Сценарии администрирования#
Администрирование компонента Pangolin (PSQL) продукта Platform V Pangolin SE (PSQ) (далее – Pangolin) осуществляется средствами, которые описаны в этом разделе.
Реализация АРМ администратора#
Для администрирования системы используется утилита psql. Эта утилита представляет собой терминальный клиент для передачи запросов к СУБД и отображения результатов.
psql [параметр...] [имя_бд [имя_пользователя]]
Примечание:
Решение по обеспечению безопасности АРМ администратора должно исходить из окружения конечной АС.
Получение информации об используемой версии#
В данном разделе приведены примеры команд для получения используемой версии Pangolin. Примеры команд одинаковы для любой из используемых ОС.
Для клиентской части#
Чтобы получить название и версию клиентской части Pangolin, запустите любую команду с ключом --product_version, например:
Команда:
pg_ctl --product_version
Результат выполнения команды:
Platform V Pangolin 5.2.0
где:
Platform V Pangolin SE — наименование продукта;
5.2.0 — версия продукта.
Чтобы получить название и версию PostgreSQL, запустите любую команду с ключом --version, например:
Команда:
pg_ctl --version
Результат выполнения команды:
pg_ctl (PostgreSQL) 13.4
Для серверной части#
Для получения названия и версии продукта серверной части подключитесь к серверу Pangolin, чтобы:
узнать версию Pangolin:
Команда:
SELECT product_version();Результат выполнения команды:
product_version --------------------------- Platform V Pangolin SE 5.1.0 (1 row)узнать версию PostgreSQL:
Команда:
SELECT version();Результат выполнения команды:
version --------------------------------------------------------------------------------------------------------- PostgreSQL 13.4 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44), 64-bit (1 row)Примечание:
Вывод может отличаться от приведенного в примере.
Получение информации о сборке продукта#
Чтобы получить информацию о сборке Pangolin, запустите любую команду с ключом --product_build_info, например:
Команда:
pg_ctl --product_build_info
Результат выполнения команды:
build 54 (22:27:09 05.02.2022) commit {хеш}
где:
54— порядковый номер сборки продукта;22:27:09 05.02.2022— время и дата сборки продукта;{хеш}— хеш-сумма исходных кодов продукта (идентификатор коммита в git репозитории продукта).
Пример вывода информации о сборке продукта для psql:
Команда:
SELECT product_build_info();
Результат выполнения команды:
build 54 (22:27:09 05.02.2022) commit {хеш}
Примечание:
Вывод может отличаться, но будет сохранена структура и формат.
Получение хеш-суммы внутренней версии компонента продукта#
Для PostgreSQL можно получить хеш-сумму с помощью параметра --product_component_hash, например:
Команда:
pg_ctl --product_component_hash
Интерфейс администратора безопасности Pangolin#
Интерфейс администратора безопасности включает в себя следующие функции:
Действия с политиками:
pm_get_policies- вывод списка политик;pm_get_policy_grants- вывод списка разрешений (правил) в составе политики;pm_make_policy- создание политики;pm_grant_to_policy- внесение в политику разрешения на действия над объектом;pm_revoke_from_policy- исключение из политики разрешения на действия над объектом;pm_suspend_object- приостановка действия политики защиты;pm_resume_object- возобновление действия политики защиты;pm_remove_policy- удаление политики защиты.
Действия с пользователями:
pm_get_assigned_policies- вывод списка политик, назначенных пользователю;pm_assign_policy_to_user- назначение политики пользователю;pm_unassign_policy_from_user- изъятие политики у пользователя.
Действия над объектами:
pm_get_protected_objects- вывод списка объектов, находящихся под защитой;pm_protect_object- помещение объекта БД под защиту;pm_unprotect_object- снятие защиты с объекта БД;pm_get_object_access_path- получение информации об эффективных действующих для указанных объекте и роли ограничениях защиты и разрешениях на доступ к объекту под защитой.
Действия для администраторов безопасности:
pm_create_security_admin- создание учетной записи администратора безопасности;pm_set_security_admin_password- изменение пароля учетной записи администратора безопасности;pm_grant_security_admin- назначение пользователя администратором безопасности;pm_revoke_security_admin- снятие с пользователя политики администратора безопасности;pm_unblock_security_admin- разблокировка заблокированной учетной записи администратора безопасности.
Интерфейс управления парольными политиками: PL/pgSQL API#
Все запросы к базе выполняются через SPI интерфейс (то есть не через внутренний API Pangolin), так как вероятность изменения SQL интерфейса меньше.
Настройки механизма хранятся в файле postgresql.conf. Данный файл также содержит значения по умолчанию для настроек парольной политики. Настройки парольной политики хранятся в таблице pg_pp_policy.
При включенной защите от привилегированных пользователей, в режиме защищенного конфигурирования, параметры парольных политик конфигурируются администратором безопасности в хранилище секретов — HashiCorp Vault, в случае отсутствия KMS-hosts (использования эмулятора) для хранения параметров используются локальные конфигурационные файлы.
Параметры парольной политики хранятся в файле в зависимости от типа конфигурации сервера, если тип конфигурации:
standalone — в файле
$PGDATA/postgresql.conf;cluster — в файле
/etc/pangolin-manager/postgres.yml.
Подробнее о параметрах файла postgresql.conf в разделе «Параметры в postgresql.conf» данного документа.
Внимание!
При подключении через Pangolin Pooler с включенной сквозной аутентификацией ограниченно действуют парольные политики в части времени действия пароля и количества подключений. Проверка происходит только при первом подключении. Это связано с тем, что при подключении под Pangolin Pooler создается токен подключения. После получения данного токена следующее переподключение произойдет через
server_lifetime.
Сценарии работы с механизмом#
Большинство операций выполняется соответствующими функциями PL/pgSQL (см.«Список PL/SQL функций продукта», раздел «Парольные политики»):
создание парольной политики;
активация парольной политики;
деактивация парольной политики;
отображение парольных политик, примененных к роли;
отображение всех активных политик;
разблокировка роли.
Включение механизма (password_policies_enable)#
Параметр password_policies_enable включает (on) или выключает (off) механизм.
Статистика и история по паролю ведется в любом состоянии механизма.
Использование значений настроек парольной политики из файла postgresql.conf (password_policy.deny_default)#
Параметр password_policy.deny_default включает (on) или выключает (off) использование значений для настроек парольной политики из файла postgresql.conf.
Примечание:
Если выключить параметр
password_policy.deny_default:password_policy.deny_default=offто для всех политик должны быть заданы все обязательные настройки (см. подраздел «Обязательные настройки парольной политики» данного документа).
Управление шифрованием пароля (password_policy.psql_encrypt_password)#
Параметр password_policy.psql_encrypt_password управляет шифрованием пароля при передаче от фронтенда (psql) к базе с помощью команды psql \password .
В случае, если шифрование отключено, пароль передается хешем. Если при этом включены проверки пароля (сам механизм и один из способов проверки пароля), парольными политиками будет вызвана ошибка.
Задание значений по умолчанию для настроек парольной политики#
Все настройки для парольной политики имеют аналог в файле postgresql.conf. Это необходимо для возможности задания значения по умолчанию для настроек парольной политики.
Подробное описание настроек приведено в разделе «Использование значений настроек парольной политики из файла postgresql.conf» данного документа.
Создать новую политику#
Примечание:
Для созданной парольной политики необходимо перечислить параметры с новыми значениями и указать связанные с ними параметры.
Если связанные параметры с основным не будут указаны, то новая политика не применится.
Для создания новой политики последовательно выполните функции:
Создания парольной политики.
Примечание:
Если какая-либо настройка политики не задана, то ее значение берется из конфигурационного файла.
Активации парольной политики.
Функции создания и активации парольной политики описаны в документе «Список PL/SQL функций продукта», раздел «Парольные политики».
Разблокировать роль#
Выполняется соответствующей SQL-функцией (см. «Список PL/SQL функций продукта» раздел «Парольные политики»).
Активировать или деактивировать политику#
Выполняется соответствующими SQL-функциями:
активация парольной политики;
деактивация парольной политики.
Подробнее о функциях для данной функциональности в документе «Список PL/SQL функций продукта», раздел «Парольные политики».
Изменить настройки политики#
Выполняется соответствующей SQL-функцией (см. «Список PL/SQL функций продукта» раздел «Парольные политики»).
При изменении параметров учитывайте зависимости между ними и изменяемую функциональность (см. ниже подраздел «Обязательные настройки парольной политики»). Нельзя изменить параметр roloid.
Сменить политику для роли#
Роли связаны с политиками по идентификатору роли. Изменить политику для роли можно следующими способами:
удалить старую политику и создать новую политику;
включить роль в другую роль с нужной политикой.
Подробнее о функциях в документе «Список PL/SQL функций продукта», раздел «Парольные политики».
Обязательные настройки парольной политики#
Функциональность |
Обязательный параметр |
Зависимые параметры |
|---|---|---|
Хранение паролей |
Один из: |
- |
Изменение пароля |
|
- |
Синтаксическая проверка пароля |
|
|
Использование пакета cracklib |
|
- |
Проверка пароля библиотекой zxcvbn |
|
|
Пользовательская PSQL функция проверки пароля |
|
- |
Аутентификация |
|
- |
Пользовательская функция проверки пароля#
Пользователь может создать PL/pgSQL функцию проверки пароля. Ниже описаны требования к пользовательской функции.
Требование |
Описание |
|---|---|
Применимо к механизмам |
Создание или изменение роли |
Не применимо к механизмам |
Аутентификация по паролю |
Требования к вызову |
Пользовательская функция проверки пароля должна вызываться из PSQL: |
Прототип |
|
Входные атрибуты |
|
Требование к возвращаемому значению |
|
Примечание:
Зашифрованный пароль приходит, если Pangolin подключен к сторонней системе аутентификации.
Параметры для управления транспортными паролями#
Параметр |
Описание |
|---|---|
|
Определяет тип пароля (транспортный или нет) для указанных ТУЗ. По умолчанию — |
|
Определяет время жизни транспортного пароля. По умолчанию — |
|
При значении |
Разблокирование и восстановление работы кластера#
Определите, на каком хосте был последний активный лидер. Это можно проверить по логам Pangolin Manager:
host1$ sudo journalctl --since "5 hours ago" -u pangolin-manager | grep "i am " | tail -1 Aug 04 22:38:17 <Адрес сервера> python3[14026]: 2020-08-04 22:38:17,824 INFO: no action. i am the leader with the lock host2$ sudo journalctl --since "5 hours ago" -u pangolin-manager | grep "i am " | tail -1 Aug 04 22:38:07 <Адрес сервера> python3[21032]: 2020-08-04 22:38:07,814 INFO: no action. i am a secondary and i am following a leaderВ данном случае лидер был на хосте «host1».
Остановите Pangolin Manager на хосте последнего лидера:
host1$ sudo systemctl stop pangolin-managerЗапустите Pangolin в однопользовательском режиме:
host1$ postgres --singleЕсли postgres не запускается даже на предположительном лидере и выводит ошибку:
2020-08-04 23:08:34 MSK [20019]: [1-1] app=,user=,db=,client= LOG: database system was shut down in recovery at 2020-08-04 23:08:30 MSK 2020-08-04 23:08:34 MSK [20019]: [2-1] app=,user=,db=,client= WARNING: recovery command file "recovery.conf" specified neither primary_conninfo nor restore_command 2020-08-04 23:08:34 MSK [20019]: [3-1] app=,user=,db=,client= HINT: The database server will regularly poll the pg_wal subdirectory to check for files placed there. 2020-08-04 23:08:34 MSK [20019]: [4-1] app=,user=,db=,client= FATAL: standby mode is not supported by single-user serversУберите файл
recovery.confиз$PGDATAи снова выполните запуск:host1$ mv $PGDATA/recovery.conf{,.back} host1$ postgres --singleВ
single userрежиме выполните SQL команды от лица пользователяpostgres. Для выхода нажмитеCtrl/Cmd-D. Разблокируйте рольpostgres:select unblock_role('postgres')Если при попытке разблокировать пользователя
postgresвыходит ошибка:backend> select unblock_role('postgres') 1: unblock_role (typeid = 16, len = 1, typmod = -1, byval = t) ---- 2022-07-05 11:58:17 MSK [19233]: [2-1] app=[unknown],user=postgres,db=postgres,client=[tty] ERROR: Cant find role with Oid 10 in password policy cache 2022-07-05 11:58:17 MSK [19233]: [3-1] app=[unknown],user=postgres,db=postgres,client=[tty] STATEMENT: select unblock_role('postgres')Выполните команду для разблокировки пользователя
postgres:backend> update pg_pp_policy set lockout='f' WHERE roloid = to_regrole('postgres'); backend>Запустите службу Pangolin Manager.:
host1$ sudo systemctl start pangolin-managerУбедитесь, что кластер вернулся в стабильное состояние. В таблице вывода в столбце
Roleдолжен быть указанLeader:host1$ list + Cluster: clustername (6857170778029161231) ----------------------------------------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +---------------------------------------+--------------------------------------------+--------------+---------+----+-----------+ | <Адрес сервера> | <Адрес сервера>:5433 | Sync Standby | running | 4 | 0 | | <Адрес сервера> | <Адрес сервера>:5433 | Leader | running | 4 | | +---------------------------------------+--------------------------------------------+--------------+---------+----+-----------+Стандартным образом разблокируйте остальных администраторов БД.
Справочник журнальных сообщений#
Сообщение |
Расшифровка |
Решение |
|---|---|---|
User blocked: too many login fails |
Пользователь заблокирован из-за превышения счетчика неудачных аутентификаций |
Пользователь будет разблокирован, когда пройдет |
Password was expired |
Пользователь заблокирован из-за просроченного пароля |
Сменить пароль пользователя |
Role blocked cause long inactivity |
Пользователь заблокирован из-за долгой неактивности |
Пользователь может быть разблокирован с помощью команд |
Password will expire in <интервал> |
Предупреждение об оставшемся времени до обязательной смены пароля |
|
Password was expired. <число> grace logins left |
Время жизни пароля превышено. Осталось <число> входов, после которых пользователь будет заблокирован |
|
Password was expired. Grace period ends in <интервал> |
Время жизни пароля превышено. Осталось <интервал>, после истечения которого пользователь будет заблокирован |
Параметры в postgresql.conf#
В данном разделе более подробно описаны параметры файла postgresql.conf.
password_policy.policy_enable (Состояние по умолчанию для парольной политики)#
Признак включенной парольной политики:
on– политика включена;off– политика выключена.
Тип |
POSIX шаблон |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|
boolean |
on/off |
on |
policyenable |
password_policy.deny_default#
Запрет использования значений для настроек политик, указанных в файле postgresql.conf:
on– включить использование значений настроенных политик, указанных в файлеpostgresql.conf;off– выключить использование значений настроенных политик, указанных в файлеpostgresql.conf.
Тип |
POSIX шаблон |
Значение по умолчанию |
|---|---|---|
boolean |
on/off |
off |
Настройка хранения паролей#
password_policy.reuse_time#
Время в секундах, в течение которого старый пароль сохраняется и попытка сменить пароль на совпадающий со старым заканчивается ошибкой.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
365 days |
reusetime |
password_policy.in_history#
Максимальное количество сохраненных старых паролей. При достижении максимума добавление еще одного старого пароля приводит к удалению наиболее старого (по pg_pp_history.createtime) из них.
Примечание:
Если задан параметр
password_policy.reuse_time, то параметрpassword_policy.in_historyне используется.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
4 |
0 – Проверка на совпадение пароля с ранее использованным не проводится (при условии |
inhistory |
Время жизни пароля#
password_policy.max_age#
Время жизни пароля в секундах, после которого пароль считается истекшим.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
0 |
0 – Проверка максимального времени жизни пароля не производится |
maxage |
password_policy.min_age#
Время в секундах, которое должно пройти между двумя изменениями пароля.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
0 |
0 – Проверка максимального времени жизни пароля не производится |
minage |
password_policy.grace_login_limit#
Максимальное количество аутентификаций, доступных роли после истечения времени жизни пароля.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
0 |
graceloginlimit |
password_policy.grace_login_time_limit#
Время в секундах после окончания действия пароля, в течение которого он продолжает работать. Если вычисленное значение graceloginlimit=0, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
3 days |
0 – аутентификация не доступна по истечении времени жизни пароля |
gracelogintimelimit |
password_policy.expire_warning#
Время в секундах до окончания действия пароля, в течение которого пользователю будет отображаться предупреждение.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
7 days |
0 – не выводит предупреждение |
expirewarning |
Поведение при неудачной аутентификации#
password_policy.lockout#
Блокировка аккаунта в результате достижения максимума попыток входа с неверным паролем:
on – включить блокировку;
off – выключить блокировку.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|
boolean |
on/off |
lockout |
on |
lockout |
password_policy.max_failure#
Максимальное количество введенных подряд неверных паролей, при достижении которого вызывается блокировка пароля.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|
integer |
[1-1000] |
1 - 1000 |
6 |
maxfailure |
password_policy.failure_count_interval#
Время в секундах, после которого обнуляется количество неверных вводов пароля.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
>= 0 |
0 |
0 – счетчик не обнуляется |
failurecountinterval |
password_policy.lockout_duration#
Время в секундах, на которое блокируется аккаунт в результате достижения максимума попыток входа с неверным паролем.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
24 hours |
0 – блокировка пользователя по количеству неудачных аутентификаций бессрочна |
lockoutduration |
Синтаксические проверки пароля#
password_policy.check_syntax#
Признак включенных правил синтаксической проверки пароля:
on– включить механизм;off– выключить механизм.
Тип |
POSIX шаблон |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|
boolean |
on/off |
on |
checksyntax |
password_policy.alpha_numeric#
Минимальное количество цифр в пароле. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
3 |
0 – не проверять |
alphanumeric |
password_policy.min_length#
Минимальная длина пароля. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
16 |
0 – не проверять |
minlength |
password_policy.min_alpha_chars#
Минимальное количество букв в пароле. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
0 |
0 – не проверять |
minalphachars |
password_policy.min_special_chars#
Минимальное количество символов в пароле, не являющихся буквой или цифрой. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
0 |
0 – не проверять |
minspecialchars |
password_policy.min_uppercase#
Минимальное количество прописных букв. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
1 |
0 – не проверять |
minuppercase |
password_policy.min_lowercase#
Минимальное количество строчных букв. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
0 |
0 – не проверять |
minlowercase |
password_policy.max_rpt_chars#
Максимальное количество повторяющихся символов. Если вычисленное значение checksyntax=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
integer |
[0-1000] |
0 - 1000 |
0 |
0 – не проверять |
maxrptchars |
Проверка максимального времени неактивности пользователя#
password_policy.track_login#
Запоминать ли время последней аутентификации:
on– запоминать;off– не запоминать.
Тип |
POSIX шаблон |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|
boolean |
[0-1000] |
off |
tracklogin |
password_policy.max_inactivity#
Время в секундах после последней аутентификации, после которого роль будет заблокирована.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Специальные значения параметров |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|---|
string |
\d+ s |
не отрицательное |
0 |
0 – функциональность отключена |
maxinactivity |
Использование библиотеки zxcvbn#
password_policy.use_password_strength_estimator#
Включить или выключить использование библиотеки zxcvbn для проверки пароля:
on– включить механизм;off– выключить механизм.
Тип |
POSIX шаблон |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|
boolean |
on/off |
on |
usepasswordstrengthestimator |
password_policy.password_strength_estimator_score#
Минимальная оценка сложности пароля, допустимая в системе. Если вычисленное значение usepasswordstrengthestimator=false, то параметр не учитывается.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|---|
integer |
[0-4] |
0 - 4 |
3 |
passwordstrengthestimatorscore |
Использование пользовательской функции проверки пароля#
password_policy.custom_function#
Название пользовательской PL/pgSQL функции проверки пароля.
Тип |
POSIX шаблон |
Аналог в таблице pg_pp_policy |
|---|---|---|
string |
[\w\d]+ |
customfunction |
Использование библиотеки cracklib#
password_policy.illegal_values#
Использовать библиотеку cracklib для проверки пароля по списку часто используемых:
on– включить проверку;off– выключить проверку.
Тип |
POSIX шаблон |
Значение по умолчанию |
Аналог в таблице pg_pp_policy |
|---|---|---|---|
boolean |
on/off |
on |
illegalvalues |
Настройка кэширования#
password_policy.pp_cache_dump_interval#
Интервал сохранения данных кэша из памяти на диск (при наличии изменений).
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
|---|---|---|---|
integer |
\d+ |
1 - до максимального значения int в системе |
10 |
password_policy.pp_cache_init_size#
Размер изначально инициализированного кэша парольных политик в пользователях.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
|---|---|---|---|
integer |
\d+ |
1 - до максимального значения int в системе |
10 |
password_policy.pp_cache_soft_max_size#
Предполагаемый максимальный размер кэша парольных политик в пользователях. Используется для оптимизации работы кэша, не задает жестких ограничений.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
|---|---|---|---|
integer |
\d+ |
1 - до максимального значения int в системе |
60 |
password_policy.pp_cache_max_size#
Ограничение сверху на размер кэша парольных политик в пользователях. В случае превышения, аутентификации новых пользователей будут заканчиваться ошибкой.
Тип |
POSIX шаблон |
Ограничение значения |
Значение по умолчанию |
|---|---|---|---|
integer |
\d+ |
1 - до максимального значения int в системе |
1000 |
psql_encrypt_password#
Шифрование пароля при передаче от фронтенда (psql) к базе:
on– включить шифрование;off– выключить шифрование.
Пароль передается в захешированном виде, при этом парольные политики вызовут ошибку, если включены проверки пароля.
Тип |
POSIX шаблон |
|---|---|
boolean |
on/off |
password_policy.deduplicate_ssl_no_ssl_fail_auth_attepmts#
Включение механизма дедупликации повторных попыток подключения psql.
Тип |
POSIX шаблон |
Значение по умолчанию |
|---|---|---|
boolean |
on/off |
on |
password_policy.allow_hashed_password#
Разрешить задание пароля в виде хеша.
Тип |
POSIX шаблон |
Значение по умолчанию |
|---|---|---|
boolean |
on/off |
off |
Авторизация и аутентификация#
Pangolin поддерживает несколько типов авторизации и аутентификации пользователей и сервисов.
В данном разделе более подробно рассмотрены варианты сквозной и двухфакторной авторизации.
Сквозная аутентификация Pangolin Pooler — Pangolin#
В Pangolin Pooler и Pangolin реализован механизм сквозной аутентификации. Программа Pangolin Pooler выступает в режиме проксирования данных аутентификации от клиента к Pangolin и обратно, аутентификация пользователя выполняется только на Pangolin.
Количество итераций обмена данными аутентификации для конкретного пользователя зависит от установленных в файле pg_hba.conf методов аутентификации. Обмен данными аутентификации между Pangolin Pooler и Pangolin выполняется по отдельным сетевым каналам. Количество сетевых каналов зависит от количества баз данных, к которым выполняется подключение пользователей.
Конфигурирование сквозной аутентификации в Pangolin Pooler#
Настроить сквозную аутентификацию в Pangolin Pooler можно с помощью конфигурационных параметров, описанных в данном разделе.
Параметры аутентификации:
auth_proxy (string)— параметр включает/выключает режим сквозной аутентификации:off— режим сквозной аутентификации выключен, выполняется локальная аутентификация пользователя (значение по умолчанию);on— режим сквозной аутентификации включен, выполняется аутентификация пользователя только на Pangolin;
auth_failure_threshold (integer)— параметр задает максимальное число НЕ аутентифицированного N раз подряд клиента с идентичными параметрами (тип соединения, адрес клиента, база данных и имя пользователя), при котором будет взведен таймер не активности аутентификации для этого клиента. Значение по умолчанию 0 (выключено);auth_inactivity_period (integer)— параметр определяет период не активности аутентификации (в секундах). Это время, в течение которого ранее НЕ аутентифицированному более N раз подряд клиенту при подключении с идентичными параметрами (тип соединения, адрес клиента, база данных и имя пользователя), Pangolin Pooler откажет в обслуживании. Значение по умолчанию 0 (выключено);auth_lost_size (integer)— параметр задает максимальное число кэшируемых записей о последних аутентификациях пользователей. Значение по умолчанию 10. Информацию о последних аутентификациях пользователей можно получить с помощью командыshow last(см. подробнее в подразделе «Команды вывода информации» текущего раздела);log_audit (integer)— включает/выключает аудит. Значение по умолчанию - 0 (выключено).
Примечание:
Увеличение значения
auth_failure_thresholdпотенциально увеличит количество обработок отказов в подключении и соответствующих записей в логах, при обычных условиях эксплуатации это не должно приводить к отказу Pangolin Pooler.Увеличение
auth_inactivity_periodпозволяет избежать увеличения обработок отказов в подключении на указанное время.Одной единицей подключения (клиентом) считается соединение с определенным набором (сочетанием) параметров: логин/пароль пользователя, имя БД для подключения, IP-адрес клиента, тип соединения. Клиент считается ранее пытавшимся подключиться, по этому же сочетанию, только без передачи пароля. Блокировка пользователя происходит по этим учетным данным подключения, то есть любое изменение данного сочетания будет считаться попыткой соединения нового пользователя.
Параметры подключений:
auth_port (integer)— номер порта, к которому нужно подключиться для выполнения аутентификации пользователей. Параметр раздела базы данных[databases];auth_pool_size (integer)— параметр задает максимальное количество соединений для выполнения аутентификации пользователей. Значение по умолчанию 1. Параметр раздела базы данных[databases].
Примечание:
Общее количество соединений не должно превышать значения
authentication_max_workers, раздел «Конфигурирование сквозной аутентификации в Pangolin».
Пример конфигурации (содержит параметры, связанные со сквозной аутентификацией):
[databases]
* = host=<IP-адрес> port=5433 auth_port=5434
[pgbouncer]
listen_addr = *
listen_port = 6544
; включена сквозная аутентификация
auth_proxy = on
; включен audit
log_audit = 1
; выставлено время выполнения аутентификации
client_login_timeout = 10
; выставлен порог, по превышению которого пользователь временно блокируется
auth_failure_threshold = 3
; выставлен период неактивности аутентификации
auth_inactivity_period = 30
; выставлен размер кешируемых записей о последних аутентификациях пользователей
auth_last_size = 20
; пользователи, прописанные в userlist, будут выполнять аутентификацию, используя данный метод
auth_type = scram-sha-256
; в файле userlist содержатся пользователи, выполняющие действия администратора или мониторинг
auth_file = ./userlist.txt
admin_users = pgbouncer
stats_users = stat
Внимание!
Сквозная аутентификация не работает для пользователей, которые указаны в секции
[users]конфигурационного файла Pangolin Pooler.
Раздел [users] содержит пары ключ=значение, где в качестве ключа принимается имя пользователя, а в качестве значения — переопределяемые для него параметры конфигурации (в формате строк подключения libpq):
pool_mode– задает режим пула для всех подключений данного пользователя;max_user_connections– задает максимум подключений для пользователя.
Пользователь, для которого переопределен один или оба параметра:
должен быть указан в параметре
stats_usersилиadmin_users;должен присутствовать в списке
userlist.txt(параметрauth_file) в виде"имя_пользователя" "хеш_пароля_пользователя".
Пример конфигурации (содержит параметры, связанные с использованием секции [users] файла /etc/pangolin-pooler/pangolin-pooler.ini):
[pgbouncer]
; в файле userlist содержатся пользователи, выполняющие действия администратора или мониторинг
auth_file = ./userlist.txt
admin_users = pgbouncer
stats_users = user1
[users]
; раздел содержит имя пользователя и переопределяемые для него параметры конфигурации
user1 = pool_mode=session max_user_connections=1
Пользователю user1 при таких настройках будут применены персональные параметры pool_mode и max_user_connections, а аутентификация в базе данных будет выполняться только после аутентификации его в Pangolin Pooler.
Конфигурирование сквозной аутентификации в Pangolin#
Настроить сквозную аутентификацию в Pangolin можно с помощью конфигурационных параметров, описанных в данном разделе.
Параметры аутентификации:
authentication_proxy (integer)— параметр включает/выключает режим сквозной аутентификации:0— режим сквозной аутентификации выключен, не позволяет выполнять аутентификацию пользователей конкретной БД в отдельном потоке (значение по умолчанию);1— режим сквозной аутентификации включен, позволяет выполнять аутентификацию пользователей конкретной БД в отдельном потоке;
authentication_max_workers (integer)- параметр определяет максимальное число одновременных подключений для выполнения аутентификации пользователей. Значение по умолчанию 16. При значении, равном 0, сквозная аутентификация выполняться не будет.Примечание:
Параметр
authentication_max_workersможно задать только при запуске сервера.auth_handshake_timeout (integer)— параметр определяет максимальное время, за которое должно произойти подтверждение аутентификации (в секундах). Значение по умолчанию 10 сек. Если потенциальный клиент не сможет выполнить подтверждение аутентификации (рукопожатие) за это время, сервер закроет соединение;auth_activity_period (integer)— параметр определяет период активности аутентификации (в секундах). Значение по умолчанию 60 сек. Это время, в течение которого ранее аутентифицированный клиент при подключении с идентичными параметрами (тип соединения, адрес клиента, база данных и имя пользователя), выполнит аутентификацию поtoken.Значение передается на Pangolin Pooler и используется для проведения более быстрой аутентификации. Возможные значения:
-1— не используется период активности аутентификации;0— период активности аутентификации не имеет ограничений по времени;> 0— имеет ограничение по времени.
Примечание:
не рекомендуется выставлять значение
auth_activity_period = 0, так как его нельзя сбросить в Pangolin Pooler без перезагрузки;выставляемого значения должно хватить, чтобы запустить пул соединений между Pangolin Pooler и Pangolin.
auth_idle_period (integer)- параметр определяет период простоя процесса сквозной аутентификации (в секундах). Значение по умолчанию 60 сек. Отсчет периода начинается после обработки последнего полученного пакета. После окончания периода будет проверено, нужно ли продолжать работу процесса сквозной аутентификации. Процесс будет прерван, если связанной с ним базы данных нет, или она была удалена или переименована.
Параметры подключений:
authentication_port (integer) — TCP-порт, открываемый сервером для выполнения аутентификации пользователей (по умолчанию порт — 5433).
Примечание:
Параметр
authentication_port (integer)можно задать только при запуске сервера.
Пример конфигурации (содержит параметры связанные со сквозной аутентификацией):
port = 5433
authentication_port = 5434
authentication_timeout 60 # sec
auth_activity_period = 60 # sec
Команды вывода информации#
Для получения информации о статусе или результатах работы механизма сквозной аутентификации были добавлены следующие команды:
SHOW AUTHSERVERS— показывает информацию о соединениях с сервером аутентификации.SHOW AUTHPOOLS— показывает информацию по пулам аутентификации.Примечание:
Новый пул аутентификации создается для каждой базы данных.
SHOW AUTHUSERS— показывает информацию о пользователях.SHOW LAST— показывает информацию об аутентификации последних N пользователей.Примечание:
auth_last_size— по умолчанию команда показывает 10 последних пользователей.При превышении этого значения первые записи удаляются, а новые добавляются в конец. Ошибка аутентификации указана в логах Pangolin или Pangolin Pooler. В каком логе и в какое время - зависит от значений параметров place и connect_time\auth_time.
SHOW LOCKED_USERS— показывает информацию о заблокированных пользователях.Команда показывает временно заблокированных пользователей. Это пользователи с идентичными параметрами: тип соединения, адрес клиента, база данных и имя пользователя, которые не смогли аутентифицироваться N раз подряд (N определяет конфигурационный параметр
auth_failure_threshold). Длительность блокировки пользователя определяется конфигурационным параметромauth_inactivity_period.
Подробное описание команд приведено в документе «Список PL/SQL функций продукта», раздел «Сквозная аутентификация».
В утилите psql имелся механизм запоминания ранее выполненных запросов. Этот механизм позволял просмотреть историю ранее выполненных команд и повторно вызвать ранее выполненные запросы.
История запросов хранилась в открытом виде в файле ~/.psql_history. При выполнении запросов, содержащих пароли это могло представлять угрозу безопасности, так как пароли хранились так же в незашифрованном виде.
В связи с новой функциональностью изменяется поведение утилиты psql по сравнению с имеющимся:
создание и чтение файла
~/.psql_historyне производится;влияние переменной окружения
PSQL_HISTORYна работу утилитыpsqlотсутствует;установка переменной
HISTFILEв утилитеpsqlне дает эффекта.
Реализованная функциональность не приводит к удалению или очищению ранее созданных файлов истории запросов. После обновления продукта рекомендуется (если необходимо) удалить ранее созданные файлы истории, выполнив команду:
rm -f ~/.psql_history
Двухфакторная аутентификация#
Двухфакторная аутентификация представляет собой технологию, обеспечивающую идентификацию пользователей при помощи запроса аутентификационных данных двух разных типов, что обеспечивает двухслойную, а значит, более эффективную защиту БД от несанкционированного проникновения.
Пользователь может подключаться к БД:
непосредственно (или напрямую) к Pangolin;
через Pangolin Pooler к Pangolin, используя сквозную аутентификацию;
через Pangolin Pooler к Pangolin, используя базовые механизмы аутентификации.
Сертификат безопасности клиента должен содержать поле CN, содержащее логин клиента и, опционально, поле SubjectAltName, содержащее один или несколько IP-адресов (возможен вариант указания подсети) и (или) DNS-имен клиента.
Для подключения непосредственно к Pangolin, в файле pg_hba.conf необходимо указать метод аутентификации: 2f-scram-sha-256, 2f-md5, 2f-password или 2f-ldap.
Для подключения через Pangolin Pooler к Pangolin, используя сквозную аутентификацию, необходимо:
в конфигурационных файлах Pangolin:
в файле
pg_hba.confнеобходимо указать метод аутентификации: 2f-scram-sha-256, 2f-md5, 2f-password или 2f-ldap;в файле
postgresql.confуказать:authentication_proxy = on;authentication_port = {AUTHPORT};
в конфигурационном файле Pangolin Pooler указать:
auth_port={AUTHPORT};auth_proxy = on;auth_type = scram-sha-256 или md5.
Для подключения через Pangolin Pooler к Pangolin, используя базовые механизмы аутентификации, необходимо в конфигурационном файле Pangolin Pooler указать:
в конфигурационных файлах Pangolin:
в файле
pg_hba.confнеобходимо указать метод аутентификации: 2f-scram-sha-256, 2f-md5, 2f-password или 2f-ldap;в файле
postgresql.confуказатьauthentication_proxy = off;
в конфигурационном файле Pangolin Pooler указать:
auth_proxy = off;auth_type = 2f-scram-sha-256 (2f-md5, 2f-plain);
Аутентификация LDAP не поддерживается Pangolin Pooler, поэтому 2f-ldap так же не поддерживается.
Внимание!
Необходимо учитывать, что разрешенными по умолчанию механизмами двухфаторной аутентификации являются 2f-scram-sha-256 и 2f-ldap.
При необходимости использования методов аутентификации 2f-md5 и 2f-password, нужно добавить эти методы в параметр
enabled_extra_auth_methodsв конфигурационном файлеpostgresql.conf.Например:
enabled_extra_auth_methods = '2f-md5,2f-password'
Настройка Pangolin для двухфакторной аутентификации#
Для выполнения двухфакторной аутентификации клиентов требуется:
в файле
postgresql.conf- включить SSL режим и прописать сертификаты:ssl = on ssl_ca_file = './root.crt' ssl_cert_file = './server.crt' ssl_key_file = './server.key'в файле pg_hba.conf указать:
тип сети - hostssl;
тип аутентификации: 2f-md5 или 2f-scram-sha-256;
# TYPE DATABASE USER ADDRESS METHOD hostssl test test1 127.0.0.1/32 2f-md5 hostssl test test1 hostname 2f-scarm-sha-256
Настройка Pangolin Pooler для двухфакторной аутентификации#
Для выполнения двухфакторной аутентификации клиентов требуется в файле конфигурации pangolin-pooler.ini (имя файла конфигурации может быть другим) указать:
параметры подключения SSL/TLS;
тип аутентификации: 2f-scram-sha-256 или 2f-md5;
Ниже приведен пример конфигурации, когда защищенное соединение выполняется между клиентом и Pangolin Pooler, а между Pangolin Pooler и Pangolin используется обычное соединение.
[pgbouncer]
auth_type = 2f-scram-sha-256
; TLS settings
client_tls_protocols = all
client_tls_sslmode = verify-full
client_tls_ca_file = ./root.crt
client_tls_cert_file = ./server.crt
client_tls_key_file = ./server.key
Настройка сквозной двухфакторной аутентификации#
Все специальные настройки были описаны ранее — необходимо только включить сквозную аутентификацию на Pangolin Pooler с Pangolin.
В файле pangolin-pooler.ini:
[pgbouncer]
auth_proxy = on
auth_type = scram-sha-256
client_tls_sslmode = verify-ca
client_tls_key_file = ./server.key
client_tls_cert_file = ./server.crt
client_tls_ca_file = ./root.crt
server_tls_sslmode = verify-full
server_tls_key_file = ./pgbouncer.key
server_tls_cert_file = ./pgbouncer.crt
server_tls_ca_file = ./root.crt
server_tls_ciphers = normal
[databases]
* = host=localhost port=5432 auth_port=5433 auth_port=5444 auth_pool_size=1
В файле postgresql.conf:
port = 5432
authentication_port = 5433
authentication_timeout = 60 # sec
auth_activity_period = 10 # sec
ssl = on
ssl_key_file = ./server.key
ssl_cert_file = ./server.crt
ssl_ca_file = ./root.crt
Управление протоколом LDAPS#
В Pangolin реализована возможность настроить шифрование запросов от сервера Postgres к AD (Active Directory). Для этого нужно настроить протокол LDAPS, использующий LDAP поверх SSL с использованием шифрования TLS. Далее приведены шаги для включения TLS соединения с LDAP.
Набор имеющихся корневых AD сертификатов скопируйте на сервер, где будет производиться установка (в случае кластера - и на мастер, и на реплику). Примером директории может быть:
etc/pki/ca-trust/source/anchors.Выполните команду
sudo update-ca-trustдля обновления списка доверенных сертификатов.В файле конфигурации
etc/openldap/ldap.confукажите путь к сертификатам в параметреTLS_CACERTDIR. Также добавьте набор шифров, используемых сервером AD:TLS_CIPHER_SUITE TLSv1.2:!NULL.Отредактируйте раздел
hba_rulesконфигурационного файла инсталлятораcustom_file_template.yml. В нем пропишите параметры подключения к серверу:ldapserver="{{ ldap_server }}" ldapport=3268 ldapbasedn="" ldapprefix="cn=" ldapsuffix=" OU=NPA OU=PAM OU=ALL DC=MustBeFilled dc=ru ldap_tls=1Запустите установку/обновление Pangolin. Ниже приведен пример строки
pg_hba.confпри включенномldaptls:host all +all-sa-pam-group 0.0.0.0/0 ldap ldaptls=1 ldapserver=X.XX.ru ldapport=389 ldapprefix="cn=" ldapsuffix=", OU=NPA, OU=PAM, OU=ALL, OU=XX, DC=X, dc=ru
Генерация сертификатов#
Для включения SSL между компонентами кластера необходимо подготовить сертификаты.
Подготовка сертификатов не выполняется инсталлятором Pangolin. Ожидается, что на хосте уже есть сертификаты, которые будут переданы на вход инсталлятору. Инсталлятор сам разместит их в нужных директориях и выдаст права для служебных пользователей (например, etcd).
Серверный сертификат (необходимо создать для каждого хоста в кластере):
Сгенерируйте ключ:
openssl genrsa -out server.key 2048Создайте файл конфигурации для создания запроса на подпись сертификата
vim server.conf:[req] req_extensions = v3_req distinguished_name = req_distinguished_name [req_distinguished_name] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = @alt_names [ ssl_client ] extendedKeyUsage = clientAuth, serverAuth basicConstraints = CA:FALSE subjectKeyIdentifier=hash authorityKeyIdentifier=keyid,issuer subjectAltName = @alt_names [ v3_ca ] basicConstraints = CA:TRUE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = @alt_names authorityKeyIdentifier=keyid:always,issuer [alt_names] DNS.1 = <host> ## hostname with domain IP.1 = <IP-адрес> ## host ip addressЭкспортируйте файл конфигурации:
CONFIG=`echo $PWD/server.conf`Создайте запрос на подпись сертификата. В
CNнеобходимо указать полныйhostname:openssl req -new -key server.key -out server.csr -subj "/CN=<host>" -config ${CONFIG}
Клиентский сертификат:
Сгенерируйте ключ:
openssl genrsa -out postgres.key 2048Создайте файл конфигурации для создания запроса на подпись сертификата
vim client.conf:[req] req_extensions = v3_req distinguished_name = req_distinguished_name [req_distinguished_name] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment [ ssl_client ] extendedKeyUsage = clientAuth basicConstraints = CA:FALSE subjectKeyIdentifier=hash authorityKeyIdentifier=keyid,issuer [ v3_ca ] basicConstraints = CA:TRUE keyUsage = nonRepudiation, digitalSignature, keyEncipherment authorityKeyIdentifier=keyid:always,issuerЭкспортируйте файл конфигурации:
CONFIG=`echo $PWD/client.conf`Создайте запрос на подпись сертификата. В
CNнеобходимо указать имя клиента/компонента (postgres, patroni, patronietcd, pgbouncer):openssl req -new -key postgres.key -out postgres.csr -subj "/CN=postgres" -config ${CONFIG}
Примечание:
При создании клиентских сертификатов, в поле
subjectAltNameможно указать IP-адрес или(и) DNS-имя машины (список машин), на которой(ых) будет использоваться сертификат. Также в этом поле можно указать адрес подсети.
Сгенерированные запросы на подпись сертификатов (файлы в формате *.csr) необходимо подписать удостоверяющем центре.
Полученные сертификаты необходимо перевести в формат PEM (например, командой openssl x509 -inform DER -outform PEM -in ./certificate.cer -out ./certificate.crt), расположить в одинаковых директориях на каждом хосте и выдать права - 600 для ключей и 644 для сертификатов, владелец — УЗ ОС postgres.
Наименование сертификатов, с которыми будет работать инсталлятор:
Назначение |
Наименование сертификата |
Наименование ключа |
|---|---|---|
Сертификат сервера |
server.crt |
server.key |
Сертификат пользователя postgres |
postgres.crt |
postgres.key |
Сертификат пользователя Pangolin Pooler |
pgbouncer.crt |
pgbouncer.key |
Сертификат пользователя patronietcd |
patronietcd.crt |
patronietcd.key |
Сертификат пользователя patroni |
patroni.crt |
patroni.key |
Поскольку в Pangolin можно указать только один корневой сертификат, а в нашем случае их два (один — УЦ непосредственно выпустивший сертификат, второй — УЦ выпустивший сертификат для УЦ и имеющий признак CA), необходимо объединить сертификаты корневого и промежуточного УЦ в один:
cat root.crt intermediate.crt > rootCA.crt
Все корневые сертификаты необходимо скопировать в папку /etc/pki/ca-trust/source/anchors и выполнить команду обновления хранилища доверенных корневых сертификатов:
sudo update-ca-trust
Настройка компонентов#
Внимание!
В процессе работы инструмента развертывания производится валидация сертификатов на их соответствие требованиям указанным в разделе «Подготовка». После работы инструмента развертывания валидация сертификатов находится на стороне владельца стенда.
Произведите настройку компонентов на использование сертификатов (задача инструмента развертывания):
В файле
postgres.conf(для стендов в конфигурации standalone-postgresql-pgbouncer). В данном случае необходимо указать путь к подписанным сертификатам для сервера БД:ssl = 'on' ssl_cert_file = '/home/postgres/ca/server.crt' ssl_key_file = '/home/postgres/ca/server.key' ssl_ca_file = '/home/postgres/ca/rootCA.crt' ssl_crl_file = 'путь к файлу со списком отозванных сертификатов'В
pangolin-pooler.iniдобавьте секцию TLS-настроек. Между Pangolin Pooler и Pangolin настраивается обязательное SSL-соединение, между Pangolin Pooler и клиентом — по требованию клиента. В обоих случаях минимальная версия TLS 1.2 и соответствующие ему шифры (Cipher suites (TLS 1.2): ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384).# TLS settings server_tls_protocols = secure server_tls_ciphers = secure server_tls_sslmode = verify-full server_tls_ca_file = /home/postgres/ca/rootCA.crt server_tls_cert_file = /home/postgres/ca/pgbouncer.crt server_tls_key_file = /home/postgres/ca/pgbouncer.key client_tls_protocols = secure client_tls_ciphers = secure client_tls_sslmode = prefer client_tls_ca_file = /home/postgres/ca/rootCA.crt client_tls_cert_file = /home/postgres/ca/server.crt client_tls_key_file = /home/postgres/ca/server.keyВ
etcd.confзначенияhttpпереведите вhttpsи добавьте секцию настроекTLS. Аутентификация в БД etcd происходит по паролю, так же необходимо указать сертификат пользователя.ETCD_NAME="<hostname>" ETCD_LISTEN_CLIENT_URLS="https://<IP-адрес>:2379" ETCD_ADVERTISE_CLIENT_URLS="<hostname>:<порт>" ETCD_LISTEN_PEER_URLS="https://<IP-адрес>:2380" ETCD_INITIAL_ADVERTISE_PEER_URLS="<hostname>:<порт>" ETCD_INITIAL_CLUSTER_TOKEN="test" ETCD_INITIAL_CLUSTER="<hostname>:<порт>,<hostname>:<порт>,<hostname>:<порт>" ETCD_INITIAL_CLUSTER_STATE="new" ETCD_DATA_DIR="/var/lib/etcd" ETCD_ELECTION_TIMEOUT="5000" ETCD_HEARTBEAT_INTERVAL="1000" ETCD_ENABLE_V2="false" # TLS settings ETCD_CIPHER_SUITES="TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384" ETCD_TRUSTED_CA_FILE="/home/postgres/ca/rootCA.crt" ETCD_CERT_FILE="/home/postgres/ca/server.crt" ETCD_KEY_FILE="/home/postgres/ca/server.key" ETCD_PEER_TRUSTED_CA_FILE="/home/postgres/ca/rootCA.crt" ETCD_PEER_CERT_FILE="/home/postgres/ca/server.crt" ETCD_PEER_KEY_FILE="/home/postgres/ca/server.key" ETCD_PEER_CLIENT_CERT_AUTH="true" ETCD_PEER_CRL_FILE="путь к файлу со списком отозванных сертификатов"В файле конфигурации pangolin-manager
postgres.ymlвнесите изменения в секцииrestapi, etcd3, postgres, pg_hba.restapiдобавить параметрыverify_client, cafile, certfile, keyfile- пути до сертификатов. Параметрverify_client: optional- означает, что все запросы «управления»PUT, POST, PATCH, DELETEтребуют аутентификации по сертификатам. Параметрыallowlist: [] allowlist_include_members: true- означают, что доступ к запросам «управления» есть только у членов кластера и хостов, которые перечислены вallowlist. ЗапросыGET(только получение сведений о кластере) будут возвращаться без аутентификации.restapi: listen: <IP-адрес>:8008 connect_address: <hostname>:<порт> allowlist: [] allowlist_include_members: true verify_client: optional cafile: /home/postgres/ca/rootCA.crt certfile: /home/postgres/ca/server.crt keyfile: /home/postgres/ca/server.key authentication: username: patroniyml password: <пароль>В секции
etcdдобавьте параметрыprotocol, cacert, cert, key. Соединение с etcd будет осуществляться по протоколу HTTPS.etcd: hosts: <hostname>:<порт>,<hostname>:<порт>,<hostname>:<порт> protocol: https cacert: /home/postgres/ca/rootCA.crt cert: /home/postgres/ca/patronietcd.crt key: /home/postgres/ca/patronietcd.key username: patronietcd password: <пароль>
В секции postgres в подразделе аутентификации пользователя patroni добавьте параметры
sslmode, sslkey, sslcert, sslrootcertи в разделеparametersукажите путь к серверному сертификату.sslmodeустанавливается в значениеverify-caиз-за особенностей локального подключения.postgresql: listen: <IP-адрес>:5433 bin_dir: /usr/pgsql-se-05/bin connect_address: <hostname>:<порт> data_dir: /pgdata/05/data/ create_replica_methods: - basebackup basebackup: format: plain wal-method: fetch authentication: replication: username: patroni database: replication sslmode: verify-ca sslkey: /home/postgres/ca/patroni.key sslcert: /home/postgres/ca/patroni.crt sslrootcert: /home/postgres/ca/rootCA.crt sslcrl: "путь к файлу со списком отозванных сертификатов" superuser: username: patroni sslmode: verify-ca sslkey: /home/postgres/ca/patroni.key sslcert: /home/postgres/ca/patroni.crt sslrootcert: /home/postgres/ca/rootCA.crt sslcrl: "путь к файлу со списком отозванных сертификатов" ssl: 'on' ssl_cert_file: /home/postgres/ca/server.crt ssl_key_file: /home/postgres/ca/server.key ssl_ca_file: /home/postgres/ca/rootCA.crt ssl_crl_file: "путь к файлу со списком отозванных сертификатов"В секции pg_hba смените метод подключения для УЗ patroni с host на hostssl:
hostssl all patroni <IP-адрес>/32 scram-sha-256 hostssl all patroni <IP-адрес>/32 scram-sha-256 hostssl replication patroni <IP-адрес>/32 scram-sha-256 hostssl replication patroni <IP-адрес>/32 scram-sha-256Если какой-либо сертификат был просрочен или отозван, необходимо выпустить новый, согласно инструкции описанной в разделе «Генерация сертификатов», и, в случае изменения наименования сертификата, произвести настройку компонента, где данный сертификат был задействован. В случае сохранения имени сертификата, необходимо перезапустить сервисы компонентов после замены файлов сертификатов.
Использование сертификатов PKCS#12 в кластере Pangolin#
В версиях Pangolin до 5.3.0 сертификаты и закрытые ключи, используемые для установки TLS/SSL соединений, хранились в кластере Pangolin в формате, не предусматривающем предъявление секрета для доступа к сертификату и/или закрытому ключу. В версии Pangolin 5.3.0 в целях повышения уровня информационной безопасности вводится авторизация для использования сертификатов и закрытых ключей на промышленных стендах.
Сертификаты и закрытые ключи, используемые в версии Pangolin 5.2.1, приведены в таблице ниже и используются для установления TLS-соединения между компонентами кластера Pangolin:
Клиентские сертификат и ключ Pangolin Pooler для подключения к серверу СУБД Pangolin |
Назначение сертификатов и закрытых ключей |
|---|---|
server.crt / server.key |
Серверный сертификат СУБД Pangolin для установления клиентских подключений |
pgbouncer.crt / pgbouncer.key |
Клиентский сертификат Pangolin Pooler для подключения к серверу СУБД Pangolin |
patroni.crt / patroni.key |
Клиентский сертификат Pangolin Manager для подключения к серверу СУБД Pangolin |
patronietcd.crt / patronietcd.key |
Клиентский сертификат Pangolin Manager для подключения к серверу etcd |
client.crt / client.key |
Клиентский сертификат пользователя postgres |
root.crt |
Корневой сертификат УЦ |
С версии Pangolin 5.3.0 данные сертификаты и закрытые ключи, за исключением root.crt и patronietcd.crt/patronietcd.key, хранятся в файловой системе в зашифрованных контейнерах PKCS#12, а парольные фразы для их расшифровки - в зашифрованном виде. Ключ для зашифровывания/расшифровывания парольных фраз генерируется на основе параметров сервера, поэтому файлы с парольными фразами не переносимы между узлами кластера Pangolin.
Примечание:
Следующая ключевая информация хранится в файловой системе в PEM-формате:
Сертификаты и закрытые ключи etcd (
etcd.crt/etcd.key,patronietcd.crt/patronietcd.key), так как этот компонент не поддерживается командой разработки Pangolin.Корневой сертификат, которым подписаны сертификаты etcd (может не совпадать с сертификатом, подписавшим сертификаты компонентов Pangolin, Pangolin Pooler и Pangolin Manager.).
Корневой сертификат
root.crt, которым подписаны сертификаты компонентов Pangolin, Pangolin Pooler и Pangolin Manager…
Для компонентов кластера введены настроечные параметры для установки пути до конфигурационного файла, включающего путь к контейнеру PKCS#12 и парольную фразу в зашифрованном виде:
в конфигурационном файле pangolin-manager
postgresql.ymlпараметрpkcs12_config_pathв секциях:restapi:pkcs12_config_path: example.p12.cfg;
postgresql:authentication:replication/superuser/rewind:pkcs12_config_path: example.p12.cfg;
postgresql:parameters:serverssl.pkcs12_config_path: example.p12.cfg;
в конфигурационном файле СУБД Pangolin
postgresql.confпараметрserverssl.pkcs12_config_path;в конфигурационном файле Pangolin Pooler
pangolin-pooler.iniпараметрыclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path;в строке подключения
psql:pkcs12_config_path(переменная окруженияPKCS12_CONFIG_PATH);pkcs12_passphrase(переменная окруженияPKCS12_PASSPHRASE) - используется для предоставления парольной фразы без ручного ввода в случае, если в файле.p12.cfgотсутствует поле passphrase. Парольная фраза может быть как в открытом, так и в зашифрованном виде. Парольная фраза зашифровывается утилитойpg_auth_password.
Формат конфигурационного файла .p12.cfg:
{
"pkcs12": "", // Путь к контейнеру PKCS#12
"passphrase": "" // Парольная фраза, зашифрованная ключом на параметрах сервера, либо в открытом виде
}
Для валидации сертификатов компонентов, выполняющих подключение, по умолчанию используется полная цепочка сертификатов в контейнере PKCS#12, если в конфигурационных файлах не прописаны прежние параметры для установки цепочки доверенных сертификатов:
в конфигурационном файле Pangolin Manager
postgresql.ymlв секциях:restapi:cafile: /path/to/CAfile.pem;capath: /path/to/CAdir(параметр введен в версии 5.3.0);
postgresql:authentication:replication/superuser/rewind:sslrootcert: /path/to/CAfile.pem;sslrootpath: /path/to/CAdir(параметр введен в версии 5.3.0);
postgresql:parameters:ssl_ca_file: /path/to/CAfile.pem;ssl_ca_path: /path/to/CAdir(параметр введен в версии 5.3.0);
в конфигурационном файле СУБД Pangolin
postgresql.conf:ssl_ca_file = '/path/to/CAfile.pem';ssl_ca_path = '/path/to/CAdir'(параметр введен в версии 5.3.0);
в конфигурационном файле Pangolin Pooler
pangolin-pooler.ini:client_tls_ca_file = /path/to/CAfile.pem;server_tls_ca_file = /path/to/CAfile.pem;client_tls_ca_path = /path/to/CAdir(параметр введен в версии 5.3.0);server_tls_ca_path = /path/to/CAdir(параметр введен в версии 5.3.0);
в строке подключения
psql:sslrootcert = /path/to/CAfile.pem(переменная окруженияPGSSLROOTCERT);sslrootpath = /path/to/CAdir(переменная окруженияPGSSLROOTPATH(параметр введен в версии 5.3.0)).
Если один из этих параметров указан, то он будет использоваться для инициализации цепочки доверенных сертификатов для проверки сертификатов: со стороны сервера - клиентского сертификата, со стороны клиента - серверного сертификата. В дополнение к приведенным вариантам поиска доверенных сертификатов добавлен поиск среди доверенных сертификатов операционной системы. Настроечный параметр для этого не требуется.
Примечание:
Клиентские компоненты кластера (
psql) используют полную цепочку сертификатов в контейнере PKCS#12 для валидации сертификатов, если в строке подключения параметрsslmodeустановлен вverify-caилиverify-full.
Порядок поиска доверенных сертификатов:
если не используются параметры, указывающие на файл, либо директорию с сертификатами: сначала в полной цепочке сертификатов из контейнера PKCS#12, затем в в директории ОС, указанной по умолчанию;
если используются параметры, указывающие на файл и/или директорию с сертификатами: сначала в файле, содержащем один или несколько доверенных сертификатов, затем в директории, если установлена, и, если в них не удалось найти нужный сертификат, то - в директории ОС, указанной по умолчанию.
Возможность конфигурирования сертификатов через PEM-файлы сохранена.
Реализация интерфейса получения контейнера PKCS#12 и парольной фразы к нему выполнена в виде плагинов (подключаемых модулей). В директории установки Pangolin созданы символические ссылки на плагины:
/usr/pangolin-5.3.0/lib/libpkcs12_exporter_plugin_link.so -> plugins/libpkcs12_exporter_plugin.so
/usr/pangolin-5.3.0/lib/libpkcs12_passphrase_plugin_link.so -> plugins/libpkcs12_passphrase_plugin.so
Для контроля сроков действия сертификатов и проверки подписи локальным корневым сертификатом в контейнерах PKCS#12 предоставляется утилита pkcs12_cert_info. По умолчанию поиск корневого сертификата также ведется в системных директориях по умолчанию. Утилита принимает на вход аргументы: путь к конфигурационному файлу со стратегией получения контейнера PCKS#12 и парольной фразы --pkcs12_config_path (-p), параметр включения проверки подписи --verify (-v), опционально путь к корневому сертификату --CAfile (-f), опционально путь к директории с корневым сертификатом --CApath (-d), опциональный параметр отключения поиска в директориях по умолчанию --no-CApath (-n).
Справка по использованию утилиты:
$ pkcs12_cert_info -h
Usage:
pkcs12_cert_info <option>...
Options:
--help [-h] This help
--pkcs12_config_path [-p] Path to config file with info how to get PKCS#12 file
--verify [-v] Check that PKCS#12 certificate trusted by anchor
--CAfile [-f] Path to root/intermediate certificate file
--CApath [-d] Path to root/intermediate certificate directory
--no-CApath [-n] Do not use the default directory of trusted certificates.
Pangolin product version information:
--product_version prints product name and version
--product_build_info prints product build number, date and hash
--product_component_hash prints component hash string
Вывод утилиты включает статус наличия закрытого ключа в контейнере, сроки действия сертификата и атрибуты, идентифицирующие сертификат (имя издателя и общее имя сертификата), а также сроки действия цепочки доверенных сертификатов. При введенном параметре проверки подписи выводится результат проверки, а также путь до использованного корневого сертификата.
Пример запуска утилиты:
$ pkcs12_cert_info -p /pg_ssl/server.p12.cfg
Certificate:
Issuer: CN=Pangolin_intermediate_CA
Validity
Not Before: Nov 8 10:52:13 2022 GMT
Not After : Nov 5 10:52:13 2032 GMT
Subject: CN=srv-0-154
Private key exists
Certificate chain:
Certificate #1:
Issuer: CN=Pangolin_CA
Validity
Not Before: Nov 8 10:52:13 2022 GMT
Not After : Nov 5 10:52:13 2032 GMT
Subject: CN=Pangolin_intermediate_CA
Certificate #2:
Issuer: CN=Pangolin_CA
Validity
Not Before: Nov 8 10:52:12 2022 GMT
Not After : Nov 5 10:52:12 2032 GMT
Subject: CN=Pangolin_CA
Использование сертификатов в локально хранящихся контейнерах PKCS#12 настраивается путем установки следующих параметров в конфигурационных файлах компонентов кластера:
в конфигурационном файле Pangolin Manager
postgresql.ymlпараметрpkcs12_config_pathв секциях:restapi;pkcs12_config_path: example.p12.cfg;
postgresql:authentication:replication/superuser/rewind;pkcs12_config_path: example.p12.cfg;
postgresql:parameters;serverssl.pkcs12_config_path: example.p12.cfg;
в конфигурационном файле СУБД Pangolin
postgresql.confпараметрserverssl.pkcs12_config_path;в конфигурационном файле Pangolin Pooler
pangolin-pooler.iniпараметрыclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path.
Изменение данных параметров не требует перезапуска компонентов кластера, достаточно выполнить перечитывание конфигурационных файлов.
Если для подключения к СУБД Pangolin требуется предоставить сертификат, и кластер настроен с использованием контейнеров PKCS#12, хранящихся в файловой системе, то в строке подключения psql необходимо указать параметр pkcs12_config_path с путем до конфигурационного файла .p12.cfg, содержащего путь к контейнеру PKCS#12 и парольную фразу в зашифрованном виде.
Примеры запуска утилиты psql:
# В файле /pg_ssl/client.p12.cfg установлена парольная фраза.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
# В файле /pg_ssl/client.p12.cfg установлена парольная фраза. Путь к /pg_ssl/client.p12.cfg указан через переменную окружения.
$ PKCS12_CONFIG_PATH=/pg_ssl/client.p12.cfg psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Парольная фраза передается в строке подключения в зашифрованном виде.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg pkcs12_passphrase=$enc$+tsiUlhEuNw4ASyvN6ta0A==$sys$mKb2BejR/MLUBzZQ2PaFs+zXGHDRljMWqX46w0CMmDWtjPDzwbxwNSfDAmVTT3Wu"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Парольная фраза передается через переменную окружения в зашифрованном виде.
$ PKCS12_PASSPHRASE='$enc$+tsiUlhEuNw4ASyvN6ta0A==$sys$mKb2BejR/MLUBzZQ2PaFs+zXGHDRljMWqX46w0CMmDWtjPDzwbxwNSfDAmVTT3Wu' psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
# В файле /pg_ssl/client.p12.cfg парольная фраза не установлена. Требуется ручной ввод парольной фразы.
$ psql "host=$(hostname -f) port=5433 dbname=postgres user=postgres sslmode=verify-full pkcs12_config_path=/pg_ssl/client.p12.cfg"
Enter passphrase for PKCS#12 file:
***
Внимание!
В режиме защищенного конфигурирования (
secure_config = on) управление параметром СУБД Pangolinserverssl.pkcs12_config_pathвыполняется на стороне хранилища секретов.
Если для валидации сертификатов не подходит полная цепочка сертификатов в контейнере PKCS#12, предоставляется возможность использования существующих параметров для установки путей к файлам с полными цепочками доверенных сертификатов или введенных в текущей работе новых параметров для установки директории с доверенными сертификатами:
в конфигурационном файле Pangolin Manager.
postgresql.ymlв секциях:restapi;cafile: /path/to/CAfile.pem;capath: /path/to/CAdir;
postgresql:authentication:replication/superuser/rewind;sslrootcert: /path/to/CAfile.pem;sslrootpath: /path/to/CAdir;
postgresql:parameters;ssl_ca_file: /path/to/CAfile.pem;ssl_ca_path: /path/to/CAdir;
в конфигурационном файле СУБД Pangolin
postgresql.conf:ssl_ca_file = '/path/to/CAfile.pem';ssl_ca_path = '/path/to/CAdir';
в конфигурационном файле Pangolin Pooler
pangolin-pooler.ini:client_tls_ca_file = /path/to/CAfile.pem;server_tls_ca_file = /path/to/CAfile.pem;client_tls_ca_path = /path/to/CAdir;server_tls_ca_path = /path/to/CAdir;
в строке подключения
psql:sslrootcert = /path/to/CAfile.pem(переменная окруженияPGSSLROOTCERT);sslrootpath = /path/to/CAdir(переменная окруженияPGSSLROOTPATH).
Поиск доверенных сертификатов также выполняется среди доверенных сертификатов операционной системы. Настроечный параметр для этого не требуется.
Пример подготовки директории с доверенными сертификатами:
# Добавление корневого сертификата в директорию с доверенными сертификатами
cp /path/to/panglolin.crt /pg_ssl/root_dir
c_rehash /pg_ssl/root_dir
Пример управления доверенными сертификатами операционной системы CentOS 7.9:
# Добавление корневого сертификата с именем Pangolin_CA в хранилище доверенных сертификатов ОС
sudo cp /path/to/panglolin.crt /etc/pki/ca-trust/source/anchors/
sudo update-ca-trust extract
trust list|grep Pangolin_CA
# Удаление корневого сертификата с именем Pangolin_CA из хранилища доверенных сертификатов ОС
sudo rm /etc/pki/ca-trust/source/anchors/panglolin.crt
sudo update-ca-trust extract
trust list|grep Pangolin_CA
Для контроля сроков действия сертификатов в контейнерах PKCS#12 предоставляется утилита pkcs12_cert_info. Утилита принимает на вход один аргумент: путь к конфигурационному файлу со стратегией получения контейнера PCKS#12 и парольной фразы. Вывод утилиты включает статус наличия закрытого ключа в контейнере, сроки действия сертификата и атрибуты, идентифицирующие сертификат (имя издателя и общее имя сертификата), а также сроки действия полной цепочки сертификатов.
В пользовательском конфигурационном файле инсталлятора введены следующие параметры:
Контейнер PKCS#12, помимо сертификата и закрытого ключа, может содержать полную цепочку сертификатов, включая корневой, которыми подписан сертификат. Для упрощения настройки доверенных SSL/TLS сертификатов в кластере предоставляется возможность использовать цепочку сертификатов из контейнера в качестве доверенных, установив параметр pkcs12_use_ca_chain_from_container в true.
# Флаг определяет, использовать ли полную цепочку сертификатов в контейнере PKCS#12 в качестве доверенной. # Если флаг true, то использовать полную цепочку доверенных сертификатов в контейнере, если есть, в качестве доверенной, иначе - false. pkcs12_use_ca_chain_from_container: trueЕсли вариант с использованием полной цепочки сертификатов из контейнера PKCS#12 не подходит для настройки доверенных SSL/TLS сертификатов, предоставляется возможность установки доверенных сертификатов через следующие параметры:
pg_certs_pwd: root_ca_file: "{{ '' | default('/pg_ssl/root.crt', true) }}" # Использовать PEM файл, который может содержать один или несколько доверенных сертификатов root_ca_path: "{{ '' | default('/pg_ssl/root_dir', true) }}" # Использовать подготовленную директорию с доверенными сертификатамиПараметры для поддержки использования сертификатов и закрытых ключей из контейнеров PKCS#12, расположенных в файловой системе:
# Активация получения контейнера PKCS#12 и парольной фразы к нему из файловой системы. # Если флаг true, то устанавливаются плагины libpkcs12_passphrase_plugin.so и libpkcs12_exporter_plugin.so. # Если флаг false, то используется прежний подход для получения ключевой информации: из файлов в PEM формате. Плагин не устанавливается. pkcs12_plugin_enable: true pg_certs_pwd: # Установка параметра p12_path обязательна при активации флага pkcs12_plugin_enable. server_p12: p12_path: "{{ '' | default('/home/postgres/ssl/server.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с серверной ключевой парой и цепочкой доверенных сертификатов. p12_pass: "{{ '' | default('', true) }}" # Парольная фраза для доступа к контейнеру PKCS#12 (server.p12), зашифрованная средствами Ansible Vault (в ходе установки парольная фраза расшифровывается и сохраняется в файл по пути p12_config_path (см. ниже) в зашифрованном виде на ключе, сгенерированном на параметрах сервера). Параметр обязателен в случае установки параметра p12_path. p12_config_path: "{{ '' | default('/home/postgres/ssl/server.p12.cfg', true) }}" # Путь к файлу в JSON-формате, содержащему параметр ("passphrase") для получения парольной фразы для доступа к контейнеру PKCS#12, зашифрованную на ключе, сгенерированном на параметрах сервера, и параметр ("pkcs12") для получения контейнера PKCS#12. Параметр обязателен при установке флага pkcs12_plugin_enable в true. postgres_p12: p12_path: "{{ '' | default('/home/postgres/ssl/client.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой пользователя postgres и цепочкой доверенных сертификатов p12_pass: "{{ '' | default('', true) }}" p12_config_path: "{{ '' | default('/home/postgres/ssl/client.p12.cfg', true) }}" pgbouncer_p12: p12_secman_integration: true p12_path: "{{ '' | default('/home/postgres/ssl/pgbouncer.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой Pangolin Pooler и цепочкой доверенных сертификатов для подключения к СУБД Pangolin p12_pass: "{{ '' | default('', true) }}" p12_config_path: "{{ '' | default('/home/postgres/ssl/pgbouncer.p12.cfg', true) }}" patroni_p12: p12_path: "{{ '' | default('/home/postgres/ssl/patroni.p12', true) }}" # Путь в файловой системе к контейнеру PKCS#12 с клиентской ключевой парой и цепочкой доверенных сертификатов для подключения Pangolin Manager к СУБД Pangolin p12_pass: "{{ '' | default('', true) }}" p12_config_path: "{{ '' | default('/home/postgres/ssl/patroni.p12.cfg', true) }}" etcd_cert: "{{ '' | default('/home/postgres/ssl/etcd.crt', true) }}" # Путь к сертификату для взаимодействия экземпляров ETCD. Может быть подписан сертификатом, отличным от сертификата, подписавшего сертификаты компонентов Pangolin, Pangolin Pooler, Pangolin Manager. Тогда потребуется указать путь к корневому сертификату в параметре etcd_root_ca. etcd_key: "{{ '' | default('/home/postgres/ssl/etcd.key', true) }}" # Путь к приватному ключу для взаимодействия экземпляров ETCD etcd_root_ca: "{{ '' | default('/home/postgres/ssl/root_etcd.crt', true) }}" # Корневой сертификат для проверки действительности сертификатов ETCDПримечания к ключам словаря
pg_certs_pwd:p12_path- путь в файловой системе к контейнеру PKCS#12 с ключевой парой и цепочкой доверенных сертификатов.p12_pass- парольная фраза для доступа к контейнеру PKCS#12, зашифрованная средствами Ansible Vault. В ходе установки парольная фраза расшифровывается и сохраняется в файл по путиp12_config_pathв зашифрованном виде на ключе, сгенерированном на параметрах сервера.p12_config_path- путь к файлу в JSON-формате.p12.cfg, содержащему поле "passphrase" с парольной фразой для доступа к контейнеру PKCS#12 и полеpkcs12с путем до контейнера PKCS#12. Файл формируется инсталлятором: в полеpkcs12прописывается путь к контейнеру PKCS#12 (из параметраp12_path), в полеpassphraseпомещается парольная фраза перешифрованная ключом, сгенерированном на основе параметров сервера (из параметраp12_pass). Формат файла:{ "pkcs12": "", // Путь к контейнеру PKCS#12 "passphrase": "" // Парольная фраза, зашифрованная ключом на параметрах сервера, либо в открытом виде }etcd_root_ca- путь к корневому сертификату ETCD. Параметр является обязательным при настройке SSL между узлами etcd.
Параметр для выбора способа хранения парольной фразы в конфигурационном файле
.p12.cfg, путь к которому указывается в параметреp12_config_path: в зашифрованном или в открытом виде.# Флаг, определяющий способ хранения парольной фразы к контейнеру PKCS#12. # Если флаг true, то парольная фраза зашифровывается ключом, генерируемым на основе параметров сервера, иначе - парольная фраза в открытом виде. pkcs12_encrypt_passphrase: true
Отключение функциональности#
Отключение функциональности выполняется переконфигурированием кластера на использование сертификатов в PEM-формате без перезапуска кластера. Достаточно выполнить перечитывание конфигурационных файлов.
Управление сертификатами для Pangolin с Secret Management System#
В целях повышения уровня информационной безопасности новая функциональность обеспечивает хранение и использование контейнеров PKCS#12 и парольных фраз к ним в хранилище секретов и сертификатов Secret Management System (SecMan) и их ротацию на промышленных стендах.
В Pangolin появляется несколько новых конфигурационных файлов. Эти файлы используются следующими компонентами кластера: СУБД Pangolin, Pangolin Pooler и Pangolin Manager. Каждый компонент использует свой конфигурационный файл. Данные, указанные в файлах, используются для генерации контейнеров PKCS#12, содержащих сертификат и частный ключ. Контейнер создается и хранится в SecMan и возвращается компоненту кластера по запросу.
Описание файла:
{
"pkcs12": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Примеры файлов для компонентов кластера:
Pangolin:
{ "pkcs12": { "name": "server", "common_name": "server", "email": "test@test.ru", "alt_names": "", "ip_sans": "", "other_sans": "", "exclude_cn_from_sans": "" } }Pangolin Pooler:
{ "pkcs12": { "name": "pgbouncer", "common_name": "pgbouncer", "email": "test@test.ru", "alt_names": "", "ip_sans": "", "other_sans": "", "exclude_cn_from_sans": "" } }Pangolin Manager:
{ "pkcs12": { "name": "patroni", "common_name": "patroni", "email": "test@test.ru", "alt_names": "", "ip_sans": "", "other_sans": "", "exclude_cn_from_sans": "" } }
Для того, чтобы использовать новые конфигурационные файлы, пути к ним нужно прописать в основных конфигурационных файлах:
В случае кластера. В файле конфигурации Pangolin Manager
postgresql.ymlв параметреpkcs12_config_pathв секцияхrestapi,postgresql/authentication/replication,postgresql/authentication/superuserиpostgresql/authentication/rewind, а также в параметреpkcs12_config_pathв секцииpostgresql/parameters:restapi: pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата postgresql: authentication: replication: pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата postgresql: authentication: superuser: pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата postgresql: authentication: rewind: pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата postgresql: parameters: serverssl.pkcs12_config_path: "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификатаВ случае standalone конфигурации. В файле конфигурации СУБД Pangolin
postgresql.conf(для случая конфигурации standalone) в параметреserverssl.pkcs12_config_path:serverssl.pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификатаВнимание!
При включенной защите параметров конфигурационный параметр
serverssl.pkcs12_config_pathдолжен быть под защитой, а его значение должно устанавливаться только через SecMan.В файле конфигурации Pangolin Pooler
pangolin-pooler.iniв параметреclient_tls_pkcs12_config_pathиserver_tls_pkcs12_config_path:client_tls_pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата server_tls_pkcs12_config_path = "" # Путь к конфигурационному файлу в JSON-формате, содержащему данные для генерации сертификата
Ротация сертификатов, получаемых из SecMan#
Ротация сертификатов, используемых компонентами кластера, осуществляется агентом, который:
контролирует срок действия сертификатов, полученных из SecMan;
обновляет сертификаты на SecMan при приближении конца их срока действия;
контролирует внешнее изменение сертификатов, обновление на SecMan, а также отзыв сертификата;
запускает процесс обновления сертификатов на кластере.
Агент pg_certs_rotate_agent#
Агент представляет собой исполняемый файл pg_certs_rotate_agent, который настраивается для работы с конкретным хранилищем сертификатов через систему плагинов. Расположен в директории /opt/pangolin-common/bin/ и запускается отдельной службой pg_certs_rotate_agent.service до запуска служб postgresql.service, pangolin-pooler.service и pangolin-manager.service.
Период проверки сертификатов и их обновления настраивается в конфигурационном файле агента. Первая проверка происходит на его старте. Следующий запуск агента может произойти до окончания заданного промежутка времени, если интервал между датой истечения и датой выпуска одного из сертификатов достигает 80% внутри текущего периода. Таким образом, агент будет запущен в этот момент времени, и следующий период будет отсчитываться уже от этой точки. Если в процессе работы агента произошла ошибка, то его следующий запуск произойдет через заданный в конфигурации период ожидания.
На схеме ниже приведены этапы работы агента:
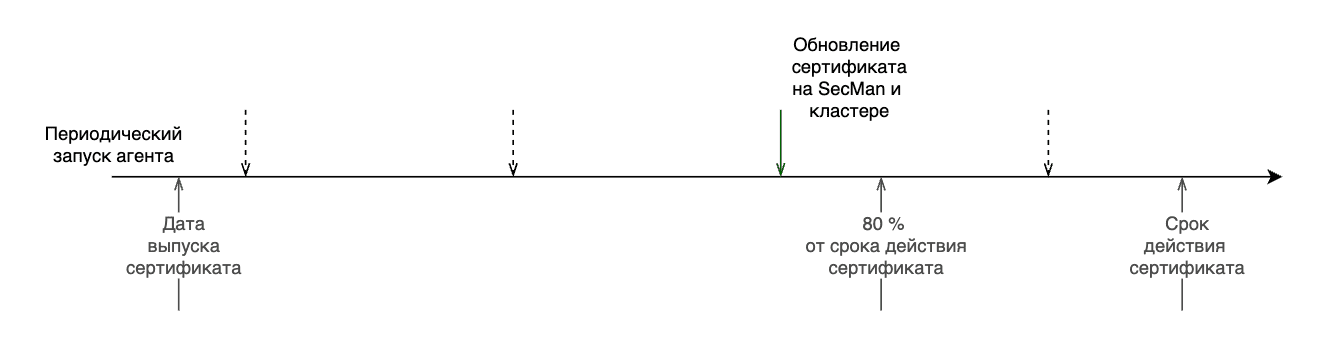
Если обновление сертификата на SecMan произошло без участия агента, то кластер до следующего запуска агента будет работать со старым сертификатом (в том числе, если сертификат отозван):
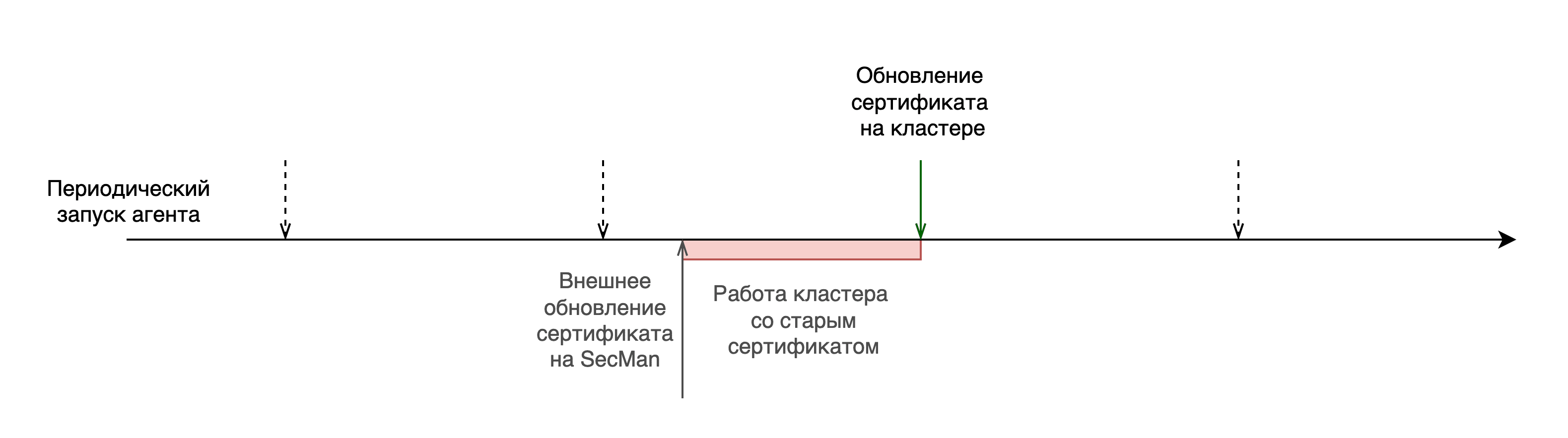
Для взаимодействия с SecMan применяется плагин remote_secman_pki_plugin, который использует протокол http/https, а также параметры подключения кластера. Параметры хранятся в зашифрованном хранилище /etc/postgres/enc_connection_settings_cert.cfg. Для расшифровки файла агент использует плагин шифрования.
Процесс инсталляции агента#
Настройка работы агента происходит на этапе установки кластера Pangolin:
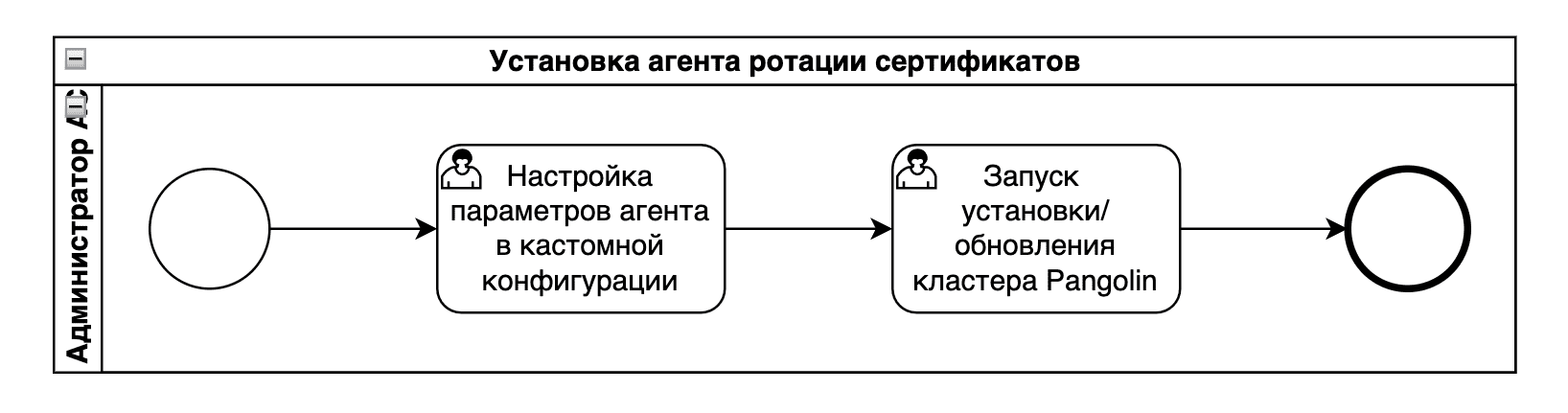
Для включения агента ротации сертификатов в конфигурационном файле инсталлятора custom_file_template.yml (см. раздел «Конфигурационные файлы для настройки СУБД Pangolin») требуется добавить параметр enable в yaml-словарь pg_certs_rotate_agent. Все параметры агента сохраняются в конфигурационном файле, который тот использует при инициализации:
путь к конфигурационному файлу агента задается при помощи параметра
agent_config, который находится вpg_certs_rotate_agent. По умолчанию используется конфигурационный файл/etc/postgres/pg_certs_rotate_agent.yaml;путь к директории для лог-файлов задается с помощью параметра
log_directoryв yaml-словареpg_certs_rotate_agent. По умолчанию используется путь/var/log/pg_certs_rotate_agent;имя лог-файла задается параметром
log_filenameв yaml-словареpg_certs_rotate_agent. По умолчанию используется имя pg_certs_rotate_agent;уровень логирования задается параметром
log_levelв yaml-словареpg_certs_rotate_agent. Возможны уровни:debug | info | warning | error | fatal. По умолчанию используется уровеньinfo;методы записи лога задаются параметром
log_destinationв yaml-словареpg_certs_rotate_agent. Возможные методы:console, fileпри любой комбинации методов. По умолчанию используется методconsole;включить/отключить функцию ротации сертификатов можно с помощью параметра
enable_updateв словареpg_certs_rotate_agent:certs. По умолчанию функция включена;период проверки сертификатов настраивается при помощи параметра
poll_period_in_min, который находится в словареpg_certs_rotate_agent:certsи задается в минутах. По умолчанию период работы будет равен 60 минутам;время ожидания повторного запуска агента в случае ошибки устанавливается в параметре
retry_interval_in_sec, который находится в словареpg_certs_rotate_agent:certsи задается в секундах. По умолчанию таймаут будет равен 30 секундам;количество повторных проверок в случае ошибки задается параметром
retry_attempts_num, который находится в словареpg_certs_rotate_agent:certs. По умолчанию настроена одна попытка;список сертификатов, за сроком действия которых «следит» агент, определяются группами
locations, которые находятся в словареpg_certs_rotate_agent:certs:watch. В каждой группе задается:в словаре
pathsмножество конфигурационных файлов сертификатов*.p12.cfg;в словаре
on_updateмножество зависимых от сертификатов команд, необходимых для обновления компонентов кластера.
Формат конфигурационного файла инсталлятора для агента ротации:
pg_certs_rotate_agent:
# Флаг определяет, запускается ли агент ротации.
# Если флаг true, то агент будет запущен, иначе - false.
enable: true
# Путь к конфигурационному файлу агента в YAML-формате
agent_config: "{{ '' | default('/etc/postgres/pg_certs_rotate_agent.yaml', true) }}"
# Путь к директории для лог-файлов
log_directory: "{{ '' | default('/var/log/pg_certs_rotate_agent', true) }}"
# Имя лог-файла
log_filename: "{{ '' | default('pg_certs_rotate_agent', true) }}"
# Уровень логирования
log_level: "{{ '' | default('info', true) }}"
# Методы записи лога
log_destination: "{{ '' | default('console', true) }}"
certs:
# Включить/выключить автоматическое обновление сертификатов
enable_update: "{{ '' | default(true, true) }}"
# Период проверки валидности сертификатов [мин]
poll_period_in_min: "{{ '' | default(60, true) }}"
# Таймаут на повторный запуск в случае ошибки [c]
retry_interval_in_sec: "{{ '' | default(30, true) }}"
# Количество попыток после неудачи
retry_attempts_num: "{{ '' | default(1, true) }}"
# Множество обновляемых сертификатов
watch:
- locations:
# Множество файлов конфигураций сертификатов
paths:
- path/to/cert/configuration/1_1
- path/to/cert/configuration/1_N
# Множество команд, которые требуется выполнить после обновления хотя бы одного из сертификатов
on_update:
- update command 1_1
- update command 1_N
# Множество файлов конфигураций
- locations:
# Множество обновляемых сертификатов
paths:
- path/to/cert/configuration/M_1
- path/to/cert/configuration/M_N
# Множество команд, которые требуется выполнить после обновления хотя бы одного из сертификатов
on_update:
- update command M_1
- update command M_N
Для каждого сертификата существует конфигурационный файл *.p12.cfg. Если кластер получает сертификат из SecMan, то в словаре pkcs12 будут описаны параметры доступа к сертификату на SecMan:
{
"pkcs12": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Если кластер использует локальный сертификат, то в словаре pkcs12 будет указан путь к локальному сертификату. Чтобы агент ротации мог обновить файл локального сертификата, необходимо в конфигурационном файле *.p12.cfg добавить словарь secman с описанием параметров доступа к сертификату на SecMan:
{
"secman": {
"name": "", // Имя роли
"common_name": "", // CN для сертификата
"email": "", // Почтовый адрес владельца сертификата
"alt_names": "", // Альтернативные имена субъектов в списке, разделенном запятыми. Это могут быть имена хостов или адреса электронной почты
"ip_sans": "", // Альтернативные имена субъекта IP в списке с разделителями-запятыми. Действителен только в том случае, если роль разрешает IP SAN (по умолчанию)
"other_sans": "", // Настраиваемые SAN со строкой OID/UTF8
"exclude_cn_from_sans": "" // Параметр, включающий/выключающий возможность исключить common_name из DNS или электронной почты SAN
}
}
Настройка параметров запущенного агента#
Примечание:
В случае кластерной конфигурации агент запускается на каждом из его узлов. Далее описывается настройка агента для standalone-конфигурации или при запуске на одном узле.
Чтобы изменить параметры запущенного агента, требуется обновить конфигурационный файл агента, который был указан в процессе инсталляции, и перезагрузить параметры службы pg_certs_rotate_agent.service:
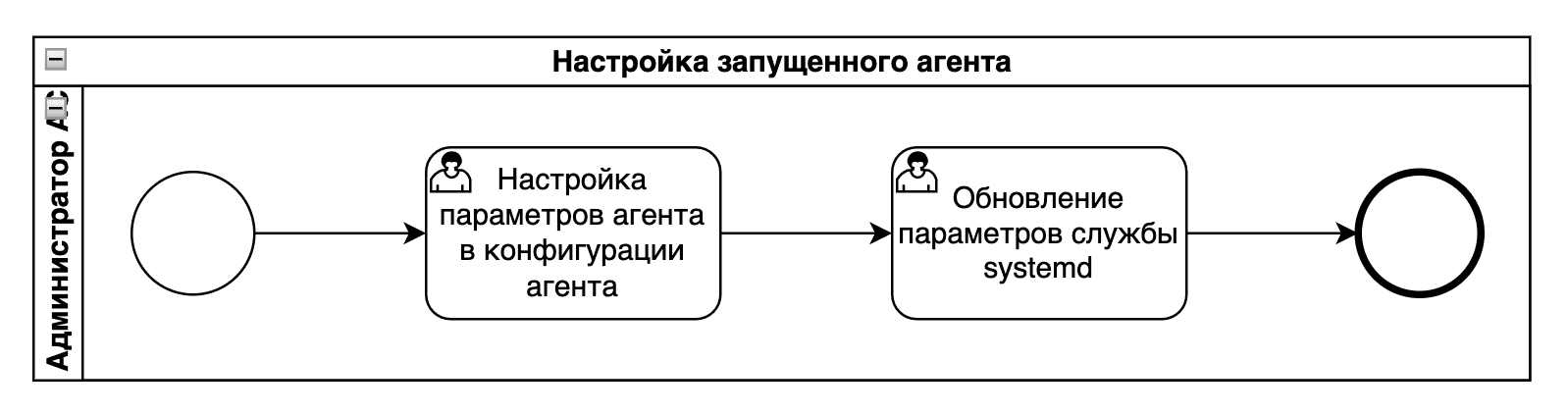
На первом шаге необходимо заполнить конфигурационный файл агента в формате YAML:
log:
directory: PATH/TO/LOG/DIRECTORY
filename: LOG_FILE_NAME
level: debug | info | warning | error | fatal
destination: console, file
certs:
enable_update: bool
poll_period_in_min: unsigned integer
retry_interval_in_sec: unsigned integer
retry_attempts_num: unsigned integer
watch:
- locations:
paths:
- PATH/TO/CERT/CONFIGURATION/1
- PATH/TO/CERT/CONFIGURATION/N
on_update:
- bash command 1
- bash command N
- locations:
paths:
- PATH/TO/CERT/CONFIGURATION/1
- PATH/TO/CERT/CONFIGURATION/M
on_update:
- bash command 1
- bash command M
Чтобы включить или отключить ротацию сертификатов, требуется установить значение ключа enable_update, который находится в yaml-словаре certs, в значение true или false соответственно.
