Базовый протокол взаимодействия Архивирования (ARCH) с Источниками#
Ограничения, накладываемые на реализацию Источником API Архивирования (ARCH)#
От Источника API Offline ТКД должен реализовывать только один модуль. Допускается, что этот модуль может иметь несколько шард; в таком случае Архивирование (ARCH) последовательно опрашивает все шарды при Offline ТКД. Список зон шард, в которых эти шарды расположены, в этом случае предварительно конфигурируется при помощи DevOps-конвейера. Более подробная информация о том, как при конфигурировании передавать в Архивирование (ARCH) данные о своем модуле, и в каких зонах он расположен, приведена в документе «Руководство прикладного разработчика», раздел «Подключение и конфигурирование».
Архивирование (ARCH) для интеграции использует RPC протокол на основе Kafka. Архивирование (ARCH) предоставляет SDK (библиотеку), инкапсулирующую работу с транспортным слоем, при этом для прикладного разработчика сигнатуры вызовов при использовании библиотеки не меняются. Технически допустимы и возможны следующие способы интеграций:
Способ интеграции |
3 поколение |
4 поколение |
|---|---|---|
SDK data-transport-api |
Да |
Нет |
SDK pprbod-transport-kafka-lib-starter |
Да |
Да |
Использование прямой реализации интерфейсов |
Да |
Да |
Во всех вариантах интеграции поддерживается возможность сложной топологии Platform V:
Источник может использовать произвольное имя шарда, соответствующее его топологии.
Базовая инсталляция Platform V предполагает разворачивание экземпляра Архивирования (ARCH) в основной (default) зоне шардирования. Вместе с тем экземпляр Архивирования (ARCH) может быть развернут:
в зоне, отличной от зоны default;
в любой другой дополнительной зоне.
Примечание:
Архивирование (ARCH) не подразумевает мультитенантности и разворачивается всегда в единственном экземпляре.
API Init#
Базовые принципы построения целевого API Init:
Передача данных по определенному типу.
Передача данных партициями, размер партиции определяется динамически (фабрикой).
Передача данных выполняется в объеме всей первоначальной выгрузки потоковым образом с разбиением на партиции со стороны Источника.
Для передачи партиции Источник разбивает ее на пакеты (batch) и отправляет эти пакеты в Архивирование (ARCH).
Для передачи одной партиции используется один асинхронный со стороны Архивирования (ARCH) и необходимое количество синхронных вызовов API загрузки пакета (части партиции) со стороны Источника.
Обработка последующих партиций определяется результатом (кодом ответа фабрики) на запрос получения данных текущей партиции.
Ключевое — это схема импорта Потоком, с фиксацией последнего полученного от ПФ при обработке данных идентификатора объекта и инициировании запроса на следующую партицию с этого идентификатора.
Синхронный API Init – текущее целевое API для Источников, использующих 4 версию Архивирования (ARCH)#
InitDataSampleApi, InitDataSampleLoad:
@Api
public interface InitDataSampleApi {
@ApiMethod(apiName = "initLoad", version = "0.0.1")
String initLoad(String type);
@ApiMethod(apiName = "getBatchCount", version = "0.0.1")
EstimateResult getBatchCount(String loadingId) throws BatchEstimateException;
@ApiMethod(apiName = "loadBatchAsync", version = "0.0.1")
void loadBatchAsync(String loadingId, int index, String requestId) throws BatchLoadException;
@ApiMethod(apiName = "abort", version = "0.0.1")
void abort(String loadingId);
}
@Api
public interface InitDataSampleLoad {
@ApiMethod(apiName = "loadInitBatch", version = "0.0.1")
void loadInitBatch(InitBatchResult initBatchResult) throws PartitionResultAcceptException;
}
Описание методов InitDataSampleApi (реализуется на стороне Источника):
initLoad– начинает выгрузку по типуtype, возвращает идентификатор выгрузки;getBatchCount– возвращает количество партиций для выгрузки, начатой вызовомinitLoad();loadBatchAsync– инициирует отправку партиции с индексомindexдля идентификатора выгрузкиloadingId. Предполагается итерирование и вызов этого метода для индексов от нуля до количества партиций, возвращенногоgetBatchCount(). ПараметрrequestIdимеет смысл глобально уникального идентификатора, значение должно коррелировать сInitBatchResult#requestIdв последующем вызовеInitDataSampleLoad.loadInitBatch(InitBatchResult) на стороне Архивирования (ARCH).abort– освобождает все ресурсы, необходимые для отправки данных, относящихся к выгрузке с идентификаторомloadingId;выполнив вызов abort(), Архивирование (ARCH) больше не планирует получать пакеты этой выгрузки.
loadInitBatch – метод InitDataSampleLoad (реализуется на стороне Архивирования (ARCH)). Загружает пакет, отправленный Источником. Отправка должна быть ранее успешно инициирована вызовом InitDataSampleApi.loadBatchAsync() на стороне Источника.
