Установка#
Установка продукта Platform V Audit SE (AUD) может осуществляться одним из способов:
Ручным способом посредством запуска скриптов Ansible;
Автоматизированным способом средствами DevOps Tools Install_EIP (PILP) продукта Platform V DevOps Tools (DOT) (опционально).
Предварительные шаги по сборке дистрибутива#
Дистрибутив поставляется в виде набора из трех частей: party, owned и vendor (опционально). Прежде чем вы сможете установить Platform V Audit SE (AUD), все части дистрибутива нужно объединить при помощи скрипта consolidate-distributive.groovy.
Для этого, создайте в своей инсталляции Jenkins задание типа pipeline. Воспользуйтесь инструкцией, которая расположена в дистрибутиве: AUD-<версия>-distrib/AUD-1.1.0-<номер билда>_consolidation_job.zip/README.md.
Для обеспечения контроля целостности компонентов, также установите на агенте Jenkins, на котором будет осуществляться сборка, консольную утилиту shasum. Ее можно установить при помощи команды sudo yum install perl-Digest-SHA -y. Во время сборки дистрибутива при помощи задания Jenkins, утилита обновит контрольные суммы собранных пакетов и компонентов.
Общая информация#
При установке и настройке Platform V Audit SE (AUD) для обеспечения безопасности необходимо выполнение следующих условий:
инсталляция Platform V Audit SE (AUD) должна осуществляться на виртуальных серверах в защищенной среде виртуализации сотрудником соответствующей квалификации, имеющим права администратора с присвоенными ему идентификационными данными для работы в среде виртуализации;
действия, проводимые при инсталляции и при инициализации Platform V Audit SE (AUD), подлежат логированию с надежными метками времени;
установка и конфигурирование Platform V Audit SE (AUD) должны осуществляться в соответствии с эксплуатационной документацией;
должно обеспечиваться предотвращение несанкционированного доступа к идентификаторам и паролям пользователей Platform V Audit SE (AUD);
должно обеспечиваться предотвращение несанкционированного доступа к идентификаторам и паролям администраторов среды виртуализации, которые необходимы для установки и настройки Platform V Audit SE (AUD). В параметрах развертывания присутствуют следующие порты межсервисного взаимодействия:
KAFKA_PORT=9093
LOGGER_SERVICE_PORT=443
SPARK_PORT=11000
ZOOKEEPER_PORT=2181
solr_port=8983
hbase_master_port=16000
hbase_worker_port=16020
hdfs_datanodes_port=50010
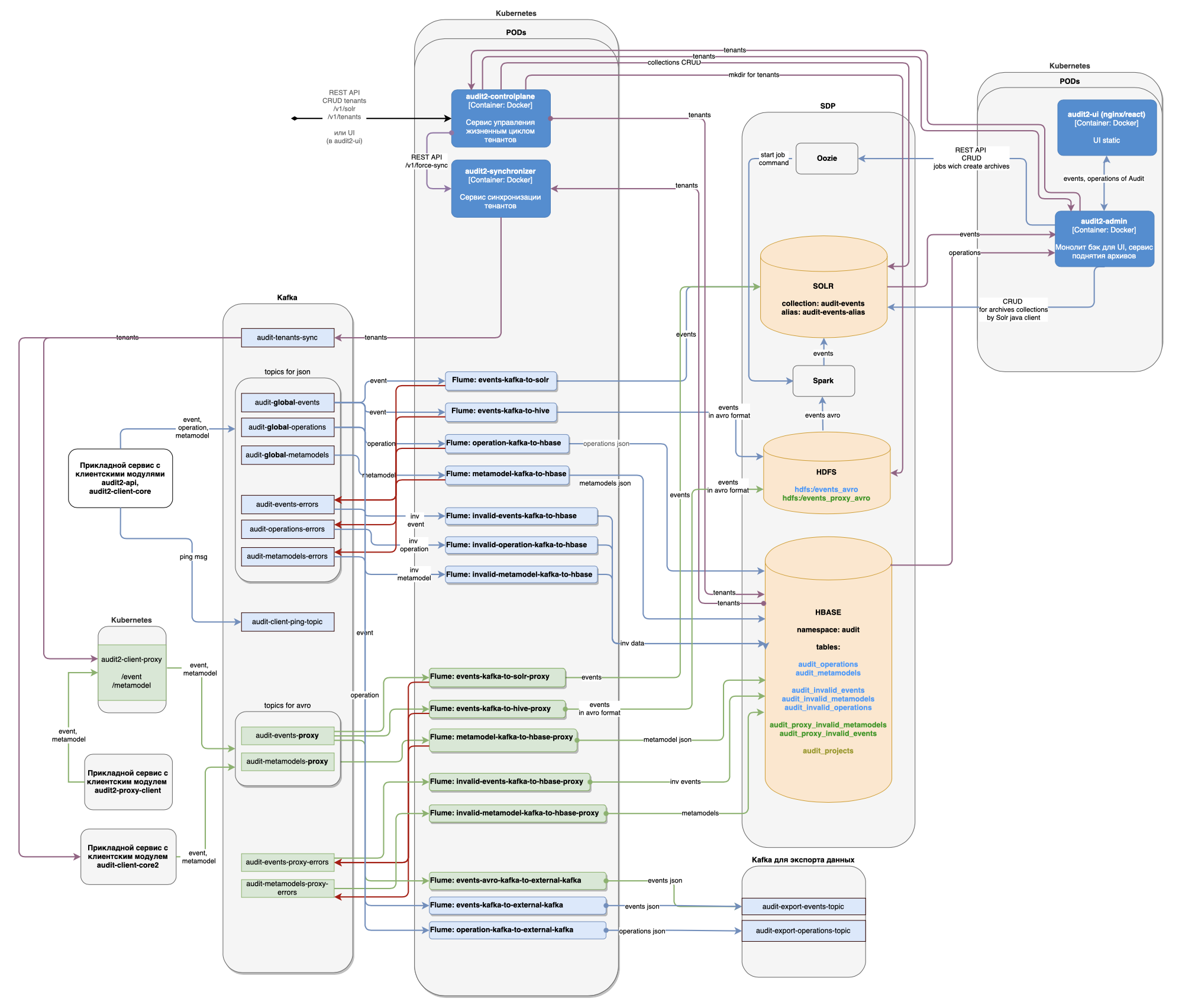
hdfs_namenode_port=8020 Пользователь получает доступ к REST и к UI Platform V Audit SE (AUD) по портам 80 (HTTP) или 443 (при включенном HTTPS). На рисунке приведена схема развертывания Platform V Audit SE (AUD).
