Интеграция отчуждаемой плагинной модели#
Назначение и архитектура#
Архивирование (ARCH) как тиражируемое решение для прикладной репликации данных потребителей (прикладных фабрик Platform V, по тексту применяются синонимы — фабрики, Источники, потребители) поддерживает платформенные механизмы работы с данными и имеет встроенные обработчики для векторов изменений, Init и ТКД в соответствии со стандартами Platform V. Реализации, поддерживаемые ядром Архивирования (ARCH) — это закрытый перечень, в который входят:
Platform V DataSpace (APT) (4 поколение Platform V);
Platform V Persistence (HBR), включая:
Platform V Persistence (HBR) 3Gen (3 поколение Platform V).
Platform V Persistence (HBR) 4Gen (4 поколение Platform V).
Любые Источники, реализующие контракт формата векторов изменений согласно транспортному формату 4.0» и логической модели по стандарту описания логической модели данных (
*.ldm).
Источники, не соответствующие перечисленным требованиям, не поддерживаются ядром Архивирования (ARCH) напрямую. Такое ограничение связано с тем, что для поддержки нестандартных форматов сериализации, нестандартных форматов представления модели данных требуется наличие внутри ядра кода Архивирования (ARCH), обеспечивающего поддержку этой нестандартной (или даже неплатформенной) логики. Наличие такой логики в виде собственных или внешних зависимостей невозможно по той причине, что как только такие зависимости появляются — они создают зависимость (двунаправленную) между релизами Архивирования (ARCH) и релизами Источника, что неприемлемо ни для Источника, ни для технологического сервиса в рамках его тиража. Для решения этой проблемы и обеспечения возможности распространения тиража на нестандартные и Legacy Источники предназначена технология отчуждаемой плагинной модели.
Плагин Архивирования (ARCH) — технологическое решение, позволяющее реализовать всю необходимую для обработки логики Источника кодовую базу на стороне Источника, оформить плагин как самостоятельный не требующий внешних зависимостей артефакт (если зависимости есть, они упаковываются в FatJAR при помощи maven-assembly-plugin). Далее нужно предоставить такой артефакт по конфигурационному pipeline в Архивирование (ARCH), после чего Архивирование (ARCH) внутренними механизмами выполнит инстанцирование необходимых классов внутри работающего Архивирования (ARCH), в рамках изолированных для каждого Источника загрузчиках классов.
Плагин обеспечивает:
требуемый для Источника алгоритм десериализации, в общем случае — любой, и различный для первоначального Init, обработки Потока и обработки ТКД/DRP;
конвертацию формата вектора в универсальный транспортный формат 4.0, в том числе логику формирования версий объектов, их идентификаторов, с учетом необходимой для Источника логики. Код плагина реализует Источник, так как он владеет необходимой информацией для формирования этих ключей, согласно требованиям выходного контракта, и согласно имеющихся на стороне Источника исходных данных;
реализацию логики преобразования идентификаторов дочерних сущностей в идентификаторы родительских при необходимости такого преобразования;
иные тонкие детали реализации, направленные на преобразование нестандартного формата Источника в универсальный формат вектора изменений.
При этом достигаются:
Возможность реализации Источником логики любой сложности.
Независимость релизного цикла технологического сервиса от релизного цикла Источника.
Валидация корректности и целостности плагина перед его запуском, что гарантирует безопасность.
Изолированность плагинов разных Источников друг от друга, что гарантирует отсутствие влияния на другие фабрики в случае дефектов в одной из реализаций.
Схема последовательности:

Поставка плагина технически выполняется через конфигурационный pipeline Архивирования (ARCH) (см. документ «Подключение и конфигурирование»), сам плагин размещается в архиве поставки Архивирования (ARCH) как отдельный артефакт, наряду с моделью, конфигурацией и белым списком, согласно составу дистрибутива фабрики DFCi (см. документ «Подключение и конфигурирование», раздел «Состав дистрибутива конфигурации Источника»).
Для выполнения произвольной фабрикой интеграции по плагинной схеме необходимо:
Ознакомиться с форматами — транспортный формат 4.0 и стандартом описания логической модели данных (
*.ldm).Подготовить формальное описание реплицируемой модели данных по формату
*.ldm.Реализовать процесс создания
*.ldmпри обновлении (расширении, изменении модели данных) фабрики.Реализовать код плагина в виде имплементации интерфейсов плагинной модели, предоставленных Архивированием (ARCH) и оформление этого артефакта согласно требованиям.
Написать требуемые unit-тесты, проверяющие корректность работы артефактов плагина на стороне Источника, исключающих технические ошибки.
Реализовать публикацию LDM-модели, выполнить разметку модели белым списком.
Реализовать базовые фазы CI-стадии процесса DFCi согласно требованиям процесса DFCi для включения в дистрибутив фабрики конфигураций и необходимых базовых артефактов Архивирования (ARCH).
Реализовать расширение CI-стадии DFCI, а именно — требуемые процедуры подписывания, включения в дистрибутив байт-кода плагина (настройка CI) и выполнение требуемых проверок.
Реализовать базовые фазы CDP-стадии процесса DFCi согласно требованиям процесса DFC для конфигурирования Архивирования (ARCH).
Выполнение интеграции#
1. Изучение целевых форматов и процессов#
Обязательным предусловием реализации плагина является ознакомление команды разработки Источника с целевыми форматами и процессами.
Формат логической модели данных (
*.ldm) является ключевым. Формат описывает структуру реплицируемых объектов.Вектор изменения — транспортный формат 4.0. Такой формат является итогом преобразования объекта, либо его дельты (изменения) в результате работы кода плагина.
Описание формата и состава артефактов конфигурирования для дистрибутива (см. раздел «Состав дистрибутива конфигурации Источника») Источника.
Общий DFCi devops-процесс обогащения дистрибутива и конфигурирования Архивирования (ARCH).
Процесс CI-фазы(см. документ «Руководство прикладного разработчика», раздел «B-Pipeline. Сборка конфигурации (конфигурационного архива) для Архивирования (ARCH)») DFCi devops процесса интеграции с Архивированием (ARCH).
Процесс CDP-фазы DFCi devops процесса для полигона ИФТ(см. «R-Pipeline. ИФТ. Фаза конфигурирования экземпляра Архивирования (ARCH)»).
Процесс CDP-фазы DFCi devops процесса для ПСИ полигона и полигона ПРОМ.
Формат описания логической модели#
Регламентируется стандартом «Стандартом моделирования логических моделей данных — версия 1.0».
Схема модели описана в справочном документе «Формат описания логической модели».
Транспортный формат 4.0#
Подробное описание транспортного формата приведено в разделе Транспортный формат 4.0.
2. Реализация создания *.ldm и ее обновление#
Генерация *.ldm файла по фактической модели — является зоной ответственности Источника. Ограничений на применяемые инструменты и алгоритмы не накладывается, но необходимо обеспечить следующее:
*.ldmфайлы генерируются по DTO-артефактам Источника.Генерация должна выполняться по принципу: один DTO-объект - одна сущность (класс) в результирующем
*.ldm-файле.Имена типов в
*.ldm-файле должны соответствовать полным именам классов DTO-сущностей (должен браться FQN, fully qualified name).Имена атрибутов должны строго соответствовать именам полей классов DTO-сущностей. В крайнем исключении допускается однозначное переименование, при условии сохранения этой же логики и в коде реализации плагина.
Типы атрибутов, являющиеся примитивами, должны соответствовать типам данных DTO-сущностей, с учетом того, что логических типов — меньшее множество, чем физических, но они однозначно сопоставляются физические на логические (см формат
*.ldm).Типы атрибутов, представляющих собой ссылки, должны строго соответствовать полным именам классов DTO-сущностей, на которые идет ссылка.
Типы, представляющие собой коллекции — должны быть представлены одним из логических типов, представляющих Set, List или MAP (см формат
*.ldm).Использование обобщенных (generic) либо типов, представляющих собой абстрактные классы, в качестве имен типов на уровне
*.ldm-модели — не допускается.В случае, если DTO/JPA сущности используют наследование, в LDM-описание должны встраиваться все поля родительских сущностей.
Embedded classes в LDM оформляются как embed-сущности согласно схеме в файле
*.ldm.Процесс генерации выполняется при сборке проекта Источника, результирующий
*.ldm-артефакт должен размещаться в каталоге target.В результирующий
*.ldm-файл входят все сущности, которые необходимо будет реплицировать в ЦСП. Технические сущности, по которым не формируется векторов изменений, допускается не включать в логическую модель. При этом необходимо включать в логическую модель все бизнес-сущности Источника, а также те технические сущности, по которым генерируются вектора изменений, в противном случае десериализация таких векторов изменений на стороне Архивирования (ARCH) будет сопровождаться ошибкой, и приводить к появлению «красных» векторов в Прикладном журнале с соответствующим информационным сообщением. Управление репликацией данных выполняется исключительно через белые списки.Для сущностей (дочерних сущностей), не имеющих собственной версии или идентификатора, должны быть сгенерированы синтетические поля версии или идентификатора соответственно, которые на последующих этапах должны будут заполняться также синтетическими данными при работе плагина.