Описание структур данных#
Оценка объема данных:
/**
* Результат оценки размера партиции
*/
public class EstimateResult implements Serializable {
private static final long serialVersionUID = -5906616942515441183L;
private final PartitionEstimateCode estimateCode;
private final Integer size;
}
/**
* Возможность оценки
*/
public enum PartitionEstimateCode {
/**
* Фабрика не умеет оценивать по списку ключей размер партиции
* (используется только при ТКД, в Init недопустимо возвращать)
*/
PS_DEFAULT,
/**
* Фабрика оценила размер партиции и подготовила данные для выгрузки
*/
PS_ADAPTIVE_READY,
/**
* Фабрика подготавливает данные
*/
PS_ADAPTIVE_PENDING;
}
/**
* Базовый класс для загрузки пакета данных со стороны Источника
*/
public abstract class PartitionResult<T extends Serializable> implements Serializable {
private static final long serialVersionUID = -5280480427310163519L;
private final long responseId; // ID пакета (части ответа)
private final String requestId; // ID запроса, с которым коррелирует ответ
private final Timestamp responseTimestamp; // Время формирования пакета
private final int partTotal; // Количество пакетов, на которые разделен ответ (N)
private final int partCurrent; // Номер текущего пакета (0..N-1)
private final String partHash; // хеш текущей части ответа
private final String entryType; // Тип объекта
private final String zoneId; // Зона шарда иcточника, откуда отправлены объекты
private final T data; // Фрагмент контейнера LoadResult – полезная нагрузка
private final String hash; // хеш всего образца для проверки на стороне приемника после получения всех партиций
...
}
public class InitBatchResult extends PartitionResult<byte[]> {
private static final long serialVersionUID = -1110331909003562897L;
public InitBatchResult(long responseId, String requestId, Timestamp responseTimestamp,
int partTotal, int partCurrent, String partHash, String entryType, String zoneId,
byte[] data, String hash) {
super(responseId, requestId, responseTimestamp, partTotal, partCurrent, partHash, entryType, zoneId, data, hash);
}
}
Передача данных:
/**
* Результат загрузки партиции
*/
public class LoadResult implements Serializable {
private static final long serialVersionUID = 7608272960976480122L;
private final ResultCode code;
private final List<DataContainer> dataContainers = new ArrayList<>();
}
/**
* Контейнер данных
*/
public class DataContainer implements Serializable {
private static final long serialVersionUID = 3239401317382698849L;
private String key; // ID объекта ПФ
private String entryType; // тип объекта
private Long version; // версия модели данных объекта
private OperationType operType; // тип операции(для ТКД - create)
private List<String> updAttrs; // список обновляемых аттрибутов
private byte[] data; // Cериализованный объект ПФ
}
/**
* Тип операции в случае векторов изменений
*/
public enum OperationType {
CREATE, UPDATE, DELETE;
}
API технического качества данных (ТКД)#
Общие сведения#
ТКД – Техническое Качество Данных, процесс, в ходе которого выполняется двусторонняя сверка данных на стороне Источника и на стороне реплики. Выполняется на основе sample (тип-идентификатор), отобранного к сверке на стороне реплики. Дополняется отбором (генерацией) sample на стороне Источника, что позволяет выявлять данные Источника, которые в силу каких-либо обстоятельств не попали в реплику. Механизм позволяет выполнять двухстороннюю сверку и выявлять данные, как отличающиеся, неактуальные (отсутствующие в Источнике), так и отсутствующие в реплике.
Терминология
Перечень типов – список типов, по которым со стороны ЦСП выполняется процедура сверки Источника и реплики.
Дата загрузки – бизнес–дата, по которой производится сверка.
