Сценарии администрирования#
Администрирование осуществляется через:
настройки окружения сервиса;
модуль пользовательского интерфейса TSA_UI;
параметры сервиса, расположенные в UI смежных сервисов, которые применяются для использования функций Архивирования (ARCH).
Резервное копирование файлов не требуется и не предусмотрено. Значения по умолчанию для параметров указаны в документе «Руководстве по установке», раздел «Установка».
Настройка инициализирующей выгрузки данных#
Инициализирующая выгрузка (далее — Init) нужна для первоначальной загрузки данных из Источника данных в ЦСП (Корпоративную Аналитическую Платформу).
Для управления инициализирующей выгрузкой данных от прикладной АС (Источника данных) до интеграционной Kafka Архивирования (ARCH), через которую происходит обмен данными между Архивированием (ARCH) и ЦСП, используется графический интерфейс Архивирования (ARCH).
Для авторизации в графическом интерфейсе необходимо иметь учетную запись с соответствующими правами на доступ к сервису. Консультацию по процессу получения прав на конкретном полигоне получите у координаторов или команды сопровождения.
Обработка сообщений от Источников по типу Init вынесена в отдельный топик raw_init. Топик raw используется только для Потока. Данная схема работает при включенных режимах синхронных ТКД и DRP. При этом логически независимые процессы не влияют друг на друга. Общее время отклика на запрос определяется только задержкой по топикам raw и data и общей загрузкой КТС.
Внимание!
Параллельный Init из одного Источника невозможен!
Не допускайте слияния процессов Init. На стороне Архивирования (ARCH) реализована автоматическая очистка топика Init. Таким образом, при старте Init топик с итоговыми данными из прошлого Init очищается. Если запустить новый процесс Init, не дождавшись окончания прошлого, данные из прошлого будут удалены!
Создание конфигурации задачи в пользовательском интерфейсе Архивирования#
Авторизуйтесь в графическом интерфейсе Архивирования.
В левой части меню выберите Управление инитом и перейдите во вкладку Шаблон задач. В интерфейсе отобразятся настроенные ранее шаблоны для различных АС.
Выберите требуемый модуль из списка. Отобразятся все шаблоны задач, используемые для запуска Init на этом контуре.
Внимание!
В списке задач и конфигураций к ним присутствуют шаблоны задач и конфигурации для всех прикладных фабрик — Источников данных Архивирования (ARCH) в контуре. Редактировать и удалять конфигурации и шаблоны других прикладных фабрик запрещено!
Для создания Init необходимо создать его конфигурацию. Для этого нажмите кнопку Создать.
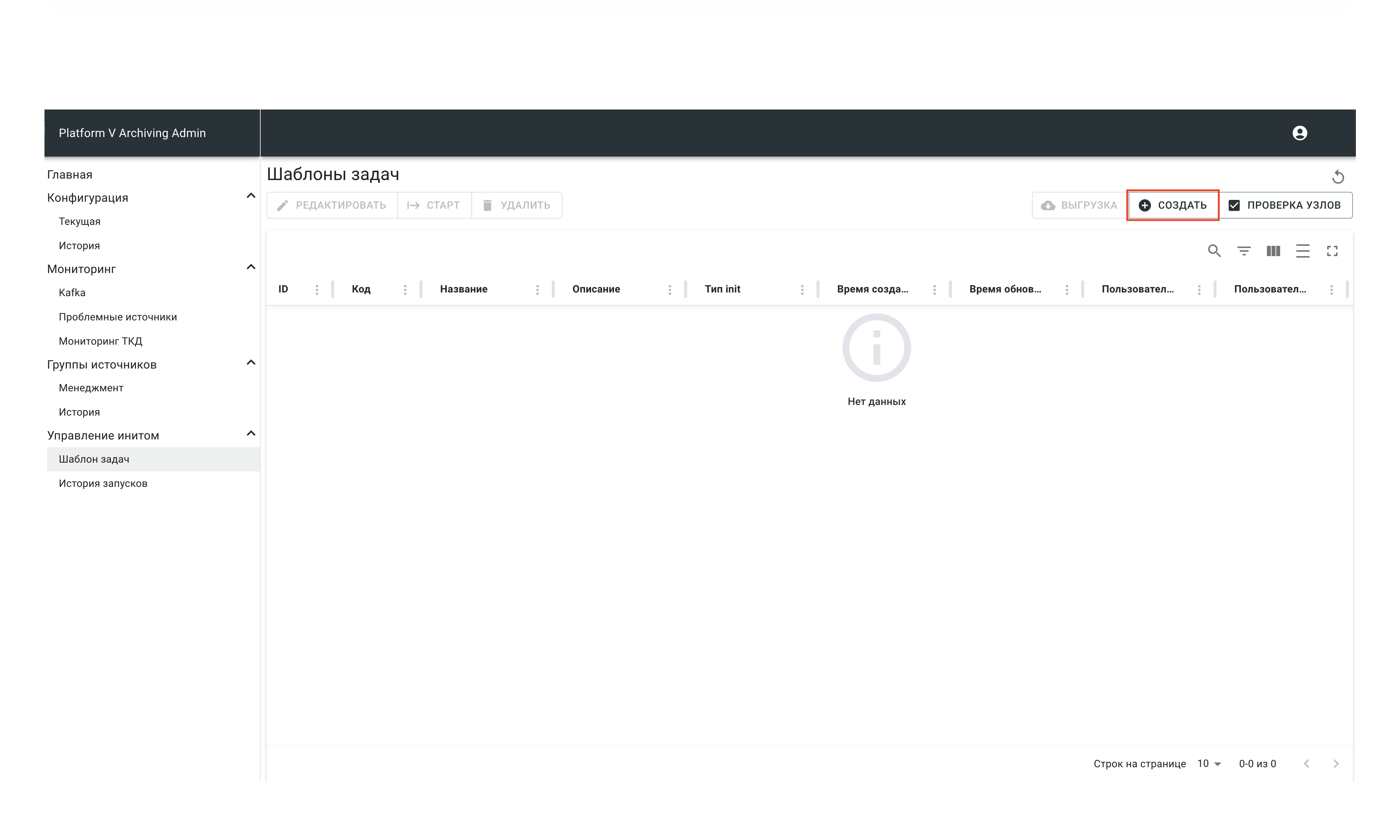
В правом меню нажмите Создать.
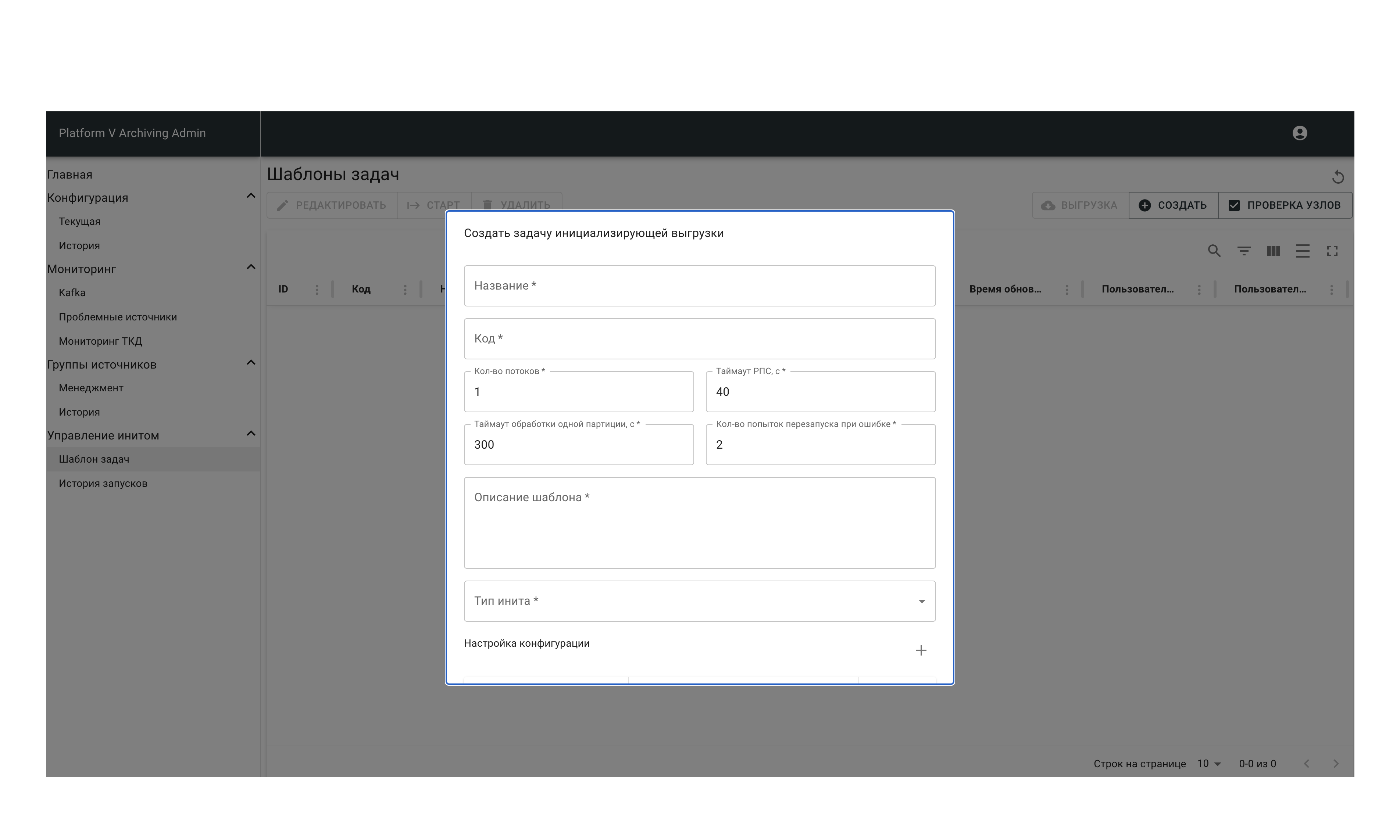
В открывшейся форме создания конфигурации шаблона задачи заполните поля:
Название — указывается по шаблону
<мнемоника Источника>-configuration-X, гдеX— это понятное для автора конфигурации обозначение, описывающее конфигурацию. Например,TEST_SOURCE-configuration-fullTypesконфигурация Источника TEST_SOURCE по выгрузке всех типов данных.Код – прописывается по аналогии с полем Название.
Количество потоков – количество обработчиков, которые могут выполнять одну задачу инициализирующей выгрузки. Начальное рекомендованное значение для тестирования - 8. Далее параметр можно менять в зависимости от времени загрузки данных. Как правило, с увеличением количества обработчиков скорость увеличивается.
Таймаут обработки одной партици — время (сек), в течение которого Boss-процесс ожидает завершения обработки одной партиции дочерним процессом. Для Источника, отдающего партиции быстро, рекомендованное значение таймаута — 1200 секунд.
