Сценарии администрирования#
№ |
Название раздела |
|---|---|
1 |
|
2 |
|
3 |
|
4 |
Реализация Graceful shutdown и конфигурирование Rolling Update сервиса Batch Tasks |
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
10 |
|
11 |
|
12 |
|
13 |
|
14 |
|
15 |
Конфигурация стратегии обновления состояния Очередей внутри сущности Задачи |
16 |
|
17 |
|
18 |
Для выполнения сценариев администрирования системному администратору должна быть выдана роль admin.
Публикация health-метрик Batch Tasks для Prometheus#
Работоспособность сервиса Пакетная обработка задач (Batch Tasks) может быть определена с помощью health-метрик на графиках системы мониторинга.
Для этого сервис Batch Tasks выполняет публикацию дополнительной readiness-метрики batch_availability_readiness в формате Prometheus, которая отображает общую готовность сервиса обрабатывать запросы. Метрика Prometheus в actuator/prometheus синхронизирована с health-метрикой /actuator/health/readiness и отражает следующие состояния:
"UP" = 1.0— если все смежные сервисы работают корректно."DOWN" = 0.0— в других случаях.
Рекомендации по заданию стойких паролей#
Пароль считается стойким, если он удовлетворяет следующим условиям:
пароль изменяется минимум один раз за 80 дней;
в пароле используются строчные и прописные буквы и цифры;
длина пароля составляет не менее 12 символов;
пароль не должен содержать логин УЗ пользователя или какую-либо его часть;
пароль должен быть уникален, недопустимо использование одного и того же пароля для нескольких УЗ одного пользователя;
пароль должен храниться в зашифрованном виде, хранение пароля в незащищенном виде (в текстовых, конфигурационных файлах, скриптов) запрещено;
в случае если хранение пароля в зашифрованном виде нереализуемо, доступ к файлам хранения должен быть ограничен только УЗ владельца.
при компрометации пароля необходимо незамедлительно его сменить;
пароль не применяется в открытых сервисах.
Приведенные рекомендации по настройке парольной политики не должны противоречить требованиям внутренних документов Заказчика, отраслевых и национальных стандартов, требований уполномоченных регуляторов и законодательства РФ.
Конфигурирование подключения сервиса к СУБД#
Чтобы выполнить конфигурирование подключения сервиса Batch Tasks к БД, например, настроить подключение к другому экземпляру БД, выполните следующие действия:
Сконфигурируйте настройки подключения Batch Tasks к БД:
измените значение параметра
jdbc-url(URL соединения с БД) на нужное;в случае, если подключение к новой БД осуществляется под новым пользователем, внесите правки в значения параметров
database.main.passwordиdatabase.main.username;разместите секреты с новыми
username,passwordв системе оркестрации контейнерами согласно инструкции, приведенной в Руководстве по установке в разделе «Настройка окружения»;проверьте актуальность настроек для новой СУБД в
batch-tasks.all.conf:
# URL соединения с основной БД. Пример: jdbc:postgresql://example.com:5432/dbname
# Если установка происходит вместе с конфигурационными файлами Istio, то порт должен совпадать с MAIN_DB_EGRESS_IN_PORT
MAIN_DB_JDBC_URL=<!- заполните самостоятельно ->
# Флаг поддержки SSL/TLS-соединения на основной БД (true/false). Если при подключении к новой БД используется SLL (true), то проверьте нижеследующие параметры (TLS_CERT_PATH, TLS_KEY_PATH, TLS_ROOT_CERT_PATH, TLS_FACTORY); если SLL при подключении к новой БД не используется (false), то эти параметры не применяются.