sampleидентификаторов – перечень идентификаторов, сформированный Источником по одному конкретному запрошенному типу на запрошенную дату загрузки (loading_date). Вsampleидентификаторов включаться должны фабрикой–Источником только объекты, существующие на эту дату.sampleИсточника – перечень объектов, сформированный Источником поsampleидентификаторов.
ТКД может быть двух типов:
Online ТКД – запрос ровно одного объекта. При этом процессе идентификаторы со стороны Источника не запрашиваются. Применяется для восстановления консистентности реплики при единичном сбое в Потоке;
Offline ТКД – процесс сверки реплики и Источника.
С точки зрения протоколов и контрактов по части запроса данных по идентификаторам и отправке полученных данных эти процессы идентичны. Далее по тексту рассматривается Offline ТКД. Online ТКД является его частным случаем.
Диаграмма общего процесса ТКД:
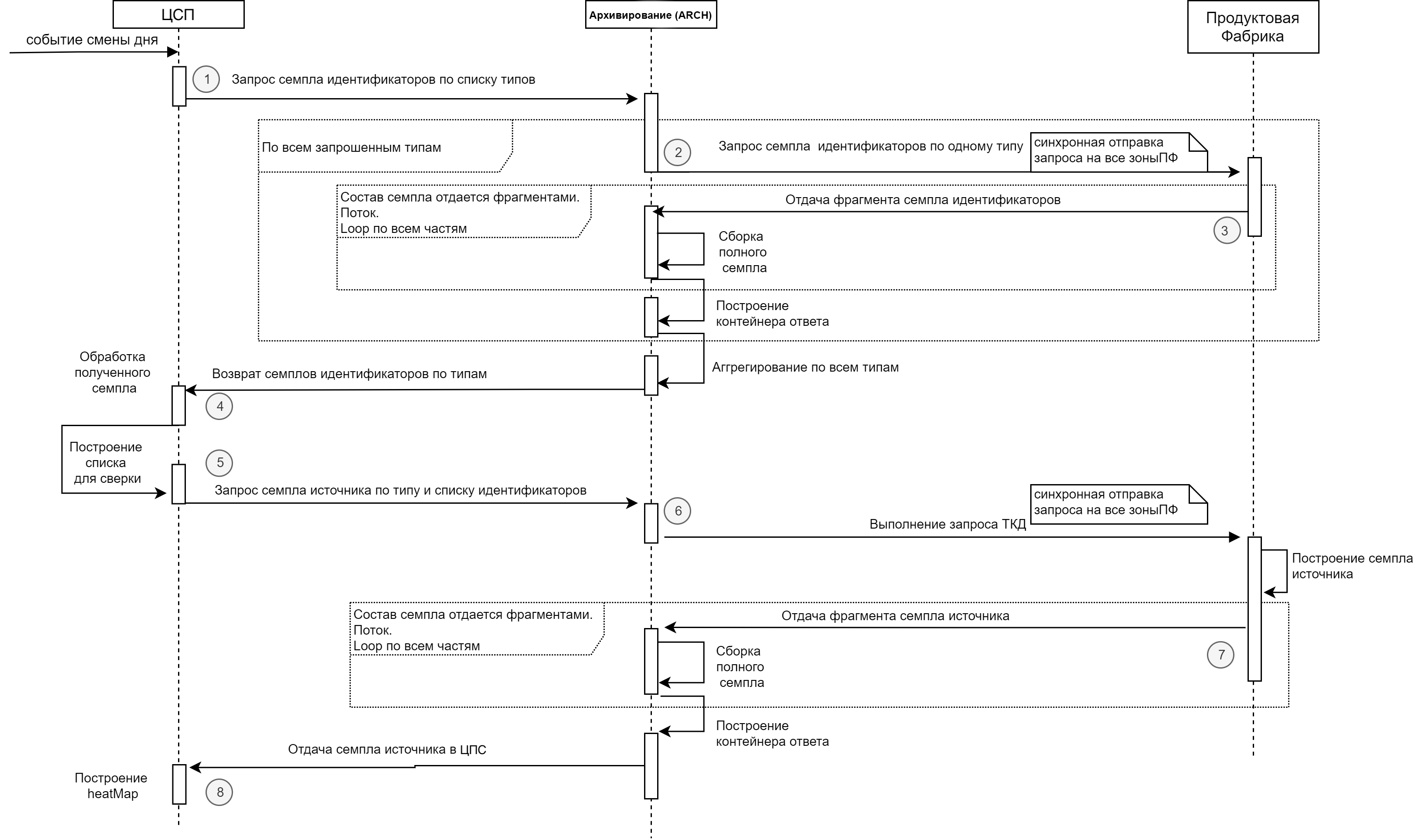
Таблица с пояснениями к диаграмме:
1 |
ЦСП |
Архивирование (ARCH) |
Асинхронный |
ЦСП запрашивает от Архивирования (ARCH) список идентификаторов в разрезе типов |
Исходные данные для Архивирования (ARCH) – перечень типов по которым надо получить образцы идентификаторов от ПФ |
|---|---|---|---|---|---|
2 |
Архивирование (ARCH) |
ПФ |
Синхронный |
Архивирование (ARCH) запрашивает от ПФ список идентификаторов по одному типу |
Запрос выполняется во все зоны/шарды ПФ – Источника |
3 |
Архивирование (ARCH) |
ПФ |
Синхронный |
ПФ отдает список идентификаторов из каждой зоны, в которой присутствуют объекты запрошенного типа. Отдача – в формате списка |
Отдача выполняется в «потоковой манере» – Архивирование (ARCH) ожидает получения порций данных в течение установленного таймаута после отправки запроса. Получение следующей порции потока возможно в течение не более того же таймаута после получения предыдущей порции |
4 |
Архивирование (ARCH) |
ПФ |
Синхронный |
Архивирование (ARCH) запрашивает от ПФ полные версии объектов по списку идентификаторов и типу |
Запрос выполняется во все зоны / шарды ПФ – Источника, если зона не указана. Если идентификатор зоны известен, то запрос направляется только в эту зону |
5 |
Архивирование (ARCH) |
ПФ |
Синхронный |
ПФ отдает полные версии объектов из каждой зоны, в которой присутствуют объекты запрошенного типа. Отдача – в формате контейнера данных объектов ПФ (описан далее). Контейнер может быть велик вследствие как большого размера одного объекта, так и большого их количества, поэтому применяется потоковая отдача |
Отдача выполняется в «потоковой манере» – Архивирование (ARCH) ожидает получения порций данных, составляющих содержимое контейнера в течение установленного таймаута после отправки запроса. Получение следующей порции потока возможно в течение не более того же таймаута после получения предыдущей порции |
6 |
Архивирование (ARCH) |
ЦСП |
Асинхронный |
Архивирование (ARCH) формирует контейнер с sample Источника по запрошенному типу |
Архивирование (ARCH) формирует контейнер по каждому типу независимо от других типов. По готовности помещает контейнер в интеграционную Kafka Архивирования (ARCH) в топик |
Все сообщения протокола, использующие криптографический хеш, подразумевают использование алгоритма sha256. Если не оговорено иное - хеш-сумма рассчитывается от всего контейнера полностью.
Предполагается оповещение ЦСП об ошибках обработки запросов Архивирования (ARCH). Для этого предусматривается возможность отправки сообщения о произошедшей ошибке и список идентификаторов, при обработке которых такая ошибка произошла.
Для работы с ошибками вводится топик _error в интеграционной Kafka, топик доступен ЦСП на чтение, Архивирование (ARCH) – на запись. В случае исключения на стороне Архивирования (ARCH) при обработке контейнера либо таймаута и, как следствие, невозможности по любой причине предоставить ЦСП запрошенную им информацию, в топик направляется сообщение соответствующего формата (описан ниже). Сообщение содержит идентификатор оригинального контейнера, что позволяет установить однозначную связь с тем, что вызвало ошибку.
