Сценарии администрирования#
Platform V Archiving не имеет собственного пользовательского интерфейса, администрирование осуществляется через:
настройки окружения сервиса;
параметры сервиса, расположенные в Platform V Configuration (далее — Конфигуратор);
параметры сервиса, расположенные в UI смежных сервисов, которые применяются для использования функций Platform V Archiving.
Резервное копирование файлов не требуется и не предусмотрено. Значения по умолчанию для параметров указаны в Руководстве по установке.
Настройка инициализирующей выгрузки данных#
Инициализирующая выгрузка (далее — Init) нужна для первоначальной загрузки данных из АС источника данных в КАП (Корпоративную Аналитическую Платформу).
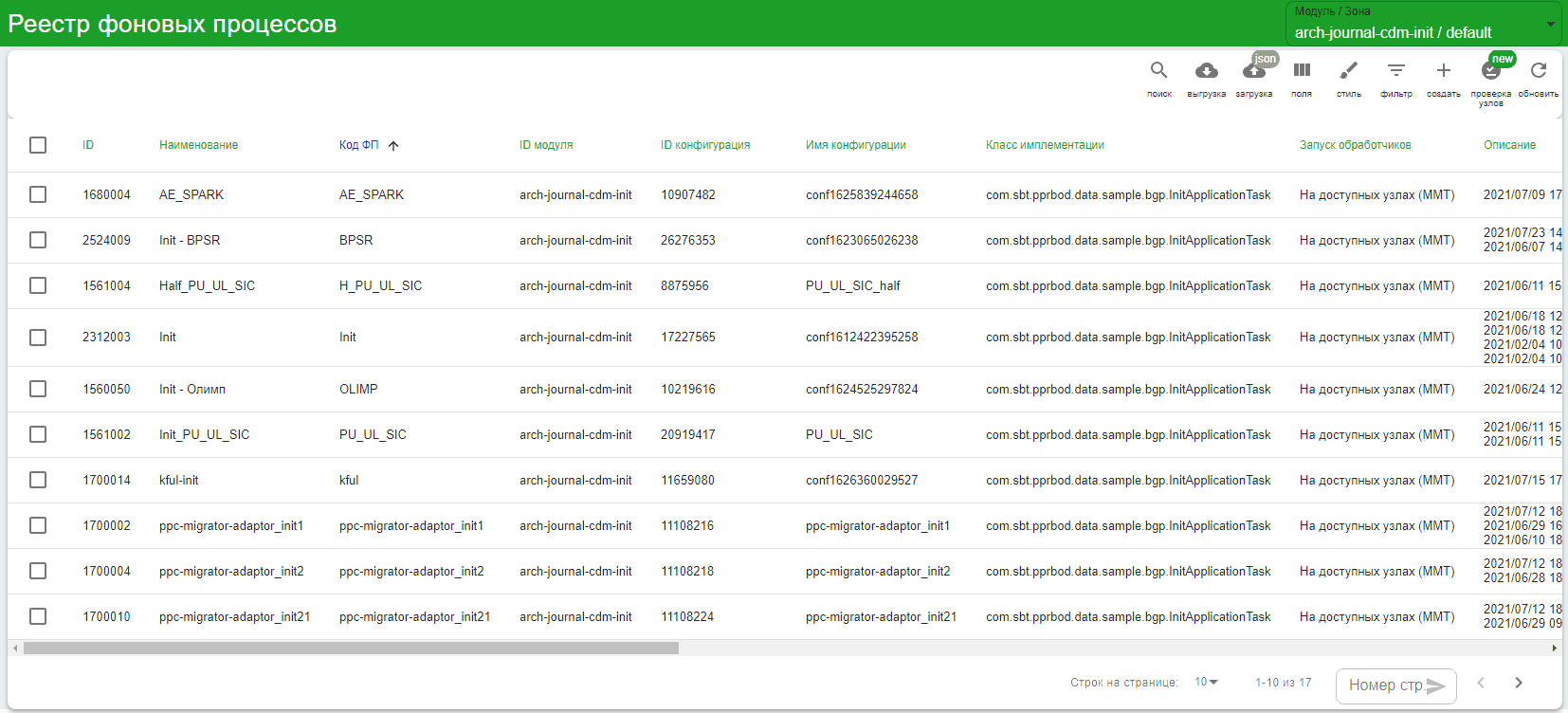
Для управления инициализирующей выгрузкой данных от прикладной АС (источника данных) до интеграционной Kafka Archiving, через которую происходит обмен данными между Archiving и Корпоративной аналитической платформой, используется графический интерфейс ТС Реестр Фоновых Процессов.
Для авторизации в графическом интерфейсе необходимо иметь учетную запись с соответствующими правами на доступ к сервису. Консультацию по процессу получения прав на конкретном полигоне получите у координаторов или команды сопровождения.
Создание конфигурации Фонового Процесса в BGP#
Авторизуйтесь в графическом интерфейсе ТС «Реестр Фоновых Процессов».
В левой части меню выберите Реестр ФП. В интерфейсе отобразятся настроенные ранее Фоновые Процессы для различных АС.
В правом верхнем углу найдите выпадающий список Модуль/Зона и проверьте, что в вариантах выбора есть:
arch-journal-cdm-init/default— для источников на БПС.Сделки или Platform V Persistence;arch-journal-dataspace-init/default— для источников на DataSpace;arhc-journal-gbk-init/default— для источников с метамоделью типа CLASSES (GBK, AEACC);arch-journal-ucp-consents-init/default— для UCP_CONSENTS.
Если все права предоставлены верно, но модулей в списке нет, то их необходимо создать. См. раздел «Создание модуля Фонового Процесса».
Примечание
Дальнейшие шаги сценария по администрированию могут выполнять как администраторы ТС Архивирование, так и администраторы АС источников данных, так как под каждый источник необходимо формировать отдельные фоновые задачи.
Выберите требуемый модуль из списка. Отобразятся все Фоновые Процессы, используемые для запуска Init на этом контуре.
Внимание
В списке фоновых процессов и конфигураций к ним присутствуют фоновые процессы и конфигурации для всех прикладных фабрик — источников данных Archiving в контуре. Редактировать и удалять конфигурации и фоновые процессы других прикладных фабрик запрещено!
Для создания Фонового Процесса необходимо создать его конфигурацию. В главном меню в разделе Справочники выберите раздел Конфигурация ФП.
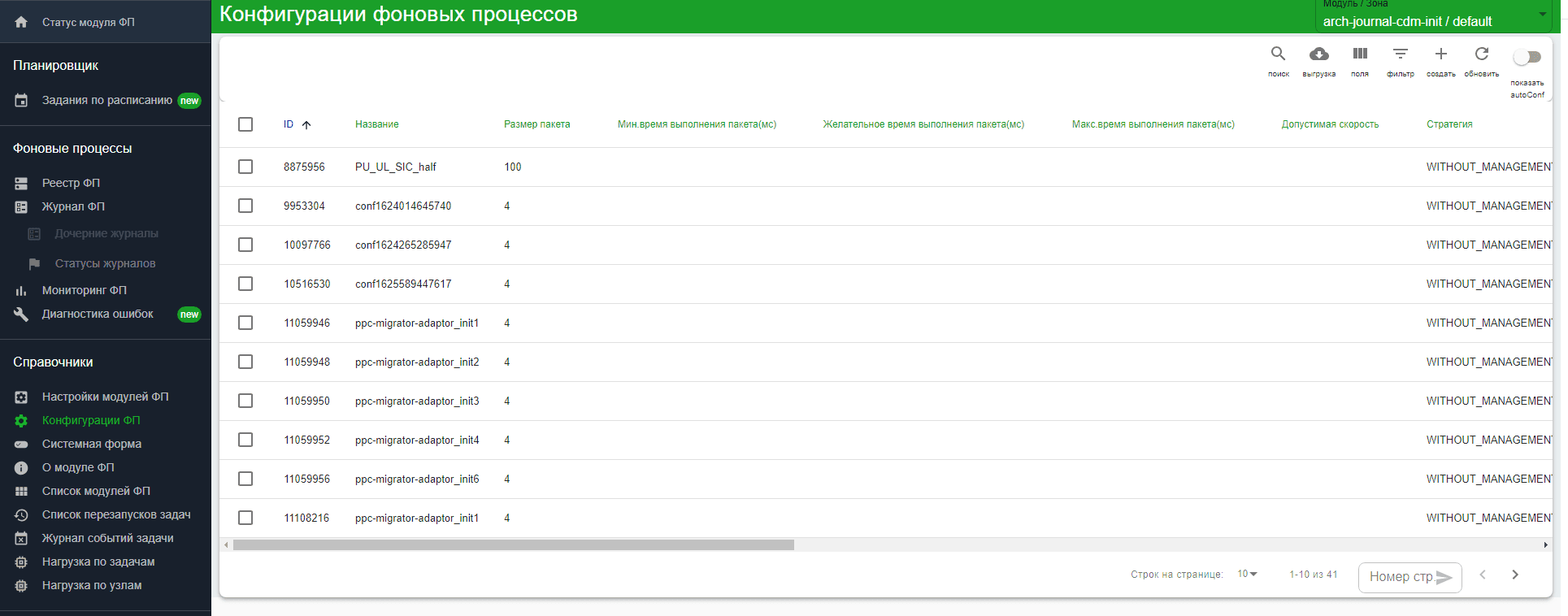
В правом меню нажмите Создать.
В открывшейся форме создания конфигурации Фонового Процесса заполните поля:
Название — указывается по шаблону
<мнемоника источника>-configuration-X, гдеX— это понятное для автора конфигурации обозначение, описывающее конфигурацию. Например,TEST_SOURCE-configuration-fullTypesконфигурация источника TEST_SOURCE по выгрузке всех типов данных.Стратегия автоматического управления - выберите
WITHOUT_MANAGEMENT.Приоритет — укажите
2(поле выведено из эксплуатации.Таймаут для обработчиков — время (сек), в течение которого Boss-процесс ожидает завершения обработки одной партиции дочерним процессом. Для источника, отдающего партиции быстро, рекомендованное значение таймаута — 1200 секунд.
Попыток перезапуска обработчика при сбое или таймауту — количество повторных запросов: от 0 до 2. Если ошибка происходит в середине партиции, перезапуск приведет к повторной отправке ранее успешно отправленной части данных.
Таймаут запуска Worker'ов ММТ — время ожидания Boss-процессом ответа от Worker'ов. Рекомендованное значение —
10000.Ленивая загрузка партиции — включена.
Размер пакета — количество элементов в одной коллекции, которое передается на обработку одному потоку. Рекомендованное значение - 1. От этого параметра зависит скорость обновления статуса фоновой задачи. Влияния на ММТ обмен «источник-Archiving» и производительность не оказывает, так как дочерний процесс обрабатывает партиции из пакета последовательно.
Количество обработчиков — количество обработчиков, которые могут выполнять один Фоновый Процесс. Начальное рекомендованное значение для тестирования - 8. Далее параметр можно менять в зависимости от времени загрузки данных. Как правило, с увеличением количества обработчиков скорость увеличивается.
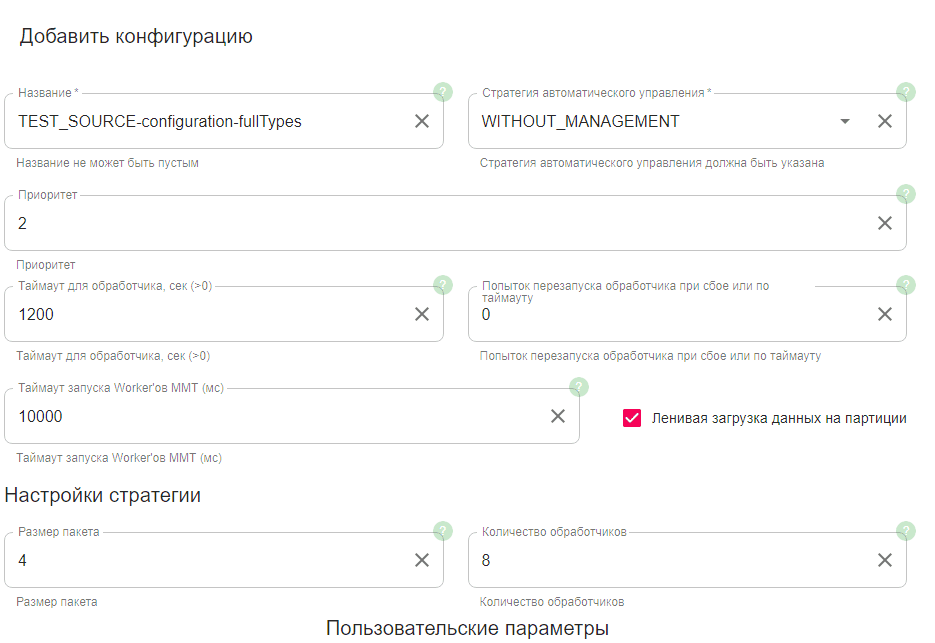
Заполните пользовательские парамеры вручную или загрузите из JSON-файла.
Для загрузки параметров через JSON-файл подготовьте файл со списком параметров и нажмите Загрузить json файл.
При заполнении вручную для создания нового параметра нажмите +.