Настройка Kafka#
В целевом виде в кластере Kafka должно быть не менее 3 серверов. Далее приведена конфигурация для целевого вида. По умолчанию предполагается размещение ZooKeeper и брокеров Kafka на одних и тех же машинах. В конфигурационном файле брокера Kafka server.properties, который устанавливается стандартно вместе с ПО Kafka, внесите следующие изменения:
Для параметра broker.id укажите порядковый номер сервера Kafka.
Для параметра log.dir укажите директорию для хранения данных. Пример: log.dir=/kafkadata
Для параметра zookeeper.connect перечислите все IP-адреса серверов и порты, на которых размещен ZooKeeper. Пример: zookeeper.connect=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181
Для параметра zookeeper.connection.timeout.ms установите значение 30000.
Для параметра zookeeper.session.timeout.ms установите значение 6000.
Для listeners укажите протокол, IP-адрес и порт сервера брокера Kafka. Пример: listeners=SSL://192.168.0.1:9093.
Установите значение security.inter.broker.protocol = SSL.
Установите значение sasl.enabled.mechanisms = GSSAPI.
Установите значение sasl.mechanism.inter.broker.protocol = GSSAPI.
Установите значение sasl.kerberos.service.name = kafka.
Для параметра ssl.keystore.location укажите размещение хранилища сертификатов. Пример: ssl.keystore.location=ssl/kafkaserver.jks
Для параметра ssl.truststore.location укажите размещение доверенного хранилища сертификатов. Пример: ssl.keystore.location=ssl/kafkaserver.jks
Для параметра ssl.keystore.password укажите пароль хранилища сертификатов.
Для параметра ssl.truststore.password укажите пароль доверенного хранилища сертификатов.
Для параметра ssl.key.password укажите пароль ключа.
Установите значение ssl.client.auth = required.
Установите значение ssl.enabled.protocols = TLSv1.2.
Установите значение zookeeper.ssl.client.enable=true.
Установите значение zookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNetty.
Для параметра zookeeper.ssl.keystore.location укажите размещение хранилища сертификатов. Пример: zookeeper.ssl.keystore.location=/opt/Apache/stores/keystore-audit-kafka.jks
Для параметра zookeeper.ssl.keystore.password укажите пароль хранилища сертификатов.
Для параметра zookeeper.ssl.truststore.location укажите размещение доверенного хранилища сертификатов. Пример: /opt/Apache/stores/truststore-audit-kafka.jks
Для параметра zookeeper.ssl.truststore.password укажите пароль доверенного хранилища сертификатов
Укажите пустое значение для параметра zookeeper.ssl.endpoint.identification.algorithm, т.е. zookeeper.ssl.endpoint.identification.algorithm =
Установите значение zookeeper.ssl.enabled.protocols=TLSv1.2.
Установите значение ssl.cipher.suites = TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256.
Установите значение authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer.
Для параметра super.users укажите DN сертификата для администрирования кластера Kafka. Пример: super.users = User:CN=MyCN,OU=0001,O=Issue Owner,C=RU
Установите значение allow.everyone.if.no.acl.found=false.
Установите значение zookeeper.set.acl=true.
Установите значение auto.create.topics.enable = false.
Установите значение delete.topic.enable = true.
Установите значение num.partitions = 21.
Установите значение offsets.topic.replication.factor = 3.
Установите значение transaction.state.log.replication.factor = 3.
Установите значение transaction.state.log.min.isr = 3.
Установите значение replica.fetch.max.bytes = 5242880.
Установите значение group.max.session.timeout.ms = 300000.
Установите значение group.initial.rebalance.delay.ms = 3000.
Установите значение socket.send.buffer.bytes = 102400.
