Руководство по системному администрированию#
Сценарии администрирования#
Примечание
Все предложенные сценарии работы DropApp Plus выполняются пользователем с ролью администратора DropApp Plus. DropApp Plus обеспечивает развертывание, масштабирование, балансировку нагрузки и позволяет администратору интегрировать решения для ведения журналов, мониторинга и оповещения.
Роль администратора – это роль сервисного пользовательского аккаунта по умолчанию (привилегированного пользователя), который автоматически создается при формировании кластера (cluster) DropApp Plus.
Примечание
Документ содержит названия переменных, конфигурационных файлов и инструментов, которые применимы для различных оркестраторов контейнерных нагрузок. Использование названий, созвучных сторонним оркестраторам, обусловлено облегчением миграции на продукт DropApp Plus.
Настройка основных параметров системы#
В этом разделе описываются основы системного администрирования в DropApp Plus. Основное внимание уделяется задачам, которые системный администратор должен выполнить сразу после успешной установки и настройки.
При развертывании DropApp Plus, осуществляется работа с кластерами. Кластер состоит из набора nodes, которые запускают контейнерные приложения. Кластер DropApp имеет, как минимум, две worker nodes.
Управляющий слой (control plane), представляет собой совокупность master nodes и управляет worker nodes и pods в кластере DropApp Plus.
После установки администратор кластера может настроить следующие компоненты:
node;
кластер;
сеть;
хранилище;
пользователи;
оповещения и уведомления.
Настройка функций операционной системы#
Machine Config Operator управляет объектами MachineConfig. Используя Machine Config Operator, выполняются следующие задачи в кластере DropApp Plus:
Настройка узлов с помощью
MachineConfigобъектов;Настройка пользовательских ресурсов, связанных с
MachineConfig.
Оператор MachineConfig управляет и применяет конфигурацию и обновления базовой операционной системы и среды выполнения контейнера, включая все, что находится между ядром и kubelet.
Оператор MachineConfig содержит компоненты:
machine-config-server: предоставляет конфигурацию Ignition новым машинам, присоединяющимся к кластеру;
machine-config-controller: координирует обновление машин до желаемых конфигураций, определенных объектом
MachineConfig. Предусмотрены опции для управления обновлением наборов машин по отдельности;machine-config-daemon: применяет новую конфигурацию машины во время обновления. Проверяет и отслеживает состояние машины в соответствии с запрошенной конфигурацией машины;
machine-config: предоставляет полный источник конфигурации машины при установке, первом запуске и обновлениях машины.
Оператор MachineConfig управляет обновлениями systemd, CRI-O и Kubelet, ядра, Network Manager и других системных функций. Он также предлагает MachineConfigCRD, который может записывать файлы конфигурации на node.
Типы компонентов, которые MachineConfig может изменить, включают:
config: создает объекты конфигурации Ignition, чтобы выполнять такие действия, как изменение файлов, системных служб и других функций на машинах с DropApp Plus:
Configuration files: создает или перезаписывает файлы в каталоге
/varили/etc;systemd unit: создает и устанавливает статус службы systemd или добавляет к существующей службе systemd с помощью дополнительных настроек;
users and groups: изменяет ключи SSH в разделе passwd после установки.
Важно
Только пользователь core может изменять ключи SSH через конфигурации.
kernelArguments: добавляет аргументы в командную строку ядра при загрузке nodes;
kernelType: опционально указывает нестандартное ядро, которое будет использоваться вместо стандартного ядра. Команда
realtimeпозволяет использовать ядро RT (для RAN);extensions: расширяет возможности SberLinux OS Core, добавив выбранное предварительно упакованное программное обеспечение;
Custom resources (для ContainerRuntime и Kubelet). Помимо конфигураций компьютера, MachineConfig управляет двумя специальными пользовательскими ресурсами для изменения настроек среды выполнения контейнера CRI-O (ContainerRuntime CR) и службы Kubelet (Kubelet CR).
Проверка состояния пула конфигурации машины#
Чтобы просмотреть количество nodes, управляемых Machine Config Operator и доступных в кластере для каждого пула конфигурации, выполните следующую команду:
oc get machineconfigpoolПример вывода:
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-… True False False 3 3 3 0 4h42m worker rendered-worker-… False True False 3 2 2 0 4h42mГде:
UPDATED- статусTrueуказывает, что Machine Config Operator применил текущую конфигурацию машины к nodes в этом пуле конфигурации. Текущая конфигурация указывается в полеSTATUSполеoc get mcpвыходных данных. СтатусFalseуказывает, что node в пуле конфигураций обновляется.UPDATING- статусTrueуказывает, что Machine Config Operator применил желаемую конфигурацию машины, указанную в пользовательском ресурсеMachineConfigPool, по крайней мере, к одному из nodes в этом пуле конфигураций. Обновляемые nodes могут быть недоступны для планирования. СтатусFalseуказывает, что все nodes обновлены.DEGRADED- статусTrueуказывает, что Machine Config Operator заблокирован от применения текущей или желаемой конфигурации машины хотя бы к одному из nodes в этом пуле конфигурации или применение конфигурации не удалось. Nodes с пониженной производительностью могут быть недоступны для планирования. СтатусFalseуказывает, что все nodes готовы.MACHINECOUNT- указывает общее количество машин в этом пуле конфигурации.READYMACHINECOUNT- указывает общее количество машин в этом пуле конфигурации, готовых к планированию.UPDATEDMACHINECOUNT- указывает общее количество машин в этом пуле конфигурации, имеющих текущую конфигурацию.DEGRADEDMACHINECOUNT- указывает общее количество машин в этом пуле конфигурации, помеченных как устаревшие или несовместимые.
В примере вывода есть три master nodes и worker nodes. Плоскость управления и связанные nodes обновляются до текущей конфигурации. Worker nodes обновляются до желаемой конфигурации машины. Две worker nodes обновляются, на это указывает
UPDATEDMACHINECOUNTравное2.Пока nodes обновляются, конфигурация машины, указанная в
CONFIG, является текущей конфигурацией, с которой обновляется пул конфигурации. После завершения обновления указанная конфигурация машины будет желаемой, до которой был обновлен пул конфигурации.Выполните проверку пула конфигурации путем вывода CRD.
Настройка функций кластера#
Администратору кластера доступны следующие ресурсы конфигурации основных функций кластера DropApp Plus:
реестр образов;
конфигурация сети;
поведение сборки изображения;
поставщик удостоверений;
конфигурация etcd;
создание комплекта машин для обработки рабочих нагрузок.
Для получения текущей документации по настройкам, которыми управляются эти ресурсы, используйте команду oc explain, например: oc explain builds --api-version=config.openshift.io/v1.
Все ресурсы конфигурации кластера имеют глобальную область действия (не в namespace) и имеют имена cluster:
Имя ресурса |
Описание |
|---|---|
|
Предоставляет конфигурацию сервера API, такую как сертификаты и центры сертификации |
|
Управляет поставщиком удостоверений и конфигурацией аутентификации для кластера |
|
Управляет конфигурацией по умолчанию и принудительной конфигурацией для всех сборок в кластере |
|
Настраивает поведение интерфейса веб-консоли, включая поведение выхода из системы |
|
Включает FeatureGates для использования функции Tech Preview |
|
Настраивает способ обработки реестров образов (разрешенные, запрещенные, небезопасные сведения о центре сертификации) |
|
Сведения о конфигурации, связанные с маршрутизацией, например, домен по умолчанию для маршрутов |
|
Настраивает поставщиков удостоверений и другое поведение, связанное с внутренними потоками сервера OAuth |
|
Настраивает способ создания проектов, включая шаблон проекта |
|
Определяет прокси-серверы, которые будут использоваться компонентами, требующие доступ к внешней сети |
|
Настраивает поведение планировщика, такое как политики и селекторы nodes по умолчанию |
Эти ресурсы конфигурации представляют собой экземпляры в области кластера с именем cluster, которые управляют поведением определенного компонента, принадлежащего конкретному оператору.
Ресурсы конфигурации оператора.
Имя ресурса |
Описание |
|---|---|
|
Управляет внешним видом консоли, например, настройками фирменного стиля |
|
Настраивает параметры внутреннего реестра образов, такие как общедоступная маршрутизация, уровни журналов, настройки прокси-сервера, ограничения ресурсов, количество реплик и тип хранилища |
|
Настраивает оператора выборки для управления тем, какие примеры потоков изображений и шаблоны устанавливаются в кластере |
Выполнение операций с узлами#
По умолчанию DropApp Plus использует вычислительные машины Platform V SberLinux OS Core 8.9.1 (далее - SLC). В роли администратора доступны следующие операции в кластере:
добавление и удаление вычислительных машин;
добавление и удаление дефектов и доступов к машинам;
настройка максимального числа pods на машину.
Добавление вычислительных машин в кластер#
Предварительные условия:
кластер успешно установлен;
образы SLC, которые использовались для создания кластера, доступны;
получен URL-адрес файла конфигурации Ignition для worker nodes кластера. Этот файл загружен на HTTP-сервер во время установки.
Выполните следующую последовательность действий:
Используйте файл ISO для установки SLC на большем количестве worker nodes. Метод установки описан в документе «Руководство по установке».
После загрузки экземпляра нажмите клавишу
TABилиEдля редактирования командной строки ядра.Добавьте параметры в командную строку ядра:
coreos.inst.install_dev=sda # Укажите блочное устройство системы, на которую будет производиться установка. coreos.inst.ignition_url=http://example.com/worker.ign # Укажите URL-адрес файла конфигурации вычислений Ignition. Поддерживаются только протоколы HTTP и HTTPS.Нажмите
Enter, чтобы завершить установку. После установки SLC система перезагрузится. После перезагрузки применится указанный файл конфигурации Ignition.Повторите шаги 1-4 в зависимости от количества необходимых worker nodes для кластера.
Настройка сети#
После установки DropApp Plus доступны для настройки следующие сетевые параметры:
входящий трафик кластера;
диапазон обслуживания порта узла;
сетевая политика;
включение прокси-сервера на уровне кластера.
Конфигурация оператора сети кластера.
Конфигурация сети кластера указывается как часть конфигурации оператора сети кластера (CNO) и хранится в объекте настраиваемого ресурса (CR) с именем cluster. CR указывает поля для NetworkAPI в operator.openshift.io группе API.
Конфигурация CNO наследует следующие поля во время установки кластера от NetworkAPI в Network.config.openshift.io группе API, и эти поля нельзя изменить:
clusterNetwork- пулы IP-адресов, из которых выделяются IP-адреса pods;serviceNetwork- пул IP-адресов для сервисов;defaultNetwork.type- поставщик кластерной сети, например, OVN-Kubernetes.
Важно
После установки кластера поля, перечисленные в предыдущем разделе, изменить нельзя.
Настройка хранилища#
По умолчанию контейнеры работают с использованием эфемерного хранилища или временного локального хранилища. Эфемерное хранилище имеет ограничение по сроку службы. Чтобы хранить данные в течение длительного времени, необходимо настроить постоянное хранилище. Настроить хранилище можно одним из следующих способов:
динамическое предоставление. Выделение хранилища по требованию, определяя и создавая классы хранения, которые управляют различными уровнями хранилища, включая доступ;
статическое представление. Использование постоянных томов Kubernetes, чтобы сделать существующее хранилище доступным для кластера. Статическая подготовка может поддерживать различные конфигурации устройств и варианты подключения.
Объект StorageClass описывает и классифицирует хранилище, которое может быть запрошено, а также предоставляет средства для передачи параметров для динамически предоставляемого хранилища по требованию. StorageClass-объекты также могут служить механизмом управления различными уровнями хранения и доступом к хранилищу. Администраторы кластера определяют и создают StorageClass-объекты, которые пользователи могут запрашивать без необходимости каких-либо подробных знаний об источниках базовых томов хранения.
Платформа постоянных томов обеспечивает эту функцию и позволяет администраторам предоставлять кластеру постоянное хранилище. Платформа также дает пользователям возможность запрашивать эти ресурсы, не зная базовой инфраструктуры.
Многие типы хранилищ доступны для использования в качестве постоянных томов. Хотя все они могут быть предоставлены администратором статически, некоторые типы хранилищ создаются динамически с использованием встроенных API-интерфейсов поставщика и плагина.
Подробнее см. «Сценарии использования опциональных компонентов» -> «CSI».
Настройка пользователей#
Токены доступа OAuth позволяют пользователям аутентифицироваться в API. Для администратора кластера доступна настройка OAuth для выполнения следующих задач:
указание поставщика удостоверений;
использование управления доступом на основе ролей для определения и предоставления разрешений пользователям;
установка оператора из
OperationHub.
По умолчанию kubeadmin в кластере существует только пользователь. Чтобы указать поставщика удостоверений, необходимо создать настраиваемый ресурс (CR), описывающий этого поставщика удостоверений, и добавить его в кластер.
Следующий пользовательский ресурс (CR) показывает параметры и значения по умолчанию, которые настраивают поставщика удостоверений. В этом примере используется поставщик удостоверений htpasswd:
apiVersion: config.openshift.io/v1
kind: OAuth
metadata:
name: cluster
spec:
identityProviders:
- name: my_identity_provider # Это имя поставщика добавляется к именам пользователей для формирования идентификационного имени
mappingMethod: claim # Управляет тем, как устанавливаются сопоставления между удостоверениями и User-объектами этого поставщика
type: HTPasswd
htpasswd:
fileData:
name: htpass-secret # Существующий секрет, содержащий файл, созданный с использованием htpasswd.
Управление оповещениями и уведомлениями#
По умолчанию оповещения о срабатывании отображаются в пользовательском интерфейсе оповещений веб-консоли.
По умолчанию оповещения не настроены на отправку в какие-либо системы уведомлений. Возможно настроить OKD для отправки оповещений следующим типам получателей:
PagerDuty;
Webhook;
Email;
Slack.
Маршрутизация оповещений получателям позволяет отправлять своевременные уведомления соответствующим группам при возникновении сбоев. Например, критические оповещения требуют немедленного внимания и обычно передаются отдельному пользователю или группе реагирования на критические ситуации. Оповещения, содержащие некритические предупреждения, вместо этого могут быть направлены в систему обработки заявок для несрочного рассмотрения.
Проверка работоспособности оповещений с помощью сторожевого таймера.
Мониторинг включает в себя постоянно срабатывающее сторожевое оповещение. Alertmanager неоднократно отправляет уведомления о предупреждениях сторожевого таймера настроенным поставщикам уведомлений. Поставщик обычно настроен на уведомление администратора, когда перестает получать оповещения сторожевого таймера. Этот механизм помогает быстро выявить любые проблемы связи между Alertmanager и поставщиком уведомлений.
Настройте приемники оповещений, чтобы получать информацию о важных проблемах в кластере:
В качестве администратора перейдите в раздел «Administration» → «Cluster Settings» → «Global Configuration» → «Alertmanager».
Альтернативно можно перейти на ту же страницу через панель уведомлений. Щелкните значок колокольчика в правом верхнем углу веб-консоли OKD и выберите «Configure» в оповещении AlertmanagerReceiverNotConfigured.
Выберите «Create Receiver» в разделе «Receivers».
В форме «Create Receiver» добавьте имя получателя и выберите тип получателя из списка.
Сценарии использования опциональных компонентов DropApp Plus#
Компоненты дистрибутива DropApp, которые могут быть использованы при реализации сценариев с данными компонентами, представлены в документе Руководство по установке в разделе «Состав дистрибутива DropApp».
API-server#
API-server — это центральный компонент кластера DropApp Plus. Он является связывающим компонентом для всех остальных сервисов. Все взаимодействие как самих компонентов, так и обращение извне к кластеру проходит через kube-apiserver и проверяется им.
Это единственный компонент кластера DropApp Plus, который общается с базой данных etcd, где хранится состояние кластера DropApp Plus.
API-Server не принимает решения, например, за то, на каком node запустить тот или иной сервис.
В нем существует логика проверки формата запросов, аутентификации, проверки прав и т.д.
Еще одной функцией API-Server является рассылка изменений конфигураций и состояния кластера DropApp Plus.
Другие компоненты подписываются на события, отслеживают их и обрабатывают, либо с определенной периодичностью считывают конфигурацию через API-Server.
Kube-scheduler#
Kube-scheduler — это компонент управляющего слоя, с его помощью необходимо отслеживать созданные pods без привязанного node и осуществлять выбор node, на котором pods должны работать. При развертывании pods на node учитывается множество факторов, включая требования к ресурсам, ограничения, связанные с аппаратными/программными политиками, принадлежности (affinity) и непринадлежности (anti-affinity) nodes/pods, местонахождения данных, предельных сроков.
Используя механизм оповещения об изменениях API-Server, kube-scheduler получает сообщения от управляющего слоя, когда необходимо запустить экземпляр сервиса и принимает решение о том, на каком node он должен быть запущен, и через API-server обновляет состояние кластера DropApp Plus. Сам kube-scheduler ничего не запускает.
Controller-manager#
Controller-manager - это компонент, отвечающий за запуск контроллеров, которые определяют текущее состояние системы.
Каждый контроллер представляет собой отдельный процесс, и для упрощения все такие процессы скомпилированы в один двоичный файл и выполняются в одном процессе.
Эти контроллеры включают:
контроллер node (Node Controller): уведомляет и реагирует на сбои node;
контроллер репликации (Replication Controller): поддерживает правильное количество pods для каждого объекта контроллера репликации в системе;
контроллер конечных точек (Endpoints Controller): заполняет объект конечных точек (Endpoints), то есть связывает сервисы (Services) и pods;
контроллеры учетных записей и токенов (Account & Token Controllers): создают стандартные учетные записи и токены доступа API для новых namespaces.
Kube-rbac-proxy#
Kube-rbac-proxy — это HTTP-прокси для одного исходящего потока, который может выполнять авторизацию RBAC для DropApp Plus API с помощью SubjectAccessReview.
В кластерах DropApp Plus без применения сетевой политики любой pod может выполнять запросы к любому другому pod в кластере. kube-rbac-proxy применяется для ограничения запросов только теми модулями, которые предоставляют действительный и авторизованный RBAC токен или клиентский TLS-сертификат.
Преимущества использования kube-rbac-proxy:
разгружает API DropApp Plus, чтобы он мог обрабатывать фактические запросы, связанные с компонентами кластера, а не запросы от клиентов;
принимает входящие HTTP-запросы, это позволяет гарантировать, что запрос авторизован и имеет право доступа к приложению, а не просто имеет сетевой доступ к объекту.
При входящем запросе kube-rbac-proxy выясняет, какой пользователь выполняет запрос. Он поддерживает использование клиентских TLS-сертификатов, а также токенов. В случае использования сертификата, он проверяется настроенным центром сертификации.
После того как пользователь прошел аутентификацию, снова используется authentication.k8s.io для выполнения SubjectAccessReview, чтобы авторизовать соответствующий запрос и убедиться, что аутентифицированный пользователь имеет необходимые роли RBAC.
У kube-rbac-proxy есть все glog флаги для ведения журнала. Чтобы использовать опциональный компонент, установите несколько флагов:
--upstream:- исходящий поток проксирования;--config-file:- файл, в котором указаны сведения о SubjectAccessReview, их необходимо выполнить по запросу. Например, можно указать, что объекту, выполняющему запрос, должно быть разрешено выполнять развертываниеget podс названиемmy-frontend-app.
Все флаги командной строки kube-rbac-proxy представлены в таблице.
Таблица. Флаги командной строки kube-rbac-proxy.
Синтаксис флага |
Значение |
|---|---|
|
Список путей, разделенных запятыми, по которым шаблон kube-rbac-proxy сопоставляет входящий запрос. Если запрос не совпадает, kube-rbac-proxy отвечает кодом состояния 404. Если этот параметр опущен, путь входящего запроса не проверяется. Нельзя использовать с параметром |
|
Значение |
|
Имя поля в заголовке запроса HTTP/2, чтобы сообщить вышестоящему серверу о группах пользователя (по умолчанию |
|
Разделитель, используемый для объединения нескольких имен групп в значении поля заголовка группы (по умолчанию |
|
Имя поля в заголовке запроса HTTP(2), сообщающее вышестоящему серверу об имени пользователя (по умолчанию |
|
Список аудиторий токенов, которые необходимо принять, разделенный запятыми. По умолчанию токен не должен иметь какой-либо конкретной аудитории. Рекомендуется установить конкретную аудиторию |
|
Любой запрос, представляющий сертификат клиента, подписанный одним из уполномоченных в файле |
|
Файл конфигурации для настройки kube-rbac-proxy |
|
Список путей, разделенных запятыми, по которым шаблон kube-rbac-proxy сопоставляет входящий запрос. Если запрос совпадает, он перенаправляет запрос без выполнения аутентификации или проверки авторизации. Нельзя использовать с флагом |
|
Путь к файлу kubeconfig*, указывающий, как подключиться к серверу API. Если значение |
|
Сертификат сервера OpenID будет проверен в файле oidc-ca при установке флага, в противном случае будет использоваться корневой набор CA хоста |
|
Идентификатор клиента для клиента OpenID Connect должен быть установлен, если установлен |
|
Идентификатор групп в заявке JWT |
|
Флаг, при установке которого все группы будут иметь префикс с этим значением, чтобы предотвратить конфликты с другими стратегиями аутентификации |
|
URL-адрес издателя OpenID, должен быть указан только в формате HTTPS. Если он установлен, он будет использоваться для проверки веб-токена OIDC JSON (JWT) |
|
Поддерживаемые алгоритмы подписи, по умолчанию |
|
Идентификатор пользователя в заявлении JWT, по умолчанию установлено значение «электронная почта» |
|
Порт для безопасного обслуживания конечных точек, специфичных для прокси-сервера (например, |
|
Адрес, который должен прослушивать HTTP-сервер kube-rbac-proxy |
|
Файл, содержащий сертификат x509 по умолчанию для HTTPS. Сертификат ЦС, если таковой имеется, объединенный после сертификата сервера |
|
Список наборов шифров для сервера, разделенный запятыми. Если этот параметр не указан, будут использоваться наборы шифров Go по умолчанию |
|
Минимальная поддерживаемая версия TLS 1.2. По умолчанию |
|
Файл, содержащий закрытый ключ x509 по умолчанию, соответствующий |
|
Интервал, с которым следует отслеживать изменения сертификата TLS 1.2, по умолчанию равен одной минуте |
|
Исходящий URL-адрес для прокси-сервера после успешной аутентификации и авторизации запросов |
|
ЦС, который исходящий поток использует для TLS 1.2-соединения. Это необходимо, когда исходящий поток использует TLS 1.2 и собственный сертификат ЦС |
|
Флаг, при установке которого клиент будет использоваться для аутентификации прокси-сервера в исходящем направлении. Также требуется установить |
|
Флаг, соответствующий сертификату из |
|
Флаг, заставляющий h2c взаимодействовать с исходящим потоком. Это необходимо, когда исходящий поток использует только h2c (открытый текст HTTP/2 — небезопасный вариант HTTP/2). Например, сервер go-grpc в небезопасном режиме без TLS 1.2 |
Глобальные флаги: |
|
|
Помощь для kube-rbac-proxy |
|
Флаг, позволяющий записывать файлы журналов в текущий каталог (не ведет запись, если |
|
Флаг, позволяющий вывести информацию о версии и выйти из приложения |
RBAC различается по двум типам, которые необходимо авторизовать: ресурсные и нересурсные. Например, авторизация запроса ресурса может заключаться в том, что запрашивающему объекту необходимо авторизоваться для выполнения действия get при развертывании DropApp.
Выполните следующие действия для защиты приложения с помощью kube-rbac-proxy (в примере ниже - prometheus-example-app). В этом примере запрашивающему объекту разрешено вызывать подресурс proxy в службе DropApp Plus с именем kube-rbac-proxy. Это настраивается в файле, переданном kube-rbac-proxy с флагом --config-file. Кроме того, необходимо установить флаг --upstream для настройки приложения, которое должно быть проксировано при успешной аутентификации и авторизации.
Kube-rbac-proxy также требует доступа RBAC для выполнения TokenReviews, а также SubjectAccessReviews. Это API-интерфейсы, доступные в DropApp Plus API для аутентификации и последующей проверки авторизации объекта.
Установка Kube-rbac-proxy#
Предварительные условия#
Предварительными условиями для установки Kube-rbac-proxy являются:
развернут кластер DropApp Plus;
установлен oc.
Установка#
Примечание
В приведенном сценарии IP адреса являются ненастоящими и приведены в качестве примера.
Для установки Kube-rbac-proxy:
Создайте файл yaml:
Создайте
deployment.yamlв DropApp Plus с использованием файлаdeployment.yaml, как представлено ниже.Команда
oc createпозволяет создать deployment на основе файлаdeployment.yaml, который содержит описание приложения и его настроек. Файлdeployment.yamlможет содержать информацию о контейнерах, ресурсах, настройках сети и другие параметры, необходимые для создания и управления deployment.oc create -f deployment.yamlВнесите при помощи текстового редактора, следующее содержание манифеста:
Пример настроек kube-rbac-proxy.yaml
apiVersion: v1 kind: ServiceAccount metadata: name: kube-rbac-proxy --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kube-rbac-proxy roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-rbac-proxy subjects: - kind: ServiceAccount name: kube-rbac-proxy namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kube-rbac-proxy rules: - apiGroups: ["authentication.k8s.io"] resources: - tokenreviews verbs: ["create"] - apiGroups: ["authorization.k8s.io"] resources: - subjectaccessreviews verbs: ["create"] --- apiVersion: v1 kind: Service metadata: labels: app: kube-rbac-proxy name: kube-rbac-proxy spec: ports: - name: HTTPs port: 8443 targetPort: HTTPs selector: app: kube-rbac-proxy --- apiVersion: v1 kind: ConfigMap metadata: name: kube-rbac-proxy data: config-file.yaml: |+ authorization: resourceAttributes: namespace: default apiVersion: v1 resource: services subresource: proxy name: kube-rbac-proxy --- apiVersion: apps/v1 kind: Deployment metadata: name: kube-rbac-proxy spec: replicas: 1 selector: matchLabels: app: kube-rbac-proxy template: metadata: labels: app: kube-rbac-proxy spec: securityContext: runAsUser: 65532 serviceAccountName: kube-rbac-proxy containers: - name: kube-rbac-proxy image: quay.io/brancz/kube-rbac-proxy:v0.14.1 args: - "--secure-listen-address=0.0.0.0:8443" - "--upstream=HTTP://127.0.0.1:8081/" - "--config-file=/etc/kube-rbac-proxy/config-file.yaml" - "--logtostderr=true" - "--v=10" ports: - containerPort: 8443 name: HTTPs volumeMounts: - name: config mountPath: /etc/kube-rbac-proxy securityContext: allowPrivilegeEscalation: false - name: prometheus-example-app image: quay.io/brancz/prometheus-example-app:v0.1.0 args: - "--bind=127.0.0.1:8081" volumes: - name: config configMap: name: kube-rbac-proxyПримечание
IP адреса являются ненастоящими и приведены в качестве примера.
Разверните объект
Job, который выполняетcurl, чтобы протестировать приложение prometheus-example-app. Поскольку он имеет правильные роли RBAC - запрос будет выполнен успешно:oc create -f client-rbac.yaml client.yamlЭто команда для создания клиента RBAC. В данном случае, команда создает два файла:
client-rbac.yamlиclient.yaml. Файлclient-rbac.yamlописывает клиента RBAC и содержит информацию о пользователях, группах и ролях, которые будут иметь доступ к ресурсам кластера. Файлclient.yamlсодержит конфигурацию клиента, включая его имя, IP-адрес и другие параметры.После выполнения команды
oc create, клиент будет создан и готов к использованию.Внесите при помощи текстового редактора, следующее содержание манифеста:
Пример манифеста
apiVersion: rbac.authorization v1 kind: ClusterRole metadata: name: kube-rbac-proxy-client rules: - apiGroups: [""] resources: ["services/proxy"] verbs: ["get"] --- apiVersion: rbac.authorization v1 kind: ClusterRoleBinding metadata: name: kube-rbac-proxy-client roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-rbac-proxy-client subjects: - kind: ServiceAccount name: default namespace: default --- apiVersion: batch/v1 kind: Job metadata: name: krp-curl spec: template: metadata: name: krp-curl spec: containers: - name: krp-curl image: quay.io/brancz/krp-curl:v0.0.2 restartPolicy: Never backoffLimit: 4При просмотре журнала вывод должен отображать следующее содержание:
oc logs job/krp-curl * Trying 10.111.34.206... * TCP_NODELAY set * Connected to kube-rbac-proxy.default.svc (10.111.34.206) port 8080 (#0) > GET /metrics HTTP/1.1 > Host: kube-rbac-proxy.default.svc:8080 > User-Agent: curl/7.57.0 > Accept: */* > Authorization: Bearer eyJhbGciOiJSUzI1NiIsInR5clkLKJlkLK;lknLKnmLKNlknlkn:LkhGfgufiytFl[p;":lpl";l'kX > < HTTP/1.1 200 OK < Content-Type: text/plain; version=0.0.4 < Date: Sun, 17 Dec 2017 13:34:26 GMT < Content-Length: 102 < { [102 bytes data] * Connection #0 to host kube-rbac-proxy.default.svc left intact # Информация о версии этого бинарного файла version{version="v0.1.0"} 0Примечание
IP адреса являются ненастоящими и приведены в качестве примера.
Machine API Operator#
Machine API Operator (MAO) - оператор, который обеспечивает управление физическими серверами и виртуальными машинамии, автоматизацию развертывания виртуальных машин в кластере DropApp Plus. Путем использования машинного API оператор позволяет управлять жизненным циклом виртуальных машин, их масштабированием, мониторингом и управлением ресурсами.
Machine API Operator поддерживает автоматическое назначение IP-адресов при создании новых виртуальных машин.
Machine API Operator управляет жизненным циклом CRD - пользовательского определения ресурса, контроллеров и объектов RBAC определенного назначения, которые расширяют Kubernetes API. Это позволяет декларативно передавать желаемое состояние машин в кластере.
Контроллеры#
MachineSet Controller - контроллер машинного набора;
Убедитесь в наличии ожидаемого количества реплик и заданной конфигурации провайдера для набора машин.
Machine Controller - контроллер машины;
Убедитесь, что экземпляр
providerсоздан для объектаMachineв данном поставщике.machine-api-provider-aws;
machine-api-provider-gcp;
machine-api-provider-azure;
cluster-api-provider-libvirt;
cluster-api-provider-openstack;
cluster-api-provider-baremetal;
cluster-api-provider-ovirt;
cluster-api-provider-ibmcloud;
Nodelink Controller - контроллер Nodelink;
Убедитесь, что у машин есть nodeRef на основе IP-адресов или соответствия providerId. Пометьте nodes меткой, содержащей имя машины.
MachineHealthCheck Controller - контроллер проверки работоспособности машины.
Убедитесь, что машины, на которые нацелены объекты
MachineHealthCheck, удовлетворяют критериям работоспособности или исправлены иным образом.
Создание машин#
Создайте новую машину, применив манифест, представляющий экземпляр CRD-машины:
Пример манифеста
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
labels:
machine.openshift.io/cluster-api-cluster: clusterID
machine.openshift.io/cluster-api-machine-role: role
machine.openshift.io/cluster-api-machine-type: role
name: machineName
namespace: openshift-machine-api
spec:
providerSpec:
value:
kind: AWSMachineProviderConfig
ami:
id: ami-0df3f99538fbef10f
apiVersion: awsproviderconfig.openshift.io/v1beta1
blockDevices:
- ebs:
iops: 0
volumeSize: 120
volumeType: gp2
credentialsSecret:
name: aws-cloud-credentials
deviceIndex: 0
iamInstanceProfile:
id: clusterID-worker-profile
instanceType: m5.large
placement:
availabilityZone: us-east-1a
region: us-east-1
securityGroups:
- filters:
- name: tag:Name
values:
- clusterID-worker-sg
subnet:
filters:
- name: tag:Name
values:
- clusterID-private-us-east-1a
tags:
- name: kubernetes.io/cluster/clusterID
value: owned
userDataSecret:
name: worker-user-data
Метка machine.openshift.io/cluster-api-cluster будет использоваться контроллерами для поиска нужного экземпляра облака.
Установите другие метки для предоставления пользователям удобного способа получения групп машин:
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
Разработка#
Сгенерируйте код:
make generateСоздайте сборку:
make buildИзвлеките
images.jsonв файл изinstall/0000_30_machine-api-operator_01_images.configmap.yamlи запустите:./bin/machine-api-operator start --kubeconfig ${HOME}/.kube/config --images-json=path/to/images.jsonСоздайте образ:
make image
Machine API Operator предназначен для работы совместно с Cluster Version Operator.
Развертывание Machine API Operator с Kubemark#
Разверните MAO через DropApp Plus:
kustomize build | oc apply -f -Предварительные требования для развертывания Kubemark actuator:
kustomize build config | oc apply -f -Создайте
clusterinfrastructure.config.openshift.io, чтобы сообщить MAO о развертывании поставщикаkubemark:apiVersion: apiextensions.k8s.io/v1beta1 kind: CustomResourceDefinition metadata: name: infrastructures.config.openshift.io spec: group: config.openshift.io names: kind: Infrastructure listKind: InfrastructureList plural: infrastructures singular: infrastructure scope: Cluster versions: - name: v1 served: true storage: true --- apiVersion: config.openshift.io/v1 kind: Infrastructure metadata: name: cluster status: platform: kubemarkЗапустите файл конфигурации
config/kubemark-config-infra.yaml:oc apply -f config/kubemark-config-infra.yaml
Machine image customization controller#
Machine image customization controller - это контроллер для настройки образов в DropApp Plus. Отвечает за управление и обновление образов контейнеров, развернутых в кластере. Он может использоваться для настройки параметров образа, таких как переменные окружения, секреты и другие настройки конфигурации. Работая с Machine image customization controller, можно легко внести изменения в образы контейнеров в кластере DropApp Plus без необходимости повторного развертывания всего приложения.
Создание образа#
Сетевые данные для каждого хоста должны быть в формате NMState под ключом с именем nmstate в секрете, указанном в networkDataName в поле PreprovisioningImage.
Все PreprovisioningImage файлы с меткой infraenvs.agent-install.openshift.io будут проигнорированы этим контроллером.
Сгенерированные URL-адреса являются случайными и изменятся при перезапуске контроллера.
Сохраняется только файл Ignition для каждого образа. При получении HTTP-запроса веб-сервер генерирует поток с архивом CPIO, содержащим файл Ignition и добавленный к initramfs. Поддерживаются запросы диапазона HTTP.
Настройки среды#
Требуются следующие переменные среды:
IRONIC_AGENT_IMAGE;
DEPLOY_ISO;
DEPLOY_INITRD.
Опциональны следующие переменные среды:
IRONIC_BASE_URL;
IRONIC_INSPECTOR_BASE_URL;
IRONIC_AGENT_PULL_SECRET;
IRONIC_AGENT_VLAN_INTERFACES;
IRONIC_RAMDISK_SSH_KEY;
REGISTRIES_CONF_PATH;
IP_OPTIONS;
HTTP_PROXY;
HTTPS_PROXY;
NO_PROXY.
Запуск контроллера#
Двоичный файл контроллера - /machine-image-customization-controller.
Для настройки используются следующие флаги командной строки:
-namespace- namespace, который отслеживает контроллер для согласования ресурсовpreprovisioningimage;-images-bind-addr- адрес и порт для привязки к веб-серверу;-images-publish-addr- адрес, с которого клиенты будут получать доступ к конечной точке образа.
Статическая работа#
Существует также отдельный двоичный файл, /machine-image-customization-server, который запускает веб-сервер с использованием статических конфигурационных файлов, а не как контроллер DropApp Plus.
Для настройки используются следующие флаги командной строки:
-nmstate-dir- расположение статических файлов NMState;-images-bind-addr- адрес и порт для привязки к веб-серверу;-images-publish-addr- адрес, с которого клиенты будут получать доступ к конечной точке образа.
Сluster-storage-operator#
Cluster Storage Operator - это инструмент, предназначенный для автоматизации развертывания, масштабирования и управления хранилищем данных, таким как Persistent Volumes (PV), Persistent Volume Claims (PVC) или Storage Classes, в кластере DropApp Plus.
Cluster Storage Operator позволяет упростить процесс управления хранилищем данных с помощью изменения настроек и управления данной частью инфраструктуры. Он также может обеспечивать более надежное и эффективное использование хранилища данных в кластере DropApp Plus.
Также Cluster Storage Operator обеспечивает установку плагинов тома CSI по умолчанию (см. «Сценарии использования опциональных компонентов» -> «CSI»).
Cluster-openshift-apiserver-operator#
Оператор Kubernetes API Server управляет и обновляет сервер Kubernetes API, развернутый поверх OpenShift. Оператор основан на платформе Go библиотеки OpenShift и устанавливается через оператор версии кластера (CVO).
Он содержит следующие компоненты:
Operator;
Bootstrap manifest renderer;
Installer based on static pods;
Configuration observer.
По умолчанию оператор предоставляет метрики Prometheus через сервис. Метрики собираются из компонента Kubernetes API Server Operator.
Configuration observer отвечает за реагирование на внешние изменения конфигурации. Например, это позволяет внешним компонентам (registry, etcd и т.д.) взаимодействовать с конфигурацией Kubernetes API (пользовательский ресурс KubeAPIServerConfig).
Operator также предоставляет события, которые могут помочь в отладке проблем. Чтобы получить события оператора, выполните следующую команду:
oc get events -n openshift-cluster-kube-apiserver-operator
Этот оператор настраивается через CRD KubeAPIServerс:
oc describe kubeapiserver
apiVersion: operator.openshift.io/v1
kind: KubeAPIServer
metadata:
name: cluster
spec:
managementState: Managed
Текущий статус оператора сообщается с помощью ресурса ClusterOperator. Чтобы получить текущий статус, выполните следующую команду:
oc get clusteroperator/kube-apiserver
Etcd#
Etcd — это высоконадежное распределенное хранилище данных. DropApp Plus хранит в нем информацию о состоянии существующих кластеров DropApp Plus, сервисах, сети и т.д.
Доступ к данным осуществляется через REST API. При изменениях записей, вместо поиска и изменения предыдущей копии, все предыдущие записи помечаются как устаревшие, а новые значения записываются в конец. Позже устаревшие значения удаляются специальным процессом. В важных системах, требующих избыточности и высокой доступности, etcd следует создавать в виде кластера, состоящего из нескольких nodes.
API server является основной точкой управления всего кластера DropApp. Он обрабатывает операции REST, проверяет их и обновляет соответствующие объекты в etcd. API server обслуживает DropApp Plus API и задуман как простой сервер, с большей частью бизнес-логики, реализованной в отдельных компонентах или в плагинах. Ниже приведены некоторые примеры API, доступных на сервере API.
# pods
api/v1/pods
# services
api/v1/services
# deployments
api/v1/deployments
Когда происходит работа с кластером DropApp Plus с использованием oc интерфейса командной строки, взаимодействие осуществляется с основным серверным компонентом API. Команды oc преобразуются в HTTP-вызовы REST и вызываются на сервере API. API server также отвечает за механизм аутентификации и авторизации. Все клиенты API должны быть аутентифицированы для взаимодействия с сервером API. Возможно написание клиентских библиотек/приложений DropApp Plus, используя API server.
Сluster-ingress-operator#
Сluster-ingress-operator — это компонент DropApp Plus, который обеспечивает внешний доступ к службам кластера путем настройки контроллеров Ingress, которые маршрутизируют трафик, как указано в ресурсах OpenShift Route и Kubernetes Ingress.
Чтобы обеспечить эту функциональность, Сluster-ingress-operator развертывает и управляет входным контроллером Kubernetes на базе HAProxy.
Сluster-ingress-operator реализует API входного контроллера OpenShift.
Сluster-ingress-operator — это основная функция DropApp Plus, которая включена по умолчанию.
Каждая новая установка имеет ingresscontroller с именем default, которое можно настроить, заменить или добавить экземпляры ingresscontroller. Чтобы просмотреть входной контроллер по умолчанию, используйте команду:
oc describe --namespace=openshift-ingress-operator ingresscontroller/default
Создавайте и редактируйте ресурсы ingresscontroller.operator.openshift.io для управления ingresscontroller.
