Сценарии администрирования#
Введение#
Руководство предназначено для администраторов безопасности (роль SECURITY_ADMIN) или администраторов эксплуатации (роль MAINTENANCE_ADMIN).
Первичная настройка кластера DataGrid#
Пример создания и настройки кластера DataGrid#
В данном примере демонстрируются создание и настройка кластера DataGrid, состоящего из двух узлов:
для демонстрации будет использоваться клиентский узел;
на серверных узлах будет включен режим persistence (данные в кешах не будут потеряны при отключении и повторном включении узлов);
для обнаружения узлов в примере будет использоваться механизм Static IP Discovery.
Примечание
В данном руководстве конфигурационный файл сервера называется serverExampleConfig.xml, но он может иметь любое имя по желанию пользователя.
Используемая в примере конфигурация (XML) указывается в конфигурационном файле $IGNITE_HOME/config/serverExampleConfig.xml.
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Включение Apache Ignite Persistent Store. -->
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
</bean>
</property>
<property name="consistentId" value="myIgniteNode01"/>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<!-- Настройка имени кеша. -->
<property name="name" value="myReplicatedCache"/>
<!-- Настройка режима работы кеша. -->
<property name="cacheMode" value="REPLICATED"/>
<!-- Другие параметры конфигурации кеша. -->
</bean>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<!--
Явное указание адреса локального узла для его запуска и нормальной работы, даже если больше узлов в кластере нет. Опционально можно указать собственный порт или диапазон портов.
-->
<value>IP OF NODE01</value>
<value>IP OF NODE02</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
</bean>
Для создания кластера из двух узлов:
Распакуйте ZIP-архив с бинарными файлами и поместите XML-файл конфигурации
serverExampleConfig.xmlс заранее заданными IP-адресами ваших серверов в папку$IGNITE_HOME/config/.Экспортируйте конфигурацию кластера при помощи команды:
export JVM_OPTS="-DIGNITE_CLUSTER_TYPE=prom -DIGNITE_CLUSTER_NAME=mycluster -DREQUIRE_AUDIT=false"Запустите DataGrid с помощью команды:
./bin/ignite.sh config/serverExampleConfig.xmlПримечание
Если не указать конфигурационный файл при запуске, то будет использоваться конфигурационный файл по умолчанию —
default-config.xml.После запуска вы увидите примерно следующий вывод:
WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.ignite.startup.cmdline.CommandLineStartup (file:/Users/user/ignite/Ignite-SE-15.0.0/libs/ignite-core-15.0.0-p1.jar) to method com.apple.eawt.Application.getApplication() WARNING: Please consider reporting this to the maintainers of org.apache.ignite.startup.cmdline.CommandLineStartup WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release [11:13:43] __________ ________________ [11:13:43] / _/ ___/ |/ / _/_ __/ __/ [11:13:43] _/ // (7 7 // / / / / _/ [11:13:43] /___/\___/_/|_/___/ /_/ /___/ [11:13:43] [11:13:43] ver. 15.0.0-p1#20220404-sha1:c5e1625b [11:13:43] 2022 Copyright(C) Apache Software Foundation [11:13:43] [11:13:43] Ignite documentation: http://ignite.apache.org [11:13:43] [11:13:43] Quiet mode. [11:13:43] ^-- Logging to file '/Users/user/ignite/Ignite-SE-15.0.0/work/log/ignite-3f988f41.0.log' [11:13:43] ^-- Logging by 'JavaLogger [quiet=true, config=null]' [11:13:43] ^-- To see **FULL** console log here add -DIGNITE_QUIET=false or "-v" to ignite.{sh|bat} [11:13:43] [11:13:43] OS: Mac OS X 10.16 x86_64 [11:13:43] VM information: Java(TM) SE Runtime Environment 15+36-1562 Oracle Corporation Java HotSpot(TM) 64-Bit Server VM 15+36-1562 [11:13:43] Please set system property '-Djava.net.preferIPv4Stack=true' to avoid possible problems in mixed environments. [11:13:43] Configured plugins: [11:13:43] ^-- grid-security-basic-plugin 1.0 [11:13:43] ^-- null [11:13:43] [11:13:43] Configured failure handler: [hnd=StopNodeOrHaltFailureHandler [tryStop=false, timeout=0, super=AbstractFailureHandler [ignoredFailureTypes=UnmodifiableSet [SYSTEM_WORKER_BLOCKED, SYSTEM_CRITICAL_OPERATION_TIMEOUT]]]] [11:13:44] Initial heap size is 256MB (should be no less than 512MB, use -Xms512m -Xmx512m). [11:13:44] Message queue limit is set to 0 which may lead to potential OOMEs when running cache operations in FULL_ASYNC or PRIMARY_SYNC modes due to message queues growth on sender and receiver sides. [11:13:45] Security status [authentication=on, sandbox=off, tls/ssl=on] SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder". SLF4J: Defaulting to no-operation (NOP) logger implementation SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details. [11:13:46] Encryption keys loaded from metastore. [grps=, masterKeyName=null] [11:13:46] Data Regions Started: 5 [11:13:46] ^-- sysMemPlc region [type=internal, persistence=true, lazyAlloc=false, [11:13:46] ... initCfg=40MB, maxCfg=100MB, usedRam=0MB, freeRam=100%, allocRam=99MB, allocTotal=0MB] [11:13:46] ^-- default region [type=default, persistence=true, lazyAlloc=true, [11:13:46] ... initCfg=256MB, maxCfg=3276MB, usedRam=0MB, freeRam=100%, allocRam=0MB, allocTotal=0MB] [11:13:46] ^-- metastoreMemPlc region [type=internal, persistence=true, lazyAlloc=false, [11:13:46] ... initCfg=40MB, maxCfg=100MB, usedRam=0MB, freeRam=100%, allocRam=99MB, allocTotal=0MB] [11:13:46] ^-- TxLog region [type=internal, persistence=true, lazyAlloc=false, [11:13:46] ... initCfg=40MB, maxCfg=100MB, usedRam=0MB, freeRam=100%, allocRam=99MB, allocTotal=0MB] [11:13:46] ^-- volatileDsMemPlc region [type=user, persistence=false, lazyAlloc=true, [11:13:46] ... initCfg=40MB, maxCfg=100MB, usedRam=0MB, freeRam=100%, allocRam=0MB] [11:13:46] ^-- Ignite persistence [used=0MB] [11:13:47] Performance suggestions for grid 'serverNodeXml' (fix if possible) [11:13:47] To disable, set -DIGNITE_PERFORMANCE_SUGGESTIONS_DISABLED=true [11:13:47] ^-- Disable fully synchronous writes (set 'writeSynchronizationMode' to PRIMARY_SYNC or FULL_ASYNC) [11:13:47] ^-- Switch to the most recent 11 JVM version [11:13:47] ^-- Specify JVM heap max size (add '-Xmx<size>[g|G|m|M|k|K]' to JVM options) [11:13:47] ^-- Set max direct memory size if getting 'OOME: Direct buffer memory' (add '-XX:MaxDirectMemorySize=<size>[g|G|m|M|k|K]' to JVM options) [11:13:47] Refer to this page for more performance suggestions: https://ignite.apache.org/docs/latest/perf-and-troubleshooting/memory-tuning [11:13:47] [11:13:47] To start Console Management & Monitoring run ignitevisorcmd.{sh|bat} [11:13:47] [11:13:47] Ignite node started OK (id=3f988f41, instance name=serverNodeXml) [11:13:47] Topology snapshot [ver=1, locNode=3f988f41, servers=1, clients=0, state=INACTIVE, CPUs=12, offheap=3.2GB, heap=4.0GB] [11:13:47] ^-- Baseline [id=0, size=1, online=1, offline=0] [11:13:47] ^-- All baseline nodes are online, will start auto-activationПримечание
В случае возникновения проблем и необходимости получить более подробную информацию из журналов выполните команду
ignite.sh -v.После запуска узлов и изменения топологии необходимо активировать кластер. Процесс активации автоматически создаст базовую топологию из всех серверных узлов со включенным persistence. Для активации откройте новое окно терминала и выполните следующую команду:
./bin/control.sh --set-state ACTIVE --user operationAdmin --keystore ./config/certs/operationAdmin.jks --truststore ./config/certs/truststore.jks --password Default-password-1 --keystore-password password --truststore-password passwordВнимание
Опции указаны для примера. Значения опций можно изменить на необходимые.
Теперь можно подключаться к этому кластеру с клиентского узла независимо от того, какой из узлов сейчас подключен, а какой — нет.
Примечание
Необходимо дождаться, пока первый узел синхронизирует кеш с кластером, и только потом отключать второй, поскольку количество узлов, которые находятся в сети в базовой топологии — 2:
[15:34:39,988][INFO][main][GridDiscoveryManager] Topology snapshot [ver=1, locNode=16835415, servers=2, clients=0, state=ACTIVE, CPUs=16, offheap=6.4GB, heap=4.0GB]
[15:34:39,988][INFO][main][GridDiscoveryManager] ^-- Baseline [id=0, size=2, online=2, offline=0]
где ^-- обозначает, что сообщение относится к сообщению строкой выше.
Подключение дополнительных модулей, включенных в поставку DataGrid, описано в подразделе «Дополнительные модули, которые входят в поставку DataGrid» раздела «Подключение и конфигурирование» документа «Руководство прикладного разработчика».
Решение проблем с подключениями узлов#
В случае, если узлы DataGrid связаны сетью, которая работает медленно или нестабильно, могут возникать проблемы с целостностью кластера. Вследствие работы «плохой» сети отдельные узлы могут исключаться из топологии как недоступные, а кластер может распадаться на несколько сегментов.
Чтобы решить эту проблему, можно изменить значения тайм-аутов в параметрах failureDetectionTimeout и connRecoveryTimeout.
Параметр failureDetectionTimeout в классе IgniteConfiguration задает количество времени, в течение которого узел ожидает ответа от узлов в установленной сессии в рамках communication или discovery SPI.
Если эта сессия прерывается по какой-либо причине, в работу силу вступает параметр connRecoveryTimeout в конфигурации TcpDiscoverySPI. Этот параметр регулирует количество времени, в течение которого узел должен продолжать попытки переподключения перед самостоятельным сегментированием.
Установив более высокие значения для этих двух параметров можно добиться стабильной топологии кластера в условиях плохой сети. Однако важно помнить: при высоких значениях параметров увеличивается время определения проблемного узла, что влияет на производительность и время отклика по другим операциям.
Подробнее настройка параметров failureDetectionTimeout и connRecoveryTimeout описана в документе «Часто встречающиеся проблемы и пути их устранения».
Резервное копирование и восстановление в DataGrid#
Ограничения процедуры создания резервной копии (снепшота)#
Процедура создания резервной копии (снепшота) имеет ряд ограничений:
сделать снепшот конкретных кешей и таблиц невозможно. При создании резервной копии всегда создается только полный снепшот;
в снепшот не включаются кеши и таблицы, не сохраненные в постоянном хранилище Ignite Persistence;
в процессе создания снепшота нельзя изменять основной ключ. Все кеши снепшота зашифрованы с помощью одного и того же главного ключа;
операция по созданию снепшота запрещена во время изменения основного ключа и/или изменения ключей группы кешей;
одновременный запуск нескольких операций создания снепшота невозможен. При попытке запуска нескольких операций параллельно DataGrid выдаст следующую ошибку:
Cluster-wide snapshot operation failed: class org.apache.ignite.IgniteException: Create snapshot request has been rejected. The previous snapshot operation was not completed.в случае выхода кластера из обслуживания процедура создания резервной копии прерывается;
сохранение параллельных обновлений DataStreamer с настройкой по умолчанию
allowOverwrite(false) в persistence-кеш может привести к тому, что данные кеша сохранятся непоследовательно;во время снятия снепшота остановить работу кеша невозможно. При попытке остановки кеша DataGrid выдаст следующее исключение:
avax.cache.CacheException: class org.apache.ignite.IgniteCheckedException: Operation rejected due to the snapshot operation in progress.восстановление из снепшота без ребалансировки можно произвести только в пределах одного кластера, при этом количество узлов в топологии и
consistentidузлов должны совпадать. В противном случае будет произведена ребалансировка после восстановления. Подробнее в разделе «Восстановление кластера из снепшота кластера с другой топологией» текущего документа.
Если какое-либо из перечисленных выше ограничений не позволяет использовать DataGrid, воспользуйтесь альтернативными инструментами для снятия снепшотов, предоставляемыми сторонними поставщиками.
Ограничения для инкрементальных снепшотов#
Процедура создания инкрементальных снепшотов также имеет ряд ограничений. Инкрементальные снепшоты НЕ МОГУТ быть созданы в следующих случаях:
в кластере представлены зашифрованные кеши;
кеши были изменены, созданы или удалены с момента снятия полного снепшота;
после ребалансировки данных в кластере.
DataGrid автоматически контролирует эти события и предотвращает создание инкрементального снепшота. В случае какого-либо из перечисленных выше ограничений требуется создать новый полный снепшот. После этого станет возможным создание инкрементальных снепшотов.
Создание резервных копий (снепшотов)#
Благодаря использованию режима Native Persistence DataGrid позволяет создавать резервные копии (полные и инкрементальные кластерные снепшоты). Резервная копия включает в себя согласованную копию всех данных кластера, сохраненных на диске, а также другие файлы, необходимые для процедуры восстановления.
Структура резервной копии схожа со структурой каталога постоянного хранилища Ignite Persistence. На схеме ниже приведен пример такой структуры:
work
└── snapshots
└── backup_name
├── increments
│ └── 0000000000000001
└── db
├── binary_meta
│ ├── node1
│ ├── node2
│ └── node3
├── marshaller
│ └── classname0
├── node1
│ └── my-sample-cache
│ ├── cache_data.dat
│ ├── part-3.bin
│ ├── part-4.bin
│ └── part-6.bin
├── node2
│ └── my-sample-cache
│ ├── cache_data.dat
│ ├── part-1.bin
│ ├── part-5.bin
│ └── part-7.bin
└── node3
└── my-sample-cache
├── cache_data.dat
├── part-0.bin
└── part-2.bin
Пояснение к схеме
Каталог/Файл |
Пояснение |
|---|---|
|
Рабочий каталог DataGrid |
|
Каталог, в котором хранятся все снепшоты |
|
Каталог, в который сохраняется конкретный снепшот. Этот каталог создается автоматически при снятии снепшота |
|
Каталог, который сохраняет инкрементальные снепшоты на основе полного снепшота |
|
Инкремент, который содержит каталог |
|
Каталог, в котором хранится база данных: метаданные, marshaller, копии кешей узлов (в примере — копии my_sample_cache для всех узлов). Также каталог |
|
Каталог, в котором хранятся метаданные всех узлов кластера (в примере — кластера из трех узлов) |
|
Каталог, в котором хранятся данные, относящиеся к marshaller для всех узлов кластера (в примере — кластера из трех узлов) |
|
Каталоги, в которых хранятся данные узлов кластера. В примере снепшот создается для кластера с тремя узлами. При этом все узлы запускаются на одной машине. Здесь узлы называются |
|
Каталог, в котором хранится копия кеша узла (в примере каждый каталог с именем узла содержит копию |
|
Файлы, содержащие копию записей данных. Процессы упреждающей журнализации и создания контрольных точек не включены в снепшот, поскольку это не требуется для корректной работы имеющейся процедуры восстановления |
Внимание
Создаваемый снепшот должен иметь уникальное имя. В случае попытки создания снепшота с именем, которое уже использовалось ранее, DataGrid выдаст следующую ошибку:
Cluster-wide snapshot operation failed:
class org.apache.ignite.IgniteException: Create snapshot request has been rejected. Snapshot with given name already exists on local node.
Примечание
Как правило, снепшоты распределены по кластеру. На схеме выше показан пример снепшота для кластера, работающего на одном физическом или виртуальном сервере. Поэтому в примере весь снепшот хранится в одном месте.
В реальных установках все узлы работают на разных физических и/или виртуальных серверах, и данные снепшота распределены по всему кластеру. Каждый узел хранит сегмент снепшота с данными, принадлежащими этому конкретному узлу.
Создание инкрементальных снепшотов#
При использовании полных снепшотов маловероятно получить низкую допустимую потерю данных (RPO), например, в диапазоне нескольких минут. Это объясняется тем, что полные снепшоты требуют дополнительных ресурсов для создания и хранения всех партиций.
Для упрощения процесса можно использовать инкрементальные снепшоты. Это позволяет:
хранить изменения данных, которые произошли с момента создания предыдущего полного или инкрементального снепшота;
упростить процесс создания снепшота с возможностью одновременной загрузки выполнения.
Примечание
Инкрементальные снепшоты состоят из сжатых сегментов WAL, которые собираются в фоновом режиме без нагрузки на ресурсы кластера.
Существует несколько особенностей использования инкрементальных снепшотов:
инкрементальные снепшоты основаны на существующем полном снепшоте;
для инкрементальных снепшотов не допускается уплотнение WAL архива;
инкрементальные снепшоты необходимо создавать на том же накопителе, на котором хранятся WAL архивы.
Во время процедуры восстановления инкрементального снепшота сначала восстанавливается полный снепшот, и только затем последовательно восстанавливаются все инкрементальные снепшоты.
Создание облегченных снепшотов#
Облегченный снепшот — вид резервной копии, которая содержит копии данных только основных партиций. Данные с резервных партиций в таком снепшоте будут отсутствовать.
Использование облегченных снепшотов позволяет:
сократить время снятия снепшота;
избежать перегрузки диска в процессе снятия снепшота;
сократить место на диске, необходимое для хранения снепшота.