Если идентификатор не получится явно выделить из поля или группы полей, или он генерируется сложной логикой — под него необходимо определить синтетическое поле. Подробно про возможные варианты генерации id описано в разделе интерфейсы плагина.
При использовании в качестве ORM Hibernate, как правило, проблем с генерацией не возникает.
Для генерации LDM модели можно использовать maven-артефакт Platform V Persistence, пример подключения:
<groupId>sbp.eip.metamodel</groupId>
<artifactId>eip-metamodel-scanner-maven-plugin</artifactId>
<version>3.1.3</version>
Плагин конфигурируется параметрами:
присутствуют для всех:
model-name — название модели;
model-version — версия модели;
file-name — название выходного xml файла. Если не заканчивается на .xml, дополняется суффиксом
.ldm.xml;
параметры пакетов:
packages — пакеты (включая подпакеты) в которых производится поиск. Можно указывать несколько через запятую;
exclude-packages (optional) — подпакеты, указанные в
packagesкоторые нужно исключить из поиска (например, если приводят к неконсистентности модели или приводят к другим ошибкам поиска);exclude-types (optional) — одиночные типы, которые нужно исключить из поиска;
additional-types (optional) — одиночные типы, не входящие в область поиска, которые необходимо добавить в поиск;
параметры hbm:
hibernate-xml-path — путь к папке с hbm.xml файлами. Можно указывать как внутренний ресурс, например,
classpath:/sbp/some/resource, так и внешний, например,file:/some/path/from/disk;exclude-packages (optional) — подпакеты которые нужно исключить из поиска;
exclude-types (optional) — одиночные типы, которые нужно исключить из поиска.
Для запуска под Java 11 и выше необходимо добавить две зависимости:
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
Пример базовой конфигурации:
<plugin>
<groupId>sbp.eip.metamodel</groupId>
<artifactId>eip-metamodel-scanner-maven-plugin</artifactId>
<version>3.1.3</version>
<configuration>
<formatted-output>true</formatted-output>
<models>
<jpa>
<model-name>v4-mapper-emu</model-name>
<model-version>0.0.1</model-version>
<file-name>v4-mapper-emu.ldm.xml</file-name>
<packages>sbp.ts.pprbod.autotest.emu.mapper.entity</packages>
<excludePackages>com.sbt.some.jpa.packages</excludePackages>
<excludeTypes>com.sbt.some.jpa.ExcludeType</excludeTypes>
<additionalTypes>com.sbt.some.packages.jpa.AdditionalType</additionalTypes>
</jpa>
</models>
</configuration>
<executions>
<execution>
<id>process</id>
<phase>process-classes</phase>
<goals>
<goal>metamodel_scanner</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
</dependencies>
</plugin>
В результате работы будут созданы *.ldm-файл и файл с белыми списками (файл whitelist.txt или заданное пользователем в аттрибуте whitelist-file-name).
Созданный белый список не имеет отношения к целевой разметке, но может использоваться командой для сверки/валидации того, какие сущности были просканированы и сгенерированы.
По умолчанию в белый список попадают все сущности вашей модели. Для исключения классов или их полей из белого списка существуют аннотации. Их использование не влияет на целевую разметку, а только на генерируемый текстовый файл белого списка.
Существует также альтернатива для Gradle.
В случае, если по каким-либо причинам использование плагина невозможно, или не подходит фабрике — требуется написание силами команды разработки фабрики собственной реализации, генерирующей LDM-описание сущностей строго в соответствии с требованиями.
В качестве примера реализации генерации LDM-файла может быть использован исходный код плагина, который можно запросить у команды Platform V Persistence, оформив соответствующее обращение через Solution Owner Архивирования (ARCH).
Аннотации для разметки чувствительных данных#
В целях повышения уровня защищенности от угроз кибербезопасности, поля доменной модели могут быть отнесены к следующим категориям:
ПДн — Персональные данные;
БТ — Банковская тайна;
ДПК — Данные платежных карт.
Каждой категории соответствует аннотация из пакета sbp.eip.metamodel.annotations:
@BankingPrivacy — аннотация служит для разметки данных, относящихся к категории «Банковская тайна».
@PaymentCardData — аннотация служит для разметки данных, относящихся к категории «Данные платежных карт».
@PersonalData — аннотация служит для разметки данных, относящихся к категории «Персональные данные».
@WhitelistDisabled — аннотация служит для разметки данных, не относящихся к какой-либо к категории. Исключается из Whitelist, но не попадает в какие-либо json-файлы чувствительных данных.
Аннотации допустимо проставлять для полей примитивных типов. Кроме того, аннотация может быть указана на уровне класса, в этом случае ее действие распространяется на все примитивные поля размечаемого класса.
Зависимость:
<artifactId>eip-metamodel-annotations</artifactId>
<groupId>sbp.eip.metamodel</groupId>
<version>3.1.14</version>
Gradle#
Пример build.gradle
buildscript {
repositories {
mavenCentral()
mavenLocal()
}
dependencies {
classpath("sbp.eip.metamodel:eip-metamodel-scanner-gradle-plugin:3.1.14", "sbp.eip.metamodel:eip-metamodel-core:3.1.14")
}
}
plugins {
id 'java'
}
group 'ggggggg'
version '1.0-SNAPSHOT'
sourceCompatibility = 1.8
repositories {
mavenCentral()
mavenLocal()
}
apply plugin: "eip-metamodel-scanner"
metamodel{
componentCode = "kjh"
// Необязательные параметры. Для примера указаны значения по умолчанию.
// formattedOutput = false
// schemaVersion = "1.0"
// formattedOutput = false
// internalPath = "."
// interruptOnError = false
// outputDirectory = null – если null, подставится корень jar
}
modelJpa{
fileName = "az.ldm.xml"
modelName = "az"
modelVersion = "1"
packages = "com"
// Необязательные параметры. Для примера указаны умолчания
// excludePackages = null
// additionalTypes = null
// excludeTypes = null
}
rootProject.tasks.getByName("jar").dependsOn scanMetamodel
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
compile project(":first")
compile project(":second")
}
Плагин сканирует проект и создает xml файлы моделей в сборку.
Параметры плагина:
formattedOutput — использовать форматирование для выходного файла, по умолчанию false.
internalPath — папка внутри сборочной директории (параметр
outputDirectory) для выходного xml-файла, по умолчанию — classes (корень jar).outputDirectory — сборочная директория, по умолчанию
build/classes/java/main(корень jar). Можно переопределить, для сохранения выходного файла не в jar.interruptOnError — прерывать сборку при возникновении ошибок в процессе сканирования, по умолчанию — false (ошибки выводятся в лог, но не прерывают сборку).
strictTypeCheck — использовать строгую проверку примитивных типов. По умолчанию - true.
Если false — то вместо неизвестных примитивных типов будет подставлен String, при этом в лог выведется предупреждение (не рекомендуется использовать, т.к. можно не заметить ошибку в модели).
componentCode — компонент-код проекта. Проставляется в соответствующее поле в xml.
Cписок моделей для поиска, доступные:
modelJpa;modelHbm;modelMapper;modelDpl.
Параметры моделей:
Присутствуют для всех:
modelName — название модели;
modelVersion — версия модели;
fileName — название выходного xml файла. Если не заканчивается на
.xml, дополняется суффиксом.ldm.xml;
Присутствуют для jpa, mapper, dpl:
packages — пакеты (включая подпакеты) в которых производится поиск. Можно указывать несколько через запятую.
exclude-packages (optional) — подпакеты, указанные в
packages, которые нужно исключить из поиска (например, если пакеты приводят к неконсистентности модели или другим ошибкам поиска).exclude-types (optional) — одиночные типы, которые нужно исключить из поиска.
additional-types (optional) — одиночные типы, не входящие в область поиска, которые необходимо добавить в поиск.
Присутствуют в hbm:
hibernate-xml-path — путь к папке с
hbm.xmlфайлами. Можно указывать как внутренний ресурс, например,classpath:/sbp/some/resource, так и внешний, например,file:/some/path/from/disk.exclude-packages (optional) — подпакеты которые нужно исключить из поиска.
exclude-types (optional) — одиночные типы, которые нужно исключить из поиска.
Присутствуют только в mapper (используются для подключения hbm разметки к модели Persistence):
hibernate-xml-path
hibernate-exclude-packages
hibernate-exclude-types
4. Реализация плагина Архивирования (ARCH)#
Плагин Архивирования (ARCH) является ключевой точкой интеграции.
