Руководство по установке#
Системные требования
Требования к хосту с установленным Jenkins
Требования безопасности
Требования к учетным записям и правам
Архитектура
Описание архитектуры развертывания кластеров Abyss
Конфигурирование DevOps
Структура конфигурационных файлов
DevOps репозиторий
Дистрибутив
Config репозиторий
Приоритеты
Preset
Service Descriptors
Конфигурирование распределения сервисов по хостам
service_mapping.yml
hosts.yml
hosts_resolve.yml
Примеры
Прочие конфигурационные файлы
unit.yml
global_service_vars.yml
devops.yml
pass.yml
Примеры
Конфигурации сервисов
Общая конфигурация сервисов Abyss
Конфигурация сервиса аутентификации (auth service)
Конфигурация сервиса архивных индексов (archive service)
Конфигурация сервиза-шлюза API (client api service)
Конфигурация сервиза потоковой обработки (flow management service)
Конфигурация сервиса полнотекстовых индексов (full text index service)
Конфигурация сервиса управления группами (group service)
Конфигурация сервиса управления источниками данных (kafka service)
Конфигурация сервиса аналитических индексов (monitoring service)
Конфигурация сервиса оркестрации процессов (pipeline service)
Конфигурация сервиса управления проектами (project service)
Конфигурация сервиса управления разрешениями (role service)
Конфигурация сервиса сбора трейсов (trace collector service)
Конфигурация сервиса обработки трейсов (trace query service)
Конфигурация сервиса авторизации (PVM authorization service)
Конфигурации СПО
Druid
Композиция дистрибутива
Ручная композиция
Композиция через Jenkins
Установка
Подготовка Git
Установка через Jenkins
Настройка credentials
Настройка Jenkins задачи
Запуск Jenkins
Ручная установка
Обновление
Удаление
Проверка работоспособности
Откат
Валидация
Часто встречающиеся проблемы и пути их устранения
Чек-лист валидации установки
Термины и сокращения#
Доступны в документе “Общее описание продукта Platform V Monitor”.
Системные требования#
Сервис |
Версия |
Обязательность |
Комментарий |
|---|---|---|---|
ОС "ALT 8 СП" или RHEL |
8.2 или 7.9, 7.8, 7.7, 7.6 |
обязательно |
Операционная система, используемая для работы Abyss. |
OIDC провайдер / IAM Proxy / СУДИР |
- |
обязательно |
Требуется для выполнения аутентификации пользователей. |
Platform V Audit SE (AUD) |
4.0 и выше |
опционально |
Аудит в prod-like окружениях является обязательным. Существует режим с записью событий аудита в логи. |
Platform V Monitor.Indicator |
4.1 |
опционально |
Реализация UI компонента. Обеспечивает визуализацию в продукте Platform V Monitor. |
Apache Kafka (рекомендуется Platform V Corax) |
2.0 и выше |
обязательно |
Распределённый программный брокер сообщений, проект с открытым исходным кодом под лицензией Apache 2.0 (рекомендуется использовать Platform V Corax). |
СУБД PostrgeSQL (рекомендуется Platform V Pangolin) |
11.6 и выше |
обязательно |
Для внутреннего хранения метаинформации о процессах сбора данных и их конфигурации. |
Ambari/SDP |
3.5 |
обязательно |
Менеджер кластеров на базе Ambari. Для управлением кластером Abyss. |
Nginx |
1.19 |
опционально |
Для балансировки внешних и внутренних запросов между сервисами. |
Репозиторий |
- |
опционально |
VCS для хранения конфигураций. Рекомендуется GitLab |
Java Virtual Machine JVM (Open JDK) |
8 |
обязательно |
Из состава SDP требуется установленные:
Zookeeper
HDFS
YARN
Требования к хосту с установленным Jenkins#
На Jenkins хосте должны быть (обязательно) установлены:
python3
ansible 2.9
rpm-build
pip пакеты:
ansible 2.9.22
colorlog
six
requests
Требования безопасности#
Требуется выпустить клиент-серверные TLS-сертификаты, сформировать keystore и truststore хранилища в формате jks. Сформированные jks требуется загрузить в Git репозиторий конфигурационных файлов кластера в каталог SSL (структура репозитория описана в разделе Структура конфигурационных файлов).
Рекомендации по использованию стойких паролей Постоянный пароль:
Должен быть не менее 8 символов;
Должен включать в себя как минимум:
1 латинскую букву в верхнем регистре;
1 латинскую букву в нижнем регистре;
1 цифру;
1 спецсимвол.
Не должен совпадать с предыдущими 11 паролями
Требования к учетным записям и правам#
Пользователю, под которым будет производиться установка, требуется выдать sudo на перезапуск Ambari:
(ALL) NOPASSWD: /usr/bin/systemctl start ambari-server
(ALL) NOPASSWD: /usr/bin/systemctl stop ambari-server
(ALL) NOPASSWD: /usr/bin/systemctl status ambari-server
(ALL) NOPASSWD: /usr/bin/systemctl restart ambari-server
Добавить в файл /etc/sudoers.d/
Defaults:<user> !requiretty
Так же требуется, чтобы у этого пользователя были выданы права на папки из devops.yml:
abyss_distr_dir
coordinator_ui_path
Platform V Pangolin SE#
Для работы компонентов сервиса требуется внешняя база данных Platform V Pangolin SE со следующими пререквизитами:
Версия 11.6 и выше
Наличие в одной базе данных раздельных схем, настроенных согласно рекомендациям Platform V Pangolin SE:
archive_service_userauth_service_userflow_service_userfulltext_service_usergroup_service_userkafka_service_usermonitoring_service_userpipeline_service_userproject_service_userrole_service_usertracing_service_userpvm_authorization_service_userДля каждой схемы необходим пользователь, с именем соответствующим названию схемы, с полными правами на эту схему.
Создание необходимых таблиц внутри схем происходит автоматически при запуске сервисов.
Архитектура#
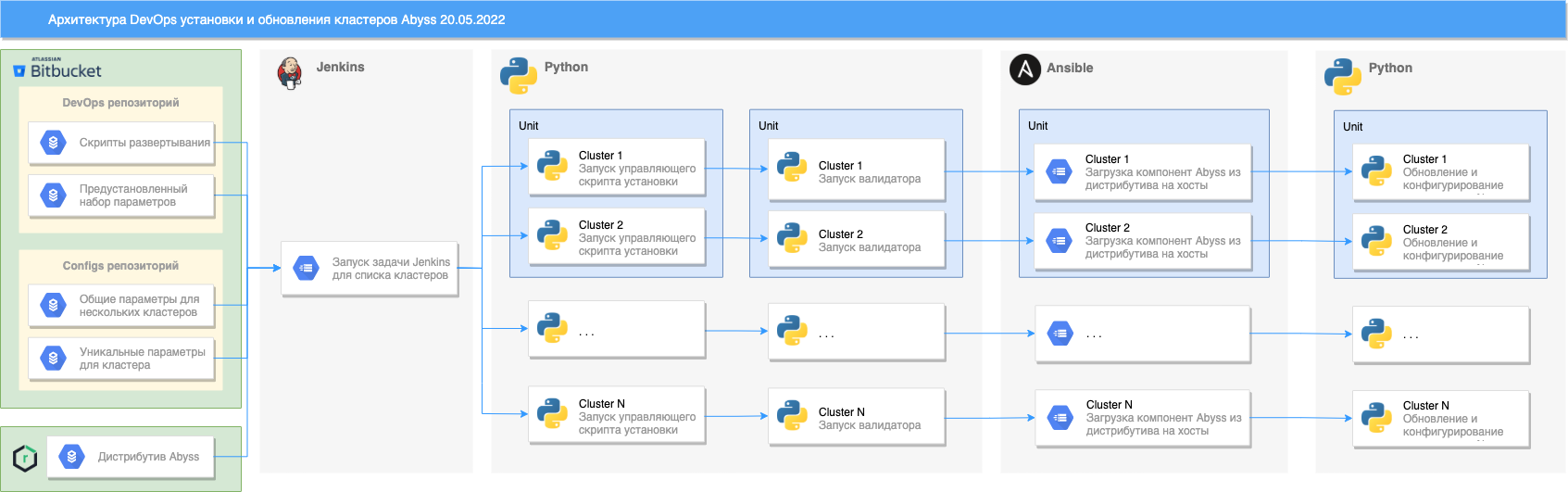
Описание архитектуры развертывания кластеров Abyss#
Установка/обновление производится путем запуска Jenkins задачи. В ходе ее работы выполняется:
Выгрузка репозитория Git со скриптами развертывания и presets.
Выгрузка репозитория Git с пользовательскими параметрами для кластеров.
Выгрузка дистрибутива Abyss из репозитория Nexus Public.
Параллельный запуск управляющего Python скрипта установки для списка кластеров/unit'ов:
Валидация конфигурационных файлов (подробнее можно узнать в разделе валидация).
Запуск Ansible playbook: 1. Загрузка сервисов Abyss на хосты.
Установка/обновление сервисов Abyss на платформу SDP.
Обновление конфигураций сервисов.
Конфигурирование DevOps#
Структура конфигурационных файлов#

DevOps репозиторий#
DevOps репозиторий Git необходим только для установки с помощью Jenkins. В нем хранится:
presets - каталог для файлов с полным списком настроек сервисов. Можно применить к любому кластеру.
Структура каталога presets
presets └── v1.0 ├── service.yml └── ...каждый preset имеет версионирование. Формат наименования версии - v + номер версии X.Y (например: v4.0)
каждый preset состоит из набора конфигурационных файлов для каждого сервиса, в которых описаны все возможные параметры с их стандартными значениями.
Файлы из DevOps репозитория использует Jenkins задача, а файлы из дистрибутива используются для ручного запуска управляющего Python скрипта (подробнее об установке можно узнать в разделе "Установка").
Дистрибутив#
В дистрибутиве содержится:
presets
example_unit - пример заполнения настроек для одного unit. Его можно брать за основу при создании своего.
devops - каталог, в котором расположены все необходимые скрипты для установки кластера без использования Jenkins. Файлы из дистрибутива используются для ручного запуска управляющего Python скрипта (подробнее об установке можно узнать в разделе установка).
Config репозиторий#
В config репозитории (вся структура папок создается пользователем на основе шаблона example_unit) содержится папка units - каталог всех конфигураций всех unit'ов (может содержать один кластер). Структура каталога units
units
├── global_service_vars.yml
└── my_unit
├── clusters
│ └── my_cluster
│ ├── devops.yml
│ ├── global_service_vars.yml
│ ├── hosts.yml
│ ├── hosts_resolve.yml
│ ├── pass.yml
│ ├── service_descriptors
│ │ ├── service.yml
│ │ └── ...
│ └── service_mapping.yml
├── global_service_vars.yml
├── service_descriptors
│ ├── service.yml
│ └── ...
└── unit.yml
Каталог units хранит в себе все unit, каждый из которых содержит:
сlusters - каталог с настройками кластеров входящими в состав unit.
service_descriptors - каталог с параметрами для unit.
service_descriptor.yml - конфигурационный файл для хранения переменных конкретного сервиса.
global_service_vars.yml - конфигурационный файл для переменных используемых сразу в нескольких service.yml.
unit.conf - файл для хранения ссылки на preset.
В каталоге сlusters хранятся настройки уникальные для отдельного кластера:
service_descriptors - каталог с параметрами для кластера.
service_name.yml - конфигурационный файл для хранения переменных конкретного сервиса.
devops.yml - файл, в котором указаны переменные необходимые для запуска Ansible.
global_service_vars.yml - конфигурационный файл для переменных используемых сразу в нескольких service.yml.
hosts.yml - файл, в котором указаны группы серверов, на которые будет производиться установка.
hosts_resolve.yml - файл, в котором перечислены dns имена хостов и соответствующие им ip адреса.
service_mapping.yml - файл с описанием состава кластера с указанными группами серверов.
pass.yml - зашифрованный файл для хранения паролей.
Приоритеты#
Конфигурации уровней preset, unit, cluster имеют разный приоритет. Наивысший приоритет имеет уровень cluster. Это значит, что все параметры определенные в preset будут переопределены, если их задать в service descriptors для unit, а они будут переопределены параметрами из service descriptors для кластера.
Каталог |
Приоритет |
|---|---|
Cluster |
1 |
Unit |
2 |
Preset |
3 |
Preset#
Preset - каталог для файлов с полным списком настроек сервисов. Можно применить к любому кластеру. В preset указаны значения по умолчанию и метаинформация для сервиса. Все preset поставляются командой Abyss и не требуют изменений.