Внимание
После восстановления из облегченного снепшота автоматически запускается процесс обмена данных между узлами — PME (Partition Map Exchange). В результате этого формируются резервные партиции. Таким образом, данные из облегченного снепшота восстанавливаются дольше, чем из полного снепшота.
Подробнее о создании и восстановлении данных из облегченных снепшотов с помощью утилиты control.sh смотрите в разделе «Утилита control».
Гарантии согласованности снепшотов#
Все снепшоты гарантируют согласованность со всеми операциями, связанными с кластером. К ним относятся изменения в данных Ignite Persistence, индексах, схемах, бинарных метаданных, marshaller и изменения в других файлах узлов.
Согласованность снепшотов кластера достигается путем запуска Partition-Map-Exchange (PME). Выполнив эту процедуру, кластер в конечном итоге достигнет той точки во времени, когда все ранее начавшиеся транзакции будут завершены, а новые приостановлены. Как только это произойдет, кластер запустит процесс создания снепшота. Процедура PME гарантирует создание такого снепшота, который включает основную и резервную копии, созданные последовательно друг за другом.
Согласованность между файлами Ignite Persistence и копиями их снепшотов достигается благодаря копированию исходных файлов в каталог назначения с отслеживанием всех параллельных текущих изменений. Это отслеживание может потребовать дополнительного пространства в хранилище Ignite Persistence (до 1х размера хранилища).
Гарантии согласованности инкрементальных снепшотов#
Инкрементальные снепшоты достигают согласованности транзакций за счет другого, неблокирующего, подхода, который основан на алгоритме Consistent Cut. Это позволяет запускать инкрементальные снепшоты одновременно с текущей загрузкой, не влияя на производительность.
Однако такой подход не гарантирует согласованность для атомарных кешей. Поэтому крайне рекомендуется проверять эти кеши после восстановления, используя команду idle_verify. Если необходимо, можно восстановить несогласованные партиции с помощью команды --consistency.
Проверка согласованности снепшотов#
Как правило, все узлы кластера работают на разных физических или виртуальных серверах, а данные снепшота распределены по всему кластеру. Каждый узел хранит свой собственный сегмент снепшота. В некоторых случаях перед восстановлением из снепшота может потребоваться проверка на полноту данных и на согласованность данных в кластере.
Для этого в DataGrid используются встроенные команды для проверки согласованности снепшота. Команды позволяют:
проверить внутреннюю согласованность данных;
вычислить партиции данных хешей и контрольных сумм страниц;
напечатать результат, если обнаружена проблема.
Команда проверки согласованности снепшотов также позволяет сравнивать хеши основных партиций с соответствующими резервными партициями и выводит сообщение, если между ними обнаружены различия.
Команда проверки согласованности снепшотов работает так же, как команда idle_verify. В случае выявление расхождений в кластере выполните восстановление согласованности в с помощью idle_verify.
Команда проверки согласованности снепшотов проверяет данные только в сегментах WAL. Она проверяет, что все транзакции, включенные в снепшот, полностью зафиксированы на всех участвующих узлах. Также вычисляются хеши этих транзакций и зафиксированных изменений данных, затем производится сравнение между узлами.
Внимание
Проверка согласованности снепшотов проверяет только транзакционные кеши. Согласованность инкрементальных снепшотов при этом не гарантируется. Проверьте атомарные кеши после восстановления с помощью команды idle_verify. При необходимости, восстановите несогласованные партиции с помощью команды --consistency.
Команды проверки согласованности рекомендуется выполнять в режиме простоя кластера (без записи данных, без выполнения транзакций и вычислительных задач).
Подробнее о проверке согласованности снепшотов с помощью утилиты control.sh смотрите в разделе «Утилита control».
Системные свойства для настройки снепшота#
В таблице ниже перечислены свойства системы, которые позволяют настраивать снепшоты:
Свойство |
Тип |
Пояснение |
Значение по умолчанию |
|---|---|---|---|
|
Логический |
Указывает, чтобы данные последовательно записывались на диск в процессе создания снепшота. Это позволяет использовать дополнительное дисковое пространство |
True |
Исполнение команд, относящихся к ограничению скорости снятия снепшота, при использовании DataGrid с настроенным плагином безопасности#
При использовании DataGrid с настроенным плагином безопасности для выполнения команд, относящихся к ограничению скорости снятия снепшота, у пользователя должны быть следующие права на выполнение задач и systemPermissions (указываются в файле igniteconfig/default-security-data.json):
{
"name": "TEST_PERM",
"perms": {
"cachePermissions": {},
"dfltAllowAll": false,
"servicePermissions": {},
"systemPermissions": [
"ADMIN_READ_DISTRIBUTED_PROPERTY",
"ADMIN_WRITE_DISTRIBUTED_PROPERTY"
],
"taskPermissions": {
"org.apache.ignite.internal.commandline.property.tasks.PropertiesListTask": [
"TASK_EXECUTE"
],
"org.apache.ignite.internal.commandline.property.tasks.PropertyTask": [
"TASK_EXECUTE"
]
}
}
}
Примечание
В данном руководстве конфигурационный файл ролевой модели называется default-security-data.json, но он может иметь любое имя по желанию пользователя. Путь к этому файлу указывается в конфигурационном файле сервера serverExampleConfig.xml.
Внесенные изменения действуют сразу на весь кластер и будут применены до момента перезагрузки кластера с очисткой distributed metastorage.
Подробнее об ограничении скорости снятия снепшотов с помощью утилиты control.sh смотрите в разделе «Утилита control».
Конфигурация каталога хранения резервной копии (снепшота)#
По умолчанию сегмент снепшота сохраняется в рабочем каталоге соответствующего узла DataGrid и использует то же пространство, в котором хранятся данные, индексы, WAL-журнал и другие файлы Native Persistence.
Примечание
Поскольку снепшот может потреблять столько же пространства на диске, сколько занимают файлы Native Persistence, и снижать производительность приложения за счет использования I/O жесткого диска совместно с рутинными задачами Native Persistence, рекомендуется хранить снепшот и файлы Native Persistence на разных дисках.
Пример изменения пути хранения снепшотов:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!--
Задает путь к корневому каталогу, в котором будут храниться файлы снепшотов. По умолчанию каталог `snapshots` находится в каталоге `IGNITE_HOME/db`.
-->
<property name="snapshotPath" value="/<ignite_home>/server/snapshotPath"/>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
File exSnpDir = U.resolveWorkDirectory(U.defaultWorkDirectory(), "ex_snapshots", true);
cfg.setSnapshotPath(exSnpDir.getAbsolutePath());
По умолчанию для снепшотов используется четыре потока. При уменьшении количества потоков время снятия снепшота может увеличиться. Однако это помогает снизить нагрузку на диск для выполнения других операций.
Создание резервной копии (снепшота)#
Для создания резервных копий в поставку DataGrid входят следующие интерфейсы:
утилита
control.sh(подробнее о создании снепшотов смотрите в разделе «Утилита control»);JMX;
Java API.
При создании снепшота в каталоге $IGNITE_HOME/work/db/.../snp создаются файлы партиций с «грязными» страницами. Каждый такой файл партиции будет иметь расширение .delta.
Пример
part-467.bin.delta
После успешного завершения операции по созданию снепшота данные файлы будут автоматически применены к созданному снепшоту и удалены.
Отображение начала и окончания процесса создания снепшота в log-файлах DataGrid#
В момент запуска операции создания снепшота в журналах DataGrid появляется следующая запись: [IgniteSnapshotManager] Cluster-wide snapshot operation started [snpName=MySnapshot, grps=[1794698200]], где:
snpName— имя снепшота;grps— список кеш-групп в снепшоте.
Когда операция создания снепшота завершается, в логах появляется следующая запись:
[IgniteSnapshotManager] Cluster-wide snapshot operation finished successfully: SnapshotOperationRequest [rqId=1a24fa7d-4e50-4714-ae68-959892c6d5a3, srcNodeId=b7b71afb-32c5-4730-b0dc-5090920cf4f0, snpName=MySnapshot, grpIds=ArrayList [1794698200], bltNodes=HashSet [b7b71afb-32c5-4730-b0dc-5090920cf4f0], err=null]
Использование интерфейса JMX#
Для проведения операций, связанных с созданием резервных копий через интерфейс JMX, используйте SnapshotMXBean:
Метод |
Описание |
|---|---|
|
Создать снепшот |
|
Создать инкрементальный снепшот |
|
Отменить создание снепшота на узле-инициаторе этой операции |
Использование Java API#
Создать снепшот также можно и из кода, используя Java API:
link:{javaCodeDir}/Snapshots.java[]
Восстановление из резервной копии (снепшота)#
Восстановление из снепшота происходит либо вручную на остановленном кластере, либо автоматически на активном кластере. Процедура восстановления состоит из копирования на каждом узле кластера данных из каталога снепшота в рабочий каталог. Текущие данные при этом удаляются или копируются в резервный каталог. Подробнее о восстановлении из снепшотов с помощью утилиты control.sh смотрите в разделе «Утилита control».
Внимание
По умолчанию автоматическая проверка целостности снепшота при восстановлении выключена. Это позволяет существенно экономить время восстановления при больших размерах снепшота. После снятия снепшота рекомендуется проверить его целостность с помощью утилиты idle_verify. Подробнее этот процесс описан в разделе «Проверка контрольных сумм партиции».
Примечание
Скрипт запуска восстановления и набор скриптов (playbook), позволяющий управлять процедурой восстановления, находятся на каждом узле и поставляются с релизом.
Автоматическое восстановление из снепшота#
Процедура автоматического восстановления из снепшота позволяет восстановить группы кешей из снепшота на работающем (активном) кластере при помощи Java API или утилиты control.sh.
Ограничения текущей реализации
В настоящий момент процедура создания резервной копии (полного или инкрементального снепшота) имеет ряд ограничений:
восстановление возможно, только если все части снепшота присутствуют в кластере. Каждый узел ищет локальные данные локального снепшота по сконфигурированному пути снепшота (задается системным свойством
snapshotPathв конфигурации кластера), используя в качестве «ключевых слов» имя снепшота и согласованный ID (consistent_id) узла. Пример конфигурации пути (указывается вserverExampleConfig.xml):
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<!-- Задает путь к корневому каталогу, в котором будут храниться файлы снепшотов. По умолчанию каталог `snapshots` находится в каталоге `IGNITE_HOME/db`.-->
<property name="snapshotPath" value="/<ignite_home>/server/snapshotPath"/>
</bean>
процедура восстановления может применяться только к группам кешей, созданным пользователем;
группы кешей, которые нужно восстановить из снепшота, не должны находиться в кластере. Если они находятся в кластере, то их нужно удалить со всех узлов кластера перед началом операции восстановления, используя Java API, либо при помощи следующей команды:
control.sh --cache destroyпроводить несколько операций восстановления параллельно запрещено. Следующая операция восстановления может быть запущена только после окончания предыдущей операции.
Восстановление кеш-группы из снепшота#
Восстановить отдельную группу кешей из снепшота можно при помощи утилиты control.sh или с помощью кода, используя Java API:
link:{javaCodeDir}/Snapshots.java[]
Настройка и запуск Playbook для управления процессом восстановления при помощи ansible#
Для запуска playbook предварительно заполните файл hosts, в котором заданы хосты кластера.
hosts
[srv_hosts]
x.x.x.x
y.y.y.y
z.z.z.z
....
n.n.n.n
Для запуска передайте следующие переменные:
Имя переменной |
Описание |
|---|---|
|
|
|
(опция) Если LFS вынесен из db |
|
|
|
Имя снепшота для восстановления |
|
(опция) По умолчанию определяется как |
|
(опция) если требуется сохранять LFS перед восстановлением из снепшота |
|
(опция) По умолчанию пишется в |
Переменные передаются как extravars:
ansible-playbook playbooks/restore_snapshots.yml -i ./hosts -e "run_on=srv_hosts ignite_se_instance_home='/ignite/server/' ignite_se_data_dir='/ignite/server/data' ignite_se_work_dir='/ignite/server/work' ignite_se_snapshot_dir='/ignite/server/work/snapshots' ignite_se_snapshot_name='snapshot_simple_1'"
Ручное восстановление из снепшота#
Структура снепшота аналогична структуре хранилища Native Persistence. Для ручного восстановления нужно восстановить снепшот на том же кластере с тем же узлом consistentId и с той же топологией. В противном случае будет произведена ребалансировка после восстановления. Подробнее — см. раздел «Восстановление кластера из снепшота кластера с другой топологией» текущего документа.
Восстановить можно только полный снепшот. Если необходимо восстановить данные из снепшота на другом кластере, в другой топологии кластера или восстановить инкрементальные снепшоты, используйте процедуру автоматического восстановления.
Внимание
В инструкции ниже упоминаются файлы и каталоги, относящиеся к {nodeId}.
Такие файлы и каталоги имеют в названии consistentId (согласованный ID) узла, который и является {nodeId}.
consistentId может быть задан в конфигурации кластера и является уникальным для кластера (указывается в serverExampleConfig.xml):
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="consistentId" value="MyId"/>
</bean>
Если consistentId не задан в конфигурации, он будет сгенерирован автоматически и будет иметь следующий формат:
node00-e64e7513-8041-4e4a-86e7-78f08700aba4
В общем случае процесс ручного восстановления выглядит так:
Остановите кластер.
Замените данные и другие файлы, используя информацию из снепшота.
Перезапустите узлы.
Подробная инструкция для ручного восстановления из снепшота:
Остановите работу кластера, который нужно восстановить.
Удалите все данные из каталога контрольной точки
$IGNITE_HOME/work/cp(данные Native Persistence и прочие данные).На каждом узле выполните следующие действия:
удалите все файлы, относящиеся к
{nodeId}из каталога$IGNITE_HOME/work/db/binary_meta;удалите все файлы, относящиеся к
{nodeId}из каталога$IGNITE_HOME/work/db/marshaller;удалите все файлы и подкаталоги, принадлежащие к узлу с
{nodeId}в каталоге$IGNITE_HOME/work/db. Очистите каталогdb/{nodeId}отдельно, если он отсутствует в каталогеwork;скопируйте файлы, относящиеся к узлу с
{nodeId}, из снепшота в каталог$IGNITE_HOME/work/. Если каталогdb/{nodeId}не находится в каталогеwork, скопируйте файлы с данными туда.
Перезапустите кластер.
Восстановление кластера из снепшота кластера с другой топологией#
При возникновении ситуации неожиданного выхода кластера из строя (например, при сбоях) может потребоваться его восстановление. Однако топологии кластеров могут отличаться, равно как и топологии снепшотов этих кластеров. Таблица ниже описывает ситуации, когда нужно создать снепшот кластера с количеством узлов N и восстановить кластер с количеством узлов M:
Условие |
Описание |
|---|---|
N == M |
Рекомендованный случай. Создание и использование снепшота на кластерах с похожей топологией |
N < M |
Запуск первых N узлов кластера с M узлов и применение снепшота. Далее необходимо добавить остальные узлы кластера с M узлов в топологию и дождаться окончания ребалансировки данных и обновления индексов |
N > M |
Не поддерживается |
Получение статуса операции восстановления из снепшота#
Получить статус текущей операции снепшота в кластере можно при помощи утилиты control.sh|bat с помощью команды --snapshot status или через JMX (интерфейс SnapshotMXBean).
SnapshotMXBean mxBean = ...;
// Статус операции для текущего снепшота в кластере.
String status = mxBean.status();
Отмена операций создания снепшота и восстановления из снепшота#
Отменить текущую операцию по созданию или восстановлению снепшота можно при помощи утилиты control.sh|bat --snapshot cancel --name <name> | --id <id> или интерфейса JMX.
Для отмены перации можно использовать имя снепшота (name) или идентификатор операции (id).
Идентификатор операции отображается при запуске операции с использованием командной строки. Также его можно запросить с помощью команды status или найти идентификатор в метриках снепшота.
Пример команды для отмены операций для снепшотов через JMX (интерфейс SnapshotMXBean):
SnapshotMXBean mxBean = ...;
// Прервать операцию для снепшота с идентификатором `9ec229f1-e0df-41ff-9434-6f08ba7d05bd`.
mxBean.cancelSnapshotOperation("9ec229f1-e0df-41ff-9434-6f08ba7d05bd");
Сценарии работы со снепшотами#
Снятие снепшотов на неполной топологии#
Для корректного снятия снепшотов должны быть настроены все baseline узлы. Проблема со снятием снепшотов возникает на неполной топологии, когда недоступен один или несколько из baseline узлов.
Настройка снятия снепшотов на неполной топологии не имеет смысла. В случае, если снепшоты со смысловым содержимым отсутствуют (BACKUPS = 0), работает PARTITION_LOSS_POLICY. В случае, если BACKUPS > 0:
восстановите узел;
дождитесь ребаланса;
снимите снепшот.
Восстановление на неполной топологии снепшота из полной топологии#
Восстановление снепшота на неполной топологии нецелесообразно (см. раздел «Снятие снепшотов на неполной топологии»). Чтобы восстановить снепшот, необходимо настроить все baseline узлы.
Восстановление на новой топологии со снепшота из меньшей топологии#
В текущей версии DataGrid 15.0 восстановление снепшота из прежней топологии внутри новой топологии невозможно. Необходимо использовать ту же топологию кластера, которая содержит те же самые узлы с теми же consistentId.