Обязательные зависимости#
Проект плагина должен включать следующие обязательные зависимости:
Интерфейсы плагинной модели. Актуальная версия - согласно версии Архивирования (ARCH). Данная зависимость обязательно должна быть
provided, так как она поставляется ядром Архивирования (ARCH) через JBoss, пример:<dependency> <groupId>sbp.ts.pprbod</groupId> <artifactId>pprbod-source-plugin-api</artifactId> </dependency> <dependency> <groupId>sbp.ts.pprbod</groupId> <artifactId>arch-journal-common-api</artifactId> </dependency>Транспортные интерфейсы Прикладного журнала (APLJ). Данная зависимость обязательно должна быть
provided, так как она поставляется ядром Архивирования (ARCH) через JBoss, пример:<dependency> <groupId>ru.sbrf.journal</groupId> <artifactId>journal-jms-dto</artifactId> </dependency>Зависимости прикладной фабрики. В этот блок обязательно должны входить зависимости, содержащие модельные DTO классы. Дополнительно — могут использоваться вспомогательные артефакты, обеспечивающие различные специфичные и реализуемые на стороне фабрики преобразования, а также требуемые и не поставляемые транзитивно зависимости.
<dependency> <groupId>com.sbt.prb</groupId> <artifactId>ucp-fatca-model</artifactId> </dependency> <dependency> <groupId>com.sbt.prb</groupId> <artifactId>ucp-retail-model</artifactId> </dependency> ... <dependency> <groupId>com.sbt.prb</groupId> <artifactId>ucp-fd-utils</artifactId> </dependency>Зависимости для unit-тестов. Наличие покрытия unit-тестами — обязательное требование. Рекомендация — JUnit.
<dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-engine</artifactId> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-api</artifactId> </dependency> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter-params</artifactId> </dependency>Плагин для генерации подписанного JAR артефакта, сериализованного в JSON-формат. Настройки плагина описаны в разделе «Подключение плагина для генерации подписанного JAR».
<plugin> <groupId>com.sbt.pprbod</groupId> <artifactId>pprbood-mvn-jar-serialize-plugin</artifactId> </plugin>Стандартный набор плагинов для сборки FatJar и выполнения unit-тестов. Наличие unit-тестов — обязательно.
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>3.0.0-M4</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.3.0</version> </plugin>
Запрещенные зависимости#
Поскольку плагин является точкой интеграции исполняемого кода, в его содержимом запрещено использовать классы, прямо или косвенно позволяющие подключаться к внешним ресурсам (файлам, сокетам, БД и пр.).
Запрещены к использованию классы (и их наследники):
работы с вводом-выводом, позволяющим читать файловую систему (java.io);
работы с сетью (javax.net и пр);
работы с СУБД;
использующие рефлексивные операции, позволяющие повысить привилегии исполнения.
Подключение плагина для генерации подписанного JAR#
Как было обозначено выше, сборка проекта должна осуществляться в fat-jar путем настройки *maven-assembly-plugin на режим включения всех зависимостей. Конфигурация плагина:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>assemble-all</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
В результате по проекту будет собран fat-jar, имя которого, при настройках по умолчанию, будет иметь вид: target/${project.artifactId}-${project.version}-jar-with-dependencies.jar. Далее по процессу, этот jar должен быть подписан и упакован в контейнер для последующего включения в дистрибутив и конфигурирования Архивирования (ARCH). Эту процедуру выполняет инструментарий в виде maven-плагина pprbood-mvn-jar-serialize-plugin. Так как ЭЦП подразумевает использование сертификата ЭП, необходим сертификат ЭП, выпущенный доверенным УЦ (УЦ Банка), тестовым или промышленным — в зависимости от полигона. Выпуск сертификата проводится по стандартной процедуре.
В POM-файл проекта плагина Источника подключается плагин pprbood-mvn-jar-serialize-plugin и выполняется настройка его параметров.
Параметры конфигурации артефакта pprbood-mvn-jar-serialize-plugin:
keyStoreType— тип хранилища сертификата ЭП. Поддерживается JKS;keyStoreFile— путь к файлу хранилища сертификата ЭП;keyStorePassword— пароль от хранилища сертификата ЭП;alias— псевдоним для приватного ключа ЭП;aliasPassword— пароль закрытого ключа ЭП;jarFile— путь к jar-файлу плагина. Должен конфигурироваться placeholder так, чтобы совпасть с именем jar, которую соберет сборщик maven-assembly-plugin;singFile— имя файла, в котором будет сформирована сигнатура (подпись) в виде отдельного файла;jsonFile— имя файла, в который будет сформирован контейнер с подписанным плагином;compressed— признак бинарного (gzip) сжатия контейнера. Настоятельно рекомендуется включать. Допустимые значения true|false;algorithm— алгоритм подписывания ЭП. Поддерживается только SHA256withRSA.
Примечание:
Целевым способом интеграции всех секретов является Secret Management System PAM (SecMan), при подключении плагина пример ниже этого не учитывает. В качестве конкретных значений секретов должны использоваться placeholders, сами же секреты должны поставляться с использованием Secman-механизмов Jenkins CI.
<plugin>
<groupId>com.sbt.pprbod</groupId>
<artifactId>pprbood-mvn-jar-serialize-plugin</artifactId>
<version>1.0-SNAPSHOT</version>
<configuration>
<keyStoreType>JKS</keyStoreType>
<keyStoreFile>tsa-test.jks</keyStoreFile>
<keyStorePassword>123456</keyStorePassword>
<alias>signature-private-key-gbk</alias>
<aliasPassword>123456</aliasPassword>
<jarFile>target/${project.artifactId}-${project.version}-jar-with-dependencies.jar</jarFile>
<singFile>${project.artifactId}-${project.version}-jar-with-dependencies.sig</singFile>
<jsonFile>${project.artifactId}-${project.version}-jar-with-dependencies.json</jsonFile>
<compressed>true</compressed>
<algorithm>SHA256withRSA</algorithm>
</configuration>
<executions>
<execution>
<phase>install</phase>
<goals>
<goal>serialize</goal>
</goals>
</execution>
</executions>
</plugin>
Результатом его работы является два файла:
Файл с контейнером плагина и подписью
<jsonFile>${project.artifactId}-${project.version}-jar-with-dependencies.json.Отдельный файл подписи
<singFile>${project.artifactId}-${project.version}-jar-with-dependencies.sig.
Файл с контейнером плагина далее включается в состав дистрибутива Источника.
Работа с ключами ЭП для плагина#
Внимание!
Плагин, предназначенный для промышленного внедрения, должен подписываться сертификатом УЦ (Удостоверяющим центром), пригодным для ПРОМ сред. Для обеспечения тестирования на тестовых средах допускается использование тестового УЦ, но дистрибутив с таким плагином не сможет быть проверен на средах ПСИ и ПРОМ.
Примечание:
Для корректной работы на тестовых средах при использовании промышленного сертификата ЭП в TrustStore серверов Архивирования (ARCH), а также в TrustStore, применяемом в CDP плагине интроспекции, должны присутствовать сертификаты корневого и промежуточного центра сертификации. В противном случае контейнер не пройдет проверку (не будет считаться выпущенным доверенным УЦ, поскольку промышленный и тестовые УЦ — разные).
Для подписывания плагина технически возможны два варианта работы:
Использование единого закрытого ключа для установки. Такой вариант применим для тестовых сред, с ограничениями может применяться для промышленных.
Использование ключа ЭП Источника, уникального для Источника. Целевой вариант. Из-за дефектов реализации не работоспособен в Архивировании (ARCH) версий ниже 4.8.0.
Использование единого ключа ЭП предполагает механизм, обеспечивающий защищенное хранение закрытой части ключа в виде секрета, доступного для использования в Jenkins Pipeline полигона на фазе CI. Выпуск сертификата ЭП при таком сценарии выполняет сопровождение Архивирования (ARCH), сертификат выпускается и публикуется в хранилище секретов Jenkins CI, далее этот секрет получается в Pipeline и прокидывается в параметры плагина Источника. Происходит подписывание плагина, генерация файлов .json и .sig.
Начиная с версии 4.8.0 механизм усовершенствован и Источнику доступна возможность самостоятельно генерировать закрытый ключ ЭП, уникальный для каждого Источника. Контейнер с ключом (JKS) выпускается Источником самостоятельно, также самостоятельно размещается в секретах Источника для последующего встраивания использования этого секрета в CI Pipeline.
