данных от ядра
dataspace.monitoring.network.maxRemoteIpPortPairKeepStatistics=50 — максимальное количество TCP-соединений для хранения статистик
dataspace.monitoring.network.headerLinePattern="local_address" — строка для фильтрации в /proc/net
dataspace.monitoring.network.statrefresh.fixedratems=1000 — частота опроса /proc/net в мс
В случае превышения разрешенного максимального количества хранимых TCP-соединений в статистике возникнет исключение SizeLimitExceededException в журнале:
- SizeLimitExceededException "Превышен допустимый размер "
- SizeLimitExceededException "Превышен допустимый размер храним пар IP:PORT, равный = "
В первую очередь необходимо понять, на самом ли деле нормально такое количество (больше 50).
При необходимости увеличить количество можно с помощью параметра:
dataspace.monitoring.network.maxRemoteIpPortPairKeepStatistics=50 — максимальное количество TCP-соединений для хранения статистик
Настройка дисковой статистики:
dataspace.monitoring.disk.enabled=true — включение/выключение целиком дисковой статистики
dataspace.monitoring.disk.excludeDirectories=/dev,/mnt — список директориев для исключения из статистики. По умолчанию — "/bin", "/sbin", "/lib", "/lib64", "/proc", "/sys", "/dev", "/media", "/mnt"
dataspace.monitoring.disk.allDirSizeBytesLimitWarn=1900000000 — лимит в байтах, выше которого будут выводиться в журнал записи о событиях WARN
dataspace.monitoring.disk.statrefresh.fixedratems=60000 — частота опроса дисковой подсистемы в мс
Регулярно (каждые 60 сек.) происходит подсчет утилизации всех директорий от корня, за исключением следующих:
"/bin", "/sbin", "/lib", "/lib64", "/proc", "/sys", "/dev", "/media", "/mnt"
В случае если суммарный объем будет выше лимита dataspace.monitoring.disk.allDirSizeBytesLimitWarn 1.9Gb в журнал будет выводиться сообщение:
2023-05-04 10:35:16,999 [scheduling-1] [WARN] (sbp.com.sbt.dataspace.suppport.monitoring.DiskMetrics) [sbp.com.sbt.dataspace.sup
pport.monitoring.DiskMetrics::loggingInfo:66] mdc:()| DiskUtilization above limit 1900000000 and 2774422061 bytes
2023-05-04 10:35:16,999 [scheduling-1] [WARN] (sbp.com.sbt.dataspace.suppport.monitoring.DiskMetrics) [sbp.com.sbt.dataspace.sup
pport.monitoring.DiskMetrics::loggingInfo:71] mdc:()| Size of directory /usr = 805536905 bytes
2023-05-04 10:35:16,999 [scheduling-1] [WARN] (sbp.com.sbt.dataspace.suppport.monitoring.DiskMetrics) [sbp.com.sbt.dataspace.sup
pport.monitoring.DiskMetrics::loggingInfo:71] mdc:()| Size of directory /opt = 1497291547 bytes
2023-05-04 10:35:17,000 [scheduling-1] [WARN] (sbp.com.sbt.dataspace.suppport.monitoring.DiskMetrics) [sbp.com.sbt.dataspace.sup
pport.monitoring.DiskMetrics::loggingInfo:71] mdc:()| Size of directory /etc = 10033814 bytes
В сообщение выше будет отображен суммарный объем и объем каждой директории. При необходимости возможно увеличить лимит настройкой в байтах:
dataspace.monitoring.disk.allDirSizeBytesLimitWarn=1900000000 < -- ~ 1.9Gb т.к. EphemeralStorage = 2Gb
В группу JVM-метрик входят:
Паузы JVM по причине перехода в safe-points.
Метрики GC.
Статистика компилятора (Jit).
JVM Memory — утилизация областей памяти (Heap & NON-Heap).
Утилизация JIT CodeHeap.
Включение/выключение функциональности:
dataspace.monitoring.jvm.enabled=false
Отправка метрик в системы хранения#
Компонент DataSpace Core поддерживает отправку в следующие специализированные системы мониторинга для хранения метрик:
InfluxDB.
Prometheus.
Отправка в InfluxDB#
Запись метрик в InfluxDB осуществляется двумя способами:
Напрямую из собственного механизма MetricsStoreEngine. В набор метрик, которые отправляются указанным способом, входят метрики cgroup, jvm, утилизации пулов потоков tomcat, длительности SQL-запросов и jdbc-методов, а также метрики приложения (application metrics).
Основной параметр, который включает/выключает отправку в influx:
dataspace.monitoring.influx.enabled=falseВключение/выключение замера и отправки в influx длительности SQL-запросов и jdbc-методов:
dataspace.monitoring.datasource.influx.enabled=falseПараметры подключения к influx:
dataspace.monitoring.influx.url=${InfluxUrl:<адрес сервера Influx>} dataspace.monitoring.influx.db=app-metrics dataspace.monitoring.influx.login=root dataspace.monitoring.influx.password=rootПараметры подключения к influx для отправки метрик cgroup:
dataspace.monitoring.cgroup.influx.url=${dataspace.monitoring.influx.url} dataspace.monitoring.cgroup.influx.enabled=true dataspace.monitoring.cgroup.influx.login=root dataspace.monitoring.cgroup.influx.password=root dataspace.monitoring.cgroup.influx.db=metricsdbПараметры подключения к influx для отправки метрик jvm:
dataspace.monitoring.jvm.influx.url=${dataspace.monitoring.influx.url} dataspace.monitoring.jvm.influx.enabled=true dataspace.monitoring.jvm.influx.login=root dataspace.monitoring.jvm.influx.password=root dataspace.monitoring.jvm.influx.db=metricsdbОтправка метрик средствами spring actuator и micrometer-registry-influx. Таким образом посылаются метрики ping БД, утилизации пула соединений БД:
management.metrics.export.influx.enabled=false management.metrics.export.influx.db=${dataspace.monitoring.influx.db} management.metrics.export.influx.step=1m management.metrics.export.influx.uri=${dataspace.monitoring.influx.url}
Генерация метрик для Prometheus#
В соответствии с механизмом сбора метрик, используемым системой Prometheus, в приложении необходимо предоставить endpoint, который Prometheus опрашивает для получения метрик.
Для активации экспорта в формате Prometheus (со встроенными метриками от SpringBoot-приложения) необходимо выполнить следующие настройки:
dataspace.monitoring.enabled=true
management.metrics.tags.application=${spring.application.name}
management.endpoints.enabled-by-default=true
management.endpoints.web.exposure.include=*
management.endpoints.jmx.exposure.include=*
management.endpoint.metrics.enabled=true
management.metrics.export.prometheus.enabled=true
management.endpoint.prometheus.enabled=true
Проверка:
Выполнить внутри Pod:
curl localhost:8080/actuator/prometheus
Вывод множество строк вида:
process_start_time_seconds{namespace="local",node_name="local",pod="...",} 1.637338200551E9
Внимание!