Взаимодействуйте с входными контроллерами с помощью утилиты oc. Каждый ingresscontroller находится в namespace openshift-ingress-operator.
Масштабируйте ingresscontroller для обеспечения внешнего доступа к службам кластера:
oc scale \
--namespace=openshift-ingress-operator \
--replicas=1 \
ingresscontroller/<name>
oc patch \
--namespace=openshift-ingress-operator \
--patch='{"spec": {"replicas": 2}}' \
--type=merge \
ingresscontroller/<name>
Примечание
Если использование параметра where не установлено в ingresscontroller, то .spec.replica возвращает ошибку
Используйте команду oc для устранения проблем оператора:
Проверьте статус оператора:
oc describe clusteroperators/ingressПросмотрите логи оператора:
oc logs --namespace=openshift-ingress-operator deployments/ingress-operatorПроверьте состояние
ingresscontroller:oc describe --namespace=openshift-ingress-operator ingresscontroller/<name>
Machine-config-operator#
Machine-config-operator (MCO) воздействует на операционную систему (ОС), управляя обновлениями и изменениями конфигурации systemd, cri-o/kubelet, kernel, NetworkManager и других компонентов, располагающихся между ядром и kubelet.
Он также предлагает новый CRD MachineConfig, который может записывать файлы конфигурации на хост.
Machine-config-operator тесно взаимодействует как с установщиком ОС, так и с самой ОС. Как только machine-api-operator подготовит машину, Machine-config-operator ее настроит.
machine-os-content#
bootimage - это исходный образ Platform V SberLinux OS Core, например: VMWare VMDK, OpenStack QCOW2 и т.д.
bootimage в то же время является частью образа machine-os-content, которым управляет Machine-config-operator.
Примечание
machine-os-content - оболочка для фиксации OSTree. Формат OSTree - это формат образов, предназначенный для обновления операционной системы на месте; он работает на уровне файловой системы, как образы контейнеров, но, в отличие от среды выполнения контейнеров, имеет инструменты для управления такими вещами, как загрузчик и обработка сохраняемости /etc и /var.
Machine-config-operator с помощью machine-os-content обновляет слой OSTree поверх прочих операционных систем, каждое обновление – новый слой, с возможностью возвращения к предыдущим версиям.
Cluster Version Operator#
Cluster Version Operator (CVO) - один из операторов кластера, которые выполняются в каждом кластере DropApp Plus. CVO использует артефакт, называемый Выпуск образа полезной нагрузки, который представляет определенную версию DropApp Plus. Образ полезной нагрузки содержит файлы манифестов, необходимые для функционирования кластера.
CVO согласовывает ресурсы внутри кластера, чтобы они соответствовали манифестам в образе полезной нагрузки. В результате CVO реализует обновления кластера. После предоставления образа полезной нагрузки для более новой версии DropApp Plus CVO согласовывает все операторы кластера с их обновленными версиями, и операторы кластера аналогичным образом обновляют свои операнды.
Как и другие операторы кластера, Cluster Version Operators настраивается с помощью ресурса Config API в кластере ClusterVersion:
oc explain clusterversion
KIND: ClusterVersion
VERSION: config.openshift.io/v1
DESCRIPTION:
ClusterVersion is the configuration for the ClusterVersionOperator. This is
where parameters related to automatic updates can be set. Compatibility
level 1: Stable within a major release for a minimum of 12 months or 3
minor releases (whichever is longer).
FIELDS:
...
spec <Object> -required-
spec is the desired state of the cluster version - the operator will work
to ensure that the desired version is applied to the cluster.
status <Object>
status contains information about the available updates and any in-progress
updates.
Ресурс ClusterVersion следует установленному шаблону DropApp Plus, где свойство spec описывает желаемое состояние, которого CVO должен достичь и поддерживать, а свойство status заполняется CVO для описания его статуса и наблюдаемого состояния.
В типовом кластере DropApp Plus ресурс ClusterVersion с областью действия кластера, называется версией:
$ oc get clusterversion version
NAME VERSION AVAILABLE PROGRESSING SINCE STATUS
version 4.11.17 True False 6d5h Cluster version is 4.11.17
Bare metal machine controllers#
Bare metal machine controller один из набора инструментов для управления инфраструктурой bare metal с использованием DropApp Plus, реализует исполнительный механизм DropApp Cluster API.
Cluster API предоставляет декларативные API в стиле DropApp Plus для создания, настройки и управления кластерами. API является общим для нескольких облачных поставщиков.
Baremetal machine controller один из поставщиков Cluster API и позволяет пользователям развертывать кластер на основе Cluster API поверх инфраструктуры bare metal.
Cluster API - подпроект DropApp Plus, ориентированный на предоставление декларативных API и инструментов для упрощения подготовки, обновления и эксплуатации нескольких кластеров DropApp Plus.
Определения API и ресурсов#
Машина#
Ресурс машины определяется проектом Machine API Operator. Машина включает поле providerSpec, которое содержит данные, относящиеся к данному поставщику Cluster API.
machine-api-operator управляет жизненным циклом CRD, контроллеров и объектов RBAC специального назначения, которые расширяют Kubernetes API. Это позволяет передавать желаемое состояние машин в кластере декларативным способом.
BareMetalMachineProviderSpec#
image - включает в себя два подполя, url и checksum, состоящие из URL-адреса образа и URL-адреса контрольной суммы для этого образа.
userData - включает в себя два подполя, name и namespace, ссылающиеся на секрет, содержащий пользовательские данные в кодировке base64, которые должны быть записаны на диск конфигурации на подготовленном BareMetalHost.
hostSelector - задает критерии для сопоставления меток на объектах BareMetalHost. Это может быть использовано для ограничения набора доступных объектов BareMetalHost, выбранных для данной машины.
Пример настройки машины:
Пример манифеста
apiVersion: cluster.k8s.io/v1alpha1
kind: Machine
metadata:
annotations:
metal3.io/BareMetalHost: metal3/master-0
creationTimestamp: "2019-05-13T13:00:51Z"
finalizers:
- machine.cluster.k8s.io
generateName: baremetal-machine-
generation: 2
name: centos
namespace: metal3
resourceVersion: "1112"
selfLink: /apis/cluster.k8s.io/v1alpha1/namespaces/metal3/machines/centos
uid: 22acee54-757f-11e9-8091-280d3563c053
spec:
metadata:
creationTimestamp: null
providerSpec:
value:
apiVersion: baremetal.cluster.k8s.io/v1alpha1
image:
checksum: http://NNN.NN.N.N/images/CentOS-7-x86_64-GenericCloud-1901.qcow2.md5sum
url: http://NNN.NN.N.N/images/CentOS-7-x86_64-GenericCloud-1901.qcow2
kind: BareMetalMachineProviderSpec
userData:
name: centos-user-data
namespace: metal3
hostSelector:
matchLabels:
key1: value1
matchExpressions:
key: key2
operator: in
values: {'abc', '123', 'value2'}
versions:
kubelet: ""
где NNN.NN.N.N – актуальный IP адрес.
Пример секрета userData:
apiVersion: v1
data:
userData: BASE64_ENCODED_USER_DATA
kind: Secret
metadata:
annotations:
creationTimestamp: 2019-05-13T13:00:51Z
name: centos-user-data
namespace: metal3
resourceVersion: "1108"
selfLink: /api/v1/namespaces/metal3/secrets/centos-user-data
uid: 22792b3e-757f-11e9-8091-280d3563c053
type: Opaque
Поле hostSelector имеет два возможных необязательных подполя:
matchLabels- пары меток ключ/значение, которые должны точно совпадать;matchExpressions- набор выражений, которые должны принимать значениеtrueдля меток наBareMetalHost.
Допустимые операторы включают:
! - Ключ не существует. Значения игнорируются;
= - Ключ равен указанному значению. Должно быть указано только одно значение;
== - Ключ равен указанному значению. Должно быть указано только одно значение;
в - Значение является членом набора возможных значений;
!= - Ключ не равен указанному значению. Должно быть указано только одно значение;
notin - Значение не является членом указанного набора значений;
exists - Ключ существует. Значения игнорируются;
gt - Значение больше указанного. Значение должно быть целым числом;
lt - Значение меньше указанного. Значение должно быть целым числом.
Пример: BareMetalHost только с ключом key1, установленным в value1, и ключом key2, установленным в value2:
spec:
providerSpec:
value:
hostSelector:
matchLabels:
key1: value1
key2: value2
Масштабирование MachineSet#
Для автоматической масштабируемости MachineSet до количества совпадающих BareMetalHosts, пометьте MachineSet ключом metal3.io/autoscale-to-hosts и любым значением.
При согласовании MachineSet контроллер подсчитает все nodes BareMetalHosts, которые:
либо соответствуют спецификации MachineSet
Spec.Template.Spec.ProviderSpec.HostSelectorи имеют значениеConsumerRef, равноеnil;либо имеют значение
ConsumerRef, которое ссылается на машину, являющуюся частью MachineSet.
Cluster-baremetal-operator#
Cluster-baremetal-operator (CBO) разработан как оператор DropApp Plus, который отвечает за развертывание всех компонентов, необходимых для обеспечения работы серверов Baremetal, на worker nodes, которые присоединяются к кластеру DropApp Plus.
CBO отвечает за обеспечение того, чтобы развертывание metal3, состоящее из контейнеров Bare Metal Operator (BMO) и Ironic, всегда выполнялось на одном из master node в кластере DropApp Plus.
CBO отвечает за проверку обновлений DropApp Plus для ресурсов, которые он просматривает, и принятие соответствующих мер. CBO сообщает о своем собственном состоянии через ресурс ClusterOperator baremetal, как того требует каждый оператор DropApp Plus. CBO считывает и проверяет, предоставленную в ресурсе Provisioning Config (CR), и передает эту информацию в развертывание metal3. Он также создает секреты, которые используются контейнерами.
Bare Metal Operator#
Bare Metal Operator реализует Kubernetes API для управления хостами baremetal. Он ведет реестр доступных хостов в качестве экземпляров пользовательского определения ресурса BareMetalHost. Bare Metal Operator позволяет:
проверить сведения об оборудовании хоста и сообщить о них на соответствующем
BareMetalHost. Сведения включают информация о процессорах, оперативной памяти, дисках, сетевых адаптерах и многом другом;предоставить хостам заданный образ;
очистить содержимое диска хоста до или после подготовки.
BareMetalHost представляет собой хост сервера и содержит информацию о сервере. Классификация полей по следующим широким категориям:
известные свойства сервера: такие поля, как свойства
bootMACAddressсервера;неизвестные свойства сервера: такие поля, как
CPUиdisk, являются свойствами сервера и обнаруживаются Ironic;предоставленное пользователем: такие поля, как
image, предоставляются пользователем для определения загрузочного образа для сервера;динамические поля: такие поля, как IP, могут динамически назначаться серверу во время выполнения DHCP-сервером.
В течение жизненного цикла Bare Metal хоста некоторые из этих полей изменяются в зависимости от информации, поступающей от Ironic или других контроллеров, в то время такие поля, как MAC-адрес, не меняются.
Bare Metal Operator также может работать с Bare metal machine controller. При участии Bare metal machine controller и Ironic ниже показан упрощенный путь передачи информации и обзор ресурса BareMetalHost:
Пример манифеста
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: node-0
namespace: metal3
spec:
bmc:
address: ipmi://NNN.NNN.NNN.N:6230
credentialsName: node-0-bmc-secret
bootMACAddress: 00:5a:91:3f:9a:bd
image:
checksum: http://MMM.MM.M.1/images/CENTOS_8_NODE_IMAGE_K8S_v1.22.2-raw.img.md5sum
url: http://MMM.MM.M.1/images/CENTOS_8_NODE_IMAGE_K8S_v1.22.2-raw.img
networkData:
name: test1-workers-tbwnz-networkdata
namespace: metal3
online: true
userData:
name: test1-workers-vd4gj
namespace: metal3
status:
hardware:
cpu:
arch: x86_64
count: 2
hostname: node-0
nics:
- ip: MMM.MM.M.73
mac: 00:5a:91:3f:9a:bd
name: enp1s0
ramMebibytes: 4096
storage:
- hctl: "0:0:0:0"
name: /dev/sda
serialNumber: drive-scsi0-0-0-0
sizeBytes: 53687091200
type: HDD
где NNN.NNN.NNN.N – актуальный IP адрес одной подсети, а MMM.MM.M.1 и MMM.MM.M.73 – актуальные IP адреса другой подсети.
Ресурс BareMetalHost содержит адрес и аутентификационную информацию для сервера.
Bare Metal Operator передает эту информацию Ironic и получает взамен сведения об оборудовании - данные проверки, такие как процессор и диск сервера. Эта информация добавляется к статусу ресурса BareMetalHost. Чтобы получить такую информацию, связанную с сервером, сервер загружается с помощью служебного ramdisk. Если происходят изменения, связанные с оборудованием, BareMetalHost обновляется соответствующим образом.
Масштабирование кластера, подготовленного пользователем, с помощью Bare Metal Operator#
После развертывания кластера инфраструктуры, подготовленного пользователем, можно использовать Bare Metal Operator (BMO) и другие компоненты metal3 для масштабирования baremetal хостов в кластере более автоматизированным способом.
Настройка Provisioning ресурса для масштабирования кластеров, подготовленных пользователем#
Создайте Provisioning пользовательский ресурс (CR), чтобы включить компоненты платформы Metal в кластере инфраструктуры, подготовленном пользователем.
Процедура#
Создайте
ProvisioningCR.Сохраните следующий YAML-настройку в файле
provisioning.yaml:apiVersion: metal3.io/v1alpha1 kind: Provisioning metadata: name: provisioning-configuration spec: provisioningNetwork: "Disabled" watchAllNamespaces: falseСоздайте
ProvisioningCR, выполнив следующую команду:oc create -f provisioning.yamlПример вывода:
provisioning.metal3.io/provisioning-configuration created
Проверка#
Убедитесь, что служба подготовки запущена, выполнив следующую команду:
oc get pods -n openshift-machine-api
Пример вывода:
NAME READY STATUS RESTARTS AGE
cluster-autoscaler-operator-678c476f4c-jjdn5 2/2 Running 0 5d21h
cluster-baremetal-operator-6866f7b976-gmvgh 2/2 Running 0 5d21h
control-plane-machine-set-operator-7d8566696c-bh4jz 1/1 Running 0 5d21h
ironic-proxy-64bdw 1/1 Running 0 5d21h
ironic-proxy-rbggf 1/1 Running 0 5d21h
ironic-proxy-vj54c 1/1 Running 0 5d21h
machine-api-controllers-544d6849d5-tgj9l 7/7 Running 1 (5d21h ago) 5d21h
machine-api-operator-5c4ff4b86d-6fjmq 2/2 Running 0 5d21h
metal3-6d98f84cc8-zn2mx 5/5 Running 0 5d21h
metal3-image-customization-59d745768d-bhrp7 1/1 Running 0 5d21h
Подготовка новых хостов в кластере, подготовленном пользователем, с помощью BMO#
BMO может быть использован для подготовки baremetal хостов в кластере, подготовленном пользователем, путем создания пользовательского ресурса BareMetalHost.
Чтобы предоставить кластеру baremetal хосты с помощью BMO, установите для спецификации spec.externallyProvisioned в пользовательском ресурсе BareMetalHost значение false.
Предварительные требования#
создан
Provisioningкластер, подготовленный пользователем;получен доступ к контроллеру управления базовой платой (BMC) к узлам;
развернута служба подготовки в кластере, создав сертификат подготовки.
Процедура#
Создайте Secret CR и BareMetalHost CR.
Сохраните следующий YAML в файле
bmh.yaml:Пример манифеста
--- apiVersion: v1 kind: Secret metadata: name: worker1-bmc namespace: openshift-machine-api type: Opaque data: username: <base64_of_uid> password: <base64_of_pwd> --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: worker1 namespace: openshift-machine-api spec: bmc: address: <protocol>://<bmc_url> credentialsName: "worker1-bmc" bootMACAddress: <nic1_mac_address> externallyProvisioned: false customDeploy: method: install_coreos online: true userData: name: worker-user-data-managed namespace: openshift-machine-apiСоздайте baremetal хост, выполнив следующую команду:
oc create -f bmh.yamlПример вывода:
secret/worker1-bmc created baremetalhost.metal3.io/worker1 createdУтвердите все запросы на подписание сертификатов (CSR).
Убедитесь, что состояние подготовки хоста подготовлено, выполнив следующую команду:
oc get bmh -AПример вывода:
NAMESPACE NAME STATE CONSUMER ONLINE ERROR AGE openshift-machine-api controller1 externally provisioned true 5m25s openshift-machine-api worker1 provisioned true 4m45sПолучите список ожидающих CSR, выполнив следующую команду:
oc get csrПример вывода:
certificatesigningrequest.certificates.k8s.io/<csr_name> approved
Верификация#
Убедитесь, что узел готов, выполнив следующую команду:
oc get nodes
Пример вывода:
NAME STATUS ROLES AGE VERSION
app1 Ready worker 47s v1.24.0+dc5a2fd
controller1 Ready master,worker 2d22h v1.24.0+dc5a2fd
Marketplace Operator#
Marketplace Operator - оператор, который позволяет управлять и разворачивать приложения и сервисы из Marketplace - рынка приложений, в кластере DropApp Plus.
Marketplace Operator позволяет пользователям просто настраивать и управлять различными приложениями, которые могут быть использованы в их кластере через централизованный механизм управления. Он обеспечивает простоту развертывания различных приложений в кластере DropApp Plus без необходимости знания их внутреннего устройства или конфигурации.
Open Virtual Networking with Kubernetes#
Подключаемый модуль OVN-Kubernetes Container Network Interface (CNI) — это поставщик сети для кластера по умолчанию. OVN-Kubernetes, основанный на открытой виртуальной сети (OVN), предоставляет реализацию сети на основе наложения.
Кластер, использующий сетевой поставщик OVN-Kubernetes, также запускает Open vSwitch (OVS) на каждом node. OVN настраивает OVS для реализации объявленной конфигурации сети.
OVN обеспечивает виртуализацию сети для контейнеров. В режиме наложения OVN может создавать логическую сеть между контейнерами, работающими на нескольких хостах. В этом режиме OVN программирует экземпляры Open vSwitch, работающие внутри хостов. Этими хостами могут быть простые машины или обычные виртуальные машины.
Telemeter#
Telemeter - это набор компонентов, используемых для удаленного мониторинга работоспособности DropApp Plus. Он позволяет кластерам отправлять данные их телеметрии в качестве метрик Prometheus.
Cервер телеметрии должен получать и отправлять метрики через несколько границ безопасности и, следовательно, должен выполнять несколько проверок аутентификации, авторизации и целостности данных. Он получает метрики и пересылает их вышестоящей службе в виде запроса на удаленную запись Prometheus через две конечные точки.
SDN#
SDN оригинальный сетевой плагин для DropApp Plus. Он использует Open vSwitch для локального подключения модулей с туннелями VXLAN для подключения различных nodes.
SDN предназначен для установки оператором Network Operator, и некоторые его компоненты, такие как Deployment и DaemonSet, находятся в образе Network Operator.
Network Operator определяет два образа: образ sdn, включающий SDN-компоненты контроллера и компоненты node, и образ kube-proxy, разворачивающийся сетевым оператором для сторонних сетевых плагинов, которым это необходимо.
SDN устарел и больше не разрабатывается. Рекомендуется использовать OVN Kubernetes.
Network-tools#
network-tools - это набор инструментов для отладки сетевых проблем кластера DropApp Plus. Также содержит инструменты для получения информации из кластера. Предназначен для управления и мониторинга сетевых соединений в кластере, отладки и диагностики проблем.
network-tools содержит:
сценарии отладки кластерной сети, написанные на bash;
часто используемые сетевые инструменты CLI, такие как ping, netcat, tcpdump, strace и др.
Чтобы использовать network-tools локально, клонируйте и запустите репозиторий ./debug-scripts/network-tools -h, в котором будут перечислены все доступные команды.
Чтобы использовать network-tools в кластере, используйте команду oc adm must-gather --image-stream openshift/network-tools:latest -- network-tools -h.
Network Metrics Daemon#
Network Metrics Daemon - это компонент, который собирает и публикует метрики, связанные с сетью.
После установки Network Metrics Daemon Kubelet публикует показатели, связанные с сетью:
container_network_receive_bytes_total;
container_network_receive_errors_total;
container_network_receive_packets_total;
container_network_receive_packets_dropped_total;
container_network_transmit_bytes_total;
container_network_transmit_errors_total;
container_network_transmit_packets_total;
container_network_transmit_packets_dropped_total.
Метки в этих метриках содержат:
имя pod (pod name);
pod namespace;
название интерфейса (interface name).
Network interface bond CNI#
Плагин Bond-CNI предоставляет метод объединения нескольких сетевых интерфейсов в единый логически связанный интерфейс.
CNI (Container Network Interface) - состоит из спецификации и библиотек для написания плагинов для настройки сетевых интерфейсов в контейнерах операционных систем, а также ряда поддерживаемых плагинов. CNI занимается только подключением контейнеров к сети и удалением выделенных ресурсов при удалении контейнера.
Чтобы добавить связанный интерфейс к контейнеру, необходимо создать определение сетевого подключения типа bond и добавить его в качестве сетевой аннотации в спецификации pod. Связанные интерфейсы могут быть взяты либо из хоста, либо из контейнера на основе значения параметра linksInContainer в определении сетевого подключения.
При настройке Bond CNI в качестве автономного плагина, интерфейсы формируются из namespace хост-сети. С помощью этих физических интерфейсов в namespace контейнерной сети создается связанный интерфейс.
При использовании с Multus появляется возможность связать два интерфейса, которые ранее были переданы в контейнер.
Основным вариантом использования соединения в контейнерах является сетевое резервирование приложения в случае сбоя сетевого устройства или пути и последующей недоступности.
Must-gather#
Must-gather - это инструмент для сбора данных кластера. Он выгружает данные clusteroperator и связанные с ними данные namespace в указанное местоположение --base-dir.
Сбор сценариев#
Сценарии сбора данных хранятся в ./collection-scripts. Содержимое этой папки помещено в /usr/bin в образе. Сценарии сбора данных должны включать логику сбора только для компонентов, которые включены как часть полезной нагрузки DropApp Plus. Сторонним компонентам рекомендуется создавать аналогичный образ Must-gather.
Запуск#
Запустите must-gather в кластере с помощью oc adm must-gather. Используйте флаг -h, чтобы просмотреть доступные параметры.
Cкрытие конфиденциальной информации#
Существует специальный раздел для скрытия и пропуска конфиденциальной информации must-gather-clean.
Machine-os-images#
Machine-os-images содержит компоненты, необходимые для создания node на базе Platform V SberLinux OS Core. Процесс включает в себя создание контейнера, который состоит из последней версии Platform V SberLinux OS Core для разработчиков, артефактов кластера DropApp Plus, демона Machine Controller и других различных контейнерных слоев.
Cloud Credential Operator#
Cloud Credential Operator - это контроллер, синхронизирующий пользовательские ресурсы CredentialsRequest. Запросы credentialsrequest позволяют компонентам DropApp Plus запрашивать подробные учетные данные для конкретного облачного провайдера, в отличие от использования учетных данных администратора или повышенных разрешений, предоставляемых через роли экземпляра.
Cluster-kube-storage-version-migrator-operator#
Cluster-kube-storage-version-migrator-operator (storage-version-migrator) - это управляемый контроллер ресурсов DropApp Plus, который отвечает за управление миграцией данных хранилища. Например, хранилища данных, используемые в приложениях или сервисах, при обновлении версии хранилища или сущности управления данными, такими как базы данных.
Storage-version-migrator помогает автоматизировать процесс миграции данных и обеспечивает их безопасность и целостность во время процесса обновления.
Storage-version-migrator переносит сохраненные в etcd данные в последнюю версию хранилища.
Мигратор состоит из двух контроллеров: триггерного контроллера и фактического контроллера миграции.
Триггерный контроллер:
обнаруживает изменения версии хранилища путем опроса документа обнаружения сервера API каждые 10 минут;
создает запросы на миграцию для типов ресурсов, версия хранилища которых изменяется.
Контроллер миграции обрабатывает запросы на миграцию один за другим. При переносе типа ресурса для всех объектов этого типа ресурсов контроллер миграции получает объект, а затем записывает его обратно на API server без изменений. Цель состоит в том, чтобы запустить API server для кодирования объекта в последней версии хранилища перед его сохранением.
Container Networking Plugins#
Некоторые сетевые плагины CNI поддерживаются Container Networking.
CNI (Container Network Interface) состоит из спецификации и библиотек для написания плагинов для настройки сетевых интерфейсов в контейнерах Linux и Windows, а также ряда поддерживаемых плагинов. CNI занимается только подключением контейнеров к сети и удалением выделенных ресурсов при удалении контейнера.
Поддерживаемые плагины#
Main: interface-creating:
bridge: Создаетbridge, добавляет к нему хост и контейнер;ipvlan: Добавляет интерфейсipvlanв контейнер;loopback: Устанавливает состояние интерфейса обратной связи наup;macvlan: Создает новый MAC-адрес, перенаправляет весь трафик идущий на него в контейнер;ptp: Создает паруveth;vlan: Выделяет устройствоvlan;host-device: Перемещает уже существующее устройство в контейнер;dummy: Создает новое фиктивное устройство в контейнере.
Windows: Windows specific:
win-bridge: Создаетbridge, добавляет к нему хост и контейнер;win-overlay: Создает интерфейс наложения для контейнера.
IPAM: Распределение IP-адресов:
dhcp: Запускает демона на хосте для выполнения DHCP-запросов от имени контейнера;host-local: Поддерживает локальную базу данных выделенных IP-адресов;static: Выделяет контейнеру один статический IPv4/IPv6-адрес.
Meta: другие плагины:
tuning: Настраивает параметрыsysctlсуществующего интерфейса;portmap: Плагин для отображения портов на основе iptables. Отображает порты из адресного пространства хоста в контейнер;bandwidth: Позволяет ограничить полосу пропускания за счет использования tbf управления трафиком (вход/выход);sbr: Плагин, который настраивает маршрутизацию на основе источника для интерфейса, от которого подключен;firewall: Плагин брандмауэра, который использует iptables или firewalld для добавления правил, разрешающих трафик в/из контейнера.
Cluster Update Keys#
Cluster Update Keys добавляет ConfigMap к образу DropApp Plus, который инструктирует оператора версии кластера проверять обновления с использованием предоставленных ключей и хранилищ перед их выполнением.
ConfigMap должен содержать аннотацию release.openshift.io/verification-config-map, которая предписывает оператору версии кластера проверять полезные нагрузки на соответствие сигнатурам OpenPGP в формате подписи атомарного контейнера.
Ключи в ConfigMap определяют, как выполняется проверка:
verifier-public-key-*: One or more GPG public keys in ASCII form that must have signed the
release image by digest.
store-*: A URL (scheme file://, http://, or https://) location that contains signatures. These
signatures are in the atomic container signature format. The URL will have the digest
of the image appended to it as "<STORE>/<ALGO>=<DIGEST>/signature-<NUMBER>" as described
in the container image signing format. The docker-image-manifest section of the
signature must match the release image digest. Signatures are searched starting at
NUMBER 1 and incrementing if the signature exists but is not valid. The signature is a
GPG signed and encrypted JSON message. The file store is provided for testing only at
the current time, although future versions of the CVO might allow host mounting of
signatures.
Cluster-policy-controller#
Cluster-policy-controller отвечает за поддержание ресурсов политики, необходимых для создания модулей в кластере. Контроллерами, управляемыми Cluster-policy-controller, являются:
контроллер согласования квот кластера – управляет использованием квот кластера;
контроллер распределения namespace SCC - выделяет UID и метки SELinux для namespaces.
контроллер утверждения кластера csr - утверждает csr для мониторинга очистки;
контроллер синхронизации меток допуска podsecurity - настраивает метки namespace допуска PodSecurity для namespaces с меткой
security.openshift.io/scc.podSecurityLabelSync: true.
Cluster-policy-controller запускается как контейнер в openshift-kube-controller-manager namespace, в статическом pod kube-controller-manager. Этот pod определяется и управляется оператором кластера kube-controller-manager, который устанавливает и поддерживает пользовательский ресурс KdubeControllerManager в кластере.
Его можно просмотреть с помощью:
oc get clusteroperator kube-controller-manager -o yaml
Сluster node tuning operator#
Сluster node tuning operator (CNT) - это оператор, который отвечает за оптимизацию и настройку nodes кластера для обеспечения оптимальной производительности и эффективности ресурсов.
Он анализирует производительность nodes и принимает решения о том, какие настройки и изменения должны быть применены для улучшения производительности и оптимизации использования ресурсов.
Сluster node tuning operator управляет настройкой на уровне cluster node.
Большинство высокопроизводительных приложений требуют определенного уровня настройки ядра. Оператор предоставляет пользователям унифицированный интерфейс управления sysctls на уровне node и больше гибкости для добавления пользовательской настройки. Оператор управляет контейнерным настроенным демоном, как набором демонов DropApp Plus. Это гарантирует, что спецификация пользовательской настройки передается всем демонам с контейнерной настройкой, запущенным в кластере, в понятном формате. Демоны запускаются на всех nodes кластера, по одному на каждый node.
При изменении профиля контейнерный настроенный демон отменит любые изменения настроек на уровне node перед применением нового профиля. Контейнерный настроенный демон обрабатывает сигналы завершения, откатывая все настройки на уровне node, которые он применил, перед корректным завершением работы.
Cluster Service CA Operator#
Cluster Service CA Operator - это оператор в DropApp Plus, который управляет сертификатным авторитетом (CA) для кластера. Он обеспечивает генерацию, обновление и управление сертификатами для различных компонентов и nodes в кластере.
Cluster Service CA Operator автоматически управляет выпуском сертификатов на основе запросов от различных компонентов в кластере. Он генерирует сертификаты для nodes кластера, служб, хранилищ данных и других ресурсов. Оператор также автоматически обновляет и перевыпускает сертификаты при истечении их срока действия.
Предоставляет возможность отслеживать и контролировать доступ к различным ресурсам и компонентам в кластере с помощью сертификатов.
Cluster Service CA Operator обычно устанавливается и конфигурируется вместе с кластером DropApp Plus и предлагает средства для управления сертификатами из командной строки или интерфейса пользователя. Интегрируется с другими компонентами и инструментами безопасности в DropApp Plus, такими как RBAC (модель на основе ролей), для обеспечения более надежной аутентификации и авторизации в кластере.
Cluster Service CA Operator запускает следующие контроллеры:
serving cert signer - выдает подписанную пару, обслуживающий сертификат/ключ, службам, помеченным
service.beta.openshift.io/serving-cert-secret-nameс помощью секрета.configmap cabundle injector - отслеживает конфигурационные карты, помеченные
service.beta.openshift.io/inject-cabundle=true, и добавляет или обновляет элемент данных (ключservice-ca.crt), содержащий пакет подписи CA в кодировке PEM. Затем пользователиconfigmapмогут доверятьservice-ca.crtв своей конфигурации клиента TLS, разрешая подключения к службам, использующим сертификаты обслуживания служб.
Cluster Network Operator#
Cluster Network Operator устанавливает и обновляет сетевые компоненты в кластере DropApp Plus.
Cluster Network Operator предоставляет инструменты для создания и настройки сетевых политик, балансировки нагрузки, маршрутизации и других функций сетевого взаимодействия внутри кластера.
Упрощает настройку и управление сетью в кластере DropApp Plus, предоставляя средства для выполнения сложных задач сетевого взаимодействия и автоматического управления сетевыми службами.
Cluster Network Operator следует шаблону контроллера: согласовывает состояние кластера с желаемой конфигурацией. Конфигурация, указанная с помощью CustomResourceDefinition с именем Network.config.openshift.io/v1, имеет соответствующий тип.
Большинство пользователей смогут использовать Config API верхнего уровня, который имеет сетевой тип. Оператор автоматически преобразует объект Network.config.openshift.io в Network.operator.openshift.io.
Чтобы связаться с оператором сети:
oc get -o yaml network.operator cluster
Когда контроллер согласован и все зависимые от него ресурсы объединены, в кластере должен быть установлен сетевой плагин и рабочая сервисная сеть. В DropApp Plus сетевой оператор кластера запускается на самом раннем этапе процесса установки – пока сервер boostrap API все еще запущен.
Cluster machine approver#
Cluster machine approver - контроллер, предоставляющий следующие функциональные возможности:
отслеживание конечной точки CSR на предмет запросов CSR;
решение о разрешении или запрете CSR;
утверждение или отклонение и обновление статуса CSR.
CSR (Certificate Signing Request - запрос на подписание сертификата) — это зашифрованный запрос на выпуск сертификата, содержащий подробную информацию о домене и организации. Генерация CSR является необходимой процедурой подготовки к получению SSL-сертификата. Сгенерированный CSR включается в анкету на получение сертификата.
DropApp Plus обладает поддержкой TLS bootstrapping для nodes.
В кластере DropApp Plus компоненты на рабочих nodes - kubelet и kube-proxy - должны взаимодействовать с компонентами плоскости управления Kubernetes, в частности с kube-apiserver. Чтобы гарантировать конфиденциальность связи, отсутствие помех и то, что каждый компонент кластера взаимодействует с другим доверенным компонентом, следует использовать клиентские сертификаты TLS на nodes.
Чтобы упростить процесс начальной загрузки этих компонентов, в DropApp Plus включен возможность запрос сертификата и подписи API.
Для нормальной работы Kubelet требуется два сертификата:
Сертификат клиента – для безопасного взаимодействия с Kubernetes API server;
Сертификат сервера – для использования в собственной локальной конечной точке HTTPs, используемой API server для обратной связи с kubelet.
При подготовке нового хоста kubelet запустится и свяжется с конечной точкой CSR API для запроса подписанных сертификатов клиента и сервера. Он выдает этот запрос, используя учетные данные bootstrap, которые находит в своей локальной файловой системе.
CSR должны быть утверждены. Они могут быть утверждены вручную через API с использованием oc, или kube-controller-manager может быть настроен для их утверждения.
Cluster machine approver - пользовательский компонент для утверждения CSR через API. Cluster machine approver используется для автоматического утверждения CSR, но с более строгими критериями, чем те, которые поддерживаются в kube-controller-manager.
На этапе начальной загрузки кластера служба approve-csr на node начальной загрузки автоматически утверждает все CSR. Эта служба в конечном итоге одобрит CSR для nodes плоскости управления, в то время как cluster-machine-approver возьмет на себя управление будущими новыми CSR от рабочих nodes.
Cluster DNS Operator#
Cluster DNS Operator развертывает и управляет CoreDNS, чтобы предоставить службу разрешения имен для pods, позволяющую обнаруживать службы DropApp Plus на основе DNS.
CoreDNS - это быстрый и гибкий DNS-сервер/переадресатор, который объединяет плагины, выполняющие определенную DNS-функцию.
Cluster DNS Operator создает рабочее развертывание по умолчанию на основе конфигурации кластера.
По умолчанию домен кластера - cluster.local.
Cluster DNS Operator поддерживается ограниченная конфигурация CoreDNS, Corefile или плагинов kubernetes.
Cluster DNS Operator развертывает CoreDNS с использованием DaemonSet, что означает, что у каждого node есть локальная CoreDNS pod-реплика. Эта топология обеспечивает масштабируемость по мере роста или сокращения кластера и устойчивость в случае, если node становится временно изолированным от других nodes.
Cluster Monitoring Operator#
Cluster Monitoring Operator управляет и обновляет стек мониторинга кластеров на основе Prometheus, развернутый поверх DropApp Plus.
Он содержит следующие компоненты:
Prometheus Operator;
Prometheus;
Alertmanager - для оповещения на уровне кластера и приложения;
kube-state-metrics;
node_exporter;
prometheus-adapter;
kubernetes-metrics-server только на кластере
TechPreviewNoUpgrade.
Prometheus Operator обеспечивает встроенное развертывание и управление Prometheus и связанными с ним компонентами мониторинга.
Prometheus отвечает за мониторинг и предупреждения в кластере и компонентах DropApp Plus.
Alertmanager - компонент кластера для обработки предупреждений, генерируемых всеми экземплярами Prometheus, развернутыми в кластере.
Kube-state-metrics - компонент мониторинга DropApp Plus, который предоставляет метрики состояния кластера, такие как, количество pods, replicaSet, deployment и других ресурсов DropApp Plus.
Node_exporter позволяет отслеживать ресурсы node: CPU, использование памяти и диска и многое другое.
prometheus-adapter может заменить сервер метрик в кластерах, на которых уже запущен Prometheus, и собирать соответствующие метрики.
Metrics-server - API-сервер, который сохраняет и предоставляет данные метрик DropApp Plus. Он используется для мониторинга ресурсов кластера, таких как CPU, память и ресурсы сети в режиме реального времени.
Добавление новых метрик для отправки с помощью телеметрии#
Чтобы добавить новые показатели для отправки с помощью телеметрии, добавьте селектор, соответствующий временному ряду в cluster-monitoring-operator.yaml.
Пример настроек cluster-monitoring-operator.yaml для Cluster Monitoring Operator:
Пример настроек cluster-monitoring-operator.yaml
# Этот configmap используется оператором мониторинга кластера для настройки
# клиента telemeter (телеметрии), который отвечает за считывание метрик из
# экземпляров Prometheus в кластере и пересылку их в службу телеметрии.
#
# Единственный поддерживаемый ключ в metrics.yaml - это "matches", представляющие список меток
# селекторов, которые определяют, какие метрики будут пересылаться. Метки
# селекторов могут выбрать одну метрику (например, '{__name__="foo"}') или все
# имена метрик, соответствующие регулярному выражению (например, '{__name__=~"foo:.+"}').
apiVersion: v1
data:
metrics.yaml: |-
matches:
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:usage recording rules summarize important usage information
# about the cluster that points to specific features or component usage
# that may help identify problems or specific workloads. For example,
# cluster:usage:openshift:build:rate24h would show the number of builds
# executed within a 24h period so as to determine whether the current
# cluster is using builds and may be susceptible to eviction due to high
# disk usage from build temporary directories.
# All metrics under this prefix must have low (1-5) cardinality and must
# be well-scoped and follow proper naming and scoping conventions.
- '{__name__=~"cluster:usage:.*"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# count:up0 contains the count of cluster monitoring sources being marked as down.
# This information is relevant to the health of the registered
# cluster monitoring sources on a cluster. This metric allows telemetry
# to identify when an update causes a service to begin to crash-loop or
# flake.
- '{__name__="count:up0"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# count:up1 contains the count of cluster monitoring sources being marked as up.