Рассмотрим структуру preset:
service_id: service_name
service_type: SERVICE_TYPE
meta:
role_N:
cardinality: 1+
logic_config_group_1:
param_1_logic_config_group_1:
default: null
required: false
...
param_N_logic_config_group_1:
default: true
required: false
...
logic_config_group_N:
param_1_logic_config_group_N:
default: null
required: false
...
param_N_logic_config_group_N:
default: true
required: false
service_id
Уникальный идентификатор сервиса. Обязательный
service_id: service_name
Примечание: может содержать буквы, цифры и знаки подчеркивания
service_type
Тип сервиса. Обязательный
service_type: SERVICE_TYPE
Примечание: может содержать буквы, цифры и знаки подчеркивания.
meta
Специализированные параметры. Обязательный
meta:
role_1:
cardinality: 1+
...
role_N:
cardinality: 1+
Key |
Description |
Required |
|---|---|---|
role_N |
Группа для специализированных параметров роли |
Да |
cardinality |
Указывает допустимое количество экземпляров роли сервиса |
Да |
config_groups
Группа для параметров ролей сервиса. Опциональный
logic_config_group_1:
param_1_logic_config_group_1:
default: null
required: false
type: string
...
param_N_logic_config_group_1:
default: true
required: false
type: string
...
role_N:
param_1_logic_config_group_N:
default: null
required: false
type: string
...
param_N_logic_config_group_N:
default: true
required: false
type: string
Для каждой роли определяются параметры:
Key |
Description |
Required |
|---|---|---|
default |
Значение параметра по умолчанию. null если параметра по умолчанию нет. |
Да |
required |
Является ли параметр обязательным true/false. |
Да |
sensitive |
Является ли значение поля секретным. Например, поле для пароля. |
Нет |
Пример preset
service_id: ARCHIVE_SERVICE
service_type: ARCHIVE_SERVICE
meta:
archive:
cardinality: 1+
archive-service-config:
abyss.audit.discovery.zookeeper.path:
default: /abyss/audit/metamodel
sensitive: false
required: true
abyss.audit.event.publish-url:
default: ''
sensitive: false
required: true
common.actuator.basic-auth.enabled:
default: 'false'
sensitive: false
required: true
common.actuator.basic-auth.password:
default: null
sensitive: true
required: true
common.actuator.basic-auth.user:
default: ''
sensitive: false
required: true
common.auth.certificate-authentication-enabled:
default: 'true'
sensitive: false
required: true
common.auth.certificate.get-cert-from-header:
default: 'true'
sensitive: false
required: true
common.auth.jwk-resource-server:
default: ''
sensitive: false
required: true
common.auth.secret:
default: null
sensitive: true
required: true
common.auth.type:
default: SECRET_AND_JWK
sensitive: false
required: true
common.discovery.type:
default: ZOOKEEPER
sensitive: false
required: true
common.discovery.zookeeper.connection:
default: ''
sensitive: false
required: true
common.discovery.zookeeper.leadership-enabled:
default: 'true'
sensitive: false
required: true
common.discovery.zookeeper.path:
default: /abyss
sensitive: false
required: true
common.discovery.zookeeper.retry-interval-ms:
default: '10000'
sensitive: false
required: true
common.global.client.ssl.key-password:
default: null
sensitive: true
required: true
common.global.client.ssl.keystore-location:
default: ''
sensitive: false
required: true
common.global.client.ssl.keystore-password:
default: null
sensitive: true
required: true
common.global.client.ssl.store-type:
default: JKS
sensitive: false
required: true
common.global.client.ssl.truststore-location:
default: ''
sensitive: false
required: true
common.global.client.ssl.truststore-password:
default: null
sensitive: true
required: true
common.global.client.ssl.verify-hosts:
default: 'false'
sensitive: false
required: true
common.http.client.connect-timeout-ms:
default: '50000'
sensitive: false
required: true
common.http.client.eviction.idle-sec:
default: '10000'
sensitive: false
required: true
common.http.client.eviction.interval-ms:
default: '10000'
sensitive: false
required: true
common.http.client.keep-alive-ms:
default: '10000'
sensitive: false
required: true
common.http.client.max-connections:
default: '1000'
sensitive: false
required: true
common.http.client.socket-timeout-ms:
default: '50000'
sensitive: false
required: true
common.internal-communication.data-center-id:
default: ''
sensitive: false
required: true
common.internal-communication.max-retries:
default: '2'
sensitive: false
required: true
common.internal-communication.ssl.protocol:
default: PLAINTEXT
sensitive: false
required: true
common.pvm-security.api-basepath:
default: v1
sensitive: false
required: true
common.pvm-security.host:
default: ''
sensitive: false
required: true
common.pvm-security.max-retries:
default: '2'
sensitive: false
required: true
common.pvm-security.password:
default: null
sensitive: true
required: true
common.pvm-security.port:
default: ''
sensitive: false
required: true
common.pvm-security.ssl-port:
default: ''
sensitive: false
required: true
common.pvm-security.ssl.protocol:
default: PLAINTEXT
sensitive: false
required: true
common.pvm-security.user:
default: admin
sensitive: false
required: true
common.security.api-paths.additional-public:
default: ''
sensitive: false
required: true
common.service.api-basepath:
default: api
sensitive: false
required: true
common.service.app-basepath:
default: coordinator
sensitive: false
required: true
common.service.zone-id:
default: ''
sensitive: false
required: true
management.endpoints.web.exposure.include:
default: prometheus
sensitive: false
required: true
management.endpoints.web.path-mapping.prometheus:
default: /metrics
sensitive: false
required: true
server.max-http-header-size:
default: 32KB
sensitive: false
required: true
server.ssl.client-auth:
default: WANT
sensitive: false
required: true
server.ssl.enabled:
default: 'true'
sensitive: false
required: true
server.ssl.key-password:
default: null
sensitive: true
required: true
server.ssl.key-store:
default: ''
sensitive: false
required: true
server.ssl.key-store-password:
default: null
sensitive: true
required: true
server.ssl.trust-store:
default: ''
sensitive: false
required: true
server.ssl.trust-store-password:
default: null
sensitive: true
required: true
service.archive.flow.checkpoint-interval-ms:
default: '600000'
sensitive: false
required: true
service.archive.flow.max-thread-datarate-bytes-per-sec:
default: '2621440'
sensitive: false
required: true
service.archive.hadoop.filesystem.custom-enabled:
default: 'true'
sensitive: false
required: true
service.archive.hdfs.storage.query-results-path:
default: /tengri/archive/results
sensitive: false
required: true
service.archive.hdfs.storage.sources-path:
default: /tengri/archive/sources
sensitive: false
required: true
service.archive.hdfs.storage.temporary-path:
default: /tengri/archive/temporary
sensitive: false
required: true
service.archive.overdraft.max-overdraft-percentage:
default: '50'
sensitive: false
required: true
service.archive.partition.granularity-default-time-unit:
default: WEEK
sensitive: false
required: true
service.archive.query.result.max-rows:
default: '-1'
sensitive: false
required: true
service.archive.query.result.max-rows-per-page:
default: '10000'
sensitive: false
required: true
service.archive.scheduler.partition.merge-enabled:
default: 'false'
sensitive: false
required: true
service.archive.scheduler.partition.merge-interval-sec:
default: '86400'
sensitive: false
required: true
service.archive.scheduler.query.result-clean-interval-sec:
default: '360'
sensitive: false
required: true
service.archive.scheduler.query.result-expired-sec:
default: '86400'
sensitive: false
required: true
service.archive.scheduler.query.status-update-interval-sec:
default: '60'
sensitive: false
required: true
service.archive.scheduler.rotation.index-filling-threshold:
default: '0.7'
sensitive: false
required: true
service.archive.scheduler.rotation.interval-sec:
default: '360'
sensitive: false
required: true
service.archive.spark.deploy-mode:
default: cluster
sensitive: false
required: true
service.archive.spark.event-logging-dir:
default: /tengri/archive/sparkLogs
sensitive: false
required: true
service.archive.spark.event-logging-enabled:
default: 'false'
sensitive: false
required: true
service.archive.spark.master:
default: yarn
sensitive: false
required: true
service.archive.yarn.application-submission-timeout-sec:
default: '60'
sensitive: false
required: true
service.archive.yarn.client.ssl.enabled:
default: 'false'
sensitive: false
required: true
service.archive.yarn.resource-manager-url:
default: ''
sensitive: false
required: true
service.jvm-params:
default: -Xmx1g -XX:+ExitOnOutOfMemoryError -XX:MaxGCPauseMillis=100 -XX:+UseG1GC
sensitive: false
required: true
service.pid-directory:
default: /var/run/abyss
sensitive: false
required: true
service.port:
default: '29103'
sensitive: false
required: true
service_properties:
default: null
sensitive: false
required: true
spring.datasource.hikari.connection-timeout:
default: '30000'
sensitive: false
required: true
spring.datasource.hikari.idle-timeout:
default: '300000'
sensitive: false
required: true
spring.datasource.hikari.leak-detection-threshold:
default: '0'
sensitive: false
required: true
spring.datasource.hikari.max-lifetime:
default: '1200000'
sensitive: false
required: true
spring.datasource.hikari.maximum-pool-size:
default: '6'
sensitive: false
required: true
spring.datasource.hikari.minimum-idle:
default: '6'
sensitive: false
required: true
spring.datasource.password:
default: null
sensitive: true
required: true
spring.datasource.type:
default: com.zaxxer.hikari.HikariDataSource
sensitive: false
required: true
spring.datasource.url:
default: ''
sensitive: false
required: true
spring.datasource.username:
default: archive_service_user
sensitive: false
required: true
spring.flyway.password:
default: null
sensitive: true
required: true
spring.flyway.user:
default: flyway_archive_service_user
sensitive: false
required: true
archive-logback-config:
logback_properties:
default: null
sensitive: false
required: true
logger.directory:
default: /var/log/abyss
sensitive: false
required: true
logger.file-size:
default: 100MB
sensitive: false
required: true
logger.kafka.bootstrap-servers:
default: ''
sensitive: false
required: true
logger.kafka.client-id:
default: abyss_archive_service
sensitive: false
required: true
logger.kafka.protocol:
default: PLAINTEXT
sensitive: false
required: true
logger.kafka.topic:
default: abyss.coordinator_logs_ambari
sensitive: false
required: true
logger.max-file-amount:
default: '10'
sensitive: false
required: true
Service Descriptors#
Service Descriptors - основные конфигурационные файлы для хранения переменных сервисов. В service descriptor требуется определить только обязательные параметры (список обязательных к заполнению параметров можно посмотреть в example_unit) и те, которые хотите переопределить, остальные параметры берутся из preset. Представленные ниже примеры НЕ являются готовыми файлами для использования.
Рассмотрим структуру service descriptor:
service_id: service_name
service_type: SERVICE_TYPE
default_config_group
logic_config_group_1:
key: value
...
logic_config_group_N:
key: value
...
custom_config_group:
logic_config_group_N
key: value
...
service_id
Уникальный идентификатор сервиса. Обязательный
service_id: service_name
Примечание: может содержать буквы, цифры и знаки подчеркивания
service_type
Тип сервиса. Соответствует service_type из preset. Обязательный
service_type: SERVICE_TYPE
Примечание: может содержать буквы, цифры и знаки подчеркивания.
config_group
Группа для логических групп параметров сервиса.
default_config_group
logic_config_group_1:
key: value
...
logic_config_group_N:
key: value
...
У каждого сервиса должна присутствовать default_config_group, а также можно создать свои конфигурационные группы (custom_config_group), для удобного управления кластером. Группа сustom_config_group наследует параметры из default_config_group.