Важно наличие тегов namespace, node_name, pod в выводе, указанном в примере выше. Они насыщаются при старте, анализируя среду, где запущено приложение (в Pod/контейнере или чистом Linux/Windows). Теги нужны в дальнейшем для Dashboards.
Проверить это возможно вызовом:
curl localhost:8080/envInfo EnvInfo{namespace='local', podName='...', nodeName='local'}
Типовой перечень опций, необходимых для получения всех метрик для Dashboard в Prometheus:
dataspace.monitoring.enabled=true
# Генерация для Прометея
# настройка для проставления тега с названием приложения в метриках
management.metrics.tags.application=${spring.application.name}
management.endpoints.enabled-by-default=true
management.endpoints.web.exposure.include=*
management.endpoints.jmx.exposure.include=*
management.endpoint.metrics.enabled=true
management.metrics.export.prometheus.enabled=true
management.endpoint.prometheus.enabled=true
# Enable System & JVM metrics
dataspace.monitoring.cgroup.enabled=true
dataspace.monitoring.jvm.enabled=true
# Enable Tomcat Metrics from JMX
server.tomcat.mbeanregistry.enabled=true
# Gather Thread pool execution time
server.tomcat.threadstatistics=true
# Enable DB & JDBC metrics
dataspace.monitoring.datasource.enabled=true
dataspace.monitoring.datasource.datasource-proxy.metrics.enable-query=true
dataspace.monitoring.datasource.datasource-proxy.metrics.enable-method=true
dataspace.monitoring.datasource.methods=commit,createStatement,rollback,close,execute,executeQuery,executeUpdate,executeBatch,executeLargeBatch,executeLargeUpdate,getConnection
dataspace.monitoring.db.ping.enabled=true
Отключение сбора метрик через Prometheus#
Если по каким-то причинам необходимо отключить сбор метрик с помощью Prometheus и, соответственно, Micrometer, необходимо установить следующим параметрам значение "false":
- management.metrics.export.prometheus.enabled=false
- management.endpoint.prometheus.enabled=false
Настройка логирования транзакций при создании и репликации#
Включение логирования формирования вектора изменений при создании транзакции: <logger name="sbp.com.sbt.dataspace.replication.journal.PayloadContainerAsJournalSender" level="debug"/>/
Появятся лог-записи вида:
2023-12-04 06:51:12,019 [/] [kafka-producer-network-thread | producer-2] [DEBUG] (sbp.com.sbt.dataspace.replication.journal.PayloadContainerAsJournalSender) [sbp.com.sbt.dataspace.replication.journal.PayloadContainerAsJournalSender::lambda$sendDataContainerWithAckRequest$0:71] mdc:()| tx 920d8725-e951-42bb-b8f5-cde89850891b: Sent LCK+DATA journal (createMode = 0, vectorVersion = 1, serviceId = 8c9b4ee6-bede-4758-937e-168198e8bec5_5ee1f4, serviceIdType = RootEntity, clientId = 7308582088956641281, prevTxId = null)
Включение логирования применения вектора изменений при репликации: <logger name="sbp.dataspace.standin.journal.StandinJournalConsumer" level="debug"/>.
Появятся лог-записи вида:
2023-12-04 06:51:12,076 [/] [consumer_DZ-49_EXPORT_FUNC_SI_LCK_LCK-1-C-1] [DEBUG] (sbp.dataspace.standin.journal.StandinJournalConsumer) [sbp.dataspace.standin.journal.StandinJournalConsumer::handle:70] mdc:()| Applied journal confirmationMode = CONFIRMED, createMode = 0, dataType = LCK, serviceId = 8c9b4ee6-bede-4758-937e-168198e8bec5_5ee1f4, serviceIdType = RootEntity, clientId = 7308582088956641281, version = 1, prevTxId = null
2023-12-04 06:51:12,150 [/] [consumer_DZ-49_EXPORT_FUNC_SI_LCK_ULCK-1-C-1] [DEBUG] (sbp.dataspace.standin.journal.StandinJournalConsumer) [sbp.dataspace.standin.journal.StandinJournalConsumer::handle:70] mdc:()| Applied journal confirmationMode = CONFIRMED, createMode = 0, dataType = ULCK, serviceId = 8c9b4ee6-bede-4758-937e-168198e8bec5_5ee1f4, serviceIdType = RootEntity, clientId = 7308582088956641281, version = 1, prevTxId = null
2023-12-04 06:51:12,471 [/] [consumer_DZ-49_EXPORT_FUNC_SI_DATASPACE-1-C-1] [DEBUG] (sbp.dataspace.standin.journal.StandinJournalConsumer) [sbp.dataspace.standin.journal.StandinJournalConsumer::handle:70] mdc:()| Applied journal confirmationMode = CONFIRMED, createMode = 0, dataType = DATASPACE, serviceId = 8c9b4ee6-bede-4758-937e-168198e8bec5_5ee1f4, serviceIdType = RootEntity, clientId = 7308582088956641281, version = 1, prevTxId = null
Журналирование методов приложения#
Как упоминалось, существует возможность записывать в журнал входы/выходы методов приложения с параметрами, результатом и временем выполнения.
Включение/выключение функциональности:
dataspace.monitoring.watch-log.enabled=true
Уровень логирования, с которым будет происходить вывод сообщений:
dataspace.monitoring.watch-log.level=debug
Примечание
По умолчанию вывод сообщений осуществляется на уровне debug.
Настройки логирования для конкретного пакета:
dataspace.monitoring.watch-log.category.sbp.sbt.dataspacecore=afterLast,printTime
Значения, которые можно указать для пакета, класса или метода:
all— выводить все.none— ничего не выводить.beforeFirst— вход для первого метода. Если не указан параметрbefore, вложенные методы логироваться не будут.before— вход для метода.args— записывать параметры.after— выход для метода.afterLast— выход для первого метода. Если не указан параметрafter, вложенные методы логироваться не будут.result— логировать результат.printTime— печать времени выполнения.