Кол-во попыток перезапуска обработчика при ошибке — количество повторных запросов: от 0 до 2. Если ошибка происходит в середине партиции, перезапуск приведет к повторной отправке ранее успешно отправленной части данных.
Тайм-аут РПС,с – ограничение времени обработки сообщений в Kafka.
Описание шаблона – описание задачи.
Тип Инита – выбор типа Init.
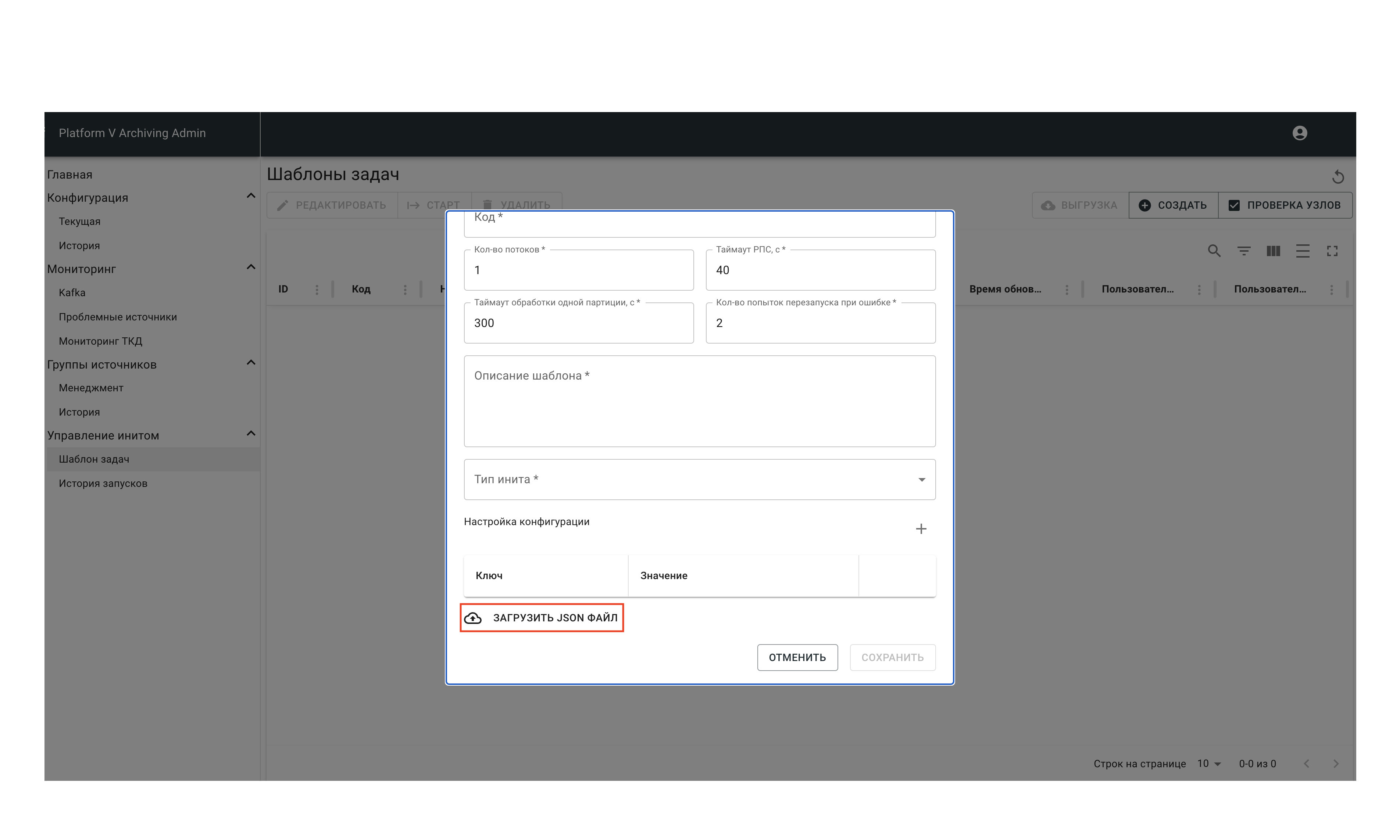
Заполните пользовательские парамеры вручную или загрузите из JSON-файла.
Для загрузки параметров через JSON-файл подготовьте файл со списком параметров и нажмите Загрузить json файл.
При заполнении вручную для создания нового параметра нажмите +.
В открывшейся форме заполните параметры:
type_0… type_<N> — обязательный параметр, определяющий, какие сущности будут выгружены из АС при запуске Init.
Пример — запуск Init по трем типам данных:
type_0=com.sbt.cdm.domain.ora.deals.cm.CmServiceAccountsAndSchedules, type_1=com.sbt.cdm.domain.ora.deals.cm.CmChildOrganizationAccrual, type_1225=com.sbt.cdm.domain.ora.deals.cm.CmServiceScheduleВнимание!
Нумерация типов должна быть последовательной:
type_0,type_1,type_2и так далее. При непоследовательной нумерации список выгружаемых типов будет сформирован некорректно.Примечание:
Создание нескольких шаблонов задач с разным набором сущностей будет полезно при тестировании для:
запуска Init небольших сущностей для сквозной проверки;
выгрузки конкретных сущностей;
запуска огромных сущностей (если такие имеются) в нерабочее время.
module_name — обязательный параметр. Укажите наименование целевой АС, в которой размещен API Архивирования (ARCH).
Также можно посмотреть в CSM или проконсультироваться с коллегами из разработки.
zone — обязательный параметр, в котором указывается зона шарда, где расположена прикладная фабрика. Если зона неизвестна, и все модули фабрики, работающие с Архивированием (ARCH), имеют одинаковую функциональность, то этот параметр можно не указывать.
hide_exceptions — необязательный параметр. Принимает значения
true/false. Отвечает за обработку исключений при загрузке партиций, при значенииtrueошибки игнорируются. По умолчанию –false.clear_topic — необязательный параметр. Определяет необходимость очистки Init-топиков перед запуском Init. Принимает значение
true/false. Отсутствие параметра эквивалентно значениюfalse. При установке вtrueпроизводится принудительная очистка топиков перед стартом задачи.Внимание!
Не допускается установка параметра в значении
trueпри запуске нескольких параллельных процессов Init по одному Источнику. В случае установки часть данных из Init может быть неконтролируемо утеряна.retry_count - обязательный параметр. Отвечает за количество попыток перезапуска при ошибке. Рекомендованное значение для параметра – 2.
aggregate_per_page – При реализации Init DataSpace Stage3 является обязательным параметром. Параметр отвечает за наполнение сообщения агрегатами. Например, при значении
1в одно сообщение помещается один агрегат. Значение по умолчанию –10. Значение определяется степенью агрегатоцентричности модели конкретного Источника. Чем больше размер агрегата, тем ниже значение параметра.Примечание
Параметр применим ТОЛЬКО для реализации Init Platform V DataSpace Stage3. Значение параметра следует определять, исходя из результатов НТ, используя в качестве базового значения величину в 150 агрегатов на страницу для Источника, у которого среднее количество дочерних объектов в одном агрегате находится в диапазоне от
10до50.init_plus_mode – необязательный параметр, отвечает за выбор режима работы Init DataSpace Stage3 / Stage3+. Возможные значения:
True|False. Значение по умолчанию –False.estimation_timeout – необязательный параметр, отвечает за ограничение времени подсчета количества партиций на стадии PREPARE. Значение по умолчанию –
600(в секундах).retry_backoff_timeout – необязательный параметр, отвечет за задержку между попытками перезапуска (Retry) в случае возникновения ошибок. Значение по умолчанию –
30(в секундах).
После заполнения всех параметров нажмите Сохранить. После закрытия формы конфигурация должна появиться в списке конфигураций.
Требования для настройки безблокировочного Init#
Безблокировочный Init доступен только для Источников на Platform V DataSpace (APT).
Требования для использования безблокировочного Init:
Версии продуктов Platform V DataSpace (APT) и Архивирования (ARCH) поддерживают данный Init.
У ЦСП есть возможность принять формат векторов, согласованный для безблокировочного Init.
Для безблокировочного Init нужно указать в настройках шаблона задач в поле Класс имплементации класс DATASPACE_STAGE3.
Виды реализации Init#
Архивирование (ARCH) предлагает несколько реализаций протоколов инициирующей выгрузки, предназначенной для различных ситуаций применения. Каждая из реализаций соответствует определенной технологии хранения и имеет свою специфику. Все реализации построены на основе единого базового принципа работы первоначального Init, но имеют особенности, учитывающие специфику конкретной технологии хранения.
Существует 3 реализации первоначального Init, поддерживаемых Архивированием (ARCH):
Асинхронный базовый Init.
Init Platform V DataSpace – Stage 1.
Init Platform V DataSpace – Stage 3.
Реализация 1 – целевая для всех категорий Источников за исключением Источников на технологии хранения Platform V DataSpace. Использует асинхронный принцип отправки данных – Источник должен принять запрос на порцию данных, запустить асинхронный процесс отправки объектов запрошенной порции (партиции) и вернуть управление Архивированием (ARCH). Полностью поддерживается на уровне SDK транспортной библиотеки Архивирования (ARCH). Использование такой реализации требует минимум трудозатрат на стороне Источника и не требует самостоятельной реализации контрактов, так как все они инкапсулированы в предоставляемый библиотекой SDK. Поддерживаются реализации как для Источников 3 поколения (RPC взаимодействие через ММТ), так и для Источников 4 поколения (RPC взаимодействие через Kafka). Out-of-box («из коробки») реализация поддержана на уровне платформенных сервисов слоя изоляции данных – Platform V Persistence (как 3, так и 4 поколение Platform V). Реализация подходит для интеграции Источников на других слоях изоляции данных – как использующих целевой транспортный формат 4.0, так и использующих собственные сериализаторы и плагинную модель.
Реализации 2-3 предназначены для Источников, использующих слой изоляции данных Platform V DataSpace. Это технология, работающая в 4 поколении Platform V. Все необходимые для работы протоколов артефакты включены в поставку Platform V DataSpace. Со стороны Источника для использования интеграции требуется только конфигурирование соответствующих springBoot-стартеров, и доработка прикладного кода не требуется.
Реализации имеют особенности:
Stage1 – Init с блокировкой («Блокировочный Init»). Выполняется при остановленной полностью транзакционной нагрузке на БД Источника. Не может выполняться на нагруженной БД. Имеет невысокую производительность при мелкой гранулярности агрегатов (маленькие агрегаты). Внедрен, промышленно эксплуатируется. Для остановки нагрузки, как правило, применяется конфигурирование БД StandIn Источника для Init вкупе с остановленным приемом БД векторов изменений.
Stage3 – Init без блокировки для маленьких агрегатов («МИМА»). Может выполняться как при остановленной нагрузке, так и под нагрузкой на БД Источника без ограничений на характер нагрузки и виды совершаемых транзакций (вставка, изменение, удаление объектов). Оптимизирован для максимальной производительности независимо от размеров агрегата.
