ru-ru.data_modeling_rdbms.проектирование-rdbms)=
Проектирование реляционной базы данных (RDBMS)#
При разработке нового прикладного решения с использованием реляционной СУБД сначала создают концептуальную модель домена в виде набора правильно нормализованных таблиц, связанных через внешние ключи.
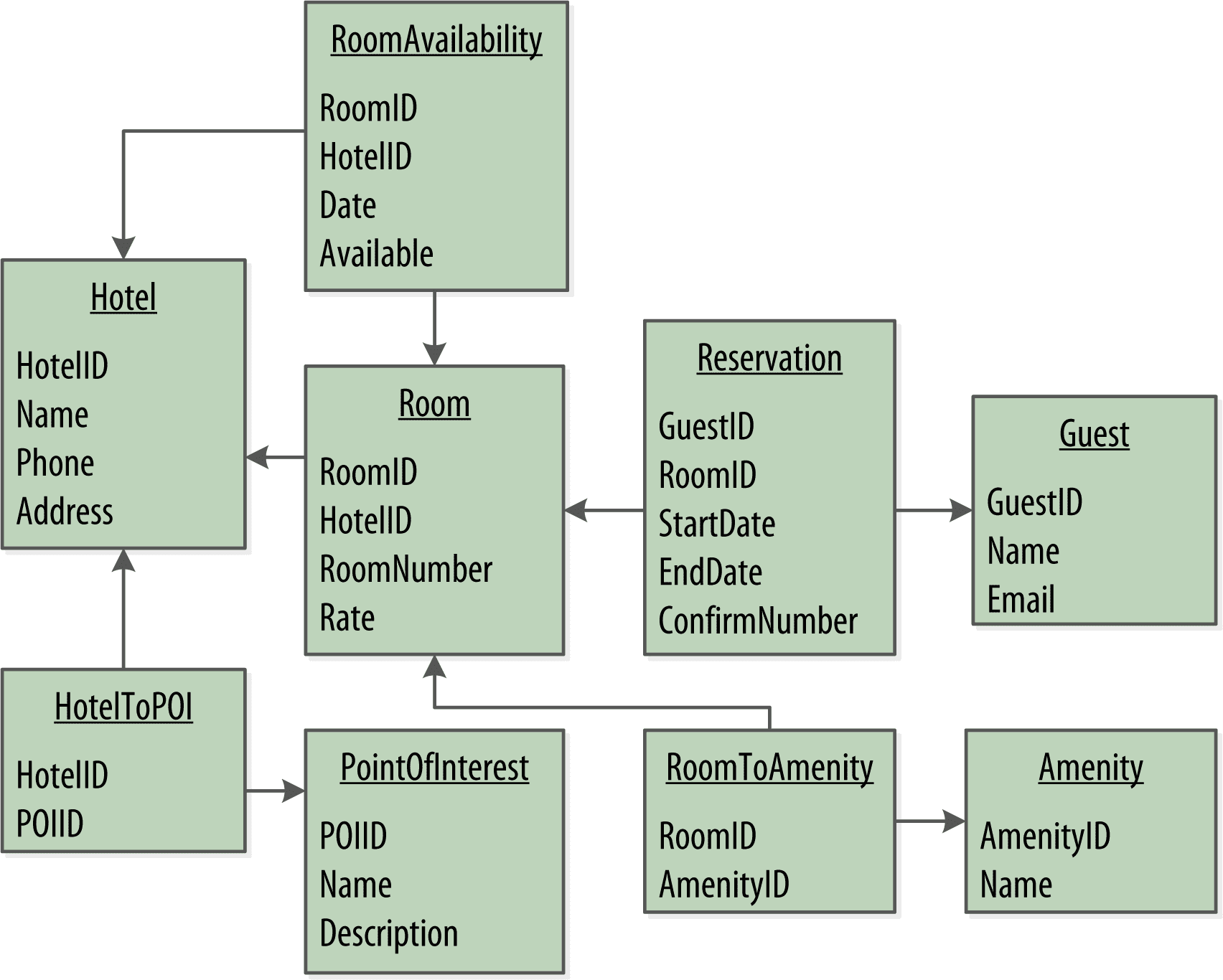
Ниже приведен пример схемы хранения данных для приложения в формате реляционного подхода. Реляционная модель предполагает наличие нескольких вспомогательных таблиц («join»-таблиц), необходимых для реализации многозначных отношений между сущностями:
На рисунке ниже показано, как можно представить хранилище данных для приложения с использованием модели реляционной базы данных. Реляционная модель включает связывание таблиц (joins), чтобы реализовать отношения многие-ко-многим из концептуальной модели: отели-достопримечательности, номера-дополнительные услуги, номера-наличие и гости-номера (через бронирование).
Различия в проектировании между реляционной СУБД и Distributed DB#
Давайте рассмотрим ключевые различия моделирования данных в Distributed DB по сравнению с реляционной СУБД.
Отсутствие joins#
В Distributed DB отсутствует такое понятие как join между таблицами. Если в ходе разработки модели данных потребуется операция соединения, придется либо самостоятельно реализовывать соединение на стороне клиента, либо создать дополнительную денормализованную таблицу, содержащую результаты такого соединения. Второй вариант предпочтителен при проектировании моделей данных в Distributed DB. Выполнение соединений непосредственно на клиентской стороне должно происходить крайне редко, поскольку правильнее всего дублировать (денормализовать) данные заранее, чтобы избежать сложных вычислений на стороне клиента.