Восстановление со снепшота, снятого после ремонта узла#
После ремонта узла может возникнуть потеря PDS (Persistent Data Store) и снепшота. Чтобы восстановить данные с потерянного снепшота, снятого на полной топологии после ремонта узла:
Проверьте, что в конфигурации потерянного узла задан
consistentId(даже с потерянным параметромlsf).При вводе узла проверьте, что узел из
baselineвосстановлен.Восстановите снепшот на полном
baseline.
Persistence-хранилище данных (Persistent Data Store)#
Persistence, или Native Persistence — это набор функций, разработанных для обеспечения постоянного хранения данных. Когда данный режим включен, DataGrid постоянно хранит все данные на диске, а необходимые данные загружаются в ОЗУ для их обработки.
Пример
Если всего существует 100 записей, а в ОЗУ может содержаться лишь 20, то все 100 записей будут храниться на диске и только 20 будут записаны в кеш для лучшей производительности.
Если Native Persistence отключен и внешнее хранилище данных не используется, DataGrid будет работать исключительно как in-memory-хранилище.
Если режим Native Persistence включен, то каждый серверный узел хранит определенный набор данных, включающий в себя только партиции, назначенные на этот узел (включая резервные партиции, если включена функция хранения резервных копий).
Функциональность режима Native Persistence состоит из следующих возможностей:
хранение партиций данных на диске;
упреждающая журнализация (журнал WAL);
создание контрольных точек (Checkpointing);
использование файла подкачки ОС.
При включенном режиме Native Persistence DataGrid хранит каждую партицию в отдельном файле на диске. Формат данных в файлах партиций соответствует формату данных в ОЗУ. При включенной функции хранения резервных копий на диске также сохраняются резервные партиции. Помимо самих партиций с данными DataGrid также хранит индексы и метаданные.
Каталог хранения файлов можно изменить в файле.
Включение Persistence-хранилища данных#
Native Persistence конфигурируется отдельно для каждого региона данных.
Чтобы включить Persistence-хранилище данных, установите значение true для свойства persistenceEnabled в файле конфигурации региона данных.
Примечание
Регионы данных могут одновременно храниться и в ОЗУ (in-memory data regions), и в Persistence-хранилище (data regions with persistence).
Пример ниже показывает, как можно включить Persistence-хранилище для стандартного региона данных (указывается в serverExampleConfig.xml):
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
</bean>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
// Конфигурация хранилища данных.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
cfg.setDataStorageConfiguration(storageCfg);
Ignite ignite = Ignition.start(cfg);
var cfg = new IgniteConfiguration
{
DataStorageConfiguration = new DataStorageConfiguration
{
DefaultDataRegionConfiguration = new DataRegionConfiguration
{
Name = "Default_Region",
PersistenceEnabled = true
}
}
};
Ignition.Start(cfg);
Конфигурация каталога Persistence-хранилища данных#
При включенном Native Persistence узел сохраняет данные пользователей, индексы и WAL-файлы в каталоге {IGNITE_WORK_DIR}/db. Данный каталог считается каталогом хранилища. Его можно изменить, установив свойство storagePath объекта DataStorageConfiguration, как показано ниже.
Каждый узел обслуживает следующие подкаталоги хранилища, в котором будут храниться кешированные данные, WAL-файлы, а также файлы архива WAL:
Подкаталог |
Описание |
|---|---|
|
Данный каталог содержит кешированные данные и индексы |
|
Данный каталог содержит WAL-файлы |
|
Данный каталог содержит файлы архива WAL |
nodeId здесь — это либо согласованный ID узла (consistent node ID), если он определен конфигурацией узла, либо автоматически сгенерированный ID узла. Он используется для обеспечения уникальности каталогов для узла.
Примечание
Если несколько узлов используют один каталог, то в нем создаются подкаталоги для каждого из узлов.
Если рабочий каталог содержит файлы persistence-хранения для нескольких узлов (т. е. существует несколько подкаталогов {nodeId} с разными ID узлов), то узел выбирает первый неиспользуемый подкаталог.
Внимание
Чтобы убедиться в том, что узел всегда использует определенный подкаталог и, следовательно, определенные партиции данных даже после его перезагрузки, установите в конфигурации узла уникальное для кластера значение метода IgniteConfiguration.setConsistentId.
Каталог можно изменить следующим образом (указывается в serverExampleConfig.xml):
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
<property name="storagePath" value="/opt/storage"/>
</bean>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
// Конфигурация хранилища данных.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
storageCfg.setStoragePath("/opt/storage");
cfg.setDataStorageConfiguration(storageCfg);
Ignite ignite = Ignition.start(cfg);
var cfg = new IgniteConfiguration
{
DataStorageConfiguration = new DataStorageConfiguration
{
StoragePath = "/ssd/storage",
DefaultDataRegionConfiguration = new DataRegionConfiguration
{
Name = "Default_Region",
PersistenceEnabled = true
}
}
};
Ignition.Start(cfg);
Конфигурация#
В таблице ниже перечислены некоторые свойства класса DataStorageConfiguration.
Свойство |
Описание |
Значение по умолчанию |
|---|---|---|
|
Максимальный размер архива WAL-журнала в файловой системе в байтах |
Размер буфера контрольных точек (checkpointing buffer) * 4 |
|
Для включения Native Persistence установите значение true |
false |
|
Путь, по которому хранятся данные |
|
|
Путь к архиву WAL-журнала |
|
|
Для включения сжатия архива WAL-журнала установите значение |
|
|
Уровень сжатия архива WAL-журнала. 1 — самое быстрое сжатие, 9 — лучшее сжатие |
1 |
|
Режим работы WAL-журнала |
|
|
Путь к каталогу, в котором хранятся активные сегменты WAL-журнала |
|
|
Размер файла сегмента WAL-журнала в байтах |
64MB |
WAL-журнал#
Изменение размера сегмента WAL-журнала#
Для изменения размера сегмента WAL-журнала выполните следующий код (указывается в serverExampleConfig.xml):
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!-- Установите размер WAL-сегментов 128 Мб. -->
<property name="walSegmentSize" value="#{128 * 1024 * 1024}"/>
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
</bean>
</property>
</bean>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
storageCfg.setWalSegmentSize(128 * 1024 * 1024);
cfg.setDataStorageConfiguration(storageCfg);
Ignite ignite = Ignition.start(cfg);
Отключение WAL-журнала#
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
cfg.setDataStorageConfiguration(storageCfg);
Ignite ignite = Ignition.start(cfg);
ignite.cluster().state(ClusterState.ACTIVE);
String cacheName = "myCache";
ignite.getOrCreateCache(cacheName);
ignite.cluster().disableWal(cacheName);
// Загрузите данные.
ignite.cluster().enableWal(cacheName);
var cacheName = "myCache";
var ignite = Ignition.Start();
ignite.GetCluster().DisableWal(cacheName);
// Загрузите данные.
ignite.GetCluster().EnableWal(cacheName);
ALTER TABLE Person NOLOGGING
//...
ALTER TABLE Person LOGGING
Сжатие записей WAL-журнала#
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration dsCfg = new DataStorageConfiguration();
dsCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);
// Параметры сжатия страницы WAL.
dsCfg.setWalPageCompression(DiskPageCompression.LZ4);
dsCfg.setWalPageCompressionLevel(8);
cfg.setDataStorageConfiguration(dsCfg);
Ignite ignite = Ignition.start(cfg);
Отключение архива WAL-журнала#
Для отключения архивирования укажите одно и то же значение как для walPath, так и для walArchivePath. В этом случае DataGrid не копирует сегменты в архив. Вместо этого он создает новые сегменты в папке WAL-журнала, а старые сегменты удаляются по мере роста самого WAL-журнала. Этот рост зависит от настроек размера архива WAL-журнала.
Безопасность и аудит#
Плагин безопасности для DataGrid#
Подготовка сертификатов пользователей#
Порядок создания и подписи сертификатов зависит от внутренних процессов в организации.
Конфигурация плагина безопасности#
Конфигурация плагина безопасности осуществляется через класс SecurityPluginConfiguration.
Доступные для конфигурации параметры:
Имя |
Значение по умолчанию |
Обязательный параметр |
Описание |
|---|---|---|---|
|
+ |
Логин, с которым узел будет осуществлять подключение к кластеру DataGrid |
|
|
+ |
Пароль, с которым узел будет осуществлять подключение к кластеру DataGrid |
|
|
+ (для серверных узлов) |
Путь к файлу (в формате |
|
|
+ |
Путь к файлу хранилища личных сертификатов |
|
|
JKS |
- |
Tип хранилища личных сертификатов |
|
+ |
Пароль от хранилища личных сертификатов |
|
|
+ |
Путь к файлу хранилища доверенных сертификатов |
|
|
+ |
Пароль от хранилища доверенных сертификатов |
|
|
+ (для серверных узлов) |
Конфигурация, используемая для подключения плагина безопасности к Platform V Audit SE |
|
|
- |
Номер порта для автоматического запуска JMX сервера, процесс аутентификации которого обрабатывается плагином безопасности. Если параметр не установлен, JMX сервер запущен не будет. Описания процесса конфигурации приведены в разделе «Конфигурирование JMX» |
|
|
- |
Имя JAAS Login Module, который будет использован для запуска защищенного JMX сервера (см. описание |
|
|
Значение, установленное для |
- |
Путь до файла хранилища доверенных сертификатов, используемого для запуска JMX сервера (см. описание |
|
JKS |
- |
Тип хранилища доверенных сертификатов, используемый для запуска JMX сервера (см. описание |
|
Значение, установленное для |
- |
Путь к файлу хранилища доверенных сертификатов, используемого для запуска JMX сервера (см. описание |
Настройка TLS#
Включение плагина безопасности обеспечивает автоматическую конфигурацию рекомендуемых параметров TLS для всех типов подключение к DataGrid на основе переданных через конфигурацию плагина параметров selfKeyStorePath и selfKeyStoreType, trustStorePath и trustStorePassword.
Внимание
В случае автоматической конфигурации TLS узлы DataGrid обмениваются данными между собой (discovery, communication), используя TLS без шифрования. Соответствующие наборы шифров (в названиях присутствует фрагмент WITH_NULL) по умолчанию отключены в JVM. Чтобы избежать плохо диагностируемых ошибок при TLS handshake, включите эти шифры явно: уберите значение NULL из параметра jdk.tls.disabledAlgorithms файла lib/security/java.security в JRE. Переход на TLS с шифрованием возможен, но повлечет существенное падение производительности, что в большинстве случаев неприемлемо.
Ручная конфигурация параметров TLS для различных способов подключения к DataGrid#
Внимание
Рекомендуемые параметры настройки TLS конфигурируются плагином безопасности автоматически. Ручная конфигурация параметров TLS необходима лишь в тех случаях, когда значения по умолчанию неприемлемы.
DiscoveryиCommunicationподключения (указывается вserverExampleConfig.xml):XML#<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration" primary="true"> ... <property name="sslContextFactory"> <bean class="org.apache.ignite.ssl.SslContextFactory"> <property name="keyStoreFilePath" value="/path/to/self-keystore.jks"/> <property name="keyStorePassword" value="self-keystore-password"/> <property name="trustStoreFilePath" value="/path/to/truststore.jks"/> <property name="trustStorePassword" value="trust-sore-password"/> <property name="cipherSuites" value="<list of required cipher suites>"/> </bean> </property> ... </bean>Подключения через
RESTиGridClient(указывается вserverExampleConfig.xml):XML#<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration" primary="true"> ... <property name="connectorConfiguration"> <bean class="org.apache.ignite.configuration.ConnectorConfiguration"> <property name="sslEnabled" value="true"/> <property name="sslClientAuth" value="true"/> <property name="sslFactory" ref="sslContextFactory"/> </bean> </property> ... </bean> <bean id="sslContextFactory" class="org.apache.ignite.ssl.SslContextFactory"> <property name="keyStoreFilePath" value="/path/to/self-keystore.jks"/> <property name="keyStorePassword" value="self-keystore-password"/> <property name="trustStoreFilePath" value="/path/to/truststore.jks"/> <property name="trustStorePassword" value="trust-sore-password"/> <property name="cipherSuites" value="<list of required cipher suites>"/> </bean>Подключения через
IgniteClientиJDBC(указывается вserverExampleConfig.xml):XML#<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration" primary="true"> ... <property name="clientConnectorConfiguration"> <bean id="clientConnectorConfiguration" class="org.apache.ignite.configuration.ClientConnectorConfiguration"> <property name="useIgniteSslContextFactory" value="false"/> <property name="sslEnabled" value="true"/> <property name="sslClientAuth" value="true"/> <property name="sslContextFactory" ref="sslContextFactory"/> </bean> </property> ... </bean> <bean id="sslContextFactory" class="org.apache.ignite.ssl.SslContextFactory"> <property name="keyStoreFilePath" value="/path/to/self-keystore.jks"/> <property name="keyStorePassword" value="self-keystore-password"/> <property name="trustStoreFilePath" value="/path/to/truststore.jks"/> <property name="trustStorePassword" value="trust-sore-password"/> <property name="cipherSuites" value="<list of required cipher suites>"/> </bean>
Настройка отправки событий ИБ в Platform V Audit SE#
Для отправки событий ИБ в систему аудита Audit SE для серверных узлов:
Передайте в
classpathпроцесса DataGrid одну из реализаций интеграции с системойAudit SE, перечисленных ниже:audit2-integrationaudit4.3-integrationaudit-rest-integration
Укажите в конфигурации плагина безопасности настройки подключения к системе
Audit SE(см. параметрauditIntegrationConfigurationклассаSecurityPluginConfiguration).
Примеры конфигурационных файлов для интеграций с системой Audit SE предоставляются по запросу.
При использовании конфигуратора для системы аудита проверьте актуальность версий библиотек Platform V Backend. В classpath не должны попадать одинаковые библиотеки разных версий.
Отключение возможности подключений IgniteClient и JDBC#
Требуется, только если кластер не должен принимать подключения IgniteClient или JDBC.
Оба вида клиентских подключений используют одно и то же свойство IgniteConfiguration — clientConnectorConfiguration или его устаревший аналог sqlConnectorConfiguration. Для отключения возможности подключений установите оба параметра в null (указывается в serverExampleConfig.xml).
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration" primary="true">
...
<property name="clientConnectorConfiguration">
<null/>
</property>
<property name="sqlConnectorConfiguration">
<null/>
</property>
...
</bean>
Системные свойства JVM#
На СУ обязательно установите следующие системные свойства:
Свойство |
Описание |
|---|---|
|
Тип кластера. Должен быть одинаковым на всех узлах. Этот же тип кластера должен использоваться в |
|
Имя кластера. Должно быть одинаковым на всех узлах. Это же имя кластера должно использоваться в |
|
Отключает регистрацию Ignite JMX management beans, если их использование не планируется |
Помимо соблюдения структуры CN плагин выполняет следующие проверки имени и типа кластера:
при попытке входа клиентского или серверного узла DataGrid в кластер значение
cluster_nameв его сертификате должно быть равным значению системного свойстваIGNITE_CLUSTER_NAMEаутентифицирующего узла (следовательно, это свойство обязательно должно быть установлено для успешного запуска плагина);при любой аутентификации значение
cluster_typeиз сертификата аутентифицируемого узла должно быть равным системному свойствуIGNITE_CLUSTER_TYPEаутентифицирующего узла. Для сертификатов администраторов эксплуатации (тип ключа — „A“) эту проверку можно отключить отдельным системным свойством-DSKIP_A_CERT_CLUSTER_TYPE_CHECK=false, чтобы упростить проведение работ на тестовых стендах.
Конфигурирование безопасных клиентских подключений#
В плагине безопасности реализована поддержка следующих типов клиентских подключений:
тонкий клиент, реализация для Java
IgniteClient client = Ignition.startClient(configuration);;DataGrid JDBC-драйвер;
GridClient. Он используется для выполнения задач map-reduce и не имеет прямого доступа к данным кешей.
Для успешного подключения на серверных узлах кластера должны быть настроены коннекторы:
ClientConnectorConfiguration— для тонких клиентов и JDBC.ConnectorConfiguration— дляGridClient. Подробности настройки содержатся в разделе «Настройка TLS».
Конфигурирование IgniteClient#
Логин и пароль устанавливаются в ClientConfiguration.
ClientConfiguration cfg = new ClientConfiguration()
.setUserName("myLogin")
.setUserPassword("myPassword")
...
Конфигурирование GridClient#
Логин и пароль устанавливаются в GridClientConfiguration.
GridClientConfiguration cfg = new GridClientConfiguration()
.setSecurityCredentialsProvider(() -> new SecurityCredentials("myLogin", "myPassword"))
...
Конфигурирование JDBC#
Пример создания подключения:
// Зарегистрируйте JDBC-драйвер.
Class.forName("org.apache.ignite.IgniteJdbcDriver");
Connection conn = DriverManager.getConnection("jdbc:ignite:thin://xxx.x.x.x/?"
+ "sslMode=require"
+ "&user=" + login
+ "&password=" + pwd
+ "&sslClientCertificateKeyStoreUrl=" + keyStorePath
+ "&sslClientCertificateKeyStorePassword=" + keyStorePassword
+ "&sslClientCertificateKeyStoreType=" + "jks"
+ "&sslTrustCertificateKeyStoreUrl=" + trustStorePath
+ "&sslTrustCertificateKeyStorePassword=" + trustStorePassword
+ "&sslTrustCertificateKeyStoreType=" + "jks");
Конфигурирование JMX#
Плагин позволяет создать защищенный JMX-сервер. Для подключающегося пользователя компонентами плагина выполняется аутентификация с использованием логина, пароля и клиентского сертификата и авторизация разрешения org.apache.ignite.plugin.security.SecurityPermission.ADMIN_OPS (проверка, является ли он администратором эксплуатации). Если используется защищенный сервер, то следует запретить возможность незащищенного подключения:
если для запуска узла используется
control.sh, укажите параметр-nojmx;если узел запускается из Java-кода, не устанавливайте свойство
com.sun.management.jmxremote.