Stage3+ – более оптимизированный Init Stage3, реализация отличается использованием метода
postLoadPage, позволяющим DataSpace зачищать страницы после загрузки каждой партиции, не дожидаясь при этом завершения всего Init.
Таблица совместимости ниже показывает область применения конкретной реализации и требуемые версии смежной системы.
Реализация |
Класс имплементации |
Поколение Источника / Транспорт |
Слой хранения |
Ограничения использования |
Минимальная версия смежной системы |
Протокол Архивирования (ARCH) (интерфейс) |
Протокол ЦСП (тип контейнера) |
|---|---|---|---|---|---|---|---|
Асинхронный базовый Init |
|
3G |
Platform V Persistence |
Нет ограничений |
ЦСП – 1.17 |
← InitDataSampleApi |
PprbInitTransportContainer |
Асинхронный базовый Init |
|
4G |
Platform V Persistence |
Нет ограничений |
ЦСП – 1.17 |
← InitDataSampleApi |
PprbInitTransportContainer |
Platform V DataSpace – Stage 1 |
|
4G |
Platform V DatSpace |
Источники, попадающие под допустимые критерии по величине агрегатов, согласно методике оценки |
ЦСП – 2.2+ |
← InitAggregateApi |
PprbInitTransportContainer |
Platform V DataSpace – Stage 3 |
|
4G |
Platform V DatSpace |
Нет ограничений |
ЦСП – 2.2+ |
← InitAggregateApi |
PprbInitTransportContainer |
Примеры настроенных задач Init#
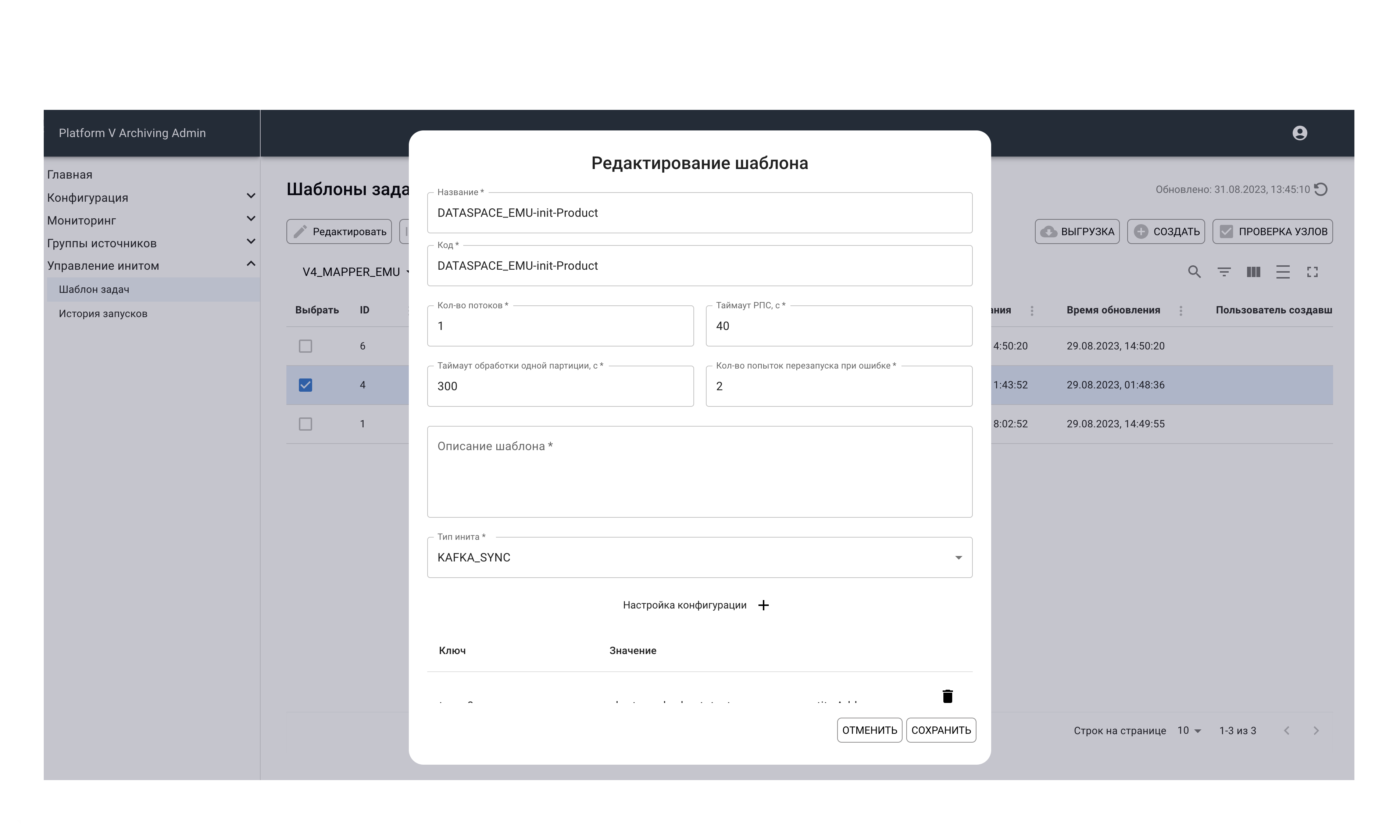
Асинхронный базовый Init – Источник 3 поколения:
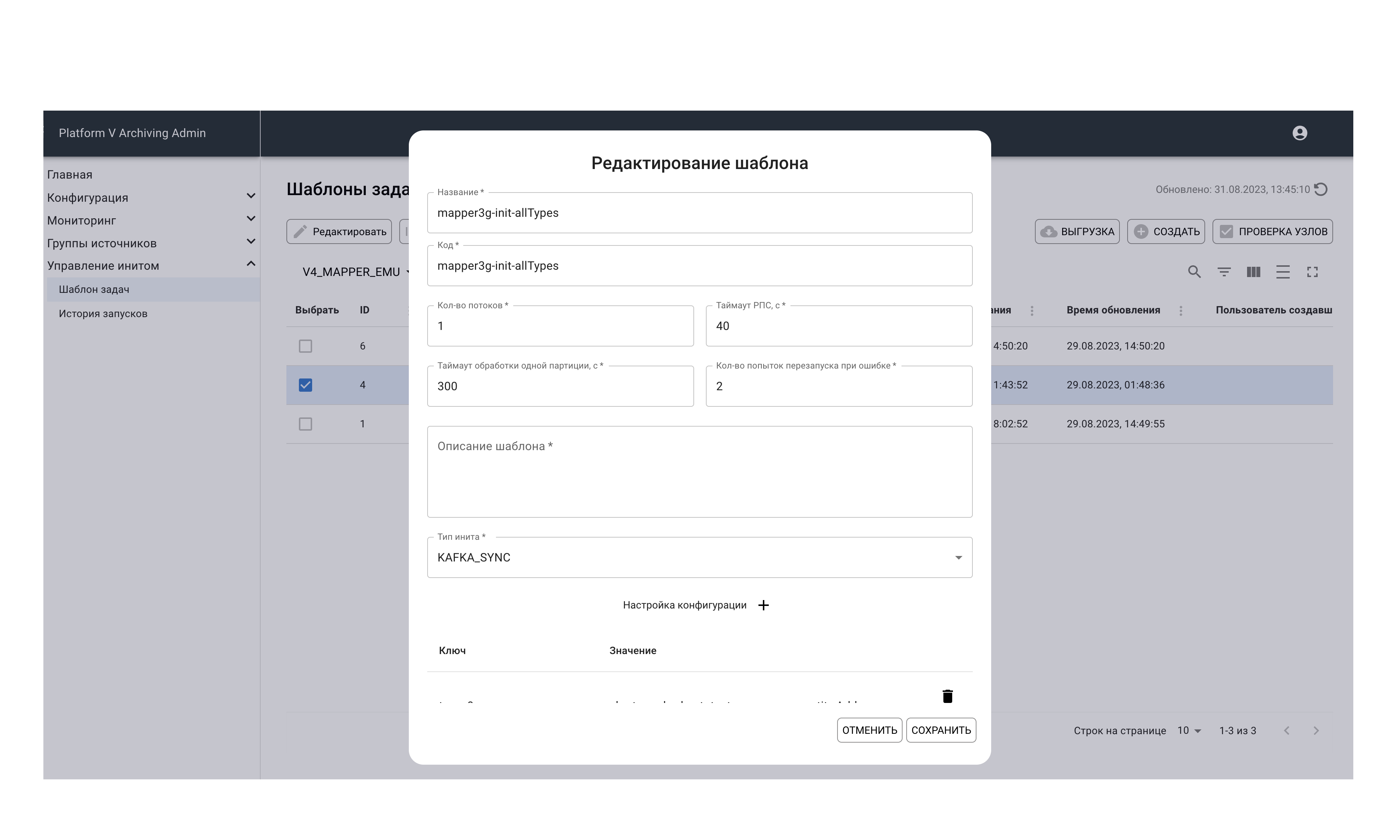
Асинхронный базовый Init – Источник 4 поколения:
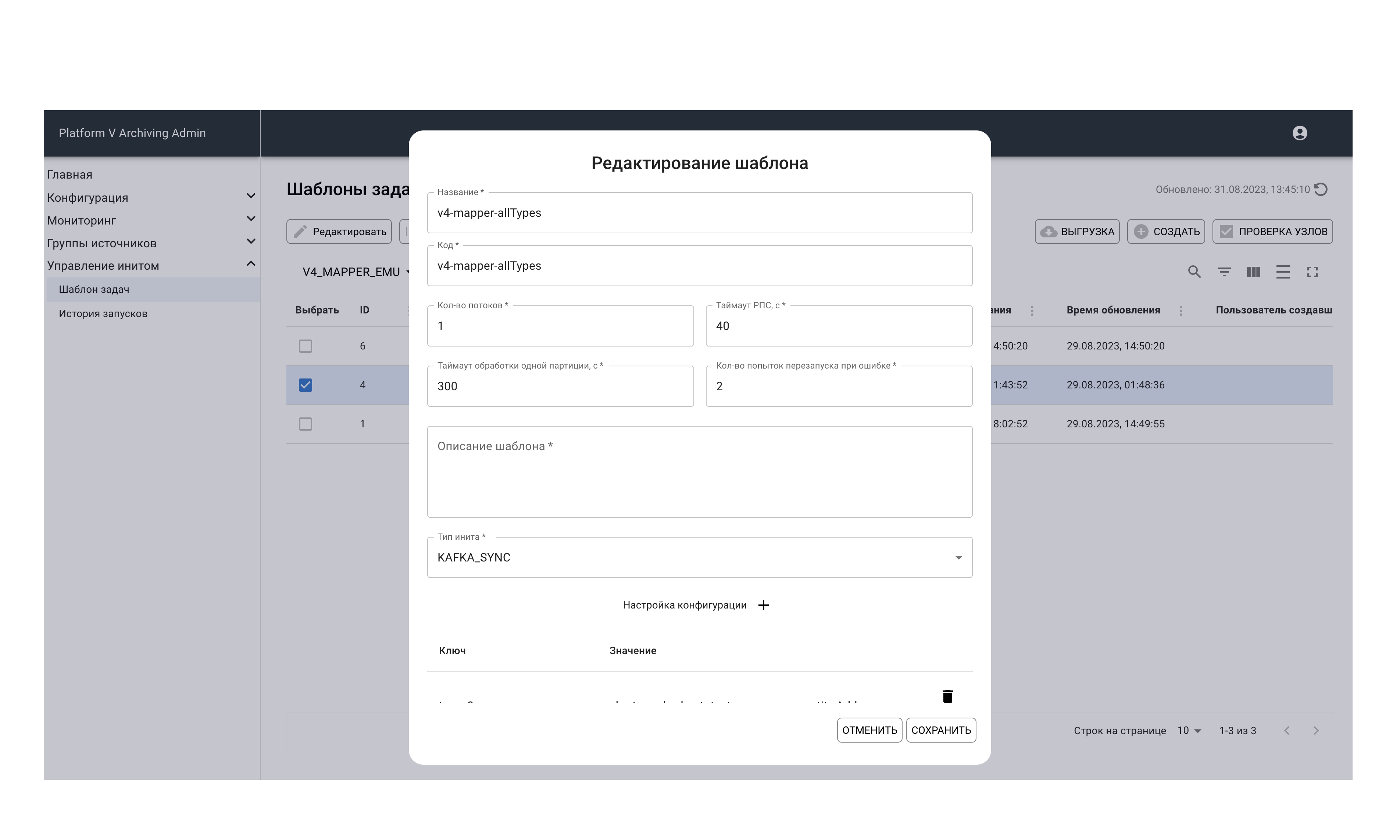
Init Platform V DataSpace – Stage 3:

Запуск Init#
Авторизуйтесь в графическом интерфейсе Архивирования (ARCH).