Открытый ключ сертификата ЭП при подписании размещается в *.json файле, в секции certificate:
{
"sign": "ckHVEVqV/3vAUCgoSudzTGAyQYYGCRy62S2f9H7jRBEIdPXYijjte5Dnls1Lr+7/HzSagpg2bqIrQe3G6+lzU8im20p/nM3DATTc7Th99HiybtLGQJ3OXs7r7lMxkCVC+e7bXlI42mXECwM76XKxBe0TP/
9gQ8zC0pNW8FTastP+wsQF2hLThHuAbt1H+p60DoI1FGPatNsXlzSHYjsvtl3TxSLGCHYxkvsrNedC8bX/ljLePiqVGu8cH1t/kpMnvRQ3mpUdRI1uxHZzUbGDSZBBZH1vondac7shz0ZUMenkTgsJ5fgo
9RmZ22uD8u8kvAcZF0/t/f+dPNyoIudjZA\u003d\u003d",
"certificate": "MIIC9TCCAd2gAwIBAgIEY5nL0DANBgkqhkiG9w0BAQsFADBjMQswCQYDVQQGEwJSVTEQMA4GA1UECAwHQmFybmF1bDEOMAwGA1UEBwwFQWx0YXkxDDAKBgNVBAoMA1NCVDEPMA0GA
1UECwwGREJJTURHMRMwEQYDVQQDDApteS10ZXN0LWNhMB4XDTIyMTIxNDEzMTI0OFoXDTIzMTIxNDEzMTI0OFowFjEUMBIGA1UEAwwLbmV3LWNsaWVudDEwggEiMA0GCSqGSIb3DQ
EBAQUAA4IBDwAwggEKAoIBAQCiy9g03iy3FaCDx8aGKPq+oicEwEuV0YCG+ybyaqMHm+8o9POz3wKzuUcVrBwoZymGXqSIELenb2kxTVbi9mtCfzmyUMlr4F4YWuRBXYBSoiyljlt
vhLZql8cstZWdwNo75cpcmuTbLyrTs0QUVwA2R3k7PyfIfqX3T6nvo/jcHx/uRu7w1iaWjJW+1T6jp3NBCsnFz0sFU+wOjZyHkPNid0K7k32qaImAUaKJkBxyLeR9VCWDvJB5ujRu
ViHg9FVT+s4mISALklfBa1G6TLNmjqAlYzxGWOujERLexOus7Z7+1mU9lvvt6q9RKwEVZdijVLOth7M0hOGzUOIF0MaLAgMBAAEwDQYJKoZIhvcNAQELBQADggEBACj7swF0hlsNE
oL3k8xSvO6Dxrv6yuvy+yQ7GEa3foZCwFr4He4Bvd+xzp5kXtJGI3i1gim6zLN7zXMr20/6xVgD9II36uuIFljyjQ1sFf6hNEec2knsvl9d/+zMNdPeTa5t+Uyxb1kYcYiUOL4lDh
6VADbHJlEMhAjTh/peNJPjHnJgmK07+Ha6voKffapGLf8GLJrK/ASqt1XhNwUWRhU3pKUFKF4I9ueC4ElpTE09+6W8XI89+4fq8GJ7OwhfbF6brXlwPkzNVwhub/4jdjkIIhJYDCo
XtdEyDj2WIO66RBsNdPYl4qOoAwv83ZzEh0dvnBhjpO8NQQ/JinI5ZD0\u003d"
}
Примечание:
Переносы строк добавлены для читаемости. В реальном файле их нет.
Внимание!
Версия
mvn-jar-serialize-pluginпри такой схеме работы должна быть не ниже 4.8.0.
Дополнительные материалы для работы с тестовыми средами#
Дополнительные материалы для работы с тестовыми средами предназначаются для разработчика и описывают способы генерации и подписывания плагина.
Методика подписания плагина с использованием jks при тестировании:
Склонируйте репозиторий с эмуляторами и откройте проект плагина в среде разработки.
Поместите в корень проекта используемый
jks:
Откройте
pom.xmlи укажите параметры дляjks:<configuration> <keyStoreType>JKS</keyStoreType> <keyStoreFile>plugin_test_client_keystore.jks</keyStoreFile> <keyStorePassword>123</keyStorePassword> <alias>client1</alias> <aliasPassword>123</aliasPassword>Запустите сборку плагина командой
maven clean install.Дождитесь завершения сборки и убедитесь, что в логах есть строчки:
[INFO] Serialization JAR start [INFO] Serialization JAR successful [INFO] Write JSON file start [INFO] Write JSON file successful [INFO] Signature JSON start [INFO] Signature JSON successful [INFO] End execute prbood-mvn-jar-serialize-pluginn. [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS
Создание валидного заверенного сертификата с парой ключей:
Потребуется два файла – заготовки KeyStore для последующего импорта в них ключей:
ca_private.jksnew_truststore.jks
Также потребуется программа KeyStore Explorer. С помощью ca_private.jks можно выпускать сертификаты и подписывать их:
Создайте новый keystore:
File -> New.Создайте в нем ключевую пару:
Tools -> Generate Key Pair:
Создайте самозаверенный сертификат:
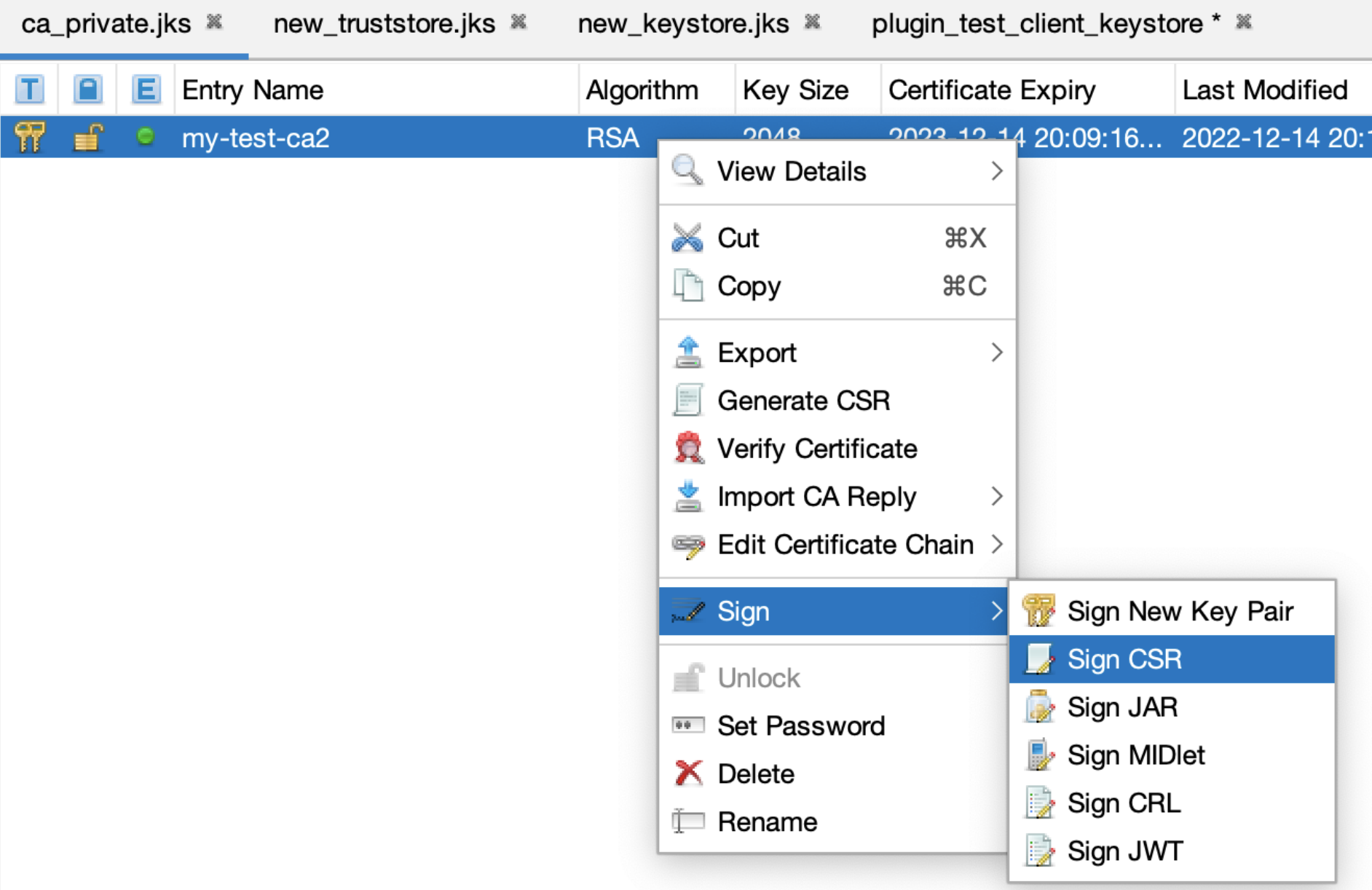
Создайте CSR (Certificate Signing Request) – нажмите по строчке с ключами и вызовите контекстное меню. В нем выберите Generate CSR. Откроется окно:
Откройте вкладку ca_private для подписи CSR:

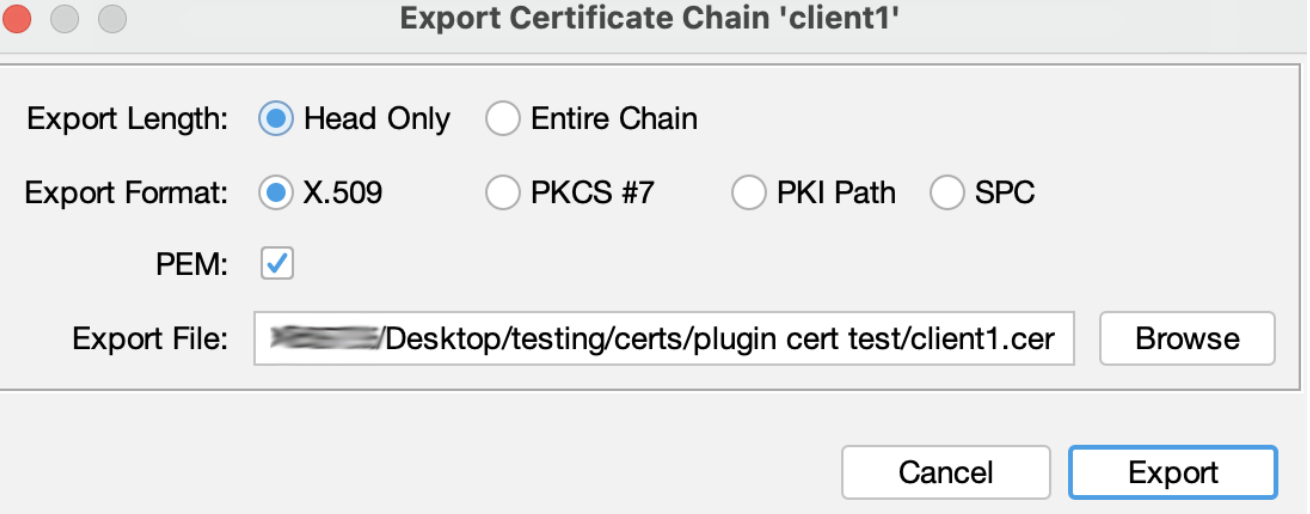
Подпишите CSR, выбрав созданный на шаге 5. Экспортируйте сертификат в файл:

Вернитесь в keystore, созданный на первом шаге.