Установите значение socket.receive.buffer.bytes = 102400.
Установите значение socket.request.max.bytes = 104857600.
Установите значение num.network.threads = 6.
Установите значение num.io.threads = 8.
Установите значение num.replica.fetchers = 2.
Установите значение num.recovery.threads.per.data.dir = 1.
Для параметра log.retention.hours укажите значение хранения данных на Kafka в часах. Значение следует указывать на основе значений входящего потока данных и размера дисков серверов Kafka. Рекомендуемое значение log.retention.hours = 168.
Установите значение log.segment.bytes = 1073741824.
Установите значение log.retention.check.interval.ms = 300000.
Установите значение log.cleaner.enable = true.
Установите значение offsets.retention.minutes = 43200.
Установите значение max.incremental.fetch.session.cache.slots = 100000.
Установите значение log.roll.hours = 1.
Установите значение queued.max.requests = 1000.
Установите значение message.max.bytes = 2097152.
Установите значение default.replication.factor = 3.
Установите значение min.insync.replicas = 2.
Установите значение log.cleaner.threads = 2.
Установите значение unclean.leader.election.enable = false.
Установите значение compression.type = snappy.
Укажите пустое значение для параметра ssl.endpoint.identification.algorithm, т.е. ssl.endpoint.identification.algorithm =
Укажите пустое значение для параметра listener.name.internal.ssl.endpoint.identification.algorithm, т.е. listener.name.internal.ssl.endpoint.identification.algorithm =
Подробное описание параметров кластера Kafka можно найти в документации Apache Kafka.
Создайте топики в основном кластере Kafka согласно таблице.
Имя топика |
Дополнительные параметры топика |
|---|---|
audit-global-events; audit-global-operations; audit-global-metamodels |
Настройте максимальный размер сообщения: max.message.bytes=2097152 |
audit-client-ping-topic |
Настройте сжатие и удаление данных: retention.ms=3600000; segment.bytes=1048576; cleanup.policy=delete |
audit-metamodels-proxy |
Настройте сжатие и удаление данных: max.message.bytes=2621440; min.compaction.lag.ms=86400000; retention.ms=2592000000; retention.bytes=1073741824; segment.bytes=104857600; cleanup.policy=delete,compact; min.cleanable.dirty.ratio=0.1 |
audit-events-proxy |
Настройте максимальный размер сообщения: max.message.bytes=2621440 |
audit-events-errors; audit-operations-errors; audit-metamodels-errors; audit-events-proxy-errors; audit-metamodels-proxy-errors |
Настройте максимальный размер сообщения: max.message.bytes=3145728 |
ssp-audit-topic; ssp-response-topic; audit-tenants-sync |
Дополнительные параметры отсутствуют |
Если кластер Platform V Corax используется для экспорта данных, создайте в нем топики согласно таблице.
Имя топика |
Дополнительные параметры топика |
|---|---|
audit-export-events-topic; audit-export-operations-topic |
Настройте максимальный размер сообщения: max.message.bytes=2621440 |
В качестве кластера Kafka для экспорта данных может использоваться основной кластер Platform V Corax или отдельностоящий кластер Platform V Corax.
Настройка элементов кластера Hadoop (SDP)#
Настройка HDFS#
Установите параметры:
Replication Factor = 3
Java Heap Size of Balancer in Bytes = 1 GiB
Java Heap Size of DataNode in Bytes = 1 GiB
Maximum Memory Used for Caching = 2 GiB
Client Java Heap Size in Bytes = 128 MiB
Java Heap Size of HttpFS in Bytes = 256 MiB
Java Heap Size of NameNode in Bytes = 4 GiB
Java Heap Size of Secondary NameNode in Bytes = 4 GiB
Default Umask = 002
Настройка HBase#
Установите параметры:
Client Java Heap Size in Bytes = 256 MiB
Java Heap Size of HBase REST Server in Bytes = 512 MiB
Java Heap Size of HBase Thrift Server in Bytes = 512 MiB
Java Heap Size of HBase Master in Bytes = 1 GiB
Java Heap Size of HBase RegionServer in Bytes = 4 GiB
Настройка Hive#
Установите параметры:
Client Java Heap Size in Bytes = 128 MiB
Java Heap Size of Hive Metastore Server in Bytes = 1 GiB
Java Heap Size of HiveServer2 in Bytes = 1 GiB
В HiveServer2 Advanced Configuration Snippet (Safety Valve) for hive-site.xml добавьте три настройки (для поддержки транзакционности) нажатием на +: a. Настройка 1: Name: hive.txn.manager Value: org.apache.hadoop.hive.ql.lockmgr.DbTxnManager Description: Used for Hive Streaming b. Настройка 2: Name: hive.compactor.initiator.on Value: true Description: Used for Hive Streaming c. Настройка 3: Name hive.compactor.worker.threads Value: 5 Description Used for Hive Streaming
Настройка Solr#
Установите параметры:
Java Heap Size of Solr Server in Bytes = 4 GiB
Java Direct Memory Size of Solr Server in Bytes = 2 GiB
При нестабильной работе Solr на больших объемах данных эти параметры следует увеличивать в два раза пока не будет достигнута стабильность в работе Solr. При этом нужно следить за тем, чтобы сумма параметров Java Heap Size всех сервисов SDP, установленных на сервере, не превышала объем оперативной памяти.