Если шаблон Init не создан, предварительно создайте его (инструкция по созданию задачи приведена в разделе «Создание конфигурации задачи в пользовательском интерфейсе Архивирования»).
Внимание!
Перед запуском Init убедитесь, что:
в базу Архивирования (ARCH) загружена конфигурация для прикладной фабрики (Источник данных), по которой выполняется данная инструкция;
на контуре, где выполняется настройка, запущен модуль, через который осуществляется взаимодействие с Архивированием (ARCH), то есть реализовано API для Init InitDataSampleApi (или DataTransportApi).
Выберите требуемый шаблон задачи из списка.
В появившемся сверху меню нажмите Запустить. Параметры запуска загрузятся из конфигурации задачи. Если перед запуском Init требуется изменить параметры его запуска, нажмите Редактировать.
Примечание:
Если при старте задачи возвращается исключение с большим stack trace, это не связано с неполадками на стороне Архивирования (ARCH). В Архивировании (ARCH) периодически возникают исключения при запросе к БД или с коммуникациями внутренних модулей, что приводит к сбоям при запуске. Если из исключения не удается однозначно понять причину ошибки (например, при некорректных параметрах Init на это будет явно указано), попробуйте запустить задачу повторно через несколько минут. Ошибки, связанные с Архивированием (ARCH), возникают тогда, когда задача уже создана и отобразилась в Истории запусков.
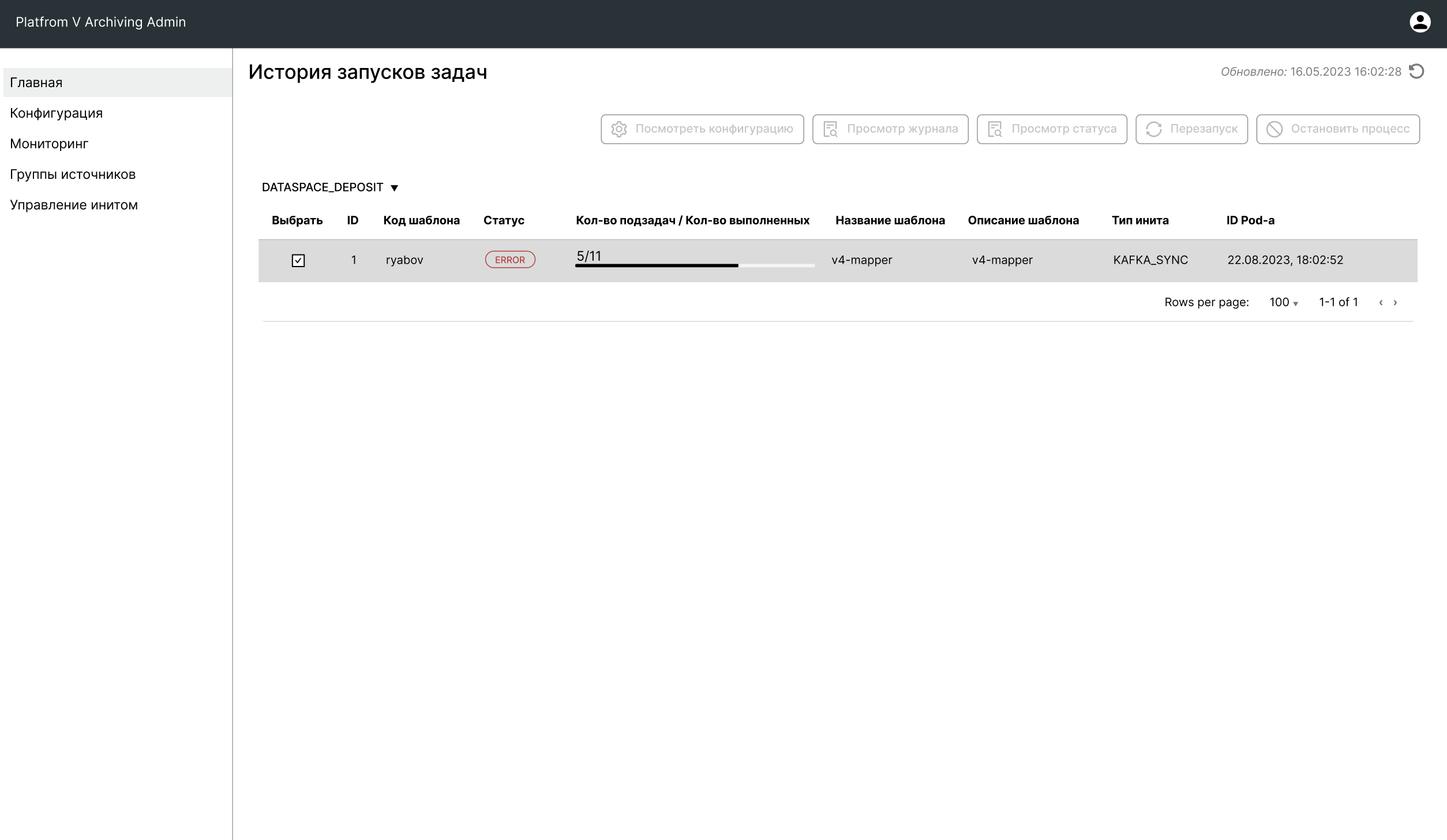
Раскройте меню слева Управление Инитом и перейдите во вкладку История запусков задач. Откроется список всех успешно созданных экземпляров задач. В верхней части списка отобразится задача, который была запущена на предыдущем шаге.
Прерывание Init#
Для прерывания Init:
Авторизуйтесь в графическом интерфейсе Архивирования (ARCH).
Выберите требуемую задачу в Журнале задач.
Нажмите кнопку Остановить процесс.
В открывшемся окне подтвердите операцию.

Просмотр состояния Init#
Системные состояния:
START – обработка команды запуска Init;
INIT – инициализация задачи Init;
PREPARE — подготовка к выполнению Init, запрос о количестве данных;
PROCCESS — выполнение инициализирующей выгрузки;
STOPPED — процесс остановлен либо вручную, либо программно. Например, в связи с тем, что загрузка не завершилась через выставленный для загрузки таймаут;
FINISH — окончание выгрузки, синхронизация и проверка завершения выгрузки всех данных;
DONE — выполнение Init завершено успешно, выгрузка данных выполнена;
ERROR — в процессе Init произошла ошибка.
Процесс выполнения отображается в столбце Прогресс. В нем указывается, сколько партиций данных из общего количества уже выгружено.
При успешном завершении задачи Init в поле Прогресс должно быть значение 5/5 (100.00%) (5 — если было рассчитано 5 партиций данных, значение может быть другим).
Внимание!
Если при выгрузке данных задача заканчивает работу со статусом DONE, а в поле Прогресс отображается 0/0 (100.00%), это означает, что при запросе количества данных Источник (прикладная фабрика) вернул количество данных (количество партиций), равное 0. Удостоверьтесь, что данные по запрашиваемым типам присутствуют в БД прикладной фабрики.
Завершение Init в статусе ERROR означает, что в процессе произошло исключение. Подробности об ошибках и способах их решений смотрите в разделе «Часто встречающиеся проблемы и пути их устранения».