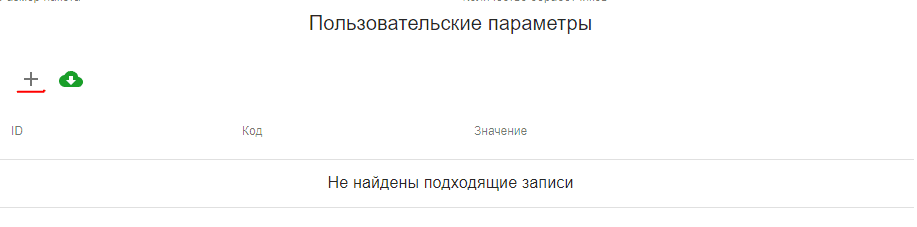
В открывшейся форме заполните параметры:
type_0… type_<N> — обязательный параметр, определяющий, какие сущности будут выгружены из АС при запуске Init.
Пример — Фоновый Процесс запускает Init по трем типам данных:
type_0=com.sbt.cdm.domain.ora.deals.cm.CmServiceAccountsAndSchedules, type_1=com.sbt.cdm.domain.ora.deals.cm.CmChildOrganizationAccrual, type_1225=com.sbt.cdm.domain.ora.deals.cm.CmServiceScheduleВнимание!
Нумерация типов должна быть последовательной:
type_0,type_1,type_2и так далее. При непоследовательной нумерации список выгружаемых типов будет сформирован некорректно.Примечание
Создание нескольких Фоновых Процессов с разным набором сущностей будет полезно при тестировании для:
запуска Init небольших сущностей для сквозной проверки;
выгрузки конкретных сущностей;
запуска огромных сущностей (если такие имеются) в нерабочее время.
necessaryTypes — необязательный параметр, определяющий, какие сущности будут повторно загружены при использовании задачи Init для сценария DRP.
Если нужно загружать не все данные, соответствующие указанным в type_0 .… type_<N> типам, добавьте этот параметр с перечислением через запятую тех дочерних типов, которые нужно загрузить повторно. Обработаны будут только объекты типов, указанных в параметре. При отсутствии этого параметра обрабатываются все дочерние типы.
Пример: требуется загрузить повторно объект типа
com.sbt.pprbod.source.Entity, который содержит объекты типов:com.sbt.pprbod.source.BigPartOfEntity;com.sbt.pprbod.source.FirstSmallPartOfEntity;com.sbt.pprbod.source.SecondSmallPartOfEntity.
При этом объект
com.sbt.pprbod.source.BigPartOfEntityзагружать не нужно. Тогда параметр necessaryTypes определяется как:com.sbt.pprbod.source.FirstSmallPartOfEntity,com.sbt.pprbod.source.SecondSmallPartOfEntity.module — обязательный параметр. Укажите наименование целевой АС, в которой размещен API Archiving.
Также можно посмотреть в CSM или проконсультироваться с коллегами из разработки.
zone — обязательный параметр, в котором указывается зона ММТ, в которой расположена прикладная фабрика. Если зона неизвестна и все модули фабрики, работающие с Archiving, имеют одинаковый функционал, то этот параметр можно не указывать.
source — обязательный параметр, в котором указывается мнемоническое название целевой АС. Если оно неизвестно, уточните его у команды разработки.
Пример:
DEALS_KB.Значение задается Вашей командой разработки в ходе выполнения инструкций по DevOps, о важности прохождении которых было написано ранее.
rawBatchSize — необязательный параметр, определяющий количество контейнеров данных, которое Archiving упаковывает в один raw-контейнер. Значение по умолчанию — 20.
Чем больше значение параметра, тем выше скорость, однако при этом возрастает загрузка оперативной памяти Archiving. Например, параметр равен 10 (по умолчанию), тогда из 3000 контейнеров данных, полученных в партиции, в топик необработанных данных отправляется 300 raw-контейнеров. Затем каждый raw-контейнер вычитывается одним из КТС, объекты извлекаются, десериализуются, фильтруются по белому списку и отправляются в КАП. Ограничением по
rawBatchSizeявляется только максимальный размер сообщения в топике Kafka (в текущей версии равен 16 МБ). Соответственно, 16 МБ / [максимальный вес вашего DataContainer'a] = [максимальный размерrawBatchSize]. При настройке производительности рекомендуется увеличивать значение: например, для мелких объектов можно установить значение 500.partitionThreshold — необязательный параметр, определяющий время ожидания выгрузки одной партиции в минутах. Значение по умолчанию — 5 минут. Если у Прикладной фабрики размер одной партиции превышает объем, который удается выгрузить за 5 минут, время выгрузки можно увеличивать с помощью этого параметра. Рекомендуется увеличить значение параметра, если Init завершается с ошибкой превышения времени ожидания выгрузки данных.
hideExceptions — необязательный параметр. Принимает значения
true/false. Отвечает за обработку исключений при загрузке партиций, при значенииtrueошибки игнорируются. По умолчаниюfalse.serialDelivery — необязательный параметр. Принимает значения
true/false. При значенииtrueгарантируется порядок записи объектов в Kafka соответствующий их очередности в списке объектаLoadResult, отправляемого фабрикой в Archiving. По умолчаниюfalse.resetPack — необязательный параметр, отвечающий за вызов метода
abort()на стороне Фабрики при запуске Init. Если указанtrue— производится принудительная пересоздание пачек на стороне источника. При продолжении Init применяется только в том случае, если при создании пачек на стороне источника новые объекты попадают в последние партиции. Применяется для любых источников и стратегий при необходимости.Перед Init следует очистить ранее имеющиеся временные данные и нарезанные пачки принудительно, если источник использует ORA_HASH, то параметр использовать нельзя.
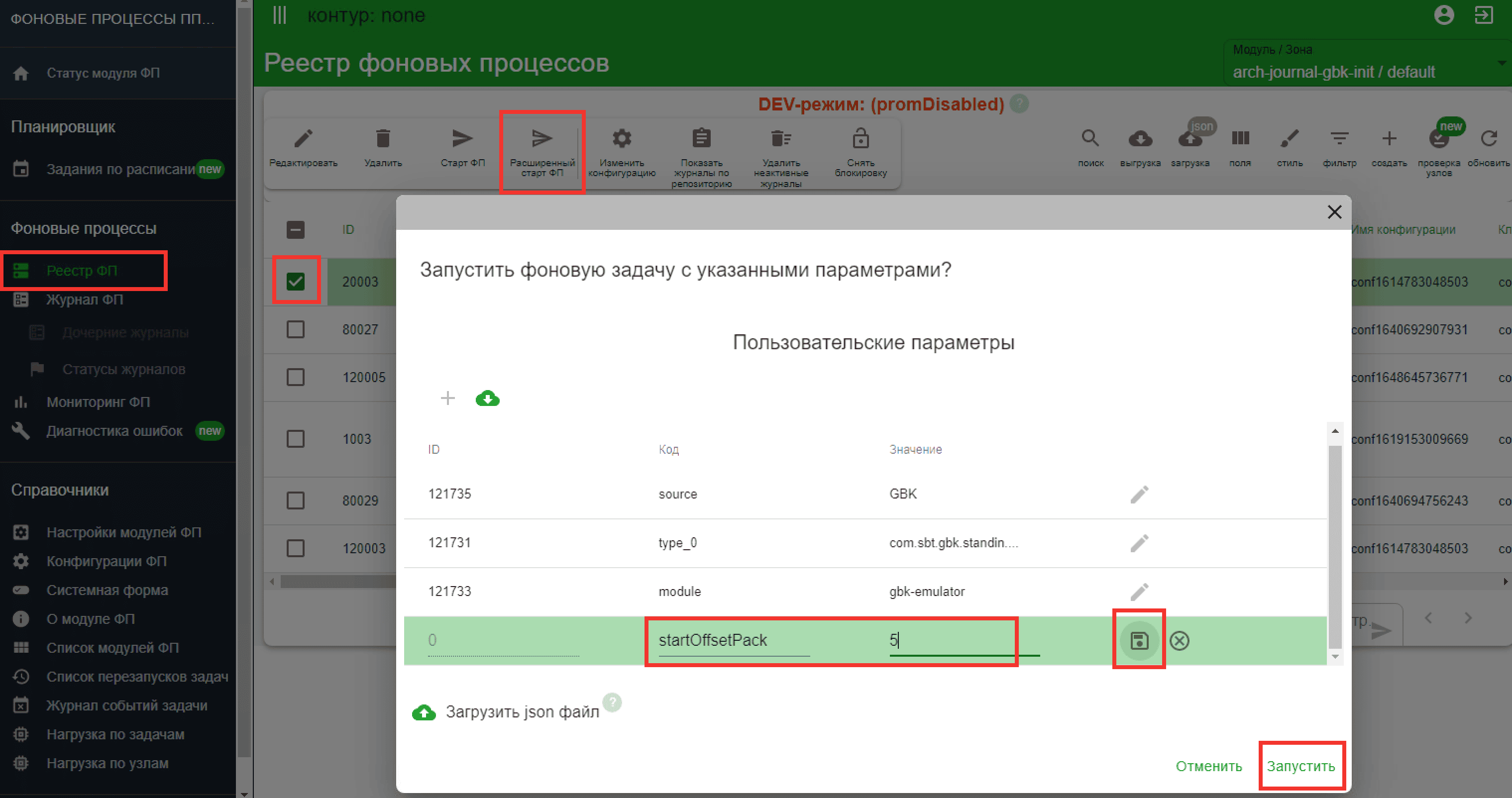
startOffsetPack — необязательный параметр, принимает значения >0. Определяет номер партиции, с которой нужно выполнить Init. Партиции до указанного номера при обработке будут пропущены. При расчете значения следует из числа успешно загруженных партиций вычесть число, равное произведению количества обработчиков и размера пачки из настройки стратегии Init, поскольку обработка данных из последних обрабатываемых партиций не определена.
Пример заполнения:

После заполнения всех параметров нажмите Сохранить. После закрытия формы конфигурация должна появиться в списке конфигураций.
Создание модуля Фонового Процесса#
Для создания нового модуля:
Авторизуйтесь в графическом интерфейсе ТС «Реестр Фоновых Процессов».
Откройте страницу Список модулей ФП (находится в группе Справочники).
В верхнем меню нажмите Создать

В открывшемся меню заполните все поля:
Идентификатор модуля — имя создаваемого модуля. В зависимости от типов присутствующих источников данных создаются модули из списка пункт 2 данного параграфа.
Название модуля - заполните идентично с Идентификатором модуля.
Зона координатора BGP - указывается
default.Отключен - указывается
Нет.
Пример:
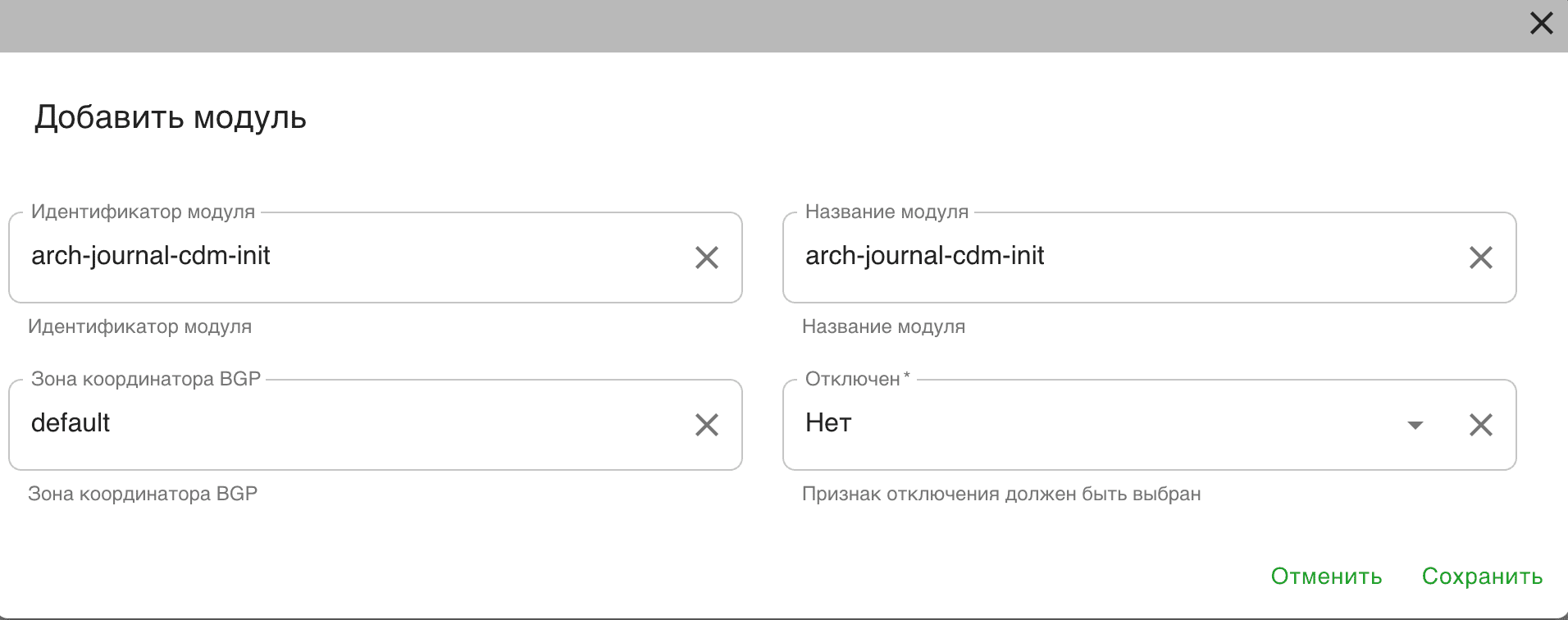
Нажмите кнопку Сохранить.
