Параллельная обработка данных в задачах сбора данных#
Данная функция обеспечить возможность настраивать параллельные потоки обработки данных с применением конфигураций обработки, фильтрации и преобразования полученных данных, для их дальнейшего сохранения в разные хранилища данных.
Шаг «Параллельная обработка данных» необязательный. Если данные не требуют параллельных преобразований, их можно сразу передать на хранение. Чтобы запустить параллельную обработку данных необходимо добавить чек-бокс с текстом «Разделить последующую обработку на потоки». По умолчанию чек-бокс — false.
Потоки очередей компонентов обработки применяются одновременно ко всем собранным и обработанным данным. Таким образом, можно разделить потоки данных для того, чтобы по-разному их дополнительно обрабатывать и сохранять.
После выбора конфигурации обработки отображаются поля конфигурации из JSON очерченные горизонтальной линией в конце конфигурации.
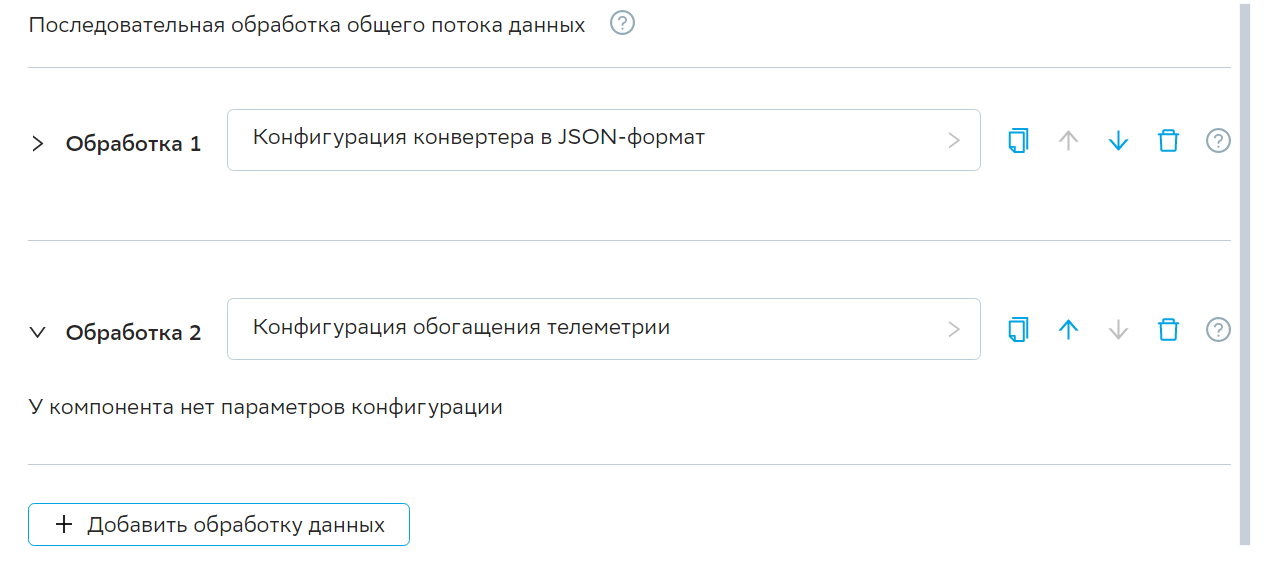
Если необходимо удалить обработку нажмите иконку «Корзина».
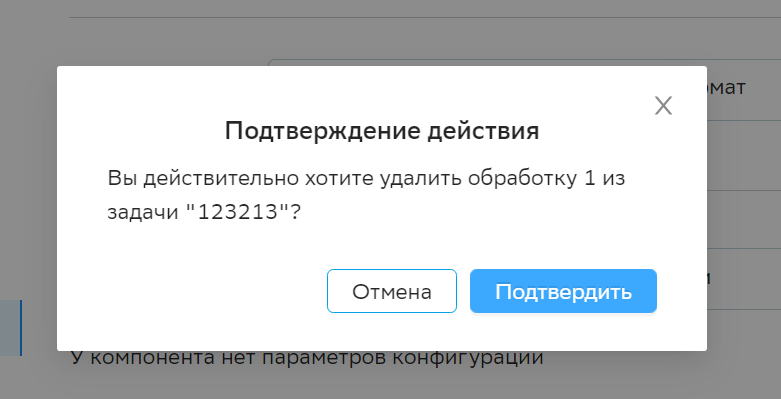
При клике на иконку «Корзина» появляется сообщение с текстом: «Вы действительно хотите удалить Обработку N из задачи Наименование задачи».