Диаграмма полного процесса (развернуто):
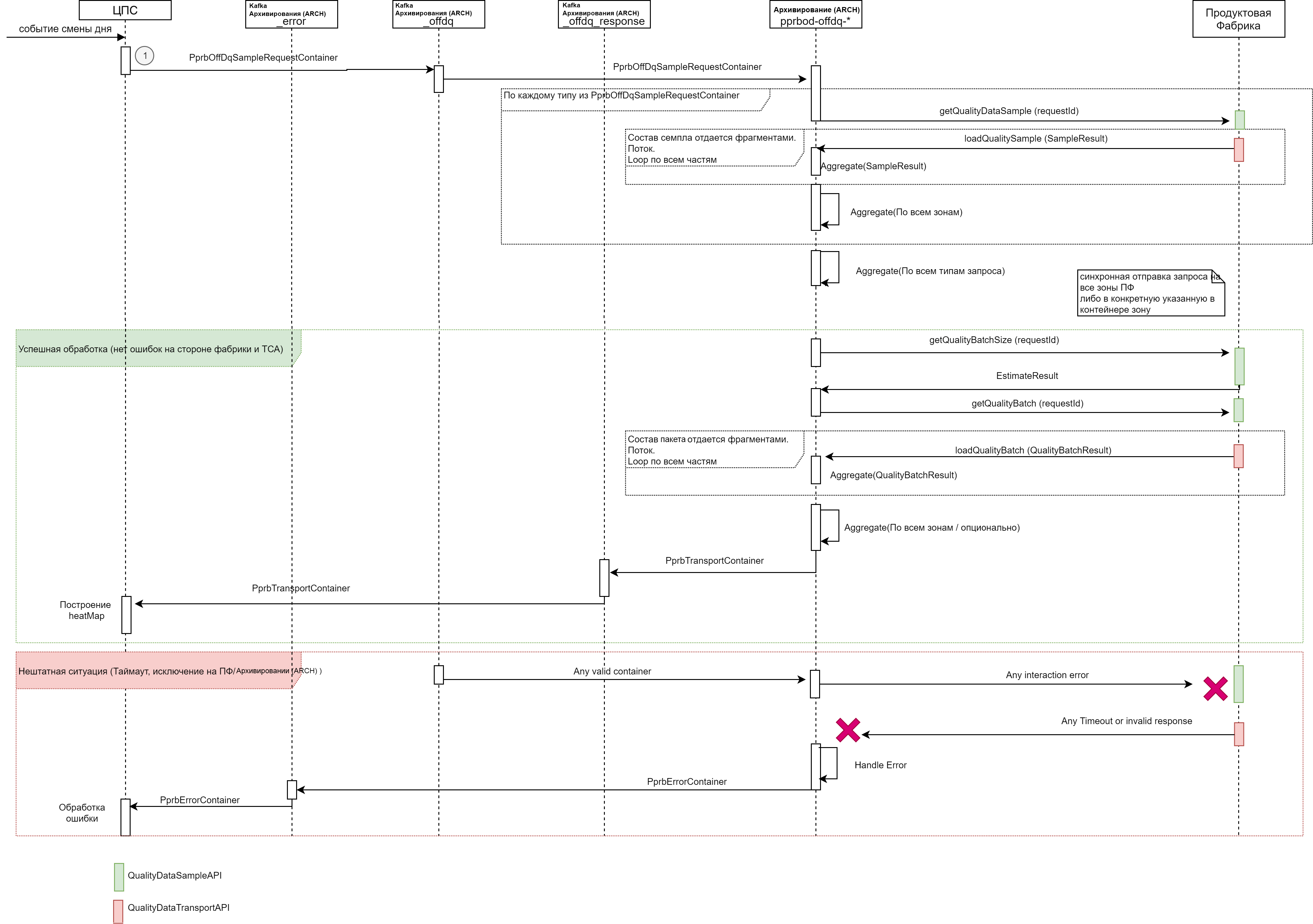
API реплики#
Взаимодействие с репликой выполняется через интеграционную Kafka Архивирования (ARCH). Для обмена информацией используются топики.
Для Online ТКД:
_dq – для запросов к Архивированию (ARCH). В топик со стороны реплики могут помещаться сообщения типа
PprbKeyContainer– запрос на получение полной версии объекта по списку по типу идентификатору и зоне._dq_response – топик ответов Архивирования (ARCH). В него со стороны Архивирования (ARCH) могут помещаться сообщения типа
PprbTransportContainer– универсальный контейнер, содержащий объекты ПФ.
Типы сообщений PprbTransportContainer не меняются.
Формат сообщения PprbKeyContainer (запрос online ТКД), транспортный контейнер ТКД запроса:
{
"name": "PprbKeyContainer",
"namespace": "com.sbt.pprbod.avro.journal.classes",
"type": "record",
"fields": [
{
"name": "key",
"type": "string"
}, { // Ключ объекта, по которому зарегистрирован инцидент ТКД
"name": "entry_type",
"type": "string"
}, { // Тип объекта
"name": "zone_id",
"type": "string"
}, // Идентификатор зоны StandIn ZoneID. Является атрибутом транспортного контейнера с собщением. Для Источников с репликацией через OGG в данном атрибуте содержится «Global name» экземпляра
]
}
Для Offline ТКД:
_offdq– для запросов к Архивированию (ARCH). В топик со стороны реплики должны помещаться сообщения типаPprbOffdqKeyContainer– запрос на получение полных версий объектов по списку идентификаторов._offdq_response– топик ответов Архивирования (ARCH). В него со стороны Архивирования (ARCH) должны помещаться сообщения типаPprbTransportContainer– универсальный контейнер, содержащий объекты ПФ.
Типы сообщений PprbTransportContainer не меняются. PprbTransportContainer дополняется опциональной зоной, которая заполняется в случае, если передаваемый идентификатор ранее был получен от Источника в эту итерацию ТКД по sample.