Пример вывода всех возможных значений (all):
dataspace.monitoring.enabled=true
dataspace.monitoring.watch-log.enabled=true
dataspace.monitoring.watch-log.level=debug
dataspace.monitoring.watch-log.category.sbp.sbt.dataspacecore=all
Вывод:
> Общий вид вывода может отличаться в зависимости от конфигурации logback
2021-11-19 18:15:07,757 DEBUG [general-pool-thread-3] dataspace.packet.processor — >> 0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process, args: '[PacketRequest(idempotencePacketId=null, commands=[PacketRequest.Command(id=0, name=create, params={"type":"Request","product":{"entityId":"7032299881217654785"}}, aggregateClass=class sbp.dataspace.deals.jpa.Request), PacketRequest.Command(id=1, name=get, params={"type":"Request","props":{"product":"entityId"},"id":"ref:0"}, aggregateClass=class sbp.dataspace.deals.jpa.Request)], aggregateClass=class sbp.dataspace.deals.jpa.Request, commandResults={}, commandsResponseMode=ARRAY, softAggregateRestriction=true, aggregateVersion=0, aggregateVersionMode=NOT_PRESENT, aggregateInstanceByApiCall=null, firstGetCommand=null, firstGetCommandNeedRemoveAggregateVersionField=false)]'
...
2021-11-19 18:15:07,758 DEBUG [general-pool-thread-3] dataspace.packet.processor — > 1:sbp.sbt.dataspacecore.lib.commandhandlers.CreateCommandHandler.execute, args: '[{"type":"Request","product":{"entityId":"7032299881217654785"}}, sbp.sbt.dataspacecore.lib.security.packet.PacketSecurityContextFactory$UnsecureContext@32eb9ac1]'
2021-11-19 18:15:07,759 DEBUG [general-pool-thread-3] dataspace.packet.processor — < v:1:sbp.sbt.dataspacecore.lib.commandhandlers.CreateCommandHandler.execute, result: 'sbp.sbt.dataspacecore.lib.packet.processor.CommandHandlerResult@1953d6db', 588us [1716us]
...
2021-11-19 18:15:07,774 DEBUG [general-pool-thread-3] dataspace.packet.processor — << v:0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process, result: 'PacketResponse(commandMap={0="7032299881217654793", 1={"type":"Request","id":"7032299881217654793","props":{"product":{"entityId":"7032299881217654785"}}}}, commandsResponseMode=ARRAY, aggregateInstance=sbp.dataspace.deals.jpa.Request@b4bc03dc, aggregateVersion=null, idempotenceResponse=false)', 15647us [16262us]
В представленном выше выводе:
важно выбирать сообщения для одного потока general-pool-thread-3;
логируются все значения (dataspacecore=all), в том числе и параметры;
в 18:15:07,757 вызвали/вошли (знак >>) в метод PacketProcessorImpl.process;
в 18:15:07,758 внутри вызова был выполнен вложенный вызов (знак >) уже к методу CreateCommandHandler.execute;
в 18:15:07,759 метод
CreateCommandHandler.executeзавершил (знак <) работу;… для сокращения убрали другие вызовы;
в 18:15:07,774 метод
PacketProcessorImpl.processзавершил (знак <<) свою работу за 15647us. С учетом работы листенеров на before и after этапах, которые обрамляют вызов метода, время составило [16262us].
Пример вывода только первого/верхнего метода без вложенных методов, аргументов и ответа, но с общим временем исполнения:
dataspace.monitoring.enabled=true
dataspace.monitoring.watch-log.enabled=true
dataspace.monitoring.watch-log.level=debug
dataspace.monitoring.watch-log.category.sbp.sbt.dataspacecore=beforeFirst,afterLast,printTime
Вывод:
2021-11-19 18:38:44,096 DEBUG [general-pool-thread-3] dataspace.packet.processor — >> 0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process
...
2021-11-19 18:38:44,117 DEBUG [general-pool-thread-3] dataspace.packet.processor — << v:0:sbp.sbt.dataspacecore.lib.packet.processor.PacketProcessorImpl.process, 20388us [20798us]
В выводе выше видим:
18:38:44,096 — время входа (знак >>) в метод
PacketProcessorImpl.process;18:38:44,117 — время выхода (знак <<) из метода
PacketProcessorImpl.process;чистое время исполнения 20388us с учетом "оборачивания" метода для журналирования составило [20798us].
Журналирование SQL-операций#
Данная функциональность позволяет записывать все SQL-операции с СУБД (при необходимости с параметрами) в журнал приложения. По умолчанию журналирование параметров отключено (см. ниже).
В журнале будет доступна следующая информация о SQL-запросе:
Name — имя ProxyDataSource;
Connection — id соединения;
Time — время выполнения запроса в ms;
Success — успешность выполнения запроса;
Type — тип стейтмента (Statement/Prepared/Callable);
Batch — batch execution;
QuerySize — число запросов;
BatchSize — размер batch-запроса;
Query — SQL-запрос;
Params — параметры SQL-операции (если включены).
Пример вывода с отключенным выводом параметров:
2021-11-19 17:55:37,769 INFO [general-pool-thread-3] dataspacecore.sql -
Name:mainDb, Connection:207, Time:1, Success:True
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["select 0, t0.OBJECT_ID, t0.PRODUCT_ENTITYID from T_REQUEST t0 where t0.OBJECT_ID = ?"]
Params:[to show params set log level to 'debug']
Ниже будут приведены варианты конфигурирования для двух ситуаций:
При запуске в облачной среде K8S через стандартный PipeLine (часть параметров уже будет предварительно настроена).
Ручной запуск во время разработки/отладки.
Включение журналирования SQL-операций в предварительно настроенной облачной среде#
Настроив параметры следующим образом, будут выводиться лог-записи по всем SQL-операциям без параметров:
dataspace.monitoring.datasource.enabled=true
dataspace.monitoring.datasource.datasource-proxy.query.enable-logging=true
dataspace.monitoring.datasource.datasource-proxy.query.log-level=info
dataspace.monitoring.datasource.datasource-proxy.query.logger-name=dataspacecore.sql
Вывод:
2021-11-19 17:55:37,769 INFO [general-pool-thread-3] dataspacecore.sql -
Name:mainDb, Connection:207, Time:1, Success:True
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["select 0, t0.OBJECT_ID, t0.PRODUCT_ENTITYID from T_REQUEST t0 where t0.OBJECT_ID = ?"]
Params:[to show params set log level to 'debug']
Для включения журналирования параметров SQL-операций необходимо:
установить параметр
dataspace.monitoring.datasource.datasource-proxy.query.log-levelв debug;изменить уровень журналирования в logback.xml для пакета, указанного в
dataspace.monitoring.datasource.datasource-proxy.query.logger-name.