Диагностика ошибок при запуске#
Правила работы с ошибками#
Если системное состояние журнала в колонке -
ERROR, выберите журнал и нажмите кнопку Просмотр журнала для выяснения причины ошибки.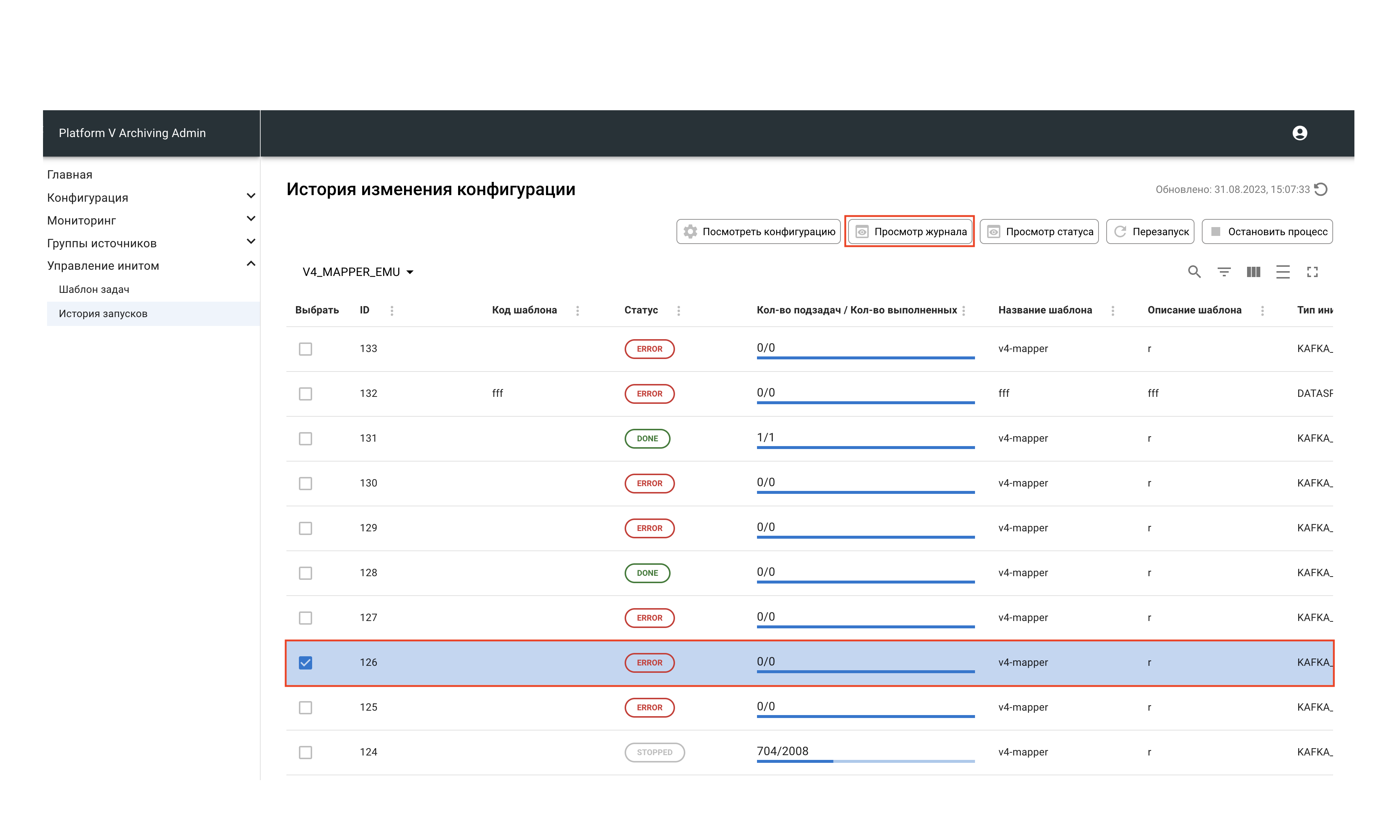
В открывшемся меню нажмите кнопку Скачать.
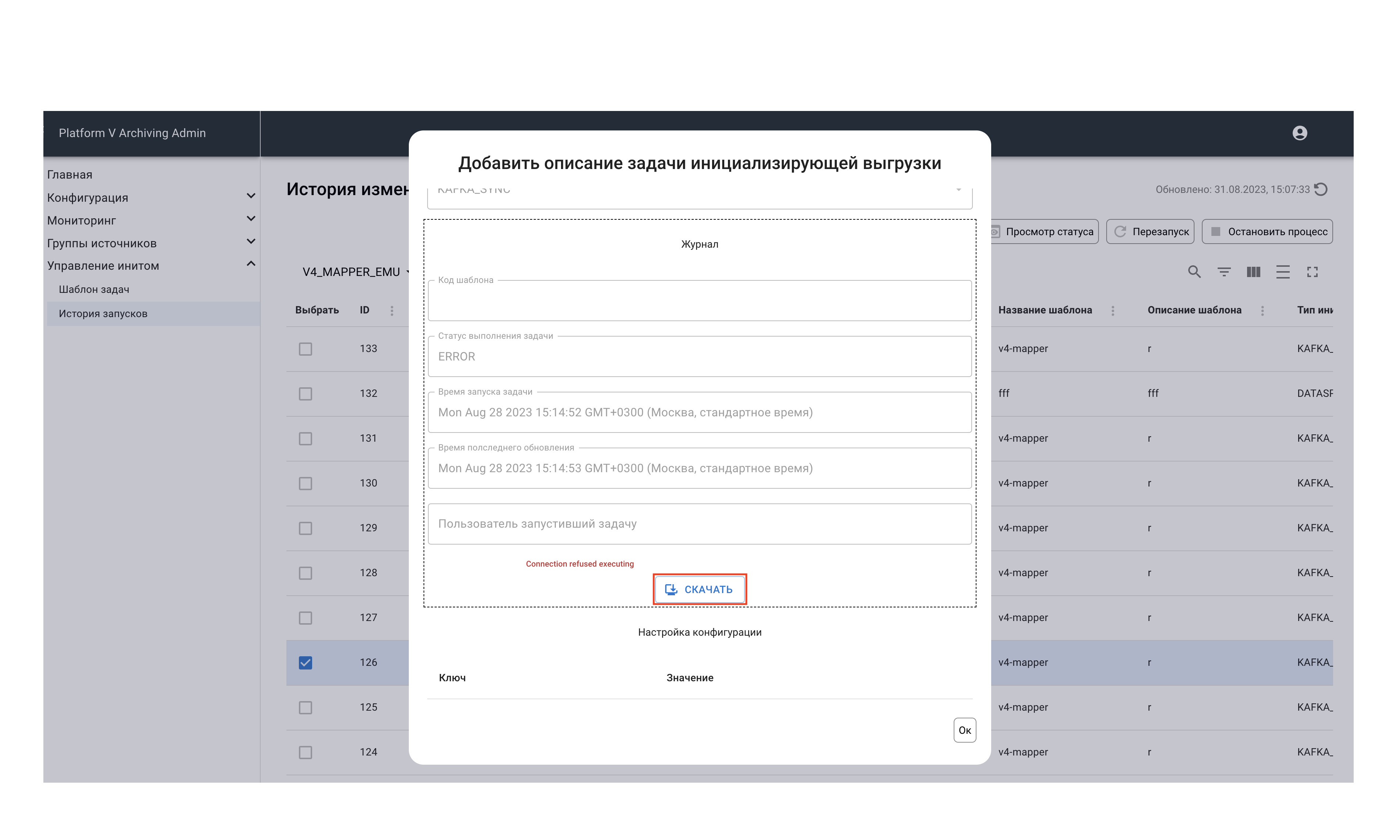
После нажатия начнется скачивание текстового документа с описанием ошибки.

Откройте полученный файл через текстовый редактор, чтобы увидеть ошибку
Работа с сервисом Прикладной журнал (APLJ)#
Настройка плагинов Kafka#
За интеграцию компонента Прикладной журнал (APLJ) и Архивирование (ARCH) отвечает плагин EXPORT_FD4. Данный плагин интегрирован с Архивированием (ARCH) посредством Kafka. Плагины настраиваются для каждой зоны Прикладного журнала (APLJ) и типа данных.
Начало работы с Прикладным журналом — смотрите документацию на компонент Прикладной журнал (APLJ), документ «Руководство по системному администрированию», раздел «Доступ к приложению».
Пример настройки выгрузки в Архивирование (ARCH) типа данных GBK_DATA в зоне GBK:
В верхней панели АРМ Прикладного Журнала выберите зону (в примере — GBK).
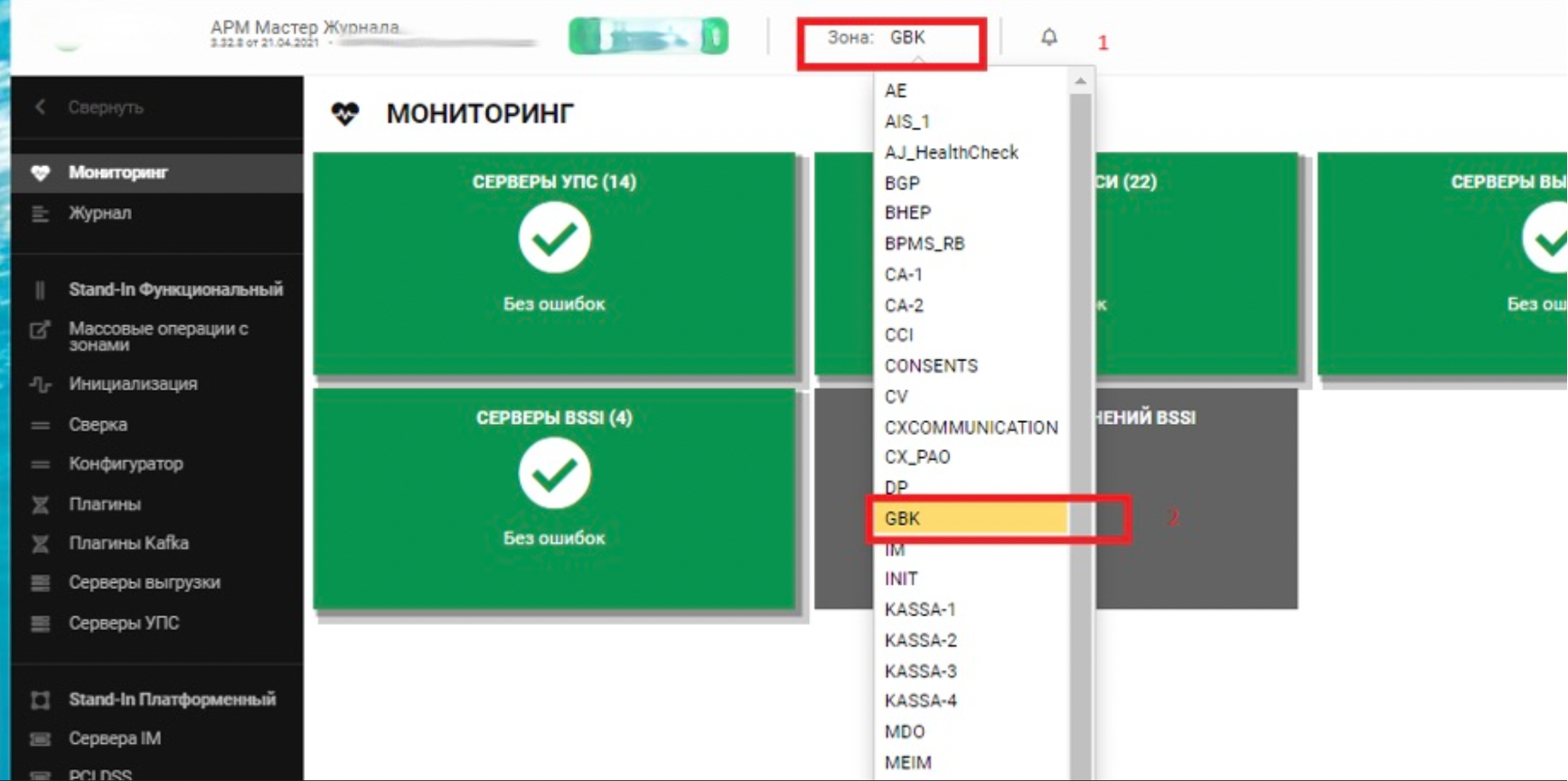
После выбора зоны в меню перейдите на вкладку Плагины Kafka и нажмите Добавить плагин.