# This information is relevant to the health of the registered
# cluster monitoring sources on a cluster. This metric allows telemetry
# to identify when an update causes a service to begin to crash-loop or
# flake.
- '{__name__="count:up1"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_version reports what payload and version the cluster is being
# configured to and is used to identify what versions are on a cluster that
# is experiencing problems.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="cluster_version"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_version_available_updates reports the channel and version server
# the cluster is configured to use and how many updates are available. This
# is used to ensure that updates are being properly served to clusters.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="cluster_version_available_updates"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_version_capability reports the names of enabled and available
# cluster capabilities. This is used to gauge the popularity of optional
# components and exposure to any component-specific issues.
- '{__name__="cluster_version_capability"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_operator_up reports the health status of the core cluster
# operators - like up, an upgrade that fails due to a configuration value
# on the cluster will help narrow down which component is affected.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster_operator_up"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_operator_conditions exposes the status conditions cluster
# operators report for debugging. The condition and status are reported.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster_operator_conditions"}'
#
# owners: (@openshift/openshift-team-cincinnati)
#
# cluster_version_payload captures how far through a payload the cluster
# version operator has progressed and can be used to identify whether
# a particular payload entry is causing failures during upgrade.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="cluster_version_payload"}'
#
# owners: (@openshift/openshift-team-installer, @openshift/openshift-team-cincinnati)
#
# cluster_installer reports what installed the cluster, along with its
# version number and invoker.
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="cluster_installer"}'
#
# owners: (@openshift/openshift-team-master, @smarterclayton)
#
# cluster_infrastructure_provider reports the configured cloud provider if
# any, along with the infrastructure region when running in the public
# cloud.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster_infrastructure_provider"}'
#
# owners: (@openshift/openshift-team-master, @smarterclayton)
#
# cluster_feature_set reports the configured cluster feature set and
# whether the feature set is considered supported or unsupported.
- '{__name__="cluster_feature_set"}'
#
# owners: (@openshift/openshift-team-etcd, @smarterclayton)
#
# instance:etcd_object_counts:sum identifies two key metrics:
# - the rough size of the data stored in etcd and
# - the consistency between the etcd instances.
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="instance:etcd_object_counts:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# alerts are the key summarization of the system state. They are reported
# via telemetry to assess their value in detecting upgrade failure causes
# and also to prevent the need to gather large sets of metrics that are
# already summarized on the cluster. Reporting alerts also creates an
# incentive to improve per cluster alerting for the purposes of preventing
# upgrades from failing for end users.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="ALERTS",alertstate="firing"}'
#
# owners: (@openshift/ops)
#
# code:apiserver_request_total:rate:sum identifies average of occurences
# of each http status code over 10 minutes
# The metric will be used for SLA analysis reports.
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="code:apiserver_request_total:rate:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:capacity_cpu_cores:sum is the total number of CPU cores in the
# cluster labeled by node role and type.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster:capacity_cpu_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:capacity_memory_bytes:sum is the total bytes of memory in the
# cluster labeled by node role and type.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="cluster:capacity_memory_bytes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:cpu_usage_cores:sum is the current amount of CPU used by
# the whole cluster.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster:cpu_usage_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:memory_usage_bytes:sum is the current amount of memory in use
# across the whole cluster.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster:memory_usage_bytes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# openshift:cpu_usage_cores:sum is the current amount of CPU used by
# OpenShift components, including the control plane and host services
# (including the kernel).
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="openshift:cpu_usage_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# openshift:memory_usage_bytes:sum is the current amount of memory used by
# OpenShift components, including the control plane and host services
# (including the kernel).
- '{__name__="openshift:memory_usage_bytes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# workload:cpu_usage_cores:sum is the current amount of CPU used by cluster
# workloads, excluding infrastructure.
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="workload:cpu_usage_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# workload:memory_usage_bytes:sum is the current amount of memory used by
# cluster workloads, excluding infrastructure.
#
# consumers: (@openshift/openshift-team-olm)
- '{__name__="workload:memory_usage_bytes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:virt_platform_nodes:sum is the number of nodes reporting
# a particular virt_platform type (nodes may report multiple types).
# This metric helps identify issues specific to a virtualization
# type or bare metal.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="cluster:virt_platform_nodes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# cluster:node_instance_type_count:sum is the number of nodes of each
# instance type and role.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="cluster:node_instance_type_count:sum"}'
#
# owners: (https://github.com/kubevirt)
#
# cnv:vmi_status_running:count is the total number of VM instances running in the cluster.
- '{__name__="cnv:vmi_status_running:count"}'
#
# owners: (https://github.com/kubevirt)
#
# cluster:vmi_request_cpu_cores:sum is the total number of CPU cores requested by pods of VMIs.
- '{__name__="cluster:vmi_request_cpu_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# node_role_os_version_machine:cpu_capacity_cores:sum is the total number
# of CPU cores in the cluster labeled by master and/or infra node role, os,
# architecture, and hyperthreading state.
#
# consumers: (@openshift/openshift-team-olm, @openshift/openshift-team-cluster-manager)
- '{__name__="node_role_os_version_machine:cpu_capacity_cores:sum"}'
#
# owners: (@openshift/openshift-team-monitoring, @smarterclayton)
#
# node_role_os_version_machine:cpu_capacity_sockets:sum is the total number
# of CPU sockets in the cluster labeled by master and/or infra node role,
# os, architecture, and hyperthreading state.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="node_role_os_version_machine:cpu_capacity_sockets:sum"}'
#
# owners: (@openshift/openshift-team-olm)
#
# subscription_sync_total is the number of times an OLM operator
# Subscription has been synced, labelled by name and installed csv
- '{__name__="subscription_sync_total"}'
#
# owners: (@openshift/openshift-team-olm)
#
# olm_resolution_duration_seconds is the duration of a dependency resolution attempt.
- '{__name__="olm_resolution_duration_seconds"}'
#
# owners: (@openshift/openshift-team-olm)
#
# csv_succeeded is unique to the namespace, name, version, and phase
# labels. The metrics is always present and can be equal to 0 or 1, where
# 0 represents that the csv is not in the succeeded state while 1
# represents that the csv is in the succeeded state.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="csv_succeeded"}'
#
# owners: (@openshift/openshift-team-olm)
#
# csv_abnormal represents the reason why a csv is not in the succeeded
# state and includes the namespace, name, version, phase, reason labels.
# When a csv is updated, the previous time series associated with the csv
# will be deleted.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="csv_abnormal"}'
#
# owners: (@openshift/team-ocs-committers)
#
# cluster:kube_persistentvolumeclaim_resource_requests_storage_bytes:provisioner:sum
# gives the total amount of storage requested by PVCs from a particular
# storage provisioner in bytes. This is a generic storage metric.
- '{__name__="cluster:kube_persistentvolumeclaim_resource_requests_storage_bytes:provisioner:sum"}'
#
# owners: (@openshift/team-ocs-committers)
#
# cluster:kubelet_volume_stats_used_bytes:provisioner:sum will gives
# the total amount of storage used by PVCs from a particular storage provisioner in bytes.
- '{__name__="cluster:kubelet_volume_stats_used_bytes:provisioner:sum"}'
#
# owners: (@openshift/team-ocs-committers)
#
# ceph_cluster_total_bytes gives the size of ceph cluster in bytes. This is a specific OCS metric.
- '{__name__="ceph_cluster_total_bytes"}'
#
# owners: (@openshift/team-ocs-committers)
#
# ceph_cluster_total_used_raw_bytes is the amount of ceph cluster storage used in bytes.
- '{__name__="ceph_cluster_total_used_raw_bytes"}'
#
# owners: (@openshift/team-ocs-committers)
#
# ceph_health_status gives the ceph cluster health status
- '{__name__="ceph_health_status"}'
#
# owners: (@openshift/team-ocs-committers)
#
# odf_system_raw_capacity_total_bytes gives the size of storage cluster in bytes. This is a specific OCS metric.
- '{__name__="odf_system_raw_capacity_total_bytes"}'
#
# owners: (@openshift/team-ocs-committers)
#
# odf_system_raw_capacity_used_bytes is the amount of storage cluster storage used in bytes.
- '{__name__="odf_system_raw_capacity_used_bytes"}'
#
# owners: (@openshift/team-ocs-committers)
#
# odf_system_health_status gives the storage cluster health status
- '{__name__="odf_system_health_status"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:ceph_osd_metadata:count is the total count of osds.
- '{__name__="job:ceph_osd_metadata:count"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:kube_pv:count is the total number of Persistent Volumes created by ODF present in OCP cluster.
# This metric is deprecated in ODF 4.12, refer to job:odf_system_pvs:count instead.
- '{__name__="job:kube_pv:count"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:odf_system_pvs:count is the total number of Persistent Volumes created by ODF present in OCP cluster.
- '{__name__="job:odf_system_pvs:count"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:ceph_pools_iops:total is the total iops (reads+writes) value for all the pools in ceph cluster
- '{__name__="job:ceph_pools_iops:total"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:ceph_pools_iops:total is the total iops (reads+writes) value in bytes for all the pools in ceph cluster
- '{__name__="job:ceph_pools_iops_bytes:total"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:ceph_versions_running:count is the total count of ceph cluster versions running.
- '{__name__="job:ceph_versions_running:count"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:noobaa_total_unhealthy_buckets:sum is the total number of unhealthy noobaa buckets
- '{__name__="job:noobaa_total_unhealthy_buckets:sum"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:noobaa_bucket_count:sum is the total number of noobaa buckets.
# This metric is deprecated in ODF 4.12, refer to odf_system_bucket_count instead.
- '{__name__="job:noobaa_bucket_count:sum"}'
#
# owners: (@openshift/team-ocs-committers)
#
# job:noobaa_total_object_count:sum is the total number of noobaa objects.
# This metric is deprecated in ODF 4.12, refer to odf_system_objects_total instead.
- '{__name__="job:noobaa_total_object_count:sum"}'
#
# owners: (@openshift/team-ocs-committers)
#
# odf_system_bucket_count is the total number of buckets in ODF system
- '{__name__="odf_system_bucket_count", system_type="OCS", system_vendor="Red Hat"}'
#
# owners: (@openshift/team-ocs-committers)
#
# odf_system_objects_total is the total number of objects in ODF system
- '{__name__="odf_system_objects_total", system_type="OCS", system_vendor="Red Hat"}'
#
# owners: (@openshift/team-ocs-committers)
#
# noobaa_accounts_num gives the count of noobaa's accounts.
- '{__name__="noobaa_accounts_num"}'
#
# owners: (@openshift/team-ocs-committers)
#
# noobaa_total_usage gives the total usage of noobaa's storage in bytes.
- '{__name__="noobaa_total_usage"}'
#
# owners: (@openshift/origin-web-console-committers)
# console_url is the url of the console running on the cluster.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="console_url"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_auth_login_requests_total:sum gives the total number of login requests initiated from the web console.
#
- '{__name__="cluster:console_auth_login_requests_total:sum"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_auth_login_successes_total:sum gives the total number of successful logins initiated from the web console.
# Labels:
# * `role`, one of `kubeadmin`, `cluster-admin` or `developer`. The value is based on whether or not the logged-in user can list all namespaces.
#
- '{__name__="cluster:console_auth_login_successes_total:sum"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_auth_login_failures_total:sum gives the total number of login failures initiated from the web console.
# This might include canceled OAuth logins depending on the user OAuth provider/configuration.
# Labels:
# * `reason`, currently always `unknown`
#
- '{__name__="cluster:console_auth_login_failures_total:sum"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_auth_logout_requests_total:sum gives the total number of logout requests sent from the web console.
# Labels:
# * `reason`, currently always `unknown`
#
- '{__name__="cluster:console_auth_logout_requests_total:sum"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_usage_users:max contains the number of web console users splitten into the roles.
# Labels:
# * `role`: `kubeadmin`, `cluster-admin` or `developer`. The value is based on whether or not the user can list all namespaces.
#
- '{__name__="cluster:console_usage_users:max"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_plugins_info:max reports information about the web console plugins and their state.
# Labels:
# * `name`: `redhat`, `demo` or `other`.
# * `state`: `enabled`, `disabled` or `notfound`
#
- '{__name__="cluster:console_plugins_info:max"}'
#
# owners: (@openshift/hybrid-application-console-maintainers)
# cluster:console_customization_perspectives_info:max reports information about customized web console perspectives.
# Labels:
# * `name`, one of `admin`, `dev`, `acm` or `other`
# * `state`, one of `enabled`, `disabled`, `only-for-cluster-admins`, `only-for-developers` or `custom-permissions`
#
- '{__name__="cluster:console_customization_perspectives_info:max"}'
#
# owners: (@openshift/networking)
#
# ovnkube_master_egress_routing_via_host" informs if the OVN-K cluster's gateway mode is
# `routingViaOVN` (0), `routingViaHost` (1) or invalid (2).
- '{__name__="cluster:ovnkube_master_egress_routing_via_host:max"}'
#
# owners: (@openshift/networking)
#
# cluster:network_attachment_definition_instances:max" gives max no of instance
# in the cluster that are annotated with k8s.v1.cni.cncf.io/networks, labelled by networks.
- '{__name__="cluster:network_attachment_definition_instances:max"}'
#
# owners: (@openshift/networking)
#
# cluster:network_attachment_definition_enabled_instance_up informs (1 or 0) if the cluster has
# at least max of one instance with k8s.v1.cni.cncf.io/networks annotation, labelled by networks (any or sriov).
- '{__name__="cluster:network_attachment_definition_enabled_instance_up:max"}'
#
# owners: (@openshift/network-edge)
#
# cluster:ingress_controller_aws_nlb_active:sum informs how many NLBs are active in AWS.
# Zero would indicate ELB (legacy). This metric is only emitted on AWS.
- '{__name__="cluster:ingress_controller_aws_nlb_active:sum"}'
#
# owners: (@openshift/network-edge)
#
# cluster:route_metrics_controller_routes_per_shard:min tracks the minimum number of routes
# admitted by any of the shards.
- '{__name__="cluster:route_metrics_controller_routes_per_shard:min"}'
#
# owners: (@openshift/network-edge)
#
# cluster:route_metrics_controller_routes_per_shard:max tracks the maximum number of routes
# admitted by any of the shards.
- '{__name__="cluster:route_metrics_controller_routes_per_shard:max"}'
#
# owners: (@openshift/network-edge)
#
# cluster:route_metrics_controller_routes_per_shard:avg tracks the average value for the
# route_metrics_controller_routes_per_shard metric.
- '{__name__="cluster:route_metrics_controller_routes_per_shard:avg"}'
#
# owners: (@openshift/network-edge)
#
# cluster:route_metrics_controller_routes_per_shard:median tracks the median value for the
# route_metrics_controller_routes_per_shard metric.
- '{__name__="cluster:route_metrics_controller_routes_per_shard:median"}'
#
# owners: (@openshift/network-edge)
#
# cluster:openshift_route_info:tls_termination:sum tracks the number of routes for each tls_termination
# value. The possible values for tls_termination are edge, passthrough and reencrypt.
- '{__name__="cluster:openshift_route_info:tls_termination:sum"}'
#
# owners: (https://github.com/openshift/insights-operator/blob/master/OWNERS)
#
# insightsclient_request_send tracks the number of metrics sends.
- '{__name__="insightsclient_request_send_total"}'
#
# owners: (@openshift/openshift-team-app-migration)
#
# cam_app_workload_migrations tracks number of app workload migrations
# by current state. Tracked migration states are idle, running, completed, and failed.
- '{__name__="cam_app_workload_migrations"}'
#
# owners: (@openshift/openshift-team-master)
#
# cluster:apiserver_current_inflight_requests:sum:max_over_time:2m gives maximum number of requests in flight
# over a 2-minute window. This metric is a constant 4 time series that monitors concurrency of kube-apiserver and
# openshift-apiserver with request type which can be either 'mutating' or 'readonly'.
# We want to have an idea of how loaded our api server(s) are globally.
- '{__name__="cluster:apiserver_current_inflight_requests:sum:max_over_time:2m"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# cluster:alertmanager_integrations:max tracks the total number of active alertmanager integrations sent via telemetry from each cluster.
- '{__name__="cluster:alertmanager_integrations:max"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# cluster:telemetry_selected_series:count tracks the total number of series
# sent via telemetry from each cluster.
- '{__name__="cluster:telemetry_selected_series:count"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# openshift:prometheus_tsdb_head_series:sum tracks the total number of active series
- '{__name__="openshift:prometheus_tsdb_head_series:sum"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# openshift:prometheus_tsdb_head_samples_appended_total:sum tracks the rate of samples ingested
# by prometheusi.
- '{__name__="openshift:prometheus_tsdb_head_samples_appended_total:sum"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# monitoring:container_memory_working_set_bytes:sum tracks the memory usage of the monitoring
# stack.
- '{__name__="monitoring:container_memory_working_set_bytes:sum"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# namespace_job:scrape_series_added:topk3_sum1h tracks the top 3 namespace/job groups which created series churns in the last hour.
- '{__name__="namespace_job:scrape_series_added:topk3_sum1h"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# namespace_job:scrape_samples_post_metric_relabeling:topk3 tracks the top 3 prometheus targets which produced more samples.
- '{__name__="namespace_job:scrape_samples_post_metric_relabeling:topk3"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# monitoring:haproxy_server_http_responses_total:sum tracks the number of times users access
# monitoring routes.
- '{__name__="monitoring:haproxy_server_http_responses_total:sum"}'
#
# owners: (@openshift/openshift-team-monitoring)
#
# profile:cluster_monitoring_operator_collection_profile:max contains information about the configured
# collection profile.
# Possible label values are:
# profile: full|minimal (refer: cluster-monitoring-operator/pkg/manifests#SupportedCollectionProfiles)
- '{__name__="profile:cluster_monitoring_operator_collection_profile:max"}'
#
# owners: (https://github.com/integr8ly, @david-martin)
#
# rhmi_status reports the status of an RHMI installation.
# Possible values are bootstrap|cloud-resources|monitoring|authentication|products|solution-explorer|deletion|complete.
# This metric is used by OCM to detect when an RHMI installation is complete & ready to use i.e. rhmi_status{stage='complete'}
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="rhmi_status"}'
#
# owners: (https://github.com/integr8ly, @boomatang)
#
# rhoam_state captures the currently installed/upgrading RHOAM versions.
# Possible label values are:
# status= in progress|complete
# upgrading= true|false
# version= x.y.z
# This metric is used by cs-SRE to gain insights into RHOAM version.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="status:upgrading:version:rhoam_state:max"}'
#
# owners: (https://github.com/integr8ly, @boomatang)
#
# rhoam_critical_alerts count of RHOAM specific critical alerts on a cluster
# Possible label values are:
# state= pending|firing
# This metric is used by CS-SRE to gain insights into critical alerts on RHOAM cluster.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="state:rhoam_critical_alerts:max"}'
#
# owners: (https://github.com/integr8ly, @boomatang)
#
# rhoam_warning_alerts count of RHOAM specific warning alerts on a cluster
# Possible label values are:
# state= pending|firing
# This metric is used by CS-SRE to gain insights into warning alerts on RHOAM cluster.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="state:rhoam_warning_alerts:max"}'
#
# rhoam_7d_slo_percentile:max Current cluster 7 day percentile
# Possible labels: None
# This metric is used by CS-SRE to monitor the SLO budget across the fleet.
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="rhoam_7d_slo_percentile:max"}'
#
# rhoam_7d_slo_remaining_error_budget:max Time in milliseconds of remaining error budget
# Possible labels: None
# This metric is used byt CS-SRE to monitor remaining error budget across the fleet
#
# consumers: (@openshift/openshift-team-cluster-manager)
- '{__name__="rhoam_7d_slo_remaining_error_budget:max"}'
#
#
# owners: (openshift/openshift-team-master, @openshift/openshift-group-b)
#
# cluster_legacy_scheduler_policy reports whether the scheduler operator is
# configured with a custom Policy file. This value is a boolean 0|1
- '{__name__="cluster_legacy_scheduler_policy"}'
#
# owners: (openshift/openshift-team-master, @openshift/openshift-group-b)
#
# cluster_master_schedulable reports whether mastersSchedulable=true in
# the scheduler operator. This value is a boolean 0|1
- '{__name__="cluster_master_schedulable"}'
#
# owners: (https://github.com/redhat-developer/codeready-workspaces, @ibuziuk)
#
# The number of workspaces with a given status STARTING|STOPPED|RUNNING|STOPPING. Type 'gauge'.
- '{__name__="che_workspace_status"}'
#
# owners: (https://github.com/redhat-developer/codeready-workspaces, @ibuziuk)
#
# The number of started workspaces. Type 'counter'.
- '{__name__="che_workspace_started_total"}'
#
# owners: (https://github.com/redhat-developer/codeready-workspaces, @ibuziuk)
#
# The number of failed workspaces.
# Can be used with the 'while' label e.g. {while="STARTING"}, {while="RUNNING"}, {while="STOPPING"}.Type 'counter'.
- '{__name__="che_workspace_failure_total"}'
#
# owners: (https://github.com/redhat-developer/codeready-workspaces, @ibuziuk)
#
# The time in seconds required for the startup of all the workspaces.
- '{__name__="che_workspace_start_time_seconds_sum"}'
#
# owners: (https://github.com/redhat-developer/codeready-workspaces, @ibuziuk)
#
# The overall number of attempts for starting all the workspaces.
- '{__name__="che_workspace_start_time_seconds_count"}'
#
# owners: (@openshift/openshift-team-hive)
#
# Track current mode the cloud-credentials-operator is functioning under.
- '{__name__="cco_credentials_mode"}'
#
# owners: (@openshift/storage)
#
# Persistent Volume usage metrics: this is the number of volumes per plugin
# and per volume type (filesystem/block)
- '{__name__="cluster:kube_persistentvolume_plugin_type_counts:sum"}'
#
# owners: (https://github.com/open-cluster-management, @open-cluster-management/cluster-lifecycle-admin)
#
# acm_managed_cluster_info provides Subscription watch and other information for the managed clusters for an ACM Hub cluster.
- '{__name__="acm_managed_cluster_info"}'
#
# owners: (https://github.com/orgs/stolostron/teams/search-admin, @acm-observability-search)
#
# acm_console_page_count:sum counts the total number of visits for each page in ACM console.
- '{__name__="acm_console_page_count:sum", page=~"overview-classic|overview-fleet|search|search-details|clusters|application|governance"}'
#
# owners: (@openshift/storage)
#
# VMWare vCenter info: version of the vCenter where cluster runs
- '{__name__="cluster:vsphere_vcenter_info:sum"}'
#
# owners: (@openshift/storage)
#
# The list of ESXi host versions used as host for OCP nodes.
- '{__name__="cluster:vsphere_esxi_version_total:sum"}'
#
# owners: (@openshift/storage)
#
# The list of virtual machine HW versions used for OCP nodes.
- '{__name__="cluster:vsphere_node_hw_version_total:sum"}'
#
# owners: (@openshift/team-build-api)
#
# openshift:build_by_strategy:sum measures total number of builds on a cluster, aggregated by build strategy.
- '{__name__="openshift:build_by_strategy:sum"}'
#
# owners: (https://github.com/red-hat-data-services/odh-deployer, Open Data Hub team)
#
# This is (at a basic level) the availability of the RHODS system.
- '{__name__="rhods_aggregate_availability"}'
#
# owners: (https://github.com/red-hat-data-services/odh-deployer, Open Data Hub team)
#
# The total number of users of RHODS using each component.
- '{__name__="rhods_total_users"}'
#
# owners: (@openshift/team-etcd)
#
# 99th percentile of etcd WAL fsync duration.
- '{__name__="instance:etcd_disk_wal_fsync_duration_seconds:histogram_quantile",quantile="0.99"}'
#
# owners: (@openshift/team-etcd)
#
# Sum by instance of total db size. Used for understanding and improving defrag controller.
- '{__name__="instance:etcd_mvcc_db_total_size_in_bytes:sum"}'
#
# owners: (@openshift/team-etcd)
#
# 99th percentile of peer to peer latency.
- '{__name__="instance:etcd_network_peer_round_trip_time_seconds:histogram_quantile",quantile="0.99"}'
#
# owners: (@openshift/team-etcd)
#
# Sum by instance of total db size in use.
- '{__name__="instance:etcd_mvcc_db_total_size_in_use_in_bytes:sum"}'
#
# owners: (@openshift/team-etcd)
#
# 99th percentile of the backend commit duration.
- '{__name__="instance:etcd_disk_backend_commit_duration_seconds:histogram_quantile",quantile="0.99"}'
#
# owners: (@tracing-team)
#
# Number of jaeger instances using certain storage type.
- '{__name__="jaeger_operator_instances_storage_types"}'
#
# owners: (@tracing-team)
#
# Number of jaeger instances with certain strategy .
- '{__name__="jaeger_operator_instances_strategies"}'
#
# owners: (@tracing-team)
#
# Number of jaeger instances used certain agent strategy
- '{__name__="jaeger_operator_instances_agent_strategies"}'
#
# owners: (https://github.com/redhat-developer/application-services-metering-operator)
#
# The current amount of CPU used by Application Services products, aggregated by product name.
- '{__name__="appsvcs:cores_by_product:sum"}'
#
# owners: (https://github.com/openshift/cluster-node-tuning-operator)
#
# Number of nodes using a custom TuneD profile not shipped by the Node Tuning Operator.
- '{__name__="nto_custom_profiles:count"}'
# owners: (@openshift/team-build-api)
#
# openshift_csi_share_configmap measures amount of config maps shared by csi shared resource driver.
- '{__name__="openshift_csi_share_configmap"}'
#
# owners: (@openshift/team-build-api)
#
# openshift_csi_share_secret measures amount of secrets shared by csi shared resource driver.
- '{__name__="openshift_csi_share_secret"}'
#
# owners: (@openshift/team-build-api)
#
# openshift_csi_share_mount_failures_total measures amount of failed attempts to mount csi shared resources into the pods.
- '{__name__="openshift_csi_share_mount_failures_total"}'
#
# owners: (@openshift/team-build-api)
#
# openshift_csi_share_mount_requests_total measures total amount of attempts to mount csi shared resources into the pods.
- '{__name__="openshift_csi_share_mount_requests_total"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of storages types used across the fleet.
- '{__name__="eo_es_storage_info"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of redundancy policies used across the fleet.
- '{__name__="eo_es_redundancy_policy_info"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of namespaces deleted per policy across the fleet.
- '{__name__="eo_es_defined_delete_namespaces_total"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of clusters with misconfigured memory resources across the fleet.
- '{__name__="eo_es_misconfigured_memory_resources_info"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of data nodes per cluster.
- '{__name__="cluster:eo_es_data_nodes_total:max"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of documents created per cluster.
- '{__name__="cluster:eo_es_documents_created_total:sum"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of documents deleted per cluster.
- '{__name__="cluster:eo_es_documents_deleted_total:sum"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# Number of shards per cluster.
- '{__name__="pod:eo_es_shards_total:max"}'
#
# elasticsearch operator metrics for Telemetry
# owners: (@openshift/team-logging)
#
# es Management state used by the cluster.
- '{__name__="eo_es_cluster_management_state_info"}'
#
# owners: (@openshift/openshift-team-image-registry)
#
# imageregistry:imagestreamtags_count:sum is the total number of existent image stream tags.
- '{__name__="imageregistry:imagestreamtags_count:sum"}'
#
# owners: (@openshift/openshift-team-image-registry)
#
# imageregistry:operations_count:sum is the total number of image pushes and pulls executed in the internal registry.
- '{__name__="imageregistry:operations_count:sum"}'
#
# owners: (@openshift/team-logging)
#
# log_logging_info gives cluster-logging-operator version, managedStatus, healthStatus specific info.
- '{__name__="log_logging_info"}'
#
# owners: (@openshift/team-logging)
#
# log_collector_error_count_total gives cluster-logging-operator deployed collector's (e.g. default collector fluentd) total number of failures in standing it up part of logging pipeline.
- '{__name__="log_collector_error_count_total"}'
#
# owners: (@openshift/team-logging)
#
# log_forwarder_pipeline_info gives cluster-logging-operator deployed logging pipelines info - healthStatus and pipelineInfo as no of total logging pipelines deployed.
- '{__name__="log_forwarder_pipeline_info"}'
#
# owners: (@openshift/team-logging)
#
# log_forwarder_input_info gives cluster-logging-operator logging pipelines input types info - namely application, infra, audit type of log sources input.
- '{__name__="log_forwarder_input_info"}'
#
# owners: (@openshift/team-logging)
#
# log_forwarder_output_info gives cluster-logging-operator logging pipelines output types info - namely to which output end point logs are being directed for further pushing them to a persistent storage.
- '{__name__="log_forwarder_output_info"}'
#
# owners: (@openshift/team-logging)
#
# cluster:log_collected_bytes_total:sum gives total bytes collected by the collector and aggregated at each cluster level
- '{__name__="cluster:log_collected_bytes_total:sum"}'
#
# owners: (@openshift/team-logging)
#
# cluster:log_logged_bytes_total:sum gives total bytes logged by the containers and aggregated at each cluster level
- '{__name__="cluster:log_logged_bytes_total:sum"}'
#
# owners: (@openshift/sandboxed-containers-operator)
#
# cluster:kata_monitor_running_shim_count:sum provides the number of VM
# running with kata containers on the cluster
- '{__name__="cluster:kata_monitor_running_shim_count:sum"}'
#
# owners: (@openshift/team-hypershift-maintainers)
#
# platform:hypershift_hostedclusters:max is the total number of clusters managed by the hypershift operator by cluster platform
- '{__name__="platform:hypershift_hostedclusters:max"}'
#
# owners: (@openshift/team-hypershift-maintainers)
#
# platform:hypershift_nodepools:max is the total number of nodepools managed by the hypershift operator by cluster platform
- '{__name__="platform:hypershift_nodepools:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of unhealthy Object Bucket Claims in addon's namespace.
- '{__name__="namespace:noobaa_unhealthy_bucket_claims:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of Object Bucket Claims in addon's namespace.
- '{__name__="namespace:noobaa_buckets_claims:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of unhealthy namespace resources in addon's namespace.
- '{__name__="namespace:noobaa_unhealthy_namespace_resources:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of namespace resources in addon's namespace.
- '{__name__="namespace:noobaa_namespace_resources:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of unhealthy namespace buckets in addon's namespace.
- '{__name__="namespace:noobaa_unhealthy_namespace_buckets:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of namespace buckets in addon's namespace.
- '{__name__="namespace:noobaa_namespace_buckets:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Number of corresponding noobaa accounts in addon's namespace.
- '{__name__="namespace:noobaa_accounts:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Total usage of the noobaa system storage resources in the addon's namespace.
- '{__name__="namespace:noobaa_usage:max"}'
#
# owners: (https://github.com/red-hat-storage/mcg-osd-deployer, Data Federation team)
#
# Status of the noobaa service in the addon's namespace.
- '{__name__="namespace:noobaa_system_health_status:max"}'
#
# owners: (https://github.com/red-hat-storage/ocs-operator, OCS Operator team)
#
# ocs_advanced_feature_usage shows whether the cluster is using any of the advanced
# features, like external cluster mode or KMS/PV Encryption etc
- '{__name__="ocs_advanced_feature_usage"}'
#
# owners: (https://github.com/openshift/machine-config-operator/)
#
# os_image_url_override:sum tells whether cluster is using default OS image or has been overridden by user
- '{__name__="os_image_url_override:sum"}'
#
# owners: (https://github.com/openshift/vmware-vsphere-csi-driver-operator, @openshift/storage)
#
# cluster:vsphere_topology_tags:max shows how many vSphere topology tag categories are configured.
- '{__name__="cluster:vsphere_topology_tags:max"}'
#
# owners: (https://github.com/openshift/vmware-vsphere-csi-driver-operator, @openshift/storage)
#
# cluster:vsphere_infrastructure_failure_domains:max shows how many vSphere failure domains, vCenters, datacenters and datastores are configured in a cluster.
- '{__name__="cluster:vsphere_infrastructure_failure_domains:max"}'
#
# owners: (@openshift/openshift-team-api, @polynomial)
#
# apiserver_list_watch_request_success_total:rate:sum represents the rate of change for successful LIST and WATCH requests over a 5 minute period.
- '{__name__="apiserver_list_watch_request_success_total:rate:sum", verb=~"LIST|WATCH"}'
#
# owners: (https://github.com/stackrox/stackrox, @stackrox/eng)
#
# rhacs:telemetry:rox_central_info provides information about a Central instance of a Red Hat Advanced
# Cluster Security installation.
# Expected labels:
# - build: "release" or "internal".
# - central_id: unique ID identifying the Central instance.
# - central_version: the product's full version.
# - hosting: "cloud-service" or "self-managed".
# - install_method: "operator", "manifest" or "helm".
- '{__name__="rhacs:telemetry:rox_central_info"}'
#
# owners: (https://github.com/stackrox/stackrox, @stackrox/eng)
#
# rhacs:telemetry:rox_central_secured_clusters provides the number of clusters secured by a Central instance of a
# Red Hat Advanced Cluster Security installation.
# Expected labels:
# - central_id: unique ID identifying the Central instance.
- '{__name__="rhacs:telemetry:rox_central_secured_clusters"}'
#
# owners: (https://github.com/stackrox/stackrox, @stackrox/eng)
#
# rhacs:telemetry:rox_central_secured_nodes provides the number of nodes secured by a Central instance of a
# Red Hat Advanced Cluster Security installation.
# Expected labels:
# - central_id: unique ID identifying the Central instance.
- '{__name__="rhacs:telemetry:rox_central_secured_nodes"}'
#
# owners: (https://github.com/stackrox/stackrox, @stackrox/eng)
#
# rhacs:telemetry:rox_central_secured_vcpus provides the number of vCPUs secured by a Central instance of a
# Red Hat Advanced Cluster Security installation.
# Expected labels:
# - central_id: unique ID identifying the Central instance.
- '{__name__="rhacs:telemetry:rox_central_secured_vcpus"}'
#
# owners: (https://github.com/stackrox/stackrox, @stackrox/eng)
#
# rhacs:telemetry:rox_sensor_info provides information about a Sensor instance of a Red Hat Advanced
# Cluster Security installation.
# Expected labels:
# - build: "release" or "internal".
# - central_id: unique ID identifying the Central instance.
# - hosting: "cloud-service" or "self-managed".
# - install_method: "operator", "manifest" or "helm".
# - sensor_id: unique ID identifying the Sensor instance.
# - sensor_version: the product's full version.
- '{__name__="rhacs:telemetry:rox_sensor_info"}'
#
# owners: (https://github.com/openshift/cluster-storage-operator, @openshift/storage)
#
# cluster:volume_manager_selinux_pod_context_mismatch_total shows how many Pods have two or more containers that have each a different SELinux context. These containers will not be able to start when SELinuxMountReadWriteOncePod feature is extended to all volumes.
- '{__name__="cluster:volume_manager_selinux_pod_context_mismatch_total"}'
#
# owners: (https://github.com/openshift/cluster-storage-operator, @openshift/storage)
#
# cluster:volume_manager_selinux_volume_context_mismatch_warnings_total shows how many Pods would not be able to start when SELinuxMountReadWriteOncePod feature is extended to all volumes, because they use a single volume and have a different SELinux contexts each.
- '{__name__="cluster:volume_manager_selinux_volume_context_mismatch_warnings_total"}'
#
# owners: (https://github.com/openshift/cluster-storage-operator, @openshift/storage)
#
# cluster:volume_manager_selinux_volume_context_mismatch_errors_total shows how many Pods did not start because they use a single ReadWriteOncePod volume and have a different SELinux context.
- '{__name__="cluster:volume_manager_selinux_volume_context_mismatch_errors_total"}'
#
# owners: (https://github.com/openshift/cluster-storage-operator, @openshift/storage)
#
# cluster:volume_manager_selinux_volumes_admitted_total shows how many Pods had set SELinux context and successfuly started.
- '{__name__="cluster:volume_manager_selinux_volumes_admitted_total"}'
kind: ConfigMap
metadata:
name: telemetry-config
namespace: openshift-monitoring
annotations:
include.release.openshift.io/ibm-cloud-managed: "true"
include.release.openshift.io/self-managed-high-availability: "true"
include.release.openshift.io/single-node-developer: "true"
Cluster Samples Operator#
Cluster Samples Operator, работающий в namespace openshift, устанавливает и обновляет потоки образов DropApp Plus и шаблоны.
Во время установки Cluster Samples Operator создает для себя объект конфигурации по умолчанию, а затем формирует примеры потоков образов и шаблоны, включая шаблоны быстрого запуска.
Конфигурация Cluster Samples Operator является ресурсом всего кластера, и развертывание находится в namespace openshift-cluster-samples-operator.
Образ для Cluster Samples Operator содержит поток образов и определения шаблонов для соответствующей версии DropApp Plus. При создании или обновлении каждого образца оператор включает аннотацию, обозначающую версию DropApp Plus. Оператор использует эту аннотацию, чтобы убедиться, что каждый образец соответствует версии выпуска. Образцы, находящиеся за пределами его инвентаря, игнорируются, как и пропущенные образцы. Модификации любых образцов, которыми управляет Оператор, при изменении или удалении аннотации к версии автоматически возвращаются.
Ресурс конфигурации Cluster Samples Operator включает в себя средство завершения, которое удаляет следующее при удалении:
потоки изображений, управляемые оператором;
шаблоны, управляемые оператором;
ресурсы конфигурации, созданные оператором;
ресурсы состояния кластера.
После удаления Cluster Samples Operator воссоздает ресурс, используя конфигурацию по умолчанию.
Image Registry Operator#
Image Registry Operator управляет одноэлементным экземпляром registry DropApp Plus и всей конфигурацией registry, включая создание хранилища.
Он помогает создать и настроить локальный registry-образов, который может использоваться для хранения и распространения контейнерных образов внутри кластера.
При первоначальном запуске оператор создаст экземпляр ресурса registry-образов по умолчанию на основе конфигурации, обнаруженной в кластере. Например, какой тип облачного хранилища использовать в зависимости от поставщика облачных услуг.
Если для определения полного ресурса registry-образов недостаточно информации, будет определен неполный ресурс, и оператор обновит статус ресурса информацией о том, чего не хватает.
Image Registry Operator запускается в namespace openshift-image-registry и также управляет экземпляром registry в этом расположении. Все ресурсы конфигурации и рабочей нагрузки для registry находятся в этом namespace.
Основными функциями Image Registry Operator являются:
установка и настройка registry-образов внутри кластера DropApp Plus;
конфигурирование параметров registry-образов, таких как авторизация и доступ к registry;
масштабирование и обновление registry-образов по мере необходимости;
мониторинг и управление состоянием registry-образов;
обеспечение безопасности registry-образов, включая авторизацию и шифрование данных.
CSI#
CSI (Container Storage Interface) - это стандарт для работы с внешними хранилищами данных в DropApp Plus Plus. CSI добавляет возможность управления хранилищами данных и настройки доступа к ним в DropApp Plus через внешние компоненты, поддерживающие стандарт CSI.
Компоненты CSI представляют собой внешние компоненты, которые не являются частью ядра DropApp Plus. Они делятся на драйверы, реализующие интерфейс CSI для работы с конкретными хранилищами, и связующие компоненты (внешние контроллеры CSI), обеспечивающие взаимодействие между драйвером и API сервером DropApp Plus. И те и другие поставляются в виде образов контейнеров.
Внешние контроллеры CSI это deployment, при котором осуществляется одновременное развертывание всех связующих компонентов в рамках одного pod на инфраструктурных узлах. Каждый компонент запускается в отдельном контейнере.
Список контейнеров, входящих в deployment внешних контроллеров CSI:
csi-external-provisioner – компонент, следящий за хранилищами и управляющий динамическим выделением в них томов CSI;
csi-external-attacher – компонент, обеспечивающий подключение и отключение томов CSI к нужным pods;
csi-external-resizer – компонент, управляющий изменением размеров томов CSI;
csi-external-snapshotter, csi-snapshot-controller и сsi-snapshot-validation-webhook – компоненты, управляющие созданием и восстановлением снимков (snapshot) томов CSI;
csi-driver-volume-name – драйвер CSI (например, csi-manila-driver или csi-driver-nfs), реализующий API для работы с определенным хранилищем.
На рабочих узлах используется deployment, в состав которого входят следующие контейнеры (запускаются в рамках одного pod):
csi-node-driver-registar - компонент, управляющий регистрацией драйверов для устройств хранения данных на узлах DropApp Plus;
csi-driver-volume-name – драйвер CSI.
Перечень драйверов и операторов в DropApp Plus для работы с CSI-хранилищами:
Manila:
csi-driver-manila;
csi-driver-manila-operator;
Shared resource:
csi-driver-shared-resource;
csi-driver-shared-resource-operator;
NFS: csi-driver-nfs.
Важно
Драйверы позволяют создавать и монтировать тома хранилищ CSI (или тома CSI), а операторы создают классы хранилищ, позволяющие управлять ими. Драйверы и операторы CSI устанавливаются вместе.
Для мониторинга работоспособности драйвера в DropApp Plus можно использовать компонент csi-livenessprobe.
Подробные описания всех компонентов, драйверов и операторов представлены в разделах ниже.
Сsi-external-provisioner#
Сsi-external-provisioner - компонент управляет динамическим выделением томов CSI. Обеспечивает создание, монтирование и удаление томов CSI по запросу. Компонент предоставляет API для создания, удаления и монтирования томов и запускается в DropApp Plus в виде pod.
Рекомендуемые флаги приведены в таблице.
Таблица. Рекомендуемые флаги Сsi-external-provisioner.