Пример:
dataspace.monitoring.datasource.enabled=true
dataspace.monitoring.datasource.datasource-proxy.query.enable-logging=true
dataspace.monitoring.datasource.datasource-proxy.query.log-level=debug
dataspace.monitoring.datasource.datasource-proxy.query.logger-name=dataspacecore.sql
ВАЖНО!!!: в файле logback.xml изменить на:
<logger name="dataspacecore.sql" level="debug"/>
Вывод:
2021-11-19 16:40:48,595 DEBUG [general-pool-thread-3] dataspacecore.sql — Name:mainDb, Connection:207, Time:2, Success:True Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["INSERT INTO T_REPL_AGGLOCK_REQUEST (rootid, version, guid, sys_lastchangedate) VALUES (?, ?, ?, LOCALTIMESTAMP) ON CONFLICT (rootid) DO NOTHING"]
Params:[(7032275574538108932,1,e5615e95-c660-47c0-b736-181bc86a98d3)]
Включение журналирования SQL-операций во время ручного запуска при отладке/разработке#
Иногда для различных задач разработки требуется ручной запуск модуля с помощью jar-файла. В таком режиме отсутствует предварительно настроенная среда, поэтому потребуются дополнительные настройки.
Ниже приведен пример запуска с включенным режимом журналирования SQL-операций без параметров:
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5009 -cp "$(printf ./deposit-model-jpa/target/standalone/*jar)" \
-Dloader.path=./deposit-model-jpa/target org.springframework.boot.loader.PropertiesLauncher \
--spring.profiles.active=local-h2-profile \
--dataspace-core.model.packagesToScan=sbp.com.sbt.dataspace \
--server.port=8088 --service.server.port=9089 \
--dataspace.monitoring.enabled=true \
--dataspace.monitoring.datasource.enabled=true \
--dataspace.monitoring.datasource.datasource-proxy.query.enable-logging=true \
--dataspace.monitoring.datasource.datasource-proxy.query.log-level=info \
--dataspace.monitoring.datasource.datasource-proxy.query.logger-name=dataspacecore.sql \
Для запуска с включенным режимом журналирования SQL-операций с параметрами необходимо:
установить параметр
dataspace.monitoring.datasource.datasource-proxy.query.log-levelв debug;изменить уровень журналирования в logback.xml для пакета, указанного в
dataspace.monitoring.datasource.datasource-proxy.query.logger-name.
Пример:
В том же каталоге расположить файл logback.xml (взять, например, иp проекта dataspace-core\dataspace-core-module\src\main\resources\logback.xml).
В нем изменить строку на: <logger name="dataspacecore.sql" level="debug"/>.
Добавив опцию "logging.config", запустить:
java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5009 -cp "$(printf ./deposit-model-jpa/target/standalone/*jar)" \
-Dloader.path=./deposit-model-jpa/target org.springframework.boot.loader.PropertiesLauncher \
-Dlogging.config=logback.xml \
--spring.profiles.active=local-h2-profile \
--dataspace-core.model.packagesToScan=sbp.com.sbt.dataspace \
--server.port=8088 --service.server.port=9089 \
--dataspace.monitoring.enabled=true \
--dataspace.monitoring.datasource.enabled=true \
--dataspace.monitoring.datasource.datasource-proxy.query.enable-logging=true \
--dataspace.monitoring.datasource.datasource-proxy.query.log-level=debug \
--dataspace.monitoring.datasource.datasource-proxy.query.logger-name=dataspacecore.sql \
Дополнительные опции журналирования SQL-операций#
Дополнительные опции (по умолчанию данный функционал отключен):
журналирование запросов, время исполнения которых превышает заданный порог в мс;
вывод в формате json;
вывод в журнал в виде нескольких строк (для удобства).
Журналирование запросов, время исполнения которых превышает заданный порог в мс#
Существует возможность логировать только медленные запросы, время выполнения (порог) которых превышает заданное значение.
Включение/выключение логирования медленных запросов:
dataspace.monitoring.datasource.datasource-proxy.slow-query.enable-logging=true
Уровень логирования для медленных запросов:
dataspace.monitoring.datasource.datasource-proxy.slow-query.log-level=warn
Категория логирования для медленных запросов:
dataspace.monitoring.datasource.datasource-proxy.slow-query.logger-name=dataspacecore.SQL.slow
Время исполнения запроса в мс, после которого запрос будет считаться медленным:
dataspace.monitoring.datasource.datasource-proxy.slow-query.threshold=100
Вывод в формате json#
Включение/выключение логирования в формате json:
dataspace.monitoring.datasource.datasource-proxy.json-format=false
Вывод в журнал в виде нескольких строк#
Вывод в виде нескольких строк:
dataspace.monitoring.datasource.datasource-proxy.multiline=true
Пример:
dataspace.monitoring.enabled=true
dataspace.monitoring.datasource.enabled=true
dataspace.monitoring.datasource.datasource-proxy.slow-query.enable-logging=true
dataspace.monitoring.datasource.datasource-proxy.slow-query.log-level=warn
dataspace.monitoring.datasource.datasource-proxy.slow-query.logger-name=dataspacecore.sql.slow
dataspace.monitoring.datasource.datasource-proxy.slow-query.threshold=0
dataspace.monitoring.datasource.datasource-proxy.multiline=true
dataspace.monitoring.datasource.datasource-proxy.json-format=false
С такими настройками в лог-записи будут выводиться только SQL-операции, время исполнения которых превышает порог 0 мс (в данном случае все).
Вывод:
2021-11-19 17:33:55,128 WARN [pool-2-thread-1] dataspacecore.sql.slow -
Name:mainDb, Connection:207, Time:0, Success:False
Type:Prepared, Batch:False, QuerySize:1, BatchSize:0
Query:["select 0, t0.OBJECT_ID, t0.PRODUCT_ENTITYID from T_REQUEST t0 where t0.OBJECT_ID = ?"]
Params:[(7032289263370633220)]
Автоматическое снятие ThreadDump#
Функциональность автоматического снятия ThreadDump возможна для следующих случаев:
Автоматическое снятие ThreadDump JVM в случае превышения порога (мс) для 95 percentile длительности исполнения задач. Порог возможно изменять в Runtime через HTTP-запрос. Используется облегченный метод снятия, практически не влияющий на производительность.
Автоматическое снятие ThreadDump JVM в случае накопления очереди в пуле задач.
Автоматическое снятие ThreadDump JVM в случае резкого падения нагрузки ("провал").
Файлы с ThreadDump создаются/сжимаются/удаляются в каталоге /tmp.
Сжатие файлов с имеющимися ThreadDump выполняется в случае отсутствия интенсивной нагрузки для минимизации влияния на полезную нагрузку.
В зависимости от причины, по которой был создан ThreadDump, в имени файла будет присутствовать один из суффиксов:
taskDurationAbove_95prc_205 — 95 percentile длительности исполнения превысил 100 мс;
queueSize — в очереди pool накопилось заданий больше значения по умолчанию (2 шт.);
zeroTaskCount — резко упала нагрузка (провал/заикание).
Пример имени файла: /tmp/stack_traces_general_taskDurationAbove_95prc_2055_20210208_13_39_44_444.out.
Внимание!