Прикрепите подписанный сертификат:
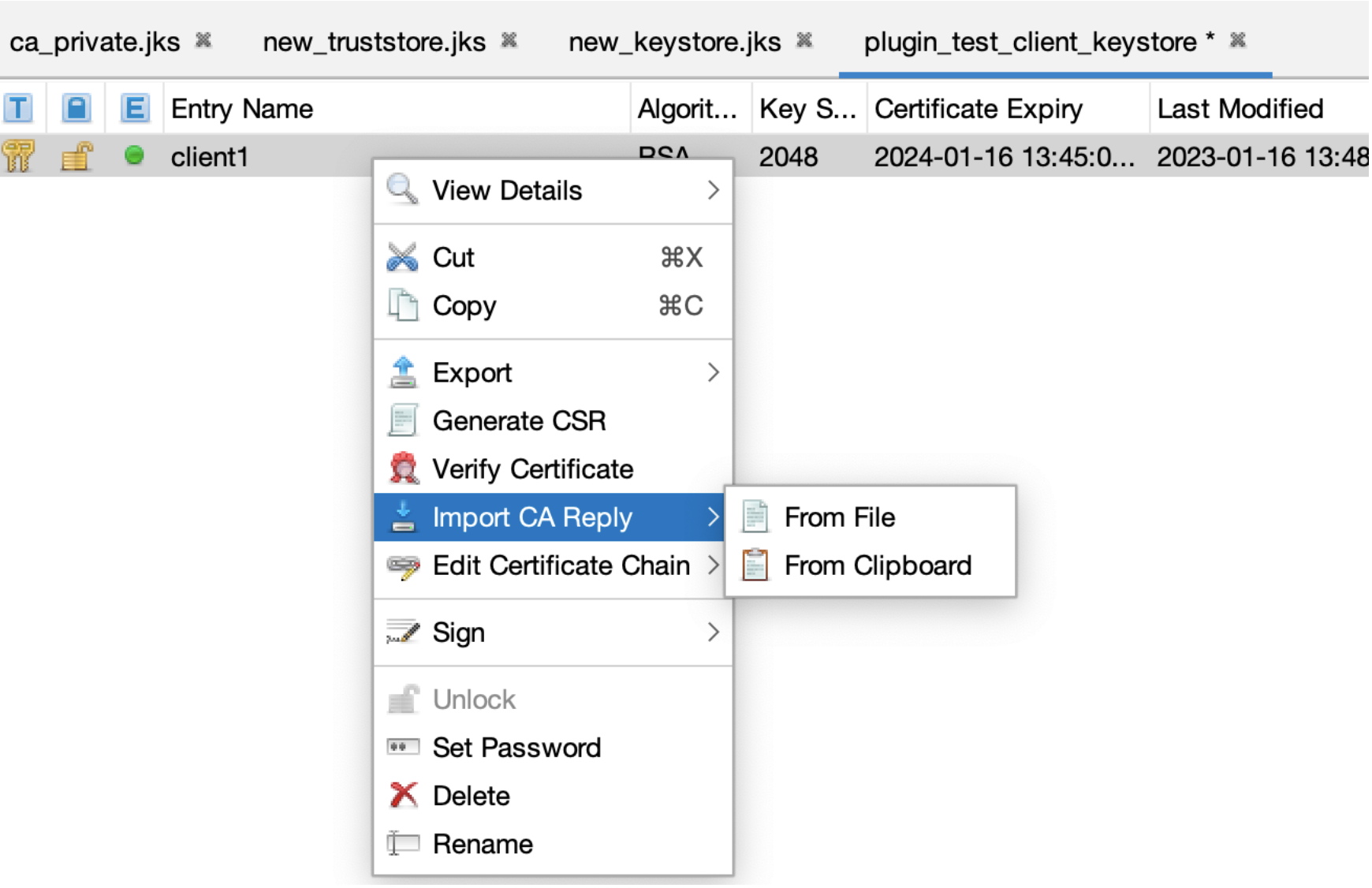
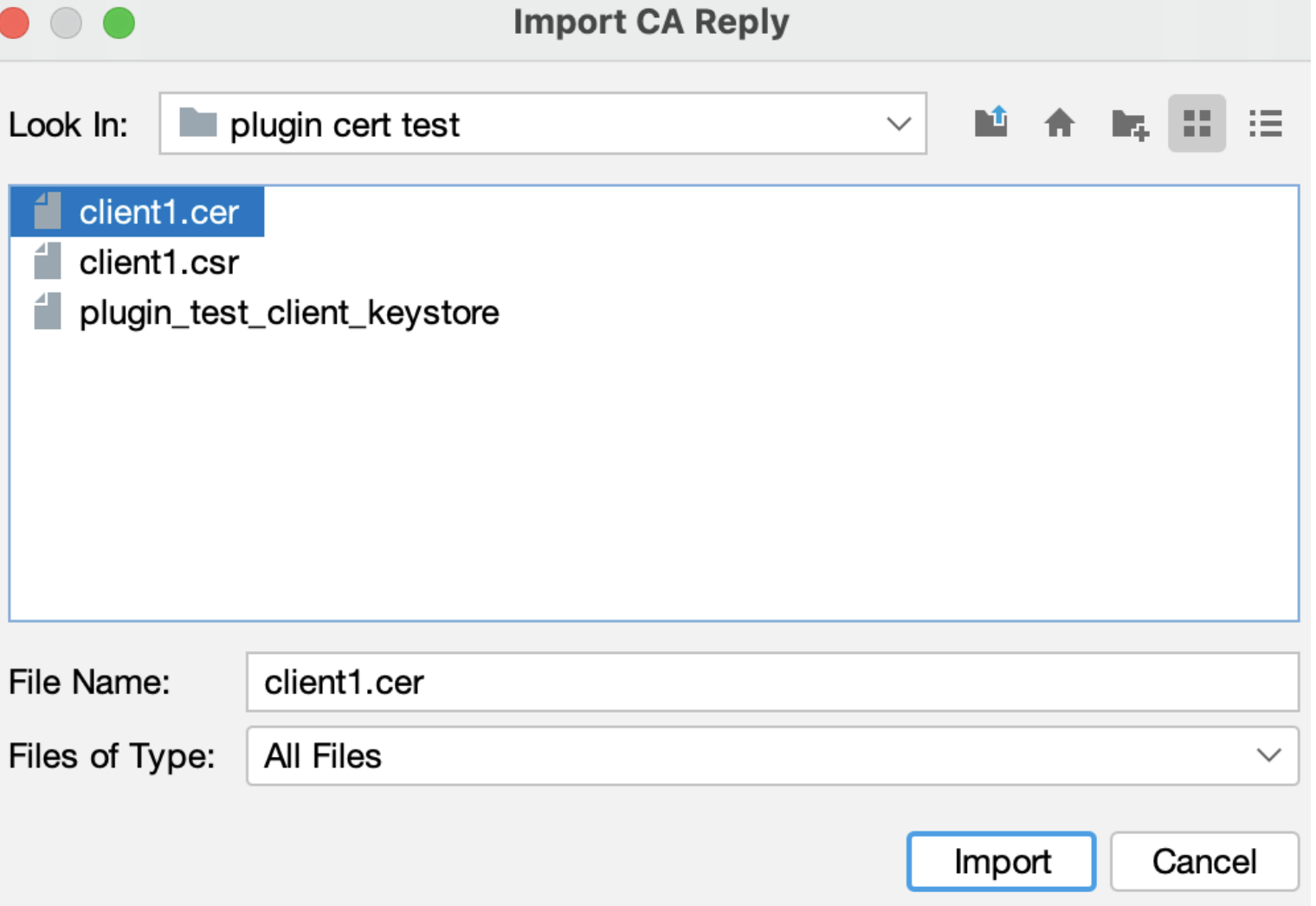
Теперь
Issuerотличается отSubject.Issuerиз trustore:
Получен валидный заверенный сертификат с парой ключей.