Синтаксис флага |
Значение |
|---|---|
|
Путь к сокету драйвера CSI внутри pod, который контейнер |
|
Включает выбор главного процесса. Флаг обязателен, если для одного драйвера CSI запущено несколько реплик одного и того же внешнего поставщика. Активным может быть только один из них. Новый главный процесс будет выбран когда текущий процесс завершит работу или перестанет отвечать на запросы в течение примерно 15 секунд |
|
Namespace, в котором будет создан объект выбора главного процесса. Рекомендуется, чтобы этот параметр заполнялся в namespace, в котором работает |
|
Продолжительность в секундах, в течение которой допускается простой процесса. По умолчанию 15 секунд |
|
Продолжительность в секундах, в течение которой главный процесс повторяет попытку обновления лидерства, прежде чем завершить работу. По умолчанию 10 секунд |
|
Продолжительность в секундах, в течение которой клиенты |
|
Тайм-аут всех обращений к драйверу CSI. Он должен быть установлен на значение, которое подходит для большинства вызовов |
|
Начальный интервал повторных попыток при неудачной инициализации или удалении. Он удваивается с каждым сбоем, до |
|
Максимальный интервал повторных попыток при неудачной инициализации или удалении. Значение по умолчанию — 5 минут |
|
Количество одновременно запущенных |
|
Количество запросов в секунду, отправленных клиентом DropApp на API server DropApp Plus. По умолчанию 5.0 |
|
Количество запросов к серверу API DropApp Plus, превышающее число запросов в секунду, которые можно отправить в любой момент времени. По умолчанию 10 |
|
Количество одновременно запущенных потоков, обрабатывающих удаление финализатора клонирования. По умолчанию 1 |
|
Cетевой адрес TCP, который будет прослушивать HTTP-сервер (порт 8080 на локальном хосте). По умолчанию используется пустая строка, что означает, что сервер отключен |
|
HTTP-путь, по которому будут отображаться метрики Prometheus. Значение по умолчанию |
|
Ввод дополнительных метаданных PVC и PV в качестве параметров при вызове |
|
Этот параметр позволяет пометить PV как доступный только для чтения при вызове тома публикации контроллера, если режим доступа PVC. По умолчанию значение |
|
Включение профилирования |
Сsi-external-provisioner может работать в одном pod с другими внешними контроллерами CSI, такими как Сsi-external-attacher, Сsi-external-snapshotter и Сsi-external-resizer.
Сsi-external-provisioner не масштабируется с большим количеством реплик. Только один экземпляр Сsi-external-provisioner избирается в качестве главного процесса и работает. Новый главный процесс переизбирается через 15 секунд после завершения работы старого процесса.
Внешний поставщик можно использовать для создания объектов CSIStorageCapacity, которые содержат информацию о емкости хранилища, доступной через драйвер. Затем планировщик DropApp Plus использует эту информацию при выборе узлов для модулей с несвязанными томами, ожидающими первого потребителя.
Все объекты CSIStorageCapacity, созданные экземпляром Сsi-external-provisioner, имеют определенные метки:
csi.storage.k8s.io/drivernameимя драйвера CSI;csi.storage.k8s.io/managed-byСsi-external-provisioner для централизованного предоставления, Сsi-external-provisioner для распределенного предоставления.
Они создаются в namespace, указанном в namespace переменной среды.
Каждый экземпляр Сsi-external-provisioner управляет именно теми объектами с метками, которые соответствуют экземпляру.
При необходимости все объекты CSIStorageCapacity, созданные экземпляром Сsi-external-provisioner, могут иметь владельца. Это гарантирует автоматическое удаление объектов при удалении драйвера CSI. Владелец определяется переменными среды POD_NAME/NAMESPACE и параметром --capacity-ownerref-level.
Если владение отключено, администратор хранилища отвечает за удаление потерянных объектов CSIStorageCapacity, и для очистки потерянных объектов драйвера можно использовать следующую команду:
oc delete csistoragecapacities -l csi.storage.k8s.io/drivername=my-csi.example.com
Следуйте последовательности действий, чтобы настроить поддержку емкости.
Установите переменные среды
POD_NAMEиNAMESPACE:env: - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.nameПримените манифест:
kind: Deployment apiVersion: apps/v1 metadata: name: csi-provisioner spec: replicas: 3 selector: matchLabels: app: csi-provisioner template: metadata: labels: app: csi-provisioner spec: serviceAccount: csi-provisioner containers: - name: csi-provisioner image: dappregistry/1.2/csi-provisioner:v3.3.0 args: - "--csi-address=$(ADDRESS)" - "--leader-election" - "--http-endpoint=:8080" env: - name: ADDRESS value: /var/lib/csi/sockets/pluginproxy/mock.socket imagePullPolicy: "IfNotPresent" volumeMounts: - name: socket-dir mountPath: /var/lib/csi/sockets/pluginproxy/ ports: - containerPort: 8080 name: http-endpoint protocol: TCP livenessProbe: failureThreshold: 1 httpGet: path: /healthz/leader-election port: http-endpoint initialDelaySeconds: 10 timeoutSeconds: 10 periodSeconds: 20 - name: mock-driver image: quay.io/k8scsi/mock-driver:canary env: - name: CSI_ENDPOINT value: /var/lib/csi/sockets/pluginproxy/mock.socket volumeMounts: - name: socket-dir mountPath: /var/lib/csi/sockets/pluginproxy/ volumes: - name: socket-dir emptyDir:Добавьте в командную строку флаг
--enable-capacity.Добавьте
StorageCapacity: trueв информационный объект CSIDriver.Если Сsi-external-provisioner не развернут
StatefulSet, настройте при помощи флага--capacity-ownerref-levelкакими объектами будет происходить управлениеCSIStorageCapacity.Настройте частоту опроса драйвера для обнаружения измененной емкости с помощью флага
--capacity-poll-interval.Настройте количество рабочих потоков, используемых параллельно с помощью флага
--capacity-threads.Включите создание информации также для классов хранения, которые используют немедленную привязку тома с файлом
--capacity-for-immediate-binding.
Csi-external-attacher#
Сsi-external-attacher - компонент управляет присоединением томов к pods. Он обеспечивает подключение томов к указанному pod. Компонент предоставляет API для присоединения томов и запускается в DropApp Plus в виде pod.
Параметры командной строки Сsi-external-attacher представлены в таблице.
Таблица. Параметры командной строки.
Синтаксис флага |
Значение |
|---|---|
|
Путь к сокету драйвера CSI внутри модуля, который контейнер внешнего подключения будет использовать для выполнения операций CSI. По умолчанию используется |
|
Включает выборы главного процесса. Это полезно, когда для одного драйвера CSI работает несколько реплик одного и того же Сsi-external-attacher. Активным может быть только один из них |
|
Namespace, в котором запускается Сsi-external-attacher, и где будет создан объект выбора главного процесса. Рекомендуется, чтобы этот параметр заполнялся из DropApp Plus DownwardAPI |
|
Тайм-аут всех обращений к драйверу CSI. Он должен быть установлен на значение, которое подходит для большинства вызовов |
|
Количество рабочих узлов для обработки |
|
Время ожидания в случае неудачного старта. По умолчанию 1 секунда |
|
Максимальное время отсрочки действия. По умолчанию 5 минут |
|
Сетевой адрес TCP, где будет прослушиваться HTTP-сервер для диагностики, включая метрики и проверку работоспособности при выборе главного процесса ( |
|
HTTP-путь, по которому будут отображаться метрики prometheus. По умолчаию |
|
Частота повторной синхронизации подключенных томов с драйвером. По умолчанию 1 минута |
|
Количество запросов в секунду, отправленных клиентом DropApp Plus на API server DropApp Plus. По умолчанию 5.0 |
|
Количество запросов к серверу API DropApp Plus, превышающее число запросов в секунду, которые можно отправить в любой момент времени. По умолчанию 10 |
|
Тип файловой системы тома для публикации по умолчанию. По умолчанию пустая строка |
Создайте новую учетную запись службы и предоставьте ей права для запуска Сsi-external-attacher.
Разверните Сsi-external-attacher:
oc create deploy/deployment.yaml
Содержание манифеста будет следующим:
apiVersion: v1
kind: ServiceAccount
metadata:
name: csi-attacher
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: external-attacher-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["csinodes"]
verbs: ["get", "list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments"]
verbs: ["get", "list", "watch", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments/status"]
verbs: ["patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: csi-attacher-role
subjects:
- kind: ServiceAccount
name: csi-attacher
# replace with non-default namespace name
namespace: default
roleRef:
kind: ClusterRole
name: external-attacher-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
# replace with non-default namespace name
namespace: default
name: external-attacher-cfg
rules:
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["get", "watch", "list", "delete", "update", "create"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: csi-attacher-role-cfg
namespace: default
subjects:
- kind: ServiceAccount
name: csi-attacher
namespace: default
roleRef:
kind: Role
name: external-attacher-cfg
apiGroup: rbac.authorization.k8s.io
Этот файл содержит все объекты RBAC, необходимые для запуска Сsi-external-attacher.
Вышеприведенная команда - для создания развертывания в DropApp Plus. Deployment - это набор компонентов, которые запускаются вместе и выполняют определенную задачу. В данном случае, команда создает deployment, который запускает контейнер с драйвером DropApp Plus.
Сsi-external-attacher может работать в одном pod с другими внешними контроллерами CSI, такими как Csi-external-provisioner, Csi-external-snapshotter и Csi-external-resizer.
Csi-external-resizer#
Csi-external-resizer - компонент управляет изменением размеров томов. Он обеспечивает операцию изменения размеров томов CSI. Компонент предоставляет API для изменения размеров томов и запускается в DropApp Plus в виде pod.
Параметры командной строки Csi-external-resizer аналогичны приведенным в таблицах разделов Сsi-external-attacher и Сsi-external-provisioner.
Создайте новую учетную запись службы и предоставьте ей права для запуска Csi-external-resizer.
Разверните Csi-external-resizer:
oc create deploy/deployment.yaml
Содержание манифеста будет следующим:
kind: Deployment
apiVersion: apps/v1
metadata:
name: csi-resizer
spec:
replicas: 1
selector:
matchLabels:
external-resizer: mock-driver
template:
metadata:
labels:
external-resizer: mock-driver
spec:
serviceAccount: csi-resizer
containers:
- name: csi-resizer
image: dappregistry/1.2/csi-resizer:v1.6.0
args:
- "--v=5"
- "--csi-address=$(ADDRESS)"
- "--leader-election"
- "--http-endpoint=:8080"
env:
- name: ADDRESS
value: /var/lib/csi/sockets/pluginproxy/mock.socket
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 8080
name: http-endpoint
protocol: TCP
livenessProbe:
failureThreshold: 1
httpGet:
path: /healthz/leader-election
port: http-endpoint
initialDelaySeconds: 10
timeoutSeconds: 10
periodSeconds: 20
volumeMounts:
- name: socket-dir
mountPath: /var/lib/csi/sockets/pluginproxy/
- name: mock-driver
image: quay.io/k8scsi/mock-driver:canary
imagePullPolicy: "IfNotPresent"
env:
- name: CSI_ENDPOINT
value: /var/lib/csi/sockets/pluginproxy/mock.socket
volumeMounts:
- name: socket-dir
mountPath: /var/lib/csi/sockets/pluginproxy/
volumes:
- name: socket-dir
emptyDir:
Вышеприведенная команда - для создания deployment в DropApp Plus. Deployment - это объект DropApp Plus, который представляет собой развертывание приложения на нескольких узлах. В этом случае, Deployment используется для развертывания драйвера DropApp Plus на нескольких узлах кластера.
Csi-external-resizer может работать в одном pod с другими внешними контроллерами CSI, такими как Сsi-external-attacher, Сsi-external-snapshotter и/или Сsi-external-provisioner.
Csi-external-snapshotter#
Csi-external-snapshotter - компонент управляет созданием и восстановлением снимков томов. Он обеспечивает создание и восстановление снимков томов CSI. Компонент предоставляет API для создания и восстановления снимков томов и запускается в DropApp Plus в виде pod.
Csi-external-snapshotter должен запускаться один раз для каждого драйвера CSI. Развертывание одного контроллера Csi-external-snapshotter работает для всех драйверов CSI в кластере.
Параметры командной строки Csi-external-snapshotter аналогичны приведенным в таблицах разделов Сsi-external-attacher и Сsi-external-provisioner.
Создайте новую учетную запись службы и предоставьте ей права для запуска Сsi-external-snapshotter.
Разверните Сsi-external-snapshotter:
oc create deploy/deployment.yaml
Содержание манифеста будет следующим:
kind: StatefulSet
apiVersion: apps/v1
metadata:
name: csi-snapshotter
spec:
serviceName: "csi-snapshotter"
replicas: 1
selector:
matchLabels:
app: csi-snapshotter
template:
metadata:
labels:
app: csi-snapshotter
spec:
serviceAccount: csi-snapshotter
containers:
- name: csi-provisioner
image: dappregistry/csi-provisioner:v3.3.0
args:
- "--v=5"
- "--csi-address=$(ADDRESS)"
env:
- name: ADDRESS
value: /csi/csi.sock
imagePullPolicy: IfNotPresent
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-snapshotter
image: dappregistry/csi-snapshotter:v3.0.3
args:
- "--v=5"
- "--csi-address=$(ADDRESS)"
- "--leader-election=false"
env:
- name: ADDRESS
value: /csi/csi.sock
imagePullPolicy: IfNotPresent
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: hostpath
image: k8s.gcr.io/sig-storage/hostpathplugin:v1.4.0
args:
- "--drivername=hostpath.csi.k8s.io"
- "--v=5"
- "--endpoint=$(CSI_ENDPOINT)"
- "--nodeid=$(KUBE_NODE_NAME)"
env:
- name: CSI_ENDPOINT
value: unix:///csi/csi.sock
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
volumeMounts:
- name: socket-dir
mountPath: /csi
volumes:
- name: socket-dir
emptyDir:
Вышеприведенная команда создает Deployments в DropApp Plus. Deployments - это объекты DropApp Plus, которые представляют собой развертывания приложений на нескольких узлах.
Csi-snapshot-controller-operator#
Csi-snapshot-controller-operator является оператором кластера DropApp Plus. Он устанавливает и обслуживает контроллер для управления снимков томов с использованием механизма Container Storage Interface (CSI) - Csi-snapshot-controller, который отвечает за просмотр объектов VolumeSnapshot CRD и управляет жизненным циклом создания и удаления моментальных снимков томов в кластере DropApp Plus, что обеспечивает более надежную и эффективную работу с данными в кластере.
Csi-snapshot-controller#
Csi-snapshot-controller - контроллер для управления снимками томов в кластере DropApp Plus. Основное назначение – создание и удаление снимков томов, а также обеспечение их валидации.
Csi-snapshot-controller предоставляет следующие функциональности:
Создание снимков томов в DropApp Plus.
Удаление снимков томов.
Проверка и валидация снимков для предотвращения создания недопустимых объектов.
Поддержка механизма выбора лидера для обеспечения надежности и отказоустойчивости.
Рекомендуемые флаги приведены в таблице.
Таблица. Рекомендуемые флаги Csi-snapshot-controller.
Синтаксис флага |
Значение |
|---|---|
|
Включает выбор лидера. Полезно, когда запущено несколько реплик одного контроллера снимков в одном развертывании DropApp Plus. Только одна из них может быть активной (=leader). Новый лидер будет выбран, если текущий лидер выйдет из строя или станет нереагирующим в течение ~15 секунд. |
|
Namespace (namespace), в котором находится ресурс выбора лидера. По умолчанию устанавливается namespace pod, если не задано. |
|
Длительность, в секундах, в течение которой не-лидеры будут ждать, чтобы принудительно захватить лидерство. По умолчанию 15 секунд. |
|
Длительность, в секундах, в течение которой действующий лидер будет повторно обновлять свое лидерство перед отказом. По умолчанию 10 секунд. |
|
Длительность, в секундах, которую клиенты |
|
QPS для клиентов, которые общаются с API-сервером DropApp Plus. По умолчанию 5.0. |
|
Прилив для клиентов, которые общаются с API-сервером DropApp Plus. По умолчанию 10. |
|
Сетевой адрес TCP, на котором слушает HTTP-сервер для диагностики, включая метрики и проверку состояния выбора лидера. По умолчанию пустая строка, что означает отключение сервера. |
|
HTTP-путь, по которому будут выставляться метрики Prometheus. По умолчанию |
|
Количество рабочих потоков. Значение по умолчанию - 10. |
|
Начальный интервал повтора неудачного создания или удаления снимка тома. Удваивается с каждой неудачной попыткой, до максимального интервала повтора. Значение по умолчанию - 1 секунда. |
|
Максимальный интервал повтора неудачного создания или удаления снимка тома. Значение по умолчанию - 5 минут. |
|
Максимальная продолжительность повтора для обнаружения CRD снимков при запуске контроллера. Значение по умолчанию - 30 секунд. |
|
Логическое значение, которое предотвращает изменение режима тома пользователем без разрешения при создании PVC из существующего |
|
Путь к файлу конфигурации клиента DropApp Plus, который использует контроллер снимков для подключения к API-серверу DropApp Plus. Если не указано, будет использован токен по умолчанию, предоставленный DropApp Plus. Этот параметр полезен только тогда, когда контроллер снимков не запущен в виде pod DropApp Plus, например, для отладки. |
|
Внутренний интервал пересинхронизации, когда контроллер снимков переоценивает все существующие экземпляры |
|
Выводит текущую версию контроллера снимков и завершает работу. |
Сценарии использования Csi-snapshot-controller#
Проверка webhook
Выполните команды для идентификации недопустимых объектов снимков томов в системе DropApp Plus:
Выполните, чтобы получить список объектов снимков томов, которые помечены как недопустимые ресурсы:
oc get volumesnapshots --selector=snapshot.storage.kubernetes.io/invalid-snapshot-resource: ""
Могут быть некорректно созданы или иметь ошибки в своей конфигурации. После идентификации недопустимых снимков, администраторы могут принять меры для их исправления или удаления.
Выполните команду, которая аналогична предыдущей, но возвращает список содержимого снимков томов, которые также помечены как недопустимые:
oc get volumesnapshotcontents --selector=snapshot.storage.kubernetes.io/invalid-snapshot-content-resource: ""
После идентификации недопустимых объектов снимков томов, администраторы могут принять меры для их исправления или удаления.
Csi-snapshot-validation-webhook#
Csi-snapshot-validation-webhook - это оператор DropApp Plus, который позволяет управлять проверкой и валидацией снимков в кластере. Csi-snapshot-validation-webhook предоставляет возможность создавать и управлять правилами проверки и валидации снимков в кластере, что упрощает процесс развертывания и управления приложениями, которые требуют доступа к снимкам. Csi-snapshot-validation-webhook также поддерживает различные типы проверки и валидации, включая проверку целостности данных и соответствие политикам безопасности, что делает его гибким и масштабируемым решением для управления снимками в кластере.
Csi-snapshot-validation-webhook предоставляет следующие функциональности:
Обеспечивает более строгую проверку параметров объектов снимков томов перед их созданием.
Маркирует недопустимые объекты снимков томов для их быстрого выявления.
Рекомендуемые флаги приведены в таблице.
Таблица. Рекомендуемые флаги Csi-snapshot-validation-webhook.
Синтаксис флага |
Значение |
|---|---|
|
Файл, содержащий сертификат x509 для HTTPS. (Сертификат CA, если есть, конкатенируется после сертификата сервера). Обязателен. |
|
Файл, содержащий закрытый ключ x509, соответствующий |
|
Безопасный порт, на котором webhook прослушивает запросы (по умолчанию 443). |
|
Путь к конфигурации клиента DropApp Plus, используемой webhook для подключения к API-серверу DropApp Plus. Если опущено, будет использован токен по умолчанию, предоставленный DropApp Plus. Этот параметр полезен только в том случае, если контроллер снимков не запускается в виде pod DropApp Plus, например, для отладки. |
|
Булево значение, которое предотвращает изменение режима тома при создании PVC из существующего |
Csi-node-driver-registrar#
Csi-node-driver-registrar - компонент управляет регистрацией драйверов для устройств хранения данных на узлах DropApp Plus. Обеспечивает регистрацию драйвера на каждом узле, который будет использоваться для работы с хранилищами данных. Компонент предоставляет API для регистрации драйверов и запускается в DropApp Plus в виде DaemonSet.
Примечание
Все приведенные компоненты csi-node-driver-registrar используются вместе для управления томами и хранилищами данных в DropApp Plus с помощью CSI стандарта.
Csi-node-driver-registrar представляет собой дополнительный контейнер, который извлекает информацию о драйвере (используя NodeGetInfo) из конечной точки CSI и регистрирует ее в kubelet на этом узле с помощью механизма регистрации подключаемого модуля kubelet.
Kubelet напрямую выполняет вызовы CSI NodeGetInfo, NodeStageVolume и NodePublishVolume для драйверов CSI. Он использует механизм регистрации подключаемого модуля kubelet для обнаружения сокета домена unix для взаимодействия с драйвером CSI. Следовательно, все драйверы CSI должны использовать этот sidecar-контейнер для регистрации в kubelet.
Таблица. Параметры командной строки.
Синтаксис флага |
Значение |
|---|---|
|
Путь к сокету драйвера внутри модуля, который контейнер Csi-node-driver-registrar будет использовать для выполнения операций CSI (например, |
|
Путь к сокету драйвера CSI на хост-узле, который kubelet будет использовать для выполнения операций CSI (например, |
Csi-node-driver-registrar не взаимодействует с API DropApp Plus, поэтому правила RBAC не нужны.
Csi-node-driver-registrar должен иметь возможность монтировать тома hostPath и иметь права доступа к файлам.
Получите доступ к сокету драйвера CSI (путь:
/var/lib/kubelet/plugins/<drivername.example.com>/).Получите доступ к регистрационному сокету (путь:
/var/lib/kubelet/plugins_registry/). Убедитесь, что плагин для регистрации доступен на хосте, на котором запущен DropApp Plus. Обычно это можно проверить, выполнив командуoc get pods -n kube-system. Если виден pod с именемetcd-<имя_хоста>, то плагин доступен.Проверьте работоспособность csi-node-driver-registrar:
containers: - name: csi-driver-registrar image: dappregistry/sig-storage/csi-node-driver-registrar:v2.5.1 args: - "--v=5" - "--csi-address=/csi/csi.sock" - "--kubelet-registration-path=/var/lib/kubelet/plugins/<drivername.example.com>/csi.sock" livenessProbe: exec: command: - /csi-node-driver-registrar - --kubelet-registration-path=/var/lib/kubelet/plugins/<drivername.example.com>/csi.sock - --mode=kubelet-registration-probe initialDelaySeconds: 30 timeoutSeconds: 15Выше приведена конфигурация контейнера для DropApp Plus, который используется для регистрации DropApp Plus CSI Driver. В контейнере используется образ Docker, он содержит программу csi-node-driver-registrar, которая регистрирует DropApp Plus CSI драйвер в кластере.
Контейнер используется для запуска программы для регистрации драйвера DropApp Plus. Драйвер – это компонент, который позволяет узлам DropApp Plus подключаться к блочным устройствам, таким как диски или сетевые хранилища. В данном случае, контейнер используется для регистрации драйвера DropApp Plus в системе.
Флаг
--mode=kubelet-registration-probeмодифицирует csi-node-driver-registrar в зонд, проверяющий, прошла ли регистрация подключаемого модуля kubelet успешно. Значение--kubelet-registration-pathдолжно быть таким же, как задано в аргументах контейнера,--csi-addressв этом режиме не требуется.Если
--http-endpointустановлено, то csi-node-driver-registrar предоставляет конечную точку проверки работоспособности по указанному адресу и пути/healthz, указывая, существует ли сокет регистрации.Примените спецификацию:
containers:
- name: csi-driver-registrar
image: /sig-storage/csi-node-driver-registrar:v2.5.1
args:
- "--csi-address=/csi/csi.sock"
- "--kubelet-registration-path=/var/lib/kubelet/plugins/<drivername.example.com>/csi.sock"
# Адрес не являтся существующим и приведен в качестве примера.
- "--health-port=9809"
volumeMounts:
- name: plugin-dir
mountPath: /csi
- name: registration-dir
mountPath: /registration
ports:
- containerPort: 9809
name: healthz
livenessProbe:
httpGet:
path: /healthz
port: healthz
initialDelaySeconds: 5
timeoutSeconds: 5
volumes:
- name: registration-dir
hostPath:
path: /var/lib/kubelet/plugins_registry/
type: Directory
- name: plugin-dir
hostPath:
path: /var/lib/kubelet/plugins/<drivername.example.com>/
# Адрес не являтся существующим и приведен в качестве примера.
type: DirectoryOrCreate
Выше представлен контейнер для DropApp Plus, используемый для регистрации DropApp Plus Controller Manager в кластере DropApp Plus. В конфигурации контейнера используется образ Docker с программой csi-node-driver-registrar. Контейнер также содержит два тома - /csi и /registration, которые используются для хранения данных регистрации DropApp Plus Controller. Порт 9809 используется для проверки работоспособности контейнера. Liveness Probe проверяет работоспособность контейнера каждые 5 секунд.
Csi-driver-manila#
Csi-driver-manila – это драйвер, который позволяет DropApp Plus выделять постоянные тома для службы общей файловой системы OpenStack Manila.
Примечание
OpenStack Manila предоставляет общее или распределенное файловое хранилище. Служба общей файловой системы обеспечивает общее управление, обмен файлами, общие снимки (snapshots) и настройку конфигурации.
Для создания томов CSI, которые подключаются к ресурсам Manila, в DropApp Plus необходимо установить csi-driver-manila и csi-driver-manila-operator в любой кластер OpenStack, где включена служба Manila.
Для динамического создания тома Manila CSI выполните следующие действия:
Создайте YAML-манифест с описанием объекта
PersistentVolumeClaim, представленным ниже:apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc-manila spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi storageClassName: csi-manila-goldгде
ReadWriteManyозначает, что том CSI будет смонтирован для чтения и записи несколькими узлами кластера.csi-manila-gold– имя класса серверной части хранилища. Классы хранилища Manila предоставляются оператором и имеют префиксcsi-manila-.Сохраните файл с описанием объекта хранилища с именем, например,
pvc-manila.yaml.Создайте объект, выполнив команду:
oc create -f pvc-manila.yamlpvc-manila.yaml– имя файла, созданного на предыдущем шаге. Замените его при необходимости.Проверьте, что том создан и готов к использованию с помощью команды:
oc get pvc pvc-manilaгде
pvc-manila– имя объекта хранилища в YAML-манифесте из шага 1.
Том Manila CSI готов к использованию при настройке pod.
Csi-driver-manila-operator#
Csi-driver-manila-operator – это оператор для развертывания csi-driver-manila в DropApp PLus.
Csi-driver-manila-operator управляет экземпляром объекта ClusterCSIDriver с именем manila.csi.openstack.org и параллельно запускает следующие контроллеры:
manilaController. Обращается к OpenStack API и проверяет предоставлена ли Manila:Если служба Manila найдена:
manilaControllerSetзапускаетcsidriverset.Controller, который устанавливает csi-driver-manila.nfsControllerзапускаетcsidriverset.Controller, который устанавливает csi-driver-nfs (csi-driver-nfs описан в разделе «CSI» -> «Csi-driver-nfs»).Создается
StorageClassдля каждого типа общего ресурса, который указан Manila. По умолчанию раз в минуту осуществляется синхронизация. При добавлении нового типа общего ресурса ему будет созданStorageClass. Если для ранее созданногоStorageClassбыл не найден соответствующий ему тип общего ресурса, то удаленияStorageClassне происходит. Отсутствие типа общего ресурса может быть вызвано временной ошибкой при изменениях в настройке OpenStack или Manila.
Если служба Manila не найдена, то
manilaControllerотмечает экземпляр объектаClusterCSIDriverфлагомManilaControllerDisabled: True. Драйверы CSI в этом случае продолжат работу, но pod сможет размонтировать их тома CSI.
secretSyncController. Синхронизирует secret (секрет), который предоставляет cloud-credentials-operator, с secret (секретом), который используется драйверами CSI.
Развертывание и управление csi-driver-manila-operator осуществляется с помощью оператора cluster-storage-operator (оператор кластерного хранилища – подробнее в разделе «Сценарии администрирования» -> «Cluster-storage-operator»).
Настройка осуществляется с использованием YAML-манифестов:
Создайте namespace для csi-driver-manila в cluster-storage-operator:
apiVersion: v1 kind: Namespace metadata: name: openshift-manila-csi-driver annotations: include.release.openshift.io/self-managed-high-availability: "true" openshift.io/node-selector: "" workload.openshift.io/allowed: "management" labels: pod-security.kubernetes.io/enforce: privileged pod-security.kubernetes.io/audit: privileged pod-security.kubernetes.io/warn: privilegedСоздайте
ServiceAccountдля csi-driver-manila-operator:apiVersion: v1 kind: ServiceAccount metadata: name: manila-csi-driver-operator namespace: openshift-cluster-csi-driversСоздайте роль
manila-csi-driver-operator-role:manila_role.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: manila-csi-driver-operator-role namespace: openshift-cluster-csi-drivers rules: - apiGroups: - '' resources: - pods - services - endpoints - persistentvolumeclaims - events - configmaps - secrets verbs: - get - list - watch - create - update - patch - delete - apiGroups: - '' resources: - namespaces verbs: - get - apiGroups: - apps resources: - deployments - daemonsets - replicasets - statefulsets verbs: - get - list - watch - create - update - patch - deleteСоздайте
RoleBindingдля связи роли:apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: manila-csi-driver-operator-rolebinding namespace: openshift-cluster-csi-drivers roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: manila-csi-driver-operator-role subjects: - kind: ServiceAccount name: manila-csi-driver-operator namespace: openshift-cluster-csi-driversСоздайте
ClusterRole:manila_clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: manila-csi-driver-operator-clusterrole rules: - apiGroups: - security.openshift.io resourceNames: - privileged resources: - securitycontextconstraints verbs: - use # The operator needs these config maps: # - read/write openshift-manila-csi-driver/cloud-provider-config # - read-only kube-system/extension-apiserver-authentication # - read/write manila-csi-driver-operator-lock - apiGroups: - '' resources: - configmaps verbs: - watch - list - get - create - delete - patch - update - apiGroups: - rbac.authorization.k8s.io resources: - clusterroles - clusterrolebindings - roles - rolebindings verbs: - watch - list - get - create - delete - patch - update - apiGroups: - '' resources: - serviceaccounts verbs: - get - list - watch - create - update - patch - delete - apiGroups: - apiextensions.k8s.io resources: - customresourcedefinitions verbs: - get - list - create - watch - delete - apiGroups: - coordination.k8s.io resources: - leases verbs: - get - list - watch - create - update - patch - delete - apiGroups: - '' resources: - nodes verbs: - get - list - watch - create - update - patch - delete - apiGroups: - '' resources: - secrets verbs: - get - list - watch # For CA certificate sync - create - patch - update - apiGroups: - '' resources: - namespaces verbs: - get - list - watch - create - patch - delete - update - apiGroups: - '' resources: - persistentvolumes verbs: - create - delete - list - get - watch - update - patch - apiGroups: - '' resources: - persistentvolumeclaims verbs: - get - list - watch - update - apiGroups: - '' resources: - persistentvolumeclaims/status verbs: - patch - update - apiGroups: - apps resources: - deployments - daemonsets - replicasets - statefulsets verbs: - get - list - watch - create - update - patch - delete - apiGroups: - storage.k8s.io resources: - volumeattachments verbs: - get - list - watch - update - delete - create - patch - apiGroups: - snapshot.storage.k8s.io resources: - volumesnapshotcontents/status verbs: - update - patch - apiGroups: - storage.k8s.io resources: - storageclasses - csinodes verbs: - create - get - list - watch - update - delete - apiGroups: - '*' resources: - events verbs: - get - patch - create - list - watch - update - delete - apiGroups: - snapshot.storage.k8s.io resources: - volumesnapshotclasses verbs: - get - list - watch - create - update - delete - apiGroups: - snapshot.storage.k8s.io resources: - volumesnapshotcontents verbs: - create - get - list - watch - update - delete - patch - apiGroups: - snapshot.storage.k8s.io resources: - volumesnapshots verbs: - get - list - watch - update - patch - apiGroups: - snapshot.storage.k8s.io resources: - volumesnapshots/status verbs: - patch - apiGroups: - storage.k8s.io resources: - csidrivers verbs: - create - get - list - watch - update - delete - apiGroups: - csi.openshift.io resources: - '*' verbs: - get - list - watch - create - update - patch - delete - apiGroups: - config.openshift.io resources: - infrastructures - proxies - apiservers verbs: - get - list - watch - apiGroups: - operator.openshift.io resources: - 'clustercsidrivers' - 'clustercsidrivers/status' verbs: - get - list - watch - create - update - patch - delete # Allow kube-rbac-proxy to create TokenReview to be able to authenticate Prometheus when collecting metrics - apiGroups: - "authentication.k8s.io" resources: - "tokenreviews" verbs: - "create" # Allow the operator to create ServiceMonitor in the driver namespace - apiGroups: - monitoring.coreos.com resources: - servicemonitors verbs: - get - create - update - patch - delete # Allow the operator to create Service in the driver namespace - apiGroups: - '' resources: - services verbs: - get - list - watch - create - update - patch - delete # Grant these permissions in the driver namespace to Prometheus - apiGroups: - '' resources: - pods - endpoints verbs: - 'get' - 'list' - 'watch' - apiGroups: - policy resources: - poddisruptionbudgets verbs: - get - list - watch - create - update - patch - deleteСоздайте
ClusterRoleBindingдля связиClusterRole:apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: manila-csi-driver-operator-clusterrolebinding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: manila-csi-driver-operator-clusterrole subjects: - kind: ServiceAccount name: manila-csi-driver-operator namespace: openshift-cluster-csi-driversНастройте
Deployment:manila_deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: manila-csi-driver-operator namespace: openshift-cluster-csi-drivers annotations: config.openshift.io/inject-proxy: manila-csi-driver-operator spec: replicas: 1 selector: matchLabels: name: manila-csi-driver-operator strategy: {} template: metadata: annotations: target.workload.openshift.io/management: '{"effect": "PreferredDuringScheduling"}' labels: name: manila-csi-driver-operator spec: containers: - args: - start - -v=${LOG_LEVEL} env: - name: DRIVER_IMAGE value: ${DRIVER_IMAGE} - name: NFS_DRIVER_IMAGE value: ${NFS_DRIVER_IMAGE} - name: PROVISIONER_IMAGE value: ${PROVISIONER_IMAGE} - name: ATTACHER_IMAGE value: ${ATTACHER_IMAGE} - name: RESIZER_IMAGE value: ${RESIZER_IMAGE} - name: SNAPSHOTTER_IMAGE value: ${SNAPSHOTTER_IMAGE} - name: NODE_DRIVER_REGISTRAR_IMAGE value: ${NODE_DRIVER_REGISTRAR_IMAGE} - name: LIVENESS_PROBE_IMAGE value: ${LIVENESS_PROBE_IMAGE} - name: KUBE_RBAC_PROXY_IMAGE value: ${KUBE_RBAC_PROXY_IMAGE} - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name image: ${OPERATOR_IMAGE} imagePullPolicy: IfNotPresent name: manila-csi-driver-operator volumeMounts: - name: cacert mountPath: /etc/openstack-ca/ - name: cloud-credentials # Create /etc/openstack/clouds.yaml mountPath: /etc/openstack/ resources: requests: memory: 50Mi cpu: 10m priorityClassName: system-cluster-critical serviceAccountName: manila-csi-driver-operator nodeSelector: node-role.kubernetes.io/master: "" tolerations: - key: CriticalAddonsOnly operator: Exists - key: node-role.kubernetes.io/master operator: Exists effect: "NoSchedule" volumes: - name: cacert # Extract ca-bundle.pem to /usr/share/pki/ca-trust-source if present. # Let the pod start when the ConfigMap does not exist or the certificate # is not preset there. The certificate file will be created once the # ConfigMap is created / the cerificate is added to it. configMap: name: cloud-provider-config items: - key: ca-bundle.pem path: ca-bundle.pem optional: true - name: cloud-credentials secret: secretName: manila-cloud-credentials optional: false securityContext: allowPrivilegeEscalation: false capabilities.drop: ALL privileged: falseСоздайте
ClusterCSIDriver:apiVersion: operator.openshift.io/v1 kind: ClusterCSIDriver metadata: name: manila.csi.openstack.org spec: managementState: Managed logLevel: Normal operatorLogLevel: Normal
Csi-driver-shared-resource#
Csi-driver-shared-resource предназначен для создания встроенных временных томов, содержащих данные из объектов Secret или ConfigMap. Обеспечивает безопасное использование содержимого этих объектов в различных namespaces в кластере DropApp Plus.
Csi-driver-shared-resource предоставляет следующие функциональности:
Позволяет администраторам кластера создавать встроенные временные тома, содержащие данные из объектов
SecretилиConfigMap.Обеспечивает безопасное использование данных из объектов
SecretилиConfigMapв различных namespaces в кластере.Поддерживает два типа общих ресурсов:
SharedSecretдляSecretобъектов иSharedConfigMapдляConfigMapобъектов.
Рекомендуемые флаги приведены в таблице.
Таблица. Рекомендуемые флаги Csi-driver-shared-resource.
Синтаксис флага |
Значение |
|---|---|
|
Применить конфигурацию из файла. |
|
Получить список |
|
Узнать, какие |
|
Создать связку роли с аккаунтом. |
Сценарии использования Csi-driver-shared-resource#
Создание SharedSecret для Secret
Выполните команду:
$ oc apply -f - <<EOF
apiVersion: sharedresource.openshift.io/v1alpha1
kind: SharedSecret
metadata:
name: my-share
spec:
secretRef:
name: <name of secret>
namespace: <namespace of secret>
EOF
Использование SharedSecret в pod
Создайте роли:
oc apply -f - <<EOF apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: shared-resource-my-share namespace: my-namespace rules: - apiGroups: - sharedresource.openshift.io resources: - sharedsecrets resourceNames: - my-share verbs: - use EOFВыполните привязку к роли:
oc create rolebinding shared-resource-my-share --role=shared-resource-my-share --serviceaccount=my-namespace:builderСоздайте pod с использованием SharedSecret:
oc apply -f - <<EOF kind: Pod apiVersion: v1 metadata: name: my-app namespace: my-namespace spec: serviceAccountName: default # containers omitted …. Follow standard use of ‘volumeMounts’ for referencing your shared resource volume volumes: - name: my-csi-volume csi: readOnly: true driver: csi.sharedresource.openshift.io volumeAttributes: sharedSecret: my-share EOF
Создание SharedConfigMap для ConfigMap
Выполните команду:
oc apply -f - <<EOF apiVersion: sharedresource.openshift.io/v1alpha1 kind: SharedConfigMap metadata: name: my-share spec: configMapRef: name: <name of configmap> namespace: <namespace of configmap> EOF
Использование SharedConfigMap в pod
Выполните шаги аналогично пункту Использование SharedSecret в pod.
Csi-driver-shared-resource-operator#
Csi-driver-shared-resource-operator предназначен для управления общими ресурсами с использованием CSI (Container Storage Interface) драйвера. Этот инструмент позволяет создавать встроенные временные тома, содержащие данные из объектов Secret или ConfigMap. Позволяет безопасно использовать содержимое этих объектов в различных namespaces кластера.
Csi-driver-shared-resource-operator предоставляет следующие функциональности:
Создание
SharedSecretиSharedConfigMapобъектов дляSecretиConfigMapсоответственно, с возможностью общего использования этих данных в различных namespaces кластера.Предоставление RBAC (Role-Based Access Control) разрешений для использования
SharedSecretиSharedConfigMapобъектов.Поддержка использования CSI Volume, который ссылается на
SharedSecretиSharedConfigMapобъекты в подах.
Csi-driver-nfs#
Csi-driver-nfs - инструмент, предназначенный для интеграции NFS (Network File System) хранилища DropApp Plus.
Csi-driver-nfs позволяет DropApp Plus использовать удаленные NFS-хранилища в качестве персистентного хранилища для контейнеров. Полезен в случаях, когда требуется доступ к общим данным или персистентным томам между различными контейнерами и/или pods в DropApp Plus кластере. Это может понадобиться для развертывания приложений, которые требуют постоянного доступа к файлам или для обмена данными между pods.