Автоматическое создание ThreadDump может привести к повышенной утилизации дискового пространства/Ephemeral-Storage в контейнере! Необходимо учитывать это при использовании данного механизма и настраивать соответствующим образом пороги/времена функциональности автоматического снятия ThreadDump, а также размер Ephemeral-Storage.
Автоматическое снятие ThreadDump JVM в случае превышения порога для 95 percentile длительности исполнения задач#
В случае активации данной функциональности будет производиться подсчет длительности исполнения каждой задачи в General или Batch-pool (фактически каждый HTTP-запрос).
На протяжении 10 секунд эта статистика будет накапливаться и для нее будет вычисляться 95 Percentile.
В случае превышения 95 percentile порога (по умолчанию — 100 ms) будет выполнена операция сбора ThreadDump (каждые 200 мс в течение 5 секунд).
Дампы потоков будут сохранены в каталоге /tmp в файле вида:
/tmp/stack_traces_general_taskDurationAbove_95prc_2055_20210208_13_39_44_444.out
- stack_traces_ префикс файла с дампами потоков
- general — имя пула, в котором произошло превышение
- taskDurationAbove_95prc_2055 — причина создания файла превышение 95 percentile, текущее значение 2055 мс
- 20210208_13_39_44_444 время создания файла c мс.
Далее в случае отсутствия нагрузки (большого количества задач в пуле) будет произведена архивация подобных файлов в файлы формата zip.
В последствии данные zip-файлы старше 240 минут (параметр lastModifiedTime, значение по умолчанию) будут удалены.
Настройка:
dataspace.monitoring.enabled=true — включает в целом мониторинг (см. выше)
server.tomcat.threadstatistic=true — включает в целом сбор статистики по пулам (см. выше)
management.trace.taskduration.enabled.general=true (default false) — включает подсчет времени исполнения каждого задания в пуле general, построения гистограммы длительности и сбор ThreadDump-ов.
management.trace.taskduration.enabled.batch=true (default false) — включает подсчет времени исполнения каждого задания в пуле batch, построения гистограммы длительности и сбор ThreadDump-ов.
management.trace.taskduration.level (default 100) — уровень в мс, в случае превышения которого 95 percentile будут собираться threadDump-ы
Порог management.trace.taskduration.level возможно изменять в Runtime путем запроса:
curl IP:8080/systemmetrics?durlevelforthreaddump=900 <- изменить порог на 900мс
Автоматическое снятие ThreadDump JVM в случае накопления очереди в пуле задач или резкого падения нагрузки ("провал")#
В случае активации данной функциональности будет анализироваться утилизация очереди пулов потоков или резкое падение
нагрузки (неожиданный провал) будет выполнена операция сбора ThreadDump (каждые 200 мс в течение 5 секунд).
Дампы потоков будут сохранены в каталоге /tmp.
Настройки:
Включить аналитику General pool, наполнение статистики его активности, затем создание дампов и т.п.:
server.tomcat.general-thread-analytics=trueСобирать ли threadDumps при появлении очереди TomCat-пула или резком падении task в TomCat-пуле:
dataspace.monitoring.cgroup.threaddump.enabled=trueДля более тонкой настройки порогов срабатывания возможно применять следующие опции:
Порог превышения очереди TomCat-пула, после которого будут сниматься ThreadDumps dataspace.monitoring.cgroup.threaddump.queueLevel=2 Снятие threadDumps при резком падении нагрузки (провалы). Если старая нагрузка была > 15, а новое < 4, значит нагрузка резко упала (провал), и будет снят threadDump: dataspace.monitoring.cgroup.threaddump.taskCountHighLevel=15 dataspace.monitoring.cgroup.threaddump.taskCountLowLevel=4 Длительность снятия threadDumps (ms) dataspace.monitoring.cgroup.threaddump.duration=5000 Частота снятия threadDumps (ms) dataspace.monitoring.cgroup.threaddump.iteration=200 Количество событий (deltaTaskCount TomCat-пула), которые будут анализироваться (накапливаться), "120" значит — "за 120 секунд" dataspace.monitoring.cgroup.activity.historydeep=120
Сжатие и удаление файлов ThreadDump#
Сжатие файлов с имеющимися ThreadDump выполняется в случае отсутствия интенсивной нагрузки для минимизации влияния на полезную нагрузку.
Для этого анализируется кеш CacheManage (см. historydeep def. 120). То есть, если в течение 2 минут нет количества tasks выше 5, принимается решение о незагруженности сервиса и возможности выполнения неважных/фоновых задач (например, сжатие threadDump).
Порог количества задач/tasks в Tomcat-пуле, выше которого принимается решение о том, что нагрузка высокая и архивация threadDump-файлов невозможна, настраивается опцией:
dataspace.monitoring.cgroup.activity.tasklevel=5
Длительность хранения ThreadDump (default 240 минут) настраивается параметром:
management.trace.deleteoldfile.minutes=240
Метрики snowflake-generator#
Для включения/отключения prometheus-метрик необходимо установить значение параметру dataspace.monitoring.snowflake.enabled=true/false.
При включенном состоянии добавятся два значения в отбрасываемые метрики:
dspc_id_generator_snowflake_ip_octet — номер октета, используемого snowflake-генератором;
dspc_id_generator_snowflake_shuffle — случайный элемент, используемы snowflake-генератором.
Трассировка#
Трассировка производится с помощью компонента OpenTracing.
Включение трассировки#
В DataSpace Core необходимо проверить, что библиотеки разрешены в конфигурационном файле:
spring.sleuth.enabled=true
spring.zipkin.enabled=true
spring.zipkin.baseURL={URL сбора лог-файлов трассировки в формате OpenZipkin}
Выключение трассировки#
Выключите признаки доступности библиотек OpenTracing в конфигурационном файле:
spring.sleuth.enabled=false
spring.zipkin.enabled=false
Добавление информации в span OpenTracing#
Следующие параметры отвечают за добавление информации в span OpenTracing:
# Добавлять информацию в span для OpenTracing
dataspace.monitoring.datasource.sleuth.enabled
# Тип информации для добавления в span для OpenTracing — CONNECTION, QUERY,FETCH
dataspace.monitoring.datasource.sleuth.include
В дополнение к указанным выше конфигурациям стартер DataSpace Core может включать дополнительную информацию по наблюдаемым методам в span OpenTracing.
Для включения дополнительной информации в span OpenTracing нужно сконфигурировать параметр dataspace.monitoring.watch-tracing.enabled:
dataspace.monitoring.watch-tracing.enabled=true
Показатели здоровья#
В DataSpace предусмотрено три способа определения состояния здоровья приложения:
Определение здоровья |
Назначение |
Ссылка на раздел |
|---|---|---|
Health API |
API определения здоровья приложения по стандарту Platform V. Предназначен для получения службами сопровождения результатов самодиагностики экземпляра приложения для определения работоспособности компонента с получением развернутой диагностики доступности API и оценки общей работоспособности. Может использоваться внешними сервисами |
|
Метрика статуса готовности — |
Отображает статус готовности сервиса DataSpace: "1" — готов, "0" — не готов. Служит для централизованного мониторинга состояния здоровья всего сервиса |
|
Endpoint |
Spring-представление состояния здоровья по всем сконфигурированным показателям здоровья |
Для целей геобалансировки и других задач управления маршрутизацией не следует использовать endpoint /actuator/health.