Защита JMX-подключений реализована с использованием JAAS Login Modules, поэтому создайте файл конфигурации, содержащий описание модуля, и задействуйте этот файл с помощью системного свойства java.security.auth.login.config.
Дополнения в конфигурации серверного узла#
Для настройки защищенного JMX-сервера в конфигурации плагина используются следующие свойства (указывается в serverExampleConfig.xml):
...
<bean id="securityPluginConfiguration" class="com.company.security.ignite.core.SecurityPluginConfiguration">
...
<property name="selfKeyStorePath" value="/path/to/serverNode-key-and-certificate.jks"/>
<property name="selfKeyStorePassword" value="password"/>
<property name="jmxPort" value="3000"/>
<property name="jmxTrustStorePath" value="/path/to/your-truststore.jks"/>
<property name="jmxTrustStorePassword" value="password"/>
<!-- Имя модуля из файла конфигурации JAAS Login Modules. -->
<property name="jmxLoginModuleName" value="JmxModule"/>
...
</bean>
...
Если свойство jmxPort не указано, то сервер не будет создан.
Подключение к JMX-коннектору при помощи внешнего Java-клиента#
Пример создания и использования javax.management.remote.JMXConnector:
import java.util.HashMap;
import java.util.Map;
import javax.management.remote.JMXConnector;
import javax.management.remote.JMXConnectorFactory;
import javax.management.remote.JMXServiceURL;
...
System.setProperty("javax.net.ssl.keyStore", "/path/to/admin/keystore.jks");
System.setProperty("javax.net.ssl.keyStorePassword", "password");
System.setProperty("javax.net.ssl.trustStore", "/path/to/Sberbank-CA-truststore.jks");
System.setProperty("javax.net.ssl.trustStorePassword", "password");
String jmxHost = "localhost";
int jmxPort = 3000;
JMXServiceURL url = new JMXServiceURL(String.format("service:jmx:rmi:///jndi/rmi://%s:%d/jmxrmi", jmxHost, jmxPort));
Map<String, Object> jmxEnv = new HashMap<>();
jmxEnv.put(JMXConnector.CREDENTIALS, new String[] { "admin", "passw0rd" });
try (JMXConnector jmxc = JMXConnectorFactory.connect(url, jmxEnv)) {
jmxc.getMBeanServerConnection().invoke(...);
...
}
Подключение к JMX-коннектору с помощью JConsole#
Для запуска jconsole выполните:
jconsole \
-J-Djavax.net.ssl.keyStore=/path/to/admin/keystore.jks \
-J-Djavax.net.ssl.keyStorePassword=password \
-J-Djavax.net.ssl.trustStore=/path/to/your-truststore.jks \
-J-Djavax.net.ssl.trustStorePassword=password
Затем заполните поля Remote Process (="host:port"), Username, Password и подключитесь.
Поддержка in-memory-кластера, обновление файла с пользователями и ролями#
Для настройки выполните следующие шаги:
Создайте bean
dataFileProviderSupplierвJsonSecurityDataSupplierImpl, указав в конструкторе путь к файлу.Создайте bean
metaStorageListenerвSecurityDataListener, указав в конструктореdataFileProviderSupplier.Добавьте bean
metaStorageListenerвSecurityPluginConfiguration.
Пример
<bean id="dataFileProviderSupplier" class="com.company.security.ignite.core.storage.metastorage.JsonSecurityDataSupplierImpl">
<constructor-arg value="path/to/security-data.json"/>
</bean>
<bean id="metaStorageListener" class="com.company.security.ignite.core.storage.metastorage.SecurityDataListener">
<constructor-arg ref="dataFileProviderSupplier"/>
</bean>
<util:list id="components" value-type="SecurityLifecycleAware">
<ref bean="evtRecorder"/>
<ref bean="metaStorageListener"/>
. . .
</util:list>
<bean id="securityPluginConfiguration" class="com.company.security.ignite.core.SecurityPluginConfiguration">
<property name="components" ref="components"/>
. . .
</bean>
Примечание
Обновление файла будет происходить при каждой записи в MetaStorage.
Генерация Salt и Salted-хеша пароля при помощи утилиты ise-user-control.sh#
Пример запуска
ise-user-control.sh generate-hash
User control utility.
Time: YYYY-MM-DDT17:55:57.432
Command [generate-hash] started.
Enter value for --password (password):
Enter value for --confirm-password (confirm password):
Salt: <salt>
Salted hash: <salted-hash>
Command [generate-hash] finished successfully.
Control utility has completed execution at: YYYY-MM-DDT17:56:05.029
Execution time: 7597 ms
Параметры безопасности#
Начальные учетные данные#
Логин |
Пароль |
Права |
|---|---|---|
|
|
Серверный узел |
|
|
Клиентский узел |
|
|
Администратор пользователей |
|
|
Администратор эксплуатации |
|
|
Администратор эксплуатации с ограниченными правами до изменения собственного пароля |
Хранилище ключей |
Пароль |
|---|---|
|
123456 |
|
123456 |
|
123456 |
|
123456 |
|
123456 |
Доверенное хранилище (truststore) |
Пароль |
|---|---|
|
123456 |
Внимание
Учетные данные, приведенные выше, действительны при локальном запуске DataGrid с конфигурацией ServerExampleConfig.xml. Для получения рекомендаций обратитесь к разделу «Парольная политика и рекомендации по заданию стойких паролей».
SSL/TLS и сертификаты#
Параметр |
Описание |
|---|---|
|
Порт сервера |
|
Задает тип хранилища ключей. По умолчанию |
|
Задает jks, содержащий ключ и сертификат для установления соединений с клиентами (браузерами) |
|
Задает jks, содержащий список сертификатов или корневых сертификатов. Используется для проверки сертификатов и установки HTTPs-соединения через браузер |
|
Задает обязательность аутентификации клиента (браузера), то есть ввода логина и пароля пользователя. При использовании SSL/TLS используется также для проверки на соответствие сертификата пользователю |
|
Каталог в файловой системе технологического сервера, где расположены пользовательские jks, которые будут применяться для создания подключения к DataGrid |
Парольная политика и рекомендации по заданию стойких паролей#
Безопасными считаются пароли, которые соответствуют следующим требованиям:
Длина пароля: не менее 8 символов.
Минимальное количество уникальных символов: не менее 6.
Количество символов неверной последовательности: 3.
Пароль должен содержать хотя бы одну букву верхнего регистра.
Пароль должен содержать хотя бы одну букву нижнего регистра.
Пароль должен содержать хотя бы одну цифру.
Пароль должен содержать хотя бы один специальный символ.
Пароль должен состоять из буквенных символов (латиница и кириллица), цифр и специальных символов.
Пароль не должен совпадать с именем пользователя.
Пароль не должен содержать трех и более символов, расположенных подряд на клавиатуре.
Быстрое развертывание в тестовых средах#
Для быстрого запуска DataGrid с настроенным SSL/TLS и плагином безопасности существуют:
config/serverExampleConfig.xml— конфигурации серверного узла;config/clientExampleConfig.xml— конфигурации клиентского узла;config/default-security-data.json— файл с начальными пользователями;config/certs/— сертификаты для SSL/TLS.
Установка переменной IGNITE_HOME#
$ export IGNITE_HOME=/path/to/Platform-V-Data-Grid-<version>
Редактирование JVM-опций для тестовых сертификатов#
Добавляем JVM_OPTS="$JVM_OPTS -DREQUIRE_AUDIT=false -DIGNITE_CLUSTER_TYPE=prom -DIGNITE_CLUSTER_NAME=mycluster" в $IGNITE_HOME/bin/ignite.sh
Запуск серверного узла#
$ $IGNITE_HOME/bin/ignite.sh $IGNITE_HOME/config/serverExampleConfig.xml
Запуск клиентского узла#
$ $IGNITE_HOME/bin/ignite.sh $IGNITE_HOME/config/clientExampleConfig.xml
Активация кластера#
$ $IGNITE_HOME/bin/control.sh --activate --host localhost --user operationAdmin --password password --keystore $IGNITE_HOME/config/certs/operationAdmin.jks --keystore-password password --truststore $IGNITE_HOME/config/certs/truststore.jks --truststore-password password
Запуск утилиты управления пользователями#
$ java -jar $IGNITE_HOME/libs/security-plugins/ui-\<version\>.jar --server.port=8990 --ssl.disabled=true --certificates.dir.path=$IGNITE_HOME/config/certs
Подключение к кластеру через браузер#
В браузере перейдите по адресу
http://localhost:8990/.Затем заполните поля в окне авторизации:
Поле |
Значение |
|---|---|
Хост |
|
Порт |
|
Логин |
|
Пароль |
|
Протокол |
|
Алгоритм |
|
Шифр |
Оставьте поле пустым |
Key store |
|
Trust store |
|
Пароль к обоим хранилищам |
|
Начальные пароли и пользователи#
Логин |
Пароль |
Права |
|---|---|---|
|
|
Серверный узел |
|
|
Клиентский узел |
|
|
Администратор пользователей |
|
|
Администратор эксплуатации |
|
|
Администратор эксплуатации с ограниченными правами до изменения собственного пароля |
Аудит#
В настоящем руководстве приводится описание REST-интерфейса.
Описание REST API для внешнего аудита#
Слушатель событий
com.sbt.security.ignite.integration.audit.rest.AuditEventListenerImplпри запуске узла регистрирует метамодель событий, отправляя ее на веб-страницуAUDIT_URL/metamodel.События, которые необходимо записывать в аудит, отправляются на веб-страницу
AUDIT_URL/event.Содержимое запросов описывается в файле
audit-client-openapi.yml.
Конфигурирование регионов данных#
Введение#
Для контроля объема доступной для кеша или группы кешей оперативной памяти в DataGrid применяется концепция регионов данных (Data Region) — расширяемых логических областей оперативной памяти, в которых располагаются данные. Изначальный размер региона данных, а также максимальный размер, который он может занимать, можно контролировать. Кроме размера, регионы данных задают настройки режима Native Persistence для кешей.
По умолчанию, если не переопределено в конфигурации, все кеши сохраняются в default data region, который создается автоматически и имеет максимальный размер 20% от свободной оперативной памяти узла. При необходимости можно указать в конфигурации несколько дополнительных регионов, например, в следующих случаях, когда:
необходимо ограничить объем оперативной памяти, доступной для определенных кешей и кеш-групп;
в кластере используются и in-memory, и persistent-кеши, так как параметры Native Persistence задаются отдельно для каждого региона данных;
требуется настроить отличные параметры для кешей — таких, как политика вытеснения страниц (
Eviction Policy), и прочих, настраиваемых в рамках конфигурации региона данных, а не кеша.
Конфигурирование региона данных по умолчанию#
По умолчанию новый кеш добавляется в регион данных, заданный по умолчанию. Воспользуйтесь конфигурацией класса IgniteConfiguration ниже для изменения настроек региона данных по умолчанию.
Примеры конфигурации:
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!--
Область памяти, к которой привязаны все кеши, если в их конфигурации не указан другой регион.
-->
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="name" value="Default_Region"/>
<!-- Максимальный размер — 40 Мб. -->
<property name="maxSize" value="#{40 * 1024 * 1024}"/>
</bean>
</property>
</bean>
</property>
<!-- Прочие свойства. -->
</bean>
</beans>
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration defaultRegion = new DataRegionConfiguration();
defaultRegion.setName("Default_Region");
defaultRegion.setMaxSize(100 * 1024 * 1024);
storageCfg.setDefaultDataRegionConfiguration(defaultRegion);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setDataStorageConfiguration(storageCfg);
// Запустите узел.
Ignite ignite = Ignition.start(cfg);
ignite.close();
var cfg = new IgniteConfiguration
{
DataStorageConfiguration = new DataStorageConfiguration
{
DefaultDataRegionConfiguration = new DataRegionConfiguration
{
Name = "Default_Region",
MaxSize = 100 * 1024 * 1024
}
}
};
// Запустите узел.
var ignite = Ignition.Start(cfg);
Добавление пользовательских регионов данных#
Возможно добавить дополнительные регионы данных с необходимыми настройками. В примере ниже приводится конфигурация класса IgniteConfiguration региона данных, занимающего до 40 Мб ОЗУ и использующего стандартную политику вытеснения Random-2-LRU.
Внимание
В конфигурации ниже создается кеш, располагающийся в новом регионе данных.
Примеры конфигурации:
<bean class="org.apache.ignite.configuration.IgniteConfiguration" id="ignite.cfg">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<!--
Область памяти, к которой привязаны все кеши, если в их конфигурации не указан другой регион.
-->
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="name" value="Default_Region"/>
<!-- Максимальный размер — 40 Мб. -->
<property name="maxSize" value="#{40 * 1024 * 1024}"/>
</bean>
</property>
<property name="dataRegionConfigurations">
<list>
<!--
Область памяти объемом 40 Мб с включенным вытеснением.
-->
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="name" value="40MB_Region_Eviction"/>
<!-- Область памяти с начальным размером 20 Мб. -->
<property name="initialSize" value="#{20 * 1024 * 1024}"/>
<!-- Максимальный размер — 40 Мб. -->
<property name="maxSize" value="#{40 * 1024 * 1024}"/>
<!-- Включение вытеснения для данной области памяти. -->
<property name="pageEvictionMode" value="RANDOM_2_LRU"/>
</bean>
</list>
</property>
</bean>
</property>
<property name="cacheConfiguration">
<list>
<!-- Кеш, который сопоставлен с определенной областью данных. -->
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="SampleCache"/>
<!--
Присвоение кешу региона `40MB_Region_Eviction`.
-->
<property name="dataRegionName" value="40MB_Region_Eviction"/>
</bean>
</list>
</property>
<!-- Прочие свойства. -->
</bean>
</beans>
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
DataRegionConfiguration defaultRegion = new DataRegionConfiguration();
defaultRegion.setName("Default_Region");
defaultRegion.setMaxSize(100 * 1024 * 1024);
storageCfg.setDefaultDataRegionConfiguration(defaultRegion);
// Область памяти объемом 40 Мб с включенным вытеснением.
DataRegionConfiguration regionWithEviction = new DataRegionConfiguration();
regionWithEviction.setName("40MB_Region_Eviction");
regionWithEviction.setInitialSize(20 * 1024 * 1024);
regionWithEviction.setMaxSize(40 * 1024 * 1024);
regionWithEviction.setPageEvictionMode(DataPageEvictionMode.RANDOM_2_LRU);
storageCfg.setDataRegionConfigurations(regionWithEviction);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setDataStorageConfiguration(storageCfg);
CacheConfiguration cache1 = new CacheConfiguration("SampleCache");
// Данный кеш будет находиться в регионе данных `40MB_Region_Eviction`.
cache1.setDataRegionName("40MB_Region_Eviction");
cfg.setCacheConfiguration(cache1);
// Запустите узел.
Ignite ignite = Ignition.start(cfg);
var cfg = new IgniteConfiguration
{
DataStorageConfiguration = new DataStorageConfiguration
{
DefaultDataRegionConfiguration = new DataRegionConfiguration
{
Name = "Default_Region",
MaxSize = 100 * 1024 * 1024
},
DataRegionConfigurations = new[]
{
new DataRegionConfiguration
{
Name = "40MB_Region_Eviction",
InitialSize = 20 * 1024 * 1024,
MaxSize = 40 * 1024 * 1024,
PageEvictionMode = DataPageEvictionMode.Random2Lru
},
new DataRegionConfiguration
{
Name = "30MB_Region_Swapping",
InitialSize = 15 * 1024 * 1024,
MaxSize = 30 * 1024 * 1024,
SwapPath = "/path/to/swap/file"
}
}
}
};
Ignition.Start(cfg);
Для получения полного списка свойств класса DataStorageConfiguration обратитесь к javadoc класса.
Стратегия «разогрева» кешей#
При перезагрузках кластера DataGrid не требуется принудительный «разогрев» оперативной памяти данными с диска. Как только топология кластера собрана, а кластер активирован, он готов к работе, и можно посылать запросы к данным и производить вычисления. В таком случае данные «поднимаются» с диска в оперативную память при первом запросе, но это может вызывать задержки во время первого обращения к записи в кеше.
Для low-latency приложений, то есть приложений, требующих быстрого ответа, доступна функция «разогрева», которая позволяет загрузить все данные в оперативную память в процессе запуска кластера, чтобы в дальнейшем при их запросе не происходило обращения к диску.
В настоящий момент стратегия разогрева данных DataGrid подразумевает под собой загрузку данных во все или только в указанные регионы данных, вплоть до исчерпания свободного места в регионе. При этом в первую очередь в память загружаются индексы. Стратегия разогрева может быть сконфигурирована как для всех регионов данных (по умолчанию), так и для каждого региона данных по отдельности.