Csi-driver-nfs предоставляет следующие функциональности:
Подключение и монтирование NFS-хранилища к pods DropApp Plus.
Создание и управление персистентными томами, основанными на NFS.
Поддержка динамического выделения хранилища (Dynamic Provisioning) на основе NFS.
Рекомендуемые флаги приведены в таблице.
Таблица. Рекомендуемые флаги Csi-driver-nfs.
Синтаксис флага |
Значение |
|---|---|
|
Создание ресурсов CSI драйвера для NFS. |
|
Создание Persistent Volume Claim (PVC) для использования с NFS. |
|
Создание pod, который использует PVC для монтирования NFS-хранилища. |
Флаги могут варьироваться в зависимости от конфигурации драйвера и DropApp Plus кластера, но обычно они включают параметры конфигурации NFS-сервера, такие как IP-адрес, путь к экспорту и т.д.
Сценарии использования Csi-driver-nfs#
Предварительные условия:
Настройте сервер NFS в кластере DropApp Plus;
Установите Csi-driver-nfs.
Использование Storage Class (класс хранилищ):
Создайте класс хранилища, указав параметры для подключения к серверу NFS:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-csi provisioner: nfs.csi.k8s.io parameters: server: nfs-server.default.svc.cluster.local share: / # csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume # csi.storage.k8s.io/provisioner-secret-name: "mount-options" # csi.storage.k8s.io/provisioner-secret-namespace: "default" reclaimPolicy: Delete volumeBindingMode: Immediate mountOptions: - nfsvers=4.1Создайте Persistent Volume Claim (PVC) с использованием нового класса хранилища:
oc create -f https://<repoexample.ru>/kubernetes-csi/csi-driver-nfs/master/deploy/example/pvc-nfs-csi-dynamic.yaml # Укажите актуальный путь до локального репозитория
Csi-livenessprobe#
Csi-livenessprobe – вспомогательный контейнер (sidecar), отслеживающий работоспособность драйвера CSI. Он сообщает об этом DropApp Plus через механизм проверки работоспособности, который использует kubelet, предоставляя конечную точку HTTP/healthz, перехватывающую livenessProbe kubelet.
Для проверки работоспособности драйвера CSI сsi-livenessprobe используется вызов метода Probe().
Рекомендуемые флаги приведены в таблице:
Синтаксис флага |
Значение |
|---|---|
|
Флаг, с помощью которого указывается путь к сокету драйвера CSI ( |
|
Флаг, с помощью которого указывается TCP-порт ( |
|
Флаг, с помощью которого указывается продолжительность одного вызова |
|
Флаг, с помощью которого указывается TCP-порт, на котором будет прослушиваться конечная точка метрик Prometheus (например, |
|
Флаг, с помощью которого указывается HTTP-путь, по которому будут доступны метрики Prometheus (по умолчанию |
|
Флаг, с помощью которого указывается TCP-адрес сети, по которому расположен HTTP-сервер, где содержится информация о проверках работоспособности драйвера CSI и го показателях. По умолчанию используется пустая строка, которая означает, что сервер отключен |
Также поддерживаются все флаги журналирования инструментов glog и klog (например, -v <log-level>, где <log-level> – уровень журнала).
Запуск контейнера осуществляется с использованием манифеста hostpath-with-livenessprobe.yaml:
kind: Pod
spec:
containers:
# Container with CSI driver
- name: hostpath-driver
image: quay.io/k8scsi/hostpathplugin:v0.2.0
# Defining port which will be used to GET plugin health status
# 9808 is default, but can be changed.
ports:
- containerPort: 9808
name: healthz
protocol: TCP
# The probe
livenessProbe:
failureThreshold: 5
httpGet:
path: /healthz
port: healthz
initialDelaySeconds: 10
timeoutSeconds: 3
periodSeconds: 2
volumeMounts:
- mountPath: /csi
name: socket-dir
# ...
# The liveness probe sidecar container
- name: liveness-probe
imagePullPolicy: Always
image: registry.k8s.io/sig-storage/livenessprobe:v2.7.0
args:
- --csi-address=/csi/csi.sock
volumeMounts:
- mountPath: /csi
name: socket-dir
# ...
Сsi-livenessprobe предоставляет только конечную точку HTTP и не содержит раздела livenessProbe. livenessProbe установлен в контейнере с драйвером CSI, что обеспечивает перезапуск контейнера драйвера в случае сбоя проверки.
Prometheus#
Prometheus — система мониторинга и оповещений, которая хранит и обрабатывает метрики в виде данных временных рядов. Информация о метриках хранится с отметкой времени, на которой она была записана, наряду с необязательными парами ключ-значение, называемыми метками. Для работы с метриками Prometheus использует язык запросов PromQL.
Система Prometheus состоит из множества компонентов, часть из которых необязательны.
Компоненты Prometheus, входящие в состав DropApp Plus:
Основной сервер Prometheus — собирает и хранит данные временных рядов;
Prometheus Operator — обеспечивает встроенное развертывание и управление Prometheus и связанными с ним компонентами мониторинга;
Alertmanager — обрабатывает и группирует оповещения, а также направляет их получателю по выбранному каналу связи;
Node Exporter — собирает системные показатели с устройства, на котором установлен Prometheus;
Config Reloader — отслеживает изменения и перезагружает конфигурационный файл Prometheus в случае необходимости.
Grafana#
Grafana — программная система визуализации данных, позволяющая представить в графическом виде временные ряды и текстовые данные.
Grafanа имеет множество встроенных настраиваемых панелей, которые можно использовать сразу после установки. Дополнительные панели распространяются в формате плагинов.
Также Grafanа поддерживает различные источники данных, такие как:
Prometheus;
Graphite;
MySQL;
InfluxDB;
Elasticsearch и другие.
Установка Grafana#
Создайте новый namespace
grafana-operator, используя веб-интерфейс или введя в терминал следующую команду:oc create namespace grafana-operatorУстановите Grafana Operator любым из следующих способов.
Примечание
Grafana Operator - оператор, позволяющий управлять экземплярами Grafana и его ресурсами. С помощью данного оператора можно устанавливать локальные экземпляры Grafana и источники данных. Автоматически синхронизирует настраиваемые и фактические ресурсы в экземпляре Grafana.
Способ 1:
Найдите в списке доступных программ Grafana Operator.
Нажмите Continue после ознакомления с текстом предупреждения.
Нажмите Install и Subscribe, чтобы принять значения конфигурации по умолчанию и установить Grafana Operator в namespace
grafana-operator.Дождитесь окончания установки.
Способ 2:
Установите Grafana Operator с помощью команды:
cat << EOF | oc create -f -Пример содержимого файла:
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: grafana-operator- namespace: grafana-operator spec: targetNamespaces: - grafana-operator --- apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: generateName: grafana-operator- namespace: grafana-operator spec: channel: v4 name: grafana-operator installPlanApproval: Automatic source: community-operators sourceNamespace: openshift-marketplace EOFДождитесь окончания установки. Статус установки можно проверить командой:
oc -n grafana-operator rollout status \ deployment grafana-operator-controller-managerСпособ 3:
Примечание
В данном сценарии используется менеджер пакетов Helm. Данный инструмент не входит в состав продукта и требует дополнительной установки.
Установите Grafana Operator с помощью команды:
helm upgrade -i grafana-operator oci://{url} --version {version}Установите Grafana любым из следующих способов.
Способ 1:
С помощью веб-интерфейса зайдите в Grafana Operator.
Нажмите кнопку Create Instance, чтобы создать новый экземпляр Grafana.
Заполните YAML-файл экземпляра Grafana. Пример создаваемого файла:
apiVersion: integreatly.org/v1alpha1 kind: Grafana metadata: name: grafana namespace: grafana-operator spec: ingress: enabled: true dataStorage: accessModes: - ReadWriteOnce size: 10Gi class: ocs-storagecluster-cephfs config: log: mode: "console" level: "warn" security: admin_user: "root" admin_password: "secret" auth: disable_login_form: False disable_signout_menu: True auth.anonymous: enabled: True dashboardLabelSelector: - matchExpressions: - {key: app, operator: In, values: [grafana]}Дополнительно. Добавьте в YAML-файл Grafana Operator следующую конфигурацию, позволяющую Grafana сканировать панель мониторинга во всем кластере:
Config: env: - name: "DASHBOARD_NAMESPACES_ALL" value: "true"
Способ 2:
Примечание
В данном сценарии используется менеджер пакетов Helm. Данный инструмент не входит в состав продукта и требует дополнительной установки.
Установите Grafana Operator с помощью команды:
helm install -n grafana-operator grafana \ ./grafana/grafana-{version}.tgz \ -f ./grafana/values.yaml \ --set ingress.hostname=grafana.${CLUSTER_HOST}где:
./grafana/values.yaml- файл с конфигурацией по умолчанию;grafana.${CLUSTER_HOST}- хост, по которому будет доступна Grafana.
Проверьте, что pod Grafana успешно запущен:
oc get pods -n grafana-operatorПример вывода команды:
NAME READY STATUS RESTARTS AGE grafana-deployment-8667d4d4fc-xxxxx 1/1 Running 0 40s
Ironic hardware inventory recorder#
Ironic hardware inventory recorder предоставляет контейнер, который содержит ironic python agent, запущенный в режиме, в котором данные самоанализа периодически передаются в подключенный экземпляр ironic inspector.
Ironic Python Agent - это агент для управления и развертывания узлов, управляемых Ironic. Запускаемый на ramdisk (оперативная память), агент предоставляет REST API для подготовки серверов и взаимодействия с аппаратным обеспечением.
Ironic inspector - это вспомогательный сервис для самоанализа, определения свойств оборудования для узла, управляемого Ironic. Предназначен для автономного мониторинга и управления функциями, встроенными непосредственно в аппаратное обеспечение серверных платформ. Позволяет автоматически собирать информацию о конфигурации аппаратного обеспечения.
Запуск Ironic hardware inventory recorder#
Запустите ironic hardware inventory recorder из образа hyperkube:v4.8:
docker run -it --rm --pull=always image_location/hyperkube:v4.8 hyperkube
где, image_location - расположение образа.
Ironic Python Agent собирает различную информацию об оборудовании и отправляет ее в Ironic Inspector при проверке.
Информация об оборудовании, которую можно получить (точный формат данных зависит от включенных настраиваемых сборщиков):
CPU - информация о процессоре: имя модели, частота, количество, архитектура, сокет;
memory - информация об оперативной памяти: общий размер в байтах, физически установленный объем памяти в МБ;
bmc_address - IPv4-адрес BMC узла (IPMI v4-адрес);
bmc_v6address - IPv6-адрес BMC узла (IPMI v6-адрес);
disks - список дисковых устройств с полями: название, модель, размер (в байтах), скорость вращения, wwn, серийный номер, uuid, поставщик, полный путь к диску, в виде
/dev/disk/by-path/<rest-of-path>;interfaces - список сетевых интерфейсов с полями: имя, MAC-адрес, ipv4 адрес, lldp, поставщик, необязательно, имя сетевой карты, заданное BIOS, максимальная поддерживаемая скорость;
system_vendor - информация о поставщике системы из SMBIOS, наименование, серийный номер и производитель, а также структура встроенного ПО с полями: поставщик, версия и дата сборки;
boot - информация о boot с полями: режим загрузки, используемый для текущей загрузки - BIOS или UEFI и интерфейс, используемый для загрузки PXE, если таковой имеется;
hostname - имя хоста для системы.
Ironic Agent#
Ironic Agent - инструментарий для использования Ironic Python Agent (IPA) поверх Platform V SberLinux OS Core. Ironic Agent отличается от стандартных образов IPA, которые создаются с помощью diskimage-builder из дистрибутива операционной системы.
diskimage-builder - это инструмент для автоматического создания настроенных образов операционной системы для использования в облачных и других средах.
Подготовка образа для развертывания - Redfish virtual media#
Bare Metal Service (BMC) - сервис ironic-компонентов, обеспечивающих поддержку управления физическими машинами и их предоставление.
Bare Metal Service получает загрузочный образ тем или иным способом, затем «вставляет» его в виртуальный диск node, как если бы он был записан на физический CD/DVD. Затем node может загрузиться с этого виртуального диска в операционную систему, находящуюся на образе.
Основное преимущество функции загрузки с виртуального носителя в том, что полностью исключается потенциально ненадежная фаза передачи образа TFTP в пакете протоколов PXE.
Типы оборудования, основанные на redfish, полностью поддерживают загрузку, развертывание и удаление пользовательских образов через виртуальный носитель. Ironic создает загрузочные ISO-образы для режимов загрузки UEFI или BIOS в момент развертывания node из образов ядра и ramdisk, связанных с node ironic.
Загрузите подходящий образ, например:
sudo curl -Lo /httpboot/fcos-ipa.iso \
{url}
Добавьте в него конфигурацию Ignition. Это может выглядеть следующим образом:
./ignition/build.py \
--host {ip-1} \
--registry {ip-2} \
--insecure-registry > ~/ironic-agent.ign
Затем используйте coreos-installer, чтобы внедрить его:
sudo ~/.cargo/bin/coreos-installer iso ignition embed \
-i ~/ironic-agent.ign -f /httpboot/fcos-ipa.iso
Настройте nodes для использования интерфейса загрузки Redfish virtual media:
baremetal node update <node> \
--driver redfish \
--boot-interface redfish-virtual-media \
--reset-interfaces
Обновите node для использования полученного образа:
baremetal node set <node> \
--driver-info redfish_deploy_iso=file:///httpboot/fcos-ipa.iso
Подготовка контейнера#
Создайте контейнер из необходимого репозитория и поместите его в реестр:
podman build -t ironic-agent -f Dockerfile.ocp
podman push ironic-agent localhost:5000/ironic-agent --tls-verify=false
Это подготовит контейнер к проверке, очистке и развертыванию nodes.
Ironic static ip downloader#
Ironic static ip downloader отвечает за загрузку и подготовку образов компонентов операционной системы компьютера к развертыванию.
Запустите ironic static ip downloader из образа hyperkube:v4.8:
docker run -it --rm --pull=always image_location/hyperkube:v4.8 hyperkube
Ironic static ip manager#
Ironic static ip manager - контейнер для установки IP-адреса для предоставляемого Pod. Ironic static ip manager использует базу данных для хранения информации о назначенных IP-адресах. Он также поддерживает автоматическое назначение IP-адресов при создании новых Pods.
Запустите ironic static ip manager из образа hyperkube:v4.8:
docker run -it --rm --pull=always image_location/hyperkube:v4.8 hyperkube
Thanos#
Thanos - это набор компонентов, объединенный в высокодоступную систему хранения/извлечения метрик с неограниченным объемом хранилища, которую можно бесшовно интегрировать поверх существующих развертываний Prometheus.
Thanos использует формат Prometheus 2.0 для экономичного хранения истории метрик в любом хранилище объектов при сохранении высокой скорости ответов на запросы.
Thanos предоставляет:
общий просмотр метрик с помощью запросов;
неограниченное хранение метрик;
дедупликацию и сегментированность блоков;
высокую доступность компонентов, включая Prometheus.
Особенности Thanos:
общий просмотр запросов на всех подключенных серверах Prometheus;
дедупликация и объединение метрик, собранных из высокодоступных пар Prometheus;
полная и бесшовная интеграция с существующими установками Prometheus;
любое хранилище объектов в качестве единственной опциональной зависимости;
дискретизация (downsampling) истории данных для существенного ускорения ответов на запросы;
межкластерная федерация - инструмент для координации конфигурации нескольких кластеров;
отказоустойчивая маршрутизация запросов;
простой gRPC Store API (система удаленного вызова процедур) для унифицированного доступа ко всем данным метрик - доступ ко всем метрикам, расположенным на разных серверах Prometheus, с помощью одного API-запроса;
простые точки интеграции для поставщиков пользовательских метрик.
Thanos состоит из набора компонентов, каждый из которых выполняет определенную роль:
Sidecar - считывает данные Prometheus для запроса и загружает их в облачное хранилище.
Store Gateway - обслуживает метрики внутри облачных хранилищ.
Compactor - уплотняет данные в облачных хранилищах.
Receiver - работает с данными из удаленного журнала предварительной записи Prometheus, предоставляет их и/или загружает в облачное хранилище.
Ruler/Rule - оценивает правила записи и оповещения относительно данных в Thanos для отображения и/или загрузки.
Querier/Query - реализует Prometheus v1 API для агрегирования данных из базовых компонентов - выступает в качестве источника метрик.
Query Frontend - реализует Prometheus v1 API для передачи его в Querier, кешируя ответ и разбивая его на запросы в день.
Sidecar#
Thanos интегрируется с существующими серверами Prometheus в виде компонента Sidecar, который выполняется на той же машине или в том же модуле, что и сервер Prometheus.
Sidecar создает резервные копии данных Prometheus в хранилище объектов и предоставляет другим компонентам Thanos доступ к метрикам Prometheus через gRPC API.
Sidecar реализует Thanos API хранилища поверх Prometheus API - это позволяет Querier рассматривать серверы Prometheus как еще один источник данных временных рядов, не обращаясь напрямую к его API.
Sidecar загружает блоки TSDB (базы данных временных рядов) в хранилище объектов, создаваемые Prometheus каждые 2 часа. Это позволяет серверам Prometheus работать с относительно низким уровнем хранения, в то время как истории данных и метрик становятся надежными и доступными для запросов через хранилище объектов.
Примечание
При настройках Prometheus без сохранения, в случае сбоя хранилища, к которому привязан Prometheus, могут быть потеряны данные метрик с временной выборкой до 2 часов (интервал загрузки данных Sidecar). Для Prometheus следует использовать надежное хранилище данных.
Sidecar может просматривать правила и конфигурацию Prometheus, распаковывать и заменять переменные окружения, если это необходимо, и запрашивать Prometheus для их перезапуска.
Конфигурация обновлений#
Thanos может отслеживать и обновлять изменения в конфигурации Prometheus, если включен --web.enable-lifecycle.
Отслеживание изменений в каталоге настраивается с помощью флага --reloader.rule-dir=DIR_NAME.
Sidecar может просматривать конфигурационный файл --reloader.config-file=CONFIG_FILE, менять найденные там переменные окружения в формате $(VARIABLE) и создавать сгенерированную конфигурацию в файле --reloader.config-envsubst-file=OUT_CONFIG_FILE.
Пример базового развертывания#
Пример конфигурации обновлений:
prometheus \
--storage.tsdb.max-block-duration=2h \
--storage.tsdb.min-block-duration=2h \
--web.enable-lifecycle
Пример базового развертывания:
thanos sidecar \
--tsdb.path "/path/to/prometheus/data/dir" \
--prometheus.url "http://localhost:9090" \
--objstore.config-file "bucket.yml"
Пример содержимого bucket.yml:
type: GCS
config:
bucket: ""
service_account: ""
prefix: ""
Настройка HTTP-клиента Prometheus#
Настройте HTTP-клиент Prometheus для Sidecar с помощью YAML, или передав содержимое YAML непосредственно флагом --prometheus.http-client, или указав путь к файлу YAML флагом --prometheus.http-client-file.
Формат конфигурации следующий:
basic_auth:
username: ""
password: ""
password_file: ""
bearer_token: ""
bearer_token_file: ""
proxy_url: ""
tls_config:
ca_file: ""
cert_file: ""
key_file: ""
server_name: ""
insecure_skip_verify: false
transport_config:
max_idle_conns: 0
max_idle_conns_per_host: 0
idle_conn_timeout: 0
response_header_timeout: 0
expect_continue_timeout: 0
max_conns_per_host: 0
disable_compression: false
tls_handshake_timeout: 0
Store Gateway#
Store Gateway позволяет хранить меньше данных на локальном хранилище и дает возможность уменьшить время хранения метрик Prometheus и повторно запрашивать все данные и метрики облачного хранилища.
Store Gateway действует как API-шлюз и не требует значительных объемов локального дискового пространства. Он присоединяется к кластеру Thanos при запуске и объявляет данные, к которым он может получить доступ. Store Gateway хранит небольшой объем информации обо всех удаленных блоках на локальном диске и синхронизирует ее с облачным хранилищем.
Пример базового развертывания#
thanos store \
--data-dir "/local/state/data/dir" \
--objstore.config-file "bucket.yml"
Пример содержимого bucket.yml:
type: GCS
config:
bucket: ""
service_account: ""
prefix: ""
Как правило, для каждого блока базы данных временных рядов, находящегося в хранилище объектов, требуется в среднем 6 МБ локального дискового пространства, но для блоков высокой мощности с большим набором меток оно может достигать 30 МБ и более.
Это справедливо для предварительно вычисленного индекса, который включает в себя символы и записи смещений (указывающие на количество байтов или битов, на которое нужно сдвинуть или сместить определенные данные), а также метаданные JSON.
Разделение по времени#
По умолчанию Store Gateway просматривает все данные в хранилище объектов и возвращает их на основе запроса временного диапазона.
Флаги Thanos --min-time, --max-time позволяют сегментировать хранилище Thanos на основе постоянного времени или продолжительности по отношению к текущему времени.
Например, установка: --min-time=-6w & --max-time=-2w заставит Store Gateway возвращать метрики, попадающие в диапазон от now - 6 weeks до now - 2 weeks (недель).
Постоянное время необходимо задать в формате RFC3339. Например, --min-time=2018-01-01T00:00:00Z, --max-time=2019-01-01T23:59:59Z.
Store Gateway может не получать новые блоки немедленно, поскольку разделение по времени частично выполняется в задании асинхронной синхронизации блоков, которое по умолчанию выполняется каждые 3 минуты.
Для повышения устойчивости к сбоям используйте перекрывающиеся временные диапазоны Sidecar и других компонентов Thanos
Querier обрабатывает перекрывающиеся временные ряды путем их объединения.
Кеш индекса#
Store Gateway поддерживает кеш индекса для ускорения размещения и поиска рядов из блоков TSDB. Поддерживаются три типа кешей:
in-memory(по умолчанию);memcached;redis.
Кеш индекса In-memory#
Кеш индекса In-memory включен по умолчанию, и его максимальный размер можно настроить с помощью флага --index-cache-size.
Кеш индекса In-memory также можно настроить с помощью --index-cache.config-file ссылкой на файл конфигурации или добавить в файл --index-cache.config конфигурацию yaml:
type: IN-MEMORY
config:
max_size: 0
max_item_size: 0
enabled_items: []
ttl: 0s
Кеш индекса Memcached#
Memcached - система кеширования объектов с распределенной памятью, предназначенная для ускорения работы динамических приложений за счет снижения нагрузки на базу данных.
Кеш индекса memcached позволяет использовать Memcached в качестве серверной части кеша. Этот тип кеша настраивается с помощью --index-cache.config-file ссылкой на файл конфигурации или добавлением в файл --index-cache.config конфигурации yaml:
type: MEMCACHED
config:
addresses: []
timeout: 0s
max_idle_connections: 0
max_async_concurrency: 0
max_async_buffer_size: 0
max_get_multi_concurrency: 0
max_item_size: 0
max_get_multi_batch_size: 0
dns_provider_update_interval: 0s
auto_discovery: false
enabled_items: []
ttl: 0s
Кеш индекса Redis#
Redis - хранилище данных в оперативной памяти используемое в качестве кеша, векторной базы данных, базы данных документов, механизма потоковой передачи и посредника сообщений.
Кеш индекса redis позволяет использовать Redis в качестве серверной части кэша. Этот тип кеша настраивается с помощью --index-cache.config-file ссылкой на файл конфигурации или добавлением в файл --index-cache.config конфигурации yaml:
type: REDIS
config:
addr: ""
username: ""
password: ""
db: 0
dial_timeout: 5s
read_timeout: 3s
write_timeout: 3s
max_get_multi_concurrency: 100
get_multi_batch_size: 100
max_set_multi_concurrency: 100
set_multi_batch_size: 100
tls_enabled: false
tls_config:
ca_file: ""
cert_file: ""
key_file: ""
server_name: ""
insecure_skip_verify: false
cache_size: 0
master_name: ""
max_async_buffer_size: 10000
max_async_concurrency: 20
enabled_items: []
ttl: 0s
Caching Bucket#
Store Gateway поддерживает Caching Bucket с chunks и кешированием метаданных для ускорения загрузки блоков TSDB. Чтобы настроить кэширование, используйте --store.caching-bucket.config=<yaml content> или --store.caching-bucket.config-file=<file.yaml>.
Chunks является частью структуры данных Prometheus TSDB, блоком, содержащим до 120 выборок для одного временного ряда.
in-memory, memcached, redis кеши поддерживаются серверной частью:
type: MEMCACHED # Case-insensitive
config:
addresses: []
timeout: 500ms
max_idle_connections: 100
max_async_concurrency: 20
max_async_buffer_size: 10000
max_item_size: 1MiB
max_get_multi_concurrency: 100
max_get_multi_batch_size: 0
dns_provider_update_interval: 10s
chunk_subrange_size: 16000
max_chunks_get_range_requests: 3
chunk_object_attrs_ttl: 24h
chunk_subrange_ttl: 24h
blocks_iter_ttl: 5m
metafile_exists_ttl: 2h
metafile_doesnt_exist_ttl: 15m
metafile_content_ttl: 24h
metafile_max_size: 1MiB
Пример YAML манифеста с использованием оператора Prometheus Store Gateway:
Пример кода Thanos Store Gateway
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/component: object-store-gateway
app.kubernetes.io/instance: thanos-store
app.kubernetes.io/name: thanos-store
app.kubernetes.io/version: v0.31.0
name: thanos-store
namespace: thanos
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: object-store-gateway
app.kubernetes.io/instance: thanos-store
app.kubernetes.io/name: thanos-store
serviceName: thanos-store
template:
metadata:
labels:
app.kubernetes.io/component: object-store-gateway
app.kubernetes.io/instance: thanos-store
app.kubernetes.io/name: thanos-store
app.kubernetes.io/version: v0.31.0
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- thanos-store
- key: app.kubernetes.io/instance
operator: In
values:
- thanos-store
namespaces:
- thanos
topologyKey: kubernetes.io/hostname
weight: 100
containers:
- args:
- store
- --log.level=info
- --log.format=logfmt
- --data-dir=/var/thanos/store
- --grpc-address=0.0.0.0:10901
- --http-address=0.0.0.0:10902
- --objstore.config=$(OBJSTORE_CONFIG)
- --ignore-deletion-marks-delay=24h
env:
- name: OBJSTORE_CONFIG
valueFrom:
secretKeyRef:
key: thanos.yaml
name: thanos-objectstorage
- name: HOST_IP_ADDRESS
valueFrom:
fieldRef:
fieldPath: status.hostIP
image: quay.io/thanos/thanos:v0.31.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 8
httpGet:
path: /-/healthy
port: 10902
scheme: HTTP
periodSeconds: 30
timeoutSeconds: 1
name: thanos-store
ports:
- containerPort: 10901
name: grpc
- containerPort: 10902
name: http
readinessProbe:
failureThreshold: 20
httpGet:
path: /-/ready
port: 10902
scheme: HTTP
periodSeconds: 5
resources: {}
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65534
seccompProfile:
type: RuntimeDefault
terminationMessagePolicy: FallbackToLogsOnError
volumeMounts:
- mountPath: /var/thanos/store
name: data
readOnly: false
nodeSelector:
kubernetes.io/os: linux
securityContext:
fsGroup: 65534
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65534
seccompProfile:
type: RuntimeDefault
serviceAccountName: thanos-store
terminationGracePeriodSeconds: 120
volumes: []
volumeClaimTemplates:
- metadata:
labels:
app.kubernetes.io/component: object-store-gateway
app.kubernetes.io/instance: thanos-store
app.kubernetes.io/name: thanos-store
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
securityContext:
allowPrivilegeEscalation: false
capabilities.drop: ALL
privileged: false
Compactor#
Compactor сканирует хранилище объектов с резервными копиями метрик, созданными Sidecar, и выполняет сжатие старых данных для повышения эффективности запросов.
Compactor понижает дискретизацию данных для ускорения ответов на запросы.
Пример базового развертывания#
thanos compact --data-dir /tmp/thanos-compact --objstore.config-file=bucket.yml
Пример содержимого bucket.yml:
type: GCS
config:
bucket: example-bucket
Уплотнение. Группы уплотнения / Потоки блоков#
Compactor отвечает за уплотнение нескольких блоков в один – ряд блоков (серия). Серия может существовать дольше, чем отдельный блок (2 часа).
Группа уплотнения / Поток блоков – набор блоков из одного источника. Потоки различаются по external_labels (внешним меткам). Блоки с одинаковыми метками считаются созданными одним и тем же источником. Внешние метки добавляются экземпляром Prometheus, который создал блок.
Уникальные метки – набор меток в экземпляре Prometheus отличающийся от других наборов меток, чтобы компилятор мог группировать блоки по экземпляру Prometheus.
Постоянные метки – один экземпляр Prometheus сохраняет те же метки при перезапуске, так что средство сжатия будет продолжать сжимать блоки из экземпляра, даже если экземпляр Prometheus выйдет из строя на некоторое время.
Примечание
Prometheus нигде не хранит внешние метки, внешние метки добавляются только во время загрузки в раздел ThanosMeta meta.json каждого блока.
Внимание
Только один экземпляр Compactor может работать с одним потоком блоков в одном хранилище объектов.
Вертикальное уплотнение#
Thanos и Prometheus поддерживают вертикальное уплотнение - процесс объединения нескольких потоков блоков в один.
В Prometheus вертикальное уплотнение запускается скрытым флагом, помещая дополнительные блоки TSDB в локальный каталог данных Prometheus. Дополнительные блоки могут накладываться на существующие. Когда Prometheus обнаруживает эту ситуацию, он выполняет вертикальное уплотнение, которое уплотняет перекрывающиеся блоки в один.
В Thanos вертикальное сжатие работает аналогично, но в большем масштабе и с использованием внешних меток для группировки, как описано в разделе Уплотнение. Группы уплотнения / Потоки блоков.
Включение вертикального уплотнения#
Включите вертикальное уплотнение, используя скрытый флаг --compact.enable-vertical-compaction.
Используйте --deduplication.replica-label=LABEL, чтобы установить одну или несколько меток, которые будут игнорироваться во время загрузки блока.
Например, если при таком наборе потоков блоков:
external_labels: {cluster="eu1", replica="1", receive="true", environment="production"}
external_labels: {cluster="eu1", replica="2", receive="true", environment="production"}
external_labels: {cluster="us1", replica="1", receive="true", environment="production"}
external_labels: {cluster="us1", replica="1", receive="true", environment="staging"}
установить --deduplication.replica-label="replica", Compactor примет набор потоков блока как:
external_labels: {cluster="eu1", receive="true", environment="production"} # из 2х потоков получится один
external_labels: {cluster="us1", receive="true", environment="production"}
external_labels: {cluster="us1", receive="true", environment="staging"}
При следующем сжатии блоки нескольких потоков будут объединены в один.
Чтобы настроить/установить другой алгоритм дедупликации, используйте флаг --deduplication.func=FUNC. Значением по умолчанию является исходная дедупликация one-to-one.
Принудительное сохранение данных#
Thanos по умолчанию хранит данные неограниченное время – рекомендуемый способ запуска Thanos.
Для настройки периодичности сохранений используйте флаги --retention.resolution-raw --retention.resolution-5m и --retention.resolution-1h. Их отсутствие или значение 0s означает, что данные не сохраняются.
Дискретизация Thanos#
Compactor берет необработанный блок и создает новый с дискретными, уменьшенными фрагментами. Уменьшенный фрагмент принимает на уровне хранилища форму AggrChunk:
message AggrChunk {
int64 min_time = 1;
int64 max_time = 2;
Chunk raw = 3;
Chunk count = 4;
Chunk sum = 5;
Chunk min = 6;
Chunk max = 7;
Chunk counter = 8;
}
Это означает, что для каждой серии собираются различные агрегации с заданным интервалом: 5 мин. или 1 час (в зависимости от разрешения). Это позволяет сохранять точность при запросах с большой продолжительностью, не извлекая слишком много выборок.
Разрешение – это интервал между точками сохранения данных:
raw- равный интервал очистки в момент получения данных;5 minutes- равный 5 минутам;1 hour- равный 1 часу.
Понижающая дискретизация Compactor выполняется за два прохода:
все
rawметрики, срок действия которых превышает 40 часов, понижаются с разрешением 5 м;все
5 minutesметрики, срок действия которых превышает 10 дней, понижаются с разрешением 1 час.
Цель понижающей дискретизации – предоставить возможность получать быстрые результаты для запросов диапазона с большими временными интервалами, такими как месяцы или годы.
Пример YAML манифеста:
Пример кода Thanos Compactor
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/component: database-compactor
app.kubernetes.io/instance: thanos-compact
app.kubernetes.io/name: thanos-compact
app.kubernetes.io/version: v0.30.2
name: thanos-compact
namespace: thanos
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: database-compactor
app.kubernetes.io/instance: thanos-compact
app.kubernetes.io/name: thanos-compact
serviceName: thanos-compact
template:
metadata:
labels:
app.kubernetes.io/component: database-compactor
app.kubernetes.io/instance: thanos-compact
app.kubernetes.io/name: thanos-compact
app.kubernetes.io/version: v0.30.2
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- thanos-compact
- key: app.kubernetes.io/instance
operator: In
values:
- thanos-compact
namespaces:
- thanos
topologyKey: kubernetes.io/hostname
weight: 100
containers:
- args:
- compact
- --wait
- --log.level=info
- --log.format=logfmt
- --objstore.config=$(OBJSTORE_CONFIG)
- --data-dir=/var/thanos/compact
- --debug.accept-malformed-index
- --retention.resolution-raw=0d
- --retention.resolution-5m=0d
- --retention.resolution-1h=0d
- --delete-delay=48h
- --compact.concurrency=1
- --downsample.concurrency=1
- --downsampling.disable
- --deduplication.replica-label=prometheus_replica
- --deduplication.replica-label=rule_replica
- |-
--tracing.config="config":
"sampler_param": 2
"sampler_type": "ratelimiting"
"service_name": "thanos-compact"
"type": "JAEGER"
env:
- name: OBJSTORE_CONFIG
valueFrom:
secretKeyRef:
key: thanos.yaml
name: thanos-objectstorage
- name: HOST_IP_ADDRESS
valueFrom:
fieldRef:
fieldPath: status.hostIP
image: quay.io/thanos/thanos:v0.30.2
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 4
httpGet:
path: /-/healthy
port: 10902
scheme: HTTP
periodSeconds: 30
name: thanos-compact
ports:
- containerPort: 10902
name: http
readinessProbe:
failureThreshold: 20
httpGet:
path: /-/ready
port: 10902
scheme: HTTP
periodSeconds: 5
resources:
limits:
cpu: 0.42
memory: 420Mi
requests:
cpu: 0.123
memory: 123Mi
terminationMessagePolicy: FallbackToLogsOnError
volumeMounts:
- mountPath: /var/thanos/compact
name: data
readOnly: false
nodeSelector:
kubernetes.io/os: linux
securityContext:
fsGroup: 65534
runAsGroup: 65532
runAsNonRoot: true
runAsUser: 65534
seccompProfile:
type: RuntimeDefault
serviceAccountName: thanos-compact
terminationGracePeriodSeconds: 120
volumes: []
volumeClaimTemplates:
- metadata:
labels:
app.kubernetes.io/component: database-compactor
app.kubernetes.io/instance: thanos-compact
app.kubernetes.io/name: thanos-compact
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
securityContext:
allowPrivilegeEscalation: false
capabilities.drop: ALL
privileged: false
Receiver/Receive#
Receiver реализует Prometheus Remote Write API.
Экземпляры Prometheus настроены на непрерывную запись в него метрик. Receiver загружает блоки TSDB в хранилище объектов каждые 2 часа. Receiver предоставляет доступ к StoreAPI, чтобы Queriers мог запрашивать полученные метрики в режиме реального времени.
Receiver поддерживает получение Экземпляров – ссылок на данные за пределами набора метрик, с помощью удаленной записи. По умолчанию экземпляры автоматически удаляются, поскольку для параметра --tsdb.max-exemplars установлено значение 0. Чтобы включить хранение экземпляров, установите флаг --tsdb.max-exemplars с ненулевым значением. Он предоставляет ExemplarsAPI, чтобы Queriers мог запрашивать сохраненные экземпляры.
Алгоритмы распределения последовательностей#
Receiver поддерживает два алгоритма распределения временных рядов по принимающим узлам, которые могут быть установлены с помощью флага receive.hashrings-algorithm.
Ketama (рекомендуется) Алгоритм Ketama - это согласованная схема хеширования, которая обеспечивает стабильное масштабирование Receivers.
Hashmod (не рекомендуется) Алгоритм Hashmod использует функцию hashmod для всех меток, чтобы решить, какой получатель отвечает за данный временной ряд. Его использование не рекомендуется, поскольку добавление новых Receiver узлов приводит к оттоку серий и скачкам использования памяти.
Receiver поддерживает получение статистики TSDB по отдельным клиентам.
Управление жизненным циклом клиента#
Клиенты в Receiver создаются динамически и не нуждаются в предварительной подготовке. При обнаружении нового значения в HTTP-заголовке клиента Receiver подготовит и начнет управлять независимой базой данных TSD для этого клиента. Блоки TSDB, отправляемые на S3, будут содержать уникальную метку tenant_id, которую можно использовать для сжатия блоков независимо для каждого клиента.
Receiver автоматически выведет клиента из эксплуатации, как только новые образцы не будут видны дольше, чем заданный для получателя период хранения --tsdb.retention. Процесс вывода клиента из эксплуатации включает в себя сброс всех образцов в памяти для этого клиента на диск, отправку всех неотправленных блоков в S3 и удаление базы данных TSD клиента из файловой системы. Если клиент получает новые образцы после вывода из эксплуатации, для клиента будет создана новая база данных TSDB.
Примеры#
Пример базового развертывания:
thanos receive \
--tsdb.path "/path/to/receive/data/dir" \
--grpc-address 0.0.0.0:10907 \
--http-address 0.0.0.0:10909 \
--receive.replication-factor 1 \
--label "receive_replica=\"0\"" \
--label "receive_cluster=\"eu1\"" \
--receive.local-endpoint 127.0.0.1:10907 \
--receive.hashrings-file ./data/hashring.json \
--remote-write.address 0.0.0.0:10908 \
--objstore.config-file "bucket.yml"
Пример конфигурации remote_write Prometheus:
remote_write:
- url: http://<thanos-receive-container-ip>:10908/api/v1/receive
где <thanos-receive-containter-ip> - это IP-адрес, доступный серверу Prometheus.
Пример содержимого bucket.yml:
type: GCS
config:
bucket: ""
service_account: ""
prefix: ""
Пример содержимого hashring.json:
[
{
"endpoints": [
"127.0.0.1:10907",
"127.0.0.1:11907",
"127.0.0.1:12907"
]
}
]
При такой конфигурации любой Receiver просматривает удаленную запись на <ip>10908/api/v1/receive и перенаправляет на исправление в хешировании, если это необходимо для клиента и репликации.
Ruler/Rule#
В случае, если Prometheus, работающий с Thanos Sidecar, не имеет достаточного объема памяти, или необходимы оповещения или правила записи, требующие глобального просмотра, у Thanos есть компонент Ruler, который выполняет оценку правил и предупреждений поверх Querier.
Ruler оценивает правила записи и оповещения Prometheus в соответствии с выбранным API запросов с помощью повторного запроса --query. Если передается более одного запроса, выполняется циклическая балансировка.
По умолчанию результаты оценки правил записываются обратно на диск в формате хранилища Prometheus 2.0. Nodes Ruler одновременно участвуют в системе как Nodes хранилища исходных данных, что означает, что они предоставляют доступ к StoreAPI и загружают сгенерированные блоки TSDB в хранилище объектов.
Данные каждого узла Ruler могут быть помечены в соответствии со схемой маркировки кластеров. Пары с высокой доступностью могут запускаться параллельно и должны отличаться назначенной меткой реплики, как и обычные серверы Prometheus.
thanos rule \
--data-dir "/path/to/data" \
--eval-interval "30s" \
--rule-file "/path/to/rules/*.rules.yaml" \
--alert.query-url "http://0.0.0.0:9090" \ # Показывает, на какой URL ссылаться в пользовательском интерфейсе.