MAIN_DB_SSL_ON=<!- заполните самостоятельно: true/false ->
# Путь до volumeMounts публичного клиентского сертификата
MAIN_DB_TLS_CERT_PATH=/app/certs/db/postgresql.crt
# Путь до volumeMounts приватного клиентского ключа
MAIN_DB_TLS_KEY_PATH=/app/certs/db/postgresql.pk8
# Путь до volumeMounts публичного родительского (CA) сертификата
MAIN_DB_TLS_ROOT_CERT_PATH=/app/certs/db/root.crt
# Фабрика для построения соединения с БД
MAIN_DB_TLS_FACTORY=org.postgresql.ssl.jdbc4.LibPQFactory
# Дополнительные параметры url основной базы данных. Добавляются в конец url путем добавления ¶m1=value1¶m2=value2&....
# Если дополнительные параметры отсутствуют, то необходимо оставить значение плейсхолдер пустым. Пример параметров: &targetServerType=master&prepareThreshold=0. При добавлении параметров учесть, что добавление начинается с символа "&"
# В этом параметре указывается схема подключения. Значение по умолчанию: ¤tSchema=tasks_schema
ADDITIONAL_PARAMETERS_MAIN_DB=¤tSchema={{ lookup('custom_vars','jdbc.tasks_postgres.schema.main') }}
MAIN_DB_JDBC_FULL_URL={{MAIN_DB_JDBC_URL}}?ssl={{MAIN_DB_SSL_ON}}&sslfactory={{MAIN_DB_TLS_FACTORY}}&sslrootcert={{MAIN_DB_TLS_ROOT_CERT_PATH}}&sslcert={{MAIN_DB_TLS_CERT_PATH}}&sslkey={{MAIN_DB_TLS_KEY_PATH}}{{ADDITIONAL_PARAMETERS_MAIN_DB}}
Для использования кластера БД Patroni в файле batch-tasks.istio.all.conf необходимо сконфигурировать следующие параметры:
### Конфигурирование параметров Stand-In БД
MAIN_DB_HOST_M=<Обязательно к заполнению>
MAIN_DB_IP_M=<Обязательно к заполнению>
MAIN_DB_PORT_M=5432
### Мастер БД в кластере Main
MAIN_DB_EGRESS_IN_PORT_M=12001
MAIN_DB_EGRESS_OUT_PORT_M=2001
### Конфигурирование параметров Stand-In БД
### Мастер БД в кластере SI - заполнить при необходимости
SI_DB_HOST_M=<Обязательно к заполнению>
SI_DB_IP_M=<Обязательно к заполнению>
SI_DB_PORT_M=5432
### Мастер БД в кластере SI
SI_DB_EGRESS_IN_PORT_M=12003
SI_DB_EGRESS_OUT_PORT_M=2003
# Флаг включения дополнительных параметров и конфигурационных файлов для возможности использования кластера Patroni
PATRONI_ENABLED=false
Если используется репликационная БД, повторите вышеуказанные действия для конфигурирования параметров подключения к репликационной базе данных (Stand-In DB).
# Host основной БД. Введите параметры для новой БД, например:
MAIN_DB_HOST=tkled-pprb00045.vm.esrt.cloud.xxxx.ru
MAIN_DB_IP=10.xx.xxx.xx
MAIN_DB_PORT=5432
# Host SI БД. Введите параметры для новой SI БД, например:
SI_DB_HOST=tkled-pprb00062.vm.esrt.cloud.xxxx.ru
SI_DB_IP=10.xx.xxx.xx
SI_DB_PORT=5432
Реализация Graceful Shutdown и конфигурирование Rolling Update сервиса Batch Tasks#
Graceful shutdown#
Batch Tasks поддерживает возможность плавного завершения работы приложения с минимизацией ошибок и потерь данных. Сервис будет обрабатывать запросы, которые поступили до момента получения сигнала завершения, фиксировать результат и после этого завершится.
Общий принцип завершения работы Pod#
Pod переводится в статус Terminating и исключается из списка конечных точек для сервиса. Начинается отсчет тайм-аута (grace period).
Выполняется команда preStop Hook. Конфигурирование команды preStop Hook в yaml-файле позволяет выполнить одно из двух действий: команду или запрос.
После завершения команды preStop Hook приложению посылается сигнал SIGTERM.
Начинается отсчет тайм-аута (grace period), за время которого приложение завершается. Конфигурируется в yaml-файле.
Если за время тайм-аута приложение еще не завершилось, посылается сигнал SIGKILL, приложение принудительно завершает работу, Pod удаляется.
Особенности tasks-worker#
Микросервис tasks-worker выполняет вызовы httpTarget с помощью Apache Async Http Client по мере появления новых Задач. При этом вызовы синхронизируются через БД (таблица билетов).
В команде preStop Hook выполняются несколько действий:
В начале команды preStop Hook останавливается цикл отбора новых Задач из БД.
Выполняется ожидание в течение времени, необходимого для завершения уже запущенной итерации отбора новых задач из БД. Конфигурируется в файле
tasks-worker.confв плейсхолдерTASK_WORKER_PRESTOP_SLEEP_DURATION_SECONDS.Выполняется ожидание завершения запущенных вызовов httpTarget, не дольше заданного времени. Если вызовы завершаются раньше, ожидание также прекращается раньше. Конфигурируется в файле
tasks-worker.confв плейсхолдерTASK_WORKER_HTTP_CLIENT_GRACE_PERIOD_SECONDS.Завершается выполнение команды preStop Hook, сервис получает
SIGTERMи завершается. Длительность выключения компонентов сервиса конфигурируется в файлеtasks-worker.confв плейсхолдерTASK_WORKER_TIMEOUT_PER_SHUTDOWN_PHASE. При этом сумма трех вышеперечисленных периодов времени не должна превысить общее время выключения Pod, которое конфигурируется в файлеtasks-worker.confв плейсхолдерTASK_WORKER_TERMINATION_GRACE_PERIOD_SECONDS.