В списке модулей должен появиться созданный модуль.
Требования для настройки безблокировочного Init#
Безблокировочный Init доступен только для источников на DataSpace.
Для использования безблокировочного Init требуется дополнительное согласование:
Убедиться у DataSpace и ТСА, что используются версии продуктов, поддерживающие данный Init.
Убедиться, что у КАП есть возможность принять формат векторов, согласованный для безблокировочного Init.
Для безблокировочного Init нужно указать в настройках BGP в поле Класс имплементации класс com.sbt.pprbod.data.kafka.bgp.InitAggregateAsyncApplicationTask.
Создание задачи Фонового Процесса в BGP#
Авторизуйтесь в графическом интерфейсе ТС «Реестр Фоновых Процессов».
В левой части меню выберите Реестр ФП. В интерфейсе отобразятся настроенные ранее Фоновые Процессы для различных АС.
Внимание!
При переходе между меню необходимо следить, чтобы в форме Модуль/Зона было указано наименование требуемого модуля, так как в интерфейсе BGP периодически происходят сбросы меню к Модулю/Зоне по умолчанию.
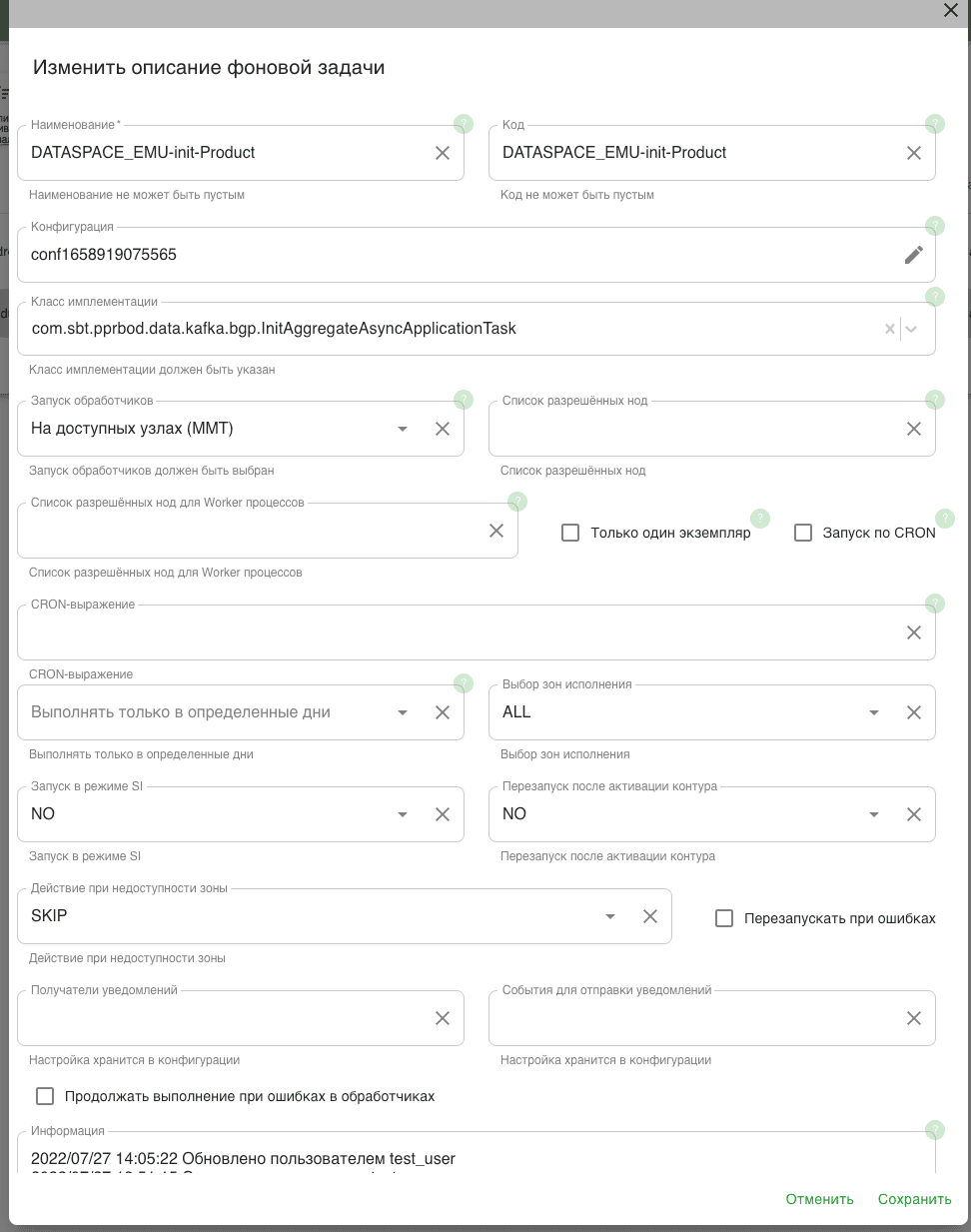
В Реестре ФП в правом верхнем углу нажмите Создать. Откроется форма Добавить описание фоновой задачи.
В открывшемся окне введите обязательные параметры (отмечены *). Необязательные параметры указываются по желанию.
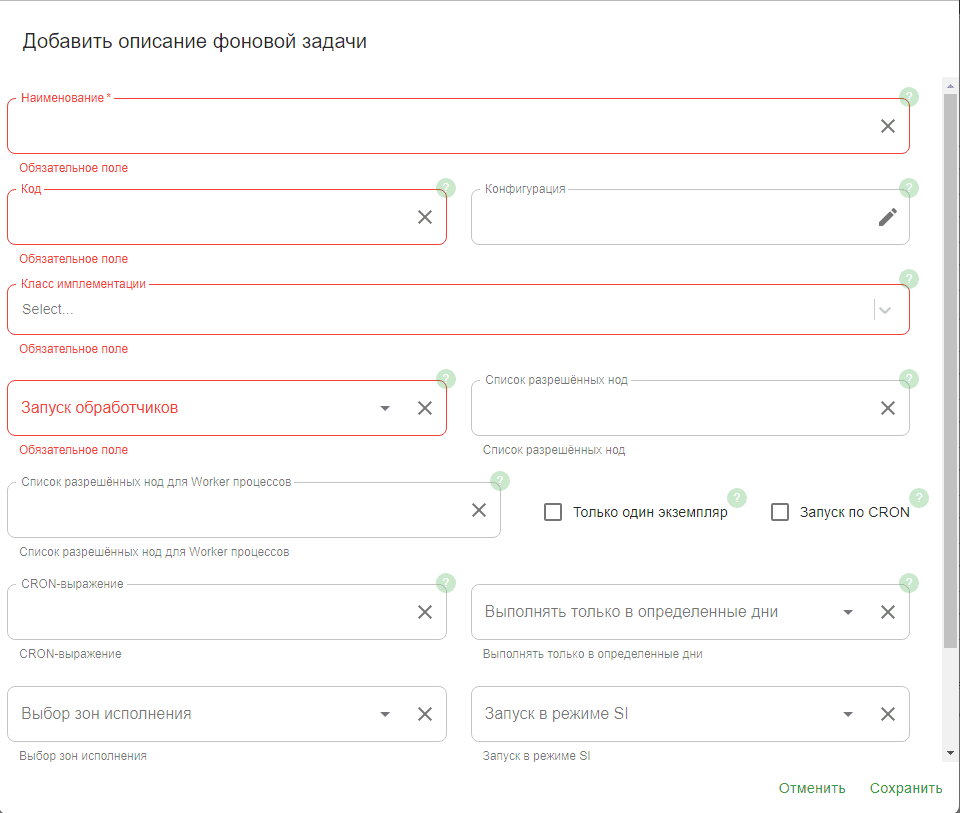
Наименование* — название фоновой задачи. Используется для поиска требуемого Фонового Процесса в интерфейсе BGP. Должно быть понятно для того, кто использует эту задачу. Название выбирается по шаблону:
<мнемоника источника>-init-<признак задачи>. Например,PU_UL_SIC-init-fulltypes— фонововая задача прикладной фабрики PU_UL_SIC по выгрузке всех типов данных.Код* — заполняется аналогично полю Наименование. Должен быть уникальным по отношению к остальным фоновым задачам в реестре ФП.
Класс имплементации* — выберите значение из списка:
модуль
arch-journal-dataspace-init, источники на DataSpace:com.sbt.pprbod.data.kafka.bgp.InitAggregateApplicationTask;модуль
arch-journal-cdm-init, источники на четвертом поколении Platform V Persistence:com.sbt.pprbod.data.kafka.bgp.InitApplicationTask;модуль
arch-journal-cdm-init, все остальные:com.sbt.pprbod.data.sample.bgp.InitApplicationTask;
Запуск обработчиков* - выберите значение из списка
На доступных узлах ММТ.Конфигурация — параметры, с которыми будет запускаться фоновая задача. Выберите ту, которая была создана на шаге 3.1.
Запуск в режиме SI — выберите
NO.Действие при недоступности зоны — выберите
SKIP.
После заполнения параметров нажмите Сохранить. Фоновый Процесс создан. Можно приступать к запуску Фонового Процесса.
Запуск Фонового Процесса#
Авторизуйтесь в графическом интерфейсе ТС «Реестр Фоновых Процессов».
Если задача Фонового процесса не создана, предварительно создайте ее (См. раздел «Создание задачи Фонового Процесса в BGP»).
Внимание!
Перед запуском Фонового Процесса убедитесь, что:
в базу Archiving загружена конфигурация для прикладной фабрики (АС источника данных), по которой выполняется данная инструкция;
на контуре, где выполняется настройка, запущен модуль, через который осуществляется взаимодействие с Archiving, то есть реализовано API для Init InitDataSampleApi (или DataTransportApi).
Выберите требуемую фоновую задачу из списка.
В появившемся сверху меню нажмите Старт ФП, затем ОК. Параметры запуска загрузятся из конфигурации Фонового процесса. Если перед запуском фоновой задачи требуется изменить параметры ее запуска, нажмите Расширенный старт ФП.
Примечание
Если при старте фоновой задачи возвращается исключение с большим stack trace, это не связано с неполадками на стороне Archiving. В BGP периодически возникают исключения при запросе к БД или с коммуникациями внутренних модулей, что приводит к сбоям при запуске. Если из исключения не удается однозначно понять причину ошибки (например, при некорректных параметрах фоновой задачи на это будет явно указано), попробуйте запустить задачу повторно через несколько минут. Ошибки, связанные с Archiving, возникают тогда, когда задача уже создана и отобразилась в Журнале ФП.
Нажмите на Журнал ФП в главном меню в разделе Фоновые Процессы. Откроется список всех успешно созданных экземпляров задач. В верхней части списка отобразится ФП, который был запущен на предыдущем шаге.
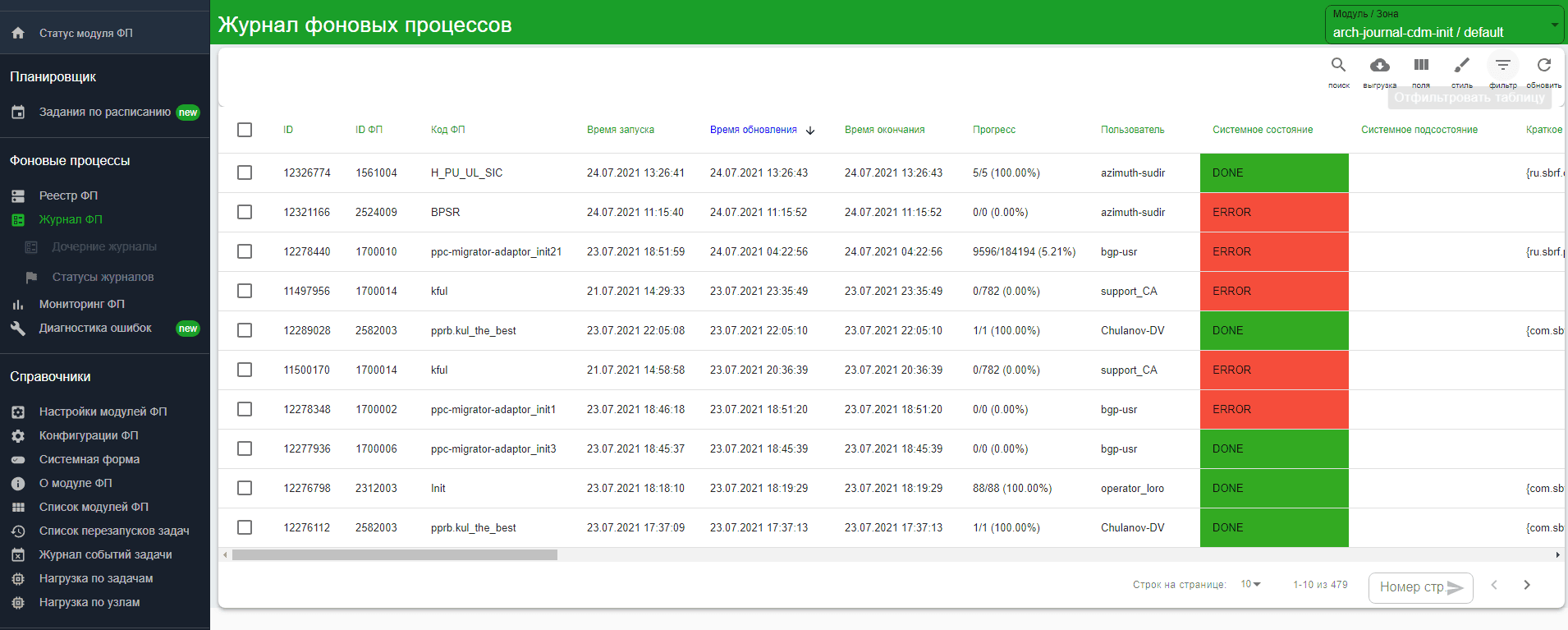
Прерывание фоновой задачи Init#
Для прерывания фоновой задачи Init:
Авторизуйтесь в графическом интерфейсе ТС «Реестр Фоновых Процессов».
