Приложение 1. Поднятие данных из архива в Solr#
Поднятие данных из архива через UI Platform V Audit SE (AUD)#
Для импорта необходимы следующие рабочие сервисы Hadoop:
YARN,
Apache Oozie,
HDFS,
Apache Solr,
Apache Spark (только при запуске восстановления данных через Spark).
Сервис поднятия данных из архива и записи в Solr требует предварительной настройки кластера.
Инструменты поднятия данных из архива Platform V Audit SE (AUD)#
Выбор инструмента для восстановления данных из архива Platform V Audit SE (AUD) производится через параметр Platform V Audit SE (AUD) oozie.wf.application.path (см. ниже).
Поднятие данных из архива через MapreduceIndexerTool#
За восстановления данных из архива через MapreduceIndexerTool отвечает Oozie workflow, расположенное в директории /audit_resources/Oozie/oozie.
MapreduceIndexerTool — утилита, включенная в дистрибутив Hadoop. Представляет собой исполняемый jar-файл (search-mr-*-job.jar) и предназначена для вычитывания данных из HDFS, формирования из них Solr-индексов и записи их в Solr.
Поднятие данных из архива через Spark#
За восстановление данных из архива через Spark отвечает Oozie workflow, расположенное в директории /audit_resources/spark.
Данный workflow запускает Spark-приложение из директории HDFS /audit_resources/spark/lib/archives-spark-application.jar. Сам jar содержит в себе логику работы приложения по восстановлению данных из архива и минимально возможное количество сторонних классов. Библиотеки классов Spark для работы приложения берутся из дистрибутива Spark и share lib oozie.
Подробно ознакомиться со Spark можно по этой ссылке.
Принцип работы Spark-приложения#
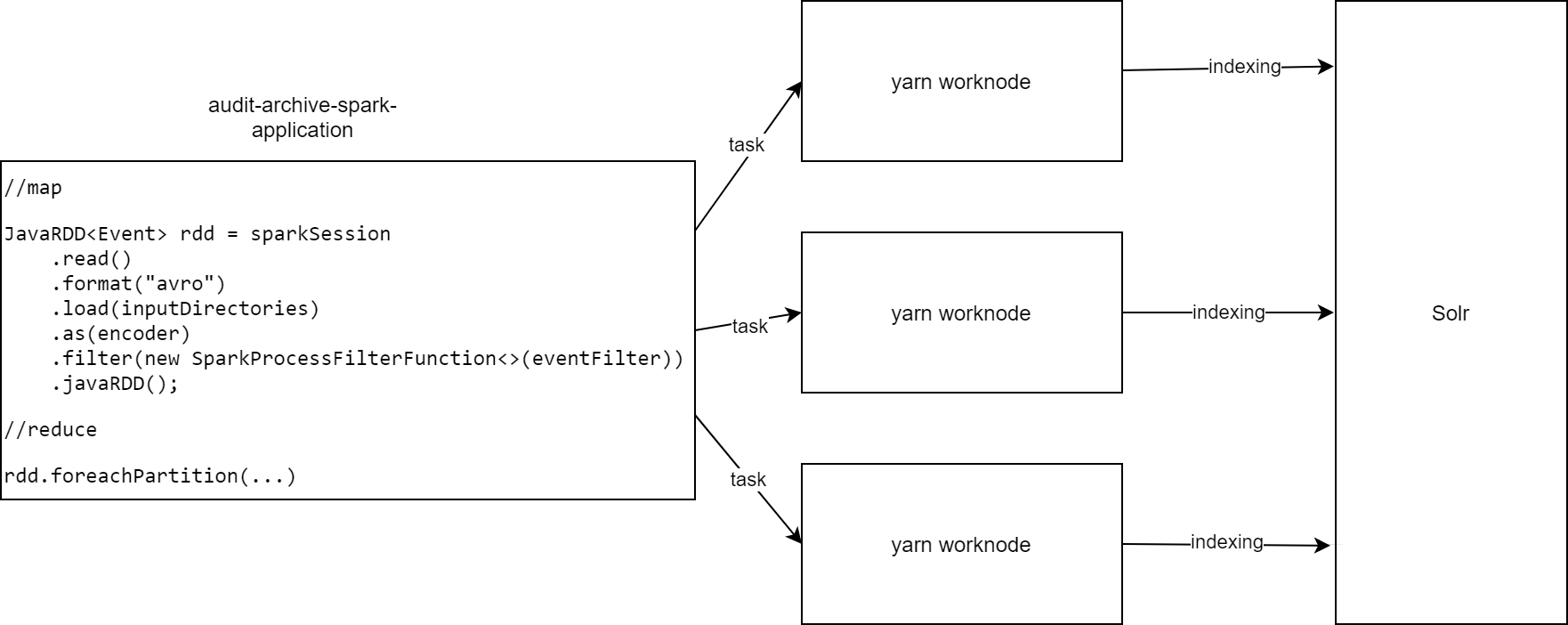
Запуск процесса восстановления данных через UI.