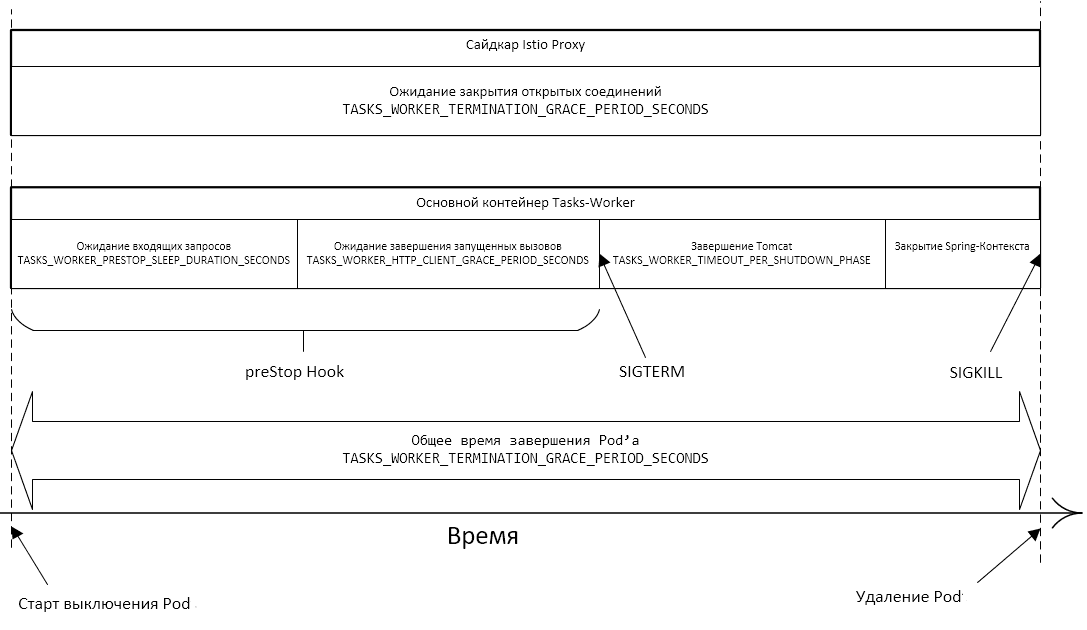
Конфигурирование параметров Graceful Shutdown#
Для конфигурирования параметров Graceful Shutdown заполните следующие файлы:
tasks-server.conf:
### Конфигурирование параметров Graceful Shutdown для TASK_SERVER
#### Сумма остальных интервалов для TASK_SERVER. Размерность: целое число секунд
TASK_SERVER_TERMINATION_GRACE_PERIOD_SECONDS=30
#### Необходимое время ожидания для завершения уже запущенной итерации отбора новых задач из БД. Размерность: целое число секунд
TASK_SERVER_PRESTOP_SLEEP_DURATION_SECONDS=10
#### Время на Graceful Shutdown для Tomcat, который обрабатывает входящие запросы. Значение параметра задается в формате Duration, например: "PT20S"; если задать просто число, то в качестве размерности будут использованы миллисекунды
TASK_SERVER_TIMEOUT_PER_SHUTDOWN_PHASE=PT20S
tasks-worker.conf:
### Конфигурирование параметров Graceful Shutdown для TASK_WORKER
#### Сумма остальных интервалов для TASK_WORKER. Размерность: целое число секунд
TASK_WORKER_TERMINATION_GRACE_PERIOD_SECONDS=45
#### Необходимое время ожидания для завершения уже запущенной итерации отбора новых задач из БД. Размерность: целое число секунд
TASK_WORKER_PRESTOP_SLEEP_DURATION_SECONDS=5
#### Время ожидания завершения запущенных вызовов httpTarget. Если вызовы завершаются раньше, ожидание также прекращается раньше. Размерность: целое число секунд
TASK_WORKER_HTTP_CLIENT_GRACE_PERIOD_SECONDS=20
#### Время на Graceful Shutdown для Tomcat, который обрабатывает входящие запросы. Значение параметра задается в формате Duration, например: "PT60S"; если задать просто число, то в качестве размерности будут использованы миллисекунды
TASK_WORKER_TIMEOUT_PER_SHUTDOWN_PHASE=PT20S
tasks-gc.conf:
### Конфигурирование параметров Graceful Shutdown для TASK_GC
#### Сумма остальных интервалов для TASK_GC. Размерность: целое число секунд
TASK_GC_TERMINATION_GRACE_PERIOD_SECONDS=30
#### Необходимое время ожидания для завершения уже запущенной итерации отбора новых задач из БД. Размерность: целое число секунд
TASK_GC_PRESTOP_SLEEP_DURATION_SECONDS=10
#### Время на Graceful Shutdown для Tomcat, который обрабатывает входящие запросы. Значение параметра задается в формате Duration, например: "PT60S"; если задать просто число, то в качестве размерности будут использованы миллисекунды
TASK_GC_TIMEOUT_PER_SHUTDOWN_PHASE=PT20S
tasks-journal-applier.conf:
### Конфигурирование параметров Graceful Shutdown для TASK_JOURNAL_APPLIER
#### Сумма остальных интервалов для TASK_JOURNAL_APPLIER. Размерность: целое число секунд
TASK_JA_TERMINATION_GRACE_PERIOD_SECONDS=30
#### Необходимое время ожидания для завершения уже запущенной итерации отбора новых задач из БД. Размерность: целое число секунд
TASK_JA_PRESTOP_SLEEP_DURATION_SECONDS=10
#### Время на Graceful Shutdown для Tomcat, который обрабатывает входящие запросы. Значение параметра задается в формате Duration, например: "PT60S"; если задать просто число, то в качестве размерности будут использованы миллисекунды
TASK_JA_TIMEOUT_PER_SHUTDOWN_PHASE=PT20S
Rolling Update#
Сервис Batch Tasks поддерживает Rolling Update — стратегию обновления без прерывания работы сервиса с постепенным отключением экземпляров старой версии и вводом экземпляров новой версии.
В системе оркестрации контейнерами предусмотрена стратегия обновления Rolling Update, которая реализует эту логику.
Чтобы просмотреть настройки стратегии обновления, в консоли системы оркестрации контейнерами выполните следующие действия:
Последовательно перейдите по вкладкам Workloads → Deployment (Deployment Configs).
В списке выберите конфигурацию
tasks-worker/tasks-server/tasks-journal-applier.В конфигурации перейдите на вкладку YAML и поиском найдите
spec.strategy.type.
