Агрегация событий#
Шаг предназначен для агрегации нескольких событий в одно с помощью модуля declarative-mapper.
Представляет собой объект с полем type со значением "aggregation" и полями:
name— имя шага;environmentVariables— загрузка переменных из файла;format— описание форматов входящих и исходящих событий:input— формат входящих событий, аналогично Преобразование форматов событий;output— формат исходящих событий;
key— описание вычисление ключа события;trigger— описание триггера агрегации событий, объект с полемtype:count— триггер подсчета заданного количества событий, в отдельном полеcountзадается число агрегируемых событий;dsl— триггер с логикой работы на DSL, содержит поля аналогичные полюdsl; Также содержит полеtimeoutсо значением таймаута в миллисекундах после получения последнего события:
dsl— описание расположения правил агрегации;stateFull— сохранениеEnvironment.cacheв состоянииFlink, логическое, по умолчаниюfalse;destination— следующий шаг потока;error— шаг обработки в случае возникновения ошибки.
Значения полей dsl и environmentVariables представляет собой объект с полями:
source— тип источника правил, принимает значения:file— правила расположены в файловой системе;classpath— правила расположены в classpath JVM.
path— путь до файла на диске или в classpath JVM.
Значения полей input и output могут иметь значения:
json— для событий в форматеJSON;xml— для событий в форматеXML;событие в формате
csv:type— со значениемcsv;columnSeparator— разделитель полей события;fieldNames— список имен полей события для использования при трансформации, также определяет порядок полей.
объект с полями:
type— со значениемavro;schema— список схем, значение аналогично полюdsl, объект имеющий логическое полеdefaultсо значениемtrue, будет считаться схемой по умолчанию.
Пример агрегации событий#
{
name: "aggregation"
type: "aggregation"
format: {
input: "json"
output: {
type: "avro"
schema: [{
source: "file"
path: "/file/path/to/avro/schema"
},{
source: "classpath"
path: "/path/to/default/avro/schema"
default: true
}]
}
}
key {
type: "dsl"
path: "testDsl/aggregation/key.tr"
}
trigger: {
type: "dsl"
path: "testDsl/aggregation/trigger.tr"
timeout: 100
}
dsl: {
path: "testDsl/aggregation/simple.tr"
}
destination: {
name: "output"
type: "destination"
topic: "output"
config: {
type: "kafka"
name: "output"
}
}
error: {
name: "deadletter"
type: "destination"
topic: "deadletter"
config: {
type: "kafka"
name: "output"
}
}
}
Avro-схема выбирается исходя из значения заголовка "schemaName" в сообщении Apache Kafka. Если заголовок не задан,
то используется схема по умолчанию или первая в списке в случае, если никакая схема не помечена полем default со значением true.
Логика потока агрегации событий#
Поток агрегации состоит из 3 частей:
Вычисление ключа события и сортировка потока событий по ключу;
Временное окно и триггер отправки событий в функцию агрегации;
Функция агрегации событий.
Вычисление ключа событий#
Логика вычисления ключа для события задается параметром key, объект с полем type которое принимает следующие значения:
key— вычисление ключа по значению ключа из сообщения Apache Kafka, представляет собой объект с полемtypeравнымkey;headers— вычисление ключа по определенным значениям заголовков, представляет собой объект с полемtypeравнымheadersи в полеkeysсодержит массив заголовков, из которых должен формироваться ключ. Значение ключа является объединением значений заголовков с разделителем|.hash— вычисление ключа хеш функцией из тела сообщения. Представляет собой объект с полемtypeравнымhash, опционально в полеalgorithmсодержит имя хеш алгоритма, по умолчаниюSHA-256.dsl— вычисление ключа с помощью правил трансформации, объект содержит поля:typeсо значением"dsl";source— источник правил трансформацииclasspathилиfile;path— путь до правил трансформации.
При вычислении ключа через DSL правил трансформации:
Вход
INсодержит событие;Environment.SourceTopicсодержит имя топика, откуда было прочитано сообщение;Environment.SourceKeyсодержит значение ключа из сообщения Apache Kafka в виде строки;Environment.kafka.headersсодержит словарь заголовков из сообщения Apache Kafka.