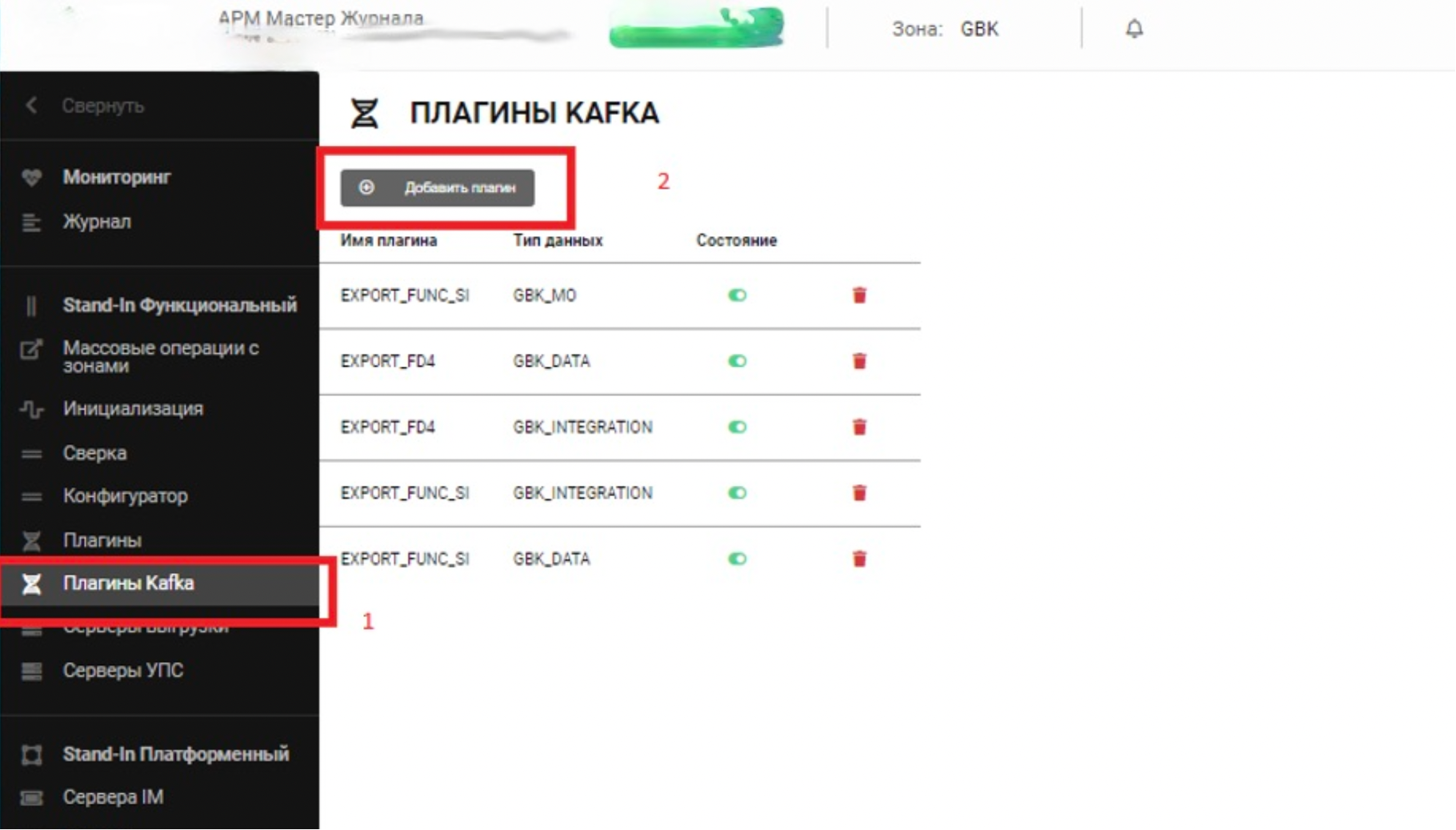
В появившемся окне выберите плагин EXPORT_FD4, тип данных (в примере — GBK_DATA), состояние – включен (зеленый переключатель) и нажмите Сохранить.
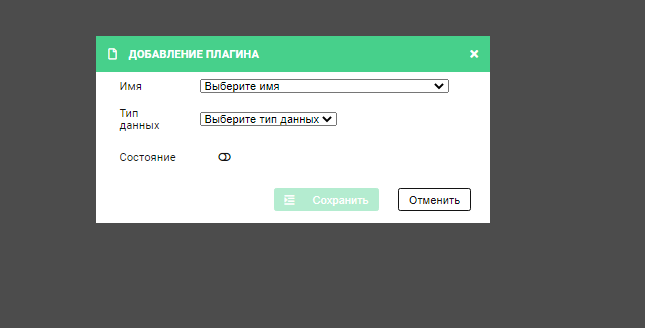
Перезагрузите АРМ и Writer Прикладного Журнала, чтобы создались необходимые топики и началась выгрузка.
Отправка журналов в очередь#
Кнопка В Очередь предназначена для отправки Журналов, не реплицированных из-за ошибки. Отправка журналов в очередь решает проблему репликации, если ее не было по следующим основным причинам:
транспортная система в какой-то момент времени не доступна. Тогда функция отправки в очередь заново отправит журнал на репликацию и если транспортная система доступна, репликация будет успешна.
недоступность принимающего модуля. Если доступность модуля восстановлена, то при отправке журналов в очередь репликация будет успешна.
ошибка связана с некорректностью работы принимающего модуля. В таком случае необходимо исправить ошибку модуля, затем выполнить отправку журнала в очередь.
Для отправки нереплицированных журналов в очередь необходимо заполнить соответствующие фильтры для выбора конкретных Журналов.
Если не выбраны конкретные Журналы, то на репликацию будут отправлены все нереплицированные записи, которые отображены в списке журналов.
Последовательность действий:
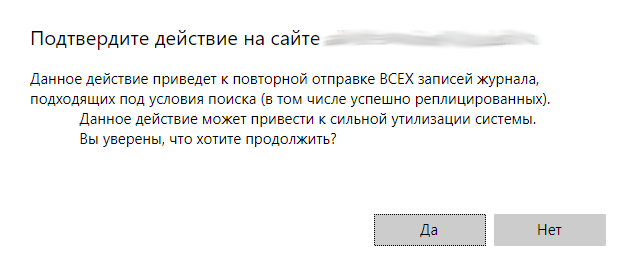
До отправки в очередь устраните причину ошибки, чтобы репликация стала возможна.
Выберите Журнал(ы), которые не реплицированы из-за ошибки, заполнив необходимые поля фильтрации.
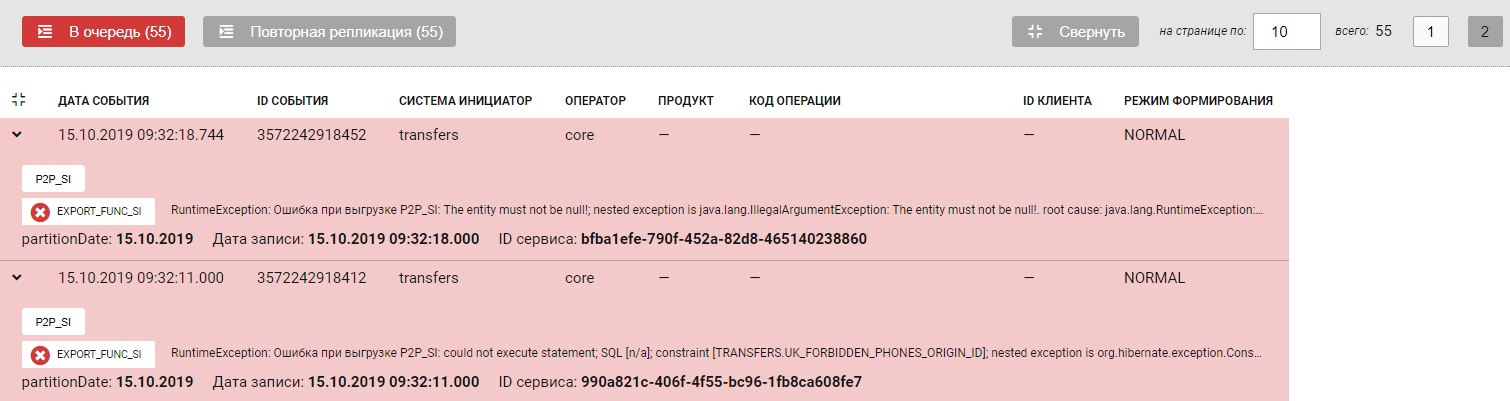
Нажмите В Очередь.
Нажмите Да, чтобы подтвердить действие.

Выполните поиск журналов повторно, с установленной галочкой С ошибками репликации.
Репликация записи успешна. Запись окрасилась в оранжевый цвет. При раскрытии информации о журнале отображена ошибка, из-за которой предыдущие попытки репликации были завершены неуспешно.

Отправка журналов на Повторную репликацию#
Кнопка Повторная репликация предназначена для того, чтобы отправить все выбранные по фильтру записи на повторную репликацию независимо от статуса.
Внимание!
На повторную репликацию будут отправлены все записи журнала (нереплицированные, реплицированные с ошибкой, реплицированные без ошибок). Поэтому следует выполнить фильтрацию Журналов таким образом, чтобы на повторную репликацию были отправлены только нужные записи, а не все записи из таблицы с Журналами.
Выберите Журнал(ы), которые необходимо отправить на повторную репликацию, заполнив необходимые поля фильтрации.
Нажмите Повторная репликация.
Нажмите Да, чтобы подтвердить действие.