Для изменения периода работы агента нужно задать новое значение ключа poll_period_in_min (в минутах), который тоже находится в словаре certs.
Для изменения времени ожидания с целью перезапуска агента (в случае ошибки) нужно задать новое значение ключа retry_interval_in_sec (в секундах). Ключ расположен в словаре certs.
Чтобы изменить количество повторных попыток в случае ошибки, нужно задать новое значение ключа retry_attempts_num, который находится в yaml-словаре certs.
Список сертификатов для обработки агентом задается в виде групп, определенных через ключ locations. Для каждой группы должна быть определена команда обновления сертификатов на кластере. Если один из сертификатов группы устаревает, обновляется на SecMan или появляется в списке отозванных, то выполняется команда, указанная по ключу on_update.
Далее приведен пример конфигурационного файла агента ротации сертификатов для конфигурации standalone-patroni-etcd-pgbouncer без контроля отозванных сертификатов:
certs:
enable_update: true
poll_period_in_min: 1440
retry_interval_in_sec: 60
retry_attempts_num: 1
watch:
- locations:
paths:
- "/home/postgres/ssl/server.p12.cfg"
- "/home/postgres/ssl/patroni.p12.cfg"
on_update:
- sudo systemctl reload pangolin-manager
- locations:
paths:
- "/home/postgres/ssl/server.p12.cfg"
- "/home/postgres/ssl/pgbouncer.p12.cfg"
on_update:
- sudo systemctl reload pangolin-pooler
При изменении имени конфигурационного файла агента требуется обновить параметры службы pg_certs_rotate_agent.service. Имя файла указывается в качестве аргумента исполняемого файла /opt/pangolin-common/bin/pg_certs_rotate_agent:
ExecStart=/opt/pangolin-common/bin/pg_certs_rotate_agent --config=/etc/postgres/pg_certs_rotate_agent.yaml
Для применения настроек необходимо перезагрузить службу:
sudo systemctl restart pg_certs_rotate_agent.service
Процесс обновления сертификатов на SecMan#
При успешном подключении к SecMan, агент запрашивает каждый контролируемый сертификат отдельно, используя метод read. Метод fetch не используется, чтобы исключить автоматический перевыпуск сертификатов без их последующего обновления на кластере. Если интервал между датой истечения и датой выпуска сертификата достигает 80% внутри следующего периода (или если сертификат попал в список отозванных), то агент, используя метод generate, запрашивает его перевыпуск. Если в процессе обновления сертификата произошла ошибка, то следующая попытка откладывается на другую итерацию работы агента через период ожидания, определенный в конфигурационном файле.
Примечание:
Контроль за попаданием сертификатов в список отозванных реализуется в сервисе обновления CRL. Сервис ротации сертификатов сообщает сервису обновления CRL серийные номера используемых на кластере сертификатов. Если сервис обновления CRL находит сертификаты в списке отозванных, то сообщает об этом сервису ротации сертификатов, после чего запускается процесс их обновления на SecMan.
Процесс обновления сертификатов на кластере#
При успешном обновлении на SecMan хотя бы одного сертификата из списка (или если обновление сертификатов на SecMan произошло без участия агента) агент запускает процесс обновления сертификатов на кластере. Для этой проверки он сохраняет серийные номера сертификатов, которые периодически сравнивает с полученными от SecMan.
Процесс обновления сертификатов на кластере состоит в перезагрузке параметров узла кластера или сервера конфигурации standalone с помощью команды, указанной в конфигурационном файле.
Внимание!
Агент не контролирует ошибки, которые могут произойти в процессе обновления сертификатов на кластере.
Отключению функциональности#
Отключение производится путем удаления описанных выше конфигурационных параметров для соответствующих компонентов.
Поддержка CRL в компонентах кластера Pangolin#
CRL представляет собой список сертификатов, которые УЦ пометил как отозванные (при этом сертификаты с истекшим сроком действия не вносятся в этот список). Каждая запись в списке включает идентификатор отозванного сертификата и дату отзыва. Дополнительная информация включает в себя ограничение по времени, если отзыв применяется в течение определенного периода времени, а также причину отзыва.
Начиная с версии 5.4.0, использование файлов CRL поддерживается всеми компонентами кластера, а автоматическое обновление неактуальных файлов CRL доступно как часть функциональности агента ротации сертификатов pg_certs_rotate_agent.
Настройка CRL#
Для поддержки CRL имеются следующие параметры в конфигурационных файлах компонентов:
postgresql.conf(Pangolin):ssl_crl_file- путь к файлу CRL, по которому выполняется проверка статуса клиентских сертификатов;ssl_crl_dir- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов.
Примечание:
При включенной защите параметров
ssl_crl_fileиssl_crl_dirинициализируются значениями из защищенного хранилища секретов.Клиентские утилиты, использующие библиотеку
libpq(psql):sslcrl(переменная окруженияPGSSLCRL) - путь к файлу CRL, по которому выполняется проверка статуса серверных сертификатов;sslcrldir(переменная окруженияPGSSLCRLDIR) - путь к директории с файлами CRL, по которым выполняется проверка статуса серверных сертификатов.
postgres.yml(Pangolin Manager):в секции restapi:
crlfile- путь к файлу CRL;crlpath- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;
в секции
postgresql/authentication/(replication/rewind/superuser):sslcrldir- путь к директории с файлами CRL, по которым выполняется проверка аннулирования серверного сертификата Pangolin;
в секции
postgresql/parameters:sslcrldir- путь к каталогу с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;
pangolin-pooler.ini(Pangolin Pooler):client_tls_crl_file- путь к файлу CRL;client_tls_crl_path- путь к директории с файлами CRL, по которым выполняется проверка аннулирования клиентских сертификатов;server_tls_crl_file- путь к файлу CRL;server_tls_crl_path- путь к директории с файлами CRL, по которым выполняется проверка аннулирования серверного сертификата Pangolin.
Внимание!
В параметрах конфигурации, приведенных выше, должны использоваться пути к существующим файлам CRL, иначе при включенном TLS/SSL запуск компонента завершится ошибкой.
Примечание:
Для использования директории c файлами CRL необходимо для каждого из файлов создать в этой директории символические ссылки, названные по хеш-значению от содержимого соответствующего файла CRL. Хеш-значения рассчитываются утилитой
c_rehash.Пример вызова утилиты:
c_rehash /pg_ssl/crlЗа подробностями обратитесь к документации OpenSSL.
Для обеспечения автоматического обновления файлов CRL расширяется функциональность агента ротации сертификатов pg_certs_rotate_agent.
Запуск агента выполняется до запуска служб postgresql.service (для конфигурации standalone), pangolin-manager.service (для кластерной конфигурации) и pangolin-pooler.service, чтобы для каждого из компонентов выгрузить файлы CRL из CDP (CRL Distribution Point - точка распространения CRL). Компоненты кластера не запустятся, если файлы CRL прописаны в конфигурационных файлах, но отсутствуют на файловой системе. После выполнения первого цикла выгрузки CRL агент нотифицирует systemd о готовности в случае успешной выгрузки всех файлов CRL, иначе переводит статус службы в failed. Время цикла выгрузки CRL ограничено за счет установки времени ожидания в 30 сек на каждый запрос к CDP.
Примечание:
Агент не удаляет файлы CRL из файловой системы, только заменяет их на новые, поэтому исчезновение файлов CRL в процессе работы компонентов является результатом ручного вмешательства. Для восстановления удаленных файлов CRL перезапустите службу агента ротации и обновления CRL.
Исполняемый файл агента принимает в качестве аргумента командной строки путь к конфигурационному файлу агента pg_certs_rotate_agent.yml, который расположен в директории /etc/postgres и включает следующие параметры:
в секции log:
directory- путь к директории для лог-файлов (обязательный параметр при выводе лога в файл);filename- имя лог-файла (по умолчаниюpg_certs_rotate_agent.log);level- (trace|debug|info|warning|error) - уровень логирования (по умолчаниюinfo);destination- методы записи лога (комбинируются через запятую):console- в стандартный поток вывода или ошибок (в случае запуска под управлением службы - в системный журнал). Значение по умолчанию;file- в файл.
в секции crl:
enable_update(true|false) - включить/выключить автоматическое обновление CRL (по умолчаниюfalse);poll_period_in_min- интервал времени, определяющий период проверки наличия обновленных CRL файлов (задается как целое неотрицательное число в минутах; по умолчанию 60 минут; 0 для отключения периодической проверки CRL). Опрос CDP должен выполняться не реже данного периода;retry_interval_on_expire_in_sec- интервал повторных попыток выгрузки CRL, для которых дата публикации или дата окончания срока действия уже наступили (задается как целое положительное число в секундах, по умолчанию 30 секунд);retry_interval_on_failure_in_sec- интервал времени, через который выполняются повторные попытки выгрузки CRL после неудачи (задается как целое положительное число в секундах, по умолчанию 30 секунд);retry_attempts_num_on_failure- количество попыток выгрузки CRL по списку URI для данного пути расположения файла CRL после неудачи (по умолчанию 1 попытка);crl_file_perm- права доступа, устанавливаемые на выгружаемые файлы CRL (задается в восьмеричном формате, по умолчанию 0644).
в секции watch:
locations- секция включает списки путей до файлов, обновление которых отслеживается (path), а также куда выгружаются новые CRL из CDP (uri):path- путь к файлу CRL;uri- массив URI для выгрузки CRL (основной и резервные);
on_update- список выполняемых команд, если файл CRL изменился (перечитывание конфигурации компонентами кластера).
Далее приведен формат конфигурационного файла агента ротации сертификатов и обновления CRL:
log:
directory: /pgerrorlogs/05/pg_certs_rotate_agent
filename: pg_certs_rotate_agent.log
level: info
destination: console,file
crl:
enable_update: false
poll_period_in_min: 60
retry_interval_on_expire_in_sec: 30
retry_interval_on_failure_in_sec: 30
retry_attempts_num_on_failure: 1
crl_file_perm: 0644
watch:
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload postgresql
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload pangolin-manager
- locations:
- path: CRLPATH_1
uri:
- URI_1
- URI_N
- path: CRLPATH_N
uri:
- URI_1
- URI_N
on_update:
- sudo systemctl reload pangolin-pooler
Справка по аргументам командной строки агента:
pg_certs_rotate_agent --help
Allowed options:
-h [ --help ] produce this help message
-p [ --pid-file ] arg (=/var/run/pg_certs_rotate_agent/pg_certs_rotate_agent.pid)
path to agent's PID file
-c [ --config ] arg (=/etc/postgres/pg_certs_rotate_agent.yml)
path to agent's configuration file
-d [ --dry-run ] check config file format and exit
Агент поддерживает режим пробного запуска с ключом --dry-run. В этом режиме проверяется корректность конфигурационного файла с последующим завершением выполнения. Результат проверки определяется кодом возврата: 0 - конфигурационный файл валидный, иначе 1. Информация об ошибке выводится в лог.
На старте агент сохраняет PID своего процесса в файл (по умолчанию /var/run/pg_certs_rotate_agent/pg_certs_rotate_agent.pid). Файл с PID процесса используется для предотвращения запуска еще одного экземпляра агента и в команде на ротацию лог-файла. Ротация лог-файлов агента выполняется с помощью утилиты logrotate. Файл конфигурации для logrotate расположен в /etc/logrotate.d/pg_certs_rotate_agent и имеет следующее содержимое:
/pgerrorlogs/05/pg_certs_rotate_agent/pg_certs_rotate_agent.log {
rotate 10
dateext
daily
missingok
notifempty
compress
create 0640 postgres postgres
sharedscripts
postrotate
[ ! -f /var/run/pg_certs_rotate_agent/pg_certs_rotate_agent.pid ] || /bin/kill -USR1 `cat /var/run/pg_certs_rotate_agent/pg_certs_rotate_agent.pid 2> /dev/null` 2>/dev/null
endscript
}
Права доступа к директории с логами /pgerrorlogs/05/pg_certs_rotate_agent:
drwxr-x--- 2 postgres postgres
Если включена автоматическая проверка обновления CRL (crl:enable_update), агент в установленное время подключается к первой доступной CDP по HTTP (crl:watch:locations:uri), выгружает файл CRL и сохраняет его в PEM-формате по пути, определенному в параметре crl:watch:locations:path (если файл CRL еще ни разу не выгружался или изменился в точке распространения).
Примечание:
Выгруженный файл CRL с истекшим сроком действия не сохраняется в файловой системе и не удаляется из нее.
Внимание!
Агент не проверяет подпись выгруженного файла CRL. Данную проверку выполняют компоненты кластера, для которых файл CRL предназначен.
Агент создает символическую ссылку на выгруженный файл CRL. Символическая ссылка именуется хеш-значением, рассчитанным по содержимому файла CRL. Если файл CRL до выгрузки нового уже существовал, то символическая ссылка на старый файл удаляется, чтобы не засорять файловую систему, поскольку хеш-значения от старого и нового файлов CRL будут отличаться. Символическая ссылка требуется, чтобы иметь возможность указывать директорию с файлами CRL в конфигурационных файлах компонентов кластера, так как OpenSSL выполняет поиск CRL по хеш-значению.
Если выгруженный файл CRL не является истекшим и не содержит серийные номера сертификатов, находящихся под контролем сервиса ротации сертификатов, агент выполнит команды перечитывания конфигурации соответствующих компонентов (crl:watch:locations:on_update). Если же файл CRL содержит серийные номера таких сертификатов, то соответствующие сертификаты будут перевыпущены сервисом ротации, а команды перечитывания конфигурации выполнятся после процедуры перевыпуска сертификатов.
Внимание!
Агент не контролирует ошибки, которые могут произойти в процессе перечитывания конфигурации компонентами кластера.
Для защиты файлов CRL от их перезаписи агентом в процедуре инициализации SSL контекста в компонентах кластера применяется блокировка на базе flock(). В процессе работы создается временный файл /tmp/.crl.lock. Агент удерживает для него эксклюзивную блокировку на время записи выгруженных CRL-файлов, тогда как компоненты кластера (на старте или при перечитывании параметров) используют для него разделяемую блокировку. Таким образом, компоненты кластера могут одновременно, не мешая друг другу, загружать файлы CRL, блокируясь только при обновлении файлов CRL агентом.
Для каждого файла CRL проверка обновления выполняется:
при запуске агента;
с периодичностью, определенной в параметре
crl:poll_period_in_min, если значение параметра больше 0;в момент следующей публикации CRL (дата в поле CRL файла
NextCRLPublish) и через каждый интервал времени, определяемый параметромcrl:retry_interval_on_expire_in_sec(если после наступления даты публикации CRL еще не выпущен);в момент истечения срока действия CRL (дата в поле CRL файла
NextUpdate) и через каждый интервал времени, определяемый параметромcrl:retry_interval_on_expire_in_sec, если после истечения срока действия CRL еще не выпущен;спустя интервал времени, задаваемый параметром
crl:retry_interval_on_failure_in_sec, после неудачной выгрузки;по требованию путем перезапуска службы агента (на его старте):
sudo systemctl restart pg_certs_rotate_agent.service
при выполнении команды reload и изменении конфигурационного файла агента:
изменился список URI;
добавлена новая команда в
crl:watch:locations:on_update;добавлен новый путь к файлу CRL.
sudo systemctl reload pg_certs_rotate_agent.service
Примечание:
Дата следующей проверки обновления для каждого файла CRL рассчитывается индивидуально.
Процесс инсталляции#
Пути к файлу CRL и директории, содержащей файлы CRL, задаются в конфигурационном файле инсталлятора и одинаковы для всех компонентов кластера. Ниже приведен формат его полей для настройки путей к файлам CRL:
pg_certs_pwd:
crl_file: "{{ '' | default('/pg_ssl/crl/root.crl', true) }}" # Путь к CRL файлу
crl_path: "{{ '' | default('/pg_ssl/crl', true) }}" # Путь к директории с файлами CRL
Для формирования конфигурационного файла агента и обновления CRL в конфигурационном файле инсталлятора необходимо добавить следующие параметры:
pg_certs_rotate_agent:
enable: true # Настроить и запустить службу агента (не учитывается при обновлении агента, только при первичном развертывании)
agent_config: /etc/postgres/pg_certs_rotate_agent.yml # Путь к конфигурационному файлу агента в формате YAML
update_agent_config: false # Обновить файл конфигурации агента (учитывается только при обновлении, значение по умолчанию - False)
log:
directory: /pgerrorlogs/05/pg_certs_rotate_agent # Путь к директории для лог-файлов
filename: pg_certs_rotate_agent.log # Имя лог-файла
level: info # Уровень логирования
destination: console,file # Методы записи лога
crl:
enable_update: false # Включить/выключить автоматическое обновление CRL
poll_period_in_min: 60 # Период проверки наличия обновленных CRL файлов
retry_interval_on_expire_in_sec: 30 # Таймаут для повторной попытки выгрузки CRL после наступления даты публикации CRL или окончания срока действия
retry_interval_on_failure_in_sec: 30 # Таймаут для повторной попытки выгрузки CRL после неудачи
retry_attempts_num_on_failure: 1 # Количество попыток выгрузки CRL по списку URI для данного пути расположения файла CRL после неудачи
crl_file_perm: 0644 # Права доступа, устанавливаемые на выгружаемые файлы CRL
watch:
- locations:
- path: path/to/crlfile_1 # Путь к обновляемому файлу CRL
uri:
- URI_1 # Основная точка распространения CRL
- URI_N # Резервная точка распространения CRL
- path: path/to/crlfile_N # Путь к обновляемому файлу CRL
uri:
- URI_1 # Основная точка распространения CRL
- URI_N # Резервная точка распространения CRL
on_update:
- sudo systemctl reload postgresql # Список выполняемых команд, если файл CRL изменился
Примечание:
Установка файлов агента на узел СУБД производится инсталлятором автоматически.
Обновление pg_certs_rotate_agent осуществляется по одному из двух сценариев:
если агент был ранее установлен в обновляемой версии СУБД Pangolin (например, при переходе с версии СУБД Pangolin 5.4.0 на более высокую):
в зависимости от значения параметра
update_agent_config, который определяется в конфигурационном файле инсталлятора, автоматически настраивается файл конфигурации агента. По умолчанию значение параметра -False, в этом случае конфигурационный файл агента не заменяется версией конфигурации из файла инсталлятора. При необходимости ее обновления инсталлятором, параметр нужно установить в значениеTrue;в зависимости от состояния службы агента (
active/inactive) по окончании обновления версии СУБД служба агента будет либо запущена, либо нет. Проверить статус службы можно следующим способом:sudo systemctl status pg_certs_rotate_agent | grep ActiveРезультат будет иметь следующий вид:
Active: active (running) since Tue 2023-05-23 15:59:02 MSK; 13s agoили
Active: inactive (dead)
если агент не был установлен в обновляемой версии СУБД Pangolin (например, при переходе с версии СУБД Pangolin 5.2.0):
файл конфигурации агента создается и настраивается в соответствии с конфигурационным файлом инсталлятора (для незаполненных полей берутся значения по умолчанию);
запуск службы агента в данном случае не производится.
Примечание:
В рамках механизма обновления версии СУБД скрипт-разведчик проверяет корректность заполнения файла конфигурации
pg_certs_rotate_agent.
В файл /etc/sudoers вручную добавляются следующие команды, разрешенные пользователю postgres для выполнения без запроса пароля:
/bin/journalctl -f -u pg_certs_rotate_agent
/usr/bin/systemctl start pg_certs_rotate_agent
/usr/bin/systemctl stop pg_certs_rotate_agent
/usr/bin/systemctl restart pg_certs_rotate_agent
/usr/bin/systemctl reload pg_certs_rotate_agent
/usr/bin/systemctl status pg_certs_rotate_agent
/usr/bin/systemctl reload pangolin-manager
/usr/bin/systemctl reload postgres
В файл конфигурации службы pangolin-manager.service необходимо добавить команду reload:
ExecReload=/bin/kill -HUP $MAINPID
Генерация и установка постоянного пароля технологической УЗ#
Расширение psql_rotate_password добавляет функцию генерации случайного пароля, удовлетворяющего парольной политике.
Установка расширения psql_rotate_password#
Установка расширения производится установщиком.
Параметры установщика (указаны значения по умолчанию):
rotate_password.enable: false
rotate_password.num_rounds: 20
Далее рассматривается, что делается в установщике или что необходимо сделать при ручной установке:
Установка расширения. Распакуйте файлы расширения в каталог с расширениями, например:
# tar xzf psql_rotate_password-<version>.tar.gz --directory $(pg_config --sharedir)/extensionНеобходимо убедиться, что используется подходящая утилита
pg_config.Создание расширения
psql_rotate_password. Установите расширение (в схемуextпо умолчанию):postgres=# CREATE EXTENSION psql_rotate_password schema ext;Рекомендуется установка для всех БД, для которых необходимо расширение.
Управление правами: по умолчанию права к функции не выставлены, то есть ее может вызвать суперпользователь, либо пользователь получивший права от схемы или БД. Отдельных правил для настройки прав не существует.
Настройка параметров#
Включение генерации пароля происходит при установке параметра rotate_password.enable в значение true (по умолчанию функциональность отключена, значение параметра - false):
rotate_password.enable: true
Параметры генерации пароля:
rotate_password.num_rounds = ''- количество попыток генерации пароля:rotate_password.valid_roles = '20'`rotate_password.valid_roles = ''- список пользователей (через запятую), для которых разрешена генерация пароля:rotate_password.valid_roles = 'user1, "User-2", user3'
При изменении параметров перечитайте конфигурацию (reload).
Использование функции генерации паролей#
Входные параметры функции rotate_password:
(обязательный)
Oidили имя пользователя;(не обязательный) длина пароля. При отсутствии будет сгенерирован по минимальной длине пароля согласно парольным политикам (случайная длина до 5 символов).
Выходной параметр: сгенерированный пароль.
Пример генерации пароля для пользователя User-2:
SELECT * FROM rotate_password('User-2');
┌───────────────────────┐
│ rotate_password │
├───────────────────────┤
│ W+3r#0291h885I`9^JpZ@ │
└───────────────────────┘
(1 row)
Возможные ошибки:
исчерпано количество попыток генерации пароля;
синтаксические параметры парольной политики пользователя вместе с переданным параметром длины пароля не позволяют сгенерировать пароль, соответствующий требованиям;
пользователь не входит в
rotate_password.valid_roles;ошибка синтаксического анализа
rotate_password.valid_roles;не найден пользователь.
Отключение функциональности#
Отключение функциональности производится путем удаления расширения:
DROP EXTENSION psql_rotate_password;
Настройка подключения к SecMan для Pangolin#
Описываемая функциональность:
обеспечивает настройку параметров подключения к хранилищу секретов SecMan;
упрощает процесс изменения параметров для работы с хранилищем секретов;
обеспечивает возможность обнаружения ошибок в параметрах подключения к хранилищу секретов на этапе конфигурирования доступа;
обеспечивает настройку системы для работы с хранилищем сертификатов;
упрощает использование утилиты в автоматизированных скриптах.
обеспечивает настройку проверки серверного сертификата хранилища секретов.
Если изменение параметров подключения к хранилищу секретов или сертификатов производится на работающем кластере, то выполните/запустите перечитывание конфигурационных параметров в компонентах кластера. Перезапуск кластера не требуется.
Дополнительные параметры для работы с хранилищем секретов SecMan#
Для подключения и работы с хранилищем секретов SecMan используются дополнительные параметры:
Доменное имя - добавляется возможность указания сервера хранилища через доменное имя, а не только через IP-адрес.
Префикс для пути хранения секретов - добавляется возможность указания префикса для пути хранения kv-секретов согласно иерархии секретов. Префикс должен содержать движок секретов. Путь, используемый для доступа к секретам:
/v1/{prefix/}data/{suffix/}{cluster id/}{subdomain/}secret_name. Пример заданного префикса:CI03170154_CI03214758/I/SERV/GLOB/SERV/KV.Точка входа для urn аутентификации:
/auth/точка_входа/login/. Указание точки входа позволяет авторизоваться по LDAP для типа авторизации Userpass (пример,auth/ad/X.XX.ru/login/). По умолчанию используются:approle- для авторизации AppRole;userpass- для авторизации Userpass.
Тенант хранилища (
x-vault-namespace) - при взаимодействии с хранилищем секретов по HTTPS тенант указывается в header запроса.Протокол взаимодействия с хранилищем секретов (HTTP или HTTPS, по умолчанию HTTPS).
Утилита setup_kms_credentials позволяет сохранять дополнительные параметры для работы с хранилищем секретов SecMan. Дополнительные параметры имеют значения по умолчанию или расширяют текущие типы данных. Это обеспечивает обратную совместимость формата шифрованного файла /etc/postgres/enc_connection_settings.cfg (владелец: kmadmin_pg, группа: kmadmin_pg, права: -rw-r--r--). Процесс добавления новых параметров не меняется.
Редактирование параметров для работы с хранилищем секретов#
В утилиту setup_kms_credentials добавляется новый режим, позволяющий редактировать параметры для работы с хранилищем секретов в существующих записях. Администратор безопасности запускает утилиту setup_kms_credentials в режиме редактирования параметров. Если хранилище содержит более одной записи, то необходимо указать, какую запись требуется обновить (список записей можно получить в режиме просмотра). После чего поочередно вводятся обновленные параметры. Если пропустить обновление параметра, то он сохраняет предыдущее значение.
Просмотр сохраненных параметров для работы с хранилищем секретов#
В утилиту setup_kms_credentials добавляется новый режим, позволяющий просматривать сохраненные параметры для работы с хранилищем секретов. Администратор безопасности запускает утилиту setup_kms_credentials в режиме просмотра параметров и получает список сохраненных параметров (за исключением паролей).
По умолчанию в режиме просмотра происходит проверка сохраненных параметров подключения к хранилищу секретов. Проверяются только параметры подключения к Хранилищу секретов. Параметры доступа к секретам в данном режиме не проверяются. Чтобы отключить проверку параметров в режиме просмотра, необходимо указать ключ --no-check.
Если в режиме проверки параметров указать ключ --debug, то утилита дополнительно выведет в лог информацию о взаимодействии с Хранилищем секретов (URL запроса, HTTP-код ответа и т.п.).
Очистка хранилища параметров подключения#
В утилиту setup_kms_credentials добавляется новый режим, позволяющий удалять записи с параметрами для работы с хранилищем секретов. Для удаления записи необходимо указать ее номер (список записей можно получить в режиме просмотра).
Настройка параметров для работы с хранилищем сертификатов#
В утилиту setup_kms_credentials добавляется аргумент --purpose, позволяющий настраивать параметры для работы с хранилищем сертификатов. Аргумент может принимать следующие значения:
secrets- настройка параметров для работы с хранилищем секретов. Параметры хранятся в шифрованном файле/etc/postgres/enc_connection_settings.cfg(владелец:kmadmin_pg, группа:kmadmin_pg, права:-rw-r--r--);certs- настройка параметров для работы с хранилищем сертификатов. Параметры хранятся в шифрованном файле/etc/postgres/enc_connection_settings_cert.cfg(владелец:kmadmin_pg, группа:kmadmin_pg, права:-rw-r--r--).
Аргумент --purpose возможно указывать во всех режимах работы утилиты setup_kms_credentials. Если аргумент не указан, то утилита производит настройку параметров для работы с Хранилищем секретов.
Указание параметров для работы с хранилищем секретов через аргументы командной строки#
В утилиту setup_kms_credentials добавлена возможность передачи параметров (кроме пароля и идентификатора секрета) через аргументы командной строки. Пароль или идентификатор секрета задаются в интерактивном режиме или через перенаправление потока ввода.
Режим позволяет упростить использование утилиты в автоматизированных скриптах.
Настройка проверки серверного сертификата хранилища секретов#
При взаимодействии с хранилищем секретов по протоколу HTTPS происходит проверка серверного сертификата. Проверка осуществляется на основании корневого сертификата, путь к которому задается с помощью директории или файла в утилите setup_kms_credentials. Если не задавать путь к корневому сертификату, то его поиск будет осуществляться в системной директории с сертификатами.
Функция check\kms_is_on() (проверка доступности плагина взаимодействия с KMS);#
Специальная проверка, которая показывает, получилось ли выбрать такие значения из файла enc_connection_settions.cfg, содержащего варианты подключения к Хранилищу секретов.
Функция проверяет, что плагин взаимодействия с KMS:
найден, доступен и подключен к КМС;
содержит в себе все функции API
sKmsConnectionInitialized.
Пример использования:
SELECT check_kms_is_on();
Отключение функциональности#
Настройка параметров подключения производится при первоначальной настройке кластера Pangolin или при изменении настроек хранилища секретов (или сертификатов). Специальные команды для отключения функциональности отсутствуют.
Утилита setup_kms_credentials#
Утилита setup_kms_credentials позволяет:
добавить одну или несколько записей. Разделитель «,»;
редактировать, удалять и проверять параметры подключения к хранилищам секретов и сертификатов.
Для вывода доступных режимов работы setup_kms_credentials необходимо выполнить:
setup_kms_credentials --help
Usage:
setup_kms_credentials [mode] <option>...
Options:
--purpose [-s] выбор типа хранилища: certs - хранилище сертификатов или secrets - хранилище секретов, значение по умолчанию: secrets
--format [-f] Формат вывода: table или json, по умолчанию table - человекочитаемый формат
--cluster [-c] имя кластера
--host [-h] доменное имя или ip адрес хранилища
--port [-p] номер порта хранилища
--protocol [-l] протокол обмена данными: http (1) или https (2), протокол по умолчанию: https
--prefix [-x] путь к хранилищу секретов на сервере (префикс для пути хранения секретов, по умолчанию: kv)
--suffix [-u] часть пути к секрету на сервере (по умолчанию: пусто)
--namespace [-n] тенант хранилища, по умолчанию: пусто
--type [-t] тип авторизации: Userpass Auth Method (1) или AppRole Auth Method (2)
--auth [-a] точка входа для аутентификации, по умолчанию: userpass
--id [-i] логин или id роли
--root-ca [-r] файл или директория, содержащая корневой сертификат для проверки хранилища секретов/сертификатов
--skip-confirm редактирование или удаление без подтверждения
--index индекс записи для режимов редактирования/удаления
--plain простой вывод
--no-check не проверять подключение
--debug показать информацию о взаимодействии с Хранилищем
--help эта страница помощи
Modes:
setup - ввести новый набор данных для хранилища (хранилищ) секретов или сертификатов, поведение по умолчанию
show - показать текущий набор параметров подключений к хранилищам секретов/сертификатов (без паролей и id секретов)
add - добавить новую запись в набор параметров подключений к хранилищам секретов/сертификатов
delete - удалить запись из набора параметров подключений к хранилищам секретов/сертификатов по номеру записи
edit - редактировать запись из набора параметров подключений к хранилищам секретов/сертификатов по номеру записи
Pangolin product version information:
--product_version показать название продукта и версию
--product_build_info показать номер сборки, дату сборки и хеш
--product_component_hash показать хеш компонента
Для работы с хранилищем сертификатов, при вызове setup_kms_credentials необходимо указывать аргумент --purpose=certs.
Примечание:
С версии 5.4.0 отсутствует обратная совместимость обновления по параметру
suffix.
Интерактивный режим добавления параметров#
/usr/pangolin-5.4.0/bin/setup_kms_credentials --purpose=certs add
Enter IP address or Domain Name of Secrets storage:
<IP-адрес>
Enter port:
<PID>
Choose protocol type or leave empty to use default (https):
1. http
2. https
1
Enter secrets prefix or leave empty to use default (kv):
<Префикс>
Enter Secrets storage namespace or leave empty:
CI00000000_CI00000000
Choose credentials type:
1. Userpass Auth Method
2. AppRole Auth Method
1
Enter auth point or leave empty to use default (userpass):
userpass
Enter login:
adminencryption
Enter password:
********
Confirm password:
********
Credentials for Secrets storage has been added successfully
Режим добавления параметров через аргументы командной строки#
/usr/pangolin-5.2.1/bin/setup_kms_credentials --purpose=certs add -c test -h <IP-адрес> -p <PID> -l 2 -x <Префикс> -n CI00000000_CI00000000 -t 1 -a userpassTest -i adminencryption -r /pg_ssl
Enter password:
********
Confirm password:
********
Credentials for Secrets storage has been added successfully
Режим добавления множественных параметров через аргументы командной строки#
Пример команды добавления нескольких записей одной командой:
./setup_kms_credentials setup --cluster test --host <hostname>,<hostname> --port <порт>,<порт> -r /pg_ssl -u
Press Ctrl+C to exit
Choose credentials type:
1. Userpass Auth Method
2. AppRole Auth Method
1
Enter login:
qewr
Enter password:
****
Confirm password:
****
Credentials for Secret storage has been set successfully
Enter login:
qwer
Enter password:
****
Confirm password:
****
Credentials for Secret storage has been added successfully
Режим просмотра добавленных параметров подключения#
Пример команды просмотра записей в человекочитаемом формате:
/usr/pangolin-5.2.1/bin/setup_kms_credentials --purpose=certs show
Pangolin cluster ID: test
Root CA path: /pg_ssl
+-------------------------------------------------------------------------------------------------------------------------------------------+
| # | protocol | host | port | prefix | namespace | cred type | auth point | id | status |
-----+----------+------------+-------+-----------+-----------------------+----------------------+------------+-----------------+-------------
| 0 | http | <IP-адрес> | <PID> | <Префикс> | CI00000000_CI00000000 | Userpass Auth Method | userpass | adminencryption | Ok |
| 1 | https | <IP-адрес> | <PID> | <Префикс> | CI00000000_CI00000000 | Userpass Auth Method | userpass | adminencryption | Ok |
+-------------------------------------------------------------------------------------------------------------------------------------------+
Режим просмотра добавленных параметров подключения в JSON#
Пример команды просмотра записей в JSON-формате:
./setup_kms_credentials show --format json
{
"cluster_id" : "test",
"credentials" :
[
{
"auth_point" : "userpass",
"host" : {IP-адрес},
"id" : "qewr",
"namespace" : "",
"port" : {Порт},
"prefix" : "kv",
"protocol" : "HTTPS",
"status" : "Storage error",
"type" : "USER_PASS"
},
{
"auth_point" : "userpass",
"host" : {IP-адрес},
"id" : "qwer",
"namespace" : "",
"port" : {Порт},
"prefix" : "kv",
"protocol" : "HTTPS",
"status" : "Storage error",
"type" : "USER_PASS"
}
],
"root_ca" : "/pg_ssl",
"suffix" : ""
}
Режим редактирования добавленных параметров подключения#
В режиме просмотра необходимо определить номер записи, которую следует отредактировать. Например, нужно отредактировать первую запись - изменить тенант хранилища. Передаем аргументом индекс записи: 1 и новый тенант хранилища CI00000001_CI00000001:
/usr/pangolin-5.2.1/bin/setup_kms_credentials --purpose=certs edit --index=1 --plain -n CI00000001_CI00000001
Enter password:
********
Confirm password:
********
+---------------------------------------------------------------------------------------------------------------------------------------+
| # | protocol | host | port | prefix | namespace | cred type | auth point | id | status |
-----+----------+------------+------+--------+-----------------------+----------------------+------------+-----------------+-------------
| 0 | http | <IP-адрес> | <PID> | <Префикс> | CI00000000_CI00000000 | Userpass Auth Method | userpass | adminencryption | N/A |
| 1 | https | <IP-адрес> | <PID> | <Префикс> | CI00000001_CI00000001 | Userpass Auth Method | userpass | adminencryption | N/A | <update data/password>
| 1 | https | <IP-адрес> | <PID> | <Префикс> | CI00000000_CI00000000 | Userpass Auth Method | userpass | adminencryption | N/A | <original>
+---------------------------------------------------------------------------------------------------------------------------------------+
Do you want to edit data? (yes/no)?:
yes
Credentials for Secrets storage has been edited successfully
Режим удаления добавленных параметров подключения#
В режиме просмотра необходимо определить номер записи, которую следует удалить. Например, нужно удалить нулевую запись.
/usr/pangolin-5.2.1/bin/setup_kms_credentials --purpose=certs delete --index=0 --plain
+---------------------------------------------------------------------------------------------------------------------------------------+
| # | protocol | host | port | prefix | namespace | cred type | auth point | id | status |
-----+----------+------------+------+--------+-----------------------+----------------------+------------+-----------------+-------------
| 0 | http | <IP-адрес> | <PID> | <Префикс> | CI00000000_CI00000000 | Userpass Auth Method | userpass | adminencryption | N/A | <delete>
| 1 | https | <IP-адрес> | <PID> | <Префикс> | CI00000001_CI00000001 | Userpass Auth Method | userpass | adminencryption | N/A |
+---------------------------------------------------------------------------------------------------------------------------------------+
Do you want to remove the record? (yes/no)?:
yes
Credentials for Secrets storage has been removed successfully
Архивирование и восстановление#
Для архивирования и восстановления в СУБД Pangolin используется система резервного копирования и репликации. Она включает в себя утилиты для резервного копирования и восстановления (например, pg_probackup), а также для потоковой и логической репликации.
Система резервного копирования Pangolin позволяет защитить данные от потери в случае отказа оборудования, ошибок оператора, ошибок приложений, проблем сервисных служб, а также используется для целей аудита.
Функции системы:
резервное копирование и восстановление данных Pangolin;
создание полной резервной копии по расписанию;
снятие резервных копий с любого сервера кластера высокой доступности;
возможность хранения метаданных на отдельном служебном сервере;
дедупликация;
восстановление состояния на определенный момент времени (в соответствии с политиками хранения копий);
обеспечение соответствия нефункциональным требованиям к системам уровня Mission critical.
В этом разделе рассматриваются следующие сценарии восстановления из резервной копии:
Полное восстановление кластера. Например, кластер полностью неработоспособен и требуется восстановление из последней резервной копии всего кластера.
Восстановление на определенный момент времени. Например, изменения в БД привели к сбою или потере данных. БД находится в рабочем состоянии, но требуется восстановление данных на определенный момент времени до сбоя. Также используется при миграции и для тестирования и аудита.
Создание резервного сервера. Например, в результате сбоя на предыдущем резервном сервере БД на нем оказывается недоступна, требуется восстановление из резервной копии.
В качестве сетевой централизованной системы хранения резервных копий используется служебная база данных (далее - «Каталог»). Интеграция с Каталогом позволяет выполнять резервное копирование экземпляров Pangolin и связанных с ними файлов журналов записи с опережением (файлы Write Ahead Log, WAL).
Резервное копирование файлов WAL обеспечивает целостность данных Pangolin. Такая резервная копия позволяет использовать таблицы базы данных во время сеанса без каких-либо ограничений.
Резервное копирование с ведомого сервера кластера производится в автоматизированном режиме с помощью клиентского приложения (Далее - «Агент»). Выполняется либо снятие полной резервной копии, либо архива файлов WAL, накопившихся со времени последней резервной копии.
Восстановление инициируется пользователем и предполагает ручное указание параметров восстановления. Pangolin потребуется учетная запись с правами на создание резервных копий: отдельная роль с минимальными правами, необходимыми для выбранной стратегии копирования. Управление функциями резервного копирования Pangolin выполняется специалистами по резервному копированию.
Поддержка резервного копирования настраивается в конфигурационном файле custom_file.yml через параметр SRC (резервная копия системы).
Резервное копирование#
Pangolin, как и все современные СУБД, поддерживает возможность резервного копирования для защиты данных от потери в случае отказа оборудования, ошибки администратора, ошибок приложений, проблем сервисных служб, а также для помощи при миграции данных на новые сервера. Начиная с версии Pangolin 4.1.0 добавлены улучшения, упрощающие мониторинг, управление и интеграцию с различными системами резервного копирования (СРК):
manage_backup.bin– вспомогательный python-скрипт, распространяемый в бинарном виде, который необходим для интеграции с различными СРК и управления процессом резервного копирования;pgse_backup– расширение, включающее набор представлений и процедур для организации и контроля мониторинга прохождения заданий резервного копирования;pg_probackup– утилита резервного копирования для подготовки и контроля архивов резервной копии.
Главные функции резервного копирования:
создание полной резервной копии данных;
резервное копирование файлов WAL (Write Ahead Log) для обеспечения целостности данных;
восстановление данных из резервной копии;
восстановление на определенный момент времени (Point-in-Time Recovery или PITR);
интеграция с системами резервного копирования.
Резервное копирование экземпляра СУБД Pangolin осуществляется python-скриптом manage_backup.bin.
Этот скрипт автоматизирует вызовы стандартных функций управления резервным копированием Pangolin: pg_start_backup, pg_stop_backup.
При запуске скрипта создается отдельный процесс с подключением к libpq. Одновременно может быть выполнено только одно резервное копирование. Если существует старый сеанс резервного копирования, новое резервное копирование не будет запущено. Ошибки могут быть обнаружены в журнале postgres и в файле backup_manager.log в каталоге (по умолчанию /pgarclogs/[pangolin_<major_version>]) резервного копирования pg_probackup.
Пример:
/usr/local/pgsql/postgres_venv/bin/python3 manage_backup.py --host 127.0.0.1 -p 5432 -U user -d db -B <path_to_label_dir> --session-id=<SESS> start
# copy data from $PGDATA...
/usr/local/pgsql/postgres_venv/bin/python3 manage_backup.py --host 127.0.0.1 -p 5432 -U user -d db -B <path_to_label_dir> --session-id=<SESS> stop
Резервное копирование журналов предзаписи (WAL) в режиме онлайн осуществляется с помощью утилиты pg_probackup. Таким образом обеспечивается целостность резервной копии и возможность восстановления данных на любой момент времени (Point-in-Time Recovery, PITR).
Такая резервная копия позволяет активно использовать таблицы базы данных во время сеанса без каких-либо ограничений в использовании. Также при использовании СРК присутствует возможность выбирать между интерактивным и запланированным резервным копированием. Снятие полной резервной копии или архива WAL (журналов, накопившихся со времени последней резервной копии) может производиться в автоматизированном режиме с помощью клиентского приложения (агента) СРК с ведомого сервера кластера. Восстановление происходит по запросу вследствие инцидента либо запланированных работ и предполагает ручное указание параметров восстановления.
Более подробно о работе pg_probackup можно ознакомиться на страницах официальной документации проекта.
Доступные типы резервного копирования#
Доступны следующие типы резервного копирования:
полная резервная копия (включает все базы данных в экземпляре Pangolin);
резервное копирование транзакций (включает только файлы WAL, заархивированные со времени предыдущего полного резервного копирования или резервного копирования транзакций. Данные резервной копии транзакции являются необходимыми для успешного восстановления кластера с применением непрерывного архивирования, поэтому цепочка архивированных WAL-файлов так же должна быть непрерывной. Для восстановления экземпляра сначала используется полная резервная копия и затем подается последовательность архивных WAL-файлов для применения на экземпляре, что позволяет восстановить копию на необходимый момент времени).
Создание полной резервной копии:
инициализация процесса создания резервной копии агентом СРК или вручную;
исполнение pre-exec-скриптов;
копирование файлов БД;
копирование архива WAL;
исполнение post-exec-скриптов;
завершение резервного копирования.
Восстановление данных#
Pangolin поддерживает различные способы восстановления данных.
Перед восстановлением данных необходимо определить следующие аспекты процесса восстановления:
Область действия:
Восстановление всего экземпляра – в таком случае восстановление производится отдельно на каждый сервер, после чего выполняется синхронизация с помощью Pangolin Manager.
Восстановление ведомого сервера – в таком случае восстановление происходит из резервной копии на последний возможный момент времени.
Расположение восстанавливаемых данных:
Исходное расположение.
Другой путь на исходном клиенте.
Другой клиент (на него тоже потребуется установить Pangolin).
Восстановление на определенный момент времени при условии наличия соответствующей цепочки восстановления (включая полный образ резервной копии и резервную копию соответствующих файлов WAL):
На время последней резервной копии транзакции (откат до последнего возможного состояния).
На определенный момент времени по выбору (восстановление на момент времени с повтором).
На момент выбранного успешного полного или резервного копирования транзакции.
На момент восстановления из резервной копии СУБД должна быть остановлена.
Более подробно с работой Pangolin Manager можно ознакомиться на страницах официальной документации проекта.
Мониторинг резервных копий#
Функциональность мониторинга резервных копий реализована через расширение pgse_backup.
При установке расширения создаются следующие объекты:
схема
backup;представления для отображения истории и контроля резервных копий
backup.data_history,backup.wal_history,backup.history;таблица для хранения настроек
backup.settings;типы данных
backup.data_history_row_type,backup.wal_history_row_type;функции для наполнения представлений
backup.read_data_history(),backup.read_wal_history(),backup.reset_history().
Для безопасного считывания файлов с историей (backup_state, wal_backup_state) используется функция Pangolin с атрибутом SECURITY DEFINER. Функция разрешает доступ к файлам с историей без прав суперпользователя, но в пределах строго фиксированного каталога, чтобы исключить доступ к чтению посторонних файлов. Директория, в которой хранятся файлы истории и предоставляется доступ через SECURITY DEFINER, задается через таблицу backup.settings. Данная таблица должна быть доступна только владельцу расширения (Администратору БД).
Информация в представлениях backup.data_history, backup.wal_history — результат работы функций backup.read_data_history и backup.read_wal_history. Данные функции через встроенную функцию PostgreSQL pg_read_file() читают файлы в формате json с историей резервного копирования, заполняемые утилитами manage_backup.bin и pg_probackup. Файлы с историей (backup_state, wal_backup_state) располагаются в каталоге резервного копирования (по умолчанию /pgarclogs/[pangolin_<major_version>] и указываются в таблице backup.settings).
postgres=# select * from backup.settings;
name | setting
------+---------------
dir | /pgarclogs/05
(1 row)
Итоговый результат сессии резервного копирования представляет собой сверку состояний из backup.data_history, backup.wal_history и доступен в backup.history, как на таблице ниже.
Состояние сессии DATA |
Состояние сессии WAL |
Итоговое состояние |
|---|---|---|
starting |
* |
starting |
started |
* |
started |
stopping |
* |
stopping |
failed |
* |
failed |
completed |
Хотя бы одна сессия WAL началась после окончания сессии DATA, включает в свой интервал stop_walfile и имеет состояние completed |
completed |
completed |
Хотя бы одна сессия WAL началась после окончания сессии DATA, включает в свой интервал stop_walfile и имеет состояние started |
wal_backup_started |
completed |
Не найдена ни одна подходящая сессия WAL |
waiting_for_wal_backup |
Ролевая модель#
Для интеграции с СРК может потребоваться выделенная роль для проведения процедуры резервного копирования со следующими разрешениями:
BEGIN;
CREATE ROLE BACKUP_USER WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO BACKUP_USER;
COMMIT;
Где:
BACKUP_USER – пользователь для возможности подключения к СУБД Pangolin со стороны СРК.
Копирование конфигурации СУБД Pangolin#
Под копирование конфигурации СУБД в Pangolin понимается копирование конфигурационных файлов, в зависимости от типа конфигурации.
Определить конфигурацию можно с помощью команды:
SHOW installer.cluster_type;
Ответ для standalone:
┌─────────────────────────────────┐
│ installer.cluster_type │
├─────────────────────────────────┤
│ standalone-postgresql-pgbouncer │
└─────────────────────────────────┘
(1 row)
Ответ для кластера:
┌────────────────────────────────┐
│ installer.cluster_type │
├────────────────────────────────┤
│ cluster-patroni-etcd-pgbouncer │
└────────────────────────────────┘
(1 row)
Файлы, подлежащие резервному копированию:
для PostgreSQL:
с Pangolin Manager:
/etc/pangolin-manager/postgres.yml;без Pangolin Manager:
$PGDATA/postgresql.confи$PGDATA/pg_hba.conf, где$PGDATA–/pgdata/06/data(для 6 версии Pangolin);
для Pangolin Pooler (pgbouncer):
конфигурационный файл:
/etc/pangolin-pooler/pangolin-pooler.ini;исполняемый файл (с версии Pangolin 6.1.2):
/opt/pangolin-pooler/bin/pangolin-pooler;
для DCS (etcd):
конфигурационный файл:
/etc/etcd/etcd.conf;
утилита перешифрования:
конфигурационный файл:
/etc/postgres/enc_util.cfg;исполняемый файл:
/opt/pangolin-common/bin/pg_auth_reencrypt;
в каталоге
/etc/postgres/:хранилище паролей (файл
enc_utils_auth_settings.cfg);файл с параметрами оборудования и сетевыми интерфейсами (файл
enc_params.cfg.postgresиenc_params.cfg.kmadmin_pg);настройки подключения к KMS (файл
enc_connection_settings.cfg);
для восстановления утилиты из резервной копии необходимо хранить набор файлов:
конфигурационный файл утилиты (
enc_util.cfg);файл с параметрами оборудования и сетевыми интерфейсами (
enc_params.cfg.postgresиenc_params.cfg.kmadmin_pg);файлы с зашифрованными параметрами подключения к БД (все что перечислено в конфигурационном файле утилиты
enc_util.cfg):/etc/postgres/enc_connection_settings.cfg;/etc/postgres/enc_connection_settings_cert.cfg;/etc/postgres/kms_static_params.cfg;/pg_ssl/intermediate/server.p12.cfg;/pg_ssl/intermediate/patroni_server.p12.cfg;/etc/postgres/enc_utils_auth_settings.cfg;/etc/pangolin-manager/postgres.yml;pg_hba.conf.
Архитектура#
Концептуальная архитектура Pangolin в части резервного копирования#
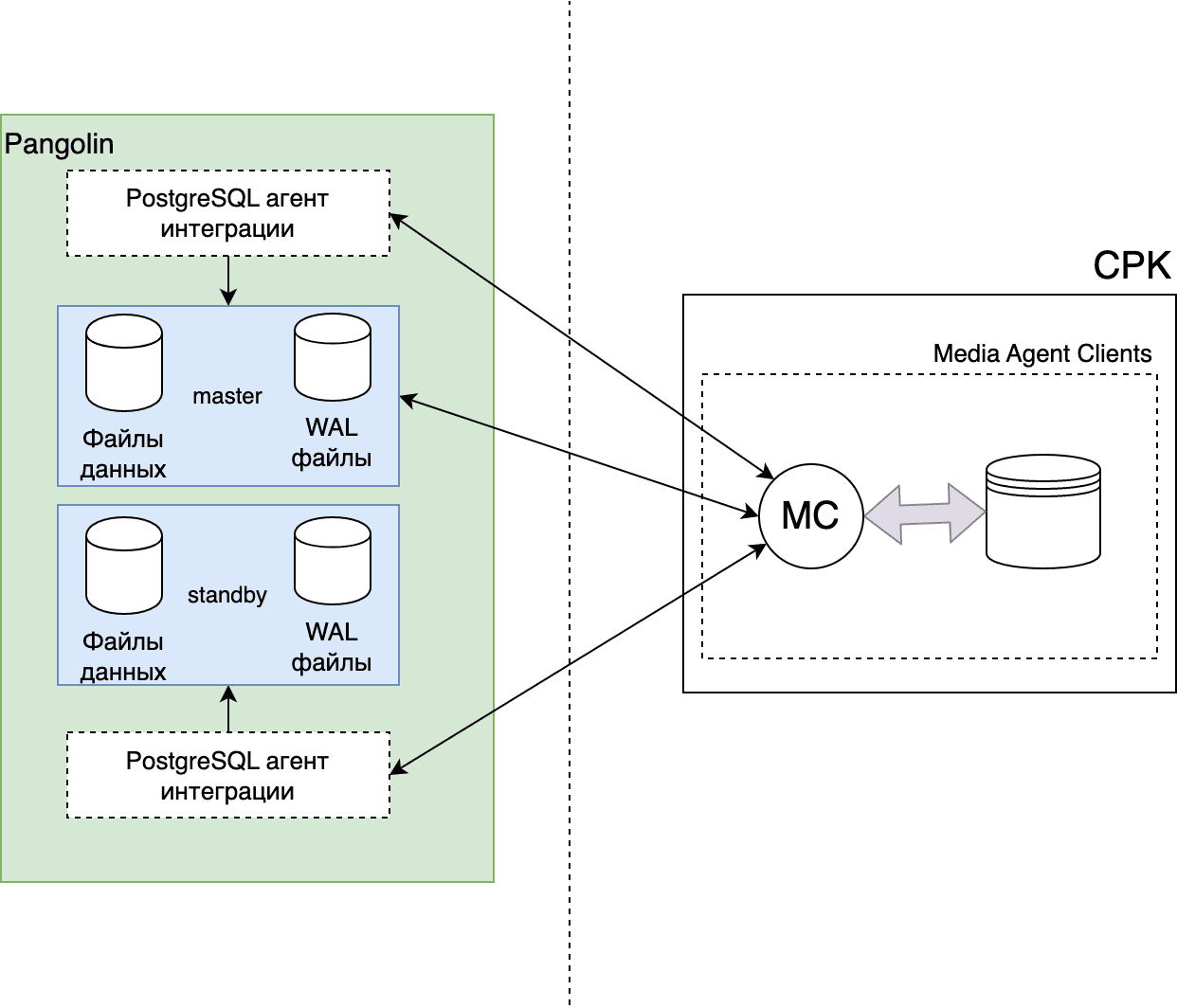
Схема процесса создания резервной копии Pangolin#

Табличное описание процесса#
Наименование шага |
Входной документ |
Описание |
Исполнитель |
Характер изменений |
Продолжительность |
Выходной документ |
ИТ-система |
Переход к шагу |
|---|---|---|---|---|---|---|---|---|
010 Инициация создания резервной копии |
Инициация создания резервной копии по расписанию либо вручную по запросу |
Инженер СРК или по расписанию |
В зависимости от размера БД |
СРК |
020 |
|||
020 Исполнение скрипта определяющего роль сервера |
Исполнение заранее заданного скрипта, определяющего роль сервера в кластере Pangolin и запускающего необходимую спецификацию копирования |
Автоматически |
СРК |
030 |
||||
030 Исполнение pre-exec скриптов |
Выполнение заранее заданных скриптов на целевом узле до создания резервной копии |
Автоматически |
Снятие резервной копии в локальный каталог резервных копий с помощью pg_probackup |
СРК Pangolin |
040 |
|||
040 Копирование файлов БД |
Копирует каталог Pangolin на серверы СРК, вносит информацию о резервной копии в Каталог |
Автоматически |
СРК |
050 |
||||
050 Копирование файлов WAL |
Копирование архива файлов WAL на серверы СРК |
Автоматически |
Резервная копия БД |
СРК |
060 |
|||
060 Исполнение post-exec скриптов |
Выполнение заранее заданных скриптов на целевом узле после завершения копирования резервной копии |
Автоматически |
Удаление локальной резервной копии с помощью pg_probackup |
СРК |
070 |
|||
070 Завершение резервного копирования |
Завершение резервного копирования |
Автоматически |
СРК |
Схема процесса восстановление Pangolin из резервной копии#

Табличное описание процесса#
Наименование шага |
Входной документ |
Описание |
Исполнитель |
Характер изменений |
ИТ-система |
Переход к шагу |
|---|---|---|---|---|---|---|
010 Инициация восстановления |
Запрос операции восстановления |
Инженер эксплуатации |
Service Manager |
020 или 025 |
||
020 Выбор экземпляра Pangolin и версии резервной копии для восстановления |
Выбор Pangolin для восстановления и версии резервной копии для восстановления |
Инженер СРК |
СРК |
030 |
||
025 Выбор КТС и версии резервной копии для восстановления |
Выбор КТС для восстановления и версии резервной копии для восстановления |
Инженер СРК |
СРК |
030 |
||
030 Проверка доступности носителей и устройств для восстановления |
Проверка доступности копий и данных для восстановления |
Автоматически |
СРК |
040 |
||
040 Установка параметров процесса восстановления |
Выбор допустимой нагрузки на сеть, а также уровня логирования при восстановлении |
Инженер СРК |
СРК |
050 или 060 |
||
050 Исполнение preexec скриптов |
Выполнение preexec-скриптов |
Автоматически |
При необходимости |
СРК |
060 |
|
060 Копирование файлов резервной копии на узел |
Копирование файлов резервной копии и архива WAL с серверов СРК на целевую систему в локальный каталог копий |
Автоматически |
СРК |
070 или 080 |
||
070 Исполнение postexec скриптов |
Выполнение postexec-скриптов |
Автоматически |
При необходимости |
СРК |
080 |
|
080 Запуск восстановления БД |
Использование восстановление из локального каталога копий с помощью pg_probackup |
Автоматически |
Pangolin |
090 или 100 или 110 |
||
090 Обновление ключа TDE |
Администратор БД производит следующие действия: |
Администратор БД |
Pangolin |
110 |
||
100 Настройка параметров recovery_conf в файла Pangolin Manager |
Настройка recovery_conf секции для успешного восстановления БД |
Администратор БД |
Pangolin |
110 |
||
110 Запуск Pangolin Manager |
Запуск службы Pangolin Manager |
Администратор БД |
Pangolin |
Администрирование#
Настройка#
Проверка установленного расширения и утилит#
Pangolin изначально поставляется со всеми необходимыми установленными расширениями и утилитами для организации резервного копирования.
Проверка наличия расширения pgse_backup :
postgres=# select * from pg_extension where extname = 'pgse_backup';
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+--------------------+----------+--------------+----------------+------------+---------------+--------------
16407 | pgse_backup | 10 | 16404 | f | 1.2 | |
(1 row)
Из вывода видно, что расширение pgse_backup (oid 16407) установлено и готово к использованию.
Внимание!
С Pangolin совместима только та утилита
pg_probackup, что идет в составе дистрибутива.
Проверка наличия утилиты pg_probackup:
$ which pg_probackup
/usr/pgsql-se-05/bin/pg_probackup
Утилита manage_backup.bin доступна в каталоге pg_backup инсталлятора и копируется в любое произвольное место на сервере с БД при интеграции Pangolin c СРК.
Настройка Pangolin для организации резервного копирования#
Установку и настройку необходимых для организации резервного копирования, расширения и утилит выполняет инсталлятор Pangolin в автоматическом режиме:
Устанавливается утилита
pg_probackup.Инициализируется локальный каталог резервных копий:
pg_probackup init -B $PGBACKUPОпределяется копируемый экземпляр (по умолчанию) резервных копий:
pg_probackup add-instance -B $PGBACKUP -D $PGDATA --instance <название экземпляра>Устанавливаются параметры БД:
wal_level = replica hot_standby = on full_pages_writes = on archive_mode = always archive_command = 'pg_probackup archive-push -B <локальный каталог копий> --instance <экземпляр> --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4' archive_timeout = 180Добавляются параметры работы
pg_probackup:pg_probackup set-config -B $PGBACKUP -D $PGDATA --instance <название экземпляра> -d <имя_базы> -h <локальный сервер> -p <локальный порт> -U <имя_пользователя>
Интеграция с системой мониторинга#
В системе мониторинга используются следующие метрики:
Метрика |
Запрос |
Описание |
|---|---|---|
backup completed count |
|
Возвращает количество успешных резервных копий за последние 24 часа |
backup failed count |
|
Возвращает количество неуспешных резервных копий за последние 24 часа |
backup wal failed count |
|
Возвращает количество неуспешных резервных копий WAL-сессий за последние 24 часа |
Если резервная копия снята успешно, то значение backup completed count будет больше 0, а значение backup wal failed count равно 0.
Состояние резервной копии на каждом экземпляре БД свое, поэтому при мониторинге необходимо опросить все узлы кластера, чтобы гарантировано получить самую последнюю резервную копию.
Управление#
Интерфейс просмотра истории резервных копий (РК)#
Просмотр истории полного цикла РК#
Для просмотра истории полного цикла РК создано специальное представление backup.data_history.
backup.data_history берет информацию из локального файла $PGBACKUP/backup_state и выводит его содержимое в виде таблицы:
postgres=# select * from backup.data_history;
session_id | state | tli | start_time | start_lsn | stop_time | stop_lsn | duration | stop_walfile
------------+-----------+-----+------------------------+------------+------------------------+------------+----------+--------------------------
FULL-16 | completed | 54 | 2020-11-13 01:52:22+03 | 4/5A000060 | 2020-11-13 01:52:31+03 | 4/5D000060 | 00:00:09 | {wal-file-хеш}
FULL-16 | completed | 54 | 2020-11-13 01:53:05+03 | 4/5A000060 | 2020-11-13 01:53:11+03 | 4/5E000060 | 00:00:06 | {wal-file-хеш}
Где:
session_id- id сессии;state- состояние сессии;tli- timeline снятой копии;start_time- начало выполнения сессии;start_lsn- позиция WAL-сегмента при переходе БД в режим снятия РК;stop_time- конец выполнения сессии;stop_lsn- позиция WAL-сегмента при выходе БД из режима снятия РК;duration- длительность сессии (end_time-start_time);stop_walfile- конечный WAL-архив.
Просмотр истории РК промежуточных WAL#
Для просмотра истории резервных копий промежуточных WAL создано специальное представление backup.wal_history:
postgres=# select * from backup.wal_history ;
session_id | state | start_time | stop_time | duration | info
------------+-----------+------------------------+------------------------+----------------
WAL-5 | completed | 2020-11-09 16:11:02+03 | 2020-11-09 16:11:04+03 | 00:00:02 | [{"tli": 40, "parent_tli": 0, "switchpoint": "0/0", "min_segn
o": {wal-file-хеш}, "max_segno": {wal-file-хеш}, "n_segments": 11, "size": 955436, "zratio": 193.16, "status": "ok", "lost_s
egments": []}]
Где:
session_id- id сессии СРК;state- состояние сессии;start_time- начало выполнения сессии;stop_time- конец выполнения сессии;duration- длительность сессии (end_time-start_time);info- информация о хранящихся на диске архивах WAL (собирается на старте копирования с помощьюpg_probackup).
В поле info помещается номер стартового и конечного архивов WAL. Если на диске отсутствуют промежуточные архивы — будет выведена ошибка, и в поле info.lost_segments будут записаны потерянные файлы.
Для мониторинга связанных сессий PGDATA и WAL используется представление backup.history. Оно учитывает представления backup.data_history и backup.wal_history. Состояние completed выставляется только тогда, когда для сессии PGDATA существует успешно завершенная сессия WAL, скопировавшая необходимый архив WAL (поле data_history.stop_walfile).
postgres=# select * from backup.history ;
session_id | state | tli | start_time | start_lsn | stop_time | stop_lsn | duration
------------+------------------------+-----+------------------------+------------+------------------------+------------+----------
FULL-5 | completed | 40 | 2020-11-09 16:36:09+03 | 2/50000028 | 2020-11-09 16:46:59+03 | 2/5103C430 | 00:10:50
FULL-5 | completed | 40 | 2020-11-09 16:47:01+03 | 2/53000028 | 2020-11-09 16:47:36+03 | 2/53000108 | 00:00:35
Автоматическая очистка истории старых резервных копий#
В файле backup_state хранится состояние нескольких резервных копий (по умолчанию последние 6).
Размер хранимой истории задается параметром утилиты manage_backup.bin: --rotate-history N - количество успешных (completed) резервных копий, хранимых в истории (0 - история не удаляется).
История сессий WAL удаляется автоматически, удаляются все записи старше самой старой сессии полного резервного копирования. Таким образом, история содержит все сессии WAL, связанные с текущими сессиями полного копирования.
Ручная очистка истории резервных копий#
Если файлы с историей резервных копий содержат данные в некорректном формате (например, в результате проблем с дисками), представления backup.*_history не смогут их прочитать. В таком случае будет выведена ошибка:
postgres=# select * from backup.history;
ERROR: invalid input syntax for type json
DETAIL: history file "/pgarclogs/05/backup_state" might be corrupted
HINT: you may need to clean up all backup history with "SELECT backup.reset_history()" CONTEXT: PL/pgSQL function backup.read_data_history() line 18 at RAISE
В случае возникновения этой ошибки можно воспользоваться механизмом ручной очистки истории. Для ручной очистки истории предусмотрена функция backup.reset_history(), доступная только администраторам БД:
postgres=# select backup.reset_history();
reset_history
---------------
(1 row)
После выполнения будут очищены сессии DATA и WAL. Также можно вручную удалить файлы /pgarclogs/05/backup_state и /pgarclogs/05/wal_backup_state или дождаться очередной сессии (DATA/WAL), которая сама очистит некорректные файлы.
Даже если файлы испорчены, сам процесс резервного копирования будет происходить без ошибок. В начале сессии испорченный файл перезапишется автоматически. Состояние старых резервных копий хранится в журнале /pgarclogs/05/backup_manager.log.
Если файлов backup_state и wal_backup_state не существует, соответствующие представления выполнятся без ошибок и вернут пустые наборы строк.
Утилита manage_backup.bin#
Утилита имеет следующие ключи:
usage: manage_backup.bin [-h] -B label_dir --host host -p port -d database -U
user [--password password] [--session-timeout sec]
[--start-timeout sec] [--stop-timeout sec]
[--patroni-host patroni_host]
[--patroni-port patroni_port]
[--rotate-history rotate_history] --session-id
session_id
action
Устранение неисправностей#
Ошибки, возникающие в процессе копирования, заносятся в журнал Pangolin, в приложение backup_session и в файл backup_manager.log в каталоге резервного копирования.
При нештатном прерывании процедуры резервного копирования (например, при отключении сервера) может возникнуть ситуация, при которой незавершенная копия останется в промежуточном состоянии. Такая процедура считается неуспешной (эквивалентной failed). В начале следующей сессии резервного копирования такие зависшие состояния будут автоматически переведены в failed.
Сообщения системного журнала опционально в формате вывода поддерживаемом функциональностью.
Безопасность#
Для проведения процедуры резервного копирования в Pangolin существует выделенная роль со следующими разрешениями:
BEGIN;
CREATE ROLE BACKUP_USER WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO BACKUP_USER;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO BACKUP_USER;
COMMIT;
Где:
BACKUP_USER - пользователь для возможности подключения к СУБД Pangolin со стороны СРК.
Роль BACKUP_USER имеет атрибут LOGIN, тем самым ей разрешена авторизация на сервере Pangolin. По умолчанию после инсталляции в конфигурационной секции pg_hba для роли BACKUP_USER определено правило: host all backup_user 0.0.0.0/0 scram-sha-256.
Пароль для этой роли задается при инсталляции с помощью переменной pg_backup_user_passwd в предустановочном конфигурационном файле custom_file_template.yml. Пароль должен удовлетворять парольной политике Pangolin. После инсталляции хеш пароля хранится в системной таблице pg_authid.
Для обеспечения безопасности критичных данных в резервных копиях в СУБД Pangolin используется прозрачное шифрование данных (TDE) (см. раздел «Прозрачное шифрование»). При включенном механизме шифруются данные, которые находятся в файлах данных, резервных копиях и временных файлах баз данных, а также данные, передаваемые по каналам связи в ходе физической и логической репликации.
Для шифрования сетевого трафика между клиентом и сервером в Pangolin встроена поддержка SSL, по умолчанию ssl = on.
Описание объектов#
Схемы#
CREATE SCHEMA backup;
Таблицы#
Имя столбца |
Тип |
Описание |
|---|---|---|
name |
text |
Поле, в котором содержится тип настройки (в данный момент он единственный и называется 'dir') |
setting |
text |
Путь к каталогу на файловой системе, где будут храниться архивы |
CREATE TABLE backup.settings(name text, setting text);
INSERT INTO backup.settings(name, setting) VALUES ('dir', '/pgarclogs/' ||
-- get major version (11, 12, ...)
(SELECT split_part((SELECT setting FROM pg_settings WHERE name = 'server_version'), '.', 1)));
Типы#
CREATE TYPE backup.data_history_row_type AS (
session_id text,
state text,
tli integer,
start_time text,
start_lsn text,
stop_time text,
stop_lsn text,
duration text,
stop_walfile text COLLATE "C"
);
CREATE TYPE backup.wal_history_row_type AS (
session_id text,
state text,
start_time text,
stop_time text,
duration text,
info json
);
Функции#
CREATE OR REPLACE FUNCTION backup.read_data_history()
RETURNS SETOF backup.data_history_row_type AS
$$
DECLARE
filename text;
json_data text;
BEGIN
filename := (SELECT setting FROM backup.settings WHERE name = 'dir') || '/backup_state';
json_data := replace(trim(pg_read_file(filename)), e'\n', '');
if (json_data = '') is not false then
return;
end if;
return QUERY SELECT * FROM json_populate_recordset(null::backup.data_history_row_type, json_data::json);
EXCEPTION
WHEN undefined_file THEN
return;
WHEN invalid_text_representation THEN
RAISE EXCEPTION '%', SQLERRM
USING DETAIL = format('history file "%s" might be corrupted', filename),
HINT = 'you may need to clean up all backup history with "SELECT backup.reset_history()"';
END;
$$
LANGUAGE plpgsql SECURITY DEFINER;
CREATE OR REPLACE FUNCTION backup.read_wal_history()
RETURNS SETOF backup.wal_history_row_type AS
$$
DECLARE
filename text;
json_data text;
BEGIN
filename := (SELECT setting FROM backup.settings WHERE name = 'dir') || '/wal_backup_state';
json_data := replace(trim(pg_read_file(filename)), e'\n', '');
if (json_data = '') is not false then
return;
end if;
return QUERY SELECT * FROM json_populate_recordset(null::backup.wal_history_row_type, json_data::json);
EXCEPTION
WHEN undefined_file THEN
return;
WHEN invalid_text_representation THEN
RAISE EXCEPTION '%', SQLERRM
USING DETAIL = format('history file "%s" might be corrupted', filename),
HINT = 'you may need to clean up all backup history with "SELECT backup.reset_history()"';
END;
$$
LANGUAGE plpgsql SECURITY DEFINER;
CREATE OR REPLACE FUNCTION backup.reset_history()
RETURNS void AS
$x$
DECLARE
dir text := (SELECT setting FROM backup.settings WHERE name = 'dir');
data_dir text := dir || '/backup_state';
wal_dir text := dir || '/wal_backup_state';
BEGIN
EXECUTE format('COPY (SELECT '''') TO %L', data_dir);
EXECUTE format('COPY (SELECT '''') TO %L', wal_dir);
END;
$x$
LANGUAGE plpgsql SECURITY DEFINER;
Представления#
Представление backup.data_history – просмотр истории полного цикла РК. Берет информацию из локального файла $PGBACKUP/backup_state и выводит его содержимое в виде таблицы.
Имя столбца |
Тип |
Описание |
|---|---|---|
session_id |
text |
Уникальный идентификатор сессии |
state |
text |
Состояние сессии |
tli |
integer |
Номер линии времени снятой копии |
start_time |
text |
Начало выполнения сессии |
start_lsn |
text |
Позиция WAL сегмента при переходе БД в режим снятия РК |
stop_time |
text |
Конец выполнения сессии |
stop_lsn |
text |
Позиция WAL сегмента при выходе БД из режима снятия РК |
duration |
text |
Длительность сессии (stop_time - start_time) |
stop_walfile |
text |
Конечный WAL архив |
CREATE VIEW backup.data_history AS
SELECT
s.session_id,
s.state,
s.tli,
TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as start_time,
s.start_lsn,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS') as stop_time,
s.stop_lsn,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS')
- TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as duration,
s.stop_walfile
FROM backup.read_data_history() AS s;
Представление backup.wal_history – для просмотра истории резервных копий (РК), промежуточных WAL.
Имя столбца |
Тип |
Описание |
|---|---|---|
session_id |
text |
Уникальный идентификатор сессии |
state |
text |
Состояние сессии |
start_time |
text |
Начало выполнения сессии |
stop_time |
text |
Конец выполнения сессии |
duration |
text |
Длительность сессии (stop_time - start_time) |
info |
json |
Информация о хранящихся на диске архивах WAL (собирается на старте копирования с помощью pg_probackup) В поле info помещается номер стартового и конечного архивов WAL. Если на диске отсутствуют промежуточные архивы — будет выведена ошибка, и в поле info.lost_segments будут записаны потерянные файлы |
CREATE VIEW backup.wal_history AS
SELECT
s.session_id,
s.state,
TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as start_time,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS') as stop_time,
TO_TIMESTAMP(s.stop_time, 'YYYY-MM-DD HH24:MI:SS')
- TO_TIMESTAMP(s.start_time, 'YYYY-MM-DD HH24:MI:SS') as duration,
s.info
FROM backup.read_wal_history() AS s;
Представление backup.history – для просмотра состояния резервных копий (РК).
Имя столбца |
Тип |
Описание |
|---|---|---|
session_id |
text |
Уникальный идентификатор сессии |
state |
text |
Состояние сессии |
tli |
integer |
Номер линии времени снятой копии |
start_time |
text |
Начало выполнения сессии |
start_lsn |
text |
Позиция WAL сегмента при переходе БД в режим снятия РК |
stop_time |
text |
Конец выполнения сессии |
stop_lsn |
text |
Позиция WAL сегмента при выходе БД из режима снятия РК |
duration |
text |
Длительность сессии (stop_time - start_time) |
CREATE VIEW backup.history AS
SELECT
d.session_id,
-- $PGDATA has been successfully backed up, look for a valid WAL backup
CASE WHEN d.state = 'completed' THEN
COALESCE(
-- WAL backup done successfully -> mark full backup record as 'completed'
(SELECT 'completed' FROM backup.wal_history w
WHERE
w.state = 'completed' AND
w.start_time >= d.stop_time AND
d.stop_walfile >= w.info -> d.tli::text ->> 'min_segno' AND
d.stop_walfile <= w.info -> d.tli::text ->> 'max_segno' LIMIT 1),
-- WAL backup has not been completed yet, but WAL session was started -> show this in our history
(SELECT 'wal_backup_started' FROM backup.wal_history w
WHERE
w.state = 'started' AND
w.start_time >= d.stop_time AND
d.stop_walfile >= w.info -> d.tli::text ->> 'min_segno'::text COLLATE "C" AND
d.stop_walfile <= w.info -> d.tli::text ->> 'max_segno'::text COLLATE "C" LIMIT 1),
-- WAL backup has not been started (or some WAL session failed) -> show that we are currently waiting for a session
'waiting_for_wal_backup')
ELSE d.state END as state,
d.tli,
d.start_time,
d.start_lsn,
d.stop_time,
d.stop_lsn,
d.duration
FROM backup.data_history d;
Развертывание на КТС#
Ниже перечислены операции, которые должны быть выполнены при развертывании на КТС, на которых будут располагаться БД. Данные действия выполняются в автоматическом режиме при развертывании инсталлятором.
Создайте директорию PGBACKUP:
/pgbackup/13.Установите
pg_probackup.Создайте локальный каталог резервных копий:
pg_probackup-13 init -B $PGBACKUP. В случае, если каталог не пустой, операция завершится с ошибкой, поэтому перед установкой каталог должен быть очищен.Определите копируемый экземпляр резервных копий:
pg_probackup-13 add-instance -B $PGBACKUP -D $PGDATA --instance <название экземпляра>.Установите параметры БД:
wal_level = replica hot_standby = on full_pages_writes = on archive_mode = always archive_command = 'pg_probackup-13 archive-push -B <локальный каталог копий> --instance <экземпляр> --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4' archive_timeout = 180Добавьте параметры работы
pg_probackup:pg_probackup-13 set-config -B $PGBACKUP -D $PGDATA --instance <название экземпляра> -d <имя_базы> -h <локальный сервер> -p <локальный порт> -U <имя_пользователя>.
Ролевая модель#
В силу особенностей работы Data Protector необходима выделенная роль для проведения процедуры резервного копирования со следующими разрешениями:
BEGIN;
CREATE ROLE masteromni WITH LOGIN;
GRANT USAGE ON SCHEMA pg_catalog TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.current_setting(text) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_is_in_recovery() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_start_backup(text, boolean, boolean) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_stop_backup(boolean, boolean) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_create_restore_point(text) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_switch_wal() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_last_wal_replay_lsn() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_current_snapshot() TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.txid_snapshot_xmax(txid_snapshot) TO masteromni;
GRANT EXECUTE ON FUNCTION pg_catalog.pg_control_checkpoint() TO masteromni;
COMMIT;
В файле pg_hba.conf необходимо разрешить подключение к кластеру баз данных пользователю с именем masteromni.
Восстановление БД из резервной копии#
Внимание!
Для восстановления необходима новая установка Pangolin, созданная вручную. При наличии доступа к изначальному кластеру, проверить, что полная резервная копия существует:
SELECT * FROM backup.history;
Внимание!
Ниже по тексту используются в качестве параметров
clusternameиnew_clustername. Это общие обозначения, которые необходимо заменить действительными. Получить их можно, например, командой:etcdctl ls /service
clustername- имя кластера на новом сервере,new_clustername- имя кластера для сервера, с которого снята резервная копия.system-
identifierдля файлаpg_probackup.confможно получить на сервере, с которого снята резервная копия командой (clusternameв данном случае нужно заменить на имя кластера):etcdctl get /service/clustername/initialize
Для восстановления БД кластера cluster-patroni-etcd-pgbouncer из резервной копии:
Остановите сервис Pangolin Manager сначала на реплике, потом на лидере:
sudo systemctl stop pangolin-managerОчистите каталоги
dataиtablespacesна реплике и лидере:rm -rf /pgdata/04/data rm -rf /pgdata/04/tablespacesОчистите хранилище etcd (
clusternameзамените на действительное имя кластера):etcdctl rm -r /service/clusternameИсправьте конфигурационный файл Pangolin Manager (
clusternameиnew_clusternameзамените на действительные лидера и реплику, добавьте секциюrecovery_confна лидере):scope: new_clustername … … … parameters: archive_mode: 'always' archive_command: '/usr/pgsql-se-04/bin/pg_probackup archive-push -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100' … … … wal_sync_method: 'fsync' work_mem: '16384kB' … … is_tde_on: 'off' recovery_conf: recovery_target_timeline: latest standby_mode: off restore_command: /usr/pgsql-se-04/bin/pg_probackup archive-get -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100 … … …Восстановите на новый сервер со старого каталоги
/pgarclogs/04,/pgdata/04/data,/pgdata/04/tablespaces.Скопируйте файл
/pgarclogs/04/backups/clustername/pg_probackup.confв/pgarclogs/04/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information pgdata = /pgdata/04/data system-identifier = 6855546122949875180 xlog-seg-size = 16777216 # Connection parameters pgdatabase = postgres pghost = {IP-адрес} pgport = {Порт} pguser = backup_userПримечание:
IP-адрес и порт (
pghostиpgport) указаны в качестве примера.Запустите сервис Pangolin Manager на лидере и убедитесь, что БД запущена и загружаются файлы журналов:
sudo systemctl start pangolin-manager less /pgerrorlogs/clustername/postgresql.logЗапустите сервис Pangolin Manager на реплике, дождитесь синхронизации и убедитесь, что кластер перешел в синхронный режим:
sudo systemctl start pangolin-manager patronictl -c /etc/pangolin-manager/postgresql.yml list
Восстановление типа инсталляции standalone-patroni-etcd-pgbouncer#
Остановите сервис Pangolin Manager:
sudo systemctl stop pangolin-managerОчистите каталоги
dataиtablespaces:rm -rf /pgdata/05/data rm -rf /pgdata/05/tablespacesОчистите хранилище etcd (
clusternameзамените на действительное имя кластера):etcdctl rm -r /service/clusternameИсправьте конфигурационный файл pangolin-manager (
clusternameиnew_clusternameзамените на действительные, добавьте секциюrecovery_conf):scope: new_clustername parameters: archive_mode: 'always' archive_command: '/usr/pgsql-se-04/bin/pg_probackup archive-push -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100' wal_sync_method: 'fsync' work_mem: '16384kB' is_tde_on: 'off' recovery_conf: standby_mode: off restore_command: /usr/pgsql-se-04/bin/pg_probackup archive-get -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100Восстановите на новый сервер со старого каталоги
/pgbackup/05,/pgdata/05/data,/pgdata/05/ts(ЗНО на СРК).Скопируйте файл
/pgbackup/04/backups/clustername/pg_probackup.confв/pgbackup/05/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information pgdata = /pgdata/04/data system-identifier = 6855546122949875180 xlog-seg-size = 16777216 # Connection parameters pgdatabase = postgres pghost = {IP-адрес} pgport = {Порт} pguser = backup_userЗапустите сервис Pangolin Manager и убедитесь, что БД запустилась и загружаются файлы журналов (в логах отсутствуют ошибки проигрывания WAL-файлов):
sudo systemctl start pangolin-manager less /pgerrorlogs/clustername/postgresql.log
Восстановление типа инсталляции standalone-postgresql-only или standalone-postgresql-pgbouncer#
Примечание:
Различий в восстановлении типов кластера standalone-postgresql-only и standalone-postgresql-pgbouncer нет.
Остановите сервис PostgreSQL :
sudo systemctl stop postgresql.serviceОчистите каталоги
dataиtablespaces:rm -rf /pgdata/05/data rm -rf /pgdata/05/tablespacesСоздайте конфигурационный файл
recovery.conf:recovery_target_timeline = 'latest' restore_command = '/usr/pgsql-se-04/bin/pg_probackup archive-get -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100'Восстановите на новый сервер со старых каталогов
/pgbackup/05,/pgdata/05/data,/pgdata/05/ts(ЗНО на СРК).Скопируйте файл
/pgbackup/04/backups/clustername/pg_probackup.confв/pgbackup/04/backups/new_clustername/pg_probackup.confи исправьте в немsystem-identifier(clusternameиnew_clusternameзамените на действительные имена кластеров):# Backup instance information pgdata = /pgdata/04/data system-identifier = 6855546122949875180 xlog-seg-size = 16777216 # Connection parameters pgdatabase = postgres pghost = {IP-адрес} pgport = {Порт} pguser = backup_userЗапустите сервис PostgreSQL, чтобы убедиться что БД запустилась, и загружаются файлы журналов (в логах отсутсвуют ошибки проигрывания WAL-файлов):
sudo systemctl start postgresql.service less /pgerrorlogs /clustername/postgresql.log
Восстановление сервера реплики из резервной копии#
Остановите сервис pangolin-manager на реплике:
sudo systemctl stop pangolin-managerОчистите каталоги
dataиtablespacesна реплике:rm -rf /pgdata/04/data rm -rf /pgdata/04/tablespacesИсправьте конфигурационный файл pangolin-manager (добавьте секцию
recovery_conf):parameters: archive_mode: 'always' archive_command: '/usr/pgsql-se-04/bin/pg_probackup archive-push -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f --compress --overwrite -j 4 --batch-size=100' wal_sync_method: 'fsync' work_mem: '16384kB' is_tde_on: 'off' recovery_conf: recovery_target_time: latest standby_mode: off restore_command: /usr/pgsql-se-04/bin/pg_probackup archive-get -B /pgarclogs/04 --instance new_clustername --wal-file-path=%p --wal-file-name=%f -j 4 --batch-size=100Внимание!
Вероятно, проигранных WAL-файлов будет недостаточно для того, чтобы догнать ведущий сервер, если нагрузка на ведущий сервер продолжает подаваться. Необходимо запросить внеочередное снятие резервной копии WAL-файлов ведущего сервера, а так же настроить синхронизацию директорий с помощью
lsyncd.Восстановите на новый сервер со старого каталоги
/pgbackup/05,/pgdata/05/data,/pgdata/05/ts(ЗНО на СРК).Запустите сервис pangolin-manager и убедитесь, что БД запустилась и загружаются файлы журналов, дождитесь синхронизации и убедитесь, что кластер перешел в синхронный режим:
sudo systemctl start pangolin-manager less /pgerrorlogs/clustername/postgresql.log
Шаблон параметров формирования SRC спецификаций для резервного копирования#
Ниже приведен пример шаблона параметров формирования SRC спецификаций для резервного копирования (файл datalist_serveraXserverb_RUN_PG_FULL.j2, где servera - имя мастера-сервера, serverb - имя реплицирующего сервера):
DATALIST "hostname-serveraXhostname-serverb_RUN_PG_FULL"`
GROUP "DININFRA"
DESCRIPTION "PostgreSQL_SE"
RECONNECT
DYNAMIC 1 1
POSTEXEC "patroni_session_run.sh" -on_host "{{ data_protector_host }}"
DEFAULTS
{
FILESYSTEM
{
-vss no_fallback
} -protect days 3
RAWDISK
{
}
}
DEVICE "{{ device }}"
{
}
FILESYSTEM "fqdn-servera" fqdn-serverb:"/"
{
-trees
"/etc/opt/omni/client/cell_server"
}
FILESYSTEM "fqdn-serverb" fqdn-serverb:"/"
{
-trees
"/etc/opt/omni/client/cell_server"
}
А также шаблон формирования расписания создания резервной копии (файл schedule_serveraXserverb_RUN_PG_FULL.j2, где servera - имя мастер-сервера, serverb - имя реплицирующего сервера):
-full
-every
-day
-at {{ (23,0,1,2) |random }}:{{ '%02d' | format( 59 | random | int )}}
Снятие резервной копии с реплики#
Функция резервного копирования позволяет снять с базы данных архивную копию, которую в дальнейшем можно использовать для восстановления. СУБД Pngolin поддерживает создание резервной копии как с лидера, так и с реплики.
Резервное копирование выполняется следующей командой:
PGPASSWORD={backup_pass} pg_probackup backup -B {PGBACKUP} --instance {cluster_name} -b FULL
Восстановление из резервной копии выполняется следующей командой:
pg_probackup restore -B {PGBACKUP} --instance {cluster_name} --recovery-target='latest
Процедуры резервного копирования на главном сервере и на копии принципиально идентичны.
Пересоздание узла арбитра#
В разделе рассматривается сценарий утраты узла арбитра. В такой ситуации необходимо восстановить только сбойный узел, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации#
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Примечание:
В примерах команд используются параметры для обозначения имен узлов вместо действительных значений.
Узел мастера обозначается параметрами: {{ master_host }} и {{ master_ip }}.
Узел реплики обозначается параметрами: {{ replica_host }} и {{ replica_ip }}.
Узел арбитра обозначается параметрами: {{ arbiter_host }} и {{ arbiter_ip }}.
Узел арбитра в сокращенной форме, используемый в etcd-командах: {{ arbiter_etcd_host }}.
Примечание:
В качестве пользователя с правами sudo используется параметр: {{ USER }}.
Директория с сертификатами обозначается параметром: {{ pg_ssl }}. Например,
pg_sslилиhome/postgres/ssl. Имя директории с сертификатами следует выбрать так же, как на мастере.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия#
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся узлам кластера Pangolin. Процедура может использоваться и для версий 6.х.х. Однако, следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Настройка репозиториев yum#
Действие выполняется на арбитре.
Для настройки репозиториев yum перенесите содержимое с аналогичных файлов на узле мастера или скопируйте сами файлы на узел арбитра и дайте такие же права:
sudo su - {{ USER }}
sudo vi /etc/yum.repos.d/D10.repo
sudo vi /etc/yum.repos.d/mirror.repo
sudo vi /etc/yum.repos.d/redhat.repo
Установка пакетов#
Действие выполняется на арбитре.
Для дальнейшей работы требуется установить ряд необходимых пакетов.
Заполните вспомогательный файл prereq.txt:
sudo su - {{ USER }}
vi /home/{{ USER }}/prereq.txt
Файл prereq.txt должен содержать следующий список пакетов:
openssl
rsync
sshpass
python3-pip
python36
python36-devel
python36-virtualenv
rsyslog
postgresql-libs
Выполните установку пакетов как в следующем примере:
sudo su - {{ USER }}
sudo yum install $(cat /home/{{ USER }}/prereq.txt)
Создание пользователя postgres#
Действие выполняется на арбитре.