Выберите требуемую задачу в Журнале ФП.
Нажмите Отправить команду ФП.
В открывшейся форме выберите Тип сообщения
STOPи нажмите Отправить.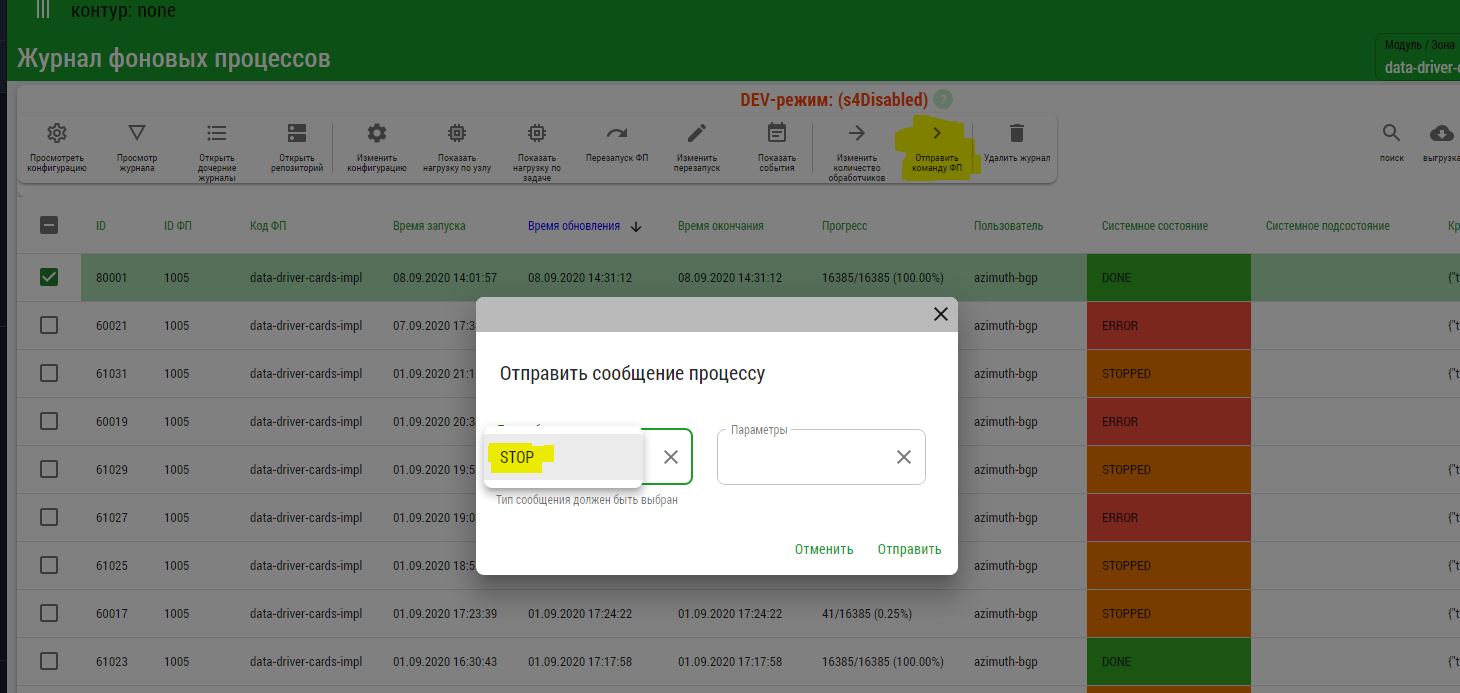
Просмотр состояния Фонового Процесса#
Системные состояния:
PREPARE — подготовка к выполнению Init, запрос о количестве данных;
PROCCESS — выполнение инициализирующей выгрузки;
STOPPED — процесс остановлен либо вручную, либо программно. Например, в связи с тем, что загрузка не завершилась через выставленный для загрузки таймаут;
FINISH — окончание выгрузки, синхронизация и проверка завершения выгрузки всех данных;
DONE — выполнение фонового процесса завершено успешно, выгрузка данных выполнена;
ERROR — в процессе выполнения фонового процесса произошла ошибка.
Процесс выполнения отображается в столбце Прогресс. В нем указывается, сколько партиций данных из общего количества уже выгружено.
При успешном завершении ФП в поле Прогресс должно быть значение 5/5 (100.00%) (5 — если было рассчитано 5 партиций данных, значение может быть другим).
Внимание!
Если при выгрузке данных Фоновый Процесс заканчивает работу со статусом DONE, а в поле Прогресс отображается 0/0 (100.00%), это означает, что при запросе количества данных источник (прикладная фабрика) вернул количество данных (количество партиций), равное 0. Удостоверьтесь, что данные по запрашиваемым типам присутствуют в БД прикладной фабрики.
Если ФП завершился в статусе ERROR, то в процессе произошло исключение. Подробнее в разделе «Часто встречающиеся проблемы и пути их устранения».
Повторный запуск ФП и продолжение Init с заданной партиции#
Повторный запуск фонового процесса применяется, если:
Init был прерван по причине перехода в платформенный Stand-In;
Init был принудительно остановлен. Для принудительной остановки фоновому процессу отправляется команда
STOP.
Ограничения:
Повторный запуск задачи не допускается при прекращении Init вследствие ошибок сериализации или любых других ошибок, за исключением перехода в Stand-In.
Если Init проводится при включенном потоке векторов изменений ПЖ, повторный запуск может применяться только при условии, что при нарезке пачек на стороне источника новые объекты (появившиеся с момента запуска предыдущего Init) добавляются в последние по счету партиции с конца.
В случае потока, остановленного на время Init, стратегия нарезки пачек не имеет значения (при условии, что поток не будет включен ранее, чем Init будет полностью завершен).
Для источников, использующих Platform V Persistence, стратегия создания пачек определяется конфигурацией BEAN SourceSystemDataProvider в коде источника.
Существующие стратегии нарезки пачек для Platform V Persistence API Archiving v4:
SIMPLE_ID— во вспомогательную таблицу предварительно записываются диапазоны ключей в партиции, и последующий Init производится выборкой по диапазону ключей. Работает только с простыми ключами.COMPOSITE_ID— во вспомогательную таблицу записывается список всех ключей партиции. Последующий Init также производится выборкой по условию. Работает как с простыми, так и с составными ключами.COMPOSITE_OR_SIMPLE_ID_AUTOSELECT— выбирается в зависимости от ключаSIMPLE_IDилиCOMPOSITE_IDавтоматически.HASHCODE— стратегия по умолчанию. Партиция выбирается посредством нахождения остатка от деления хеша строки на количество партиций. Не использует вспомогательную таблицу. Работает как с простыми, так и с составными ключами.
Стратегии 1-3 допускают использование продолжения Init при выключенном потоке и удовлетворяют ограничению 2.
Стратегия 4 не допускает продолжения Init при включенном потоке и приводит к повышенной нагрузке на источник при Init и низкой его скорости.
Настройка стратегий на стороне источника:
@Bean
public SourceSystemDataProvider dataProvider(EntityManagerFactory entityManagerFactory) {
return new HibernateDataProviderFactory()
.setEntityManagerFactory(entityManagerFactory)
// Стратегия партиционирования (по умолчанию - HASHCODE)
.setPartitioningStrategy(PartitioningStrategyType.COMPOSITE_OR_SIMPLE_ID_AUTOSELECT)
// Необязательные параметры. Указаны значения по умолчанию
// Количество объектов в партиции. Имеет значение для всех стратегий
.setPartitionSize(50)
// Следующие параметры имеют значение только для COMPOSITE_ID и
COMPOSITE_OR_SIMPLE_ID_AUTOSELECT.
// Указаны значения по умолчанию
// Количество строк, вычитываемых за один раз при записи во вспомогательную таблицу
.setInitialFetchSize(20000)
// Количество строк, вставляемых в дополнительную таблицу за один раз (updateBatch())
.setInsertBatchSize(50)
.build();
}
Продолжение Init с заданной партиции#
Для продолжения Init с заданной партиции:
Запустите фоновую задачу с указанным параметром
startOffsetPack>0. Укажите номер партиции, с которого нужно выполнять Init. Партиции до указанного номера при обработке будут пропущены. При расчете значения следует из числа успешно загруженных партиций вычесть число, равное произведению количества обработчиков на размер пакета из настройки стратегии Init, поскольку обработка данных из последних обрабатываемых партиций не определена. Если полученное значение партиции меньше или равно 0, Init следует запускать с начала.Внимание!
Для корректного продолжения Init с заданной партиции задание Init должно содержать только один тип (ограничение будет снято в будущих версиях).
Партиции до указанного номера при обработке будут пропущены. Количество обработанных партиций не будет совпадать с общим числом партиций.
Пересоздание партиций при продолжении нежелательна. Рекомендуется при продолжении Init явно указать это, передавая в задачу параметр
resetPack=false.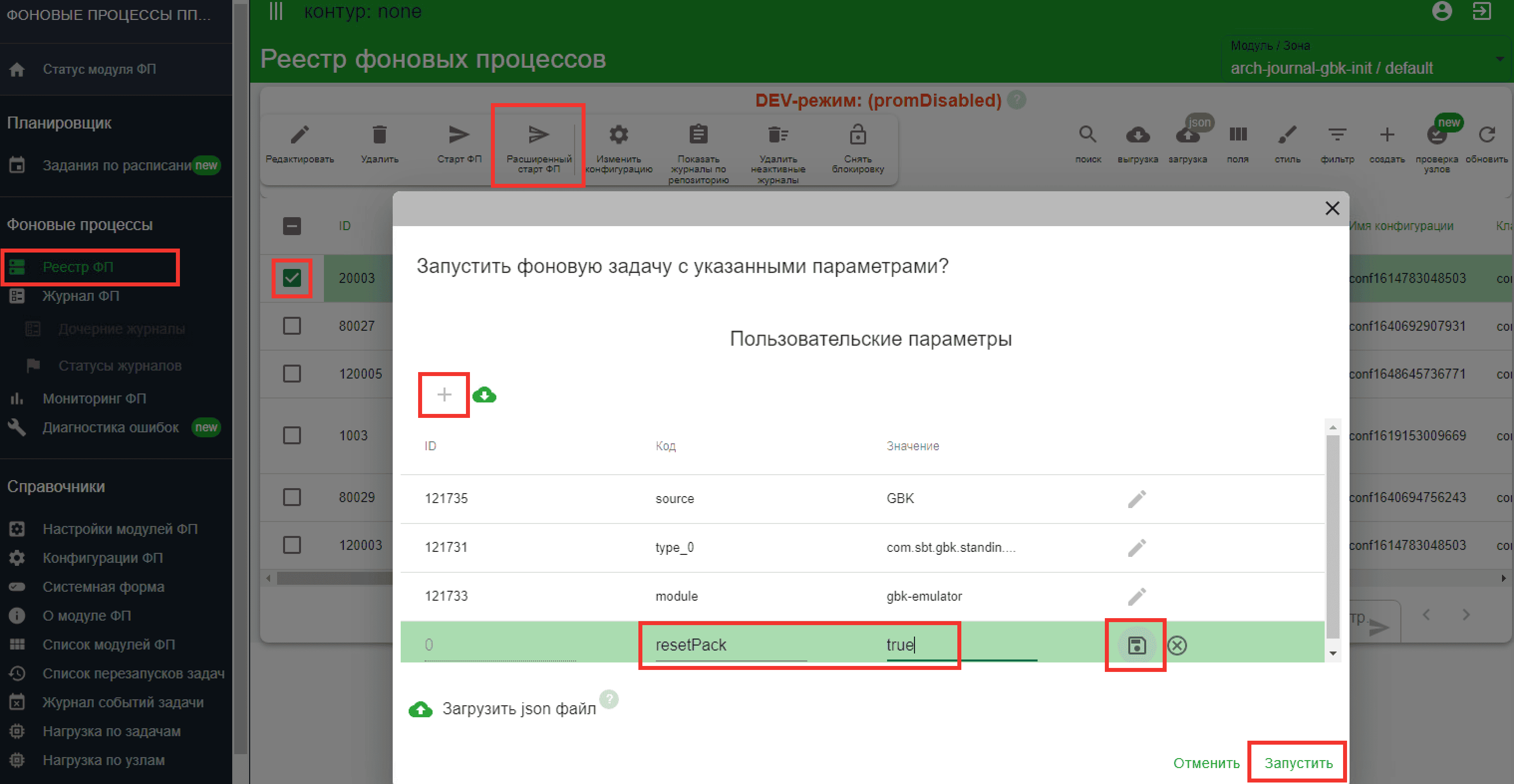
В случае прерывания Init по причине перехода в Stand-In возможность продолжения на Stand-In контуре определяется тем, поддерживает ли источник в Stand-In модули, реализующие API Init. Если не поддерживает, то продолжение возможно только после возвращения в NORMAL.