Настройка ZooKeeper#
Установите параметры: Java Heap Size of ZooKeeper Server in Bytes = 4 GiB
Настройка YARN#
Установите параметры:
ApplicationMaster Memory = 1 GiB
ApplicationMaster Java Maximum Heap Size = 768 MiB
Map Task Memory = 1 GiB
Reduce Task Memory = 1 GiB
Map Task Maximum Heap Size = 768 MiB
Reduce Task Maximum Heap Size = 768 MiB
Client Java Heap Size in Bytes = 768 MiB
Java Heap Size of JobHistory Server in Bytes = 1 GiB
Java Heap Size of NodeManager in Bytes = 256 MiB
Container Memory = 8 GiB
Container Virtual CPU Cores = 4
Java Heap Size of ResourceManager in Bytes = 1 GiB
Container Memory Minimum = 0 GiB
Container Memory Increment = 128 MiB
Container Memory Maximum = 2 GiB
Настройка Oozie#
Установите параметр: Java Heap Size of Oozie Server in Bytes = 256 MiB
Настройка Kubernetes#
Настройте local ephemeral storage для Pod c приложением audit2-ui.
Порядок установки#
Подготовка дистрибутива Platform V Audit SE (AUD)#
Перед установкой Platform V Audit SE (AUD) необходимо настроить Jenkins freestyle job и выполнить её. Для этого создайте Jenkins freestyle job и укажите в pipeline использование файла consolidate-united-distributive.groovy из состава дистрибутива Platform V Audit SE (AUD). Данный файл может находиться в внутри архива consolidate-united-distrib.zip, внутри которого также содержится файл README.md с описанием параметров groovy-скрипта.
Установка компонентов в кластере Hadoop (SDP)#
Обновление компонентов Platform V Audit SE (AUD), размещенных в кластере Hadoop (SDP) происходит с помощью ansible-скриптов из состава дистрибутива Platform V Audit SE (AUD). Скрипты размещены в дистрибутиве по пути distrib-<version>-MS/other/ansible.
Пререквизиты обновления в кластере Hadoop (SDP)#
Перед самой первой установкой Platform V Audit SE (AUD) на кластере Hadoop (SDP) запустите скрипты из дистрибутива:
Для подготовки структуры директорий на HDFS запустите скрипт audit-prerequisites-hdfs.sh.
Пример команды:sh distrib-\<version\>-MS/other/ansible/audit-prerequisites-hdfs.sh ANSIBLE_USER
где ANSIBLE_USER - ssh-пользователь, под которым будет происходить работа ansible и который входит в состав группы администраторов HDFS - supergroup.
Важно! При работе скриптов иногда требуется чистка директории audit_resources, поэтому требуется, чтобы на HDFS существовала домашняя директория у пользователя ANSIBLE_USER.Для выполнения настроек в Linux на всех серверах кластера Hadoop (SDP) выполнить скрипт audit-prerequisites-node.sh. Пример команды:
sh distrib-\<version\>-MS/other/ansible/audit-prerequisites-node.sh ANSIBLE_USERпричем команда должна выполняться в режиме sudo.
При последующих обновлениях Platform V Audit SE (AUD) на кластере Hadoop (SDP) шаги из данного раздела выполнять не требуется.
Подготовка к обновлению в кластере Hadoop (SDP)#
Перед запуском ansible-скриптов для обновления компонентов Platform V Audit SE (AUD) в кластере Hadoop (DSP) необходимо скопировать из дистрибутива всю структуру директории distrib-\<version\>-MS/other/inventory-sample и заполнить в файлах ambari-environment.yml и ambari-vault.yml стендозависимые параметры.
Ansible-скрипты рассчитаны только на работу с inventory-файлами, созданными по образцу поставляемых в дистрибутиве по пути distrib-\<version\>-MS/other/inventory-sample.
Список inventory-файлов и параметров в них
Файл |
Параметр |
|---|---|
ambari-environment.yml |
data_center_id |
ambari_server |
|
ambari_server_port |
|
ambari_cluster |
|
kerberos_enabled |
|
service_status_pause_timer |
|
hive_host |
|
hive_port |
|
solr_endpoint |
|
solr_shards |
|
solr_replicas |
|
solr_max_shards |
|
days_for_data_save |
|
ambari-vault.yml |
vault_ansible_user |
vault_ansible_password |
|
vault_ambari_user |
|
vault_ambari_password |
|
vault_kerberos_hdfs_user |
|
vault_kerberos_hdfs_password |
|
vault_kerberos_hive_user |
|
vault_kerberos_hive_password |
|
vault_hive_principal |
|
vault_kerberos_hbase_user |
|
vault_kerberos_hbase_password |
|
vault_kerberos_solr_user |
|
vault_kerberos_solr_password |
|
vault_solr_principal |
|
tasks-enabler.yml |
hide_logs |
cleanup_hive |
|
cleanup_hbase |
|
cleanup_solr |
Ручное обновление в кластере Hadoop (SDP)#
Выполните обновление схем данных в хранилищах Hive, Solr, Hbase посредством запуска ansible-скриптов из директории дистрибутива distrib-<version>-MS/other/ansible с помощью команды:
ansible-playbook /path/to/audit-ambari-update.yml -i /path/to/inventory, где /path/to/inventory - путь до директории inventory-файлов, созданных по инструкции, описанной в разделе Подготовка.