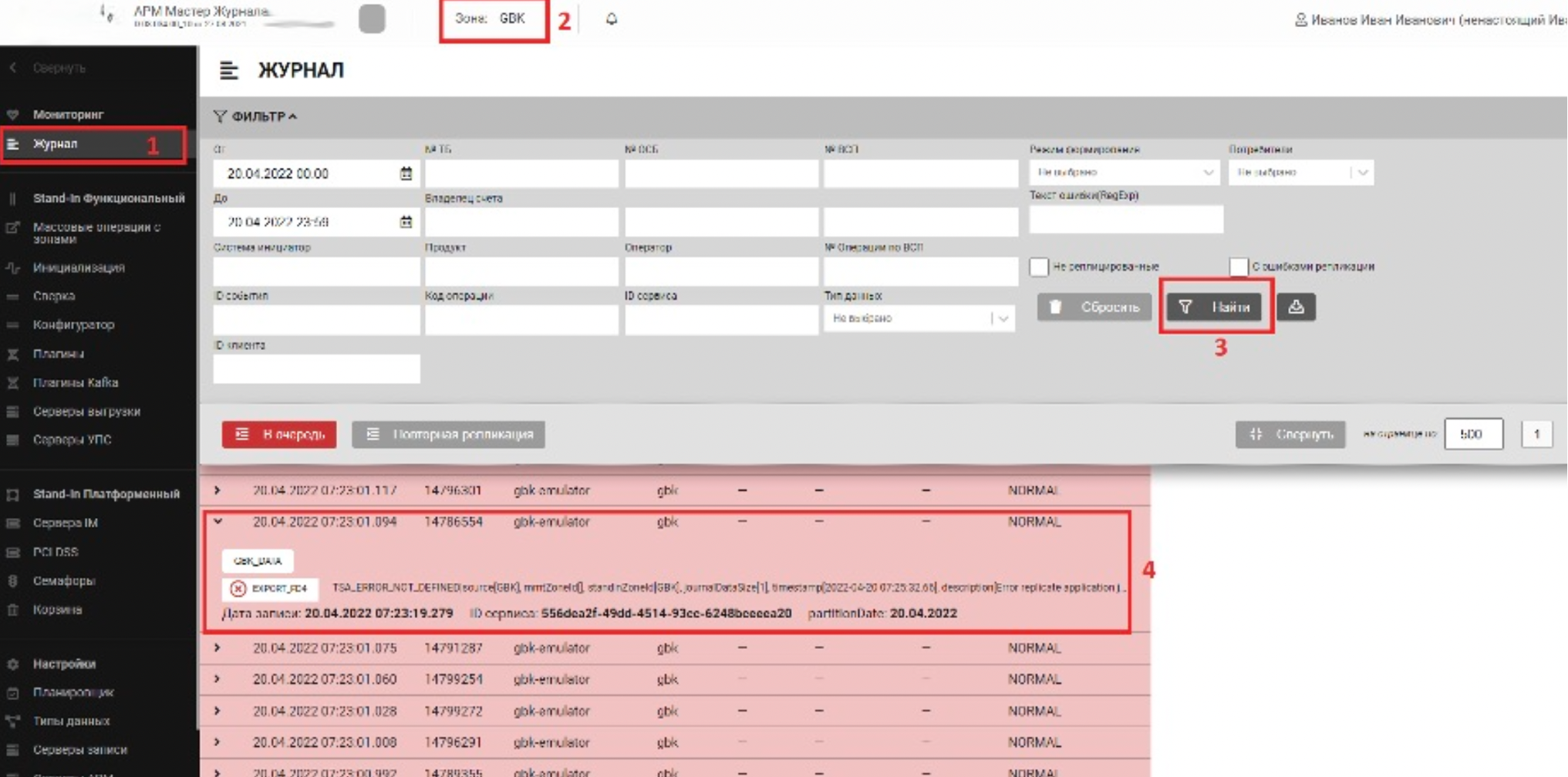
Анализ сообщений об ошибках в Прикладном журнале (APLJ)#
Алгоритм действий по анализу ошибок векторов репликации следующий:
Зайдите в Прикладной журнал (APLJ) и посмотрите векторы изменений.
Выберите требуемый журнал.
Выберите зону и Источник.
Отфильтруйте данные для просмотра векторов. Векторы, отмеченные красным, сигнализируют об ошибке.
Кликните на вектор, чтобы увидеть подробности по ошибке.
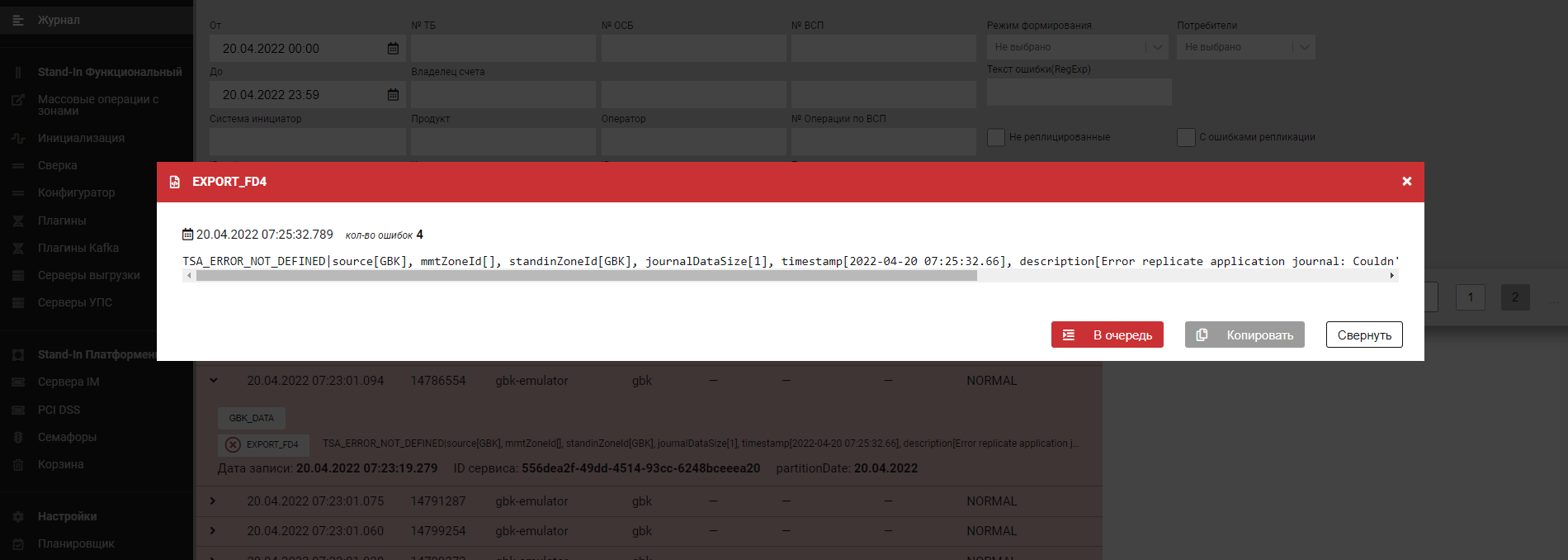
Содержимое сообщения описывает произошедшую ошибку.
В случае обнаружения ошибки репликации векторов в Прикладном журнале (APLJ) имеет смысл задать режим расширенного логирования для конкретных модулей и перезапустить репликацию пачки векторов. Также можно дождаться следующего ошибочного вектора (при стабильно появляющейся ошибке) и проанализировать его результаты.
Ошибки со стороны ЦСП#
Ошибки, вызванные невозможностью применить data-container на стороне ЦСП и возвращаемые в ответе коммита ЦСП в топик коммитов.
Общий формат: строка, первая часть (до вертикальной черты) — код ошибки, вторая — информационные параметры. В Прикладном журнале (APLJ) будет отображена точно в переданном виде.
Название |
Код |
Формат описания |
Описание ошибки |
|---|---|---|---|
Ошибка нарушения последовательности операций |
|
`ERROR_WRONG_OPERATION_SEQUENCE |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s]` |
Неверная версия |
|
`ERROR_WRONG_VERSION |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s]` |
Неверный формат |
|
`ERROR_CONTAINER_DATA |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s], description[%s]` |
Нотация параметров:
type— передаваемый Архивированием (ARCH) тип;key— передаваемый в контейнере ключ;operation— тип операции из контейнера;version— версия из контейнера;hversion— версия HBase;timestamp— время возникновения ошибки;description— описание ошибки (только для ситуации неверного формата). В случае исключения параметр записывается исключение без stack trace.
Примечание:
Параметры могут отсутствовать или быть недоступны в точке возникновения ошибки - в таком случае они заполняются значением
[ ].Параметры могут иметь значение
null— в таком случае они заполняются как["null"].
Пример разбора ошибки#
Получено сообщение:
ERROR_CONTAINER_DATA|type[com.sbt.bm.ucp.consents.model.dictionary.UcpConsentOperatorType], key[UcpConsentOperatorType_432.1653997258660], operation[null], version[0], hversion[], timestamp[2022-05-31 14:41:31.141], description[Part of the data is absent.].Согласно мнемонике, это ошибка со стороны ЦСП (смотрите таблицу выше) - неверный формат. Далее необходимо проанализировать сообщение по полям (названия полей смотрите в таблице выше).
Итоговое сообщение об ошибке:
description[Part of the data is absent.].
Режимы работы загрузчика в ЦСП#
Основные режимы работы загрузчика ЦСП#
Основные режимы работы загрузчика ЦСП:
Default (устаревшее, используется для обратной совместимости до версии Архивирования (ARCH) 3) — при такой конфигурации online ТКД не работает. Если пришел объект, версия которого ниже, чем в Hbase, объект игнорируется (не сохраняется в Hbase, не возникает инцидент. Верно для любого режима), происходит переход к сверке следующего объекта. Сверка версий происходит в версии writer с online ТКД.
Online ТКД (без полноты) — версии объекта анализируются и, в зависимости от сценария, объект либо сохраняется в Hbase в случае успеха, либо в специальный топик ТКД на стороне Архивирования (ARCH) отправляется запрос полной версии объекта. В случае аварийного сценария прием данных контейнером, в котором возник данный сценарий, приостанавливается до момента получения ответа на аварийный запрос из Архивирования (ARCH).
Retry (waitcommit) (с полнотой) — writer не запрашивает ТКД синхронно, а вместо этого помечает сообщение в технологической таблице как «поломанное» и ожидающее retry, откатывает изменения по нему, отправляет сообщение в топик retry и продолжает работать. Если через 15 минут не будет получен правильный вектор, загрузчик прекращает работу.
Примечание:
Platform V DataSpace (APT) работает только в режиме Retry, остальные Источники могут использовать и другие режимы:
Platform V DataSpace (APT) writer сверяет версию дочернего объекта с текущей версией агрегата.
Platform V DataSpace (APT) writer всегда обновляет версию агрегата, даже если самого корневого объекта не было в контейнере.
Platform V DataSpace (APT) writer не запрашивает ТКД синхронно, а вместо этого помечает сообщение как «поломанное», откатывает изменения по нему, отправляет сообщение в топик retry и продолжает работать.
Параметры работы загрузчика ЦСП:
Strict/ Non-Strict — используется только в ТКД и только для Источников, которые не хранят версию. Strict означает, что приходящий вектор изменений должен иметь версию «+1» к текущей. Strict неприменимо к Источникам, использующим любые не монотонно растущие последовательности в качестве версии.
Полнота (waitcommit) может быть включена для любого writer, это обычная отправка коммитов. Требуется согласованное включение как для ЦСП, так и для Источника, и возможно не для всех Источников.
Online ТКД используется вне зависимости от того, какой формат версии используется Источником. Пропуск версии важен только для Дельты (Векторов изменений).
Типы векторов изменений:
Дельта-сообщение — изменение некоторых полей в Источнике. В определенном поле указан список измененных полей.
Снепшоты — полное состояние объекта. Для них список значений полей (значение поля) будет
NULL.
ЦСП по этому полю распознает тип вектора.
Поле тип операции может быть нулевым (NULL). В этом случае, если тип операции NULL, ЦСП трактует операцию как INSERT. Это работает в случае полного состояния объекта - все поля со всеми ограничениями, требуемые для операции INSERT.
Типы Источников, с которыми работает Архивирование (ARCH):
Источники, которые отправляют как Дельта-сообщения, так и снепшоты, Для Источников, отправляющих Дельта-сообщения, может использоваться только режим Strict.