Включение функции «разогрева» для всех регионов данных#
Для включения функции «разогрева» для всех регионов данных укажите LoadAllWarmUpStrategy в DataStorageConfiguration#setDefaultWarmUpConfiguration:
Примеры конфигурации:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultWarmUpConfiguration">
<bean class="org.apache.ignite.configuration.LoadAllWarmUpConfiguration"/>
</property>
</bean>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
// Изменение стратегии прогрева по умолчанию для всех регионов данных.
storageCfg.setDefaultWarmUpConfiguration(new LoadAllWarmUpConfiguration());
cfg.setDataStorageConfiguration(storageCfg);
Включение функции «разогрева» для определенного региона данных#
Для включения функции «разогрева» для определенного региона данных укажите LoadAllWarmUpStrategy в DataRegionConfiguration#setWarmUpConfiguration:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<property name="dataRegionConfigurations">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="name" value="NewDataRegion"/>
<property name="initialSize" value="#{100 * 1024 * 1024}"/>
<property name="persistenceEnabled" value="true"/>
<property name="warmUpConfiguration">
<bean class="org.apache.ignite.configuration.LoadAllWarmUpConfiguration"/>
</property>
</bean>
</property>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
// Установите другую стратегию прогрева для пользовательского региона данных.
DataRegionConfiguration myNewDataRegion = new DataRegionConfiguration();
myNewDataRegion.setName("NewDataRegion");
// Можно настроить начальный размер и другие параметры.
myNewDataRegion.setInitialSize(100 * 1024 * 1024);
// Выполнение загрузки данных с диска в DRAM при перезапуске.
myNewDataRegion.setWarmUpConfiguration(new LoadAllWarmUpConfiguration());
// Подключение персистентности регионов данных. DataGrid считывает данные с диска при запросе таблиц/кешей из этого региона.
myNewDataRegion.setPersistenceEnabled(true);
// Применение настроек.
storageCfg.setDataRegionConfigurations(myNewDataRegion);
cfg.setDataStorageConfiguration(storageCfg);
Остановка работы функции «разогрева» для всех регионов данных#
Для остановки работы функции «разогрева» для всех регионов данных укажите NoOpWarmUpConfiguration в DataStorageConfiguration#setDefaultWarmUpConfiguration:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultWarmUpConfiguration">
<bean class="org.apache.ignite.configuration.NoOpWarmUpConfiguration"/>
</property>
</bean>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.setDefaultWarmUpConfiguration(new NoOpWarmUpConfiguration());
cfg.setDataStorageConfiguration(storageCfg);
Остановка работы функции «разогрева» для определенного региона данных#
Для остановки работы функции «разогрева» для определенного региона данных передайте параметр конфигурации NoOpWarmUpStrategy в DataRegionConfiguration#setWarmUpConfiguration:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="dataStorageConfiguration">
<property name="dataRegionConfigurations">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="name" value="NewDataRegion"/>
<property name="initialSize" value="#{100 * 1024 * 1024}"/>
<property name="persistenceEnabled" value="true"/>
<property name="warmUpConfiguration">
<bean class="org.apache.ignite.configuration.NoOpWarmUpConfiguration"/>
</property>
</bean>
</property>
</property>
</bean>
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
// Установите другую стратегию прогрева для пользовательского региона данных.
DataRegionConfiguration myNewDataRegion = new DataRegionConfiguration();
myNewDataRegion.setName("NewDataRegion");
// Можно настроить начальный размер и другие параметры.
myNewDataRegion.setInitialSize(100 * 1024 * 1024);
// Выполнение загрузки данных с диска в DRAM при перезапуске.
myNewDataRegion.setWarmUpConfiguration(new NoOpWarmUpConfiguration());
// Подключение персистентности регионов данных. DataGrid считывает данные с диска при запросе таблиц/кешей из этого региона.
myNewDataRegion.setPersistenceEnabled(true);
// Применение настроек.
storageCfg.setDataRegionConfigurations(myNewDataRegion);
cfg.setDataStorageConfiguration(storageCfg);
Остановка работы функции «разогрева» с помощью утилиты control.sh#
Для остановки работы функции «разогрева» с помощью утилиты control.sh запустите команду:
control.sh --warm-up --stop --yes
Остановка работы функции «разогрева» с помощью JMX#
Для остановки работы функции «разогрева» с помощью JMX используйте следующий метод: org.apache.ignite.mxbean.WarmUpMXBean#stopWarmUp.
Механизм Change Data Capture (CDC) и межкластерная репликация#
Введение#
Change Data Capture (CDC) — это сценарий, предназначенный для асинхронной передачи измененных данных с целью их дальнейшей обработки.
Примеры сценариев для использования CDC:
потоковая передача изменений в Хранилище;
обновление поисковых индексов;
подсчет статистики (потоковые запросы);
аудит логов;
асинхронное взаимодействие со внешней системой (модерирование, запуск бизнес-процессов и прочее).
На механизме CDC основан процесс межкластерной репликации в DataGrid: в этом процессе CDC обрабатывает сегменты WAL-журнала, а затем доставляет локальные изменения к потребителям. Информация о межкластерной репликации в DataGrid находится в разделе «Межкластерная репликация в DataGrid» ниже.
DataGrid реализует CDC с помощью приложения ignite-cdc.sh и Java API.
CDC запускается на всех серверных узлах кластера DataGrid в отдельной JVM.
Алгоритм работы механизма CDC#
Механизм CDC работает как для persistence-кластеров, так и для in-memory-кластеров. Ниже представлена схема и алгоритм работы механизма CDC.
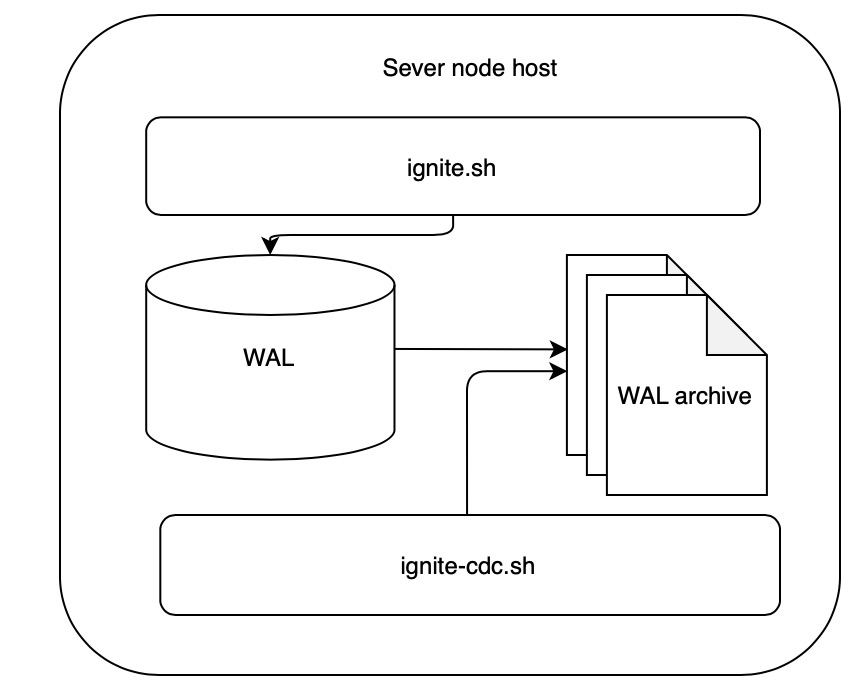
Для persistence-кластеров используется следующий алгоритм работы механизма:
При включенном механизме CDC серверный узел DataGrid создает в специальной директории
db/cdc/{consistent_id}(значение по умолчанию) жесткую ссылку на каждый сегмент архива WAL-журнала.Затем приложение
ignite-cdc.shзапускается на отдельной JVM и обрабатывает сегменты WAL-журнала, которые были перенесены в архив совсем недавно.После обработки сегмента приложением он удаляется. Само дисковое пространство освобождается при удалении обеих ссылок (в архиве WAL-журнала и в каталоге CDC).
CdcConsumer сохраняет состояние обработки в виде указателей на последние обработанные события в файлах cdc-*-state.bin. CdcConsumer может запрашивать сохранение (обновление) состояния у приложения ignite-cdc.sh. При запуске ignite-cdc.sh обработка событий будет продолжаться, начиная с последнего сохраненного состояния.
Внимание
Алгоритм работы механизма для in-memory-кластеров практически идентичен алгоритму работы CDC для persistence-кластеров. Отличие состоит в том, что в режиме in-memory узел записывает в WAL-журнал данные только тех областей данных (data region), для которых включен CDC.
Конфигурация#
Параметры конфигурации узла DataGrid#
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Свойство включает CDC на серверном узле для региона данных. Позволяет явно настроить регионы данных, для которых CDC включен |
|
|
Путь к каталогу CDC |
|
|
Тайм-аут для принудительной отправки сегмента WAL-журнала в архив (даже если обработка сегмента не завершена). Внимание Необходимо обязательно установить тайм-аут, иначе репликация будет происходить только при архивировании WAL-сегмента по его заполненности, что непредсказуемо по длительности. Расхождения между кластерами в таком случае могут достигать нескольких минут или десятков минут (зависит от нагрузки). Если нагрузка низкая, ротация может происходить еще реже |
|
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Свойство включает CDC на серверном узле для региона данных. Позволяет явно настроить регионы данных, для которых CDC включен |
false |
|
Путь к каталогу CDC |
«db/wal/cdc» |
|
тайм-аут для принудительной отправки сегмента WAL-журнала в архив (даже если обработка сегмента не завершена). |
-1 (disabled) |
Параметры конфигурации приложения CDC#
CDC конфигурируется так же, как и узел DataGrid — через XML-файл Spring:
ignite-cdc.shтребует указанияIgniteConfigurationиCdcConfigurationв одном конфигурационном файле;IgniteConfigurationиспользуется для установки общих параметров, например, пути к каталогу CDC,consistentIdузла и других;CdcConfigurationсодержит непосредственно настройки приложенияignite-cdc.sh.
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
тайм-аут для ожидания блокировки. При запуске CDC устанавливает блокировку на каталог во избежание параллельной обработки каталога CDC-журнала другим работающим приложением |
1000 мс |
|
Время между последовательными проверками, в течение которого приложение находится в спящем режиме, если новые файлы отсутствуют |
1000 мс |
|
Свойство, определяющее, должны ли ключ и значение измененных записей быть предоставлены в бинарном формате |
true |
|
Реализация |
null |
|
Массив SPI «экспортеров» для передачи метрик приложения CDC. Подробнее в разделе «Конфигурация экспортеров и включение метрик в New Metrics System» |
null |
Свойства кластера#
Свойства кластера, перечисленные в таблице ниже, позволяют настраивать CDC во время работы кластера (подробнее о работе со свойствами кластера см. на сайте Apache Ignite).
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Принудительное отключение CDC во избежание переполнения диска. Полезно, если приложение CDC не работает в течение длительного времени. Внимание! Отключение CDC приведет к потере данных об изменениях |
false |
CDC API#
org.apache.ignite.cdc.CdcEvent
Полное описание интерфейса можно найти в официальной документации CdcEvent Interface или в документе «Справочник Java API DataGrid».
Имя |
Описание |
|---|---|
|
Ключ измененной записи |
|
Значение измененной записи. Метод вернет |
|
ID кеша, на котором происходит изменение. Значение метода равно значению параметра |
|
Партиция DataGrid, в которой располагается измененная запись |
|
Флаг primary-узла. Возвращает |
|
|
org.apache.ignite.cdc.CdcConsumer
Полное описание интерфейса можно найти в официальной документации CdcConsumer Interface или в документе «Справочник Java API DataGrid».
org.apache.ignite.cdc.CdcConsumer — обработчик (потребитель) событий-изменений. CdcConsumer может быть реализован пользователем самостоятельно. В дистрибутиве поставляется три реализации CDC (подробнее в разделе «Межкластерная репликация в DataGrid»).
Имя |
Описание |
|---|---|
|
Вызывается один раз при запуске приложения CDC. Реестр |
|
Основной метод обработки изменений. Когда данный метод возвращает |
|
Вызывается один раз при остановке приложения CDC |
Метрики#
ignite-cdc.sh доступен тот же набор SPI для экспорта метрик, что и DataGrid. Следующие метрики предоставляются приложением (дополнительные метрики могут быть предоставлены потребителем):
Имя |
Описание |
|---|---|
|
Индекс текущего обрабатываемого сегмента WAL |
|
Индекс сегмента WAL, содержащего последнее зафиксированное состояние |
|
Зафиксированное смещение в байтах внутри сегмента WAL |
|
Временная метка (в миллисекундах), указывающая на начало обработки последнего сегмента |
|
Обрабатываемый приложением каталог с |
|
Обрабатываемый приложением каталог |
|
Каталог CDC, из которого приложение считывает данные |
|
Время обработки WAL-сегмента в миллисекундах |
Логирование#
ignite-cdc.sh использует ту же конфигурацию логирования, что и узел DataGrid. Единственное отличие — события записываются в файл ignite-cdc.log.
Жизненный цикл ignite-cdc.sh#
Внимание
В приложении ignite-cdc.sh реализован подход fail-fast. В случае любой ошибки приложение прекращает работу. Процедура перезапуска должна быть настроена средствами операционной системы.
После запуска приложение ignite-cdc.sh:
Находит необходимые общие каталоги. Используются значения из предоставленной
IgniteConfiguration.Блокирует CDC каталог.
Загружает сохраненное состояние («отметку» последнего обработанного события).
Запускает
CdcConsumer.Запускает бесконечный цикл ожидания и обработки новых доступных WAL-сегментов.
Останавливает потребитель данных в случае ошибки или получения сигнала об остановке.
Обработка пропущенных сегментов#
Механизм CDC может быть отключен вручную или путем настройки максимального размера каталога. В этом случае создание hardlink не происходит.
Внимание
Все изменения в пропущенных сегментах будут потеряны.
Если механизм CDC включен и был обнаружен пропуск в сегментах, например:
0000000000000002.wal;0000000000000010.wal;0000000000000011.wal;
то ignite-cdc.sh выдаст ошибку следующего вида:
Found missed segments. Some events are missed. Exiting! [lastSegment=2, nextSegment=10]
Примечание
Перед перезапуском CDC убедитесь, что данные, хранящиеся на разных кластерах, согласованы между собой. Если данные не согласованы, выполните восстановление согласованности с помощью команды повторной отправки, создания снепшота или другим пользовательским способом.
Чтобы исправить эту ошибку, выполните следующую команду с помощью утилиты control:
# Удаление из кластера CDC-ссылок до последнего пропуска в них.
control.(sh|bat) --cdc delete_lost_segment_links
# Удаление на заданном узле CDC-ссылок до последнего пропуска в них.
control.(sh|bat) --cdc delete_lost_segment_links --node-id node_id
Команда удалит все ссылки на сегменты перед последним пропуском.
Например, CDC был выключен несколько раз:
0000000000000002.wal;0000000000000003.wal;0000000000000008.wal;0000000000000010.wal;0000000000000011.wal.
Необходимо выполнить команду удаления CDC-ссылок, при этом будут удалены следующие ссылки:
0000000000000002.wal;0000000000000003.wal;0000000000000008.wal.
После запуска приложение ignite-cdc.sh начнет работу с сегмента 00000000000000000010.wal.
Принудительная повторная отправка всех данных кеша в CDC#
Если изменение данных в кеше произошло при отключенном механизме CDC, то эти изменения не будут зафиксированы обработчиком CDC, так как не будет создана CDC-ссылка на сегмент с этими данными. В этом случае необходимо выполнить повторную отправку данных из существующих кешей. Это важно, например, перед запуском репликации, чтобы восстановить согласованность данных в кешах между кластерами.
Примечание
Повторная отправка будет отменена если кластер не был отребалансирован или изменилась топология (добавлен или удален узел, изменена базовая топология).
Для повторной отправки данных кеша выполните следующую команду с помощью утилиты control:
control.(sh|bat) --cdc resend --caches cache1,...,cacheN
Команда итерируется по кешам и записывает основные копии записей данных в WAL-журнал для последующего захвата приложением CDC (ignite-cdc.sh).
Примечание
Отсутствуют гарантии уведомления обработчика CDC (реализации CdcConsumer) при параллельных обновлениях кеша — порядок событий, дублирование записей и прочее. Используйте интерфейс CdcEvent#version для определения версии записей (полное описание интерфейса можно найти в официальной документации CdcEvent Interface или в документе «Справочник Java API DataGrid»).
Межкластерная репликация в DataGrid#
Механизм межкластерной репликации основан на механизме CDC, описанном выше.
Механизм репликации асинхронный. Обеспечивается модулем расширения Change Data Capture Extension (cdc-ext).
В зависимости от архитектуры сети и требований безопасности доступны три схемы межкластерной репликации:
DataGrid to DataGrid через тонкий клиент Java (Java thin client).
DataGrid to DataGrid через клиентский узел.
DataGrid с использованием Platform V Corax.
Примечание
Все три схемы CDC поддерживают репликацию изменений TypeMapping и BinaryType. Подробнее — см. документ «Справочник Java API DataGrid».
Для разрешения возможных конфликтов изменения данных при использовании Active-Active режима репликации необходимо настроить модуль ConflictResolver для каждой схемы межкластерной репликации. Подробное описание этого модуля содержится в следующем разделе.