Формат сообщения PprbOffDqKeyContainer дополняется идентификатором зоны.
Транспортный контейнер ТКД запроса:
{
"name": "PprbOffDqKeyContainer",
"namespace": "com.sbt.pprbod.avro.journal.classes",
"type": "record",
"fields": [
{"name": "key", "type": {"type": "array", "items": "string"} }, // Массив ключей, по которым необходимо получить полные версии объектов из системы-Источника
{"name": "entry_type", "type": "string"}, // Тип объекта
{"name": "global_type", "type": "string"} // Глобальный тип. Является атрибутом транспортного контейнера с сообщением (не заполняется, нужно будет удалить)
{"name": "zone_id", "type": ["null", "string"]} // Идентификатор зоны. Заполняется, если идентификатор получен из `sample` Источника и таким образом известен
]
}
Формат сообщения об ошибке PprbErrorContainer, транспортный контейнер сообщений ошибок:
{
"name": "PprbErrorContainer",
"namespace": "com.sbt.pprbod.avro.journal.classes",
"type": "record",
"fields": [
{"name": "data_type", "type": "string" }, // "PprbData_1.0"
{"name": "message_id", "type": "string"}, // Id сообщения, при обработке которого возникло исключение
{"name": "interaction_type", "type": "string"}, // Тип взаимодействия при котором случилась ошибка: STREAM - Поток, DQ - Решение инцидента качества, QFFDQ - Решение запроса ТКД
{"name": "exception_code", "type": "string"}, // Код ошибки обработки контейнера (по классифиактору Архивирования (ARCH))
{"name": "exception_timestamp", "type": "long"}, // Время когда ошибка зафиксирована
{"name": "exception_trace", "type": ["null","string"]}, // Опциональный стектрейс
{"name": "exception_message", "type": ["null","string"]}, // Опциональное инфосообщение
{"name": "id_sample", "type":{ // Массив идентификаторов либо идентификатор, обработка которых не удалась
"type": "array",
"items": "string"
}
}
]
}
API Прикладной фабрики для ТКД#
Приведена спецификация Java API для процесса Offline ТКД для использования с Kafka с поддержкой возможности дробления ответа фабрики-Источника на части.
Соглашения о сериализации
Рекомендуется использование Kryo версии 4.0.2 и класс com.sbt.pprbod.data.utils.KryoUtils, в котором уже сделаны все необходимые настройки.
В случае ограничений, делающих невозможным использование утилит Архивирования (ARCH) для сериализации, возможно использование собственного формата сериализации путем реализации интерфейса com.sbt.pprbod.common.api.TkdObjectDeserializer.
При реализации собственного десериализатора и использовании в нем Kryo необходимо отключать регистрацию классов, то есть не использовать com.esotericsoftware.Kryo.Kryo#register(java.lang.Class), так как порядок обхода при регистрации на стороне Источника и на стороне Архивирования (ARCH) не детерменирован, и в случае отличия это приводит к ошибкам сериализации.
Если для отправки журналов в прикладной журнал используется универсальный вектор Прикладного журнала (APLJ), то формировать объекты для Init и ТКД также необходимо в формате универсального вектора, преобразованного в массив байт.
Соглашения о версионировании объектов:
ПФ ведет уникальное на своей стороне версионирование объектов. В случае изменения структуры (модели данных) объекта должна монотонно увеличиваться и его версия. Версионирование ведется в разрезе каждого типа объекта.
Если фабрика не поддерживает ведение версионирования модели данных, в качестве версии модели данных всегда передается 0.
Важно:
Ведение версии модели данных может сказаться на возможности Архивирования (ARCH) понять, какую схему преобразования следует использовать, что для ЦСП в дальнейшем может помешать верно интерпретировать полученные данные, а в Архивирование (ARCH) – повлечь невозможность их верной сериализации в плоскую модель.
Типы данных и интерфейсы для получения sample идентификаторов:
Структуры для запроса sample идентификаторов, транспортное сообщение запроса sample одного типа:
public abstract class PartitionResult < T extends Serializable > implements Serializable {
private static final long serialVersionUID = -5280480427310163519 L;
private final long responseId; // ID партиции ответа
private final String requestId; // ID запроса, с которым коррелирует ответ
private final Timestamp responseTimestamp; // Время формирования части ответа
private final int partTotal; // Количество партиций, на которые разделен ответ (N)
private final int partCurrent; // Номер текущей партиции (0..N-1)
private final String partHash; // Хеш текущей части `sample` для проверки на стороне приемника
private final String entryType; // Тип объекта
private final String zoneId; // Зона шарда иcточника, откуда отправлены объекты
private final T data; // Фрагмент контейнера LoadResult – полезная нагрузка
private final String hash; // Хеш всего образца для проверки на стороне приемника после получения всех партиций
...
}
public class SampleResult extends PartitionResult<ArrayList<String>> {
private static final long serialVersionUID = 370903970994546191 L;
protected SampleResult(
long responseId,
String requestId,
Timestamp responseTimestamp,
int partTotal,
int partCurrent,
String partHash,
String entryType,
String zoneId,
ArrayList<String> data,
String hash
) {
super(
responseId,
requestId,
responseTimestamp,
partTotal,
partCurrent,
partHash,
entryType,
zoneId,
data,
hash
);
}
}
Отличается способ использования транспортного контейнера. Если в исходном API ТКД (синхронный) Источник реализовывал на своей стороне интерфейс public interface QualityDataTransportApi, в текущем API применяется иной подход:
Для получения
sampleидентификаторов Источник реализует на своей стороне API public interface QualityDataSampleApi, а именно – методgetQualitySample, который должен на стороне Источника построить срез в виде списка идентификаторов и подготовить ответ, вернув соответствующий код.Ответ в формате потока
sampleидентификаторов Источник отправляет на API Archiving public interface QualityDataSampleLoad, а именно –loadQualitySample– потоковый, принимающий 1 и более партициюsampleидентификаторов в количествеpartTotal.