Параметр конфигурируется в файле batch-tasks.k8s.all.conf.
При обновлении приложения стратегией Rolling создается новый Replication Controller. При этом количество Pod в старом Replication Controller постепенно сокращается, а в новом — увеличивается до тех пор, пока в старом не достигнет нуля, а в новом — значения, заданного параметром replicas (в OpenShift конфигурация tasks-server параметр spec.replicas).
Чтобы просмотреть настройки количества реплик, в консоли системы оркестрации контейнерами выполните следующие действия:
В меню Workloads выберите раздел Deployment (Deployment Configs).
В списке выберите необходимую конфигурацию
tasks-server/tasks-worker/tasks-gc/tasks-journal-applier.В конфигурации перейдите на вкладку YAML.
Поиском найдите параметр
spec.replicas.
Параметр конфигурируется в файлах:
tasks-server.confс плейсхолдерTASK_SERVER_REPLICAS_COUNT;tasks-worker.confс плейсхолдерTASK_WORKER_REPLICAS_COUNT;tasks-journal-applier.confс плейсхолдерTASK_JA_APPLIER_REPLICAS_COUNT.
Для gc не конфигурируется, т.к. для корректной работы Pod необходим только один экземпляр.
Доступные стратегии развертывания#
Существует две стратегии развертывания, которые могут комбинироваться:
Поочередное завершение работы старых Pods и запуск на их месте новых Pods:
плюсы: способ не требует дополнительных ресурсов,
минусы: во время обновления количество работающих Pods будет меньше, чем количество реплик.
Поочередный запуск новых Pods, а после их успешного запуска (получение успешной liveness/readiness probes) — завершение старых pods:
плюсы: доступность сервиса не уменьшается,
минусы: требует дополнительных ресурсов.
При комбинировании способов ожидаемые:
недостатки:
временное уменьшение количества работающих экземпляров сервиса,
временное использование дополнительных ресурсов.
преимущества:
более быстрое обновление.
Выбор стратегии остается за администраторами системы оркестрации контейнерами.
Конфигурирование параметров Rolling Update#
Пример заполненного файла tasks-server.conf:
## Конфигурирование параметров Rolling Update
### Дополнительная информация
#### Примеры к параметрам *_UPDATE_MAX_UNAVAILABLE: 1) При replicas=3 и maxUnavailable=1 во время обновления количество работающих Pods не будет опускаться ниже 2 и работа сервиса не будет прерываться. 2) При replicas=2 и maxUnavailable=2 стратегия Rolling сводится к стратегии Recreate — останавливаются оба Pods, вместо них запускаются два новых. Непрерывная работа сервиса в этом случае не обеспечивается
#### Внимание! Значения параметров *_MAX_UNAVAILABLE и *_MAX_SURGE не могут одновременно быть равны нулю
### Конфигурирование параметров Rolling Update для TASK_SERVER
#### Время в секундах на полное обновление. При превышении выполняется откат к предыдущей версии
TASK_SERVER_ROLLING_UPDATE_TIMEOUT_SECONDS=600
#### Насколько можно сократить количество работающих Pods относительно соответствующего параметра *_REPLICAS_COUNT
TASK_SERVER_ROLLING_UPDATE_MAX_UNAVAILABLE=1
#### Насколько общее число Pods (число: работающие + запускающиеся + завершающиеся) может превысить соответствующий параметр *_REPLICAS_COUNT
TASK_SERVER_ROLLING_UPDATE_MAX_SURGE=0
Пример заполненного файла tasks-worker.conf:
### Конфигурирование параметров Rolling Update для TASK_WORKER
#### Время в секундах на полное обновление. При превышении выполняется откат к предыдущей версии
TASK_WORKER_ROLLING_UPDATE_TIMEOUT_SECONDS=600
#### Насколько можно сократить количество работающих Pods относительно соответствующего параметра *_REPLICAS_COUNT
TASK_WORKER_ROLLING_UPDATE_MAX_UNAVAILABLE=1
#### Насколько общее число Pods (число: работающие + запускающиеся + завершающиеся) может превысить соответствующий параметр *_REPLICAS_COUNT
TASK_WORKER_ROLLING_UPDATE_MAX_SURGE=0
Пример заполненного файла tasks-gc.conf:
### Конфигурирование параметров Rolling Update для TASK_GC
#### Время в секундах на полное обновление. При превышении выполняется откат к предыдущей версии
TASK_GC_ROLLING_UPDATE_TIMEOUT_SECONDS=600
#### Насколько можно сократить количество работающих Pods относительно соответствующего параметра *_REPLICAS_COUNT
TASK_GC_ROLLING_UPDATE_MAX_UNAVAILABLE=1
#### Насколько общее число Pods (число: работающие + запускающиеся + завершающиеся) может превысить соответствующий параметр *_REPLICAS_COUNT
TASK_GC_ROLLING_UPDATE_MAX_SURGE=0
Пример заполненного файла tasks-journal-applier.conf:
### Конфигурирование параметров Rolling Update для TASK_JOURNAL_APPLIER
#### Время в секундах на полное обновление. При превышении выполняется откат к предыдущей версии
TASK_JA_ROLLING_UPDATE_TIMEOUT_SECONDS=600
#### Насколько можно сократить количество работающих Pods относительно соответствующего параметра *_REPLICAS_COUNT
TASK_JA_ROLLING_UPDATE_MAX_UNAVAILABLE=1
#### Насколько общее число Pods (число: работающие + запускающиеся + завершающиеся) может превысить соответствующий параметр *_REPLICAS_COUNT
TASK_JA_ROLLING_UPDATE_MAX_SURGE=0
Администрирование внешних средств защиты информации осуществляется в соответствии с их документацией.