Источники, которые всегда отправляют снепшоты. Такие Источники не передают список полей для обновления. В этом случае может использоваться режим Non-Strict для загрузчика.
Снепшот — это полный элемент. В этом случае для любой системы в любом режиме нет проблемы с пропуском версий или снепшотом с версией ниже текущей: ошибка в Архивировании (ARCH) или Прикладной журнал (APLJ) не отправляется. Если версия ниже текущей, сообщение об ошибке записывается в лог ЦСП, и сообщение игнорируется.
Переиспользование ID означает ошибки на Источнике.
В случае включенной полноты пустые транспортные контейнеры не отбрасываются. В них отправляются служебные пакеты. Загрузчик также должен работать в режиме включенной полноты. Загрузчики в случае не включенной полноты отбрасывают пустые контейнеры. В этом случае в ЦСП ничего не отправляется, вектор изменений отображается желтым (Warning).
Реакция ЦСП в зависимости от приходящего события и состояния объекта в ЦСП#
Вектор изменений#
Комментарии по таблице:
Insert— операция добавления объекта в ЦСП;Update— операция обновления объекта в ЦСП;Delete— операция удаления объекта из ЦСП;пересечение столбцов — выполняемая операция:
Apply— применение операции;Ignore— игнорирование операции;Error— генерирование ошибки выполнения операции.
Insert |
Update |
Delete |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Отношение номера версии текущего и пришедшего вектора |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
Объект, по которому пришло событие, не существует в ЦСП |
Apply |
Apply |
Apply |
Apply |
Error |
Error |
Error |
Error |
Error |
Error |
Error |
Error |
Объект, по которому пришло событие, существует в ЦСП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Apply |
Error |
Ignore |
Apply |
Apply |
Error |
Объект, по которому пришло событие, удален из ЦСП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Error |
Error |
Ignore |
Ignore |
Error |
Error |
Снепшот#
Комментарии по таблице:
Insert— операция добавления объекта в ЦСП;Update— операция обновления объекта в ЦСП;Delete— операция удаления объекта из ЦСП;пересечение столбцов — выполняемая операция:
Apply— применение операции;Ignore— игнорирование операции;Error— генерирование ошибки выполнения операции.
Insert |
Update |
Delete |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Отношение номера версии текущего и пришедшего вектора |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
Объект, по которому пришло событие, не существует в ЦСП |
Apply |
Apply |
Apply |
Apply |
? |
? |
? |
? |
Error |
Error |
Error |
Error |
Объект, по которому пришло событие, существует в ЦСП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Apply |
Apply |
Error |
Объект, по которому пришло событие, удален из ЦСП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Error |
Error |
Ignore |
Ignore |
Error |
Error |
Оптимизация параметров тракта#
Настройка производительности возможна по каждому из направлений работы Архивирования (ARCH) (Init, Поток, ТКД), Все три направления будут рассмотрены по отдельности.
Включение режима подтвержденных транзакций по Источнику#
Чтобы включить режим, выполните следующие шаги:
На стороне Архивирования (ARCH) в PACMAN (CFGA) по модулю
pprbod-applied-journal-handlerуказать мнемонику Источника (см. Руководство по установке, раздел pprbod-applied-journal-handler).На стороне Источника нужны соответствующие доработки для поддержки отправки подтверждения о транзакциях. Дополнительно подписка на плагин для обработки подтвержденных журналов на БД SI контура Источника (Пример названия плагина: EXPORT_FINC_SI_CONFIRMED).
На стороне Прикладного журнала (APLJ) нужно настроить плагин(ы):
EXPORT_FD4 в режиме работы «Ожидание при подтверждении». Например, по Источнику есть две зоны TEST1 и TEST2:
Зона TEST1 имеет два настроенных плагина EXPORT_FD4 на типы TYPE1 и TYPE2 (нужно удалить эти плагины по типам и настроить заново с ожиданием подтверждения).
Зона TEST2 имеет один настроенный плагин EXPORT_FD4 тип - TYPE3 (нужно удалить этот плагин по типу и настроить его заново с ожиданием подтверждения).
EXPORT_FINC_SI_CONFIRMED в режиме работы «Ожидание при подтверждении». Тот же Источник из примера выше – две зоны TEST1 и TEST2. Нужно добавить EXPORT_FINC_SI_CONFIRMED новый плагин в Прикладном журнале (APLJ), затем:
Зона TEST1 имеет два настроенных плагина EXPORT_FD4 в режиме ожидания подтверждения на типы TYPE1 и TYPE2 (нужно настроить новый плагин с ожиданием подтверждения на типы TYPE1 и TYPE2).
Зона TEST2 имеет один настроенный плагин EXPORT_FD4 в режиме ожидания подтверждения на тип TYPE3 (нужно настроить новый плагин с ожиданием подтверждения на тип TYPE3).
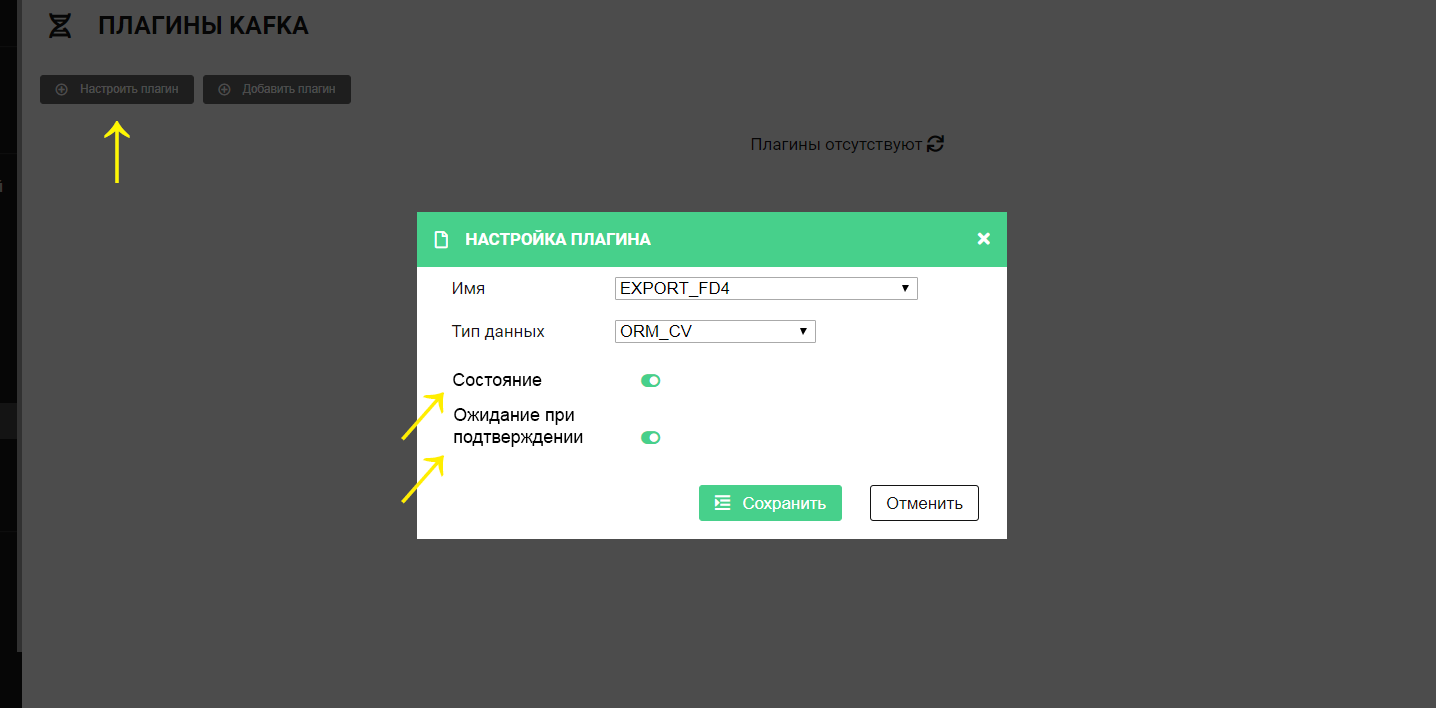
Требования к настройкам:
Настройки Архивирования (ARCH) и Прикладного журнала (APLJ) должны быть применены симметрично, то есть обязательно соблюдение п. 1 и п. 3 (в случае настройки только одного из пунктов поведение подтверждения транзакций будет некорректно).
Настройка брокеров и Kafka producer#
Для осуществления семантики чтения at-least-once и избежания потери данных и, как следствие, некорректной работы Архивирования (ARCH) рекомендуются следующие настройки producer и брокеров Kafka.
Настройка producer#
retries = 10– количество повторов попыток отправки сообщения;retry.backoff.ms = 100– задержка между повторными попытками;acks = all– все синхронизированные брокеры должны ответить, что сообщение получено;enable.idempotence=true– включение идемпотентности.
Настройка брокеров#
replication = N, гдеN=Количество брокеров - 1;min.insync.replicas = M, гдеM=N - 1, ноM> 1. Минимальное количество синхронизированных брокеров. Должно быть меньше общего количества реплик.
Добавление нового узла#
Добавление нового узла выполняется для каждого нового узла (первый узел формируется в процессе первичной установки).
Для ввода в решение нового узла Архивирования (ARCH):
Скопируйте сертификаты Kafka, выпущенные в рамках раздела «Создание клиентских сертификатов, выдача прав» Руководства по установке, на новый узел. Адрес каталога, где будут размещены сертификаты, должен совпадать с адресами каталогов на уже присутствующих узлах Архивирования (ARCH).
Скопируйте сертификаты ОТТ для всех модулей Архивирования (ARCH), которые были выпущены в рамках пункта «Подключение Архивирования (ARCH) к ОТТ» Руководства по установке. Адрес каталога, где будут размещены сертификаты, должен совпадать с адресами каталогов на уже присутствующих узлах Архивирования (ARCH).
Установите компоненты по инструкции, приведенной в документе «Руководство по установке», раздел «Установка».
Обновление конфигурации решения#
Изменение максимального количества подключений к БД Архивирования (ARCH)#
БД Архивирования (ARCH) имеет фиксированный пул подключений. Каждый новый узел требует дополнительного места для подключения.
Рассчитайте требуемый размер пула по формуле:
[количество серверов Архивирования (ARCH) в решении] * jdbc.maxPoolSize + 10, где значениеjdbc.maxPoolSize. Число 10 добавляется в случае необходимости дополнительных подключений.Рассчитанный размер пула установите в соответствии с новым количеством серверов Архивирования (ARCH).
Отслеживание работоспособности системы#
Отслеживание работоспособности системы реализуется посредством наблюдения за логами системы, а также показателями мониторинга. Данный процесс и показатели подробно описаны в документе «Руководство по системному администрированию».
Отслеживание работоспособности системы реализуется посредством наблюдения за логами системы и показателями мониторинга. Данный процесс и показатели подробно описаны в разделах «События системного журнала» и «События мониторинга» Инструкции по системному администрированию.