В UI Platform V Audit SE (AUD) пользователь выбирает параметры для восстановления данных (период времени, в который были записаны данные, подлежащие восстановлению, фильтры для событий аудита). Нажимает кнопку запуска.
Создается новая коллекция в Solr, предназначенная для восстановленных данных. Обновляется alias Platform V Audit SE (AUD).
Формируется задача для Oozie по запуску workflow.xml по пути в HDFS (конфигурация аудита "oozie.wf.application.path"). В задачу передаются заданные параметры. Происходит вызов Oozie по адресу oozie.url.
Запуск Spark-приложения на стороне Oozie и YARN. Через workflow.xml происходит запуск Spark-приложения на кластере YARN. Мастером выбирается любой узел yarn. Если в результате инициализации Spark-приложения произойдет ошибка, последует повторный запуск на другом узле yarn. Если второй запуск выдаст ошибку, то восстановление данных будет считаться проваленным с соответствующим статусом FAILED в Oozie.
Работа Spark-приложения.
В Spark-приложения передаются параметры для восстановления из UI Platform V Audit SE (AUD) через аргументы, а также параметры для Spark через системные переменные. Происходит инициирование Spark-сессии.
После инициации создается mapreduce-запрос на кластер HDFS по директориям, переданным через UI Platform V Audit SE (AUD). Формируется перечень "pointer'ов" на события аудита (сами события не загружаются в память мастер-приложения).
Формируются задачи для reduce-запросов. По умолчанию, при работе с HDFS Spark выбирает размер reduce-запроса 128 МБ (по размеру файла HDFS), распределенно сериализует параметры для запроса и отправляет на узлы yarn на выполнение (т.е. каждый узел yarn обрабатывает 128 МБ данных аудита за task).
В результате получения запроса на выполнения YARN создает Solr-клиента, выгружает из HDFS события аудита по заданному перечню "pointers", полученных от мастера, in-memory (т.е. без записи в жесткий диск) и отправляет их в Solr единым batch'ом (т.е. коммит в Solr происходит только после записи всей пачки событий). Если в результате выполнения таски произошла ошибка, к примеру, сбой Solr, тогда будет выброшено исключение, работа по восстановлению данных остановится, а сама job Oozie будет считаться невыполненной. Тем не менее в Solr коллекции будут присутствовать события, которые успели записаться в Solr до момента выброса исключения.
Использование директории, содержащей скрипты Platform V Audit SE (AUD) на HDFS#
Скрипты Platform V Audit SE (AUD), необходимые для импорта данных, помещаются в директорию HDFS по адресу /audit_resources/.
Данная директория автоматически обновляется при установке новой версии Platform V Audit SE (AUD) на стенд через скрипты развертывания. Соответственно, необходимо только прописать конфигурацию серверной части Platform V Audit SE (AUD) с указанием на данные директории:
Для запуска через MapreduceIndexerTool:
audit2@oozie.wf.application.path=hdfs://<host активной name node HDFS>:<port>/audit_resources/Oozie/oozie
audit2@mapred.resultDir=hdfs://<IP-адрес активной name node HDFS>:<port>/audit_resources/archivedSolrIdx
Для запуска через Spark:
audit2@oozie.wf.application.path=hdfs://<host активной name node HDFS>:<port>/audit_resources/spark
audit2@mapred.resultDir=hdfs://<IP-адрес активной name node HDFS>:<port>/audit_resources/archivedSolrIdx
По умолчанию данным директориям присваиваются права 777, так как доступ к директориям необходим внутренним пользователям различных сервисов, принадлежащих к разным группам пользователей.