Создайте пользователя postgres, если он отсутствует на узле арбитра:
sudo su - {{ USER }}
sudo useradd -m -G postgres postgres
Заполните /home/postgres/.bash_profile:
перенесите содержимое с мастера;
удалите все записи после строки
PATH=$PATH:$HOME/.local/bin:$HOME/bin;добавьте следующие записи в конец полученного файла:
export PATH
export CLNAME=clustername
export CLNAME=KSG
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
sudo chown postgres:postgres /home/postgres/.bash_profile
sudo chmod 700 /home/postgres/.bash_profile
Генерация сертификатов#
Перенесите root-сертификат с узла мастера на арбитр и сгенерируйте серверный сертификат на арбитре для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Создание директории с сертификатами#
Действие выполняется на арбитре.
Создайте директорию с сертификатами на узле арбитра:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/
sudo mkdir -p /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/
sudo chmod 0755 /{{ pg_ssl }}/
Копирование root во временную директорию на мастере#
Действие выполняется на мастере.
Скопируйте root во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
Перенос сертификатов на арбитр#
Действие выполняется на арбитре.
Перенесите сертификаты на арбитр:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
Удаление временной директории на мастере#
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата#
Действие выполняется на арбитре.
Заполните конфигурационный файл server.cnf подставьте актуальное имя узла и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ arbiter_host }}
IP = {{ arbiter_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ arbiter_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Настройка прав sudo#
Действие выполняется на арбитре.
Добавьте общие правила в /etc/sudoers (специфичные только для узла арбитра):
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Содержимое sudoers, необходимое для узла арбитра
postgres ALL=(ALL) NOPASSWD: /usr/bin/systemctl daemon-reload, /usr/bin/systemctl stop etcd, /usr/bin/systemctl start etcd, /usr/bin/systemctl restart etcd, /usr/bin/systemctl status etcd, /usr/bin/systemctl status etcd -l, /usr/bin/systemctl status etcd --no-pager --full, /usr/bin/systemctl enable etcd, /usr/bin/systemctl disable etcd, /bin/journalctl -u etcd
Перевод Pangolin Manager в режим паузы#
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка etcd#
Предварительная очистка#
Действие выполняется на арбитре.
Опционально можно выполнить очистку узла от предыдущих инсталляций, если это необходимо. Если виртуальная машина новая, то выполнять данное действие нет необходимости.
sudo su - {{ USER }}
sudo systemctl stop etcd
sudo yum remove etcd -y
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/etcd
sudo rm /etc/systemd/system/etcd.service
Конфигурирование файла службы#
Действие выполняется на арбитре.
Заполните файл службы. Информацию перенесите из аналогичного файла на узле мастере.
sudo su - {{ USER }}
sudo vi /etc/systemd/system/etcd.service
sudo chown postgres:postgres /etc/systemd/system/etcd.service
sudo chmod 640 /etc/systemd/system/etcd.service
Установка etcd#
Действие выполняется на арбитре.
Выполните установку etcd. Версия etcd должна совпадать с версией, установленной на мастере.
sudo su - {{ USER }}
sudo yum install etcd-3.3.11
Конфигурирование etcd#
Действие выполняется на арбитре.
Заполните конфигурационный файл etcd. Содержимое файла перенесите с узла мастера и откорректируйте значения следующих параметров для работы на узле арбитра:
ETCD_NAME
ETCD_ADVERTISE_CLIENT_URLS
ETCD_INITIAL_ADVERTISE_PEER_URLS
sudo su - {{ USER }}
sudo mkdir -p /etc/etcd
sudo chown postgres:postgres /etc/etcd
sudo chmod 700 /etc/etcd
sudo vi /etc/etcd/etcd.conf
sudo chown postgres:postgres /etc/etcd/etcd.conf
sudo chmod 700 /etc/etcd/etcd.conf
Создание рабочей директории#
Действие выполняется на арбитре.
Создайте рабочую директорию etcd:
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Настройка .bash_profile пользователя postgres#
Действие выполняется на арбитре.
Найдите в файле .bash_profile на узле мастера 4 строки с префиксом: alias members, alias elist, alias elog, alias health и добавьте их в конец аналогичного файла на арбитре. Откорректируйте имена узлов и IP-адреса на значения, соответствующие узлу арбитра:
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
Процедура 1. Мягкий способ без замены всех узлов.#
Внимание:
Процедура 1 применяется в следующих случаях:
в etcd не включена аутентификация (до версии Pangolin v.5.x.x);
известен пароль etcd-пользователя root.
В противном случае переходим к Процедуре 2 (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла арбитра», подраздел «Процедура 2. Способ с полной заменой всех узлов»), где производится полная замена всех узлов.
В соответствии с Процедурой 1 потерянный узел кластера удаляется и взамен него добавляется новый. Остановка всего кластера etcd не выполняется. При этом все настройки кластера, включая аутентификационные (если они есть), перенесутся на новый узел etcd. Таким образом, Процедура 1 предлагает более «мягкий» вариант конфигурирования кластера etcd после потери одного из узлов.
Особенности использования Процедуры 1 на реплике:
Процедура 1 может также использоваться для пересоздания утерянного узла реплики (не арбитра, как в данной статье).
В этом случае на реплике формируется новый (взамен утраченного) конфигурационный файл (Pangolin Manager) postgres.yml, в который вносится пароль служебного пользователя patronietcd, с помощью которого Pangolin Manager подключается к etcd. Пароль этого пользователя записывается в etcd при настройке в нем аутентификации и все еще продолжает храниться на уцелевших узлах etcd.
Однако, если в postgres.yml на мастере этот пароль хранится в зашифрованном виде, а сам пароль неизвестен, то нельзя взять пароль из postgres.yml на мастере и записать его в аналогичный файл на реплике. Это связано с тем, что зашифрованные пароли привязаны к конкретному узлу (там, где производилось шифрование). Расшифровать пароль нельзя. Поэтому в этом случае дополнительно потребуется сгенерировать новый пароль и заново описать пользователей в etcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подраздел «Процедура 2. Способ с полной заменой всех узлов», подраздел «Настройка аутентификации в etcd»).
Если же помнить пароли пользователей, их зашифрованные версии (каждого узла) или иметь резервную копию файла postgresql.yml утерянного узла реплики, то при работе с репликой достаточно выполнить только Процедуру 1. Дополнительные действия из подраздела «Настройка аутентификации в etcd» (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подраздел «Процедура 2. Способ с полной заменой всех узлов») не требуются.
Дополнительная возможность
Существует еще одна альтернатива удалению и добавлению узла etcd-кластера. Это использование команды Pangolin Manager: pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml remove. В этом случае удаляется вся DCS-информация о кластере, включая все узлы. Аутентификационные настройки etcd (и пользователи) сохраняются. Однако в этом случае также встает вопрос необходимости генерации нового пароля patronietcd, если зашифрованный ранее на реплике вариант неизвестен.
Первоначальная оценка состояния кластера#
Действие выполняется на мастере.
Выполните оценку состояния кластера:
sudo su - postgres
etcdctl cluster-health
Анализ состояния кластера:
Когда все узлы кластера функционируют и аутентификация не включена - можно наблюдать следующий результат:
$ etcdctl cluster-health
member {хеш} is healthy: got healthy result from http://{{ replica_host }}:{Порт}
member {хеш} is healthy: got healthy result from http://{{ arbiter_host }}:{Порт}
member {хеш} is healthy: got healthy result from http://{{ master_host }}:{Порт}
cluster is healthy
Когда узел арбитра не функционирует и аутентификация включена - можно наблюдать следующий результат команды проверки состояния кластера (описание параметра {{ root_pass }} можно найти в подразделе «Настройка аутентификации в etcd» (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подраздел «Процедура 2. Способ с полной заменой всех узлов»)):
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }},{{ replica_host }}:2379,{{ arbiter_host }}:2379 --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' endpoint health
{{ master_host }}:2379 is healthy: successfully committed proposal: took = 1.22267ms
{{ replica_host }}:2379 is healthy: successfully committed proposal: took = 1.477113ms
{{ arbiter_host }}:2379 is unhealthy: failed to connect: rpc error: code = Unavailable desc = grpc: the connection is unavailable
Error: unhealthy cluster
Идентификаторы узлов в случае, когда аутентификация включена, можно получить при помощи следующей команды:
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }} --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS |
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
| {хеш} | started | {{ master_host }} | https://{{ master_host }}:{Порт} | https://{{ master_host }}:{Порт}
|
| {хеш} | started | {{ replica_host }} | https://{{ replica_host }}:{Порт} | https://{{ replica_host }}:{Порт} |
| {хеш} | started | {{ arbiter_host }} | https://{{ arbiter_host }}:{Порт} | https://{{ arbiter_host }}:{Порт} |
+------------------+---------+--------------------+-----------------------------------+-----------------------------------+
Ошибки, получаемые во время анализа:
Результат (ошибочный) ниже можно наблюдать, если в etcd включена аутентификация, но в команде не указан пользователь root и его пароль. По нему можно оценить, что наблюдаются неявные признаки того, включена или нет аутентификация в etcd. Если пароль неизвестен, см. Процедуру 2 (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла арбитра», подраздел «Процедура 2. Способ с полной заменой всех узлов»).
Данный результат приведен для примера - на практике могут быть получены и другие варианты:
$ etcdctl cluster-health
cluster may be unhealthy: failed to list members
Error: client: etcd cluster is unavailable or misconfigured; error #0: net/http: HTTP/1.x transport connection broken: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
; error #1: dial tcp {IP-адрес}:{Порт}: connect: connection refused
error #0: net/http: HTTP/1.x transport connection broken: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
error #1: dial tcp {IP-адрес}:{Порт}: connect: connection refused
Удаление потерянного узла арбитра#
Действие выполняется на мастере.
Удалите из кластера узел арбитра, как в следующем примере. Если он существовал ранее и был утерян - информация о нем будет отображаться в результате команды cluster-health или member list.
В данном примере узел относится к узлу арбитра ('{{ arbiter_host }}') и аутентификация не включена:
sudo su - postgres
$ etcdctl member remove {хеш}
Removed member {хеш} from cluster
В данном примере приведен вариант команды и результат в случае, когда аутентификация включена:
sudo su - postgres
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:{Порт},{{ replica_host }}:{Порт},{{ arbiter_host }}:{Порт} --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' member remove {хеш}
Member a7f7ea42134ef0f7 removed from cluster {хеш}
Добавление нового узла арбитра#
Действие выполняется на мастере.
Добавьте новый узел кластера etcd. В команде указывается узел арбитра и порт 2380.
В данном примере приводится вариант команды и результат, когда аутентификация не включена:
sudo su - postgres
$ etcdctl member add {{ arbiter_etcd_host }} https://{{ arbiter_host }}:{Порт}
Added member named {{ arbiter_etcd_host }} with ID {хеш} to cluster
В данном примере приводится результат команды и результат, когда аутентификация включена:
sudo su - postgres
$ ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:{Порт},{{ replica_host }}:{Порт},{{ arbiter_host }}:{Порт} --cert=/{{ pg_ssl }}/client.crt --key=/{{ pg_ssl }}/client.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' member add {{ arbiter_etcd_host }} --peer-urls=https://{{ arbiter_host }}:{Порт}
Member {хеш} added to cluster {хеш}
...
Корректировка настроек etcd перед стартом#
Действие выполняется на арбитре.
В конфигурационном файле на узле арбитра установите параметр ETCD_INITIAL_CLUSTER_STATE в значение "existing":
Внимание:
Старт etcd на узле арбитра без параметра
ETCD_INITIAL_CLUSTER_STATE="existing"не будет успешным.
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
Старт etcd на узле арбитра#
Действие выполняется на арбитре.
Запустите службу etcd на узле арбитра:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
sudo systemctl status etcd
sudo etcdctl cluster-health
Корректировка настроек etcd после старта#
Действие выполняется на арбитре.
В конфигурационном файле на узле арбитра установите параметр ETCD_INITIAL_CLUSTER_STATE в значение "new". Затем произведите рестарт службы:
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
sudo systemctl restart etcd
Процедура 2. Способ с полной заменой всех узлов#
Внимание:
Процедура 2 выполняется, если не были выполнены шаги Процедуры 1 (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подраздел «Процедура 1. Мягкий способ без замены всех узлов»), то есть в случае, когда в etcd включена аутентификация и неизвестен etcd-пароль
root.Пункт 2.8.3 может выполняться независимо от выбора Процедуры в случае, если возникает необходимость переописать в etcd параметры аутентификации.
Пересоздание рабочих директорий#
Действие выполняется на всех узлах.
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (они будут заполнены впоследствии автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера#
Действие выполняется на всех узлах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd#
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Внимание:
Команды ниже соответствуют версии Pangolin 5.2.1.
Примечание:
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.
Примечание:
Пароль пользователя
patronietcdможно сгенерировать с помощью команды:openssl rand -base64 24.В примере в качестве пароля root использован параметр: {{ patronietcd_pass }}.
Затем пароль надо зашифровать (на узле мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для шифрования, запрашивает пароль и выдает его зашифрованный вид:pg_auth_password enc.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Корректировка паролей в Pangolin Manager#
Действие выполняется на мастере и реплике.
Так как в пункте 2.8.3 поменялся пароль пользователя patronietcd, необходимо обновить его в конфигурационных файлах Pangolin Manager на мастере и реплике:
Внимание:
Пароль, зашифрованный на мастере, должен быть указан в
postgres.ymlна мастере.Пароль, зашифрованный на реплике, должен быть указан в
postgres.ymlна реплике.
Заполните новые пароли в postgres.yml:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Актуализация настроек Pangolin Manager посредством рестарта#
Действие выполняется на мастере и реплике.
Актуализируйте новые файлы postgres.yml, содержащие новые пароли patronietcd:
sudo su - core_dev
sudo systemctl restart pangolin-manager
Перевод Pangolin Manager в рабочий режим#
Действие выполняется на мастере.
Выведите Pangolin Manager из режима паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Пересоздание узла реплики с использованием средств автоматической инсталляции#
В случае утраты узла реплики необходимо восстановить только сбойный узел, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации#
Примечание:
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Примечание:
В примерах команд используются параметры для обозначения имен узлов вместо действительных значений.
Узел мастера обозначается параметрами: {{ master_host }} и {{ master_ip }}. Например,
srv1.db.dev, {IP-адрес}.Узел реплики обозначается параметрами: {{ replica_host }} и {{ replica_ip }}. Например,
srv2.db.dev, {IP-адрес}.Узел арбитра обозначается параметрами: {{ arbiter_host }} и {{ arbiter_ip }}. Например,
srv3.db.dev, {IP-адрес}.
Примечание:
В качестве пользователя с правами sudo используется параметр: {{ USER }}. Например
core_dev.Директория с сертификатами обозначается параметром: {{ pg_ssl }}. Например,
pg_sslилиhome/postgres/ssl. Имя директории с сертификатами следует выбрать так же, как на мастере.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия#
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся узлам кластера Pangolin. Процедура может быть использована для различных версий Pangolin: 4.x.x - 5.x.x. Однако, следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Перевод Pangolin Manager в режим паузы#
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка Pangolin#
Действие выполняется на реплике.
Произведите установку Pangolin с помощью автоматических средств (например, Ansible или Jenkins). При установке выберите конфигурацию standalone, соответствующую целевому кластеру и содержащую такой же перечень компонентов Pangolin. Например, вместо cluster-patroni-etcd-pgbouncer следует выбрать standalone-patroni-etcd-pgbouncer. В процессе дальнейшей инициализации данный standalone-узел, установленный автоматически, будет включен в кластер.
Останов служб#
Действие выполняется на реплике.
Остановите службы на реплике:
sudo su - {{ USER }}
sudo systemctl stop pangolin-pooler
sudo systemctl stop pangolin-manager
sudo systemctl stop etcd
Генерация сертификатов#
В данном разделе выполняется генерация серверного сертификата и перенос клиентских сертификатов с мастера для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Очистка директории с сертификатами#
Действие выполняется на реплике.
Удалите все сертификаты на реплике:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/*
Копирование сертификатов во временную директорию на мастере#
Действие выполняется на мастере.
Скопируйте root и клиентские сертификаты во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.key /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.key
Перенос сертификатов на реплику#
Действие выполняется на реплике.
Перенесите сертификаты с мастера на реплику:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.key
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.crt
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.key
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
sudo chmod 644 /{{ pg_ssl }}/client.crt
sudo chmod 600 /{{ pg_ssl }}/client.key
sudo chmod 644 /{{ pg_ssl }}/etcd.crt
sudo chmod 600 /{{ pg_ssl }}/etcd.key
sudo chmod 644 /{{ pg_ssl }}/patroni.crt
sudo chmod 600 /{{ pg_ssl }}/patroni.key
sudo chmod 644 /{{ pg_ssl }}/patronietcd.crt
sudo chmod 600 /{{ pg_ssl }}/patronietcd.key
sudo chmod 644 /{{ pg_ssl }}/pgbouncer.crt
sudo chmod 600 /{{ pg_ssl }}/pgbouncer.key
Удаление временной директории на мастере#
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата#
Действие выполняется на реплике.
Заполните конфигурационный файл server.cnf, подставьте актуальное имя узла и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ replica_host }}
IP = {{ replica_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ replica_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Конфигурирование etcd#
Корректировка конфигурационного файла#
Действие выполняется на реплике.
Скорректируйте конфигурационный файл etcd. Значение ETCD_INITIAL_CLUSTER следует взять с мастера.
sudo su - {{ USER }}
sudo vi /etc/etcd/etcd.conf
Пересоздание рабочих директорий#
Действие выполняется на всех узлах.
Примечание: Если в etcd не включена аутентификация или известен пароль
root(внутренний пользователь etcd), можно удалить сбойный узел (member) из кластера etcd и добавить взамен него новый, не выключая весь кластер. В противном случае приходится пересоздавать узлы etcd полностью. Ниже приводится процедура полного пересоздания узлов etcd.Процедура включения в кластер отдельного узла описана в документе «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подразделе «Процедура 1. Мягкий способ без замены всех узлов».
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (они будут впоследствии заполнены автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера#
Действие выполняется на всех узлах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd#
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Примечание:
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.
Примечание:
Пароль пользователя
patronietcdможно сгенерировать с помощью команды:openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ patronietcd_pass }}.Затем пароль надо зашифровать (на узле мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для шифрования, запрашивает пароль и выдает его зашифрованный вид:pg_auth_password enc.
Примечание:
В командах ниже можно использовать либо серверный, либо клиентский сертификат
postgres.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Конфигурирование Pangolin Managers#
Настройка конфигурационных файлов#
Действие выполняется на мастере и реплике.
Отредактируйте конфигурационные файлы Pangolin Manager на мастере и реплике, выполнив действия ниже:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Выполните следующие действия:
обновите пароль
patronietcd, если он поменялся в пункте 2.4обновите пароль
patroniyml- для этого сгенерируйте и зашифруйте его так же, как и дляpatronietcdубедитесь в корректности значения пароля для
ldapbindpasswdи если есть необходимость сгенерируйте, зашифруйте и внесите его вpostgres.ymlв секциюpg_hbaи др (по-необходимости)
Внимание:
Пароль, зашифрованный на мастере, должен быть указан в
postgres.ymlна мастере.Пароль, зашифрованный на реплике, должен быть указан в
postgres.ymlна реплике.
Дополнительно на реплике выполните следующие действия:
измените название параметра
etcd.hostнаetcd.hosts, значение возьмите с мастера;добавьте параметры
bootstrap.synchronous_modeиbootstart.synchronous_mode_strictтак же, как на мастере;добавьте параметр
postgresql.callbacks.on_role_changeтак же, как на мастере;измените значение параметра
postgresql.parameters.installer.cluster_type, чтобы оно было таким же, как на мастере;приведите блок параметров
pg_hbaв соответствие с аналогичными параметрами на мастере (по умолчанию можно просто перенести все значения блока с мастера на реплику);при необходимости можно также произвести другие изменения.
Конфигурирование PostgreSQL#
Настройка директорий PostgreSQL#
Действие выполняется на реплике.
Пересоздайте директории PostgreSQL. Имена директорий следует скорректировать, если текущие названия на мастере отличаются от используемых в примере имен.
sudo su - {{ USER }}
sudo rm -rf /pgerrorlogs/05/
sudo rm -rf /pgdata/05/data/
sudo rm -rf /pgarclogs/05/
sudo rm -rf /pgdata/05/tablespaces/
sudo mkdir -p /pgerrorlogs/05
sudo chown postgres:postgres /pgerrorlogs/05
sudo chmod 0700 /pgerrorlogs/05
sudo mkdir -p /pgdata/05/data
sudo chown postgres:postgres /pgdata/05/data
sudo chmod 0700 /pgdata/05/data
sudo mkdir -p /pgarclogs/05
sudo chown postgres:postgres /pgarclogs/05
sudo chmod 0700 /pgarclogs/05
sudo mkdir -p /pgdata/05/tablespaces
sudo chown postgres:postgres /pgdata/05/tablespaces
sudo chmod 0700 /pgdata/05/tablespaces
sudo mkdir -p /etc/postgres
sudo chown postgres:postgres /etc/postgres
sudo chmod 0700 /etc/postgres
Настройка прав sudo#
Действие выполняется на реплике.
Скорректируйте содержимое /etc/sudoers - скопируйте содержимое с мастера или заполните в соответствии с конфигурацией:
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Внимание:
Файл
/etc/sudoers- очень чувствительный элемент. В случае наличия в нем синтаксической ошибки можно потерять права sudo.Чтобы проверить корректную работу sudo, можно выполнить переключение на другого пользователя, например:
sudo su - postgres.
Одним из вариантов актуализации /etc/sudoers является перенос файла с мастера целиком. Пример выполнения:
копирование файла во временную директорию на мастере (выполняется на стороне мастера):
sudo su - {{ USER }}
sudo cp /etc/sudoers /tmp/
sudo chown {{ USER }}:{{ USER }} /tmp/sudoers
копирование файла из временной директории мастера в целевую директорию на реплике (выполняется на стороне реплики):
sudo su - {{ USER }}
sudo scp {{ USER }}@{{ master_ip }}:/tmp/sudoers /tmp/
sudo chown root:root /tmp/sudoers
sudo cp /tmp/sudoers /etc/sudoers
sudo rm /tmp/sudoers
удаление временного файла на мастере (выполняется на стороне мастера):
sudo rm /tmp/sudoers
Настройка хранилища паролей для пользователя Pangolin Manager#
В данном разделе производится настройка хранилища паролей для пользователя patroni.
Если текущий пароль patroni неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль patroni известен - достаточно выполнить только пункт 4.3.2 на реплике.
Пароль, указывающийся с помощью параметра {{ patroni_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики с использованием средств автоматической инсталляции», подраздел «Настройка аутентификации в etcd»).
Начиная с версии 4.4.0 хранилище паролей (файл /etc/postgres/enc_utils_auth_settings.cfg) создается автоматически при установке Pangolin.
Пользователь patroni используется, как служебный пользователь кластера Pangolin, использующийся, в частности, для репликации (детали можно найти в /etc/pangolin-manager/postgres.yml).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "patroni" WITH ENCRYPTED PASSWORD '{{ patroni_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей (пароль запрашивается при выдаче команды pg_auth_config add):
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h localhost -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U patroni -d replication
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U patroni -d replication
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U patroni -d replication
pg_auth_config add -s -h localhost -p 5433 -U patroni -d postgres
pg_auth_config add -s -h localhost -p 5433 -U patroni -d replication
pg_auth_config add -s -h {{ master_host }} -p 5433 -U patroni -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U patroni -d replication
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U patroni -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U patroni -d replication
pg_auth_config show
Настройка хранилища паролей для пользователя backup_user#
В данном разделе производится настройка хранилища паролей для пользователя backup_user.
Если текущий пароль backup_user неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль backup_user известен - достаточно выполнить только пункт 4.4.2 на реплике.
Пароль, указывающийся с помощью параметра {{ backup_user_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики с использованием средств автоматической инсталляции», подраздел «Настройка аутентификации в etcd»).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "backup_user" WITH PASSWORD '{{ backup_user_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей:
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ master_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ replica_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h 127.0.0.1 -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ master_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ replica_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h localhost -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h 127.0.0.1 -p 5433 -U backup_user -d postgres
pg_auth_config show
Настройка хранилища паролей для пользователя profile_tuz#
В данном разделе производится настройка хранилища паролей для пользователя profile_tuz.
Если текущий пароль profile_tuz неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль profile_tuz известен - достаточно выполнить запись пароля в хранилище паролей на реплике.
Пароль, указывающийся с помощью параметра {{ profile_tuz_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики с использованием средств автоматической инсталляции», подраздел «Настройка аутентификации в etcd»).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "profile_tuz" WITH PASSWORD '{{ profile_tuz_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей:
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h localhost -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U profile_tuz -d "First_db"
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h localhost -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h localhost -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h {{ master_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config show
Установка пароля для пользователя kmadmin_pg#
Действие выполняется на мастере и реплике.
Если на мастере существует пользователь kmadmin_pg, то следует установить пароль на реплике соответственно:
sudo su - {{ USER }}
sudo passwd kmadmin_pg
Внимание:
Шаги подраздела «Конфигурирование PostgreSQL» выше (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики с использованием средств автоматической инсталляции») приведены для стандартной конфигурации Pangolin 5.1.0. Если на практике конфигурация действующего кластера отличается (есть дополнительная функциональность, пользователи, и тп), то недостающие действия должны также быть также выполнены на реплике для полного соответствия мастеру.
Запуск реплики#
Актуализация нового конфигурационного файла на мастере#
Действие выполняется на мастере.
Актуализируйте новый файл postgres.yml и выведите Pangolin Manager из режима паузы:
sudo su - {{ USER }}
sudo systemctl restart pangolin-manager
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Старт Pangolin Manager на реплике и восстановление базы данных#
Действие выполняется на реплике.
Запустите Pangolin Manager, который восстановит реплику в соответствии с bootstrap-логикой файла postgres.yml. В результате получится работающий кластер.
sudo su - {{ USER }}
sudo systemctl start pangolin-manager
Конфигурирование Pangolin Pooler#
Примечание:
Данный блок является опциональным и необходим в случае наличия компонента Pangolin Pooler.
Корректировка конфигурационных файлов#
Действие выполняется на реплике.
Скорректируйте конфигурационные файлы Pangolin Pooler, сравнивая их с аналогичными файлами на мастере:
sudo su - {{ USER }}
sudo vi /etc/pangolin-pooler/pangolin-pooler.ini
sudo vi /etc/pangolin-pooler/userlist.txt
sudo vi /etc/logrotate.d/pangolin-pooler
Запуск Pangolin Pooler#
Действие выполняется на мастере и реплике.
Перезапустите службу Pangolin Pooler:
sudo su - {{ USER }}
systemctl restart pangolin-pooler
Пересоздание узла реплики из дистрибутива#
Полностью утерян узел реплики. Необходимо восстановить только сбойный узел, а не весь кластер целиком. Для восстановления потребуется полностью новая виртуальная машина.
Процедура инициализации#
Примечание:
Для наглядности приведенных ниже действий и их последовательности в описываемой процедуре приводятся примеры команд. Допускается выполнение данных действий какими-либо другими средствами или командами, более удобными с точки зрения пользователя.
Примечание:
В примерах команд используются параметры для обозначения имен узлов вместо действительных значений.
Узел мастера обозначается параметрами: {{ master_host }} и {{ master_ip }}. Например,
srv1.db.dev, {IP-адрес}.Узел реплики обозначается параметрами: {{ replica_host }} и {{ replica_ip }}. Например,
srv2.db.dev, {IP-адрес}.Узел арбитра обозначается параметрами: {{ arbiter_host }} и {{ arbiter_ip }}. Например,
srv3.db.dev, {IP-адрес}.
Примечание:
В качестве пользователя с правами sudo используется параметр: {{ USER }}. Например
core_dev.Директория с сертификатами обозначается параметром: {{ pg_ssl }}. Например,
pg_sslилиhome/postgres/ssl. Имя директории с сертификатами следует выбрать так же, как на мастере.В качестве пользователя
nexus(репозиторий дистрибутивов) используется параметр: {{ nexus_login }}.
Примечание:
В случае необходимости конфигурации дополнительных компонентов, таких как RSYSLOG или SRC, следует обращаться к соответствующим материалам.
Подготовительные действия#
Для выполнения процедуры предполагается наличие новой виртуальной машины, на которой будет производиться инсталляция. Параметры виртуальной машины должны соответствовать сохранившимся узлам кластера Pangolin. Процедура может быть использована для различных версий Pangolin: 4.x.x - 5.x.x. Однако следует учитывать тот факт, что примеры команд и набор необходимых действий приводятся для версий Pangolin 5.1.0-5.2.0 и операционной системы Red Hat Enterprise Linux Server release 7.9. В других версиях могут отличаться имена файлов, директорий, набор компонентов, особенности конфигурации, влияющие на выбор того или иного формата команд, и др.
Скачивание дистрибутива#
Действие выполняется на реплике.
Скачайте дистрибутив. В качестве примера рассмотрим дистрибутив Pangolin 5.1.0. Версия дистрибутива должна совпадать с установленной на мастере версией.
sudo su - {{ USER }}
mkdir -p /tmp/pangolin_510
cd /tmp/pangolin_510
curl -O -u {{ nexus_login }} <URL>/Pangolin-D-05.001.00-40-distrib.tar.gz
tar -xvf /tmp/pangolin_510/Pangolin-D-05.001.00-40-distrib.tar.gz
Настройка репозиториев yum#
Действие выполняется на реплике.
Настройте репозитории yum. Для этого перенесите содержимое с аналогичных файлов на узле мастера или скопируйте сами файлы на узел арбитра и дайте такие же права.
sudo su - {{ USER }}
sudo vi /etc/yum.repos.d/D10.repo
sudo vi /etc/yum.repos.d/mirror.repo
sudo vi /etc/yum.repos.d/redhat.repo
Установка пакетов#
Действие выполняется на реплике.
Для дальнейшей работы требуется установить ряд необходимых пакетов.
Заполните вспомогательный файл prereq.txt:
sudo su - {{ USER }}
vi /home/{{ USER }}/prereq.txt
Файл prereq.txt должен содержать следующую информацию:
openssl
rsync
sshpass
python3-pip
python36
python36-devel
python36-virtualenv
rsyslog
postgresql-libs
Выполните установку пакетов как в следующем примере:
sudo su - {{ USER }}
sudo yum install $(cat /home/{{ USER }}/prereq.txt)
Создание пользователя postgres#
Действие выполняется на реплике.
Создайте пользователя postgres, если он отсутствует на узле реплики:
sudo su - {{ USER }}
sudo useradd -m -G postgres postgres
Заполните /home/postgres/.bash_profile - перенесите содержимое с мастера и скорректируйте имена узлов и IP-адреса для работы на узле реплики:
sudo su - {{ USER }}
sudo vi /home/postgres/.bash_profile
sudo chown postgres:postgres /home/postgres/.bash_profile
sudo chmod 700 /home/postgres/.bash_profile
Создание установочной директории PostgreSQL#
Действие выполняется на реплике.
Создайте установочную директорию PostgreSQL. Имя директории следует выбрать таким же, как на мастере:
Примечание:
В нашем примере (Pangolin 5.1.0) используется имя директории:
pgsql-se-05. В других версиях имя может быть иным.
sudo su - {{ USER }}
sudo mkdir -p /usr/pgsql-se-05/
sudo chown postgres:postgres /usr/pgsql-se-05/
sudo chmod 0700 /usr/pgsql-se-05/
Создание виртуального окружения PostgreSQL#
Действие выполняется на реплике.
Создайте виртуальное окружение PostgreSQL:
sudo su - postgres
virtualenv-3 /usr/pgsql-se-05/postgresql_venv --python=python3
Настройка вспомогательных файлов#
Действие выполняется на реплике.
Заполните вспомогательные файлы: packlist.txt и requirements.txt:
sudo su - postgres
vi /home/postgres/packlist.txt
mkdir -p /home/postgres/installer_cache_dir/python_packages
vi /home/postgres/installer_cache_dir/python_packages/requirements.txt
Содержимое файла packlist.txt:
PyYAML==5.3.1
netaddr==0.7.19
psycopg2-binary==2.8.4
flake8==3.7.9
ruamel.yaml==0.16.12
argparse==1.4.0
requests==2.23.0
python-daemon==2.2.4
pexpect==4.8.0
cryptography==3.3.1
ansible-core==2.11.5
Содержимое файла requirements.txt (также можно найти в дистрибутиве: '/tmp/pangolin_510/installer/roles/checkup/files/requirements.txt):
urllib3==1.25.9
PyYAML==5.3.1
six==1.15.0
kazoo==2.8.0
psycopg2-binary==2.8.4
flake8==3.7.9
python-dateutil==2.8.1
boto==2.49.0
requests==2.23.0
python-etcd==0.4.5
click==7.1.2
prettytable==0.7.2
psutil==5.7.3
cdiff==1.0
python-daemon==2.2.4
setuptools-rust==1.1.1
Настройка виртуального окружения PostgreSQL#
Действие выполняется на реплике.
Выполните установку необходимых в виртуальном окружении пакетов:
source /usr/pgsql-se-05/postgresql_venv/bin/activate
pip3 install --index-url=<URL> --trusted host=<host> --upgrade pip
pip3 install --index-url=<URL> -r /home/postgres/packlist.txt
pip download -r /home/postgres/installer_cache_dir/python_packages/requirements.txt --dest /home/postgres/installer_cache_dir/python_packages --only-binary :all
deactivate
Генерация сертификатов#
В данном разделе выполняется генерация серверного сертификата и перенес клиентских сертификатов с мастера для того, чтобы все сертификаты кластера были подписаны одним root-сертификатом.
Создание директории для сертификатов#
Действие выполняется на реплике.
Создайте директорию для сертификатов на реплике:
sudo su - {{ USER }}
sudo rm -rf /{{ pg_ssl }}/
sudo mkdir -p /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/
sudo chmod 0755 /{{ pg_ssl }}/
Копирование сертификатов во временную директорию на мастере#
Действие выполняется на мастере.
Скопируйте root и клиентские сертификаты во временную директорию на мастере:
sudo su - {{ USER }}
mkdir /tmp/{{ pg_ssl }}
sudo cp /{{ pg_ssl }}/root.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/root.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/client.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/etcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patroni.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/patronietcd.key /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.crt /tmp/{{ pg_ssl }}/
sudo cp /{{ pg_ssl }}/pgbouncer.key /tmp/{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/root.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/etcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patroni.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/patronietcd.key
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.crt
sudo chown {{ USER }}:{{ USER }} /tmp/{{ pg_ssl }}/pgbouncer.key
Перенос сертификатов на реплику#
Действие выполняется на реплике.
Перенесите сертификаты с мастера на реплику:
sudo su - {{ USER }}
sudo scp -r {{ USER }}@{{ master_ip }}:/tmp/{{ pg_ssl }}/* /{{ pg_ssl }}/
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/root.key
sudo chown postgres:postgres /{{ pg_ssl }}/root.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.crt
sudo chown postgres:postgres /{{ pg_ssl }}/client.key
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.crt
sudo chown {{ USER }}:{{ USER }} /{{ pg_ssl }}/etcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patroni.key
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.crt
sudo chown postgres:postgres /{{ pg_ssl }}/patronietcd.key
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.crt
sudo chown postgres:postgres /{{ pg_ssl }}/pgbouncer.key
sudo chmod 644 /{{ pg_ssl }}/root.crt
sudo chmod 600 /{{ pg_ssl }}/root.key
sudo chmod 644 /{{ pg_ssl }}/client.crt
sudo chmod 600 /{{ pg_ssl }}/client.key
sudo chmod 644 /{{ pg_ssl }}/etcd.crt
sudo chmod 600 /{{ pg_ssl }}/etcd.key
sudo chmod 644 /{{ pg_ssl }}/patroni.crt
sudo chmod 600 /{{ pg_ssl }}/patroni.key
sudo chmod 644 /{{ pg_ssl }}/patronietcd.crt
sudo chmod 600 /{{ pg_ssl }}/patronietcd.key
sudo chmod 644 /{{ pg_ssl }}/pgbouncer.crt
sudo chmod 600 /{{ pg_ssl }}/pgbouncer.key
Удаление временной директории на мастере#
Действие выполняется на мастере.
Удалите временную директорию на мастере:
sudo su - {{ USER }}
rm -rf /tmp/{{ pg_ssl }}
Генерация серверного сертификата#
Действие выполняется на реплике.
Заполните конфигурационный файл server.cnf, подставьте актуальное имя узла и IP-адрес в разделе [alt_names]:
sudo su - {{ USER }}
vi /{{ pg_ssl }}/server.cnf
Содержимое файла server.cnf:
[req]
req_extensions = v3_req
distinguished_name = req_distinguished_name
[req_distinguished_name]
[v3_req]
basicConstraints = CA:FALSE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
[ssl_client]
extendedKeyUsage = clientAuth, serverAuth
basicConstraints = CA:FALSE
subjectKeyIdentifier=hash
authorityKeyIdentifier=keyid,issuer
subjectAltName = @alt_names
[v3_ca]
basicConstraints = CA:TRUE
keyUsage = nonRepudiation, digitalSignature, keyEncipherment
subjectAltName = @alt_names
authorityKeyIdentifier=keyid:always,issuer
[alt_names]
DNS = {{ replica_host }}
IP = {{ replica_ip }}
Сгенерируйте серверный сертификат, подписывая его с помощью root:
sudo su - {{ USER }}
openssl req -new -nodes -text -out /{{ pg_ssl }}/server.csr -keyout /{{ pg_ssl }}/server.key -config /{{ pg_ssl }}/server.cnf -subj "/CN={{ replica_host }}"
openssl x509 -req -in /{{ pg_ssl }}/server.csr -text -days 365 -CA /{{ pg_ssl }}/root.crt -CAkey /{{ pg_ssl }}/root.key -CAcreateserial -extfile /{{ pg_ssl }}/server.cnf -extensions ssl_client -out /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.crt
sudo chown postgres:postgres /{{ pg_ssl }}/server.key
sudo chmod 644 /{{ pg_ssl }}/server.crt
sudo chmod 600 /{{ pg_ssl }}/server.key
sudo cp /{{ pg_ssl }}/root.crt /etc/pki/ca-trust/source/anchors/ && sudo update-ca-trust
Перевод Pangolin Manager в режим паузы#
Действие выполняется на мастере.
Переведите Pangolin Manager в режим паузы:
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml pause
Установка etcd#
Очистка узла от предыдущих инсталляций#
Действие выполняется на реплике.
Опционально можно выполнить очистку узла от предыдущих инсталляций, если это необходимо. Если виртуальная машина новая, то выполнять данное действие нет необходимости.
sudo su - {{ USER }}
sudo systemctl stop etcd
sudo yum remove etcd -y
sudo rm -rf /var/lib/etcd
sudo rm -rf /etc/etcd
sudo rm /etc/systemd/system/etcd.service
Конфигурирование файла службы#
Действие выполняется на реплике.
Заполните файл службы. Информацию в него перенесите из аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /etc/systemd/system/etcd.service
sudo chown postgres:postgres /etc/systemd/system/etcd.service
sudo chmod 640 /etc/systemd/system/etcd.service
Установка etcd#
Действие выполняется на реплике.
Выполните установку etcd. Версия должна быть такой же, как и на мастере.
sudo su - {{ USER }}
sudo yum install etcd-3.3.11
Конфигурирование etcd#
Действие выполняется на реплике.
Заполните конфигурационный файл etcd. Содержимое файла перенесите с мастера и скорректируйте значения параметров:
ETCD_NAME
ETCD_ADVERTISE_CLIENT_URLS
ETCD_INITIAL_ADVERTISE_PEER_URLS
sudo su - {{ USER }}
sudo mkdir -p /etc/etcd
sudo chown postgres:postgres /etc/etcd
sudo chmod 700 /etc/etcd
sudo vi /etc/etcd/etcd.conf
sudo chown postgres:postgres /etc/etcd/etcd.conf
sudo chmod 700 /etc/etcd/etcd.conf
Пересоздание рабочих директорий#
Действие выполняется на всех узлах.
Примечание:
Если в etcd не включена аутентификация или известен пароль root (внутренний пользователь etcd), то можно удалить сбойный узел (member) из кластера etcd и добавить взамен него новый, не выключая весь кластер. В противном случае приходится пересоздавать все узлы etcd полностью. Ниже приводится процедура полного пересоздания узлов etcd.
Процедура включения в кластер отдельного узла описана в документе «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», подразделе «Процедура 1. Мягкий способ без замены всех узлов».
Остановите службу etcd:
sudo su - {{ USER }}
sudo systemctl stop etcd
Пересоздайте рабочие директории etcd на каждом узле (впоследствии они будут заполнены автоматически во время первого старта):
sudo su - {{ USER }}
sudo rm -rf /var/lib/etcd
sudo mkdir -p /var/lib/etcd
sudo chown postgres:postgres /var/lib/etcd
sudo chmod 700 /var/lib/etcd
Старт etcd-кластера#
Действие выполняется на всех узлах.
Запустите службу etcd:
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start etcd
Настройка аутентификации в etcd#
Действие выполняется на мастере.
Опишите пользователей в etcd и включите аутентификацию:
Внимание:
Команды ниже соответствуют версии Pangolin 5.2.1.
Пользователь
rootявляется техническим и используется только во время данного конфигурирования. Его возможно запомнить и использовать в дальнейшем, но по умолчанию он не используется после инсталляции.Пароль можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ root_pass }}.
Пароль пользователя patronietcd можно сгенерировать с помощью команды:
openssl rand -base64 24.В примере в качестве пароля
rootиспользован параметр: {{ patronietcd_pass }}.Затем пароль надо зашифровать (на узле мастера и реплики), чтобы впоследствии поместить в
postgres.yml. Команда, используемая для шифрования пароля (пароль будет запрошен и выдан результат шифрования):pg_auth_password enc.
Примечание:
В командах ниже можно использовать либо серверный, либо клиентский сертификат
postgres.
sudo su - postgres
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' role add patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt role grant-permission patroni readwrite --prefix=true /service/
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user grant-role patronietcd patroni
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add root:'{{ root_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt user add patronietcd:'{{ patronietcd_pass }}'
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role add patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt role grant patroni -path '/service/*' -readwrite
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' user grant patronietcd -roles patroni
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' auth enable
ETCDCTL_API=2 etcdctl --endpoints https://{{ master_host }}:2379 --cert-file=/{{ pg_ssl }}/server.crt --key-file=/{{ pg_ssl }}/server.key --ca-file=/{{ pg_ssl }}/root.crt -u root:'{{ root_pass }}' role revoke guest -path '/*' --readwrite
ETCDCTL_API=3 etcdctl --endpoints={{ master_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key member list -w table
ETCDCTL_API=3 etcdctl --endpoints={{ replica_host }}:2379 --cert=/{{ pg_ssl }}/server.crt --key=/{{ pg_ssl }}/server.key --cacert=/{{ pg_ssl }}/root.crt --user=root:'{{ root_pass }}' user list
Установка Pangolin Manager#
Установка пакета pangolin-manager#
Действие выполняется на реплике.
sudo yum install pangolin-manager
Корректировка конфигурационного файла на мастере#
Действие выполняется на мастере.
Отредактируйте конфигурационный файл Pangolin Manager на мастере, выполнив действия ниже:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/postgres.yml
Выполните следующие действия:
обновите пароль
patronietcd, если он поменялся на шаге настройки аутентификации в etcd;обновите пароль
patroniyml- для этого сгенерируйте и зашифруйте его так же, как и дляpatronietcd;убедитесь в корректности значения пароля для
ldapbindpasswdи при необходимости сгенерируйте, зашифруйте и внесите его вpostgres.ymlв секциюpg_hba;при необходимости можно произвести другие изменения.
Внимание:
Пароль, зашифрованный на мастере, должен быть указан в
postgres.ymlна мастере.
Настройка конфигурационного файла на реплике#
Действие выполняется на реплике.
Заполните конфигурационный файл на реплике - перенесите в него содержимое с аналогичного файла на мастере и отредактируйте, выполнив действия ниже:
sudo su - {{ USER }}
sudo mkdir -p /etc/pangolin-manager
sudo chown postgres:postgres /etc/pangolin-manager
sudo chmod 700 /etc/pangolin-manager
sudo vi /etc/pangolin-manager/postgres.yml
sudo chown postgres:postgres /etc/pangolin-manager/postgres.yml
sudo chmod 600 /etc/pangolin-manager/postgres.yml
Необходимо выполнить следующие действия:
обновите пароль
patronietcd, если он поменялся на шаге настройки аутентификации в etcd;обновите пароль
patroniyml- для этого сгенерируйте и зашифруйте его так же, как и дляpatronietcd;убедитесь в корректности значения пароля для
ldapbindpasswdи при необходимости сгенерируйте, зашифруйте и внесите его вpostgres.ymlв секциюpg_hba;скорректируйте значение параметра
name(во второй строке) - имя узла мастера необходимо поменять на имя узла реплики;скорректируйте значение параметра
restapi.connect_address- имя узла мастера необходимо поменять на имя узла реплики;скорректируйте значение параметра
postgresql.connect_address- имя узла мастера необходимо поменять на имя узла реплики;при необходимости можно произвести другие изменения.
Внимание:
Пароль, зашифрованный на реплике, должен быть указан в
postgres.ymlна реплике.
Внимание:
Приведенные выше действия соответствуют версии Pangolin Manager 1.1.0. В других версиях функциональность может отличаться и, соответственно, могут потребоваться иные действия при работе с файлом
postgres.yml.
Настройка скрипта управления Pangolin Pooler#
Действие выполняется на реплике.
Заполните скрипт управления службой Pangolin Pooler - содержимое перенесите из аналогичного файла на мастере:
sudo su - {{ USER }}
sudo vi /etc/pangolin-manager/reload_pangolin_pooler.sh
sudo chown postgres:postgres /etc/pangolin-manager/reload_pangolin_pooler.sh
sudo chmod 500 /etc/pangolin-manager/reload_pangolin_pooler.sh
Настройка службы Pangolin Manager#
Действие выполняется на реплике.
Заполните скрипт управления службой Pangolin Manager - содержимое перенесите из аналогичного файла с мастера:
sudo su - {{ USER }}
sudo vi /etc/systemd/system/pangolin-manager.service
sudo chown root:root /etc/systemd/system/pangolin-manager.service
sudo chmod 640 /etc/systemd/system/pangolin-manager.service
Копирование системных файлов#
Действие выполняется на реплике.
Скопируйте файлы Pangolin Manager из дистрибутива в рабочие каталоги:
Примечание:
Pangolin Manager устанавливается из пакета pangolin-manager.
sudo yum install pangolin-manager
Установка PostgreSQL#
Внимание:
Перечень выполняемых действий может варьироваться от версии к версии.
Создание директорий#
Действие выполняется на реплике.
Cоздайте директории PostgreSQL с такими же именами, как на мастере. Если имена отличаются от используемых в примере, то команды следует скорректировать.
sudo su - {{ USER }}
sudo rm -rf /pgerrorlogs/05/
sudo rm -rf /pgdata/05/data/
sudo rm -rf /pgarclogs/05/
sudo rm -rf /pgdata/05/tablespaces/
sudo mkdir -p /pgerrorlogs/05
sudo chown postgres:postgres /pgerrorlogs/05
sudo chmod 0700 /pgerrorlogs/05
sudo mkdir -p /pgdata/05/data
sudo chown postgres:postgres /pgdata/05/data
sudo chmod 0700 /pgdata/05/data
sudo mkdir -p /pgarclogs/05
sudo chown postgres:postgres /pgarclogs/05
sudo chmod 0700 /pgarclogs/05
sudo mkdir -p /pgdata/05/tablespaces
sudo chown postgres:postgres /pgdata/05/tablespaces
sudo chmod 0700 /pgdata/05/tablespaces
sudo mkdir -p /etc/postgres
sudo chown postgres:postgres /etc/postgres
sudo chmod 0700 /etc/postgres
Установка СУБД Pangolin#
Действие выполняется на реплике.
Выполните установку СУБД Pangolin из дистрибутива. Начиная с Pangolin 5.1.0 инсталляция происходит в /usr/pgsql-se-05 автоматически, в частности, создаются необходимые в дальнейшем директории.
Примечание:
Имя файла в дистрибутиве может отличаться от примера ниже в зависимости от версии. Имя рабочей директории Pangolin подразумевается в зависимости от устанавливаемой версии продукта и не является параметром при установке.
sudo su - {{ USER }}
sudo rpm -qa | grep pangolin
sudo rpm -ivh /tmp/pangolin_510/platform-v-pangolin-dbms-05.001.00-redhat7_9.x86_64.rpm
Настройка файла версии#
Действие выполняется на реплике.
Скопируйте файл версии из дистрибутива или с мастера:
sudo su - {{ USER }}
sudo cp /tmp/pangolin_510/installer/files/version /usr/pgsql-se-05/share/version
sudo chown postgres:postgres /usr/pgsql-se-05/share/version
sudo chmod 0700 /usr/pgsql-se-05/share/version
Настройка прав директории bin#
Действие выполняется на реплике.
Установите права на директорию usr/pgsql-se-05/postgresql_venv/bin/:
sudo su - {{ USER }}
sudo chown postgres:postgres /usr/pgsql-se-05/postgresql_venv/bin/
sudo chmod 0700 /usr/pgsql-se-05/postgresql_venv/bin/
Копирование утилит#
Действие выполняется на реплике.
Скопируйте утилиты для работы БД и установите необходимые права:
sudo su - {{ USER }}
sudo cp -r /tmp/pangolin_510/3rdparty/cracklib/libcrack.so /usr/pgsql-se-05/lib
sudo cp -r /tmp/pangolin_510/3rdparty/cracklib/pw_dict.hwm /usr/pgsql-se-05/lib
sudo cp -r /tmp/pangolin_510/3rdparty/cracklib/pw_dict.pwd /usr/pgsql-se-05/lib
sudo cp -r /tmp/pangolin_510/3rdparty/cracklib/pw_dict.pwi /usr/pgsql-se-05/lib
sudo chown postgres:postgres /usr/pgsql-se-05/lib/libcrack.so
sudo chown postgres:postgres /usr/pgsql-se-05/lib/pw_dict.hwm
sudo chown postgres:postgres /usr/pgsql-se-05/lib/pw_dict.pwd
sudo chown postgres:postgres /usr/pgsql-se-05/lib/pw_dict.pwi
sudo chmod 0600 /usr/pgsql-se-05/lib/libcrack.so
sudo chmod 0600 /usr/pgsql-se-05/lib/pw_dict.hwm
sudo chmod 0600 /usr/pgsql-se-05/lib/pw_dict.pwd
sudo chmod 0600 /usr/pgsql-se-05/lib/pw_dict.pwi
sudo mkdir -p /usr/pgsql-se-05/3rdparty
sudo chown postgres:postgres /usr/pgsql-se-05/3rdparty
sudo chmod 0700 /usr/pgsql-se-05/3rdparty
sudo cp -r /tmp/pangolin_510/3rdparty/pgrouting.tar.gz /usr/pgsql-se-05/3rdparty/
sudo cp -r /tmp/pangolin_510/3rdparty/postgis.tar.gz /usr/pgsql-se-05/3rdparty/
sudo chown -R postgres:postgres /usr/pgsql-se-05/3rdparty/pgrouting.tar.gz
sudo chown -R postgres:postgres /usr/pgsql-se-05/3rdparty/postgis.tar.gz
sudo chmod -R 0700 /usr/pgsql-se-05/3rdparty/pgrouting.tar.gz
sudo chmod -R 0700 /usr/pgsql-se-05/3rdparty/postgis.tar.gz
sudo su - postgres
cd /usr/pgsql-se-05/3rdparty
tar -xvf pgrouting.tar.gz
tar -xvf postgis.tar.gz
rm -rf pgrouting.tar.gz
rm -rf postgis.tar.gz
exit
sudo chown -R postgres:postgres /usr/pgsql-se-05/3rdparty/pgrouting
sudo chown -R postgres:postgres /usr/pgsql-se-05/3rdparty/postgis
sudo chmod -R 0700 /usr/pgsql-se-05/3rdparty/pgrouting
sudo chmod -R 0700 /usr/pgsql-se-05/3rdparty/postgis
Копирование дополнительных утилит и документации#
Действие выполняется на реплике.
Скопируйте утилиту migration_tools, diagnostic_tool и каталог с документацией:
Внимание:
Утилита diagnostic_tools копируется в случае наличия в дистрибутиве.
sudo su - {{ USER }}
sudo mkdir -p /usr/pgsql-se-05/migration_tools
sudo chown postgres:postgres /usr/pgsql-se-05/migration_tools
sudo chmod 0700 /usr/pgsql-se-05/migration_tools
sudo cp -r /tmp/pangolin_510/migration_tools/db-data-comparator /usr/pgsql-se-05/migration_tools/
sudo cp -r /tmp/pangolin_510/migration_tools/ora2pg /usr/pgsql-se-05/migration_tools/
sudo cp -r /tmp/pangolin_510/migration_tools/pgloader /usr/pgsql-se-05/migration_tools/
sudo chown -R postgres:postgres /usr/pgsql-se-05/migration_tools/
sudo chmod 0700 /usr/pgsql-se-05/migration_tools/
sudo cp -r /tmp/pangolin_510/diagnostic_tool /usr/pgsql-se-05/
sudo chown -R postgres:postgres /usr/pgsql-se-05/diagnostic_tool
sudo chmod 0700 /usr/pgsql-se-05/diagnostic_tool
sudo cp -r /tmp/pangolin_510/documentation /usr/pgsql-se-05/
sudo chown -R postgres:postgres /usr/pgsql-se-05/documentation
sudo chmod 0700 /usr/pgsql-se-05/documentation
sudo cp /tmp/pangolin_510/readme.txt /usr/pgsql-se-05/
sudo cp /tmp/pangolin_510/releasenotes.json /usr/pgsql-se-05/
sudo chown postgres:postgres /usr/pgsql-se-05/readme.txt
sudo chmod 0700 /usr/pgsql-se-05/readme.txt
sudo chown postgres:postgres /usr/pgsql-se-05/releasenotes.json
sudo chmod 0700 /usr/pgsql-se-05/releasenotes.json
Копирование timescaledb#
Действие выполняется на реплике.
Скопируйте timescaledb:
sudo su - {{ USER }}
sudo chown -R postgres:postgres /tmp/pangolin_510/timescaledb
sudo chmod -R 0700 /tmp/pangolin_510/timescaledb
sudo cp -rp /tmp/pangolin_510/timescaledb/usr/pgsql-se-05/lib/ /usr/pgsql-se-05/
sudo cp -rp /tmp/pangolin_510/timescaledb/usr/pgsql-se-05/share/extension/ /usr/pgsql-se-05/share/
Настройка crontab#
Действие выполняется на реплике.
Заполните файл postgresql_clean_logs - содержимое перенесите с мастера. Затем настройте crontab - так же, как на мастере.
sudo su - {{ USER }}
sudo vi /usr/local/sbin/postgresql_clean_logs
sudo chown postgres:postgres /usr/local/sbin/postgresql_clean_logs
sudo chmod 0751 /usr/local/sbin/postgresql_clean_logs
crontab -e
Создание и настройка пользователя kmadmin_pg#
Действие выполняется на реплике.
Создайте пользователя kmadmin_pg (если его нет) и задайте пароль {{ kmadmin_pg_pass }}. Содержимое файла .bashrc перенесите с мастера.
sudo su - {{ USER }}
sudo useradd -m -G kmadmin_pg kmadmin_pg
sudo printf '{{ kmadmin_pg_pass }}' | chpasswd --encrypted
sudo vim /home/kmadmin_pg/.bashrc
sudo chown kmadmin_pg:kmadmin_pg /usr/pgsql-se-05/bin/encrypt_params_file
sudo chmod 0700 /usr/pgsql-se-05/bin/encrypt_params_file
sudo chown kmadmin_pg:kmadmin_pg /usr/pgsql-se-05/bin/generate_encryption_key
sudo chmod 0700 /usr/pgsql-se-05/bin/generate_encryption_key
sudo chown kmadmin_pg:kmadmin_pg /usr/pgsql-se-05/bin/setup_kms_credentials
sudo chmod 0700 /usr/pgsql-se-05/bin/setup_kms_credentials
sudo chown root:kmadmin_pg /usr/pgsql-se-05/bin/initprotection
sudo chmod 0750 /usr/pgsql-se-05/bin/initprotection
sudo chown postgres:postgres /usr/pgsql-se-05/lib/libfe_elog.so
sudo chmod 0604 /usr/pgsql-se-05/lib/libfe_elog.so
sudo chown postgres:postgres /usr/pgsql-se-05/lib/plugins
sudo chmod 0704 /usr/pgsql-se-05/lib/plugins
sudo chown postgres:kmadmin_pg /etc/postgres
sudo chmod 0731 /etc/postgres
sudo chmod 0701 /usr/pgsql-se-05
sudo chmod 0701 /usr/pgsql-se-05/bin
sudo chmod 0705 /usr/pgsql-se-05/lib
sudo chmod 0705 /usr/pgsql-se-05/lib/plugins
Настройка прав sudo#
Действие выполняется на реплике.
Скорректируйте содержимое /etc/sudoers - скопируйте содержимое с мастера и заполните в соответствии с конфигурацией:
sudo su - {{ USER }}
sudo visudo --file /etc/sudoers
Внимание:
Файл
/etc/sudoers- очень чувствительный элемент. В случае наличия в нем синтаксической ошибки можно потерять права sudo.Чтобы проверить корректную работу sudo, можно выполнить переключение на другого пользователя, например:
sudo su - postgres.
Одним из вариантов актуализации /etc/sudoers является перенос файла с мастера целиком. Пример выполнения:
копирование файла во временную директорию на мастере (выполняется на стороне мастера)
sudo su - {{ USER }}
sudo cp /etc/sudoers /tmp/
sudo chown {{ USER }}:{{ USER }} /tmp/sudoers
копирование файла из временной директории мастера в целевую директорию на реплике (выполняется на стороне реплики)
sudo su - {{ USER }}
sudo scp {{ USER }}@{{ master_ip }}:/tmp/sudoers /tmp/
sudo chown root:root /tmp/sudoers
sudo cp /tmp/sudoers /etc/sudoers
sudo rm /tmp/sudoers
удаление временного файла на мастере (выполняется на стороне мастера)
sudo rm /tmp/sudoers
Настройка хранилища паролей для пользователя patroni#
Действие выполняется на реплике.
В данном разделе производится настройка хранилища паролей для пользователя patroni.
Если текущий пароль patroni неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль patroni известен - достаточно выполнить только запись пароля в хранилище паролей на реплике.
Пароль, указывающийся с помощью параметра {{ patroni_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики из дистрибутива», подраздел «Настройка аутентификации в etcd»).
Примечание:
Начиная с версии 4.4.0 хранилище паролей (файл
/etc/postgres/enc_utils_auth_settings.cfg) создается автоматически при установке Pangolin.Пользователь
patroniиспользуется как служебный пользователь кластера Pangolin, использующийся, в частности, для репликации (детали можно найти в/etc/pangolin-manager/postgres.yml).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "patroni" WITH ENCRYPTED PASSWORD '{{ patroni_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей (пароль запрашивается при выдаче команды pg_auth_config add):
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h localhost -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U patroni -d replication
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U patroni -d replication
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U patroni -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U patroni -d replication
pg_auth_config add -s -h localhost -p 5433 -U patroni -d postgres
pg_auth_config add -s -h localhost -p 5433 -U patroni -d replication
pg_auth_config add -s -h {{ master_host }} -p 5433 -U patroni -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U patroni -d replication
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U patroni -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U patroni -d replication
pg_auth_config show
Настройка хранилища паролей для пользователя backup_user#
В данном разделе производится настройка хранилища паролей для пользователя backup_user.
Если текущий пароль backup_user неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль backup_user известен - достаточно выполнить только запись пароля в хранилище паролей на реплике.
Пароль, указывающийся с помощью параметра {{ backup_user_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики из дистрибутива», подраздел «Настройка аутентификации в etcd»).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "backup_user" WITH PASSWORD '{{ backup_user_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей (пароль запрашивается при выдаче команды pg_auth_config add):
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ master_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h {{ replica_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U backup_user -d postgres
pg_auth_config remove -s -h 127.0.0.1 -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ master_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h {{ replica_ip }} -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h localhost -p 5433 -U backup_user -d postgres
pg_auth_config add -s -h 127.0.0.1 -p 5433 -U backup_user -d postgres
pg_auth_config show
Настройка хранилища паролей для пользователя profile_tuz#
В данном разделе производится настройка хранилища паролей для пользователя profile_tuz.
Если текущий пароль profile_tuz неизвестен, то задается новый пароль, а затем он записывается в хранилища паролей на мастере и реплике. Если текущий пароль profile_tuz известен - достаточно выполнить только запись пароля в хранилище паролей на реплике.
Пароль, указывающийся с помощью параметра {{ profile_tuz_pass }}, можно сгенерировать так же, как и для patronietcd (см. документ «Руководство администратора», «Часто встречающиеся проблемы и пути их устранения», раздел «Пересоздание узла реплики из дистрибутива», подраздел «Настройка аутентификации в etcd»).
Изменение пароля#
Действие выполняется на мастере.
Измените пароль в СУБД на мастере:
## ALTER USER "profile_tuz" WITH PASSWORD '{{ profile_tuz_pass }}';
Запись пароля в хранилище паролей#
Действие выполняется на мастере и реплике.
Выполните запись пароля в хранилище паролей (пароль запрашивается при выдаче команды pg_auth_config add):
sudo su - postgres
pg_auth_config show
pg_auth_config remove -s -h localhost -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h localhost -p 5433 -U profile_tuz -d "First_db"
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h {{ master_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config remove -s -h {{ replica_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h localhost -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h localhost -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h {{ master_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h {{ master_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U profile_tuz -d postgres
pg_auth_config add -s -h {{ replica_host }} -p 5433 -U profile_tuz -d "First_db"
pg_auth_config show
Запуск реплики#
Актуализация нового конфигурационного файла на мастере#
Действие выполняется на мастере.
Актуализируйте новый файл postgres.yml и выведите Pangolin Manager из режима паузы:
sudo su - {{ USER }}
sudo systemctl restart pangolin-manager
sudo su - postgres
pangolin-manager-ctl -c /etc/pangolin-manager/postgres.yml resume
Старт Pangolin Manager на реплике и восстановление базы данных#
Действие выполняется на реплике.
Запустите Pangolin Manager, который восстановит реплику в соответствии с bootstrap-логикой файла postgres.yml. В результате получится работающий кластер.
sudo su - {{ USER }}
sudo systemctl daemon-reload
sudo systemctl start pangolin-manager
Конфигурирование Pangolin Pooler#
Примечание:
Данный блок является опциональным и необходим в случае наличия компонента Pangolin Pooler.
Настройка файла службы Pangolin Pooler#
Действие выполняется на реплике.
Заполните файл службы Pangolin Pooler. Содержимое файла перенесите с аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /etc/systemd/system/pangolin-pooler.service
sudo chown root:root /etc/systemd/system/pangolin-pooler.service
sudo chmod 0644 /etc/systemd/system/pangolin-pooler.service
Установка Pangolin Pooler#
Действие выполняется на реплике.
Выполните установку компонента Pangolin Pooler:
sudo yum install pangolin-pooler-1.1.0-rhel8.7.x86_64.rpm
Конфигурирование Pangolin Pooler#
Действие выполняется на реплике.
Заполните файл pangolin-pooler.ini - содержимое перенесите с аналогичного файла на мастере и скорректируйте для узла реплики:
sudo su - {{ USER }}
sudo mkdir -p /etc/pangolin-pooler
sudo chown postgres:postgres /etc/pangolin-pooler
sudo chmod 0700 /etc/pangolin-pooler
sudo vi /etc/pangolin-pooler/pangolin-pooler.ini
sudo chown postgres:postgres /etc/pangolin-pooler/pangolin-pooler.ini
sudo chmod 0600 /etc/pangolin-pooler/pangolin-pooler.ini
Конфигурирование userlist.txt#
Действие выполняется на реплике.
Заполните файл userlist.txt - содержимое перенесите с аналогичного файла на мастере и скорректируйте для узла реплики:
sudo su - {{ USER }}
sido vi /etc/pangolin-pooler/userlist.txt
sudo chown postgres:postgres /etc/pangolin-pooler/userlist.txt
sudo chmod 0600 /etc/pangolin-pooler/userlist.txt
Настройка ротации журналов#
Действие выполняется на реплике.
Выполните конфигурирование ротации журналов. Содержимое файла pangolin-pooler перенесите из аналогичного файла на мастере.
sudo su - {{ USER }}
sudo vi /etc/logrotate.d/pangolin-pooler
sudo chown postgres:postgres /etc/logrotate.d/pangolin-pooler
sudo chmod 0644 /etc/logrotate.d/pangolin-pooler
Запуск Pangolin Pooler#
Действие выполняется на мастере и реплике.
Перезапустите службу Pangolin Pooler:
sudo systemctl restart pangolin-pooler
Мониторинг блокировок#
Для оперативного мониторинга заблокированных объектов предусмотрен отдельный инструмент psql_lockmon.
Механизм отслеживания блокировок представляет собой набор представлений, позволяющий проводить оперативный мониторинг блокировок в разрезе:
заблокированных объектов;
типов блокировок;
параметров сессии, которая заблокировала объект (при наличии прав);
длительности сессий, запросов, ожидания блокировок, смены статуса (при наличии прав);
текста последнего запроса в сессии (при наличии прав);
дерева блокировок, при наличии очереди заблокированных объектов.
Поставка механизма отслеживания блокировок производится в виде расширения psql_lockmon.
Предусмотрена автоматизация развертывания решения на уровне специализированного сценария (custom.yml). Решение по умолчанию устанавливается в БД пользователя и в шаблонную БД.
Управление учетными записями#
Учетные записи пользователей и технические учетные записи создаются, удаляются и изменяются администраторами безопасности и администраторами Pangolin.
Разрешения для учетных записей регулируются политиками, которые определяют права доступа той или иной роли к объектам базы данных.
Парольные политики описываются в документе «Список PL/SQL функций продукта», раздел «Парольные политики».
Разграничение доступа к данным#
В этом разделе описываются механизмы разграничения доступа к данным(включая функции маскирования, хеширования и т.п).
Управление доступом на уровне ролей (RBAC)#
Система ограничивает доступ пользователей к объектам БД в зависимости от их роли и привилегий, которые назначены для этой роли.
Подробнее в разделе «Ролевая модель и права доступа».
Row level security#
Механизм ограничения доступа пользователей к отдельным строкам в таблицах.
Защита от привилегированных пользователей#
В Pangolin используется механизм защиты данных от привилегированных пользователей, построенный на принципе разделения ролей.
В стандартном PostgreSQL привилегированные пользователи имеют доступ к объектам БД и настройкам подключения:
администраторы БД имеют произвольный доступ к любым пользовательским данным, что может привести к утечкам конфиденциальной информации;
администраторы ОС могут менять настройки БД таким образом, чтобы получать доступ к пользовательским данным, что тоже ведет к утечкам.
В Pangolin Администраторы БД и ОС теряют возможность самостоятельно управлять некоторыми параметрами и перестают иметь полный доступ ко всем объектам БД.
В дополнение к роли суперпользователя, которая есть в стандартной версии PostgreSQL, в Pangolin можно создать специальную роль Администратора безопасности (АБ).
АБ – независимый администратор, не обладающий особыми правами в операционной системе (в том числе не имеющий прав Linux-пользователя postgres) и не имеющий доступа к объектам БД. Внутри БД роль Администратора безопасности является особенной — она не может быть изменена суперпользователем. Таким образом, ни один из пользователей не может единолично получить доступ к конфиденциальным данным или изменить важные для безопасности настройки БД и права доступа.
Администратор безопасности создается при инициализации кластера, либо существующим администратором безопасности через функцию pm_grant_security_admin.
Примечание:
Для модификации защиты и предоставления прав доступа доступны только объекты, расположенные в базе, к которой осуществлено подключение.
Ниже описаны основные функции, подробнее о функциях в документе «Список PL/SQL функций продукта», раздел «Защита от привилегированных пользователей».
В случае если необходимо выделить права доступа к какому-то конкретному объекту в защищенной схеме, этот объект ставится под индивидуальную защиту. Настройка доступа к такому объекту происходит без учета защиты схемы, в которой этот объект расположен.
Внимание!
При включенном механизме защиты от привилегированных пользователей прямая модификация записей в системных каталогах, относящихся к защищаемым объектам, запрещена.
Имеется опасность свободного использования расширения
pageinspectи схожих с ним на БД с включенной защитой от привилегированных пользователей, в связи с тем чтоpageinspectпозволяет посмотреть расшифрованные данные и не учитывает защиту от привилегированных пользователей.
Ниже описаны основные функции, подробнее о функциях в «Список PL/SQL функций продукта», раздел «Защита от привилегированных пользователей».
Помещение объекта под защиту#
Для защиты пользовательских данных, хранимых в объектах базы, можно поставить объект под защиту с помощью функции pm_protect_object, например:
SELECT pm_protect_object('role', 'u1');
При включенной защите от привилегированных пользователей функция pm_protect_object при помещении под защиту объекта типа «роль» выполняет завершение открытых сессий указанного пользователя, исходно открытых другой ролью (случаи set role, set session authorization), где роль выступает как session_user либо как current_user, если исходный пользователь не имеет права на переключение на эффективную роль сессии в соответствии с текущим состоянием каталогов безопасности.
Снятие защиты с объекта#
В случае, если защита более не требуется, она может быть снята вызовом функции pm_unprotect_object, например:
SELECT pm_unprotect_object('table','ext.t1');
Получение доступа к защищенному объекту#
При включенной защите от привилегированных пользователей функция вывода объекта из-под защиты pm_unprotect_object не снимает защиту с администраторов безопасности, до исключения их из роли sec_admin_role, и групповой роли администраторов безопасности sec_admin_role, поднимая ошибку с сообщением «Can't remove protection for a security administrator's role».
Получить список всех объектов, находящихся под защитой#
Чтобы получить список всех объектов, находящихся под защитой, нужно вызвать функцию pm_get_protected_objects.
pm_get_protected_objects()
При включенной защите от привилегированных пользователей функция pm_get_protected_objects возвращает в результате выполнения поля:
state OID - состояние защиты объекта. Не
NULLозначает приостановленную защиту объекта;staterole OID - роль для которой изменено состояние защиты объекта.
Доступ к защищенному объекту#
Доступ к объекту, находящемуся под защитой, запрещен всем пользователям, включая владельца и суперпользователя.
Для осуществления доступа к таким объектам создаются политики доступа через функцию pm_make_policy, и наполняются правилами доступа к объекту (какие действия над объектом разрешены для выполнения).
Пример создания политики:
SELECT pm_make_policy('pol1');
Функция pm_grant_to_policy добавляет правило в политику, например:
SELECT pm_grant_to_policy('pol1', 'table', 'ext.t1', array['select','update']::name[]);
Обратите внимание, что выдача прав на действия update, delete или insert одновременно с отсутствием выданных прав на действие select все равно позволит косвенным образом получить доступ к содержимому таблицы.
Так право на delete позволит выполнить запрос вида BEGIN; DELETE FROM mytable RETURNING *; ROLLBACK;, который по смыслу эквивалентен SELECT * FROM mytable;.
Назначение политики пользователю#
Политика может быть назначена пользователю с помощью функции pm_assign_policy_to_user. Он получит разрешение на выполнение действий над защищенными объектами согласно правилам назначенной политики.
Пример назначения политики пользователю:
SELECT pm_assign_policy_to_user('u1', 'pol1');
Пользователю может быть назначено любое количество политик, и они могут содержать правила доступа к различным объектам.
Изъятие выданных прав доступа#
Изъятие ранее выданных прав доступа может осуществляться двумя способами:
вызовом функции
pm_unassign_policy_from_user(единовременный отзыв всех правил политики), например:SELECT pm_unassign_policy_from_user('u1','pol1');удалением конкретных правил из указанной политики при помощи функции
pm_revoke_from_policy, например:SELECT pm_revoke_from_policy('pol1', 'function', 'public.f1', array['call', 'drop', 'alter']::name[]);
Помещение всех объектов схемы под защиту#
Тип объектов schema помещается под защиту функциями интерфейса администратора безопасности. При этом все объекты, находящиеся в схеме, автоматически считаются защищенными. Операции изменения и удаления непосредственно самой защищенной схемы могут быть выданы через настройку политик функциями интерфейса администратора безопасности.
Функциональность наполнения политик доступа правилами, разрешающими выполнение действий не над конкретным объектом, а над типом объектов в защищенной схеме, использует ту же функцию pm_grant_to_policy, что и при работе с защитой конкретных объектов, однако, имеет отличный синтаксис для параметра, задающего объект:
SELECT pm_grant_to_policy('имя_политики', 'тип_объекта', 'имя_схемы.*', array['действие1', ..., 'действиеN']::name[]);
Примечание:
Символ
*после имени схемы означает применимость этого правила ко всем объектам заданного типа в данной схеме, как к существующим на момент определения правила, так и ко вновь добавляемым в данную схему.
Пример обобщенного правила для действия SELECT над всеми таблицами в защищенной схеме myschema:
SELECT pm_grant_to_policy('schema_objects_policy', 'table', 'myschema.*', array['select']::name[]);
Объект в защищенной схеме может находиться под индивидуальной защитой. В этом случае настройка доступа к нему производится без учета защиты схемы в которой объект расположен.
Предоставление доступа ко всем объектам защищенной схемы#
Исходя из ранее созданных политик и логики приложения, определите необходимость отдельной политики для предоставления доступа к защищенной схеме. В случае необходимости создайте новые политики доступа к защищенным объектам (pm_make_policy). Затем наполните политику правилами доступа (pm_grant_to_policy). Для этого добавьте в политику правила доступа для всех таблиц (партиций, представлений, функций) схемы (см. пример и примечание в предыдущем подразделе). С помощью команды pm_assign_policy_to_user, назначьте наполненную правилами доступа политику пользователям.
Предоставление доступа к объекту в защищенной схеме#
Для предоставления доступа к отдельному объекту в защищенной схеме необходимо определить тип защиты объекта, если:
объект под защитой — политики, разрешающие доступ к объекту, содержат правила доступа только к данному объекту БД;
объект под защитой через схему — доступ к объекту предоставляется политиками, содержащими правила доступа ко всем объектам данного типа в схеме.
После определения типа защиты необходимо наполнить политику правилами, при этом, если:
объект под защитой: наполните политику правилами доступа к конкретному объекту;
объект под защитой через схему: наполните политику правилами доступа ко всем объектам данного типа, находящимся в защищенной схеме.
В случае предоставления доступа к объекту в защищенной схеме необходимо назначить политику с правами доступа на выполнение действий над объектом пользователю БД.
Перенос объекта из защищенной схемы#
Перенос объектов из защищенной схемы в другую невозможен, так как нет гарантии сохранения согласованности правил доступа к переносимому объекту. Таким образом, при необходимости переноса объекта в другую схему с сохранением защиты этого объекта, переносимый объект должен быть помещен под индивидуальную защиту, а правила доступа должны быть настроены индивидуально для переносимого объекта. При достаточности правил доступа целевой схемы (если она под защитой) для типа объектов, соответствующего типу перенесенного объекта, индивидуальная защита с объекта может быть снята.
Обращение к объекту БД#
Выполнение запроса, содержащего обращение к объекту БД, происходит, если имеются права на доступ к объекту или на доступ к типу объектов защищенной схемы.
Механизм защиты данных проверяет выполнение хотя бы одного из двух условий:
нахождение запрашиваемого объекта под защитой и наличие у субъекта (пользователя) разрешений на выполнение действия над объектом БД;
нахождение схемы, содержащей запрашиваемый объект, под защитой и наличие у субъекта (пользователя) разрешений на выполнение действия над данным типом объектов БД.
Если проверка пройдена и есть права на доступ, запрашивающей стороне будет возвращен результат выполнения запроса. В случае отсутствия прав на доступ, запрос завершится ошибкой.
Параметры настройки, управляемые администраторами безопасности через KMS в режиме защищенного конфигурирования, находятся в таблице документа «Параметры, настраиваемые через KMS».
Назначить пользователю политики администратора безопасности#
Функция pm_grant_security_admin назначает пользователю политики администратора безопасности.
Формат:
pm_grant_security_admin(role_name name)
Входные параметры:
role_name(name) — имя пользователя.
Пример:
Команда:
SELECT pm_grant_security_admin('u1');
При включенной защите от привилегированных пользователей функция pm_grant_security_admin:
проверяет пользовательскую роль на наличие опции
SUPERUSERили вхождение в любую роль, отличную от sec_admin_role. При наличии такой опции или роли, поднимается ошибка с сообщением о невозможности назначить такого пользователя администратором безопасности;для указанного пользователя устанавливаются опции
LOGIN,NOINHERIT,IN ROLE sec_admin;указанному пользователю устанавливает изменение его роли при логине на
sec_admin_role.
Указанному пользователю-администратору безопасности выдает политику secAdminUser. Также для пользователя не устанавливаются (снимаются, если есть) ограничения на время действия пароля через VALID UNTIL.
Сама функция помещается под защиту утилитой initprotection. Привилегия на ее выполнение включается в политику для роли sec_admin_role в initprotection.
Снять с пользователя политики администратора безопасности#
Функция pm_revoke_security_admin снимает с пользователя политики администратора безопасности.
Формат:
pm_revoke_security_admin(role_name name)
Входные параметры:
role_name(name) — имя пользователя.
Пример:
Команда:
SELECT pm_revoke_security_admin('u1');
При включенной защите от привилегированных пользователей функция pm_revoke_security_admin:
изымает у указанного пользователя роль
sec_admin_role;исключает переключение пользователя на роль
sec_admin_roleпри логине;изымает у пользователя политику
secAdminUser;функция помещается под защиту утилитой initprotection;
привилегия на выполнение функции включается в политику для роли
sec_admin_roleв initprotection.
Примечание:
При включенной защите от привилегированных пользователей функции
pm_grant_to_policy,pm_revoke_from_policy,pm_unprotect_object,pm_get_protected_objectsне производят изменений предустановленных политик и объектов.
Защита переноса между табличными пространствами#
Данная функциональность призвана защищать данные пользователя на уровне физического представления и представляет собой пересечение функциональностей «Прозрачное шифрование данных (TDE)» и «Защита данных от привилегированных пользователей». Включает расширение механизма защиты данных, которое не позволяет пользователям, имеющим права на изменение объектов, переносить их между табличными пространствами. Исключает возможность раскрытия данных при переносе в не зашифрованное целевое табличное пространство.
Управление механизмом защиты данных от привилегированных пользователей осуществляет администратор безопасности. В случае необходимости предоставления доступа к защищенным объектам сотрудники сопровождения производят выдачу прав согласно действующим нормативным документам на уровне ролевой модели и передают запрос на выдачу прав администратору безопасности
Для переноса индекса между табличными пространствами проверяется наличие прав на перенос самого объекта, которому этот индекс соответствует.
Партиционированная таблица не имеет физического представления в файловой системе, права на изменение табличного пространства для такой таблицы должны выдаваться отдельно. Поскольку в целевом случае партиции защищаются через партиционированную таблицу, для перемещения их между табличными пространствами проверяется право на выполнение действия у родительской (партиционированной) таблицы.
Если запрошен перенос таблицы или индекса, у которых исходное табличное пространство было зашифровано, а новое нет (явно указаны параметры rel_tablespace и/или ind_tablespaces), то результатом будет:
отказ в выполнении переноса с ошибкой
Action is forbidden— если политика по таблице отсутствует или не содержит явного разрешения на действиеmove;успешный перенос таблицы или индекса с переносом объекта — если защита объекта отключена или политика по таблице разрешает действие
move.
Маскирование запросов#
СУБД, в том числе Pangolin, предназначены для оперирования с данными. Среди данных могут присутствовать такие, разглашение которых нежелательно, по причине наличия в них категорированной информации, либо информации, раскрытие которой может предоставлять возможность несанкционированного доступа к СУБД.
Модель функционирования СУБД Pangolin строится на выполнении запросов со стороны аутентифицированных и авторизованных пользователей. В том числе запросов на:
управление ролями и пользователями, включая задание параметров аутентификации и авторизации, в том числе паролей;
управление структурой хранимых данных, включая БД, схемы, табличные пространства, объекты схем;
выполнение действий над хранимыми данными, таких как выборка, вставка, изменение и удаление.
Запросы, поступающие на вход СУБД, проходят многоступенчатую обработку, и могут быть выведены в лог или служебные представления СУБД в неизмененном виде, в соответствии с настройками СУБД или расширений, выполняющих обработку запросов.
Известные для СУБД Pangolin точки, в которых может быть выполнен вывод пользовательских запросов, следующие:
Что |
Когда |
Условие |
Кто может задать/использовать |
|---|---|---|---|
Полный текст запроса, соответствующего условию |
Вывод в лог сразу после получения запроса |
Параметр |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов |
Полный текст запроса, соответствующего условию |
Вывод в лог после выполнения запроса |
Параметр |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов |
Полный текст запроса + ошибочная лексема при ошибке разбора |
При выводе сообщения в лог, в том числе при ошибке |
Параметр |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов |
Урезанный до 1024 символов текст любого запроса |
При запросе из представления |
По своей сессии, запросе пользователем с ролью |
Администратор СУБД авторизованный пользователь |
Запрос на задание или изменение пароля с паролем |
При сохранении в файл |
Установленное расширение pg_stat_statements, при запросе пользователем с ролью |
Администратор СУБД авторизованный пользователь ОС, имеющий доступ к файлу |
Урезанный до 1024 символов текст любого запроса, выполнение которого попало на момент формирования среза сессий со стороны ASH (performance insight) |
При сохранении в файлы ASH. При запросе из представления ASH |
Без ограничений |
Администратор СУБД авторизованный пользователь ОС, имеющий доступ к файлам ASH |
Полный текст запроса, соответствующего условию |
При выводе в лог результат работы расширения |
Установленное расширение |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов |
Полный текст запроса, соответствующего условию |
При выводе в лог результат работы расширения |
Установленное расширение |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов |
Полный текст запроса, соответствующего условию аудита |
При выводе в лог записей аудита, соответствующих критериям аудита |
Соответствие сессии и/или запроса заданным критериям аудита |
Администратор СУБД пользователь ОС, имеющий доступ к файлам логов (содержащих, среди прочего, записи лога аудита) |
Выполняемые запросы могут содержать следующую информацию, которая не должна быть доступна администраторам СУБД (superuser) или лицам, имеющим доступ к файлам логов, но не имеющим доступ к БД (администраторы ОС):
значения паролей или хешей паролей в запросах на задание или изменение паролей пользователей;
значения параметров-паролей в функциях API администраторов безопасности;
явно заданные как константы значения параметров в функциях;
явно заданные как константы значения, вставляемые (
INSERT) в таблицы и представления, в том числе заданные через выраженияSELECTилиCTE;явно заданные как константы значения, задаваемые для изменения полей (
UPDATE) в таблицах и представлениях, или используемые для фильтрации записей для изменения;явно заданные как константы значения, задаваемые как условия выражений
SELECT,UPDATEиDELETEпо полям таблиц и представлений.
Для поддержки возможности сокрытия такой информации реализована функциональность маскирования указанных выше значений для категорий запросов при:
выводе запроса в лог по условию
log_statement=условие, влияет на попадание в лог запросов определенных типов - либоdll(только запросы DDL), либоmod(запросы DDL, модификации данных иCOPY FROM), либоall(все запросы);выводе запроса в лог по условию
log_min_duration_statement=минимальная длительность, влияет на попадание в лог запросов с определенной длительностью;выводе запроса в лог при ошибке по условию
log_min_error_statement=уровень логирования запросов, влияет на попадание в лог запросов определенных типов;вывод в лог информации об обрабатываемых запросах от расширения
auto_explain;вывод в лог информации об обрабатываемых запросах от расширения
pg_hint_plan;вывод в лог (аудита) в соответствии с критериями аудита, включая значения параметров подготовленных запросов при
pgaudit.log_parameter = on;накопление, сохранение в файл
pg_stat_tmp/pgss_query_texts.statи получение запросов из представленияpg_stat_statements;накопление и получение текстов запросов из представления
pg_stat_activity.
Включение маскирования запросов выполняется для всех указанных выше случаев, без разделения по категориям маскируемых запросов.
Внимание!
Сохранение текста запроса в файлы ASH (performance insight) - регулируется собственными параметрами
performance insightиperformance_insights.masking.При этом, при заданном маскировании запросов через параметр
masking_modeсо значениемfull, маскирование запросов в ASH (performance insight) будет выполняться независимо от значения параметраperformance_insights.masking. Это связано с тем, что ASH пользуется текстами запросов, помещенных в представлениеpg_stat_activity, и при включенном маскировании тексты запросов в представлении находятся в уже замаскированном виде.
Особенности маскирования запросов:
текст подготовленных запросов при их вызове через
EXECUTEтакже обрабатывается по вышеуказанным правилам;в случае вывода ошибки, в которой отдельно выводится лексема, которую Pangolin считает ошибочной: она должна быть замаскирована по тем же правилам. То есть, если эта лексема была замаскирована в полном тексте запроса, то должна быть замаскирована и в ошибке. Исключением являются ошибки в лексемах, определяющих категорию запроса -
SELECT/INSERT/UPDATE/DELETEиCREATE/ALTER ROLE/USER;маскирование анонимных запросов работает в режиме полного маскирования.
Настройка маскирования#
Маскирование запросов настраивается новым конфигурационным параметром masking_mode, который может принимать два значения:
disabled- механизм отключен, маскирование запросов не производится, за исключением значений паролей и параметров функций, принимающих пароли, которые маскируются всегда;full- механизм маскирования работает по всем обрабатываемым запросамSELECT/INSERT/UPDATE/DELETEи их параметрам, а также запросамCREATE/ALTER ROLE/USERи параметру пароля в их составе.
По умолчанию механизм выключен (disabled), параметр хранится в $PGDATA/postgresql.conf - в случае конфигурации сервера standalone, в случае конфигурации cluster - в файле /etc/pangolin-manager/postgres.yml; а при защищенном конфигурировании (настроенное соединение с KMS + значение параметра secure_config = on) берется из хранилища секретов (KMS), из параметра кластера с именем masking_mode.
Для изменения значения параметра masking_mode выполните перезапуск СУБД Pangolin.
Автоматическое завершение неактивных соединений#
Соединения, остающиеся неактивными определенное время, подлежат принудительному завершению. Для завершения таких соединений используется фоновый процесс «idle sessions terminator», осуществляющий мониторинг и завершение бездействующих клиентских сеансов. Этот процесс запускается при старте сервера Pangolin и завершается вместе с остановкой сервера.
Процесс регулируется двумя параметрами:
check_idle_time_delay- интервал мониторинга в миллисекундах;backend_idle_alive_time- допустимое время бездействия в секундах.
Если хотя бы один из этих параметров равен нулю, неактивные соединения завершаться не будут.
Прозрачное шифрование#
В Pangolin используется прозрачное шифрование данных (TDE). С его помощью шифруются данные:
хранящиеся в журналах изменений, файлах данных, резервных копиях и временных файлах БД;
передаваемые по каналам связи в ходе физической и логической репликаций.
Решение HashiCorp Vault используется как система управления, обеспечивая защищенное хранение ключей шифрования и настроек.
Настройка прозрачного шифрования хранимых данных (TDE) в Pangolin возможна с использованием хранилища секретов в HashiCorp Vault или с использованием хранилища KMS-заменителя.
При ротации на стороне хранилища секретов необходимо соблюдать структуру хранения параметров. При этом на стороне СУБД работает фоновый процесс, периодически проверяющий изменение мастер-ключа и при его изменении выполняющий перешифрование ключей в локальном хранилище ключей keyring БД, которое размещается в общей памяти сервера.
Ротация мастер-ключа кластера высокой доступности так же может инициироваться и выполняться посредством выполнения смены мастер-ключа на узле лидера БД, входящем в кластер.