Выпуск просроченного сертификата:
Для выпуска просроченного сертификата проделайте те же шаги, но на шаге 6 при подписи CSR укажите такую дату, чтобы сертификат истек как можно скорее.
Для этого нажмите на значок календаря и выберите период, равный двум минутам:
Проделайте дальнейшие шаги и убедитесь, что сертификат просрочен:

Выпуск недоверенного сертификата:
Есть несколько вариантов для выпуска недоверенного сертификата:
Самый простой – оставьте сертификат самозаверенным. Проигнорируйте шаги 4-11.
Подпишите сертификат другой парой ключей, не соответствующих truststore, указанному в конфигураторе Архивирования (ARCH).
Структура плагина#
Плагин должен представлять собой FatJar, содержащий:
реализацию интерфейса
com.sbt.pprbod.plugin.PprbodSourceChangeVectorPlugin— базовый интерфейс плагина на основе транспортного формата 4.0.реализацию интерфейса
com.sbt.pprbod.common.api.UniversalChangeVectorDeserializer— интерфейс-десериализатор, преобразующий custom формат вектора изменений и DataContainer-а API в Транспортный формат 4.0.реализацию интерфейса
com.sbt.pprbod.common.api.PprbodRemaper— интерфейс, реализующий ремаппинг дочерних сущностей в родительские, при необходимости.утилитные классы, в которые инкапсулируется бизнес-логика — требуемые для преобразований помощники. Классы, выполняющие преобразование, содержащие непосредственно реализацию специфичных алгоритмов десериализации.
Все реализации должны находиться в пакете com.sbt.pprbod.artifacts.<МНЕМОНИКА ИСТОЧНИКА>. Пакет com.sbt.pprbod.artifacts является пакетом, структурно объединяющим пользовательские реализации. Имя проекта также должно соответствовать мнемонике Источника. Поскольку мнемоника Источника может содержать символы, не подходящие для имени пакета или имени проекта, так как мнемоника — это строка, такие символы должны быть удалены или заменены на подчеркивание _.
Рекомендуется соблюдать требования, приведенные в примере ниже.
Требования к структуре проекта плагина:
Плагин может быть как дочерним проектом в составе проекта фабрики-Источника, так и самостоятельным проектом.
Проект плагина должен именоваться по следующему шаблону:
<МНЕМОНИКА ИСТОЧНИКА>-plugin, то есть для Источника с мнемоникойucp-retailимя проекта должно быть ucp-retail-plugin.Проект должен содержать исходные коды реализации интерфейсов и утилитных классов из списка выше, размещенных в пакете
com.sbt.pprbod.artifacts.<МНЕМОНИКА ИСТОЧНИКА>.Имена классов, реализующих интерфейсы, должны обязательно предваряться префиксом, соответствующим мнемонике Источника. Допускается нестрогое соответствие мнемонике, но должно быть семантически схоже.
Имена утилитных и вспомогательных классов не регламентируются.
Проект должен содержать unit-тесты, покрывающие реализованные интерфейсы.
Поскольку ядро системы содержит базовые платформенные реализации, следующий перечень классов является зарезервированным, и не может быть использован Источниками:
com.sbt.pprbod.artifacts.mapper.MapperPprbodSourcePlugin;com.sbt.pprbod.artifacts.mapper.MapperJsonPprbodSourcePlugin;com.sbt.pprbod.artifacts.mapper.MapperChangeVectorPlugin;com.sbt.pprbod.artifacts.mapper.MapperJsonChangeVectorPlugin;com.sbt.pprbod.artifacts.consents.ConsentsPprbodSourcePlugin;com.sbt.pprbod.artifacts.consents.ConsentsChangeVectorPlugin;com.sbt.pprbod.artifacts.gbk.GbkPprbodSourcePlugin;com.sbt.pprbod.artifacts.gbk.GbkChangeVectorPlugin;com.sbt.pprbod.artifacts.cdm.CdmPprbodSourcePlugin;com.sbt.pprbod.artifacts.cdm.CdmChangeVectorPlugin.
Типовая структура проекта:


Реализация логики плагина заключается в написании имплементаций интерфейсов плагина, при этом для формирования выходного формата (вектора изменений) должны использоваться методы API из SDK (см. документ «SDK плагинной модели»).
Удобной и хорошей практикой является написание отдельных классов (мапперов), осуществляющих (реализующих) логику конвертации для каждого типа сущности, входящей в модель Источника. Структура такого решения показана на рисунке ниже, подробное описание приведено в разделе «SDK плагинной модели». При таком подходе в реализации интерфейса com.sbt.pprbod.common.api.UniversalChangeVectorDeserializer логика формирования векторов изменения выполняется для каждого типа сущности вызовом соответствующей реализации класса-маппера, что прозрачно для понимания. Ниже примеры структуры, выполненной по приведенным правилам. Исходный код плагина (примера плагина) предоставляется по запросу в команду 3 линии сопровождения Архивирования (ARCH).
Реализация интерфейса UniversalChangeVectorDeserializer:

Пакет плагина:

Пакет с мапперами в разрезе сущностей:

При этом нужно выносить в абстрактные реализации схожую или общую логику формирования векторов изменений, если она может быть переиспользована для некоторого класса или группы сущностей модели, в примере ниже — это справочники (UcpClientCommunicationChannelMapper, UcpClientDataChangeInitiatorMapper, UcpConsentMarkMapper) и абстрактный класс с общей для них логикой AbstractNsiDictionaryBaseMapper от которого они наследуются, лишь переопределяя нужные точки.
Абстрактный класс-маппер:

Реализация для сущности-конкретики без специфики:

Реализация для сущности-конкретики со спецификой:

Интерфейсы плагина#
Интерфейс PprbodSourceChangeVectorPlugin содержит три метода:
UniversalChangeVectorDeserializer createUniversalChangeVectorDeserializer(Supplier\PprbodSourceInfo> pprbodSource)- конструктор для создания десериализатора векторов изменений, использующий реализациюUniversalChangeVectorDeserializer. Обязательный.PprbodRemaper createPprbodRemaper(Supplier<PprbodSourceInfo> pprbodSource)- конструктор для создания ремаппера, использующий реализациюPprbodRemaper(при наличии). Имеет реализацию по умолчанию. Реализация по умолчанию не осуществляет ремаппинг сущности (результатом ремаппинга является исходная сущность).boolean useCustomNonEscapedKeys()— метод, определяющий использует ли Источник custom экранирование спецсимволов. Имеет реализацию по умолчанию, реализация по умолчанию не предполагает custom логики экранирования спецсимволов.Значение true используется если: ключ генерируется сложной программной логикой и не подходит под какое-то одно примитивное поле или композитный ключ типа IdClass/EmbeddedId. Например, когда генерация ключа выполняется некоторой сложной логикой. Сама логика генерации ключа, в таком случае, реализуется внутри классов-мапперов (см. структура плагина, выше), либо — непосредственно в коде реализации интерфейса
UniversalChangeVectorDeserializer.
public interface PprbodSourceChangeVectorPlugin {
/**
* создать десериализатор, преобразующий custom формат вектора изменений и DataContainer-а API в Транспортный формат 4.0.
*
* @param pprbodSource Источник.
* @return десериализатор, преобразующий custom формат вектора изменений и DataContainer-а API в Транспортный формат 4.0.
*/
UniversalChangeVectorDeserializer createUniversalChangeVectorDeserializer(Supplier<PprbodSourceInfo> pprbodSource);
/**
* @param pprbodSource Источник.
* @return Ремаппер, преобразовывающий (исходные) типы и ключи из ЦСП запроса в базовые.
* Если возвращает null, то будет использован ремапер по умолчнию (возвращающий тот же класс, что и получен на вход).
*/
@Nullable
default PprbodRemaper createPprbodRemaper(Supplier<PprbodSourceInfo> pprbodSource) {
return null;
}
/**
* Использует ли плагин custom ключи, которые не требуется экранировать,
* или же ключ экранируется стандартным образом.
* При использовании стандартного экранирования в элементах ключа экранируются символы:
* \ -> \\
* _ -> \_
* . -> \. =
* Для разделения элементов композитного ключа используется знак "_".
* Если использовать custom ключи, то экранирования происходить не будет,
* но для этого ключ должен состоять строго из одного элемента.
* Использование композитных ключей совместно с useCustomNonEscapedKeys()==true
* не допускается и будет приводить к исключению.
* Так же в этом случае накладывается ограничение на тип ключа:
* он должен быть строкой java.lang.String.
*
* Данная опция используется для сложных ключей, которые не поддаются
* приведению к стандартным композитным ключам из нескольких полей.
* И ее использование допускается только по индивидуальной договоренности с ЦСП
* и после тщательного тестирования.
*
* @return true, если ключ custom и его не нужно экранировать. false, если ключ экранируется.