Полный список файлов, которые должны быть в директории:
Для работы через MapreduceIndexerTool:
${oozie.wf.application.path}>/createIndex.sh
${oozie.wf.application.path}>/lib
${oozie.wf.application.path}>/lib/log4j.properties
${oozie.wf.application.path}>/lib/prepareDataFromAvroToSolr.conf
${oozie.wf.application.path}>/lib/solr-index-creator.jar
${oozie.wf.application.path}>/workflow.xml
Для работы через Spark:
${oozie.wf.application.path}>/lib/archives-spark-application.jar
${oozie.wf.application.path}>/workflow.xml
Для всех директорий и файлов, использующих импорт, выделяются права 777 в связи с тем, что к разным папкам и файлам обращаются внутренние пользователи Hadoop с разными группами и разными операциями (чтение/запись).
Внимание! Для корректной работы импорта данных из архива при больших объемах данных (в особенности!) необходимо выполнить настройку ресурсов на YARN. Это задача для администратора конкретного кластера Hadoop.
Рекомендованные настройки YARN#
ApplicationMaster Memory = 1 GiB
ApplicationMaster Java Maximum Heap Size = 768 MiB
Map Task Memory = 1 GiB
Reduce Task Memory = 1 GiB
Map Task Maximum Heap Size = 768 MiB
Reduce Task Maximum Heap Size = 768 MiB
Client Java Heap Size in Bytes = 768 MiB
Java Heap Size of JobHistory Server in Bytes = 1 GiB
Java Heap Size of NodeManager in Bytes = 256 MiB
Container Memory = 8 GiB
Container Virtual CPU Cores = 4
Java Heap Size of ResourceManager in Bytes = 1 GiB
Container Memory Minimum = 0 GiB
Container Memory Increment = 128 MiB
Container Memory Maximum = 2 GiB
Параметры#
fs.defaultFS#
Обязательность параметра: обязательный.
Описание:
Файловая система hdfs по умолчанию. Указывается по имени IP-адреса активной name node в hdfs.
Пример:
audit2@fs.defaultFS=hdfs://<IP-адрес активной NameNode>:<номер порта>
IP-адрес можно узнать в Ambari:
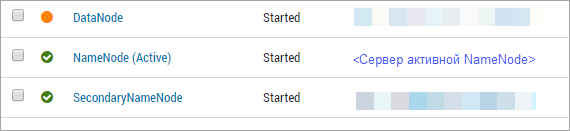
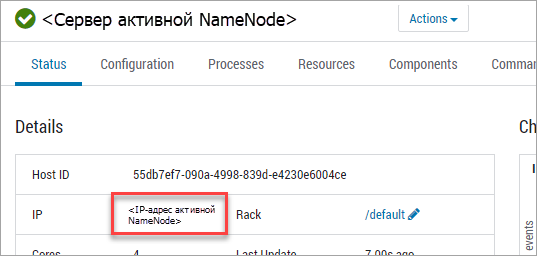
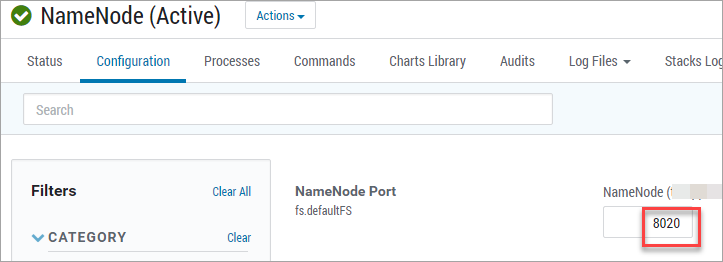
mapred.resultDir#
Обязательность параметра: обязательный.
Описание:
Полный путь в HDFS по имени IP-адреса активной name node в HDFS.
Папка для промежуточных результатов mapreduce-запросов. Рекомендуется использовать директорию в HDFS, создаваемую при обновлении стенда через скрипты развертывания по адресу /audit_resources/archivedSolrIdx.
Пример:
audit2@mapred.resultDir=hdfs://<IP-адрес активной NameNode>:<номер порта>/audit_resources/archivedSolrIdx
Описание того, как выяснить IP-адрес и порт активной NameNode, приведено выше (см. описание для параметра fs.defaultFS).
Внимание! При тестировании обнаружено, что в некоторых случаях настройка mapred.resultDir работает по имени хоста. Видимо, это связано с конфигурацией хостинга на узле, но заранее конкретно выявить то, какой вариант является правильным, пока не представляется возможным.
Решение проблем с подключением импорта проходит посредством просмотра логов YARN и логов серверной части Platform V Audit SE (AUD).
mapred.check.result.timeout.millis#
Обязательность параметра: необязательный.
Описание: Периодичность обновления результатов работы mapreduce в миллисекундах.