Устанавливается таймаут, в течение которого Архивирование (ARCH) ожидает как получения порции данных sample после вызова getQualityDataSample, так и получения следующей партиции при ее наличии. По умолчанию таймаут составляет 10 минут.
Интерфейс и методы для формирования списка идентификаторов по типу:
Интерфейс для получения списка идентификаторов по типу:
public interface QualityDataSampleApi {
...
@ApiMethod(apiName = "getQualitySample", version = "0.0.1")
void getQualitySample(String type, String requestId, int sampleThreshold) throws QualityDataSampleException;
...
}
Интерфейс QualityDataSampleApi реализуется Источником.
Интерфейс и методы для получения потока идентификаторов по типу (sample):
Интерфейс для получения списка идентификаторов по типу:
public interface QualityDataSampleLoad {
...
@ApiMethod(apiName = "loadQualitySample", version = "0.0.1")
void loadQualitySample(SampleResult sampleResult) throws PartitionResultAcceptException;
...
}
Интерфейс QualityDataSampleLoad. Реализуется на стороне Архивирования (ARCH), вызывается со стороны фабрики–Источника. Фиксируется контракт, что в одном пакете SampleResult не могут присутствовать идентификаторы, составляющие в совокупной длине более 1000 символов.
Типы данных и интерфейсы для получения результата запроса объектов (sample Источника):
Транспортное сообщение запроса sample одного типа:
{public enum PartitionEstimateCode {
/**
* Фабрика не умеет оценивать по списку ключей размер партиции
*/
PS_DEFAULT,
/**
* Фабрика оценила размер партиции и подготовила данные для выгрузки
*/
PS_ADAPTIVE_READY,
/**
* Фабрика подготавливает данные
*/
PS_ADAPTIVE_PENDING;
}
/**
* Результат оценки размера партиции
*/
public class EstimateResult implements Serializable {
private static final long serialVersionUID = -5906616942515441183L;
private final PartitionEstimateCode estimateCode;
private final Integer size;
}
Структуры для отдачи полных версий объекта (транспортный контейнер) (применяется структура LoadResult):
Транспортное сообщение запроса sample одного типа:
/**
* Результат загрузки партиции
*/
public class LoadResult implements Serializable {
private static final long serialVersionUID = 7608272960976480122L;
private final ResultCode code;
private final List<DataContainer> dataContainers = new ArrayList<>();
}
/**
* Контейнер данных
*/
public class DataContainer implements Serializable {
private static final long serialVersionUID = 3239401317382698849L;
private String key; // id объекта ПФ
private String entryType; // тип объекта
private Long version; // версия модели данных объекта
private OperationType operType; // тип операции (для ТКД – create)
private List<String> updAttrs; // список обновляемых аттрибутов
private byte[] data; // сериализованный объект ПФ
}
/**
* Тип операции в случае векторов изменений
*/
public enum OperationType {
CREATE, UPDATE, DELETE;
}
Правила заполнения данных:
Если запрошен существующий (актуальный, присутствующий на стороне фабрики ответ):
в
DataContainer#keyвносится ключ по специальному формату – без префикса типа, то есть невербальный (подробное описание приведено в документе «Руководство прикладного разработчика», раздел «Описание форматов репликации», подраздел «Формат ключей для объектов»).в
DataContainer#entryTypeвносится полный тип передаваемого объекта;в
DataContainer#versionвносится версия передаваемого объекта;в
DataContainer#operTypeвносится Create (неизменяемо);в
DataContainer#updAttrsвносится пустой список;в
DataContainer#dataвносятся сериализованные данные (согласно соглашениям о сериализации, описанным выше, либо индивидуальному контракту).
Если запрошен несуществующий или удаленный объект, допускаются две схемы формирования ответа в зависимости от реализации:
Прикладная фабрика использует логическое удаление данных (объекты физически никогда не удаляются из БД, а помечаются удаленными), запрос ключа по удаленному объекту и запрос никогда не существовавшего ключа - это две разные ситуации. В таком случае следует заполнять данные следующим образом:
Если запрошен ранее существовавший, но удаленный объект (объект по ключу найден, но помечен удаленным), формируется контейнер удаленного объекта:
В
DataContainer#keyвносится запрашиваемый ключ по формату, приведенному в документе «Руководство прикладного разработчика», раздел «Форматы обмена данными с Архивированием (ARCH)». Формат ключей для объектов (раздел формат ключей) без префикса типа.в
DataContainer#entryTypeвносится полный тип запрашиваемого объекта;в
DataContainer#versionвносится версия передаваемого объекта согласно БД, либо0(если версия для таких объектов более не доступна);в
DataContainer#operTypeвноситсяDelete(не изменяемо);в
DataContainer#updAttrsвносится пустой список;DataContainer#dataзаполняется объектом запрошенного типа, у которого заполнены атрибут ключа и версии, а все обязательные поля заполнены значениями по умолчанию, либо заглушечными данными (их состав не имеет значения).
Если запрошен никогда не существовавший объект, контейнер ответа вообще не формируется, и ответ в Архивирование не отправляется. Архивирование самостоятельно обработает ситуацию отсутствия ответа и отправит соответствующий код ответа (
Response Is Missing, RIM) в ЦСП.