*/
default boolean useCustomNonEscapedKeys() {
return false;
}
}
Класс, реализующий имплементацию интерфейса PprbodSourceChangeVectorPlugin указывается в качестве класса имплементации в конфигурации Архивирования (ARCH) в файле SourceDescription.yml в значении параметра deserializerName, и, по сути, является точкой входа в плагин.
Параметр PprbodSourceInfo — сущность, представляющая полную информацию об Источнике - его модель, белый список, и все его параметры — com.sbt.pprbod.entity.PprbodSourceInfo — передается ядром Архивирования (ARCH), на основе переданной в Архивирование (ARCH) Источником конфигурации (sourceDescription.yaml, *.ldm-модели Источника и разметки «белого списка») — описан далее в разделе «SDK плагинной модели».
Интерфейс UniversalChangeVectorDeserializer#
Содержит реализацию десериализаторов, преобразующих custom формат вектора изменений и DataContainer API в Транспортный формат 4.0. Содержит два метода:
JournalContainer toUniversalChangeVector(@Nonnull Journal journal)— метод, обеспечивающий десериализацию и преобразование вектора изменений Прикладного журнала (APLJ) любого формата в Транспортный формат 4.0. Эта реализация работает при обработке потока векторов изменения из Прикладного журнала (APLJ) в Потоке.JournalContainer toUniversalChangeVector(@Nonnull byte[] data, String entryType)— метод, обеспечивающий десериализацию и преобразование контейнера, содержащего определенный тип объекта (entryType содержит его FQN) Init/ТКД согласно реализованного Источником протокола взаимодействия с Архивированием. Метод вызывается при работе процессов первоначального Init и при вызовах ТКД/DRP.
package com.sbt.pprbod.common.api;
public interface UniversalChangeVectorDeserializer {
/**
* Десериализовать журнал и преобразовать в транспортный формат 4.0
*
* @param journal Прикладной журнал (APLJ)
* @return контейнер транспортного формата 4.0
*/
JournalContainer toUniversalChangeVector(@Nonnull Journal journal);
/**
* Десериализовать контейнер данных, передаваемый в API Архивирования (ARCH) и преобразовать в Транспортный формат 4.0
*
* @param data данные контейнера
* @param entryType тип данных в контейнере (класс сериализованной сущности)
* @return контейнер транспортного формата 4.0
*/
JournalContainer toUniversalChangeVector(@Nonnull byte[] data, String entryType);
}
Реализация метода toUniversalChangeVector должна включать:
Реализацию десериализации соответствующего контейнера (вектора изменений для Потока, транспортного контейнера для протокола Init/ТКД). На этом этапе после десериализации становится доступным:
либо полный исходный объект;
либо информация об изменении, представленная согласно логике Источника (идентификатор и тип изменившегося объекта, его актуальная версия, список изменившихся полей и их новые значения).
После десериализации контейнера — логику, обеспечивающую формирование универсального вектора изменений на основе данных, полученных в результате десериализации.
Для формирования универсального вектора необходимо использовать методы интерфейсов
com.sbt.pprbod.plugin.ChangeVectorBuilderFactory,com.sbt.pprbod.plugin.PprbodSourceChangeVectorPluginиз состава SDK плагинной модели (com.sbt.pprbod.plugin).При использовании сериализаторов, поведение которых может определяться тем, каким загрузчиком классов они загружены (как правило это так), например KRYO, Jackson, и т.д. — для обеспечения корректной сериализации/десериализации обязательно необходимо выполнять явную установку ClassLoader, инициализируя ClassLoader сериализатора тем загрузчиком, которым загружены классы плагинной модели.
Пример инициализации ClassLoader для KRYO, сериализация вынесена в отдельный утилитный класс в пакете плагина (рекомендуемый способ оформления):
package com.sbt.pprbod.artifacts.ucp;
import com.esotericsoftware.kryo.*;
...
import ...;
public class CustomSerializationUtils {
private static final ThreadLocal<Kryo> KRYO_TL = ThreadLocal.withInitial(() -> {
Kryo kryo = new Kryo(new CollectionClassResolver(), new MapReferenceResolver());
kryo.setDefaultSerializer(CompatibleFieldSerializer.class);
kryo.setReferences(false);
kryo.setClassLoader(CustomSerializationUtils.class.getClassLoader());
configureCollectionSerializers(kryo);
return kryo;
});
public CustomSerializationUtils() {
}
public static <T> String serialize(T value, boolean compress) {
Kryo kryo = (Kryo) KRYO_TL.get();
...
}
Интерфейс PprbodRemaper#
Содержит реализацию ремаппера. Ремаппер нужен для определения родительского (корневого) по иерархии объекта, который может быть физически выбран Источником из БД и возвращен как самостоятельная сущность.
Ремаппер применяется для тех Источников, в которых не все по иерархии модели объекты (как правило, дочерние) физически хранятся в БД как самостоятельные сущности, либо по причинам, связанным с особенностями архитектуры Источника, извлечение таких сущностей вне контекста корневых объектов — неэффективно.
Реализация ремаппера должна содержать логику, определяющую по ключу и идентификатору способ получения родительской сущности, содержащей запрошенную дочернюю сущность. Для выполнения такого преобразования может понадобиться выполнить разбор ключа дочерней сущности по определенным правилам (определяется логикой формирования ключа).
Интерфейс содержит единственный метод.
public interface PprbodRemaper {
/**
* @param sourceType Исходный тип.
* @param sourceKey Исходный ключ.
* @return PprbodBaseKey – пара: базовый тип, базовый ключ.
*/
@Nonnull
PprbodBaseKey resolveBaseKey(@Nonnull String sourceType,
@Nonnull String sourceKey);
}
SDK плагинной модели#
SDK плагинной модели включает в себя интерфейсы и их реализации, предоставляемые ядром Архивирования (ARCH) для работы с векторами изменений в универсальном формате, а именно — набор реализаций, позволяющих сконструировать вектор в формате универсального транспортного формата 4.0, удовлетворяющий всем требованиям ядра Архивирования (ARCH).
Классы SDK определены в пакете com.sbt.pprbod.plugin и включают:
public interface ChangeVectorBuilderpublic interface ChangeVectorBuilderFactorypublic interface PprbodSourceChangeVectorPlugin@Deprecated public interface PprbodSourcePlugin— неиспользуемый интерфейс, применять нельзя (будет удален в следующих версиях).
Сущности, которыми оперирует прикладной разработчик при использовании SDK описаны в пакете com.sbt.pprbod.entity:
com.sbt.pprbod.entity.PprbodSourceInfo— DTO с информацией об Источнике и его конфигурации (модели, параметрах, кроме белого списка).com.sbt.pprbod.entity.WhiteListDTO— DTO с информацией о белом списке (типах и полях, входящих в «белый список»).
ENUM, используемые в конфигурации Источника, определены в пакете com.sbt.pprbod.entity.enums:
com.sbt.pprbod.entity.enums.DataContainerVersionStrategy— доступные стратегии наследования версии от родительского объекта:AS_IS— все сущности имеют свою версию, наследование и переопределение версии сущностей не применяется;INHERIT_GLOBAL— сущность, не имеющая собственного поля версионирования, наследует версию корневой (глобальной или корневой) сущности;ZERO_IF_NULL– при отсутствии поля версии в сущности, версия инициализируется значением-константой (по умолчанию 0).
com.sbt.pprbod.entity.enums.PprbodSourceModelType— определяет типы Источников. Для плагинной модели у Источника всегда должен применяться один вариант — MAPPER_METAMODEL_WITH_CLASSES.com.sbt.pprbod.entity.enums.WhiteListMode— применяемый режим работы белого списка:ENABLED— отдаются только те типы и атрибуты, которые перечислены в разметке белого списка (входят в его контент);DISABLED— белый список не учитывается, отдаются все типы и атрибуты;ROOT_TYPES— в белом списке указываются только типы, отдаются все атрибуты типов, включенных в белый список.
SDK описан в разделе «SDK плагинной модели».
Основной ключевой точкой является написание кода, конструирующего вектор изменения.
Как строить вектора изменений#
Рекомендуемый вариант использования SDK для построения ChangeEvent — использовать ChangeVectorBuilderFactory, для создания Change Event использовать фабричный метод createEventBuilder(), и, используя полученный экземпляр builder, установить значения полей примитивов, ссылок, версий, и т.д. Builder инстанцируется из имеющихся реализаций, предоставленных SDK.
Конфигурирование ChangeEvent:
import com.sbt.pprbod.builder.ChangeVectorBuilderFactoryImpl;
import com.sbt.pprbod.plugin.ChangeVectorBuilderFactory;
import ....
...
private final ChangeVectorBuilderFactory factory = new ChangeVectorBuilderFactoryImpl();
...