Функции для поддержки ротации и изменения мастер-ключей на стороне БД:
block_rotate_master_key— захватывает блокировку изменения мастер-ключа, служит для исключения ротации мастер-ключа TDE на кластере при работе таких утилит, какpg_rewind;unblock_rotate_master_key— снимает блокировку изменения мастер-ключа на кластере;set_master_key— устанавливает новое значение мастер-ключа;rotate_master_key— генерирует и устанавливает новое значение мастер-ключа;reencrypt_keys— перешифровывает keyring актуальным мастер-ключом, опираясь на информацию о предыдущем использованном мастер-ключе;restore_keys— перешифровывает keyring актуальным мастер-ключом, в том числе поддерживает нахождение мастер-ключа из истории в хранилище секретов, которым был зашифрован конкретный ключ шифрования объекта. Используется в том числе в восстановлении резервных копий, снятых во время действия предыдущих мастер-ключей.
Подробное описание функций для поддержки ротации и изменения ключей шифрования на стороне БД в документе «Список PL/SQL функций продукта».
Прозрачное шифрование предотвращает несанкционированный доступ к пользовательским данным, хранящимся:
в файлах отношений БД на базе СУБД Pangolin;
во временных файлах, формируемых СУБД Pangolin в процессе работы;
в журналах предварительной записи СУБД Pangolin;
в резервных копиях баз данных Pangolin.
Средства криптографической защиты информации#
Для использования шифрования между клиентом и сервером необходимо настроить OpenSSL на клиенте и на сервере.
SSL включается с помощью параметра ssl = on в файле postgresql.conf.
SSL использует файлы сертификата и закрытого ключа сервера. По умолчанию они называются server.crt и server.key. Эти названия менять не рекомендуется.
Доступ к файлу server.key должен быть ограничен командой chmod 0600 server.key.
Чтобы клиенты могли подключаться к серверу с помощью сертификатов, поместите сертификаты корневых центров сертификации в каталог data, укажите имя файла с сертификатами в параметре ssl_ca_file в postgresql.conf.
После этого добавьте параметр clientcert=1 в соответствующие строки hostssl в файле pg_hba.conf.
Оптимизация таблиц#
В процессе работы с Pangolin возникает table bloat — ситуация, при которой данные таблиц будут храниться неэффективно. Они фрагментируются, что приводит к ухудшению производительности и нерациональному использованию места на диске.
Примеры ситуаций, при которых может возникать фрагментация:
непредвиденный скачок запросов
UPDATEи/илиDELETE, сильно отличающийся от обычного профиля нагрузки;наличие долгих транзакций, препятствующих удалению старых версий записей (
VACUUMне может удалить запись, если есть хотя бы одна незакрытая транзакция старше записи, удалившей или изменившей эту запись);наличие незавершенных PREPARED-транзакций;
наличие открытых слотов репликации. Это может произойти из-за сильной задержки между лидером и репликой либо в случае недоступности реплики;
фрагментация может накапливаться естественным образом, если в таблице есть типы данных переменной длины. Это приводит к образованию кусков удаленных данных такого размера, которые сложно будет перезаписать.
Механизм работы с данными в PostgreSQL#
При первом наполнении таблицы данные добавляются последовательно и равномерно занимают блоки. Пример наполнения записями таблицы bloated_table:
CREATE TABLE bloated_table(id integer, data integer);
INSERT INTO bloated_table SELECT i, random() FROM generate_series(1, 1000000) AS g(i);
Посмотреть статистику по таблице можно с помощью запроса к pg_stat_user_tables командой ANALYZE:
ANALYZE bloated_table;
SELECT n_tup_ins, n_tup_upd, n_tup_del, n_live_tup, n_dead_tup FROM pg_stat_user_tables WHERE relname = 'bloated_table';
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 0 | 1000000 | 0
Полученные результаты:
n_tup_ins,n_tup_upd,n_tup_del— количество вставок, изменений, удалений строк таблицы;n_live_tup— актуальные записи;n_dead_tup— «мертвые» записи, помеченные на удаление.
Команда pg_size_pretty покажет объем таблицы на диске:
SELECT pg_size_pretty(pg_table_size('bloated_table'));
pg_size_pretty
----------------
35 MB
Симуляция фрагментации методом удаления каждой второй строки:
DELETE FROM bloated_table WHERE (id % 2) = 0;
Статистика таблицы после фрагментации:
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 500000 | 500000 | 500000
pg_size_pretty
----------------
35 MB
Теперь 500 000 записей считаются «мертвыми» (dead) и могут быть удалены сборщиком мусора (VACUUM). При штатной работе это сделает auto vacuum, а для таблицы из примера очистка запущена вручную:
VACUUM bloated_table;
...
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000000 | 0 | 500000 | 500000 | 0
pg_size_pretty
----------------
35 MB
«Мертвых» записей больше нет, но размер таблицы не изменился. VACUUM не возвращает место на диске кроме случаев, когда удаляет последний блок с данными. Свободное место будет переиспользовано Pangolin для новых записей.
Примечание:
Обновление существующих записей также может привести к фрагментации:
UPDATEиDELETEне изменяют значение текущей строки (tuple), а создают ее новую версию.
Анализ фрагментации таблиц#
В PostgreSQL есть расширение pgstattuple, позволяющее анализировать состояние таблиц. Оно устанавливается вместе с Pangolin по умолчанию.
Пример использования:
test=> SELECT * FROM pgstattuple('bloated_table');
-[ RECORD 1 ]------+-------
table_len | 458752
tuple_count | 1470
tuple_len | 438896
tuple_percent | 95.67
dead_tuple_count | 11
dead_tuple_len | 3157
dead_tuple_percent | 0.69
free_space | 8932
free_percent | 1.95
Значение строк вывода:
free_percent— процент свободных записей. Чем он выше, тем больше фрагментирована таблица. Нормальными считаются значения не более 20%;table_len— физическая длина отношения в байтах;tuple_count— количество «живых» записей;tuple_len— общая длина «живых» записей в байтах;tuple_percent— процент «живых» записей;dead_tuple_count— количество «мертвых» записей;dead_tuple_len— общая длина «мертвых» записей в байтах;dead_tuple_percent— процент «мертвых» записей;free_space— общий объем свободного пространства в байтах.
Примечание:
Рекомендуется периодически проверять активные и перенесшие всплеск нагрузки таблицы.
Стандартные утилиты PostgreSQL#
Вернуть освобожденное после VACUUM место на диске можно стандартными средствами PostgreSQL:
VACUUM FULLполностью пересоберет таблицу, освободив все неиспользуемые строки:VACUUM FULL bloated_table; ... pg_size_pretty ---------------- 17 MBCLUSTERвыполнит все операции VACUUM FULL и упорядочит строки по индексу, уменьшая количество обращений к диску на некоторых запросах:CLUSTER bloated_table USING <index_name>;
Использовать VACUUM FULL и CLUSTER на БД под нагрузкой не рекомендуется. Эти команды работают медленно и полностью блокируют обрабатываемую таблицу. Для решения table bloat без прибегания к блокировке в состав Pangolin входят утилиты по реорганизации данных: pg_repack и pgcompacttable.
Расширение pg_repack#
Инструмент для реорганизации таблиц без эксклюзивной блокировки. Позволяет реорганизовать таблицы и индексы к ним и переносить их в другое табличное пространство.
Функциональность:
реорганизация таблиц без блокировки, в отличие от стандартных средств PostgreSQL
VACUUM FULLиCLUSTER. Производительность сравнима сCLUSTER;удаление пустот в таблицах и индексах;
восстановление физического порядка кластеризованных индексов.
Установка не требуется, включить расширение в Pangolin:
CREATE EXTENSION pg_repack;
Реорганизации таблиц без блокировки#
Особенности функциональности:
для работы pg_repack требуются права суперпользователя;
в реорганизуемых таблицах требуется наличие primary key или хотя бы одного уникального поля;
во время работы утилиты с обрабатываемой таблицей можно производить любые манипуляции, кроме DDL.
Алгоритм:
Создается таблица для логирования операций над оригинальной таблицей, которые будут происходить во время выполнения алгоритма.
В оригинальной таблице создаются триггеры для операций
Insert,UpdateиDelete. Триггеры записывают действия в созданную таблицу для логирования.Создается новая таблица – копия оригинальной таблицы.
Копируются индексы из оригинальной таблицы в новую.
К новой таблице применяются все операции из таблицы логирования (см. шаг 1).
Выполняется swap оригинальной и новой таблиц.
Удаляется оригинальная таблица.
На шагах 1, 2, 6 и 7 для оригинальной таблицы применяется короткая Access Exclusive-блокировка. Данная блокировка незначительна по времени. На остальных шагах к оригинальной таблице применяется Access Share-блокировка.
Недостатки pg_repack#
Имеются следующие недостатки:
отсутствие ограничений на работу с диском и невозможность распределить нагрузку. Это приводит к значительной нагрузке на диск и падению производительности при работе с большими таблицами (падение сравнимо с вызовом полного копирования таблицы);
во время работы переполняется WAL, что приводит к задержке между лидером и репликой и может привести к падению экземпляра Pangolin. При обработке больших таблиц рекомендуется отключить слот репликации на время работы утилиты;
для реорганизации требуется дополнительное место на диске, равное сумме размеров оригинальной таблицы, таблиц с логами и индексов. При небольшой нагрузке размером логов можно пренебречь.
Пример использования#
Реорганизовать таблицу «bloated_table»:
pg_repack -U <username> -d <dbname> -t bloated_table
Ключи:
-U USERNAME— имя пользователя;-d DBNAME— имя базы данных;--table TABLE_NAMEили-t SCHEME_NAME.TABLE_NAME— выбор таблицы для обработки;--schema SCHEME_NAME— выбор схемы для обработки;--index INDEX_NAME— выбор индекса для обработки;--jobs NUMBER_OF_PROCESSES— запустить несколько параллельных процессов для ускорения обработки.
Внимание!
При включенном прозрачном шифровании (TDE) использовать
pg_repackзапрещено.
Инструмент pgcompacttable#
Инструмент представляет собой скрипт реорганизации данных в раздутых таблицах (bloated tables) без применения Access Exclusive блокировки.
Отличия от pg_repack:
не требует много места на диске:
таблицы обрабатываются «на месте»;
индексы перестраиваются друг за другом, от меньшего к большему. Максимальное требуемое место на диске равно размеру наибольшего индекса;
таблицы обрабатываются с настраиваемыми задержками для предотвращения перегрузки IO и всплесков задержки репликации (см. ключ
--delay-ratio);не может переносить таблицы или индексы в другое табличное пространство.
Принцип работы pgcompacttable#
Вызовом команды
SET field_name = field_nameвыполняется фиктивное обновление всех записей таблицы, начиная с конца. Утилита проходит по таблице итеративно. На первом шаге обновляется несколько страниц (число считается динамически, максимум 5). Задержка перед обработкой каждого поля вычисляется как произведение--delay-ratioи длительности предыдущей итерации. Это позволяет контролировать нагрузку на БД.Внимание!
Pangolin гарантирует, что все новые данные заполняют свободные места, начиная с начала таблицы. Таким образом, по прохождению всех строк таблица будет укомплектована.
После обработки таблицы
pgcompacttableперестраивает индексы за три шага:Создается новый индекс (команда
CREATE INDEXс параметромCONCURRENTLY).Происходит замена (swap) имени старого индекса на новый (команда
ALTER INDEX RENAME).Удаляется старый индекс (команда
DROP INDEXс параметромCONCURRENTLY).
На шаге ii может возникнуть длительная блокировка. Чтобы не блокировать индексы на длительное время,
pgcompacttableвыполняет множество коротких попыток замены индексов. Поведение управляется ключами:--reindex-retry-count– максимальное количество попыток;--reindex-retry-pause– задержка между попытками;--reindex-lock-timeout– максимальное время выполнения переименования. При превышении количества попыток выводится WARNING-сообщение вида:
Reindex <имя индекса>, lock has not been acquiredПосле обработки всех строк запускается
VACUUMдля удаления пустых блоков с конца таблицы.
Запуск скрипта#
Для запуска скрипта требуются права superuser.
Рекомендуется запускать его от имени владельца кластера. В этом случае скрипт может использовать ionice в бэкенде PostrgreSQL для понижения приоритетов IO.
Используемые ключи делятся на группы:
общие ключи;
ключи настройки соединения;
ключи работы с БД;
ключи настройки поведения инструмента.
Общие ключи:
-?,--help— вывести короткую справку об инструменте;-m,--man— вывести полную справку об инструменте;-V,--version— вывести версию инструмента;-q,--quiet— включить тихий режим. В этом режиме выводятся только сообщения об ошибках и результирующее сообщение;-v,--verbose— включить режим протоколирования. В этом режиме выводятся все сообщения.
Ключи настройки соединения:
-h HOST,--host HOST— имя или IP-адрес сервера базы данных;-p PORT,--port PORT— порт для подключения к базе данных;-U USER,--user USER— имя пользователя базы данных, под которым выполняется подключение. По умолчанию имя текущего пользователя, получаемое командойwhoami;-W PASSWD,--password PASSWD— пароль для указанного пользователя.
Примечание:
Инструмент
pgcompacttableиспользует Perl модуль DBI для соединения с базой данных.Если настройки соединения не передаются в ключах, то инструмент использует переменные окружения
PGHOST,PGPORT, имя текущего пользователя иPGPASSWORD.Если пароль не задан, инструмент попробует применить пароль (в порядке обращения):
Из файла, указанного в переменной окружения
PGPASSFILE.Из файла
HOME/.pgpass.
Ключи работы с БД:
-a,--all– обработать все базы данных в кластере;-d DBNAME,--dbname DBNAME– имя базы данных для обработки. По умолчанию – все базы данных, которыми владеет пользователь, под которым выполняется подключение;-n SCHEMA,--schema SCHEMA– имя схемы для обработки. По умолчанию обрабатывается публичная (public) схема;-N SCHEMA,--exclude-schema SCHEMA– имя исключаемой из обработки схемы;-t TABLE,--table TABLE– имя таблицы для обработки. По умолчанию – все таблицы обрабатываемой схемы;--tables-like 'LIKE expression'– SQL LIKE условие поиска таблиц для обработки. По умолчанию – все таблицы обрабатываемой схемы;-T TABLE,--exclude-table TABLE– имя исключаемой из обработки схемы.
Инструмент игнорирует не найденные в кластере базы данных, схемы и таблицы. Избыточные исключения так же игнорируются.
Все ключи, кроме --all, можно использовать несколько раз.
Ключи настройки поведения инструмента:
-R,--routine-vacuum– включить использованиеVACUUM. По умолчанию выключено;-r,--no-reindex– выключить переиндексирование таблиц после их обработки;--no-initial-vacuum– выключить запускVACUUMперед обработкой таблицы;-i,--initial-reindex– включить переиндексирование таблицы перед ее обработкой;-s,--print-reindex-queries– выводить запросы на переиндексацию. Пример применения: выполнение самостоятельного переиндексирования после работы инструмента;--reindex-retry-count– максимальное количество попыток замены имени индекса. По умолчанию100;--reindex-retry-pause– задержка между попытками реиндексации, в секундах. По умолчанию 1 секунда;--reindex-lock-timeout– задержка перед переиндексацией после выполнения запросовALTER TABLE, в миллисекундах. По умолчанию1000миллисекунд;-f,--force– принудительная реорганизация всех таблиц в указанной базе данных;-E RATIO,--delay-ratio RATIO– коэффициент для вычисления задержки между раундами. Задержка вычисляется как произведение времени выполнения прошлого раунда и указанного коэффициента. По умолчанию2;-Q Query,--after-round-query Query– SQL выражение, выполняемое после каждого раунда обработки базы данных;-o COUNT,--max-retry-count COUNT– максимальное количество попыток повторной обработки в случае ошибки. По умолчанию10.
Внимание!
Таблицы и индексы с «раздутием» меньше 20% считаются нормальными.
Пример использования#
Реорганизовать таблицу bloated_table:
pgcompacttable --dbname -t bloated_table
Расширение pg_squeeze#
Расширение предназначено для оптимизации хранения данных в таблицах и индексах методом переупаковки данных в новый объект.
Предусмотрен обмен данными между расширением и администратором СУБД только через следующие объекты:
Объект |
Тип |
Назначение |
|---|---|---|
squeeze.tables |
таблица |
Регистрация автоматически обслуживаемых таблиц, по одной записи на таблицу |
squeeze.log |
таблица |
Журнал переупаковок, заполняется по записи на каждую успешно переупакованную таблицу |
squeeze.errors |
таблица |
Журнал ошибок, заполняется ошибками переупаковки |
squeeze.start_worker(); |
функция |
Запустить фоновую обработку |
squeeze.stop_worker(); |
функция |
Остановить фоновую обработку |
squeeze.squeeze_table(); |
функция |
Переупаковать таблицу вручную |
Проверка расширения#
Для проверки подключения расширения необходимо:
Убедиться, что установлены следующие параметры сервера:
wal_level: logical
max_replication_slots = 1 # или добавить 1 к существующему значению
shared_preload_libraries = 'pg_squeeze' # или добавить библиотеку к существующим
Проверить наличие схемы
squeeze, а также подключение под ТУЗsqueeze_tuz;Перезапустить узлы для применения.
Включение автоматической обработки#
Установите два параметра сервера:
squeeze.worker_autostart = 'my_database your_database'
squeeze.worker_role = squeeze_tuz
При следующем перезапуске сервера запустятся четыре обработчика: планировщик и переупаковщик по my_database, такие же процессы по your_database. Все обработчики получат привилегии суперпользователя squeeze_tuz.
Настройка существующей базы#
Добавьте установленное расширение к существующей базе, для этого подключитесь к базе суперпользователем и выполните команду:
CREATE EXTENSION pg_squeeze;
Чтобы настроить автоматический запуск фоновых обработчиков по базе, дополните или добавьте параметр сервера:
squeeze.worker_autostart = 'my_database your_database next_database'
Регистрация таблицы#
Подключитесь к базе в качестве суперпользователя, после чего выполните:
INSERT INTO squeeze.tables (tabschema, tabname, first_check) VALUES ('app', 'foo', now());
Поля таблицы и их значения подробно описаны ниже.
Отмена регистрации#
Подключитесь к базе в качестве суперпользователя, после чего выполните:
DELETE FROM squeeze.tables WHERE tabschema='app' and tabname='foo';
Ручная переупаковка таблицы#
Выполните команду:
SELECT squeeze.squeeze_table('app', 'pgbench_accounts', null, null, null);
Полная форма: squeeze.squeeze_table(tabchema name, tabname name, clustering_index name, rel_tablespace name, ind_tablespaces name[]). Параметры - см. ниже.
Поля таблицы squeeze.tables и параметры функции squeeze.squeeze_table#
Следующие параметры применяются как при регистрации таблицы для автоматической обработки, так и при ручной переупаковке. Им соответствуют и поля таблицы squeeze.tables, и аргументы squeeze.squeeze_table():
tabschema– название схемы;tabname– название таблицы;clustering_index– название существующего индекса обрабатываемой таблицы. Когда обработка будет завершена, записи в таблице будут физически упорядочены и отсортированы в порядке ключа индекса;rel_tablespace– существующее табличное пространство, в которое должна быть перемещена таблица.NULLозначает, что таблицу следует оставить на своем месте;ind_tablespaces– двумерный массив, в котором каждая запись задает соответствие табличного пространства индексу. Первая и вторая колонка представляют из себя название индекса и табличного пространства соответственно. Все индексы, для которых соответствие не задано, останутся в изначальном табличном пространстве.Внимание!
Если табличное пространство задано для таблицы, но не для индексов, то в это табличное пространство перемещается только таблица. Индексы в таком случае остаются в первоначальном пространстве. Таким образом, пространство таблицы не принимается по умолчанию и для индексов.
Следующие параметры применяются только при регистрации таблицы, им соответствуют поля таблицы squeeze.tables:
schedule– указывает, когда следует проверять и, возможно, переупаковывать таблицу. Расписание задается значением следующего составного типа данных, который напоминает по значению элемент файлаcrontab:CREATE TYPE schedule AS ( minutes minute[], hours hour[], days_of_month dom[], months month[], days_of_week dow[] );Здесь
minutes(от 0 до 59) иhours(от 0 до 23) задают время проверки внутри суток, аdays_of_month(от 1 до 31),months(от 1 до 12) иdays_of_week(от 0 до 7, где 0 и 7 означают воскресенье) определяют дни проверок; Проверка выполняется, еслиminute,hourиmonthсовпадают с текущим временем. При этомNULLозначает любую минуту, час и день соответственно. Для того чтобы проверка запустилась, как минимум один из параметровdays_of_month,days_of_weekдолжен совпасть с текущим временем. В противном случае оба параметра должны бытьNULL. Например, следующая таблица будет проверяться в 22:30 каждую среду и пятницу:INSERT INTO squeeze.tables (tabschema, tabname, schedule, free_space_extra, vacuum_max_age, max_retry) VALUES ('app', 'bar', ('{30}', '{22}', NULL, NULL, '{3, 5}'), 30, '2 hours', 2);free_space_extra– минимальный процент дополнительного свободного пространства, при котором запускается переупаковка таблицы. «Дополнительный» означает, что порожденноеfillfactorсвободное пространство - не причина сжимать таблицу; Например, еслиfillfactorравен 60, то как минимум 40 процентов каждой страницы (блока) должны оставаться свободными при обычной работе. Так, для детектирования со стороныpg_squeezeсостояния таблицы при 70 процентах свободного места, необходимо установить порогfree_space_extraв значение 30. Порог вычисляется как разность требуемых свободных 70 процентов и 40 процентов, свободных поfillfactor. Значение по умолчанию дляfree_space_extraравно 50.min_size– минимальное дисковое пространство, которое должна занимать на диске таблица, чтобы подходить для обработки. Значение по умолчанию -8;vacuum_max_age– максимальное время после завершения последней процедурыVACUUMпо таблице, в течение которого карта свободного места (free space map, FSM) считается свежей. Как только этот интервал истек, доля устаревших версий записей (dead tuples), возможно, становится значительной. Поэтому для оценки потенциального эффектаpg_squeezeпотребуется больше усилий, чем простейшая проверка FSM. Значение по умолчанию -1 hour;max_retry– максимальное число повторных попыток переупаковки таблицы, если произошел сбой первой попытки обработки соответствующей задачи. Типичная причина повтора обработки - то, что определение таблицы поменялось на протяжении операции переупаковки. Если достигнуто максимальное число повторов, то обработка таблицы считается завершенной. Как только наступит следующее запланированное время, будет создана следующая задача. Значение по умолчанию -0(т.е. не повторять);skip_analyze– указывает, что за обработкой таблицы не должна следовать командаANALYZE. Значение по умолчанию -false, поэтому по умолчаниюANALYZEпосле обработки таблицы выполняется.
По требованиям к механизму защиты данных от привилегированных пользователей в Pangolin (перенос таблиц между табличными пространствами как отдельное подлежащее защите действие), запрещено переносить объекты из зашифрованного табличного пространства в открытое как при автоматической обработке, так и вручную. В случае возникновения ошибки Action is forbidden, которая связана с отказом в выполнении переноса в новое табличное пространство, необходимо обратиться к администратору безопасности для получения соответствующих прав. Отказ происходит, когда при явно установленных параметрах rel_tablespace или ind_tablespaces и включенной защите объекта запрошена переупаковка таблицы или индекса, у которых исходное табличное пространство было зашифровано, а новое таковым не является.
Мониторинг метрик репликации#
Рекомендуется обеспечить на стороне инфраструктуры мониторинг стандартной логической репликации. Как минимум, необходимо отслеживать следующие метрики:
SELECT slot_name,
pg_wal_lsn_diff(restart_lsn, pg_current_wal_lsn()) process_lag_bytes,
pg_wal_lsn_diff(confirmed_flush_lsn, pg_current_wal_lsn()) apply_lag_bytes
FROM pg_replication_slots WHERE slot_type='logical';
Для найденных slot_name можно построить графики process_lag_bytes и apply_lag_bytes с триггерами, например, 256 МБ/1 ГБ warning/critical.
В списке рекомендованных метрик для Pangolin эти метрики объединены под именем pgse_replication_slots_retained_bytes_active. Подробнее о событиях мониторинга смотрите в разделе «События мониторинга». В разделе репликация той же таблицы доступны запросы и правила для более подробного отслеживания процесса. А на странице мониторинг статуса репликации можно узнать смысл этой информации и познакомиться с примерным решением в виде панели отчетов для Grafana.
Можно использовать для мониторинга любое решение на выбор. Чтобы узнать подробнее об использовании Grafana для мониторинга параметров Pangolin и сборе метрик смотрите документ «Установка и настройка дополнительных компонентов системы, не входящих в состав дистрибутива Pangolin», раздел «Мониторинг с помощью Grafana».
Чтобы исправить ситуацию по сигналам на эти метрики, если слот репликации относится к pg_squeeze, следует прервать переупаковку. Возможно, для этого придется самостоятельно удалить процесс ручной переупаковки или фоновый процесс-переупаковщик, после чего можно будет удалить не используемый слот. Далее операцию ручной переупаковки придется повторить. В случае фонового процесса, он будет запланирован на следующий интервал автоматически.
Стандартная метрика для отслеживания свободного пространства на дисковом томе, который хранит WAL, также должна быть включена.
Аудит действий, выполняемых расширением#
Для того чтобы в логе сервера присутствовали записи аудита с маркером AUDIT:, интегрированное решение pgaudit должно быть корректно настроено. Расширение pg_squeeze самостоятельно регистрирует два события:
факт вызова функции переупаковки
squeeze.squeeze_table(), вне зависимости от способа вызова функции - в ручном или автоматическом режиме. Данное событие соответствует классу событий аудитаMISC.факт переноса таблицы и/или индекса в другое табличное пространство, выполняемого в рамках функции по переупаковке таблицы. Данное событие соответствует классу событий аудита
DDL.
Настройка аудита для регистрации этих действий заключается в добавлении MISC и DDL в переменную pgaudit.log в соответствии с ролевой моделью, то есть:
при ручном способе переупаковки эти классы аудита должны быть установлены для пользователя, выполняющего вызов переупаковщика;
при автоматизированной переупаковке - для пользователя, от которого запущен процесс, запускающий переупаковку по расписанию (
squeeze.worker_role- если запуск рабочего процесса осуществляется на старте сервера или тот пользователь, который запустил процесс вручную).
Например:
ALTER ROLE db_admin SET pgaudit.log='ddl, role, connection, misc_set, misc';
First_db=# \drds db_admin
List of settings
Role | Database | Settings
----------+----------+-------------------------------------------------------
db_admin | | pgaudit.log=ddl, role, connection, misc_set, misc
(1 row)
Для аудита событий добавления/изменения/модификации расписания автоматизированного переупаковщика необходимо настроить аудит над объектом squeeze.tables. С инструкцией можно ознакомиться в документации pgaudit. Ниже приведен пример настройки:
CREATE ROLE squeeze_auditor;
GRANT INSERT, UPDATE, DELETE, TRUNCATE ON squeeze.tables TO squeeze_auditor;
\dp+ squeeze.tables
ALTER ROLE db_admin set pgaudit.role=squeeze_auditor;
\drds db_admin
List of settings
Role | Database | Settings
----------+----------+-------------------------------------------------------
db_admin | | pgaudit.log=ddl, role, connection, misc_set, function+
| | pgaudit.role=squeeze_auditor
(1 row)
Также в параметр log_line_prefix может быть добавлен тип процесса - %b. Это позволит различать в логе записи о ручной и автоматизированной переупаковке.
Аналитика производительности Pangolin#
Для сбора данных в Pangolin создается дочерний процесс, в цикле которого происходит периодический опрос статистики активности и блокировок.
Для последующего анализа собранной статистики можно сформировать отчет с указанием временного диапазона. Отчет сохраняется в формате HTML. Описание и примеры разделов отчета представлены в отдельном документе.
Конфигурационные параметры#
Примечание:
Для применения внесенных изменений настроечных параметров необходимо выполнить перезагрузку.
При изменении пути к папке хранения файлов необходимо содержимое старой папки перенести в новую.
Настройка параметров для аналитики производительности осуществляется в файле postgresql.conf:
performance_insights.enable— включает/выключает функциональность (значение по умолчанию — false);performance_insights.sampling_enable— включает/выключает сбор данных (значение по умолчанию — true). После изменения настроек параметра требуется выполнить одно из предложенных действий:перезагрузка;
вызов команды
SELECT pg_reload_conf();;отправить сигнал SIGHUB;
performance_insights.sampling_period— задает периодичность сбора данных в миллисекундах (значение по умолчанию —1s). Минимальное значениеmin - 100ms, значениеmax— не ограничено;performance_insights.num_samples_in_ram— количество итераций сбора данных активности текущих сессий, хранящихся в оперативной памяти (значение по умолчанию — 900). Определяет время хранения данных активности текущих сессий в оперативной памяти. Время определяется количеством сборов данных (performance_insights.num_samples_in_ram), умноженным на периодичность сбора данных (performance_insights.sampling_period). Таким образом, время хранения данных активности текущих сессий по умолчанию (900 * 1s) —> 900 секунд (или 15 минут), при этом:minзначение - 1;maxзначение — не ограничено (2147483647);
performance_insights.num_samples_in_files— количество итераций сбора данных активности текущих сессий, хранящихся в файлах (на диске) (значение по умолчанию — 86400). Определяет время хранения данных активности текущих сессий в файлах (на диске). Время определяется количеством сборов данных (performance_insights.num_samples_in_files) умноженное на периодичность сбора данных (performance_insights.sampling_period). Таким образом, время хранения данных активности текущих сессий по умолчанию (86400 * 1s) —> 86400 секунд (или 1 сутки), при этом:minзначение - 1;maxзначение — не ограничено (2147483647);
performance_insights.directory— путь к папке, в которую сохраняются файлы с полученными данными (значение по умолчанию${PGDATA}/pg_perf_insights);Внимание!
Рекомендуется задать директорию хранения, находящуюся за пределами директории с данными СУБД (PGDATA).
В противном случае возможна потеря статистики при реиницилизации кластера.
performance_insights.masking— включает/выключает маскирование параметров запроса, параметров соединения и имени пользователя (значение по умолчанию — true). Параметрperformance_insights.maskingрекомендуется поместить под защиту.
Функции#
Для работы с данными по аналитике производительности Pangolin применяются следующие функции:
pg_stat_get_activity_history— возвращает набор записей с данными об активности сессий в определенный момент времени;pg_stat_get_activity_and_lock_status_history— возвращает данные активности текущих сессий вместе с данными блокировок (если они имеются) и затраченными ресурсами (CPU, IO);pg_stat_get_activity_history_last— возвращает набор записей с данными об активности сессий в последний период обновления истории;pg_lock_status_history— возвращает набор записей с информацией о блокировках в определенный момент времени;pg_stat_activity_history_reset— функция для управления сохраненными данными, которая полностью очищает историю;pg_stat_activity_and_lock_status_history_report— формирует отчет из собранных данных.
Примечание:
По умолчанию функции по аналитике производительности может вызвать суперпользователь или пользователь, у которого есть привилегии групповой роли
pg_read_all_perfinsight.
Подробное описание функций приведено в документе «Список PL/SQL функций продукта», раздел «Аналитика производительности Pangolin».
Получение диагностической информации об узле СУБД#
Утилита формирования диагностического отчета предназначена для упрощения и ускорения сбора информации о состоянии и настройках стенда Pangolin. Информация собирается посредством запуска утилиты и передачи в нее определенных параметров сбора и формирует на выходе набор файлов, упакованный в tar.gz архив. Некоторые компоненты отчета требуют повышенных привилегий или доступов к каталогам.
После установки Pangolin утилита доступна в каталоге /usr/pgsql-05-se/diagnostic_tool. Есть возможность скопировать каталог в любое другое доступное пользователю место. Утилита представляет собой скомпилированный бинарный файл и набор .so библиотек. Утилита не требует выполнения дополнительных действий для работоспособности и установки дополнительных модулей.
Примечание:
Утилита
diagnostic_toolверсии 1.0 работает с версией Pangolin не ниже 5.2.0.
Файловый состав утилиты следующий:
diag— основной файл, который является точкой входа и используется для запуска сбора статистики. Утилита осуществляет сбор аргументов, вывод справки и последовательный запуск модулей сбора информации. После окончания работы утилиты осуществляется архивирование отчета, вывод сообщения о завершении работы и пути до сформированного отчета;utils/common.so— модуль общих переиспользуемых функций (печать в общий лог, создание каталогов, синтаксический анализ текста в csv и т.д.);utils/vars.so— модуль глобальных переменных;utils/sql.so— модуль SQL-скриптов для работы с БД;utils/linux_info.so— модуль сбора информации об ОС;utils/linux_stat.so— модуль сбора статистики использования ОС;utils/logs_collect.so— модуль сбора лог-файлов;utils/config.so— модуль сбора конфигурационных файлов.
Использование#
Для запуска утилиты необходимо перейти в каталог diagnostic_tool с исполняемым файлом утилиты и ее библиотеками. Затем произвести запуск утилиты. Примеры:
./diag
./diag --help
./diag --host 127.0.0.1 --port 5433 --user psimax --database first_db --pgbuser pgbouncer --logs --log_lines_count 10
Утилита поддерживает следующие параметры:
$ ./diag --help
usage: diag [-h] [-H HOST] [-p PORT] [-U USER] [-d DATABASE]
[--pgbuser PGBUSER] [--logs] [--pgdata PGDATA]
[--log_lines_count LOG_LINES_COUNT] [--version]
This is the Pangolin or PostgreSQL Diagnostics Collection Script. Some parts
of script need superuser or root privileges, if the privileges are
insufficientsome information cannot be collected.
optional arguments:
-h, --help show this help message and exit
-H HOST, --host HOST database server host or socket directory (default:
127.0.0.1)
-p PORT, --port PORT database server port (default: 5433)
-U USER, --user USER database user name (default: postgres)
-d DATABASE, --database DATABASE
database name (default: postgres)
--pgbuser PGBUSER Pangolin Pooler user name
--logs collect log files
--pgdata PGDATA pgdata dir path
--log_lines_count LOG_LINES_COUNT
count last lines of log for collecting (default: 300)
--version show program's version number and exit
Описание параметров:
-U USER,--user USERПараметр username для подключения к СУБД Pangolin.
Значение по умолчанию:
postgres.-p PORT,--port PORTПараметр port для подключения к СУБД Pangolin.
Значение по умолчанию:
5433.-h,--helpВыводит справку по использованию утилиты.
-H HOST,--host HOSTПараметр host для подключения к СУБД Pangolin.
Значение по умолчанию:
127.0.0.1.-d DATABASE,--database DATABASEПараметр database для подключения к СУБД Pangolin.
Значение по умолчанию:
postgres.--pgdata PGDATAПараметр, определяющий путь к
$PGDATA. Если не задан — будет произведена попытка поиска данного каталога в переменных окружения и запущенных процессах Pangolin.Значение по умолчанию отсутствует.
--pgbuser PGBUSERПараметр username для подключения к виртуальной БД Pangolin Pooler для сбора статистики использования Pangolin Pooler.
Значение по умолчанию отсутствует.
--logsПараметр, включающий сбор лог-файлов. По умолчанию лог-файлы не собираются.
--log_lines_count LOG_LINES_COUNTПараметр, определяющий, сколько последних строк лог-файлов сохранить в отчет. Параметр введен для ограничения размера итогового отчета, количество строк должно быть достаточным для анализа и не слишком большим для экономии размера, как правило, достаточно 300-700 последних строк.
Значение по умолчанию:
300.--versionВыводит версию утилиты и завершает работу.
В случае, если переданные параметры --user или --pgbuser отличаются от значений по умолчанию, утилита запросит пароль для данных пользователей. В ответ на запрос утилиты введите соответствующий пароль (пароль при вводе не отображается).
После того, как утилита отработала, она выдаст сообщение о том, где сохранена диагностическая информация. Отчет формируется в каталоге с утилитой из префикса pgse_diag_out_ и временной метки запуска утилиты YYYYMMDD_HHmmSS, где YYYY — год, MM — месяц, DD — день, HH — часы, mm — минуты, SS — секунды. Сформированный архив с отчетом можно скопировать с удаленного узла, например, с помощью scp:
scp postgres@{IP-адрес}:/home/postgres/diagnostic_tool/pgse_diag_out_20220607_145935.tar.gz .
Чтобы проверить содержимое архива его нужно распаковать:
tar -xvf ./pgse_diag_out_20220607_145935.tar.gz
Внимание!
Перед отправкой отчета нужно убедиться в отсутствии недопустимой к передаче информации, а именно:
непараметризованных запросов или значений параметров в секции
collect hot statements statфайлаdiag.log;непараметризованных запросов или значений параметров в секции
collect slow statements statфайлаdiag.log;непараметризованных запросов или значений параметров в файле
csv/dbms/hot_statements.csv;непараметризованных запросов или значений параметров в файле
csv/dbms/slow_statements.csv;логинов/паролей, а также иной чувствительной информации в секции
collect running servicesфайлаdiag.log(в колонкеCOMMANDстрока запуска процесса);логинов/паролей, а также иной чувствительной информации в файле
csv/psaux.csv(в колонкеCOMMANDстрока запуска процесса);логинов/паролей(в том числе хешей паролей) в конфигурационном файле
config/pg_hba.conf;логинов/паролей(в том числе хешей паролей) в конфигурационном файле
config/postgresql.yml(конфигурационный файл Pangolin Manager, проверить в том числе секциюpg_hba);непараметризованных запросов и значений параметров в файле
logs/postgresql-XXXXXXXX.log, гдеXXXXXXXXкомбинация из даты и порядкового номера лог файла.
Отчетность по нагрузке Pangolin#
Отчетность по нагрузке в Pangolin реализована с помощью расширения pg_profile. Для расширения pg_profile в БД создается набор таблиц под историческое хранилище. Это хранилище будет накапливать статистические выборки с кластера postgres. Выборки собираются вызовом функции take_sample(). Для сбора статистики по расписанию можно использовать cron или расширение pg_cron.
Периодические выборки могут помочь найти источники интенсивной нагрузки в прошлом. Например, стало известно о деградации производительности, которая была несколько часов назад. Для решения подобных проблем можно построить отчет между двумя выборками, охватывающими период проблемы с производительностью, чтобы увидеть профиль нагрузки БД. Это поможет узнать точное время возникновения проблемы с производительностью. Для этого рекомендуется использовать инструмент мониторинга (например, Zabbix).
Выборку можно сохранить непосредственно перед запуском любой бизнес-задачи (блока транзакций) и после того, как она будет выполнена.
Когда сохраняется выборка, вызывается функция pg_stat_statements_reset() как гарантия того, что отчеты не будут потеряны из-за достижения параметра pg_stat_statements.max. Отчет будет содержать раздел, информирующий о том, что количество собранной статистики в любой выборке достигнет 90% от параметра pg_stat_statements.max.
При установке расширения автоматически создается локальный сервер. Это сервер для кластера, где установлено расширение pg_profile.
Для подключения к БД используется расширение db_link.
Управление планами запросов#
Расширения pg_outline и pg_hint_plan входят в состав Platform V Pangolin. Эти расширения, в совокупности, предоставляют возможность фиксации и подмены планов запросов для оптимизации работы планировщика запросов.
Расширение pg_outline
Функциональные возможности:
управление (добавить, заменить, удалить, включить, выключить) правилами подмены (фиксациями подсказок
pg_hint_plan) планов запросов;возврат информации о созданных правилах подмены планов запросов;
возврат идентификатора запроса (
queryId) для текста запроса (queryText).
Расширение pg_hint_plan
Функциональные возможности:
подсказки (hint) планировщику запросов для управления планами выполнения запросов, в части:
методов сканирования таблиц;
методов соединения таблиц;
порядка соединения;
корректировки числа строк результата соединения;
настройки параллельности обработки таблиц;
установки значений параметров конфигурации на время планирования запроса;
управление планами подготовленных запросов (prepared statements) через заданные в тексте этих запросов подсказок (hint);
управление планами запросов в составе PL/pgSQL-блока через подсказки (hint), заданные в тексте запросов в PL/pgSQL-блоках;
дополнение запросов подсказками «на лету» на этапе планирования запроса на уровне всей СУБД в составе Platform V Pangolin. Это позволяет выполнять:
компенсационную корректировку запросов на основе заполняемой таблицы подсказок, которая устанавливает соответствие текста дополняемого запроса и имени приложения (опционально);
компенсационную корректировку для:
запросов с динамическими параметрами (подсказкой плейсхолдеров, вместо конкретных значений);
подготовленных запросов;
управление (через настроечные параметры) на уровне сессии пользователя или всей СУБД в составе Platform V Pangolin:
активностью расширения;
использованием функциональности дополнения подсказками через таблицу подсказок;
уровнем логирования, с которым в лог будут писаться сообщения об ошибках разбора подсказок;
детализацией записей отладочной информации расширения;
уровнем логирования, с которым в лог будут писаться сообщения с отладочной информацией.
Использование подсказок#
Подсказки (hint) должны быть заданы в первом комментарии вида /* */ в тексте запроса. Первым символом в теле комментария должен быть +.
Пример запроса с подсказками (в качестве метода соединения выбрано соединение по хешу, а pgbench_accounts сканируется последовательным способом).
/*+
HashJoin(a b)
SeqScan(a)
*/
EXPLAIN SELECT *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
QUERY PLAN
---------------------------------------------------------------------------------------
Sort (cost=31465.84..31715.84 rows=100000 width=197)
Sort Key: a.aid
-> Hash Join (cost=1.02..4016.02 rows=100000 width=197)
Hash Cond: (a.bid = b.bid)
-> Seq Scan on pgbench_accounts a (cost=0.00..2640.00 rows=100000 width=97)
-> Hash (cost=1.01..1.01 rows=1 width=100)
-> Seq Scan on pgbench_branches b (cost=0.00..1.01 rows=1 width=100)
(7 rows)
В следующем примере применяются только подсказки HashJoin и SeqScan, так как IndexScan не входит в первый комментарий.
/*+
HashJoin(a b)
SeqScan(a)
*/
/*+ IndexScan(a) */
EXPLAIN SELECT /*+ MergeJoin(a b) */ *
FROM pgbench_branches b
JOIN pgbench_accounts a ON b.bid = a.bid
ORDER BY a.aid;
QUERY PLAN
---------------------------------------------------------------------------------------
Sort (cost=31465.84..31715.84 rows=100000 width=197)
Sort Key: a.aid
-> Hash Join (cost=1.02..4016.02 rows=100000 width=197)
Hash Cond: (a.bid = b.bid)
-> Seq Scan on pgbench_accounts a (cost=0.00..2640.00 rows=100000 width=97)
-> Hash (cost=1.01..1.01 rows=1 width=100)
-> Seq Scan on pgbench_branches b (cost=0.00..1.01 rows=1 width=100)
(7 rows)
Фиксация метода сканирования#
Для того, чтобы сформировать план запроса, планировщику необходимо для начала определиться с методами сканирования источников данных. Pangolin предлагает следующие методы доступа к источникам:
Sequential Scan — последовательное сканирование таблицы.
Полный перебор всех блоков таблицы с извлечением 100% данных.
Подходит для:
очень маленьких таблиц (десятки блоков);
полностью кэшированных таблиц, которые помещаются в области разделяемых буферов сервера и файловом кэше ОС;
всех остальных случаев, когда требуется извлечь данные полностью или почти полностью.
Не подходит для:
извлечения малой доли данных (до 1-3%) из объемной таблицы.
Index Scan — индексное сканирование таблицы.
Индекс — заранее подготовленный, отсортированный перечень значений ключа поиска. К значениям ключа в индексе приложены ссылки на страницы (блоки) таблицы и записи в них. Исполнитель сначала ищет в списке значение ключа (или диапазон значений в прямом или обратном порядке), затем читает ссылки, извлекает по ссылкам блоки таблицы, определяет видимость записей и извлекает из видимых записей данные тех полей таблицы, которых не было в ключе.
Подходит для:
выбора небольшого количества данных из большой таблицы (соответствующее условие в разделе WHERE запроса называют предикат высокой селективности);
получения данных в порядке сортировки по ключу индекса, потому что индекс хранит уже отсортированные списки.
Не подходит для:
извлечения большей части записей таблицы (более 10%), потому что чтение хаотично разбросанных блоков таблицы включает множество случайных дисковых операций, а разрешение множества ссылок добавляет нагрузку на процессор.
Index-only Scan — cтрогое индексное сканирование таблицы.
Вид индексного сканирования, при котором обращений к таблице почти не происходит, потому что все требуемые для запроса данные уже есть в индексе, а видимость большинства записей уже описана в карте видимости таблицы.
Подходит для:
такого индексного сканирования, когда запрос не требует данных, не входящих в индекс.
Неприменим, когда:
данных в индексе недостаточно для получения результатов запроса;
у таблицы нет карты видимости, не выполнялся autovacuum или VACUUM.
Bitmap Index Scan — сканирование таблицы по битовой карте индекса.
Промежуточный вариант между последовательным сканированием таблицы и поиском по индексу.
Пример:
Для предикатов с не самой высокой селективностью невыгодно читать таблицу полностью (90% блоков — лишние, не содержат интересных данных) или извлекать блоки таблицы в случайном порядке. Пример такого предиката: id between 100 and 1000000 на таблице с десятком млн записей, где:
при последовательном сканировании пришлось бы прочесть с диска множество лишних блоков;
при поиске по индексу — обработать порядка миллиона ссылок из индекса на записи в хаотично разбросанных блоках таблицы.
Поэтому лучше действовать в две стадии:
Сформировать битовую карту всей таблицы, в которой 1 биту будет соответствовать 1 запись (точная битовая карта, exact) или 1 блок таблицы (грубая карта, lossy), для чего пройти весь индекс, выставляя в 1 биты, указывающие на искомые записи или блоки, содержащие искомые записи.
Один раз последовательно пройти таблицу, интересуясь только отмеченными в полученной карте записями / блоками.
Если в запросе есть несколько низкоселективных предикатов, то соответствующие им битовые карты могут быть объединены в одну общую карту. В этом случае сначала строятся промежуточные карты по каждому из индексов, затем они побитово объединяются в результирующую карту таблицы двоичными логическими операциями, а затем по общей карте выполняется единственный проход таблицы.
TID Scan — сканирование таблицы по TID (tuple identifier).
Быстрое прямое извлечение записи по ее внутреннему физическому адресу, например:
where ctid='(1000,10)'::tid, где:ctid— это псевдоколонка любой из таблиц, физический идентификатор записи. Он состоит из номера блока (в примере1000) и номера записи в блоке (в примере10).
Примечание:
В Pangolin для того, чтобы индекс мог поддерживать поиск по набору полей, ключ поиска должен лидировать в ключе индекса, начиная с первого поля.
Исключение – строгое индексное сканирование, которое может выполняться и без первых полей в ключе. В этом случае индекс служит не в качестве указателя для поиска записей, а в качестве частичного «снимка» таблицы или кэша часто запрашиваемых полей.
Фиксация метода объединения результатов#
Методы объединения источников в общий результат:
Nested Loop – вложенный цикл.
В цикле открывается перебор подходящих записей ведущего (внешнего) источника. Для каждой из записей внешнего источника выбираются все записи из внутреннего (ведомого) источника, подходящие по условию соединения. Далее происходит переход к следующей записи ведущего источника. Для внешних соединений ведущим (первым по порядку, во внешнем цикле) всегда будет внешний источник, левый для LEFT OUTER JOIN или правый для RIGHT OUTER JOIN.
Подходит для:
очень небольших наборов данных, особенно когда поддерживается индексами с обеих сторон соединения;
условий соединения, которые не являются равенствами (
ON a.id >= b.first_a_id) (более того, это единственный метод выполнения таких условий).
Не подходит:
при отсутствии индекса по ключу соединения со стороны ведомого источника — становится крайне неудобно отбирать записи из ведомого источника столько раз, сколько записей вернул ведущий;
при большом количестве записей в любом из источников.
Hash Join – хеш-соединение.
Выбирается полностью ключ объединения из обоих источников. Для этого строится хеш-таблица выборки ключа из ведущего источника, размещается в памяти (
work_mem), если места не хватает - то во временных файлах на диске. Из ведомого источника отбирать значения ключа, хешировать их и искать совпадения значений хеш-функций ключа:hash(a.id) = hash(b.a_id). При совпадении хешей сравнить ключи по данным из таблиц, разрешая конфликты хеширования и извлекая те данные, которых нет в ключе объединения.Подходит:
для объединения больших объемов данных, в том числе без поддержки индексов;
для условий объединения по присутствию в списке (EXISTS, IN) – называется Hash Semi Join;
и по отсутствию в списке (NOT EXISTS, NOT IN) — это Hash Anti Join.
Не подходит:
когда ограничены физические ресурсы: недостаточно
work_mem, мало свободного пространства для временных файлов – приходится хешировать ведущий источник порциями, повторять проходы ведомого источника по каждой из порций;для внешних соединений — не поддерживает их.
Merge Join – соединение слиянием сортированных списков.
Выбирается полностью ключ объединения из обоих источников. Для этого оба источника должны быть отсортированы. Далее сортированные списки значений объединяются между собой.
Подходит для:
внешних соединений средних по объемам источников, особенно при поддержке индексов с обеих сторон.
Не подходит:
когда ограничены физические ресурсы: недостаточно
work_mem, мало места на диске, ограничены процессорные ресурсы для сортировки. Столь же чувствителен кwork_mem, как и хеш-соединение. Предполагает размещение в памяти / на диске полных списков значений ключа для выполнения сортировки.
Фиксация порядка соединения таблиц#
Порядок таблиц в соединении имеет большое значение для планировщика. Например, 10 раз просканировать таблицу из 1 млн записей или 1 млн раз просканировать таблицу из 10 записей — операции разного порядка, по времени и по затратам ресурсов они существенно различаются.
Если количество соединяемых источников не превышает 3-5, то планировщику легко перебрать все варианты соединяемых пар. Если же источников более 12 (порог настраивается), то из-за огромного количества вариантов сочетаний будет применяться эвристический алгоритм (GEQO). Его задача — найти не самый оптимальный план, но сделать это быстро.
Если оптимальный порядок соединения найден, то зафиксировать его позволяет подсказка Leading.
Leading(таблица таблица[ таблица...])— указание планировщику: объединять источники в указанном порядке, от ведущей таблицы до ближайшей к результату.Leading(<пара для объединения>)— указание объединять пару источников в указанном порядке и направлении. Пара для объединения — пара, в которую могут входить таблицы и/или другие пары. Описания пар, заключенные в скобки, могут образовывать вложенные структуры.
Примеры:
Указание использовать порядок объединения
/*+ Leading(t2 t3 t1) */ select t1.f2, t2.f2 from table1 t1 join table2 t2 on t1.f1=t2.f1 join table1 t3 on t3.f1=t2.f1 where t2.f1<1000;Указание использовать порядок объединения с группировкой
/*+ Leading((t2 (t3 t1))) */ select t1.f2, t2.f2 from table1 t1 join table2 t2 on t1.f1=t2.f1 join table1 t3 on t3.f1=t2.f1 where t2.f1<1000;
Установка pg_profile и pg_stat_kcache#
Установка всех расширений и их первоначальная настройка производится инсталлятором.
Расширению
pg_profileтребуются расширенияplpgsql,dblink.Расширению
pg_stat_kcacheтребуетсяpg_stat_statements(устанавливается по умолчанию на всех серверах). Такжеpg_stat_statementsдолжен быть указан в параметреshared_preload_librariesраньше.
Параметры установщика#
Параметр |
Значение по умолчанию |
Описание |
|---|---|---|
|
true |
Установка базы с установленным расширением |
|
20 |
Количество основных объектов (statements, relations и т.д.), которые должны быть представлены в каждой отсортированной таблице отчета. Параметр влияет на размер выборки - чем больше объектов требуется отобразить в отчете, тем больше объектов нужно сохранить в выборке |
|
7 |
Срок хранения выборок в днях |
|
off |
Когда этот параметр включен, |
|
0,30 * * * * |
Строка в стиле crontab для насторойки периодов сбора статистики, по умолчанию: раз в полчаса, каждый час в 0 и 30 минут |
|
on |
Отслеживание выполняемых серверным процессом команд |
|
on |
Контроль, собирается ли статистика о доступе к таблицам и индексам |
|
on |
Отслеживание времени чтения и записи блоков |
|
off |
Отслеживание использования пользовательских функций |
|
top |
Контроль учитываемых модулем операторов |
|
5000 |
Максимальное количество операторов, отслеживаемых модулем (то есть максимальное количество строк в представлении |
|
true |
Установка базы с установленным расширением pg_kcache |
|
on |
Включение механизма подсчета ( |
|
1000000 |
Максимальное количество отношений (имеющих физические файлы на диске) в базе. В случае превышения заданного значения новое отношение создать будет нельзя. Нужно помнить, что к этим отношениям относятся таблица, индекс, генератор последовательности, таблица хранения сверхбольших атрибутов, материализованное представление. Необходимо внимательно отнестись к этому параметру и установить значение «с запасом» |
|
1024 |
Параметр определяет количество отношений в базе (имеющих физические файлы на диске), на которые будет предаллоцирован кэш. Кэш-таблица для отслеживания размеров объектов будет размещена одним выровненным куском памяти, и поиск по ней будет быстрее |
Установка в ручном режиме#
При ручной установке необходимо выполнить следующие шаги:
Установите файлы расширения
pg_profile.Распакуйте файлы расширения в каталог с расширениями Pangolin, например:
tar xzf pg_profile-<version>.tar.gz --directory $(pg_config --sharedir)/extensionНеобходимо убедиться, что используется подходящая утилита
pg_config.Создайте расширения
pg_profile.Рекомендуется установка в отдельную схему – расширение создает свои собственные таблицы, представления, последовательности и функции. Создайте схему для сбора статистики и установите расширение в эту схему:
CREATE SCHEMA pgse_profile; CREATE EXTENSION dblink schema ext; CREATE EXTENSION plpgsql schema pgse_profile; CREATE EXTENSION pg_stat_statements schema ext; CREATE EXTENSION pg_profile SCHEMA pgse_profile;Настройте пользователя:
CREATE ROLE profile_tuz NOLOGIN; REVOKE ALL ON SCHEMA pgse_profile FROM public; GRANT USAGE ON SCHEMA ext TO profile_tuz; GRANT USAGE ON SCHEMA pgse_profile TO profile_tuz; GRANT pg_read_all_stats TO profile_tuz; GRANT EXECUTE ON FUNCTION pg_stat_statements_reset TO profile_tuz; GRANT all ON all TABLES IN SCHEMA ext TO profile_tuz; GRANT SELECT, USAGE ON all sequences IN SCHEMA ext TO profile_tuz; GRANT EXECUTE ON all functions in SCHEMA ext TO profile_tuz; GRANT all ON all tables in SCHEMA pgse_profile TO profile_tuz; GRANT SELECT, USAGE ON all sequences IN SCHEMA pgse_profile TO profile_tuz; GRANT EXECUTE ON all functions IN SCHEMA pgse_profile TO profile_tuz; GRANT USAGE ON TYPE dblink_pkey_results TO profile_tuz;Настройте права пользователя
as_admin.Настройте серверы
pg_profileи задачи cron:SELECT pgse_profile.create_server('master', 'dbname={{ db_name }} host={{ hostname }} port={{ port }} user=profile_tuz');Если установка мастер + standalone:
SELECT pgse_profile.create_server('slave', 'dbname={{ db_name }} host={{ hostname }} port={{ port }} user=profile_tuz'); ()В общем случае, если на одном экземпляре есть несколько БД, достаточно добавить один сервер, который обойдет все базы.
SELECT cron.schedule('{{ pg_profile.stats_periods }}', 'SELECT pgse_profile.take_sample()');Обновите
pg_profileдо новой версии.Новые версии
pg_profileбудут содержать скрипт миграции (когда это возможно). В случае обновления необходимо установить новые файлы расширения (см. шаг 1) и обновить расширение:ALTER EXTENSION pg_profile UPDATE;Установите расширение
pg_stat_kcache.Распакуйте файлы расширения в каталог с расширениями Pangolin:
tar xzf pg_stat_kcache-<version>.tar.gz --directory $(pg_config --sharedir)/extensionУбедитесь, что используется подходящая утилита
pg_config.Cоздайте расширение
pg_stat_kcache.Пропишите расширение в параметр предзагружаемых библиотек:
shared_preload_libraries = 'pg_stat_statements,pg_stat_kcache'Внимание!
Расширение
pg_stat_kcacheдолжно идти послеpg_stat_statements, иначе база не запустится.Установите расширение в схему
ext:CREATE EXTENSION pg_stat_kcache schema ext; -- Настройте пользователя: GRANT EXECUTE ON FUNCTION ext.pg_stat_kcache_reset TO profile_tuz; GRANT EXECUTE ON FUNCTION ext.pg_stat_kcache TO profile_tuz; -- Настроить права пользователя as_admin: GRANT EXECUTE ON FUNCTION ext.pg_stat_kcache_reset to as_admin; GRANT EXECUTE ON FUNCTION ext.pg_stat_kcache to as_admin;Обновите
pg_stat_kcacheдо новой версии.Новые версии
pg_stat_kcacheбудут содержать скрипт миграции (когда это возможно). Так, в случае обновления необходимо будет установить новые файлы расширения (см. шаг 1) и обновить расширение:ALTER EXTENSION pg_profile UPDATE;
Собрать статистику с других кластеров#
Расширение pg_profile, установленное на один кластер, может собирать также статистику с других кластеров, именуемых servers (далее — серверы).
Для этого:
при помощи функции
create_server()создайте необходимые серверы, указав имя и строку подключения (подробнее о функции читайте в документе «Список PL/SQL функций продукта», раздел «Отчетность по нагрузке Pangolin»);убедитесь, что подключение может быть установлено ко всем БД всех серверов.
После этих действий можно собирать, например, статистику с пассивного узла кластера СУБД (Standby) подключаясь к ней с активного узла кластера СУБД (Active).
Настройка параметров#
Задать параметры настроек можно в файле postgresql.conf (указаны значения по умолчанию):
track_activities = on— мониторинг текущих команд для каждого процесса вpg_stat_activity;track_counts = on— мониторинг текущих команд для каждого процесса вpg_stat_all_tables;track_io_timing = on— мониторинг времени чтения/записи блоков вpg_stat_statements,pg_stat_kcache;track_functions = none— включает подсчет вызовов функций и времени их выполнения. Значениеplвключает отслеживание только функций на процедурном языке, аall— также функций на языкахSQLиCдля представленияpg_stat_user_functions;track_activity_query_size = 1024— задает число байт, которое будет зарезервировано для отслеживания выполняемой в данный момент команды в каждом активном сеансе вpg_stat_statements.
Параметры pg_profile#
pg_profile.topn = 20— количество основных объектов (statements, relations и т.д.), которые должны быть представлены в каждой отсортированной таблице отчета. Этот параметр влияет на размер выборки — чем больше объектов необходимо отобразить в отчете, тем больше объектов нужно сохранить в выборке;pg_profile.max_sample_age = 7— срок хранения выборок в днях. Выборки, возраст которых равенpg_profile.max_sample_ageдней и более, будут автоматически удалены при следующем вызовеtake_sample();pg_profile.track_sample_timings = off— когда этот параметр включен, расширениеpg_profileбудет отслеживать точное время сбора выборок;pg_profile.query_length = 20000— ограничение размера запросов, применяется только к тем запросам, которые выполнялись во время сбора статистики. Не применяется к запросам изpg_stat_statements.
Параметры pg_stat_statements (влияют на pg_stat_kcache)#
pg_stat_statements.max = 5000(из установщика) — максимальное количество различных запросов, по которым хранится статистика. Если этот параметр будет недостаточно большим — расширениеpg_profileбудет выдавать предупреждения (в случае, если кэш при сборе статистики заполнен на 80%);pg_stat_statements.track = 'top'— типы запросов (top/nested) по которым хранится статистика:top,all,none;pg_stat_statements.track_utility = 'on'— при значении параметраoff, статистика будет храниться только для запросов SELECT, INSERT, UPDATE и DELETE;pg_stat_statements.track_planning = 'off'— сохранять отдельно статистику этапа планирования;pg_stat_statements.save = 'on'— сохранять статистику в файл, в случае штатной перезагрузки сервера.
Параметры pg_stat_kcache#
pg_stat_kcache.linuz_hz = -1— установить частоту аппаратных прерываний (тиков ЦПУ) для компенсации ошибок выборки. Для данного расширения можно явно указать, какой параметр задан в системе (параметр CONFIG_HZ ядра linux). По умолчанию установлено значение-1— это означает, что расширение попытается автоматически рассчитать эту частоту при старте.
Параметры подсчета точных размеров отношений (указаны значения по умолчанию)#
relnblocks_enable = 'on'— включение механизма подсчета (pg_profileавтоматом подхватит значение из этого механизма, а не изpg_class);relnblocks_hash_max_size = 1000000— максимальное количество отношений (имеющих физические файлы на диске) в базе. В случае переполнения этого числа новое отношение нельзя будет создать.Внимание!
Необходимо внимательно отнестись к параметру
relnblocks_hash_max_sizeи взять достаточный запас, так как к этим отношениям относятся:таблица;
индекс;
генератор последовательности;
таблица хранения сверхбольших атрибутов;
материализованное представление.
`relnblocks_hash_init_size = 1024` — количество отношений (имеющих физические файлы на диске) в базе, на которые будет предварительно выделен кэш.В этом случае хеш-таблица для отслеживания размеров объектов будет размещена одним выровненным куском памяти, и поиск по ней будет быстрее.
Использование pg_profile#
Во время установки расширение создает один активированный локальный сервер для кластера, где установлено расширение.
При необходимости можно добавить дополнительные сервера для сбора статистики командой:
SELECT pgse_profile.create_server('omega','host=name_or_ip dbname=postgres port=5432');
Выборки#
Каждая выборка содержит статистическую информацию о рабочей нагрузке БД со времени предыдущей выборки.
Функция сбора выборок также обслуживает хранилище сервера — удаляет устаревшие выборки в соответствии с политикой хранения.
Сохранение выборки#
Нужно собрать не меньше 2 выборок, чтобы иметь возможность создания первого отчета между 1-ой и 2-ой выборками. Выборки для всех активированных серверов собираются вызовом функции take_sample(). Как правило, собирают одну или две выборки в час.
Для взятия выборок по расписанию можно использовать cron или похожие инструменты. Пример с 30-ти минутным периодом:
*/30 * * * * psql -c 'SELECT pgse_profile.take_sample();' > /dev/null 2>&1
Рассмотренный выше вызов функции не имеет проверки на ошибки результатов take_sample().
Функцию take_sample() можно вызвать так, чтобы она вернула OK для всех серверов, где выборка взята успешно, и показала текст ошибки для неудачных попыток:
select * from take_sample();
server | result | elapsed
-----------+-------------------------------------------------------------------------------+---------------
ok_node | OK | 00:00:00.48
fail_node | could not establish connection +| 00:00:00
| SQL statement "SELECT dblink_connect('server_connection',server_connstr)" +|
| PL/pgSQL function take_sample(integer) line 69 at PERFORM +|
| PL/pgSQL function take_sample_subset(integer,integer) line 27 at assignment +|
| SQL function "take_sample" statement 1 +|
| FATAL: database "nodb" does not exist |
(2 rows)
Хранение данных выборки#
Чтобы не хранить данные выборок вечно, существует политика хранения.
Уровни хранения:
Обычное хранение (действует, если не определен другой уровень хранения). Задайте параметр
pg_profile.max_sample_ageв файлеpostgresql.conf.Определите параметр
max_sample_ageсервера при создании сервера или с помощью функцииset_server_max_sample_age()для существующего сервера.Примечание:
Параметр
max_sample_ageотменяет глобальный параметрpg_profile.max_sample_ageдля конкретного сервера.Baseline переопределяет срок хранения для включенных (included) выборок с наивысшим приоритетом. Создайте baseline (см. ниже раздел «Baselines»).
Список выборок#
Используйте функцию show_samples(), чтобы получить список существующих выборок в репозитории. Эта функция также покажет обнаруженное время сброса статистики.
Подробное описание функции show_samples() в документе «Список PL/SQL функций продукта», раздел «Отчет по нагрузке Pangolin».
Тайминги сбора выборок#
Расширение pg_profile будет собирать подробную статистику по времени сбора выборок, когда включен параметр pg_profile.track_sample_timings.
Baselines#
Baseline — это именованная последовательность выборок с собственными настройками хранения.
Baseline можно использовать в функциях построения отчетов как интервал выборки. Неопределенный baseline хранения означает бесконечное хранение.
Baselines можно использовать для сохранения информации о загруженности базы данных за определенный период времени. Например, можно сохранить выборки, собранные во время нагрузочного тестирования или во время регулярной нагрузки на систему для дальнейшего использования.
Отчеты#
Отчеты создаются в формате HTML функциями по работе с отчетами. В pg_profile есть два типа доступных отчетов:
регулярные отчеты — содержат статистическую информацию о загруженности экземпляра за период отчета;
отчеты по изменениям — содержат данные из двух интервалов со значениями статистики с одинаковых объектов, расположенных один за другим, что упрощает сравнение рабочей нагрузки.
Посмотреть отчет можно в любом веб-браузере.
Функции регулярных отчетов и отчетов по изменениям описаны в документе «Список PL/SQL функций продукта», раздел «Отчет по нагрузке Pangolin».
Построить отчет по изменениям можно также с помощью следующих комбинаций:
get_diffreport([server name,] baseline varchar(25), time_range tstzrange [, description text])
get_diffreport([server name,] time_range tstzrange, baseline varchar(25) [, description text])
get_diffreport([server name,] start1_id integer, end1_id integer, baseline varchar(25) [, description text])
get_diffreport([server name,] baseline varchar(25), start2_id integer, end2_id integer [, description text])
Описание и примеры разделов отчета по нагрузке представлены в отдельном документе «Описание структуры отчета по нагрузке Pangolin».
Примеры формирования отчетов#
psql -Aqtc "SELECT profile.get_report(480,482)" -o report_480_482.html
Для любых других серверов по их именам:
psql -Aqtc "SELECT profile.get_report('omega',12,14)" -o report_omega_12_14.html
Формирование отчета по временному промежутку:
psql -Aqtc "select profile.get_report(tstzrange('2020-05-13 11:51:35+03','2020-05-13 11:52:18+03'))" -o report_range.html
Формирование отчета за последние 24 часа:
psql -Aqtc "select profile.get_report(tstzrange(now() - interval '1 day',now()))" -o last24h_report.html
Отключение функциональности#
Отключение pg_stat_kcache#
Удалите значение
pg_stat_kcacheиз параметраshared_preload_libraries.Перезагрузите сервер.
Отключение подсчета точного размера отношений:#
Установите relnblocks_enable в off.
Отключение сбора статистика pg_profile (не требует перезагрузки#
Определите jobid задачи для
pg_profileс помощью запроса:SELECT * from cron.job;Отключите задачу запросом:
SELECT cron.unschedule(jobid);
Отслеживание времени изменения объекта СУБД#
В целях повышения удобства сопровождения СУБД, при выявлении причин снижения ее производительности, вызванного выполнением DDL-операций над объектами БД, предоставляется инструмент в виде двух представлений psql_dba_objects и psql_all_objects.
Данные представления используются для отслеживания даты/времени последней модификации объектов СУБД psql_dba_objects и psql_all_objects.
Пример выполнения запроса представления psql_dba_objects:
select * from pg_catalog.psql_dba_objects;
-[ RECORD 1 ]-+------------------------------
oid | 16384
name | t1
namespace | 2200
type | table
owner | postgres
ispredef | f
created | 2022-05-31 12:58:20.765479+03
last_ddl_time | 2022-05-31 12:58:20.765479+03
deleted |
Пример выполнения запроса представления psql_all_objects:
select * from pg_catalog.psql_all_objects;
-[ RECORD 1 ]-+------------------------------
oid | 16384
name | t1
namespace | 2200
type | table
owner | postgres
ispredef | f
created | 2022-05-31 12:58:20.765479+03
last_ddl_time | 2022-05-31 12:58:20.765479+03
deleted |
Примечание:
Обновление поля
last_ddl_timeосуществляется в обработчиках DDL-команд, изменяющих логическую структуру объекта, а так жеGRANT/REVOKE. В обработчиках остальных DDL-команд, не модифицирующих логическую структуру объекта, значение поля не меняется. К таким DDL-командам относятся:
REINDEX;
CLUSTER;
TRUNCATE;
VACUUM;
VACUUM FULL;
REFRESH MATERIALIZED VIEW [CONCURRENTLY].
Для очистки записей о датах изменения удаленных объектов используется функция purge_object_mod_dates([start_time timestamptz, end_time timestamptz]) → void.
Функция принимает на вход начало и конец интервала времени, в пределах которого требуется очистить записи объектов, даты удаления которых попадают в этот интервал. Входные аргументы могут быть опущены, тогда функция удалит записи о всех удаленных объектах за все время существования БД.
В качестве неопределенной границы интервала времени может использоваться значение NULL. Вызов упрощенной вариации функции без аргументов purge_object_mod_dates() равнозначен вызову purge_object_mod_dates(NULL, NULL) и purge_object_mod_dates('-infinity', 'infinity').
Пример использования функции purge_object_mod_dates():
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('-infinity', '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, 'infinity');
select purge_object_mod_dates('-infinity', 'infinity');
select purge_object_mod_dates(NULL, '2022-06-08 10:24:51'::timestamptz);
select purge_object_mod_dates('2022-06-08 09:24:51'::timestamptz, NULL);
select purge_object_mod_dates(NULL, NULL);
select purge_object_mod_dates();
select purge_object_mod_dates(now() - interval '1 day', now());
Для сохранения информации о датах изменения удаленных объектов, в течение некоторого интервала времени, введен параметр object_modification_date_keep_interval. В пределах этого интервала времени функции очистки запрещено удалять записи с датами изменения удаленных объектов, которые входят в этот интервал. Интервал отсчитывается от момента выполнения функции очистки psql_purge_object_mod_dates(). Параметр принимает неотрицательные значения типа interval. Если указан нулевой интервал (0), то ограничения на выполнение функции очистки не накладываются. Значение по умолчанию - 1 week (1 неделя). Для изменения параметра необходим перезапуск сервера Pangolin.
Внимание!
Может потребоваться увеличить параметр
max_worker_processes, чтобы это число включало дополнительные рабочие процессы, обновляющие даты создания и модификации объектов в новой БД после ее создания.
Отключению функциональности#
Для включения/отключения функциональности предназначен конфигурационный параметр enable_monitor_object_modification_date (в файле postgresql.conf). Значение параметра по умолчанию - on. Для изменения параметра необходим перезапуск сервера Pangolin.
Управление планами запросов#
Для возможности ручной оптимизации планов запросов в Pangolin используются расширения pg_outline и pg_hint_plan.
Расширение pg_hint_plan#
Расширение pg_hint_plan управляет планом выполнения с помощью фраз-подсказок (hint), записываемых в виде простых описаний в SQL-комментариях особого вида.
Настроечные параметры pg_hint_plan#
Для Pangolin расширение pg_hint_plan модифицировано: запросы создания, изменения и удаления ролей не обрабатываются расширением pg_hint_plan и не попадают в лог даже при включенном детальном логировании расширения.
Наименование |
Описание |
Значение по умолчанию |
Рекомендуемое значение |
|---|---|---|---|
|
Включает/выключает |
|
|
|
Разрешает/запрещает использование подсказок (hint) для запросов из таблицы подсказок |
|
|
|
Определяет уровень логирования, с которым в журнал будут попадать сообщения об ошибках разбора подсказок. Допустимые значения*: |
|
|
|
Указывает детализацию отладочных сообщений. Допустимые значения**: |
|
|
|
Определяет уровень логирования для отладочных сообщений. Допустимые значения*: |
|
* — Уровни важности сообщений ошибок синтаксического анализа и отладочных сообщений. Описание допустимых значений:
ERROR— сообщает об ошибке, из-за которой прервана текущая команда;WARNING— предупреждения о возможных проблемах;NOTICE— информация, которая может быть полезной пользователям;INFO— неявно запрошенная пользователем информация;LOG— информация, полезная для администраторов;DEBUG— максимальный уровень детализации для разработчиков.
** – Детализация отладочных сообщений — количество информации, записываемой в журнал сервера для каждого сообщения. Каждое последующее значение добавляет больше полей в выводимое сообщение. Описание допустимых значений:
off— 0 (сообщения выключены);on— 1;detailed— 2;verbose— 3.
Активация расширения#
Расширение pg_hint_plan по умолчанию выключено.
Чтобы включить расширение pg_hint_plan, используйте настроечные параметры pg_hint_plan.enable_hint и pg_hint_plan.enable_hint_table:
для применения ко всем сессиям — установите значение
onвpostgresql.conf;для конкретных сессий — установите значение
trueчерез командыSETилиALTER USER SET/ALTER DATABASE SET.
Пример:
SET pg_hint_plan.enable_hint = TRUE;
SET pg_hint_plan.enable_hint_table = TRUE;
Установка в ручном режиме#
В некоторых случаях (например, создана новая база, или расширения не были установлены во время работы инсталлятора Pangolin) установку расширений необходимо произвести вручную, для этого:
Добавьте значения
pg_stat_statements,pg_hint_planиpg_outlineв настроечный параметрshared_preload_librariesв конфигурационном файлеPostgreSQL.conf.Подключите расширения:
create extension pg_stat_statements; create extension pg_hint_plan; create extension pg_outline;Включите расширения
pg_outlineиpg_hint_plan(см. раздел «Управление планами запросов»).
Отключение функциональности#
Чтобы отключить функциональность расширения, установите значение off для настроечных параметров pg_hint_plan.enable_hint и pg_hint_plan.enable_hint_table.
Для полного отключения функциональности исключите загрузку библиотеки для всего экземпляра Pangolin одним из следующих способов:
исключите библиотеку из параметра
shared_preload_libraries;измените настройки конкретных сессий через
ALTER USER SET/ALTER DATABASE SET.
После отключения функциональности удалите расширение командой:
DROP EXTENSION pg_hint_plan
Включение журналирования#
Чтобы включить журналирование, в конфигурации сервера необходимо применить рекомендуемые настройки:
pg_hint_plan.parse_messages = warning
pg_hint_plan.debug_print = off
pg_hint_plan.message_level = debug
Методы доступа#
Чтобы вручную закрепить в запросе оптимальный метод доступа или отменить неоптимальный, применяются следующие подсказки:
Метод доступа |
Узел в плане |
Подсказка для включения |
Подсказка для выключения |
|---|---|---|---|
Последовательное сканирование таблицы |
Seq Scan |
SeqScan(таблица) |
NoSeqScan(таблица) |
Индексное сканирование таблицы |
Index Scan |
IndexScan(таблица[ индекс…]) |
NoIndexScan(таблица) |
Строгое индексное сканирование таблицы |
Index Only Scan |
IndexOnlyScan(таблица[ индекс…]) |
Любая подсказка из |
Сканирование таблицы по битовой карте индекса |
Bitmap Index Scan → |
BitmapScan(таблица[ индекс…]) |
NoBitmapScan(таблица) |
Сканирование таблицы по TID |
Tid Scan |
TidScan(таблица) |
NoTidScan(таблица) |
Здесь POSIX Regexp... – список регулярных выражений, используемых для того, чтобы не перечислять поодиночке множество индексов с похожими названиями.
Чтобы зафиксировать метод доступа, в подсказке указывается псевдоним таблицы-источника и, если в методе используются индексы — их также нужно перечислить, разделяя список пробелами.
Внимание!
Подсказка NoIndexScan включает в себя действие подсказки NoIndexOnlyScan.
Наличие карты видимости таблицы (слой visibility map) необходимо для метода доступа Index Only Scan. Этот слой по умолчанию не создается при создании таблицы, поэтому до первого autovacuum / VACUUM / VACUUM FULL по новой таблице не получится осуществить доступ к таблице методом Index Only Scan.
Если индекс, указанный в подсказке IndexOnlyScan, недостаточен для поддержки строгого сканирования (например, не хватает полей до списка запрошенных), то индексное сканирование таблицы может неожиданно выполняться через другой индекс.
Примеры:
Указание использовать сканирование по конкретному индексу:
/*+ IndexScan(t1 ix_table1_2ind_f1_f2) */ select ctid, * from table1_2ind t1 where f1 = 10;Указание не использовать последовательное сканирование:
/*+ NoSeqScan(t1) */ select * from table1 t1 where t1.f1 > 1;
Закрепить в запросе выбранный метод объединения можно при помощи подсказок:
Метод объединения источников |
Узел в плане |
Подсказка для включения |
Подсказка для выключения |
|---|---|---|---|
Nested Loop – вложенный цикл |
Nested Loop |
NestLoop(таблица таблица[ таблица…]) |
NoNestLoop(таблица таблица[ таблица…]) |
Hash Loin - хеш-соединение |
Hash Join |
HashJoin(таблица таблица[ таблица…]) |
NoHashJoin(таблица таблица[ таблица…]) |
Merge Join - соединение слиянием сортированных списков |
Merge Join |
MergeJoin(таблица таблица[ таблица…]) |
NoMergeJoin(таблица таблица[ таблица…]) |
Примеры:
Указание использовать объединение nested loop:
/*+ NestLoop(t1 t2)*/ select t1.f2, t2.f2 from table1 t1, table2 t2 where t1.f1=t2.f1;Указание не использовать объединение hash join:
/*+ NoHashJoin(t1 t2) */ select t1.f2 from table1 t1 where t1.f2 in (select f2 from table2 t2 where f2 > '10000');
Список подсказок (hints)#
Подсказки подразделяются на шесть групп по видам объектов, на которые они могут воздействовать, и видам воздействия. Список доступных подсказок перечислен ниже:
Группа |
Формат |
Описание |
|---|---|---|
Метод сканирования |
|
Принудительное последовательное сканирование таблицы |
|
Принудительное сканирование таблицы по TID |
|
|
Принудительное сканирование таблицы по индексу. Сканирование ограничивается заданными индексами |
|
|
Принудительное сканирование таблицы по индексу. Сканирование ограничивается заданными индексами. Если сканирование только по индексу невозможно, может использоваться обычное сканирование по индексу |
|
|
Принудительное сканирование таблицы по битовой карте. Сканирование ограничивается заданными индексами |
|
|
Принудительно выбирает сканирование таблицы по индексу. Сканирование ограничивается индексами с именами, соответствующими указанному регулярному выражению POSIX |
|
|
Принудительно выбирает сканирование таблицы только по индексу. Сканирование ограничивается индексами с именами, соответствующими указанному регулярному выражению POSIX |
|
|
Принудительно выбирает сканирование таблицы по по битовой карте. Сканирование ограничивается индексами с именами, соответствующими указанному регулярному выражению POSIX |
|
|
Принудительное отключение выбора последовательного сканирования таблицы |
|
|
Принудительное отключение выбора сканирования таблицы по TID |
|
|
Принудительное отключение выбора сканирования таблицы по индексу и сканирования только по индексу для заданной таблицы |
|
|
Принудительное отключение выбора сканирования только по индексу для заданной таблицы |
|
|
Принудительное отключение выбора сканирования по битовой карте для таблицы |
|
Метод соединения |
|
Принудительный выбор вложенного цикла для соединений с заданными таблицами |
|
Принудительный выбор соединения по хешу для соединений с заданными таблицами |
|
|
Принудительный выбор соединения слиянием для соединений с заданными таблицами |
|
|
Принудительное отключение выбора вложенного цикла для соединений с заданными таблицами |
|
|
Принудительное отключение выбора соединения по хешу для соединений с заданными таблицами |
|
|
Принудительное отключение выбора соединения слиянием для соединений с заданными таблицами |
|
Порядок соединения |
|
Принудительный выбор заданного порядка соединения |
|
Принудительный выбор заданного порядка и направления соединения. Соединяемая пара — это пара таблиц и/или других соединяемых пар, заключенная в скобки, что позволяет образовывать вложенные структуры |
|
Корректировка числа строк |
|
Корректировка числа строк, получаемых в результате соединения указанных таблиц. Для корректировки можно задать абсолютное значение (# |
Настройка параллельных запросов |
|
Принудительное включение или отключение параллельной обработки заданной таблицы. <число исполнителей> определяет желаемое количество параллельных исполнителей (значение 0 отключает параллельное выполнение). Если третий параметр равен |
GUC |
|
Установка значения для GUC-параметра на время планирования запроса |
Примечание:
Подробная информация о расширении
pg_hint_planприведена в официальной документации.
Особенности#
В данном разделе приведены особенности работы с расширением pg_hint_plan.
Использование с PL/pgSQL#
Расширение pg_hint_plan работает с запросами в PL/pgSQL блоках с некоторыми ограничениями:
подсказки (hint) действуют только на следующие типы запросов:
запросы, возвращающие одну запись (
SELECT,INSERT,UPDATEиDELETE);запросы, возвращающие множественные записи (
RETURN QUERY);динамические SQL-выражения (
EXECUTE);открытие курсора (
OPEN);итерация по результату запроса (
LOOP FOR);
комментарий с подсказкой (hint) должен быть помещен после первого слова запроса, так как обработка выражений PL/pgSQL отбрасывает комментарии вне выражений (комментарий перед выражением также будет отброшен).
CREATE FUNCTION hints_func(integer) RETURNS integer AS $$ DECLARE id integer; cnt integer; BEGIN SELECT /*+ NoIndexScan(a) */ aid INTO id FROM pgbench_accounts a WHERE aid = $1; SELECT /*+ SeqScan(a) */ count(*) INTO cnt FROM pgbench_accounts a; RETURN id + cnt; END; $$ LANGUAGE plpgsql;
Строчные и прописные символы в именах объектов#
Имена объектов в подсказках (hint) регистрозависимы.
Например, имя объекта TBL в подсказке соответствует только имени "TBL" в базе данных и не соответствует именам без кавычек TBL, tbl и Tbl.
Экранирование спецсимволов в именах объектов#
Объекты в параметрах подсказок pg_hint_plan, которые содержат скобки, двойные кавычки или пробелы, должны быть заключены в двойные кавычки. Правила экранирования символов в Pangolin аналогичны правилам PostgreSQL.
Конкретный вход таблицы при множественном использовании#
Расширение pg_hint_plan идентифицирует целевые объекты подсказок (hint) с использованием псевдонимов (alias), если они заданы.
Пример применения: необходимо указать на конкретное использование объекта в выражении, в котором объект используется множество раз.
/*+ HashJoin(t1 t1) */
EXPLAIN SELECT * FROM s1.t1
JOIN public.t1 ON (s1.t1.id=public.t1.id);
INFO: hint syntax error at or near "HashJoin(t1 t1)"
DETAIL: Relation name "t1" is ambiguous.
...
/*+ HashJoin(pt st) */
EXPLAIN SELECT * FROM s1.t1 st
JOIN public.t1 pt ON (st.id=pt.id);
QUERY PLAN
---------------------------------------------------------------------
Hash Join (cost=64.00..1112.00 rows=28800 width=8)
Hash Cond: (st.id = pt.id)
-> Seq Scan on t1 st (cost=0.00..34.00 rows=2400 width=4)
-> Hash (cost=34.00..34.00 rows=2400 width=4)
-> Seq Scan on t1 pt (cost=0.00..34.00 rows=2400 width=4)
Управление планом запроса в представлении или правиле перезаписи#
Подсказки (hint) не применимы к представлениям в выражениях, но могут влиять на поведение запросов, если находятся в тексте самих представлений.
Это возможно, если имена объектов в подсказках соответствуют именам объектов в представлениях.
Если имена не совпадают, объектам в представлениях можно назначить псевдонимы. Использование псевдонимов в запросах позволит обращаться к представлениям и влиять на поведение запроса.
CREATE VIEW v1 AS SELECT * FROM t2;
EXPLAIN /*+ HashJoin(t1 v1) */
SELECT * FROM t1 JOIN v1 ON (c1.a = v1.a);
QUERY PLAN
------------------------------------------------------------------
Hash Join (cost=3.27..18181.67 rows=101 width=8)
Hash Cond: (t1.a = t2.a)
-> Seq Scan on t1 (cost=0.00..14427.01 rows=1000101 width=4)
-> Hash (cost=2.01..2.01 rows=101 width=4)
-> Seq Scan on t2 (cost=0.00..2.01 rows=101 width=4)
Наследование таблиц#
Подсказки (hint) могут указывать только на родителя наследования, и подсказка влияет на всех наследников. Подсказки, одновременно указывающие прямо на наследников, игнорируются.
Подсказки для множественных запросов#
У одного множественного выражения может быть ровно один комментарий с подсказкой, и подсказки влияют на все отдельные выражения в множественном выражении.
Примечание:
В интерактивном интерфейсе
psqlвыполнение запросов выглядит как операция из множества шагов, однако внутренне представляет собой последовательность отдельных выражений, поэтому подсказки (hint) влияют только на следующее отдельное выражение.
Выражение VALUES#
Все выражения VALUES в предложении FROM имеют внутреннее имя VALUES, поэтому к ним можно обращаться, только если они единственные VALUES в запросе. По результатам выполнения EXPLAIN два или более выражения VALUES в запросе будут выглядеть по-разному, но это лишь визуальное улучшение, и они не различимы.
/*+ MergeJoin(*VALUES*_1 *VALUES*) */
EXPLAIN SELECT * FROM (VALUES (1, 1), (2, 2)) v (a, b)
JOIN (VALUES (1, 5), (2, 8), (3, 4)) w (a, c) ON v.a = w.a;
INFO: pg_hint_plan: hint syntax error at or near "MergeJoin(*VALUES*_1 *VALUES*) "
DETAIL: Relation name "*VALUES*" is ambiguous.
QUERY PLAN
-------------------------------------------------------------------------
Hash Join (cost=0.05..0.12 rows=2 width=16)
Hash Cond: ("*VALUES*_1".column1 = "*VALUES*".column1)
-> Values Scan on "*VALUES*_1" (cost=0.00..0.04 rows=3 width=8)
-> Hash (cost=0.03..0.03 rows=2 width=8)
-> Values Scan on "*VALUES*" (cost=0.00..0.03 rows=2 width=8)
Подзапросы#
Подзапросы в следующем контексте иногда можно указать в подсказке (hint), используя имя ANY_subquery.
IN (SELECT ... {LIMIT | OFFSET ...} ...)
= ANY (SELECT ... {LIMIT | OFFSET ...} ...)
= SOME (SELECT ... {LIMIT | OFFSET ...} ...)
Для такого синтаксиса при планировании объединений для таблиц, включающих подзапрос, планировщик внутренне присваивает этому подзапросу имя, поэтому подсказки объединения применимы к таким объединениям с использованием неявного имени, как показано ниже.
/*+HashJoin(a1 ANY_subquery)*/
EXPLAIN SELECT *
FROM pgbench_accounts a1
WHERE aid IN (SELECT bid FROM pgbench_accounts a2 LIMIT 10);
QUERY PLAN
---------------------------------------------------------------------------------------------
Hash Semi Join (cost=0.49..2903.00 rows=1 width=97)
Hash Cond: (a1.aid = a2.bid)
-> Seq Scan on pgbench_accounts a1 (cost=0.00..2640.00 rows=100000 width=97)
-> Hash (cost=0.36..0.36 rows=10 width=4)
-> Limit (cost=0.00..0.26 rows=10 width=4)
-> Seq Scan on pgbench_accounts a2 (cost=0.00..2640.00 rows=100000 width=4)
Использование подсказки IndexOnlyScan#
Сканирование индекса может неожиданно начать выполняться для другого индекса в том случае, если индекс, указанный в подсказке IndexOnlyScan, оказывается неподходящим для сканирования строго по индексу.
Поведение подсказки NoIndexScan#
Подсказка NoIndexScan включает NoIndexOnlyScan.
Подсказка Parallel и UNION#
UNION может работать в параллельном режиме, только если все базовые подзапросы безопасны для параллельного выполнения. И наоборот, принудительное параллельное выполнение любого из подзапросов позволяет параллельно исполняемому UNION работать параллельно.
Между тем, подсказка PARALLEL с нулевыми рабочими параметрами запрещает параллельное сканирование.
Установка значений параметров pg_hint_plan через подсказку Set#
Параметры pg_hint_plan изменяют поведение самих себя в указанном случае, поэтому некоторые параметры работают не так, как ожидалось:
подсказки по изменению
enable_hint,enable_hint_tablesигнорируются, хотя в логах отладки они указываются как примененные «used hints»;установка
debug_printиmessage_levelначинает работать с середины обработки целевого запроса.
Ошибки#
Расширение pg_hint_plan прекращает синтаксический анализ при любой ошибке и в большинстве случаев использует подсказки (hint), уже проанализированные на момент ошибки. Далее приведены типичные ошибки.