Пример заполненного service descriptor
service_id: Abyss_Auth_service
service_type: AUTH_SERVICE
default_config_group:
auth-logback-config:
logger.file-size: '{{ logger_file_size }}'
logger.kafka.bootstrap-servers: '{{ logger_kafka_bootstrap_servers }}'
logger.kafka.protocol: '{{ logger_kafka_protocol }}'
logger.kafka.topic: '{{ logger_kafka_topic }}'
logger.max-file-amount: '{{ logger_max_file_amount }}'
auth-service-config:
abyss.audit.event.publish-url: '{{ abyss_audit_event_publish_url }}'
common.actuator.basic-auth.enabled: '{{ actuator_basic_auth_enabled }}'
common.actuator.basic-auth.user: '{{ actuator_basic_auth_user }}'
common.actuator.basic-auth.password: '{{ actuator_basic_auth_password }}'
common.auth.jwk-resource-server: '{{ auth_jwk_resource_server }}'
common.auth.secret: '{{ jwt_secret }}'
common.discovery.zookeeper.connection: '{{ zk_hosts }}'
common.discovery.zookeeper.path: '{{ services_zk_chroot }}'
common.global.client.ssl.key-password: '{{ ssl.key_password }}'
common.global.client.ssl.keystore-location: '{{ ssl_keystore_location }}'
common.global.client.ssl.keystore-password: '{{ ssl.keystore_password }}'
common.global.client.ssl.truststore-location: '{{ ssl_truststore_location }}'
common.global.client.ssl.truststore-password: '{{ ssl.truststore_password }}'
common.internal-communication.data-center-id: '{{ common_internal_communication_data_center_id }}'
common.internal-communication.ssl.protocol: '{{ common_internal_communication_ssl_protocol }}'
common.pvm-security.host: '{{ pvm_security_host }}'
common.pvm-security.password: '{{ pvm_internal_user_password }}'
common.pvm-security.port: '{{ pvm_security_port }}'
common.pvm-security.ssl.protocol: '{{ pvm_security_ssl_protocol }}'
common.pvm-security.ssl-port: '{{ pvm_security_ssl_port }}'
common.pvm-security.user: '{{ pvm_internal_user_name }}'
service.auth.ldap.password: '{{ ldap_user_password }}'
service.auth.ldap.search-dns: '["DC=domen,DC=sbt,DC=ru"]'
service.auth.ldap.url: ldap://
service.auth.ldap.username: ldap_user@domen.ru
service.auth.admin.username: '{{ pvm_internal_user_name }}'
service.auth.admin.password: '{{ pvm_internal_user_password }}'
service.jvm-params: -Xmx64m -XX:+ExitOnOutOfMemoryError -XX:MaxGCPauseMillis=100 -XX:+UseG1GC
server.ssl.enabled: '{{ service_ssl_enable }}'
server.ssl.key-password: '{{ ssl.key_password }}'
server.ssl.key-store: '{{ ssl_keystore_location }}'
server.ssl.key-store-password: '{{ ssl.keystore_password }}'
server.ssl.trust-store: '{{ ssl_truststore_location }}'
server.ssl.trust-store-password: '{{ ssl.truststore_password }}'
spring.datasource.url: jdbc:postgresql://{{ database_host }}:{{ database_port }}/{{ global_database_name }}
spring.datasource.password: '{{ global_database_password }}'
spring.flyway.password: '{{ flyway_password }}'
Конфигурирование распределения сервисов по хостам#
Для настройки распределения сервисов по хостам требуется заполнить:
service_mapping.yml - файл с описанием состава кластера с указанными группами серверов.
hosts.yml - файл, в котором указаны группы серверов, на которые будет производиться установка.
hosts_resolve.yml - файл, в котором перечислены dns имена хостов и соответствующие им ip адреса.
Представленные ниже примеры НЕ являются готовыми файлами для использования.
service_mapping.yml#
services:
service_1_id:
config_groups:
default_config_group:
hosts_group:
- service_id_host_1
custom_config_group:
hosts_group:
- service_id_host_2
roles:
role_1:
hosts_group:
- service_id_host_1
- service_id_host_2
...
Key |
Description |
|---|---|
services |
Корневая группа |
service_id |
service_id сервиса из service descriptor, для которого хотите настроить распределение хостов |
roles |
Группа, в которой описаны роли сервисов |
role |
Роль сервиса из service descriptor |
config_groups |
Группа, в которой описаны все группы конфигураций для сервиса |
default_config_group/custom_config_group |
Указывает какую группу параметров из service descriptor необходимо установить на настраиваемую роль |
hosts_group |
Указывает какую на какую группу хостов из hosts.yml необходимо установить настраиваемую роль. Можно указать несколько групп хостов. Общее количество хостов для роли не должно превышать заданное вcardinality из preset |
hosts.yml#
group_host:
hosts:
- host1
- host2
...
Key |
Description |
|---|---|
group_host |
Название группы хостов, используется в service_mapping.yml |
hosts |
Список хостов в этой группе |
В hosts.yml существуют зарезервированные имена
Имя группы |
Описание |
|---|---|
ambari_server_hosts |
Группа для хоста, на котором установлен Ambari server. Обязательная группа для кластера на платформе SDP. |
nginx_hosts |
Группа для хостов Nginx, на которых будет установлен Coordinator UI. |
hosts_resolve.yml#
Опциональный конфигурационный файл требуется, если с хоста установки нет доступа к хостам кластера по dns имени.
host1: ip1
host2: ip2
Примеры#
Пример заполненного service_mapping.yml
services:
ambari_server:
hosts_group:
- ambari_server_hosts
Abyss_Archive_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
archive:
hosts_group:
- ambari_server_hosts
Abyss_Auth_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
auth:
hosts_group:
- ambari_server_hosts
PVM_AUTHORIZATION_SERVICE:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
pvm_authorization:
hosts_group:
- ambari_server_hosts
Abyss_Client_Api_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
client_api:
hosts_group:
- ambari_server_hosts
Abyss_Flow_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
flow:
hosts_group:
- ambari_server_hosts
Abyss_FullTextIndex_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
fulltextindex:
hosts_group:
- ambari_server_hosts
Abyss_Group_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
group:
hosts_group:
- ambari_server_hosts
Abyss_Kafka_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
kafka:
hosts_group:
- ambari_server_hosts
Abyss_Monitoring_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
monitoring:
hosts_group:
- ambari_server_hosts
Abyss_Pipeline_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
pipeline:
hosts_group:
- ambari_server_hosts
Abyss_Project_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
project:
hosts_group:
- ambari_server_hosts
Abyss_Role_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
role:
hosts_group:
- ambari_server_hosts
TraceCollector_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
trace_collector_server:
hosts_group:
- ambari_server_hosts
TraceQuery_service:
config_groups:
default_config_group:
hosts_group:
- ambari_server_hosts
roles:
trace_query:
hosts_group:
- ambari_server_hosts
ABYSS_SOLR:
config_groups:
default_config_group:
hosts_group:
- solr_hosts
roles:
abyss_solr_server:
hosts_group:
- solr_hosts
Пример заполненного hosts.yml
nginx_hosts:
hosts:
- abyss-install-5-postgres
coordinator_hosts:
hosts:
- abyss-install-2
yarn_jobhistory_hosts:
hosts:
- abyss-install-3
yarn_rm_hosts:
hosts:
- abyss-install-2
- abyss-install-3
zookeeper_hosts:
hosts:
- abyss-install-1
- abyss-install-2
- abyss-install-3
hdfs_namenodes_hosts:
hosts:
- abyss-install-1
- abyss-install-2
hdfs_datanodes_hosts:
hosts:
- abyss-install-2
- abyss-install-3
- abyss-install-4
hdfs_balancer_hosts:
hosts:
- abyss-install-4
hdfs_httpfs_hosts:
hosts:
- abyss-install-2
hdfs_journalnode_hosts:
hosts:
- abyss-install-2
- abyss-install-3
- abyss-install-4
Пример заполненного hosts_resolve.yml
abyss-install-1: ip
abyss-install-2: ip
abyss-install-3: ip
abyss-install-4: ip
abyss-install-5-postgres: ip
Прочие конфигурационные файлы#
Представленные ниже примеры НЕ являются готовыми файлами для использования.
unit.yml#
Содержит ссылку на preset. unit.conf example
preset_name: "v1.0"
global_service_vars.yml#
Конфигурационный файл для переменных используемых сразу в нескольких service descriptor.
Вы можете придумать любую переменную (разделителем слов может быть только нижнее подчеркивание) и передать ее в service descriptor. global_service_vars.yml example
ssl_truststore_location: "/abyss/ssl/server.truststore.jks"
zookeeper_hosts: "host1:port"
service descriptor example
service_id: service_name
service_type: SERVICE_TYPE
default_config_group:
auth-service-config:
abyss.audit.event.publish-url:
ssl.keystore_location: "{{ ssl_truststore_location }}"
...
devops.yml#
Конфигурационный файл для переменных необходимых для запуска Ansible. devops.yml example
ansible_user: "my_ansible_user"
ansible_become: "false"
abyss_distr_dir: "/abyss/install"
coordinator_ui_path: "/abyss/tengri-ui"
Key |
Description |
Required |
|---|---|---|
ansible_user |
Пользователь, под которым будет запускаться ansible. |
Да |
ansible_become |
Параметр, отвечающий за работу ansible через sudo. |
Нет |
abyss_distr_dir |
Папка для хранения файлов установщика Abyss. |
Да |
coordinator_ui_path |
Папка на хосте nginx куда будут скопированы файлы для Coordinator UI. |
Да |
cluster_manager_user |
Пользователь для подключения к менеджеру кластера. |
Да |
cluster_manager_password |
Пароль от пользователя для подключения к кластеру. |
Да |
cluster_manager_port |
Порт, на котором расположен менеджер кластера. |
Да |
cluster_manager_scheme |
Используемый протокол для подключения (http/https). |
Да |
pass.yml#
Конфигурационный файл для паролей требуется зашифровать. Для этого требуется:
Придумать пароль, с помощью которого будет выполняться шифрование конфигураций, и сохранить его в файл.
Выполнить команду:
pass.yml example:
ansible-vault encrypt --vault-password-file <path_to_vault_password_file> pass.yml
path_to_vault_password_file - путь до созданного файла с паролемpass.yml - путь до файла pass.yml
Загрузить файл с паролем в Jenkins Credential с типом Secret file.
В настройках Jenkins задачи установки в параметре ANSIBLE_VAULT_FILE_CRED указать id созданного Credential.
Для локальной расшифровки pass.yml используйте команду: pass.yml example:
ansible-vault decrypt --vault-password-file <path_to_vault_password_file> pass.yml
Параметры из pass.yml можно передать в service descriptor , global_service_vars.yml или devops.yml . pass.yml example:
cluster_manager_password: "pass"
global_database_password: "pass"
ssl:
key_password: "pass"
keystore_password: "pass"
truststore_password: "pass"
service descriptor example
service_id: service_name
service_type: SERVICE_TYPE
default_config_group:
auth-service-config:
logger_ssl_client_truststore_location: "{{ ssl_truststore_location }}"
logger_ssl_client_truststore_password: "{{ ssl.truststore_password }}"
logger_ssl_server_keystore_location: /abyss/ssl/server.keystore.jks
logger_ssl_server_keystore_password: "{{ ssl.keystore_password }}"
Примеры#
Пример заполненного unit.yml
preset_name: "v1.0"
Пример заполненного global_service_vars.yml
zk_hosts=abyss-install-1:2181,abyss-install-2:2181,abyss-install-3:2181
kafka_bootstrap_servers=abyss-install-4:9093,abyss-install-3:9093,abyss-install-2:9093
druid_router_host=abyss-install-5-postgres
yarn_rm_host=abyss-install-3
flink_masters_hosts=abyss-install-1,abyss-install-2
database_host=abyss-install-5-postgres
database_port=5432
tracing_url=http://host:port/api/v2/spans
ssl_truststore_location=/tengri/ssl/server.truststore.jks
ssl_keystore_location=/tengri/ssl/server.keystore.jks
ssl_protocol=SSL_WANT
kafka_security_protocol=SSL
pvm_internal_user_name=admin
solr_basic_user=admin
solr_basic_enabled=true
# Dynamic params
hue_webhdfs_name='{ "SERVICE_TYPE":"HDFS","SERVICE_ROLE":"HDFS-HTTPFS","VALUE_PARAM":"name" }'
Пример заполненного devops.yml
ansible_user: "root"
# user, password, port and scheme for Ambari
cluster_manager_user: "admin"
cluster_manager_password: "{{cluster_manager_password}}"
cluster_manager_port: "8080"
cluster_manager_scheme: "http"
abyss_distr_dir: "/tengri/install"
ssl_deploy_dir: "/tengri/ssl"
Пример заполненного pass.yml
cluster_manager_password: "pass"
global_database_password: "pass"
ssl:
key_password: "pass"
keystore_password: "pass"
truststore_password: "pass"
jwt_secret: "secret"
jwt_encodng_key: "pass"
pvm_internal_user_password: "pass"
solr_basic_password: "pass"
druid_basic_password: "pass"
Конфигурация сервисов#
Общая конфигурация сервисов Abyss#
Параметры из этого раздела необходимо указать во всех service descriptor'ах сервисов Abyss:
Archive service;
Auth service;
Client Api service;
Flow service;
Full text index service;
Group service;
Kafka service;
Monitoring service;
Pipeline service;
Project service;
PVM authorization service;
Role service;
Trace collector service;
Trace query service.