Автоматическое обновление в кластере Hadoop (SDP) (опционально)#
В компоненте PILP Install_EIP необходимо:
Разместить структуру файлов, созданных по инструкции в разделе Подготовка, в репозитории конфигурации компонента PILP Install_EIP.
Добавить шаг запуска ansible-playbook в файле STAND_NAME/AUDIT_DIR/actions.xml с указанием пути до структуры с inventory-файлами.
Выполнить шаг для запуска соответствующего ansible-playbook.
Установка компонентов в Kubernetes#
Ручное обновление компонентов в Kubernetes#
Для ручного обновления требуется:
Иметь возможность запускать bash-скрипты (.sh).
Локально установленную и настроенную утилиту kubectl (настройка описана ниже в разделе Настройка утилиты kubectl).
Скрипт
deploy-k8s.sh, автоматизирующий работу со стендозависимыми параметрами (текст скрипта приведен далее, в разделе Запуск скрипта deploy-k8s.sh).Заполнить в файле, поставляемом в дистрибутиве по пути
distrib-\<version\>-MS/doc/os_props.conf, параметры приложений, развертываемых в Kubernetes. Путь до этого файла указывается при запуске скриптаdeploy-k8s.shчерез параметр--param-file.Скопировать из дистрибутива все файлы из директории
distrib-\<version\>-MS/modules/<module_name>/certsи разместить в одной директории. Заполнить сертификатами и паролями сертификатов все директории. Путь до этой директории указывается при запуске скриптаdeploy-k8s.shчерез параметр--secrets-dir.
Настройка утилиты kubectl
Для работы с Kubernetes через командную строку, необходимо установить утилиту kubectl и настроить ее для работы с кластером Kubernetes:
Прописать реквизиты кластера
kubectl config set-cluster <cluster_config_name> --server=https://K8S_ip_address_or_FQDN:6443 --insecure-skip-tls-verifyПрописать учетную запись для подключения к кластеру
kubectl config set-credentials <user_config_name> --token=<TOKEN>где <TOKEN> это автоматически сгенерированный логин-токен для вашего сервис-аккаунта. Найти его можно в описание самого сервис-аккаунта. Он прописан как секрет, с именем "<service_account_name>-token-<случайная последовательность символов>". Из этого секрета нужно скопировать содержимое поля token и указать вместо <TOKEN>.Создать контекст "Context" - информации об адресе подключения и учетных данных:
kubectl config set-context <context_config_name> --namespace=<k8s_namespace_name> --cluster=<cluster_config_name> --user=<user_config_name>Включить использование контекста для всех выполняемых команд:
kubectl config use-context <context_config_name>Проверить конфигурацию с помощью команды:
kubectl config viewПроверить какой контекст сейчас используется можно с помощью команды:
kubectl config current-context
Запуск скрипта deploy-k8s.sh
Для запуска скрипта deploy-k8s.sh выполните команду, указав значения параметров --param-file, --secrets-dir, --create-secrets:
sh deploy-k8s.sh --distrib-dir /path/to/distrib --param-file /path/to/param_file --secrets-dir /path/to/secrets_dir --create-secrets true
В таблице приведено описание параметров скрипта deploy-k8s.sh:
Параметр (флаг) |
Описание |
Значение по умолчанию |
|---|---|---|
–distrib-dir |
путь к дистрибутиву Platform V Audit SE (AUD) |
отсутствует |
–param-file |
путь к файлу параметров (os_props.conf) |
…/inventories/kubernetes/os_props_dzo.conf |
–templates-dir |
путь к директории с template Ingress/Egress |
…/inventories/kubernetes/templates/ |
–secrets-dir |
путь к директории с файлами, из которых необходимо создать secret |
…/inventories/kubernetes/certs/ |
–configs-dir |
путь к директории с файлами, из которых необходимо создать configMap |
…/inventories/kubernetes/configs/ |
–create-secrets |
При значении true включает создание secret в Kubernetes |
false |
–create-configs |
При значении true включает создание configMap в Kubernetes |
false |
–create-templates |
При true включает создание template в Kubernetes |
false |
–modules |
список модулей Platform V Audit SE (AUD), которые будут установлены в Kubernetes |
audit2-admin,audit2-ui,audit2-flume,audit2-client-proxy,audit2-synchronizer,audit2-controlplane |
–ignore |
список файлов, которые будут проигнорированы (скрипт удаляет их перед шагом установки) |
Текст скрипта deploy-k8s.sh:
#!/bin/bash
BUILD_DIR=build
# Default values
PARAM_FILE=../inventories/kubernetes/k8s-props.conf
TEMPLATES_DIR=../inventories/kubernetes/templates/
SECRETS_DIR=../inventories/kubernetes/certs/
CONFIGS_DIR=../inventories/kubernetes/configs/
CREATE_SECRETS=false
CREATE_CONFIGS=false
CREATE_TEMPLATES=false