Вместо этого рекомендуются (в порядке приоритета):
метрика статуса готовности
available— позволяет получить общее состояние всех экземпляров сервиса;Health API — при этом должны опрашиваться все экземпляры приложения, например, с использованием средств, предоставляемых продуктом Platform V Synapse.
При использовании API необходимо учитывать, что возвращается состояние того экземпляра DataSpace, который обработал запрос API, а не всего сервиса в целом. Например, если один из экземпляров испытывает перегрузки, он может вернуть "fail", хотя остальные экземпляры могут продолжать обрабатывать запросы. Если экземпляр недоступен, то он скорее всего будет выведен из балансировки оркестратором Kubernetes и запрос на него маршрутизирован не будет.
Health API#
Сервис DataSpace в своем составе имеет дополнительный API, отображающий состояние его компонентов. Health API показывает состояние сервиса DataSpace на основе перечисленных в списке indicatorlist (см. настройку ниже) показателей здоровья из числа имеющихся (см. раздел "Показатели здоровья").
Примечание
При пользовании API необходимо учитывать, что Health API возвращает состояние того pod DataSpace, который обработал запрос, а не всего сервиса в целом.
Для получения состояния здоровья через Health API необходимо выполнить запрос:
curl http://localhost:8080/health
Response в формате JSON:
{
"status": "pass",
"serviceId": "dataspace-core-test",
"description": "Dataspace status",
"checks": {
"memUsageWithoutCache": [
{
"observedValue": "68",
"observedUnit": "percent",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"vmRssUsage": [
{
"observedValue": "71",
"observedUnit": "percent",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"vmSwapUsage": [
{
"observedValue": "0",
"observedUnit": "byte",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"healthCheckWrite": [
{
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"cpuUsage": [
{
"observedValue": "4",
"observedUnit": "percent",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"cpuThrottled": [
{
"observedValue": "0",
"observedUnit": "percent",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"fullGCEventCount": [
{
"observedValue": "0",
"observedUnit": "count",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
],
"safepointTime": [
{
"observedValue": "336",
"observedUnit": "microsecond",
"status": "pass",
"time": "2022-12-10T09:44:00Z"
}
]
}
}
Поля имеют следующие значения:
status — интегральный статус на основе статуса checks/компонентов;
description — описание;
serviceId — ID сервиса. Проставляется на основе опции модуля dataspace.service.name;
checks — используемые проверки. Строится на основе показателей здоровья, используемых в модуле (см. раздел "Показатели здоровья").
Перечень показателей здоровья, учитываемых в этом API, настраивается в списке indicatorlist:
dataspace.monitoring.healthapi.indicatorlist=ping,warmup,activeDataSource,healthCheckWrite,healthCheckBackgroundTasks,cpuUsage,cpuThrottled,memUsageWithoutCache,vmRssUsage,vmSwapUsage,safepointTime,fullGcEventCount
Сообщение следующего вида говорит о том, что в списке индикаторов, участвующих в Health-API, присутствует индикатор XXX, но его нет среди активных индикаторов:
2023-05-04 10:56:32,585 [general-pool-thread-26] [WARN] (sbp.com.sbt.dataspace.support.config.HealthApiService) [sbp.com.sbt.dat
aspace.support.config.HealthApiService::lambda$getHealthApiResponse$1:88] mdc:()| Из списка HealthIndicators, участвующих в Heal
th API, не найден активный индикатор XXX
Необходимо отредактировать список в соответствии с имеющимися активными индикаторами (их список доступен через endpoint /actuator/health):
dataspace.monitoring.healthapi.indicatorlist=
Отключить/включить Health API возможно опцией (значение по умолчанию — "true"):
dataspace.healthcheck.api.health.enabled=true
Метрика статуса готовности DataSpace#
DataSpace предоставляет метрику статуса готовности — available.
Пример метрики статуса готовности:
# HELP available Статус готовности модуля: 1 — готов, 0 — не готов
# TYPE available gauge
available{application="dataspace-core",deployment_type="DSPC_BNDL",metrics_name="health_status",model_name="transfers_c2c",model_version="DEV-SNAPSHOT",namespace="local",node_name="local",owner_id="458585",pod="dataspace-core-test",} 1.0
Данная метрика available отображает статус готовности сервиса DataSpace: "1" — готов, "0" — не готов.
Свое состояние метрика available формирует на основе Health API (см. раздел "Health API").
Endpoint /actuator/health#
Сервис DataSpace в своем составе имеет предоставляемый Spring-механизм получения показателей здоровья, отображающий состояние его компонентов.