Параметры базы данных:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
spring.datasource.url |
JDBC URL для подключения к БД. |
string |
- |
spring.datasource.username |
Имя пользователя для подключения к БД. |
string |
- |
spring.datasource.password |
Пароль для подключения к БД. |
password |
- |
spring.datasource.type |
Тип источника данных при подключении к БД. |
string |
- |
Дополнительные параметры для настройки HikariDataSource:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
spring.datasource.hikari.connection-timeout |
Таймаут получения соединения из пула соединений. К таймауту может приводить длительное подключение к БД или отсутствие свободных соединений в пуле. Задается в миллисекундах. |
long |
30000 |
spring.datasource.hikari.minimum-idle |
Минимальное количество неиспользованных (свободных) соединений, которое пул соединений должен поддерживать. Не рекомендуется устанавливать данный параметр, и использовать пул фиксированного размера когда задается только maximum-pool-size. По умолчанию равно maximum-pool-size. |
long |
6 |
spring.datasource.hikari.maximum-pool-size |
Максимальный размер пула соединений. |
long |
6 |
spring.datasource.hikari.idle-timeout |
Таймаут нахождения неиспользованного соединения в пуле соединений. Применяется только при установленном параметре minimum-idle, меньшим чем maximum-pool-size. Задается в миллисекундах. |
long |
30000 |
spring.datasource.hikari.max-lifetime |
Максимальное время жизни соединения в пуле. Используемые соединения не закрываются при достижении данного значения. Рекомендуется обязательно устанавливать и использовать значение на несколько секунд меньше чем таймаут используемой БД. Задается в миллисекундах. |
long |
1200000 |
spring.datasource.hikari.leak-detection-threshold |
Время, по истечении которого соединение, находящееся в использовании считается для пула потерянным (не будет возвращено в пул). Для такого соединения формируется запись в журнале. Задается в миллисекундах. |
long |
0 |
Параметры попыток внутреннего взаимодействия сервисов:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.internal-communication.max-retries |
Максимальное количество попыток отправить запрос. |
int |
2 |
Параметры путей:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.security.api-paths.additional-public |
Дополнительные публичные пути (для которых не требуется аутентификация), которые добавляются к публичным путям по умолчанию. |
string |
- |
Параметры логирования:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
logger.kafka.protocol |
Протокол для подключения к Kafka. Возможные значения: - PLAINTEXT; - SSL; - SASL_PLAINTEXT; - SASL_SSL. |
string_enum |
SSL |
logger.kafka.bootstrap-servers |
Список Kafka брокеров для отправки логов. Список должен содержать больше, чем одного брокера для большей доступности, но не обязательно перечислять их всех. |
string |
- |
logger.kafka.topic |
Имя топика Kafka, где будут храниться логи. |
string |
abyss.coordinator_logs |
logger.kafka.client-id |
Имя Kafka клиента, которое будет использоваться для логгера. |
string |
abyss_client_api_service |
logger.directory |
Директория, в которой будут храниться логи сервиса. |
string |
/tengri/log/client-api |
logger.file-size |
Размер лог файла. |
string |
200MB |
logger.max-file-amount |
Максимальное число файлов логов на сервере. |
long |
10 |
Параметры Discovery:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.discovery.type |
Два возможных значения: STATIC и ZOOKEEPER. Определяет, каким способом будет происходить регистрация сервисов, с помощью zookeeper или же статически, используя список готовый список хостов. |
string |
ZOOKEEPER |
common.discovery.zookeeper.connection |
Список серверов ZooKeeper для подключения. |
string |
- |
common.discovery.zookeeper.retry-interval-ms |
Интервал между попытками переподключения к ZooKeeper в миллисекундах. |
10000 |
10000 |
common.discovery.zookeeper.path |
Путь в ZooKeeper, где хранится информация о хостах (где хранятся метаданные chroot). |
/abyss |
/abyss |
common.discovery.zookeeper.leadership-enabled |
Включает механизм выбора лидера в сервисе среди узлов кластера. |
true |
true |
Параметры http-клиента:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.http.client.socket-timeout-ms |
Максимальный период неактивности между двумя TCP-пакетами. |
long |
50000 |
common.http.client.connect-timeout-ms |
Сколько времени в миллисекундах поддерживать соединение для бездействующих соединений. |
|
50000 |
common.http.client.eviction.interval-ms |
Интервал, по истечении которого будут закрыты все бездействущие соединения. |
long |
10000 |
common.http.client.eviction.idle-sec |
Время в секундах, в течении которого в текущем соединении ничего не происходит. |
long |
10000 |
common.http.client.max-connections |
Максимальное количество соединений. |
long |
1000 |
common.http.client.keep-alive-ms |
Временя в миллисекундах, в течение которого необходимо поддерживать соединение после того, как завершится первый запрос (Добавлено для того, чтобы соединение могло переиспользоваться для нового запроса). |
long |
10000 |
Безопасность:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
server.ssl.enabled |
Включение SSL службы на сервисе (для входящих соединений) |
boolean |
false |
server.ssl.key-password |
Пароль от ключа хранилища keystore.jks |
pasword |
- |
server.ssl.key-store |
Расположение хранилища ключей ssl |
string |
- |
server.ssl.key-store-password |
Пароль от хранилища приватных ключей |
pasword |
- |
server.ssl.trust-store |
Расположение хранилища с доверенными с сертификатами |
string |
- |
server.ssl.trust-store-password |
Пароль от хранилища с доверенными с сертификатами |
password |
- |
server.ssl.client-auth |
Аутентификация клиента: Отсутствует (NONE)/ Не обязательна (WANT) / Необходима (NEED) |
string |
NONE |
common.global.client.ssl.truststore-location |
Путь к хранилищу доверенных сертификатов (глобальный для всего модуля) |
string |
- |
common.global.client.ssl.keystore-location |
Путь к хранилищу клиентских (глобальный для всего модуля) |
string |
- |
common.global.client.ssl.truststore-password |
Пароль к хранилищу доверенных сертификатов (глобальный для всего модуля) |
password |
- |
common.global.client.ssl.keystore-password |
Пароль к хранилищу клиентских сертификатов (глобальный для всего модуля) |
password |
- |
common.global.client.ssl.key-password |
Пароль от приватного ключа (глобальный для всего модуля) |
password |
- |
common.global.client.ssl.store-type |
Тип хранилища сертификатов. Допустимые значения - JKS, PKCS12. |
string_enum |
JKS |
common.global.client.ssl.verify-hosts |
Параметр включающий проверку сертификата хоста при установлении SSL соединения. |
boolean |
false |
common.auth.type |
Тип аутентификации, два возможных значения SECRET, SECRET_AND_JWK. (Для подключения к OIDC провайдеру) |
string |
SECRET_AND_JWK |
common.auth.secret |
Пароль, используется для проверки подписи токена. (Для подключения к OIDC провайдеру) |
password |
- |
common.auth.jwk-resource-server |
Сервер ресурсов jwk (с ключами для проверки подписи JWT). (Для подключения к OIDC провайдеру) |
string |
- |
common.auth.certificate-authentication-enabled |
Параметр, определяющий, возможна ли аутентификация с сертификатом. |
boolean |
true |
common.auth.certificate.get-cert-from-header |
Нужно ли доставать сертификат из заголовка sslClientCertHeader. |
boolean |
true |
Параметры SSL для внутреннего взаимодействия:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.internal-communication.ssl.protocol |
Протокол межмодульного взаимодействия, возможны три варианта: |
string_enum |
SSL_WANT |
PLAINTEXT - вариант подключения без SSL. |
|||
SSL_WANT - опциональный SSL (если включен на модуле, к которому осуществляется подключение). |
|||
SSL_REQUIRED - подключение с SSL. |
Параметры URL API сервисов:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
common.service.api-basepath |
Путь к API |
string |
api |
common.service.app-basepath |
Путь к приложению |
string |
coordinator |
JVM:
Имя параметра |
Описание |
Тип |
Значение по умолчанию |
|---|---|---|---|
service.jvm-params |
Параметры передающиеся в JVM |
string |
-Xmx1g -XX:+ExitOnOutOfMemoryError -XX:MaxGCPauseMillis=100 -XX:+UseG1GC |
Параметры подключения к сервису авторизации:
Параметр |
Описание |
Тип |
Значение по-умолчанию |
|---|---|---|---|
common.pvm-security.ssl.protocol |
Протокол подключения к сервису авторизации |
string_enum |
SSL_REQUIRED |
common.pvm-security.max-retries |
Максимальное количество переподключений к сервису авторизации |
long |
2 |
common.pvm-security.user |
Пользователь для подключения к сервису авторизации |
string |
- |
common.pvm-security.password |
Пароль от пользователя для подключения к сервису авторизации |
string |
- |
common.pvm-security.host |
Хост, на котором расположен сервис авторизации |
string |
- |
common.pvm-security.port |
Порт, на котором запущен сервис авторизации |
long |
- |
common.pvm-security.ssl-port |
Защищенный порт, на котором запущен сервис авторизации |
long |
- |
Конфигурация сервиса аутентификации (auth service)#
В preset и service descriptor сервису соответствует service_type = AUTH_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Имя параметра: |
Описание: |
Тип: |
Значение по умолчанию: |
|---|---|---|---|
service.port |
Порт на котором запускается сервис |
port |
29090 |
service.auth.ldap.enabled |
Включить/отключить аутентификацию по LDAP |
boolean |
true |
service.auth.ldap.identity-attribute |
Аттрибут в записи LDAP каталога который содержит имя пользователя |
string |
name |
service.auth.ldap.search-dns |
Пути LDAP каталога используемые для поиска |
string |
["DC=domen,DC=sbt,DC=ru"] |
service.auth.ldap.url |
URL LDAP сервиса |
string |
ldap:// |
service.auth.ldap.username |
Логин для авторизации в LDAP сервисе |
string |
- |
service.auth.ldap.password |
Пароль для авторизации в LDAP сервисе |
password |
- |
service.auth.users.local-registration-enabled |
Включить/отключить локальную регистрацию |
boolean |
false |
service.auth.users.local-auth-enabled |
Можно ли авторизоваться используя локальные учётные записи |
boolean |
true |
Параметры администратора:
Имя параметра: |
Описание: |
Тип: |
Значение по умолчанию: |
|---|---|---|---|
service.auth.admin.username |
Логин администратора Coordinator UI. |
string |
admin |
service.auth.admin.password |
Пароль администратора Coordinator UI. |
string |
- |
Параметры поиска:
Имя параметра: |
Описание: |
Тип: |
Значение по умолчанию: |
|---|---|---|---|
service.auth.search.min-mask-length |
Минимальная длина пользовательской маски при поиске. |
long |
5 |
service.auth.search.max-users-to-return |
Максимальное количество пользователей, которые будут возвращены при поиске. |
long |
50 |
Конфигурация сервиса архивных индексов (archive service)#
В preset и service descriptor сервису соответствует service_type = ARCHIVE_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором запускается сервис |
port |
29103 |
service.archive.query.result.max-rows-per-page |
Максимально возможно число записей на одной странице. Так же будет использовано если в запросе число записей на странице не будет указано явно. Участвует в валидации запросов, при указании в запросе числа записей больше этого параметра, будет возвращена ошибка. |
long |
10000 |
Параметры подключения к hadoop:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.hadoop.filesystem.custom-enabled |
Настройка, разрешающая нестандартную настройку файловой системы Hadoop. |
boolean |
true |
Настройки партиций:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.partition.granularity-default-time-unit |
Параметр определяет единицу измерения времени по умолчанию для интервалов времени партиций индекса. Допустимые значения: HOUR, DAY, WEEK, MONTH. |
string |
WEEK |
Параметры хранилища:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.hdfs.storage.sources-path |
Корневая директория хранилища архивных данных в HDFS |
string |
/tengri/archive/sources |
service.archive.hdfs.storage.query-results-path |
Путь для сохранения результатов запросов по архивным данным |
string |
/tengri/archive/results |
service.archive.hdfs.storage.temporary-path |
Путь к каталогу для хранения временных данных в HDFS. |
string |
/tengri/archive/temporary |
Настройки планировщика обработки архивов:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.scheduler.rotation.interval-sec |
Интервал в секундах для выполнения ротации. |
long |
360 |
service.archive.scheduler.rotation.index-filling-threshold |
Порог заполнения индекса при котором выполняется ротация. |
double |
0.7 |
service.archive.scheduler.query.result-clean-interval-sec |
Интервал в секундах для выполнения очистки устаревших результатов запросов. |
long |
360 |
service.archive.scheduler.query.result-expired-sec |
Интервал в секундах устаревания результатов запросов. |
long |
86400 |
service.archive.scheduler.query.status-update-interval-sec |
Интервал обновления статусов запросов. Задается в секундах. |
long |
60 |
service.archive.scheduler.partition.merge-enabled |
Параметр разрешающий слияние разделов индексов. |
boolean |
false |
service.archive.scheduler.partition.merge-interval-sec |