Значение по умолчанию: 15 000.
oozie.url#
Обязательность параметра: обязательный.
Описание: Url-путь к Oozie.
Можно узнать в конфигурации сервиса Oozie.
Пример:
audit2@oozie.url=http://<IP-адрес активной NameNode>:<номер порта>/oozie/
IP-адрес можно узнать в Ambari:
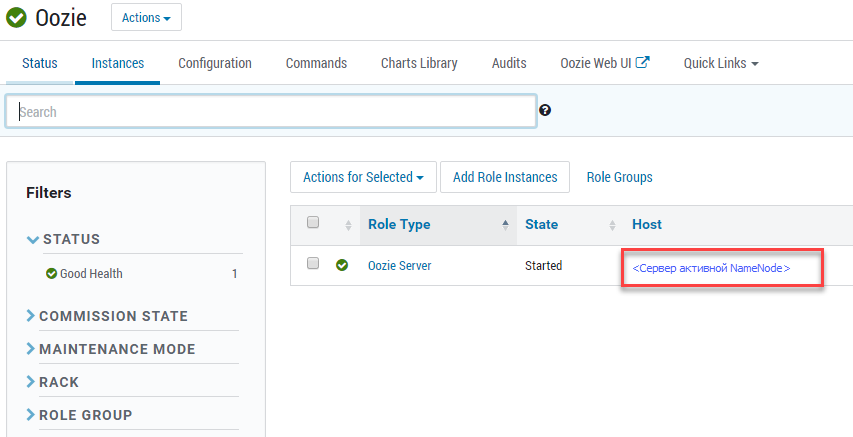
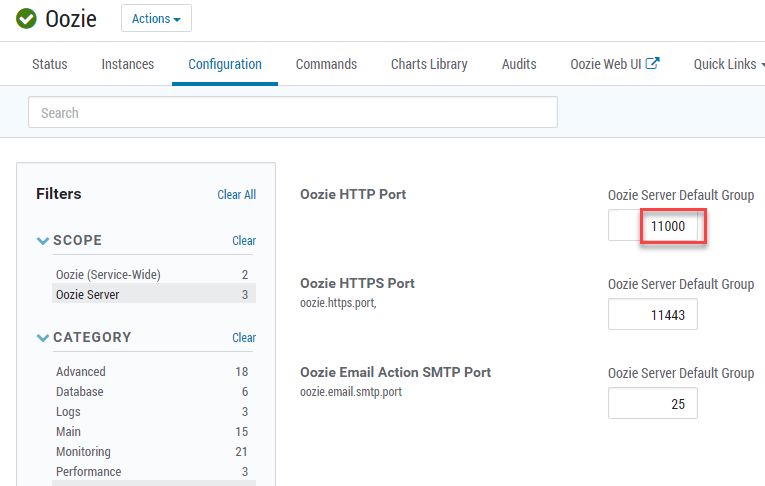
oozie.wf.application.path#
Обязательность параметра: обязательный.
Описание:
Полный путь в HDFS по имени хоста Hadoop. Указывается host-адрес NameNode HDFS, находящейся в активном состоянии. В противном случае job импорта будет падать.
Указывается директория, в которой расположены скрипты для работы архивирования и файл workflow.xml. Рекомендуется использовать директории в HDFS, создаваемые при обновлении стенда через скрипты развертывания по адресам:
При использовании MapreduceIndexerTool: oozie.wf.application.path=hdfs://
:8020/audit_resources/Oozie/oozie При использовании Spark: oozie.wf.application.path=hdfs://
:8020/audit_resources/spark
Пример с использованием MapreduceIndexerTool:
audit2@oozie.wf.application.path=hdfs://<IP-адрес активной NameNode>:<номер порта>/audit_resources/Oozie/oozie
oozie.check.status.timeout.millis#
Обязательность параметра: необязательный.
Описание: Периодичность обновления статусов задач в миллисекундах. Значение по умолчанию: 10 000.
pipeline.job.max#
Обязательность параметра: необязательный.
Описание: Значение по умолчанию: 20.
pipeline.job.min#
Обязательность параметра: необязательный.
Описание: Значение по умолчанию: 5.
Просмотр результата работы задания YARN#
Ниже описан просмотр результата в случае, если задание импорта создалось и нужная задача импорта отображается в UI Platform V Audit SE (AUD) на форме «Администрирование».
Для доступа к логам YARN необходимо зайти в UI YARN через Ambari.