При вычислении ключа с типом dsl правила трансформации должны завершаться вызовом функции return(<key>), где <key> — значение ключа.
Выходы OUT и HEADERS скрипта трансформации игнорируются.
Окно агрегации событий#
После вычисления ключа событие попадает в окно агрегации. В универсальном обработчике используется глобальное окно агрегации.
Иллюстрация сессионного окна из документации Apache Flink#
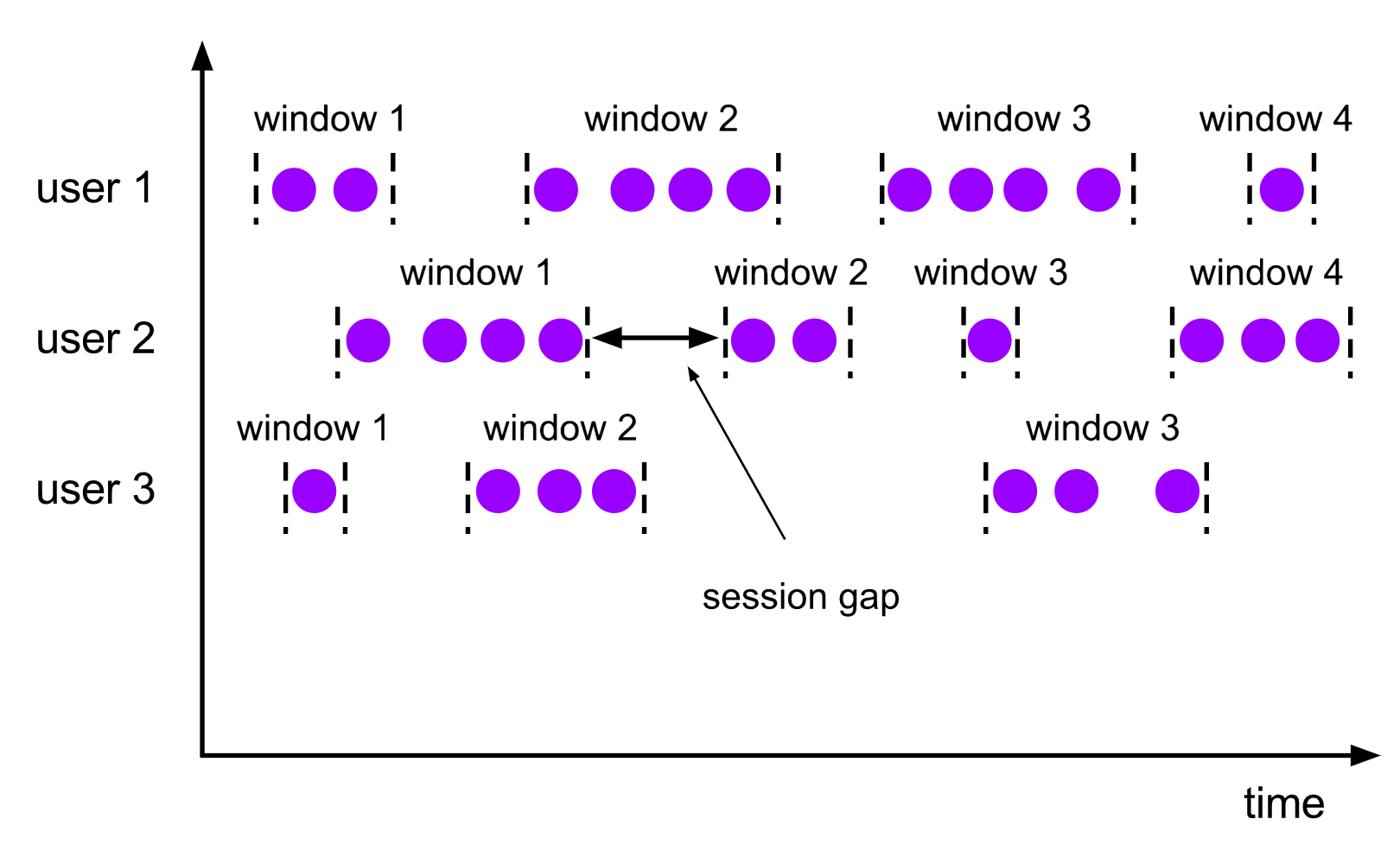
В нашем случае параметр timeout у триггера задает session gap, то есть максимальное время между получением событий с одним ключом.