Настройка геобалансировщика#
Для настройки геобалансировки с health-check в файле batch-tasks.istio.all.conf установите параметры согласно таблице.
Параметр |
Описание |
|---|---|
CN_CERT_GEOBALANCER=geobalancer_cn |
Значения клиентского сертификата геобалансировщика (CN) |
INGRESS_HEALTH_URL=health-istio-ingressgateway-${NAMESPACE}.apps.${OPENSHIFT_CLUSTER} |
Host роутера Ingress на health-endpoint |
INGRESS_HEALTH_PORT=5444 |
Входной порт Ingress для приема HTTPS-трафика на health-endpoint |
INGRESS_HTTPS_HEALTH_GW_NAME=batch-ingress-health-gw |
Наименование Ingress Gateway для HTTPS-трафика на health-endpoint |
Просмотр метрик мониторинга#
Для просмотра метрик мониторинга с использованием компонента Объединенный мониторинг Unimon (MONA):
В среде контейнеризации перейдите на вкладку PODs и выберите pod, например,
tasks-server.Перейдите в терминал и введите команду:
curl localhost:8081/actuator/prometheus
В полученном сообщении отобразятся отбрасываемые метрики с событиями мониторинга (также приведены в разделе «События мониторинга»).
Перейдите в систему отображения метрик (например, Prometheus), указав необходимую метрику. Например,
system_cpu_usage.
Контроль сертификатов#
Подробная инструкция по получению сертификатов приведена в Руководстве по установке в разделе «Настройка окружения».
Сертификаты хранятся в зашифрованном виде на сервере, где будет развернут компонент, и необходимы для всех TLS/mTLS-соединений. Сервис Batch Tasks не предусматривает дополнительных средств защиты сертификатов. Также сертификаты могут храниться в зашифрованном виде в SecMan (при наличии интеграции).
Для управления ключами и сертификатами необходимо использовать либо стандартный механизм Kubernetes Secrets, либо продукт Secret Management System (инструкция по интеграции с продуктом приведена в Руководстве по установке в разделе «Настройка интеграции со смежными сервисами».
При развертывании дистрибутива работа с секретными данными происходит на следующих этапах:
Передача секретных данных в систему оркестрации контейнерами.
Использование секретных данных при выполнении шагов развертывания (например, для добавления скриптов с использованием библиотеки Liquibase).
В первом случае необходимо передать в систему оркестрации контейнерами секрет, во втором — просто хранить секретные данные, которые будут использоваться при работе Jenkins Job. В обоих случаях также имеется возможность получить секреты из SecMan.
Сервис Batch Tasks может использовать сторонние сертификаты:
Istio (Ingress, Egress) при использовании Istio для сетевой безопасности;
клиентский и серверный сертификаты для подключения к БД по SSL (при необходимости);
сертификат для ОТТ (при необходимости).
Рекомендации по работе с сертификатами:
Сертификат должен быть подписан только удостоверяющим центром (CA). Необходимо удостовериться в отсутствии самоподписных сертификатов.
Сертификат должен «принадлежать» сервису Batch Tasks (нельзя использовать один и тот же сертификат для функционирования разных сервисов в рамках одной инсталляции Platform V).
Сертификат должен быть действительным на текущую дату. Необходима проверка срока действия сертификата.
Сертификат не должен быть отозван соответствующим удостоверяющим центром (CA). Необходима проверка списков исключения сертификатов.
Должны быть подключены механизмы аутентификации, авторизации и валидации по сертификатам (при интеграции сервиса с компонентами Platform V, реализующими данный функционал, например OTT).
Приватный/доверенный ключ не должен распространяться по каналам связи и должен иметь стойкий пароль.
Управление сертификатами для mTLS взаимодействий внутри проекта осуществляется механизмами системы оркестрации контейнерами.
Для хранения ключевой информации в системе оркестрации контейнерами должны использоваться только защищенные артефакты Secret.
Сертификаты для тестовых и промышленных сред должны быть выданы удостоверяющим центром.
Для сред разработки разрешено использование самоподписанных сертификатов.
Инструкция по получению сертификатов приведена в Руководстве по установке в разделе «Настройка окружения».
По истечении срока действия сертификата необходимо перевыпустить его и разместить в том же хранилище, где был размещен предыдущий сертификат с истекшим сроком действия.
Безопасная загрузка настроек сервиса Batch Tasks#
В сервисе Batch Tasks первоначальный запуск контейнера и загрузка всех настроек, необходимых для запуска компонента, происходят при старте контейнера из ConfigMap, Secrets, внешнего хранилища конфигураций, интегрированного в среду исполнения. Монтирование секретов происходит в папку вместо монтирования в переменные окружения. Также секреты могут быть получены из сервиса SecMan.
Приложению для запуска и работы нужны конфигурационные файлы, в которых прописаны настройки и сертификаты. Сертификаты хранятся в Secrets и монтируются на файловую систему при старте контейнера, откуда их читает приложение. Конфигурационные файлы хранятся в ConfigMaps и также монтируются на файловую систему контейнера.