Для получения общего состояния здоровья необходимо выполнить запрос:
curl http://localhost:8080/actuator/health
Response в формате JSON:
{
"status": "UP",
"components": {
"activeDataSource": {
"status": "UP",
"details": {
"database": "PostgreSQL",
"validationQuery": "isValid()"
}
},
"cpuThrottled": {
"status": "UP",
"details": {
"CpuThrottledPercent ": "0",
"CpuThrottledThreshold": "95"
}
},
"cpuUsage": {
"status": "UP",
"details": {
"CpuUsageThreshold": "95",
"CpuUsagePercent ": "2"
}
},
"db": {
"status": "UP",
"components": {
"activeDataSource": {
"status": "UP",
"details": {
"database": "PostgreSQL",
"validationQuery": "isValid()"
}
},
"dataSource": {
"status": "UP",
"details": {
"database": "PostgreSQL",
"validationQuery": "isValid()"
}
},
"standinDataSource": {
"status": "UP",
"details": {
"database": "H2",
"validationQuery": "isValid()"
}
}
}
},
"gc": {
"status": "UP",
"details": {
"FullGcEventCountThreshold": "1",
"FullGcEventCount": "0"
}
},
"healthCheckBackgroundTasks": {
"status": "UP",
"details": {
"BACKGROUND_TASKS_STOPPED": "Active: false"
}
},
"healthCheckRead": {
"status": "UP",
"details": {
"ACTIVE_DB_READ_NOT_READY": "Active: false",
"ACTIVE_DB_SCHEMA_NOT_COMPATIBLE": "Active: false",
"INACTIVE_DB_NOT_READY": "Active: true, Reason: org.springframework.jdbc.BadSqlGrammarException: PreparedStatementCallback; bad SQL grammar [select * from T_DSPC_SYS_CONFIG where OBJECT_ID=?]; nested exception is org.h2.jdbc.JdbcSQLSyntaxErrorException: Table \"T_DSPC_SYS_CONFIG\" not found; SQL statement:\nselect * from T_DSPC_SYS_CONFIG where OBJECT_ID=? [42102-200]"
}
},
"healthCheckWrite": {
"status": "UP",
"details": {
"ACTIVE_DB_NOT_READY": "Active: false",
"ACTIVE_DB_READ_NOT_READY": "Active: false",
"ACTIVE_DB_SCHEMA_NOT_COMPATIBLE": "Active: false",
"INACTIVE_DB_NOT_READY": "Active: true, Reason: org.springframework.jdbc.BadSqlGrammarException: PreparedStatementCallback; bad SQL grammar [select * from T_DSPC_SYS_CONFIG where OBJECT_ID=?]; nested exception is org.h2.jdbc.JdbcSQLSyntaxErrorException: Table \"T_DSPC_SYS_CONFIG\" not found; SQL statement:\nselect * from T_DSPC_SYS_CONFIG where OBJECT_ID=? [42102-200]"
}
},
"memUsageWithoutCache": {
"status": "UP",
"details": {
"ContainerCacheUsageMib": "0",
"ContainerMemLimitMib": "2048",
"ContainerMemUsageWithoutCacheThresholdPercent": "95",
"ContainerMemUsageWithCacheMib": "1472",
"ContainerMemUsageWithoutCachePercent": "71"
}
},
"ping": {
"status": "UP"
},
"safepointTime": {
"status": "UP",
"details": {
"SafepointTime95prcMks ": "336",
"SafepointTimeMksThreshold": "2000000"
}
},
"vmRssUsage": {
"status": "UP",
"details": {
"JvmRssUsageKbytesHeapAndNon-Heap": "1507328",
"JvmRssUsagePercent": "71",
"JvmRssUsagePercentThreshold": "90"
}
},
"vmSwap": {
"status": "UP",
"details": {
"JvmSwapBytes ": "0",
"JvmSwapBytesThreshold": "1024"
}
},
"warmup": {
"status": "UP"
}
},
"groups": [
"liveness",
"readiness"
]
}
В ответе показано общее состояние здоровья сервиса в поле status, которое принимает значение "UP" при условии status=UP для всех включенных показателей здоровья, в противном случае значение — "DOWN".
Описание показателей здоровья#
Имеются следующие показатели здоровья:
activeDataSource — компонент, отображающий статус состояния активного DataSource.
cpuThrottled — компонент, отображающий процент нехватки CPU (CPU Throttling). Рекомендованное значение — "0".
Настройки:
dataspace.healthcheck.cpu.throttled.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.cpu.throttledpercent.threshold=95 пороговое значение в процентах перевода индикатора в DOWN dataspace.healthcheck.cpu.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильcpuUsage — компонент, отображающий процент потребления CPU (CPU Usage). Хорошие показатели не должны превышать 70%.
Настройки:
dataspace.healthcheck.cpu.usage.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.cpu.usagepercent.threshold=95 пороговое значение в процентах перевода индикатора в DOWN dataspace.healthcheck.cpu.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильdb — компонент, отображающий статус состояния всех доступных DataSource, подключенных к базам данных.
gc — компонент, отображающий количество событий аварийной полной сборки мусора функционалом Garbage Collection. Должен быть равен "0".
Настройки:
dataspace.healthcheck.fullgceventcount.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.fullgceventcount.threshold=1 пороговое значение в количестве раз/событий для перевода индикатора в DOWN dataspace.healthcheck.fullgceventcount.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильping — внутренний Spring-индикатор PingHealthIndicator, отображающий доступность JVM.
memUsageWithoutCache — компонент, отображающий количество используемой контейнером памяти без учета кеша операционной системы (page cache).
Настройки:
dataspace.healthcheck.mem.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.mem.usagewithoutcache.threshold=95 пороговое значение в процентах перевода индикатора в DOWN dataspace.healthcheck.mem.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильsafepointTime — компонент, отображающий время, в течении которого потоки, обрабатывающие запросы, были приостановлены для обработки внутренних задач JVM. Рекомендованное значение — не выше 100 миллисекунд.
Настройки:
dataspace.healthcheck.safepointtime.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.safepointtime.threshold=2000000 пороговое значение в микросекундах для перевода индикатора в DOWN dataspace.healthcheck.safepointtime.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильvmRssUsage — компонент, отображающий потребление памяти только процессом JVM (JVM Heap + Non-Heap).
Настройки:
dataspace.healthcheck.vmrss.usage.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.vmrss.usage.threshold=90 пороговое значение в процентах перевода индикатора в DOWN dataspace.healthcheck.vmrss.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильvmSwap — компонент, отображающий объемы памяти процесса JVM, сброшенной на диск операционной системой. Желательно не должен превышать "0".
Настройки:
dataspace.healthcheck.vmswap.usage.enable=true включен(true)/отключен(false) сбор статистики dataspace.healthcheck.vmswap.usage.threshold:1024 пороговое значение в байтах перевода индикатора в DOWN dataspace.healthcheck.vmrss.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентильwarm — компонент, отображающий завершение этапа прогрева во время старта модуля.
Настройки расчета показателей здоровья#
В настройках модуля присутствуют Spring-настройки, которые определяют состав показателей здоровья.
В примере ниже показан набор опций по умолчанию для показателей здоровья, которые можно включить ("true") или отключить ("false"):
management.health.db.enabled=false
management.health.ping.enabled=true
management.health.warmup.enabled=true
management.health.healthCheckWrite.enabled=true
management.health.healthCheckRead.enabled=true
management.health.healthCheckBackgroundTasks.enabled=true
management.health.activeDataSource.enabled=true
management.health.memUsageWithoutCache.enabled=true
management.health.vmRssUsage.enabled=true
management.health.vmSwapUsage.enabled=true
management.health.cpuUsage.enabled=true
management.health.cpuThrottled.enabled=true
management.health.fullGCEventCount.enabled=true
management.health.safepointTime.enabled=true
Показатели здоровья входят в состав:
общего мониторинга сервисов DataSpace, который включен по умолчанию, но при необходимости может быть отключен;
readiness/liveness-проверок (но не в полном составе).
Перечень индикаторов, входящих в состав readiness-проверки (готовности обрабатывать запросы) настраивается параметром (пример):
management.endpoint.health.group.readiness.include=ping,warmup,healthCheckWrite,cpuUsage,cpuThrottled,memUsageWithoutCache,vmRssUsage,vmSwapUsage,safepointTime,fullGcEventCount
Перечень индикаторов, входящих в состав liveness-проверки (жизнеспособности) настраивается параметром (пример):
management.endpoint.health.group.liveness.include=ping
Внимание!