Синтаксические ошибки — любые синтаксические ошибки или неправильные имена подсказок (hint) сообщаются как синтаксическая ошибка. Эти ошибки регистрируются в журнале сервера с уровнем сообщения, который указан в
pg_hint_plan.message_level, при условии, чтоpg_hint_plan.debug_printимеет значение отличное отoff.Неверно указан объект — если объект указан неверно — подсказки (hint) будут тихо проигнорированы. Об этом виде ошибки сообщается в журнале сервера как «not used hints», при условии, что
pg_hint_plan.debug_printимеет значение отличное отoff.Избыточные или конфликтующие подсказки — при повторяющихся или конфликтующих подсказках (hint), применяться будет последняя подсказка (hint). Об ошибках такого типа в журнале сервера сообщается как о «duplication hints» при условии, что
pg_hint_plan.debug_printимеет значение отличное отoff.Вложенные комментарии — комментарий-подсказка (hint) не может включать в себя другой комментарий блока. При нахождении такого комментария
pg_hint_plan, в отличие от других ошибок, прекращает синтаксический анализ и отбрасывает все уже проанализированные подсказки (hint). Об этой ошибке сообщается так же, как и о других ошибках.
Функциональные ограничения#
В данном разделе приведены функциональные ограничения для расширения pg_hint_plan.
Влияние некоторых GUC параметров планировщика — планировщик не учитывает порядок присоединения для предложений
FROM, где количество элементов превышаетfrom_collapse_limit. В таком случае расширениеpg_hint_planне может повлиять на порядок присоединения.Подсказки, пытающиеся задать невыполнимые планы — в случае, когда указанный подсказкой (hint) план выполнить нельзя, планировщик выбирает любые исполнимые планы:
использовать вложенный цикл для
FULL OUTER JOIN;использовать индексы, столбцы которых не указаны в условиях;
выполнить сканирование по TID для запросов без условий по
ctid.
Запросы в ECPG —
ECPGудаляет комментарии в запросах, написанных какembedded SQL, поэтому подсказки (hint) не могут передаваться из этих запросов. Единственное исключение — командаEXECUTEпередает заданную строку без изменений. Для таких случаев используйте таблицу подсказок.Работа совместно с pg_stat_statements — расширение
pg_stat_statementsгенерирует идентификатор запроса (query id), игнорируя комментарии. В результате одинаковые запросы с разными подсказками (hint) объединяются в один и тот же запрос.
Расширение pg_outline#
Расширение pg_outline устанавливается во время работы инсталлятора Pangolin и по умолчанию выключено.
Активация расширения#
Перед использованием расширения pg_outline рекомендуется настроить защиту от изменения таблицы outline.outlines и триггера предотвращения изменения таблицы (pg_outline_prevent_table_modification). Для этого нужно поместить таблицу outline.outlines под защиту при включенной защите от привилегированных пользователей.
Включить расширение pg_outline можно:
только для текущей сессии:
SET pg_outline.enable = TRUE;для всех сессий — в
postgresql.confпропишите:pg_outline.enable = on
Подмена подсказок#
Получение идентификатора запроса (query ID)#
Идентификатор запроса используется для сопоставления выполняемого запроса и правила фиксации и/или подмены этого запроса.
Получить идентификатор в ручном режиме можно через:
расширение
pg_stat_statement;функцию
outline.identify(подробнее в документе «Список PL/SQL функций продукта», раздел «Функциональные возможности расширенияpg_outline»).
Получение идентификатора при помощи расширения pg\_stat\_statement#
Для получения идентификатора при помощи расширения pg_stat_statement выполните:
Если запрос, для которого нужно узнать идентификатор, выполняется впервые, сначала выполните любой простой запрос, например:
SELECT * FROM table1;Найдите идентификатор запроса (поле
queryid) в таблице расширенияpg_stat_statements:SELECT * FROM pg_stat_statements;Примечание:
Идентификатор запроса (поле
queryid) представляет собой целое положительное или отрицательное число.
Получение идентификатора при помощи функции outline.identify#
Для получения идентификатора передайте текст запроса в качестве аргумента:
SELECT outline.identify( 'SELECT * FROM mytable WHERE x=10;' );
Примечание:
В тексте запроса (
queryText) обязательно укажите все константы. Это необходимо для определения типа данных этих констант (само значение констант неважно).
Особенности#
В данном разделе приведены особенности работы с расширением pg_outline.
Номера ссылок#
Не допускается указывать номер ссылки больший, чем количество констант в исходном запросе. В остальном на количество и порядок следования ссылок в подменяющем запросе ограничений нет.
Формирование идентификатора#
В зависимости от метода передачи параметров некоторые запросы могут иметь разный идентификатор (queryid). Например, два идентичных (в генерализованном виде) запроса будут иметь разные query_id:
PREPARE foo1(int) AS SELECT f1, f2 FROM table1 where f1 = $1
PREPARE foo2 AS SELECT f1, f2 FROM table1 where f1 = 123
Хранение планов запросов. Расширение pg_store_plans#
Расширение pg_store_plans предназначено для накапливания статистики по планам выполнения всех SQL-запросов, выполняемых в БД.
Для использования расширения необходимо дополнить список shared_preload_libraries файла postgresql.conf названием расширения, поскольку ему требуется доступ в разделяемую общую память. Для добавления или удаления расширения требуется перезапуск сервера.
Внимание!
Pangolin 5.X.X базируется на ядре PostgreSQL 13. В данной версии поле queryid рассчитывается по алгоритму, похожему на алгоритм расчета queryid в расширении pg_stat_statements. Значение данного поля можно использовать в качестве ключа объединения с pg_stat_statements.
Начиная с PostgreSQL 14 появился единый идентификатор запроса, сгенерированный ядром, и в расширении pg_store_plans используется уже он. Также появился параметр GUC compute_query_id. Если для compute_query_id установлено значение
off, pg_store_plans автоматически отключается. Возможные значения данного параметра:
off- всегда отключено;
on- всегда включено;
auto(значение по умолчанию) - позволяет таким модулям какpg_stat_statementsавтоматически включить данное вычисление;
regress- действует так же, какauto, но идентификатор запроса не показывается в выводе команды EXPLAIN, что облегчает автоматическое регрессионное тестирование.
В рамках работы с расширением доступны представления pg_store_plans и pg_store_plans_info.
Представление pg_store_plans#
Для каждого отдельного набора идентификаторов базы данных, идентификатора пользователя и идентификатора запроса предоставляет статистику, собранную расширением.
Имя |
Тип |
Описание |
|---|---|---|
|
oid |
OID пользователя, который выполнил запрос |
|
bigint |
OID базы данных, в которой был выполнен запрос |
|
bigint |
Идентификатор запроса, сгенерированный ядром или расчитанный расширением. Позволяет получить текст запроса из расширения |
|
text |
Хеш-код плана, вычисляемый на основе нормализованного представления плана |
|
bigint |
Текст плана запроса. Формат задается параметром конфигурации |
|
double precision |
Количество выполнений запросов с данным планом |
|
double precision |
Общее время, затраченное на выполнение запросов с использованием плана, в миллисекундах |
|
double precision |
Минимальное время, затраченное на выполнение запроса с использованием плана, в миллисекундах |
|
double precision |
Максимальное время, затраченное на выполнение запроса с использованием плана, в миллисекундах |
|
double precision |
Среднее время, затраченное на выполнение запроса с использованием плана, в миллисекундах |
|
bigint |
Стандартное отклонение времени, затраченное на выполнение запроса с использованием плана, в миллисекундах |
|
bigint |
Общее количество строк, извлеченных или затронутых оператором с использованием плана |
|
bigint |
Количество обращений к блокам в общем кеше («попадание» в кеш) с помощью запроса, использующего данный план |
|
bigint |
Количество блоков, прочитанных из общего буферного кеша запросом с использованием данного плана |
|
bigint |
Общее количество измененных, но не сохраненных запросом файлов сегментов данных («dirty blocks») |
|
bigint |
Общее количество блоков, записанных запросом с использованием данного плана |
|
bigint |
Общее количество обращений к блокам локального кеша («попаданий» в кеш) запроса, использующего данный план |
|
bigint |
Общее количество блоков локального кеша, измененных, но не сохраненных запросом файлов сегментов данных («dirty blocks») |
|
bigint |
Общее количество блоков локального кеша, записанных запросом с использованием данного плана |
|
bigint |
Общее количество блоков локального кеша, записанных запросом с использованием данного плана |
|
bigint |
Общее количество временных блоков, прочитанных запросом с использованием данного плана |
|
double precision |
Общее время, затраченное запросом, использующим данный план, на чтение блоков, в миллисекундах (если включена опция |
|
double precision |
Общее время, затраченное запросом, использующим данный план, на запись блоков, в миллисекундах (если включена опция |
|
timestamp with time zone |
Временная метка для первого вызова запроса с использованием этого плана |
|
timestamp with time zone |
Временная метка для последнего вызова запроса с использованием этого плана |
Ниже приведен DDL представления:
postgres=# \d+ pg_store_plans
View "ext.pg_store_plans"
Column | Type | Collation | Nullable | Default | Storage | Description
---------------------+--------------------------+-----------+----------+---------+----------+-------------
userid | oid | | | | plain |
dbid | oid | | | | plain |
queryid | bigint | | | | plain |
planid | bigint | | | | plain |
plan | text | | | | extended |
calls | bigint | | | | plain |
total_time | double precision | | | | plain |
min_time | double precision | | | | plain |
max_time | double precision | | | | plain |
mean_time | double precision | | | | plain |
stddev_time | double precision | | | | plain |
rows | bigint | | | | plain |
shared_blks_hit | bigint | | | | plain |
shared_blks_read | bigint | | | | plain |
shared_blks_dirtied | bigint | | | | plain |
shared_blks_written | bigint | | | | plain |
local_blks_hit | bigint | | | | plain |
local_blks_read | bigint | | | | plain |
local_blks_dirtied | bigint | | | | plain |
local_blks_written | bigint | | | | plain |
temp_blks_read | bigint | | | | plain |
temp_blks_written | bigint | | | | plain |
blk_read_time | double precision | | | | plain |
blk_write_time | double precision | | | | plain |
first_call | timestamp with time zone | | | | plain |
last_call | timestamp with time zone | | | | plain |
View definition:
SELECT pg_store_plans.userid,
pg_store_plans.dbid,
pg_store_plans.queryid,
pg_store_plans.planid,
pg_store_plans.plan,
pg_store_plans.calls,
pg_store_plans.total_time,
pg_store_plans.min_time,
pg_store_plans.max_time,
pg_store_plans.mean_time,
pg_store_plans.stddev_time,
pg_store_plans.rows,
pg_store_plans.shared_blks_hit,
pg_store_plans.shared_blks_read,
pg_store_plans.shared_blks_dirtied,
pg_store_plans.shared_blks_written,
pg_store_plans.local_blks_hit,
pg_store_plans.local_blks_read,
pg_store_plans.local_blks_dirtied,
pg_store_plans.local_blks_written,
pg_store_plans.temp_blks_read,
pg_store_plans.temp_blks_written,
pg_store_plans.blk_read_time,
pg_store_plans.blk_write_time,
pg_store_plans.first_call,
pg_store_plans.last_call
FROM pg_store_plans() pg_store_plans(userid, dbid, queryid, planid, plan, calls, total_time, min_time, max_time, mean_time, stddev_time, rows, shared_blks_hit, shared_blks_read, shared_blks_dirtied, shared_blks_written, local_blks_hit, local_blks_read, local_blks_dirtied, local_blks_written, temp_blks_read, temp_blks_written, blk_read_time, blk_write_time, first_call, last_call);
Данное представление, функции pg_store_plans_reset() и pg_store_plans(), а также ряд вспомогательных функций доступны только в базах данных, где pg_store_plans установлен с помощью CREATE EXTENSION. Тем не менее статистика собирается по всем базам данных сервера всякий раз, когда расширение pg_store_plans загружается на сервер, независимо от его наличия в БД. Установленное расширение позволяет получить к ней доступ.
Пользователям, кроме суперпользователя, не разрешается видеть поля plan, queryid и planid для запросов, выполняемых другими пользователями. Пример вывода значений данных полей с доступом и без:
postgres=> select queryid, planid, plan from ext.pg_store_plans\gx
-[ RECORD 1 ]---------------------------------------------------------------------------------------------------------------
queryid |
planid |
plan | <insufficient privilege>
-[ RECORD 2 ]---------------------------------------------------------------------------------------------------------------
queryid | 1534825379
planid | 326764836
plan | Function Scan on pg_store_plans (cost=0.00..10.00 rows=1000 width=224) (actual time=0.173..0.176 rows=27 loops=1)
План запроса и queryid, вычисляемый для идентификации исходного запроса, рассчитываются аналогично тому, как это реализовано в расширении pg_stat_statements. Два плана считаются одинаковыми, если их текстовое представление одинаково за исключением значений литеральных констант или изменяющихся значений, таких как затраты или измеренное время.
Идентификатор плана planid вычисляется без учета изменяющихся свойств планов. В поле plan представления pg_store_plans продолжают отображаться самые актуальные значения для этих изменяющихся свойств.
pg_store_plans и pg_stat_statements поддерживают свои записи индивидуально (для этих двух расширений статистика сбрасывается отдельно функциями pg_stat_statements_reset() и pg_store_plans_reset()), поэтому существует вероятность, особенно для запросов с низкой частотой выполнения, что запрос по плану или наоборот будет не найден.
Представление pg_store_plans_info#
Статистика самого расширения pg_store_plans собирается и становится доступной через представление pg_store_plans_info:
Имя |
Тип |
Описание |
|---|---|---|
dealloc |
bigint |
Общее количество раз, когда записи |
stats_reset |
timestamp with time zone |
Время последнего сброса всей статистики в представлении |
Ниже приведен DDL представления:
postgres=# \d+ pg_store_plans_info
View "ext.pg_store_plans_info"
Column | Type | Collation | Nullable | Default | Storage | Description
-------------+--------------------------+-----------+----------+---------+---------+-------------
dealloc | bigint | | | | plain |
stats_reset | timestamp with time zone | | | | plain |
View definition:
SELECT pg_store_plans_info.dealloc,
pg_store_plans_info.stats_reset
FROM pg_store_plans_info() pg_store_plans_info(dealloc, stats_reset);
Параметры конфигурации#
pg_store_plans.max (integer)
максимальное количество планов, отслеживаемых расширением (максимальное количество строк в представлении
pg_store_plans). Если наблюдается больше различных планов, чем указанное в значении, информация о наименее выполняемом плане отбрасывается. Значение по умолчанию 1000. Этот параметр может быть установлен только при запуске сервера;pg_store_plans.track (enum)
аналогично
pg_stat_statements,pg_store_plans.trackуправляет тем, какие запросы учитываются расширением. Только суперпользователи могут изменять этот параметр. Возможные значения:top(значение по умолчанию) - отслеживание инструкций верхнего уровня (тех, которые выдаются непосредственно клиентами);all- для отслеживания вложенных инструкций (например, инструкций, вызываемых внутри функций, за исключением некоторых команд, см. ниже). Команды, выполняемые в рамках командCREATE EXTENSIONиALTER EXTENSIONпри установке данного значения игнорируются;none- для отключения сбора статистики;verbose- для отслеживания всех команд, включая исключенные всеми предыдущими значениями;
pg_store_plans.max_plan_length (integer)
максимальная длина текста планов в байтах в формате raw (сокращенный JSON для хранения). Длина текста плана усекается, если она превышает это значение. Значение по умолчанию равно 5000. Этот параметр может быть установлен только при запуске сервера;
pg_store_plans.plan_storage (enum)
определяет способ хранения текстов планов на сервере. Возможные значения:
file(значение по умолчанию) - тексты планов сохраняются во временном файле аналогично расширению pg_stat_statements;shmem- хранение текстов планов в оперативной памяти;
pg_store_plans.plan_format (enum)
управление форматом планов в
pg_store_plans. Значения по умолчаниюtextиспользуется для отображения в обычном текстовом представлении, а возможные значенияjson,xmlиyamlиспользуются для соответствующих им форматов. Для получения внутреннего представления, которое может быть переданоpg_store_plans_*plan-функциям, используется значениеraw;pg_store_plans.min_duration (integer)
минимальное время выполнения инструкции в миллисекундах, которое приведет к занесению плана инструкции в журнал. При установке этого параметра в нулевое значение (по умолчанию) регистрируются все планы. Только суперпользователи могут изменять этот параметр;
pg_store_plans.log_analyze (boolean)
включение выходных данные
EXPLAIN ANALYZE(а не толькоEXPLAIN). По умолчанию этот параметр отключен (false);pg_store_plans.log_buffers (boolean)
включение в план
EXPLAIN(ANALYZE,BUFFERS) выходных данных (не толькоEXPLAIN). По умолчанию этот параметр отключен (false);pg_store_plans.log_timing (boolean)
отключение записи фактического времени (
false). Накладные расходы на повторное считывание системных часов могут значительно замедлить выполнение запроса в некоторых системах, поэтому может быть полезно установить этот параметр в значениеfalse, когда требуется только фактическое количество строк, а не точное время выполнения для каждого узла. Время выполнения всей инструкции измеряется всегда, когдаpg_store_plans.log_analyzeимеет значениеtrue(значение по умолчанию);pg_store_plans.log_triggers (boolean)
включение в зарегистрированные планы статистики выполнения триггера. Этот параметр не действует, если не включен параметр
pg_store_plans.log_analyze;pg_store_plans.verbose (boolean)
включение в план вывода
EXPLAIN VERBOSE(не толькоEXPLAIN). По умолчанию этот параметр отключен (false);pg_store_plans.save (boolean)
флаг, указывающий, следует ли сохранять статистику планов при отключении сервера. Если он выключен, то статистика не сохраняется при завершении работы и не перезагружается при запуске сервера. Значение по умолчанию — включено (
true). Этот параметр можно задать только в файлеpostgresql.confили в командной строке сервера.Примечание:
pg_store_plansтребует дополнительной разделяемой памяти в объеме, пропорциональном значениюpg_store_plans.max. Когда дляpg_store_plans.plan_storageустановлено значениеshmem, ему требуется дополнительная общая память для хранения текстов планов в количестве, равном произведению максимального количества сохраняемых планов (pg_store_plans.max) и максимальной длины отдельного плана (pg_store_plans.max_plan_length). Если дляpg_store_plans.plan_storageустановлено значениеfile, тексты плана записываются во временный файл аналогичноpg_stat_statements. Еслиpg_store_plans.maxнедостаточно велик для хранения всех планов,pg_store_plansосвобождает место для новых планов, удаляя некоторую часть записей. После нескольких итераций такого удаленияpg_store_plansзапускает сборку мусора во временном файле, что может существенно повлиять на нагрузку. Проанализировать данный процесс можно при помощиpg_store_plans_info.dealloc.Если значение
pg_store_plans.maxдостаточно велико, чтобы сборка мусора не происходила, рекомендуется устанавливать параметрpg_store_plans.plan_storageв значениеfile.Эти параметры должны быть установлены в
postgresql.conf. Ниже приведен пример настройки:# postgresql.conf shared_preload_libraries = 'pg_store_plans, pg_stat_statements' pg_store_plans.max = 10000 pg_store_plans.track = all
Пример использования расширения#
bench=# SELECT pg_store_plans_reset();
$ pgbench -i bench
$ pgbench -c10 -t1000 bench
bench=# \x
bench=# SELECT s.query, p.plan,
p.calls as "plan calls", s.calls as "stmt calls",
p.total_time / p.calls as "time/call", p.first_call, p.last_call
FROM pg_stat_statements s
JOIN pg_store_plans p USING (queryid) WHERE p.calls < s.calls
ORDER BY query ASC, "time/call" DESC;
-[ RECORD 1 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
query | UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2
plan | Update on pgbench_tellers (cost=0.00..7.88 rows=0 width=0) +
| -> Seq Scan on pgbench_tellers (cost=0.00..7.88 rows=1 width=10) +
| Filter: (tid = 1)
plan calls | 396
stmt calls | 10000
time/call | 16.15434492676767
first_call | 2021-11-25 15:11:38.258838+09
last_call | 2021-11-25 15:11:40.170291+09
-[ RECORD 2 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
query | UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2
plan | Update on pgbench_tellers (cost=0.14..8.15 rows=0 width=0) +
| -> Index Scan using pgbench_tellers_pkey on pgbench_tellers (cost=0.14..8.15 rows=1 width=10) +
| Index Cond: (tid = 8) +
plan calls | 9604
stmt calls | 10000
time/call | 10.287281695439345
first_call | 2021-11-25 15:11:40.161556+09
last_call | 2021-11-25 15:12:09.957773+09
-[ RECORD 3 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
query | select s.query, p.plan, p.calls as "plan calls", s.calls as "stmt calls", p.total_time / p.calls as "time/call", p.first_call, p.last_call from pg_stat_statements s join pg_store_plans p using (queryid) where p.calls < s.calls order by query asc, "time/call" desc
plan | Sort (cost=309.71..313.88 rows=1667 width=104) +
| Sort Key: pg_stat_statements.query, ((pg_store_plans.total_time / (pg_store_plans.calls)::double precision)) DESC +
| -> Merge Join (cost=119.66..220.50 rows=1667 width=104) +
| Merge Cond: (pg_stat_statements.queryid = pg_store_plans.queryid) +
| Join Filter: (pg_store_plans.calls < pg_stat_statements.calls) +
| -> Sort (cost=59.83..62.33 rows=1000 width=48) +
| Sort Key: pg_stat_statements.queryid +
| -> Function Scan on pg_stat_statements (cost=0.00..10.00 rows=1000 width=48) +
| -> Sort (cost=59.83..62.33 rows=1000 width=72) +
| Sort Key: pg_store_plans.queryid +
| -> Function Scan on pg_store_plans (cost=0.00..10.00 rows=1000 width=72) +
plan calls | 3
stmt calls | 4
time/call | 16.387161
first_call | 2021-11-25 15:20:57.978082+09
last_call | 2021-11-25 15:23:48.631993+09
-[ RECORD 4 ]-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
query | select s.query, p.plan, p.calls as "plan calls", s.calls as "stmt calls", p.total_time / p.calls as "time/call", p.first_call, p.last_call from pg_stat_statements s join pg_store_plans p using (queryid) where p.calls < s.calls order by query asc, "time/call" desc
plan | Sort (cost=309.71..313.88 rows=1667 width=104) +
| Sort Key: pg_stat_statements.query, ((pg_store_plans.total_time / (pg_store_plans.calls)::double precision)) DESC +
| Sort Method: quicksort Memory: 26kB +
| -> Merge Join (cost=119.66..220.50 rows=1667 width=104) +
| Merge Cond: (pg_stat_statements.queryid = pg_store_plans.queryid) +
| Join Filter: (pg_store_plans.calls < pg_stat_statements.calls) +
| Rows Removed by Join Filter: 7 +
| -> Sort (cost=59.83..62.33 rows=1000 width=48) +
| Sort Key: pg_stat_statements.queryid +
| Sort Method: quicksort Memory: 27kB +
| -> Function Scan on pg_stat_statements (cost=0.00..10.00 rows=1000 width=48) +
| -> Sort (cost=59.83..62.33 rows=1000 width=72) +
| Sort Key: pg_store_plans.queryid +
| Sort Method: quicksort Memory: 30kB +
| -> Function Scan on pg_store_plans (cost=0.00..10.00 rows=1000 width=72) +
plan calls | 1
stmt calls | 4
time/call | 4.46928
first_call | 2021-11-25 15:12:27.142535+09
last_call | 2021-11-25 15:12:27.142536+09
Шифрование и хранение параметров подключения#
Для исключения хранения паролей в открытом виде и предотвращения компрометации паролей в Pangolin подготовлен набор утилит, позволяющих шифровать и хранить пароли в зашифрованном виде:
pg_auth_config— утилита шифрования/хранения параметров подключения к БД. Располагается в каталоге$PGHOME/bin(пример:/usr/pgsql-se-04/bin/), доступна только владельцу (postgres);pg_auth_password— утилита шифрования паролей. Позволяет получить пароль в зашифрованном виде после ввода исходного пароля. Располагается в каталоге$PGHOME/bin(пример:/usr/pgsql-se-04/bin/), доступна только владельцу (postgres).
При работе с расширением oracle_fdw пароль пользователя oracle вносится в хранилище паролей, но при проверке хранилища этот пароль не проверяется при вызове команды: pg_auth_config check.
Внимание!
Ключи, используемые при шифровании паролей, уникальны для сервера. Они вычисляемые и нигде не хранятся.
Как следствие, пароли в зашифрованном виде и файл хранилища:
применимы только в рамках сервера, где выполнялось шифрование;
уникальные/свои для каждого узла кластера.
В случае изменения конфигурации сервера могут потребоваться действия по пересозданию зашифрованного хранилища/перешифрованию паролей в конфигурационных файлах.
Утилита шифрования и хранения параметров подключения к БД (pg_auth_config)#
Утилиты, выполняющие автоматизированное подключение к БД, должны выполнить получение параметров подключения из защищенного хранилища для дальнейшего подключения к БД.
Утилита pg_auth_config формирует зашифрованное хранилище, которое хранится в файле /etc/postgres/enc_utils_auth_settings.cfg. Ключи, используемые при шифровании, уникальны в рамках хоста. Они не хранятся, а вычисляются в процессе. Также возможно добавление нескольких записей одной командой через разделитель «,».
Примечание:
В качестве ключа шифрования используется фраза, конструируемая из параметров:
парольная фраза - CPU manufacturer ID CPU, CPU stepping, CPU model, CPU family, CPU feature flags, список MAC адресов постоянных сетевых интерфейсов, список IP постоянных сетевых интерфейсов
соль - тип credentials, machineId из /etc/machine-id, UUID корневой файловой системы, домен для использования credentials (сейчас 'POSTGRESQL' - для шифрования конфигов компонент HA кластера или 'KMS' - для шифрования параметров доступа к KMS)
Алгоритм определяется сконфигурированным плагином шифрования (по умолчанию AES-256). Хранилище может быть расшифровано только на хосте где было создано. Оно автоматически формируется на этапе установки дистрибутива Pangolin.
Запуск утилиты pg_auth_config отображает параметры использования:
Usage:
./pg_auth_config show | add | remove | check | reset [options...]
Options:
--help This help
--host [-h] host for which password will be used
--json [-j] show in json format
--port [-p] port for which password will be used
--user [-U] user name for which password will be used
--database [-d] database for which password will be used
The './pg_auth_config' utility is used to securely save password information
for internal Pangolin utilities
the concept is simular to .pgpass, except this utility encrypts pasword information
Параметры host и port необходимы для того, чтобы пароль нельзя было использовать для подключения к произвольным БД, в том числе к модифицированным версиям postgres, показывающим, с каким паролем пыталось произойти подключение. Запись в хранилище можно перезаписать только целиком. Например, нельзя поменять отдельно только host. Для добавления множества записей одной командой количество host, port, database, написанных через разделитель , должно совпадать:
add— команда добавляет в хранилище пароль пользователяname. По умолчанию утилита дважды просит ввести пароль. Передача пароля через командную строку отсутствует.Внимание!
В момент добавления пароля в хранилище его корректность не проверяется (т.е. не проводится сверка с паролем, хранящимся в БД).
Пример использования:
./pg_auth_config add -h 127.0.0.1 -p 5432 -d postgres -U test enter password: **** confirm password: ****Опция
--skip-confirmпозволяет не запрашивать второго ввода пароля. Данную опцию рекомендуется использовать в автоматизированных системах, когда ввод пароля автоматизирован../pg_auth_config add -h 127.0.0.1 -p 5432 -d postgres -U test -skip-confirm enter password: **** confirm password: ****Через разделитель
,можно добавить несколько записей одной командой:./pg_auth_config add -h <IP-адрес>,<IP-адрес> -p 5432,1234 -U postgres -d database,dabataseshow— команда выводит в консоль содержимое хранилища (за исключением паролей).Пример использования:
$ pg_auth_config show | host | port | database | username | |----------------------------------------------------------| | localhost | 5433 | postgres | patroni | | localhost | 5433 |replication | patroni | | <hostname> | 5433 | postgres | patroni | | <hostname> | 5433 |replication | patroni | | <hostname> | 5433 | database | user | | <hostname> | 5433 | database | user1 |Команда
showпозволяет выборочно выводить в консоль данные, используя конкретные параметры подключения:host,port,databaseилиuser.Пример использования:
-- Пример просмотра данных с параметрами host и port $ pg_auth_config show -h 127.0.0.1 -p 5433 | host | port | database | username | |------------------------------------------------| | 127.0.0.1 | 5433 | postgres |backup_user | -- Пример просмотра данных с параметрами database $ $ pg_auth_config show -d replication | host | port | database | username | |--------------------------------------------------------| | localhost | 5433 |replication | patroni | |srv-1-1 | 5433 |replication | patroni | |srv-1-2 | 5433 |replication | patroni |Команда
showможет использоваться вместе с опцией--json.Пример использования:
./pg_auth_config show --json { "records" : [ { "database" : "database", "host" : {IP-адрес}, "port" : {Порт}, "username" : "postgres" }, { "database" : "dabatase", "host" : {IP-адрес}, "port" : {Порт}, "username" : "postgres" } ] }check— команда проверяет актуальность данных в хранилище с данными БД. При подключении к БД используются параметры подключения из хранилища.Пример использования:
$ pg_auth_config check Connection settings for host: "localhost", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "localhost", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-1-1", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "srv-1-1", port "5433", database "replication", user "patroni" are OK Could not connect with host: "srv-1-1", port "5433", database "postgres", user "test"... -- Сообщение "Connection settings for host..." говорит о пройденной успешной проверке -- Сообщение "Could not connect with host:..." говорит о неуспешной проверкеЕсли не удалось установить соединение с сервером по причине «исчерпан лимит подключений», формируется соответствующее сообщение с подсказкой:
too many clients, try again.Команда
checkпозволяет выборочно проверять актуальность данных, используя конкретные параметры подключения:host,port,databaseилиuser.Пример использования:
-- Пример проверки данных с параметрами host и port: $ pg_auth_config check -h 127.0.0.1 -p 5433 Connection settings for host: "127.0.0.1", port "5433", database "postgres", user "backup_user" are OK -- Пример проверки данных с параметрами database: $ pg_auth_config check -d replication Connection settings for host: "localhost", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-1-1", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-1-2", port "5433", database "replication", user "patroni" are OK -- Пример проверки данных с параметрами user: $ pg_auth_config check -U patroni Connection settings for host: "localhost", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "localhost", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-1-1", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "srv-1-1", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-1-2", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "srv-1-2", port "5433", database "replication", user "patroni" are OK -- Пример проверки данных с параметрами host, port, database, user: $ pg_auth_config check -h 127.0.0.1 -p 5433 -d replication -U patroni Connection settings for host: "127.0.0.1", port "5433", database "replication", user "patroni" are OKПримечание:
Во всех режимах работы утилиты проверяется введенное значения порта. Значение порта должно находиться в диапазоне от 1 до 65535 (включительно).
Внимание!
Команда в рамках работы расширения
oracle_fdwс хранилищем паролей не проверяет пароль пользователя БД Oracle.remove— команда удаляет запись, связанную сhost,port,database,user. Команда выводит запрос на подтверждение операции удаления.Пример использования:
$ pg_auth_config remove -h srv-1-1 -p 5433 -U user -d database Do you want to remove auth record? (yes/no)?: yes Going to remove auth record for user: "user", host: "srv-1-1", port: "5433", database: "database" record removedreset— команда очищает хранилище. Команда выводит запрос на подтверждение очистки хранилища. После выполнения команды файл/etc/postgres/enc_utils_auth_settings.cfgпереименовывается в/etc/postgres/enc_utils_auth_settings.cfg.reset. Утилита не имеет команды для восстановления файла. Для восстановления необходимо самостоятельно переименовать файл/etc/postgres/enc_utils_auth_settings.cfg.resetв/etc/postgres/enc_utils_auth_settings.cfg.Пример использования:
-- Очистка хранилища $ pg_auth_config reset Do you want to reset auth config? (yes/no)?: yes Auth config was reset -- Просмотр содержимого хранилища после очистки $ pg_auth_config show | host | port | database | username | |-----------------------------------------------| -- Восстановление файла хранилища $ mv /etc/postgres/enc_utils_auth_settings.cfg.reset /etc/postgres/enc_utils_auth_settings.cfg -- Просмотр содержимого хранилища после восстановления $ pg_auth_config show | host | port | database | username | |---------------------------------------------------------| | localhost | 5433 | postgres | patroni | | localhost | 5433 |replication | patroni | |srv-1-1 | 5433 | postgres | patroni | |srv-1-1 | 5433 |replication | patroni | |srv-1-2 | 5433 | postgres | patroni | |srv-1-2 | 5433 |replication | patroni | ...edit— позволяет редактировать существующие записи в хранилище, без необходимости пересоздавать их. Поиск записей для редактирования осуществляется с использованием ключа, состоящего из имени хоста, номера порта, имени пользователя, названия базы данных.Для поиска записей требуется указать минимум одно поле ключа. Поля задаются через существующие аргументы утилиты:
--host [-h] — имя хоста --port [-p] — номер порта --user [-U] — имя пользователя --database [-d] — название базы данныхПример запуска утилиты в режиме редактирования (поиск по ключу: имя пользователя
patroni, название базы данныхpostgres):pg_auth_config edit -U patroni -d postgresПри этом, если:
не задано ни одного поля, то работа утилиты завершится, и будет выведено предупреждение:
At least one field must be defined: host, port, username, databaseзаписи, соответствующие ключу поиска, не найдены, то работа утилиты завершится, и будет выведено предупреждение:
Nothing to update: records not foundзаписи, соответствующие ключу поиска, найдены, то утилита перейдет в интерактивный режим ввода новых значений (см. ниже раздел «Ввод новых значений для редактируемых полей»).
Функция добавления пароля в зашифрованное хранилище#
Возможны ситуации когда администратору АС требуется завести задание в pg_cron. Для выполнения задания, pg_cron должен подключаться к БД, используя параметры подключения из зашифрованного хранилища. То есть зашифрованное хранилище должно содержать запись для выполнения задания pg_cron. Администратор АС не может использовать утилиту pg_auth_config для самостоятельного добавления записи в зашифрованное хранилище и не может раскрыть пароль администратору БД, чтобы последний добавил запись. Для решения данной ситуации в Pangolin добавлена функция - add_auth_record_to_storage.
Подробное описание функции в документе «Список PL/SQL функций продукта», раздел «Шифрование и хранение параметров подключения».
Ввод новых значений для редактируемых полей#
Ввод новых значений для редактируемых записей осуществляется в интерактивном режиме с помощью команды edit. Для всех полей будет предложено ввести новые значения. Например, предложение на ввод новых значений для поля port (номер порта):
enter port or leave empty to skip update:
Примечание:
Ввод нового пароля будет запрошен, если ключ поиска содержит имя пользователя.
Если новые значения получены, то утилита выведет список обновляемых записей.
Пример обновления двух записей. Обновляются поля port (номер порта) и username (имя пользователя»):
Going to update 2 records:
| host | port | database | username |
|-----------------------------------------------------|
| 127.0.0.1 |9000 -> 9001 | somedb1 |user1 -> user4 |
| 127.0.0.2 |9000 -> 9001 | somedb1 |user1 -> user4 |
В случае, если при запуске не указан ключ -s (--skip-confirm), то будет запрошено подтверждение операции редактирования записей:
Do you want to update auth records? (yes/no)?:
Для продолжения требуется ввести:
«y» или «yes» — для подтверждения операции редактирования;
«n» или «no» — для отмены операции редактирования.
Предупреждения и ошибки#
В случае, если:
не ввести ни одного нового значения для запрашиваемых полей, то работа утилиты завершится, и будет выведено предупреждение:
Nothing to update: no new values providedновые значения совпадают со старыми (например, найдена одна запись), то работа утилиты завершится, и будет выведено предупреждение:
Nothing to update: new values for the records are the same as the old onesв процессе обновления полей возникают дублирующие друг друга записи, то такие записи будут удалены.
Примечание:
Если записи дублируют друг друга, то сохраняется первая запись в списке.
Для удаляемых записей будет указан признак «
< rm» в конце записи. Пример удаления двух дублирующих записей (обновляется поле «название базы данных», уже существуют записи, совпадающие с обновляемыми):Going to update 2 records: | host | port | database | username | |----------------------------------------------------------------------| | localhost | 5433 |replication -> postgres | patroni | < rm |srv-0-153 | 5433 |replication -> postgres | patroni | < rm
Описание процессов использования утилиты pg_auth_config#
Процесс добавления пароля (параметров подключения к БД) в зашифрованное хранилище#
Не имеет значения с какого узла кластера начинать изменение пароля. Файл конфигурации созданный на одном узле, например на лидере, не может быть расшифрован на реплике и наоборот.
Выполняется проверка сотрудником сопровождения либо автоматически при первичной инсталляции Pangolin: будет настраиваться standalone или cluster. В случае типа конфигурации: standalone - переход к шагу 2; cluster - переход к шагу 3.
Выполняется добавление параметров подключения к БД в зашифрованное хранилище через утилиту pg_auth_config на standalone:
вызывается утилита с параметрами подключения к БД:
pg_auth_config add --h <host> – p <port> --U <user> --d <dbname>;вводится пароль пользователя;
в результате параметры подключения добавлены в зашифрованное хранилище.
Выполняется добавление параметров подключения к БД в зашифрованное хранилище через утилиту
pg_auth_configна cluster:вызывается утилита с параметрами подключения к БД:
pg_auth_config add --h <host> – p <port> --U <user> --d <dbname>на первом узле кластера;вводится пароль пользователя;
в результате параметры подключения добавлены в зашифрованное хранилище на первом узле кластера;
вызывается утилита с параметрами подключения к БД:
pg_auth_config add --h <host> – p <port> --U <user> --d <dbname>на втором узле кластера;вводится пароль пользователя;
в результате параметры подключения добавлены в зашифрованное хранилище на втором узле кластера.
В случае ручного добавления параметров подключения к БД рекомендуется выполнить проверку актуальности данных в зашифрованном хранилище на корректность введенных паролей командой
pg_auth_config check.
Процесс добавления пароля (параметров подключения к БД) в зашифрованное хранилище Администратором АС#
Не имеет значения с какого узла кластера начинать добавление/изменение пароля. Пароль добавленный в зашифрованное хранилище с помощью функции add_auth_record_to_storage, не реплицируется на второй узел кластера.
Выполняется проверка администратором АС: будет настраиваться standalone или cluster. В случае типа конфигурации: standalone — переход к шагу 2; cluster — переход к шагу 3.
Выполняется добавление параметров подключения к БД в зашифрованное хранилище с помощью функции
add_auth_record_to_storageна standalone:вызывается функция
add_auth_record_to_storageс указанием параметров подключения, например:select add_auth_record_to_storage('127.0.0.1', 5433, 'db_name', 'user', 'password');в результате параметры подключения добавлены в зашифрованное хранилище.
Выполняется добавление параметров подключения к БД в зашифрованное хранилище через утилиту
pg_auth_configна cluster:вызывается функция
add_auth_record_to_storageс указанием параметров подключения на первом узле кластера, например:select add_auth_record_to_storage('127.0.0.1', 5433, 'db_name', 'user', 'password');в результате параметры подключения добавлены в зашифрованное хранилище на первом узле кластера;
вызывается функция
add_auth_record_to_storageс указанием параметров подключения на втором узле кластера, например:select add_auth_record_to_storage('127.0.0.1', 5433, 'db_name', 'user', 'password');в результате параметры подключения добавлены в зашифрованное хранилище на втором узле кластера.
Рекомендуется выполнить проверку актуальности данных в зашифрованном хранилище на корректность введенных паролей командой
pg_auth_config check.
Утилита шифрования паролей, представленных в открытом виде (pg_auth_password)#
Для исключения хранения паролей в открытом виде и предотвращения компрометации паролей командой развития Pangolin разработана утилита для шифрования паролей pg_auth_password. Утилита pg_auth_password располагается в каталоге $PGHOME/bin, доступна только владельцу (postgres).
Утилита pg_auth_password выполняет только одно действие - шифрование паролей.
На вход утилита pg_auth_password принимает пароль, результат выполнения выводится в консоль. Зашифрованный пароль используется в конфигурационных файлах.
Формат зашифрованного пароля:
$enc$<encrypted_password_in_base64>
- $enc$ — признак зашифрованного пароля;
- <encrypted_password_in_base64> — зашифрованный пароль в формате base64.
Зашифрованный пароль используется:
Pangolin Manager для выполнения запросов по REST API и взаимодействия с etcd (прописывается в конфигурации Pangolin Manager);
postgre для выполнения ldap binding (прописывается в ldap записи pg_hba.conf файла).
Параметры использования#
Запуск утилиты pg_auth_passwordс опцией --help отображает параметры использования:
$ pg_auth_password --help
The 'pg_auth_password' is utility to encrypt the password
Usage:
pg_auth_password enc [OPTION]
Options:
-s, --skip-confirm manual input without confirmation
-W, --password <password> password is entered as an argument
Other options:
-V, --version output version information, then exit
-h, --help show this help, then exit
Pangolin product version information:
--product_version prints product name and version
--product_build_info prints product build number, date and hash
--product_component_hash prints component hash string
Утилита имеет одну команду - enc и несколько опций (--skip-confirm, --password <password>), которые упрощают действия по шифрованию пароля.
enc— команда шифрует пароль, который может быть введен или передан в виде аргумента. По умолчанию утилита дважды просит ввести пароль. Результат выводится в консоль.Пример использования:
$ pg_auth_password enc enter password: ********************** enter password: ********************** $enc$srfPu47aKUK2k+9ZCMoFDAMyd6ltSHBxOjcIXN8EpmM=
Использование утилиты с опциями:
--skip-confirm / -s: подтверждение пароля не требуется. Данную опцию рекомендуется использовать в автоматизированных системах, когда ввод пароля автоматизирован.Пример использования:
$ pg_auth_password enc -s enter password: *************** $enc$BlHR2dOnMoGsDwqoWveLag== -- либо pg_auth_password enc --skip-confirm enter password: *************** $enc$BlHR2dOnMoGsDwqoWveLag==--password / -W: пароль передается в виде аргумента. При указании данной опции — запрос пароля из консоли не производится.Пример использования:
$ pg_auth_password enc -W test $enc$xmZrbJFMvzu51EYZIWckyg== -- либо $ pg_auth_password enc --password test $enc$xmZrbJFMvzu51EYZIWckyg==
Описание процессов использования утилиты pg_auth_password#
Процесс добавления зашифрованного пароля в конфигурационной файл#
Примечание:
Параметры хранятся в файле в зависимости от типа конфигурации сервера: если тип конфигурации standalone: в файле
$PGDATA/pg_hba.conf, в случае типа конфигурации cluster или standalone+Pangolin Manager: в файле/etc/pangolin-manager/postgres.ymlв секцииpg_hba.
Выполняется проверка сотрудником сопровождения либо автоматически при первичной инсталляции Pangolin: будет настраиваться standalone или cluster. В случае типа конфигурации: standalone — переход к шагу 2; cluster — переход к шагу 3.
Выполняется формирование зашифрованного пароля через утилиту
pg_auth_passwordна standalone:вызывается утилита
pg_auth_password enc;вводится пароль для получения его в зашифрованном виде;
полученный зашифрованный пароль в формате base64 копируется и вносится для нужного пользователя в конфигурационный файл путем редактирования;
для вступления в силу выполняется перечитывание конфигурации командой
reload.
Выполняется формирование зашифрованного пароля через утилиту
pg_auth_passwordна первом узле кластера:вызывается утилита
pg_auth_password encна первом узле кластера;вводится пароль для получения его в зашифрованном виде;
полученный зашифрованный пароль в формате base64 копируется и вносится для нужного пользователя в конфигурационный файл путем редактирования;
для вступления в силу выполняется перечитывание конфигурации командой
reload.
Выполняется формирование зашифрованного пароля через утилиту
pg_auth_passwordна втором узле кластера:вызывается утилита
pg_auth_password encна втором узле кластера;вводится пароль для получения его в зашифрованном виде;
полученный зашифрованный пароль в формате base64 копируется и вносится для нужного пользователя в конфигурационный файл путем редактирования;
для вступления в силу выполняется перечитывание конфигурации командой
reload.
Аутентификация утилит через зашифрованный пароль#
В момент, когда утилита, используя функции libpq, подключится к БД, происходит чтение и расшифровка файла с конфигурацией, поиск пароля.
Пароль ищется по ключу: <host>#<port>#<db>#<user>.
Выполняется старт подключения утилиты к БД, создается сессия в БД.
Из конфигурации утилиты зачитываются параметры подключения к БД:
host,port,db,user.Выполняется расшифровка файла
/etc/postgres/enc_utils_auth_settings.cfgс паролями для подключения.Выполняется поиск пароля по полученным параметрам подключения по ключу
host#port#db#user#.В случае успешной расшифровки найденного пароля выполняется подключение к БД с передачей хеша пароля, происходит авторизация по паролю в БД.
В случае отсутствия файла
/etc/postgres/enc_utils_auth_settings.cfgили невозможности его расшифровать, в лог журнала формируется сообщение с типомWARNING.В случае, если пароль не найден, в лог журнала формируется сообщение с типом
WARNING.
Аутентификация пользователя, использующего зашифрованный пароль от ТУЗ для подключения к ldap/AD#
Выполняется подключение пользователя к БД, создается сессия в БД.
Зачитываются параметры для подключения к ldap/AD из конфигурационного файла.
Выполняется анализ поля ldapbindpasswd: является ли пароль зашифрованным или пароль представлен в открытом виде.
Если пароль зашифрован, то выполняется его расшифровка и выполняется аутентификация с ldap/AD.
В случае, если пароль представлен в открытом виде, то выполняется аутентификация с ldap/AD.
Далее выполняется анализ результата аутентификации с ldap/AD.
Если аутентификация пройдена, то выполняется подключение пользователя к БД.
Если аутентификация не пройдена, то выполняется разрыв соединения с клиентом.
Дополнительные доработки в инсталляторе в рамках интеграции утилиты хранения пароля#
Для корректной работы
manage_backup.binв скрипт запуска необходимо добавить следующие переменные окружения:LD_LIBRARY_PATH="/usr/pgsql-se-04/lib" PG_PLUGINS_PATH="/usr/pgsql-se-04/lib" PYTHONPATH="/usr/pgsql-se-04/postgresql_venv/lib/python3.6/site-packages/" PGHOME="/usr/pgsql-se-04/"Для механизма отката необходимо учесть, что для отката etcd старой версии (в версиях Pangolin до 4.4.1) необходим пароль в открытом виде (который нужно восстановить). Данный пароль брался из старого конфигурационного файла Pangolin Manager. Теперь нужно хранить все старые пароли etcd в зашифрованном с помощью ansible-vault виде, а способ получения пароля должен быть переписан.
Восстановление работоспособности узла кластера при смене параметров сервера#
В состав Pangolin включена утилита pg_auth_reencrypt, которая используется для восстановления работоспособности узла кластера при смене параметров сервера.
После установки Pangolin утилита доступна в каталоге /opt/pangolin-common/pg_auth_reencrypt.
Утилита запускается в двух режимах:
автоматический — запуск настраивается при установке Pangolin;
ручной — вызов бинарного файла утилиты с указанием требуемых параметров и предварительной настройкой утилиты.
Автоматический запуск утилиты (службой systemd)#
Установщик Pangolin создает новую службу/службы systemd (зависит от конфигурации кластера) для запуска и отслеживания состояния демона утилиты.
В автоматическом режиме утилита в процессе работы создает файл enc_params.cfg + '.' + 'имя_пользователя' в каталоге /etc/postgres. Файл создается с правами -rw-rw-r-- владельцем, от имени которого был запущен демон. Содержимое файла зашифровано. Утилита используется для хранения текущих параметров сервера. Изменение параметров сервера детектируется на основе данного файла.
Служба/службы запускаются при старте ОС и запускают демонов утилиты перешифрования, которые периодически (с периодом 5 секунд) проверяют параметры оборудования и, если они поменялись, обновляют файлы с шифрованной информацией. В зависимости от конфигурации кластера файлы могут принадлежать:
пользователю — Администратору СУБД (
postgres). В данном случае запускается один демон утилиты от имени пользователяpostgres;или пользователям — Администратору СУБД (
postgres) и Администратору безопасности (kmadmin_pg). В этом случае запускаются два демона: от имени пользователяpostgresи от имени пользователяkmadmin_pg.
Список файлов для разных пользователей определяется конфигурацией утилиты (тег «owner», см. ниже «Конфигурационный файл утилиты»).
Для управления демоном утилиты служба создает каталог /var/run/pangolin_reencrypt/, где демон создает файл pangolin_reencrypt_<имя_пользователя_запустившего_утилиту>, содержащий идентификатор процесса pid. Отсутствие каталога не приводит к завершению работы утилиты с ошибкой, но будет выведено предупреждение в журнал: Create pid file failed. Сигналы для управления утилитой приводятся ниже в подразделе «Управление утилитой».
Ручной запуск утилиты#
Для запуска утилиты в ручном режиме требуется:
подготовить конфигурационный файл утилиты;
запустить бинарный файл утилиты с требуемыми параметрами (см. ниже «Параметры запуска утилиты»):
/etc/postgres/pg_auth_reencrypt [OPTION]
При ручном запуске утилита также создает файл enc_params.cfg + '.' + 'имя_пользователя' с правами -rw-rw-r-- в каталоге /etc/postgres. Владельцем файла в данном случае будет пользователь, от имени которого была запущена утилита. Если у пользователя нет прав на создание файла в каталоге /etc/postgres, работа утилиты будет завершена с ошибкой.
Ручной запуск утилиты перешифрования на кластере#
На версиях кластера от 4.4.0 (где внедрено шифрование файлов с параметрами подключения) возможна ручная установка утилиты, для этого:
Расположите исполняемый файл утилиты в каталоге
/opt/pangolin-common/bin/pg_auth_reencrypt(владелец:root, группа: root, права:-rwxr-xr-x). Исполняемый файл утилиты располагается в дистрибутиве по путиpg_auth_reencrypt/opt/pangolin-common/bin/pg_auth_reencrypt.Расположите файл конфигурации утилиты
/etc/postgres/enc_util.cfg(владелец:root, группа:root, права:rw-r--r–). Зависит от конфигурации кластера (см. ниже «Шаблон конфигурации утилиты перешифрования»).Создайте службу-шаблон с запуском демона в systemd (см. ниже «Шаблон спецификации службы для утилиты перешифрования»):
имя службы
pangolin_reencrypt@.service;служба запускается от пользователя переданного с помощью параметра (пример:
pangolin_reencrypt@postgres.service);служба должна создавать каталог
/var/run/pangolin_reencryptдляpidфайла(ов). Владелецpostgres, группаkmadmin\_pg,g+rw;служба должна запускать утилиту перешифрования паролей
/opt/pangolin-common/bin/pg_auth_reencrypt;служба должна автоматически запускаться при каждой загрузке Linux и в случае сбоев (
Restart=on-failure);
Обновите службы systemd (
sudo systemctl daemon-reload).Запустите новую службу/службы (в зависимости от конфигурации кластера) и установите принудительный запуск при каждой загрузке ОС (
sudo systemctl enable --now pangolin_reencrypt.service).
Шаблон конфигурации утилиты перешифрования#
{
"files" :
[
### файл 1: включается, если на кластере активирован tde или admin_protection
{
"name" : "{{ KMS_CONFIG }}",
"owner" : "kmadmin_pg",
"domain" : "kms"
},
### файл 2: включается на всех конфигурациях
{
"name" : "{{ pg_encrypt_cfg }}",
"owner" : "postgres",
"domain" : "postgres"
},
### файл 3: включается для конфигураций с Pangolin Manager
{
"name" : "/etc/pangolin-manager/postgres.yml",
"owner" : "postgres",
"secrets" :
[
{
"type" : "tag",
"name" : "restapi/authentication/password",
"domain" : "postgres"
},
{
"type" : "tag",
"name" : "etcd/password",
"domain" : "postgres"
},
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
### файл 4: включается для конфигураций без Pangolin Manager
{
"name" : "pg_hba.conf",
"owner" : "postgres",
"secrets" :
[
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
]
}
Примечание:
###— начало комментария, необходимо удалить перед записью конфигурации на диск. Если условие в комментарии не выполняется, то вместе с комментарием нужно удалить описание файла, следующее за ним.
Шаблон спецификации службы для утилиты перешифрования#
[Unit]
Description=Runners Pangolin reencrypt service (%i)
After=syslog.target network.target
[Service]
Type=forking
User=%i
Group=%i
Environment="PGDATA=<path>/data"
Environment="PG_PLUGINS_PATH=<path>/lib"
PermissionsStartOnly=true
ExecStartPre=/bin/mkdir -p /var/run/pangolin_reencrypt
ExecStartPre=/bin/chown postgres:kmadmin_pg /var/run/pangolin_reencrypt
ExecStartPre=/bin/chmod g+rw /var/run/pangolin_reencrypt
ExecStartPost=/bin/sleep 1
ExecStart=/opt/pangolin-common/bin/pg_auth_reencrypt -l2 -d
PIDFile=/var/run/pangolin_reencrypt/pangolin_reencrypt_%i.pid
Restart=on-failure
[Install]
WantedBy=multi-user.target
Примечание:
<path>— домашняя директория Pangolin
Конфигурационный файл утилиты#
Установщик Pangolin создает конфигурационный файл утилиты enc_util.cfg, который расположен в каталоге /etc/postgres. Файл создается с правами -rw-r--r-- и владельцем root:root. Вносить изменения в файл может только привилегированный пользователь.
Конфигурационный файл хранится в формате JSON. Файлы с шифрованными параметрами подключения к БД задаются ключом files.
Для каждого файла указывается:
имя, через ключ
name. Если указано неполное имя файла, то поиск файла происходит в каталоге, определенном через переменную окруженияPGDATA;владелец файла, через ключ
owner. Утилита проверяет пользователя, который ее запустил: если в конфигурации утилиты для файла указан другой владелец, то утилита пропускает этот файл;домен шифрования, через ключ
domain. В случае, если файл шифруется полностью, то кроме имени и владельца требуется указать домен через ключdomain, для которого производится шифрование. Когда требуется зашифровать отдельные пароли в файлах, то с помощью ключаsecretsуказывается массив с описанием метода поиска пароля в файле. Метод поиска задается с помощью ключей:type— указывает тип поиска;name— указывает идентификатор пароля.Примечание:
Если в
typeустановлено значение«tag»— файл разбирается по форматуyml. Поиск пароля происходит по тегам, указанным в полеnameв порядке записи (теги разделены символом'/').Если в
typeустановлено значение«text», то поиск пароля в файле происходит по строкеname=<искомый_пароль>.
Для файла или отдельного пароля в файле можно указать булевый признак опциональности через ключ opt. Если признак задан и равен true, то отсутствие файла на диске или отстуствие пароля внутри файла не приводит к ошибкам в работе утилиты. Если признак не задан или задан и равен false, то отсутствие файла или отстуствие пароля внутри файла приведет к ошибкам в работе утилиты, при условии что утилита запущена без параметра -f (см. Параметры запуска утилиты).
Пример конфигурационного файла утилиты для конфигурации без Pangolin Manager, но с tde:
{
"files" :
[
{
"name" : "/etc/postgres/enc_connection_settings.cfg",
"owner" : "kmadmin_pg",
"domain" : "kms",
"opt" : true
},
{
"name" : "/etc/postgres/enc_utils_auth_settings.cfg",
"owner" : "postgres",
"domain" : "postgres"
},
{
"name" : "pg_hba.conf",
"owner" : "postgres",
"secrets" :
[
{
"type" : "text",
"name" : "ldapbindpasswd",
"domain" : "postgres"
}
]
}
]
}
Параметры запуска утилиты#
-c --conf— необязательный параметр. Задает файл конфигурации утилиты, который требуется проверить на наличие ошибок. Утилита проверит файл на наличие ошибок и завершит работу с кодом 0, если конфигурация не содержит ошибок, и 1, если указанный файл невалиден.Параметр может быть комбинирован с параметром
-l, при этом будет выведено диагностическое сообщение о результате проверки конфигурации. Рекомендуется проверить конфигурационный файл на наличие ошибок в процессе обновления файла/etc/postgres/enc_util.cfg, который используется утилитой при перешифровании.Если задан параметр
-c, то параметры-f -r -sбудут проигнорированы.-l --log— необязательный параметр. Включает лог утилиты. Совместим со всеми остальными параметрами.-f --force— необязательный параметр. Запускает утилиту в режиме игнорирования ошибок. Совместим со всеми параметрами.Если указан параметр
-c, параметр-fучитываться не будет.-r, --roll— необязательный параметр. Запускает утилиту в режиме отката операции перешифрования. Может задавать файл, для которого требуется применить процесс отката. Если файл не задан, то процесс отката перешифрования применяется ко всем файлам, указанным в конфигурации утилиты. Совместим со всеми параметрами.Если указан параметр
-c, параметр-rучитываться не будет.-s, --stable— необязательный параметр. Учитывается только в режиме перешифрования. Запрещает обновление/создание файла с параметрами оборудования. Используется при запуске утилиты для файлов с шифрованной информацией, принадлежащих разным пользователям.Примечание:
Параметр
-s, --stableнеобходимо указывать при первых запусках утилиты. Порядок вызовов утилиты имеет значение, поскольку при последнем вызове (без параметра-s) будет создан файл с параметрами оборудования, принадлежащий пользователю на момент вызова.-e, --enc— необязательный параметр. Задает отдельный файл для перешифрования, который должен быть описан в конфигурации утилиты. Если этот параметр задан — перешифрование осуществляется только для данного файла, остальные файлы из конфигурации не перешифровываются.-d, --daemon— необязательный параметр. Запускает утилиту в виде службы Linux (демона) для непрерывного отслеживания изменения параметров оборудования сервера (проверка изменения происходит с периодом 5 секунд).-p, --pid-file— необязательный параметр. Позволяет указать путь к PID-файлу, отличный от значения по умолчанию:/var/run/pangolin_reencrypt/pangolin_reencrypt__%i.pid.Примечание:
Ключи
-d,-c(проверка конфигурации),-e(перешифрование отдельного файла),-r(откат операции перешифрования) несовместимы: если используются два и более ключа, то утилита не запускается.
Управление службой утилиты#
Управлять утилитой pg_auth_reencrypt, запущенной в виде службы, можно с помощью следующих сигналов Linux:
SIGTERM - отправка запроса на завершение работы;
SIGUSR1 - отправка запроса на внеочередную проверку параметров оборудования;
SIGRTMIN - отправка запроса на проверку параметров (формируется таймером с периодом 5 секунд).
Режим игнорирования ошибок#
По умолчанию утилита останавливает свою работу, если в процессе перешифрования/отката перешифрования одного из файлов возникла ошибка. При возникновении ошибки в процессе перешифрования все файлы возвращаются в исходное состояние, выводится сообщение об ошибке и возвращается соответствующий код. Откат перешифрования в случае отсутствия резервной копии одного из файлов завершается с ошибкой, все файлы остаются в исходном состоянии.
В режиме игнорирования ошибок возникновение ошибки в процессе перешифрования/отката перешифрования файлов не приводит к остановке работы утилиты, последовательно предпринимаются попытки перешифровать/восстановить все файлы, указанные в файле конфигурации.
Режим отката операции перешифрования#
Перед началом процесса перешифрования утилита создает резервные копии файла с параметрами оборудования и файлов с шифрованными параметрами подключения к БД. Резервная копия создается в том же каталоге, где и исходный файл. Имя резервной копии файла формируется по принципу: .имя_оригинала_с_расширением.bak (пример для файла enc_params.cfg: .enc_params.cfg.bak).
В режиме отката операции перешифрования утилита возвращает файлы в исходное состояние на основании резервных копий.
Код завершения работы утилиты#
В случае успеха утилита возвращает ноль. Если работа утилиты завершилась с ошибкой — утилита возвращает код ошибки:
0 — операция перешифрования, откат операции перешифрования завершились с успехом (файл конфигурации не содержит ошибок для параметра
-c);1 — ошибка в файле конфигурации утилиты;
2 — работа завершена с ошибкой (подробности указаны в логе).
Отключение функциональности утилиты#
Для отключения функциональности:
Остановите службу/службы systemd Linux, запускающие демон утилиты.
Для службы, запущенной от имени пользователя
kmadmin_pg:sudo systemctl stop pangolin_reencrypt@kmadmin_pgДля службы, запущенной от имени пользователя
postgres:sudo systemctl stop pangolin_reencrypt@postgresПереведите состояние служб в
disable.Для службы, запущенной от имени пользователя
kmadmin_pg:sudo systemctl disable --now pangolin_reencrypt@kmadmin_pgДля службы, запущенной от имени пользователя
postgres:sudo systemctl disable --now pangolin_reencrypt@postgresЕсли демон утилиты запущен вручную, то требуется отправить процессу демона сигнал
SIGTERM, для этого:Определите идентификаторы процессов демона:
ps aux | grep -i pg_auth_reencryptДля всех найденных процессов демона отправьте сигнал:
kill -SIGTERM <pid>
<pid>— найденный идентификатор процесса демона.
Лог утилиты#
Утилита формирует лог в стандартный поток вывода Linux. Журнал (log) содержит информацию о процессе работы утилиты. Журнал (log) утилиты может быть перенаправлен в файл средствами ОС. Включение журналирования задается параметром -l или --log. По умолчанию утилита выводит сообщения только в случае ошибок.
В режиме работы демона записи (log) переводятся в системный журнал Linux syslog. В этом режиме дополнительно в записи журнала поступает информация о результате инициализации демона. В случае успешного запуска демона утилиты в логе появится строка Reencrypt daemon was started for <имя_пользователя_запустившего_утилиту>.
В утилите предусмотрена возможность задать уровни логирования:
уровень 1 (
-l1или--log=1) — показывать только ошибки;уровень 2 (
-l2или--log=2) — показывать записи (log) по перешифрованию данных и ошибки;уровень 3 (
-l3или--log=3) — показывать лог по проверке параметров оборудования, перешифрованию данных и ошибки.
По умолчанию (без указания уровня: -l или --log) используется 3 уровень логирования.
Примечание:
Для режима демона рекомендуется запускать утилиту с уровнем лога не выше 2, чтобы в системный журнал попадали только ключевые моменты работы.
Примеры:
Ошибка в конфигурационном файле:
2022-06-06 17:33:52.870752130 [18572] ERROR: Configuration file content (json) error: /etc/postgres/enc_util.cfg 2022-06-06 17:33:52.870818918 [18572] LOG: Load configuration /etc/postgres/enc_util.cfg FAILЗапуск утилиты первый раз:
2022-06-06 17:29:33.914889769 [18200] LOG: Load configuration /etc/postgres/enc_util.cfg ok 2022-06-06 17:29:33.916778674 [18200] LOG: Start saving current encrypting params 2022-06-06 17:29:33.923238749 [18200] LOG: Saving current encrypting params okПовторный запуск утилиты при неизменных параметрах сервера:
2022-06-06 17:29:46.226502410 [18264] LOG: Load configuration /etc/postgres/enc_util.cfg ok 2022-06-06 17:29:46.228432243 [18264] LOG: Check encrypting params in file 2022-06-06 17:29:46.234465754 [18264] LOG: Encrypting params in file are equal to the current
Включение/отключение функциональности шифрования паролей#
Новая функциональность позволяет развернуть СУБД Pangolin без шифрованного хранилища.
Описание решения#
Реализация решения в части инсталлятора#
В скриптах развертывания и обновления создание шифрованного хранилища и шифрование паролей в конфигурационных файлах (postgres.yml и pg_hba.conf) определено под условие, которое контролируется параметром auth_encrypt в пользовательском конфигурационном файле. Значение по умолчанию: true.
В конфигурационный файл Pangolin Manager (postgres.yml) добавлены следующие параметры:
postgresql.pgpass - путь к файлу со строкой подключения, если шифрованное хранилище отсутствует. Значение по умолчанию: /home/postgres/.pgpass.
```
postgres.yml
postgresql:
{%- if not auth_encrypt %}
pgpass: "{{ PGUSERHOME }}/.pgpass"
{%- endif %}
```
postgresql.authentication.replication.password - пароль суперпользователя для репликации. Значение по умолчанию: patroni_password.
```
postgres.yml
postgresql:
authentication:
replication:
{%- if not auth_encrypt %}
password: '{{ patroni_user_pass }}'
{%- endif %}
```
postgresql.authentication.superuser.password - пароль для суперпользователя. Значение по умолчанию: patroni_password.
```
postgres.yml
postgresql:
authentication:
superuser:
{%- if not auth_encrypt %}
password: '{{ patroni_user_pass }}'
{%- endif %}
```
Внесены изменения в конфигурацию службы pangolin_reencrypt. Следующий блок не будет записан, если файл /etc/postgres/enc_utils_auth_settings.cfg не был найден.
```
enc_util.cfg
{% if pgar_encrypt_config_exists.stat.exists -%}
{
"name" : "/etc/postgres/enc_utils_auth_settings.cfg",
"owner" : "postgres",
"domain" : "postgres"
},
{% endif -%}
```
Реализована возможность задать индивидуальный пароль для пользователя patroni в пользовательском конфигурационном файле. Регулируется параметром patroni_password(опциональный). Если пароль не задан, будет сгенерирован случайный.
В процессе обновления была реализована проверка на наличие шифрованного хранилища. При наличии файла /etc/postgres/enc_utils_auth_settings.cfg параметр auth_encrypt выставляется в true.
Реализация решения в части Pangolin Manager#
Pangolin Manager. автоматически создает файл .pgpass, если зашифрованное хранилище паролей отсутствует. Создание файла происходит, если не проинициализирован контекст(отсутствует плагин шифрования) или отсутствует файл /etc/postgres/enc_utils_auth_settings.cfg. Данные о том, где создать файл Pangolin Manager определяет из конфигурационного файла postgres.yml, секция postgresql.pgpass.
Скорректирована запись в логе Pangolin Manager при работе без шифрованного хранилища. Сообщение лога «using password from encrypted store for …» заменено на «using password from the config for …».
Утилита pg_auth_config создает файл /etc/postgres/enc_utils_auth_settings.cfg только при добавлении записи в файл(аргумент add). Если файл не существовал, аргументы remove, show, check и edit создавали файл нулевого размера. Логика работы этих команд изменена. При отсутствии файла они будут выдавать ошибку \x1B[0mCannot load auth config (file is not found), где \x1B[0m - спец. цветовой символ (белый).
Ограничения#
Есть ограничения в работе службы pangolin_reencrypt. Отсутствие файла или пароля внутри файла, которые прописаны в конфигурации службы pangolin_reencrypt, приведет к ошибке в работе перешифрования. Поэтому служба включается в процессе инсталляции только тогда, когда auth_encrypt: true и auth_reencrypt: true.
Перед стартом инсталляции нельзя задать перечень ролей, пароли которых будут включены в шифрование или блоки конфигурационных файлов, содержащие пароли, которые нужно зашифровать.
Включение функциональности#
Автоматическая установка#
Значение true для параметра auth_encrypt позволит включить использование решения.
Автоматическое обновление#
Реализация решения в обновлении не предусмотрена. Включить функциональность шифрования нельзя, если на исходном стенде ее не было.
Ручное включение#
Примечание:
Действия производятся на ранее установленном стенде без шифрованного хранилища паролей.
Процесс включения шифрованного хранилища можно условно разделить на два этапа:
перевод не зашифрованных паролей в конфигурационных файлах
postgres.ymlиpg_hba.confв зашифрованный вид с помощью утилиты шифрования паролейpg_auth_password:Для стенда в кластерной конфигурации зашифруйте пароли следующих секций в файле
postgres.yml:postgres.yml restapi: authentication: username: patroniyml password: 'TestPasswordPatroniYml1029)' etcd: username: patronietcd password: 'TestPasswordPatroniEtcd1029)' postgresql: pg_hba: ... ldapbindpasswd="TestPassword4556@!"...Действие по шифрованию нужно производить поочередно на каждом узле. Произведите шифрование паролей на лидере:
TestPasswordPatroniYml1029) sudo su - postgres pg_auth_password enc*Ожидаемый результат:* enter password: *************************** enter password: *************************** $enc$0OGvuDcN3OGvOJ0rWuWHUPnLUi2KHB0pXN7qwdOslWQ=$sys$1rYgVwagOzQAtgRdQkTPa7VuSQBqRxSDGZTgzNU7MsRbgqWYmq1hKMZ+DJ4KVh0zTestPasswordPatroniEtcd1029) sudo su - postgres pg_auth_password enc*Ожидаемый результат:* enter password: *************************** enter password: *************************** $enc$FPXR02NNWvpBXBWAE2hGLf/h651PazUo74fMmuU+m54=$sys$La7Kg5kJI6EURc86vGa2y7kAyOSeRyHy6bNKBJJdAZCvz83n+kcmHWbx4TqOynQBTestPassword4556@! sudo su - postgres pg_auth_password enc*Ожидаемый результат:* enter password: *************************** enter password: *************************** $enc$LuwiEsacN+HGUbS0Jq5xPy/q1PKJRvrRD0Sjsodolvc=$sys$p58nbXXZGe89HLU3bPOiT9Kjlf7fuwnzyl3fsSi25lRF5QIaRm2SgJo3mLGX5SdVЗамените открытые пароли на лидере на полученный результат шифрования:
*Ожидаемый результат:* postgres.yml restapi: authentication: username: patroniyml password: '$enc$2sWVW/CcM9Xg5pqXTvUNwF0wLKcgoV9nYZQh2B8J2PM=$sys$ofOrezSeQpXa5rx+dgyLg7VuSQBqRxSDGZTgzNU7MsRbgqWYmq1hKMZ+DJ4KVh0z' etcd: username: patronietcd password: '$enc$FPXR02NNWvpBXBWAE2hGLf/h651PazUo74fMmuU+m54=$sys$La7Kg5kJI6EURc86vGa2y7kAyOSeRyHy6bNKBJJdAZCvz83n+kcmHWbx4TqOynQB' postgresql: pg_hba: ... ldapbindpasswd="$enc$LuwiEsacN+HGUbS0Jq5xPy/q1PKJRvrRD0Sjsodolvc=$sys$p58nbXXZGe89HLU3bPOiT9Kjlf7fuwnzyl3fsSi25lRF5QIaRm2SgJo3mLGX5SdV"...Перечитайте конфигурацию на лидере:
sudo su - postgres reload*Ожидаемый результат:* + Cluster: clustername (7205282150766022368) ------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------------------+---------------------------+--------------+---------+----+-----------+ | srv-0-172 | srv-0-172:5433 | Leader | running | 2 | | | srv-0-182 | srv-0-182:5433 | Sync Standby | running | 2 | 0 | +----------------------+---------------------------+--------------+---------+----+-----------+ Are you sure you want to reload members srv-0-182, srv-0-172? [y/N]: y Reload request received for member srv-0-182 and will be processed within 10 seconds Reload request received for member srv-0-172 and will be processed within 10 secondsПроизведите действия с пункта 2 по 4 на реплике.
создание шифрованного хранилища паролей с помощью утилиты
pg_auth_config:Для корректной работы компонента
Pangolin Managerдобавьте следующие строки в хранилище с помощью утилитыpg_auth_config, где-h- хост, для которого будет использоваться пароль;-p- порт, для которого будет использоваться пароль;-U- имя пользователя, для которого будет использоваться пароль;-d- база данных, для которой будет использоваться пароль. Действие нужно произвести на обоих узлах:sudo su - postgres pg_auth_config add -s -h localhost -p 5433 -U patroni -d postgres*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "localhost", port: "5433", database: "postgres" New record addedsudo su - postgres pg_auth_config add -s -h localhost -p 5433 -U patroni -d replication*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "localhost", port: "5433", database: "replication" New record addedsudo su - postgres pg_auth_config add -s -h srv-0-172 -p 5433 -U patroni -d postgres*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "srv-0-172", port: "5433", database: "postgres" New record addedsudo su - postgres pg_auth_config add -s -h srv-0-172 -p 5433 -U patroni -d replication*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "srv-0-172", port: "5433", database: "replication" New record addedsudo su - postgres pg_auth_config add -s -h srv-0-182 -p 5433 -U patroni -d postgres*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "srv-0-182", port: "5433", database: "postgres" New record addedsudo su - postgres pg_auth_config add -s -h srv-0-182 -p 5433 -U patroni -d replication*Ожидаемый результат:* Enter password: ******************* Going to add auth record for user: "patroni", host: "srv-0-182", port: "5433", database: "replication" New record addedПроверьте работоспособность хранилища паролей:
sudo su - postgres pg_auth_config check*Ожидаемый результат:* Connection settings for host: "localhost", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "localhost", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-0-172", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "srv-0-172", port "5433", database "replication", user "patroni" are OK Connection settings for host: "srv-0-182", port "5433", database "postgres", user "patroni" are OK Connection settings for host: "srv-0-182", port "5433", database "replication", user "patroni" are OKУдалите из конфигурационного файла
Pangolin Managerследующие параметры:postgresql.pgpass: /home/postgres/.pgpass,postgresql.authentication.replication.password: 'TestPasswordPatroni5647*&',postgresql.authentication.superuser.password: 'TestPasswordPatroni5647*&'.Удалите файл
/home/postgres/.pgpassна обоих узлах.Перечитайте конфигурацию и перезапустите сервер на лидере:
sudo su - postgres reload*Ожидаемый результат:* + Cluster: clustername (7205282150766022368) ------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------------------+---------------------------+--------------+---------+----+-----------+ | srv-0-172 | srv-0-172:5433 | Leader | running | 2 | | | srv-0-182 | srv-0-182:5433 | Sync Standby | running | 2 | 0 | +----------------------+---------------------------+--------------+---------+----+-----------+ Are you sure you want to reload members srv-0-182, srv-0-172? [y/N]: y Reload request received for member srv-0-182 and will be processed within 10 seconds Reload request received for member srv-0-172 and will be processed within 10 secondssudo su - postgres restart --force*Ожидаемый результат:* + Cluster: clustername (7205282150766022368) ------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------------------+---------------------------+--------------+---------+----+-----------+ | srv-0-172 | srv-0-172:5433 | Leader | running | 2 | | | srv-0-182 | srv-0-182:5433 | Sync Standby | running | 2 | 0 | +----------------------+---------------------------+--------------+---------+----+-----------+ Success: restart on member srv-0-172 Success: restart on member srv-0-182Аналогичным образом производится добавление паролей для других пользователей БД в шифрованное хранилище паролей.
Подключите службу перешифрования на обоих узлах:
sudo su systemctl start pangolin_reencrypt@postgres.service systemctl status pangolin_reencrypt@postgres.service*Ожидаемый результат:* ● pangolin_reencrypt@postgres.service - Runners Pangolin reencrypt service (postgres) Loaded: loaded (/etc/systemd/system/pangolin_reencrypt@.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2023-01-31 11:30:43 MSK; 5h 48min ago Process: 3316 ExecStartPost=/bin/sleep 1 (code=exited, status=0/SUCCESS) Process: 3311 ExecStart=/opt/pangolin-common/bin/pg_auth_reencrypt -l2 -d (code=exited, status=0/SUCCESS) Process: 3310 ExecStartPre=/bin/chmod g+rw /var/run/pangolin_reencrypt (code=exited, status=0/SUCCESS) Process: 3305 ExecStartPre=/bin/chown postgres:kmadmin_pg /var/run/pangolin_reencrypt (code=exited, status=0/SUCCESS) Process: 3303 ExecStartPre=/bin/mkdir -p /var/run/pangolin_reencrypt (code=exited, status=0/SUCCESS) Main PID: 3315 (pg_auth_reencry) CGroup: /system.slice/system-pangolin_reencrypt.slice/pangolin_reencrypt@postgres.service └─3315 /opt/pangolin-common/bin/pg_auth_reencrypt -l2 -d Jan 31 11:30:42 srv-0-172 systemd[1]: Starting Runners Pangolin reencrypt service (postgres)... Jan 31 11:30:42 srv-0-172 pg_auth_reencrypt[3315]: Reencrypt daemon was started for postgres Jan 31 11:30:42 srv-0-172 pg_auth_reencrypt[3315]: Load configuration /etc/postgres/enc_util.cfg ok Jan 31 11:30:43 srv-0-172 systemd[1]: Started Runners Pangolin reencrypt service (postgres). Jan 31 11:30:47 srv-0-172 pg_auth_reencrypt[3315]: Start saving current encrypting params Jan 31 11:30:47 srv-0-172 pg_auth_reencrypt[3315]: Saving current encrypting params ok
Отключение функциональности#
Автоматическая установка#
Значение false для параметра auth_encrypt позволит отключить использование решения.
Автоматическое обновление#
Отключение решения для стендов с шифрованым хранилищем не предусмотрено.
Ручное отключение#
Примечание:
Действия производятся на ранее установленном стенде с шифрованным хранилищем паролей. Также необходимо заранее знать пароли пользователей БД, которые находятся в шифрованном хранилище паролей.
Произвести выключение шифрованного хранилища можно следующим образом:
Создайте файл
/home/postgres/.pgpassна реплике, назначьте права0600и владельца/группуpostgres:sudo su - postgres mkdir /home/postgres/.pgpass chown postgres:postgres /home/postgres/.pgpass chmod 0600 /home/postgres/.pgpass ls -la /home/postgres/.pgpass*Ожидаемый результат:* -rw------- 1 postgres postgres 2152 Mar 1 17:40 .pgpassДобавьте строку подключения в файл
/home/postgres/.pgpassдля пользователяpatroni:echo "srv-0-172:5433:*:patroni:TestPasswordPatroni5647*&" > /home/postgres/.pgpassПолучите список серверов расширения
pg_profile, если оно используется:select pgse_profile.show_servers();*Ожидаемый результат:* show_servers --------------------------------------------------------------------------------------------------------------------- (master,"dbname=First_db host=srv-0-172 port=5433 user=profile_tuz",t,) (replica,"dbname=First_db host=srv-0-182 port=5433 user=profile_tuz",t,) (2 rows)Скорректируйте строки подключения/добавьте параметр
passwordко всем существующим серверам, полученным на предыдущем шаге, в расширенииpg_profile, если используется:sudo su - postgres psql SELECT pgse_profile.set_server_connstr('master', 'dbname=First_db host=srv-0-172 pprb_dev port=5433 user=profile_tuz password=TestProfileUser56&*'); SELECT pgse_profile.set_server_connstr('replica', 'dbname=First_db host=srv-0-182 pprb_dev port=5433 user=profile_tuz password=TestProfileUser56&*');*Ожидаемый результат:* set_server_connstr -------------------- 1 (1 row)Скорректируйте конфигурационный файл Pangolin Manager, добавив следующие параметры:
postgresql.pgpass: /home/postgres/.pgpass,postgresql.authentication.replication.password: 'TestPasswordPatroni5647*&',postgresql.authentication.superuser.password: 'TestPasswordPatroni5647*&'на обоих узлах.Остановите службу перешифрования на обоих узлах:
sudo su systemctl stop pangolin_reencrypt@postgres.service systemctl status pangolin_reencrypt@postgres.service*Ожидаемый результат:* ● pangolin_reencrypt@postgres.service - Runners Pangolin reencrypt service (postgres) Loaded: loaded (/etc/systemd/system/pangolin_reencrypt@.service; disabled; vendor preset: disabled) Active: inactive (dead) Feb 06 12:51:21 srv-1-7 systemd[1]: [/etc/systemd/system/pangolin_reencrypt@.service:19] Unknown lvalue 'TimeoutStopFailureMode' in section 'Service' Feb 06 16:22:28 srv-1-7 systemd[1]: [/etc/systemd/system/pangolin_reencrypt@.service:19] Unknown lvalue 'TimeoutStopFailureMode' in section 'Service'Удалите все записи из шифрованного хранилища паролей на обоих узлах:
sudo su - postgres pg_auth_config reset pg_auth_config show*Ожидаемый результат:* Cannot load auth config (file is not found)Перечитайте конфигурацию и перезапустите сервер на лидере:
sudo su - postgres reload*Ожидаемый результат:* + Cluster: clustername (7205282150766022368) ------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------------------+---------------------------+--------------+---------+----+-----------+ | srv-0-172 | srv-0-172:5433 | Leader | running | 2 | | | srv-0-182 | srv-0-182:5433 | Sync Standby | running | 2 | 0 | +----------------------+---------------------------+--------------+---------+----+-----------+ Are you sure you want to reload members srv-0-182, srv-0-172? [y/N]: y Reload request received for member srv-0-182 and will be processed within 10 seconds Reload request received for member srv-0-172 and will be processed within 10 secondssudo su - postgres restart --force*Ожидаемый результат:* + Cluster: clustername (7205282150766022368) ------+--------------+---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------------------+---------------------------+--------------+---------+----+-----------+ | srv-0-172 | srv-0-172:5433 | Leader | running | 2 | | | srv-0-182 | srv-0-182:5433 | Sync Standby | running | 2 | 0 | +----------------------+---------------------------+--------------+---------+----+-----------| Success: restart on member srv-0-172 Success: restart on member srv-0-182
Нативное интервальное партицирование#
Нативное интервальное партицирование (или автопартицирование) — это механизм, который позволяет автоматически создавать партиции (секции) для таблиц по мере необходимости этих партиций. Необходимость возникает при вставке новых или перемещении данных со значениями, не подходящими под критерий данных для существующих партиций.
Автопартицирование может быть вложенным. При вложенном автопартицировании все создаваемые таблицы, кроме самой последней по уровню вложенности, являются партицированными таблицами. Реальные данные в такой схеме хранятся только в самой последней таблице. Автопартицирование создаст необходимые таблицы на всех уровнях вложенности.
Внимание!
При удалении или перемещении данных пустые партиции не удаляются.
Автопартицирование не исключает возможности управлять партициями вручную. При этом все стандартные механизмы в СУБД продолжают работать. Однако нужно учитывать потенциальное пересечение интервалов партиций, если партиции, создаваемые вручную, частично пересекаются с диапазонами автоматически создаваемых партиций. Для исключения пересечения необходимо убедиться, что настройки автопартицирования не приведут к созданию партиций, имеющих пересекающиеся диапазоны данных с существующими партициями.
Автопартицирование работает следующим образом. При создании партицированной таблицы (корневой таблицы) указываются параметры автопартицирования. При вставке или изменении данных СУБД пытается найти подходящую партицию. Если подходящая партиция не найдена, то происходит поиск правила автопартицирования для таблицы. Если правило найдено, то происходит создание новой таблицы и затем повторная попытка вставки данных. Данный процесс может повторяться рекурсивно для вложенного автопартицирования.
Примечание:
Для высоконагруженных систем, выполняющих DML-операции без использования ключа секционирования, рекомендуется обратить внимание на количество создаваемых секций, так как для каждой секции, в момент выполнения операции, на уровне ядра СУБД выставляются дополнительные блокировки
RowExclusiveLockиAccessShareLockв представленииpg_locks, что потенциально может привести к исчерпанию ограниченияmax_locks_per_transactionи деградации производительности, связанной с ожиданиемLockManager.Оптимальное количество секций зависит от профиля нагрузки на систему.
Синтаксис команды создания таблицы с включенным автопартицированием#
При создании таблицы через CREATE TABLE вместо стандартной конструкции PARTITION BY можно использовать новую конструкцию AUTO PARTITION BY:
CREATE * TABLE * auto_partition_spec [ ... ] *
Где auto_partition_spec:
{ AUTO PARTITION BY RANGE ( key [, ... ] ) PERIOD ( period [, ... ] ) [ OFFSET ( offset [, ... ] ) ] |
AUTO PARTITION BY HASH ( key [, ... ] ) MODULUS ( modulus [, ... ] ) |
AUTO PARTITION BY LIST ( key [, ... ] ) }
Где * — любые допустимые стандартные конструкции запроса.
Параметры:
key— ключ партицирования. Допустимы те же значения, что и в стандартной конструкцииPARTITION BY;period— значение периода партиций (разности значений междуFROMиTOв создаваемых партициях);offset— значение смещения периода партиций. По умолчанию равен 0 (для числовых интервалов) либо эпохе (для дат);modulus— значение модуля (MODULUS) создаваемых партиций.
Параметры должны быть указаны в соотвествии с количеством и типом данных, приведенных в ключе партицирования key.
Подряд может быть указано несколько AUTO PARTITION. Это задействует вложенное партицирование в указанном порядке. Первым следует описание автопартицирования для таблицы верхнего уровня, последним — для таблицы нижнего уровня.
Примечание:
Примеры задания команд для различных правил автопартицирования приведены в подразделе «Примеры задания команд для различных правил автопартицирования» текущего раздела.
Правила автопартицирования#
Под параметрами партицирования понимаются параметры, задающие правила определения принадлежности записи к существующей или вновь создаваемой партиции.
Правила автопартицирования для стратегии RANGE#
Для интервальных (RANGE) партиций указываются следующие параметры:
PERIOD— период партицирования, определяющий размер диапазона значений, которые будет содержать каждая партиция. Это значение будет соответствовать разности между параметрамиTOиFROMдля автоматически создаваемой партиции;OFFSET— смещение значений, определяющее смещение значенийTOиFROMотносительно условного нуля.
Так, при создании таблицы с параметрами PERIOD (10) OFFSET (3), партиции будут создаваться для диапазонов значений «… (-7 3) (3 13) (13 23) …».
Если не указывать смещение, то партиции будут создаваться со смещением:
для числовых значений — со смещением 0;
для значений даты или времени — со смещением от эпохи (2000-01-01 00:00:00).
Формулы, по которым вычисляется диапазон партиции для значения value:
FROM = value - ( (value - OFFSET) % PERIOD )
TO = FROM + PERIOD
. где % — оператор вычисления остатка от деления левого операнда на правый. Для дат и времени под делением понимается количество интервалов времени, прошедших с момента эпохи (для дат и меток времени) или начала дня (для времен).
Для данной стратегии доступны следующие типы данных:
INTEGER(все варианты);NUMERIC(все варианты);DATE;TIMESTAMP;TIMESTAMPTZ(используется часовой пояс, установленный на сервере);любые другие типы, для которых определены операторы, позволяющие вычислить значение формул расчета диапазона.
Примечание:
Технически имеется возможность использовать типы данных с плавающей запятой (
REAL), однако эта возможность, вероятно, будет отключена, поскольку может вызывать неожиданное поведение.
Правила автопартицирования для стратегии HASH#
Для хеш (HASH) партиций должен быть указан модуль (MODULUS).
Модуль определяет количество возможных партиций. При вставке или изменении данных рассчитывается хеш-значение для данных. Далее производится вычисление остатка от деления от этого значения по указанному модулю. Этот остаток (REMAINDER) определяет партицию, в которую попадут данные.
При включенном автопартицировании при необходимости будут создаваться партиции с указанным MODULUS и рассчитанным REMAINDER для новых данных.
Правила автопартицирования для стратегии LIST#
Для перечисляемых (LIST) партиций параметры отсутствуют.
При поступлении данных со значением ключа партицирования, не попадающими ни в одну созданную партицию, будет создана новая партиция для этого значения.
Именование партиций#
Новые партиции создаются с именем, состоящим из:
имени вышестоящей по уровню вложенности таблицы;
символов
«_p»;числа — условного номера партиции, в типичной ситуации равному порядковому номеру в порядке создания партиций, начиная с 0.
Просмотр параметров автопартицирования#
Просмотр при помощи утилиты psql#
В утилите psql в вывод команд /dP и /dPn добавлен столбец Autopartition parameters, который содержит в текстовом виде параметры автопартицирования для перечисленных таблиц.
Просмотр при помощи функции pg_autopartition_params#
Функция pg_autopartition_params принимает в качестве аргумента идентификатор (OID) таблицы и возвращает текст — параметры автопартицирования для указанной таблицы.
Если таблица с указанным OID отсутствует, то выполнение прекратится с соответствующей ошибкой.
Если таблица с указанным OID не является автопартицированной, то функция вернет пустую строку.
Просмотр через системный каталог#
Допускается просматривать текущие параметры автопартицирования, расположенные в системном каталоге pg_catalog.pg_autopartition.
Рекомендуется использовать данный способ только при однократной ручной диагностике инцидентов.
Блокировки при автопартицировании#
В момент автоматического создания партиции устанавливается блокировка уровня AccessExclusive для партицированной таблицы. Это влечет установку блокировок уровня ShareRowExclusive на зависимые ограничения (constraints) таблицы и может привести к взаимоблокировкам (deadlock) транзакций либо возникновению ресурсного голодания и сильному снижению производительности.