DEPLOYED_MODULES="audit2-admin,audit2-ui,audit2-flume,audit2-client-proxy,audit2-synchronizer,audit2-controlplane"
IGNORED_FILES="virtualservice-ingress.yml,\
virtualservice-ingress-mtls.yml,\
audit2-ui-route.yml,\
audit2-synchronizer-route.yml,\
audit2-controlplane-route.yml,\
audit2-client-proxy-route.yml,\
audit2-admin-route.yml,\
deployment-metamodel-avro-kafka-v5-to-kafka-v6-converter-template.yaml,\
configmap-metamodel-avro-kafka-v5-to-kafka-v6-converter-template.yaml,\
deployment-events-avro-kafka-v5-to-kafka-v6-converter-template.yaml,\
configmap-events-avro-kafka-v5-to-kafka-v6-converter-template.yaml,\
deployment-pkb-events-avro-kafka-to-external-kafka-template.yaml,\
configmap-pkb-events-avro-kafka-to-external-kafka-template.yaml,\
deployment-pkb-events-kafka-to-external-kafka-template.yaml,\
configmap-pkb-events-kafka-to-external-kafka-template.yaml,\
deployment-simple-events-kafka-to-hbase-template.yaml,\
configmap-simple-events-kafka-to-hbase-template.yaml"
usage() {
echo "Usage: $0 --distrib-dir /path/to/distrib [ OPTIONS ]"
echo ""
echo "Options:"
echo " -h : Print this usage guide"
echo " --distrib-dir : Path to audit distribution"
echo " --param-file : Path to parameters file | Default value: $PARAM_FILE"
echo " --templates-dir : Path to custom templates directory | Default value: $TEMPLATES_DIR"
echo " --secrets-dir : Path to secrets directory | Default value: $SECRETS_DIR"
echo " --configs-dir : Path to configMaps directory | Default value: $CONFIGS_DIR"
echo " --create-secrets : Enables secret creation (true/false) | Default value: $CREATE_SECRETS"
echo " --create-configs : Enables configMaps creation (true/false) | Default value: $CREATE_CONFIGS"
echo " --create-templates: Enables custom templates creation (true/false) | Default value: $CREATE_TEMPLATES"
echo " --modules : List of audit modules ('module1,module2,module3') | Default value: $DEPLOYED_MODULES"
echo " --ignore : List of ignored files ('file1,file2,file3') | Default value: $IGNORED_FILES"
exit 1
}
if [[ $# -eq 0 ]] ; then
usage
exit 0
fi
while [[ $# -gt 0 ]]; do
case "$1" in
-h) usage;;
--distrib-dir) shift; DISTRIB_PATH=$1;;
--param-file) shift; PARAM_FILE=$1;;
--templates-dir) shift; TEMPLATES_DIR=$1; echo "Used templates dir: $TEMPLATES_DIR";;
--secrets-dir) shift; SECRETS_DIR=$1; echo "Used secrets dir: $SECRETS_DIR";;
--configs-dir) shift; CONFIGS_DIR=$1; echo "Used configMaps dir: $CONFIGS_DIR";;
--modules) shift; DEPLOYED_MODULES=$1;;
--ignore) shift; IGNORED_FILES=$1;;
--create-secrets) shift; CREATE_SECRETS=$1;;
--create-configs) shift; CREATE_CONFIGS=$1;;
--create-templates) shift; CREATE_TEMPLATES=$1;;
*) usage;;
esac
shift
done
DISTRIB_MODULES=$(find $DISTRIB_PATH/modules/ -mindepth 1 -maxdepth 1 -type d -exec basename {} \;)
FLUME_MODULES=$(find $DISTRIB_PATH/modules/audit2-flume/configs/ -mindepth 1 -maxdepth 1 -type d -exec basename {} \;)
function copyManifests {
echo ""
echo "============ COPYING MANIFESTS ==========="
for module_name in $DISTRIB_MODULES; do
if [ "$module_name" == "audit2-flume" ]; then
for flume_module in $FLUME_MODULES; do
mkdir -p $BUILD_DIR/$module_name/
echo "---- Copying $module_name/$flume_module manifests ----"
cp $DISTRIB_PATH/modules/$module_name/configs/$flume_module/*.yaml $BUILD_DIR/$module_name
done
else
mkdir -p $BUILD_DIR/$module_name
echo "---- Copying $module_name manifests ----"
cp $DISTRIB_PATH/modules/$module_name/configs/*.yml $BUILD_DIR/$module_name
fi
done
if $CREATE_TEMPLATES; then
mkdir -p $BUILD_DIR/templates
cp $TEMPLATES_DIR/* $BUILD_DIR/templates
fi
}
function removeIgnoredFiles {
echo ""
echo "============ REMOVING IGNORED MANIFESTS ==========="
while IFS=',' read -ra FILES_TO_REMOVE; do
for removed_file in "${FILES_TO_REMOVE[@]}"; do
echo "---- Removing $removed_file ----"
find $BUILD_DIR -type f -name $removed_file -delete
done
done <<< "$IGNORED_FILES"
}
function createSecrets {
echo ""
echo "============ CREATING SECRETS ==========="
mkdir -p $BUILD_DIR/secrets
for secret_name in `ls $SECRETS_DIR`; do
echo "---- Creating Secret file $secret_name ----"
kubectl create secret generic $secret_name \
--from-file=$SECRETS_DIR/$secret_name/ \
--dry-run=client \
-o yaml >> $BUILD_DIR/secrets/$secret_name.yml
done
}
function createConfigMaps {
mkdir -p $BUILD_DIR/configmaps
echo ""
echo "============ CREATING CONFIGMAPS ==========="
for configmap_name in `ls $CONFIGS_DIR`; do
echo "--- Creating ConfigMap file $configmap_name ----"