В момент возникновения таймаута все собранные события в окне передаются в функцию агрегации, а окно агрегации очищается.
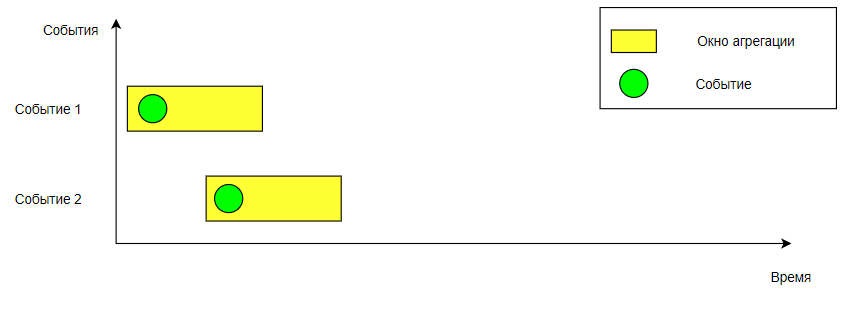
Для каждого нового события создается свое окно агрегации, затем ищется существующее окно для событий с таким же ключом. Если окно было создано ранее, то старое окно и новое объединяются. При этом начало нового окна становится началом первого окна, а конец берется из второго окна.
Окна до объединения#
Окна после объединения#
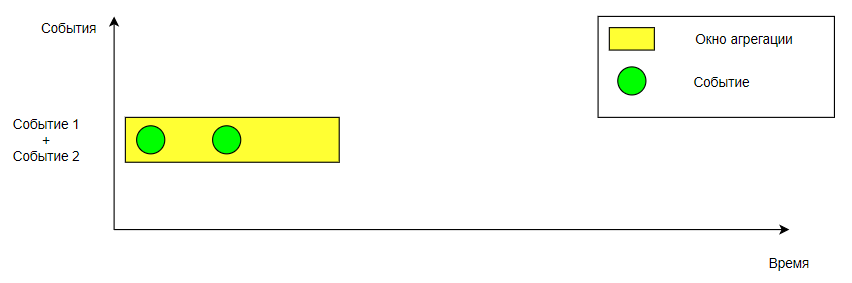
В процессе объединения окон происходит объединение состояний, после чего вызывается триггер.
Триггер отправки событий в функцию агрегации#
Предусмотрено 4 вида триггера:
Триггер подсчета количества событий в окне агрегации, срабатывает при накоплении заданного числа событий или при наступлении таймаута относительно получения первого события.
Триггер с логикой на DSL правил трансформации событий, срабатывает согласно заданным в DSL правилам или при наступлении таймаута относительно получения первого события.
Триггер срабатывания по времени, срабатывает раз в сутки в заданное время.
Триггер срабатывания по времени из события, срабатывает раз в сутки согласно заданному времени, полученному из события при помощи DSL.
Настройка триггера подсчета количества событий#
Задается объектом в поле trigger шага агрегации с полями:
type— со значением"count";count— целое число, равное количеству ожидаемых событий. Триггер срабатывает в момент достижения количества событий этого значения;timeout— время в миллисекундах после получения последнего события в окне агрегации и до срабатывания триггера по таймауту;shouldFireAtProcessingTimeдолжен ли срабатывать триггер по таймауту относительно получения первого события, значение по умолчаниюtrue.