Для уменьшения вероятности возникновения таких ситуаций рекомендуется ограничить количество зависимых таблиц по внешнему ключу как для самой автопартицированной таблицы, так и для других таблиц, ссылающихся на автопартицированную таблицу.
Также возможна ручная установка эксклюзивной блокировки при помощи SQL-запроса LOCK TABLE в начале транзакции, перед вставкой или изменением данных, для того, чтобы момент взаимоблокировки был обнаружен и потенциально разрешен до начала операции создания партиции.
Отключение автопартицирования#
Функция создания таблиц с автопартицированием не может быть отключена.
На таблицы, созданные без указания схемы автопартицирования, функции автопартицирования не распространяются.
Примеры задания команд для различных правил автопартицирования#
Автопартицирование RANGE#
-- Партиции будут создаваться с интервалом в 10 единиц, начиная с 0.
CREATE TABLE table1( col1 int ) AUTO PARTITION BY RANGE (col1) PERIOD(10);
INSERT INTO table1(col1) VALUES (1); -- автоматически будет создана партиция table1_p0 с диапазоном FROM (0) TO (10)
INSERT INTO table1(col1) VALUES (2); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES (5); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES (15); -- автоматически будет создана партиция table1_p1 с диапазоном FROM (10) TO (20)
INSERT INTO table1(col1) VALUES (20); -- автоматически будет создана партиция table1_p2 с диапазоном FROM (20) TO (30)
Автопартицирование HASH#
CREATE TABLE table1( col1 int ) AUTO PARTITION BY HASH (col1) MODULUS (16);
INSERT INTO table1(col1) VALUES (1); -- автоматически будет создана партиция table1_p0 для значений MODULUS (16) REMAINDER (X)
INSERT INTO table1(col1) VALUES (1); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES (2); -- автоматически будет создана партиция table1_p1 для значений MODULUS (16) REMAINDER (X)
INSERT INTO table1(col1) VALUES (17); -- попадет в table1_p1
Автопартицирование LIST#
-- Партиции будут создаваться для каждого значения.
CREATE TABLE table1( col1 int ) AUTO PARTITION BY LIST (col1);
INSERT INTO table1(col1) VALUES (1); -- автоматически будет создана партиция table1_p0 для значений VALUES (1)
INSERT INTO table1(col1) VALUES (1); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES (2); -- автоматически будет создана партиция table1_p1 для значений VALUES (2)
INSERT INTO table1(col1) VALUES (15); -- автоматически будет создана партиция table1_p2 для значений VALUES (15)
Автопартицирование RANGE со смещением#
-- Партиции будут создаваться с интервалом в 3 единицы, со смещением 2.
CREATE TABLE table1( col1 INTEGER ) AUTO PARTITION BY RANGE (col1) PERIOD(3) OFFSET(2);
INSERT INTO table1(col1) VALUES (1); -- автоматически будет создана партиция table1_p0 для диапазона FROM (-1) TO (2)
INSERT INTO table1(col1) VALUES (2); -- автоматически будет создана партиция table1_p1 для диапазона FROM (2) TO (5)
INSERT INTO table1(col1) VALUES (3); -- попадет в table1_p1
INSERT INTO table1(col1) VALUES (4); -- попадет в table1_p1
INSERT INTO table1(col1) VALUES (5); -- автоматически будет создана партиция table1_p2 для диапазона FROM (5) TO (8)
Автопартицирование по сложному ключу партицирования#
-- Партиции будут создаваться с интервалами 10 (для поля col1) и 25 (для поля col2) со смещением 5 для поля col2.
CREATE TABLE table1( col1 int, col2 int ) AUTO PARTITION BY RANGE (col1, col2) PERIOD(10, 25) OFFSET(0, 5);
INSERT INTO table1(col1, col2) VALUES (0,0); -- автоматически будет создана партиция table1_p0 для диапазона FROM (0,-20) TO (10,5)
INSERT INTO table1(col1, col2) VALUES (5,0); -- попадет в table1_p0
INSERT INTO table1(col1, col2) VALUES (0,5); -- автоматически будет создана партиция table1_p1 для диапазона FROM (0,5) TO (10,30)
INSERT INTO table1(col1, col2) VALUES (10,10); -- автоматически будет создана партиция table1_p2 для диапазона FROM (10,5) TO (20,30)
INSERT INTO table1(col1, col2) VALUES (3,25); -- попадет в table1_p1
INSERT INTO table1(col1, col2) VALUES (15,29); -- попадет в table1_p2
Автопартицирование для типа данных TIMESTAMP#
-- Партиции будут создаваться с интервалом в 1 день, начиная в 10:30 дня и заканчивая в 10:30 (не включительно) следующего дня.
CREATE TABLE table1( col1 TIMESTAMP ) AUTO PARTITION BY RANGE (col1) PERIOD ( INTERVAL '1 day' ) OFFSET ( INTERVAL '10 hours 30 minutes' );
INSERT INTO table1(col1) VALUES ('2022-01-01 15:13:00'); -- автоматически будет создана партиция table1_p0 для диапазона FROM ('2022-01-01 10:30:00') TO ('2022-01-02 10:30:00')
INSERT INTO table1(col1) VALUES ('2022-01-01 10:31:00'); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES ('2022-01-01 10:29:00'); -- автоматически будет создана партиция table1_p1 для диапазона FROM ('2021-12-31 10:30:00') TO ('2022-01-01 10:30:00')
Автопартицирование для типа данных DATE#
-- Партиции будут создаваться с интервалом в 1 месяц, начиная с 5-го числа
CREATE TABLE table1( f DATE ) AUTO PARTITION BY RANGE (f) PERIOD ( INTERVAL '1 month' ) OFFSET ( INTERVAL '4 days' );
INSERT INTO table1(col1) VALUES ('2022-01-01'); -- автоматически будет создана партиция table1_p0 для диапазона FROM ('2021-12-05') TO ('2022-01-05')
INSERT INTO table1(col1) VALUES ('2022-01-04'); -- попадет в table1_p0
INSERT INTO table1(col1) VALUES ('2022-01-05'); -- автоматически будет создана партиция table1_p1 для диапазона FROM ('2022-01-05') TO ('2022-02-05')
INSERT INTO table1(col1) VALUES ('2022-01-29'); -- попадет в table1_p1
INSERT INTO table1(col1) VALUES ('2022-02-04'); -- попадет в table1_p1
Вложенное (каскадное) автопартицирование#
-- Партиции будут создаваться с интервалом в 10, которые, в свою очередь, будут являться партицированными таблицами, для которых будут создаваться партиции по модулю 16.
CREATE TABLE table1( col1 INTEGER , col2 INTEGER ) AUTO PARTITION BY RANGE (col1) PERIOD(10) AUTO PARTITION BY HASH (col2) MODULUS (16);
INSERT INTO table1(col1) VALUES (5,10); -- автоматически будет создана партиция table1_p0 для диапазона FROM (0) TO (10) с автопартицированием AUTO PARTITION BY HASH (col2) MODULUS (16)
-- и автоматически будет создана партиция table1_p0_p0 для таблицы table1_p0 c MODULUS (16) REMAINDER(X)
INSERT INTO table1(col1) VALUES (8,11); -- автоматически будет создана партиция table1_p0_p1 для таблицы table1_p0 c MODULUS (16) REMAINDER(X)
INSERT INTO table1(col1) VALUES (8,26); -- попадет в table1_p0_p1
INSERT INTO table1(col1) VALUES (12,10); -- автоматически будет создана партиция table1_p1 для диапазона FROM (10) TO (20) с автопартицированием AUTO PARTITION BY HASH (col2) MODULUS (16)
-- и автоматически будет создана партиция table1_p1_p0 для таблицы table1_p1 c MODULUS (16) REMAINDER(X)
INSERT INTO table1(col1) VALUES (18,26); -- попадет в table1_p1_p1
Поддержка подготовленных запросов для транзакционного режима кластера высокой доступности Pangolin#
Для работы кластера высокой доступности Pangolin на данный момент рекомендована конфигурация с настройкой менеджера пула соединений в транзакционном режиме.
Необходимость использования транзакционного режима обусловлена двумя факторами:
необходимостью установления большого количества подключений со стороны клиентских приложений;
ограниченностью количества процессов Pangolin, обслуживающих подключения клиентских приложений. Такое ограничение связано с особенностями архитектуры Pangolin.
Исходя из указанного, менеджер пула соединений кластера высокой доступности эксплуатируется в транзакционном режиме, при котором формируются разделенные пулы соединений:
со стороны клиентских приложений к менеджеру пула соединений;
со стороны менеджера пула соединений к Pangolin.
А также происходит выделение соединений из пула соединений к Pangolin на время выполнения транзакции, инициированной со стороны клиентского приложения.
Изменения настроек для сессионных переменных, подготовленные запросы (prepared statements), планы запросов и значения связанных переменных для подготовленных запросов сохраняются в контексте процесса, обслуживающего клиентское подключение на Pangolin, которое вызвало установку значения сессионной переменной или подготовку запроса. Подключение не сбрасывается на менеджер пула соединений, и не приводится в соответствие с новым клиентским подключением, при передаче соединения с Pangolin другому подключению клиентского приложения.
Менеджер пула соединений предоставляет возможность выполнить сброс значений сессионных настроек при передаче соединения с Pangolin другому соединению клиентского приложения, но это приводит к падению производительности и не обеспечивает решения проблемы подготовленных запросов.
Указанное выше делает невозможным использование подготовленных запросов (например, используемых драйвером jdbc) через менеджер пула соединений в транзакционном режиме и приводит к необходимости отключения использования подготовленных запросов на стороне клиентских приложений, использующих jdbc. Это, в свою очередь, способствует снижению производительности выполнения запросов, которые могли бы выполняться как подготовленные запросы.
Также возможно возникновение коллизий, связанных с изменением драйверами режима транзакций на стороне клиентских приложений read-only/read-write, в соответствии с логикой работы драйверов, и несоответствия ожидаемого режима транзакций фактически установленному в контексте процесса Pangolin, что приводит к ошибкам при выполнении запросов к Pangolin.
Реализованные функции#
для клиентских приложений:
прозрачное использование подготовленных запросов при включенном транзакционном режиме менеджера пула соединений кластера высокой доступности;
прозрачное переключение режимов транзакций
read-only/read-writeпри включенном транзакционном режиме менеджера пула соединений кластера высокой доступности;прозрачное переключение значений
search_path(восстановление списка используемых схем для клиентской сессии при включенном транзакционном режиме менеджера пула соединений кластера высокой доступности);прозрачное переключение сессионных и текущих ролей при включенном транзакционном режиме менеджера пула соединений кластера высокой доступности;
повышенная производительность выполнения запросов, которые могут выполняться как подготовленные, относительно режима с отключенными подготовленными запросами (конкретные показатели повышения производительности сильно зависят от сложности подготавливаемых запросов);
отсутствие необходимости дополнительной настройки параметров драйверов на стороне клиентских приложений.
Ограничения#
решение не обеспечивает прозрачности работы с подготовленными запросами при переключении клиентского приложения между серверами кластера высокой доступности Pangolin, то есть запрос, подготовленный на одном сервере не будет доступен к выполнению на другом;
решение накладывает ограничение на количество одновременно обслуживаемых клиентских сессий и на количество единовременно хранящихся подготовленных запросов в рамках сессии. Ограничение регулируется настроечными параметрами экземпляров Pangolin;
решение не позволяет хранить и обрабатывать для клиентских сессий значения
search_pathдлиной более чем 1023 байта (задается настроечным параметром);при достижении предела количества сессий или подготовленных запросов на сессию, решение будет пытаться вытеснить наиболее старые, по времени создания, экземпляры аналогичных сущностей. При невозможности это сделать - будет отказывать в выполнении операции, в рамках которой производится попытка выполнить добавление нового экземпляра;
решение не рекомендовано применять для выполнения одинаковых запросов, часто переподготавливаемых с разными именами.
Описание ролей пользователей#
Управление параметрами настройки функциональности выполняется пользователями с правами Администраторов СУБД.
Вызов функций мониторинга и получения статистики по реализованной функциональности выполняется пользователями с правами Администратора СУБД или пользователями, которым делегированы права на вызов таких функций.
Подготовка, выполнение подготовленных запросов и их удаление выполняются пользователями, имеющими права на подключение, подготовку и выполнение запросов.
Интерфейс пользователя#
Сохраняется реализованный ранее в PostgreSQL интерфейс работы с подготовленными запросами:
выполнение SQL-запросов
PREPARE,EXECUTE,DESCRIBEиDEALLOCATE;выполнение драйверами запросов расширенного протокола PostgreSQL, в том числе через драйвера
jdbc.
Инициализация, условия выполнения программы, завершение программы#
Для работы в режиме поддержки подготовленных запросов в транзакционном режиме Pangolin Pooler необходимо выполнить:
настройку параметров в
postgresql.conf(илиpostgres.ymlPangolin Manager) экземпляров БД кластера высокой доступности;настройки идентификаторов региона и обработчика в
pangolin-pooler.iniэкземпляров Pangolin Pooler кластера высокой доступности;включение транзакционного режима в
pangolin-pooler.iniэкземпляров Pangolin Pooler кластера высокой доступности;перезапуск экземпляров Pangolin кластера высокой доступности;
перезапуск экземпляров Pangolin Pooler кластера высокой доступности.
Описание настроечных параметров функциональности#
В Pangolin Pooler:
session_region_id- идентификатор региона для клиентских сессий, генерируемый алгоритмом snowflakeID, 0-23;session_worker_id- идентификатор обработчика для клиентских сессий, генерируемый алгоритмом snowflakeID, 0-1023.
Примечание:
Необходимость отдельного
session_worker_idобусловлена возможностью запуска на одном узле нескольких процессов Pangolin Pooler. Для разделения множества идентификаторов между такими процессами используется параметрsession_worker_id- свой для каждого процесса Pangolin Pooler узла (session_region_id).Необходимо учитывать что каждый узел кластера должен иметь свое значение параметра
session_region_id.
В Pangolin:
shared_prepared_statements- управляет включением/выключением функциональности разделяемых подготовленных запросов,BOOLEAN;max_client_sessions- максимальное количество клиентских сессий. Рекомендуется устанавливать с двухкратным запасом для демпфирования асинхронности удаления данных отключенных сессий;max_prepared_statements_per_session- максимальное количество именованных запросов на клиентскую сессию;max_shared_prepared_statements_names- предел количества хранимых вshared memoryуникальных подготовленных запросов;max_local_prepared_statements_names- предел количества локально хранимых в памяти процессов бэкенда картированных наименований подготовленных запросов;max_local_prepared_statements- предел количества локально хранимых в памяти процессов бэкенда подготовленных запросов;shared_prepared_statements_search_path_length- максимальная длина значенияsearch_pathклиентской сессии, включая нулевой байт окончания строки (по умолчанию 128, минимум 16, максимум 1024).
Описание принципов работы и особенностей функциональности#
Решение построено на следующих базовых принципах:
решение предназначено только для работы в транзакционном режиме Pangolin Pooler;
Pangolin Pooler производит присваивание открываемым клиентским сессиям идентификаторов (используется алгоритм
Snowflake ID). Присваиваемые идентификаторы уникальны среди всего множества Pangolin Pooler, работающих в кластере;при закрытии клиентского соединения на Pangolin с Pangolin Pooler по первому свободному соединению передается сообщение о закрытии клиентской сессии для удаления ее информации из карт контекста;
при связывании клиентского соединения с клиент-Pangolin Pooler с соединением Pangolin Pooler-Pangolin производится обязательная передача идентификатора связываемой клиентской сессии (клиентского соединения) и идентификатора текущего baseline Pangolin Pooler. Второе нужно для отслеживания случаев падения Pangolin Pooler и удаления информации всех клиентских сессий, уже не актуальных (находящихся ниже baseline);
при получении сообщения с идентификатором клиентских сессий серверный процесс Pangolin сохраняет контекст (значения сессионных переменных клиентской сессии, см. функцию
get_client_sessionsв документе «Список PL/SQL функций продукта», раздел «Парольные политики») в общей памяти и поднимает значения сессионных переменных новой клиентской сессии, если они есть в общей памяти;подготовленный запрос на базовом уровне идентифицируется хешем, вычисленным из указанных выше параметров, и на уровне привязки к клиентским сессиям — сочетанием идентификатора клиентской сессии и имени подготовленного запроса в клиентской сессии, в привязке к хешу запроса;
при выполнении подготовки запроса по SQL-запросу или сообщению расширенного протокола происходит поиск ранее сохраненного в общей памяти (и на диске) подготовленного запроса с таким же текстом, набором параметров и
search_path. Это нужно для избегания многократного хранения больших объемов одинаковой информации о запросах. При отсутствии такого ранее сохраненного запроса происходит его сохранение в файл на диске в директорииpg_prep_statsбазы данных. Это необходимо, так как тексты запросов могут быть потенциально очень большими. Также происходит регистрация привязки сочетания идентификатора клиентской сессии с именем подготовленного запроса к хешу подготовленного запроса в карте в общей памяти. Для неименованных запросов имя запроса принимается равным плейсхолдеру;при необходимости выполнения подготовленного запроса в процессе бэкенда производится следующий порядок действий (предполагается, что в бэкенде уже установлен контекст нужной клиентской сессии):
Производится поиск подготовленного запроса, сохраненного в локальном кэше процесса, для текущей клиентской сессии и указанного имени. Если такой находится, то используется этот запрос. Параметры, влияющие на локальный кэш подготовленных запросов процессов бэкендов:
max_local_prepared_statements_names— для карты «клиентская сессия+имя=хеш»;max_local_prepared_statements— для непосредственно уникальных подготовленных запросов;
Если запрос не находится локально, то производится поиск в общей памяти, по карте клиентская сессия+имя=хеш и по хешу — сам подготовленный запрос. Если не находится, то на этом выполнение подготовленного запроса завершается, т.к. его нет.
Если запрос нашелся в общей памяти, то он поднимается в кэш процесса бэкенда. Если там нет места — вытесняется, при необходимости, наиболее старая запись из карты имени и наиболее старая запись из карты уникальных подготовленных запросов, на которую нет ссылок из карты имен. Если возможности вытеснения нет, то будет поднята ошибка, поэтому важно правильно оценивать и выставлять значения параметров локального кэша бэкендов.
Если запрос не был найден локально и нашелся только в общей памяти — готовится подготовленный запрос в процессе бэкенда с синтаксическим анализом его структуру. В кэш ложится уже проанализированный и подготовленный запрос. Желательно минимизировать вытеснения уникальных подготовленных запросов, поэтому значения параметра
max_local_prepared_statementsрекомендуется делать больше, чем ожидаемое количество уникальных подготовленных запросов.Производится выполнение подготовленного запроса.
при считывании сохраненного на диске текста запроса производится проверка его целостности и неизменности путем сопоставления с хешем запроса — именем файла. Поэтому не рекомендуется изменять файлы подготовленного запроса вручную - это может нарушить работу системы.
Примечание:
Описание API функциональности подготовленных запросов приведено в документе Список PL/SQL функций продукта.
Функциональность FOREIGN DATA WRAPPER для БД Oracle#
Расширение oracle_fdw — это внешняя оболочка данных, которая позволяет получать доступ к таблицам и представлениям базы данных Oracle через сторонние таблицы. Когда клиент СУБД Pangolin обращается к внешней таблице, расширение oracle_fdw обращается к соответствующим данным во внешней базе данных Oracle через библиотеку интерфейса вызовов Oracle (OCI) на сервере PostgreSQL в СУБД Pangolin. Это расширение PostgreSQL предоставляет доступ к базам данных Oracle из СУБД Pangolin, включая отображение условий WHERE и требуемых столбцов, а также всестороннюю поддержку EXPLAIN.
Для обработки и проверки создаваемого расширения oracle_fdw используются функции oracle_fdw_handler и oracle_fdw_validator. Описание всех функций расширения в разделе «Функциональность FOREIGN DATA WRAPPER для БД Oracle» документа «Список PL/SQL функций продукта».
Расширение появилось в СУБД Pangolin в версии 4.5.0.
Примечание:
Внутреннее устройство описано в подразделе «Расширение oracle_fdw»] данного документа.
Расширение oracle_fdw#
Расширение oracle_fdw — это внешняя оболочка данных, которая позволяет получать доступ к таблицам и представлениям баз данных Oracle через сторонние таблицы из СУБД Pangolin, включая отображение условий WHERE и требуемых столбцов, а также всестороннюю поддержку EXPLAIN.
Расширение oracle_fdw устанавливает значение параметра postgres в параметр MODULE в сессии Oracle и pid backend-процесса в параметр ACTION. Это позволяет идентифицировать сессию Oracle и делает возможной ее трассировку с помощью DBMS_MONITOR, SERV_MOD_ACT_TRACE_ENABLE.
Расширение oracle_fdw использует предварительную выборку результатов Oracle, чтобы избежать ненужных обходов между клиентом и сервером. Количество строк предварительной выборки можно настроить с помощью опции таблицы prefetch, по умолчанию оно равно 200.
В Oracle при планировании запросов функция EXPLAIN PLAN помещает планы выполнения запросов в таблицу PLAN_TABLE. Вместо того, чтобы использовать PLAN_TABLE для формирования плана запроса Oracle (что потребовало бы создания такой таблицы в базе данных Oracle), oracle_fdw использует планы выполнения, хранящиеся в кэше библиотеки. Для этого явно описывается запрос Oracle, что заставляет Oracle анализировать запрос. Сложность заключается в том, чтобы найти SQL_ID и CHILD_NUMBER запроса в V$SQL, потому что столбец SQL_TEXT содержит только первые 1000 байт запроса. Поэтому oracle_fdw добавляет комментарий, содержащий MD5-хеш текста запроса, к самому запросу. Данный способ используется для поиска в V$SQL. Фактический план выполнения или информация о затратах извлекаются из V$SQL_PLAN.
Расширение oracle_fdw использует уровень изоляции транзакций SERIALIZABLE на стороне Oracle, что соответствует REPEATABLE READ в Postgresql. Это необходимо, поскольку один запрос PostgreSQL может привести к нескольким запросам в Oracle (например, во время вложенного JOIN), и результаты должны быть согласованными.
Транзакция Oracle фиксируется непосредственно перед фиксацией локальной транзакции, так что завершенная транзакция PostgreSQL гарантирует завершение транзакции Oracle. Однако существует небольшая вероятность того, что транзакция PostgreSQL не сможет завершиться, даже если транзакция Oracle зафиксирована. Этого нельзя избежать без использования двухфазных транзакций и менеджера транзакций, что выходит за рамки того, что может разумно предоставить внешняя обертка данных.
Подготовленные запросы, передаваемые в Oracle, не поддерживаются по той же причине.
Установка и настройка#
Для использования расширения:
Установите
oracle clientверсии не ниже 11.2:sudo yum localinstall oracle-instantclient18.5-basic-18.5.0.0.0-3.x86_64.rpmДобавьте в систему библиотеки клиента. Для этого добавьте строку
/usr/lib/oracle/18.5/client64/lib/в файл/etc/ld.so.confи сохраните его.Выполните настройку необходимых переменных окружения:
echo "[ -n \"\$PATH\" ] && export PATH=\$PATH:/usr/lib/oracle/19.14/client64/bin || export PATH=/usr/lib/oracle/19.14/client64/bin" >> /etc/profile.d/ora2pg.sh export PATH="$PATH:/usr/lib/oracle/19.14/client64/bin" echo "export ORACLE_HOME=/usr/lib/oracle/19.14/client64" >> /etc/profile.d/ora2pg.sh export ORACLE_HOME="/usr/lib/oracle/19.14/client64" echo "export NLS_LANG=AMERICAN_AMERICA.AL32UTF8" >> /etc/profile.d/ora2pg.sh export NLS_LANG="AMERICAN_AMERICA.AL32UTF8" echo "[ -n \"\$LD_LIBRARY_PATH\" ] && export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:/usr/lib/oracle/19.14/client64/lib || export LD_LIBRARY_PATH=/usr/lib/oracle/19.14/client64/lib" >> /etc/profile.d/ora2pg.sh [ -n "$LD_LIBRARY_PATH" ] && export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/lib/oracle/19.14/client64/lib" || export LD_LIBRARY_PATH=/usr/lib/oracle/19.14/client64/libПримечание:
Порядок установки переменной
LD_LIBRARY_PATHописан в разделе ниже.Когда библиотеки и файлы клиента Oracle появятся в системе, добавьте расширение в БД (необходимы права суперпользователя). После этого дайте права на использование расширения
oracle_fdwдля ролиas_admin:set role db_admin; create extension oracle_fdw schema ext; grant usage on foreign data wrapper oracle_fdw to as_admin;При необходимости обновите расширение:
ALTER EXTENSION oracle_fdw UPDATE;
Порядок установки переменной LD_LIBRARY_PATH в окружении Pangolin Manager#
При работе экземпляра под управлением Pangolin Manager игнорируется переменная окружения LD_LIBRARY_PATH, инициализированная в .bash_profile в домашней директории пользователя postgres. Это происходит потому, что в systemd unit жестко прописано новое значение этой переменной.
Для того чтобы переменная применилась, ее необходимо вносить непосредственно в systemd unit Pangolin Manager, расположение которого можно узнать командой:
systemctl status pangolin-manager.service
По умолчанию он расположен в каталоге /etc/systemd/system/pangolin-manager.service.
Порядок действий:
Пользователем с правами
sudoоткройте на редактирование файлpangolin-manager.service.Если в качестве
Environmentуже задана переменнаяPG_LD_LIBRARY_PATH, добавьте в нее существующий путь к библиотекам Oracle Client, например,/usr/lib/oracle/19.18/client64/lib. В результате строка будет выглядеть примерно так:Environment="PG_LD_LIBRARY_PATH=/usr/pangolin-5.5.0/lib:/usr/lib/oracle/19.18/client64/lib"Если переменная
PG_LD_LIBRARY_PATHотсутствует, добавьте строку сLD_LIBRARY_PATHили приведите ее к виду:Environment="LD_LIBRARY_PATH=/usr/pangolin-5.5.0/lib:/usr/lib/oracle/19.18/client64/lib"Обновите конфигурацию
systemd:sudo systemctl daemon-reloadОстановите сервис pangolin-manager:
sudo systemctl stop pangolin-managerЗапустите сервис pangolin-manager:
sudo systemctl start pangolin-manager
После запуска сервиса переменная будет определена на уровне службы Pangolin Manager.
Параметры#
Параметры оболочки внешних данных (FOREIGN DATA WRAPPER)#
Внимание!
Рекомендуем всегда создавать новую оболочку внешних данных (
SQL CREATE FOREIGN DATA WRAPPER), если необходимо, чтобы параметры были постоянными. Если вы измените обертку внешних данныхoracle_fdw, созданную по умолчанию, любые изменения будут потеряны при сбросе или восстановлении.
Для расширения oracle_fdw используется необязательный параметр nls_lang.
Когда клиент СУБД Pangolin обращается к внешней таблице базы данных Oracle, oracle_fdw обращается к соответствующим данным во внешней базе данных Oracle через библиотеку интерфейса вызовов Oracle (OCI) на сервере СУБД Pangolin.
Чтобы получить доступ к библиотеке OCI из oracle_fdw, установите переменную окружения NLS_LANG для Oracle в параметр nls_lang. Параметр NLS_LANG находится в форме language_territory.charset (например, AMERICAN_AMERICA.AL32UTF8). Этот параметр должен соответствовать кодировке вашей базы данных. Если это значение не задано, расширение oracle_fdw автоматически определит правильную кодировку либо выдаст предупреждение, если определить кодировку не удалось.
Параметры сервера - источника внешних данных (foreign server options)#
Ниже перечислены параметры для работы с внешним сервером (foreign server):
dbserver(обязательный параметр) – строка подключения к сторонней БД Oracle может быть в любой из форм, поддерживаемых Oracle.Например:
CREATE SERVER ora_test FOREIGN DATA WRAPPER oracle_fdw OPTIONS (dbserver 'host_ora:1521/EPXDB01'); CREATE SERVERгде:
host_ora:1521– имя:номер порта сервера Oracle;EPXDB01– имя сервера базы данных.
Для локальных подключений в значение параметра
dbserverустановите пустую строку (протоколBEQUEATH).isolation_level(необязательно) – уровень изоляции транзакций используемый в БД Oracle. Допустимые значенияserializable(по умолчанию),read_committedилиread_only.Примечание:
Обратите внимание, что таблица Oracle может быть запрошена более одного раза во время одной транзакции СУБД Pangolin (например, во время объединения (
JOIN) таблиц). Чтобы убедиться, что не может возникнуть несоответствий, вызванных конкурентными транзакциями, уровень изоляции транзакций должен гарантировать стабильность чтения. Это возможно только с помощью уровней изоляции OracleSERIALIZABLEилиREAD ONLY.Реализация наиболее строгого уровня изоляции
SERIALIZABLEв Oracle довольно нестабильна и вызывает ошибки сериализации ORA-08177 в неожиданных ситуациях, например, вставки в таблицу. ИспользованиеREAD COMMITTEDпозволяет обойти эту проблему, но существует риск возникновения несоответствий. В случае его использования рекомендуем узнать, может ли внешнее сканирование выполняться более одного раза. Для этого нужно проверить планы выполнения запросов (EXPLAIN).nchar(boolean, необязательно, значение по умолчаниюoff):Установка этого параметра в значение
onпозволяет выбрать более дорогостоящее преобразование символов на стороне Oracle. Это необходимо, если используется однобайтовый набор символов базы данных Oracle, но при этом присутствуют столбцыNCHARилиNVARCHAR2, содержащие символы, которые не могут быть представлены в наборе символов базы данных.Установка
ncharвonоказывает заметное влияние на производительность и вызывает ошибки ORA-01461 с операторамиUPDATE, которые устанавливают строки более 2000 байт (или 16383, если у васMAX_STRING_SIZE = EXTENDED). Эта ошибка, по-видимому, является ошибкой Oracle.
Параметры прав доступа (USER MAPPING)#
user(обязательно). Имя пользователя Oracle для подключения.password(необязательно). Пароль пользователя Oracle для подключения. В СУБД Pangolin возможно использование шифрованного хранилища паролей (утилитаpg_auth_config). Если пароль не задан в параметреpassword, он будет взят из хранилища паролей по соответствию имени хоста, порта и имени БД из строки подключения, указанной в используемомforeign server.
Параметры внешней таблицы (FOREIGN TABLE)#
table(обязательно):Имя таблицы Oracle. Должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, имя содержит только символы в верхнем регистре.
Чтобы определить внешнюю таблицу на основе произвольного запроса Oracle, установите этот параметр для запроса, заключенного в круглые скобки, например:
OPTIONS (table '(SELECT col FROM tab WHERE val = ''string'')')Параметр
schemaв данном случае указывать не нужно.Инструкции
INSERT,UPDATEиDELETEбудут работать со сторонней таблицей, основанной на таких запросах, если вы хотите избежать этого (или путаницы с сообщениями об ошибках Oracle для более сложных запросов), используйте опциюreadonly.dblink(необязательно):Oracle database link, через который доступна таблица. Должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре.schema(необязательно):Схема с таблицей (или владелец). Полезно для доступа к таблицам, которые не принадлежат подключающемуся пользователю Oracle. Название схемы должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре.
max_long(необязательно, значение по умолчанию «32767»):Максимальный размер полей с типом
LONG,LONG RAWиXMLTYPEв таблице Oracle. Возможными значениями являются целые числа от 1 до 1073741823 (максимальный размерbyteaв PostgreSQL). Этот объем памяти будет выделен как минимум дважды, поэтому большие значения будут занимать много памяти. Еслиmax_longменьше размера самого большого из полученных значений, вы получите ошибкуORA-01406: fetched column value was truncated.readonly(необязательно, значение по умолчанию«false»):Операции
INSERT,UPDATEиDELETEдоступны только для таблиц, где данный параметр не равенyes/on/true.sample_percent(необязательно, значение по умолчанию «100»):Данный параметр влияет только на выполнение операции
ANALYZEи может пригодиться для выполненияANALYZEочень больших таблиц за разумное время. Значение должно быть в диапазоне от 0,000001 до 100, оно определяет процент блоков таблицы Oracle, которые будут выбраны случайным образом для вычисления статистики таблицы базы данных Pangolin. Это достигается с помощью выраженияSAMPLE BLOCK(x)в Oracle. ПостроениеANALYZEзавершится с ошибкойORA-00933для таблиц, определенных с помощью запросов Oracle, и может завершиться с ошибкойORA-01446для таблиц, определенных со сложными представлениями (view) Oracle.prefetch(необязательно, значение по умолчанию «200»):Задает количество строк, которые будут извлечены с помощью одного кругового перехода между СУБД Pangolin и Oracle во время сканирования внешней таблицы. Реализовано с помощью предварительной выборки строк Oracle. Значение должно находиться в диапазоне от 0 до 10240, где нулевое значение отключает предварительную выборку. По умолчанию строки выбираются порциями по 200 штук. Высокие значения могут повысить производительность, но будут использовать больше памяти сервера СУБД Pangolin.
Примечание:
Если запрос Oracle включает столбец
BLOB,CLOBилиBFILE, предварительная выборка строк не будет работать (ограничения Oracle). Как следствие, запросы к таким столбцам во внешней таблице будут выполняться долго при извлечении большого количества строк.
Параметры полей#
key(необязательно, значение по умолчанию«false»):Если значение равно
yes/on/true, соответствующее поле в таблице Oracle является первичным ключом. Чтобы работали операцииUPDATEиDELETE, установите этот параметр для всех столбцов, относящихся к первичному ключу таблицы.strip_zeros(необязательно, значение по умолчанию"false"):Если значение равно
yes/on/true,ASCII 0символы будут удалены из строки перед передачей. Такие символы допустимы в Oracle, но не в PostgreSQL, поэтому они вызовут ошибку при чтенииoracle_fdw. Данная опция актуальна только для типовcharacter, character varyingиtext.
Использование расширения oracle_fdw#
Привилегии Oracle#
Учетная запись в Oracle должна иметь привилегию CREATE SESSION и права на чтение таблиц или представлений в запросе.
Для выполнения EXPLAIN VERBOSE пользователь также должен обладать привилегией SELECT на представлениях V$SQL и V$SQL_PLAN.
Подключение к внешней БД#
Расширение oracle_fdw кэширует соединения Oracle, поскольку создание сеанса Oracle для каждого отдельного запроса обходится дорого. Все соединения автоматически закрываются по окончании сеанса со стороны СУБД Pangolin.
Функция oracle_close_connections() может быть использована для закрытия кэшированных соединений Oracle. Это может быть полезно для длительных сеансов, которые не обращаются к внешним таблицам постоянно и хотят избежать блокировки ресурсов, необходимых для открытых подключений к Oracle. Вы не можете вызвать эту функцию внутри транзакции, которая модифицирует данные в Oracle.
Поля и столбцы внешних таблиц#
Когда вы определяете внешнюю таблицу, столбцы таблицы базы данных Oracle сопоставляются столбцам СУБД Pangolin в порядке, в котором они указаны.
Расширение oracle_fdw будет включать в запрос Oracle только те столбцы, которые действительно необходимы для запроса СУБД Pangolin.
Таблица СУБД Pangolin может содержать больше или меньше столбцов, чем таблица базы данных Oracle. Если в ней больше столбцов, и эти столбцы используются, появится предупреждение и будут возвращены значения NULL.
Если необходимо выполнить операцию UPDATE или DELETE, убедитесь, что параметр key установлен для всех столбцов, принадлежащих первичному ключу таблицы. Невыполнение этого требования приведет к ошибкам.
Типы данных#
Необходимо определить столбцы таблиц СУБД Pаngolin с типами данных, которые может преобразовать oracle_fdw (см. таблицу преобразования ниже). Это ограничение применяется только в том случае, если столбец действительно используется, поэтому можно определять «фиктивные» столбцы для непереводимых типов данных до тех пор, пока к ним не будет получен доступ (этот трюк работает только с SELECT, а не при изменении внешних данных). Если значение из Oracle превышает размер столбца СУБД Pаngolin (например, длину столбца varchar или максимальное целочисленное значение), будет выведено сообщение об ошибке во время выполнения.
Данные преобразования типов автоматически выполняются расширением oracle_fdw:
Oracle type |
Possible PostgreSQL types |
|---|---|
CHAR |
char, varchar, text |
NCHAR |
char, varchar, text |
VARCHAR |
char, varchar, text |
VARCHAR2 |
char, varchar, text, json |
NVARCHAR2 |
char, varchar, text |
CLOB |
char, varchar, text, json |
LONG |
char, varchar, text |
RAW |
uuid, bytea |
BLOB |
bytea |
BFILE |
bytea (read-only) |
LONG RAW |
bytea |
NUMBER |
numeric, float4, float8, char, varchar, text |
NUMBER(n,m) with m<=0 |
numeric, float4, float8, int2, int4, int8, boolean, char, varchar, text |
FLOAT |
numeric, float4, float8, char, varchar, text |
BINARY_FLOAT |
numeric, float4, float8, char, varchar, text |
BINARY_DOUBLE |
numeric, float4, float8, char, varchar, text |
DATE |
date, timestamp, timestamptz, char, varchar, text |
TIMESTAMP |
date, timestamp, timestamptz, char, varchar, text |
TIMESTAMP WITH TIME ZONE |
date, timestamp, timestamptz, char, varchar, text |
TIMESTAMP WITH LOCAL TIME ZONE |
date, timestamp, timestamptz, char, varchar, text |
INTERVAL YEAR TO MONTH |
interval, char, varchar, text |
INTERVAL DAY TO SECOND |
interval, char, varchar, text |
XMLTYPE |
xml, char, varchar, text |
MDSYS.SDO_GEOMETRY |
geometry (see "PostGIS support" below) |
Если тип NUMBER привести к boolean, тогда "0" превратится в "false", все остальное в "true".
Вставка или обновление XMLTYPE работает только со значениями, которые не превышают максимальную длину типа данных VARCHAR2 (4000 или 32767, в зависимости от параметра MAX_STRING_SIZE).
Тип данных NCLOB в настоящее время не поддерживается, поскольку Oracle не может автоматически преобразовать его в кодировку клиента.
Если нужны преобразования, отличающиеся от вышеуказанных, определите соответствующее представление (view) в Oracle или Pangolin.
Инструкции WHERE и ORDER BY#
СУБД Pаngolin будет использовать все применимые части предложения WHERE в качестве фильтра для проверки. Запрос Oracle, который создает oracle_fdw, будет содержать предложение WHERE, соответствующее этим критериям фильтрации, всякий раз, когда такое условие может быть безопасно переведено в Oracle SQL. Эта функция, также известная как выдвижение предложений WHERE, может значительно сократить количество строк, извлекаемых из Oracle, и может позволить оптимизатору Oracle выбрать подходящий план доступа к требуемым таблицам.
Аналогично, предложения ORDER BY будут перенесены в Oracle там, где это возможно. Обратите внимание, что ORDER BY, сортирующее по символьной строке, будет пропущено, поскольку нет гарантий, что порядок сортировки в СУБД Pаngolin и Oracle будет одинаковым.
Для использования попробуйте писать простые условия для внешней таблицы. Выберите типы данных столбцов СУБД Pаngolin, соответствующие типам Oracle, поскольку в противном случае условия не могут быть переведены.
Выражения now(), transaction_timestamp(), current_timestamp, current_date и localtimestamp будут переведены правильно.
В выводе EXPLAIN будет показан используемый запрос Oracle, чтобы была возможность увидеть, какие условия были переведены в Oracle и как.
Объединения (JOIN) между внешними таблицами#
Начиная с версии PostgreSQL 9.6 расширение oracle_fdw может передавать инструкцию join на сервер Oracle, то есть join между двумя внешними таблицами приведет к одному запросу Oracle, который выполняет join на стороне Oracle.
Необходимые условия:
обе таблицы должны относиться к одному внешнему серверу Oracle;
JOINмежду 3 и более таблицами не произойдет;JOINдолжен использоваться в выраженииSELECT;oracle_fdwдолжен быть способен выполнить всеJOINи условияWHERE;перекрестный
JOINбез условий не будет выполнен;если выполнен
JOIN,ORDER BYвыполнен не будет.
Важно, чтобы статистика для обеих внешних таблиц была собрана с помощью ANALYZE для определения наилучшей стратегии объединения.
Изменение внешних данных#
Расширение oracle_fdw поддерживает операции INSERT, UPDATE и DELETE на внешних таблицах. Данные операции доступны по умолчанию (также и в БД, обновленной с ранних версий PostgreSQL) и могут быть отключены опцией readonly на внешней таблице.
Чтобы операции UPDATE и DELETE работали, столбцы, относящиеся к первичному ключу в таблице Oracle, должны иметь установленную опцию key. Значения данных столбцов используются для идентификации строк внешней таблицы, поэтому убедитесь, что опция установлена на ВСЕХ столбцах, относящихся к первичному ключу.
Если во время вставки один из столбцов внешней таблицы пропущен, этому столбцу присваивается значение, определенное в предложении DEFAULT для внешней таблицы СУБД Pangolin (или NULL, если предложение DEFAULT отсутствует). Предложения DEFAULT в соответствующих столбцах Oracle не используются. Если внешняя таблица СУБД Pangolin не включает все столбцы таблицы Oracle, для столбцов, не включенных в определение внешней таблицы, будут использоваться предложения DEFAULT в Oracle.
Директива RETURNING в операцих INSERT, UPDATE или DELETE поддерживается, кроме столбцов Oracle с типами данных LONG или LONG RAW (сам Oracle не поддерживает данные типы данных в RETURNING).
Триггеры для внешних таблиц поддерживаются, начиная с версии PostgreSQL 9.4. Триггеры, определенные с использованием AFTER и FOR EACH ROW, требуют, чтобы во внешней таблице не было столбцов с типом данных Oracle LONG или LONG RAW. Это происходит потому, что такие триггеры используют предложение RETURN, упомянутое выше.
Во время изменения внешних данных производительность может снижаться, особенно когда затрагивается много строк, потому что (так работают внешние обертки данных) каждая строка должна обрабатываться индивидуально.
Транзакции пересылаются в Oracle, поэтому BEGIN, COMMIT, ROLLBACK и SAVEPOINT работают должным образом. Подготовленные запросы, относящиеся к Oracle, не поддерживаются.
Поскольку oracle_fdw по умолчанию использует сериализованные транзакции, возможно, что запросы на изменение данных приведут к сбою сериализации:
ORA-08177: can't serialize access for this transaction
Это может произойти, если несколько транзакций одновременно изменяют таблицу и вероятность этого возрастает на длинных транзакциях. Такие ошибки могут быть идентифицированы по статусу SQLSTATE(40001). Приложение, использующее oracle_fdw, должно повторить транзакции, которые завершаются с этой ошибкой.
По возможности используйте другие уровни изоляции транзакций (READ COMMITTED или READ ONLY), чтобы избежать данной ошибки.
Планы запросов (EXPLAIN)#
Команда EXPLAIN в СУБД Pаngolin покажет запрос, который фактически отправлен в Oracle. EXPLAIN VERBOSE покажет план выполнения Oracle (но это не будет работать с версиями Oracle 9i и ниже).
Сбор статистики (ANALYZE)#
Можно использовать ANALYZE для сбора статистики внешней таблицы. oracle_fdw поддерживает такую возможность.
Без статистики СУБД Pаngolin не может оценить количество строк для запросов по внешней таблице, что может привести к выбору неправильных планов выполнения. СУБД Pаngolin не будет автоматически собирать статистику для внешних таблиц с помощью демона autovacuum, как это делается для обычных таблиц, поэтому особенно важно запускать ANALYZE для внешних таблиц после создания и всякий раз, когда внешняя таблица значительно изменилась.
Примечание
Для внешней таблицы Oracle выполнение
ANALYZEприведет к полному последовательному сканированию таблицы. Для того, чтобы ускорить процесс, можно использовать параметр таблицыsample_percent.
Поддержка геоданных PostGIS#
Тип данных geometry доступен только если установлено расширение PostGIS.
Поддерживаются только такие геометрические типы, как: POINT, LINE, POLYGON, MULTIPOINT, MULTILINE и MULTIPOLYGON в двух и трех измерениях. Пустые значения PostGIS не поддерживаются, поскольку они не имеют аналогов в Oracle Spatial.
Значения NULL для Oracle SRID будут преобразованы в 0 и наоборот. Для других преобразований между Oracle SRID и PostGIS SRID создайте файл srid.map в каталоге общего доступа PostgreSQL. Каждая строка этого файла должна содержать SRID Oracle и соответствующий SRID PostGIS, разделенные пробелами. Сохраняйте размер файла небольшим для обеспечения хорошей производительности.
Импорт определения сторонних таблиц (IMPORT FOREIGN SCHEMA)#
Расширение oracle_fdw имеет функцию, которая позволяет массово создавать сторонние таблицы. Можно создать внешнюю таблицу, используя CREATE FOREIGN TABLE. При этом необходимо определить каждый столбец в соответствии с его определением на стороне БД Oracle. Это достаточно трудоемко, если количество таблиц велико.
С помощью IMPORT FOREIGN SCHEMA есть возможность создавать сторонние таблицы для каждой из таблиц, определенных в импортированной схеме, с возможностью импорта только некоторых из этих таблиц.
Примечание
Предложение DEFAULT не импортируется, поэтому его необходимо добавить отдельно к столбцам позже.
В дополнение к документации по IMPORT FOREIGN SCHEMA, учитывайте следующее:
IMPORT FOREIGN SCHEMAсоздаст внешние таблицы для всех объектов, найденных вALL_TAB_COLUMNS, включая таблицы, представления и материализованные представления, но не синонимы.Поддерживаемые параметры для
IMPORT FOREIGN SCHEMA:case– управляет регистром имен таблиц и столбцов при импорте; Возможные значения:keep: оставить имена такими как в Oracle, как правило в верхнем регистре.lower: преобразовать имена всех таблиц и столбцов в нижний регистр.smart: преобразовать только имена, записанные полностью в верхнем регистре в Oracle (значение по умолчанию).
collation: порядок сортировки, используемый при преобразовании регистра при выборе значенияlowerилиsmartдля параметраcase. По умолчанию используется порядок сортировки используемый в БД. Поддерживаются только значения, которые есть в схемеpg_catalog. Доступные параметры сортировки указаны в таблицеpg_collation, значенияcollname.dblink:dblinkна базу данных Oracle, через которую осуществляется доступ к схеме. Имя должно быть написано точно так же, как оно было сохранено в системном каталоге Oracle. Как правило, оно содержит только символы в верхнем регистре.readonly: устанавливает опциюreadonlyдля всех импортируемых таблиц(см. описание опций таблиц).max_long: устанавливает опциюmax_longдля всех импортируемых таблиц (см. описание опций таблиц).sample_percent: устанавливает опциюsample_percentдля всех импортируемых таблиц (см. описание опций таблиц).prefetch: устанавливает опциюprefetchдля всех импортируемых таблиц (см. описание опций таблиц).Имя схемы должно быть написано точно так же, как оно сохранено в системном каталоге Oracle. Как правило, имя содержит только символы в верхнем регистре. Поскольку PostgreSQL переводит имена в нижний регистр перед обработкой, необходимо обернуть имя схемы двойными кавычками (например,
"SCOTT").Имена таблиц в выражениях, использующих
LIMIT TOилиEXCEPT, должны быть написаны так, как они будут отображаться в PostgreSQL после преобразования регистра (см. параметрcase).
Обратите внимание, что IMPORT FOREIGN SCHEMA не работает с СУБД Oracle версии 8i и ниже.
Пример использования#
Ниже приведен простейший пример использования расширения oracle_fdw. Более детальная информация описана в разделах «Параметры» и «Использование расширения oracle_fdw». Пример предполагает, что работа ведется под пользователем ОС postgres и он может подключиться к БД Oracle:
sqlplus orauser/orapwd@//dbserver.mydomain.com:1521/ORADB
Проверка подключения к БД необходима, чтобы убедиться, что Oracle клиент и окружение настроены корректно и все работает правильно. Кроме этого необходимо, чтобы расширение oracle_fdw присутствовало в инсталляции Pangolin (убедитесь, что версия Pangolin используется не ниже 4.5.0).
Предположим, что необходимо получить доступ к таблице Oracle, которая имеет вид:
SQL> DESCRIBE oratab
Name Null? Type
------------------------------- -------- ------------
ID NOT NULL NUMBER(5)
TEXT VARCHAR2(30)
FLOATING NOT NULL NUMBER(7,2)
Для этого:
Сконфигурируйте
oracle_fdwпод администратором СУБД Pangolin:CREATE EXTENSION oracle_fdw; CREATE SERVER oradb FOREIGN DATA WRAPPER oracle_fdw OPTIONS (dbserver '//dbserver.mydomain.com:1521/ORADB');Выдайте права на использование стороннего сервера пользователю:
GRANT USAGE ON FOREIGN SERVER oradb TO pguser;Подключитесь к БД пользователем
pguserи выполните:CREATE USER MAPPING FOR pguser SERVER oradb OPTIONS (user 'orauser');Пароль пользователя Oracle должен быть сохранен в шифрованном хранилище паролей, утилита
pg_auth_config;Создайте внешнюю таблицу:
CREATE FOREIGN TABLE oratab ( id integer OPTIONS (key 'true') NOT NULL, text character varying(30), floating double precision NOT NULL ) SERVER oradb OPTIONS (schema 'ORAUSER', table 'ORATAB');
Теперь вы можете обращаться к данной таблице, как к обычной таблице PostgreSQL в СУБД Pangolin.
Функциональность FOREIGN DATA WRAPPER для БД MSSQL#
Обертка внешних данных (PostgreSQL foreign data wrapper) может подключаться к базам данных, использующим протокол табличного потока данных (TDS), таким как базы данных Sybase и Microsoft SQL server. Обертки внешних данных позволяют работать с таблицами из внешних БД как с собственными.
Для этой обертки требуется библиотека, реализующая интерфейс DB-Library, например FreeTDS.
Обертка работает с версиями PostgreSQL старше 9.2.
Установка#
Расширение появилось в дистрибутиве Pangolin, начиная с версии 4.4.0. Для его использования версия Pangolin должна быть не ниже, в противном случае требуется обновить СУБД.
Для корректной работы расширения в системе должен быть установлен драйвер freetds версии не ниже 1.1.20 (необходимо включить репозиторий EPEL в /etc/yum.repos.d/mirror.repo):
sudo yum install freetds
Расширение доработано под использование pg_auth_config. Необходимо добавить параметры подключения к БД MSSQL и пароль при помощи утилиты:
pg_auth_config add --host <ip_address_mssql> --port <mssql_port> --user <mssql_user> --database <mssql_database>
После того как все подготовительные действия выполнены, создайте и настройте расширение в БД:
--Создать расширение в схеме ext
set role db_admin;
create extension tds_fdw schema ext;
--Дать права на использование расширения роли as_admin
GRANT USAGE ON FOREIGN DATA WRAPPER tds_fdw TO as_admin;
Использование#
Права на создание внешних таблиц и подключений должны быть у роли as_admin, для этого данной роли при создании расширения выдается право USAGE на foreign data wrapper (см. раздел «Установка» документа «Руководство по установке»). Далее роль as_admin самостоятельно создает user mapping, foreign server и foreign tables. Доступы к сторонним таблицам разграничиваются на стороне стороннего сервера, хранящего эти объекты (в данном случае БД MSSQL), поэтому пользователь, добавленный в user mapping должен иметь минимально необходимый для работы набор привилегий в соответствии с утвержденной ролевой моделью MSSQL. Для работы приложения роль as_admin может выдать право USAGE на foreign server для роли as_TUZ.
Foreign server#
Возможные параметры foreign server:
servername(обязательный, значение по умолчанию:127.0.0.1) – имя сервера, IP-адрес или fqdn внешнего сервера. Это может быть имя источника данных (DSN), указанное в файлеfreetds.conf(см. FreeTDS name lookup). Можно передать в этой опции список серверов, разделенных запятой, где серверы будут последовательно перебираться до первого успешного подключения. Это используется для автоматического fail-over на второй сервер;port(необязательный) – порт стороннего сервера. Параметр опциональный, может быть указан здесь или в файлеfreetds.conf(при условии, чтоservernameэто DSN);database(необязательный) – внешняя база данных для подключения;dbuse(необязательный, значение по умолчанию:0) – данная опция говоритtds_fdwподключаться напрямую к БД, если параметрdbuse = 0. Еслиdbuseне равен0,tds_fdwбудет подключаться к БД по умолчанию, после чего выберет БД вызовом функцииdbuse()из библиотеки DB-Library;language(необязательный) – язык, используемый в сообщениях, и локаль, применяемая для форматирования дат. FreeTDS по умолчанию используетus_englishна многих системах. Язык можно задать в файлеfreetds.conf.character_set(необязательный) – клиентский набор символов, используемый для подключения, если нужно устанавливать его по какой-то причине. Для протокола TDS версии 7.0+, подключение использует UCS-2, данный параметр не нужно менять в большинстве случаев. См. Localization and TDS 7.0;tds_version(необязательный) – версия протокола TDS используемого для данного сервера. См. Choosing a TDS protocol version и History of TDS Versions;msg_handler(необязательный, значение по умолчанию:blackhole) – функция обработчика сообщений TDS. Может бытьnoticeилиblackhole. При значенииnotice, сообщения от TDS будут переданы в сообщения PostgreSQL. При значенииblackholeсообщения TDS будут игнорироваться;fdw_startup_cost(необязательный) – стоимость представления накладных расходов на использование FDW. Используется при планировании запросов;fdw_tuple_cost(необязательный) – стоимость представления накладных расходов на выборку строк с сервера. Используется при планировании запросов.
Некоторые параметры внешней таблицы, допустимые в определении сервера, могут также быть установлены на уровне сервера:
use_remote_estimate;row_estimate_method.
Пример:
CREATE SERVER mssql_svr
FOREIGN DATA WRAPPER tds_fdw
OPTIONS (servername '127.0.0.1', port '1433', database 'tds_fdw_test', tds_version '7.1');
Foreign table#
Допустимые параметры foreign table:
query(обязательный, если не указан параметрtable_name) – не может быть указан одновременно с параметромtable_name. Строка запроса, формирующая внешнюю таблицу;schema_name(необязательный) – имя схемы, содержащей внешнюю таблицу. Имя схемы может быть так же включено вtable_name;table_name(обязательный, если не указан параметрquery) – имя внешней таблицы. Сокращенный вариант –table. Не может быть указан одновременно с параметромquery;match_column_names(необязательный) – определяет, следует ли сопоставлять локальные столбцы с удаленными столбцами путем сравнения их имен или использовать порядок их отображения в результирующем наборе;use_remote_estimate(необязательный) – параметр, определяющий оценивается ли размер таблицы при выполнении операции на удаленном сервере (как определеноrow_estimate_method), или в соответствии сlocal_tuple_estimateиспользуется локальная оценка;local_tuple_estimate(необязательный) – локально установленная оценка количества кортежей, которая используется, когда параметрuse_remote_estimateвыключен;row_estimate_method(необязательный, значение по умолчанию:execute). Может принимать одно из следующих значений:execute– выполнить запрос на удаленном сервере и получить актуальное количество строк в запросе;showplan_all– получить расчетное количество строк с использованием MS SQL ServerSET SHOWPLAN_ALL.
Допустимые параметры столбцов в foreign table:
column_name(необязательный) – имя столбца на удаленном сервере. Если этот параметр не задан, предполагается, что удаленное имя столбца совпадает с локальным именем столбца. Если дляmatch_column_namesдля таблицы установлено значение0, то имена столбцов не используются, и этот параметр игнорируется.
Пример с использованием table_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (table_name 'dbo.mytable', row_estimate_method 'showplan_all');
С использованием schema_name и table_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (schema_name 'dbo', table_name 'mytable', row_estimate_method 'showplan_all');
С использованием query:
CREATE FOREIGN TABLE mssql_table (
id integer,
data varchar)
SERVER mssql_svr
OPTIONS (query 'SELECT * FROM dbo.mytable', row_estimate_method 'showplan_all');
С использованием column_name:
CREATE FOREIGN TABLE mssql_table (
id integer,
col2 varchar OPTIONS (column_name 'data'))
SERVER mssql_svr
OPTIONS (schema_name 'dbo', table_name 'mytable', row_estimate_method 'showplan_all');
User mapping#
Допустимые параметры:
username(обязательный) – логин пользователя на внешнем сервере;password(необязательный) – пароль пользователя на внешнем сервере. Если не указан, будет взят по параметрам сервера из foreign server вpg_auth_config.
Пример:
CREATE USER MAPPING FOR postgres
SERVER mssql_svr
OPTIONS (username 'sa', password '');
Foreign schema#
Допустимые параметры:
import_default(необязательный, значение по умолчанию:false) – определяет, включаются ли значенияDEFAULTдля столбцов в определения внешних таблиц;import_not_null(необязательный, значение по умолчанию:true) – определяет, включать ли ограничения столбцаNOT NULLв определения внешних таблиц.
Пример:
IMPORT FOREIGN SCHEMA dbo
EXCEPT (mssql_table)
FROM SERVER mssql_svr
INTO public
OPTIONS (import_default 'true');
Параметры#
Допустимые параметры#
tds_fdw.show_before_row_memory_stats- выводит статистику контекста памяти в лог PostgreSQL перед извлечением каждой строки;tds_fdw.show_after_row_memory_stats- выводит статистику контекста памяти в лог PostgreSQL после извлечения каждой строки;tds_fdw.show_finished_memory_stats- выводит статистику контекста памяти в лог PostgreSQL после завершения транзакции.
Установка параметров#
Для установки параметра используйте команду SET:
postgres=# SET tds_fdw.show_finished_memory_stats=1;
SET
EXPLAIN#
EXPLAIN (VERBOSE) – показывает запрос, сформированный в удаленной системе.
Примечание:
В случае работы с данными в Unicode при получении от MS SQL Server ошибки следующего вида:
NOTICE: DB-Library notice: Msg #: 4004, Msg state: 1, Msg: Unicode data in a Unicode-only collation or ntext data cannot be sent to clients using DB-Library (such as ISQL) or ODBC version 3.7 or earlier., Server: PILLIUM\SQLEXPRESS, Process: , Line: 1, Level: 16 ERROR: DB-Library error: DB #: 4004, DB Msg: General SQL Server error: Check messages from the SQL Server, OS #: -1, OS Msg: (null), Level: 16Можно вручную установить параметр
tds versionв файлеfreetds.confв значение 7.0 или выше. См. The freetds.conf File и Choosing a TDS protocol version.
Примечание:
Хотя многие новые версии протокола TDS будут использовать только USC-2 для взаимодействия с сервером, FreeTDS конвертирует UCS-2 в набор символов, выбранных пользователем. Для установки набора, можно задать параметр
client charsetв файлеfreetds.conf. См. The freetds.conf File и Localization and TDS 7.0.
Примечание:
Предусмотрено шифрование соединения с MSSQL Server. Данная возможность предоставляется драйвером FreeTDS, поэтому ее необходимо сконфигурировать в файле
freetds.conf. См. The freetds.conf File.
Поддержка 1С#
Функциональность позволяет использовать Pangolin в качестве СУБД для «Платформы 1С: Предприятие» версии 8.2 и 8.3.
Функциональность активирует ряд оптимизаций планировщика запросов и внутренних алгоритмов, изменений поведения СУБД, а также новых расширений.
Включение функциональности#
В разделе рассмотрены следующие варианты включения функциональности:
при установке Pangolin через скрипты развертывания;
на уже развернутом экземпляре Pangolin.
Включение функциональности при установке Pangolin через скрипты развертывания#
Включение функциональности осуществляется через новый параметр enable_1c_support в custom_config_initial.yml.
Примечание:
Подробнее о
custom_config_initial.ymlчитайте в документе «Руководство по установке», раздел «Автоматизированная установка Pangolin».
Данный параметр определяет значение настроек СУБД, относящихся к расширениям, оптимизациям и изменениям в поведении алгоритмов. При установке параметра enable_1c_support в значение true изменяются параметры СУБД:
pg_stat_track_io_timing: 'off'– но только если не задан конфигурационный файлpg_stat_track_io_timing, иначе будет использоваться значение заданное в нем;optimize_for_1c: 'on';включаются (добавляются в параметр
shared_preload_libraries) и активируются расширенияfasttrun,fulleq,mcharв схемеpublic;autovacuum: 'on';synchronous_commit: 'off';max_locks_per_transaction = '256';row_security: 'False';temp_buffers: '256MB';bgwriter_delay: '20ms';bgwriter_lru_multiplier: '4.0';bgwriter_lru_maxpages: '400';autovacuum_max_workers: <количество ядер/2, но не менее 4>;autovacuum_naptime: '20s';from_collapse_limit: '8';join_collapse_limit: '8';geqo: 'on';geqo_threshold: '12';standard_conforming_strings: 'off';escape_string_warning: 'off';plantuner.fix_empty_table: 'on';online_analyze.enable: 'off';online_analyze.table_type: 'temporary';online_analyze.verbose: 'off';online_analyze.threshold: '50';online_analyze.scale_factor: '0.1';online_analyze.local_tracking: 'on';online_analyze.min_interval: '10000'.
При изменении параметров, указанных выше, осуществляется включение набора оптимизаций в поведении алгоритмов:
сбор статистики для мультистолбцовых индексов с целью лучшего предсказания избирательности мультистолбцовых
JOIN;оптимизация выполнения некоторых планов, в случае если достоверно известно, что часть этих планов возвращает пустые множества;
предпочтение использования хеш-планов если разница в стоимости планов небольшая;
оптимизация копирования внутренних структур памяти в ядре СУБД;
добавлена периодическая проверка активности клиентских подключений;
анализ условий выборки
WHEREи оптимизация условия, если это позволит использовать индексное сканирование;улучшение расчета избирательности на основе статистики мультистолбцовых ключей;
улучшен расчет стоимости для выражений
COALESCE;изменен расчет стоимости выборки одной строки;
оптимизация
JOINсамих на себя по уникальным столбцам. Отдельно отключается при помощи параметраenable_self_join_removal;оптимизация путем перестановки последовательности группировки по
GROUP BY;изменен алгоритм нечеткого (fuzzy) сравнения возможных путей выполнения плана в части сравнения стоимостей путей, использующих индекс;
оптимизирован алгоритм построения плана в части поиска уникальных слияний;
изменен путь поиска функций
like_escapeиsimilar_to_escapeпри лексическом анализе выражений для возможности использования расширенияmchar;добавлена поддержка операций над
Mcharстроками;оптимизирован внутренний алгоритм подбора уникального названия столбца;
доработаны алгоритмы оценки избирательности на основе гистограмм для мультистолбцовых ключей;
установка параметра
default_with_oidsприводит не к фатальной ошибке, а к предупреждению.
Описание новых расширений:
fastrun– добавляет функциюfasttruncateдля быстрой, но транзакционно небезопасной очистки временных таблиц;fulleq– добавляет оператор==сравнения типов данных, который возвращаетtrueесли значения равны, либо обаNULL;mchar– добавляет операторы для работы с типом данных Mchar, используемом в Microsoft SQL Server;online_analyze– осуществляет анализ данных сразу после вызововINSERT/UPDATE/DELETE/SELECT INTO;plantuner– упрощенное расширение по управлению планами запросов.
Команда CREATE EXTENSION была расширена в части возможности указать старую версию расширения, когда необходимо произвести обновление расширения с версии, которая была разработана в виде отдельно созданных объектов. Это актуально только при миграции базы данных с версий PostgreSQL до 9.1.
Внимание!
Работа баз данных, созданных с включенным параметром
optimize_for_1cна старых версиях продукта не гарантируется.При включении параметра в базе, созданной предыдущими версиями, целостность данных гарантируется, но возможны изменения в скорости работы и изменения поведения связанные с изменением путей поиска путей функций.
Включение функциональности на развернутом экземпляре Pangolin#
Включение поддержки 1С н развернутом экземпляре Pangolin выполняется через установку значения параметра optimize_for_1c в on (Администратором АС):
ALTER SYSTEM SET optimize_for_1c='on';
reload
Включить только для текущей сессии (все пользователи СУБД):
SET optimize_for_1c='on'
Установка расширений fastrun, fulleq, mchar, online_analyze и plantuner осуществляется во всех случаях, однако автоматическое включение и активация происходят только при выборе установки с поддержкой 1С, а также установки ролевой модели. Для установки данных расширений на уже развернутом экземпляре Pangolin необходимо выполнить следующие команды:
CREATE EXTENSION "fasttrun" WITH SCHEMA "public";
CREATE EXTENSION "fulleq" WITH SCHEMA "public";
CREATE EXTENSION "mchar" WITH SCHEMA "public";
Отключение функциональности#
Отключение оптимизаций и изменений поведения алгоритмов контролируется параметрами конфигурации:
Параметр |
Описание |
Значения |
|---|---|---|
|
Контролирует включение всех оптимизаций и изменений поведения алгоритмов описанных выше |
|
|
Контролирует оптимизацию |
|
Для отключения функциональности выполните команды:
ALTER SYSTEM SET optimize_for_1c='off';
reload
Выдача прав на создание информационной базы данных 1С для не суперпользователей#
Для выдачи разрешений не суперпользователю на создание информационной базы 1С через консоль администрирования 1С необходимо, чтобы:
пользователь имел включенную опцию
CREATEDB;пользователю были выданы права на системную роль
pg_create_plpgsql_language.
Опция CREATEDB позволит пользователю создать новую пустую базу данных в СУБД.
Системная роль pg_create_plpgsql_language предоставляет разрешения на выполнение двух SQL запросов, не зависимо от наличия у пользователя прав суперпользователя, при помощи которых происходит инициализация поддержки языка pl/pgsql:
CREATE OR REPLACE FUNCTION plpgsql_call_handler() RETURNS language_handler AS '$libdir/plpgsql' LANGUAGE C;
CREATE PROCEDURAL LANGUAGE 'plpgsql' HANDLER plpgsql_call_handler;
Расширение TimescaleDB#
TimescaleDB – это база данных временных рядов с открытым исходным кодом, оптимизированная для быстрой работы с данными и обработки сложных запросов.
TimescaleDB работает на полноценном SQL и, соответственно, проста в использовании, как традиционная реляционная база данных, но масштабируется так, как раньше могла только NoSQL.
При выборе между реляционным подходом и NoSQL приходится идти на компромиссы, тогда как TimescaleDB предлагает преимущества обоих подходов:
Простота использования:
Предоставляется полноценный интерфейс SQL для всех элементов, изначально поддерживаемых PostgreSQL (включая вторичные индексы, вложенные запросы, объединения, оконные функции, а также агрегатные функции, не основанные на времени).
Возможно подключение к любому клиенту, который работает с PostgreSQL, никаких изменений не требуется.
Учитываются ориентированные на время особенности, предоставляются функции API и средства оптимизации.
Осуществляется поддержка политик хранения данных.
Масштабируемость:
Данные прозрачно сегментируются по пространству и времени для масштабирования в высоту (один узел) и в ширину (в разработке).
Запись данных производится на высокой скорости (включая пакетные коммиты, индексы в памяти, транзакционную поддержку, поддержку наполнения исторических данных).
Осуществляется подбор оптимального размера блоков (двумерных разделов данных), который на отдельных узлах обеспечивает быструю запись и обработку даже больших объемов данных.
Производится распараллеливание операций между блоками и серверами.
Надежность:
Решение разработано в качестве расширения на базе PostgreSQL.
Гибкие настройки управления (совместимость с существующей экосистемой и инструментарием PostgreSQL).
Примечание:
API TimescaleDB по управлению гипертаблицами приведен в документе «Список PL/SQL функций продукта», раздел «API TimescaleDB. Управление гипертаблицами».
Данные временных рядов#
Многие приложения и базы данных приравнивают данные временных рядов к чему-то вроде серверных метрик определенного формата:
Name: CPU
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70
2017-01-01 01:03:00 71
2017-01-01 01:04:00 72
2017-01-01 01:05:01 68
Во многих приложениях для мониторинга часто собираются различные показатели (например, процессор, память, сетевая статистика, время автономной работы). Таким образом, не всегда имеет смысл думать о каждой метрике отдельно. Рассмотрим альтернативную «расширенную» модель данных, которая поддерживает корреляцию между метриками, собранными в одно и то же время.
Metrics: CPU, free_mem, net_rssi, battery
Tags: Host=MyServer, Region=West
Data:
2017-01-01 01:02:00 70 500 -40 80
2017-01-01 01:03:00 71 400 -42 80
2017-01-01 01:04:00 72 367 -41 80
2017-01-01 01:05:01 68 750 -54 79
Этот тип данных относится к гораздо более широкой категории, будь то показания температуры от датчика, цена акций, состояние машины или даже количество входов в приложение.
Данные временных рядов — это данные, которые в совокупности отражают то, как система, процесс или поведение изменяются с течением времени.
Характеристики данных временных рядов#
Среди характеристик временных рядов можно выделить:
Ориентированность на время: записи данных всегда имеют временную метку.
Только добавление: данные практически исключительно добавляются наращиванием (INSERT).
Актуальность: новые данные обычно относятся к последним временным интервалам, что позволяет реже делать обновления или заполнять недостающие данные о старых интервалах.
Частота (или регулярность) не важна. Данные можно получать каждую миллисекунду или час. Кроме этого, сбор может быть как регулярным, так и нерегулярным (например, по событию).
Ключевая особенность данных временных рядов заключается в том, что изменения в них выполняются вставками, а не заменами (как это происходит, например, при работе с реляционными данными).
Данные временных рядов используются в различных сферах, среди которых:
Мониторинг компьютерных систем: метрики виртуальных машин, серверов, контейнеров (процессор, объем свободной памяти, объем/скорость дисковых операций), метрики сервисов и приложений (частота запросов, время обработки).
Финансовые трейдинговые системы: классические ценные бумаги, криптовалюты, платежи, транзакции.
Интернет вещей: данные с датчиков на промышленных машинах и оборудовании, носимых устройствах, транспортных средствах, физических контейнерах, грузовых поддонах, устройствах для умных домов и т.д.
Обработка событий: данные о взаимодействии пользователя и клиента, такие как истории перемещений, просмотры страниц, логины, регистрации и т.д.
Бизнес-аналитика: отслеживание ключевых показателей и общего состояния бизнеса.
Мониторинг окружающей среды: температура, влажность, давление, рН, количество пыльцы, расход воздуха, окись углерода (CO), диоксид азота (NO2), твердые частицы (PM10).
Модель данных#
Как реляционная база данных с полноценным SQL TimescaleDB поддерживает гибкие модели данных, которые могут быть оптимизированы для различных случаев использования. Это несколько отличает TimescaleDB от большинства других баз данных временных рядов, которые обычно используют модели «узких таблиц».
TimescaleDB может поддерживать модели как с широкими, так и с узкими таблицами. В этом разделе описаны различные компромиссы производительности и последствия использования этих двух моделей на примере Интернета вещей (IoT).
К примеру, существует распределенная группа из 1000 устройств IoT, предназначенных для сбора данных об окружающей среде с различными интервалами. Эти данные могут включать:
Идентификаторы: device_id, timestamp
Метаданные: location_id, dev_type, firmware_version, customer_id
Метрики устройств: cpu_1m_avg, free_mem, used_mem, net_rssi, net_loss, battery
Метрики датчиков: temperature, humidity, pressure, CO, NO2, PM10
Входные данные могут выглядеть следующим образом:
timestamp |
device_id |
cpu_1m_avg |
free_mem |
temperature |
location_id |
dev_type |
|---|---|---|---|---|---|---|
2017-01-01 01:02:00 |
abc123 |
80 |
500MB |
72 |
335 |
field |
2017-01-01 01:02:23 |
def456 |
90 |
400MB |
64 |
335 |
roof |
2017-01-01 01:02:30 |
ghi789 |
120 |
0MB |
56 |
77 |
roof |
2017-01-01 01:03:12 |
abc123 |
80 |
500MB |
72 |
335 |
field |
2017-01-01 01:03:35 |
def456 |
95 |
350MB |
64 |
335 |
roof |
2017-01-01 01:03:42 |
ghi789 |
100 |
100MB |
56 |
77 |
roof |
Далее рассмотрены различные способы моделирования этих данных.
Модель с узкими таблицами#
Временные ряды могут быть представлены как:
отдельные сущности (например, cpu_1m_avg и free_mem как две разных вещи);
последовательности пар «время»-«значение» для каждой метрики;
наборы тегов и связанные с ними метрики (каждая комбинация метрики и набора тегов рассматривается как отдельный «временной ряд», содержащий последовательность пар время/значение).
При таком подходе наш пример выше превращается в 9 различных «временных рядов», каждый из которых определяется уникальным набором тегов.
1. {name: cpu_1m_avg, device_id: abc123, location_id: 335, dev_type: field}
2. {name: cpu_1m_avg, device_id: def456, location_id: 335, dev_type: roof}
3. {name: cpu_1m_avg, device_id: ghi789, location_id: 77, dev_type: roof}
4. {name: free_mem, device_id: abc123, location_id: 335, dev_type: field}
5. {name: free_mem, device_id: def456, location_id: 335, dev_type: roof}
6. {name: free_mem, device_id: ghi789, location_id: 77, dev_type: roof}
7. {name: temperature, device_id: abc123, location_id: 335, dev_type: field}
8. {name: temperature, device_id: def456, location_id: 335, dev_type: roof}
9. {name: temperature, device_id: ghi789, location_id: 77, dev_type: roof}
Количество временных рядов будет расти пропорционально перекрестному произведению мощностей множеств каждого тега, то есть (количество имен) × (количество идентификаторов устройств) × (количество идентификаторов местоположений) × (типы устройств). Некоторые базы данных временных рядов плохо справляются с объемными тегами (включающими большое количество множеств), что в конечном итоге ограничивает количество типов устройств, а также число устройств, которые можно хранить в одной базе данных.
TimescaleDB поддерживает узкие модели и не подвержен тем ограничениям, с которыми сталкиваются другие базы данных временных рядов. Узкая модель полезна, каждая метрика собирается независимо. Она позволяет создавать новые метрики, добавляя новые теги и не требуя формального изменения схемы.
Однако узкая модель менее эффективна, если для многих метрик характерна одна и та же метка времени, поскольку метка времени записывается для каждой метрики. Это приводит к росту требуемых ресурсов на хранение и обработку данных. Кроме этого, запросы, которые коррелируют различные метрики, усложняются, поскольку каждая дополнительная метрика требует очередной JOIN-операции. Если запрашиваются несколько метрик сразу, то рекомендуется хранить их в формате широких таблиц.
Модель с широкими таблицами#
TimescaleDB полностью поддерживает модели с широкими таблицами. Запросы по нескольким метрикам в этой модели проще, так как они не требуют JOIN-операций. Кроме того, запись данных происходит быстрее, так как для нескольких метрик записывается только одна временная метка.
Типичная модель с широкой таблицей будет соответствовать потоку данных, в котором несколько метрик собираются в заданную временную метку:
timestamp |
device_id |
cpu_1m_avg |
free_mem |
temperature |
location_id |
dev_type |
|---|---|---|---|---|---|---|
2017-01-01 01:02:00 |
abc123 |
80 |
500MB |
72 |
42 |
field |
2017-01-01 01:02:23 |
def456 |
90 |
400MB |
64 |
42 |
roof |
2017-01-01 01:02:30 |
ghi789 |
120 |
0MB |
56 |
77 |
roof |
2017-01-01 01:03:12 |
abc123 |
80 |
500MB |
72 |
42 |
field |
2017-01-01 01:03:35 |
def456 |
95 |
350MB |
64 |
42 |
roof |
2017-01-01 01:03:42 |
ghi789 |
100 |
100MB |
56 |
77 |
roof |
Здесь каждая строка представляет собой новый шаг сбора данных с набором измерений и метаданных в данный момент времени. Это позволяет сохранять связи внутри данных и задавать более сложные запросы.
JOIN-операции с реляционными данными#
Модель данных TimescaleDB имеет еще одно сходство с реляционными базами данных: она поддерживает операции JOIN. Например, можно хранить дополнительные метаданные во вторичной таблице, а затем использовать эти данные во время запроса.
В примере ниже создается отдельная таблица locations, сопоставляющая location_id с дополнительными метаданными для местоположения:
location_id |
name |
latitude |
longitude |
zip_code |
region |
|---|---|---|---|---|---|
42 |
Grand Central Terminal |
40.7527° N |
73.9772° W |
10017 |
NYC |
77 |
Lobby 7 |
42.3593° N |
71.0935° W |
02139 |
Massachusetts |
Объединив эту таблицу с созданной выше, можно, например, создать запрос на вычисление средней free_mem устройств, у которых zip_code=10017.
Без JOIN понадобилась бы денормализация данных, а также сохранение всех метаданных со строками измерений. Это привело бы к «раздуванию» таблиц и затруднило бы управление ими.
С помощью операций JOIN можно хранить метаданные независимо, что упрощает обновление сопоставлений.
Например, если нужно обновить поле «region» для location_id 77 (т.е. изменить «Massachusetts» на «Boston»), возвращаться и перезаписывать данные не нужно.
Архитектура и концепции#
Введение#
TimescaleDB, предоставляет собой отдельные таблицы, называемые гипертаблицами (hypertable), которые являются абстракцией или виртуальным представлением множества отдельных таблиц, содержащих данные. Эти отдельные таблицы называются блоками (chunk).

Блоки создаются путем секционирования данных гипертаблиц на одно или несколько измерений: все гипертаблицы разбиваются по временному интервалу и дополнительно могут быть разбиты по ключу. В качестве ключа могут выступать, например: идентификатор устройства, местоположение, идентификатор пользователя. Такое секционирование может быть названо секционированием по времени и пространству.
Термины#
Гипертаблицы#
Основная точка взаимодействия с данными - это гипертаблица, абстракция одной непрерывной таблицы во всех пространственных и временных интервалах. К ней можно обращаться с помощью стандартного SQL.
Практически все операции пользователей с TimescaleDB происходят с гипертаблицами. Создание таблиц и индексов, их изменение, вставка данных и их выбор должны выполняться на основе гипертаблиц.
Гипертаблица определяется стандартной схемой с именами и типами столбцов. В одном из столбцов обязательно указывается значение времени, а в необязательном столбце может быть отражен дополнительный ключ секционирования.
В одной базе TimescaleDB может храниться несколько гипертаблиц, каждая с различными схемами.
Гипертаблица в TimescaleDB создается двумя SQL-командами: CREATE TABLE (со стандартным синтаксисом SQL) и SELECT create_hypertable ().
Индексы по времени и ключу секционирования для гипертаблиц создаются автоматически, но пользователем могут быть созданы дополнительные индексы (TimescaleDB поддерживает полный спектр типов индексов PostgreSQL).
Блоки#
TimescaleDB автоматически разбивает каждую гипертаблицу на блоки, причем каждый блок соответствует определенному временному интервалу и области пространства ключа секционирования (с использованием хэширования). Эти разделы не пересекают друг друга, что помогает планировщику запросов минимизировать набор блоков, по которым он должен пройти для разрешения запроса.
Каждый блок реализован с использованием стандартной таблицы базы данных. (Внутри PostgreSQL блоки на самом деле - «дочерние» таблицы «родительской» гипертаблицы.)
Блоки всегда создаются оптимального размера для того, чтобы все B-деревья для индексов таблицы помещались в памяти. Это позволяет избежать переполнения памяти при изменении произвольных местоположений в этих деревьях.
Кроме того, если нет слишком больших блоков, дорогостоящих операций можно избежать путем освобождения памяти от удаленных данных в соответствии с автоматизированными политиками хранения. Такие операции можно выполнять, удаляя определение блока (внутренней таблицы), а не отдельные строки.
Один узел и кластер#
TimescaleDB активно секционирует данные как на одном сервере, так и в кластере.
Хотя секционирование традиционно используется только для масштабирования на нескольких машинах, его можно использовать и для достижения более высоких скоростей обработки данных и запросов (в том числе параллельных) даже на отдельных машинах.
Текущая версия TimescaleDB с открытым исходным кодом поддерживает только развертывание на одном узле. Следует отметить, что эта версия TimescaleDB тестировалась на гипертаблицах с более чем 10 миллиардами строк на машинах потребительского класса и не выявила потерь производительности по операции INSERT.
Преимущества секционирования на одном узле#
Распространенной проблемой при масштабировании производительности базы данных на одной машине является компромисс стоимости и эффективности между памятью и диском. Со временем данные перестают помещаться в памяти, и приходится записывать данные и индексы на диск.
Когда данные достигнут такого размера, что все страницы индексов (например, B-деревья) перестанут помещаться в памяти, обновление случайной части дерева может инициировать обращение к диску. Базы данных, такие как PostgreSQL, хранят B-дерево (или другую структуру данных) для каждого индекса таблицы, чтобы значения в этом индексе можно было эффективно находить. Таким образом, проблема усугубляется по мере роста количества индексируемых столбцов.
Поскольку каждый из блоков, созданных TimescaleDB хранится как отдельная таблица базы данных, все его индексы строятся только по этим, гораздо меньшим, таблицам, а не по одной таблице, представляющей весь набор данных. Следовательно, если правильно определить размер этих блоков, можно полностью поместить самые новые таблицы (и их B-деревья) в память и избежать проблем чтения с диска, сохраняя при этом поддержку нескольких индексов.
Распределенные базы данных и узлы#
Распределенная гипертаблица существует в распределенной базе данных, состоящей из нескольких баз, хранящихся в одном или нескольких экземплярах TimescaleDB. База данных, являющаяся частью распределенной базы данных, может выполнять роль либо узла доступа, либо узла данных (но не обоих одновременно).
Клиент подключается к базе данных - узлу доступа. Затем узел доступа распределяет запросы по узлам данных и агрегирует результаты, полученные от узлов данных. Узлы доступа хранят общекластерную информацию о различных узлах данных, а также о том, как блоки распределяются между этими узлами данных. Узлы доступа также могут хранить нераспределенные гипертаблицы, а также обычные таблицы PostgreSQL.
Узлы данных не хранят информацию по всему кластеру и в остальном функционируют, как автономные экземпляры TimescaleDB. Прямые обращения к гипертаблицам или блокам на узлах данных выполнять нельзя. Это может привести к несогласованности распределенных гипертаблиц.
Важно отметить, что узлы доступа и узлы данных работают на TimescaleDB и во всех отношениях действуют точно так же, как один экземпляр TimescaleDB с операционной точки зрения.
Настройка распределенных гипертаблиц#
Для обеспечения оптимальной производительности распределенные гипертаблицы должны быть секционированы по времени и пространству. Если данные секционируются только по времени, то каждый новый блок будет заполняться, пока узел доступа не выберет другой узел данных для хранения следующего блока, поэтому в течение этого интервала времени все записи в последний интервал будут обрабатываться одним узлом данных, а не балансироваться по нагрузке между всеми доступными узлами данных. С другой стороны, если включить секционирование по пространству, узел доступа распределит блоки между несколькими узлами данных так, чтобы для заданного интервала времени были созданы несколько блоков, и как чтение, так и запись в этот последний интервал времени будут сбалансированы по нагрузке на весь кластер.
По умолчанию количество разделов пространства устанавливается равным количеству узлов данных, если не указано иное. Система увеличит количество пространственных разделов при добавлении новых узлов данных, если это необходимо. При настройке вручную для оптимального распределения данных между узлами данных рекомендуется, чтобы число пространственных разделов было равно или кратно числу узлов данных, связанных с распределенной гипертаблицей. Если создано несколько пространственных разделов, только первый будет использоваться для определения того, как блоки распределяются между серверами.
Масштабирование распределенных гипертаблиц#
По мере роста объема данных временных рядов распространенным вариантом использования становится добавление узлов данных для расширения хранилища и вычислительной емкости распределенных гипертаблиц. Таким образом, TimescaleDB можно эластично масштабировать, просто добавляя узлы данных в распределенную базу данных.
Как упоминалось ранее, TimescaleDB регулирует количество пространственных разделов по мере добавления новых узлов данных. Хотя в существующих блоках пространственные разделы не обновятся, новые настройки будут применены к вновь созданным блокам. Из-за такого поведения не требуется перемещать данные между узлами данных при увеличении размера кластера - достаточно обновлять способ распределения данных на следующий интервал времени. Записи для новых входящих данных будут использовать новые параметры секционирования, в то время как узел доступа все еще может поддерживать запросы по всем блокам (даже тем, которые были созданы с использованием старых параметров секционирования). Обратите внимание, что, хотя количество пространственных разделов может быть изменено, столбец, данные по которому секционируются, не может быть изменен.
Преимущества использования TimescaleDB относительно реляционных баз данных#
TimescaleDB предлагает три ключевых преимущества по сравнению с PostgreSQL и другими традиционными СУБД для хранения данных временных рядов:
гораздо более высокая скорость приема и обработки данных, особенно при больших размерах баз данных;
производительность запросов варьируется от эквивалентной до на порядки большей;
особенности, уникальные для временных данных.
TimescaleDB позволяет использовать весь спектр функций и инструментов PostgreSQL, например: JOIN-операции с реляционными таблицами, геопространственные запросы через PostGIS, pg_dump и pg_restore.
Скорость обработки данных#
TimescaleDB обеспечивает гораздо более высокую и стабильную скорость приема и обработки данных временных рядов по сравнению с PostgreSQL.
В разделе про архитектуру уже говорилось, что производительность PostgreSQL начинает значительно падать, как только индексированные таблицы перестают помещаться в памяти. В частности, всякий раз, когда добавляется новая строка, база данных должна обновлять индексы (например, B-деревья) для каждого из индексированных столбцов таблицы, что будет включать подгрузку одной или нескольких страниц с диска. Расширение объема памяти только снижает пропускную способность (показатель 10K-100K+ строк в секунду может упасть до сотен строк в секунду, как только таблица временных рядов разрастется до десятков миллионов строк).
TimescaleDB решает эту проблему за счет активного использования пространственно-временного секционирования, даже при работе на одной машине. Таким образом, все записи в последние временные интервалы относятся только к таблицам, которые остаются в памяти, и в результате обновление любых вторичных индексов также происходит быстро.
Тесты показывают явное преимущество такого подхода. Приведенный ниже тест на 1 миллиард строк (на одной машине) эмулирует сценарий мониторинга, когда клиенты базы данных вставляют пакеты данных среднего размера, содержащие время, набор тегов устройства и несколько числовых метрик (в данном случае 10). Здесь эксперименты проводились на стандартной виртуальной машине Azure (DS4 v2, 8 core) с подключенным по сети SSD-накопителем.
И PostgreSQL, и TimescaleDB начинают примерно с одинаковой пропускной способности (106K и 114K соответственно) для первых 20 млн запросов, или более 1 млн метрик в секунду. Однако на уровне около 50 млн строк производительность PostgreSQL начинает резко падать. Ее среднее значение за последние 100 млн строк составляет всего 5 тыс. строк/сек, в то время как TimescaleDB сохраняет свою пропускную способность в 111 тыс. строк/сек.
TimescaleDB загружает базу данных с одним миллиардом строк в пятнадцать раз быстрее PostgreSQL и показывает пропускную способность более чем в 20 раз больше, чем у PostgreSQL при этих больших объемах данных.
Проведенные тесты TimescaleDB показывают, что она поддерживает стабильную производительность на уровне более 10 миллиардов строк, даже с одним диском.
Производительность запросов#
На машинах с одним диском многие простые запросы, которые выполняют индексированный поиск или сканирование таблиц, работают с одинаковой производительностью и на PostgreSQL, и на TimescaleDB.
Например, в таблице на 100 млн строк с индексированным временем, именем хоста и информацией об использовании ЦП следующий запрос займет менее 5 мс для каждой базы данных:
SELECT date_trunc('minute', time) AS minute, max(user_usage)
FROM cpu
WHERE hostname = 'host_1234'
AND time >= '2017-01-01 00:00' AND time < '2017-01-01 01:00'
GROUP BY minute ORDER BY minute;
Аналогичные запросы, которые включают базовое сканирование по индексу, также эквивалентно эффективны:
SELECT * FROM cpu
WHERE usage_user > 90.0
AND time >= '2017-01-01' AND time < '2017-01-02';
Более крупные запросы, включающие основанные на времени группировки, довольно распространены в ориентированном на время анализе и часто достигают более высокой производительности в TimescaleDB.