Репликация DataGrid to DataGrid через тонкий клиент Java (Java thin client)#
IgniteToIgniteCdcStreamer запускает тонкий клиент Java, подключающийся к удаленному кластеру-получателю. При наличии подключения к удаленному кластеру тонкий клиент Java будет реплицировать в него изменения данных, захваченные на кластере-источнике:
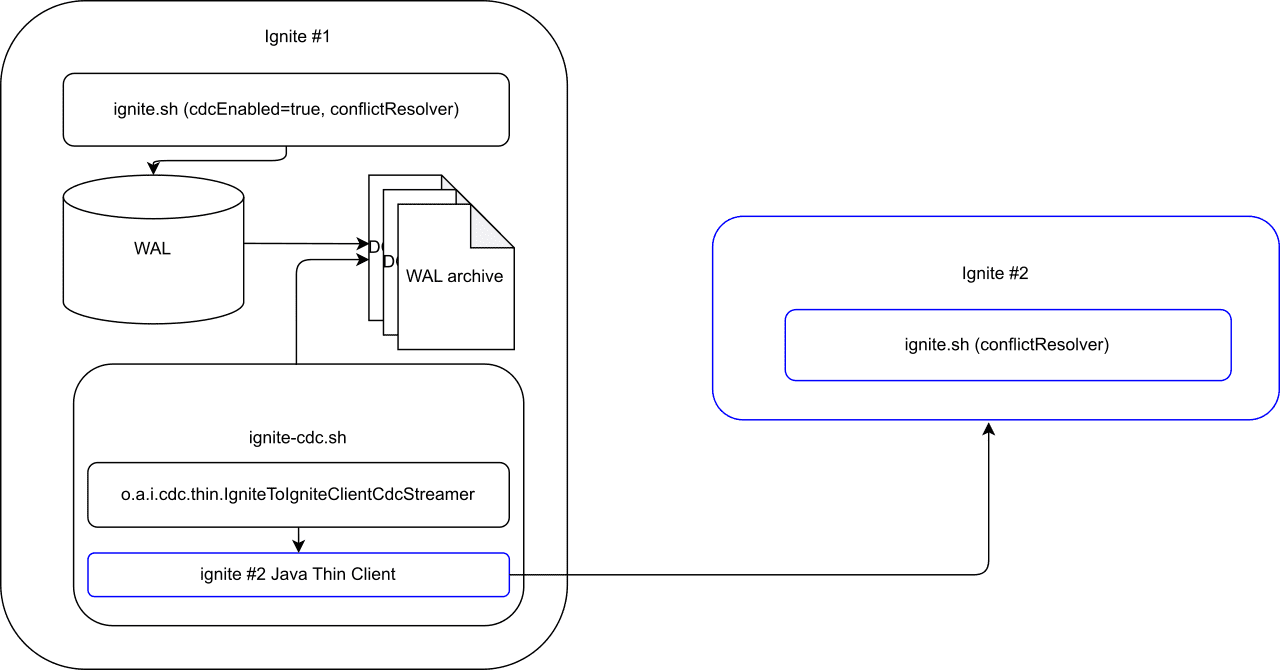
Внимание
Экземпляры приложения ignite-cdc.sh должны быть настроены и запущены на каждом серверном узле кластера-источника для передачи всех изменений данных.
Данная схема репликации требует возможности организации прямого соединения между двумя кластерами DataGrid.
Примечание
На текущий момент данная схема позволяет обеспечить репликацию только между двумя кластерами. Для соединения более двух кластеров можно воспользоваться схемой из раздела «Репликация DataGrid с использованием Platform V Corax».
Описание конфигурации#
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Набор (set) имен реплицируемых кешей |
null |
|
Конфигурация клиентского узла, реплицирующего изменения на кластер-получатель |
null |
|
Свойство отвечает за то, какие партиции будут реплицироваться: либо только primary-партиции, либо все, чтобы в случае выхода primary-партиции из строя изменения поступили от backup-партиций |
|
|
Максимальный размер пакета изменений, которые необходимо отправить |
|
Метрики#
Имя |
Описание |
|---|---|
|
Количество событий, примененных к кластеру-получателю |
|
Отметка времени последнего примененного события |
|
Количество обработанных изменений в |
|
Количество обработанных изменений в |
Репликация DataGrid to DataGrid через клиентский узел#
IgniteToIgniteCdcStreamer запускает клиентский узел, подключающийся к удаленному кластеру-получателю. При наличии подключения к удаленному кластеру клиентский узел будет реплицировать в него изменения данных, захваченные на кластере-источнике.
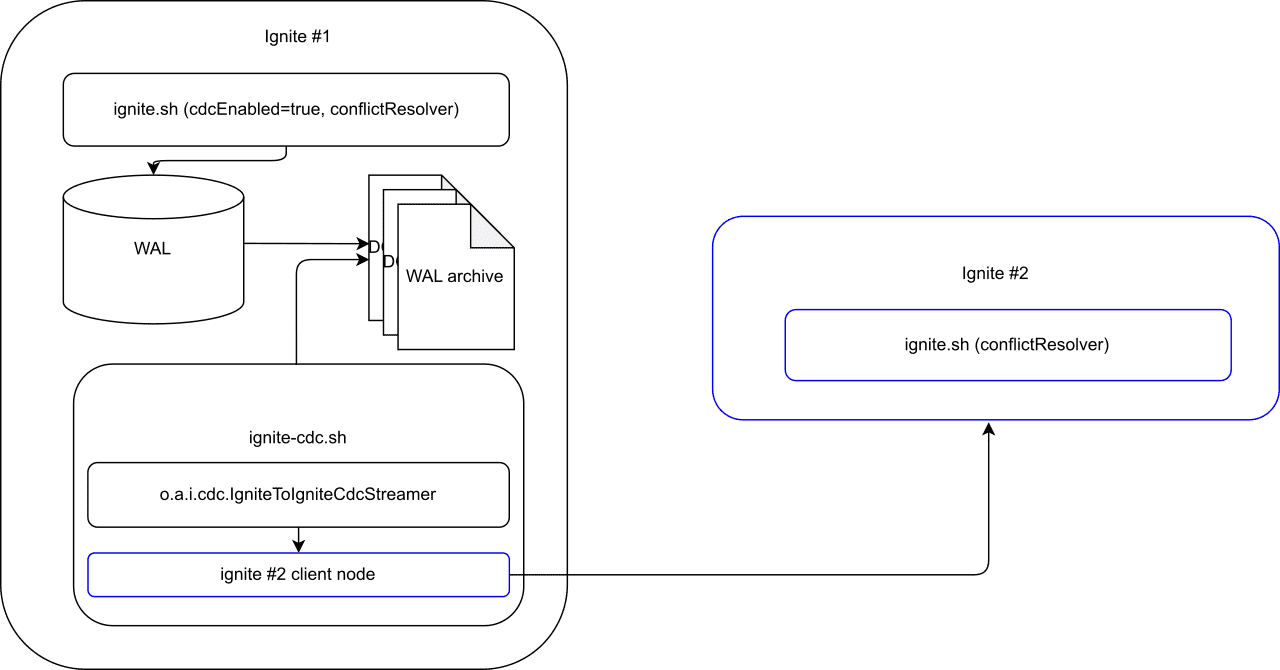
Внимание
Экземпляры приложения ignite-cdc.sh должны быть настроены и запущены на каждом серверном узле кластера-источника для передачи всех изменений данных.
Данная схема репликации требует возможности организации прямого соединения между двумя кластерами DataGrid.
Примечание
На текущий момент данная схема позволяет обеспечить репликацию только между двумя кластерами. Для соединения более двух кластеров можно воспользоваться схемой из раздела «Репликация DataGrid с использованием Platform V Corax».
Описание конфигурации#
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Набор (set) имен реплицируемых кешей |
null |
|
Конфигурация клиентского узла, реплицирующего изменения на кластер-получатель |
null |
|
Свойство отвечает за то, какие партиции будут реплицироваться: либо только primary-партиции, либо все, чтобы в случае выхода primary-партиции из строя изменения поступили от backup-партиций |
|
|
Максимальный размер пакета изменений, которые необходимо отправить |
|
Метрики#
Имя |
Описание |
|---|---|
|
Количество событий, реплицированных на кластер-получатель |
|
Отметка времени последнего примененного события |
|
Количество обработанных изменений в |
|
Количество обработанных изменений в |
Репликация DataGrid с использованием Platform V Corax#
Этот способ репликации изменений между кластерами требует настройки двух приложений:
ignite-cdc.shс классомorg.apache.ignite.cdc.kafka.IgniteToKafkaCdcStreamer, который будет захватывать изменения из кластера-источника и записывать их в topic Corax.kafka-to-ignite.sh, который будет считывать изменения из topic Corax и затем записывать их в кластер-получатель.
Внимание
Экземпляры приложения ignite-cdc.sh должны быть настроены и запущены на каждом серверном узле кластера-источника для передачи всех изменений данных.
Для обеспечения гарантий последовательного чтения данных при использовании репликации через Platform V Corax в topic метаданных должна быть только одна партиция.
Схема предполагает использование Platform V Corax (далее – Corax) для передачи изменений в другой кластер. Подойдут конфигурации стратегии доставки at least once и exactly once. Идемпотентность потребителя гарантируется модулем conflictResolver, гарантирующим что повторно отправленное изменение не будет применено дважды. Кроме того, в отличие от схемы DataGrid to DataGrid, данная схема позволяет производить репликацию данных между несколькими кластерами (3 и более), которые могут содержаться в ЦОД (в примерах — ЦОД-1 и ЦОД-2). Репликация возможна как между кластерами, содержащимися в одном ЦОД, так и между кластерами, содержащимися в разных ЦОД. Различий в схеме репликации и ее настройке нет.
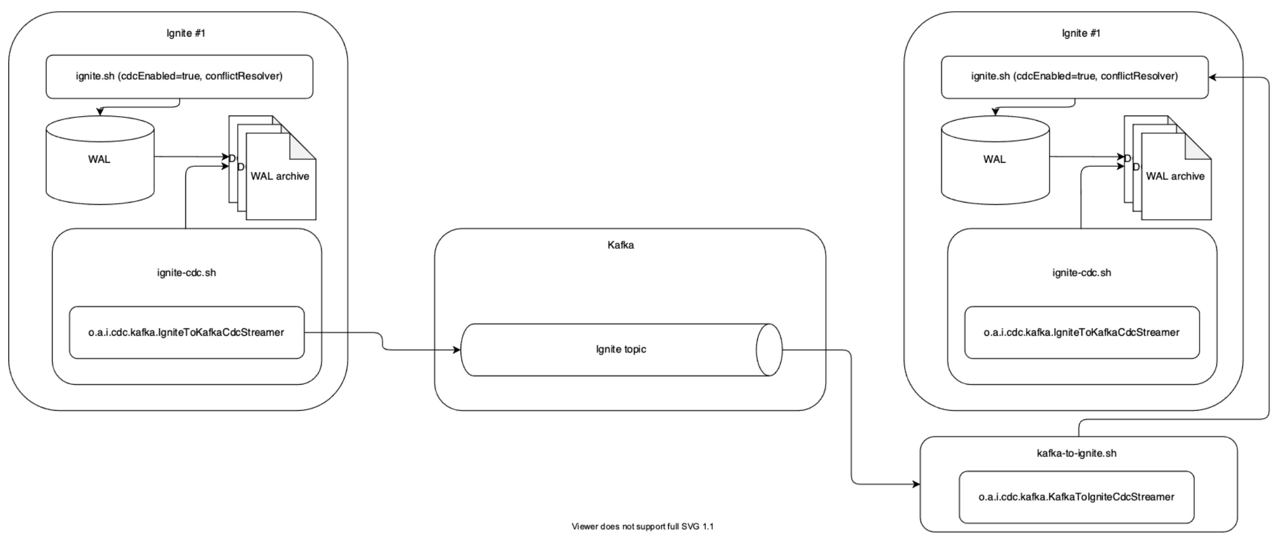
IgniteToKafkaCdcStreamer отправляет захваченные на кластере-источнике изменения в topic Platform V Corax. KafkaToIgniteCdcStreamerвычитывает изменения из topic и применяет на удаленном сервере-приемнике.
Для двусторонней репликации (Active-Active) запись событий CDC и IgniteToKafkaCdcStreamer (ignite-cdc.sh) включаются на всех кластерах. Для применения изменений на каждом приемнике необходимо запустить как минимум по одному экземпляру KafkaToIgniteCdcStreamer для каждого из topics с событиями CDC других кластеров-источников (topic кластера-приемника вычитывать на самом кластре-приемнике не нужно). Кроме того, для разрешения конфликтных изменений необходмо настроить CacheVersionConflictResolver при помощи соответствующего плагина.
Описание конфигурации#
Конфигурация IgniteToKafkaCdcStreamer
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Набор (set) имен реплицируемых кешей |
null |
|
Свойства producer Corax |
null |
|
Имя topic Corax для событий CDC |
null |
|
Количество партиций topic Corax для событий CDC |
null |
|
Topic для репликации изменений |
null |
|
Свойство отвечает за то, какие партиции будут реплицироваться: либо только primary-партиции, либо все, чтобы в случае выхода primary-партиции из строя изменения поступили от backup-партиций |
|
|
Максимальный размер конкурентно создаваемых записей Corax. |
|
|
тайм-аут запроса Corax, мс |
|
Параметр kafkaRequestTimeout устанавливает, сколько IgniteToKafkaCdcStreamer будет ожидать завершения запроса KafkaProducer.
Внимание
Значение параметра kafkaRequestTimeout зависит от потребностей конкретного приложения. Если значение слишком маленькое, могут наблюдаться падения IgniteToKafkaCdcStreamer во время долгой отправки сообщений в Corax.
Параметр kafkaProperties устанавливает настройки KafkaProducer. Рекомендуется использовать отдельный файл для хранения необходимых свойств конфигурации. На этот файл можно сослаться в конфигурации IgniteToKafkaCdcStreamer.
bootstrap.servers=xxx.x.x.x:9092
request.timeout.ms=10000
<bean id="cdc.streamer" class="org.apache.ignite.cdc.kafka.IgniteToKafkaCdcStreamer">
<property name="topic" value="${send_data_kafka_topic_name}"/>
<property name="metadataTopic" value="${send_metadata_kafka_topic_name}"/>
<property name="kafkaPartitions" value="${send_kafka_partitions}"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
<property name="onlyPrimary" value="false"/>
<property name="kafkaProperties" ref="kafkaProperties"/>
</bean>
<util:properties id="kafkaProperties" location="file:kafka_properties_path/kafka.properties"/>
Важно
Параметр request.timeout.ms является обязательным.
Метрики#
Имя |
Описание |
|---|---|
|
Количество событий, примененных к Corax |
|
Отметка времени последнего примененного события |
|
Количество обработанных изменений в |
|
Количество обработанных изменений в |
|
Количество байтов, отправленных в Corax |
|
Количество маркеров об обработанных изменениях в |
Приложение kafka-to-ignite.sh#
Приложение kafka-to-ignite.sh должно быть запущено рядом с кластером-получателем для обеспечения высокой скорости соединения. Приложение будет считывать события CDC из topic Corax и затем применять их к кластеру-получателю.
Внимание
В приложении kafka-to-ignite.sh реализован подход fail-fast. В случае любой ошибки приложение прекращает работу. Процедура перезапуска должна быть настроена средствами операционной системы.
Количество экземпляров приложения не обязательно должно совпадать с количеством узлов сервера-получателя, а должно выбираться с точки зрения достаточности для обработки нагрузки, создаваемой кластером-источником. Каждый экземпляр приложения настраивается для обработки указанного диапазона партиций topic, чтобы распределить нагрузку. Если запускается один экземпляр kafka-to-ignite.sh, то его необходимо настроить на весь диапазон партиций topic. KafkaConsumer для каждой партиции Corax будет создан для обеспечения равномерного получения данных.
Установка#
Компоненты CDC поставляются с дистрибутивом. Для включения CDC перенесите модуль cdc-ext из $IGNITE_HOME/libs/optional в $IGNITE_HOME/libs.
Конфигурация#
Приложение kafka-to-ignite.sh конфигурируется через классы POJO или XML-файл Spring как обычный узел DataGrid. Конфигурационный файл должен содержать следующие классы (beans), которые будут загружены во время запуска:
Один из экземпляров (bean) конфигурации клиента (узла или тонкого клиента):
IgniteConfiguration: конфигурация клиентского узла;ClientConfiguration: конфигурация тонкого клиента Java;
экземпляр
java.util.Propertiesс именемkafkaProperties: конфигурацияKafkaConsumer;org.apache.ignite.cdc.kafka.KafkaToIgniteCdcStreamerConfiguration: Опции, специфичные для приложенияkafka-to-ignite.sh.
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Набор (set) имен реплицируемых кешей |
null |
|
Тайм-аут запроса |
3000 |
|
Начальная партиция Corax (включительно) для topic событий CDC |
-1 |
|
Конечная партиция Corax (не включая) для topic CDC событий |
-1 |
|
Тайм-аут запроса Corax (мс) |
3000 |
|
Максимальный размер конкурентно создаваемых записей Corax. |
1024 |
|
Группа для |
|
|
Topic для репликации изменений |
null |
|
Количество потоков для выполнения консьюмерами. |
16 |
|
Имя topic Corax для событий CDC |
null |
Параметр kafkaRequestTimeout задает тайм-ауты для методов KafkaConsumer, кроме KafkaConsumer#poll.
Внимание
Перед установкой значения kafkaRequestTimeout нужно провести тестирование на конкретном приложении.
Параметр kafkaConsumerPollTimeout задает тайм-аут для метода KafkaConsumer#poll.
Внимание
Перед установкой значения kafkaConsumerPollTimeout нужно провести тестирование на конкретном приложении. Слишком большие значения параметра могут сильно повлиять на производительность приложения.
Партиции topics Corax равномерно распределены по всем потокам обработки входящих сообщений (параметр threadCount). Каждый поток может обрабатывать только одну партицию за раз. Другие партиции не будут обработаны, пока не завершится процесс приема сообщений с текущей.