Диагностика ошибок при запуске#
Правила работы с ошибками#
Если системное состояние журнала в колонке -
ERROR, выберите журнал и нажмите на кнопку Просмотр журнала для выяснения причины ошибки. Примеры: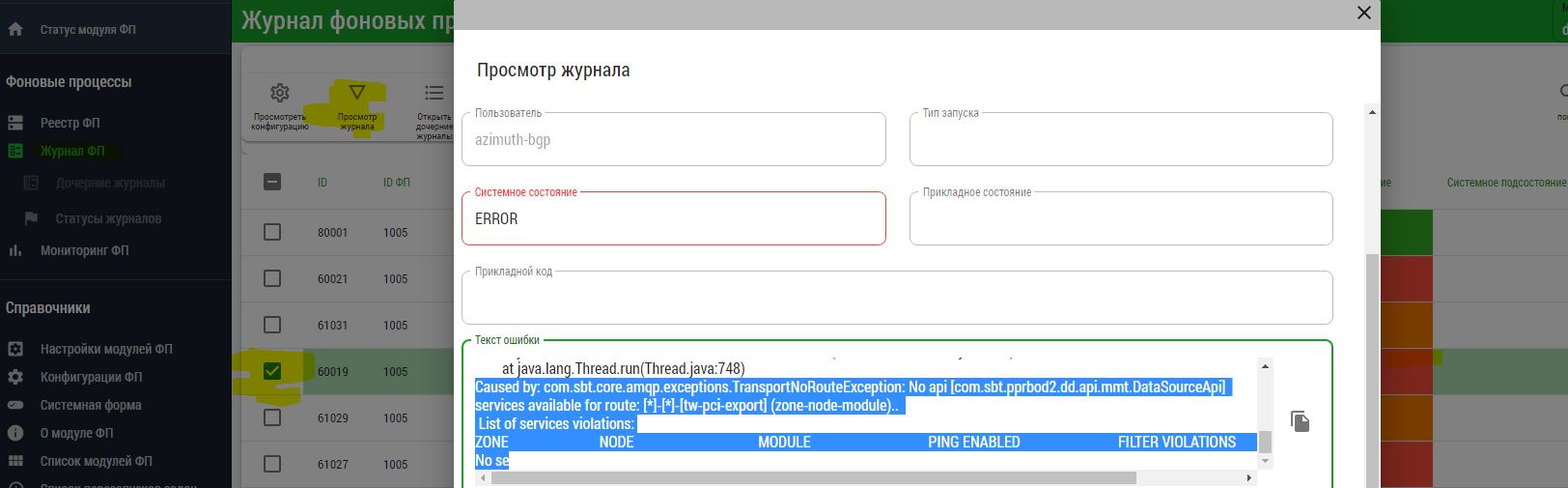
В данном примере
TransportNoRouteExceptionскорее всего говорит о том, что в зоне ММТ нет модуля источника, реализующего API для получения количества партиций и загрузки самих партиций.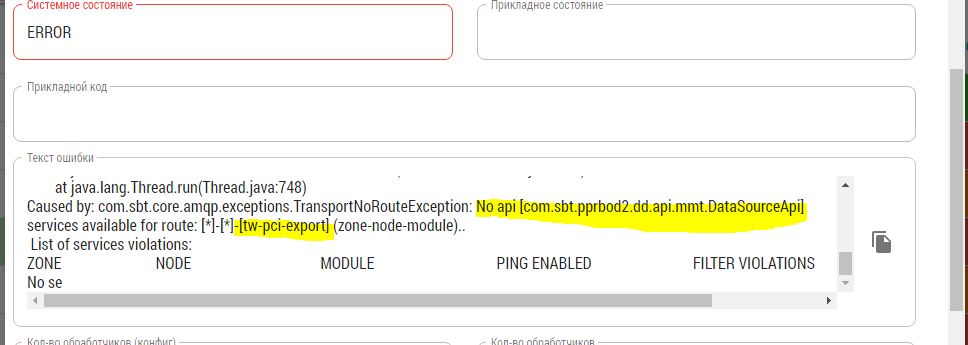
Причиной ошибки ниже скорее всего является недоступность модуля с исполняющей задачей (адаптер на стороне Archiving) в зоне ММТ. Для решения необходимо проверить, работает ли на стенде соответствующий модуль.
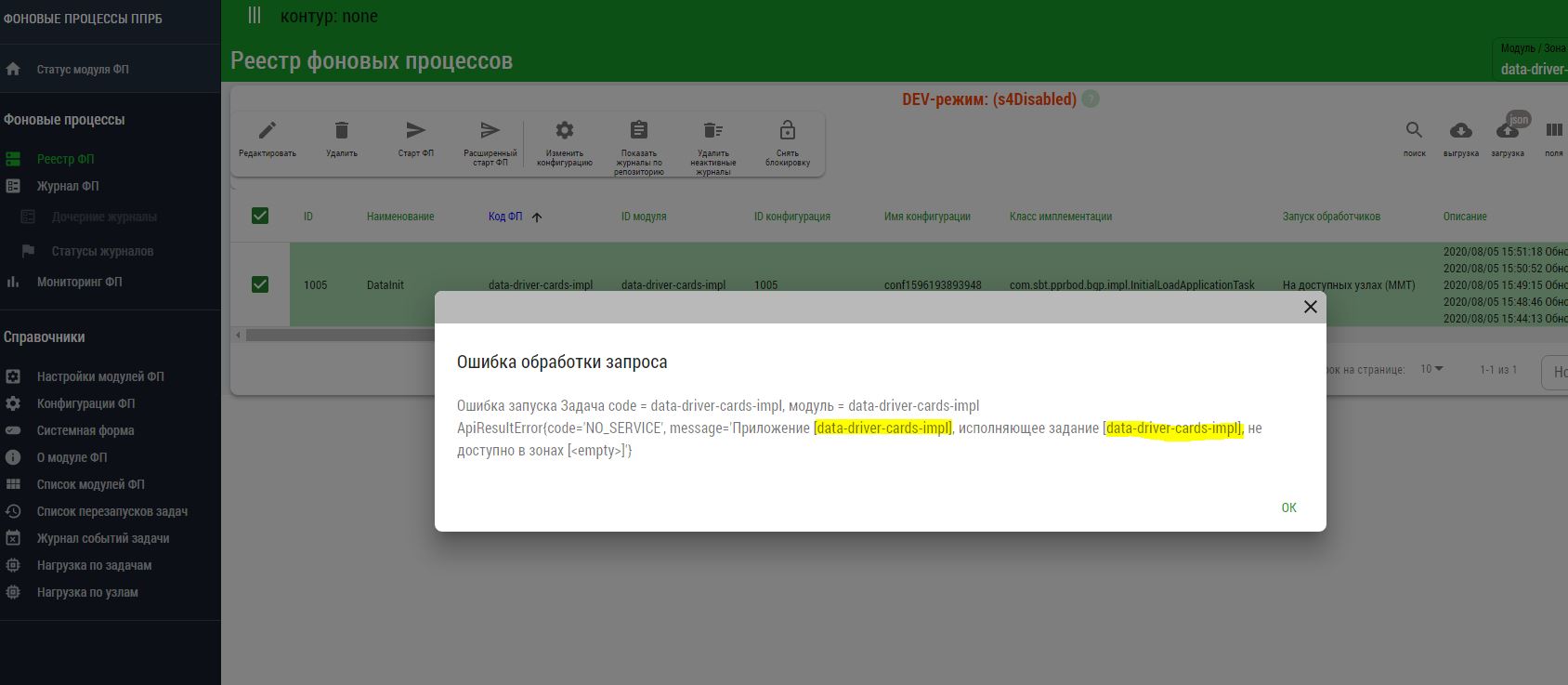
Если во время запуска задачи появляется сообщение вида:
java.lang.IllegalStateException: Не удалось авторизоваться при запуске задачи[id=2001]: Проверьте наличие ТУЗ(data-driver-cards-impl_bgpTech) в подсистеме доступа.обратитесь к администратору или поддержке. Данная ошибка может означать, что со стороны Archiving не заведен технический пользователь в SPAS:
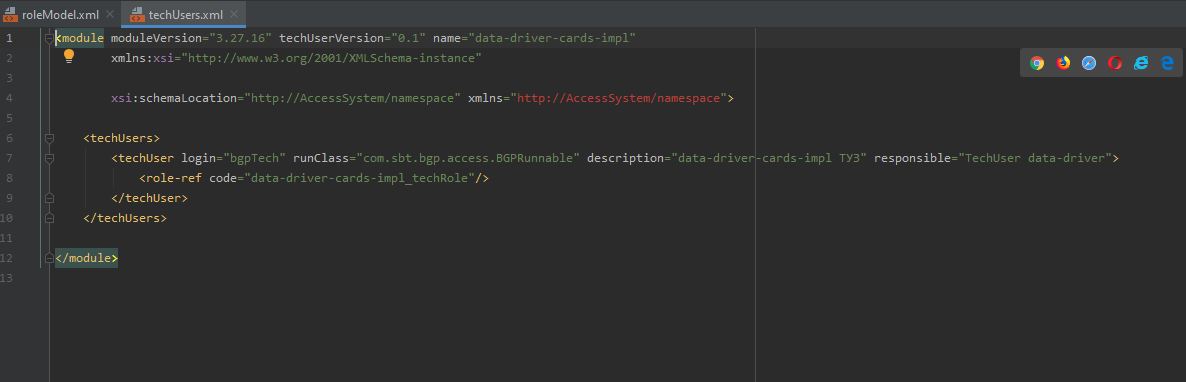
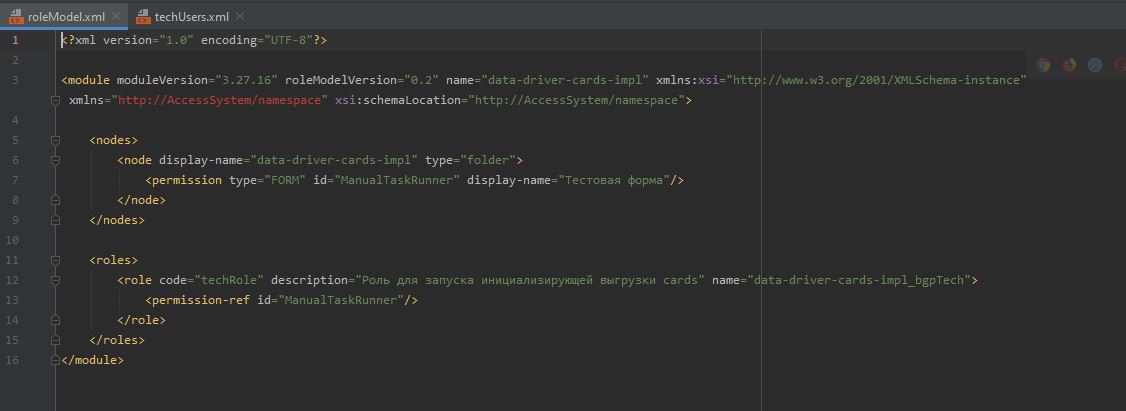
с ролью:
Состояние ниже говорит о том, что источник по типу вернул 0 партиций, и по ним задача формально отработала успешно:

Ситуация ниже выявлена в логах на одном из источников и говорит о том, что передаваемая по ММТ партиция не прошла по ограничению размера сообщения в ММТ. Логи ошибки:
17:07:50.719 [ERROR] [com.sbt.core.transport.messaging.sender.KafkaBrokerMessageSender] [bgp-worker-executor41] - Error while sending message. messageKey: [TransportMessageKey(version=14.6.2, transportType=KAFKA, messageDirection=SERVER_MESSAGE_CHANNEL, destinationNodeId=cdm81kbift, destinationModuleId=arch-journal-cdm, publicApi=com.sbt.pprbod.dd.api.mmt.DataDriverApi, apiMethod=loadData, methodCallType=ASYNC, correlationId=e25eeabb-89a6-4716-a1ef-bb0eb54672cd, sourceNodeId=wf_tkli-pprb4210, sourceModuleId=mega-bas, login=mega-bas_bgpTech, ticket=mega-bas_bgpTech#246b2307985dc1cf6e8bee8e2d88b09133683452860276274885, sourceZoneId=Z_CM_1, destinationZoneId=default, sourceSystemId=null, messageType=RPC_REQUEST)], destination: [default-out]. Exception: The message is 6450008 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.. mega-bas_2020-08-14_29.log:org.apache.kafka.common.errors.RecordTooLargeException: The message is 6450008 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.