Например, следующий запрос, который проходит по 33 млн строк, в 5 раз быстрее в TimescaleDB, когда вся гипертаблица состоит из 100 млн строк, и примерно в 2 раза быстрее, когда она состоит из 1 млрд строк:
SELECT date_trunc('hour', time) as hour,
hostname, avg(usage_user)
FROM cpu
WHERE time >= '2017-01-01' AND time < '2017-01-02'
GROUP BY hour, hostname ORDER BY hour;
Более того, другие запросы (например, с упорядочиванием по времени), могут быть гораздо более производительными в TimescaleDB. Например, TimescaleDB вводит временную оптимизацию merge append, которая минимизирует количество групп, подлежащих обработке, для выполнения представленного ниже запроса (учитывая, что база знает заранее, что время уже упорядочено). Для таблицы на 100 млн строк результат обработки в 396 раз быстрее, чем у PostgreSQL (82 мс против 32,566 мс):
SELECT date_trunc('minute', time) AS minute, max(usage_user) FROM cpu WHERE time < '2017-01-01' GROUP BY minute ORDER BY minute DESC LIMIT 5;
Таким образом, почти для каждого рассмотренного запроса TimescaleDB достигает либо аналогичной, либо превосходящей (или значительно превосходящей) производительности в сравнении со стандартной PostgreSQL.
В качестве недостатка TimescaleDB в сравнении с PostgreSQL можно привести более сложное планирование (учитывая, что одна гипертаблица порой состоит из большого количества блоков). Это может привести к нескольким дополнительным миллисекундам времени планирования, что может иметь непропорциональное влияние на запросы с очень низкой задержкой (менее 10 мс).
Дополнительные функции для временных данных#
TimescaleDB включает в себя ряд ориентированных на время функций, которые не встречаются в традиционных реляционных базах данных.
К ним относятся специальные оптимизации запросов (например, merge append, упомянутый выше), которые обеспечивают некоторые из улучшений производительности для ориентированных на время запросов, а также другие функции, ориентированные на время (некоторые из которых перечислены ниже).
Использование в аналитике#
TimescaleDB включает в себя новые функции для ориентированной на время аналитики, например:
time_bucket: более мощная версия стандартной функции date_trunc. Эта функция позволяет использовать произвольные временные интервалы (например, 5 минут, 6 часов и так далее), а также гибкие группировки и смещения, а не только секунды, минуты, часы и так далее;
агрегаты last и first: эти функции позволяют получить значение одного столбца по порядку другого. Например, last (temperature, time) вернет последнее значение температуры, основанное на времени внутри группы (например, час).
Эти типы функций позволяют выполнять очень естественные ориентированные на время запросы. Следующий финансовый запрос, например, выводит на печать открытие, закрытие, максимум и минимум цены каждого актива:
SELECT time_bucket('3 hours', time) AS period asset_code, first(price, time) AS opening, last(price, time) AS closing, max(price) AS high, min(price) AS low FROM prices WHERE time > NOW() - INTERVAL '7 days' GROUP BY period, asset_code ORDER BY period DESC, asset_code;
Способность last упорядочивать по вторичному столбцу (даже отличающемуся от агрегата) позволяет выполнять некоторые сложные типы запросов. Например, в финансовой отчетности часто применяется метод битемпорального моделирования, который отдельно определяет время, связанное с наблюдением, и время, когда это наблюдение было зарегистрировано. В такой модели исправления вставляются в виде новой строки (с более поздним полем time_recorded) и не заменяют существующие данные.
Следующий запрос возвращает дневную цену для каждого актива, упорядоченную по последней зарегистрированной цене:
SELECT time_bucket('1 day', time) AS day, asset_code, last(price, time_recorded) FROM prices WHERE time > '2017-01-01' GROUP BY day, asset_code ORDER BY day DESC, asset_code;
Подробнее о текущем (и растущем) списке временных функций TimescaleDB рассказывается в документе «Список PL/SQL функций продукта», раздел «TimescaleDB. Управление гипертаблицами».
Управление временными данными#
TimescaleDB предоставляет ряд возможностей управления данными, которые не всегда доступны или эффективны в PostgreSQL. Например, при работе с данными временных рядов данные часто накапливаются очень быстро. К примеру, необходимо описать политику хранения данных следующего вида: «хранить необработанные данные только в течение недели».
На самом деле это часто сочетается с использованием непрерывных агрегатов, поэтому можно сохранить две гипертаблицы: одну с необработанными данными, другую с данными, которые уже были свернуты в поминутные или почасовые агрегаты. Затем можно определить различные политики хранения для двух гипертаблиц, сохраняя агрегированные данные гораздо дольше.
TimescaleDB позволяет эффективно удалять старые данные на уровне блоков, а не на уровне строк, благодаря функции drop_chunks.
SELECT drop_chunks('conditions', INTERVAL '7 days');
Эта команда удалит все блоки (файлы) из таблицы conditions, которые включают только данные старше этой продолжительности, а не какие-либо отдельные строки данных в блоках. Так избегается фрагментация в основных файлах базы данных, а это, в свою очередь, позволяет исключить очистку памяти - операцию, которая может быть непомерно дорогой в очень больших таблицах.
Первоначальное заполнение данными#
Если используется кластерный вариант поставки Pangolin, то перед первоначальным наполнением данных необходимо перевести кластер в асинхронный режим и остановить ведомый сервер. Далее ведущий сервер пополняется данными. Чтобы возобновить потоковую репликацию, требуется привести ведомый сервер в состояние, когда он сможет воспроизводить файлы журнала с ведущего сервера:
Удалите директории БД и табличных пространств ведомого сервера:
rm -rf $PGDATA/* ; rm -rf <tablespace_location>/*
Выполните команду восстановления используя IP-адрес ведущего сервера:
pg_basebackup -h <primary_ip> -D <local_data_directory> -U <user with replication grants> -P -R -X stream
Запустите Pangolin на ведомом сервере, дождитесь синхронизации.
Так же возможно использовать команду reinit сервиса Pangolin Manager.
Индекс RUM#
Индексный метод доступа RUM является одним из инструментов оптимизации доступа к данным. RUM основан на GIN-подобном индексном методе и, кроме того, включает дополнительную методику оценки релевантности результата поиска («дистанцией»).
Функциональность поставляется в качестве расширения в составе продукта, не требует специальных шагов по настройке со стороны сотрудников сопровождения. Активация расширения не требует изменения параметров конфигурации БД.
Установка расширения производится в выбранной БД следующим способом:
SET ROLE db_admin;
CREATE EXTENSION IF NOT EXISTS rum WITH SCHEMA ext;
RESET ROLE;
RUM имеет качественное преимущество в возможности ранжирования результатов поиска по «дистанции»/«схожести». При этом «дистанция»/«схожесть» имеют другой алгоритм обработки, чем существующие функции ts_rank, ts_rank_cd.
Для незначительного уменьшения размера индекса можно использовать классы операторов hash, если не предполагается префиксного поиска.
RUM имеет количественное преимущество перед существующими индексными методами только при соблюдении следующих условий:
Запрос SQL должен иметь условие поиска по дистанции. В случае FTS -
tsqueryдолжен использовать оператор дистанции «<=>»,«<2>»,«<3>» и тому подобные.Запрос SQL, содержащий условие поиска по дистанции, должен оперировать термами низкой или средней селективности (при возможности их оценки).
В иных случаях предпочтительнее использовать другие индексы.
Отключение функциональности#
Отключение расширения влечет за собой удаление всех ранее созданных индексов RUM, дальнейшую невозможность использовать классы операторов, операторы и функции, добавленные расширением. Отключение функциональности требует прав db_admin.
Удаление расширения производится следующим способом:
SET ROLE db_admin;
DROP EXTENSION IF EXISTS rum CASCADE;
RESET ROLE;
Получение хеш-сумм паролей для заполнения пользовательского конфигурационного файла Pangolin#
Утилита расчета хеш-суммы в формате PostgreSQL предназначена для вычисления хеш-суммы переданной в нее текстовой строки. Используется для вычисления хеш-сумм для использования в сценариях автоматизации, например, для заполнения пользовательского конфигурационного файла инсталлятора, в котором задаются имена учетных записей и их пароли, в том числе в виде хеш-сумм scram-sha-256 или md5. Делается это для того, чтобы пароль в открытом виде не попадал в логи СУБД при создании пользователя.
Утилита поставляется как есть, в виде python-скрипта и работает на любой платформе, где есть Python.
Утилита одинаково работает на python2 и python3.
Утилита расположена в директории utilities в дистрибутиве продукта и не попадает в финальную инсталляцию кластера. Для использования утилиты необходимо извлечь ее из дистрибутива и запустить в среде исполнения python:
tar -zxvf pangolin_5_3_0.tar.gz utilities/psql_get_password_hash/psql_get_password_hash.py
python ./utilities/psql_get_password_hash/psql_get_password_hash.py --help
Утилита принимает на вход следующие параметры (в случае, если параметр не задан, используется значение по умолчанию):
-h,--help- выводит справку по использованию утилиты;-t TYPE,--type TYPE- тип вычисляемого хеша. Возможные варианты:scram-sha-256,md5,linux-sha-512(значение по умолчанию -scram-sha-256);-P PASSWORD,--password PASSWORD- параметр password (пароль, для которого вычисляется хеш-сумма). Если не задан, утилита запросит интерактивно;-U USERNAME,--username USERNAME- параметр username (необходим для вычисления хешаmd5илиsha-512). Если не задан и необходим (тип вычисляемого хешаmd5илиsha-512), утилита запросит интерактивно.
Примеры использования утилиты psql_get_password_hash#
Вычисление хеша
scram-sha-256(пароль можно как передать параметром, так и ввести в ответ на запрос утилиты):$ python3 psql_get_password_hash.py -t scram-sha-256 -P password SCRAM-SHA-256$4096:rvPI7j0HTxgxAqW1lCGifA==$OrTN09KVqBA6fpT/EOT4S0W3VH0k4Fuye6LMYNtiS/k=:ddiQjzHNY0X9zXVlBri8DQTIbRkCwvhvOaOH+JHrpVA= $ python3 psql_get_password_hash.py -t scram-sha-256 Password: SCRAM-SHA-256$4096:XGI8E5PEm0feXlCvo/YK5A==$TK6u0sWYH+LvRcKsP95z/m20qP6K1GnE6WfrwBXOfYw=:Swh0UixWfJimW+7XjOMZuaY9cMOH/aIhImex3oOZrss=Вычисление хеша
md5(пароль можно как передать параметром, так и ввести в ответ на запрос утилиты, для расчетаmd5в PostgreSQL также используется имя пользователя):$ python3 psql_get_password_hash.py -t md5 -P password -U user md54d45974e13472b5a0be3533de4666414 $ python3 psql_get_password_hash.py -t md5 Password: Username: md54d45974e13472b5a0be3533de4666414 $ python3 psql_get_password_hash.py -t md5 -P 'password' -U 'user' md54d45974e13472b5a0be3533de4666414Вычисление хеша
sha-512(для заведения пользователей Linux пароль можно как передать параметром, так и ввести в ответ на запрос утилиты):$ python3 psql_get_password_hash.py -t linux-sha-512 -P password -U postgres postgres:$6$EvwbrlgjZc8neqdE$vOKjo6npaL6kv055Qan4Xh3zUWTJ0yJxvHPTd948n2Mx4cR6HTFSPVf/dd/1TBTSq3418WkSeR3HyfE57ClEt. $ python3 psql_get_password_hash.py -t linux-sha-512 Password: Username: postgres:$6$mxdF1yYWtwiMS8vT$a2nFRoXu1PBH56/ejQhh.5G0OoxgW7aKEXpXUaH0gTcrqqCYjeLy2zVNVwXtAWmV7rMemCiodkNxmhOIp8wu0. $ python3 psql_get_password_hash.py -t linux-sha-512 -P 'password' -U 'postgres' postgres:$6$Hw0Zt4v+sZGOag5C$lKnLZ1lqmUhZEJQNe6oHIlFycxjMIlZwwWyRac59D8kpUI95ivvSJ0u9JxHuaCtD4fV/5B/Tv.N9qgyw5YMI81
В случае использования в пароле специальных символов их можно экранировать символом \. В случае, если необходимо передать сам символ \, он экранируется аналогично, то есть \\. При вводе пароля по запросу утилиты символы передаются как символы и в маскировании не нуждаются. Пример (на примере md5, поскольку данный метод будет давать всегда одинаковую хеш-сумму):
# qwerty'
# admin
$ python3 psql_get_password_hash.py -t md5
Password:
Username:
md5d8fd40d277741197a0a25ea10529e67b
# При передаче пароля параметром любой символ можно экранировать обратным слэшем
$ python3 psql_get_password_hash.py -t md5 -U admin -P qwerty\'
md5d8fd40d277741197a0a25ea10529e67b
$ python3 psql_get_password_hash.py -t md5 -U admin -P \q\w\e\r\t\y\'
md5d8fd40d277741197a0a25ea10529e67b
# Обратный слэш тоже можно экранировать
$ python3 psql_get_password_hash.py -t md5 -U admin -P \\qwerty\'
md5989af44547db1322f6e633d2ab68f75e
Планировщик задач pg_cron#
Расширение pg_cron используется в СУБД Pangolin для выполнения задач по расписанию.
Обновление pg_cron до версии 1.4.2 добавляет новые возможности в виде новых функций, параметров конфигурирования и режима работы.
В новой версии добавлены перегруженные и новые функции, которые работают с именованными задачами. При поиске задачи по имени (например, в функции cron.unschedule) используется пара имя задачи/имя пользователя.
При этом имя пользователя передается неявно, через чтение текущего пользователя, поэтому из-под одного пользователя нельзя завершить задачу другого пользователя по имени – так можно завершить только свою задачу.
Настройка#
Расширение уже входит в поставку Pangolin. Для его использования необходимо:
Пропишите в конфигурационном файле Pangolin:
shared_preload_libraries = 'pg_cron' cron.database_name = 'postgres'где
postgres- имя БД, в которой будет работатьcron.От пользователя с правами
superuserвключите расширение:CREATE EXTENSION pg_cron;Выдайте права на схему
cronнужному пользователю:GRANT USAGE ON SCHEMA cron TO <имя пользователя pg_cron>;Перезагрузите Pangolin.
Так как процессу pg_cron необходимо создавать подключение к БД, добавляем пароль пользователя, созданного на предыдущем шаге, в хранилище паролей.
SELECT add_auth_record_to_storage('localhost', <порт СУБД>, <имя БД>, <имя пользователя pg_cron>, 'пароль пользователя pg_cron');
Создание пользователя для расширения pg_cron#
Проверьте, что расширение установлено.
Создайте пользователя (например,
cronuser):CREATE USER cronuser WITH PASSWORD 'passwd'Разрешите использование схемы
cronновому пользователю:GRANT USAGE ON SCHEMA cron TO cronuser;Добавьте пароль пользователя в хранилище паролей.
SELECT add_auth_record_to_storage('localhost', <порт СУБД>, <имя БД>, `cronuser`, 'passwd');
Отключение функциональности#
Примечание:
Отключение функциональности без потери данных невозможно
Выполните следующие SQL-запросы:
/* Так как откат до предыдущей версии не поддерживается расширением, сначала его необходимо удалить */
DROP EXTENSION IF EXISTS pg_cron;
/* Добавляем расширение версии 1.2 */
CREATE EXTENSION pg_cron VERSION '1.2';
/* Если понадобится провести обновление версии pg_cron, то выполните */
/* ALTER EXTENSION pg_cron UPDATE TO '1.4-1'; */
Работа внутри кластера#
pg_cron можно безопасно использовать в схеме с реализацией. Данные cron можно модифицировать только с текущего лидер-сервера.
Примечание:
Так как
pg_cronдля выполнения задач сохраняетhost:ipсервера (127.0.0.1:5433), необходимо на всех экземплярах выставить одинаковый порт. В противном случае приswitchover/failoverpg_cronпопытается подключиться к старому лидеру.
pg_cron рекомендуется использовать для задач:
периодический вызов VACUUM в соответствии со спецификой загруженности сервера;
секционирование таблиц. Например, для гибкого управления данными (удаление или перенос отдельных секций вместо целой таблицы). Соответственно, добавление новой секции – это часть процесса управления секционированной таблицей, необходимая при расширении таблицы с течением времени и созданием новых секций.
Управление задачами планировщика#
Внимание!
Задачи запускаются только на лидер-сервере. Пока сервер в состоянии горячего резерва (Hot Standby), задачи не запускаются и ждут, пока сервер не станет лидером.
Задачи запускаются с правами пользователя, создавшего задачу.
Формат таблицы cron.job#
Таблица содержит все запланированные задачи.
Только пользователь с правами суперпользователя может напрямую работать с данной таблицей (см. «Продвинутая работа с таблицей запланированных задач»).
Поле |
Описание |
|---|---|
jobid |
Идентификатор задачи |
schedule |
Дата и время выполнения задачи или временной период для выполнения задачи |
command |
Выполняемая команда |
nodename |
Имя узла, где будет выполнена команда. В качестве имени узла можно использовать одно из возможных значений: hostname, localhost, IP-адрес, Unix-сокет (значение конфигурационного параметра - |
nodeport |
Порт для подключения к узлу PostgreSQL (по умолчанию 5432) |
database |
Имя базы данных, в который будет выполнена команда |
username |
Пользователь, создавший команду |
Создание задачи в pg_cron#
Зайдите под пользователем, созданным в разделе «Создание пользователя для расширения pg_cron».
Создайте задачу в
cron:SELECT cron.schedule(period, command);где:
period– строка, означающая дату или временной период для выполнения задачи. Формат строки:| * | * | * | * | * | |---------------|-------------|-------------|--------------|-----------------------------------| | минуты (0-59) | часы (0-23) | день (1-31) | месяц (1-12) | день недели (0-6, 7 равноценно 0) |
Значение
*означает повторение события.Примеры:
* * * * * - каждую минуту;
0 5 * * * - каждый день в 5:00;
*/10 * * * * - каждые 10 минут;
0 0 1 1 * - 1 января каждого года;
0 9 * * 1,3,5 - в понедельник, среду и пятницу в 9 утра;
0 0 1 * * - каждое 1-е число месяца.
command– исполняемая команда, форматы:$$ SQL-req $$- для SQL-запроса;'PostreSQL SQL command'- одиночная PostreSQL SQL команда.
Примеры:
Вывести все задачи в планировщике:
SELECT cron.schedule('59 23 * * *', $$SELECT * FROM cron.job$$);Выполнить команду VACUUM:
SELECT cron.schedule('59 23 * * *', 'VACUUM');
Выведите содержимое таблицы
cron.job, чтобы проверить, что задача создана:SELECT * from cron.job;
Задачи могут выполняться параллельно, но они будут запущены с небольшим временным смещением.
Если задача A требует завершения задачи B, то задача A будет ждать завершения команды B.
Удаление задачи из pg_cron#
Выведите данные таблицы
cron.job:SELECT * from cron.job;По таблице найдите
jobidзадачи, которую необходимо удалить.Выполните команду удаления задачи:
SELECT cron.unschedule(jobid);Проверьте, что задача удалена (вывести таблицу
cron.job).
Внимание!
Удаление чужой задачи при наличии соответствующих прав возможно только через
IDзадачи.
Просмотр задач в планировщике#
Для просмотра задач выведите содержимое таблицы cron.job:
SELECT * FROM cron.job;
Выводятся только задачи, созданные пользователем, который выполнил команду.
Продвинутая работа с таблицей запланированных задач#
Пользователь с правами суперпользователя может редактировать данные таблицы cron.job, например, для:
создания любой задачи с любыми параметрами;
запуска задачи на другом узле;
запуска задачи на другом сервере;
изменения пользователя, который создал задачу.
Пример:
INSERT INTO cron.job (schedule, command, nodename, nodeport, database, username)
VALUES ('0 4 * * *', 'VACUUM', 'node-1', 5432, 'postgres', 'marco');
Примечание:
Для работы с удаленными серверами добавьте соответствующие записи в хранилище паролей для всех удаленных узлов.
Примеры#
Удалить старые данные в субботу, 3:30 ночи:
SELECT cron.schedule('30 3 * * 6', $$DELETE FROM events WHERE event_time < now() - interval '1 week'$$);
Выполнять VACUUM каждый день в 10:00 утра:
SELECT cron.schedule('0 10 * * *', 'VACUUM');
Посмотреть текущие задачи:
SELECT * FROM cron.job;
Отменить задачу:
SELECT cron.unschedule(43);
Пример работы с именованными задачами:
/* Создаем задачу */
select cron.schedule('My select', '0 8 * * *', 'select 1');
schedule
----------
15
(1 row)
/* Проверяем, что задача создалась */
select * from cron.job where jobname='My select';
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+-----------+----------+-----------+----------+----------+----------+--------+-----------
15 | 0 8 * * * | select 1 | localhost | 5433 | postgres | postgres | t | My select
(1 row)
/* Удаляем задачу */
select cron.unschedule('My select');
unschedule
------------
t
(1 row)
/* Проверяем, что задача удалена */
select * from cron.job where jobname='My select';
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+----------+---------+----------+----------+----------+----------+--------+---------
(0 rows)
/* Создаем задачу */
select cron.schedule('My select', '0 8 * * *', 'select 1');
schedule
----------
16
(1 row)
/* Проверяем, что задача создалась */
select * from cron.job where jobname='My select';
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+-----------+----------+-----------+----------+----------+----------+--------+-----------
16 | 0 8 * * * | select 1 | localhost | 5433 | postgres | postgres | t | My select
(1 row)
/* Меняем имя пользователя задачи */
select cron.alter_job(job_id:=16, username:='test_tuz');
alter_job
-----------
(1 row)
/* Проверяем, что задача поменялась */
select * from cron.job where jobname='My select';
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+-----------+----------+-----------+----------+----------+----------+--------+-----------
16 | 0 8 * * * | select 1 | localhost | 5433 | postgres | test_tuz | t | My select
(1 row)
/* Пытаемся удалить задачу по имени, получаем сообщение об ошибке, хотя имя задачи указано верно */
select cron.unschedule('My select');
ERROR: could not find valid entry for job 'My select'
/* Удаляем задачу по ID */
select cron.unschedule(16);
unschedule
------------
t
(1 row)
/* Проверяем, что задача удалена */
select * from cron.job where jobname='My select';
jobid | schedule | command | nodename | nodeport | database | username | active | jobname
-------+----------+---------+----------+----------+----------+----------+--------+---------
(0 rows)
Функция
cron.scheduleтеперь имеет перегруженный вариант со следующими параметрами:Имя параметра
Тип данных
Комментарий
job_name
name
Имя задачи
schedule
text
Расписание в формате cron
command
text
Команда, выполняемая задачей
Пример использования:
/* Создаем задачу */ select cron.schedule('My vacuum', '0 3 * * *', 'VACUUM'); /* Меняем ранее созданную задачу в части расписания и команды */ select cron.schedule('My vacuum', '0 5 * * *', 'select 1');Функция возвращает
IDсозданной задачи.Функция
cron.unscheduleтеперь имеет перегруженный вариант со следующим параметром:Имя параметра
Тип данных
Комментарий
job_name
name
Имя задачи
Пример использования:
/* Удаляем задачу */ select cron.unschedule('My vacuum');Добавлена функция
cron.alter_jobдля изменения ранее созданных задач.Имя параметра
Тип данных
Комментарий
job_id
bigint
ID задачи
schedule
text
Расписание в формате cron
command
text
Команда, выполняемая задачей
database
text
База данных
username
text
Имя пользователя
active
boolean
Запускается ли задача
Примеры использования:
/* * Задаем все параметры * Задача должна была быть ранее создана * Меняем задачу с ID 4: * расписание: '0 4 * * *' * база данных: 'First_db' * имя пользователя: 'test_tuz' * команда, выполняемая задачей: 'select 2' * запускается ли задача: true */ select cron.alter_job(job_id:=4,schedule:='0 4 * * *',database:='First_db', username:='test_tuz', command:='select 2', active:=true); /* Отключаем задачу с ID 4 не удаляя ее */ select cron.alter_job(job_id:=4, active:=false); /* Включаем задачу с ID 4 обратно */ select cron.alter_job(job_id:=4, active:=true);Добавлена функция
cron.schedule_in_database, позволяющая запускать задачи сразу с указанием необходимой базы данных и имени пользователя.Имя параметра
Тип данных
Комментарий
job_name
text
ID задачи
schedule
text
Расписание в формате cron
command
text
Команда, выполняемая задачей
database
text
База данных
username
text
Имя пользователя
active
boolean
Запускается ли задача
/* * Создаем задачу с именем: 'Mysel' * расписание: '0 4 * * *' * база данных: 'postgres' * имя пользователя: 'postgres' * команда, выполняемая задачей: 'select 2' * запускается ли задача: false */ select cron.schedule_in_database(job_name:='Mysel',schedule:='0 4 * * *',database:='postgres', username:='postgres', command:='select 2', active:=false);Функция возвращает
IDсозданной задачи.Добавлена таблица аудита задач. Пример чтения из таблицы аудита задач:
select * from cron.job_run_details; jobid | runid | job_pid | database | username | command | status | return_message | start_time | end_time -------+-------+---------+----------+----------+----------+-----------+----------------+-------------------------------+------------------------------- 22 | 114 | 30463 | postgres | postgres | select 2 | succeeded | SELECT 1 | 2022-11-22 16:31:00.008602+03 | 2022-11-22 16:31:00.014413+03 /* * ID задачи: 22 * номер задачи в очереди выполнения: 114 * PID процесса задачи: 30463 * база данных: postgres * имя пользователя: postgres * команда, выполняемая задачей: 'select 2' * статус выполнения задачи: 'succeeded' * сообщение статуса выполнения: 'SELECT 1' * время начала выполнения задачи: 2022-11-22 16:31:00.008602+03 * время окончания выполнения задачи: 2022-11-22 16:31:00.014413+03 */Добавлен параметр
cron.enable_superuser_jobs, значение по умолчаниюon. Разрешает/запрещает задачи от имени пользователя с правамиsuperuser. Изменение значения требует перезапуска базы данных.Добавлен параметр
cron.log_min_messages, значение по умолчаниюwarning. Управляет уровнем логгирования расширенияpg_cron. Изменение значения требует перезапуска базы данных.Добавлен параметр
cron.use_background_workers, значение по умолчаниюoff. Управляет режимом выполнения задач расширенияpg_cron.
Примечание:
Режим работы через фоновые рабочие процессы отключен в обновлении.
При значении off задачи создаются через открытие соединения к базе, что требует настройки файла pg_hba.conf и хранилища паролей.
При значении on задачи создаются с использованием фоновых рабочих процессов.
Изменение значения требует перезапуска базы данных.
Обеспечение аварийного завершения СУБД Pangolin при отключении СХД#
Реализованная функциональность предназначена для определения отказа/отключения системы хранения данных (далее СХД) в кластере. При определении отказа/отключения системы хранения данных СУБД Pangolin аварийно завершается, а Pangolin Manager переключает лидера кластера.
Пути к каталогам для определения состояния СХД:
постоянные пути:
подкаталоги
PGDATA:global– подкаталог, содержащий общие таблицы кластера, такие какpg_database;pg_wal– подкаталог, содержащий файлы WAL;pg_commit_ts– подкаталог, содержащий данные о времени фиксации транзакций;pg_dynshmem– подкаталог, содержащий файлы, используемые подсистемой динамически разделяемой памяти;pg_notify– подкаталог, содержащий данные состояния прослушивания и уведомлений;pg_prep_stats– подкаталог для хранения файлов текстов запросов на подготовку для задачи «Поддержка prepared statements для транзакционного режима»;pg_serial– подкаталог, содержащий информацию о выполненных сериализуемых транзакциях;pg_snapshots– подкаталог, содержащий экспортированные снапшоты;pg_subtrans– подкаталог, содержащий данные о состоянии подтранзакций;pg_twophase– подкаталог, содержащий файлы состояний для подготовленных транзакций;pg_multixact– подкаталог, содержащий данные о состоянии мультитранзакций;base– подкаталог, содержащий подкаталоги для каждой базы данных;pg_pp_cache– password policy cache;pg_replslot– подкаталог, содержащий данные слота репликации;pg_stat– подкаталог, содержащий постоянные файлы для подсистемы статистики;pg_stat_tmp– подкаталог, содержащий временные файлы для подсистемы статистики;pg_xact– подкаталог, содержащий данные о состоянии транзакции;pg_logical– подкаталог, содержащий данные о состоянии для логического декодирования;pg_perf_insights– подкаталог, содержащий файлы с данными для задачи аналитики производительности;pg_auth– подкаталог используется задачей «Сквозная аутентификация»;
каталог
log_directory;
каталоги табличных пространств.
В СУБД Pangolin появляются новые параметры:
enable_filesystem_checker– определяет включение функциональности:True– функциональность включена,False– выключена (по умолчанию);disk_check_timeout– таймаут в секундах – периодичность проверки, имеет значение по умолчанию 5 секунд;disk_operation_timeout– таймаут в секундах – на ожидание завершения процесса записи/чтения, имеет значение по умолчанию 3 секунды;disk_retry_count– параметр определяет количество неудачных попыток файловых операций до аварийного переключения лидера кластера (failover), значение по умолчанию: 3;force_failover_timeout– параметр определяет период времени, в течение которого Pangolin гарантированно не запустится после отключения СХД, для того чтобы Pangolin Manager выполнил переключение лидера кластера. Значение рассчитывается по формуле:ttl + 2*loop_wait + 5
где:
ttl - параметр Pangolin Manager, промежуток времени до запуска процесса автоматического перехода на другой ресурс; loop_wait - параметр Pangolin Manager, период опроса кластера. 5 - константа, используемая для того, чтобы значение параметра force_failover_timeout гарантированно было больше ttl + 2*loop_wait.disk_check_tablespaces_count- определяет максимально возможное число табличных пространств, для которых может быть включена проверка, значение по умолчанию 128.
Отключение функциональности#
Для отключения функциональности:
В файле конфигурации Pangolin Manager (
/etc/pangolin-manager/postgres.yaml) измените строку:enable_filesystem_checker:'True'На строку:
enable_filesystem_checker:'False'Выполните команды:
patronictl -c /etc/pangolin-manager/postgres.yml reload clustername patronictl -c /etc/pangolin-manager/postgres.yml restart clusternameили
reload --force restart --force
Резервирование подключений для ролей#
В Pangolin реализована возможность резервирования количества доступных подключений для ролей, как индивидуально, так и по признаку вхождения в групповую роль. Это гарантирует пользователю наличие свободных подключений к БД в любое время.
Настроить резервирование соединения можно индивидуально или для группы ролей. При этом редактируются разные файлы:
для конфигурации
standalone— файлpg_quota.conf. После редактирования файла требуется выполнить перезагрузку БД;для конфигурации
cluster— настройка резервирования соединений осуществляется через файл/etc/pangolin-manager/postgresql.yml. После редактирования файла требуется выполнить перезагрузку БД и Pangolin Manager.
Пустые строки в файле pg_quota.conf игнорируются, как и любой текст комментария после значка #. Записи не продолжаются на следующей строке.
Записи начинаются с имени роли (role_name), за которой через пробел и/или tabs следует хотя бы одно поле в формате ключ=значение (поле reserved_connections).
В open source версии PostgreSQL отсутствует возможность резервирования подключений для пользователей, не являющихся superuser. Это приводит к проблеме - нет возможности получить соединение к БД, когда все свободные подключения к БД заняты и пользователь не superuser.
В Platform V Pangolin реализована возможность резервировать для ролей количество доступных подключений как индивидуально, так и по признаку вхождения в групповую роль. Это гарантирует пользователю наличие свободных подключений к БД в любое время.
В каждой БД создается файл pg_quota.conf. Файл содержит записи для ролей, требующих зарезервировать соединения.
Файл pg_quota.conf не синхронизируется с репликой средствами оркестратора Pangolin Manager. Файл pg_quota.conf содержится в копии БД, полученной pg_basebackup или pg_probackup.
Примечание:
Если записей несколько и квота есть для каждой роли, то берется квота первой записи для конкретной аутентифицирующейся роли.
Файл pg_quota.conf создается командой initdb при инициализации каталога с данными. Однако его можно разместить в любом другом месте, используя конфигурационный параметр quota_file. Файл pg_quota.conf считывается только при запуске системы.
Внимание!
Файл
pg_quota.confне считывается при получении сигнала SIGHUP, так как нет возможности перераспределить уже открытые соединения под новые квоты.
Редактировать файл могут администраторы БД. Файл не является обязательным. Если он не задан или отсутствует, используются лимиты для superuser (если роль superuser) и/или лимиты из общего пула — при этом работает стандартный механизм выдачи подключений.
Пример файла pg_quota.conf:
user reserved_connections=3
+db_admin reserved_connections=5
Примечание:
Файл не обязан содержать все роли, описанные в БД. Он может содержать только роли, для которых необходимо квотирование.
Для отключения функциональности требуется:
для конфигурации
standalone— удалить файлpg_quota.confи перезапустить БД;для конфигурации
cluster— удалить секциюpg_quotaв файле/etc/pangolin-manager/postgresql.ymlи выполнить перезагрузку БД и Pangolin Manager.
Расширение pg_pathman#
pg_pathman - это расширение, реализующее оптимизированное решение для секционирования больших и распределенных баз данных.
Секционированием данных называется разбиение одной большой логической таблицы на несколько меньших физических секций. Секционирование может принести следующую пользу:
В определенных ситуациях оно кардинально увеличивает быстродействие, особенно когда большой процент часто запрашиваемых строк таблицы относится к одной или лишь нескольким секциям. Секционирование может сыграть роль ведущих столбцов в индексах, что позволит уменьшить размер индекса и увеличит вероятность нахождения наиболее востребованных частей индексов в памяти.
Когда в выборке или изменении данных задействована большая часть одной секции, последовательное сканирование этой секции может выполняться гораздо быстрее, чем случайный доступ по индексу к данным, разбросанным по всей таблице.
Массовую загрузку и удаление данных можно осуществлять, добавляя и удаляя секции, если это было предусмотрено при проектировании секционированных таблиц. Операция
ALTER TABLE DETACH PARTITIONили удаление отдельной секции с помощью командыDROP TABLEвыполняются гораздо быстрее, чем массовая обработка. Эти команды также полностью исключают накладные расходы, связанные с выполнениемVACUUMпослеDELETE.Редко используемые данные можно перенести на более дешевые и медленные носители.
PostgreSQL поддерживает несколько типов секционирования:
по диапазонам;
по списку;
по хэшу.
Преимущества и рекомендации по применению pg_pathman#
Расширение pg_pathman использует оптимизированные алгоритмы планирования и функции секционирования, учитывающие внутреннюю структуру секционированных таблиц, что позволяет добиться лучшей производительности. Конфигурация разбиения сохраняется в таблице pathman_config; каждая ее строка содержит запись для одной секционированной таблицы (название отношения, столбец разбиения и тип секционирования).
Расширение предоставляет ряд оптимизаций, улучшающих производительность:
вставка новой записи эффективнее в отсутствие пользовательских триггеров;
список секций кэшируется, и поиск по ним осуществляется за log(N) (актуально при большом количестве секций);
из плана запроса исключается сканирование родительской таблицы.
pg_pathman можно использовать, чтобы:
секционировать большие базы данных, не прерывая их работу;
ускорять выполнение запросов с секционированными таблицами;
управлять существующими и добавлять новые секции не прерывая работу;
добавлять в качестве секций сторонние таблицы;
соединять секционированные таблицы для операций чтения и записи.
Расширение pg_pathman поддерживает две стратегии секционирования: по кэшу и по диапазонам.
Установка#
Для установки pg_pathman выполните шаги:
Добавьте
pg_pathmanв настроечный параметрshared_preload_librariesв конфигурационном файлеPostgreSQL.conf.Внимание!
pg_pathman может конфликтовать с другими расширениями, которые используют те же функции для перехвата управления. В связи с этим необходимо всегда добавлять это расширение в конец списка
shared_preload_libraries.Создайте расширение в БД:
CREATE EXTENSION pg_pathman;
Преимущества по отношению к секционированию с помощью наследования#
Функциональность pg_pathman можно реализовать путем создания дочерних таблиц вручную. Для этого необходимо сделать следующее:
Создайте родительскую таблицу:
CREATE TABLE measurements (log_date date, data text);
Создайте набор дочерних таблиц (секций):
CREATE TABLE measurement_y2020m02 ( CHECK ( logdate >= DATE '2020-02-01' AND logdate < DATE '2020-03-01' ) ) INHERITS (measurement);
CREATE TABLE measurement_y2020m03 ( CHECK ( logdate >= DATE '2020-03-01' AND logdate < DATE '2020-04-01' ) ) INHERITS (measurement);
Для перенаправления
INSERTв нужную секцию, создайте триггер для таблицыmeasurements:
CREATE OR REPLACE FUNCTION measurement_insert_trigger()
RETURNS TRIGGER AS $$
BEGIN
IF ( NEW.logdate >= DATE '2006-02-01' AND
NEW.logdate < DATE '2006-03-01' ) THEN
INSERT INTO measurement_y2006m02 VALUES (NEW.*);
ELSIF ( NEW.logdate >= DATE '2006-03-01' AND
NEW.logdate < DATE '2006-04-01' ) THEN
INSERT INTO measurement_y2006m03 VALUES (NEW.*);
...
ELSIF ( NEW.logdate >= DATE '2020-01-01' AND
NEW.logdate < DATE '2020-02-01' ) THEN
INSERT INTO measurement_y2008m01 VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'Date out of range. Fix the measurement_insert_trigger() function!' ;
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
pg_pathman автоматизирует и оптимизирует этот процесс. Например, с его помощью можно сократить весь приведенный выше код до одной строки:
SELECT create_range_partitions('measurements', 'logdate', '2006-02-01'::date, '1 month'::interval);
Поддержка функциональных пакетов Oracle для Pangolin (orafce)#
Описание расширения#
Расширение orafce представляет собой портирование части пакетов Oracle и функций по работе с данными. Использование этого расширения позволяет сократить время для миграции баз данных с Oracle на Pangolin.
Тем не менее, orafce принципиально не меняет модель работы с данными в Postgresql и не добавляет новых уровней поведения, не заложенных в модель Postgresql.
В частности:
добавление «пакетов» Oracle не позволяет использовать переменные «пакета». Функциональный класс переменных отсутствует и не может быть портирован;
портирована модель Oracle 10g1.
Добавление расширения#
Выполните команду:
CREATE EXTENSION IF NOT EXISTS orafce;
Функциональность#
Пакет dbms_alert#
Пакет добавляет модель межсессионного взаимодействия.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Процедура |
_signal |
name::text, message::text |
- |
Internal |
Триггер |
deferred_signal |
- |
trigger |
Internal |
Процедура |
register |
name::text |
- |
Регистрация ipc c именем name |
Процедура |
remove |
name::text |
- |
Удаление ipc с именем name |
Процедура |
removeall |
- |
- |
Удаление всех ipc |
Процедура |
set_defaults |
sensitivity::float8 |
- |
Определение sensitivity |
Процедура |
signal |
event::text, _message::text |
- |
Регистрация сигнала для ipc event с сообщением _message |
Функция |
waitany |
timeout::float8 |
name::text, message::text,status::int |
Ожидание сигналов в течение timeout сек |
Функция |
waitone |
name::text, timeout::float8 |
message::text, status::int |
Ожидание сигнала в ipc name в течение timeout сек |
Пример использования:
Сессия 1 |
Сессия 2 |
Сессия 3 |
Комментарий |
|---|---|---|---|
select dbms_alert.register('alert1'); |
select dbms_alert.register('alert1'); |
Регистрация очереди событий alert1 |
|
select * from dbms_alert.waitany(10); |
select * from dbms_alert.waitany(10) |
Ожидание событий в течение 10 секунд |
|
select dbms_alert.signal('alert1','Alert 1'); |
Добавление события «Alert 1» в очереди alert1 |
Пакет dbms_assert#
Пакет добавляет дополнительные проверки в целях защиты от SQL injection.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
enquote_literal |
str::varchar |
::varchar |
Квотирование строки. Верификация двойного квотирования строки |
Функция |
enquote_name |
str::varchar, [lowercase::bool] |
::varchar |
Квотирование имени объекта sql. Опциональный параметр - приведение имени к нижнему регистру (ВНИМАНИЕ: поведение отличается от Oracle. В Oracle имя приводится к верхнему регистру) |
Функция |
noop |
str::varchar |
::varchar |
Функция-заглушка. Изменений не производится |
Функция |
qualified_sql_name |
str::varchar |
::varchar |
Проверка того, что входной параметр является правильным именем объекта sql |
Функция |
schema_name |
str::varchar |
::varchar |
Проверка существования в БД определенной схемы |
Функция |
simple_sql_name |
str::varchar |
::varchar |
Проверка применимости входного параметра для использования в качестве идентификатора sql |
Функция |
object_name |
str::varchar |
::varchar |
Проверка существования нефункционального объекта в БД с именем входного параметра |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select dbms_assert.enquote_literal(E'O'Reilly'); |
'O''Reilly' |
select dbms_assert.enquote_name(E'O'Reilly'); |
"o'reilly" |
select dbms_assert.enquote_name(E'O'Reilly',false); |
"O'Reilly" |
select dbms_assert.noop(E'O'Reilly'); |
O'Reilly |
select dbms_assert.qualified_sql_name(E'O'Reilly'); |
ERROR: string is not qualified SQL name |
select dbms_assert.qualified_sql_name(E'noop'); |
noop |
select dbms_assert.qualified_sql_name(E'noop1'); |
noop1 |
select dbms_assert.qualified_sql_name(E'1noop'); |
1noop |
select dbms_assert.qualified_sql_name(E'noOP'); |
noOP |
select dbms_assert.schema_name(E'public'); |
public |
select dbms_assert.schema_name(E'noop'); |
ERROR: invalid schema name |
select dbms_assert.simple_sql_name(E'public'); |
public |
select dbms_assert.simple_sql_name(E'O'Reilly'); |
ERROR: string is not simple SQL name |
select dbms_assert.object_name(E'object_name'); |
ERROR: invalid object name |
select dbms_assert.object_name(E'information_schema'); |
ERROR: invalid object name |
select dbms_assert.object_name(E'pg_class'); |
pg_class |
Пакет dbms_output#
Пакет добавляет консольный вывод сообщений.
В Pangolin используется RAISE, однако поведение функций пакета отличается от принятого в Pangolin порядка выдачи сообщений тем, что функции пакета представляют собой очередь сообщений и могут быть прочитаны внутри сеанса.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Процедура |
disable |
- |
- |
Отключение вывода сообщений |
Процедура |
enable |
[buffer_size::int] |
- |
Включение вывода сообщений. Опциональный параметр указывает размер буфера в байтах |
Функция |
get_line |
- |
line::text, status::int |
Получение сообщений |
Функция |
get_lines |
numlines::int |
lines::text[],numlines::int |
Получение блока последних сообщений |
Процедура |
new_line |
- |
- |
Добавление нового пустого сообщения |
Функция |
put |
a::text |
- |
Добавление нового сообщения (блок) |
Функция |
put_line |
a::text |
- |
Добавление нового сообщения (строка) |
Процедура |
serveroutput |
::bool |
- |
Переключение вывода сообщений в консоль |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select dbms_output.enable(); |
|
select dbms_output.put(E'One\nTwo'); |
|
select dbms_output.get_lines(2); |
lines I numlines |
select dbms_output.get_line(); |
line I status |
select dbms_output.put_line(E'One\nTwo'); |
|
select dbms_output.get_line(); |
line I status |
select dbms_output.serveroutput(true); |
|
select dbms_output.put(E'One\nTwo'); |
|
select dbms_output.get_line(); |
line I status |
select dbms_output.disable(); |
Пакет dbms_pipe#
Пакет добавляет эмуляцию каналов Oracle. Реализация основана на использовании shared memory экземпляра:
максимальное количество каналов - 50;
длина канала определяется не в байтах, а в количестве элементов;
возможна отправка сообщений без ожидания;
возможна отправка пустых сообщений;
тип timestamp для next_item_type = 13;
Pangolin не поддерживает тип RAW. Используйте тип bytea.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Представление |
db_pipes |
- |
name::varchar items::int4 size::int4 limit::int4 private::bool owner::varchar |
Список каналов |
Процедура |
create_pipe |
::text, [::int4,[::bool]] |
- |
Создание канала. Передаваемые параметры: имя, размер, признак частного канала |
Функция |
next_item_type |
- |
::int4 |
Определение формата сообщения в канале: |
Процедура |
pack_message |
::bytea ::int4 ::int8 ::numeric ::text ::date ::timestamptz ::bytea ::record |
- |
Добавление сообщения в канал |
Процедура |
purge |
::text |
- |
Очистка канала. Параметр - имя канала |
Функция |
receive_message |
::text [::int4] |
::int4 |
Прием сообщения. Копирование сообщения в локальный буфер. Параметры - имя канала, время ожидания в секундах, результат - код возврата: |
Процедура |
remove_pipe |
::text |
- |
Удаление канала. Параметр - имя канала |
Процедура |
reset_buffer |
- |
- |
Очистка буфера |
Функция |
send_message |
::text[::int4 [::int4]] |
::int4 |
Передача сообщения. Параметры: имя канала, таймаут в секундах, максимальный размер канала. Канал, созданный этой функцией, будет удален после передачи сообщения (в отличие от канала, созданного функцией create_pipe). Код возврата совпадает с кодами функции receive_message |
Функция |
unique_session_name |
- |
::varchar |
Возвращает уникальное имя сессии, в которой создан канал |
Функция |
unpack_message_bytea |
- |
::bytea |
Распаковка сообщения bytea |
Функция |
unpack_message_date |
- |
::date |
Распаковка сообщения date |
Функция |
unpack_message_number |
- |
::numeric |
Распаковка сообщения number |
Функция |
unpack_message_record |
- |
::record |
Распаковка сообщения record |
Функция |
unpack_message_timestamp |
- |
::timestamptz |
Распаковка сообщения timestamp |
Функция |
unpack_message_text |
- |
::text |
Распаковка сообщения text |
Пример использования:
Сессия 1 |
Сессия 2 |
Комментарий |
|---|---|---|
select dbms_pipe.create_pipe('pipe1',10,true); |
Создание частного канала с именем pipe1 |
|
select * from dbms_pipe.db_pipes; |
Список: name I items I size I limit I private I owner |
|
select * from dbms_pipe.pack_message(timestamp 'epoch'+interval '2 days'); |
||
select * from dbms_pipe.pack_message((date 'epoch'+interval '2 days')::date); |
||
select * from dbms_pipe.pack_message(2::int4); |
||
select * from dbms_pipe.pack_message(2::int8); |
||
select * from dbms_pipe.pack_message(2::numeric); |
||
select * from dbms_pipe.pack_message(2::text); |
||
select * from dbms_pipe.send_message('pipe1',20,0); |
Вывод кода возврата: 0 |
|
select dbms_pipe.receive_message('pipe1',1); |
Вывод кода возврата: 0 |
|
select dbms_pipe.next_item_type(); |
Вывод 13 (timestamp) |
|
select dbms_pipe.unpack_message_timestamp(); |
Вывод 1970-01-03 00:00:00+03 (для временной зоны MSK) |
|
select dbms_pipe.next_item_type(); |
Вывод 12 (date) |
|
select dbms_pipe.unpack_message_timestamp(); |
ERROR: datatype mismatch |
|
select dbms_pipe.unpack_message_date(); |
Вывод: 1970-01-03 |
|
select dbms_pipe.next_item_type(); |
Вывод: 9 (number) |
|
select dbms_pipe.unpack_message_number(); |
Вывод: 2 |
|
select dbms_pipe.next_item_type(); |
Вывод 9 (number) |
|
select dbms_pipe.unpack_message_number(); |
Вывод: 2 |
|
select dbms_pipe.next_item_type(); |
Вывод 9 (number) |
|
select dbms_pipe.unpack_message_number(); |
Вывод: 2 |
|
select dbms_pipe.next_item_type(); |
Вывод 11 (text) |
|
select dbms_pipe.unpack_message_text(); |
Вывод: 2 |
|
select dbms_pipe.next_item_type(); |
Вывод: 0 (конец канала) |
|
select * from dbms_pipe.remove_pipe('pipe1'); |
Пакет dbms_random#
Пакет добавляет генерацию псевдослучайных чисел Oracle.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Процедура |
initialize |
::int4 |
- |
Инициализация генератора псевдослучайных чисел c заданным зерном (seed) |
Функция |
normal |
- |
::float |
Генерация числа в нормальном распределении |
Функция |
random |
- |
::int4 |
Генерация числа в полном диапазоне int4 (-231…231) |
Процедура |
seed |
::int4 |
- |
Передача зерна (seed) генератору |
Процедура |
seed |
::text |
- |
Передача зерна (seed) генератору |
Функция |
string |
opt::text, len::int4 |
text |
Генерация случайной строки длиной len. Параметры: 'u','U' - UPPERCASE ALPHA 'l','L' - lowercase alpha 'a','A' - MiXeD AlPhA 'x','X', UPPERCASE ALPHANUMERIC 'p','P' - Anu printable characters |
Процедура |
terminate |
- |
- |
Окончание работы пакета |
Функция |
value |
[ low::float, high::float] |
- |
Генерация псевдослучайного номера из диапазона [low,high) |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select dbms_random.initialize(ceil(random*1000)::int4); |
- |
select dbms_random.normal(); |
0.699305225607144 |
select dbms_random.normal(); |
-2.494277780294369 |
select dbms_random.string('u',10); |
{строка} |
select dbms_random.string('l',10); |
{строка} |
select dbms_random.string('a',15); |
{строка} |
select dbms_random.string('x',10); |
{строка} |
select dbms_random.string('p',15); |
{строка} |
select dbms_random.value(-10,10); |
3.7091398146003485 |
select dbms_random.terminate(); |
- |
Пакет dbms_utility#
Пакет добавляет просмотр стека вызовов.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
format_call_stack |
[ ::text ] |
text |
Возвращает стек вызовов внутри блока pl/pgsql |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
do |
Call stack ---- PL/pgSQL Call Stack ----- |
Пакет utl_file#
Пакет добавляет операции с файловой системой.
В каждой сессии допускается до 10 открытых файловых дескрипторов. Длина строки ограничена 32Кб.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Таблица |
utl_file_dir |
dir::text dirname::text |
- |
Таблица псевдонимов |
Домен |
file_type |
file_type::integer |
- |
Домен для хранения файлового дескриптора |
Функция |
fclose |
file::utl_file.file_type |
::utl_file.file_type |
Закрытие файлового дескриптора |
Процедура |
fclose_all |
- |
- |
Закрытие всех открытых файловых дескрипторов |
Процедура |
fcopy |
src_location::text |
- |
Копирование файла. |
Процедура |
fflush |
file::utl_file.file_type |
- |
Сброс буфера на диск |
Функция |
fgetattr |
location::text |
fexist::boolean |
Получение атрибутов файла |
Функция |
fopen |
location::text |
::utl_file.file_type |
Открытие файлового дескриптора.Параметр open_mode стандартный('r','rw','a',…) |
Процедура |
fremove |
location::text |
- |
Удаление файла |
Процедура |
frename |
location::text |
- |
Переименование/перемещение файла |
Функция |
get_line |
file::utl_file.file_type len::int4 |
buffer::text |
Получение строки из открытого файла |
Функция |
get_nextline |
file::utl_file.file_type |
buffer::text |
Получение строки из открытого файла |
Функция |
is_open |
file::utl_file.file_type |
::boolean |
Проверка корректности файлового дескриптора |
Функция |
new_line |
file::utl_file.file_type |
::boolean |
Добавление новой строки в открытый файл |
Функция |
put |
file::utl_file.file_type |
::boolean |
Добавление записи в файл |
Функция |
put_line |
file::utl_file.file_type |
::boolean |
Добавление новой строки в открытый файл |
Функция |
putf |
file::utl_file.file_type |
::boolean |
Форматированный вывод в открытый файл |
Функция |
tmpdir |
- |
::text |
Вывод значения системной переменной $TEMP |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
INSERT INTO utl_file.utl_file_dir(dir,dirname) VALUES ('temp','/tmp') |
|
COPY (SELECT * FROM pg_settings) TO '/tmp/pg_settings.csv'; |
|
do |
Содержимое файла /tmp/pg_settings.csv |
SELECT utl_file.fremove('temp','pg_settings.csv'); |
|
SELECT utl_file.fclose_all(); |
Пакет plunit#
Пакет добавляет функции проверок.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Процедура |
assert_equals |
expected::anyelement |
- |
Проверка условия expected = actual |
Процедура |
assert_equals |
expected::float8 |
- |
Проверка условия expected=actual в пределах range |
Процедура |
assert_false |
condition::bool |
- |
Проверка логического условия FALSE |
Процедура |
assert_true |
condition::bool |
- |
Проверка логического условия TRUE |
Процедура |
assert_not_equals |
expected::anyelement |
- |
Проверка условия expected != actual |
Процедура |
assert_not_equals |
expected::float8 |
- |
Проверка условия expected != actual в пределах range |
Продедура |
assert_not_null |
actual::anyelement |
- |
Проверка входного параметра на присутствие значения (NOT NULL) |
Продедура |
assert_null |
actual::anyelement |
- |
Проверка входного параметра на отсутствие значения (IS NULL) |
Продедура |
fail |
[ message::varchar] |
- |
Безусловный возврат с ошибкой |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select plant.assert_equals(clock_timestamp(),current_timestamp,'Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_equals) |
select plant.assert_equals(clock_timestamp()::date,current_timestamp::date,'Failed'); |
- |
select plant.assert_not_equals(clock_timestamp(),current_timestamp,'Failed'); |
- |
select plant.assert_not_equals(clock_timestamp()::date,current_timestamp::date,'Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_not_equals) |
select plant.assert_false(clock_timestamp()::date=current_timestamp::date,'Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_false) |
select plant.assert_true(clock_timestamp()=current_timestamp,'Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_true) |
select plant.assert_not_null(clock_timestamp,'Failed'); |
- |
select plant.assert_null(clock_timestamp,'Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_null) |
select plant.fail('Failed'); |
ОШИБКА: 23514: Failed ПОДРОБНОСТИ: Plunit.assertion fails (assert_fail) |
Пакет plvchr#
Пакет добавляет специфичные для Oracle функции для работы с текстом.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
_is_kind |
str::text,kind::int4 c::int4, kind::int4 |
boolean |
Базовая функция для is_% функций |
Функция |
char_name |
c::text |
varchar |
Возвращает код символа в кодировке ASCII |
Функция |
first |
str::text |
varchar |
Возвращает первый символ в строке |
Функция |
last |
str::text |
varchar |
Возвращает последний символ в строке |
Функция |
nth |
str::text, n::int4 |
text |
Возвращает n-ый символ в строке |
Функция |
quoted1 |
str::text |
varchar |
Возвращает текст, заключенный в апострофы |
Функция |
quoted2 |
str::text |
varchar |
Возвращает текст, заключенный в кавычки |
Функция |
stripped |
str::text char_in::text |
varchar |
Удаляет символы подстроки char_in из str с учетом регистра символов |
Функция |
is_blank |
str::text c::int4 |
boolean |
Проверяет значения параметра на заполненность |
Функция |
is_digit |
str::text c::int4 |
boolean |
Проверяет значения параметра на цифровой формат |
Функция |
is_letter |
str::text c::int4 |
boolean |
Проверяет значения параметра на текстовый формат |
Функция |
is_other |
str::text c::int4 |
boolean |
Проверяет значения параметра на несоответствие ни цифровому, ни текстовому формату |
Функция |
is_quote |
str::text c::int4 |
boolean |
Проверяет значения текстового параметра на квотирование (кавычки или апострофы) |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select plvchr.char_name('Pangolin'); |
P |
select plvchr.first('Pangolin'); |
P |
select plvchr.last('Pangolin'); |
n |
select plvchr.nth('Pangolin',2); |
a |
select plvchr.nth('Pangolin',-2); |
i |
select plvchr.quoted1('Pangolin'); |
'Pangolin' |
select plvchr.quoted2('Pangolin'); |
"Pangolin" |
select plvchr.quoted('Pangolin','Pango'); |
li |
select plvchr.quoted('Pangolin','pango'); |
Pli |
select plvchr.is_blank('Pangolin'); |
false |
select plvchr.is_digit('Pangolin'); |
false |
select plvchr.is_letter('Pangolin'); |
true |
select plvchr.is_other('Pangolin'); |
false |
select plvchr.is_quote('Pangolin'); |
false |
select plvchr.is_quote('''Pangolin"'); |
true |
Пакет plvdate#
Пакет добавляет специфичные для Oracle функции для работы с датами.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
add_bizdays |
::date, ::int4 |
date |
Получение рабочей даты, спустя |
Функция |
bizdays_between |
::date, ::date |
int4 |
Количество рабочих дней между двумя датами |
Функция |
days_inmonth |
::date |
int4 |
Количество дней в месяце |
Процедура |
default_holidays |
::text |
- |
Загрузка рабочего календаря. Принимаемые конфигурации: Czech German Austria Poland Slovakia Russia GB USA |
Функция |
include_start |
[ ::boolean ] |
boolean |
Включение первой даты в расчет |
Функция |
noinclude_start |
- |
boolean |
Исключение первой даты из расчета |
Функция |
isbizday |
::date |
boolean |
Является ли дата рабочим днем |
Функция |
isleapyear |
::date |
boolean |
Является ли год високосным |
Функция |
nearest_bizday |
::date |
date |
Ближайший рабочий день для даты |
Функция |
next_bizday |
::date |
date |
Следующий рабочий день |
Функция |
prev_bizday |
::date |
date |
Предыдущий рабочий день |
Функция |
set_nonbizday |
::date |
boolean |
Определение нерабочего дня. Возвращаемый параметр - рекурсия (каждый год) |
Процедура |
set_nonbizday |
::text |
- |
Задать день недели как нерабочий |
Функция |
unset_nonbizday |
::date |
boolean |
Определение рабочего дня. Возвращаемый параметр - рекурсия (каждый год) |
Процедура |
unset_nonbizday |
::text |
- |
Задать день недели как рабочий |
Функция |
use_easter |
- |
boolean |
Задать Пасху как нерабочий день. Возвращаемый параметр - рекурсия (каждый год) |
Процедура |
use_easter |
::boolean |
- |
Задать Пасху как нерабочий день |
Функция |
unuse_easter |
- |
boolean |
Задать Пасху как рабочий день. Возвращаемый параметр - рекурсия (каждый год) |
Процедура |
unuse_easter |
::boolean |
- |
Задать Пасху как рабочий день |
Функция |
use_great_friday |
- |
boolean |
Задать Страстную пятницу как нерабочий день. Возвращаемый параметр - рекурсия (каждый год) |
Процедура |
use_great_friday |
::boolean |
- |
Задать Страстную пятницу как нерабочий день |
Функция |
using_easter |
- |
boolean |
Проверка, является ли Пасха рабочим днем |
Функция |
using_great_friday |
- |
boolean |
Проверка, является ли Страстная пятница рабочим днем |
Функция |
version |
- |
cstring |
Версия схемы |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select plvdate.default_holidays('Russia'); |
|
select plvdate.isleapyear('2020-01-01'); |
true |
select plvdate.isleapyear('2021-01-01'); |
false |
select plvdate.isbizday('2021-03-08'); |
false |
select plvdate.isbizday('2021-02-22'); |
true |
select plvdate.add_bizdays('2021-02-22',15); |
2021-03-17 |
select plvdate.bizdays_between('2021-04-30','2021-05-10'); |
6 |
select plvdate.days_inmonth('2021-02-22'); |
28 |
select plvdate.nearest_bizday('2021-02-22'); |
2021-02-24 |
select plvdate.next_bizday('2021-02-22'); |
2021-02-24 |
select plvdate.prev_bizday('2021-02-22'); |
2021-02-19 |
select plvdate.set_nonbizday('2021-02-22',false); |
|
select plvdate.unset_nonbizday('2021-02-20',false); |
ОШИБКА: 42704: nonbizday unregisteration error ПОДРОБНОСТИ: Nonbizday not found. |
select plvdate.using_easter(); |
false |
select plvdate.using_greater_friday(); |
false |
select plvdate.version(); |
PostgreSQL PLVdate, version 3.7, October 2018 |
Пакет plvlex#
Пакет основан на оригинальном PL/Vision LEXical analysis и добавляет специфичные для Oracle функции для работы с лексемами.
Внимание!
Данный пакет основан на ключевых словах Postgresql и не является полностью совместимым с Oracle.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
tokens |
str::text, skip_spaces::boolean, qualified_names::boolean |
SETOF record |
Лексический анализатор. Возвращаемые параметры: |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
|
pos I token I code I class I separator I mod |
Пакет plvstr#
Пакет добавляет специфичные для Oracle функции для работы со строками и текстовыми данными.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Функция |
betwn |
str::text,start::int4,_end::int4[,inclusive:boolean] |
text |
Производит поиск подстроки в пределах от start до _end символа |
Функция |
instr |
str::text,patt::text[,start::int4[,nth::int4]] |
int4 |
Производит поиск позиции подстроки |
Функция |
is_prefix |
str::int8,prefix::int8 |
boolean |
Производит проверку: начинается ли искомая строка с определенного префикса |
Функция |
left |
str::text,n::int4 |
varchar |
Возвращает n символов с начала строки |
Функция |
right |
str::text,n::int4 |
varchar |
Возвращает n символов с конца строки |
Функция |
lpart |
str::text,div::text[,start::int4[,nth::int4[,allifnotfound::boolean]]] |
text |
Возвращает подстроку, находящуюся до строки поиска |
Функция |
rpart |
str::text,div::text[,start::int4[,nth::int4[,allifnotfound::boolean]]] |
text |
Возвращает подстроку, находящуюся после первого символа строки поиска |
Функция |
lstrip |
str::text,substr::text[,num::int4] |
text |
Усекает строку слева, если строка начинается с поисковой строки |
Функция |
rstrip |
str::text,substr::text[,num::int4] |
text |
Усекает строку справа, если строка заканчивается на поисковую строку |
Функция |
rvrs |
str::text,start::int4[,_end::int4] |
text |
Выставляет в обратном порядке символы в строке |
Функция |
substr |
str::text,start::int4[,len::int4] |
varchar |
Возвращает подстроку, начиная с позиции start (и длиной len) |
Функция |
swap |
str::text,replace::text[,start::int4,length::int4] |
text |
Производит поиск и замену подстроки replace в строке (начиная с позиции start, длиной length) |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select plvstr.betwn('Pangolin','go','i') |
goli |
select plvstr.instr('Pangolin','go') |
4 |
select plvstr.is_prefix('Pangolin','Pan') |
true |
select plvstr.is_prefix('Pangolin','pan') |
false |
select plvstr.left('Pangolin',5) |
Pango |
select plvstr.right('Pangolin',5) |
golin |
select plvstr.lpart('Pangolin','go') |
Pan |
select plvstr.rpart('Pangolin','go') |
olin |
select plvstr.lstrip('Pangolin','go') |
Pangolin |
select plvstr.lstrip('Pangolin','Pan') |
golin |
select plvstr.rstrip('Pangolin','lin') |
Pango |
select plvstr.rvrs('Pangolin') |
nilgonaP |
select plvstr.substr('Pangolin',5) |
olin |
select plvstr.swap('Pangolin','go') |
gongolin |
Пакет plvsubst#
Пакет добавляет специфичные для Oracle функции форматирования текста.
Объекты схемы:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Процедура |
setsubst |
[ str::text] |
- |
Задать маску поиска. Маска по умолчанию - '%s' |
Функция |
subst |
- |
text |
Получить маску поиска |
Функция |
string |
template_in::text[,vals_in::text[,delim_in::text[,substr-in::text]]] template_in::text[,values_in::text[][,subst::text]] |
text |
Применение форматирования по шаблону |
Пример использования:
Сессия 1 |
Результат выполнения |
|---|---|
select plvsubst.string('%s codename %s','Postgresql,Pangolin'); |
Postgresql codename Pangolin |
select plvsubst.string('%s codename %s',ARRAY['Postgresql','Pangolin']); |
Postgresql codename Pangolin |
select plvsubst.subst(); |
%s |
Изменения уровня базы данных#
Новые обьекты:
Тип |
Имя |
Входные переменные функции |
Выходные переменные функции |
Описание |
|---|---|---|---|---|
Представление |
dual |
- |
dummy::varchar |
Специфичное для Oracle представление, необходимое для поддержки стандарта SQL |
Тип |
dummy |
- |
- |
|
Тип |
varchar2 |
- |
- |
Специфичный для Oracle тип текстовых данных (single-byte) |
Тип |
nvarchar2 |
- |
- |
Специфичный для Oracle тип текстовых данных (multi-byte) |
Расширение btree_gin#
Работа с индексами GIN#
GIN (Generalized Inverted Index, обратный индекс) - используется преимущественно для полнотекстового поиска.
Для примера, создадим таблицу:
CREATE TABLE users ( first_name text, last_name text );
Заполним ее случайными строками:
insert into users SELECT md5(random()::text), md5(random()::text) FROM (SELECT * FROM generate_series(1,1000000) AS id) AS x;
Поиск по строке может занимать длительное время:
SELECT count(*) FROM users where first_name ilike '%aeb%';
Для ускорения поиска используем GIN индекс:
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE INDEX users_search_idx ON users USING gin (first_name gin_trgm_ops, last_name gin_trgm_ops);
где gin_trgm_ops из расширения pg_trgm - указание Pangolin использовать триграммы для построения индекса.
Применение GIN на практике не ограничивается использованием расширения pg_trgm. В данном случае оно выбрано в целях упрощения примера.
Проверьте, что время выполнения запроса уменьшается:
SELECT count(*) FROM users where first_name ilike '%aeb%';
Описание btree_gin#
btree_gin добавляет возможность использовать индекс GIN с операциями, характерными для b-tree.
Допустим, в таблицу добавилось дополнительное поле с возрастом:
alter table users add age integer default 0;
Если необходимо фильтровать пользователей по возрасту, то использование существующего индекса GIN может оказаться эффективней введения дополнительного BTREE-индекса:
CREATE EXTENSION btree_gin;
DROP INDEX user_search_index;
CREATE INDEX users_search_idx ON users USING gin (first_name gin_trgm_ops, last_name gin_trgm_ops, age);
Теперь можно эффективно фильтровать по возрасту:
EXPLAIN SELECT count(*) FROM users where first_name ilike '%aeb%' and age >= 27;
Так же как и btree_gist, btree_gin работает менее эффективно, чем простой b-tree. Его разумно использовать, если индекс уже включает в себя объекты операции GIN (как в примере выше).
Установка#
Расширение входит в стандартную поставку Pangolin. Для использования расширения необходимо выполнить:
CREATE EXTENSION btree_gin;
Расширение btree_gist#
Работа с индексами GiST#
GiST (Generalized search tree) - сбалансированное дерево поиска, схожее с b-tree. Однако, в отличие от b-tree, которое поддерживает только операторы <, >, =, GiST дает возможность использовать самые разнообразные операторы, например (<@, &&). При этом смысл операторов определяется типом данных, для которого он применяется. Таким образом, GiST предоставляет расширяемый интерфейс для хранения и поиска по любым типам данных с использованием операций, специфичных именно для этого типа.
Рассмотрим в качестве примера задачу поиска по временным интервалам (тип tsrange). Допустим, сдается дом, и есть таблица, хранящая интервалы бронирования:
create table reservations(during tsrange);
insert into reservations(during) values
('[2016-12-30, 2017-01-09)'),
('[2017-02-23, 2017-02-27)'),
('[2017-04-29, 2017-05-02)');
create index on reservations using gist(during);
На вход подается интервал [2017-01-01, 2017-04-01), нужно найти все интервалы, пересекающиеся с ним:
select * from reservations where during && '[2017-01-01, 2017-04-01)';
Для типа tsrange оператор && означает «пересечение».
Индекс GiST может применяться для поддержки ограничений исключения (exclude).
Добавим ограничение, которое запретит бронирование, если нужные даты уже заняты:
alter table reservations add exclude using gist(during with &&);
Попытка добавить интервал, уже имеющийся в таблице, завершится ошибкой:
insert into reservations(during) values ('[2017-01-01, 2017-04-01)');
Описание расширения btree_gist#
Допустим, нужно сдавать несколько домиков. В таблицу reservation добавим номер дома:
alter table reservations add house_no integer default 1;
Необходимо изменить ограничение исключения так, чтобы учитывать и номер дома. Однако GiST не поддерживает операцию равенства для целых чисел.
В этом случае поможет расширение btree_gist, которое добавляет GiST-поддержку операций, характерных для B-деревьев (<, >, =):
create extension btree_gist;
alter table reservations drop constraint reservations_during_excl;
alter table reservations add exclude using gist(during with &&, house_no with =);
Убедимся, что можно забронировать на те же даты не только первый домик, но и второй
insert into reservations(during, house_no) values ('[2017-01-01, 2017-04-01)', 2);
Необходимо учитывать, что при необходимости простого сравнения (<, >, =), более предпочтительно использовать простые b-tree индексы, так как они работают быстрее.
btree_gin имеет смысл использовать только в том случае, если условие дополнительно содержит операцию над сложными объектами, как в примере выше.
В дополнение к основным операциям b-tree, btree_gin добавляет оператор <> (не равно), который удобно использовать в ограничениях исключения (exclude constraints). Например:
CREATE TABLE zoo ( cage INTEGER, animal TEXT, EXCLUDE USING gist (cage WITH =, animal WITH <>) );
Установка#
Расширение входит в стандартную поставку Pangolin. Для использования необходимо выполнить:
CREATE EXTENSION btree_gist;
Расширение psql_diagpack#
Описание#
Расширение psql_diagpack создает представления, которые отображают в удобном для восприятия пользователем виде информацию из системных представлений:
Представление |
Отображаемая информация |
|---|---|
|
Список запросов, отсортированных по убыванию времени, проведенного на CPU или событиях ожидания, отличных от IO |
|
Список запросов, отсортированных по убыванию времени, проведенного на IO |
|
Список запросов, отсортированных по убыванию общего времени выполнения |
|
Дерево блокировок |
|
Отчет по статусу репликации |
|
Список самых больших таблиц (полный размер) в БД |
|
Список самых больших отношений в БД |
|
Расширенный отчет по активности процессов |
|
Отчет о текущей активности процессов очистки ( |
|
Отчет о распределении процессов по событиям ожидания |
|
Список таблиц, отсортированных по объему пространства, не занятого для хранения актуальных версий записей |
|
Список таблиц, отсортированных по доле пространства, не занятого для хранения актуальных версий записей |
|
Список неиспользуемых индексов |
|
Список индексов, перекрываемых другими индексами |
Настройка#
Проверка наличия/установка необходимых расширений#
Поскольку часть представлений из поставки данного расширения требуют наличия установленного расширения pg_stat_statements, необходимо проследить, чтобы данное расширение было установлено. С помощью метакоманды psql \dx проверьте, что расширение pg_stat_statements присутствует в списке:
psql -d TESTDB -c '\dx'
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
...
pg_stat_statements | 1.8 | ext | track planning and execution statistics of all SQL statements executed
...
Также проверьте, чтобы схема, в которой установлено расширение pg_stat_statements, присутствовало в search_path:
psql -d TESTDB -c 'show search_path'
search_path
-------------
ext, public
Если схема отсутствует в search_path, ее можно добавить для заданного пользователя (например, одной из приведенных ниже команд), чтобы не выполнять команду SET SEARCH_PATH TO ... каждый раз вручную:
psql -d TESTDB -c 'alter role TEST_ROLE set search_path to EXTENSION_SCHEMA,...';
-- или
psql -d TESTDB -c 'alter database TESTDB set search_path to EXTENSION_SCHEMA,...';
Если производится установка на оригинальную версию PostgreSQL, необходимо установить данное расширение вручную. Для этого в postgresql.conf добавьте значение 'pg_stat_statements' в параметр shared_preload_libraries:
...
shared_preload_libraries = 'pg_stat_statements'
...
После этого, создайте расширение pg_stat_statements в заданной БД:
psql -d TESTDB <<EOF
create extension pg_stat_statements;
EOF
Выдача необходимых привилегий#
По умолчанию, пользователь может видеть только тексты запросов для процессов, которые были запущены под той же самой ролью. Если требуется видеть тексты запросов для всех процессов, необходимо предоставить пользователю привилегию pg_read_all_stats. Выдать привилегию пользователю можно командой:
grant pg_read_all_stats to USER;
Установка расширения psql_diagpack#
Теперь можно создать непосредственно расширение:
psql -d TESTDB -c 'create extension psql_diagpack'
Проверка корректности установки#
Следует проверить, что расширение установлено корректно.
Расширения pg_stat_statements и psql_diagpack должны фигурировать в списке установленных расширений:
psql -d TESTDB -c '\dx'
Name | Version | Schema | Description
--------------------+---------+------------+------------------------------------------------------------------------
pg_stat_statements | 1.8 | ext | track planning and execution statistics of all SQL statements executed
psql_diagpack | 1.0 | ext | Administrative views for PostgreSQL monitoring
Следующие два запроса должны возвращать данные:
psql -d TESTDB -c 'table dba_query_cpu_time limit 2'
time_percent | iotime_percent | cputime_percent | total_exec_time | avg_time | avg_cpu_time | avg_io_time | calls | calls_percent | rows | row_percent | query
--------------+----------------+-----------------+-----------------+----------+--------------+-------------+-------+---------------+------+-------------+------------------------------------------------
68.77 | 0.00 | 68.77 | 43.90 | 43904.56 | 43.90 | 0.00 | 1 | 6.67 | 0 | 0.00 | create extension psql_diagpack schema ext
23.15 | 0.00 | 23.15 | 14.78 | 7391.40 | 7.39 | 0.00 | 2 | 13.33 | 0 | 0.00 | create extension pg_stat_statements schema ext
(2 rows)
psql -d TESTDB -c 'table dba_bloat_wastedbytes limit 2'
nspname | tabname | relname | reltype | tsize | tplcnt | dtplcnt | wspaceprc | wspaceb
------------+------------------+-----------------------------------+---------+---------+--------+---------+-----------+------------
pg_catalog | pg_proc | pg_proc | table | 1112 kB | 3295 | 5 | 13.1 | 145 kB
pg_catalog | pg_depend | pg_depend_reference_index | index | 392 kB | 8597 | 0 | 35.2 | 138 kB
(2 rows)
Управление#
Расширение psql_diagpack не предоставляет никаких параметров для изменения поведения расширения или иных средств управления.
Устранение неполадок#
Если при просмотре представлений dba_locks и dba_activity вместо текстов запросов отображается строка Insufficient privilege, то необходимо предоставить пользователю привилегию pg_read_all_stats, чтобы наблюдать тексты запросов для всех процессов.
Безопасность#
Поскольку psql_diagpack предполагает необходимость только Read Only доступа к БД, риски его использования относительно невелики. Тем не менее возможность наблюдать тексты запросов в представлениях pg_stat_activity и pg_stat_statements дает возможность злоумышленнику-инсайдеру обнаружить, к примеру, запросы, которые запускаются без использования переменных привязки. Из текста подобных запросов можно получить элементы персональных данных, либо рассмотреть возможность использования подобных запросов для проведения атаки типа «SQL-инъекция».
Описание объектов#
Представления#
dba_query_cpu_and_waits_time: Получение списка запросов, отсортированных по убыванию времени, проведенного на CPU или событиях ожидания, отличных от IO#
Название поля |
Тип |
Описание поля |
|---|---|---|
time_pcnt |
numeric(5,2) |
Доля времени, проведенного на выполнении данного запроса, в общем времени, проведенном на выполнении запросов для данной БД |
io_pcnt |
numeric(5,2) |
Доля времени, проведенного на IO при выполнении данного запроса, в общем времени, проведенном на IO при выполнении запросов для данной БД |
cpu_and_waits_pcnt |
numeric(5,2) |
Доля времени, проведенного на CPU при выполнении данного запроса, в общем времени, проведенном на CPU или событиях ожидания, отличных от IO, при выполнении запросов для данной БД |
calls_pcnt |
numeric(5,2) |
Доля от общего количества выполнений запросов в данной БД |
rows_pcnt |
numeric(5,2) |
Доля от общего количества обработанных записей в данной БД |
total_time_ms |
bigint |
Время, потраченное на все выполнения данного запроса (в миллисекундах) |
total_io_ms |
bigint |
Время, проведенное на IO в рамках всех выполнений данного запроса (в миллисекундах) |
shr_blks |
numeric |
Количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках всех выполнений данного запроса |
calls |
numeric |
Число выполнений запроса |
rows |
numeric |
Число обработанных записей |
avg_time_us |
bigint |
Среднее время выполнения запроса (в микросекундах) |
avg_io_us |
bigint |
Среднее время проведенное на IO в рамках выполнения запроса (в микросекундах) |
avg_shr_blks |
bigint |
Среднее количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках выполнения данного запроса |
query |
text |
Текст запроса |
DDL:
First_db=# \d+ dba_query_cpu_and_waits_time
View "public.dba_query_cpu_and_waits_time"
Column | Type | Collation | Nullable | Default | Storage | Description
--------------------+--------------+-----------+----------+---------+----------+-------------
time_pcnt | numeric(5,2) | | | | main |
io_pcnt | numeric(5,2) | | | | main |
cpu_and_waits_pcnt | numeric(5,2) | | | | main |
calls_pcnt | numeric(5,2) | | | | main |
rows_pcnt | numeric(5,2) | | | | main |
total_time_ms | bigint | | | | plain |
total_io_ms | bigint | | | | plain |
shr_blks | numeric | | | | main |
calls | numeric | | | | main |
rows | numeric | | | | main |
avg_time_us | bigint | | | | plain |
avg_io_us | bigint | | | | plain |
avg_shr_blks | bigint | | | | plain |
query | text | | | | extended |
View definition:
WITH summ AS (
SELECT GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time)) AS sum_total_exec_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time)) AS sum_io_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time)) AS sum_cpu_and_waits_time,
sum(pg_stat_statements.calls) AS sum_calls,
sum(pg_stat_statements.rows) AS sum_rows
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
), _pg_stat_statements AS (
SELECT pg_stat_statements.query,
sum(pg_stat_statements.total_exec_time) AS total_exec_time,
sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time) AS io_time,
sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time) AS cpu_and_waits_time,
sum(pg_stat_statements.calls) AS calls,
sum(pg_stat_statements.rows) AS rows,
sum(pg_stat_statements.shared_blks_read + pg_stat_statements.shared_blks_hit) AS shr_blks
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
GROUP BY pg_stat_statements.query
)
SELECT (100::double precision * _pg_stat_statements.total_exec_time / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * _pg_stat_statements.io_time / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * _pg_stat_statements.cpu_and_waits_time / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * _pg_stat_statements.calls / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * _pg_stat_statements.rows / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
_pg_stat_statements.total_exec_time::bigint AS total_time_ms,
_pg_stat_statements.io_time::bigint AS total_io_ms,
_pg_stat_statements.shr_blks,
_pg_stat_statements.calls,
_pg_stat_statements.rows,
(_pg_stat_statements.total_exec_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_time_us,
(_pg_stat_statements.io_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_io_us,
(_pg_stat_statements.shr_blks / _pg_stat_statements.calls)::bigint AS avg_shr_blks,
_pg_stat_statements.query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.cpu_and_waits_time / (( SELECT summ.sum_cpu_and_waits_time
FROM summ))) >= 0.02::double precision
UNION ALL
SELECT (100::double precision * sum(_pg_stat_statements.total_exec_time) / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * sum(_pg_stat_statements.io_time) / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * sum(_pg_stat_statements.cpu_and_waits_time) / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * sum(_pg_stat_statements.calls) / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * sum(_pg_stat_statements.rows) / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
sum(_pg_stat_statements.total_exec_time)::bigint AS total_time_ms,
sum(_pg_stat_statements.io_time)::bigint AS total_io_ms,
sum(_pg_stat_statements.shr_blks) AS shr_blks,
sum(_pg_stat_statements.calls) AS calls,
sum(_pg_stat_statements.rows) AS rows,
(sum(_pg_stat_statements.total_exec_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_time_us,
(sum(_pg_stat_statements.io_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_io_us,
(sum(_pg_stat_statements.shr_blks) / sum(_pg_stat_statements.calls))::bigint AS avg_shr_blks,
'other'::text AS query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.cpu_and_waits_time / (( SELECT summ.sum_cpu_and_waits_time
FROM summ))) < 0.02::double precision
ORDER BY 3 DESC;
Пример эксплуатации#
Подайте нагрузку на БД с помощью утилиты pg_bench:
pgbench -i -s 10 --foreign-keys First_db
pgbench -c 5 -j 5 -T 30 -P 10 First_db
Пример вывода списка тяжелых запросов:
psql -d First_db -c 'table dba_query_cpu_and_waits_time'
time_pcnt | io_pcnt | cpu_and_waits_pcnt | calls_pcnt | rows_pcnt | total_time_ms | total_io_ms | shr_blks | calls | rows | avg_time_us | avg_io_us | avg_shr_blks | query
-----------+---------+--------------------+------------+-----------+---------------+-------------+----------+--------+---------+-------------+-----------+--------------+------------------------------------------------------------------------------------------------------
56.89 | 0.00 | 57.51 | 14.26 | 2.90 | 17074 | 0 | 141083 | 33940 | 33940 | 503 | 0 | 4 | UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2
9.58 | 0.00 | 9.68 | 14.26 | 2.90 | 2875 | 0 | 106137 | 33940 | 33940 | 85 | 0 | 3 | UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2
9.06 | 0.75 | 9.15 | 0.00 | 0.00 | 2720 | 2 | 50693 | 1 | 0 | 2720126 | 2395 | 50693 | CREATE EXTENSION "pg_profile" WITH SCHEMA "pgse_profile"
9.01 | 0.01 | 9.10 | 14.26 | 2.90 | 2703 | 0 | 456267 | 33940 | 33940 | 80 | 0 | 13 | INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES ($1, $2, $3, $4, CURRENT_TIMESTAMP)
4.45 | 11.42 | 4.38 | 14.26 | 2.90 | 1336 | 37 | 292065 | 33940 | 33940 | 39 | 1 | 9 | UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2
4.12 | 39.08 | 3.74 | 42.95 | 2.92 | 1237 | 125 | 229422 | 102216 | 34102 | 12 | 1 | 2 | other
3.65 | 15.65 | 3.52 | 0.00 | 85.48 | 1096 | 50 | 6 | 1 | 1000000 | 1095872 | 50228 | 6 | copy pgbench_accounts from stdin
3.23 | 33.09 | 2.90 | 0.00 | 0.00 | 968 | 106 | 49305 | 1 | 0 | 968289 | 106225 | 49305 | vacuum analyze pgbench_accounts
(8 rows)
dba_query_io_time: Получение списка запросов, отсортированных по убыванию времени, проведенного на IO#
Название поля |
Тип |
Описание поля |
|---|---|---|
time_pcnt |
numeric(5,2) |
Доля времени, проведенного на выполнении данного запроса, в общем времени, проведенном на выполнении запросов для данной БД |
io_pcnt |
numeric(5,2) |
Доля времени, проведенного на IO при выполнении данного запроса, в общем времени, проведенном на IO при выполнении запросов для данной БД |
cpu_and_waits_pcnt |
numeric(5,2) |
Доля времени, проведенного на CPU при выполнении данного запроса, в общем времени, проведенном на CPU или событиях ожидания, отличных от IO, при выполнении запросов для данной БД |
calls_pcnt |
numeric(5,2) |
Доля от общего количества выполнений запросов в данной БД |
rows_pcnt |
numeric(5,2) |
Доля от общего количества обработанных записей в данной БД |
total_time_ms |
bigint |
Время, потраченное на все выполнения данного запроса (в миллисекундах) |
total_io_ms |
bigint |
Время, проведенное на IO в рамках всех выполнений данного запроса (в миллисекундах) |
shr_blks |
numeric Количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках всех выполнений данного запроса |
|
calls |
numeric |
Число выполнений запроса |
rows |
numeric |
Число обработанных записей |
avg_time_us |
bigint |
Среднее время выполнения запроса (в микросекундах) |
avg_io_us |
bigint |
Среднее время проведенное на IO в рамках выполнения запроса (в микросекундах) |
avg_shr_blks |
bigint |
Среднее количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках выполнения данного запроса |
query |
text Текст запроса |
DDL:
First_db=# \d+ dba_query_io_time
View "public.dba_query_io_time"
Column | Type | Collation | Nullable | Default | Storage | Description
--------------------+--------------+-----------+----------+---------+----------+-------------
time_pcnt | numeric(5,2) | | | | main |
io_pcnt | numeric(5,2) | | | | main |
cpu_and_waits_pcnt | numeric(5,2) | | | | main |
calls_pcnt | numeric(5,2) | | | | main |
rows_pcnt | numeric(5,2) | | | | main |
total_time_ms | bigint | | | | plain |
total_io_ms | bigint | | | | plain |
shr_blks | numeric | | | | main |
calls | numeric | | | | main |
rows | numeric | | | | main |
avg_time_us | bigint | | | | plain |
avg_io_us | bigint | | | | plain |
avg_shr_blks | bigint | | | | plain |
query | text | | | | extended |
View definition:
WITH summ AS (
SELECT GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time)) AS sum_total_exec_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time)) AS sum_io_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time)) AS sum_cpu_and_waits_time,
sum(pg_stat_statements.calls) AS sum_calls,
sum(pg_stat_statements.rows) AS sum_rows
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
), _pg_stat_statements AS (
SELECT pg_stat_statements.query,
sum(pg_stat_statements.total_exec_time) AS total_exec_time,
sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time) AS io_time,
sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time) AS cpu_and_waits_time,
sum(pg_stat_statements.calls) AS calls,
sum(pg_stat_statements.rows) AS rows,
sum(pg_stat_statements.shared_blks_read + pg_stat_statements.shared_blks_hit) AS shr_blks
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
GROUP BY pg_stat_statements.query
)
SELECT (100::double precision * _pg_stat_statements.total_exec_time / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * _pg_stat_statements.io_time / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * _pg_stat_statements.cpu_and_waits_time / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * _pg_stat_statements.calls / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * _pg_stat_statements.rows / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
_pg_stat_statements.total_exec_time::bigint AS total_time_ms,
_pg_stat_statements.io_time::bigint AS total_io_ms,
_pg_stat_statements.shr_blks,
_pg_stat_statements.calls,
_pg_stat_statements.rows,
(_pg_stat_statements.total_exec_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_time_us,
(_pg_stat_statements.io_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_io_us,
(_pg_stat_statements.shr_blks / _pg_stat_statements.calls)::bigint AS avg_shr_blks,
_pg_stat_statements.query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.io_time / (( SELECT summ.sum_io_time
FROM summ))) >= 0.02::double precision
UNION ALL
SELECT (100::double precision * sum(_pg_stat_statements.total_exec_time) / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * sum(_pg_stat_statements.io_time) / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * sum(_pg_stat_statements.cpu_and_waits_time) / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * sum(_pg_stat_statements.calls) / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * sum(_pg_stat_statements.rows) / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
sum(_pg_stat_statements.total_exec_time)::bigint AS total_time_ms,
sum(_pg_stat_statements.io_time)::bigint AS total_io_ms,
sum(_pg_stat_statements.shr_blks) AS shr_blks,
sum(_pg_stat_statements.calls) AS calls,
sum(_pg_stat_statements.rows) AS rows,
(sum(_pg_stat_statements.total_exec_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_time_us,
(sum(_pg_stat_statements.io_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_io_us,
(sum(_pg_stat_statements.shr_blks) / sum(_pg_stat_statements.calls))::bigint AS avg_shr_blks,
'other'::text AS query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.io_time / (( SELECT summ.sum_io_time
FROM summ))) < 0.02::double precision
ORDER BY 2 DESC;
Пример эксплуатации#
Подайте нагрузку на БД с помощью утилиты pg_bench:
pgbench -i -s 10 --foreign-keys First_db
pgbench -c 5 -j 5 -T 30 -P 10 First_db
Пример вывода списка тяжелых запросов:
psql -d First_db -c 'table dba_query_io_time'
time_pcnt | io_pcnt | cpu_and_waits_pcnt | calls_pcnt | rows_pcnt | total_time_ms | total_io_ms | shr_blks | calls | rows | avg_time_us | avg_io_us | avg_shr_blks | query
-----------+---------+--------------------+------------+-----------+---------------+-------------+----------+--------+-------+-------------+-----------+--------------+---------------------------------------------------------------------
4.98 | 76.21 | 4.48 | 14.28 | 19.90 | 747 | 80 | 106453 | 17532 | 17532 | 43 | 5 | 6 | UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2
3.02 | 22.91 | 2.88 | 0.00 | 0.00 | 452 | 24 | 31655 | 1 | 1 | 452237 | 24130 | 31655 | SELECT pgse_profile.take_sample()
92.00 | 0.88 | 92.65 | 85.72 | 80.10 | 13789 | 1 | 559617 | 105211 | 70568 | 131 | 0 | 5 | other
(3 rows)
dba_query_run_time: Получение списка запросов, отсортированных по убыванию общего времени выполнения#
Название поля |
Тип |
Описание поля |
|---|---|---|
time_pcnt |
numeric(5,2) |
Доля времени, проведенного на выполнении данного запроса, в общем времени, проведенном на выполнении запросов для данной БД |
io_pcnt |
numeric(5,2) |
Доля времени, проведенного на IO при выполнении данного запроса, в общем времени, проведенном на IO при выполнении запросов для данной БД |
cpu_and_waits_pcnt |
numeric(5,2) |
Доля времени, проведенного на CPU при выполнении данного запроса, в общем времени, проведенном на CPU или событиях ожидания, отличных от IO, при выполнении запросов для данной БД |
calls_pcnt |
numeric(5,2) |
Доля от общего количества выполнений запросов в данной БД |
rows_pcnt |
numeric(5,2) |
Доля от общего количества обработанных записей в данной БД |
total_time_ms |
bigint |
Время, потраченное на все выполнения данного запроса (в миллисекундах) |
total_io_ms |
bigint |
Время, проведенное на IO в рамках всех выполнений данного запроса (в миллисекундах) |
shr_blks |
numeric |
Количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках всех выполнений данного запроса |
calls |
numeric |
Число выполнений запроса |
rows |
numeric |
Число обработанных записей |
avg_time_us |
bigint |
Среднее время выполнения запроса (в микросекундах) |
avg_io_us |
bigint |
Среднее время проведенное на IO в рамках выполнения запроса (в микросекундах) |
avg_shr_blks |
bigint |
Среднее количество страниц (из буферного кэша и из файловой системы), прочитанных в рамках выполнения данного запроса |
query |
text |
Текст запроса |
DDL:
First_db=# \d+ dba_query_run_time
View "public.dba_query_run_time"
Column | Type | Collation | Nullable | Default | Storage | Description
--------------------+--------------+-----------+----------+---------+----------+-------------
time_pcnt | numeric(5,2) | | | | main |
io_pcnt | numeric(5,2) | | | | main |
cpu_and_waits_pcnt | numeric(5,2) | | | | main |
calls_pcnt | numeric(5,2) | | | | main |
rows_pcnt | numeric(5,2) | | | | main |
total_time_ms | bigint | | | | plain |
total_io_ms | bigint | | | | plain |
shr_blks | numeric | | | | main |
calls | numeric | | | | main |
rows | numeric | | | | main |
avg_time_us | bigint | | | | plain |
avg_io_us | bigint | | | | plain |
avg_shr_blks | bigint | | | | plain |
query | text | | | | extended |
View definition:
WITH summ AS (
SELECT GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time)) AS sum_total_exec_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time)) AS sum_io_time,
GREATEST(0.001::double precision, sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time)) AS sum_cpu_and_waits_time,
sum(pg_stat_statements.calls) AS sum_calls,
sum(pg_stat_statements.rows) AS sum_rows
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
), _pg_stat_statements AS (
SELECT pg_stat_statements.query,
sum(pg_stat_statements.total_exec_time) AS total_exec_time,
sum(pg_stat_statements.blk_read_time + pg_stat_statements.blk_write_time) AS io_time,
sum(pg_stat_statements.total_exec_time - pg_stat_statements.blk_read_time - pg_stat_statements.blk_write_time) AS cpu_and_waits_time,
sum(pg_stat_statements.calls) AS calls,
sum(pg_stat_statements.rows) AS rows,
sum(pg_stat_statements.shared_blks_read + pg_stat_statements.shared_blks_hit) AS shr_blks
FROM pg_stat_statements
WHERE pg_stat_statements.dbid = (( SELECT pg_database.oid
FROM pg_database
WHERE pg_database.datname = current_database()))
GROUP BY pg_stat_statements.query
)
SELECT (100::double precision * _pg_stat_statements.total_exec_time / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * _pg_stat_statements.io_time / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * _pg_stat_statements.cpu_and_waits_time / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * _pg_stat_statements.calls / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * _pg_stat_statements.rows / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
_pg_stat_statements.total_exec_time::bigint AS total_time_ms,
_pg_stat_statements.io_time::bigint AS total_io_ms,
_pg_stat_statements.shr_blks,
_pg_stat_statements.calls,
_pg_stat_statements.rows,
(_pg_stat_statements.total_exec_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_time_us,
(_pg_stat_statements.io_time * 1000::double precision / _pg_stat_statements.calls::double precision)::bigint AS avg_io_us,
(_pg_stat_statements.shr_blks / _pg_stat_statements.calls)::bigint AS avg_shr_blks,
_pg_stat_statements.query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.total_exec_time / (( SELECT summ.sum_total_exec_time
FROM summ))) >= 0.02::double precision
UNION ALL
SELECT (100::double precision * sum(_pg_stat_statements.total_exec_time) / (( SELECT summ.sum_total_exec_time
FROM summ)))::numeric(5,2) AS time_pcnt,
(100::double precision * sum(_pg_stat_statements.io_time) / (( SELECT summ.sum_io_time
FROM summ)))::numeric(5,2) AS io_pcnt,
(100::double precision * sum(_pg_stat_statements.cpu_and_waits_time) / (( SELECT summ.sum_cpu_and_waits_time
FROM summ)))::numeric(5,2) AS cpu_and_waits_pcnt,
(100::numeric * sum(_pg_stat_statements.calls) / (( SELECT summ.sum_calls
FROM summ)))::numeric(5,2) AS calls_pcnt,
(100::numeric * sum(_pg_stat_statements.rows) / (( SELECT summ.sum_rows
FROM summ)))::numeric(5,2) AS rows_pcnt,
sum(_pg_stat_statements.total_exec_time)::bigint AS total_time_ms,
sum(_pg_stat_statements.io_time)::bigint AS total_io_ms,
sum(_pg_stat_statements.shr_blks) AS shr_blks,
sum(_pg_stat_statements.calls) AS calls,
sum(_pg_stat_statements.rows) AS rows,
(sum(_pg_stat_statements.total_exec_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_time_us,
(sum(_pg_stat_statements.io_time) * 1000::double precision / sum(_pg_stat_statements.calls)::double precision)::bigint AS avg_io_us,
(sum(_pg_stat_statements.shr_blks) / sum(_pg_stat_statements.calls))::bigint AS avg_shr_blks,
'other'::text AS query
FROM _pg_stat_statements
WHERE (_pg_stat_statements.total_exec_time / (( SELECT summ.sum_total_exec_time
FROM summ))) < 0.02::double precision
ORDER BY 1 DESC;
Пример эксплуатации#
Подайте нагрузку на БД с помощью утилиты pg_bench:
pgbench -i -s 10 --foreign-keys First_db
pgbench -c 5 -j 5 -T 30 -P 10 First_db
Пример вывода списка тяжелых запросов:
psql -d First_db -c 'table dba_query_run_time'
time_pcnt | io_pcnt | cpu_and_waits_pcnt | calls_pcnt | rows_pcnt | total_time_ms | total_io_ms | shr_blks | calls | rows | avg_time_us | avg_io_us | avg_shr_blks | query
-----------+---------+--------------------+------------+-----------+---------------+-------------+----------+-------+-------+-------------+-----------+--------------+------------------------------------------------------------------------------------------------------
67.95 | 0.00 | 67.95 | 14.28 | 19.94 | 16443 | 0 | 122563 | 29646 | 29646 | 555 | 0 | 4 | UPDATE pgbench_branches SET bbalance = bbalance + $1 WHERE bid = $2
11.67 | 0.00 | 11.67 | 14.28 | 19.94 | 2824 | 0 | 92859 | 29646 | 29646 | 95 | 0 | 3 | UPDATE pgbench_tellers SET tbalance = tbalance + $1 WHERE tid = $2
10.85 | 3.93 | 10.85 | 14.28 | 19.94 | 2626 | 0 | 387742 | 29646 | 29646 | 89 | 0 | 13 | INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES ($1, $2, $3, $4, CURRENT_TIMESTAMP)
5.80 | 0.00 | 5.80 | 14.28 | 19.94 | 1405 | 0 | 189541 | 29646 | 29646 | 47 | 0 | 6 | UPDATE pgbench_accounts SET abalance = abalance + $1 WHERE aid = $2
3.73 | 1.45 | 3.73 | 42.86 | 20.25 | 903 | 0 | 160965 | 88958 | 30106 | 10 | 0 | 2 | other
(5 rows)
dba_locks: Построение дерева блокировок#
Название поля |
Тип |
Описание поля |
|---|---|---|
pid_string |
text |
Цепочка блокировок, которая привела к ожиданию получения блокировки данным процессом |
root_pid |
integer |
Корневой узел цепочки блокировок, которая привела к ожиданию получения блокировки данным процессом |
tid |
text |
Идентификатор транзакции |
lock_time |
interval |
Время ожидания блокировки |
state |
text |
Состояние / текущее событие ожидания |
datname |
name |
Имя БД |
lock_mode_type_info |
text |
Дополнительная информация о блокировке, которую ожидает данный процесс |
query_text |
text |
Текст запроса |
usename |
name |
Имя роли, под которой установлено соединение |
client_addr |
inet |
IP-адрес, с которого установлено соединение |
application_name |
text |
Имя приложения, из которого установлено соединение |
DDL:
First_db=# \d+ dba_locks
View "public.dba_locks"
Column | Type | Collation | Nullable | Default | Storage | Description
---------------------+----------+-----------+----------+---------+----------+-------------
pid_string | text | | | | extended |
tid | text | | | | extended |
lock_time | interval | | | | plain |
state | text | | | | extended |
datname | name | | | | plain |
lock_mode_type_info | text | C | | | extended |
query_text | text | | | | extended |
usename | name | | | | plain |
client_addr | inet | | | | main |
application_name | text | | | | extended |
root_pid | integer | | | | plain |
View definition:
with recursive tree (lev,pid,root_pid,pid_string,waitstart) as (
select
1 as lev,
all_blocking_pids.pid,
all_blocking_pids.pid as root_pid,
all_blocking_pids.pid::text as pid_string,
null::timestamptz as waitstart
from
(
select distinct unnest(pg_blocking_pids(pid)) as pid
from pg_locks
where not granted
) all_blocking_pids
where not exists (
select 1
from pg_locks blocking_pids_locks
where blocking_pids_locks.pid = all_blocking_pids.pid
and not granted
)
or all_blocking_pids.pid = 0
union all
select
tree.lev + 1,
locks_nl.pid,
tree.root_pid,
tree.pid_string || '>' || locks_nl.pid::text,
locks_nl.waitstart
from
pg_locks locks_nl,
unnest(pg_blocking_pids(locks_nl.pid)) blocking_pids_nl (pid),
tree
where not locks_nl.granted
and tree.pid = blocking_pids_nl.pid
and tree.lev <= 1000
)
select
rn_tree.pid_string,
(
case when rn_tree.pid != 0
then (
select transactionid::text
from pg_locks tid_locks
where tid_locks.pid = rn_tree.pid
and tid_locks.locktype = 'transactionid'
and tid_locks.mode = 'ExclusiveLock'
and tid_locks.granted = true
)
else 'prep.trans.'