Комплексный показатель здоровья db по умолчанию отключен. Настраивается опцией
management.health.db.enabled=falseилиtrue.Состояние БД учитывается за счет показателя activeDatasource.
Проверить его состояние возможно вызовом:
curl localhost:8080/actuator/health Output: ... activeDataSource": { "status": "UP", "details": { "database": "PostgreSQL", "validationQuery": "isValid()" } ...
Если в настройки мониторинга вносились изменения, необходимо убедиться, что следующие настройки активны:
dataspace.monitoring.enabled=true
dataspace.monitoring.jvm.enabled=true
dataspace.monitoring.cgroup.enabled=true
dataspace.healthcheck.enable=true
Корректировка или отключение показателя здоровья#
Если по каким-то причинам в pod высокая утилизация CPU, это приведет к переводу readiness-проверки в статус "DOWN", так как в ее состав входит показатель здоровья cpuUsage.
management.health.cpuUsage.enabled=true.
В свою очередь readiness-проба в статусе "DOWN" приведет к выводу pod из балансировки:
"cpuUsage": {
"status": "DOWN",
"details": {
"CpuUsageThreshold": "95",
"CpuUsagePercent ": "100"
}
},
Для корректировки данной ситуации возможны различные варианты:
проанализировать причины высокого потребления CPU и уменьшить его;
скорректировать порог, при котором показатель здоровья переходит в статус "DOWN";
отключить показатель.
Корректировка показателя процента потребления CPU (CPU Usage)#
Имеется возможность увеличить порог срабатывания за счет его увеличения (например, до "99") с помощью опции:
dataspace.healthcheck.cpu.usagepercent.threshold=95 — пороговое значение в процентах перевода индикатора в DOWN
Также имеется возможность увеличить количество событий, которые учитываются при подсчете CPU usage (например, до 300 секунд), чтобы сгладить пики или провалы:
dataspace.healthcheck.cpu.expireseconds=30 длительность хранения метрики, на основе которого рассчитывается 95 перцентиль
Отключение показателя процента потребления CPU (CPU Usage)#
Имеется возможность отключить показатель процента потребления CPU:
management.health.cpuUsage.enabled=false <- изменить на false
Если показатель включен в состав readiness/liveness-проверок или Health-API, необходимо исключить cpuUsage из списков в настройках (по умолчанию включен в их состав):
management.endpoint.health.group.readiness.include=.... <- удалить cpuUsage
management.endpoint.health.group.liveness.include=.... <- удалить cpuUsage
dataspace.monitoring.healthapi.indicatorlist=.... <- удалить cpuUsage
Использование метрик для идентификации потребителя#
Сервис DataSpace предоставляет дополнительную информацию для идентификации потребителя в виде дополнительных меток на метрике статуса готовности available.
В перечень дополнительных меток входят:
owner_id— формируется на основе опции настройки сервисаdataspace.owner.id;model_name— имя модели, используемое при ее генерации;model_version— версия модели, используемая при генерации;deployment_type— тип развертывания. Задается опциейdataspace.deployment.typeиз переменной окруженияDEPLOYMENT_TYPE.
Также метка owner_id проставляется на метрике количества вызовов:
http_server_requests_seconds_bucket{application="dataspace-core",exception="None",method="GET",namespace="local",node_name="local",outcome="SUCCESS",owner_id="458585",pod="dataspace-core-test",status="200",uri="/health",le="0.2",} 3.0
В примере выше зафиксировано три вызова по адресу /health со статусом "200", выполненных к модели потребителя с owner_id="458585".
Часто встречающиеся проблемы и пути их устранения#
При увеличении нагрузки/запросов DataSpace все же не принимает большее количество запросов#
Место возникновения: метрики на стороне потребителя, метрики DataSpace.
Зачастую при подаче значительной нагрузке на сервис DataSpace и постепенном ее увеличении в какой-то момент количество исполняемых запросов перестает расти. В случае отсутствия признаков утилизации ресурсов (CPU, блокировок, БД) со стороны контейнера с DataSpace причиной может являться недостаточность ресурсов у прокси-сервиса istio-proxy (Envoy), через который проходит весь сетевой трафик любого POD.
Утилизацию ресурсов Envoy возможно посмотреть в системе мониторинга облачной среды в целом, но для быстрого анализа возможно воспользоваться bash-скриптом который можно выполнить с консоли Envoy-контейнера.
Описание скрипта расположено в разделе "Скрипт анализа утилизации ресурсов контейнера"
Данный скрипт каждую секунду выводит в консоль текущую утилизацию CPU (usage/limit/Throttling) и Memory(Usage/Limit). В случае необходимости можно отправлять данные в InfluxDB. Таким образом, воспользовавшись данных скриптом, можно моментально получить текущую утилизацию ресурсов любого контейнера Linux.
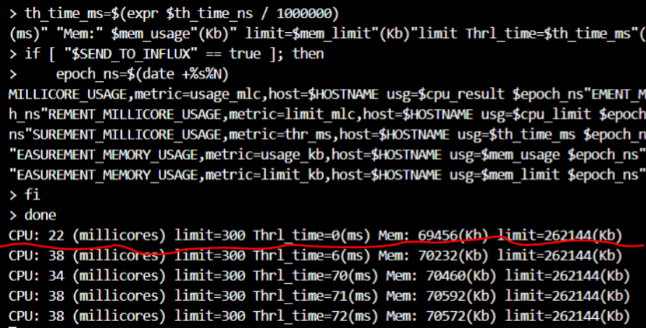
Возможное решение: проконсультироваться со специалистом DevOps о том, как в Deployments указать большее количество ресурсов для контейнера Istio-proxy. Настройки могут отличаться в зависимости от стенда.
Необходимо уменьшить количество одновременных сессий к СУБД#
В зависимости от ситуации, характеристик стенда и т.п. требуется изменить количество сессий к СУБД, открываемых по умолчанию. В стандартной поставке — 50 сессий.
Для этого необходимо изменить следующие настройки:
spring.datasource.hikari.connection-timeout=10000
spring.datasource.hikari.minimum-idle=10
spring.datasource.hikari.maximum-pool-size=50
spring.datasource.hikari.pool-name=mainDb
server.tomcat.min-spare-threads=10
server.tomcat.max-threads=50
Внимание!
По умолчанию количество сессий к СУБД равно размеру Tomcat-пула (оба по умолчанию составляют 50). Соответственно, если изменяется размер пула Tomcat, необходимо пропорционально изменить количество сессий к БД.
Если есть жесткая необходимость уменьшить количество сессий к СУБД на тестовом стенде, необходимо во время целевой нагрузки выяснить максимальное количество сессий к СУБД, которое было использовано в пике, и выставить такое же значение.