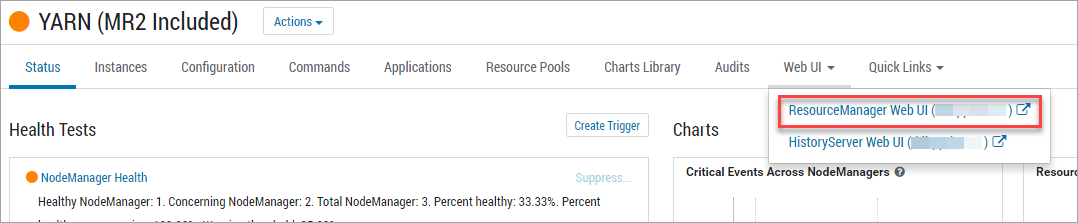
В UI YARN отображаются все выполненные задачи по импорту данных. Каждая задача импорта запускает одну задачу в yarn с именем oozie:launcher:T=shell:W=indexer:A=indexer… (это выполнение скрипта Platform V Audit SE (AUD) createIndex.sh) , а также две задачи с именами org.apache.solr.hadoop.MapReduceIndexerTool/MorphlineMapper (это выполнение двух mapreduce запросов в рамках выполнения скрипта createIndexer.sh).
В случае успешного выполнения импорта у данных задач YARN будет проставлен статус выполнения SUCCEEDED. Результат выполнения KILLED или FAILED хотя бы для одной задачи означает, что импорт данных выполнен некорректно.
Для диагностики проблемы необходимо зайти в задачу oozie:launcher:T=shell:W=indexer:A=indexer и посмотреть логи stderr:
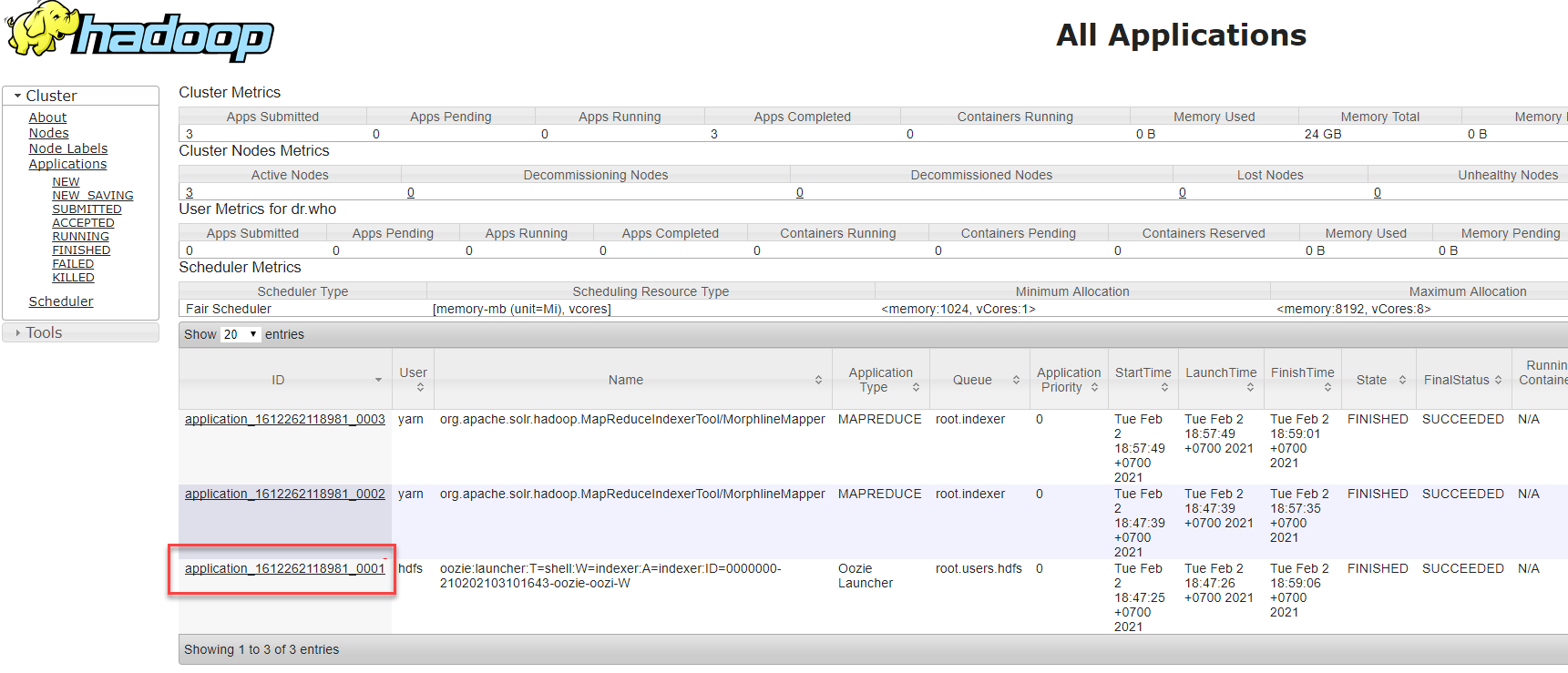
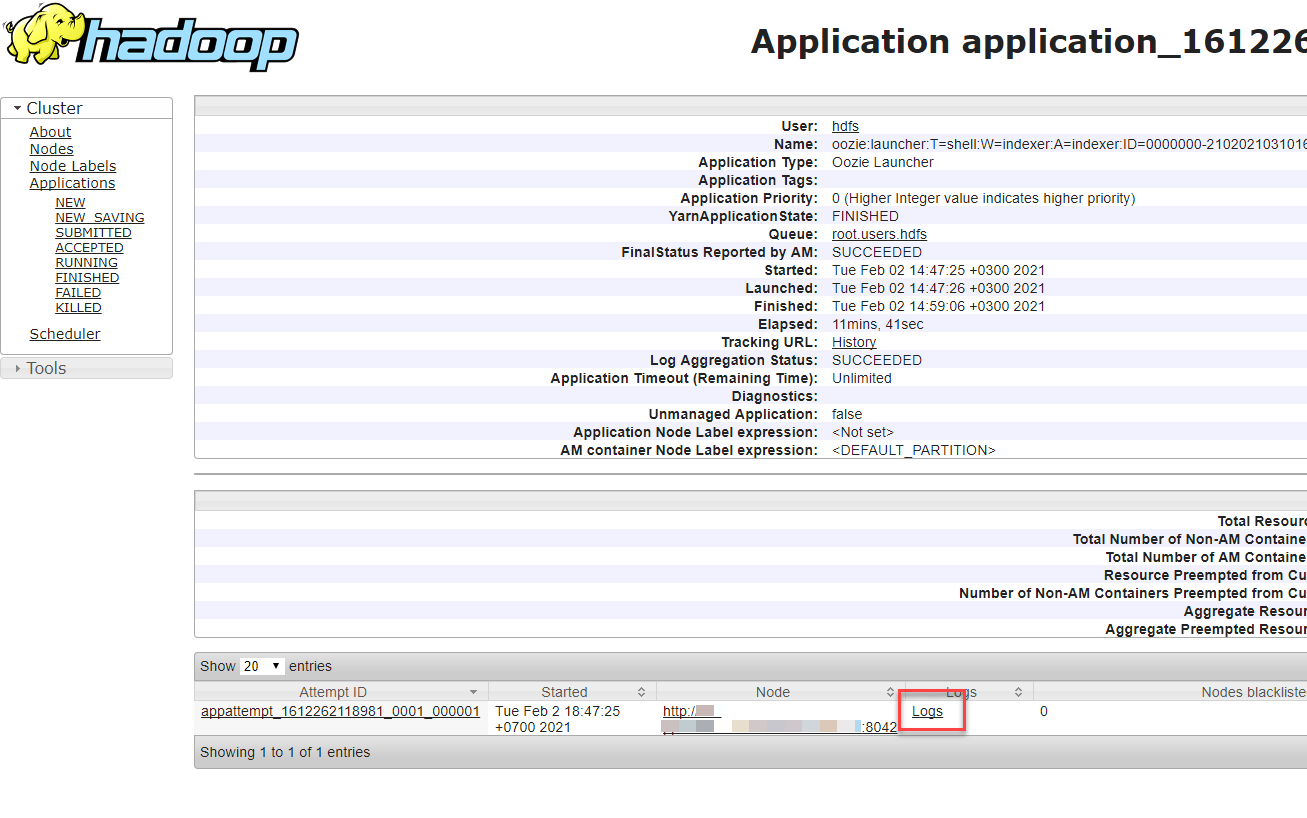
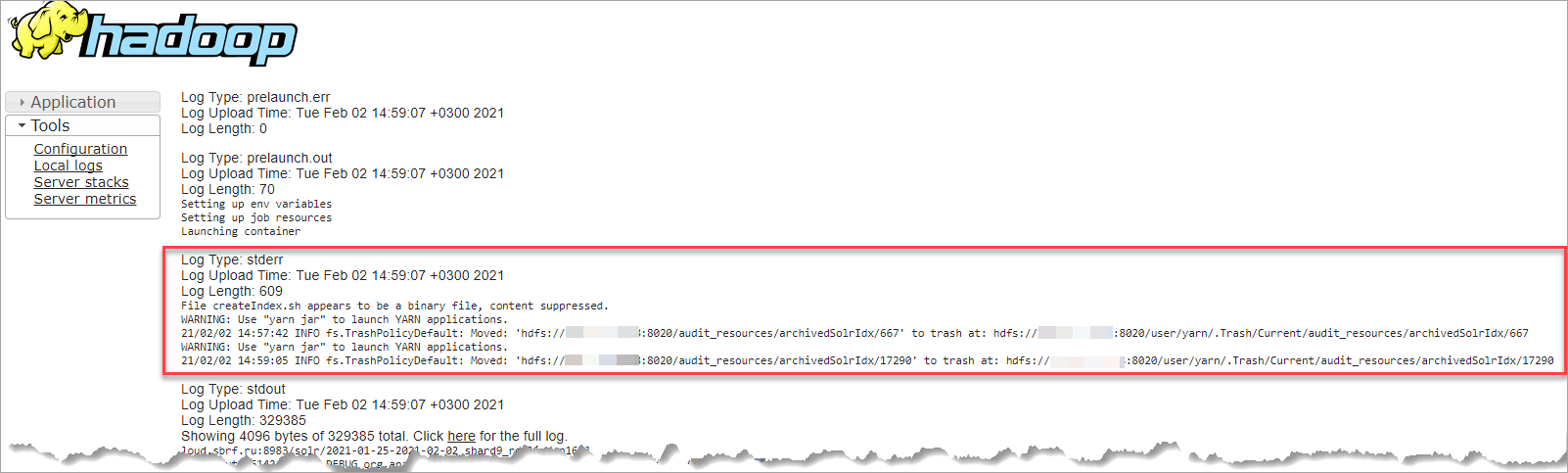
Если лог выводится только в виде, приведенном на рисунке ниже, то необходимо зайти на Ambari по SSH и выполнить запрос yarn logs -containerId container_1626834573894_0001_01_000001.

Диагностика проблем#