--alertmanagers.url "http://alert.thanos.io" \
--query "query.example.org" \
--query "query2.example.org" \
--objstore.config-file "bucket.yml" \
--label 'monitor_cluster="cluster1"' \
--label 'replica="A"'
Настройка Ruler#
Файлы Ruler используют YAML, синтаксис файла правил следующий:
groups:
[ - <rule_group> ]
Простой пример файла правил:
groups:
- name: example
rules:
- record: job:http_inprogress_requests:sum
expr: sum(http_inprogress_requests) by (job)
<rule_group>
# Имя группы. Должно быть уникальным в пределах файла.
name: <string>
# Как часто оцениваются правила в группе.
[ interval: <duration> | default = global.evaluation_interval ]
rules:
[ - <rule> ... ]
Thanos поддерживает два типа правил, которые могут быть настроены и затем оцениваться через регулярные интервалы времени: правила записи и правила оповещения.
Правила записи#
Правила записи позволяют предварительно вычислять часто необходимые или требующие больших вычислительных затрат выражения и сохранять их результат в виде нового набора временных рядов. Запрос предварительно вычисленного результата в таком случае часто будет намного быстрее, чем выполнение исходного выражения каждый раз, когда это необходимо. Это особенно полезно для панелей мониторинга, которым необходимо повторно запрашивать одно и то же выражение при каждом обновлении.
Правила записи и оповещения существуют в группе правил. Правила внутри группы выполняются последовательно через регулярные промежутки времени.
Синтаксис правил записи следующий:
# Имя временного ряда для вывода. Должно быть допустимым именем метрики.
record: <string>
# Выражение PromQL для вычисления. В каждом цикле вычисления
# производятся в реальном времени, и результат записывается как новый набор
# временных рядов с именем метрик, указанным в 'record'.
expr: <string>
# Метки для добавления или перезаписи перед сохранением результата.
labels:
[ <labelname>: <labelvalue> ]
Правила оповещения#
Синтаксис правил оповещения следующий:
# Имя предупреждения. Должно быть допустимым именем метрики.
alert: <string>
# Выражение PromQL для вычисления. В каждом цикле вычисления
# производятся в реальном времени, и все результирующие временные ряды становятся
# ожидающими/запускающими предупреждениями.
expr: <string>
# Оповещения считаются срабатывающими, если они были возвращены в течение указанного времени.
# Оповещения, которые долго не срабатывали, считаются ожидающими.
[ for: <duration> | default = 0s ]
# Как долго будет продолжать срабатывать предупреждение после того, как условие,
# которое его вызвало будет сброшено.
[ keep_firing_for: <duration> | default = 0s ]
# Метки для добавления или перезаписи для каждого предупреждения.
labels:
[ <labelname>: <tmpl_string> ]
# Примечания для добавления к каждому предупреждению.
annotations:
[ <labelname>: <tmpl_string> ]
Частичный ответ#
Подробнее про частичный ответ в разделе Querier/Query.
Rule позволяет указывать группы правил с дополнительными полями, которые управляют стратегией частичного ответа, например:
groups:
- name: "warn strategy"
partial_response_strategy: "warn"
rules:
- alert: "some"
expr: "up"
- name: "abort strategy"
partial_response_strategy: "abort"
rules:
- alert: "some"
expr: "up"
- name: "by default strategy is abort"
rules:
- alert: "some"
expr: "up"
Рекомендуется сохранять частичный отклик в качестве abort для предупреждений, используется по умолчанию.
Основные оповещения Rule#
Чтобы быть уверенным в том, что оповещение работает, важно отслеживать Rule и оповещение со Scraper (Prometheus + Sidecar), который находится в том же кластере.
Наиболее важными метриками для оповещения являются:
thanos_alert_sender_alerts_dropped_total. Если значение больше0, это означает, что оповещения, запускаемые Rule, не отправляются вalertmanager, что может указывать на проблемы с подключением, несовместимостью или неправильной настройкой.prometheus_rule_evaluation_failures_total. Если значение больше0, это означает, что это правило не удалось вычислить, что приводит либо к пробелу в правиле, либо к потенциально игнорируемому предупреждению. Этот показатель может указывать на проблемы в используемойqueryAPI endpoint.strategyметка сообщит, происходят ли сбои из-за правил, допускающих частичный ответ, или нет.prometheus_rule_group_last_duration_seconds > prometheus_rule_group_interval_seconds. Если разница положительная, это означает, что вычисление правила заняло больше времени, чем запланированный интервал, и данные для некоторых интервалов могли отсутствовать. Это может указывать на то, что серверной части запроса (например, Querier) требуется слишком много времени для оценки запроса. Это может указывать на другие проблемы, такие как медленныйStoreAPisили слишком сложное выражение запроса в правиле.thanos_rule_evaluation_with_warnings_total. Этот показатель покажет, сколько оценок закончилось каким-либо предупреждениемwarnпри использовании правила и оповещения со значением стратегии частичного ответа.
Представление#
Поскольку узлы правил передают обработку запросов на узлы запросов, они должны испытывать небольшую нагрузку. При необходимости может быть применено функциональное сегментирование путем разделения наборов правил между парами с высокой доступностью. Правила обрабатываются с дедуплицированными данными в соответствии с меткой реплики, настроенной на Nodes запросов.
Внешние метки#
Обязательно добавлять определенные внешние метки для указания источника Ruler (например, label='replica="A"' или для cluster). В противном случае запуск нескольких реплик Rule будет невозможен, что приведет к конфликту во время сжатия.
Например:
Ruler находится в кластере
mon1, где уже есть Prometheus;согласованные метки, которые можно использовать по умолчанию,
cluster=eu1для Prometheus иcluster=mon1для Ruler;настройки оповещения
ScraperIsDown, которое отслеживает службу из кластераwork1;оповещение
ScraperIsDown, при срабатывании, приводит кScraperIsDown{cluster=mon1}, поскольку внешние метки всегда заменяют исходные метки.
Отсутствие вынешних меток для настроект оповещения, в случае запуска нескольких реплик Rule, приводит к сбрасыванию важных метаданных и не позволяет определить, в каком именно cluster предупреждение ScraperIsDown обнаружило проблему, не прибегая к ручному запросу.
Пользовательский интерфейс Ruler#
На HTTP-адресе Ruler предоставляет свой пользовательский интерфейс, отображающий предупреждения и правила, аналогично странице предупреждений Prometheus. Каждое предупреждение связано с запросом, для перехода к настроенному alert.query-urlнажмите на предупреждение.
Высокая доступность Ruler#
Ruler стремится использовать подход, аналогичный подходу Prometheus с возможностью настройки внешних меток и перемаркировки.
Для высокой доступности Ruler необходимы следующие настройки маркировки:
метки, идентифицирующие высокую доступность Ruler и метку реплики с разным значением для каждого экземпляра Ruler, например:
cluster="eu1",replica="A"иcluster=eu1,replica="B"с помощью флага--label;метки, которые необходимо удалить непосредственно перед отправкой в
alermanager, чтобыalertmanagerмог дедуплицировать оповещения, например--alert.label-drop="replica".
Расширенная настройка повторной маркировки возможна с помощью флагов --alert.relabel-config и --alert.relabel-config-file. Ruler удаляет метки, перечисленные в --alert.label-drop, перед повторной маркировкой предупреждения.
Ruler без сохранения состояния с помощью удаленной записи#
Ruler без сохранения состояния обеспечивает практически неограниченную горизонтальную масштабируемость. Ruler не имеет полнофункциональной базы данных временных рядов TSDB для хранения результатов, но использует хранилище только для WAL и отправляет данные в удаленное хранилище с помощью удаленной записи.
WAL (Write-Ahead Logging) - журнал предварительной записи. Обеспечивает поддержку резервного копирования (например, облачного) и восстановления на определенный момент времени.
Хранилище WAL повторно использует вышестоящий агент Prometheus agent и совместимо со старыми данными TSDB.
Режим без сохранения состояния можно включить, указав Prometheus remote write config в файле с помощью --remote-write.config или встроенного флага --remote-write.config-file. Например:
thanos rule \
--data-dir "/path/to/data" \
--eval-interval "30s" \
--rule-file "/path/to/rules/*.rules.yaml" \
--alert.query-url "http://0.0.0.0:9090" \ # Указывает, на какой URL следует ссылаться в пользовательском интерфейсе.
--alertmanagers.url "http://alert.thanos.io" \
--query "query.example.org" \
--query "query2.example.org" \
--objstore.config-file "bucket.yml" \
--label 'monitor_cluster="cluster1"' \
--label 'replica="A"' \
--remote-write.config-file 'rw-config.yaml'
Где rw-config.yaml может выглядеть следующим образом:
remote_write:
- url: http://e2e_test_rule_remote_write-receive-1:8081/api/v1/receive
name: thanos-receiver
follow_redirects: false
- url: https://e2e_test_rule_remote_write-receive-2:443/api/v1/receive
remote_timeout: 30s
follow_redirects: true
queue_config:
capacity: 120000
max_shards: 50
min_shards: 1
max_samples_per_send: 40000
batch_send_deadline: 5s
min_backoff: 5s
max_backoff: 5m
Конфигурация Alertmanager#
Флаги --alertmanagers.config и --alertmanagers.config-file позволяют указать несколько Alertmanagers. Эти записи обрабатываются как единая группа высокой доступности. Это означает, что ошибка отправки оповещения объявляется только в том случае, если Ruler не удается отправить сообщение во все экземпляры.
Формат конфигурации следующий:
alertmanagers:
- http_config:
basic_auth:
username: ""
password: ""
password_file: ""
bearer_token: ""
bearer_token_file: ""
proxy_url: ""
tls_config:
ca_file: ""
cert_file: ""
key_file: ""
server_name: ""
insecure_skip_verify: false
static_configs: []
file_sd_configs:
- files: []
refresh_interval: 0s
scheme: http
path_prefix: ""
timeout: 10s
api_version: v1
Querier/Query#
Querier/Query реализует API Prometheus HTTP v1 для запроса данных в кластере Thanos через PromQL.
Querier собирает данные, необходимые для оценки запроса, из базового StoreAPIs, оценивает запрос и возвращает результат. Выступает в качестве источника метрик.
Querier полностью не имеет состояния и горизонтально масштабируется.
Пример команды для запуска Querier:
thanos query \
--http-address "0.0.0.0:9090" \
--endpoint "<store-api>:<grpc-port>" \
--endpoint "<store-api2>:<grpc-port>"
Общий просмотр#
Поскольку для Querier backend - это все, что реализует gRPC StoreAPI, появляется возможность агрегировать данные из любого количества различных хранилищ, таких как:
Prometheus Sidecar;
Store Gateway - хранилище объектов;
Ruler - глобальные оценки правил оповещения/записи;
Receiver - метрики, полученные из потоков удаленной записи Prometheus;
Querier, с возможностью накладывать Querier друг на друга;
системы, отличные от Prometheus, например, OpenTSDB.
Настройка sum(cpu_used{cluster=~"кластер-(eu1|eu2|eu3|us1|us2|us3)", job="service1"}) - даст сумму ЦП, используемых во всех перечисленных кластерах для службы service1.
В одном кластере функционально сегментируется Prometheus или используется разные экземпляры Prometheus для разных клиентов. Querier даст доступ к обоим в рамках одного Query запроса.
Время выполнения дедупликации групп высокой доступности#
Prometheus отслеживает состояние и не позволяет реплицировать свою базу данных. Это означает, что повышение высокой доступности за счет запуска нескольких реплик Prometheus сложно в использовании. Querier извлекает данные из реплик и дедуплицирует эти сигналы, заполняя пробелы, если таковые имеются, прозрачно для пользователя, выполняющего запрос.
Дедупликация#
Querier может дедуплицировать серии, которые были собраны из пар источников данных с высокой доступностью, таких как Prometheus. Два или более рядов, отличающихся только заданной меткой реплики, будут объединены в один временной ряд. Это также заполняет пробелы в сборе данных из одного источника.
Обзор Query API#
Для дополнительных функций Thanos добавляет поверх Prometheus:
режим частичного ответа;
пользовательские поля ответов;
другие параметры.
Частичный ответ#
QueryAPI и StoreAPI имеют дополнительный режим, управляемый с помощью параметра запроса PartialResponseStrategy. Этот параметр определяет компромисс между точностью и доступностью.
Частичный ответ - это потенциально пропущенный результат в запросе к QueryAPI или StoreAPI. Это может произойти, если один из StoreAPI возвращает ошибку или интервал, в то время как пара других возвращает успех. Если происходит частичный отклик, QueryAPI возвращает предупреждения.
Query поддерживает две стратегии:
warn;
abort (по умолчанию).
Querier также позволяет настраивать различные интервалы:
--query.timeout;--store.response-timeout.
Настраиваемые поля ответов#
Любое дополнительное поле не нарушает совместимость, однако нет гарантии, что Grafana или любой другой клиент поймет их.
Пример настройки:
type queryData struct {
ResultType promql.ValueType `json:"resultType"`
Result promql.Value `json:"result"`
// Additional Thanos Response field.
Warnings []error `json:"warnings,omitempty"`
}
Параллельный выбор#
Querier имеет возможность выполнять параллельный выбор для каждого запроса. Он анализирует данный оператор PromQL и выполняет селекторы одновременно для обнаруженных StoreAPIs. Максимальное количество одновременных запросов контролируется флагом query.max-concurrent-select.
Файл SD
Флаг --store.sd-files указывает путь к файлу в формате JSON или YAML, который содержит список целевых объектов в целевом формате Prometheus.
Пример файла SD в YAML:
- targets:
- prometheus-0.thanos-sidecar:10901
- prometheus-1.thanos-sidecar:10901
- thanos-store:10901
- thanos-short-store:10901
- thanos-rule:10901
- targets:
- prometheus-0.thanos-sidecar.infra:10901
- prometheus-1.thanos-sidecar.infra:10901
- thanos-store.infra:10901
Активное отслеживание запросов#
--query.active-query-path - это опция, которая позволяет пользователю указать каталог, который будет содержать файл queries.active для отслеживания активных запросов.
Клиентские метрики#
Информация о клиенте регистрируется в соответствующих экспортируемых Thanos метриках в Querier, Query Frontend и Store Gateway. Чтобы использовать эту функциональность, запросы к компоненту Query/Query Frontend должны включать идентификатор клиента в соответствующем заголовке HTTP-запроса, настроенном с помощью --query.tenant-header. Информация о клиенте передается через компоненты Query Frontend, Store Gateway, что также позволяет использовать метрики для каждого клиента в этих компонентах. Если для запросов к компоненту запроса не задан заголовок клиента, будет использоваться клиент по умолчанию, определенный с помощью --query.tenant-default-id.
Query Frontend#
Query Frontend реализует службу, которую можно поместить перед Query для улучшения чтения.
Query Frontend полностью не зависит от состояния и масштабируется по горизонтали.
Пример команды для запуска Query Frontend:
thanos query-frontend \
--http-address "0.0.0.0:9090" \
--query-frontend.downstream-url="<thanos-querier>:<querier-http-port>"
Разделение#
Query Frontend разделяет длинный запрос на несколько коротких запросов на основе настроенного флага --query-range.split-interval. Значение по умолчанию --query-range.split-interval равно 24 часам. Когда кеширование включено, оно должно быть больше 0.
Разделение запросов дает некоторые преимущества:
защита. Это предотвращает возникновение проблем с OOM при выполнении запросов;
улучшенное распараллеливание;
улучшенная балансировка нагрузки для запросов.
Повторная попытка#
Query Frontend поддерживает механизм повторных попыток для повторения запроса при сбое HTTP-запросов. Существует флаг --query-range.max-retries-per-request для ограничения максимального времени повторных попыток.
Кеширование#
Query Frontend поддерживает кеширование результатов запроса и повторно использует их при последующих запросах.
Оперативная память#
Пример настройки:
type: IN-MEMORY
config:
max_size: ""
max_size_items: 0
validity: 0s
max_size: максимальный объем кеш-памяти в байтах. Может быть применен суффикс единицы измерения (КБ, МБ, ГБ).
Примечание
Если оба параметра max_size и max_size_items не заданы, то кеш не будет создан.
Если задан любой из параметров max_size или max_size_items, то нет ограничений на другое поле.
Memcached#
Пример настройки:
type: MEMCACHED
config:
addresses: []
timeout: 0s
max_idle_connections: 0
max_async_concurrency: 0
max_async_buffer_size: 0
max_get_multi_concurrency: 0
max_item_size: 0
max_get_multi_batch_size: 0
dns_provider_update_interval: 0s
auto_discovery: false
set_async_circuit_breaker_config:
enabled: false
half_open_max_requests: 0
open_duration: 0s
min_requests: 0
consecutive_failures: 0
failure_percent: 0
expiration: 0s
expiration указывает время действия кеша memcached. Если установлено значение 0 секунд, то по умолчанию используется время истечения срока действия в 24 часа.
Конфигурация memcached по умолчанию:
type: MEMCACHED
config:
addresses: [your-memcached-addresses]
timeout: 500ms
max_idle_connections: 100
max_item_size: 1MiB
max_async_concurrency: 10
max_async_buffer_size: 10000
max_get_multi_concurrency: 100
max_get_multi_batch_size: 0
dns_provider_update_interval: 10s
expiration: 24h
Redis#
Конфигурация redis по умолчанию:
type: REDIS
config:
addr: ""
username: ""
password: ""
db: 0
dial_timeout: 5s
read_timeout: 3s
write_timeout: 3s
max_get_multi_concurrency: 100
get_multi_batch_size: 100
max_set_multi_concurrency: 100
set_multi_batch_size: 100
tls_enabled: false
tls_config:
ca_file: ""
cert_file: ""
key_file: ""
server_name: ""
insecure_skip_verify: false
cache_size: 0
master_name: ""
max_async_buffer_size: 10000
max_async_concurrency: 20
set_async_circuit_breaker_config:
enabled: false
half_open_max_requests: 10
open_duration: 5s
min_requests: 50
consecutive_failures: 5
failure_percent: 0.05
expiration: 24h0m0s
expiration указывает время действия кеша redis. Если установлено значение 0 секунд, то по умолчанию используется время истечения срока действия в 24 часа.
Рекомендуемая конфигурация Downstream Tripper#
Настройте параметры HTTP-клиента, который Query Frontend использует для URL-адреса downstream с параметрами --query-frontend.downstream-tripper-config и --query-frontend.downstream-tripper-config-file. По умолчанию клиент Go HTTP будет поддерживать только два незанятых соединения для каждого хоста.
Ключи, обозначающие длительность, представляют собой строки, которые могут заканчиваться на s или m для обозначения секунд или минут соответственно. Все остальные ключи являются целыми числами. Поддерживаемые ключи:
idle_conn_timeout- время ожидания незанятых соединений;response_header_timeout- максимальное время ожидания заголовка ответа;tls_handshake_timeout- максимальная продолжительность подтверждения TLS;expect_continue_timeout- исходный код перехода;max_idle_conns- максимальное количество незанятых подключений ко всем хостам;max_idle_conns_per_host- максимальное количество незанятых подключений к каждому хосту;max_conns_per_host- максимальное количество подключений к каждому хосту.
Отправка заголовков to Downstream Queriers#
Флаг --query-frontend.forward-header предоставляет список заголовков запросов, пересылаемых интерфейсом запроса нижестоящим запросчикам.
Cluster authentication operator#
Cluster authentication operator - это оператор, который отвечает за управление и настройку аутентификации и авторизации в кластере DropApp Plus. Обеспечивает управление конфигурациями: идентификационные провайдеры, поддержка LDAP, OAuth, Kerberos и другие механизмы аутентификации.
С помощью Cluster authentication operator можно настраивать и управлять различными функциями аутентификации для пользователей и сервисных аккаунтов в DropApp Plus.
Выполните команду, чтобы просмотреть установленный пользовательский ресурс аутентификации в кластере:
oc get clusteroperator authentication -o yaml
Чтобы просмотреть определение пользовательского ресурса в кластере, выполните команду:
oc get crd authentications.operator.openshift.io -o yaml
Cluster autoscaler#
Сluster autoscaler - это компонент, который автоматически масштабирует кластер DropApp Plus в зависимости от текущей загрузки и потребностей ресурсов. Сluster autoscaler работает на уровне кластера и отвечает за автоматическое добавление или удаление nodes, чтобы обеспечить оптимальное использование ресурсов и удовлетворение требований приложений.
Cluster autoscaler мониторит нагрузку на кластер и использует алгоритмы принятия решений. Определяет, когда следует масштабировать кластер путем добавления новых nodes или удаления неиспользуемых. Анализирует фактическое использование ресурсов и рассчитывает будущую загрузку на основе исторических данных.
Механизм Cluster autoscaler:
Автоматическое масштабирование кластера - компонент, который автоматически регулирует размер кластера DropApp Plus, чтобы у всех pods было место для запуска и не было ненужных nodes. Поддерживает несколько провайдеров общедоступного облака.
Автоматическое масштабирование вертикальных pods - набор компонентов, которые автоматически регулируют объем процессора и памяти, запрашиваемый pods, работающими в кластере DropApp Plus.
Addon Resizer - упрощенная версия автоматического масштабирования vertical pod, которая изменяет запросы ресурсов развертывания на основе количества nodes в кластере DropApp Plus.
Диаграммы - поддерживаются диаграммы Helm для компонентов, указанных в п. 1 - 3.
Cluster config operator#
Cluster config operator - компонент, который управляет глобальными конфигурационными настройками и параметрами кластера DropApp Plus. Отвечает за поддержку и обновление настроек, которые применяются ко всем nodes и проектам в кластере.
Обрабатывает изменения в глобальной конфигурации кластера, такие как при добавлении, изменении или удалении настроек, и автоматически применяет эти изменения для всего кластера, что позволяет обеспечить единообразность настроек и упрощает управление конфигурацией.
Глобальные конфигурационные настройки, которыми управляет Cluster config operator, включают параметры безопасности: политики безопасности и учетные записи для удаленного доступа, настройки квот ресурсов, а также дополнительные параметры конфигурации DropApp Plus.
Является важной частью системы управления конфигурацией в DropApp Plus и позволяет администраторам настроить и поддерживать глобальные настройки кластера без необходимости вмешательства в каждый node или проект отдельно.
Openshift controller manager#
OpenShift Controller Manager - компонент, который управляет и контролирует работу кластера DropApp Plus.
Состоит из контроллеров, каждый из которых отвечает за определенную функциональность:
authorizationпредоставляет стандартные роли связывания учетных записей службы для проектов DropApp Plus.serviceaccountsуправляет секретами, которые позволяют извлекать и отправлять образы из репозитория DropApp Plus.unidlingуправляет пробуждением приложений при обнаружении входящего сетевого трафика.
Docker Registry#
Docker Registry - это инструмент, который позволяет хранить, управлять и обмениваться образами Docker.
Docker Registry находит применение в различных сценариях разработки, тестирования и развертывания программного обеспечения на основе контейнеров. Используется в DevOps-практиках для автоматизации процессов сборки, тестирования, размещения и запуска приложений. Также широко применяется в облачных и микросервисных архитектурах, где обеспечивает легкость управления контейнерами и их зависимостями. Docker Registry может быть использован для создания частных репозиториев образов с закрытым доступом, что полезно для организаций, желающих сохранить контроль над своим программным обеспечением.
Назначение Docker Registry состоит в обеспечении удобного и эффективного способа хранения и распространения Docker образов. Он позволяет пользователям загружать собственные образы, а также скачивать и использовать образы, созданные другими пользователями или организациями. Docker Registry также обеспечивает механизмы безопасности, аутентификации и авторизации для контроля доступа к образам.
Функциональность Docker Registry:
Хранение образов: предоставляет централизованное хранилище для Docker образов, что позволяет пользователям сохранять образы в одном месте.
Распространение образов: пользователи могут загружать Docker образы в Registry и скачивать образы, созданные другими пользователями или организациями.
Управление версиями: обеспечивает возможность управления версиями Docker образов. Это позволяет пользователям создавать, обновлять и удалять различные версии образов.
Механизмы безопасности: предоставляет механизмы аутентификации и авторизации для обеспечения безопасного доступа к образам. Это может включать в себя использование токенов доступа, SSL-шифрование и другие методы защиты данных.
Репликация и распределение: некоторые реализации Docker Registry поддерживают функциональность репликации образов для обеспечения их доступности и надежности. Это позволяет создавать распределенные хранилища образов для повышения производительности и отказоустойчивости.
Метаданные и поиск: может хранить метаданные об образах, такие как теги, описание и информацию о зависимостях. Это облегчает поиск и организацию образов в хранилище.
Поддержка частных репозиториев: может быть настроен как частный репозиторий образов с ограниченным доступом для конкретных пользователей или организаций. Это обеспечивает контроль над доступом к образам и их безопасностью.
Основные команды и флаги для работы с Docker Registry:
docker login: команда для аутентификации пользователя на удаленном Docker Registry:--username, -u: имя пользователя для аутентификации;--password, -p: пароль для аутентификации;--email: электронная почта пользователя.
docker logout: команда для выхода из системы удаленного Docker Registry.docker push: команда для загрузки (публикации) локального Docker образа в удаленное хранилище Docker Registry:--username, -u: имя пользователя для аутентификации;--password, -p: пароль для аутентификации;--email: электронная почта пользователя.
docker logout: команда для выхода из системы удаленного Docker Registry.docker push: команда для загрузки (публикации) локального Docker образа в удаленное хранилище Docker Registry:<имя_репозитория>:<тег>: имя и тег образа для публикации.
docker pull: команда для загрузки Docker образа с удаленного Docker Registry на локальную машину:<имя_репозитория>:<тег>: имя и тег образа для загрузки.
docker tag: команда для присвоения дополнительных меток Docker образу перед публикацией в реестре:<старое_имя_образа>:<тег>: старое имя и тег образа;<новое_имя_образа>:<тег>: новое имя и тег образа.<старое_имя_образа>:<тег>: старое имя и тег образа;<новое_имя_образа>:<тег>: новое имя и тег образа.
docker rmi: команда для удаления Docker образов с локальной машины:<имя_образа>:<тег>: имя и тег образа для удаления.
docker search: команда для поиска Docker образов в удаленном Docker Registry.docker inspect: команда для получения информации о Docker образе или контейнере.docker push: команда для загрузки Docker образа в Docker Registry:--all-tags, -a: пушить все теги образа на Docker Registry;--disable-content-trust: отключить проверку подлинности контента при публикации образа.--disable-content-trust: отключить проверку подлинности контента при публикации образа.
docker pull: команда для загрузки Docker образа с Docker Registry:--all-tags, -a: загрузить все теги образа с Docker Registry.--all-tags, -a: загрузить все теги образа с Docker Registry.
docker logout: команда для выхода из системы Docker Registry.
Сценарии использования Docker Registry#
Создание Docker образа приложения#
Cоздайте Dockerfile, который содержит инструкции по сборке образа, включая установку зависимостей и окружения.
Тестирование локально#
Запустите контейнер из созданного образа на локальных машинах для тестирования приложения в контролируемой среде:
Соберите Docker образ:
docker build -t myapp .Запустите контейнер из собственного образа:
docker run -d -p 8080:80 myappПроверьте работоспособность приложения, например, веб-приложения, открыв его в веб-браузере или отправив запросы через
curl:curl -X GET http://localhost:5000/v2/_catalog
Эта команда отправит GET-запрос на порт 5000 локального сервера, чтобы получить список всех доступных образов в Docker Registry. Если приложение работает корректно, в ответ будет получен файл в формате JSON, содержащий список образов.
Если при выполнении команды отсутствует ответ или появляется сообщение об ошибке, это может указывать на проблемы с настройкой или работой Docker Registry. В этом случае рекомендуется проверить конфигурацию Docker Registry и убедиться, что Docker Registry запущен и доступен на порту 5000.
Загрузка образа в Docker Registry#
После успешного тестирования загрузите Docker образ в Docker Registry для дальнейшего использования другими членами команды или в процессе CI/CD:
Авторизуйтесь в Docker Registry, если требуется:
docker login <URL_реестра>Присвойте образу дополнительных метаданных, включая его тег и имя репозитория, чтобы обеспечить правильное расположение и идентификацию образа в Registry: `
docker tag myapp <URL_реестра>/myapp:latestгде:
myapp- имя локального образа;<URL_реестра>- URL вашего Docker Registry;myapp:latest- новая метка, которую вы присваиваете образу перед загрузкой в Registry.
Примечание
После выполнения этой команды, образ myapp будет иметь новую метку latest и будет доступен по адресу <URL_реестра>/myapp:latest в Docker Registry. Это обеспечит правильное размещение и идентификацию образа в Registry для последующей загрузки и использования другими пользователями или системами.
Загрузите образ в Docker Registry:
docker push <URL_реестра>/myapp:latest
Интеграция с CI/CD#
Настройте и используйте системы непрерывной интеграции и непрерывной доставки (CI/CD) для автоматизации процесса разработки и развертывания программного обеспечения с использованием Docker Registry.
Примечание
Этот шаг обычно выполняется в рамках инструментов CI/CD, таких как Jenkins, GitLab CI, Travis CI и другие. Настройте вашу систему CI/CD для автоматической сборки, тестирования и загрузки Docker образа в Docker Registry после каждого коммита или слияния ветки.
Развертывание в производстве#
Docker образ из Docker Registry загружается на серверы для развертывания в производственной среде:
Авторизуйтесь в Docker Registry, если требуется:
docker login <URL_реестра>Загрузите образ на сервер:
docker pull <URL_реестра>/myapp:latestЗапустите контейнер из загруженного образа на сервере:
docker run -d -p 80:80 <URL_реестра>/myapp:latest
Масштабирование и обновление#
При необходимости приложение может масштабироваться горизонтально или обновляться до новой версии путем загрузки нового Docker образа в Docker Registry и на серверы, для этого нужно выполнить шаги загрузки и развертывания в производственной среде.
Сценарий проверки контейнер образа Docker Registry#
Запустите docker-registry из образа hyperkube:v4.8:
docker run -it --rm --pull=always /dplus-docker-registry/docker-registry:v4.8 --help
Проверьте, что stdout содержит usage: node_exporter [] и не содержит ошибки.
Operator Registry#
Operator Registry - это инструмент, предназначенный для централизованного хранения метаданных операторов, их версий и другой связанной информации, обеспечивающий удобный доступ к этим данным.
Operator Registry необходим для эффективного управления операторами в кластерах. Используется для:
централизованного хранения и управления метаданными операторов;
упрощения установки, обновления и удаления операторов в кластерах;
интеграции с операторами сторонних разработчиков или сообществ;
сoздания собственных директорий операторов для стандартизации процессов управления приложениями.
Operator Registry предоставляет следующую функциональность:
Генерация и обновление баз данных реестра и образов индексов: Operator Registry позволяет генерировать и обновлять базы данных, содержащие информацию о доступных операторах и их версиях, а также создавать образы индексов для эффективного доступа к этим данным.
Поддержка gRPC интерфейса: Registry предоставляет интерфейс для взаимодействия с базой данных реестра через gRPC, что позволяет разработчикам и администраторам получать доступ к информации о доступных операторах и их метаданных.
Разбор конфигурационных файлов: Operator Registry имеет возможность разбирать конфигурационные файлы операторов и загружать их содержимое в базу данных для дальнейшего использования.
Поддержка OCI-совместимых контейнерных образов: Operator Registry работает с OCI-совместимыми контейнерными образами, используя их для хранения манифестов и метаданных операторов.
Публикация и обновление операторов: разработчики могут публиковать свои операторы в Registry и обновлять их версии, обеспечивая администраторам возможность установки и обновления операторов в их кластерах.
Интеграция с Operator Lifecycle Manager: Operator Registry интегрируется с Operator Lifecycle Manager, позволяя кластерам управлять пакетами операторов через
CatalogSourcesиSubscription.
Основные команды и флаги для работы с Operator Registry:
opm index add: команда для добавления новой версии оператора в индекс:--bundles, -b: URL контейнера с манифестом пакета оператора;--tag: тег образа для сохранения результата;--from-index: флаг, в котором нужно использовать предыдущий индекс для построения нового.
opm index rm: команда для удаления всех версий пакета оператора из индекса:
--operators, -o: имя оператора, которое нужно удалить из индекса;--tag: тег образа для сохранения результата.
opm index prune: команда для удаления всех пакетов операторов из индекса, кроме указанного:--packages, -p: имя пакета оператора, которое нужно сохранить в индексе;--tag: тег образа для сохранения результата;--from-index: флаг, в котором нужно использовать предыдущий индекс для построения нового.
opm index export: команда для экспорта пакета из индекса в каталог в формате манифеста приложения:--index: URL образа индекса;--packages, -p: имя пакета оператора, которое нужно экспортировать;--container-tool: инструмент контейнеризации для выполнения экспорта (по умолчаниюpodman);--download-folder: путь для сохранения экспортированных файлов (по умолчанию./downloaded)
opm registry add: команда для добавления версии пакета оператора в базу данных реестра:--bundles, -b: URL контейнера с манифестом пакета оператора;--database, -d: путь к файлу базы данных реестра, куда нужно добавить пакет оператора;--container-tool: инструмент контейнеризации, который будет использоваться (по умолчаниюpodman);--tag: тег образа для сохранения результата.
opm registry rm: команда для удаления всех версий пакета оператора из реестра:--operators, -o: имя оператора, которое нужно удалить из реестра;--database, -d: путь к файлу базы данных реестра, из которого нужно удалить оператора.
opm registry prune: команда для удаления из базы реестра всех пакетов, кроме указанного:--packages, -p: имя пакета оператора, которое нужно сохранить в реестре;--database, -d: путь к файлу базы данных реестра, из которой нужно удалить все пакеты, кроме указанного.
opm registry server: команда для запуска сервера gRPC API, который будет обрабатывать запросы к реестру:--port, -p: порт, на котором будет запущен сервер;--database, -d: путь к файлу базы данных реестра.
Примечание
Команды требуют инструмент контейнеризации, который используется вне среды, например Docker или Podman.
Сценарии использования Operator Registry#
Создание индекса операторов#
Создайте индекс операторов, добавляя bundles с указанным тегом к индексу:
opm index add --bundles quay.io/my-container-registry-namespace/my-manifest-bundle:0.0.1 --tag quay.io/my-container-registry-namespace/my-index:1.0.0
Отправка созданного индекса в реестр контейнеров#
Загрузите индекс операторов в указанный контейнерный реестр (в данном случае, quay.io), чтобы он был доступен для других пользователей и кластеров:
podman push quay.io/my-container-registry-namespace/my-index:1.0.0
Обновление индекса операторов#
Добавьте новую версию bundles к существующему индексу. В команде указывается исходный индекс --from-index, к которому добавляется новая версия и новый тег для обновленного индекса:
opm index add --bundles quay.io/my-container-registry-namespace/my-manifest-bundle:0.0.2 --from-index quay.io/my-container-registry-namespace/my-index:1.0.0 --tag quay.io/my-container-registry-namespace/my-index:1.0.1
Запуск сервера реестра#
Запустите сервер Operator Registry. По умолчанию он прослушивает порт 50051 для gRPC-запросов:
opm registry server -d "test-registry.db" -p 50051
Использование индекса с помощью Operator Lifecycle Manager#
Создайте
CatalogSourcesс ссылкой на подготовленный образ. В данном примере предполагается, что создан и загружен образ с именемexample-registry:latest:apiVersion: operators.coreos.com/v1alpha1 kind: CatalogSource metadata: name: example-manifests namespace: default spec: sourceType: grpc image: example-registry:latestПроверьте каталог pods, чтобы убедиться, что интерфейс
gRPCправильно запускается:oc logs example-manifests-wfh5h -n defaultПросмотрите список
packagemanifests, чтобы убедиться, что операторы из каталога стали доступны:watch oc get packagemanifestsПолучите информацию о канале по умолчанию (например,
etcd):oc get packagemanifests etcd -o jsonpath='{.status.defaultChannel}'Создайте
Subscriptionдля установки оператора и получения последующих обновлений каталога:apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: etcd-subscription namespace: default spec: channel: alpha name: etcd source: example-manifests sourceNamespace: default
Operator Lifecycle Manager#
Operator Lifecycle Manager - инструмент, который упрощает управление жизненным циклом операторов в кластере.
Operator Lifecycle Manager призван автоматизировать управление жизненным циклом операторов, предоставляя механизмы установки, обновления и управления RBAC операторами в кластере. Позволяет облегчить процесс управления приложениями в кластере, особенно теми, которые используют операторы для автоматизации операций.
Operator Lifecycle Manager предоставляет следующую функциональность:
Обновление по воздуху и каталоги (Over-the-Air Updates and Catalogs):
Operator Lifecycle Manager обеспечивает механизмы обновления для автоматического поддержания актуальности приложений. Это позволяет операторам получать и устанавливать обновления автоматически, без необходимости ручного вмешательства;
каталоги предоставляют централизованный ресурс, из которого можно получить информацию о доступных операторах и их версиях. Operator Lifecycle Manager использует каталоги для предоставления пользователю списка операторов, которые могут быть установлены и обновлены.
Модель зависимостей (Dependency Model): операторы могут выражать зависимости от платформы и от других операторов с помощью формата упаковки, предоставляемого Operator Lifecycle Manager. Это позволяет операторам точно определить требования к окружению и другим операторам, от которых они зависят, и гарантировать их работоспособность в течение всего жизненного цикла.
Обнаружение (Discoverability): Operator Lifecycle Manager делает операторы и их сервисы доступными для пользователей кластера для выбора и установки. Пользователи могут легко найти и установить операторы, которые им необходимы, благодаря механизмам поиска и предоставления информации о доступных операторах.
Стабильность кластера (Cluster Stability): Operator Lifecycle Manager предотвращает установку конфликтующих операторов, которые могут владеть одними и теми же API. Это гарантирует стабильность работы кластера и предотвращает возможные конфликты между операторами, которые могут нарушить нормальную работу приложений.
Декларативное управление интерфейсом пользователя (Declarative UI Controls): Operator Lifecycle Manager позволяет операторам вести себя как управляемые сервисы, предоставляя API для взаимодействия с ними. Это обеспечивает удобный и единообразный способ взаимодействия с операторами через командную строку или графические интерфейсы пользователя.
Operator Lifecycle Manager тесно связан с catalogs и packageserver:
Catalogs: представляют собой репозитории с определениями приложений и CRD (Custom Resource Definitions), которые используются для управления операторами. Operator Lifecycle Manager использует информацию из этих каталогов для установки, обновления и управления зависимостями операторов. Каталоги содержат пакеты, которые предоставляются различными каналами (например, alpha, beta, stable), чтобы пользователи могли выбрать необходимую им версию оператора.
Package Server: представляет собой компонент, который предоставляет пакеты с определениями операторов и их зависимостями. Обычно служит в качестве хранилища для каталогов и обеспечивает доступ к ним через различные протоколы, такие как HTTP или gRPC. Operator Lifecycle Manager использует пакетные серверы для загрузки пакетов с определениями операторов и их зависимостей, чтобы пользователи могли установить необходимые им операторы.
Основные команды и флаги для работы с Operator Lifecycle Manager:
olm install <имя_operator>: команда для установки оператора из каталога:--namespace <namespace>: namespace, в которое устанавливается оператор;--catalog <имя_catalog>: каталог, из которого следует установить оператор;--version <version>: версия оператора для установки;--from <source>: источник для установки оператора (например, пакетный сервер или URL).
olm update <имя_operator>: команда для обновления оператора до последней доступной версии:--namespace <namespace>: namespace, в котором находится оператор для обновления.
olm delete <имя_operator>: команда для удаления оператора из кластера:--namespace <namespace>: namespace, в котором находится оператор для удаления.
olm catalog list: команда показывает список доступных каталогов.olm catalog add <имя_catalog> <source>: команда для добавления нового каталога с указанным именем и источником.olm catalog remove <имя_catalog>: команда для удаления каталога из Operator Lifecycle Manager.olm catalog update <имя_catalog>: команда для обновления информации о каталоге.olm describe <тип_object> <имя_object>: команда показывает подробную информацию об объекте Operator Lifecycle Manager (например, операторе).olm version: команда выводит информацию о версии Operator Lifecycle Manager.olm unsubscribe <имя_subscription>: команда показывает текущий статус Operator Lifecycle Manager в кластере.