CreateEvent build = factory.createEventBuilder()
.primitiveField("versionStartDate", object.getVersionStartDate())
.primitiveField("version", object.version())
.primitiveField("userLogin", object.getUserLogin())
.primitiveField("updateDateTime", object.getUpdateDateTime())
.replaceReferenceCollection("subsidiariesBlackList", object.getSubsidiariesBlackList().stream()
.map(UskEntityToVectorMapper::dictionaryKey).collect(Collectors.toList()))
.primitiveField("startDate", object.getStartDate())
.referenceField("sourceSystem", dictionaryKey(object.getSourceSystem()))
.replaceReferenceCollection("retailChannels",
object.getRetailChannels() == null ? null : object.getRetailChannels().stream()
.map(UskEntityToVectorMapper::dictionaryKey).collect(Collectors.toList()))
.replaceReferenceCollection("retailOfferTypes",
object.getRetailOfferTypes() == null ? null : object.getRetailOfferTypes().stream()
.map(UskEntityToVectorMapper::dictionaryKey).collect(Collectors.toList()))
.referenceField("purpose", dictionaryKey(object.getPurpose()))
.referenceField("procedure", dictionaryKey(object.getProcedure()))
.primitiveField("partyId", object.getPartyId())
.referenceField("partner", dictionaryKey(object.getPartner()))
.referenceField("mark", dictionaryKey(object.getMark()))
.primitiveField("endDate", object.getEndDate())
.primitiveField("dateTo", object.getDateTo())
.primitiveField("dateFrom", object.getDateFrom())
.replaceReferenceCollection("dataScopeTypes", object.getDataScopeTypes().stream()
.map(UskEntityToVectorMapper::dictionaryKey).collect(Collectors.toList()))
.referenceField("dataResource", dictionaryKey(object.getDataResource()))
.referenceField("consentType", dictionaryKey(object.getConsentType()))
.replaceReferenceCollection("communicationChannels", object.getCommunicationChannels().stream()
.map(UskEntityToVectorMapper::dictionaryKey).collect(Collectors.toList()))
.version(object.version().longValue())
.alias(ClientConsent.class.getName())
.key(object.getId())
.build();
Далее, с помощью фабричного метода changeVectorBuilder(), строится непосредственно вектор изменений, фабричная функция возвращает конфигурируемый buider — нужно лишь задать ему параметры в соответствии со спецификой требуемого вектора изменений и бизнес-операции (создание/изменение/удаление/снепшот):
return factory.changeVectorBuilder()
.addCreateEvent(build)
.vectorType(VectorType.SNAPSHOT).build();
Фабрика возвращает готовый объект вектора изменений, удовлетворяющий всем требованиям, который корректно обрабатывается ядром Архивирования (ARCH).
Альтернативный использованию фабричной функции вариант — это использование конструкторов, но он не рекомендуется.
Необходимые unit-тесты#
Ввиду высокой сложности логики плагина требуется обязательное 100 % покрытие методов плагина unit-тестами. Это необходимое условие минимизации проблем и уменьшения time-to-market. В случае выявления проблем интеграции, связанных с работой реализации плагина, первая и ключевая формальная проверка, которая будет делаться — это ревью проекта на предмет покрытия модульными unit-тестами. При их отсутствии или явной недостаточности — диагностика проблемы стороной Архивирования (ARCH) по существу не будет производиться.
В случае рекомендуемой структуры плагина (с вынесением под каждую сущность классов-мапперов) unit-тестами должны покрываться все их реализации.
В общем случае unit-тесты должны выполнять:
Строгую формальную проверку сформированного результирующего объекта ChangeVector (его json-представления, либо самого объекта) на отсутствие отклонений от структуры транспортного формата 4.0.
Строгую проверку атрибутов-примитивов на соответствие значений атрибутов (включая коллекции примитивов, поэлементно) исходным значениям, на предмет отсутствия искажений (с учетом конвертации форматов).
Проверку корректности генерации идентификаторов, версий.
Строгую проверку на наличие у всех результирующих объектов (уже в представлении универсального транспортного формата) ключа (идентификатора) и версии.
Строгую формальную проверку на соответствие атрибутного состава результирующего вектора изменений сгенерированной на шаге 2 LDM-модели(типы атрибутов должны совпадать, обязательные атрибуты — быть заполненными, состав ключей — соответствовать объявленному в LDM в части полей и обязательности их заполнения).
Рекомендуется, чтобы объем кодовой базы unit-тестов проекта превышал объем кодовой базы плагина (по loc-оценке, брутто) не менее чем в 2-2,5 раза.
Для проверки корректности работы сериализаторов в условиях работы изолированного модульного загрузчика классов (а именно так модуль будет работать внутри Архивирования (ARCH)) — необходимо реализовать и выполнять unit-тесты в условиях, когда классы плагина загружены отдельным загрузчиком классов (а не System ClassLoader). Это можно сделать, например, реализовав urlClassLoader, и выполняя им загрузку с диска JAR плагина, после чего на нем и прогонять тесты.
5. Реализация формирования артефактов конфигурации Архивирования (ARCH) в дистрибутиве Источника#
Для того, чтобы Архивирование (ARCH) использовал плагин:
Включите плагин (контейнер, подписанный ЭЦП) в состав дистрибутива Источника.
Заполните файл
SourceDescription.ymlсогласно сформированным классам реализации плагинной модели.Соберите результирующий дистрибутив со всеми остальными артефактами конфигурирования Архивирования (ARCH), включая модель и белый список, согласно процедуре обогащения дистрибутива и конфигурирования Архивирования (ARCH) по DFCi devops-процесс.
При использовании плагина — артефакт конфигурации SourceDescription.yml должен быть заполнен следующим образом:
name — мнемонический код Источника;
description — наименование Источника, справочно;
modelType — MAPPER_METAMODEL (универсальный вектор);
whiteListMode — ENABLED (разметка поатрибутно). Технически возможно использование ROOT_TYPES, но это требует согласования архитектурного исключения, без которого применение ROOT_TYPES невозможно;
deserializerName — FQN класса, реализующего интерфейс PprbodSourceChangeVectorPlugin;
modelProviderType — MAPPER (универсальный вектор);
groupId — GAV-координата, ID группы плагина, по которым он был собран и опубликован в Nexus CI;
artifactId — GAV-координата, ID артефакта плагина, по которым он был собран и опубликован в Nexus CI;
version_artifact — GAV-координата, версия плагина.
Остальные параметры — согласно базовым рекомендациям DFCi
groupId, artifactId, version_artifact должны строго совпадать с той сборкой плагина, которая фактически помещена в дистрибутив. В противном случае загрузчик классов не примет плагин.
Сам плагин размещается в дистрибутиве Источника, в зависимости одном из каталогов:
/other/model/plugin;/conf/data/arch/model/plugin.
В обоих случаях в каталоге размещается два файла, полученных в результате сериализации плагина в формат контейнера:
файл плагина (
*.json), имя по формату<мнемоника плагина>-<версия плагина>-jar-with-dependencies.jar;файл его подписи (
*.sig), имя по формату<мнемоника плагина>-<версия плагина>-jar-with-dependencies.sig.
При конфигурировании по рекомендациям именно такого формата имена генерируются плагином maven-assembly-plugin на шаге 4 настоящего руководства.
Пример содержимого корректно сформированного дистрибутива:

6. Реализация требуемых фаз CI для валидации плагина#
Согласно архитектуре, плагин Источника валидируется многократно:
(CI) При создании дистрибутива проект плагина должен пройти SAST сканирование.
(CI) Перед созданием дистрибутива плагин подписывается.
(CDP) При дальнейшей обработке на фазе конфигурирования (CDP) — подпись плагина проверяется, проверяется также его формальная структура.
(CDP) Перед попыткой конфигурирования Архивирования (ARCH) проводится инстроспекция (проверка) плагина, что позволяет выявить нежелательные (недопустимые) манипуляции исходным кодом плагина, такие как доступ к внешним ресурсам, БД, и прочим точкам расширения, использование рефлексии и т.д., что недопустимо в плагине.
(RUNTIME) На этапе инстанцирования еще раз проверяется ЭЦП контейнера плагина.
При нарушении любого из пунктов — плагин не будет задействован Архивированием (ARCH).
Пункты 2-5 не требуют каких-либо дополнительных действий на стороне фабрики.
Пункт 1 предполагает сканирования исполняемого кода плагина по общим базовым стандартам. Согласно схеме (схема из архитектуры, помечено красным):

Пояснение — на схеме предполагался отдельный QG-флаг, но его признали избыточным, и был использован базовый DFCi флаг Архивирования (ARCH).
Требуется в CI-конвейре Источника обеспечить:
Выполнения SAST-сканирования исходного кода плагина, хеш commit должен соответствовать тому, с которого плагин собран.
По результату выполнения этого сканирования в QGM для дистрибутива фабрики в пространстве КЭ фабрики (Источника) должен быть выставлен флаг pprbod.ift = QG_SAST_PP_OK | QG_SAST_PP_FAIL при успехе или непрохождении по Quality Gates по результатам сканирования плагина.
На этапе конфигурирования Архивирования (ARCH), перед этапом валидации конфигурации (tsa_validate) проверяется наличие и значение флага pprbod.ift в пространстве КЭ Источника. Если значение не равно QG_SAST_PP_OK или флаг отсутствует — выполнение конвейера прервется.