kubectl create configmap $configmap_name \
--from-file=$CONFIGS_DIR/$configmap_name/ \
--dry-run=client \
-o yaml >> $BUILD_DIR/configmaps/$configmap_name.yml
done
}
function processPlaceholders {
echo ""
echo "============ PROCESS PLACEHOLDERS ==========="
# Read with:
# IFS (Field Separator) =
# -d (Record separator) newline
# first field before separator as key
# second field after separator and reminder of record as value
while IFS='=' read -d $'\n' -r key value; do
# Skip lines starting with sharp or lines containing only space or empty lines
[[ "$key" =~ ^([[:space:]]*|[[:space:]]*#.*)$ ]] && continue
echo "Replacing parameter $key with value = $value"
if [[ "$OSTYPE" == "linux-gnu"* ]]; then
# RHEL
find $BUILD_DIR -type f -exec sed -i "s|\${$key}|$value|g" {} \;
else
# MacOS
find $BUILD_DIR -type f -exec sed -i '' "s|\${$key}|$value|g" {} \;
fi
done < $PARAM_FILE
}
function replaceIstioName {
local old_istio_name="istiod-basic"
local new_istio_name="istiod-common-install"
if [[ "$OSTYPE" == "linux-gnu"* ]]; then
# RHEL
find $BUILD_DIR -type f -exec sed -i "s|$old_istio_name|$new_istio_name|g" {} \;
else
# MacOS
find $BUILD_DIR -type f -exec sed -i '' "s|$old_istio_name|$new_istio_name|g" {} \;
fi
}
function deployToK8S {
local path_to_manifests=$1
find $path_to_manifests -type f -exec kubectl apply -f {} \;
# find $path_to_manifests -type f -exec echo {} \;
}
rm -r $BUILD_DIR
copyManifests
removeIgnoredFiles
createSecrets
createConfigMaps
processPlaceholders
replaceIstioName
echo ""
echo "============ APPLY MODULES MANIFESTS ==========="
for module_name in $DISTRIB_MODULES; do
if [[ $DEPLOYED_MODULES == *"$module_name"* ]];
then
echo "--- Apply module $module_name manifests ----"
deployToK8S $BUILD_DIR/$module_name
else
echo "--- Skip apply module $module_name manifests ----"
fi
done
if $CREATE_SECRETS; then
echo ""
echo "============ APPLY SECRETS ==========="
deployToK8S $BUILD_DIR/secrets
fi
if $CREATE_CONFIGS; then
echo ""
echo "============ APPLY CONFIGMAPS ==========="
deployToK8S $BUILD_DIR/configmaps
fi
if $CREATE_TEMPLATES; then
echo ""
echo "============ APPLY CUSTOM TEMPLATES ==========="
deployToK8S $BUILD_DIR/templates
fi
Автоматическое обновление компонентов в Kubernetes (опционально)#
Шаг 1.#
В файл конфигурации PILP Install_EIP STAND_NAME/AUDIT_DIR/os_yaml_dirs.conf внести список директорий с модулями Platform V Audit SE (AUD), которые предназначены для установки в Kubernetes:
distrib-\<version\>-MS/modules/audit2-client-proxy/configs
distrib-\<version\>-MS/modules/audit2-admin/configs
distrib-\<version\>-MS/modules/audit2-controlplane/configs
distrib-\<version\>-MS/modules/audit2-synchronizer/configs
distrib-\<version\>-MS/modules/audit2-ui/configs
distrib-\<version\>-MS/modules/audit2-flume/configs/common
distrib-\<version\>-MS/modules/audit2-flume/configs/events-avro-kafka-to-external-kafka
distrib-\<version\>-MS/modules/audit2-flume/configs/events-kafka-to-external-kafka
distrib-\<version\>-MS/modules/audit2-flume/configs/events-kafka-to-hive
distrib-\<version\>-MS/modules/audit2-flume/configs/events-kafka-to-hive-proxy
distrib-\<version\>-MS/modules/audit2-flume/configs/events-kafka-to-solr
distrib-\<version\>-MS/modules/audit2-flume/configs/events-kafka-to-solr-proxy
distrib-\<version\>-MS/modules/audit2-flume/configs/invalid-events-kafka-to-hbase
distrib-\<version\>-MS/modules/audit2-flume/configs/invalid-events-kafka-to-hbase-proxy
distrib-\<version\>-MS/modules/audit2-flume/configs/invalid-metamodel-kafka-to-hbase
distrib-\<version\>-MS/modules/audit2-flume/configs/invalid-metamodel-kafka-to-hbase-proxy
distrib-\<version\>-MS/modules/audit2-flume/configs/invalid-operation-kafka-to-hbase
distrib-\<version\>-MS/modules/audit2-flume/configs/metamodel-kafka-to-hbase
distrib-\<version\>-MS/modules/audit2-flume/configs/metamodel-kafka-to-hbase-proxy
distrib-\<version\>-MS/modules/audit2-flume/configs/operation-kafka-to-external-kafka
distrib-\<version\>-MS/modules/audit2-flume/configs/operation-kafka-to-hbase
Шаг 2.#
В файл конфигурации PILP Install_EIP STAND_NAME/AUDIT_DIR/os_ignore.conf внести список файлов, игнорируемых при развертывании:
parameters.conf
audit2-client-proxy-route.yml
audit2-admin-route.yml
audit2-controlplane-route.yml
audit2-synchronizer-route.yml
audit2-ui-route.yml
virtualservice-ingress.yml
virtualservice-ingress-mtls.yml
Эти файлы необходимы только при развертывании компонентов в отдельном namespace.