Сценарии использования Operator Lifecycle Manager#
Установка операторов из каталогов#
Найдите доступные операторы в каталоге Operator Lifecycle Manager:
olm catalog listВыберете нужного оператора из списка:
olm catalog describe <имя_operator>Установите оператор в кластер:
olm install <имя_operator> --namespace <namespace>
Обновление операторов в кластере#
Проверьте доступные обновления для установленных операторов:
olm update listОбновите операторов до последней версии:
olm update <имя_operator> --namespace <namespace>
Управление зависимостями между операторами#
Создайте управление зависимостями между операторами:
olm install <имя_operator> --from <source> --namespace <namespace>
Управление зависимостями осуществляется через ClusterServiceVersion (CSV) и OperatorGroup.
Создание пользовательских операторов и их управление через Operator Lifecycle Manager#
Создайте пользовательский оператор с помощью Operator SDK:
operator-sdk new my-operator
Управление жизненным циклом оператора осуществляется через Operator Lifecycle Manager, включая установку, обновление и удаление.
Декларативное управление интерфейсом пользователя для операторов#
Определите пользовательский интерфейс через
DescriptorsвClusterServiceVersion (CSV).Посмотрите описание пользовательского интерфейса оператора:
olm describe csv <имя_csv> --namespace <namespace>
Multus CNI#
Multus CNI - это плагин для DropApp Plus, который позволяет подключать несколько сетевых интерфейсов к pods в кластере.
Обычно в DropApp Plus каждый pod имеет только один сетевой интерфейс, однако Multus CNI расширяет эту возможность, позволяя создавать многоразовые pods с несколькими интерфейсами. Действует как «meta-plugin», который вызывает несколько других CNI-плагинов для создания дополнительных сетевых интерфейсов. Multus CNI следует стандарту определения пользовательских ресурсов сети и обеспечивает унифицированный способ указания конфигураций дополнительных сетевых интерфейсов. Инструмент полезен для сценариев, требующих подключения pods к нескольким сетям одновременно, или для обеспечения отдельных сетевых путей различных типов трафика в кластере.
Multus CNI предоставляет функции:
Поддержка добавления нескольких сетевых интерфейсов к pods.
Использование Custom Resource Definitions (CRD) для хранения конфигураций дополнительных интерфейсов.
Поддержка различных типов сетевых интерфейсов, таких как MACVLAN, VLAN, VXLAN и другие.
Возможность управления сетевыми конфигурациями через аннотации и настройки CRD.
Расширяемость и гибкость конфигурации сетевых интерфейсов.
Основные команды и флаги для работы с Multus CNI:
oc apply -f <file>: команда для установки Multus CNIс помощью YAML-файла.oc get pods --all-namespaces | grep -i multus: команда для проверки запущенных pods Multus CNI.oc get network-attachment-definitions: команда для получения списка созданных конфигураций дополнительных интерфейсов.oc describe network-attachment-definitions <name_interface>: команда для подробного описания конфигурации определенного дополнительного интерфейса.
Предварительные условия: перед выполнением сценария настройте Kubelet на использование CNI.
Сценарий для установки Multus CNI:
Установите Multus CNI. Рекомендуемый метод установки - установка через Daemonset. Для этого можно использовать «толстый» (thick) или «тонкий» (thin) плагин:
пример установки «толстого» (thick) плагина:
oc apply -f https://<repoexample.ru>/k8snetworkplumbingwg/multus-cni/master/deployments/multus-daemonset-thick.yml # Укажите актуальный путь до локального репозиторияпример установки «тонкого» (thin) плагина:
oc apply -f https://<repoexample.ru>/k8snetworkplumbingwg/multus-cni/master/deployments/multus-daemonset.yml # Укажите актуальный путь до локального репозитория
Сценарии использования Multus CNI#
Проверка установки#
Чтобы проверить установку, выполните следующие действия:
Проверьте, что все pods Multus CNI запущены без ошибок:
oc get pods --all-namespaces | grep -i multusУбедитесь, что автоматически сгенерированный файл конфигурации существует в директории
/etc/cni/net.d/:ls /etc/cni/net.d/
Создание дополнительных интерфейсов#
Создайте конфигурации для каждого из дополнительных интерфейсов, которые подключаете к контейнерам, и пользовательские ресурсы для каждого интерфейса. В рамках процесса быстрой установки создается CRD - пользовательское определение ресурса, которое служит местом для хранения ресурсов. В CRD будете хранить конфигурации для каждого интерфейса.
Создайте конфигурацию для дополнительного интерфейса. Например, создайте конфигурацию
macvlan:cat <<EOF | oc create -f - apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: macvlan-conf spec: config: '{ "cniVersion": "0.3.0", "type": "macvlan", "master": "eth0", "mode": "bridge", "ipam": { "type": "host-local", "subnet": "NNN.NNN.N.0/24", "rangeStart": "NNN.NNN.N.200", "rangeEnd": "NNN.NNN.N.216", "routes": [ { "dst": "0.0.0.0/0" } ], "gateway": "NNN.NNN.N.1" } }' EOF
где NNN.NNN.N.0/24 – выбранная подсеть, а NNN.NNN.N.200, NNN.NNN.N.216, NNN.NNN.N.1 – актуальные IP адреса выбранной подсети.
Получите более подробную информацию о конфигурации:
oc describe network-attachment-definitions macvlan-confПроверьте созданную конфигурацию:
oc get network-attachment-definitionsМожно добавлять больше интерфейсов в pod. Добавьте еще интерфейсов, создав соответствующие конфигурации и аннотируя pods. Например, добавьте два
macvlanинтерфейса:cat <<EOF | oc create -f - apiVersion: v1 kind: Pod metadata: name: samplepod annotations: k8s.v1.cni.cncf.io/networks: macvlan-conf,macvlan-conf spec: containers: - name: samplepod command: ["/bin/ash", "-c", "trap : TERM INT; sleep infinity & wait"] image: alpine EOF
Примечание
Аннотация теперь гласит k8s.v1.cni.cncf.io/networks: macvlan-conf,macvlan-conf. Где одна и та же конфигурация используется дважды, разделенная запятой.
Создание pod с дополнительным интерфейсом#
Создайте pods с аннотациями, указывающими на использование созданной конфигурации. Например, создайте pod с использованием конфигурации macvlan:
cat <<EOF | oc create -f -
apiVersion: v1
kind: Pod
metadata:
name: samplepod
annotations:
k8s.v1.cni.cncf.io/networks: macvlan-conf
spec:
containers:
- name: samplepod
command: ["/bin/ash", "-c", "trap : TERM INT; sleep infinity & wait"]
image: alpine
EOF
Проверка созданного pod#
Проверьте, какие интерфейсы присоединены к созданному pod:
oc exec -it samplepod -- ip a
Проверка аннотаций Network Status#
Получите информацию об аннотациях Network Status для подтверждения успешной работы CNI-плагинов:
oc describe pod samplepod
Multus Admission Controller#
Network Attachment Definition (NAD) Admission Controller представляет собой инструмент, который используется для проверки ресурсов, определенных согласно спецификации Custom Resource Definition (CRD) от Network Plumbing Working Group. Предназначен для обеспечения соответствия создаваемых пользователем ресурсов Network Attachment Definition требованиям и форматам. Это специфический контроллер, который обеспечивает соблюдение определенных стандартов при создании сетевых ресурсов.
Multus Admission Controller предоставляет функции:
Валидация ресурсов: проверка создаваемых пользователем ресурсов Network Attachment Definition на соответствие определенным требованиям и форматам.
Предоставление обратной связи: в случае обнаружения ошибок или несоответствий в формате или структуре создаваемых ресурсов, контроллер возвращает сообщение об ошибке, предоставляя информацию о том, что именно не так.
Улучшение опыта пользователя: путем предоставления обратной связи о формате и структуре ресурсов, контроллер помогает пользователям создавать правильно сформированные и валидные сетевые ресурсы, что улучшает их опыт работы.
Основные команды для работы с Multus Admission Controller:
./hack/webhook-deployment.sh: команда для развертывания контроллера.make: команда для сборки контроллера.
Сценарий установки Multus Admission Controller:
Развертывание веб-приложения webhook: создайте файл SSL-сертификата, который будет использоваться для контроллера допуска:
./hack/webhook-create-signed-cert.shПримечание
Если хотите использовать non-self-signed certificate, создайте секретный ресурс.
oc create secret generic net-attach-def-admission-controller-secret \ --from-file=key.pem=<your server-key.pem> \ --from-file=cert.pem=<your server-cert.pem> \ -n kube-systemЗапустите Kubernetes Job, который создаст следующие необходимые ресурсы для запуска webhook:
конфигурация валидации webhook;
сервис для экспозиции развертывания webhook к API-серверу.
Выполните команду:
cat deployments/webhook.yaml | ./hack/webhook-patch-ca-bundle.sh | oc create -f - oc apply -f deployments/service.yamlПримечание
Проверьте, что у Kubernetes controller manager установлены параметры
--cluster-signing-cert-fileи--cluster-signing-key-file, указывающие на пути паре ключей CA, чтобы убедиться, что API сертификатов включено для генерации сертификата, подписанного кластером CA.Если Job успешно завершен, можете запустить фактическое веб-приложение webhook.
Создайте развертывание сервера webhook:
oc apply -f deployments/deployment.yaml
Сценарии использования Multus Admission Controller#
Проверка работоспособности валидационного webhook#
Чтобы проверить работоспособность валидационного webhook, выполните следующие действия:
Создайте неверный ресурс Network Attachment Definition:
cat <<EOF | oc create -f - apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: invalid-net-attach-def spec: config: '{ "invalid": "config" }' EOFWebhook: должен отклонить запрос:
Error from server: error when creating "STDIN": admission webhook "net-attach-def-admission-controller-validating-config.k8s.cni.cncf.io" denied the request: invalid config: error parsing configuration: missing 'type'Создайте правильно определенный ресурс:
cat <<EOF | oc create -f - apiVersion: "k8s.cni.cncf.io/v1" kind: NetworkAttachmentDefinition metadata: name: correct-net-attach-def spec: config: '{ "cniVersion": "0.3.0", "name": "a-bridge-network", "type": "bridge", "bridge": "br0", "isGateway": true, "ipam": { "type": "host-local", "subnet": "NNN.NNN.N.0/24", "dataDir": "/mnt/cluster-ipam" } }' EOFгде
NNN.NNN.N.0/24– выбранная подсеть.Ресурс должен быть разрешен и создан:
networkattachmentdefinition.k8s.cni.cncf.io/correct-net-attach-def created
Устранение неполадок#
Сервер webhook выводит много отладочных сообщений, которые могут помочь найти причину проблемы. Чтобы отобразить журналы, выполните:
oc logs -l app=net-attach-def-admission-controller
Пример вывода журналов для обработки запросов:
I1212 13:47:03.169902 1 main.go:34] starting net-attach-def-admission-controller webhook server
I1212 13:47:47.917792 1 webhook.go:71] validating network config spec: { "invalid": "config" }
I1212 13:47:47.918067 1 webhook.go:79] spec is not a valid network config list: error parsing configuration list: no name - trying to parse into standalone config
I1212 13:47:47.918089 1 webhook.go:82] spec is not a valid network config: { "invalid": "config" }
I1212 13:47:47.918115 1 webhook.go:175] sending response to the Kubernetes API server
I1212 13:48:25.173150 1 webhook.go:71] validating network config spec: { "cniVersion": "0.3.0", "name": "a-bridge-network", "type": "bridge", "bridge": "br0", "isGateway": true, "ipam": { "type": "host-local", "subnet": "NNN.NNN.N.0/24", "dataDir": "/mnt/cluster-ipam" } }
I1212 13:48:25.173233 1 webhook.go:79] spec is not a valid network config list: error parsing configuration list: no 'plugins' key - trying to parse into standalone config
I1212 13:48:25.173271 1 webhook.go:88] AdmissionReview request allowed: Network Attachment Definition '{ "cniVersion": "0.3.0", "name": "a-bridge-network", "type": "bridge", "bridge": "br0", "isGateway": true, "ipam": { "type": "host-local", "subnet": "NNN.NNN.N.0/24", "dataDir": "/mnt/cluster-ipam" } }' is valid
I1212 13:48:25.173287 1 webhook.go:175] sending response to the Kubernetes API server
где NNN.NNN.N.0/24 – выбранная подсеть.
Сбор метрик с помощью Prometheus#
Для сбора метрик с помощью Prometheus выполните следующие действия:
Выполните скрипт для установки Prometheus:
./hack/prometheus-deployment.shПосле установки Prometheus необходимо настроить сбор метрик с контроллера допуска Network Attachment Definition. Для этого может потребоваться изменить файл конфигурации Prometheus.
После настройки Prometheus он будет регулярно собирать метрики с контроллера допуска Network Attachment Definition. Используйте веб-интерфейс Prometheus для просмотра собранных метрик и их анализа.
Метрики, собранные с контроллера допуска Network Attachment Definition, могут быть использованы для мониторинга количества экземпляров сетевых ресурсов, аннотированных сетевыми аннотациями. Можно создать оповещения или графики на основе собранных метрик, чтобы отслеживать и управлять сетевыми ресурсами в кластере.
Примечание
Перед использованием метрик рекомендуется ознакомиться с документацией Prometheus и настроить соответственно вашим потребностям.
Multus Whereabout CNI#
Multus Whereabout CNI - это плагин IP Address Management (IPAM) для контейнерной сети (CNI), который назначает IP-адреса на уровне кластера.
Multus Whereabout CNI используется для управления IP-адресами в DropApp Plus и позволяет назначать IP-адреса на уровне всего кластера. Полезен в сценариях, где требуется точное управление IP-адресами для контейнеров, особенно в средах, где используются дополнительные сетевые интерфейсы и многоуровневая сеть.
Multus Whereabout CNI предоставляет функции:
Назначение IP-адресов в пределах указанного диапазона.
Исключение определенных диапазонов IP-адресов из назначения.
Поддержка IPv4 и IPv6.
Возможность назначения нескольких IP-адресов из разных диапазонов.
Поддержка конфигураций DualStack для одновременного использования IPv4 и IPv6.
Определение начального и конечного IP-адреса для диапазона назначения.
Использование различных хранилищ (etcd, Kubernetes Custom Resource) для отслеживания использованных IP-адресов.
Основные команды и флаги для работы с Multus Whereabout CNI:
oc apply -f <файл.yaml>: команда для применения конфигурационных файлов YAML, необходимых для установки Multus Whereabout CNI.range: команда для определения диапазона IP-адресов, в пределах которого будут назначаться адреса.exclude: команда для определения диапазона IP-адресов, которые следует исключить из назначения.ipRanges: команда определения списка диапазонов IP-адресов для назначения нескольких адресов.enable_overlapping_ranges: флаг для включения или отключения проверки на перекрытие диапазонов IP-адресов.
Руководство по установке Multus Whereabout CNI:
Можно установить с помощью Daemonset или Helm 3.
Примечание
В данном сценарии используется менеджер пакетов Helm. Данный инструмент не входит в состав продукта и требует дополнительной установки.
Установите этот плагин с помощью Daemonset:
git clone https://<repoexample.ru>/k8snetworkplumbingwg/whereabouts && cd whereabouts # Укажите актуальный путь до локального репозитория
oc apply \
-f doc/crds/daemonset-install.yaml \
-f doc/crds/whereabouts.cni.cncf.io_ippools.yaml \
-f doc/crds/whereabouts.cni.cncf.io_overlappingrangeipreservations.yaml
Установите этот плагин с помощью Helm:
git clone https://<repoexample.ru>/k8snetworkplumbingwg/helm-charts.git # Укажите актуальный путь до локального репозитория
cd helm-charts
helm upgrade --install multus ./multus --namespace kube-system
helm upgrade --install whereabouts ./whereabouts --namespace kube-system
Helm установит crdи daemonset.
Сценарии использования Multus Whereabout CNI#
IPAM конфигурации#
Включена полная конфигурация CNI (Container Network Interface). Интерес представляет раздел ipam этой конфигурации CNI. В данном примере используется плагин CNI macvlan.
Обычно уже есть конфигурация CNI для существующего подключаемого pod CNI в кластере, требуется скопировать раздел ipam и изменить значения в нем.
{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"range": "NNN.NNN.N.225/28",
"exclude": [
"NNN.NNN.N.229/30",
"NNN.NNN.N.236/32"
]
}
}
где NNN.NNN.N.225/28, NNN.NNN.N.229/30, NNN.NNN.N.236/32 - актуальные IP адреса выбранных подсетей.
Примечание
Перед применением убедитесь, что параметр master установлен на имя сетевого интерфейса, существующего на pods.
Конфигурации с использованием Multus Admission Controller#
Multus Whereabout CNI особенно полезен в сценариях, где используются дополнительные сетевые интерфейсы. Собственный ресурс Multus Admission Controller может использоваться с метаплагином CNI, таким как Multus CNI, для присоединения нескольких интерфейсов к pods.
Multus Admission Controller содержит конфигурацию CNI, упакованную в собственный ресурс. Вот пример содержащего конфигурацию CNI, которая использует Multus Whereabout CNI для IPAM:
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: whereabouts-conf
spec:
config: '{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"range": "NNN.NNN.N.NNN/NN"
}
}'
где NNN.NNN.N.NNN/NN - актуальный IP адрес выбранной подсети.
Настройки IPv6#
Пример найстройки IPv6:
{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"range": "2001::0/116",
"gateway": "2001::f:1"
}
}
Конфигурации IPAM для назначения нескольких IP-адресов#
Поле ipRanges может использоваться для предоставления списка конфигураций диапазонов для назначения нескольких IP-адресов.
{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"ipRanges": [{
"range": "NNN.NNN.NN.N/NN"
}, {
"range": "MMM.MMM.MM.M/MM"
}]
}
}
где NNN.NNN.NN.N/NN и MMM.MMM.MM.M/MM – актуальные IP адреса выбранных подсетей.
Также поле ipRanges можно использовать в сочетании с основным полем range следующим образом:
{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"ipRanges": [{
"range": "NNN.NNN.NN.N/NN"
}, {
"range": "MMM.MMM.MM.M/MM"
}],
"range": "abcd::1/64"
}
}
где NNN.NNN.NN.N/NN и MMM.MMM.MM.M/MM – актуальные IP адреса выбранных подсетей.
Конфигурации IPAM для назначения нескольких IP-адресов#
Поле ipRanges можно использовать для настройки DualStack:
{
"cniVersion": "0.3.0",
"name": "whereaboutsexample",
"type": "macvlan",
"master": "eth0",
"mode": "bridge",
"ipam": {
"type": "whereabouts",
"ipRanges": [{
"range": "NNN.NNN.NN.N/NN"
}, {
"range": "abcd::1/64"
}]
}
}
где NNN.NNN.NN.N/NN – актуальный IP адрес выбранной подсети.
Multus Networkpolicy#
Multus NetworkPolicy - это инструмент, предоставляемый для обеспечения сетевой безопасности. Используется для управления доступом к сетевым ресурсам в кластере, позволяя администраторам определять правила безопасности для сетевых подключений. В основном Multus NetworkPolicy решает проблему безопасности сети для сетей, созданных с помощью Custom Resource Definition (CRD) (расширенных ресурсов, определенных пользователем), которые находятся за пределами DropApp Plus.
Multus NetworkPolicy реализует функциональность сетевых политик (Network Policies) для сетей, созданных с помощью net-attach-def (еще одного типа CRD) с использованием iptables. Это позволяет применять сетевые политики для таких сетей и обеспечивать их безопасность на уровне сети.
Большинство опций командной строки имеют описание в справке, поэтому выполните с --help, чтобы увидеть опции.
./multi-networkpolicy-iptables --help
Сценарии использования Multus Networkpolicy#
Добавление исключительных префиксов IPv6 для разрешения трафика#
Эти опции позволяют указать исключительные префиксы IPv6, которые должны быть разрешены в сетевой политике, даже если они не указаны в самой политике.
--allow-ipv6-src-prefix=fe80::/10
--allow-ipv6-dst-prefix=fe80::/10,ff00::/8
Добавление пользовательских правил iptables/ip6tables#
Эти опции позволяют добавлять пользовательские правила iptables/ip6tables для IPv4 и IPv6 сетей в соответствующие секции входящего и исходящего трафика.
--custom-v4-ingress-rule-file
--custom-v4-egress-rule-file
--custom-v6-ingress-rule-file
--custom-v6-egress-rule-file
Создание файлов с пользовательскими правилами iptables/ip6tables#
Файлы testv6IngressRules.txt и testv6EgressRules.txt содержат пользовательские правила для разрешения определенного трафика в IPv6-сети.
cat testv6IngressRules.txt
# comment: это правило разрешает пакеты DHCPv6 с локальных адресов
-m udp -p udp --dport 546 -d fe80::/64 -j ACCEPT
cat testv6EgressRules.txt
# comment: это правило разрешает пакеты DHCPv6 на dhcp relay агенты/серверы
-m udp -p udp --dport 547 -d ff02::1:2 -j ACCEPT
Запуск multi-networkpolicy-iptables с указанием файлов пользовательских правил#
Для запуска multi-networkpolicy-iptables с указанием опций, необходимых для конфигурации, включая файлы с пользовательскими правилами для входящего и исходящего трафика в IPv6-сетях, воспользуйтесь командой:
./multi-networkpolicy-iptables \
(здесь указываются другие опции) \
--custom-v6-ingress-rule-file testv6IngressRules.txt \
--custom-v6-egress-rule-file testv6EgressRules.txt
Multus Route Override CNI#
Multus Route Override CNI - это плагин Meta CNI для переопределения IP-маршрута, предоставленного предыдущими плагинами CNI. Этот инструмент полезен в случаях использования с определением прикрепления к сети Network Attachment Definition (NAD), когда требуется изменить маршрутизацию в контейнере. Может быть использован в среде DropApp Plus с такими инструментами как podman и crio.
Multus Route Override CNI предоставляет функции:
Переопределение IP-маршрутов в контейнере.
Возможность очистки маршрутов (flush routes) и/или шлюзов (flush gateway).
Добавление и удаление конкретных маршрутов в контейнерном namespace.
Поддержка пропуска команды проверки CNI.
Основные команды и флаги:
flushroutes: команда указывает, нужно ли очистить все маршруты (кроме маршрутов интерфейсов и link-local).flushgateway: команда указывает, нужно ли очистить шлюз по умолчанию (gateway).delroutes: команда выводит список маршрутов для удаления. Каждый маршрут - это словарь с полямиdstи опциональнымgw.addroutes: команда выводит список маршрутов для добавления. Каждый маршрут - это словарь с полямиdstи опциональнымgw.skipcheck: команда указывает, нужно ли пропустить проверку CNI.
Сценарии эксплуатации кластера DropApp с помощью oc#
С помощью интерфейса командной строки oc возможно создавать приложения и управлять проектами DropApp Plus с терминала. oc используется в следующих ситуациях:
работа напрямую с исходным кодом проекта;
сценарии операций DropApp Plus;
управление проектами, когда ресурсы ограничены пропускной способностью и веб-консоль недоступна.
Установите CLI, загрузив двоичный файл из комплекта поставки.
Установка oc в Linux#
Поместите двоичный файл
ocиз состава поставки в каталогPATH.Чтобы проверить
PATH, выполните следующую команду:echo $PATHПосле установки CLI он доступен с помощью
ocкоманды:oc <command>
Установка oc в Windows#
Переместите двоичный файл
ocв каталогPATH.Чтобы проверить файл в
PATH, откройте командную строку и выполните следующую команду:C:\> pathПосле установки CLI он доступен с помощью
ocкоманды:C:\> oc <command>
Установка oc на macOS#
Переместите двоичный файл
ocв каталогPATH.Чтобы проверить файл в
PATH, откройте командную строку и выполните следующую команду:echo $PATHПосле установки CLI он доступен с помощью
ocкоманды:oc <command>
Вход в CLI#
Предварительные условия:
есть доступ к кластеру;
установлен CLI
oc.
Выполните следующую последовательность:
Введите команду
oc loginи передайте имя пользователя:oc login -u user1При появлении запроса введите необходимую информацию:
Server [https://localhost:8443]: https://openshift.example.com:6443 # Введите URL-адрес сервера DropApp Plus. The server uses a certificate signed by an unknown authority. You can bypass the certificate check, but any data you send to the server could be intercepted by others. Use insecure connections? (y/n): y # Укажите, следует ли использовать небезопасные соединения Authentication required for https://openshift.example.com:6443 (openshift) Username: user1 Password: # Введите пароль пользователя. Login successful. You don't have any projects. You can try to create a new project, by running oc new-project <projectname> Welcome! See 'oc help' to get started.
Примечание
После входа в веб-консоль, возможно сгенерировать команду oc login, включающую необходимый токен и информацию о сервере. Использовуйте эту команду для входа в интерфейс командной строки OKD без интерактивных подсказок. Чтобы ее сгенерировать, выберите «Copy login command» в раскрывающемся меню имени пользователя в правом верхнем углу веб-консоли.
Синтаксис#
Для выполнения команд oc в терминале используйте следующий синтаксис:
oc [command] [TYPE] [NAME] [flags]
Где:
command: определяет выполняемую операцию с одним или несколькими ресурсами, например,create,get,describe,delete;TYPE: определяет тип ресурса. Типы ресурсов не чувствительны к регистру, кроме этого возможно использовать единственную, множественную или сокращенную форму;NAME: определяет имя ресурса. Имена чувствительны к регистру. Если имя не указано, то отображаются подробности по всем ресурсам, например,oc get pod.flags: определяет дополнительные флаги. Использование флагов -s или –server используется, чтобы указать адрес и порт API-сервера.
При выполнении операции с несколькими ресурсами можно выбрать каждый ресурс по типу и имени, либо сделать это в одном или нескольких файлов.
Выбор ресурсов по типу и имени позволяет:
группировать ресурсы, если все они одного типа:
TYPE1 name1 name2 name<#>. Например,oc get pod example-pod1 example-pod2.осуществить выбор нескольких типов ресурсов по отдельности. Например,
TYPE1/name1 TYPE1/name2 TYPE2/name3 TYPE<#>/name<#>.
Использование интерфейса командной строки#
Следующие команды позволяют выполнять типичные задачи с помощью интерфейса командной строки.
Используйте команду
oc new-projectдля создания нового проекта:oc new-project my-projectПример вывода:
Now using project "my-project" on server "https://openshift.example.com:6443".Используйте команду
oc new-appдля создания нового приложения:oc new-app https://github.com/sclorg/cakephp-exПример вывода:
--> Found image 40de956 (9 days old) in imagestream "openshift/php" under tag "7.2" for "php" ... Run 'oc status' to view your app.Используйте команду
oc get podsдля просмотра pods текущего проекта.oc get pods -o wideПример вывода:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE cakephp-ex-1-build 0/1 Completed 0 5m45s NN.NNN.N.NN ip-NN-N-NNN-NN.ec2.internal <none> cakephp-ex-1-deploy 0/1 Completed 0 3m44s MM.MMM.M.M ip-MM-M-MMM-MM.ec2.internal <none> cakephp-ex-1-ktz97 1/1 Running 0 3m33s PP.PPP.P.PP ip-PP-P-PPP-PPP.ec2.internal <none>где
NN.NNN.N.NN,MM.MMM.M.MиPP.PPP.P.PPв примере вывода – актуальные IP адреса pods.Используйте команду
oc logsдля просмотра журналов pod:oc logs cakephp-ex-1-deployПример вывода:
--> Scaling cakephp-ex-1 to 1 --> SuccessИспользуйте команду
oc projectдля просмотра текущего проекта:oc projectПример вывода:
Using project "my-project" on server "https://openshift.example.com:6443".Используйте команду
oc statusдля просмотра информации о текущем проекте, такой как информация о службах, развертывании и конфигурации сборки.oc statusПример вывода:
In project my-project on server https://openshift.example.com:6443 svc/cakephp-ex - NNN.NN.NNN.NN ports 8080, 8443 dc/cakephp-ex deploys istag/cakephp-ex:latest <- bc/cakephp-ex source builds https://github.com/sclorg/cakephp-ex on openshift/php:7.2 deployment #1 deployed 2 minutes ago - 1 pod 3 infos identified, use 'oc status --suggest' to see details.где
NNN.NN.NNN.NN– актуальный IP адрес.Используйте команду
oc api-resource, чтобы просмотреть список поддерживаемых ресурсов API на сервере:oc api-resourcesПример вывода:
NAME SHORTNAMES APIGROUP NAMESPACED KIND bindings true Binding componentstatuses cs false ComponentStatus configmaps cm true ConfigMap ...Используйте
oc helpдля получения списка и описания всех доступных команд CLI:oc helpПример вывода:
OpenShift Client This client helps you develop, build, deploy, and run your applications on any OpenShift or Kubernetes compatible platform. It also includes the administrative commands for managing a cluster under the 'adm' subcommand. Usage: oc [flags] Basic Commands: login Log in to a server new-project Request a new project new-app Create a new application ...Используйте флаг
--help, чтобы получить справку по конкретной команде CLI:oc create --helpПример вывода:
Create a resource by filename or stdin JSON and YAML formats are accepted. Usage: oc create -f FILENAME [flags] ...Используйте команду
oc explainдля просмотра описания и полей конкретного ресурса:oc explain podsПример вывода:
KIND: Pod VERSION: v1 DESCRIPTION: Pod is a collection of containers that can run on a host. This resource is created by clients and scheduled onto hosts. FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#resources ...Выйдите из интерфейса командной строки DropApp Plus, чтобы завершить текущий сеанс, используя команду
oc logout:oc logoutПример вывода:
Например, для службы с именем foo, которая сопоставляется контейнеру с именем bar, определены следующие переменные:
FOO_SERVICE_HOST=<the host the service is running on> FOO_SERVICE_PORT=<the port the service is running on>Получите доступ к API DropApp, используя oc клиентские библиотеки или отправляя запросы REST.
Во всех кластерах DropApp есть две категории пользователей: учетные записи служб, управляемые DropApp, и обычные пользователи.
Предполагается, что независимая от кластера DropApp служба управляет обычными пользователями через администратора, распространяющего закрытые ключи. В связи с этим в DropApp нет объектов, которые представляют обычные учетные записи пользователей. Обычных пользователей нельзя добавить в кластер DropApp с помощью вызова API.
Авторизация отделена от аутентификации и контролирует обработку HTTP-вызовов. Пройдите проверку подлинности, прежде чем запрос может быть авторизован (и предоставлено разрешение на доступ).
Используйте контроллеры допуска explains plug-ins which intercepts requests to the DropApp API server after authentication and authorization.
Процесс контроля допуска выполняется в два этапа. На первом этапе выполняются изменяющие контроллеры допуска. На втором этапе выполняется проверка контроллеров допуска. Еще раз обратите внимание, что некоторые контроллеры выполняются обоими этапами.
Если какой-либо из контроллеров на любом этапе отклоняет запрос, весь запрос немедленно отклоняется, и конечному пользователю возвращается ошибка.
Контроллеры допуска иногда могут иметь побочные эффекты, то есть изменять связанные ресурсы как часть обработки запроса. Любой побочный эффект требует соответствующего процесса исправления или согласования, поскольку данный контроллер допуска не знает наверняка, что данный запрос пройдет все другие контроллеры допуска.
Используйте функцию ядра SLO Sysctls в кластере DropApp, который описывает администратору, как использовать sysctl - интерфейс командной строки для установки параметров ядра.
Используйте аудит, чтобы взаимодействовать с журналами аудита DropApp. Каждый запрос может быть записан с соответствующим этапом. Определенные этапы являются:
RequestReceived - этап для событий, генерируемых, как только обработчик аудита получает запрос, и до того, как он будет делегирован вниз по цепочке обработчиков.
ResponseStarted - этап после отправки заголовков ответа, но до отправки тела ответа. Этот этап генерируется только для длительных запросов (например, watch).
ResponseComplete - этап, когда ответ завершен, и байты отправляться не будут.
Panic - события, генерируемые при возникновении kernel panic.
Настройка кластера DropApp:
При определении конфигураций укажите последнюю стабильную версию API.
Файлы конфигурации храните в системе управления версиями перед отправкой в кластер DropApp. Это позволяет быстро откатить изменение конфигурации при необходимости. Это также помогает в повторном создании и восстановлении кластера.
Запишите файлы конфигурации, используя YAML, а не JSON. Хотя эти форматы могут использоваться взаимозаменяемо почти во всех сценариях, YAML, как правило, более удобен для пользователя.
Группируйте связанные объекты в один файл всякий раз, когда это имеет смысл. Часто одним файлом управлять проще, чем несколькими. Посмотрите файл guestbook-all-in-one.yaml в качестве примера этого синтаксиса.
Обратите также внимание, что многие oc команды могут вызываться в каталоге. Например, можно вызвать каталог конфигурационных файлов oc apply.
Не указывайте значения по умолчанию без необходимости: простая, минимальная конфигурация сделает ошибки менее вероятными.
Поместите описания объектов в аннотации, чтобы обеспечить лучший самоанализ.
Naked pods в сравнении с наборами копий, развертываниями и заданиями:
Не используйте открытые pods (то есть pods, не привязанные к набору реплик или развертыванию), если можно этого избежать. Открытые pods не будут перенесены в случае сбоя узла.
Развертывание, которое одновременно создает набор копий, чтобы гарантировать, что желаемое количество pods всегда доступно, и определяет стратегию замены pods (например, RollingUpdate), почти всегда предпочтительнее, чем прямое создание pods.
Услуги:
Создайте службу перед соответствующими рабочими нагрузками ее серверной части (развертываниями или наборами реплик) и перед любыми рабочими нагрузками, которым требуется доступ к ней. Когда DropApp запускает контейнер, он предоставляет переменные среды, указывающие на все службы, которые были запущены при запуске контейнера. Например, если служба с именем foo существует, все контейнеры получат следующие переменные в своей исходной среде:
FOO_SERVICE_HOST=<the host the Service is running on>
FOO_SERVICE_PORT=<the port the Service is running on>
Это подразумевает требование к порядку – все, к чему pod может получить доступ, должно быть создано перед pod, иначе переменные среды не будут заполнены. DNS не имеет этого ограничения. Необязательным (хотя и настоятельно рекомендуемым) кластерным дополнением является DNS-сервер. DNS-сервер проверяет API DropApp на наличие новых services и создает набор записей DNS для каждой. Если DNS был включен во всем кластере DropApp, то все pods должны иметь возможность автоматически разрешать имена services.
Не указывайте hostPort для pod, если это не является абсолютно необходимым. Когда pod привязан к hostPort, это ограничивает количество мест, которые pod может запланировать, потому что каждая комбинация hostIP, hostPort, protocol должна быть уникальной. Если не указать hostIP и protocol явно, DropApp Plus будет использовать 0.0.0.0 по умолчанию hostIP и TCP по умолчанию protocol.
Если вам нужен доступ к порту только для целей отладки, возможно использование прокси-сервера api-server или oc port-forward.
Если необходимо предоставить доступ к порту pod на узле, рассмотрите возможность использования службы NodePort, прежде чем прибегать к hostPort.
Использование меток:
Определите и используйте метки, которые идентифицируют семантические атрибуты приложения или развертывания, такие как { app.kubernetes.io/name: MyApp, tier: frontend, phase: test, deployment: v3 }. Можно использовать метки для выбора подходящих pods для других ресурсов; например, службы, которая выбирает все tier: frontend pods или все phase: test компоненты app.dropapp.io/name: MyApp.
Служба может охватывать несколько развертываний, если в ее селекторе не указаны метки, относящиеся к конкретной версии. Когда вам нужно обновить работающую службу без простоев, используйте deployment.
Желаемое состояние объекта описывается deployment, и если применяются изменения к этой спецификации, контроллер развертывания изменяет фактическое состояние на желаемое состояние с контролируемой скоростью.
Используйте общие метки DropApp для распространенных вариантов использования. Эти стандартизированные метки обогащают метаданные таким образом, что позволяют инструментам, включая oc и панель управления, работать совместимым образом.
Можно манипулировать метками для отладки. Поскольку контроллеры DropApp (такие, как - ReplicaSet) и службы соответствуют pods с использованием меток выбора, удаление соответствующих меток из pod остановит его рассмотрение контроллером или передачу трафика службой. Если удалить метки существующего pod, его контроллер создаст новый pod, который займет его место. Для интерактивного удаления или добавления меток используйте oc label.
Использование oc:
Используйте oc apply -f <directory>. Команда ищет конфигурацию DropApp во всех .yaml, .yml и .json файлах в <directory> и передает ее apply.
Используйте селекторы меток для get и delete операций вместо конкретных имен объектов. Смотрите разделы, посвященные селекторам меток и эффективному использованию меток.
Используйте oc create deployment и oc expose для быстрого создания одноконтейнерных развертываний и служб.
Операции#
В следующей таблице приведены краткие описания и общий синтаксис всех операций oc:
Операция |
Синтаксис операции |
Описание операции |
|---|---|---|
annotate |
|
Добавить или обновить аннотации одного или нескольких ресурсов |
api-versions |
|
Вывести доступные версии API |
apply |
|
Внести изменения в конфигурацию ресурса из файла или потока stdin |
attach |
|
Подключиться к запущенному контейнеру либо для просмотра потока вывода, либо для работы с контейнером (stdin) |
autoscale |
|
Автоматически промасштабировать набор pods, управляемых контроллером репликации |
cluster-info |
|
Показать информацию о главном узле и сервисах в кластере DropApp |
config |
|
Изменить файлы kubeconfig. Подробные сведения смотрите в отдельных подкомандах |
create |
|
Создать один или несколько ресурсов из файла или stdin |
delete |
|
Удалить ресурсы из файла, потока stdin, либо с помощью селекторов меток, имен, селекторов ресурсов или ресурсов |
describe |
|
Показать подробное состояние одного или нескольких ресурсов |
diff |
|
Файл Diff или stdin в соответствии с текущей конфигурацией |
edit |
|
Отредактировать и обновить определение одного или нескольких ресурсов на сервере, используя редактор по умолчанию |
exec |
|
Выполнить команду в контейнере pod. |
explain |
|
Посмотреть документацию по ресурсам. Например, pods, узлы, сервисы и т.д. |
expose |
|
Создать DropApp-сервис из контроллера репликации, сервиса или pod |
get |
|
Вывести один или несколько ресурсов |
label |
|
Добавить или обновить метки для одного или нескольких ресурсов |
logs |
|
Вывести логи контейнера в pod |
patch |
|
Обновить один или несколько полей ресурса, используя стратегию слияния патча |
port-forward |
|
Переадресовать один или несколько локальных портов в pod |
proxy |
|
Запустить прокси для API DropApp |
replace |
|
Заменить ресурс из файла или потока stdin |
rolling-update |
|
Выполнить плавающее обновление, постепенно заменяя указанный контроллер репликации и его pods |
run |
|
Запустить указанный образ в кластере DropApp |
scale |
|
Обновить размер указанного контроллера репликации |
version |
|
Отобразить версию DropApp, запущенного на клиенте и сервере |
Типы ресурсов#
В таблице перечислены все доступные типы ресурсов вместе с сокращенными аббревиатурами.