Обработка сразу удалится из задачи сбора данных независимо от результата ее сохранения.
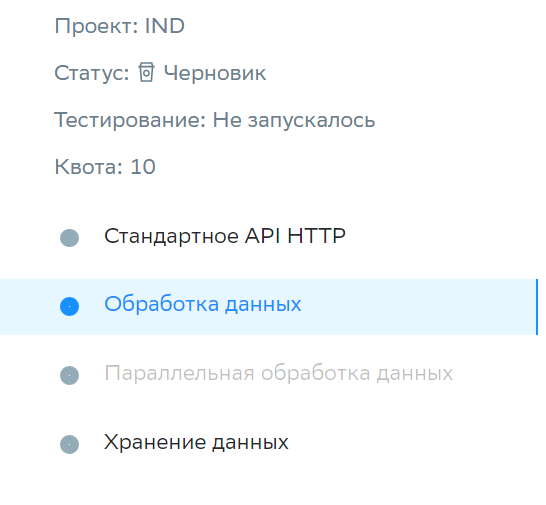
После выбора чек бокса «Разделить последующую обработку на потоки» в навигационной панели появляется неактивный шаг «Параллельная обработка данных»(сразу после шага «Обработка данных»)
Кнопка страницы «Перейдите к хранению» изменяется на «Перейдите к параллельной обработке»
После нажатия кнопки «Перейдите к параллельной обработке» пользователь переходит к шагу «Параллельная обработка данных»
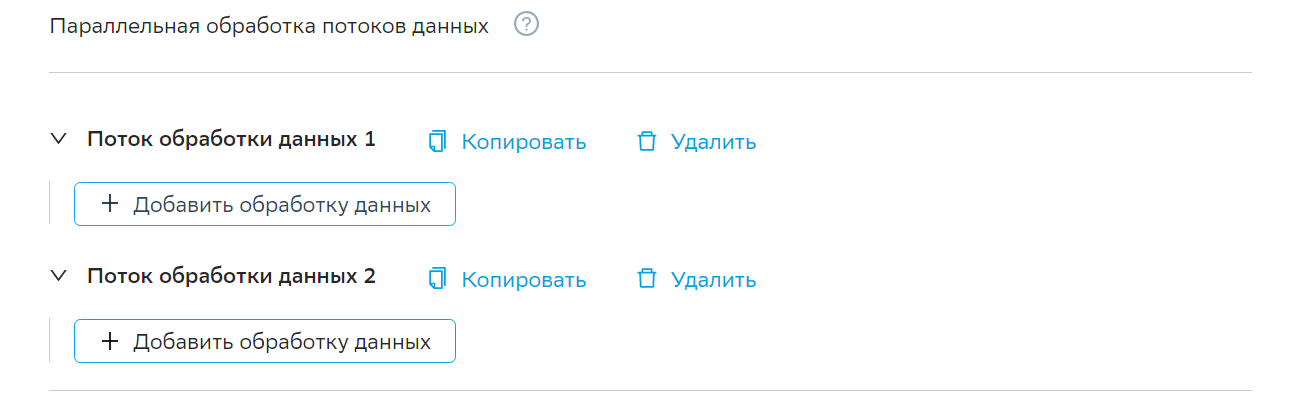
Далее пользователь должен выбрать конфигурации обработок которые будут применены последовательно в потоке в параллель с другими потоками.
Поток так же можно оставить пустым (без обработок), тогда все полученные данные на шаге сбора и последовательной обработки могут быть направлены на хранение через этот поток.
Иконки действий у варианта хранения#
 Копировать — копирует весь вариант хранения данных вместе с выбранными потоками обработки в конец списка, в качестве нового варианта.
Копировать — копирует весь вариант хранения данных вместе с выбранными потоками обработки в конец списка, в качестве нового варианта.
 Удалить — удаляет вариант хранения данных вместе с потоками относящимися к нему.
Удалить — удаляет вариант хранения данных вместе с потоками относящимися к нему.
При клике на кнопку «Удалить» появляется информационное сообщение.