Отсутствие целостности ссылок#
Хотя Distributed DB поддерживает такие механизмы, как легковесные транзакции и пакетные операции (batches), сама система не обеспечивает концепцию ссылочной целостности между таблицами, как это делается в классических реляционных СУБД.
В традиционных системах реляционных баз данных можно задать внешний ключ (foreign key) в одной таблице, ссылающийся на первичный ключ записи в другой таблице. В Distributed DB же такой контроль отсутствует — система не проверяет соблюдение внешних ключей и не гарантирует ссылочную целостность автоматически.
Хранение идентификаторов, связанных с другими сущностями, в таблицах по-прежнему является распространенным требованием к проектированию, но операции вроде каскадного удаления недоступны.
Денормализация#
В проектировании реляционных баз данных обычно подчеркивается важность нормализации. Однако это не преимущество при работе с Distributed DB, так как система работает оптимально при денормализованной модели данных. На практике компании часто также денормализуют данные в реляционных базах из-за двух основных причин:
Производительность: сложно добиться приемлемых показателей производительности при выполнении большого количества соединений (join) над большими объемами исторических данных. Поэтому данные денормализуются под конкретные запросы. Это работает, но противоречит принципам проектирования реляционных СУБД и заставляет задуматься, действительно ли они подходят для таких задач.
Структура бизнес-документов: существует необходимость сохранения неизменяемого состояния документа (например, счета-фактуры) в определенный момент времени. В классической реляционной модели это достигается созданием внешнего ссылочного отношения, где документ ссылается на другие таблицы, содержащие изменяемые данные. Однако изменение данных в этих внешних таблицах может привести к нарушению целостности документа, зафиксированного на момент выставления счета, что нарушает требования аудита, отчетности и законодательства.
В классическом подходе нормализация данных противоречит принципам работы реляционных баз данных, согласно которым рекомендуется избегать денормализации. Однако в Distributed DB денормализация является естественным и допустимым подходом. Она становится необходимой лишь тогда, когда модель данных сложная и требует значительных усилий по управлению несколькими таблицами вручную.
Исторически процесс денормализации в Distributed DB предполагал проектирование и управление множеством отдельных таблиц с использованием различных методик, описанных в документации. В Distributed DB есть функция — материализованные представления (materialized views <materialized-views>). Эта функциональность позволяет создавать несколько денормализованных представлений данных на основе базовой таблицы. Distributed DB берет на себя ответственность за поддержание синхронизации материализованных представлений с основной таблицей.
Проектирование запросов (query-first design)#
Классическое реляционное моделирование начинается с описания концептуальной предметной области, выделения сущностей этой области в отдельные таблицы, назначения первичных ключей и внешних ключей для моделирования связей между сущностями. Когда возникает отношение «многие ко многим», создаются специальные таблицы-соединители (join tables), представляющие собой набор уникальных ключей. Эти таблицы физически не существуют в реальности, являясь неизбежным следствием особенностей реляционного моделирования.
После завершения построения всех таблиц, переходят к написанию запросов, объединяющих разнородные данные с использованием ранее созданных связей. Запросы в реляционном мире считаются вторичными по отношению к самой модели данных. Предполагается, что при правильной организации таблиц всегда можно извлечь нужные данные, даже если придется применять сложные вложенные запросы или конструкции JOIN.
В Distributed DB подход кардинально иной. Здесь не начинают с построения модели данных, а сразу задают модель запросов. Вместо того чтобы сначала спроектировать структуру данных и потом писать запросы, в Distributed DB поступают наоборот: сначала формулируют типовые запросы, которыми будет пользоваться приложение, а затем уже строят необходимые таблицы вокруг этих запросов.
Критики утверждают, что проектирование запросов изначально ограничивает гибкость архитектуры приложения и самого процесса моделирования базы данных. Тем не менее, разумно ожидать, что разработчики будут тщательно продумывать запросы в своем приложении, подобно тому, как они задумываются о предметной области в реляционных системах. Ошибки возможны в обоих случаях, и изменения в запросах могут потребовать адаптации данных, аналогично ситуации с добавлением новых таблиц или изменением существующих в реляционных базах данных.
Оптимизация хранения данных#
В классических реляционных базах данных пользователям редко приходится задумываться о том, каким образом таблицы хранятся на диске, и практически отсутствуют рекомендации по проектированию моделей данных, ориентированные на особенности физического размещения таблиц. В отличие от этого, в Distributed DB вопрос хранения играет ключевую роль.
Поскольку каждая таблица в Distributed DB хранится в отдельном файле на диске, важно группировать тесно связанные столбцы в рамках одной таблицы. Основной задачей при создании моделей данных в Distributed DB станет минимизация количества разделов, которые необходимо сканировать для выполнения запроса. Дело в том, что раздел представляет собой неделимый элемент хранения, распределяемый целиком среди узлов кластера. Следовательно, запрос, выполняющий поиск по одному разделу, обеспечит наилучшую производительность.
Сортировка как архитектурное решение#
В реляционных базах данных (RDBMS) сортировка результатов запроса выполняется простым добавлением оператора ORDER BY в SQL-запрос. По умолчанию записи возвращаются в порядке вставки, но порядок можно изменить, добавив нужный столбец или список столбцов в оператор ORDER BY.
Однако в Distributed DB подход к сортировке совершенно иной — это решение проектирования, а не простая настройка запроса. Порядок сортировки фиксирован и зависит исключительно от выбора колонок группировки, указанных при создании таблицы командой CREATE TABLE. Хотя оператор ORDER BY поддерживается в CQL (Cassandra Query Language) для команды SELECT, он работает строго в пределах тех колонок, которые были указаны при создании таблицы.