Интервал выполнения слияния разделов индексов. |
long |
86400 |
Параметры Flink:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.flow.checkpoint-interval-ms |
Промежуток между сохранениями состояния задачи Flink |
long |
10000 |
service.archive.flow.max-thread-datarate-bytes-per-sec |
Максимальная скорость обработки данных один экземпляром задачи Flink |
long |
2621440 |
Настройки для Yarn:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.yarn.resource-manager-url |
URL менеджера ресурсов YARN. |
string |
- |
service.archive.yarn.application-submission-timeout-sec |
Таймаут публикации для приложений в YARN. |
long |
60 |
service.archive.yarn.client.ssl.enabled |
Параметр, включающий использование SSL при доступе к YARN. |
boolean |
false |
Параметры Spark:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.archive.spark.deploy-mode |
Режим развертывания для приложения Spark. Допустимые значения: client, cluster. |
string_enum |
cluster |
service.archive.spark.master |
Мастер для приложения Spark. Допустимое значение: YARN |
string_enum |
yarn |
service.archive.spark.event-logging-enabled |
Параметр включающий логирование событий Spark. |
boolean |
true |
service.archive.spark.event-logging-dir |
Директория где будут журналироваться события Spark, если параметр spark.eventLog.enabled = true. Для каждого приложения будет создан свой подкаталог для логирования событий, специфичных для приложения. |
string |
hdfs:///nameservice1/tengri/archive/sparkLogs |
Параметры Spark History Server:
Имя параметра |
Описание |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
spark.history.ui.port |
Порт для подключения к веб-интерфейсу history server |
port |
18080 |
spark.history.service.jvm.params |
Параметры, передаваемые jvm |
string |
-XX:MaxGCPauseMillis=100 -XX:+UseG1GC |
spark.history.fs.cleaner.enabled |
Определяет будет ли history server периодически очищать хранилище от логов событий |
boolean |
false |
Конфигурация сервиса-шлюза API (client api service)#
В preset и service descriptor сервису соответствует service_type = CLIENT_API_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором запускается сервис |
port |
29099 |
service.client-api.version |
Версия API |
string |
v1 |
service.client-api.cache.retentionSeconds |
Время в секундах до истечения срока действий данных в кэше. |
long |
3600 |
Параметры логирования для журнала запросов:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.client-api.query-journal.enabled |
Включение или отключение логов для журнала запросов |
boolean |
true |
query-journal.kafka.topic |
Топик, в котором хранится журнал запросов |
string |
abyss.coordinator_audit |
Параметры логирования совершенных запросов:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.client-api.endpoint.logger.black-list |
Запросы, которые не подлежат логированию |
string |
/coordinator/api/v1/index/fulltext/task/project/*/name/*/query; /coordinator/api/v1/index/fulltext/pattern/project/*/name/*/query; /coordinator/api/v1/index/analytical/task/project/*/query; /coordinator/api/v1/index/analytical/dictionary/project/*/name/*; /coordinator/api/v1/index/archive/task/project/*/name/*/query/*/result" |
service.client-api.endpoint.logger.enabled |
Включение/отключение записи логов запросов |
boolean |
true |
service.client-api.endpoint.logger.max-body-size |
Максимальный размер тела для записи логов |
long |
200 |
service.client-api.endpoint.logger.min-status |
Минимальный статус HTTP для записи логов, запись логов идет только с установленного значения и выше |
long |
200 |
service.client-api.endpoint.logger.white-list |
Конечная точка для записи логов |
string |
/** |
Конфигурация сервиса потоковой обработки (flow management service)#
В preset и service descriptor сервису соответствует service_type = FLOW_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29096 |
service.flow.timezone.available-zones |
Список поддерживаемых временных зон, разделенный точкой с запятой. |
string |
Europe/Kaliningrad; Europe/Moscow; Europe/Samara; Asia/Yekaterinburg; Asia/Omsk; Asia/Novosibirsk; Asia/Irkutsk; Asia/Yakutsk; Asia/Vladivostok; Asia/Magadan; Asia/Kamchatka; UTC |
Глобальные настройки SSL для Flow Job:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.global.client.ssl.truststore-location |
Общий параметр для внешних взаимодействий flink-flow-job.jar по SSL (Solr, Kafka). Путь к truststore, в котором содержится клиентские сертификаты |
string |
- |
service.flow.job.global.client.ssl.truststore-password |
Общий параметр для внешних взаимодействий flink-flow-job.jar по SSL (Solr, Kafka). Пароль к truststore файлу, в котором содержатся клиентские сертификаты |
password |
- |
service.flow.job.global.client.ssl.keystore-location |
Общий параметр для внешних взаимодействий flink-flow-job.jar по SSL (Solr, Kafka). Путь к keystore, в котором содержатся клиентские сертификаты |
string |
- |
service.flow.job.global.client.ssl.keystore-password |
Общий параметр для внешних взаимодействий flink-flow-job.jar по SSL (Solr, Kafka). Пароль к keystore файлу, в котором содержатся клиентские сертификаты |
password |
- |
service.flow.job.global.client.ssl.key-password |
Общий параметр для внешних взаимодействий flink-flow-job.jar по SSL (Solr, Kafka). Пароль к приватному ключу |
password |
- |
service.flow.job.global.client.ssl.store-type |
Протокол используемый для подключения к Flink |
string_enum |
SSL |
service.flow.job.checkpoint-interval-ms |
Интервал через который производится сохранение состояния функции в Flink (checkpointing). Данный параметр необходим для обеспечения устойчивости к падению при запуске функций с соотоянием (statefull functions) |
long |
5000 |
service.flow.job.global.client.ssl.verify-hostname |
Проверка имени хоста |
boolean |
false |
Настройки клиента для чтения из Kafka:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.kafka.client.consumer.bootstrap-servers |
Список bootstrap серверов для подключения Kafka (для чтения данных) |
string |
- |
service.flow.job.kafka.client.consumer.security-protocol |
Протокол безопасности, который будет использоваться при взаимодействии с Kafka (для чтения данных) |
string_enum |
PLAINTEXT |
Настройки клиента Kafka Producer:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.kafka.client.producer.bootstrap-servers |
Список bootstrap серверов для подключения Kafka (для записи данных) |
string |
- |
service.flow.job.kafka.client.producer.security-protocol |
Протокол безопасности, который будет использоваться при взаимодействии с Kafka (для записи данных) |
string_enum |
SSL_WANT |
Настройки клиента Solr:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.solr.client.sink-threads-shutdown-timeout-sec |
Время, в течении которого будет ожидаться завершение всех текущих операций по построению индекса в Solr. При достижении таймаута, все операции будут завершены (с возможной потерей данных) |
long |
40 |
service.flow.job.solr.client.connection-timeout-ms |
Таймаут соединения при подключении к серверам Solr |
long |
10000 |
service.flow.job.solr.client.socket-timeout-ms |
Таймаут чтения для сокетов, которые используются при подключении к серверам Solr |
long |
10000 |
service.flow.job.solr.client.basic-auth.enabled |
Включение аутентификации. |
boolean |
false |
service.flow.job.solr.client.basic-auth.user |
Имя пользователя |
string |
- |
service.flow.job.solr.client.basic-auth.password |
Пароль пользователя |
password |
- |
service.flow.job.solr.client.ssl-enabled |
Нужно ли использовать SSL при взаимодействии с серверами Solr |
boolean |
false |
Настройки клиента Solr Zookeeper:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.solr.client.zookeeper.connection |
Список хостов ZooKeeper-а, которые будут использоваться при конфигурировании клиента к Solr |
string |
- |
service.flow.job.solr.client.zookeeper.chroot |
Путь к директории ZooKeeper хоста, в которой хранятся данные Solr-а. Используется при конфигурировании клиента к Solr |
string |
/solr |
Настройки Flink Zookeeper:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.flink-standalone.client.zookeeper.connection |
Список адресов Zookeeper-а, необходимых для получения метаинформации о хостах Flink |
string |
- |
service.flow.flink-standalone.client.zookeeper.chroot |
Путь к директории ZooKeeper, в которой располагается метаинформация о хостах Flink |
string |
/flink |
Настройки Flow Job:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.checkpoint-interval-ms |
Интервал через который производится сохранение состояния функции в Flink (checkpointing). Данный параметр необходим для обеспечения устойчивости к падению при запуске функций с состоянием (statefull functions) |
long |
5000 |
Настройки Flow Job для стратегии FixedDelayStrategy:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.flow.job.fixed-delay.attempts |
Необходимое число перезапусков задачи перед тем, как она будет переведена в статус failed. Этот параметр заполняется, в случае если в качестве restart-strategy выбрано значение fixed-delay |
long |
5 |
service.flow.job.fixed-delay.delay |
Задержка перед повторной попыткой перезапуска задачи, перед тем как она будет переведена в статус failed |
string |
1 m |
Конфигурация сервиса полнотекстовых индексов (full text index service)#
В preset и service descriptor сервису соответствует service_type = FULLTEXTINDEX_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29090 |
spring.datasource.username |
Пользователь используемый для подключения к базе данных |
string |
fulltext_service_user |
Настройки выделения термов при поиске:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.query.highlighting.fragsize |
Примерный размер фрагментов возвращаемых при поиске. Если размер фрагмента задан значением 0, то возвращается содержимое всего поля. |
long |
0 |
service.fulltext.query.highlighting.pre-tag |
Тег устанавливаемый перед найденным элементом (термом) для выделения. |
string |
<em> |
service.fulltext.query.highlighting.post-tag |
Тег устанавливаемый после найденного элемента (терма) для выделения. |
string |
</em> |
service.fulltext.query.highlighting.required-field-match |
Параметр управляющий выделением искомых термов и их соответствием полям. Если установлен в значение false то все найденные термы запроса будут выделены для всех полей. Если установлен в значение true то выделятся будут только термы найденные в заданных в поиске полях. |
boolean |
true |
service.fulltext.query.highlighting.snippets |
Количество фрагментов возвращаемых в результатах поиска. |
long |
1 |
Настройки ротации:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.rotation.min-allowed-rotation-interval-sec |
Минимальное время в секундах до выполнения ротации разделов индекса. |
long |
60 |
Настройки аутентификации:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.solr.client.basic-auth.enabled |
Параметр включающий использование аутентификации при доступе к Solr. |
false |
false |
service.fulltext.solr.client.basic-auth.user |
Имя пользователя для доступа к Solr. |
string |
- |
service.fulltext.solr.client.basic-auth.password |
Пароль пользователя для доступа к Solr. |
password |
- |
Общие настройки Solr:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.solr.replica-rules |
Правило распределения реплик Solr. |
string |
["shard:*,replica:<2,host:*"] |
Настройки подключения к zookeeper:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.solr.client.zookeeper.chroot |
Корневой каталог Zookeeper с метаданными Solr. |
string |
/solr |
service.fulltext.solr.client.zookeeper.client-timeout-ms |
Таймаут клиентской сессии Zookeeper. |
long |
30000 |
service.fulltext.solr.client.zookeeper.client-connect-timeout-ms |
Таймаут установления подключения к Zookeeper. |
long |
30000 |
service.fulltext.solr.client.zookeeper.connection |
Список серверов Zookeeper для подключения. |
string |
- |
Настройки модели индекса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.index.model.max-shard-size-bytes |
Максимальный размер шарда в Solr для индекса. |
long |
21474836480 |
service.fulltext.index.model.max-data-rate-bytes-per-sec-per-shard |
Максимальная скорость записи данных в шард (байт в секунду) для индекса. |
long |
4194304 |
service.fulltext.index.model.index-partition-ratio |
Количество партиций для индекса. Поскольку партиции индекса удаляются целиком при ротации данных, малое количество партиций может привести к потере актуальных данных |
long |
4 |
service.fulltext.index.model.index-filling-ratio |
Относительная величина заполнения раздела индекса. При превышении данной величины запись будет выполнятся в следующий раздел. |
double |
0.9 |
service.fulltext.index.model.index-size-correction-ratio |
Коэффициент коррекции размера индекса. |
double |
2.5 |
service.fulltext.index.model.avg-to-max-index-speed-ratio |
Коэффициент средней величины скорости от максимального значения. |
double |
0.7 |
Настройки SSL для подключения к Solr:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.solr.client.ssl.enabled |
Параметр включающий использование SSL при доступе к Solr. |
boolean |
true |
Настройки запросов поиска:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.fulltext.query.fields-scan.min-shards-to-scan |