Имя ресурса |
Короткое имя |
Группа API |
Значение в namespace |
Вид ресурса |
|---|---|---|---|---|
bindings |
- |
- |
true |
Binding |
componentstatuses |
cs |
- |
false |
ComponentStatus |
configmaps |
cm |
- |
true |
ConfigMap |
endpoints |
ep |
- |
true |
Endpoints |
limitranges |
limits |
- |
true |
LimitRange |
namespaces |
ns |
- |
false |
Namespace |
nodes |
no |
- |
false |
Node |
persistentvolumeclaims |
pvc |
- |
true |
PersistentVolumeClaim |
persistentvolumes |
pv |
- |
false |
PersistentVolume |
pods |
po |
- |
true |
Pod |
podtemplates |
- |
- |
true |
PodTemplate |
replicationcontrollers |
rc |
- |
true |
ReplicationController |
resourcequotas |
quota |
- |
true |
ResourceQuota |
secrets |
- |
- |
true |
Secret |
serviceaccounts |
sa |
- |
true |
ServiceAccount |
services |
svc |
- |
true |
Service |
mutatingwebhookconfigurations |
- |
admissionregistration.k8s.io |
false |
MutatingWebhookConfiguration |
validatingwebhookconfigurations |
- |
admissionregistration.k8s.io |
false |
ValidatingWebhookConfiguration |
customresourcedefinitions |
crd, crds |
apiextensions.k8s.io |
false |
CustomResourceDefinition |
apiservices |
- |
apiregistration.k8s.io |
false |
APIService |
controllerrevisions |
- |
apps |
true |
ControllerRevision |
daemonsets |
ds |
apps |
true |
DaemonSet |
deployments |
deploy |
apps |
true |
Deployment |
replicasets |
rs |
apps |
true |
ReplicaSet |
statefulsets |
sts |
apps |
true |
StatefulSet |
tokenreviews |
- |
authentication.k8s.io |
false |
TokenReview |
localsubjectaccessreviews |
- |
authorization.k8s.io |
true |
LocalSubjectAccessReview |
selfsubjectaccessreviews |
- |
authorization.k8s.io |
false |
SelfSubjectAccessReview |
selfsubjectrulesreviews |
- |
authorization.k8s.io |
false |
SelfSubjectRulesReview |
subjectaccessreviews |
- |
authorization.k8s.io |
false |
SubjectAccessReview |
horizontalpodautoscalers |
hpa |
autoscaling |
true |
HorizontalPodAutoscaler |
cronjobs |
cj |
batch |
true |
CronJob |
jobs |
- |
batch |
true |
Job |
certificatesigningrequests |
csr |
certificates.k8s.io |
false |
CertificateSigningRequest |
leases |
- |
coordination.k8s.io |
true |
Lease |
events |
ev |
events.k8s.io |
true |
Event |
ingresses |
ing |
extensions |
true |
Ingress |
networkpolicies |
netpol |
networking.k8s.io |
true |
NetworkPolicy |
poddisruptionbudgets |
pdb |
policy |
true |
PodDisruptionBudget |
podsecuritypolicies |
psp |
policy |
false |
PodSecurityPolicy |
clusterrolebindings |
- |
rbac.authorization.k8s.io |
false |
ClusterRoleBinding |
clusterroles |
- |
rbac.authorization.k8s.io |
false |
ClusterRole |
rolebindings |
- |
rbac.authorization.k8s.io |
true |
Role |
roles |
- |
rbac.authorization.k8s.io |
true |
Role |
priorityclasses |
pc |
scheduling.k8s.io |
false |
PriorityClass |
csidrivers |
- |
storage.k8s.io |
false |
CSIDriver |
csinodes |
- |
storage.k8s.io |
false |
CSINode |
storageclasses |
sc |
storage.k8s.io |
false |
StorageClass |
volumeattachments |
- |
storage.k8s.io |
false |
VolumeAttachment |
Опции вывода#
В следующих разделах рассматривается форматирование и сортировка вывода определенных команд.
Форматирование вывода#
Стандартный формат вывода всех команд oc представлен в понятном для человека текстовом формате. Чтобы вывести подробности в определенном формате можно добавить флаги -o или --output к команде oc.
Синтаксис#
Команды должны иметь следующую форму:
oc [command] [TYPE] [NAME] -o <output_format>
В зависимости от операции, вoc поддерживаются форматы вывода, представленные в таблице ниже:
Выходной формат |
Описание |
|---|---|
|
Вывод таблицы с использованием списка пользовательских столбцов, разделенного запятыми |
|
Вывод таблицы с использованием шаблона с пользовательскими столбцами в файле |
|
Вывод API-объекта в формате JSON |
|
Вывод поля, определенного в выражении jsonpath |
|
Вывод полей, определенных в выражении jsonpath из файла |
|
Вывод только имени ресурса |
|
Вывод в текстовом формате с дополнительной информацией. Для pods отображается имя узла |
|
Вывод API-объекта в формате YAML |
Пример формата вывода представлен следующей командой, которая выводит подробную информацию по указанному pod в виде объекта в YAML-формате:
oc get pod web-pod-13je7 -o yaml
Пользовательские столбцы#
Для определения пользовательских столбцов и вывода в таблицу только нужных данных, можно использовать опцию custom-columns. Возможно так же определить пользовательские столбцы в самой опции, либо сделать это в файле шаблона:-o custom-columns=<spec> или -o custom-columns-file=<filename>.
Опциональные примеры команд:
Столбцы указаны в самой команде:
oc get pods <pod-name> -o custom-columns=NAME:.metadata.name,RSRC:.metadata.resourceVersionСтолбцы указаны в файле шаблона:
oc get pods <pod-name> -o custom-columns-file=template.txtГде файл template.txt содержит следующий вывод:
NAME RSRC metadata.name metadata.resourceVersion
Результат выполнения любой из показанной выше команды представлен ниже:
NAME RSRC
submit-queue 610995
Получение вывода с сервера#
oc может получать информацию об объектах с сервера. Это означает, что для любого обозначенного объекта сервер вернет столбцы и строки. Благодаря тому, что сервер изолирует реализацию вывода – гарантируется единообразный и понятный для человека вывод на всех машинах, использующих один и тот же кластер DropApp.
Эта функциональность включена по умолчанию. Чтобы отключить ее, необходимо добавить флаг --server-print=false в команду oc get.
Пример вывода информации о состоянии pod с использованием команды oc get:
oc get pods <pod-name> --server-print=false
Вывод будет выглядеть следующим образом:
NAME READY STATUS RESTARTS AGE
pod-name 1/1 Running 0 1m
Сортировка списка объектов#
Для вывода объектов в виде отсортированного списка в терминал используется флаг --sort-by к команде oc. Для сортировки объектов нужно указать любое числовое или строковое поле в флаге --sort-by. Для определения поля следует использовать выражение jsonpath.
Синтаксис команды будет выглядеть следующим образом:
oc [command] [TYPE] [NAME] --sort-by=<jsonpath_exp>
Чтобы вывести список pods, отсортированных по имени, необходимо выполнить команду:
oc get pods --sort-by=.metadata.name
Распространенные сценарии использования oc#
В разделе приведены наиболее распространенные сценарии использования операций oc: oc apply. Эта команда необходима для внесения изменения или обновления ресурса из файла/потока stdin.
Чтобы использовать oc:
Создайте сервис из определения в example-service.yaml:
oc apply -f example-service.yamlСоздайте контроллер репликации из определения в example-controller.yaml:
oc apply -f example-controller.yamlСоздайте объекты, которые определены в файлах с расширением .yaml, .yml или .json в директории directory.
oc apply -f <directory>Выведите один или несколько ресурсов и все pods в текстовом формате:
oc get pods -AПроверить все pods в определенном namespace.
oc get pods -n [namespace]Выведите все pods в текстовом формате вывода и включите дополнительную информацию (например, имя узла).
oc get pods -o wideВыведите контроллер репликации с указанным именем в текстовом формате вывода:
oc get replicationcontroller <rc-name>Выведите все контроллеры репликации и сервисы вместе в текстовом формате вывода:
oc get rc,servicesВыведите все наборы демонов в текстовом формате вывода:
oc get dsВыведите все pods, запущенные на узле server01:
oc get pods --field-selector=spec.nodeName=server01Посмотрите подробное состояние одного или нескольких ресурсов. Обратите внимание, что по умолчанию также включаются неинициализированные ресурсы. Например, описать состояние pod в namespace cube system.
oc describe pod <pod-name> -n kube-systemПосмотрите информацию об узле с именем
<node-name>.:oc describe nodes <node-name>Посмотрите подробности pod
<pod-name>:oc describe <pod-name>Посмотрите подробности всех pods, управляемых контроллером репликации
<rc-name>.Примечание: Любые pods, созданные контроллером репликации, имеют префикс с именем контроллера репликации:
oc describe pods <rc-name>Посмотрите подробности по всем pods:
oc describe podsПримечание: Команда
oc getиспользуется для получения одного или нескольких ресурсов одного и того же типа. Она поддерживает большой набор флагов, с помощью которых можно настроить формат вывода, например, с помощью флага-oили--output.Чтобы отслеживать изменения в конкретном объекте, необходимо указать флаг
-wили--watch. Командаoc describeфокусируется на описании взаимосвязанных аспектов указанного ресурса. При генерации вывода для пользователя она может обращаться к API-серверу. Например, командаoc describe nodeвыдает не только информацию об узле, но и краткий обзор запущенных на нем pods, генерируемых событий и т.д.Удалите ресурсы из файла потока
stdinпри помощи селекторов меток, селекторов ресурсов или имен ресурсов:oc delete ([-f FILENAME] | TYPE [(NAME | -l label | --all)])Примеры:
# Удалить pod, используя тип и имя, указанные в pod.json. oc delete -f ./pod.json # Удалить pod на основе типа и имени в JSON, переданном в stdin. cat pod.json | oc delete -f - # Удалить pod и сервисы с одинаковыми названиями "baz" и "foo" oc delete pod,service baz foo # Удалить pod и сервисы с именем метки=myLabel. oc delete pods,services -l name=myLabel # Удалить pod с UID 1234-56-7890-234-456. oc delete pod 1234-56-7890-234234-456456 # Удалить все pods oc delete pods --allУдалите pod по типу и имени, которые указаны в файле pod.yam:
oc delete -f pod.yamlУдалите все pods и сервисы с именем метки
<label-name>:oc delete pods,services -all name=<label-name>Удалите все pods, включая неинициализированные:
oc delete pods --allПолучите вывод от запущенной команды
dateв pod<pod-name>. По умолчанию отобразится следующий вывод из первого контейнера:oc exec <pod-name> dateПолучите вывод из запущенной команды
dateв контейнере<container-name>для pod<pod-name>:oc exec <pod-name> -c <container-name> dateЗапустите интерактивный терминал
(TTY)и/bin/bashв pod<pod-name>. По умолчанию отобразится следующий вывод из первого контейнера:oc exec -ti <pod-name> /bin/bashВыведите логи контейнера в pod:
oc logsВыведите текущие логи в pod, как представлено ниже при помощи команды
<pod-name>:oc logs <pod-name>Выведите логи в pod
<pod-name>в режиме реального времени. Это похоже на команду 'tail -f' Linux.oc logs -f <pod-name>
Управление рабочей нагрузкой посредством oc#
Создание нового namespace:
Для создания нового namespace используйте команду:
oc create namespace <test>Для создания/редактирования ресурсов используйте команду:
oc edit / oc patchДля удаления ресурсов используйте команду:
oc delete ([-f FILENAME] | TYPE [(NAME | -l label | --all)])Пример создания нового namespace с названием myapp:
oc create namespace myappВ результате будет получен вывод:
~# oc create namespace myapp namespace/myapp created ~#Убедитесь, что новое namespace отображается, при помощи команды:
oc get namespaceВ результате будет получен вывод:
~# oc get ns NAME STATUS AGE default Active 71m kube-system Active 71m kube-public Active 71m kube-node-lease Active 71m myapp Active 49s ~#
Запуск рабочей нагрузки oc:
Сценарий возможно осуществить с помощью команды oc create. Для изменения и создания объектов, используйте команды oc, которые берут на вход описание объектов:
oc create -f {файл с описанием объекта} для создания объектов;
oc apply -f {файл с описанием объекта} для обновления объектов;
oc delete -f {файл с описанием объекта} для удаления объекта.
Примечание: написание объекта может быть в различных форматах - json, yaml и т.д.
На основе текущего namespace и по стандартным для объекта полям - apiVersion, kind, metadata.name, oc находит соответствующий ресурс в API и совершает запросы к API Server. Для этого:
Воспользуйтесь описанием ресурса в файле { }.json и создайте объект pod с помощью следующей команды:
oc create -f hello-service.jsonЗапрос сделанный oc в API Server, будет идентичен запросу в сценарий запуска нагрузки.
После этого шага запросите статус объекта pod:
oc get pod hello-demoВ результате будет получен вывод:
~# oc get pod hello-demo NAME READY STATUS RESTARTS AGE hello-demo 1/1 Running 0 4m34s ~#При необходимости удалите ресурс, отвечающий за рабочую нагрузку с помощью команды:
oc delete -f hello-service.jsonВ результате будет получен вывод:
~# oc delete -f hello-service.json pod "hello-demo" deleted ~#
Сетевые политики (Network Policies)#
Если необходимо управлять потоком трафика на уровне IP-адреса или порта (уровень OSI 3 или 4), то можно рассмотреть возможность использования NetworkPolicies для конкретных приложений в кластере DropApp. Сетевые политики – это конструкция, ориентированная на приложения, которая позволяет указать, как pod разрешено взаимодействовать с различными сетевыми «объектами» (термин «объект» используется здесь, чтобы избежать перегрузки более распространенных терминов, таких как «конечные точки» и «службы», которые имеют специфические коннотации DropApp) по сети. Сетевые политики применяются к соединению с pods на одном или обоих концах и не имеют отношения к другим подключениям.
Объекты, с которыми pod может взаимодействовать, идентифицируются с помощью комбинации следующих 3 идентификаторов:
других pods, которые разрешены (исключение: pod не может заблокировать доступ к себе);
разрешенные namespaces;
IP-блоки (исключение составляет трафик к узлу, на котором запущен pod. С этого узла трафик всегда разрешен, независимо от IP-адреса pod или самого узла).
При определении сетевой политики на основе pod или namespace используйте селектор, чтобы указать, какой трафик разрешен для и из pod, которые соответствуют селектору. Когда создаются сетевые политики на основе IP, пользователи определяют политики на основе блоков IP (диапазонов CIDR).
Предварительные требования:
Сетевые политики реализуются с помощью сетевого плагина. Чтобы использовать сетевые политики, необходимо использовать сетевое решение, поддерживающее NetworkPolicy. Создание ресурса NetworkPolicy без контроллера, который его реализует, не будет иметь эффекта.
Два вида изоляции pod:
Существует два вида изоляции для pod: изоляция для «Egress» и изоляция для «Ingress». Они касаются того, какие соединения могут быть установлены. «Изоляция» здесь не является абсолютной, скорее это означает «применяются некоторые ограничения». Альтернатива «неизолированный для $direction» означает, что в указанном направлении не применяются никакие ограничения. Два вида изоляции (или более, чем два вида) объявляются независимо, и оба имеют отношение к соединению от одного pod к другому.
По умолчанию pod не изолирован для выхода: разрешены все исходящие подключения. Pod изолирован для выхода, если существует какая-либо сетевая политика, которая одновременно выбирает pod и имеет «Egress» в своем policyTypes. Когда pod изолирован для выхода, единственными разрешенными подключениями из pod являются те, которые разрешены Egress списком сетевой политики и применяются к pod.
По умолчанию pod не изолирован для входа: разрешены все входящие подключения. Pod изолирован для входа, если существует какая-либо сетевая политика, которая одновременно выбирает pod и имеет «Ingress» в policyTypes: такая политика применяется к pod для входа. Когда pod изолирован для входа, единственными разрешенными подключениями к pod являются соединения с узла pod и те, которые разрешены Ingress списком сетевой политики и применяются к pod для входа.
Сетевые политики не конфликтуют: они дополняют друг друга. Если какая-либо политика или положения применяются к данному pod для данного направления, соединения, разрешенные в этом направлении из этого pod, являются объединением того, что разрешено применимыми политиками. Таким образом, порядок оценки не влияет на результат политики.
Для того чтобы соединение из pod источника в pod назначения было разрешено, необходимо разрешить подключение как политикой «Ingress» в pod источника, так и политикой «Egress» в pod назначения. Если какая-либо из сторон не разрешает подключение, этого не произойдет.
Ресурс сетевой политики:
Пример сетевой политики может выглядеть следующим образом:
service/networking/networkpolicy.yaml Скопируйте сервис / сеть/networkpolicy.yaml в буфер обмена
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
namespace: default
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: NNN.NN.0.0/16
except:
- NNN.NN.1.0/24
- namespaceSelector:
matchLabels:
project: myproject
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: MM.M.M.0/24
ports:
- protocol: TCP
port: 5978
где NNN.NN.0.0/16, NNN.NN.1.0/24, MM.M.M.0/24 – выбранные подсети.
Примечание: Подключение политики выхода в pod источника и политики входа в pod на сервере API для кластера DropApp на сервере API для кластера DropApp не будет иметь никакого эффекта, если выбранная сеть поддерживает сетевую политику.
Обязательные поля (Mandatory Fields): как и во всех других конфигурациях DropApp, для сетевой политики необходимы поля apiVersion, kind и metadata.
Спецификация (spec): спецификация NetworkPolicy содержит всю информацию, необходимую для определения конкретной сетевой политики в данном namespace.
Pod-cелектор (podSelector): каждая сетевая политика включает в себя podSelector, выбирающий группировку pods, к которым применяется политика. В примере политики выбираются pods с меткой role=db. Пустое значение podSelector выбирает все pods в namespace.
Типы политик (policyTypes): каждая сетевая политика включает в себя policyTypes список, который может включать в себя ingress, egress или сразу оба типа. Поле policyTypes указывает, применяется ли данная политика к входящему трафику в выбранный pod, исходящему трафику из выбранных pods или к обоим типам. Если в сетевой политике указано не policyTypes, то по умолчанию всегда будет установлено ingress, а egress установится, если сетевая политика имеет какие-либо правила выхода.
Вход (ingress): каждая сетевая политика может включать список разрешенных ingress правил. Каждое правило разрешает трафик, соответствующий разделам from и ports. Пример политики (представлен выше) содержит единственное правило, которое сопоставляет трафик на одном порту с одним из трех источников, первый из них указан через ipBlock, второй через namespaceSelector, а третий через podSelector.
Выход (egress): каждая сетевая политика может содержать список разрешенных egress правил. Каждое правило разрешает трафик, соответствующий разделам to и ports. Пример политики (представлен выше) содержит единственное правило, которое сопоставляет трафик по одному порту в любой выбранной подсети (в примере MM.M.M.0/24).
Ниже представлен пример сценария NetworkPolicy:
Изолируйте role=db pods в default namespace как для входящего, так и для исходящего трафика (если они еще не были изолированы).
Используйте правила входа для разрешения подключения ко всем pods в default namespace с меткой role=db на TCP-порту 6379 из:
любого pod в default namespace с меткой
role=frontend;любого pod в namespace с меткой
project=myproject;IP–адреса в диапазонах
NNN.NN.0.0–NNN.NN.0.255иNNN.NN.2.0-NNN.NN.255.255(т.е. все из них,NNN.NN.0.0/16кромеNNN.NN.1.0/24).
Используйте правила выхода для разрешения подключения из любого pod в default namespace с меткой role=db к CIDR
MM.M.M.0/24на TCP-порту 5978.Logged "user1" out on "https://openshift.example.com"
События системного журнала#
Администратор кластера может развернуть ведение журнала DropApp Plus для агрегирования всех журналов из кластера, таких как: журналы аудита системы nodes, журналы контейнера приложений и журналы инфраструктуры. Logging объединяет журналы со всего кластера и сохраняет их в хранилище журналов по умолчанию.
Для визуализации данных журнала возможно использовать веб-консоль Kibana. Не входит в состав поставки DropApp Plus и не является обязательным инструментом.
Logging объединяет следующие типы журналов:
application— журналы контейнера, генерируемые пользовательскими приложениями, работающими в кластере, за исключением приложений-контейнеров инфраструктуры;infrastructure— журналы, генерируемые компонентами инфраструктуры, работающими в кластере и nodes. Компоненты инфраструктуры — это pods, которые запускаются в проектахopenshift,kubeилиdefault.audit— журналы, созданныеAuditd- системой аудита nodes, которые хранятся в файле/var/log/audit/audit.log, а также журналы аудита с API-серверов Kubernetes и DropApp Plus.
Основными компонентами Logging являются:
сбор — это компонент, который собирает логи из кластера, форматирует их и пересылает в хранилище логов. По умолчанию реализуется с помощью Fluentd. Не входит в состав поставки DropApp Plus и не является обязательным инструментом;
хранилище журналов — это компонент, где хранятся журналы. По умолчанию реализуется с помощью Elasticsearch. Не входит в состав поставки DropApp Plus и не является обязательным инструментом. Хранилище журналов по умолчанию оптимизировано для краткосрочного хранения;
визуализация — это компонент пользовательского интерфейса, который можно использовать для просмотра журналов, графиков, диаграмм и т.д. По умолчанию реализуется с помощью Kibana. Не входит в состав поставки DropApp Plus и не является обязательным инструментом.
Поля записи системного журнала#
Следующие поля могут присутствовать в записях журнала, экспортируемых Logging:
message;
structured;
@timestamp;
hostname;
ipaddr4;
ipaddr6;
level;
pid;
service;
tags;
file;
offset;
kubernetes:
kubernetes.pod_name;
kubernetes.pod_id;
kubernetes.namespace_name;
kubernetes.namespace_id;
kubernetes.host;
kubernetes.container_name;
kubernetes.annotations;
kubernetes.labels;
kubernetes.event;
kubernetes.event.verb;
kubernetes.event.metadata;
kubernetes.event.involvedObject;
kubernetes.event.reason;
kubernetes.event.source_component;
OpenShift;
openshift.labels.
Записи системного журнала форматируются как объекты JSON.
Для поиска по этим полям в Elasticsearch и Kibana используйте при поиске полное имя поля, разделенное точками. Например, с URL-адресом Elasticsearch /_search для поиска имени pod используйте /_search/q=kubernetes.pod_name:name-of-my-pod.
Поля верхнего уровня могут присутствовать в каждой записи.
Исходный текст записи журнала имеет кодировку UTF-8.
Уровни ведения журнала из различных источников#
Следующие значения уровней ведения журнала записываются в файл syslog.h, и им предшествуют их числовые эквиваленты:
0=
emerg: система непригодна для использования;1=
alert: меры должны быть приняты немедленно;2=
crit: критические условия;3=
err: условия ошибки;4=
warn: условия предупреждения;5=
notice: нормальное, но значимое состояние;6=
info: информационный;7=
debug: сообщения уровня отладки;
Два следующих значения не являются частью syslog.h, но широко используются:
8=
trace: сообщения уровня трассировки, которые более подробны, чемdebugсообщения;9=
unknown: когда система журналирования получает значение, которое она не распознает.
Важно
Использование уровней журналирования ниже 6: info, debug, trace, unknown не рекомендуется в промышленных инсталляциях в виду большого объема событий, а так же большой вероятности вывода чувствительной информации (данных пользователей, IP-адресов и пр.).
События мониторинга#
События показывают, что происходит в кластере DropApp Plus при изменении состояния или ошибках, вызванных другими ресурсами системы. События — это тип ресурса, который автоматически создается всеми основными компонентами и расширениями в кластере через API-сервер.
Доступ к логам событий можно получить напрямую из кластера при помощи команды oc.
Чтобы получить список событий, запустите команду, которая выводит список событий по определенному ресурсу или всему кластеру DropApp Plus.
DropApp Plus включает предварительно настроенный, предустановленный и самообновляемый стек, который обеспечивает мониторинг основных компонентов. Существует возможность включить мониторинг для пользовательских проектов.
Администратор кластера может настроить стек мониторинга с использованием поддерживаемых конфигураций.
По умолчанию включен набор оповещений, которые немедленно уведомляют администраторов кластера о проблемах. Панели мониторинга по умолчанию в веб-консоли OKD включают визуальное представление показателей кластера.
С помощью веб-консоли OKD возможно просматривать показатели, оповещения и управлять ими, а также просматривать информационные панели мониторинга. DropApp Plus также предоставляет доступ к сторонним интерфейсам, таким как Prometheus и Grafana.
После установки DropApp Plus администраторы кластера могут дополнительно включить мониторинг пользовательских проектов. Используя эту функцию, администраторы кластера, разработчики и другие пользователи могут указать, как отслеживать службы и модули в их собственных проектах.
Стек мониторинга#
Стек мониторинга DropApp Plus основан на проекте с открытым исходным кодом Prometheus и его экосистеме. Стек мониторинга включает в себя следующее:
Компоненты мониторинга платформы по умолчанию. Набор компонентов мониторинга платформы устанавливается в проект openshift-monitoring по умолчанию при установке DropApp Plus. Это обеспечивает мониторинг основных компонентов DropApp Plus, включая службы Kubernetes. Стек мониторинга по умолчанию также обеспечивает удаленный мониторинг работоспособности кластеров. Эти компоненты показаны в разделе «Установлено по умолчанию» на схеме.
Компоненты для мониторинга пользовательских проектов. После опционального включения мониторинга для пользовательских проектов в проект openshift-user-workload-monitoring устанавливаются дополнительные компоненты мониторинга. Это обеспечивает мониторинг пользовательских проектов. Эти компоненты показаны в разделе «Пользователь» на схеме.
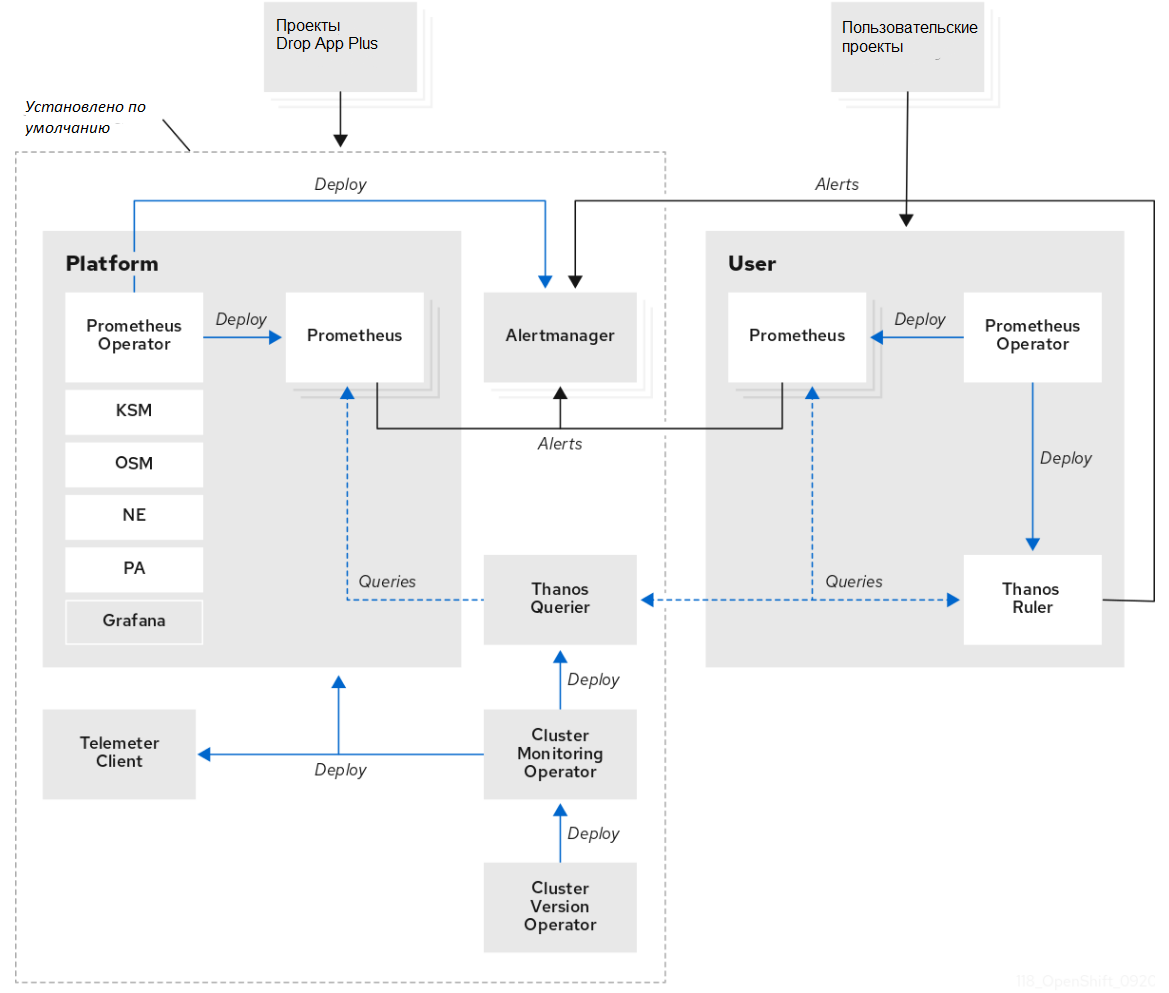
Компоненты мониторинга по умолчанию#
По умолчанию стек мониторинга DropApp Plus включает в себя следующие компоненты:
Компонент |
Описание |
|---|---|
Cluster Monitoring Operator |
Развертывает, управляет и автоматически обновляет экземпляры Prometheus и Alertmanager, Thanos Querier, Telemeter Client и целевые показатели метрик. CMO развертывается оператором версий кластера (CVO). Центральный компонент стека мониторинга |
Prometheus Operator |
Создает, настраивает и управляет экземплярами Prometheus и экземплярами Alertmanager. Также автоматически генерирует целевые конфигурации мониторинга на основе запросов меток |
Prometheus |
Является базой данных временных рядов и механизмом оценки правил для метрик. Prometheus отправляет оповещения в Alertmanager для обработки |
Prometheus Adapter |
Преобразует запросы nodes и pods для использования в Prometheus. Преобразуемые показатели ресурсов включают показатели использования ЦП и памяти. Адаптер Prometheus предоставляет API метрик ресурсов кластера для горизонтального автоматического масштабирования pods. Адаптер Prometheus также используется командами |
Alertmanager |
Обрабатывает оповещения, полученные от Prometheus. Alertmanager также отвечает за отправку оповещений во внешние системы уведомлений |
kube-state-metrics agent |
Преобразует объекты DropApp Plus в метрики, которые может использовать Prometheus. KSM на предыдущей схеме |
openshift-state-metrics agent |
Расширяет kube-state-metrics за счет добавления показателей для ресурсов, специфичных для DropApp Plus. OSM на предыдущей схеме |
node-exporter agent |
Собирает метрики о каждом node кластера. Развертывается на каждом node. NE на предыдущей схеме |
Thanos Querier |
Объединяет и, при необходимости, дедуплицирует основные метрики DropApp Plus и метрики для определяемых пользователем проектов в едином многопользовательском интерфейсе |
Grafana |
Предоставляет информационные панели для анализа и визуализации показателей. Экземпляр Grafana, поставляемый со стеком мониторинга вместе с панелями мониторинга, доступен только для чтения |
Telemeter Client |
Отправляет часть данных из экземпляров платформы Prometheus, чтобы облегчить удаленный мониторинг работоспособности кластеров |
Все компоненты в стеке мониторинга автоматически обновляются при обновлении DropApp Plus.
Цели мониторинга по умолчанию#
Cтек мониторинга по умолчанию отслеживает:
CoreDNS;
Elasticsearch (if Logging is installed);
etcd;
Fluentd (if Logging is installed);
HAProxy;
Image registry;
Kubelets;
Kubernetes API server;
Kubernetes controller manager;
Kubernetes scheduler;
Metering (if Metering is installed);
OpenShift API server;
OpenShift Controller Manager;
Operator Lifecycle Manager (OLM).
Компоненты мониторинга пользовательских проектов#
DropApp Plus включает в себя дополнительное усовершенствование стека мониторинга, которое позволяет отслеживать службы и pods в определяемых пользователем проектах. Эта функция включает в себя следующие компоненты:
Компонент |
Описание |
|---|---|
Prometheus Operator |
Оператор, который создает, настраивает и управляет экземплярами Prometheus и Thanos Ruler в одном проекте |
Prometheus |
Система мониторинга, с помощью которой осуществляется мониторинг определяемых пользователем проектов. Prometheus отправляет оповещения в Alertmanager для обработки |
Thanos Ruler |
Механизм оценки правил для Prometheus, который развертывается как отдельный процесс. В DropApp Plus Thanos Ruler обеспечивает оценку правил и предупреждений для мониторинга пользовательских проектов |
Цели мониторинга пользовательских проектов#
Если мониторинг включен для пользовательских проектов, возможно отслеживать:
Метрики, предоставляемые через endpoints службы в определяемых пользователем проектах;
Pods, работающие в определяемых пользователем проектах.
Сообщения администратору#
Примеры сообщений приведены в разделах «Сценарии администрирования» и «Сценарии эксплуатации кластера DropApp Plus с помощью oc».
Метрики мониторинга#
Метрики кластера#
Общие метки для всех метрик master nodes:
Метка |
Значение |
|---|---|
cluster-id |
Имя кластера |
host |
Идентификатор кластера |
Метрики master node:
Имя, Тип |
Описание |
|---|---|
master.cpu.utilization_percent DGAUGE, % |
Утилизация процессора |
master.memory.utilization_percent DGAUGE, % |
Утилизация памяти |
Метрики Nodes#
Общие метки для всех метрик node:
Метка |
Значение |
|---|---|
cluster-id |
Имя кластера |
host |
Идентификатор nodes |
Метрики nodes:
Тип, единицы измерения |
Описание |
|---|---|
node.cpu.allocatable_cores DGAUGE, % |
Количество доступных ресурсов процессора node |
node.cpu.core_usage_time COUNTER, миллисекунды |
Совокупная загрузка процессора на всех ядрах, используемых node |
node.cpu.total_cores DGAUGE, штуки |
Общее количество процессорных ядер node |
node.ephemeral_storage.allocatable_bytes IGAUGE, байты |
Количество доступных ресурсов эфемерного хранилища node |
node.ephemeral_storage.inodes_free IGAUGE, штуки |
Число свободных индексных дескрипторов |
node.ephemeral_storage.inodes_total IGAUGE, штуки |
Общее число индексных дескрипторов |
node.ephemeral_storage.total_bytes IGAUGE, байты |
Размер эфемерного хранилища |
node.ephemeral_storage.used_bytes IGAUGE, байты |
Использование эфемерного хранилища node |
node.memory.allocatable_bytes IGAUGE, байты |
Количество доступных ресурсов оперативной памяти node |
node.memory.total_bytes IGAUGE, байты |
Общий объем памяти node |
node.memory.used_bytes IGAUGE, байты |
Использование памяти node |
node.memory.working_set_bytes IGAUGE, байты |
Используемая память рабочего набора node |
node.network.received_bytes_count COUNTER, байты |
Входящий трафик (получено байтов из сети) |
node.network.sent_bytes_count COUNTER, байты |
Исходящий трафик (передано байтов в сеть) |
node.pid.limit IGAUGE, штуки |
Ограничение количества идентификаторов процессов в node |
node.pid.used IGAUGE, штуки |
Использование идентификаторов процессов в node |
Метрики pods#
Общие метки для всех метрик pod:
Метка |
Значение |
|---|---|
cluster-id |
Имя кластера |
namespace |
Имя namespace |
pod |
Имя pod |
Метрики pods:
Тип, единицы измерения |
Описание |
|---|---|
podcpucore_usage_tim COUNTER, миллисекунды |
Совокупная загрузка процессора на всех ядрах, используемых pod |
podephemeral_storageused_bytes IGAUGE, байты |
Использование эфемерного хранилища pod |
podmemoryused_bytes IGAUGE, байты |
Использование памяти pod |
podmemoryworking_set_bytes IGAUGE, байты |
Используемая память рабочего набора pod |
podnetworkreceived_bytes_count COUNTER, байты |
Входящий трафик (получено байтов из сети) |
podnetworksent_bytes_count COUNTER, байты |
Исходящий трафик (передано байтов в сеть) |
podvolumetotal_bytes IGAUGE, байты |
Общий объем временного тома |
Дополнительные метки: volume podvolumeused_bytes IGAUGE, байты |
Использование временного тома |
Дополнительные метки: volume podvolumeutilization DGAUGE, % |
Утилизация временного тома |
Метрики постоянного тома#
Общие метки для всех метрик постоянного тома:
Метка |
Значение |
|---|---|
cluster-id |
Имя кластера |
namespace |
Имя namespace |
persistentvolumeclaim |
Имя Persistent Volume Claim |
Метрики постоянного тома:
Тип, единицы измерения |
Описание |
|---|---|
persistent_volume.inodes_free IGAUGE, штуки |
Число свободных индексных дескрипторов |
persistent_volume.inodes_tota lIGAUGEE, штуки |
Общее число индексных дескрипторов |
persistent_volume.total_bytes IGAUGE, байты |
Общий объем постоянного тома |
persistent_volume.used_bytes IGAUGE, байты |
Использование постоянного тома |
persistent_volume.utilization DGAUGE, % |
Утилизация постоянного тома |
Часто встречающиеся проблемы и пути их устранения#
Устранение неполадок мониторинга#
Недоступность пользовательских метрик#
Ресурсы ServiceMonitor позволяют определить, как использовать метрики, предоставляемые службой, в определяемых пользователем проектах. Выполните действия, описанные в сценарии, если при создании ServiceMonitor не появилось соответствующих метрик в пользовательском интерфейсе.
Предварительные условия:
есть доступ к кластеру с ролью администратора;
установлен инструмент CLI (
oc);включен и настроен мониторинг для определяемых пользователем рабочих нагрузок;
создан
user-workload-monitoring-configConfigMap-объект;создан ресурс
ServiceMonitor.
Выполните следующую последовательность:
Убедитесь, что соответствующие метки совпадают в конфигурациях службы и
ServiceMonitor. Получите метку, определенную в сервисе. В следующем примере запрашивается службаprometheus-example-appв проектеns1:oc -n ns1 get service prometheus-example-app -o yamlПример вывода:
labels: app: prometheus-example-appУбедитесь, что метка
matchLabels appв конфигурации ресурсаServiceMonitorсоответствует выходной метке на предыдущем шаге:oc -n ns1 get servicemonitor prometheus-example-monitor -o yamlПример вывода:
spec: endpoints: - interval: 30s port: web scheme: http selector: matchLabels: app: prometheus-example-appПросмотрите журналы Prometheus Operator в проекте
openshift-user-workload-monitoring:oc -n openshift-user-workload-monitoring get podsПример вывода:
NAME READY STATUS RESTARTS AGE prometheus-operator-776fcbbd56-2nbfm 2/2 Running 0 132m prometheus-user-workload-0 5/5 Running 1 132m prometheus-user-workload-1 5/5 Running 1 132m thanos-ruler-user-workload-0 3/3 Running 0 132m thanos-ruler-user-workload-1 3/3 Running 0 132mПолучите журналы из контейнера
prometheus-operatorв podsprometheus-operator. В следующем примере pods называетсяprometheus-operator-776fcbbd56-2nbfm:Запустите эту команду, чтобы увидеть, существует ли ConfigMap в кластере DropApp. Например:
oc -n openshift-user-workload-monitoring logs prometheus-operator-776fcbbd56-2nbfm -c prometheus-operatorПросмотрите целевой статус проекта непосредственно в пользовательском интерфейсе Prometheus.
Установите переадресацию портов на экземпляр Prometheus в
openshift-user-workload-monitoring:
oc port-forward -n openshift-user-workload-monitoring pod/prometheus-user-workload-0 9090Откройте
http://localhost:9090/targetsв браузере и просмотрите состояние цели проекта непосредственно в пользовательском интерфейсе Prometheus. Проверьте сообщения об ошибках, относящиеся к цели.
Настройте ведение журнала отладки для оператора Prometheus.
Отредактируйте объект
user-workload-monitoring-configв проектеopenshift-user-workload-monitoring:
oc -n openshift-user-workload-monitoring edit configmap user-workload-monitoring-configДобавьте
logLevel: debugдляprometheusOperatorвdata/config.yaml, чтобы установить уровень ведения журналаdebug:
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: | prometheusOperator: logLevel: debugСохраните файл, чтобы применить изменения.
Убедитесь, что уровень журнала
debugбыл применен к развертываниюprometheus-operatorв проектеopenshift-user-workload-monitoring:
oc -n openshift-user-workload-monitoring get deploy prometheus-operator -o yaml | grep "log-level"Пример вывода:
- --log-level=debugВ журнале уровня отладки будут показаны все вызовы, сделанные оператором Prometheus.
Убедитесь, что pod
prometheus-operatorмработает:
oc -n openshift-user-workload-monitoring get pods