ConfigMap и Secret подключаются к файловой системе контейнера в режиме .spec.containers[].volumeMounts[].readOnly: true.
В конфигурационных файлах вместо настроек, которые нельзя хранить в ConfigMaps в открытом виде (например, логины и пароли), оставлены плейсхолдерs. Пароли хранятся в Secrets и монтируются при запуске контейнера в отдельную папку. Приложение при запуске читает конфигурационный файл и секреты и подставляет вместо плейсхолдерs соответствующие значения из Secrets.
Настройки ConfigMap в виде переменных окружения не передаются.
Обязательный секрет#
В каталоге /install/secrets дистрибутива представлены шаблоны секретов для инсталляции.
Для подстановки значений из Secrets вместо плейсхолдерs необходимо наличие секрета в namespace системы оркестрации контейнерами Kubernetes или OpenShift с именем batch-tasks-app-secret, содержащего набор полей с необходимыми именами:
kind: Secret
apiVersion: v1
metadata:
name: batch-tasks-app-secret
data:
access.secret-key: <!- SPAS secret key ->
database.main.password: <!- main database password ->
database.main.username: <!- main database username ->
database.stand-in.password: <!- stand-in database password ->
database.stand-in.username: <!- stand-in database username ->
journal.ssl.key.password: <!- journal ssl key password ->
journal.ssl.keystore.password: <!- journal ssl keystore password ->
journal.ssl.truststore.password: <!- journal ssl truststore password ->
type: Opaque
«Безопасная» загрузка#
Секрет монтируется в определенную папку внутри контейнера (/app/secrets), для каждого поля в секрете создается файл с определенным именем, содержимое файла — значение поля в секрете. Имена файлов в этой папке совпадают с именами плейсхолдерs в конфигурационном файле. Вспомогательный класс EnvironmentPostProcessor читает файлы из этой папки и вместо каждого плейсхолдерs подставляет значение из соответствующего файла. Таким образом: пароли хранятся в секретах, а не в открытом виде, они не объявляются как переменные окружения, а загружаются из файлов напрямую.
Рекомендации к проверке подлинности сертификатов#
Для проверки подлинности сертификата выполните команду:
keytool -v -list -keystore <FileName>.jks | awk '/Owner:|Issuer:|Valid from/'
Вывод содержит следующую информацию:
Owner: информация о CN сертификата.Issuer: УЦ банка.Valid from: срок действия сертификата.
Порядок действий в случае компрометации криптографических ключей#
При компрометации криптографических ключей (для выпуска и подписи токена) рекомендуется:
Приостановить информационное взаимодействие с применением скопрометированного ключа.
Незамедлительно поставить в известность Администратора безопасности или иное уполномоченное лицо Организации по вопросам информационной безопасности о произошедшем инциденте.
Следовать указания Администратора безопасности. Общий порядок действий:
вывод из эскплуатации скомпрометированного ключа;
проведение мероприятий по замене ключа;
проверка работоспособности с новым ключом.
Конфигурирование валидатора URL#
Для включения валидатора UrlValidator для проверки HttpTarget.url в Configmap микросервиса tasks-server установите значение параметра enabled=true.
static:
task:
url:
validation:
enabled: {{URL_VALIDATOR_ENABLED}} # Флаг включения валидации Httptarget.url: true - включена; false - выключена
domains: {{URL_DOMAINS}}
При включенном UrlValidator существует возможность расширения списка доменов первого уровня, чтобы валидатор их успешно обрабатывал и не генерировал исключение InvalidFormat url.
Для расширения доменов первого уровня (валидатор обрабатывает и не генерирует исключение InvalidFormat url) перечислите через запятую домены в параметре domains.
Включение/отключение health-check для сервиса Аудит#
Для включения/отключения работы health-check в файле task-server.conf для параметра TASK_AUDIT_HEALTH_CHECK установите нужное значение флага true/false.
При значении параметра false проверка доступности сервиса Аудит не проверяется. В этом случае при недоступности сервиса Аудит, события могут не попадать в Аудит (readiness probe Аудита в actuator/health нет).
При значении параметра true и недоступном сервисе Аудит, трафик не принимается и не отправляется до тех пор, пока Аудит не станет доступным (в Batch Tasks значение readiness probe false).
# Проверка доступности сервиса Аудит (Readiness), так же включает в себя прерывание операций при ошибке отправки события в аудит: true — проверка доступности Аудит и прерывание операции включены, false — проверка доступности Аудит и прерывание операции выключены
TASK_AUDIT_HEALTH_CHECK=true
По умолчанию health check включен, для отключения перед установкой сервиса в репозитории конфигураций необходимо установить значение параметра false.
Переопределение метрик#
Режим переопределения метрик#
Для включения механизма переопределения записи метрик:
в файле
batch-tasks.all.confустановите значение параметраTASK_OVERRIDE_METRIC_MODE=true;в файле
batch-tasks.all.confустановите режим переопределения установив соответствующее значение параметраTASK_OVERRIDE_METRIC_MODE.