Шаг 3.#
Необходимо скопировать из дистрибутива все директории из distrib-<version>-MS/modules/MODULE_NAME/configs/certs (для сервисов обработки соответственно distrib-<version>-MS/modules/audit-cloud-flume/configs/common/certs) в директорию конфигурации EIP STAND_NAME/AUDIT_DIR/openshift.
Сервисы обработки
events-kafka-to-solr
events-kafka-to-hive
operation-kafka-to-hbase
metamodel-kafka-to-hbase
invalid-events-kafka-to-hbase
invalid-operation-kafka-to-hbase
invalid-metamodel
events-kafka-to-solr-proxy
events-kafka-to-hive-proxy
metamodel-kafka-to-hbase-proxy
invalid-events-kafka-to-hbase-proxy
invalid-metamodel-kafka-to-hbase-proxy
events-avro-kafka-to-external-kafka
events-kafka-to-external-kafka
operation-kafka-to-external-kafka
Шаг 4.#
Заполните в PILP Install_EIP в директории STAND_NAME/AUDIT_DIR/openshift все вложенные файлы с сертификатами и паролями от них, после чего зашифруйте их с помощью утилиты ansible-vault. Внимание! Менять названия папок и файлов запрещено, потому что это приведет к некорректной установке компонентов.
Шаг 5.#
Замените в PILP Install_EIP файл конфигурации STAND_NAME/AUDIT_DIR/os_props.conf файлом из дистрибутива distrib-<version>-MS/doc/os_props.conf и заполните его стендозависимыми значениями. Файл os_props.conf содержит все параметры всех модулей Platform V Audit SE (AUD), которые предназначены для установки в Kubernetes. Примечание: Дублирующиеся параметры закомментированы, а не удалены для того, чтобы было понятно, в конфигурацию какого модуля они попадают.
Шаг 5.1 - Настройка параметров журналирования в компоненте Журналирование (LOGA) продукта Platform V Monitor (OPM)
По умолчанию, сведения о работе Platform V Audit SE (AUD) сохраняются локально в журналах подов в Kubernetes. Чтобы обеспечить централизованное хранение и доступ к журналам при помощи компонента Журналирование (LOGA) продукта Platform V Monitor (OPM), внесите следующие настройки в конфигурационный файл os_props.conf.
В разделе AUDIT-CLIENT-PROXY:
LOGGER_SERVICE_HOSTNAME="стендо-зависимое имя домена, назначенное Pod с установленным компонентом Журналирование (LOGA) продукта Platform V Monitor (OPM)"
LOGGER_SIDECAR_IMAGE="стендо-зависимый URL к репозиторию в Nexus, где находится вспомогательное приложение sidecar, ответственное за сбор локальных журналов и отправку их в компонент Журналирование (LOGA) продукта Platform V Monitor (OPM)"
LOGGER_SERVICE_PORT="443"
За более детальной информацией обратитесь к документации для компонента Журналирование (LOGA) продукта Platform V Monitor (OPM).
Шаг 5.2 - Настройка параметров для инструментов аутентификации и авторизации Platform V IAM SE (IAM)
Для подключения к компонентам AUTH и AUTZ аутентификации и авторизации Platform V IAM SE (IAM), внесите следующие настройки в конфигурационный файл os_props.conf, в раздел AUDIT-CLOUD-ADMIN:
OSA_BASE_URL="URL, по которому расположена развернутая служба аутентификации и авторизации Platform V IAM SE (IAM)"
IAM_AUTH_PUBLICKEY_LOCATIONS="URL, по которым расположены публичные ключи к сертификатам безопасности"
За более детальной информацией обратитесь к документации сервиса Platform V IAM SE (IAM).
Шаг 6.#
Запустите задачу в PILP Install_EIP для обновления компонентов Platform V Audit SE (AUD) в Kubernetes.