После срабатывания триггера происходит передача накопленных событий в функцию агрегации и очистка окна.
trigger: {
type: "count"
count: 2
timeout: 100
}
Настройка триггера с логикой на DSL#
Задается объектом в поле trigger шага агрегации с полями:
type— со значением"dsl";source— источник правил трансформации, может принимать значения"classpath"и"file", по умолчанию"classpath";path— путь до файла с правилами;timeout— время в миллисекундах после получения последнего события в окне агрегации и до срабатывания триггера по таймауту;shouldFireAtProcessingTime— должен ли срабатывать триггер по таймауту относительно получения первого события, значение по умолчаниюtrue.
trigger: {
type: "dsl"
source: "file"
path: "/path/to/dsl/script.tr"
timeout: 100
}
После срабатывания триггера по таймауту происходит передача накопленных событий в функцию агрегации и очистка окна.
При добавлении нового события в окно агрегации происходит выполнение DSL правил трансформации:
Вход
INсодержит новое событие;Environment.SourceTopicсодержит имя топика, откуда было прочитано сообщение;Environment.SourceKeyсодержит значение ключа из сообщения Apache Kafka в виде строки;Environment.cacheсодержит элементы, сохраняющиеся между вызовами триггера;Environment.TriggerFireMsсодержит время вызова триггер в миллисекундах в формате Unix;Environment.kafka.headersсодержит словарь заголовков из сообщения Apache Kafka.
DSL скрипт правил трансформации должен вернуть функцией return() один из следующих статусов:
return("continue")— продолжение накопление событий в окне агрегации;return("fire")— передача накопленных событий в функцию агрегации без очистки и закрытия окна;return("purge")— очистка и закрытие окна без передачи накопленных событий в функцию агрегации;return("fireAndPurge")— передача накопленных событий в функцию агрегации с очисткой и закрытием окна.
Выходы OUT и HEADERS в триггере игнорируются.
Если функция return() не была вызвана или вызвана с другим значением, то накопленные события будут переданы в функцию агрегации, а окно очищено и закрыто.
Настройка триггера срабатывания по времени#
Задается объектом в поле trigger шага агрегации с полями:
typeсо значением"time";time— время, равное ожидаемому времени срабатывания, триггер срабатывает в момент достижения текущего времени этого значения;timePattern— формат времени;maxEmptyIntervals— количество пустых интервалов до сброса ключей агрегации.
После срабатывания триггера происходит передача накопленных событий в функцию агрегации и очистка окна.
trigger: {
type: "time"
time: "11:05:00+03:00"
timePattern: "HH:mm:ssXXX"
maxEmptyIntervals: 3
}
Настройка триггера срабатывания по времени из события#
Задается объектом в поле trigger шага агрегации с полями:
typeсо значением"timeFromEvent";source— источник правил трансформации, может принимать значения"classpath"и"file", по умолчанию"classpath";path— время, равное ожидаемому времени срабатывания, триггер срабатывает в момент достижения текущего времени этого значения;timePattern— формат времени;maxEmptyIntervals— количество пустых интервалов до сброса ключей агрегации.
После срабатывания триггера происходит передача накопленных событий в функцию агрегации и очистка окна.
trigger: {
type: "timeFromEvent"
path: "testDsl/aggregation/time.tr"
timePattern: "HH:mm:ss"
maxEmptyIntervals: 3
}
Функция агрегации событий#
Функция агрегации принимает на вход массив событий, выполняет правила трансформации и на выход возвращает одно или несколько событий в зависимости от логики правил трансформации.
При выполнении DSL правил трансформации:
Вход
INсодержит события из окна агрегации;Environment.sourcesсодержит массив переменных окружения для каждого события, индекс элементов соответствует индексам событий изIN. Каждый элемент массива содержит поля:SourceTopic— содержит имя топика, откуда было прочитано сообщение;SourceKey— содержит значение ключа из сообщения Apache Kafka в виде строки;kafka.headers— содержит словарь заголовков из сообщения Apache Kafka;
Environment.cache— содержит элементы, сохраняющиеся между вызовами функции агрегации;Environment.loadedVariables— содержит элементы, загруженные из JSON файла из параметраenvironmentVariablesшага агрегации;Environment.AggregationKey— содержит значение ключа агрегации;Environment.AggregationWindowTimeMs— содержит продолжительность существования окна агрегации в миллисекундах;Environment.AggregationEventCount— содержит количество событий, переданных в функцию агрегации.