Минимальное количество шардов (сегментов,кусков) которые будет просмотрены при выполнении запросов. |
long |
3 |
service.fulltext.query.fields-scan.index-fields-scan-precision |
Параметр определяет относительное количество шардов которые будет просмотрены при выполнении запросов. Например значение 0.5 приводит к поиску в половине имеющихся шардов. Если при расчете количества шардов получается количество меньшее чем заданное параметром min_shards_to_scan то требуемое количество шардов будет установлено в значение min_shards_to_scan. |
double |
0.2 |
service.fulltext.query.fields-scan.index-fields-fetch-timeout-ms |
Общий таймаут поиска в индексе. |
long |
6000 |
service.fulltext.query.fields-scan.shard-fields-fetch-timeout-ms |
Таймаут поиска для одной шарды индекса. |
long |
2000 |
Конфигурация сервиса управления группами (group service)#
В preset и service descriptor сервису соответствует service_type = GROUP_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
database.username |
Пользователь используемый для подключения к базе данных |
string |
group_service_user |
service.port |
Порт на котором будет запущен сервис |
port |
29091 |
Параметры клиента к сервису авторизации:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.pvm-security.poll-interval-sec |
Интервал актуализации данных из сервиса авторизации |
long |
- |
Конфигурация сервиса управления источниками данных (kafka service)#
В preset и service descriptor сервису соответствует service_type = KAFKA_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29094 |
service.kafka.client.bootstrap-servers |
Список bootstrap серверов для Kafka клиента |
string |
- |
service.kafka.client.security-protocol |
Протокол, по которому будет осуществляться взаимодействие с Kafka. Допустимые значения: PLAINTEXT, SSL, SASL_PLAINTEXT, SASL_SSL |
string_enum |
SSL |
Параметры подключения сервиса к Kafka:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.kafka.client.consumer.group-id |
Уникальный идентификатор группы Kafka consumer |
string |
tengri_kafka_service |
Параметры по генерации схемы по последним сообщениям в Kafka:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.kafka.schema-extractor.date-time-formats |
Допустимые значения форматов даты и времени для JSON схемы Kafka сообщения, перечисленные через`;` |
string |
yyyy-MM-dd'T'HH:mm:ss.SSS'Z'; yyyy-MM-dd'T'HH:mm:ss,SSS'Z'; yyyy-MM-dd'T'HH:mm:ss.SSS; yyyy-MM-dd'T'HH:mm:ss,SSS; yyyy-MM-dd'T'HH:mm:ss'Z'; yyyy-MM-dd'T'HH:mm:ss; yyyy-MM-dd'T'HH:mm'Z'; yyyy-MM-dd'T'HH:mm; yyyy-MM-dd HH:mm:ss.SSS'Z'; yyyy-MM-dd HH:mm:ss,SSS'Z'; yyyy-MM-dd HH:mm:ss.SSS; yyyy-MM-dd HH:mm:ss,SSS; yyyy-MM-dd HH:mm:ss'Z'; yyyy-MM-dd HH:mm:ss; yyyy-MM-dd HH:mm'Z'; yyyy-MM-dd HH:mm; yyyy-MM-dd |
service.kafka.schema-extractor.text-type-recognition-threshold |
Пороговое значение, по которому определяется текстовый тип поля в схеме сообщения Kafka топика во время процедуры автоматического определения схемы по последним сообщением в топике. Если для каждого рассмотренного сообщения длина текстового поля меньше порогового значения, заданного в этом параметре, то тип поля определяется, как`STRING`. Если среди рассматриваемых сообщений для заданного поля есть значение, длина которого больше порогового значения, указанного в исходном параметре, то тип данного поля будет определен, как `TEXT` |
long |
200 |
Настройки ACL:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.kafka.acl.allow-wildcard-dn |
Разрешать ли использовать wildcard (`*`) для задания множества пользователя при формировании ACL (Access Control List) записи для Kafka топика |
boolean |
false |
Параметры логирования:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
logger_kafka_group_id |
Имя группы в kafka используемой для записи логов |
string |
logger_tengri_kafka_service |
Конфигурация сервиса аналитических индексов (monitoring service)#
В preset и service descriptor сервису соответствует service_type = MONITORING_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29095 |
service.analytical.query.datasource.namespacing.enabled |
Флаг определяющий способ обработки пространств имён для источников данных (datasource) false - Все источники данных использованные в запросы должны принадлежать одному проекту true - Все источники данных использованные в запросе должны содержать краткое имя проекта |
boolean |
false |
service.analytical.query.datasource.namespacing.delimiter |
Разделитель между именем источника данных и кратким именем проекта |
string |
:: |
Настройки hadoop:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.hadoop.filesystem.custom-enabled |
Настройка разрешающая нестандартную настройку файловой системы Hadoop. |
boolean |
true |
Настройки lookup:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.lookup.dictionary-poll-period-sec |
Период опрашивания изменений в словарях. |
long |
60 |
service.analytical.lookup.injective-mode |
Параметр управляющий инъективностью lookup при их создании или обновлении. Инъективные lookup должны включать все значения ключей которые есть в наборах данных с которыми будет использоваться lookup. Каждому ключу инъективнового lookup должно соответствовать уникальное значение. Параметр соответствует параметру injective для Druid и более подробно описан в документации Druid. |
boolean |
false |
service.analytical.lookup.initialize-druid-for-lookups-on-start |
Параметр инициализирующий использование lookup при старте сервиса. |
boolean |
true |
Настройки словарей:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.dictionary.store-path |
Путь к каталогу HDFS для хранения словарей. |
string |
/tengri/monitoring/dictionaries |
service.analytical.dictionary.max-size-bytes |
Максимальный размер словаря в байтах. |
long |
1073741824 |
Настройки запросов:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.query.datasource.on-missing-behaviour |
Настройка поведения при выполнении запросов в случае отсутствия источника данных в Druid. Допустимые значения: EMPTY_ARRAY_RESPONSE, ERROR. Если установлено EMPTY_ARRAY_RESPONSE, то возвращается пустой массив как результат выполнения запроса. Если установлено ERROR, то возвращается ошибка. |
string_enum |
EMPTY_ARRAY_RESPONSE |
service.analytical.query.datasource.namespacing.enabled |
Включает использование пространств имен в запросах. |
boolean |
false |
service.analytical.query.datasource.namespacing.delimiter |
Разделитель между кратким именем проекта и именем источника данных. В запросах с использованием пространства имен источник данных должен быть представлен в формате\"projectShortName::datasourceName\", где :: разделитель (значение разделителя по умолчанию). |
string |
:: |
Настройки индексов:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.index.min-state-change-interval-ms |
Минимальный интервал смены состояния аналитического индекса. Задается в миллисекундах. |
long |
60000 |
Настройки аутентификации:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.druid.client.basic-auth.enabled |
Параметр включающий использование аутентификации при доступе к Druid. |
false |
false |
service.analytical.druid.client.basic-auth.user |
Имя пользователя для доступа к Druid. |
string |
- |
service.analytical.druid.client.basic-auth.password |
Пароль пользователя для доступа к Druid. |
password |
- |
Настройки взаимодействия с Druid:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.druid.supervisors-pull-interval-sec |
Интервал периодичного запроса информации о супервизорах Druid. |
long |
10 |
service.analytical.druid.query-url |
URL для выполнения запросов в Druid. |
string |
- |
service.analytical.druid.cache.enabled |
Параметр, управляющий кэшированием метаданных от Druid. |
true |
true |
service.analytical.druid.client.ssl.enabled |
Параметр, включающий использование SSL при доступе к Druid. |
false |
false |
Настройки взаимодействия с Kafka для Druid:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.analytical.druid.kafka.consumer.bootstrap-servers |
Список брокеров Kafka для инициализации подключения для Druid. Например 0.116.204.84:9093,10.116.204.89:9093,10.116.204.90:9093 |
string |
- |
service.analytical.druid.kafka.consumer.security-protocol |
Настройка безопасности для взаимодействия с Kafka для Druid. |
PLAINTEXT |
SSL_WANT |
service.analytical.druid.kafka.consumer.ssl.truststore-location |
Путь к хранилищу доверенных сертификатов для взаимодействия с Kafka для Druid. |
string |
- |
service.analytical.druid.kafka.consumer.ssl.keystore-location |
Путь к хранилищу клиентских сертификатов для взаимодействия с Kafka для Druid. |
string |
- |
service.analytical.druid.kafka.consumer.ssl.truststore-password |
Пароль к хранилищу доверенных сертификатов для взаимодействия с Kafka для Druid. |
password |
- |
service.analytical.druid.kafka.consumer.ssl.keystore-password |
Пароль к хранилищу клиентских сертификатов для взаимодействия с Kafka для Druid. |
password |
- |
service.analytical.druid.kafka.consumer.ssl.key-password |
Пароль клиентского ключа для взаимодействия с Kafka для Druid. |
password |
- |
service.analytical.druid.kafka.consumer.ssl.endpoint-identification-algorithm |
Алгоритм верификации брокеров для взаимодействия с Kafka для Druid. Если задано https то выполняется проверка на соответствие имени хоста его SSL сертификату. Для отключения верификации необходимо задать пустую строку. |
string |
<пустая строка> |
Конфигурация сервиса оркестрации процессов (pipeline service)#
В preset и service descriptor сервису соответствует service_type = PIPELINE_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29098 |
spring.datasource.username |
Пользователь используемый для подключения к базе данных |
string |
pipeline_service_user |
service.pipeline.task.index.processing.sink.solr.parallelism.ratio |
Коэффициент параллелизма Flink для записи в Solr |
long |
1.0 |
service.pipeline.task.index.processing.max-thread-datarate-bytes-per-sec |
Максимальная скорость записи данных в шард (байт в секунду) для индекса. |
long |
2621440 |
service.pipeline.task.index.sink.solr-sink-nthreads |
Количество потоков для одной задачи записи в Solr |
long |
1 |
Конфигурация сервиса управления проектами (project service)#
В preset и service descriptor сервису соответствует service_type = PROJECT_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29093 |
database.username |
Пользователь используемый для подключения к базе данных |
string |
project_service_user |
Конфигурация сервиса управления разрешениями (role service)#
В preset и service descriptor сервису соответствует service_type = ROLE_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.port |
Порт на котором будет запущен сервис |
port |
29092 |
service.role.security.admin-names-list |
Список, содержащий логины администраторов. |
string |
["abyss_internal_admin"] |
Параметры клиента к сервису авторизации:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
service.pvm-security.poll-interval-sec |
Интервал актуализации данных из сервиса авторизации |
long |
- |
Конфигурация сервиса сбора трейсов (trace collector service)#
В preset и service descriptor сервису соответствует service_type = TRACE_COLLECTOR_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
server_port |
Порт на котором будет запущен сервис |
port |
29100 |
zipkin.kafka.trace_topic |
Топик в Kafka в котором будут хранится логи трассировки |
string |
tracing |
Параметры подключения сервиса к Kafka:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
kafka.group.id |
Имя группы в kafka используемой сервисом |
string |
tengri_trace_collector |
Конфигурация сервиса обработки трейсов (trace query service)#
В preset и service descriptor сервису соответствует service_type = TRACE_QUERY_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
server_port |
Порт на котором будет запущен сервис |
port |
29101 |
service.druid.cache.enabled |
Включить/Выключить кэширование в Druid |
boolean |
true |
service.druid.cache.lagRetentionSeconds |
Время хранения данных о задержках в кэше Druid |
long |
60 |
service.druid.cache.maxSize |
Максимальный размер кэша Druid |
long |
100 |
service.druid.cache.statsRetentionSeconds |
Время хранения статистических данных в кэше Druid |
long |
60 |
service.druid.cache.supervisorsPullIntervalSeconds |
Интервал между запросами информации о супервизорах Druid |
long |
10 |
service.druid.cache.taskStatsRetentionSeconds |
Время хранения статистических данных о задачах в кэше Druid |
long |
60 |
service.druid.queryURL |
URL роли "Router" сервиса Druid |
string |
- |
service.druid.security.enabled |
Включить авторизацию через учетные данные для подключения к Druid |
boolean |
true |
service.druid.security.password |
Пароль для подключения к Druid |
password |
- |
service.druid.security.username |
Логин администратора для подключения к Druid |
string |
admin |
Журналирование в Kafka:
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
kafka.group.id |
Имя группы в kafka используемой сервисом |
string |
tengri_trace_query |
Конфигурация сервиса авторизации (PVM authorization service)#
В preset и service descriptor сервису соответствует service_type = PVM_AUTHORIZATION_SERVICE (см. разделы Preset и Service Descriptors).
Параметры необходимые к заполнению в service descriptor.yml.