Конфигурация KafkaConsumer указывается с помощью bean kafkaProperties. Параметры Corax удобно хранить отдельно и задавать в конфигурации CDC-клиента следующим образом:
bootstrap.servers=xxx.x.x.x:xxxx
request.timeout.ms=10000
group.id=kafka-to-ignite-dc1
auto.offset.reset=earliest
enable.auto.commit=false
<util:properties id="kafkaProperties" location="file:kafka_properties_path/kafka.properties"/>
Важно
Параметр request.timeout.ms является обязательным.
Метрики#
Имя |
Описание |
|---|---|
|
Количество событий, полученных из Corax |
|
Отметка времени последнего события, полученного из Corax |
|
Количество событий, отправленных в кластер-приемник |
|
Отметка времени последнего события, примененного в кластере-приемнике |
|
Количество маркеров об обработанных изменениях в |
Логирование#
kafka-to-ignite.sh использует ту же конфигурацию логирования, что и узел DataGrid. Единственное отличие — события записываются в файл kafka-ignite-streamer.log.
Разрешение конфликтов репликации при помощи CacheVersionConflictResolver#
Отказоустойчивость#
В промышленной среде для обеспечения отказоустойчивости настройте CdcStreamer с параметром onlyPrimary=false, чтобы кластер-источник отправлял одно и то же изменение несколько раз, а именно (CacheConfiguration#backups + 1) раз.
Примечание
Реализация плагина из дистрибутива DataGrid не поддерживает слияние имеющейся версии и версии-кандидата, а только выбирает одну из них на основании алгоритма, описанного далее.
Реализация conflict resolver по умолчанию будет использоваться, если пользовательский conflict resolver не задан.
Плагин включен в дистрибутив DataGrid. Библиотеки расположены в каталоге libs/optional/ignite-cdc-ext. Приложение kafka-to-ignite.sh расположено в каталоге bin.
Конфигурация плагина CacheVersionConflictResolver#
Имя |
Описание |
Значение по умолчанию |
|---|---|---|
|
Локальный идентификатор кластера. Может принимать значения от 1 до 31 |
null |
|
Набор (set) кешей для обработки плагином |
null |
|
Опциональное поле для разрешения конфликта. |
null |
|
Пользовательское средство разрешения конфликта. Опционально. |
null |
Механизм работы модуля#
Реплицированные данные содержат дополнительную информацию, в частности, версии записей (CacheEntryVersion) из кластера-источника. Алгоритм разрешения конфликтов по умолчанию основан на сравнении версий записи и поля conflictResolveField.
Разрешение конфликтов на основе версии записи#
Этот подход обеспечивает окончательную гарантию согласованности только в том случае, если каждая запись обновляется только из одного кластера.
Алгоритм разрешения конфликтов:
Изменение из «локального» кластера (
clusterIdсоответствует текущему кластеру) всегда применяется безусловно. Любые реплицированные данные могут быть перезаписаны локально.Если имеющаяся запись и запись-кандидат из одного и того же кластера (
clusterIdсовпадает), то будет выбрано значение с бо́льшим значениемCacheEntryVersion.При невозможности разрешить конфликт изменение не принимается, что приводит к потере консистентности между кластерами. Ошибка разрешения конфликта выводится в log-файл.
Внимание
При таком подходе не происходит репликация обновлений и удалений записей из кластера-получателя на кластер-источник.
Для обеспечения максимальной производительности и во избежание ситуации, описанной в пункте 3, рекомендуется избегать пересечений по ключам при проектировании, а при наличии пересечений обоснованно выбирать поля для сравнения изменений.
Разрешение конфликтов на основе значения записи#
Этот подход обеспечивает конечную гарантию согласованности, даже если запись была обновлена из разных кластеров.
Примечание
Поле разрешения конфликта, указанное в conflictResolveField, должно содержать монотонно возрастающее значение, предоставленное пользователем. Например, идентификатор запроса или метку времени.
Внимание
При таком подходе не происходит репликация удалений записей из кластера-получателя на кластер-источник, поскольку удаления не могут быть версионированы по полю.
Алгоритм разрешения конфликтов:
Изменение из «локального» кластера (
clusterIdсоответствует текущему кластеру) всегда применяется безусловно. Любые реплицированные данные могут быть перезаписаны локально.Если имеющаяся запись и запись-кандидат из одного и того же кластера (
clusterIdсовпадает), то будет выбрано значение с бо́льшим значениемCacheEntryVersion.Если конфликт еще не разрешен и задано поле
conflictResolveField, то оно сравнивается у текущей записи и у записи-кандидата — выбирается запись с бо́льшим значениемconflictResolveField.При невозможности разрешить конфликт изменение не принимается, что приводит к потере консистентности между кластерами. Ошибка разрешения конфликта выводится в log-файл.
Пользовательские правила для разрешения конфликтов#
Пользователь может задать собственные правила для разрешения конфликтов, исходя из характера данных и операций. Это может быть полезно, когда стандартные стратегии для разрешения конфликтов неприменимы.
Выбор правильной стратегии разрешения конфликтов зависит от конкретного случая использования и требует хорошего понимания используемых данных и их использования. При выборе стратегии разрешения конфликтов следует учитывать характер транзакций, скорость изменения данных и последствия потенциальной потери или перезаписи данных.
Пользовательское средство разрешения конфликтов может быть задано с помощью conflictResolver и позволяет сравнивать или объединять конфликтные данные любым требуемым способом.
Пример настройки плагина CacheVersionConflictResolver#
Указывается в serverExampleConfig.xml.
<property name="pluginProviders">
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<property name="clusterId" value="1" />
<property name="caches">
<list>
<value>queryId</value>
</list>
</property>
<property name="conflictResolveField" value="modificationDate"/>
</bean>
</property>
Режимы репликации#
Существует два режима репликации:
Active-Active: в данном режиме прикладные приложения записывают данные в оба кластера. Для примеров настройки далее это означает, что можно реплицировать данные как из кластера ignite-1984 в кластер ignite-2029, так и наоборот;
Active-Passive: в данном режиме прикладные приложения записывают данные только в один кластер. Второй кластер в данном режиме неактивен и используется только в случае возникновения проблем (холодный резерв, standIn) или для выполнения запросов на чтение (например, для составления отчетов).
Данные режимы работают для обеих представленных схем репликации.
Примеры конфигурации при различных способах репликации#
DataGrid to DataGrid через клиентский узел#
Примечание
Конфигурация ниже предназначена для локального развертывания (на localhost). Настройки указаны для примера.
Конфигурация кластера-источника:
Имя файла: ignite-1984.xml.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-1984-server" />
<property name="consistentId" value="ignite-1984-server" />
<property name="localHost" value="xxx.x.x.x" />
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47500" />
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses"
value="xxx.x.x.x:47500..47510" />
</bean>
</property>
<property name="joinTimeout" value="10000" />
</bean>
</property>
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true" />
<!-- Свойство `cdcEnabled` (ниже) включает функциональность CDC. -->
<property name="cdcEnabled" value="true" />
</bean>
</property>
<!-- При данном значении свойства `walForceArchiveTimeout` выше каждый сегмент WAL-журнала будет доступен для обработки через 5 секунд после перенесения его в архив. -->
<property name="walForceArchiveTimeout" value="5000"/>
</bean>
</property>
<!--Ниже нужно указать конфигурацию модуля `conflictResolver`. -->
<property name="pluginProviders">
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<property name="clusterId" value="1" />
<!-- `clusterId` (выше) должен быть разным для каждого кластера. -->
<!-- Ниже нужно сконфигурировать кeши, для которых будет срабатывать `conflictResolver`. -->
<property name="caches">
<util:list>
<bean class="java.lang.String">
<constructor-arg type="String" value="terminator" />
<property name="conflictResolveField" value="modificationDate"/>
</bean>
</util:list>
</property>
</bean>
</property>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="atomicityMode" value="ATOMIC"/>
<property name="name" value="terminator"/>
</bean>
</list>
</property>
</bean>
<!-- Ниже указывается конфигурация механизма CDC. Утилита `ignite-cdc.sh` должна запускаться на всех серверных узлах кластера DataGrid, поэтому конфигурация CDC хранится в том же файле, в котором хранится конфигурация серверного узла. -->
<bean id="cdc.cfg" class="org.apache.ignite.cdc.CdcConfiguration">
<!--Конфигурация здесь отличается от конфигурации по умолчанию только свойством `consumer` (потребитель). Здесь оно относится к классу `IgniteToIgniteCdcStreamer`. -->
<property name="consumer" ref="cdc.streamer" />
</bean>
<!-- Внутри класса передается конфигурация клиентского узла, который будет подключаться к кластеру-получателю данных. -->
<bean id="cdc.streamer" class="org.apache.ignite.cdc.IgniteToIgniteCdcStreamer">
<property name="destinationIgniteConfiguration">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-2029-cdc-client" />
<property name="clientMode" value="true" />
<property name="localHost" value="xxx.x.x.x" />
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47600" />
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses"
value="xxx.x.x.x:47600..47610" />
</bean>
</property>
<property name="joinTimeout" value="10000" />
</bean>
</property>
</bean>
</property>
<property name="onlyPrimary" value="false"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
<property name="maxBatchSize" value="256"/>
</bean>
</beans>
Конфигурация кластера-получателя:
Примечание
Представленная ниже конфигурация актуальна для режима репликации Active-Active. При использовании режима Active-Passive на кластере-получателе org.apache.ignite.cdc.CdcConfiguration не настраивается. Также при Active-Passive на обоих кластерах не потребуется настройка conflictResolver. Для получения более подробной информации о режимах репликации перейдите к разделу «Режимы репликации» ниже.
Имя файла: ignite-2029.xml.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-2029" />
<property name="consistentId" value="ignite-2029" />
<property name="localHost" value="xxx.x.x.x" />
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47600" />
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses"
value="xxx.x.x.x:47600..47610" />
</bean>
</property>
<property name="joinTimeout" value="10000" />
</bean>
</property>
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true" />
<!-- Свойство `cdcEnabled` (ниже) включает функциональность CDC. -->
<property name="cdcEnabled" value="true" />
</bean>
</property>
<property name="walForceArchiveTimeout" value="5000"/>
</bean>
</property>
<property name="pluginProviders">
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<property name="clusterId" value="2" />
<property name="caches">
<util:list>
<bean class="java.lang.String">
<constructor-arg type="String" value="terminator" />
<property name="conflictResolveField" value="modificationDate"/>
</bean>
</util:list>
</property>
</bean>
</property>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="atomicityMode" value="ATOMIC"/>
<property name="name" value="terminator"/>
</bean>
</list>
</property>
</bean>
<bean id="cdc.cfg" class="org.apache.ignite.cdc.CdcConfiguration">
<property name="consumer" ref="cdc.streamer" />
</bean>
<bean id="cdc.streamer" class="org.apache.ignite.cdc.IgniteToIgniteCdcStreamer">
<property name="destinationIgniteConfiguration">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-1984-cdc-client" />
<property name="clientMode" value="true" />
<property name="localHost" value="xxx.x.x.x" />
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47500" />
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses"
value="xxx.x.x.x:47500..47510" />
</bean>
</property>
<property name="joinTimeout" value="10000" />
</bean>
</property>
</bean>
</property>
<property name="onlyPrimary" value="false"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
<property name="maxBatchSize" value="256"/>
</bean>
</beans>
После конфигурирования кластеров необходимо запустить утилиту ignite-cdc.sh на каждом серверном узле. Для запуска выполните следующие действия:
Выполните команду
ignite-cdc.sh ignite-1984.xml.Выполните команду
ignite-cdc.sh ignite-2029.xml.
DataGrid to DataGrid через тонкий клиент Java#
Примечание
Конфигурация ниже предназначена для локального развертывания (на localhost). Настройки указаны для примера.
Настройка аналогична настройке «Репликация DataGrid to DataGrid через клиентский узел». Отличие в том, что в экземпляре CdcConfiguration в поле consumer необходимо указать IgniteToIgniteClientStreamer.
<bean class="org.apache.ignite.cdc.CdcConfiguration">
<property name="consumer">
<bean class="org.apache.ignite.cdc.thin.IgniteToIgniteClientCdcStreamer">
<property name="destinationClientConfiguration">
<bean class="org.apache.ignite.configuration.ClientConfiguration">
<property name="addresses">
<list>
<!-- Список адресов кластера-получателя. -->
<value>xxx.x.x.x:10800</value>
</list>
</property>
</bean>
</property>
</bean>
</property>
<!-- Остальная конфигурация `CdcConfiguration`. -->
</bean>
DataGrid с использованием Platform V Corax#
Пример настройки двусторонней (Active-Active) репликации
Примечание
В примере ниже описывается конфигурация для локального развертывания (на localhost) и передачи данных между двумя ЦОД. Настройки указаны для примера.
Перед началом работы необходимо запустить Corax и Zookeeper. Затем создать topics (число партиций и названия для примера):
bin/kafka-topics.sh --create --partitions 16 --replication-factor 1 --topic dc1_to_dc2 --bootstrap-server localhost:9092
bin/kafka-topics.sh --create --partitions 16 --replication-factor 1 --topic dc2_to_dc1 --bootstrap-server localhost:9092
bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic metadata_from_dc1 --bootstrap-server localhost:9092
bin/kafka-topics.sh --create --partitions 1 --replication-factor 1 --topic metadata_from_dc2 --bootstrap-server localhost:9092
Конфигурация кластера-источника для ЦОД-1
Имя файла: ignite-dc1-kafka.xml.
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util" xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
https://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-2029-server"/>
<property name="consistentId" value="ignite-2029-server"/>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="terminator"/>
</bean>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47800"/>
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses" value="xxx.x.x.x:47800"/>
</bean>
</property>
<property name="joinTimeout" value="10000"/>
</bean>
</property>
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
<!-- Свойство `cdcEnabled` (ниже) включает функциональность CDC. -->
<property name="cdcEnabled" value="true"/>
</bean>
</property>
<!-- При данном значении свойства `walForceArchiveTimeout` каждый сегмент WAL-журнала будет доступен для обработки через 5 секунд после перенесения его в архив. -->
<property name="walForceArchiveTimeout" value="5000"/>
</bean>
</property>
<property name="clientConnectorConfiguration" ref="clientConnectorConfiguration"/>
<property name="communicationSpi" ref="communicationSpi"/>
<property name="connectorConfiguration" ref="connectorConfiguration"/>
<!-- Ниже нужно указать конфигурацию модуля `conflictResolver`. -->
<property name="pluginProviders">
<list>
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<property name="clusterId" value="1"/>
<!-- `clusterId` (выше) должен быть разным для каждого кластера. -->
<property name="caches">
<!-- Ниже нужно сконфигурировать кеши, для которых будет срабатывать `conflictResolver`. -->
<set>
<value>terminator</value>
</set>
</property>
<property name="conflictResolveField" value="modificationDate"/>
</bean>
</list>
</property>
</bean>
<!-- Ниже указывается конфигурация сервера. -->
<bean id="clientConnectorConfiguration" class="org.apache.ignite.configuration.ClientConnectorConfiguration">
<property name="port" value="11000"/>
</bean>
<!-- Ниже указывается конфигурация сервера. -->
<bean id="connectorConfiguration" class="org.apache.ignite.configuration.ConnectorConfiguration">
<property name="port" value="11300"/>
</bean>
<!-- Ниже указывается конфигурация сервера. -->
<bean id="communicationSpi" class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="48800"/>
</bean>
<util:properties id="kafkaProperties" location="file:/config/path/kafka.properties"/>
<bean id="cdc.cfg" class="org.apache.ignite.cdc.CdcConfiguration">
<property name="consumer">
<!-- Ниже указывается конфигурация механизма CDC. Утилита `ignite-cdc.sh` должна запускаться на всех серверных узлах кластера DataGrid, поэтому конфигурация CDC хранится в том же файле, в котором хранится конфигурация серверного узла. -->
<bean class="org.apache.ignite.cdc.kafka.IgniteToKafkaCdcStreamer">
<property name="topic" value="dc1_to_dc2"/>
<property name="metadataTopic" value="metadata_from_dc1"/>
<property name="kafkaPartitions" value="16"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
<property name="maxBatchSize" value="256"/>
<property name="onlyPrimary" value="false"/>
<property name="kafkaProperties" ref="kafkaProperties"/>
</bean>
</property>
</bean>
</beans>
Конфигурация кластера-источника для ЦОД-2
Имя файла: ignite-dc2-kafka.xml.