Возможные значения TASK_OVERRIDE_METRIC_MODE:
default - нет возможности переопределения метрик из Counter в Gauge, присутствуют метрики с окончанием на «sum» и «max»
timer - есть возможность переопределения метрик из Counter в Gauge, присутствуют метрики с окончанием на «sum» и «max»
target - есть возможность переопределения метрик из Counter в Gauge, метрики с окончанием на «sum» и «max» отсутствуют
Переопределение метрик из типа Counter (счетчик) в Gauge (измеритель)#
Переопределить метрики из типа Counter (счетчик) в Gauge (измеритель) возможно двумя способами.
Переопределение всех метрик:
в файле
tasks-server.confустановите значение параметраTASK_SERVER_GAUGE_ALL_METRICS_FLAG=TRUE.при необходимости повторите для файлов:
task-worker.conf,tasks-gc.conf,tasks-journal-applier.conf.
Точечное переопределение метрик:
в файле
tasks-server.confустановите значение параметраTASK_SERVER_GAUGE_ALL_METRICS_FLAG=FALSE.в файле
tasks-server.confв параметреTASK_SERVER_LIST_GAUGE_METRICSперечислите наименования метрик. Например:TASK_SERVER_LIST_GAUGE_METRICS=batch.tasks-server.task.update.count.request.active,batch.tasks-server.task.restart.count.request.active.при необходимости повторите для файлов:
task-worker.conf,tasks-gc.conf,tasks-journal-applier.conf.
Для определения метрик, которые переопределены, имеется возможность установки суффикса. Для этого в файле tasks-server.conf укажите значение параметра:
# Суффикс наименований метрик, которые переопределены
TASK_SERVER_METRICS_SUFFIX=<например: "_counter", "_gauge">
При необходимости повторите для файлов: task-worker.conf, tasks-gc.conf, tasks-journal-applier.conf.
Механизм включения/отключения заданных пользователем метрик#
В сервисе реализовано три режима работы: disabled, exclude, expand.
В режиме
disabled— сервис игнорирует значение параметраTASK_SERVER_METRICS_LIST_FROM_MODE. Установлен по умолчанию.В режиме
exclude— сервис не выполняет отправку метрик заданных в настройке параметраTASK_SERVER_METRICS_LIST_FROM_MODE, метрики, не указанные в настройке, сервис продолжает отправлять.В режиме
expand— сервис выполняет отправку только тех метрик, которые указаны в настройке параметраTASK_SERVER_METRICS_LIST_FROM_MODE, метрики, указанные в настройке, сервис отправляет.
Каждый pod сервиса оперирует своими метриками, поэтому для настройки механизма необходимо настраивать метрики для каждого микросервиса: tasks-journal-applier, tasks-worker, tasks-gc, tasks-server.
Пример
Для включения в микросервис tasks-server метрик: batch_tasks_server_task_create_count_request_success, batch_tasks_server_task_create_count_request_failed заполните в файле tasks-server.conf блок кода (отправляются только метрики, указанные в параметре TASK_SERVER_METRICS_LIST_FROM_MODE).
# Параметр задает текущий режим работы метрик, может принимать следующие значения: disabled, exclude, expand.
TASK_SERVER_METRICS_MODE=expand
# Список метрик, которые нужно включить (mode=expand) или наоборот исключить (mode=exclude)
TASK_SERVER_METRICS_LIST_FROM_MODE=batch.tasks-server.task.create.count.request.success,batch.tasks-server.task.create.count.request.failed
Учет нагрузки в разрезе потребителей#
Учет нагрузки в разрезе потребителей отображается на дашборде с использованием инструмента Grafana. Для запуска дашборда:
Скачайте файл dashboard_billing.json.
Перейдите на страницу Grafana, например:
https://ext-iam-spas-01.opsmon.xxx/indicator/.На странице последовательно выберите Create — Dashboard и нажмите кнопку Add a new panel.
На открывшейся странице JSON Model слева выберите поле JSON Model.
В поле добавьте содержимое файла, скачанного в п.1, и нажмите кнопку Save Changes.
На странице JSON Model в поле datasource укажите наименование источника данных.
Выберите слева на поле Variables.
На открывшейся странице:
выберите поле druidtable;
в поле Value укажите наименование таблицы, которая соответствует контуру, где располагаются стенды;
нажмите Update;
нажмите Save dashboard.
Конфигурация стратегии удаления Очередей#
Предупреждение
Для применения стратегии физического удаления из БД:
Очередь должна находиться в статусе
CLOSED.Очередь не должна иметь Задачи в статусе
RUNNINGиQUEUED.
Для конфигурирования стратегии удаления Очередей в файле tasks-server.conf установите значение параметра TASK_SERVER_USING_GC_TO_DELETE_QUEUE = true — для применения стратегии по умолчанию (хранение в БД — 24 ч).
Для удаления из БД в момент выполнения API запроса delete установите значение флага TASK_SERVER_USING_GC_TO_DELETE_QUEUE = false. Пример:
# Флаг переключения удаления Очереди через GC или при выполнении запроса: true — удаление через время с помощью tasks-gc, false — физическое удаление при выполнении запроса
TASK_SERVER_USING_GC_TO_DELETE_QUEUE=false
Прерывание передачи событий аудита#
В сервисе Batch Tasks реализована возможность прерывания текущей операции при ошибке отправки событий в Аудит (AUDT). Для этого в файле batch-tasks.all.conf установите значение флага TASK_AUDIT_ERROR_ENABLED=TRUE. Если значение параметра не установлено, то по умолчанию устанавливается значение TRUE.