Прикладная фабрика использует физическое удаление данных (объекты физически удаляются из БД, отличить никогда не создававшийся объект от удаленного фабрика не может). Формируется контейнер удаленного объекта:
В
DataContainer#keyвносится запрашиваемый ключ по формату, приведенному в документе «Руководство прикладного разработчика», раздел «Форматы обмена данными с Архивированием (ARCH)». Формат ключей для объектов (раздел формат ключей) - без префикса типа.в
DataContainer#entryTypeвносится полный тип запрашиваемого объекта;в
DataContainer#versionвносится версия передаваемого объекта согласно БД, либо 0 (если версия для таких объектов более не доступна);в
DataContainer#operTypeвноситсяDelete(не изменяемо);в
DataContainer#updAttrsвносится пустой список;DataContainer#dataзаполняется объектом запрошенного типа с заполненными атрибутом ключа и версией. Все обязательные поля заполнены значениями по умолчанию, либо заглушечными данными (их состав не имеет значения).
Если фабрика данных является шардированной (мультитенантной), возможны следующие варианты:
Каждый шард работает независимо. В топологии конфигурации источника указывается полный перечень шард. Каждая возвращает ответ на запрос ТКД всегда. Шарды, на которых данный объект физически отсутствует всегда возвращают контейнер удаленного объекта. Такое поведение является целевым. При таком поведении любой не вернувшийся ответ от одной шарды на запрос ТКД с точки зрения Архивирования будет считаться неполученным, вне зависимости от ответов других шард.
Модуль интеграции с Архивированием выполняется вне схемы шардирования и существует в единственном экземпляре. Обслуживает обращение к разным шардам БД Источника, скрывая эту реализацию от Архивирования. При таком поведении Источник на стороне Архивирования конфигурируется с точки зрения топологии как одношардовый. Сценарий является допустимым, прозрачен с точки зрения взаимодействий, но имеет повышенную трудоемкость для реализации Источником.
Объект QualityBatchResult – пакет для отправки в потоке результатов формирования пакета данных.
Транспортное сообщение QualityBatchResult:
public class QualityBatchResult extends PartitionResult<byte[]> {
private static final long serialVersionUID = 6961184569997647971L;
public QualityBatchResult(long responseId, String requestId, Timestamp responseTimestamp,
int partTotal, int partCurrent, String partHash, String entryType, String zoneId,
byte[] data, String hash) {
super(responseId, requestId, responseTimestamp, partTotal, partCurrent, partHash, entryType, zoneId, data, hash);
}
}
Отличается способ использования транспортного контейнера. Если в исходном API ТКД (синхронный) Источник реализовывал на своей стороне интерфейс public interface QualityDataTransportApi, в текущем API применяется иной подход:
Для получения
sampleИсточник реализует на своей стороне API public interface QualityDataSampleApi, а именно – его методыEstimateResult(оценки размера пакета данных) иgetQualityBatch(запрос данных).После построения контейнера
LoadResultон сериализуется в массив байт с использованием стандартной Java сериализации.Поток байт разбивается на части размером по 900 кБайт (946176 байт), и каждый такой фрагмент упаковывается в объект
QualityBatchResult. Далее все этиQualityBatchResultотправляются Архивированием (ARCH) в потоке.Ответ в формате потока в виде объектов
QualityBatchResultИсточник отправляет на API Archiving public interface QualityDataSampleLoad, а именно методloadQualityBatch.
Устанавливается таймаут, в течение которого Архивирование (ARCH) ожидает как получения порции данных контейнера после вызова getQualityBatch, так и получения следующей партиции при ее наличии: по умолчанию таймаут составляет 10 минут.
Интерфейс и методы для отправки запроса к Источнику по списку идентификаторов:
Интерфейс для получения данных по списку идентификаторов:
public interface QualityDataSampleApi {
...
@ApiMethod(apiName = "getQualityBatchSize", version = "0.0.1")
EstimateResult getQualityBatchSize(String type) throws BatchEstimateException;
@ApiMethod(apiName = "getQualityBatch", version = "0.0.1")
void getQualityBatch(List<String> keys, String type, String requestId) throws QualityBatchCreationException;
...
}
Интерфейс QualityDataSampleApi реализуется Источником.
Метод getQualityBatchSize в текущих интеграциях не требует какой-либо наполненной смыслом реализации на стороне Источника, допустимо возвращать константу – комфортное для него количество объектов, которое он готов передавать за один вызов.
В метод getQualityBatch в качестве значения ключа key вносится ключ по специальному формату – без префикса типа (невербальный) с экранированными разделителями.
Интерфейс и методы для получения потока идентификаторов по типу (sample):
Интерфейс для получения потока полных версий объектов:
public interface QualityDataSampleLoad {
...
@ApiMethod(apiName = "loadQualityBatch", version = "0.0.1")
void loadQualityBatch(QualityBatchResult qualityBatchResult) throws PartitionResultAcceptException;
...
}
Интерфейс LoadQualityBatch. Реализуется на стороне Архивирования (ARCH), вызывается со стороны фабрики-Источника либо непосредственно с соблюдением контракта, либо с использованием клиентской библиотеки Архивирования (ARCH), которая инкапсулирует формирование потока и всех необходимых хешей и идентификаторов.
Фиксируется следующий контракт:
В одном пакете
QualityBatchResultсодержится набор байт, представляющих фрагмент контейнераLoadResult. Контейнер сериализован в поток с использованием Java сериализации.Количество байт в одном сообщении не превышает 900 кБайт (946176 байт).
Фрагменты отправляются последовательно в порядке, соответствующем порядку следования фрагментов при их разбиении на стороне Источника.