Выход OUT должен содержать исходящее событие или массив исходящих событий.
Выход HEADERS может содержать следующие поля:
TargetTopic— имя топика назначения события;TargetKey— значение ключа в сообщении Apache Kafka;kafka— словарь заголовков сообщения Apache Kafka, не поддерживает вложенные словари;BranchName— имя следующего шага из побочной ветки потока.
Если исходящих событий больше одного, то выход HEADERS должен содержать массив элементов с перечисленными выше полями.
Порядок элементов должен соответствовать порядку событий в выходе OUT.
Поддерживается вызов функции return("decline"), который прерывает функцию агрегации и фильтрует полученные события.
Поддерживается вызов функции return("passthrough"), который передает входящие сообщение на следующий шаг без изменений
(имеется возможность изменять заголовки и другую информацию при помощи DSL).
Вызов функции return() с любым другим параметром прервет дальнейшее выполнение правил трансформации,
при этом уже заполненные выходы OUT и HEADERS будут обработаны и преобразованы в исходящие события.
Описание параметров среды исполнения#
Параметры можно передать файлом в формате HOCON через аргумент --reactiveConfig (короткий вариант -rc) или через переменные окружения. Переменные окружения будут перезаписывать параметры из файла.
Общие настройки приложения#
Имя |
Переменная окружения |
Значение по умолчанию |
Описание |
|---|---|---|---|
batchSize |
EPF_batchSize |
1000 |
Размер обрабатываемой пачки сообщений |
timeout |
EPF_timeout |
1000 |
Таймаут обработки пачки сообщений в миллисекундах |
queryPartitionsInterval |
EPF_queryPartitionsInterval |
60000 |
Интервал опроса исходящего топика на количество партиций |
producerFlushInterval |
EPF_producerFlushInterval |
1000 |
Интервал принудительной отправки сообщений в исходящий топик в миллисекундах |
secret |
EPF_secret |
Секрет для расшифровки паролей конфигурации |
|
storage.type |
EPF_storage_type |
Тип хранилища агрегации, по умолчанию используется хранилище в оперативной памяти |
Настройки хранилища агрегации в топике Кафки#
При значении storage.type равной kafka.
Имя |
Переменная окружения |
Значение по умолчанию |
Описание |
|---|---|---|---|
storage.topic |
EPF_storage_topic |
aggregation |
Имя топика |
storage.initMs |
EPF_storage_initMs |
200 |
Таймаут инициализации хранилища при старте приложения |
storage.pollTimeout |
EPF_storage_pollTimeout |
100 |
Таймаут получения сообщений из Кафки |
storage.kafka |
EPF_storage_kafka |
Настройки клиента Кафки |
Настройки хранилища агрегации с использованием EVTA#
При значении storage.type равной grpc.
Имя |
Переменная окружения |
Значение по умолчанию |
Описание |
|---|---|---|---|
storage.pollTimeout |
EPF_storage_pollTimeout |
100 |
Таймаут получения сообщений из EVTA |
storage.grpc.subscribePort |
EPF_storage_grpc_subscribePort |
80 |
Порт EVTA, на котором запущен адаптер интерфейс для подписки |
storage.grpc.publishPort |
EPF_storage_grpc_publishPort |
80 |
Порт EVTA, на котором запущен адаптер интерфейс для публикации |
storage.grpc.host |
EPF_storage_grpc_host |
localhost |
Хост, на котором запущен адаптер |
storage.grpc.retry |
EPF_storage_grpc_retry |
5 |
Количество попыток при подключении клиента к EVTA |
storage.grpc.timeout |
EPF_storage_grpc_retry |
5 |
Таймаут при подключении клиента к EVTA |