Предупреждение
Если значение параметра TASK_AUDIT_ERROR_ENABLED=FALSE, то прерывание операции не выполняется, и при недоступности сервиса Аудит передаваемые события аудита не сохраняются.
Конфигурация стратегии обновления состояния Очередей внутри сущности Задачи#
Для конфигурации стратегии обновления состояния Очередей для сущности Задачи один раз в минуту в ConfigMaps в файле tasks-worker.conf установите значения параметров интервалов и лимитов для обновления:
# Интервал обновления состояния Очереди внутри Задачи
TASK_WORKER_UPDATE_QUEUE_STATE_INTERVAL=PT1M
# Задержка перед первым обновлением
TASK_WORKER_UPDATE_QUEUE_STATE_DELAY=PT1s
# Лимит для обновления состояния Очереди внутри Задачи для Очереди
TASK_WORKER_UPDATE_QUEUE_STATE_QUEUE_LIMIT=20
# Лимит для обновления состояния Очереди внутри Задачи для Задачи
TASK_WORKER_UPDATE_QUEUE_STATE_TASK_LIMIT=200
Конфигурирование параметров упругости#
Для конфигурирования параметров упругости в таблице resource_name (в основной и репликационной БД) создаются тенанты с лимитами, которые предварительно были созданы в файле custom_property.yml. При этом:
Партиций может быть создано меньше, если лимит для Очередей изначально создан меньше, чем количество партиций.
Если лимит Очередей изначально меньше, чем количество партиций, то после последующего увеличения лимита Очередей для тенанта и после рестарта pod tasks-server партиции досоздаются до заданного количества партиций. Также производится перерасчет значений параметров
partition_limitдля каждой партиции. Если были созданы Очереди, то их количество так же будет перераспределено по партициям, где главным условием является то, что количество созданных Очередей для каждой партиции не должно превышать значение в параметреpartition_limit. Неравномерность распределения количества созданных Очередей по партициям не имеет значения.Если лимит Очередей изначально больше, чем количество партиций, то после последующего уменьшения (меньше чем количество партиций) лимита Очередей для тенанта и после рестарта pod tasks-server часть партиций в параметре
partition_limitпринимает значение равным 0, т.е. использоваться для подсчета количества созданных Очередей не будут.В параметре
partition_limitуказываются лимиты для каждой партиции, которые рассчитываются по формуле:queue_limit / количество партиций. А также учитывается остаток от деления и распределяется как+1наpartition_limitдля каждой партиции. Такое вычисление применяется для каждого тенанта.
Для настройки ограничений на создание Очередей и Задач в разрезе потребителей:
В файле
batch-tasks.all.confустановите флаг включения механизма лимитов тенантов (true — для включения (установлено по умолчанию), false — для выключения):
# Включение/выключение механизма лимитов тенантов
TASK_LIMIT_ENABLED=true
В файле
batch-tasks.all.confустановите значения переменных (минимальное значение — 1, максимальное — определяют администраторы сопровождения, по умолчанию (рекомендовано) для Очередей — 1000, для Задач — 10 000):
# Лимит на создание Очередей в разрезе тенантов
TASK_QUEUES_LIMIT=1000
# Лимит на создание Задач в разрезе тенантов
TASK_TASKS_LIMIT=10000
Для настройки ограничений на создание Очередей и Задач в разрезе тенанта:
В файле
custom_property.ymlустановите значение лимитов на Задания в блоке настроекtenants. Пример заполнения:
# Блок добавления тенантов
tenants:
- name: httptarget
module_id: httptarget
queuesLimit: 100
tasksLimit: 1000
Описание блока кода по добавлению тенантов#
Параметр |
Описание |
|---|---|
name |
Имя тенанта |
module_id |
ID тенанта |
queues_limit |
Максимальное количество Очередей |
tasks_limit |
Максимальное количество Задач |
queue_in_pause_limit |
Максимальное количество Очередей со статусом «Пауза» |
host |
Хост тенанта |
port |
Порт тенанта |
egress_port |
Выходной порт |
inner_port |
Внутренний порт |
protocol |
Протокол |
tls_mode |
Режим tls |
timeout |
Тайм-аут |
common_names |
Фильтр для проверки сертификата |
cn |
Регулярное выражение, которое будет использоваться для сопоставления значений, переданных в заголовке |
program_size |
Максимальный размер программы |
В файле
tasks-server.confустановите значение параметраTASK_CREATE_RN_LIMIT_ENABLED=true. Пример:
# Включение/выключение механизма создания тенантов в таблице БД resource-name. false - тенант с дефолтными лимитами не создается в таблице resource-name, true - тенант с дефолтными лимитами создается в таблице resource-name
TASK_CREATE_RN_ENABLED=true
Переустановите сервис Batch Tasks с использованием Deploy Tools.
Отслеживание выполнения миграции#
Отслеживать статусы миграции можно через таблицу «task_limits_reconfigure_process» в базе данных.
Определение момента отправления вектора в ПЖ#
В сервисе Batch Scheduler реализована возможность выбора момента отправки вектора в ПЖ: перед коммитом транзакции или после.
Для отправки вектора в ПЖ перед коммитом транзакции в файле batch-tasks.all.conf установите значение флага true и значение флага false - для отправки после коммита транзакции. Пример:
AJ_SENDER_BEFORE_COMMIT_ENABLED=true