Поле
responseIdв контейнере заполняется монотонно возрастающими значениями, уникальными в пределах одного запросаrequestId, порядок сортировки этих идентификаторов соответствует порядку частей контейнера для его последующего склеивания на стороне Архивирования (ARCH) и десериализации.Хеш
partHashсчитается от всего объектаQualityBatchResultдля каждой партиции.Хеш hash считается от полного набора байт всего сериализованного контейнера
LoadResultдо его разбивки на части.
Обработка нештатных ситуаций при отправке ключей:
При отборе ключей на стороне Источника возможно возникновение различных нештатных ситуаций. Наиболее типовая – когда ключ по идентификатору на стороне Источника не найден.
Поскольку запросы выполняются не по одному ключу, а по списку (множеству) – в случае, если какой-то один (или несколько) ключ из множества не найден или не может быть выбран, независимо от причины, это не должно блокировать выборку и отправку остальных ключей. Поскольку Источник вправе отправлять данные, запрошенные одним вызовом getQualityBatch, путем выполнения более чем одного вызова loadQualityBatch, необходимо анализировать нештатные ситуации. При возникновении нештатной ситуации при формировании единого пакета необходимо при их возникновении выполнять дробление отправляемых порций данных следующим образом:
данные, вызывающие нештатную ситуацию, отправляются одиночными пакетами
QualityBatchResult, содержащими ровно один объект (вызвавший исключение);данные, которые не вызывают исключений, группируются в один или несколько вызовов
loadQualityBatch.
Пример:
Исходный запрос ключей и результат выборки каждого их них:
Ключ |
Результат |
|---|---|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
Результат (вызовы loadQualityBatch) могут выглядеть следующим образом (варианты А и Б):
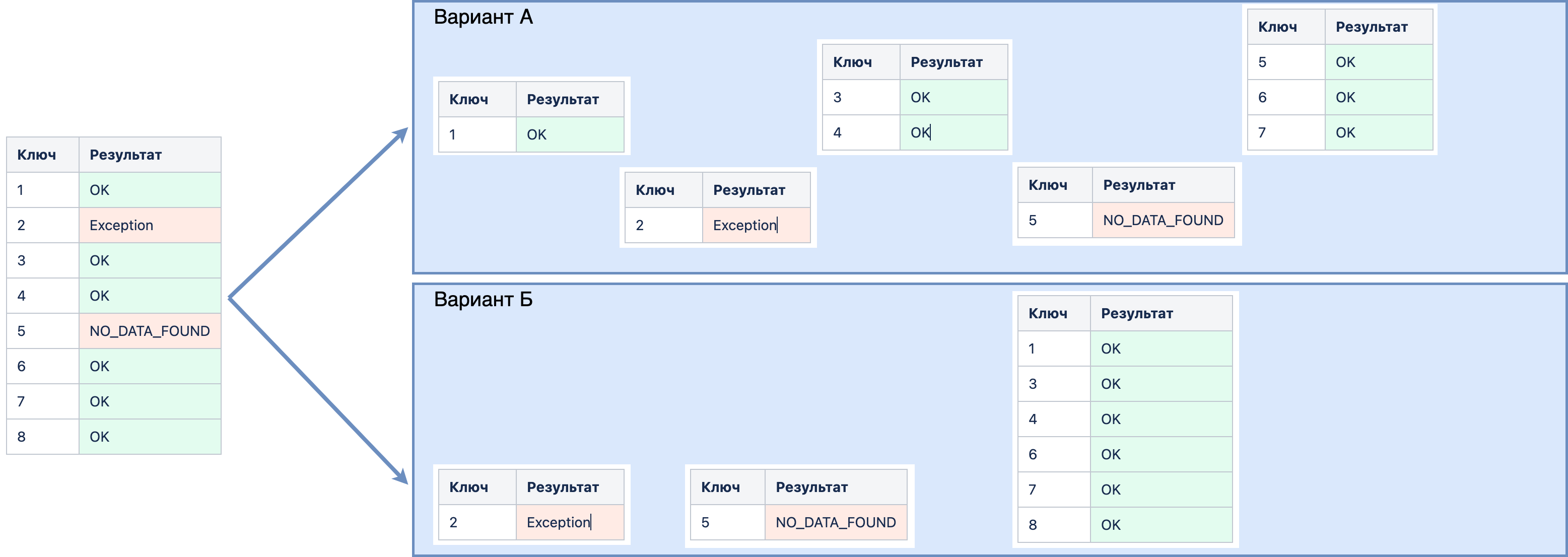
Вариант А наиболее прост в реализации – формируется единая порция QualityBatchResult с момента последнего успешно полученного ключа и до исключения, для исключения формируется единичный пакет QualityBatchResult.
Вариант Б – группировка успешных ключей в одну порцию (более оптимально, но требует сложной логики реализации).
Синхронный API ТКД V1 (Устаревшее API)#
@Api
public interface QualityDataTransportApi {
@ApiMethod(apiName = "getQualityBatchSize", version = "0.0.1")
EstimateResult getQualityBatchSize(String type) throws BatchEstimateException;
@ApiMethod(apiName = "loadQualityBatch", version = "0.0.1")
LoadResult loadQualityBatch(List<String> keys, String type) throws BatchLoadException;
}
getQualityBatchSize– получить рекомендованный размер партиции для типаtype. Вернется результат оценки партиции, где в полеsizeбудет указан рекомендованный размер пакета.loadQualityBatch– получить объекты ключейkeysтипаtype. ВернетсяLoadResult, содержащий запрашиваемые объекты.