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util https://www.springframework.org/schema/util/spring-util.xsd">
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="igniteInstanceName" value="ignite-1984-server"/>
<property name="consistentId" value="ignite-1984-server"/>
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="terminator"/>
</bean>
</list>
</property>
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47850"/>
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses" value="xxx.x.x.x:47850"/>
</bean>
</property>
<property name="joinTimeout" value="10000"/>
</bean>
</property>
<property name="dataStorageConfiguration">
<bean class="org.apache.ignite.configuration.DataStorageConfiguration">
<property name="defaultDataRegionConfiguration">
<bean class="org.apache.ignite.configuration.DataRegionConfiguration">
<property name="persistenceEnabled" value="true"/>
<!-- Свойство `cdcEnabled` (ниже) включает функциональность CDC. -->
<property name="cdcEnabled" value="true"/>
</bean>
</property>
<!-- При данном значении свойства `walForceArchiveTimeout` каждый сегмент WAL-журнала будет доступен для обработки через 5 секунд после перенесения его в архив. -->
<property name="walForceArchiveTimeout" value="5000"/>
</bean>
</property>
<!-- Ниже нужно указать конфигурацию модуля `conflictResolver`. -->
<property name="pluginProviders">
<list>
<bean class="org.apache.ignite.cdc.conflictresolve.CacheVersionConflictResolverPluginProvider">
<!-- `clusterId` должен быть разным для каждого кластера. -->
<property name="clusterId" value="2"/>
<property name="caches">
<!-- Здесь нужно сконфигурировать кеши, для которых будет срабатывать `conflictResolver`. -->
<set>
<value>terminator</value>
</set>
</property>
<property name="conflictResolveField" value="modificationDate"/>
</bean>
</list>
</property>
<property name="clientConnectorConfiguration" ref="clientConnectorConfiguration"/>
<property name="communicationSpi" ref="communicationSpi"/>
<property name="connectorConfiguration" ref="connectorConfiguration"/>
</bean>
<bean id="clientConnectorConfiguration" class="org.apache.ignite.configuration.ClientConnectorConfiguration">
<property name="port" value="11050"/>
</bean>
<bean id="connectorConfiguration" class="org.apache.ignite.configuration.ConnectorConfiguration">
<property name="port" value="11350"/>
</bean>
<bean id="communicationSpi" class="org.apache.ignite.spi.communication.tcp.TcpCommunicationSpi">
<property name="localPort" value="48850"/>
</bean>
<util:properties id="kafkaProperties" location="file:/config/path/kafka.properties"/>
<bean id="cdc.cfg" class="org.apache.ignite.cdc.CdcConfiguration">
<property name="consumer">
<bean class="org.apache.ignite.cdc.kafka.IgniteToKafkaCdcStreamer">
<property name="topic" value="dc2_to_dc1"/>
<property name="metadataTopic" value="metadata_from_dc2"/>
<property name="kafkaPartitions" value="16"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
<property name="maxBatchSize" value="256"/>
<property name="onlyPrimary" value="false"/>
<property name="kafkaProperties" ref="kafkaProperties"/>
</bean>
</property>
</bean>
</beans>
Пример конфигурации для подключения к Platform V Corax
Примечание
Настройки ниже являются содержимым файла kafka.properties. В данном примере его содержимое одинаково для обоих ЦОД.
bootstrap.servers=xxx.x.x.x:9092
request.timeout.ms=10000
Конфигурация kafka-to-ignite.sh в ЦОД-1, вычитывающего изменения из ЦОД-2
Примечание
Представленная ниже конфигурация актуальна для режима репликации Active-Active. При использовании режима Active-Passive на кластере-получателе org.apache.ignite.cdc.CdcConfiguration и CacheVersionConflictResolver не настраивается. Для получения более подробной информации о режимах репликации перейдите к разделу «Режимы репликации» ниже.
Имя файла: kafka2ignite_dc1.xml.
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<bean id="streamer.cfg" class="org.apache.ignite.cdc.kafka.KafkaToIgniteCdcStreamerConfiguration">
<property name="topic" value="dc2_to_dc1"/>
<property name="metadataTopic" value="metadata_from_dc2"/>
<property name="kafkaPartsFrom" value="0"/>
<property name="kafkaPartsTo" value="16"/>
<property name="threadCount" value="4"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
</bean>
<util:properties id="kafkaProperties" location="file:/config/path/kafka2ignite_dc1.properties"/>
<bean id="ignIgniteConfiguration" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi" ref="ignTcpDiscoverySpi"/>
<property name="clientMode" value="true"/>
<property name="consistentId" value="kafka-to-ignite_dc2"/>
</bean>
<!-- `TcpDiscoverySpi`. -->
<bean id="ignTcpDiscoverySpi" class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47801"/>
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>xxx.x.x.x:47800..47809</value>
</list>
</property>
</bean>
</property>
</bean>
</beans>
Конфигурация KafkaConsumer для ЦОД-1
Файл kafka2ignite_dc1.properties
bootstrap.servers=xxx.x.x.x:9092
request.timeout.ms=10000
group.id=kafka-to-ignite-dc1
auto.offset.reset=earliest
enable.auto.commit=false
Конфигурация kafka-to-ignite.sh в ЦОД-2, вычитывающего изменения из ЦОД-1
Имя файла: kafka2ignite_dc2.xml.
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:util="http://www.springframework.org/schema/util"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<bean id="streamer.cfg" class="org.apache.ignite.cdc.kafka.KafkaToIgniteCdcStreamerConfiguration">
<property name="topic" value="dc1_to_dc2"/>
<property name="metadataTopic" value="metadata_from_dc1"/>
<property name="kafkaPartsFrom" value="0"/>
<property name="kafkaPartsTo" value="16"/>
<property name="threadCount" value="4"/>
<property name="caches">
<list>
<value>terminator</value>
</list>
</property>
</bean>
<util:properties id="kafkaProperties" location="file:/config/path/kafka2ignite_dc2.properties"/>
<bean id="ignIgniteConfiguration" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="discoverySpi" ref="ignTcpDiscoverySpi"/>
<property name="clientMode" value="true"/>
<property name="consistentId" value="kafka-to-ignite_dc2"/>
</bean>
<!-- `TcpDiscoverySpi`. -->
<bean id="ignTcpDiscoverySpi" class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="localPort" value="47851"/>
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>xxx.x.x.x:47850..47859</value>
</list>
</property>
</bean>
</property>
</bean>
</beans>
Конфигурация KafkaConsumer для ЦОД-2:
Файл kafka2ignite_dc2.properties
bootstrap.servers=xxx.x.x.x:9092
request.timeout.ms=10000
group.id=kafka-to-ignite-dc2
auto.offset.reset=earliest
enable.auto.commit=false
Конфигурация kafka-to-ignite.sh c тонким клиентом
Возможно использование тонкого клиента вместо клиентского узла.
Настройка аналогична настройке kafka-to-ignite.sh с клиентским узлом с тем отличием, что вместо экземпляра IgniteConfiguration необходимо указать ClientConfiguration.
<bean id="client.cfg" class="org.apache.ignite.configuration.ClientConfiguration">
<property name="addresses">
<list>
<!-- Список адресов кластера-получателя. -->
<value>xxx.x.x.x:10800</value>
</list>
</property>
</bean>
Остальные настройки KafkaToIgniteCdcStreamerConfiguration и kafkaProperties аналогичны.
После конфигурирования кластеров необходимо запустить утилиту ignite-cdc.sh на каждом серверном узле, а на принимающем узле необходимо запустить утилиту kafka-to-ignite.sh. В ignite-cdc.sh необходимо передавать путь к XML-конфигурации серверных узлов, а в kafka-to-ignite.sh — путь к XML-конфигурации Platform V Corax to DataGrid:
Запуск DataGrid to Platform V Corax:
ignite-cdc.sh ignite-dc1-kafka.xmlignite-cdc.sh ignite-dc2-kafka.xmlЗапуск Platform V Corax to DataGrid:
kafka-to-ignite.sh kafka2ignite_dc1.xmlkafka-to-ignite.sh kafka2ignite_dc2.xml
Возможные проблемы в работе репликации и методы их устранения#
Чтобы
CdcStreamerне завершил работу с ошибкой, до запуска репликации необходимо:Активировать кластер-получатель.
Создать реплицируемый кеш на кластере-получателе.
Во избежание возникновения сбоев на серверных узлах
cdcWalPathиwalArchivePathдолжны быть расположены в одном разделе файловой системы. В противном случае серверный узел завершит работу с ошибкой.Во избежание зацикливания сообщений при репликации в режиме Active-Active необходимо убедиться, что:
Для всех реплицируемых кешей настроен
conflictResolver.В
conflictResolverуказаны разныеclusterIdдля разных кластеров.Если conflictResolveField не указан в conflictResolver, то для уже имеющихся локально записей конфликтные изменения с удаленного кластера разрешаться не будут.
Во избежание ошибок при работе с одинаково названными SQL-таблицами необходимо настроить
value_type. По умолчанию узел-получатель генерирует свое собственное имя для связанной с ним SQL-таблицы. Чтобы реплицированные данные корректно отображались через SQL-запросы на узле-получателе, укажите одинаковое значениеvalue_typeдля обеих таблиц на исходном и принимающем узлах.Пример кода
CREATE TABLE Person (id int primary key, varchar name) with cache_name='Person', value_type='SQL_PERSON_TABLE_TYPE'При создании таблицы в DDL-команде добавьте:
имя типа данных (обязательно) — укажите уникальный численно-буквенный код;
имя кеша (опционально) — используйте любой кеш, не существующий на момент запуска команды.
Пример кода
CREATE TABLE binary12 (id INT PRIMARY KEY, str VARCHAR, xxx number) WITH "cache_name=binary12, value_type=PayloadTest15"Проверьте выполнение команды на исходном и принимающем кластерах. После проверки включите кеш в CDC.
Примечание
Чтобы использовать SQL-запросы в целевом кластере по данным, реплицированным CDC, установите одинаковый
VALUE_TYPEвlink:sql-reference/ddl#create-table[CREATE TABLE]для каждой таблицы в исходном и целевом кластерах.
Восстановление согласованности партиций с помощью cli-утилит#
Введение#
DataGrid предоставляет гарантии согласованности данных, означающие, что все копии партиций будут содержать одни и те же значения для каждого из ключей.
Однако по различным причинам эти гарантии могут быть нарушены. Такими причинами могут быть:
дефекты;
сбои;
неидемпотентные операции над данными, выполняемые более одного раза.
Для восстановления согласованности данных существует cli-утилита, использующая специальный режим чтения из всех копий партиции и проверяющая, что значения в них одинаковы. Если значения в основной и резервной партициях отличаются, утилита исправит это при помощи одной из стратегий восстановления согласованности. Стратегии описываются далее в разделе «Стратегии проверки и восстановления согласованности данных».
Стратегии проверки и восстановления согласованности данных#
Существует пять стратегий проверки и восстановления согласованности данных:
LWW — Last Write Wins — побеждает последняя (самая новая) запись:
Использование данной стратегии может приводить к исключению
IgniteExceptionв случае, если восстановление согласованности данных невозможно (невозможно определить самую новую запись). Это происходит в следующих случаях:для одного и того же ключа найдены значения
nullи отличное отnull. У пропущенной записи (null) нет версии и сравнить ее с версионированной записью невозможно;записи одной версии имеют различные значения.
PRIMARY — Value from the primary node wins — побеждает значение, полученное с основной копии партиции;
RELATIVE_MAJORITY — Relative majority wins — побеждает относительное большинство (самое часто встречающееся значение):
Внимание
Данная стратегия, в отличие от стратегии с «абсолютным большинством», работает для четного числа копий. Использование данной стратегии может приводить к исключению
IgniteException, если определить самое часто встречающееся значение не представляется возможным.Например, даны 5 копий партиции (из них 1 копия — основная, 4 копии — резервные):
Если значение
Aвстречается 2 раза, а значенияX,YиZ— по 1 разу, то в результате побеждает значениеA.Если значения
AиBвстречаются по 2 раза, а значениеX— 1 раз, то такая стратегия не сможет определить победителя.
Если даны 4 копии партиции (из них 1 копия — основная, 3 копии — резервные), то любое значение, найденное два или более раз, когда другие найдены только один раз, является победителем.
REMOVE — Inconsistent values will be removed — несогласованные значения будут удалены. Это означает потерю несогласованных данных;
CHECK_ONLY — Only check will be performed — будет проведена только проверка согласованности.
Проверка и восстановление согласованности с помощью утилиты control#
Проверка и восстановление согласованности осуществляются с помощью утилиты control, которая включает в себя набор команд. Описание команд приведено в разделе «Проверка и восстановление данных».
Пример целевого использования механизма#
Внимание
Мониторинг события нарушения согласованности на кластере по умолчанию отключен.
Чтобы включить обработку события нарушения согласованности EVT_CONSISTENCY_VIOLATION, добавьте в конфигурацию класса org.apache.ignite.configuration.IgniteConfiguration следующее свойство (указывается в serverExampleConfig.xml).
<property name="includeEventTypes">
<list>
<util:constant static-field="org.apache.ignite.events.EventType#EVT_CONSISTENCY_VIOLATION"/>
</list>
</property>
Это необходимо для работы механизма восстановления согласованности.
Подход к целевому использованию механизма восстановления согласованности включает в себя использование утилиты idle_verify для проверки согласованности данных. Такой подход позволяет избежать излишнего перемещения данных по сети. Вместо этого по сети перемещается лишь вычисленный локальный хеш, что повышает производительность работы механизма.
Алгоритм работы механизма при таком подходе:
Утилита
idle_verifyпроверяет согласованность данных на кластере без нагрузки (иначе есть риск ложного срабатывания).Утилита
idle_verifyпредоставляет информацию о наличии несогласованности.Каждое расхождение логируется при помощи стратегии
CHECK_ONLY.log-файл (например,
consistency.log) анализируется администратором.Примечание
По умолчанию запись происходит в общий лог DataGrid. Однако можно сконфигурировать запись в любой другой файл по усмотрению пользователя. Для этого измените путь к файлу на желаемый в конфигурации logger (переменная
filename), например:XML#<File name="CONSISTENCY" fileName="${sys:IGNITE_HOME}/work/log/consistency.log"> <PatternLayout> <Pattern>"[%d{ISO8601}][%-5p][%t][%c{1}] %m%n"</Pattern> </PatternLayout> </File>Для устранения случаев несогласованности используются стратегии LWW, PRIMARY, RELATIVE_MAJORITY, REMOVE.
Для реализации подхода:
Запустите утилиту
idle_verifyна проверку согласованности данных с необходимыми вам аргументами:control.sh --cache idle_verify --host localhost --user user --password ***** --keystore /path/to/keystore.jks --keystore-password ***** --truststore /path/to/truststore.jks --truststore-password *****Утилита
idle_verifyобнаруживает несогласованность:idle_verify check has finished, found 2 conflict partitions. Conflict partition: PartitionKey [grpId=1544803905, grpName=default, partId=5] Partition instances: [PartitionHashRecord [isPrimary=true, partHash=97506054, updateCntr=3, size=3, consistentId=bltTest1], PartitionHashRecord [isPrimary=false, partHash=65957380, updateCntr=3, size=2, consistentId=bltTest0]] Conflict partition: PartitionKey [grpId=1544803905, grpName=default, partId=6] Partition instances: [PartitionHashRecord [isPrimary=true, partHash=97595430, updateCntr=3, size=3, consistentId=bltTest1], PartitionHashRecord [isPrimary=false, partHash=66016964, updateCntr=3, size=2, consistentId=bltTest0]]Запустите проверку согласованности при помощи стратегии
CHECK_ONLYдля оценки расхождений; подробнее о проверки согласованности с помощью control.sh смотрите в разделе «Восстановление согласованности кешей».Просмотрите log-файл, оцените его и примите решение относительно выбора стратегии восстановления согласованности.
Запустите команду
repairдля запуска механизма Read repair на устранение расхождений, используя одну из описанных выше стратегий; подробнее о выполнении команды с помощью control.sh смотрите в разделе «Восстановление согласованности кешей».
Плагин Topology Validator#
Введение#
Включение плагина Topology Validator в конфигурацию серверных узлов DataGrid позволяет автоматически блокировать запись во все кеши кластера в случае потери связи с частью узлов.
Конфигурация#
Для настройки плагина TopologyValidator:
Создайте экземпляр класса
CacheTopologyValidatorPluginProviderи укажите его в конфигурации всех серверных узлов DataGrid:Java#new IgniteConfiguration() ... .setPluginProviders(new CacheTopologyValidatorPluginProvider());Явно задайте узлы, входящие в базовую топологию (baseline topology), либо сконфигурируйте автонастройку базовой топологии с тайм-аутом, значительно превышающим тайм-аут определения сбоя (failure detection timeout).
Примечание
В текущей версии реализации плагина
TopologyValidatorиспользовать автонастройку базовой топологии с тайм-аутом, равным нулю, запрещено.Узлы, сконфигурированные в базовой топологии, будут интерпретироваться кластером как «идеальный» набор узлов кластера, который будет использован для определения узлов, связь с которыми потеряна для каждого из сегментов.
Сконфигурируйте порог деактивации. На его основе вычисляется число узлов, связь с которыми может быть потеряна без ограничения возможности записи в кеши сегмента.
Для вычисления используется формула:
N = B - [B * dth] - 1где:
N — число узлов, связь с которыми может быть потеряна без ограничения возможности записи в кеши сегмента;
B — число узлов в базовой топологии;
dth — порог деактивации;
[x] — функция округления значения x до ближайшего целого в меньшую сторону.
Значение порога деактивации по умолчанию равно 0.5. Это значит, что сегмент продолжит обрабатывать запросы на запись только в том случае, если в его составе находится более половины узлов из базовой топологии. При значении порога деактивации 0.5 и выше продолжить обрабатывать запросы на запись может не более, чем один сегмент.
Для установки значения порога деактивации установите распределенное свойство конфигурации
org.apache.ignite.topology.validator.deactivation.thresholdпри помощи утилитыcontrol.sh. Для этого используйте следующую команду:control.sh --property set --name topology.validator.deactivation.threshold --val new_valгде
new_val— новое значение порога деактивации.
Блокировка и восстановление обработки запросов на запись в кеши#
Блокировка обработки запросов записи в кеши осуществляется путем автоматического перевода кластера в статус READ-ONLY. Чтобы разблокировать возможность выполнения операций записи, вручную переведите кластер в статус ACTIVE. Это можно сделать при помощи утилиты control.sh или при помощи Java API.