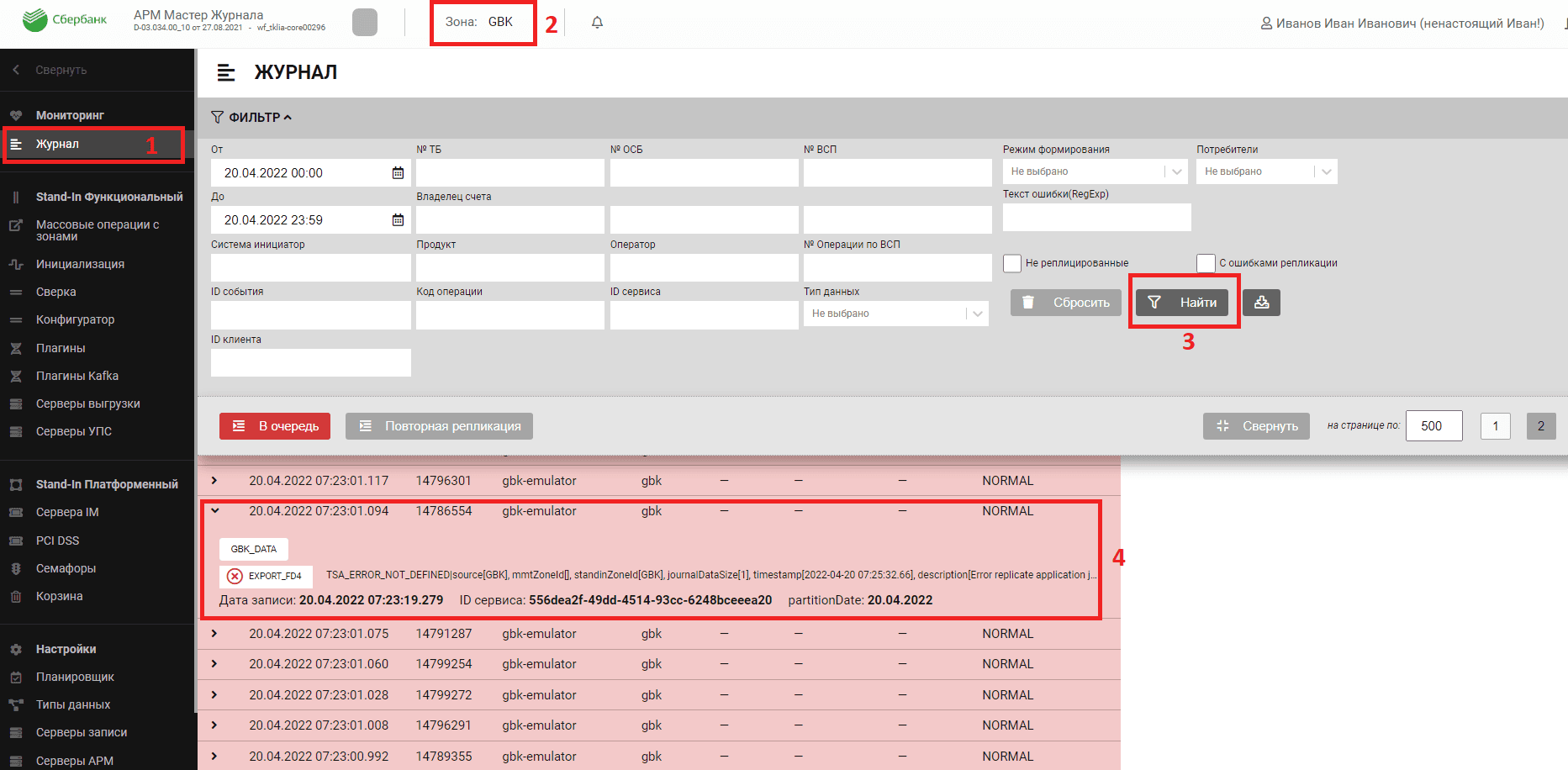
Работа с сервисом Прикладной Журнал#
Настройка плагинов Kafka#
За интеграцию компонента «Прикладной журнал Platform V Data Tools» и Platform V Archiving отвечает плагин EXPORT_FD4. Данный плагин интегрирован с Archiving посредством Kafka. Плагины настраиваются для каждой зоны ПЖ и типа данных.
Начало работы с Прикладным журналом — смотрите документацию на компонент «Прикладной журнал Platform V Data Tools», документ «Руководство по системному администрированию», раздел «Доступ к приложению».
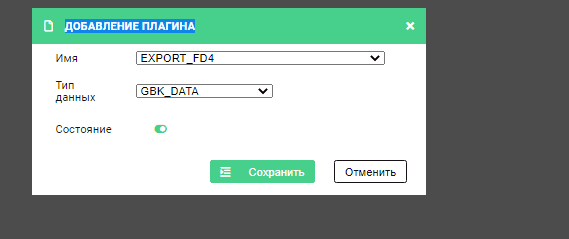
Пример настройки выгрузки в Archiving типа данных GBK_DATA в зоне GBK:
В верхней панели АРМ Прикладного Журнала выберите зону (в примере — GBK).
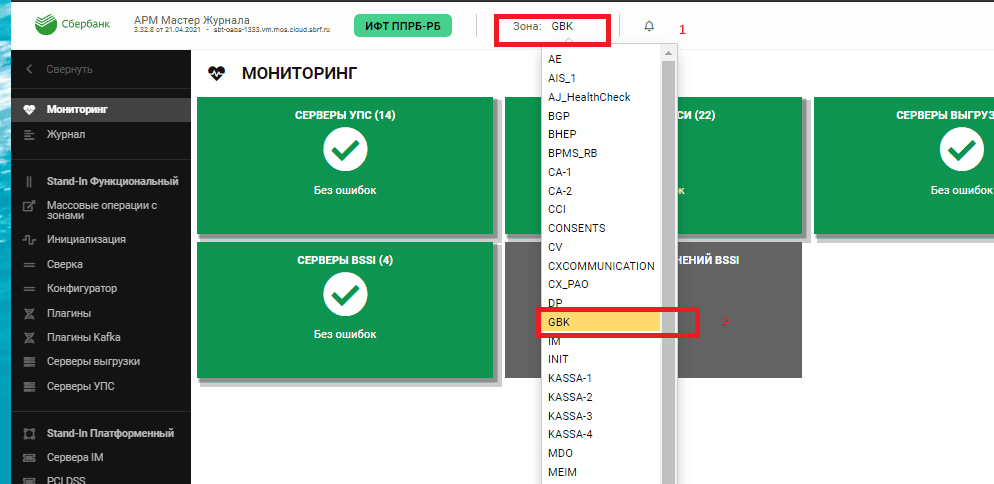
После выбора зоны в меню перейдите на вкладку Плагины Kafka и нажите Добавить плагин.
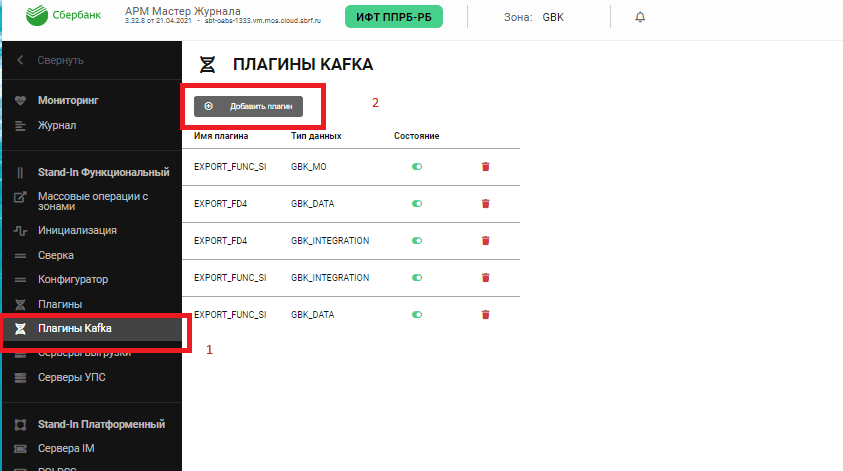
В появившемся окне выберите плагин EXPORT_FD4, тип данных (в примере — GBK_DATA), состояние - включен (зеленый переключатель) и нажмите Сохранить.
Перезагрузите АРМ и Writer Прикладного Журнала, чтобы создались необходимые топики и началась выгрузка.
Отправка журналов в очередь#
Кнопка В Очередь предназначена для отправки Журналов, не реплицированных из-за ошибки. Отправка журналов в очередь решает проблему репликации, если ее не было по следующим основным причинам:
Транспортная система в какой-то момент времени не доступна. Тогда функция отправки в очередь заново отправит журнал на репликацию и если транспортная система доступна, репликация будет успешна.
Недоступность принимающего модуля. Если доступность модуля восстановлена, то при отправке журналов в очередь репликация будет успешна.
Ошибка связана с некорректностью работы принимающего модуля. В таком случае необходимо исправить ошибку модуля, затем выполнить отправку журнала в очередь.
Для отправки не реплицированных журналов в очередь необходимо заполнить соответствующие фильтры для выбора конкретных Журналов.
Если не выбраны конкретные Журналы, то на репликацию будут отправлены все нереплицированные записи, которые отображены в списке журналов.
Последовательность действий:
До отправки в очередь устраните причину ошибки, чтобы репликация стала возможна.
Выберите Журнал(ы), которые не реплицированы из-за ошибки, заполнив необходимые поля фильтрации.
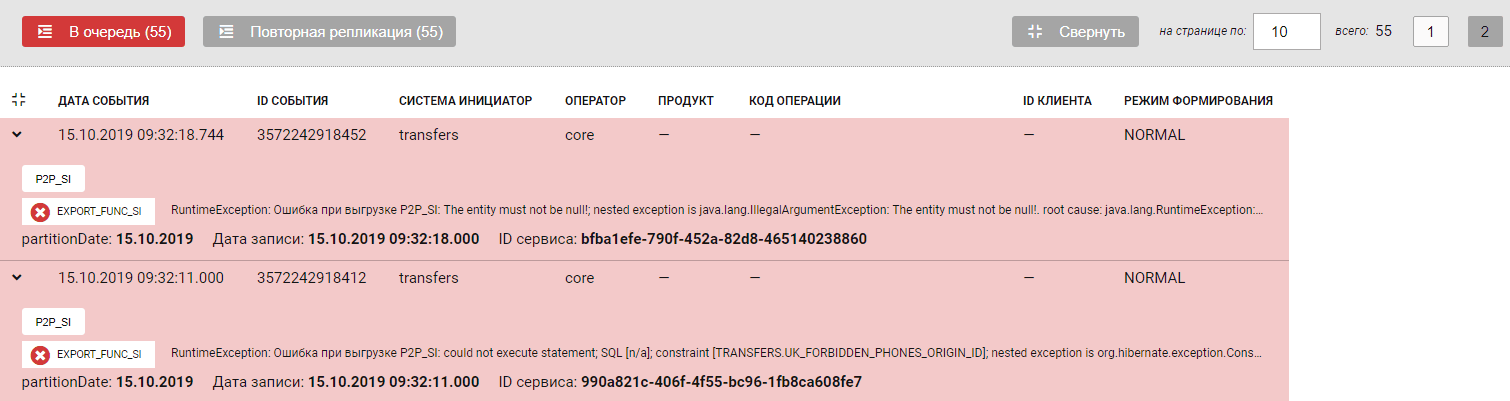
Нажмите В Очередь.
Нажмите Да, чтобы подтвердить действие.

Выполните поиск журналов повторно, с установленной галочкой С ошибками репликации.
Репликация записи успешна. Запись окрасилась в оранжевый цвет. При раскрытии информации о журнале отображена ошибка, из-за которой предыдущие попытки репликации были завершены неуспешно.

Отправка журналов на Повторную репликацию#
Кнопка Повторная репликация предназначена для того, чтобы отправить все выбранные по фильтру записи на повторную репликацию независимо от статуса.
Внимание!
На повторную репликацию будут отправлены все записи журнала (нереплицированные, реплицированные с ошибкой, реплицированные без ошибок). Поэтому следует выполнить фильтрацию Журналов таким образом, чтобы на повторную репликацию были отправлены только нужные записи, а не все записи из таблицы с Журналами.
Выберите Журнал(ы), которые необходимо отправить на повторную репликацию, заполнив необходимые поля фильтрации.
Нажмите Повторная репликация.
Нажмите Да, чтобы подтвердить действие.

Анализ сообщений об ошибках в ПЖ#
Алгоритм действий по анализу ошибок векторов репликации следующий:
Заходим в ПЖ и смотрим векторы изменения
Выберите требуемый журнал.
Выберите зону и источник.
Отфильтруйте данные для просмотра векторов. Векторы, отмеченные красным, сигнализируют об ошибке.
Кликните на вектор, чтобы увидеть подробности по ошибке.