Параметры сервиса
Параметр |
Описание параметра |
Тип параметра |
Значение по умолчанию |
|---|---|---|---|
server.port |
Порт |
int |
8080 |
service.pvm.user-catalog.type |
Users type Значения: LDAP, LOCAL, BOTH |
string_enum |
LOCAL |
service.pvm.auth.type |
Тип аутентификации в сервисе: JWTSEC или BASIC |
string_enum |
BASIC |
spring.liquibase.enabled |
Включить автоматическую миграцию БД |
boolean |
true |
spring.liquibase.changelog |
Путь к файлу с описанием изменений структуры БД |
string |
classpath:/db/changelog/changelog-master.xml |
spring.security.user.name |
Пользователь для аутентификации |
string |
- |
spring.security.user.password |
Пароль для аутентификации |
password |
- |
spring.ldap.urlsldap.ssl.key-store |
Параметры LDAP (нужны только при профилеldap) |
List<String> |
- |
spring.ldap.base |
Параметры LDAP (нужны только при профилеldap) |
string |
- |
spring.ldap.username |
Параметры LDAP (нужны только при профилеldap) |
string |
- |
spring.ldap.password |
Параметры LDAP (нужны только при профилеldap) |
string |
- |
ldap.ssl.trust-store |
Расположение доверенного хранилища ssl используемого LDAP-сервисом |
string |
- |
ldap.ssl.trust-store-password |
Пароль от доверенного хранилища используемого LDAP-сервисом |
password |
- |
ldap.ssl.key-store |
Расположения хранилища ключей ssl используемого LDAP-сервисом |
string |
- |
ldap.ssl.key-store-password |
Пароль от хранилища ключей используемого LDAP-сервисом |
password |
- |
permissions_model |
Модель разрешений |
string |
- |
pvm_authorization_service_java_opts |
jvm параметры |
string |
-Xmx512m -XX:+ExitOnOutOfMemoryError -XX:MaxGCPauseMillis=100 -XX:+UseG1GC -Duser.timezone=UTC -Dfile.encoding=UTF-8 |
Настройка СПО#
Druid#
Основные параметры:
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
druid.zk.service.host |
zookeeper hosts |
Хосты на которых установлен zookeeper |
druid.zk.paths.base |
/druid |
Путь до каталога druid в zookeeper |
druid.storage.type |
hdfs |
Тип Deep Storage |
druid.storage.storageDirector |
/user/druid/segments |
Каталог в Hdfs для сегментов |
druid.indexer.logs.type |
hdfs |
Тип хранилища логов задач индексации порождаемых Middle manager |
druid.indexer.logs.directory |
/user/druid/log |
Каталог в Hdfs для логов задач |
druid.indexer.logs.kill.enabled |
true |
Автоматическое ротирование логов |
druid.indexer.logs.kill.durationToRetain |
1209600000 (14 дней) |
Время хранения логов в миллисекундах |
druid.metadata.storage.type |
postgresql |
Тип хранилища метаданных, необходимо использовать Postgres |
druid.metadata.storage.connector.connectURI |
- |
Строка подключения к БД |
druid.metadata.storage.connector.user |
user |
Пользователь |
druid.metadata.storage.connector.password |
password |
Пароль |
druid.sql.enable |
true |
Включить использование SQL |
Druid Historical
Отвечает за хранение данных.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
druid.processing.numThreads |
8 |
Установить значение равное кол-во ядер CPU - 1 |
druid.processing.numMergeBuffers |
2 |
Количество создаваемых буферов для обработки данных. Рекомендуется задать значение равное 1/4 druid.processing.numThreads |
druid.processing.buffer.sizeBytes |
536 870 912 (512 mb) |
Объем буфера для обработки данных. Рекомендуется использовать значение по умолчанию. |
druid.server.maxSize |
53687091200 |
Максимальный размер, выделенный для хранения данных на Historical. |
druid.segmentCache.locations |
[{"path": "/tengri/druid", "maxSize": 53687091200}] |
Путь до дискового каталога, где будут храниться данные. |
druid.cache.enabled |
true |
Включить кеширование |
druid.cache.type |
caffeine |
Тип кеширования. Рекомендуется использовать значение по умолчанию. |
druid.cache.sizeInBytes |
1 073 741 824 (1 gb) |
Размер кеша |
druid.cache.evictOnClose |
true |
Включить автоочистку кеша |
JVM config |
-server -Xmx12g -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:MaxDirectMemorySize=7g |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
Druid Broker
Обрабатывает запросы и выполняет агрегацию данных полученных с Historical.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
JVM config |
-server -Xmx10g -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:MaxDirectMemorySize=8g |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
druid.processing.numMergeBuffers |
2 |
Количество создаваемых буферов для обработки данных. Рекомендуется задать значение равное значению параметра druid.processing.numMergeBuffers для Druid Historical |
druid.processing.buffer.sizeBytes |
536 870 912 (512 mb) |
Объем буфера для обработки данных. Рекомендуется использовать значение по умолчанию. |
Druid Overlord
Управляет задачами индексации внутри кластера и отвечает за распределение нагрузки.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
JVM config |
-server -Xmx2g -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
Druid Coordinator
Отвечает за доступность данных в кластере.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
JVM config |
-server -Xmx2g -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
druid.coordinator.kill.on |
True |
Включить очистку deep storage от устаревших сегментов |
druid.coordinator.kill.period |
PT6H (Каждые 6 часов) |
Интервал очистки устаревших сегментов |
druid.coordinator.kill.durationToRetain |
PT1H |
Не удалять сегменты за последний период (1 час) |
druid.coordinator.kill.maxSegments |
1000000 |
Максимальное количество сегментов для очистки |
druid.coordinator.kill.pendingSegments.on |
true |
Автоматическая очистка ожидающих сегментов |
Druid Router
Осуществляет маршрутизацию запросов между множеством Brokers, Coordinators и Overlords.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
JVM config |
-Xmx2g |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
druid.router.managementProxy.enabled |
true |
Включение прокси управления, чтобы производить все действия из одной точки |
druid.router.http.numMaxThreads |
100 |
Максимальное количество потоков обработки данных |
druid.router.http.readTimeout |
PT5M |
Timeout ожидания ответа от Broker |
druid.router.http.numConnections |
50 |
Максимальное количество одновременных подключений |
Druid Middle Manager
Отвечает за прием данных.
Параметр |
Значение по умолчанию |
Описание параметра |
|---|---|---|
JVM config MM |
-server -Xmx1024m -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=200 |
JVM параметры. Рекомендуется использовать значение по умолчанию. |
JVM config Indexer Task |
-server -Xmx512m -Xms256m -XX:+ExitOnOutOfMemoryError -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:MaxDirectMemorySize=1G |
JVM параметры Indexer. Рекомендуется использовать значение по умолчанию. |
druid.worker.capacity |
7 |
Максимальное кол-во задач |
druid.processing.numThreads |
1 |
Количество потоков обработки, доступных для параллельной обработки сегментов. |
druid.processing.numMergeBuffers |
1 |
Количество создаваемых буферов для обработки данных. |
druid.processing.buffer.sizeBytes |
134217728 (128 mb) |
Объем буфера |
druid.indexer.task.baseDir |
/tengri/druid/ |
Каталог для хранения промежуточных сегментов во время выполнения задачи индексации |
druid.indexer.task.restoreTasksOnRestart |
true |
Восстанавливать задачи после перезапуска процесса |
Композиция дистрибутива#
Дистрибутив поставляется в разделенном состоянии в виде двух архивов - owned.zip и party.zip. Для корректной установки требуется скомпоновать эти архивы в один. Компоновка возможна двумя способами:
Ручная (без использования Jenkins);
С использованием Jenkins.
Ручная композиция#
Для ручной компоновки необходимо:
Разархивировать архивы owned.zip и party.zip;
Скопировать скрипты rpms_inject_and_build_all.sh и rpm_inject_and_build.sh из ./devops/scripts в корневую папку дистрибутива;
Запустить скрипт rpms_inject_and_build_all.sh:
./rpms_inject_and_build_all.sh
После выполнения скрипта в текущей директории появится объединенный дистрибутив.
Композиция через Jenkins#
В проект Jenkins добавить Shared Lib:
Name: ru.sbt.eventlogging
Default version: master
Allow default version to be overridden: true
Include @Library changes in job recent changes: true
Retrieval method: Legacy SCM
Git:
Repository URL: <sshGitLink>
Credentials: ваш credentials для доступа к репозиторий
Branch Specifier (blank for 'any'): */${library.ru.sbt.eventlogging.version}
Создать новую задачу Jenkins с именем AbyssCombineRelease. В настройках выбрать галку Prepare an environment for the run и заполнить содержимое Properties Content.
# Используемая ветка DevOps
DEVOPS_GIT_BRANCH=master
# Имя Jenkins хосты
Jenkins_Slave=Linux_Default
# GAV артефакта в Nexus (можно не указывать, тогда будут использованы дефолтные параметры ниже)
#NEXUS_REPO_ID=Nexus_PROD
#GROUP_ID=Nexus_PROD
#ARTIFACT_ID=CI02809205_tengri_new_main
# URL используемого Nexus
NEXUS_URL=https://
# Credentials для загрузки дистрибутива из Nexus
NEXUS_CRED=tengri_with_pass
# При необходимости деплоя в Nexus отличный от Nexus загрузки, указать
#TARGET_NEXUS_URL=https:// (если не переопределять данный параметр, значение берется из NEXUS_URL)
#TARGET_NEXUS_REPO_ID=Nexus_PROD (если не переопределять данный параметр, значение берется из NEXUS_REPO_ID)
#TARGET_NEXUS_CRED (если не переопределять данный параметр, значение берется из NEXUS_CRED)
#TARGET_NEXUS_GROUP_ID (если не переопределять данный параметр, значение берется из GROUP_ID)
#TARGET_NEXUS_ARTIFACT_ID (если не переопределять данный параметр, значение берется из ARTIFACT_ID)
После, в разделе Pipeline Definition выбрать DevOps репозиторий, указать используемый credentials и задать параметры:
Branches to build: */${DEVOPS_GIT_BRANCH}
Script Path: jenkinsJobs/AbyssCombineRelease.groovy
Lightweight checkout: false
Запустить сборку, в результате будет произведена инициализация остальных параметров
Запустить задачу компоновки:
Название параметра |
Описание |
|---|---|
UPD_JOB |
Флаг используемый для обновления конфигурации задачи Jenkins |
VERSION |
Флаг используемый для обновления конфигурации задачи Jenkins |
Установка#
Перед установкой убедитесь, что хосты подготовлены в соответствии с требованиями описанными в разделе "Системные требования".
Подготовка Git#
Создать config репозиторий Git;
Сформировать (с описанием всех параметров сервисов можно ознакомиться в разделе "Конфигурация сервисов") и загрузить в config репозиторий Git конфигурационные файлы (структура репозитория описана в разделе Структура конфигурационных файлов):
service_descriptors: * Сервис архивных индексов (archive service); * Сервис аутентификации (auth service); * Сервис-шлюз API (client api service); * Сервис потоковой обработки (flow management service); * Сервис полнотекстовых индексов (full text index service); * Сервис управления группами (group service); * Сервис управления источниками данных (kafka service); * Сервис аналитических индексов (monitoring service); * Сервис оркестрации процессов (pipeline service); * Сервис управления проектами (project service); * Сервис авторизации (PVM authorization service); * Сервис управления разрешениями (role service); * Сервис сбора трейсов (trace collector service); * Сервис обработки трейсов (trace query service); * Druid; * Flink; * Solr;
devops.yml;
global_service_vars.properties;
hosts.yml;
hosts_resolve.yml;
service_mapping.yml;
pass.yml.
Создать DevOps репозиторий Git (опционально, если требуется установка через Jenkins)
Загрузить в DevOps репозиторий Git скрипты развертывания из дистрибутива (структура репозитория описана в разделе Структура конфигурационных файлов); 1. jenkinsJobs; 2. python_devops_new.
Загрузить в DevOps репозиторий Git presets (структура репозитория описана в разделе Структура конфигурационных файлов).
Целевым способом установки Abyss является установка через Jenkins, но есть и другой вариант, позволяющий запустить Python скрипт установки напрямую с хоста.
Рассмотрим оба варианта.
Установка через Jenkins#
Настройка credentials#
Требуется добавить необходимые credentials в Jenkins:
Credential типа Username with password с УЗ, используемой для выгрузки дистрибутива из Nexus;
Credential типа SSH Username with private key с УЗ, используемой для взаимодействия с Git;
Credential типа Secret file с файлом, содержащим пароль используемый для (де)шифрования Ansible Vault;
Credential типа SSH Username with private key с УЗ, которая будет осуществлять подключение к хостам по ssh (предполагается, что публичная часть ключа уже добавлена на все задействованные в установке хосты).