Не удается зайти в форму «Администрирование» в UI Platform V Audit SE (AUD)#
Описание:
Не удается зайти в форму «Администрирование» в UI Platform V Audit SE (AUD).
Решение:
Убедиться, что версия Platform V Audit SE (AUD) актуальна. При необходимости, переустановить Platform V Audit SE (AUD). Убедиться с помощью сервиса Объединенный сервис авторизации (AUTZ) продукта Platform V IAM SE (IAM), что ролевая модель Platform V Audit SE (AUD) не ниже актуальной версии. Пользователю должно быть назначено право ASSupport (Сотрудник сопровождения АС) либо PlatformAdmin (Администратор платформы).
Не появляется новая задача в списке после запуска импорта#
Описание:
Не появляется новая задача в списке после запуска импорта на форме «Администрирование».
Решение:
Проблема свидетельствует об одной из следующих неисправностей:
не удается создать таблицу Solr;
нет подключения к Oozie.
Для устранения неисправности следует:
Проверить состояние Solr кластера, а также значение конфигурации solr.collection.alias. Если значение конфигурации пустое, создание таблицы Solr невозможно.
Убедиться в работоспособности сервиса Oozie и проверить конфигурацию oozie.url на корректность Работоспособность сервиса Oozie проверяется через Ambari:

Состояние задачи FAILED#
Состояние задачи FAILED может указывать на ошибку в работе pipeline или на неработоспособность YARN (например, если для процесса mapreduce недостаточно физической и (или) виртуальной памяти, недостаточно места на диске и т. д.).
Для устранения данной проблемы следует:
Проверить размещение скриптов сервиса в директории HDFS (oozie.wf.application.path), корректность соответствующей конфигурации, корректность конфигурации mapred.resultDir.
Проверить, что настройки в конфигурации заполнены корректно. Для настроек, указанных ниже, должен быть один и тот же <FQDN>:
mapred.resultDir=hdfs://<FQDN>:8020/audit_resources/archivedSolrIdx
oozie.wf.application.path=hdfs://<FQDN>:8020/audit_resources/Oozie/oozie
Проверить права на папках в HDFS audit_resources/Oozie, audit_resources/archivedSolrIdx:
hdfs dfs -chmod 777 /audit_resources/Oozie
hdfs dfs -chmod 777 /audit_resources/archivedSolrIdx
Для папки /user/yarn необходимо присвоить владельца yarn:yarn.