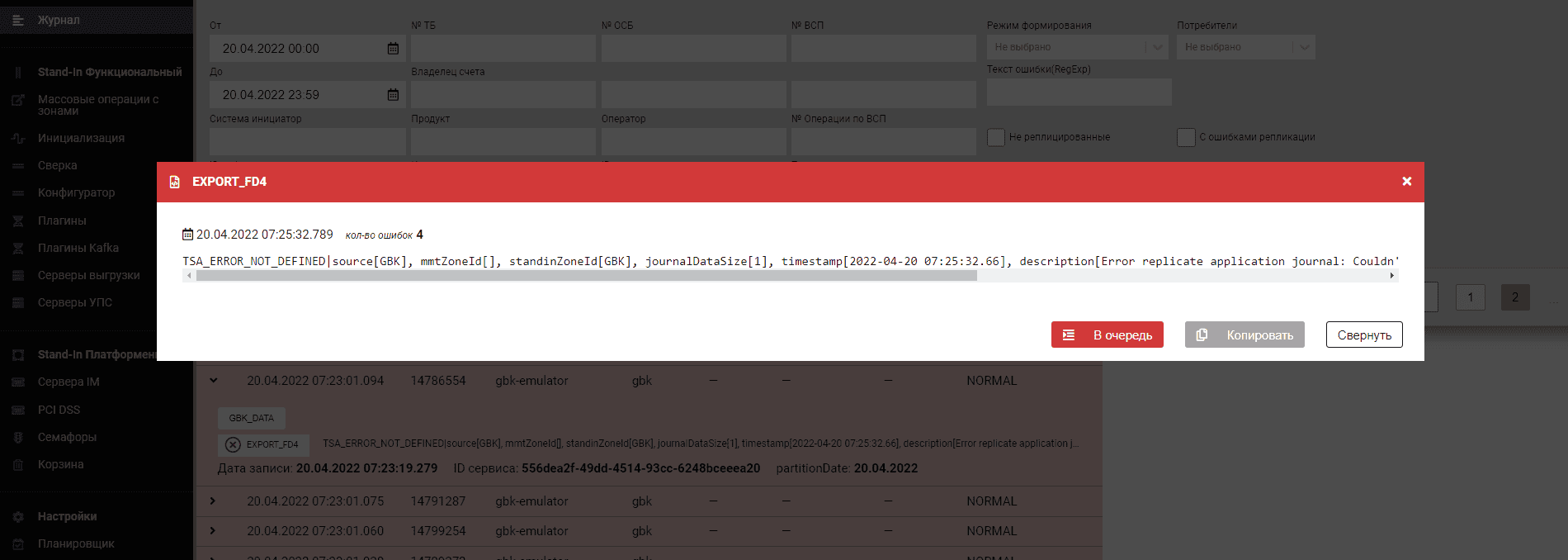
Содержимое сообщения описывает произошедшую ошибку.
В случае обнаружения ошибки репликации векторов в ПЖ, имеет смысл задать режим расширенного логирования для конкретных модулей и перезапустить репликацию пачки векторов. Также можно дождаться следующего ошибочного вектора (при стабильно появляющейся ошибке) и проанализировать его результаты.
Ошибки со стороны Archiving#
*TSA_ERROR_SEND — возникает только при приеме векторов. Это ошибка работы с Kafka (например, не запустился Kafka-продюсер). Рекомендуется перезапустить модули и провести диагностику Kafka. Обычно ошибка является массовой.
TSA_ERROR_SERIALIZATION — рекомендуется проверить модель (возможно, в Archiving присутствует внутренняя ошибка либо модель данных, которую использует источник, неактуальна).
TSA_ERROR_NOT_DEFINED — все остальные ошибки. Рекомендуется проанализировать логи для модуля pprbod-stream-processor.
Общий формат сообщения об ошибках:
Код |
Формат описания |
Описание ошибки |
|---|---|---|
|
`TSA_ERROR_SEND |
source[%s], mmtZoneId[%s], standinZoneId[%s], journalDataSize[%s], timestamp[%s], description[%s]` |
|
`TSA_ERROR_SERIALIZATION |
source[%s], mmtZoneId[%s], standinZoneId[%s], journalDataSize[%s], timestamp[%s], description[%s]` |
|
`TSA_ERROR_NOT_DEFINED |
source[%s], mmtZoneId[%s], standinZoneId[%s], journalDataSize[%s], timestamp[%s], description[%s]` |
Нотация параметров:
source— мнемоника источника;mmtZoneId— зона топологии, в которой возникла ошибка (ММТ или транспортной Kafka);Stand-InZoneId— зона ПЖ, в которой проходил обрабатываемый вектор;journalDataSize— размер журнала (Байт);timestamp— время возникновения ошибки;description— описание ошибки. В случае исключения параметр записывается исключение без stack trace.
Примечание:
Параметры могут отсутствовать или быть недоступны в точке возникновения ошибки - в таком случае они заполняются значением
[ ].Параметры могут иметь значение
null— в таком случае они заполняются как["null"].
Ошибки со стороны КАП#
Ошибки, вызванные невозможностью применить data-container на стороне КАП и возвращаемые в ответе коммита КАП в топик коммитов.
Общий формат: строка, первая часть (до вертикальной черты) — код ошибки, вторая — информационные параметры. В ПЖ будет отображена точно в переданном виде.
Название |
Код |
Формат описания |
Описание ошибки |
|---|---|---|---|
Ошибка нарушения последовательности операций |
|
`ERROR_WRONG_OPERATION_SEQUENCE |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s]` |
Неверная версия |
|
`ERROR_WRONG_VERSION |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s]` |
Неверный формат |
|
`ERROR_CONTAINER_DATA |
type[%s], key[%s], operation[%s], version[%s], hversion[%s], timestamp[%s], description[%s]` |
Нотация параметров:
type— передаваемый Archiving тип;key— передаваемый в контейнере ключ;operation— тип операции из контейнера;version— версия из контейнера;hversion— версия HBase;timestamp— время возникновения ошибки;description— описание ошибки (только для ситуации неверного формата). В случае исключения параметр записывается исключение без stack trace.
Примечание:
Параметры могут отсутствовать или быть недоступны в точке возникновения ошибки - в таком случае они заполняются значением
[ ].Параметры могут иметь значение
null— в таком случае они заполняются как["null"].
Пример разбора ошибки#
Получено сообщение:
ERROR_CONTAINER_DATA|type[com.sbt.bm.ucp.consents.model.dictionary.UcpConsentOperatorType], key[UcpConsentOperatorType_432.1653997258660], operation[null], version[0], hversion[], timestamp[2022-05-31 14:41:31.141], description[Part of the data is absent.].Согласно мнемонике, это ошибка со стороны КАП (смотрите таблицу выше) - неверный формат. Далее необходимо проанализировать сообщение по полям (названия полей смотрите в таблице выше).
Итоговое сообщение об ошибке:
description[Part of the data is absent.].
Режимы работы загрузчика в КАП#
Основные режимы работы загрузчика КАП#
Основные режимы работы загрузчика КАП:
Default (устаревшее, используется для обратной совместимости до версии Archiving 3) — при такой конфигурации online ТКД не работает. Если пришел объект, версия которого ниже, чем в Hbase, объект игнорируется (не сохраняется в Hbase, не возникает инцидент. Верно для любого режима), происходит переход к сверке следующего объекта. Сверка версий происходит в версии writer с online ТКД.
Online ТКД (без полноты) — версии объекта анализируются и, в зависимости от сценария, объект либо сохраняется в Hbase в случае успеха, либо в специальный топик ТКД на стороне Archiving отправляется запрос полной версии объекта. В случае аварийного сценария прием данных контейнером, в котором возник данный сценарий, приостанавливается до момента получения ответа на аварийный запрос из Archiving.
Retry (waitcommit) (с полнотой) — writer не запрашивает ТКД синхронно, а вместо этого помечает сообщение в технологической таблице как «поломанное» и ожидающее retry, откатывает изменения по нему, отправляет сообщение в топик retry и продолжает работать. Если через 15 минут не будет получен правильный вектор, загрузчик прекращает работу.
Примечание:
DataSpace работает только в режиме Retry, остальные источники могут использовать и другие режимы:
DataSpace writer сверяет версию дочернего объекта с текущей версией агрегата.
DataSpace writer всегда обновляет версию агрегата, даже если самого корневого объекта не было в контейнере.
DataSpace writer не запрашивает ТКД синхронно, а вместо этого помечает сообщение как «поломанное», откатывает изменения по нему, отправляет сообщение в топик retry и продолжает работать.
Параметры работы загрузчика КАП:
Strict/ Non-Strict — используется только в ТКД и только для источников, которые не хранят версию. Strict означает, что приходящий вектор изменений должен иметь версию «+1» к текущей. Strict неприменимо к источникам, использующим любые не монотонно растущие последовательности в качестве версии.
Полнота (waitcommit) может быть включена для любого writer, это обычная отправка коммитов. Требуется согласованное включение как для КАП, так и для источника, и возможно не для всех источников.
Online ТКД используется вне зависимости от того, какой формат версии используется источником. Пропуск версии важен только для Дельты (Векторов изменений).
Типы векторов изменений:
Дельта-сообщение — изменение некоторых полей в источнике. В определенном поле указан список измененных полей.
Снепшоты — полное состояние объекта. Для них список значений полей (значение поля) будет
NULL.
КАП по этому полю распознает тип вектора.
Поле тип операции может быть нулевым (NULL). В этом случае, если тип операции NULL, КАП трактует операцию как INSERT. Это работает в случае полного состояния объекта - все поля со всеми ограничениями, требуемые для операции INSERT.
Типы источников, с которыми работает Archiving:
Источники, которые отправляют как Дельта-сообщения, так и снепшоты, Для источников, отправляющих Дельта-сообщения, может использоваться только режим Strict.
Источники, которые всегда отправляют снепшоты. Такие источники не передают список полей для обновления. В этом случае может использоваться режим Non-Strict для загрузчика.
Снепшот — это полный элемент. В этом случае для любой системы в любом режиме нет проблемы с пропуском версий или снепшотом с версией ниже текущей: ошибка в Archiving или ПЖ не отправляется. Если версия ниже текущей, сообщение об ошибке записывается в лог КАП, и сообщение игнорируется.
Переиспользование ID означает ошибки на источнике.
В случае включенной полноты пустые транспортные контейнеры не отбрасываются. В них отправляются служебные пакеты. Загрузчик также должен работать в режиме включенной полноты. Загрузчики в случае не включенной полноты отбрасывают пустые контейнеры. В этом случае в КАП ничего не отправляется, вектор изменений отображается желтым (Warning).
Реакция КАП в зависимости от приходящего события и состояния объекта в КАП#
Вектор изменений#
Комментарии по таблице:
Insert— операция добавления объекта в КАП;Update— операция обновления объекта в КАП;Delete— операция удаления объекта из КАП;пересечение столбцов — выполняемая операция:
Apply— применение операции;Ignore— игнорирование операции;Error— генерирование ошибки выполнения операции.
Insert |
Update |
Delete |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Отношение номера версии текущего и пришедшего вектора |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
Объект, по которому пришло событие, не существует в КАП |
Apply |
Apply |
Apply |
Apply |
Error |
Error |
Error |
Error |
Error |
Error |
Error |
Error |
Объект, по которому пришло событие, существует в КАП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Apply |
Error |
Ignore |
Apply |
Apply |
Error |
Объект, по которому пришло событие, удален из КАП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Error |
Error |
Ignore |
Ignore |
Error |
Error |
Cнапшот#
Комментарии по таблице:
Insert— операция добавления объекта в КАП;Update— операция обновления объекта в КАП;Delete— операция удаления объекта из КАП;пересечение столбцов — выполняемая операция:
Apply— применение операции;Ignore— игнорирование операции;Error— генерирование ошибки выполнения операции.
Insert |
Update |
Delete |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Отношение номера версии текущего и пришедшего вектора |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
< |
= |
+1 |
>+1 |
Объект, по которому пришло событие, не существует в КАП |
Apply |
Apply |
Apply |
Apply |
? |
? |
? |
? |
Error |
Error |
Error |
Error |
Объект, по которому пришло событие, существует в КАП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Apply |
Apply |
Error |
Объект, по которому пришло событие, удален из КАП |
Ignore |
Ignore |
Apply |
Apply |
Ignore |
Ignore |
Error |
Error |
Ignore |
Ignore |
Error |
Error |
Оптимизация параметров тракта#
Настройка производительности возможна по каждому из направлений работы Archiving (Init, Поток, ТКД), Все три направления будут рассмотрены по отдельности.
Настройка брокеров и продюсеров Kafka#
Для осуществления семантики чтения at-least-once и избежания потери данных и, как следствие, некорректной работы Archiving рекомендуются следующие настройки продюсеров и брокеров Kafka.
Настройка продюсеров#
retries = 10– количество повторов попыток отправки сообщения;retry.backoff.ms = 100– задержка между ретраями;acks = all– все синхронизированные брокеры должны ответить, что сообщение получено;enable.idempotence=true– включение идемпотентности;
Настройка брокеров#
replication = N, гдеN=Количество брокеров - 1;min.insync.replicas = M, гдеM=N - 1, ноM> 1. Минимальное количество синхронизированных брокеров. Должно быть меньше общего количества реплик.
Инициализирующая выгрузка (Init)#
Важные параметры конфигурации:
Размер пакета — количество партиций, который обрабатывает Worker за одну итерацию. Не рекомендуется увеличивать, так как вместе с этим увеличивается время, которое требуется обработчику для отправки в BGP статистики о количестве обработанных партиций. Партиции обрабатываются последовательно, при этом размер отдельного объекта влияния не оказывает.