Настройка Jenkins задачи#
Создать новую Jenkins задачу с именем AbyssMultiInstall
В настройках выбрать Prepare an environment for the run и заполнить содержимое Properties Content
# Лейбл используемого Jenkins агента
Jenkins_Slave=Linux_Default
# docker
# Linux_Default
# Используемая ветка DevOps репозиторий
DEVOPS_GIT_BRANCH=master
############ ID используемых секретов ############
# Credential ID уз используемой для подключения к хостам по ssh
INSTALLER_KEY=installer_test_key
# Credential ID секрета используемого для расшифровки pass.yml
ANSIBLE_VAULT_FILE_CRED=vaultFile
# Credential ID УЗ используемой для подключения к Nexus
NEXUS_CRED=abyss_with_pass
# Credential ID УЗ используемой для подключения к Git репозиторию DevOps.
GIT_CRED=abyss
############ Базовые URL ############
# Базовый url Nexus, используемого для хранения релизных артефактов
NEXUS_URL=
# Базовый ssh-url проекта в Git, используемого для хранения исходного кода DevOps.
GIT_BASE_SSH_URL=
############ Параметры подключения к config репозиторию unit-ов ############
CONFIG_REPO_NAME=abyss_devops_config
############ Дефолтные значения параметров ############
#DEFAULT_UNITS_LIST=TengriST, TengriDEV
#DEFAULT_INSTALL_COMPONENTS=ARCHIVE_SERVICE,AUTH_SERVICE,CLIENT_API_SERVICE,FLOW_SERVICE,FULLTEXTINDEX_SERVICE,GROUP_SERVICE,KAFKA_SERVICE,MONITORING_SERVICE,PIPELINE_SERVICE,PROJECT_SERVICE,PVM_AUTHORIZATION_SERVICE,ROLE_SERVICE,TENGRI_TRACE_COLLECTOR,TENGRI_TRACE_QUERY_SERVICE,TENGRI_UI,TENGRI_SOLR,FLINK,TRACE_QUERY_SERVICE
############ DEV mode параметры ############
JOB_ENV_MODE=DEV
DEPLOY_REPO_USER_HOST=login@host
#DRY_RUN_CONFIGS=true
DISTRIB_REPO_DIR=/tengri/distrib_repo
Описание доступных параметров:
Key |
Default |
Description |
Required |
|---|---|---|---|
Jenkins_Slave |
Лейбл используемого Jenkins агента. |
Да |
|
DEVOPS_GIT_BRANCH |
Используемая ветка DevOps репозитория (значение параметра передается в раздел Pipeline Definition). |
Да |
|
INSTALLER_KEY |
Credential ID уз используемой для подключения к хостам по ssh. |
Да |
|
ANSIBLE_VAULT_FILE_CRED |
Credential ID секрета используемого для расшифровки pass.yml (если планируется хранить pass.yml в открытом виде, задавать данный параметр не требуется). |
Нет |
|
NEXUS_CRED |
Credential ID уз используемой для подключения к Nexus. |
Да |
|
GIT_CRED |
Credential ID уз используемой для подключения к Git репозиторию DevOps. |
Да |
|
NEXUS_URL |
Базовый url Nexus-а, используемого для хранения релизных артефактов. |
Да |
|
GIT_BASE_SSH_URL |
Базовый ssh-url проекта в Git, используемого для хранения исходного кода DevOps. |
Да |
|
NEXUS_REPO_ID |
Nexus_PROD |
Repo ID релизного артефакта в Nexus. |
Нет |
GROUP_ID |
Nexus_PROD |
Group ID релизного артефакта в Nexus. |
Нет |
ARTIFACT_ID |
CI02809205_tengri_new_main |
Artifact ID релизного артефакта в Nexus. |
Нет |
CONFIG_REPO_BASE_SSH_URL |
env.GIT_BASE_SSH_URL |
Базовый ssh-url проекта в Git, используемого для хранения конфигураций unit-ов (при отсутствии данного параметра, берется значение параметра GIT_BASE_SSH_URL). |
Нет |
CONFIG_REPO_GIT_CRED |
env.GIT_CRED |
Credential ID уз используемой для подключения к Git репозиторию конфигураций unit-ов (при отсутствии данного параметра, берется значение параметра GIT_CRED). |
Нет |
CONFIG_REPO_NAME |
Название репозитория конфигураций unit-ов. |
Нет |
|
VIRTUAL_ENV_DIR |
${env.WORKSPACE}/abyss-venv |
Директория, в которой будет создано python virtual env (можно переопределять, при желании использовать уже существующий python virtual env на хосте и не конфигурировать его при каждой сборке) |
Да |
PYTHON_VERSION |
3 |
Версия python, используемая при создании python virtual env . |
Нет |
PIP_INSTALL_EXTRA_OPTIONS |
"" |
Параметр, используемый для передачи дополнительных параметров, используемых pip. Полезно, например, при необходимости явным образом указать адрес репозитория python библиотек |
Нет |
DEFAULT_UNITS_LIST |
"" |
Список дефолтных Unit, данный список будет прогружен в дефолт значение стартового параметра UNITS_LIST. |
Нет |
DEFAULT_INSTALL_COMPONENTS |
"" |
Список дефолтных компонентов для установки, данный список будет прогружен в дефолт значение стартового параметра INSTALL_COMPONENTS. |
Нет |
DEFAULT_CONFIG_REPO_BRANCH |
master |
Дефолтное значение параметра CONFIG_REPO_BRANCH. |
Нет |
DEFAULT_START_STAGE |
PREPARE_PACKAGES |
Дефолтное значение параметра START_STAGE. |
Нет |
DEFAULT_STOP_STAGE |
RUN_SERVICES |
Дефолтное значение параметра STOP_STAGE |
Нет |
DO_NOT_USE_DYNAMIC_PARAMS |
false |
Флаг для принудительного отключения всех динамических параметров. |
Нет |
В разделе Pipeline Definition выбрать DevOps репозиторий, указать используемый credentials и задать параметры:
Branches to build: */${DEVOPS_GIT_BRANCH}
Script Path: jenkinsJobs/AbyssMultiInstall.groovy
Lightweight checkout: false
Добавить ssh ключ от хостов в credentials Jenkins (тип - SSH Username with private key).
Запустить сборку, в результате будет произведена инициализация остальных параметров.
Запуск Jenkins#
Для установки кластера Abyss требуется запустить созданную ранее задачу AbyssMultiInstall, заполнив параметры:
Параметр |
Описание |
|---|---|
UNITS_LIST |
Список Unit'ов для установки, созданные пользователем на этапе формирования config репозитория. |
При выборе Unit установка будет производится на все кластера в его составе. |
|
Также можно выбрать конкретный кластер входящий в состав Unit. |
|
Элементы перечисляются через запятую без пробелов. Кластер в составе unit указывается через двоеточие (UNIT_NAME:CLUSTER_NAME) |
|
Пример: Unit1,Unit2,Unit3:Cluster1 |
|
INSTALL_COMPONENTS |
Список сервисов требуемых для установки/обновления |
DRY_RUN_CONFIGS |
Режим работы задачи, при котором собирается разница между параметрами из репозитория Git и установленными на кластере (при выборе производится только сбор разницы, все шаги установки игнорируются). |
CONFIG_REPO_BRANCH |
Ветка config репозитория Git, в которой расположены конфигурационные файлы Units. |
START_STAGE/STOP_STAGE |
Начальный/конечны шаг установки. Возможные варианты для выбора: |
PREPARE_CLUSTER - подготовка кластера к установке Abyss (обновление компонента sdp-select) |
|
PREPARE_PACKAGES - подкладка на хосты необходимых в рамках обновления релиза пакетов (rpm, ui) |
|
INSTALL_SERVICES - добавление и конфигурирование сервисов в кластер (если сервис уже создан то шаг создания проигнорируется) |
|
RUN_SERVICES - запуск/перезапуск сервисов |
|
VERSION |
Версия дистрибутива для установки.Пример: D-19.000.00_00 |
Установка нового кластера и обновление существующего происходит одной и той же задачей, но с разными начальным и конечным шагом установки.
По завершению работы задачи будет развернуты все кластера из списка UNITS_LIST, на хосты указанные в соответствующих hosts.yml, инфраструктурой кластера указанной в servise_mapping.yml и параметрами сервиса указанными в preset.yml + service descriptor.yml
Ручная установка#
Для установки Abyss в ручном режиме осуществляется только на один unit. Для этого требуется запустить Python скрипт.
В дистрибутиве содержатся все необходимые скрипты в папке devops.
Для установки требуется запустить …/devops_entry_point.py передав в него необходимые аргументы:
Аргумент |
Описание |
Значение по умолчанию |
|---|---|---|
–config_root_dir |
Путь до каталога установщика, в нем должна содержаться папка units и abyss_presets * units - необходимо создать в соответствии с архитектурой* abyss_presets - содержится в дистрибутиве |
Корневая папка установщика (devops) |
–unit |
Имя unit. |
Обязательный для заполнения |
–cluster |
Имя устанавливаемого кластера из unit'а. |
Обязательный для заполнения |
–update_components |
Список компонент для обновления. Можно указать ALL для установки всех компонент. |
Обязательный для заполнения |
–start_stage |
Начальный шаг установки: |
PREPARE_HOSTS |
PREPARE_CLUSTER - подготовка кластера к установке Abyss (обновление компонента sdp-select) |
||
PREPARE_PACKAGES - подкладка на хосты необходимых в рамках обновления релиза пакетов (rpm, ui) |
||
INSTALL_SERVICES - добавление и конфигурирование сервисов в кластер (если сервис уже создан то шаг создания проигнорируется) |
||
RUN_SERVICES - запуск/перезапуск сервисов |
||
–stop_stage |
Конечный шаг установки: |
|
PREPARE_CLUSTER - подготовка кластера к установке Abyss (обновление компонента sdp-select) |
||
PREPARE_PACKAGES - подкладка на хосты необходимых в рамках обновления релиза пакетов (rpm, ui) |
||
INSTALL_SERVICES - добавление и конфигурирование сервисов в кластер (если сервис уже создан то шаг создания проигнорируется) |
||
RUN_SERVICES - запуск/перезапуск сервисов |
||
–dry_run_mode |
Собирает разницу между параметрами из репозитория Git и установленными на кластере (при выборе производится только сбор разницы, все шаги установки игнорируются) |
False |
Пример запуска
python3 ./devops_entry_point.py --config_root_dir=path/to/devops --unit=unit_name --cluster=cluster_name --update_components=auth_service,pipeline_service
Обновление#
Для обновления требуется запустить задачу Jenkins (удаление предыдущей версии не требуется):
Сделайте резервную копию базы данных.
Выберите необходимую версию дистрибутива.
Установите START_STAGE со значением PREPARE_PACKAGES.
Выберите необходимый список кластеров UNIT_LIST.
Перечислите список необходимых сервисов для обновления INSTALL_COMPONENTS.
Выберите ветку с конфигурационными файлами CONFIG_REPO_BRANCH.
Удаление#
Остановить все сервисы: UI Ambari -> Service Name -> Actions -> Stop
Удалить папку /ambari_server
Удалить все rpm сервисов Abyss через yum
yum remove <service_name>
Удалите Coodrinator UI.
rm -rf /tengri/tengri-ui
Откат#
Для отката требуется:
Восстановить базу данных из резервной копии;
Установить предыдущую версию Abyss (удаление предыдущей версии не требуется).
Проверка работоспособности#
После установки кластера SDP требуется провести проверку.
Проверить что в кластер добавлены все требуемые сервисы (остальные можно удалить):
Zookeeper
HDFS
YARN
Flink
Solr
Druid
Сервис архивных индексов (archive service);
Сервис аутентификации (auth service);
Сервис-шлюз API (client api service);
Сервис потоковой обработки (flow management service);
Сервис полнотекстовых индексов (full text index service);
Сервис управления группами (group service);
Сервис управления источниками данных (kafka service);
Сервис аналитических индексов (monitoring service);
Сервис оркестрации процессов (pipeline service);
Сервис управления проектами (project service);
Сервис авторизации (PVM authorization service);
Сервис управления разрешениями (role service);
Сервис сбора трейсов (trace collector service);
Сервис обработки трейсов (trace query service);
Проверить статус работоспособности каждого из перечисленных выше сервисов в UI Ambari:
"Зеленый" индикатор статуса сервиса;
В логах сервиса на хосте нет логов с типом ERROR.
Проверить работоспособность кластера через Coordinator UI; Для проверки работоспособности кластера после разворачивания следует проверить состояние компонентов в интерфейсе администрирования кластера. Компоненты должны быть подняты, ошибки отсутствовать.Вторым шагом будет аутентификация в Coordinator UI и создание с помощью него основных сущностей, необходимых для записи данных в хранилища:
Создание проекта и задание квот;
Создание топика Kafka и отправка в него сообщений;
Создание задачи полнотекстовой индексации и получение обработанных записей (проверка осуществляется в UI Solr);
Создание задачи аналитической индексации и получение обработанных записей (проверка осуществляется в UI Druid);
Создание задачи архивной индексации и получение обработанных записей;
Создание datasource трейсинга.
Создание данных сущностей производится на соответствующих вкладках. В случае возникновения вопросов по работе с Coordinator UI следует обратиться к "Руководству оператора" настоящей документации.
Валидация#
В ходе работы установщика все конфигурационные файлы будут проверены на корректность заполнения. В этой статье указаны критерии по которым будут осуществляться проверки.
Проверка существования preset указанного в unit.yml.
Проверка существования в preset параметров указанных в service descriptors.
Проверка того, что параметры из service descriptors отмеченные в preset как required заполнены.
Проверка того, что параметры из service descriptors отмеченные в preset как sensitive передается через placeholder.
Проверка того, что все service_id в service descriptors уникальные.
Проверка того, что количество экземпляров ролей сервисов указанных в sevice_mapping.yml и hosts.yml соответствует регулярному выражению cardinality в preset.
Проверка того, что конфигурационные группы указанные в service_mapping.yml объявлены в соответствующих service descriptors.
Проверка соответствия содержимого параметров из service descriptor соответствует регулярному выражению из validation_regex в preset.
Часто встречающиеся проблемы и пути их устранения#
Не зафиксировано часто встречающихся проблем при установке.
Чек-лист валидации установки#
Подготовлены хосты в соответствии с системными требованиями.
Развернута база данных.
Создана и настроена задача Jenkins.
Подготовлены конфигурационные файлы и загружены в Git (структура репозитория описана в разделе Структура конфигурационных файлов).
Задача Jenkins успешно завершена.
Развернут кластер Abyss.