Состояние задачи SUSPENDED#
Проблема может указывать на то, что в Ambari в HDFS переопределена активная NameNode.
Для устранения данной проблемы следует:
Остановить NameNode (Active).
Проверить настройку mapred.resultDir в конфигурации модуля audit2-admin. Она должна быть такой же, как NameNode (Active) для HDFS в Ambari. Если это не так, то нужно либо исправить значение параметра и рестартовать модуль audit2-admin, либо в Ambari в HDFS переопределить NameNode (Standby) в NameNode (Active).
В импортированных события отсутствуют названия, узел пользователя, логин пользователя#
Для устранения проблемы следует проверить, что в ZooKeeper, к которому подключен Solr, отсутствует старая схема Solr /configs/audit-events/schema.xml. В случае ее наличия, необходимо удалить данную схему.
Резервирование сегментов (shards)#
Проверить что в Solr имеются коллекции с необходимыми именами, например "audit-events".
Открыть WebUI SOLR, перейти в пункт CLOUD -> GRAPH.
Создать реплику ядра SOLR для всех shards, расположенных в резервируемом хосте, c помощью HTTP API SOLR, подставляя правильные значения IP/SHARD_NAME в ссылке http://IP:8983/solr/admin/collections?action=ADDREPLICA&collection=audit-events&shard=SHARD_NAME
В отдельной вкладке открыть WebUI SOLR, перейти в пункт CLOUD -> GRAPH и дождаться, когда новые ядра получат статус "Active"/
Зайти на master node в кластере (на ней установлен Ambari) по SSH и выполнить команды:
export HADOOP_USER_NAME=hdfs hdfs fsck /По результату проверки будет предоставлен отчет о состоянии директорий на HDFS, находящихся в корне "/" файловой системы. Необходимо обратить внимание на строчку "Under-replicated blocks", она должна быть равна нулю. Если этот параметр отличается от нуля, то выполнить команды:
принудительно выставить всем файлам необходимый фактор репликации (его можно найти в конфигурации сервиса HDFS в Ambari):
hdfs dfs -setrep -R <rep> /запустить балансировку:
hdfs balancerПроверить, что не осталось нереплицированных блоков.
Зайти в конфигурацию сервисов Flume, в названии которых есть SOLR.
Найти все три параметра «solr.nodes» и удалить из них IP-адрес резервируемого хоста.
Перезагрузить сервисы Flume, в названии которых есть SOLR.
Проверить, что в данных Flume нет ошибок в логах.
Проверить работоспособность UI Platform V Audit SE (AUD).
Настройка SSL при импортировании#
В случае включения SSL на Solr UI Platform V Audit SE (AUD) устанавливает защищенное соединение настройками:
archives.solr.ssl.enabled = true
archives.solr.ssl.hostname.verification.enabled = true
archives.solr.ssl.truststore.type = JKS
archives.solr.ssl.truststore.location = [путь до сертификатов Solr, на сервере, где размещен YARN]
archives.solr.ssl.truststore.password = [пароль]
archives.solr.ssl.keystore.type = JKS
archives.solr.ssl.keystore.location = [путь до сертификатов Solr, на сервере, где размещен YARN]
archives.solr.ssl.keystore.password = [пароль] Сертификаты keystore и truststore для Solr необходимо разместить в папке сервера, где размещен YARN. У папки должны быть права не ниже 775.
Адреса агентов YARN можно узнать через UI Ambari:
Добавлен http-клиент для работы с Oozie на Apache httpclient и feign (по аналогии с proxy-клиент).
Добавлены новые настройки в серверную часть Platform V Audit SE (AUD):
stringProperty name="archives.oozie.ssl.truststore.location" required="false" defaultValue=""/
stringProperty name="archives.oozie.ssl.truststore.password" required="false" protected="true" defaultValue=""/
stringProperty name="archives.oozie.ssl.keystore.location" required="false" defaultValue=""/
stringProperty name="archives.oozie.ssl.keystore.password" required="false" protected="true" defaultValue=""/
stringProperty name="archives.oozie.ssl.key.password" required="false" protected="true" defaultValue=""/
Настройка MapReduce для поднятия из архива#
Информацию о настройке MapReduce можно найти по этой ссылке.