Количество обработчиков — в среднем сервер Archiving нормально работает с 4 потоками BGP. Исходя из этого, количество обработчиков можно установить равным 4 * [количество стендов]. Параметр можно увеличивать, но кратно количеству серверов, чтобы нагрузка распределялась равномерно, так как Обработчики распределяются по стендам равномерно. Рабочий диапазон значений параметра: минимум (*2 узлов), максимум (*12 узлов). Без дополнительной настройки BGP установить выше 10 потоков на узел невозможно.
rawBatchSize — количество дата-контейнеров, которое Archiving упаковывает в один контейнер необработанных данных. Чем больше — тем выше скорость. Например, если параметр равен 10 (по умолчанию), тогда из 3000 дата контейнеров, полученных в партиции, в топик необработанных данных будет отправлено 300 raw контейнеров. Далее каждый raw-контейнер вычитывается одним из КТС, откуда объекты извлекаются и десериализуются, фильтруются по белому списку и отправляются в КАП. Ограничение параметра — только максимальный размер сообщения в топике Kafka (в текущей версии 16 МБ). Следовательно, [максимальный размер rawBatchSize] = 16 МБ / [максимальный вес вашего DataContainer]. Имеет смысл увеличивать до 100…500, особенно для мелких объектов.
partitionsThreshold (доступен с версии 4.4.11) — параметр позволяет регулировать максимальное время ожидания Archiving пакетов данных по партиции источника. Значение по умолчанию — 5 минут, однако из-за размера партиции возможная неполная ее передач за указанное время. Размер партиции можно увеличить на стороне источника, параллельно увеличив время ожидания партиции на Archiving.
Партиционирование топиков#
Рекомендуемые параметры:
количество партиций в топике данных = числу узлов
(pprbod-source-provider-v4@kafka.topics.data.partitions);количество партиций в топике Init = числу узлов (
pprbod-source-provider-v4@kafka.topics.init.partitions)количество партиций в топике необработанных данных _raw = число узлов х*7 (
pprbod-source-provider-v4@kafka.topics.raw.partitions);количество партиций в системных топиках _eventbus = числу узлов (
pprbod-source-provider-v4@kafka.topics.eventbus.partitions);фактор репликации на все топики не более 2 (рекомендованное значение - 1, в этом случае производительность будет максимальной) (
pprbod-source-provider-v4@kafka.topics.*.replication=1).
Параметры фоновой задачи#
размер пакета = 1;
количество обработчиков: минимум (*2 узлов), максимум (*12 узлов);
таймаут обработчика = 1200 сек;
rawBatchSize = 500;
Поток (обработка векторов изменений от источника в КАП через ПЖ)#
Производительность настраивается партицированием топиков. Настройки те же, что и для раздела «Инициализирующая выгрузка (Init)». Другие параметры на производительность не влияют.
ТКД и DRP#
Топик ответов на запросы offline-ТКД и топик ответов восстановления данных (DRP) также может быть партицирован. Партиционирование используется при больших репликах данных. Партиционирование топиков требует согласования с КАП.
Партиционирование топиков#
Рекомендуемые параметры:
количество партиций топика offline ТКД = количество узлов Archiving в решении (
pprbod-source-provider-v4@kafka.topics.offdq.partitions);количество партиций топика ответов offline ТКД = количество узлов Archiving в решении (
pprbod-source-provider-v4@kafka.topics.offdqresponse.partitions);количество партиций топика ТКД = количество узлов Archiving в решении (
pprbod-source-provider-v4@kafka.topics.dq.partitions);количество партиций топика ответов ТКД = количество узлов Archiving в решении (
pprbod-source-provider-v4@kafka.topics.dqresponse.partitions);количество партиций топика ошибок = 1 (всегда) (
pprbod-source-provider-v4@kafka.topics.error.partitions);количество партиций в системных топиках _eventbus = числу узлов (
pprbod-source-provider-v4@kafka.topics.eventbus.partitions).
Масштабирование сервиса#
Archiving является горизонтально масштабируемым сервисом, то есть для увеличения или уменьшения пропускной способности можно изменять число серверов, на которых установлены компоненты сервиса. При администрировании Archiving может быть реализован сценарий, при выполнении которого необходимо увеличить или уменьшить количество узлов, на которых установлен сервис.
В архитектуре Archiving предусмотрена возможность работы сервиса с различным количеством узлов для увеличения или уменьшения предельного объема обрабатываемых данных в единицу времени в зависимости от потребностей. Минимальное допустимое количество узлов - 1. При первоначальной настройке сервиса (подробнее см. Руководство по установке) производится конфигурация определенных параметров Archiving в зависимости от того, сколько узлов предполагается использовать. В случае изменения этого количества, необходимо изменение значений тех же параметров.
Добавление нового узла#
Добавление нового узла выполняется для каждого нового узла (первый узел формируется в процессе первичной установки).
Для ввода в решение нового узла Archiving:
Скопируйте сертификаты Kafka, выпущенные в рамках раздела «Создание клиентских сертификатов, выдача прав» Руководства по установке, на новый узел. Адрес каталога, где будут размещены сертификаты, должен совпадать с адресами каталогов на уже присутствующих узлах Archiving.
Скопируйте сертификаты Ignite, выпущенные в рамках пункта «Выпуск сертификата Archiving для Ignite SE 4.2100.6» Руководства по установке. Адрес каталога, где будут размещены сертификаты, должен совпадать с адресами каталогов на уже присутствующих узлах Archiving.
Скопируйте сертификаты ОТТ для всех модулей Archiving, которые были выпущены в рамках пункта «Подключение Archiving к ОТТ» Руковоства по установке. Адрес каталога, где будут размещены сертификаты, должен совпадать с адресами каталогов на уже присутствующих узлах Archiving.
Установите компоненты согласно параграфу «Установка модулей на WildFly» Руководства по установке.
Обновление конфигурации решения#
Изменение максимального количества подключений к БД Archiving#
БД Archiving имеет фиксированный пул подключений. Каждый новый узел требует дополнительного места для подключения.
Рассчитайте требуемый размер пула по формуле:
[количество серверов Archiving в решении] * jdbc.maxPoolSize + 10, где значение
jdbc.maxPoolSize— параметр Platform V Configuration в артефакте pprbod-source-provider-v4 (по умолчанию 5). Число 10 добавляется в случае необходимости дополнительных подключений.Рассчитанный размер пула установите в соответствии с новым количеством серверов Archiving.
Конфигурация Archiving в Platform V Configuration#
В конфигурации Archiving присутствуют параметры, которые считываются в зависимости от количества узлов сервиса на полигоне. Их необходимо изменить в соответствии с инструкцией ниже:
pprbod-source-provider-v4
Параметр
Назначение
Формула расчета
kafka.topics.dq.partitionsколичество узлов на полигоне
<количество партиций топика ТКД> (<рекомендованное значение> — <количество узлов ТСА на полигоне)>
kafka.topics.offdq.partitionsколичество узлов на полигоне
<количество партиций топика оффлайн ТКД> (<рекомендованное значение)> - <количество узлов ТСА на полигоне>)
kafka.topics.raw.partitionsколичество узлов на полигоне
<количество партиций топика сырых данных> (<рекомендованное значение> — <количество узлов ТСА>)
kafka.topics.eventbus.partitionsколичество узлов на полигоне
<количество партиций системных топиков> (<рекомендованное значение> — <количество узлов ТСА>)
kafka.topics.batch.replicationколичество узлов на полигоне
<количество партиций батч топика> (<рекомендованное значение> — <количество узлов ТСА>)
pprbod-grid-lib-v4
Параметр
Назначение
Значение
addresses(массив)список discovery-адресов (все узлы, где установлено ТСА)
Elementадрес старого узла
<IP-адрес>:<порт>Elementдобавление нового узла
<IP-адрес>:<порт>
Топики в интеграционной Kafka Archiving
Несмотря на изменение параметров Archiving в Platform V Configuration, топики в интеграционной Kafka Archiving автоматически не обновят свои конфигурации. Необходимо создать их заново вручную.
Системные топики (используемые только Archiving)
Наименование топика |
Количество партиций |
Фактор репликации |
|---|---|---|
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
|
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
Топики интеграции с КАП (изменения необходимы по каждому источнику данных на полигоне):
Наименование топика |
Количество партиций |
Фактор репликации |
|---|---|---|
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
|
По количеству узлов ТСА |
По количеству брокеров Kafka |
Время хранения данных в каждом из топиков зависит от требований решения. Можно ориентироваться на те значения, которые были установлены на топиках до пересоздания.
Внимание!
После пересоздания топиков необходимо перезагрузить Archiving и загрузчики КАП, отвечающие за поток ТКД и DRP.
Отказоустойчивость (поддержка платформенного Stand-In)#
Режимы работы и принцип переключения#
Archiving обеспечивает бесшовную работу прикладных фабрик при переходе между платформенными контурами Normal (основной) и Stand-In (резерв). Archiving использует шину Kafka на общем для Normal и Stand-In контуров кластере. Режим работы Archiving 4 после интеграции с семафорами ПЖ исключает одновременную работу консюмеров на основном и Stand-In-контурах.
Технически работа контура в Stand-In или Normal по своей логике ничем не отличается. Принципиально важно следующее: в момент времени активным может быть только один контур — Staind-In или Normal.
Режимы работы Archiving4 после интеграции с семафорами ПЖ:
Контур активен, работает в стационарном режиме обрабатывает все векторы и контейнеры: поток, Init, online/offline ТКД и DRP.
Контур неактивен, векторы и контейнеры не обрабатываются.
Переключение режимов контуров:
Переход контура из активного состояния в неактивное (переход с Normal на Stand-In или с Stand-In на Normal) занимает около 40 секунд. При данном переходе последние вычитанные сообщения дообрабатываются и происходит остановка обработки данных.
Особенности работы в зависимости от типа взаимодействия Archiving и ПФ:
Init (первоначальная выгрузка данных) — Фоновые Процессы запущенные по текущему активному контуру завершатся ошибкой.
Поток (обработка векторов изменений) — все взятые в обработку векторы будут обработаны. Происходит остановка обработки потока в Archiving 4. Векторы, которые не успели обработаться, и остались на стороне Archiving 4 и векторы, которые могли скопиться в ПЖ , при активации другого контура будут обработаны уже им.
online ТКД — все взятые в обработку сообщения будут обработаны, далее происходит остановка обработки online dq.
offline ТКД и DRP — все взятые в обработку контейнеры с ключами будут обработаны. По ключам, по которым обработка прошла с ошибкой или которые еще не были обработаны, будет отправлена информация в топик ошибок с соответствующим статусом. Далее происходит остановка обработки offline ткд и DRP, происходит закрытие сессии.
Переход контура из неактивного состояния в активное (переход с Normal на Stand-In или с Stand-In на Normal) занимает порядка 40 секунд. При таком переходе происходит активация обработки данных.
Данные (векторы и контейнеры) которые не были обработаны предыдущим контуром дообрабатываются текущим активным контуром с момента обработки последнего сообщения предыдущим контуром.
Типы взаимодействия Archiving и ПФ :
Init (первоначальная выгрузка данных) — Фоновые Процессы, которые завершились ошибкой, нужно перезапустить. Если ФД поддерживает отправку с заданной партиции можно запустить ФП с номером партиции, который нужно продолжить ФП.
Поток (обработка векторов изменений) — векторы, которые не успели обработаться предыдущим контуром, дообрабатываются. Происходит подписка на чтение журналов по зонам ПЖ, идет обработка всех скопившихся журналов.
Online ТКД — обработка ключей с момента обработки последнего сообщения предыдущим контуром если такие имеются.
Jffline ТКД и DRP — обработка контейнеров с ключами, которые не обработал предыдущий контур.
Варианты администрирования#
При работающем потоке#
Включен online-поток на контуре Normal. Если контур переходит в SI, то все накопленные векторы обработаются автоматически в контуре SI, никакие действия предпринимать не нужно.
При нахождении в Staind-In и переходе в Normal, логика аналогична: все накопленные векторы при смене активности обработаются автоматически в Normal контуре.
При работающем Init#
При запущенном процессе Init на Normal. Если контур переходит в SI, ФП успешно успел завершиться, перезапуск не требуется. Если ФП завершается с ошибкой и требуется перезапуск ФП, выполните шаги для повторного запуска с заданной партиции:
Авторизуйтесь в UI BGP Normal контура и найдите нужный ФП.
Найдите колонку Прогресс 250/500 (50.00%).
Зайдите в настройки конфигурации данного ФП (Изменить конфигурацию -> <Размер пакета> * <Количество обработчиков>).
Пример:
4 * 5 = 20.Рассчитайте, с какой партиции нужно запустить ФП. Из числа успешно загруженных партиций (в данном случае 250) вычесть число равное произведению количества обработчиков на размер пачки из настроек стратегии инита.
Пример:
250 - 20 = 230.Перейдите в Реестр Фоновых Процессов и запустите расширенный старт ФП с параметром
startOffsetPack = 230.
При работающем online ТКД#
При запущенном процессе online ТКД — аналогично при работающем потоке (все накопленные сообщения обработает контур SI).
При работающем offline ТКД или DRP#
Идет процесс offline ТКД/DRP. Контур переходит в SI.
Если по финальному отчету offline ТКД нет явных ошибок и пропусков по ключам, то перезапуск процесса не требуется. В противном случае если есть ошибки и/или пропуски, выполните Повторный запуск.
По процессу DRP: КАП не формирует финальный отчет, поэтому нужно выяснить, был ли в это время переход в Staind-In и если да и требуется перезапуск процесса DRP, выполните Повторный запуск.
Повторный запуск: по истечении таймаута (5-10 минут) и при необходимости ТКД/DRP, можно запустить находясь в Stand-In если работу в платформенном Stand-In для ТКД/DRP поддержит сам источник.
При переходе контура с Normal на Staind-In или с Staind-In на Normal, процесс offline ТКД или DRP запускать не рекомендуется.
При смене активности контуров в момент offline ТКД/DRP, данные процессы завершаются. По всем ключам, не взятым в работу, будут ошибки и пропуски на том контуре, на котором был запущен процесс.