end
) as tid,
date_trunc('second',clock_timestamp() - rn_tree.waitstart) as lock_time,
case when rn_tree.lev > 1 then 'blocked' else pgsa.state || ' / ' || pgsa.wait_event end as state,
pgsa.datname,
(
select string_agg(
locks.mode
|| ' / ' || locks.locktype
|| ' ('
|| case
when locks.locktype = 'transactionid'
then 'tid = ' || locks.transactionid
|| coalesce(
(
select ', global XID = ' || gid
from pg_prepared_xacts prep_trans
where prep_trans.transaction=locks.transactionid
),
''
)
when locks.locktype = 'relation'
then locks.full_relation_name
when locks.locktype = 'tuple'
then locks.full_relation_name || ', ctid=(' || locks.page || ',' || locks.tuple || ')'
else ''
end
|| ')'
, ' / '
)
from (
select
*,
(
select
'['
|| (case rels.relkind
when 'r' then 'ORD.TABLE'
when 'i' then 'INDEX'
when 'S' then 'SEQUENCE'
when 't' then 'TOAST.TABLE'
when 'v' then 'VIEW'
when 'm' then 'MAT.VIEW'
when 'c' then 'COMP.TYPE'
when 'f' then 'FOREIGN.TABLE'
when 'p' then 'PART.TABLE'
when 'I' then 'PART.INDEX'
end
)
|| '] '
|| (select nspname from pg_namespace where oid = rels.relnamespace)
|| '.'
|| rels.relname
|| ', oid = ' || pgl.relation
from pg_class rels
where rels.oid = pgl.relation
) as full_relation_name
from pg_locks pgl
) locks
where locks.pid = rn_tree.pid
and locks.granted = false
) as lock_mode_type_info,
regexp_replace(pgsa.query, E'[\\n\\r]+', ' ', 'g') as query_text,
pgsa.usename,
pgsa.client_addr,
pgsa.application_name,
rn_tree.root_pid -- adding it here to make the aggregates like root_pid,count(*) possible.
from (
select
lt.*,
row_number() over(partition by pid order by lev,pid_string) as rn
from tree lt
) rn_tree
left outer join pg_stat_activity pgsa on (pgsa.pid = rn_tree.pid)
where rn_tree.rn = 1
order by pid_string;
Пример эксплуатации#
«Создайте» дерево блокировок. В рамках нескольких подключений выполните следующие команды:
a => \set AUTOCOMMIT 'off'
a => create table ttt_test(id bigint, name text);
a => insert into ttt_test(id,name)
values (1,'test 1'),(2,'test 2'),(3,'test 3');
a => commit;
a => update ttt_test set name = 'test 1 - mod' where id = 1;
b => \set AUTOCOMMIT 'off'
b => update ttt_test set name = 'test 2 - mod' where id = 2;
b => update ttt_test set name = 'test 1 - mod' where id = 1;
c => update ttt_test set name = 'test 2 - mod' where id = 2;
d => update ttt_test set name = 'test 1 - mod' where id = 1;
e => update ttt_test set name = 'test 2 - mod' where id = 2;
Пример вывода получившегося дерева блокировок посредством представления dba_locks:
psql -d First_db -c 'table dba_locks'
pid_string | tid | lock_time | state | datname | lock_mode_type_info | query_text | usename | client_addr | application_name | root_pid
---------------------+-------+------------+----------------------------------+----------+---------------------------------------------------------------------------+---------------------------------------------------------+----------+--------------+-------------------------------------------+----------
7800 | 96222 | 00:02:10 | idle in transaction / ClientRead | First_db | | SHOW search_path | postgres | {IP-адрес} | DBeaver 22.0.1 - SQLEditor <Script.sql> | 7800
7800>7879 | 96223 | 00:01:35 | blocked | First_db | ShareLock / transactionid (tid = 96222) | update ttt_test set name = 'test 1 - mod' where id = 1 | postgres | {IP-адрес} | DBeaver 22.0.1 - SQLEditor <Script-3.sql> | 7800
7800>7879>7911 | 96224 | 00:01:19 | blocked | First_db | ShareLock / transactionid (tid = 96223) | update ttt_test set name = 'test 2 - mod' where id = 2 | postgres | {IP-адрес} | DBeaver 22.0.1 - SQLEditor <Script-4.sql> | 7800
7800>7879>7911>7953 | 96226 | 00:00:54 | blocked | First_db | ExclusiveLock / tuple ([ORD.TABLE] ext.ttt_test, oid = 17865, ctid=(0,2)) | update ttt_test set name = 'test 2 - mod' where id = 2 | postgres | {IP-адрес} | DBeaver 22.0.1 - SQLEditor <Script-6.sql> | 7800
7800>7879>7925 | 96225 | 00:01:04 | blocked | First_db | ExclusiveLock / tuple ([ORD.TABLE] ext.ttt_test, oid = 17865, ctid=(0,1)) | update ttt_test set name = 'test 1 - mod' where id = 1 | postgres | {IP-адрес} | DBeaver 22.0.1 - SQLEditor <Script-5.sql> | 7800
(5 rows)
dba_standby_check: Построение отчета по статусу репликации#
Название поля |
Тип |
Описание поля |
|---|---|---|
pid |
integer |
Идентификатор процесса WAL sender, отвечающего за отсылку данных данному подписчику |
client |
inet |
IP-адрес подписчика |
user |
name |
Имя роли, используемой для репликации |
state |
text |
Поле-флаг, отображающее информацию о синхронности репликации |
application_name |
text |
Имя приложения, подписанного на репликацию |
sending_lag |
numeric |
Величина отставания (в байтах) между позицией WAL, записанной в локальный журнал, и позицией WAL, отосланной данному подписчику |
receiving_lag |
numeric |
Величина отставания (в байтах) между позицией WAL, отосланной данному подписчику, и позицией WAL, записанной в журнал подписчика |
replaying_lag |
numeric |
Величина отставания (в байтах) между позицией WAL, записанной в журнал подписчика, и позицией WAL, примененной к файлам данных подписчика |
total_lag |
numeric |
Величина отставания (в байтах) между позицией WAL, записанной в локальный журнал, и позицией WAL, примененной к файлам данных подписчика |
DDL:
First_db=# \d+ dba_standby_check
View "public.dba_standby_check"
Column | Type | Collation | Nullable | Default | Storage | Description
------------------+---------+-----------+----------+---------+----------+-------------
pid | integer | | | | plain |
client | inet | | | | main |
user | name | | | | plain |
state | text | | | | extended |
application_name | text | | | | extended |
sending_lag | numeric | | | | main |
receiving_lag | numeric | | | | main |
replaying_lag | numeric | | | | main |
total_lag | numeric | | | | main |
View definition:
SELECT pg_stat_replication.pid,
pg_stat_replication.client_addr AS client,
pg_stat_replication.usename AS "user",
pg_stat_replication.sync_state AS state,
pg_stat_replication.application_name,
pg_wal_lsn_diff(pg_current_wal_lsn(), pg_stat_replication.sent_lsn) AS sending_lag,
pg_wal_lsn_diff(pg_stat_replication.sent_lsn, pg_stat_replication.flush_lsn) AS receiving_lag,
pg_wal_lsn_diff(pg_stat_replication.flush_lsn, pg_stat_replication.replay_lsn) AS replaying_lag,
pg_wal_lsn_diff(pg_current_wal_lsn(), pg_stat_replication.replay_lsn) AS total_lag
FROM pg_stat_replication;
Пример эксплуатации#
Создайте сервер для реплики.
Добавьте запись для репликации в pg_hba.conf лидер-сервера:
host replication postgres 10.40.X.X/32 trust
Создайте, физическую резервную копию, предварительно настроенную для потоковой репликации:
pg_basebackup --pgdata=/pgdata/05-replica/data --write-recovery-conf --tablespace-mapping=/pgdata/05/tablespaces/Tbl_t=/pgdata/05-replica/tablespaces/Tbl_t --verbose
Поменяйте в postgresql.conf резервной копии следующие параметры:
authentication_port = '15544'
port='15433'
archive_command = '... -B /pgarclogs/05-replica...'
log_directory = '/pgerrorlogs/05-replica'
hba_file = '/pgdata/05-replica/data/pg_hba.conf'
ident_file = '/pgdata/05-replica/data/pg_ident.conf'
Запустите сервер-реплику:
pg_ctl -D /pgdata/05-replica/data start
Проверьте статус репликации на лидер-сервере:
psql -d First_db -c 'table dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 0 | 0 | 0 | 0
Подайте на лидер-сервер нагрузку в рамках одного подключения:
psql -d First_db <<EOF
drop table ttt_test;
create table ttt_test(id bigint, name text);
insert into ttt_test(id,name)
select a.t, lpad('',1000,'test')
from generate_series(1,1000000) a(t);
EOF
Проверьте статус репликации в рамках другого подключения:
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 0 | 0 | 0 | 0
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 64110592 | 10223616 | 16777552 | 91111760
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 0 | 0 | 400 | 400
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 36904960 | 10166272 | 16777616 | 63848848
...
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 77119488 | 23535616 | 16778200 | 117433304
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 68041512 | 22618112 | 16778072 | 107437696
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 0 | 0 | 6774384 | 6774384
(1 row)
psql -d First_db -c 'select * from dba_standby_check'
pid | client | user | state | application_name | sending_lag | receiving_lag | replaying_lag | total_lag
------+------------+----------+-------+------------------+-------------+---------------+---------------+-----------
4739 | {IP-адрес} | postgres | async | walreceiver | 0 | 0 | 0 | 0
(1 row)
dba_top_tables: Построение списка самых больших таблиц (полный размер) в БД#
Название поля |
Тип |
Описание поля |
|---|---|---|
schema_name |
name |
Имя схемы |
table_name |
name |
Имя таблицы |
persistence |
text |
Тип хранения таблицы (permanent / temporary / unlogged) |
tab_size |
text |
Размер таблицы |
toast_size |
text |
Размер TOAST сегмента |
idx_size |
text |
Размер всех индексов по данной таблице |
total_size |
text |
Полный размер таблицы |
DDL:
First_db=# \d+ dba_top_tables
View "public.dba_top_tables"
Column | Type | Collation | Nullable | Default | Storage | Description
-------------+------+-----------+----------+---------+----------+-------------
schema_name | name | | | | plain |
table_name | name | | | | plain |
persistence | text | | | | extended |
tab_size | text | | | | extended |
toast_size | text | | | | extended |
idx_size | text | | | | extended |
total_size | text | | | | extended |
View definition:
SELECT n.nspname AS schema_name,
c.relname AS table_name,
case relpersistence
when 'p' then 'permanent'
when 't' then 'temporary'
when 'u' then 'unlogged'
end as persistence,
pg_size_pretty(pg_relation_size(c.oid::regclass)) AS tab_size,
pg_size_pretty(pg_table_size(c.oid::regclass) - pg_relation_size(c.oid::regclass)) AS toast_size,
pg_size_pretty(pg_indexes_size(c.oid::regclass)) AS idx_size,
pg_size_pretty(pg_total_relation_size(c.oid::regclass)) AS total_size
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE (n.nspname <> ALL (ARRAY['pg_catalog'::name, 'information_schema'::name])) AND n.nspname !~ '^pg_toast'::text AND (c.relkind = ANY (ARRAY['r'::"char", 'm'::"char"]))
ORDER BY (pg_total_relation_size(c.oid::regclass)) DESC
LIMIT 30;
Пример эксплуатации#
Пример вывода списка самых больших таблиц:
psql -d First_db -c 'table dba_top_tables'
schema_name | table_name | tab_size | toast_size | idx_size | total_size
--------------+------------------------------+------------+------------+----------+------------
public | pgbench_accounts | 130 MB | 64 kB | 21 MB | 152 MB
public | pgbench_history | 1648 kB | 32 kB | 0 bytes | 1680 kB
pgse_profile | last_stat_tables | 328 kB | 32 kB | 88 kB | 448 kB
pgse_profile | last_stat_indexes | 224 kB | 32 kB | 96 kB | 352 kB
public | pgbench_tellers | 216 kB | 32 kB | 16 kB | 264 kB
...
dba_top_objects: Построение списка самых больших отношений в БД#
Название поля |
Тип |
Описание поля |
|---|---|---|
schema_name |
name |
Имя схемы |
table_name |
name |
Имя таблицы, к которой относится данное отношение (в случае таблицы и мат. представления - имя самой таблицы; в случае индекса, TOAST сегмента или индекса по TOAST сегменту - имя таблицы, к которой они относятся) |
object_name |
name |
Имя отношения |
object_type |
text |
Тип отношения |
persistence |
text |
Тип хранения таблицы (permanent / temporary / unlogged) |
size |
text |
Размер отношения |
DDL:
First_db=# \d+ dba_top_objects
View "public.dba_top_objects"
Column | Type | Collation | Nullable | Default | Storage | Description
-------------+------+-----------+----------+---------+----------+-------------
schema_name | name | | | | plain |
table_name | name | | | | plain |
object_name | name | | | | plain |
object_type | text | | | | extended |
persistence | text | | | | extended |
size | text | | | | extended |
View definition:
SELECT n.nspname AS schema_name,
CASE
WHEN c.relkind = 't'::"char" THEN ( SELECT c2.relname
FROM pg_class c2
WHERE c2.reltoastrelid = c.oid)
WHEN c.relkind = 'i'::"char" AND n.nspname ~ '^pg_toast'::text THEN ( SELECT c4.relname
FROM pg_index i1,
pg_class c3,
pg_class c4
WHERE i1.indexrelid = c.oid AND c3.oid = i1.indrelid AND c4.reltoastrelid = c3.oid)
WHEN c.relkind = 'r'::"char" THEN c.relname
WHEN c.relkind = 'i'::"char" THEN ( SELECT c5.relname
FROM pg_index i2,
pg_class c5
WHERE i2.indexrelid = c.oid AND c5.oid = i2.indrelid)
WHEN c.relkind = 'm'::"char" THEN c.relname
ELSE NULL::name
END AS table_name,
c.relname AS object_name,
CASE
WHEN c.relkind = 't'::"char" THEN 'toast'::text
WHEN c.relkind = 'i'::"char" AND n.nspname ~ '^pg_toast'::text THEN 'toast index'::text
WHEN c.relkind = 'r'::"char" THEN 'table'::text
WHEN c.relkind = 'i'::"char" THEN 'index'::text
WHEN c.relkind = 'm'::"char" THEN 'mat.view'::text
ELSE NULL::text
END AS object_type,
case c.relpersistence
when 'p' then 'permanent'
when 't' then 'temporary'
when 'u' then 'unlogged'
end as persistence,
pg_size_pretty(pg_relation_size(c.oid::regclass)) AS size
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE n.nspname <> ALL (ARRAY['pg_catalog'::name, 'information_schema'::name])
ORDER BY (pg_relation_size(c.oid::regclass)) DESC
LIMIT 30;
Пример эксплуатации#
Пример вывода списка самых больших отношений в БД:
psql -d First_db -c 'table dba_top_objects'
schema_name | table_name | object_name | object_type | size
--------------+--------------------------+---------------------------+-------------+---------
public | pgbench_accounts | pgbench_accounts | table | 130 MB
public | pgbench_accounts | pgbench_accounts_pkey | index | 21 MB
public | pgbench_history | pgbench_history | table | 1648 kB
pg_toast | pg_rewrite | pg_toast_2618 | toast | 672 kB
pg_toast | pg_proc | pg_toast_1255 | toast | 344 kB
...
dba_activity: Построение расширенного отчета по активности процессов#
Название поля |
Тип |
Описание поля |
|---|---|---|
pid |
integer |
Идентификатор процесса |
state |
text |
Статус процесса |
xact_age |
interval |
Время, прошедшее с момента открытия транзакции |
query_age |
interval |
Время, прошедшее с момента начала обработки запроса |
change_age |
interval |
Время, прошедшее с момента последнего изменения статуса процесса |
wait_event_type |
text |
Тип события ожидания |
wait_event |
text |
Событие ожидания |
datname |
name |
Имя БД |
query |
text |
Текст обрабатываемого запроса |
usename |
name |
Имя роли, под которой установлено соединение |
client_addr |
inet |
IP машины, с которой было установлено соединение |
client_port |
integer |
TCP-порт, который был использован для установки соединения |
backend_type |
text |
Тип процесса |
backend_xmin_age |
integer |
Возраст снимка (snapshot age) для процесса |
DDL:
First_db=# \d+ dba_activity
View "public.dba_activity"
Column | Type | Collation | Nullable | Default | Storage | Description
------------------+----------+-----------+----------+---------+----------+-------------
pid | integer | | | | plain |
state | text | | | | extended |
xact_age | interval | | | | plain |
query_age | interval | | | | plain |
change_age | interval | | | | plain |
wait_event_type | text | | | | extended |
wait_event | text | | | | extended |
datname | name | | | | plain |
query | text | | | | extended |
usename | name | | | | plain |
client_addr | inet | | | | main |
client_port | integer | | | | plain |
backend_type | text | | | | extended |
backend_xmin_age | integer | | | | plain |
View definition:
SELECT pgsa.pid,
pgsa.state,
date_trunc('second'::text, clock_timestamp() - pgsa.xact_start) AS xact_age,
date_trunc('second'::text, clock_timestamp() - pgsa.query_start) AS query_age,
date_trunc('second'::text, clock_timestamp() - pgsa.state_change) AS change_age,
pgsa.wait_event_type,
pgsa.wait_event,
pgsa.datname,
pgsa.query,
pgsa.usename,
pgsa.client_addr,
pgsa.client_port,
pgsa.backend_type,
age(pgsa.backend_xmin) AS backend_xmin_age
FROM pg_stat_activity pgsa
WHERE ((clock_timestamp() - pgsa.xact_start) > '00:00:00.1'::interval OR (clock_timestamp() - pgsa.query_start) > '00:00:00.1'::interval AND pgsa.state = 'idle in transaction (aborted)'::text) AND pgsa.pid <> pg_backend_pid()
ORDER BY (COALESCE(pgsa.xact_start, pgsa.query_start));
Пример эксплуатации#
В данном примере наблюдается картина, использованная для демонстрации представления dba_locks (мониторинг дерева блокировок):
psql -d First_db -c 'table dba_activity'
pid | state | xact_age | query_age | change_age | wait_event_type | wait_event | datname | query | usename | client_addr | client_port | backend_type | backend_xmin_age
------+---------------------+----------+-----------+------------+-----------------+---------------+----------+--------------------------------------------------------+----------+--------------+-------------+----------------+------------------
7800 | idle in transaction | 00:11:14 | 00:11:08 | 00:11:08 | Client | ClientRead | First_db | SHOW search_path | postgres | {IP-адрес} | {Порт} | client backend |
7879 | active | 00:10:33 | 00:10:33 | 00:10:33 | Lock | transactionid | First_db | \r +| postgres | {IP-адрес} | {Порт} | client backend | 5
| | | | | | | | update ttt_test set name = 'test 1 - mod' where id = 1 | | | | |
7911 | active | 00:10:18 | 00:10:18 | 00:10:18 | Lock | transactionid | First_db | update ttt_test set name = 'test 2 - mod' where id = 2 | postgres | {IP-адрес} | {Порт} | client backend | 5
7925 | active | 00:10:03 | 00:10:03 | 00:10:03 | Lock | tuple | First_db | update ttt_test set name = 'test 1 - mod' where id = 1 | postgres | {IP-адрес} | {Порт} | client backend | 5
7953 | active | 00:09:52 | 00:09:52 | 00:09:52 | Lock | tuple | First_db | update ttt_test set name = 'test 2 - mod' where id = 2 | postgres | {IP-адрес} | {Порт} | client backend | 5
(5 rows)
dba_activity_vacuum: Построение отчета о текущей активности процессов очистки (AUTOVACUUM+VACUUM+VACUUM FULL)#
Название поля |
Тип |
Описание поля |
|---|---|---|
relname |
name |
Имя таблицы, обрабатываемой процессом очистки |
age |
integer |
Возраст самой старой незамороженной транзакции для данной таблицы |
pid |
integer |
Идентификатор (PID) обслуживающего процесса |
datid |
oid |
OID базы данных, к которой подключен этот обслуживающий процесс |
datname |
name |
Имя базы данных, к которой подключен этот обслуживающий процесс |
relid |
oid |
OID очищаемой таблицы |
command |
text |
'VACUUM' для процессов автоматической и ручной очистки; 'VACUUM FULL' для операций ручной полной очистки; 'CLUSTER' для операции кластеризации таблиц |
phase |
text |
Текущая фаза очистки |
heap_blks_total |
bigint |
Общее число блоков кучи в таблице на момент начала процесса очистки |
heap_blks_scanned |
bigint |
Число просканированных блоков кучи. Так как для оптимизации сканирования применяется карта видимости, некоторые блоки могут пропускаться без осмотра; пропущенные блоки входят в это общее число, так что по завершении очистки это число станет равно heap_blks_total. Этот счетчик увеличивается только в фазе scanning heap. |
heap_blks_vacuumed |
bigint |
Число очищенных блоков кучи. Если в таблице нет индексов, этот счетчик увеличивается только в фазе vacuuming heap (очистка кучи). Блоки, не содержащие «мертвых» кортежей, при этом пропускаются, так что этот счетчик иногда может увеличиваться резкими рывками. В случае операций VACUUM FULL / CLUSTER - NULL. |
index_vacuum_count |
bigint |
Количество завершенных циклов очистки индекса. В случае операций VACUUM FULL / CLUSTER - NULL. |
max_dead_tuples |
bigint |
Число «мертвых» кортежей, которое мы можем сохранить, прежде чем потребуется выполнить цикл очистки индекса, в зависимости от maintenance_work_mem. В случае операций VACUUM FULL/CLUSTER - NULL. |
num_dead_tuples |
bigint |
Число «мертвых» кортежей, собранных со времени последнего цикла очистки индекса. В случае операций VACUUM FULL / CLUSTER - NULL. |
DDL:
First_db=# \d+ dba_activity_vacuum
View "public.dba_activity_vacuum"
Column | Type | Collation | Nullable | Default | Storage | Description
--------------------+---------+-----------+----------+---------+----------+-------------
relname | name | | | | plain |
age | integer | | | | plain |
pid | integer | | | | plain |
datid | oid | | | | plain |
datname | name | | | | plain |
relid | oid | | | | plain |
command | text | | | | extended |
phase | text | | | | extended |
heap_blks_total | bigint | | | | plain |
heap_blks_scanned | bigint | | | | plain |
heap_blks_vacuumed | bigint | | | | plain |
index_vacuum_count | bigint | | | | plain |
max_dead_tuples | bigint | | | | plain |
num_dead_tuples | bigint | | | | plain |
View definition:
SELECT c1.relname,
age(c1.relfrozenxid) AS age,
v1.pid,
v1.datid,
v1.datname,
v1.relid,
'VACUUM'::text AS command,
v1.phase,
v1.heap_blks_total,
v1.heap_blks_scanned,
v1.heap_blks_vacuumed,
v1.index_vacuum_count,
v1.max_dead_tuples,
v1.num_dead_tuples
FROM pg_stat_progress_vacuum v1,
pg_class c1
WHERE v1.relid = c1.oid
UNION ALL
SELECT c2.relname,
age(c2.relfrozenxid) AS age,
v2.pid,
v2.datid,
v2.datname,
v2.relid,
v2.command,
v2.phase,
v2.heap_blks_total,
v2.heap_blks_scanned,
NULL::bigint AS heap_blks_vacuumed,
NULL::bigint AS index_vacuum_count,
NULL::bigint AS max_dead_tuples,
NULL::bigint AS num_dead_tuples
FROM pg_stat_progress_cluster v2,
pg_class c2
WHERE v2.relid = c2.oid;
Пример эксплуатации#
Создайте таблицу, заполните ее данными, обновите достаточно большую долю данных, чтобы сработал AUTOVACUUM:
psql -d First_db <<EOF
drop table ttt_test;
create table ttt_test(id bigint, name text);
insert into ttt_test(id,name)
select a.t, lpad('',1000,'test')
from generate_series(1,3000000) a(t);
update ttt_test
set name = lpad('',1000,'TEST')
where mod(id,4) = 0;
EOF
Раз в несколько секунд проверяйте, не начал ли работать AUTOVACUUM:
psql -d First_db -c 'table dba_activity_vacuum'
relname | age | pid | datid | datname | relid | command | phase | heap_blks_total | heap_blks_scanned | heap_blks_vacuumed | index_vacuum_count | max_dead_tuples | num_dead_tuples
----------+-----+------+-------+----------+-------+---------+---------------+-----------------+-------------------+--------------------+--------------------+-----------------+-----------------
ttt_test | 2 | 9118 | 16800 | First_db | 17882 | VACUUM | scanning heap | 493434 | 48657 | 0 | 0 | 291 | 0
(1 row)
Запустите VACUUM FULL вручную в одном сеансе:
a => psql -d First_db -c 'VACUUM FULL ttt_test'
Проверьте в другом сеансе, что активность наблюдается посредством представления:
b => psql -d First_db -c 'table dba_activity_vacuum'
relname | age | pid | datid | datname | relid | command | phase | heap_blks_total | heap_blks_scanned | heap_blks_vacuumed | index_vacuum_count | max_dead_tuples | num_dead_tuples
----------+-----+------+-------+----------+-------+-------------+-------------------+-----------------+-------------------+--------------------+--------------------+-----------------+-----------------
ttt_test | 3 | 7761 | 16800 | First_db | 17882 | VACUUM FULL | seq scanning heap | 535715 | 359999 | | | |
(1 row)
dba_waits: Построение отчета о распределении процессов по событиям ожидания#
Название поля |
Тип |
Описание поля |
|---|---|---|
datname |
name |
Имя БД |
cnt |
bigint |
Количество процессов, ожидающих на данном событии |
wait_event |
text |
Событие ожидания |
state |
text |
Статус процесса |
wait_event_type |
text |
Тип события ожидания |
DDL:
First_db=# \d+ dba_waits
View "public.dba_waits"
Column | Type | Collation | Nullable | Default | Storage | Description
-----------------+--------+-----------+----------+---------+----------+-------------
datname | name | | | | plain |
state | text | | | | extended |
wait_event_type | text | | | | extended |
wait_event | text | | | | extended |
cnt | bigint | | | | plain |
View definition:
SELECT pg_stat_activity.datname,
pg_stat_activity.state,
pg_stat_activity.wait_event_type,
pg_stat_activity.wait_event,
count(*) AS cnt
FROM pg_stat_activity
GROUP BY pg_stat_activity.datname, pg_stat_activity.state, pg_stat_activity.wait_event_type, pg_stat_activity.wait_event
ORDER BY pg_stat_activity.state, (count(*)) DESC, pg_stat_activity.datname;
Пример эксплуатации#
В данном примере наблюдается картина, использованная для демонстрации представления dba_locks (мониторинг дерева блокировок):
psql -d First_db -c 'table dba_waits'
datname | state | wait_event_type | wait_event | cnt
----------+---------------------+-----------------+-------------------------+-----
First_db | active | Lock | transactionid | 2
First_db | active | Lock | tuple | 2
First_db | active | | | 1
First_db | idle | Client | ClientRead | 1
postgres | idle | Extension | Extension | 1
First_db | idle in transaction | Client | ClientRead | 1
| | Activity | BgWriterHibernate | 1
| | Activity | PasswordPolicyCacheMain | 1
| | Activity | WalWriterMain | 1
| | Activity | LogicalLauncherMain | 1
| | Activity | CheckpointerMain | 1
| | Activity | AutoVacuumMain | 1
| | Activity | PerfInsightsMain | 1
(13 rows)
dba_bloat_wastedbytes: Построение списка таблиц, отсортированных по объему пространства, не занятого для хранения актуальных версий записей#
Название поля |
Тип |
Описание поля |
|---|---|---|
nspname |
name |
Имя схемы |
tabname |
name |
Имя таблицы, к которой относится отношение |
relname |
name |
Имя отношения |
reltype |
text |
Тип отношения |
tsize |
text |
Размер отношения (в байтах) |
tplcnt |
bigint |
Количество актуальных версий записей в отношении |
wspaceprc |
double precision |
Оценка доли пространства в отношении, не занятого для хранения актуальных версий записей |
wspaceb |
text |
Оценка размера пространства (в байтах) в отношении, не занятого для хранения актуальных версий записей |
DDL:
First_db=# \d+ dba_bloat_wastedbytes
View "public.dba_bloat_wastedbytes"
Column | Type | Collation | Nullable | Default | Storage | Description
-------------------+---------+-----------+----------+---------+----------+-------------
nspname | name | | | | plain |
tblname | name | | | | plain |
relname | name | | | | plain |
relkind | "char" | | | | plain |
relsize | text | | | | extended |
wstd_space | text | | | | extended |
bloat | numeric | | | | main |
min_poss_bloat | numeric | | | | main |
reltuples | bigint | | | | plain |
avg_tpl_size | integer | | | | plain |
avg_full_tpl_size | bigint | | | | plain |
max_rows_per_page | integer | | | | plain |
View definition:
SELECT foo3.nspname,
foo3.tblname,
foo3.relname,
foo3.relkind,
pg_size_pretty(foo3.relpages::numeric * foo3.block_size) AS relsize,
pg_size_pretty((foo3.relpages::double precision - foo3.expected_pages)::integer::numeric * foo3.block_size) AS wstd_space,
round(((foo3.relpages::double precision - foo3.expected_pages) / foo3.relpages::double precision)::numeric, 2) AS bloat,
round(((foo3.page_usable_space - foo3.avg_full_tpl_size::double precision * foo3.max_rows_per_page) / foo3.page_usable_space)::numeric, 2) AS min_poss_bloat,
foo3.reltuples::bigint AS reltuples,
foo3.datawidth AS avg_tpl_size,
foo3.avg_full_tpl_size,
foo3.max_rows_per_page::integer AS max_rows_per_page
FROM ( SELECT foo2.nspname,
foo2.tblname,
foo2.relname,
foo2.relkind,
foo2.relpages,
foo2.reltuples,
foo2.fillfactor,
foo2.hdr,
foo2.maxalign,
foo2.block_size,
foo2.datawidth,
foo2.hdr_and_nullbits,
foo2.datawidth_ma,
foo2.hdr_and_nullbits_ma,
foo2.avg_full_tpl_size,
foo2.page_usable_space,
foo2.avg_full_tpl_size::double precision * foo2.reltuples / foo2.page_usable_space AS expected_pages,
floor(foo2.page_usable_space / foo2.avg_full_tpl_size::double precision) AS max_rows_per_page
FROM ( SELECT foo1.nspname,
foo1.tblname,
foo1.relname,
foo1.relkind,
foo1.relpages,
foo1.reltuples,
foo1.fillfactor,
foo1.hdr,
foo1.maxalign,
foo1.block_size,
foo1.datawidth,
foo1.hdr_and_nullbits,
foo1.datawidth_ma,
foo1.hdr_and_nullbits_ma,
CASE
WHEN foo1.relkind = 'i'::"char" THEN (foo1.datawidth_ma + 8 + 4)::bigint
ELSE foo1.datawidth_ma + foo1.hdr_and_nullbits_ma + 4
END AS avg_full_tpl_size,
foo1.fillfactor::double precision / 100::double precision * (foo1.block_size - 24::numeric)::double precision AS page_usable_space
FROM ( SELECT foo.nspname,
foo.tblname,
foo.relname,
foo.relkind,
foo.relpages,
foo.reltuples,
foo.fillfactor,
foo.hdr,
foo.maxalign,
foo.block_size,
foo.datawidth,
foo.hdr_and_nullbits,
foo.datawidth + foo.maxalign -
CASE
WHEN (foo.datawidth % foo.maxalign) = 0 THEN foo.maxalign
ELSE foo.datawidth % foo.maxalign
END AS datawidth_ma,
foo.hdr_and_nullbits + foo.maxalign -
CASE
WHEN (foo.hdr_and_nullbits % foo.maxalign::bigint) = 0 THEN foo.maxalign::bigint
ELSE foo.hdr_and_nullbits % foo.maxalign::bigint
END AS hdr_and_nullbits_ma
FROM ( SELECT ns.nspname,
rels.tblname,
rels.relname,
rels.relkind,
rels.relpages,
rels.reltuples,
CASE
WHEN "position"(rels.reloptions::text, 'fillfactor='::text) > 0 THEN (regexp_match(rels.reloptions::text, 'fillfactor=(\d+)'::text))[1]
ELSE
CASE
WHEN rels.relkind = 'i'::"char" THEN '90'::text
ELSE '100'::text
END
END AS fillfactor,
constants.hdr,
constants.maxalign,
constants.block_size,
sum((1::double precision - COALESCE(stat.null_frac, 0::real)) * COALESCE(stat.avg_width, 2048)::double precision)::integer AS datawidth,
constants.hdr + 1 + sum(
CASE
WHEN stat.null_frac <> 0::double precision THEN 1
ELSE 0
END) / 8 AS hdr_and_nullbits
FROM ( SELECT tbl.relnamespace,
tbl.oid AS reloid,
tbl.relname,
tbl.relkind,
tbl.relpages,
tbl.reltuples,
tbl.reloptions,
tbl.relname AS tblname
FROM pg_class tbl
WHERE (tbl.relkind = ANY (ARRAY['r'::"char", 'm'::"char"])) AND tbl.relpages > 10
UNION ALL
SELECT ind.relnamespace,
ind.oid AS reloid,
ind.relname,
ind.relkind,
ind.relpages,
ind.reltuples,
ind.reloptions,
indtbl.relname AS tblname
FROM pg_class ind
JOIN pg_index pgi ON pgi.indexrelid = ind.oid
JOIN pg_class indtbl ON indtbl.oid = pgi.indrelid
WHERE ind.relkind = 'i'::"char" AND ind.relpages > 10) rels
JOIN pg_namespace ns ON ns.oid = rels.relnamespace
JOIN pg_attribute att ON att.attrelid = rels.reloid
LEFT JOIN pg_stats stat ON stat.schemaname = ns.nspname AND stat.tablename = rels.tblname AND stat.attname = att.attname AND stat.inherited = false,
( SELECT ( SELECT current_setting('block_size'::text)::numeric AS current_setting) AS block_size,
CASE
WHEN "substring"(split_part(foo_1.v, ' '::text, 2), '#"[0-9]+.[0-9]+#"%'::text, '#'::text) = ANY (ARRAY['8.0'::text, '8.1'::text, '8.2'::text]) THEN 27
ELSE 23
END AS hdr,
CASE
WHEN foo_1.v ~ 'mingw32'::text OR foo_1.v ~ '64-bit'::text THEN 8
ELSE 4
END AS maxalign
FROM ( SELECT version() AS v) foo_1) constants
WHERE att.attnum > 0
GROUP BY ns.nspname, rels.tblname, rels.relname, rels.relkind, rels.relpages, rels.reltuples, (
CASE
WHEN "position"(rels.reloptions::text, 'fillfactor='::text) > 0 THEN (regexp_match(rels.reloptions::text, 'fillfactor=(\d+)'::text))[1]
ELSE
CASE
WHEN rels.relkind = 'i'::"char" THEN '90'::text
ELSE '100'::text
END
END), constants.hdr, constants.maxalign, constants.block_size) foo) foo1) foo2) foo3
WHERE (foo3.relpages::double precision - foo3.expected_pages)::integer > 0
ORDER BY (foo3.relpages::double precision - foo3.expected_pages) DESC
LIMIT 200;
Пример эксплуатации#
Создайте таблицу, заполните ее данными и измените их. Поскольку используется fillfactor=100 (по умолчанию), при обновлении часто придется переносить записи в другие страницы. Размер записи с заголовками составляет ~1044 байта, в одну страницу будет помещаться 7 записей. Поэтому даже после VACUUM FULL останется какое-то количество незаполненного пространства (хотя таблица и станет меньше):
psql -d First_db <<EOF
drop table ttt_test;
create table ttt_test(id bigint, name text);
create index on ttt_test(name,id);
insert into ttt_test(id,name)
select a.t, lpad('',1000,'test') || a.t
from generate_series(1,100000) a(t);
update ttt_test
set name = lpad('',1000,'TEST') || id
where mod(id,10) = 0;
EOF
Подождите, пока AUTOVACUUM не закончит собирать статистику по новой таблице:
psql -d First_db -c 'table dba_bloat_wastedbytes'
nspname | tblname | relname | relkind | relsize | wstd_space | bloat | min_poss_bloat | reltuples | avg_tpl_size | avg_full_tpl_size | max_rows_per_page
--------------+--------------------+---------------------------------+---------+---------+------------+-------+----------------+-----------+--------------+-------------------+-------------------
ext | ttt_test | ttt_test | r | 123 MB | 23 MB | 0.19 | 0.11 | 100000 | 1016 | 1044 | 7
public | pgbench_accounts | pgbench_accounts | r | 128 MB | 1864 kB | 0.01 | 0.01 | 1000000 | 97 | 132 | 61
pg_catalog | pg_proc | pg_proc | r | 1624 kB | 544 kB | 0.34 | 0.01 | 3393 | 286 | 324 | 25
pg_catalog | psql_omd | psql_omd | r | 464 kB | 256 kB | 0.55 | 0.00 | 4098 | 24 | 52 | 157
pgse_profile | last_stat_indexes | last_stat_indexes | r | 440 kB | 224 kB | 0.52 | 0.02 | 435 | 465 | 500 | 16
...
psql -d First_db -c 'VACUUM FULL ttt_test'
psql -d First_db -c 'table dba_bloat_wastedbytes'
nspname | tblname | relname | relkind | relsize | wstd_space | bloat | min_poss_bloat | reltuples | avg_tpl_size | avg_full_tpl_size | max_rows_per_page
--------------+--------------------+---------------------------------+---------+---------+------------+-------+----------------+-----------+--------------+-------------------+-------------------
ext | ttt_test | ttt_test | r | 112 MB | 12 MB | 0.11 | 0.11 | 100000 | 1016 | 1044 | 7
public | pgbench_accounts | pgbench_accounts | r | 128 MB | 1864 kB | 0.01 | 0.01 | 1000000 | 97 | 132 | 61
pg_catalog | pg_proc | pg_proc | r | 1624 kB | 544 kB | 0.34 | 0.01 | 3393 | 286 | 324 | 25
pg_catalog | psql_omd | psql_omd | r | 464 kB | 256 kB | 0.55 | 0.00 | 4098 | 24 | 52 | 157
pgse_profile | last_stat_indexes | last_stat_indexes | r | 440 kB | 224 kB | 0.52 | 0.02 | 435 | 465 | 500 | 16
...
Оценка доли пространства, не используемого для актуальных версий записей, снизилась до минимально возможной оценки (bloat = min_poss_bloat).
dba_bloat_tbloat: Построение списка таблиц, отсортированных по доле пространства, не занятого для хранения актуальных версий записей#
Название поля |
Тип |
Описание поля |
|---|---|---|
nspname |
name |
Имя схемы |
tabname |
name |
Имя таблицы, к которой относится отношение |
relname |
name |
Имя отношения |
reltype |
text |
Тип отношения |
tsize |
text |
Размер отношения (в байтах) |
tplcnt |
bigint |
Количество актуальных версий записей в отношении |
wspaceprc |
double precision |
Оценка доли пространства в отношении, не занятого для хранения актуальных версий записей |
wspaceb |
text |
Оценка размера пространства (в байтах) в отношении, не занятого для хранения актуальных версий записей |
DDL:
First_db=# \d+ dba_bloat_tbloat
View "public.dba_bloat_tbloat"
Column | Type | Collation | Nullable | Default | Storage | Description
-------------------+---------+-----------+----------+---------+----------+-------------
nspname | name | | | | plain |
tblname | name | | | | plain |
relname | name | | | | plain |
relkind | "char" | | | | plain |
relsize | text | | | | extended |
wstd_space | text | | | | extended |
bloat | numeric | | | | main |
min_poss_bloat | numeric | | | | main |
reltuples | bigint | | | | plain |
avg_tpl_size | integer | | | | plain |
avg_full_tpl_size | bigint | | | | plain |
max_rows_per_page | integer | | | | plain |
View definition:
SELECT foo3.nspname,
foo3.tblname,
foo3.relname,
foo3.relkind,
pg_size_pretty(foo3.relpages::numeric * foo3.block_size) AS relsize,
pg_size_pretty((foo3.relpages::double precision - foo3.expected_pages)::integer::numeric * foo3.block_size) AS wstd_space,
round(((foo3.relpages::double precision - foo3.expected_pages) / foo3.relpages::double precision)::numeric, 2) AS bloat,
round(((foo3.page_usable_space - foo3.avg_full_tpl_size::double precision * foo3.max_rows_per_page) / foo3.page_usable_space)::numeric, 2) AS min_poss_bloat,
foo3.reltuples::bigint AS reltuples,
foo3.datawidth AS avg_tpl_size,
foo3.avg_full_tpl_size,
foo3.max_rows_per_page::integer AS max_rows_per_page
FROM ( SELECT foo2.nspname,
foo2.tblname,
foo2.relname,
foo2.relkind,
foo2.relpages,
foo2.reltuples,
foo2.fillfactor,
foo2.hdr,
foo2.maxalign,
foo2.block_size,
foo2.datawidth,
foo2.hdr_and_nullbits,
foo2.datawidth_ma,
foo2.hdr_and_nullbits_ma,
foo2.avg_full_tpl_size,
foo2.page_usable_space,
foo2.avg_full_tpl_size::double precision * foo2.reltuples / foo2.page_usable_space AS expected_pages,
floor(foo2.page_usable_space / foo2.avg_full_tpl_size::double precision) AS max_rows_per_page
FROM ( SELECT foo1.nspname,
foo1.tblname,
foo1.relname,
foo1.relkind,
foo1.relpages,
foo1.reltuples,
foo1.fillfactor,
foo1.hdr,
foo1.maxalign,
foo1.block_size,
foo1.datawidth,
foo1.hdr_and_nullbits,
foo1.datawidth_ma,
foo1.hdr_and_nullbits_ma,
CASE
WHEN foo1.relkind = 'i'::"char" THEN (foo1.datawidth_ma + 8 + 4)::bigint
ELSE foo1.datawidth_ma + foo1.hdr_and_nullbits_ma + 4
END AS avg_full_tpl_size,
foo1.fillfactor::double precision / 100::double precision * (foo1.block_size - 24::numeric)::double precision AS page_usable_space
FROM ( SELECT foo.nspname,
foo.tblname,
foo.relname,
foo.relkind,
foo.relpages,
foo.reltuples,
foo.fillfactor,
foo.hdr,
foo.maxalign,
foo.block_size,
foo.datawidth,
foo.hdr_and_nullbits,
foo.datawidth + foo.maxalign -
CASE
WHEN (foo.datawidth % foo.maxalign) = 0 THEN foo.maxalign
ELSE foo.datawidth % foo.maxalign
END AS datawidth_ma,
foo.hdr_and_nullbits + foo.maxalign -
CASE
WHEN (foo.hdr_and_nullbits % foo.maxalign::bigint) = 0 THEN foo.maxalign::bigint
ELSE foo.hdr_and_nullbits % foo.maxalign::bigint
END AS hdr_and_nullbits_ma
FROM ( SELECT ns.nspname,
rels.tblname,
rels.relname,
rels.relkind,
rels.relpages,
rels.reltuples,
CASE
WHEN "position"(rels.reloptions::text, 'fillfactor='::text) > 0 THEN (regexp_match(rels.reloptions::text, 'fillfactor=(\d+)'::text))[1]
ELSE
CASE
WHEN rels.relkind = 'i'::"char" THEN '90'::text
ELSE '100'::text
END
END AS fillfactor,
constants.hdr,
constants.maxalign,
constants.block_size,
sum((1::double precision - COALESCE(stat.null_frac, 0::real)) * COALESCE(stat.avg_width, 2048)::double precision)::integer AS datawidth,
constants.hdr + 1 + sum(
CASE
WHEN stat.null_frac <> 0::double precision THEN 1
ELSE 0
END) / 8 AS hdr_and_nullbits
FROM ( SELECT tbl.relnamespace,
tbl.oid AS reloid,
tbl.relname,
tbl.relkind,
tbl.relpages,
tbl.reltuples,
tbl.reloptions,
tbl.relname AS tblname
FROM pg_class tbl
WHERE (tbl.relkind = ANY (ARRAY['r'::"char", 'm'::"char"])) AND tbl.relpages > 10
UNION ALL
SELECT ind.relnamespace,
ind.oid AS reloid,
ind.relname,
ind.relkind,
ind.relpages,
ind.reltuples,
ind.reloptions,
indtbl.relname AS tblname
FROM pg_class ind
JOIN pg_index pgi ON pgi.indexrelid = ind.oid
JOIN pg_class indtbl ON indtbl.oid = pgi.indrelid
WHERE ind.relkind = 'i'::"char" AND ind.relpages > 10) rels
JOIN pg_namespace ns ON ns.oid = rels.relnamespace
JOIN pg_attribute att ON att.attrelid = rels.reloid
LEFT JOIN pg_stats stat ON stat.schemaname = ns.nspname AND stat.tablename = rels.tblname AND stat.attname = att.attname AND stat.inherited = false,
( SELECT ( SELECT current_setting('block_size'::text)::numeric AS current_setting) AS block_size,
CASE
WHEN "substring"(split_part(foo_1.v, ' '::text, 2), '#"[0-9]+.[0-9]+#"%'::text, '#'::text) = ANY (ARRAY['8.0'::text, '8.1'::text, '8.2'::text]) THEN 27
ELSE 23
END AS hdr,
CASE
WHEN foo_1.v ~ 'mingw32'::text OR foo_1.v ~ '64-bit'::text THEN 8
ELSE 4
END AS maxalign
FROM ( SELECT version() AS v) foo_1) constants
WHERE att.attnum > 0
GROUP BY ns.nspname, rels.tblname, rels.relname, rels.relkind, rels.relpages, rels.reltuples, (
CASE
WHEN "position"(rels.reloptions::text, 'fillfactor='::text) > 0 THEN (regexp_match(rels.reloptions::text, 'fillfactor=(\d+)'::text))[1]
ELSE
CASE
WHEN rels.relkind = 'i'::"char" THEN '90'::text
ELSE '100'::text
END
END), constants.hdr, constants.maxalign, constants.block_size) foo) foo1) foo2) foo3
WHERE (foo3.relpages::double precision - foo3.expected_pages)::integer > 0
ORDER BY (round(((foo3.relpages::double precision - foo3.expected_pages) / foo3.relpages::double precision)::numeric, 2)) DESC
LIMIT 200;
Пример эксплуатации#
В данном разделе приведен пример вывода списка таблиц с самой большой долей пространства, не используемого для актуальных версий записей.
Очень часто наверху списка оказываются словарные небольшие таблицы, поэтому использование представления dba_bloat_wastedbytes в общем случае более полезно:
psql -d First_db -c 'table dba_bloat_tbloat'
nspname | tblname | relname | relkind | relsize | wstd_space | bloat | min_poss_bloat | reltuples | avg_tpl_size | avg_full_tpl_size | max_rows_per_page
--------------+--------------------+---------------------------------+---------+---------+------------+-------+----------------+-----------+--------------+-------------------+-------------------
public | pgbench_tellers | pgbench_tellers | r | 216 kB | 208 kB | 0.98 | 0.00 | 100 | 12 | 44 | 185
pg_catalog | psql_omd | psql_omd_oid_index | i | 208 kB | 120 kB | 0.57 | 0.00 | 4098 | 8 | 20 | 367
pg_catalog | psql_omd | psql_omd | r | 464 kB | 256 kB | 0.55 | 0.00 | 4098 | 24 | 52 | 157
pgse_profile | last_stat_tables | last_stat_tables | r | 336 kB | 176 kB | 0.53 | 0.00 | 318 | 468 | 508 | 16
pgse_profile | last_stat_indexes | last_stat_indexes | r | 440 kB | 224 kB | 0.51 | 0.02 | 436 | 465 | 500 | 16
...
Выполните полную очистку таблицы с самой большой долей неиспользуемого пространства. В данном случае это pgbench_tellers:
psql -d First_db -c 'VACUUM FULL pgbench_tellers'
Перепроверьте информацию по таблице:
psql -d First_db -c 'table dba_bloat_tbloat'
Поскольку таблица пропала из выборки dba_bloat_tbloat (доля неиспользуемого пространства стала околонулевой), можно проверить ее текущий размер посредством команды:
psql -d First_db -c "select relpages*8192 as relation_size from pg_class where relname = 'pgbench_tellers'"
relation_size
---------------
8192
(1 row)
Размер таблицы действительно уменьшился до одной страницы.
dba_unused_indexes: Построение списка неиспользуемых индексов#
Название поля |
Тип |
Описание поля |
|---|---|---|
schemaname |
name |
Имя схемы |
relname |
name |
Имя таблицы, к которой относится индекс |
index_name |
name |
Имя индекса |
indexdef |
text |
«Определение» индекса: алгоритм индексирования, список колонок индекса, дополнительные свойства (набор INCLUDE колонок, ограничения WHERE, параметры хранения) |
index_size |
text |
Размер индекса |
last_db_stats_reset |
timestamp with time zone |
Время последнего сброса статистики по БД |
DDL:
First_db=# \d+ dba_unused_indexes
View "public.dba_unused_indexes"
Column | Type | Collation | Nullable | Default | Storage | Description
---------------------+--------------------------+-----------+----------+---------+----------+-------------
schema_name | name | | | | plain |
tab_name | name | | | | plain |
idx_name | name | | | | plain |
idx_def | text | | | | extended |
idx_size | text | | | | extended |
last_db_stats_reset | timestamp with time zone | | | | plain |
View definition:
SELECT pgsai.schemaname AS schema_name,
pgsai.relname AS tab_name,
pgsai.indexrelname AS idx_name,
"substring"(pgi.indexdef, "position"(pgi.indexdef, ' USING '::text) + 7) AS idx_def,
pg_size_pretty(pg_relation_size(pgsai.indexrelid::regclass)) AS idx_size,
stats_reset.stats_reset AS last_db_stats_reset
FROM pg_stat_all_indexes pgsai,
pg_indexes pgi,
( SELECT pg_stat_database.stats_reset
FROM pg_stat_database
WHERE pg_stat_database.datname = current_database()) stats_reset
WHERE pgsai.idx_scan = 0 AND (pgsai.schemaname <> ALL (ARRAY['pg_catalog'::name, 'information_schema'::name])) AND pgsai.relname !~~ 'pg_toast%'::text AND pgi.schemaname = pgsai.schemaname AND pgi.tablename = pgsai.relname AND pgi.indexname = pgsai.indexrelname
ORDER BY (pg_relation_size(pgsai.indexrelid::regclass)) DESC
LIMIT 30;
Пример эксплуатации#
Создайте таблицу с двумя индексами:
psql -d First_db <<EOF
drop table ttt_test;
create table ttt_test(
id bigint,
name text
);
insert into ttt_test
select
a.t,
'name ' || a.t
from generate_series(1,100000) a(t);
create index ttt_test_id_name_unused on ttt_test(id,name);
create index ttt_test_name_id_unused on ttt_test(name,id);
EOF
В верхней части списка неиспользуемых индексов наблюдаются оба индекса (поскольку они крупнее остальных неиспользуемых индексов):
psql -d First_db -c 'table dba_unused_indexes'
schema_name | tab_name | idx_name | idx_def | idx_size | last_db_stats_reset
--------------+------------------------------+---------------------------------+------------------------------------------------------+------------+-------------------------------
ext | ttt_test | ttt_test_name_id_unused | btree (name, id) | 3984 kB | 2023-07-13 12:31:05.637901+03
ext | ttt_test | ttt_test_id_name_unused | btree (id, name) | 3976 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_statements | ix_sample_stmts_qid | btree (queryid_md5) | 32 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_kcache | pk_sample_kcache_n | btree (server_id, sample_id, datid, userid, queryid) | 32 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_kcache_total | pk_sample_kcache_total | btree (server_id, sample_id, datid) | 16 kB | 2023-07-13 12:31:05.637901+03
...
Используйте один из индексов:
explain analyze
select * from ttt_test where name = 'name 1000';
Index Only Scan using ttt_test_name_id_unused on ttt_test (cost=0.42..2.44 rows=1 width=19) (actual time=0.072..0.072 rows=1 loops=1)
Index Cond: (name = 'name 1000'::text)
Heap Fetches: 0
Planning Time: 0.328 ms
Execution Time: 0.113 ms
Перепроверьте список неиспользуемых индексов:
psql -d First_db -c 'table dba_unused_indexes'
schema_name | tab_name | idx_name | idx_def | idx_size | last_db_stats_reset
--------------+------------------------------+---------------------------------+------------------------------------------------------+------------+-------------------------------
ext | ttt_test | ttt_test_id_name_unused | btree (id, name) | 3976 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_statements | ix_sample_stmts_qid | btree (queryid_md5) | 32 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_kcache | pk_sample_kcache_n | btree (server_id, sample_id, datid, userid, queryid) | 32 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_kcache_total | pk_sample_kcache_total | btree (server_id, sample_id, datid) | 16 kB | 2023-07-13 12:31:05.637901+03
pgse_profile | sample_statements_total | pk_sample_statements_total | btree (server_id, sample_id, datid) | 16 kB | 2023-07-13 12:31:05.637901+03
...
Индекс ttt_test_name_id_unused из списка пропал, поскольку был использован.
dba_duplicated_indexes: Построение списка индексов, перекрываемых другими индексами#
Название поля |
Тип |
Описание поля |
|---|---|---|
tab_name |
text |
Имя схемы + имя таблицы |
idx_name |
regclass |
Имя индекса |
idx_def |
text |
«Определение» индекса: алгоритм индексирования, список колонок индекса, дополнительные свойства (набор INCLUDE колонок, ограничения WHERE, параметры хранения) |
used_by_constraints |
text |
Список ограничений целостности, использующих данный индекс (имя ограничения целостности и тип) |
idx_size |
bigint |
Размер индекса |
cover_idx_name |
regclass |
Имя перекрывающего индекса |
cover_idx_def |
text |
«Определение» перекрывающего индекса: алгоритм индексирования, список колонок индекса, дополнительные свойства (набор INCLUDE колонок, ограничения WHERE, параметры хранения) |
cover_used_by_constraints |
text |
Список ограничений целостности, использующих перекрывающий индекс (имя ограничения целостности и тип) |
DDL:
First_db=# \d+ dba_duplicated_indexes
View "public.dba_duplicated_indexes"
Column | Type | Collation | Nullable | Default | Storage | Description
---------------------------+--------+-----------+----------+---------+----------+-------------
schema_name | name | | | | plain |
tab_name | name | | | | plain |
idx_name | name | | | | plain |
idx_def | text | | | | extended |
used_by_constraints | text | C | | | extended |
idx_size | bigint | | | | plain |
cover_idx_name | name | | | | plain |
cover_idx_def | text | | | | extended |
cover_used_by_constraints | text | C | | | extended |
View definition:
WITH indlist AS (
SELECT pgi.schemaname AS schema_name,
pgi.tablename AS table_name,
pgi.indexname AS index_name,
"substring"(pgi.indexdef, "position"(pgi.indexdef, ' USING '::text) + 7) AS indexdef,
( SELECT string_agg(attrs.attname::text, ', '::text) AS string_agg
FROM ( SELECT a.attname
FROM pg_attribute a
WHERE a.attrelid = ((pgi.schemaname::text || '.'::text) || pgi.indexname::text)::regclass::oid
ORDER BY a.attnum) attrs) AS column_list,
( SELECT string_agg(((c.conname::text || '('::text) || c.contype::text) || ')'::text, ','::text) AS string_agg
FROM pg_constraint c
WHERE c.conindid = ((pgi.schemaname::text || '.'::text) || pgi.indexname::text)::regclass::oid) AS used_by_constraints,
pg_relation_size(((pgi.schemaname::text || '.'::text) || pgi.indexname::text)::regclass) AS index_size
FROM pg_indexes pgi
WHERE pgi.schemaname <> ALL (ARRAY['pg_catalog'::name, 'information_schema'::name, 'pg_toast'::name])
)
SELECT il1.schema_name,
il1.table_name AS tab_name,
il1.index_name AS idx_name,
il1.indexdef AS idx_def,
il1.used_by_constraints,
il1.index_size AS idx_size,
il2.index_name AS cover_idx_name,
il2.indexdef AS cover_idx_def,
il2.used_by_constraints AS cover_used_by_constraints
FROM indlist il1,
indlist il2
WHERE il2.schema_name = il1.schema_name AND il2.table_name = il1.table_name AND il2.index_name <> il1.index_name AND "position"(il2.column_list, il1.column_list) = 1
ORDER BY il1.index_size DESC
LIMIT 30;
Пример эксплуатации#
Создайте таблицу с несколькими индексами, часть из которых «перекрывает» друг друга:
psql -d First_db <<EOF
drop table ttt_test;
create table ttt_test(
id bigint primary key,
name text
);
create index ttt_test_id_test on ttt_test using hash(id);
create index ttt_test_id_name_test on ttt_test(id,name);
create index ttt_test_name_id_test on ttt_test(name,id);
EOF
Вывод списка дублирующих индексов:
psql -d First_db -c 'table dba_duplicated_indexes'
schema_name | tab_name | idx_name | idx_def | used_by_constraints | idx_size | cover_idx_name | cover_idx_def | cover_used_by_constraints
-------------+----------+------------------+------------+---------------------+----------+-----------------------+------------------+---------------------------
ext | ttt_test | ttt_test_id_test | hash (id) | | 49152 | ttt_test_id_name_test | btree (id, name) |
ext | ttt_test | ttt_test_id_test | hash (id) | | 49152 | ttt_test_pkey | btree (id) | ttt_test_pkey(p)
ext | ttt_test | ttt_test_pkey | btree (id) | ttt_test_pkey(p) | 8192 | ttt_test_id_name_test | btree (id, name) |
ext | ttt_test | ttt_test_pkey | btree (id) | ttt_test_pkey(p) | 8192 | ttt_test_id_test | hash (id) |
(4 rows)
В полученном списке наблюдаются индексы ttt_test_id_test и ttt_test_pkey по два раза, потому что каждый из них может быть использован вместо другого, индекс ttt_test_id_name_test, у которого первая колонка также id, может быть использован вместо каждого из них.
Переход на поставку компонентов Pangolin в виде RPM-пакетов#
Был реализован переход на использование пакетной установки для компонентов:
Pangolin Pooler;
Pangolin Manager;
Pangolin Backup tools.
Pangolin Pooler#
Компонент Pangolin Pooler – это доработанная версия pgbouncer, а именно программа, управляющая пулом соединений Pangolin DBMS. Любое конечное приложение может подключиться к Pangolin Pooler, как если бы это был непосредственно сервер DBMS, и Pangolin Pooler создаст подключение к реальному серверу, либо задействует одно из ранее установленных подключений. Предназначение Pangolin Pooler — минимизировать издержки, связанные с установлением новых подключений к Pangolin DBMS. RPM/DEP-пакет Pangolin Pooler имеет следующую структуру:
/etc/
| |___pangolin-pooler/
| | |___pangolin-pooler.ini
| | |___userlist.txt
| │___systemd/
| | |___system/
| | |___ pangolin-pooler.service
/opt/
| |___pangolin-pooler-{pangolin-pooler-full-version}/
| | |___ share/
| | | |___license/
| | | | |___ ...
| | | |___doc/
| | | |___man/
| | |___ bin/
| | | |___ pangolin-pooler
| | | |___ post.sh
| |___ |___ lib/
|______|____|___...
При установке пакета или его обновлении с предыдущей версии выполняется следующее:
Исполняемые файлы и библиотеки помещаются в каталог
/opt/pangolin-pooler.Создается файл настроек по пути
/etc/pangolin-pooler/pangolin-pooler.iniпри его отсутствии.Создается сервис
pangolin-pooler.serviceпри его отсутствии.Создается пользователь
posgtresсUID=26по умолчанию.
Особенности:
Может быть установлена только одна версия Pangolin Pooler.
Нумерация версии начата с 1.1.0 после переименования с PgBouncer на Pangolin Pooler.
Обновление компонента предполагает замену только исполняемых файлов и библиотек с сохранением файла настроек и файла службы.
Pangolin Manager#
Компонент Pangolin Manager – это доработанная версия patroni, python-приложения для создания и управления Pangolin DBMS-кластеров работающих на основе потоковой репликации. RPM/DEP пакет Pangolin Manager имеет следующую структуру:
/etc/
| |___pangolin-manager/
| | |___postgres.yml
| │___systemd/
| | |___system/
| | |___ pangolin-manager.service
/opt/
| |___pangolin-manager{pangolin-manager-full-version}/
| | |___share/
| | | |___license/
| | | | |___ ...
| | |___ bin/
| | | |___pangolin-manager
| | | |___pangolin-manager-bin
| | | |___pangolin-manager.bin
| | | |___pangolin-manager-ctl.bin
| | | |___pangolin-manager-raft-controller.bin
| | | |___patroni/
| | | | |___...
| | | |___pangolin-manager-ctl
| | | |___pangolin-manager-raft-controller
| | | |___post.sh
| |___ |___ lib/
| | |___postgresql_se_libs/
|______|____|___python.tar.gz
Pangolin Backup Tools#
Компонент Pangolin Backup Tools представляет собой набор утилит и скриптов, позволяющий настроить процесс резервного копирования хранимых в СУБД Pangolin данных. RPM/DEP-пакет Pangolin Backup Tools будет иметь следующую структуру:
/etc/
|___ pangolin-backup-tools/
|___ pangolin-backup-tools.cfg
/opt/
|___pangolin-backup-tools-{pangolin-backup-tools-full-version}/
|___ bin/
| |___manage_backup.bin
| |___manage_backup.sh
| |___pangolin_arclogs.sh
| |___post.sh
|___ lib/
|___postgresql_se_libs/
|___python.tar.gz
Поддержка топологии N-ЦОД в Pangolin Pooler#
Логическое объединение кластеров, содержащее все множество синхронизируемых данных, обрабатываемых одним потребителем во всех центрах обработки данных (ЦОД), реализует N-ЦОД архитектурный подход управления данными. Для синхронизации данных может использоваться любой из инструментов межкластерной репликации, а устойчивость к сбоям достигается за счет резервирования.
Для обслуживания узлов кластеров, включаемых в архитектуру N-ЦОД, при сценариях, требующих соответствия требованиям высокой доступности и аварийного восстановления (HA/DR), Pangolin Pooler дополнен функциями:
прерывания существующих и прекращения приема новых клиентских соединений;
возобновления приема новых соединений;
автоматической приостановки приема новых соединений;
остановки обслуживания существующих клиентских соединений при истечении заданного интервала времени.
В следующих подразделах данные функции будут рассмотрены более подробно.
Прерывание существующих и прекращение приема новых клиентских соединений#
При получении в административной консоли команды NDC_SUSPEND Pangolin Pooler прерывает все существующие соединения к базам данных, а также все клиентские соединения, кроме соединений с административной консолью (для обеспечения связи с базой Pangolin Pooler). Получив эту команду, Pangolin Pooler переходит в режим NDC_DISALLOWED и прекращает обработку входящих клиентских соединений. Поведение аналогично вызову команды KILL <db> для всех баз данных, с которыми были установлены соединения, за исключением того, что базы данных не переходят в режим выключения.
Пример использования команды:
psql -h somehost -p 6544 -U someuser pgbouncer -c "NDC_SUSPEND"
Возобновление приема новых клиентских соединений и их обслуживание#
При получении команды NDC_KEEPALIVE Pangolin Pooler переходит в режим NDC_ALLOWED (если до этого он был в другом режиме) и возобновляет прием новых клиентских соединений, а также их обработку. При этом Pangolin Pooler сохраняет момент времени получения этой команды и использует его в дальнейшем при автоматическом переключении в режим приостановки приема клиентских соединений.
Пример использования команды:
psql -h somehost -p 6544 -U someuser pgbouncer -c "NDC_KEEPALIVE"
Автоматическая приостановка приема новых и остановка обслуживания существующих клиентских соединений при истечении заданного интервала времени#
Момент времени старта Pangolin Pooler или получения команды NDC_KEEPALIVE сохраняется и сравнивается в основном цикле обработки событий с текущим моментом времени. Если разница между этими моментами времени превышает установленное в конфигурационном параметре ndc_suspending_timeout значение, то Pangolin Pooler прерывает все существующие соединения и приостанавливает прием новых соединений так же, как и после получения команды NDC_SUSPEND. Значение параметра задается в секундах и по умолчанию равно 0. При изменении значения параметра ndc_suspending_timeout перезапускать (выполнять restart) Pangolin Pooler не нужно.
Если значение ndc_suspending_timeout равно нулю, то проверка на необходимость разорвать существующие соединения и прекратить прием новых не выполняется.
Если текущее значение заменено на значение по умолчанию, то возобновляется прием и обработка клиентских соединений (Pangolin Pooler переходит в режим NDC_ALLOWED).
Если значение по умолчанию заменено на другое, то сохраняется момент времени смены параметра, и начинается проверка необходимости автоматического переключения в режим приостановки приема и обслуживания клиентских соединений.
Примечание:
Для организации непрерывного приема и обработки клиентских соединений необходимо регулярно отправлять запрос на выполнение команды
NDC_KEEPALIVE.
Пример конфигурации:
[pgbouncer]
; ...
ndc_suspending_timeout = 60
Плагин wal2json#
Для реализации возможности логической репликации в формате JSON в состав продукта дополнительно включен плагин вывода для логического декодирования - wal2json.
Плагин имеет доступ к кортежам, созданным с помощью INSERT и UPDATE. Кроме того, доступ к UPDATE/DELETE старых версий строк (row) возможен в зависимости от настроенного идентификатора реплики. Изменения могут быть применены с помощью протокола потока изменений (слоты логической репликации) или с помощью специального SQL API.
Поддерживается два формата вывода:
объект JSON для каждой транзакции: все новые/старые кортежи доступны в объекте JSON. Есть опции для включения таких свойств, как временная метка транзакции, соответствие схеме, типы данных и идентификаторы транзакций;
объект JSON для каждого кортежа: для начала и окончания транзакции объект JSON необязателен; дополнительно представлен набор опций для включения отдельных свойств объектов.
Для использования плагина требуется уровень WAL >= logical, для этого необходимо задать значение параметра wal_level = 'logical'. После смены значения этого параметра требуется перезапустить сервер Pangolin.
Параметры плагина, задаваемые при подключении к слоту репликации:
include-xids: добавитьxidк каждому набору изменений. Значение по умолчанию -false.use-xid32: использовать 32-битныйxidв наборе изменений. Значение по умолчанию -false.include-timestamp: добавить временную метку (timestamp) к каждому набору изменений. Значение по умолчанию -false.include-schemas: добавить схему (schema) к каждому изменению. Значение по умолчанию -true.include-types: добавить тип к каждому изменению. Значение по умолчанию -true.include-typmod: добавить модификатор к типам, у которых он есть (например,varchar(20)вместоvarchar). Значение по умолчанию -true.include-type-oids: добавитьoidsтипа. Значение по умолчанию -false.include-domain-data-type: заменить доменное имя базовым типом данных. Значение по умолчанию -false.include-column-positions: добавить позицию столбца (pg_attribute.attnum). Значение по умолчанию -false.include-origin: добавить источник фрагмента данных. Значение по умолчанию -false.include-not-null: добавить ненулевую информацию в качествеcolumnoptionals. Значение по умолчанию -false.include-default: добавить выражение (expression) по умолчанию. Значение по умолчанию -false.include-pk: добавить информацию о primarykeyв видеpk. Имя столбца и тип данных включены. Значение по умолчанию -false.numeric-data-types-as-string: использовать строку для числовых типов данных. Спецификация JSON не распознаетInfinityиNaNкак допустимые числовые значения. Для чисел двойной точности могут возникнуть потенциальные[проблемы совместимости](https://datatracker.ietf.org/doc/html/rfc7159#section-6). Значение по умолчанию -false.pretty-print: добавить пробелы и отступы в структуры JSON. Значение по умолчанию -false.write-in-chunks: запись после каждого изменения вместо каждого набора изменений. Используется только тогда, когдаformat-versionв значении1. Значение по умолчанию -false.include-lsn: добавитьnextlsnк каждому набору изменений (changeset). Значение по умолчанию -false.include-transaction: выдает записи, обозначающие начало и конец каждой транзакции. Значение по умолчанию -true.filter-origins: исключить изменения из указанных источников. Значение по умолчанию пустое, что означает, что источник не будет отфильтрован. Набор значений, разделенных запятой.filter-tables: исключить строки (rows) из указанных таблиц. Значение по умолчанию пустое, что означает, что ни одна таблица не будет отфильтрована. Набор значений, разделенных запятой. Таблицы должны соответствовать требованиям схемы. Имя вида*.fooозначает таблицуfooво всех схемах, а имя видаbar.*означает все таблицы в схеме bar. Специальные символы (пробел, одинарная кавычка, запятая, точка, звездочка) должны быть экранированы обратной косой чертой. Схема и таблица чувствительны к регистру.add-tables: включить только строки (rows) из указанных таблиц. По умолчанию используются все таблицы из всех схем. В нем действуют те же правила, что и вfilter-tables.filter-msg-prefixes: исключить сообщения, если префикс есть в списке. Значение по умолчанию пустое, что означает, что ни одно сообщение не будет отфильтровано. Задается в виде набора значений, разделенных запятой.add-msg-prefixes: включить только сообщения, если префикс есть в списке. По умолчанию используются все префиксы. Задается в виде набора значений, разделенных запятой. Значениеfilter-msg-prefixesприменяется перед этим параметром.format-version: определяет, какой формат вывода использовать. Значение по умолчанию равно1.actions: определяет, какие операции будут отправляться. По умолчанию используются все действия (INSERT,UPDATE,DELETEиTRUNCATE). Однако, если используетсяformat-version 1,TRUNCATEне будет включен (для поддержания обратной совместимости).
Контроль потребления ресурсов БД (оперативная память и ЦП)#
Функциональность реализована в виде расширения psql_resources_consumption_limits, позволяет ограничивать потребление ресурсов: оперативной памяти и ЦПУ, с помощью процессов СУБД. Входит в состав поставки Enterprise.
В Pangolin 6.1.0 поддерживается:
функциональность фиксированного задания ограничений ресурсов для процессов сессий СУБД;
завершение с ошибкой сессии, превысившей ограничение на потребление ресурса, и всех ее подпроцессов;
обнаружение превышения квоты на ресурсы асинхронно.
Примечание:
Управление ограничениями на уровне отдельной сессии не поддерживается.
Внимание!
Процессы расширений ограничены в соответствии с установленными лимитами (включая задания
pg_cronи т.п. ).
Схема процесса#
Процесс первоначальной настройки и изменения настройки квотирования ресурсов:
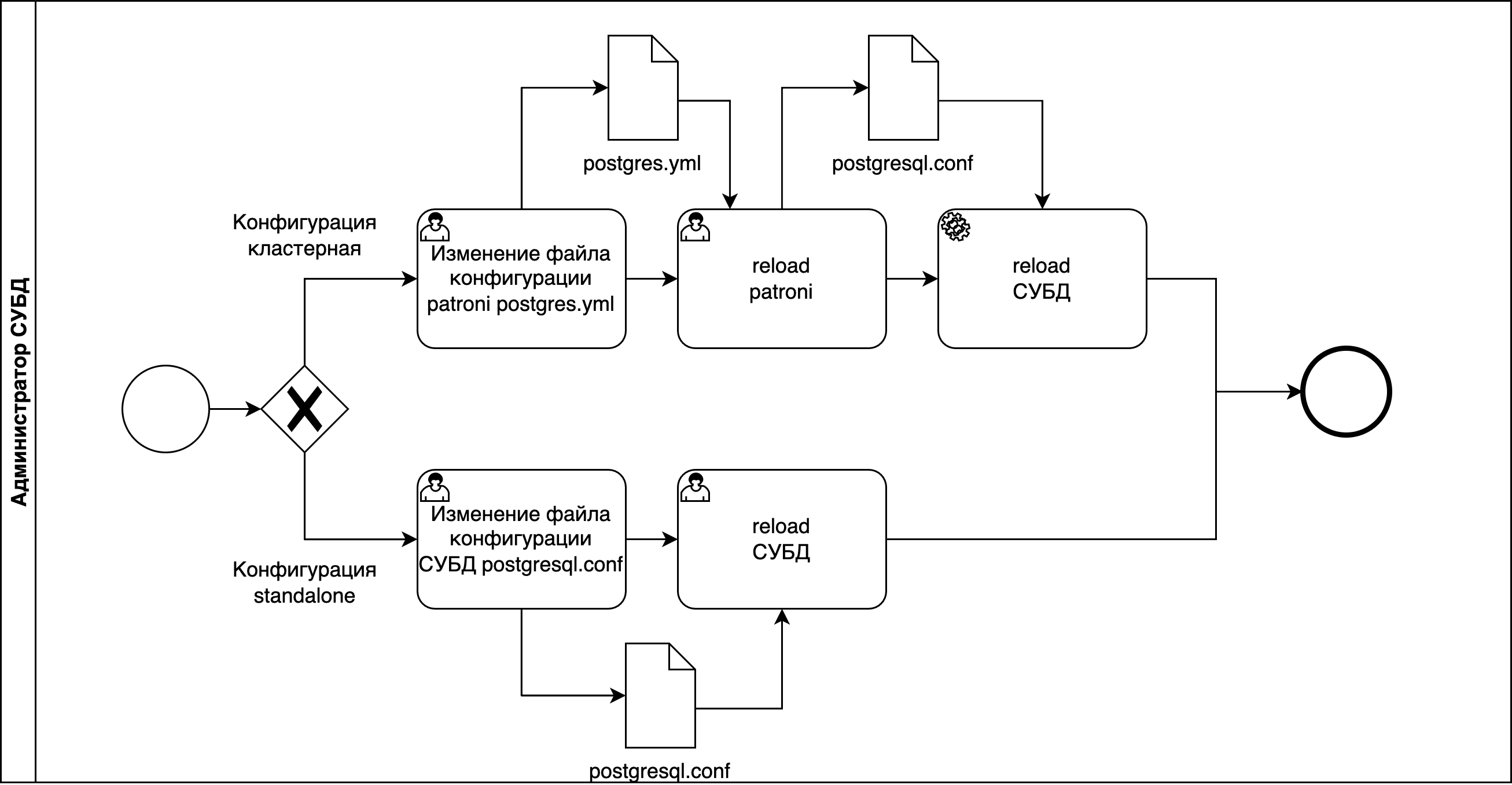
Включение функциональности на запущенном кластере Pangolin#
Внимание!
В процессе установки Pangolin функциональность не включается.
Для включения функциональности выполните шаги:
Добавьте имя библиотеки расширения в параметр
shared_preload_librariesконфигурационного файлаpostgresql.conf/postgres.yml:shared_preload_libraries = 'psql_resources_consumption_limits'Перезагрузите кластер:
restart --force && reload --forceВыполните команду по добавлению расширения (для создания представления мониторинга):
CREATE EXTENSION psql_resources_consumption_limits;
Примечание:
Необходимо учесть увеличение
background workerна единицу и увеличить лимитbackground worker.
Настройка фиксированных ограничений#
Задается параметрами, перед каждым параметром указывается имя расширения через точку.
Пример:
psql_resources_consumption_limits.check_interval
mem_limit- ограничение на суммарное потребление оперативной памяти одной сессией;Задается в килобайтах kB (kilobytes), мегабайтах MB (megabytes), гигабайтах GB (gigabytes), терабайтах TB (terabytes), без указания единиц - килобайты.
Допускаются только положительные целочисленные значения. При указании отрицательного значения или лимита, превышающего физическую память КТС (параметр
MemTotalв файле/proc/meminfo), Pangolin не запускается с выводом ошибки о недопустимом значении или превышении лимита. Если задано нулевое значение, то контроль за потреблением оперативной памяти отключен. По умолчанию лимит равен нулю (контроль отключен).cpu_limit- ограничение на процент потребления ядер CPU всеми процессами одной сессии;Задается в процентах.
Допускаются положительные целочисленные значения. При указании отрицательного значения или лимита превышающего количество ядер CPU КТС, умноженных на 100, Pangolin не запускается с выводом ошибки о невалидном значении или превышении лимита. Если задано нулевое значение, то контроль за потреблением CPU отключен. По умолчанию лимит равен нулю (контроль отключен).
Допускаются значения больше 100, например, 350, что означает: «потребление CPU всеми процессами сессии не может превысить 3.5 ядер"».
mem_exceeding_reaction- реакция на превышение лимита потребления оперативной памяти:terminate(значение по умолчанию) - прерывание всех процессов сессии с выводом сообщения в лог;alert- вывод сообщения в лог о превышении лимита;
cpu_exceeding_reaction- реакция на превышение лимита потребления CPU:terminate(значение по умолчанию) - прерывание всех процессов сессии с выводом сообщения в лог;alert- вывод сообщения в лог о превышении лимита;
alert_log_level- уровень лога для реакций alert на превышения лимитов. Принимает значения:debug5;debug4;debug3;debug2;debug1;debug;info;notice;log;warning(значение по умолчанию);
Примечание:
При установке
mem_exceeding_reaction,cpu_exceeding_reactionиalert_log_levelв значения, отличные от допустимых, выводится предупреждение о невалидности параметра, и используется значение по умолчанию.
alert_timeout- время ожидания для повторного вывода сообщения в лог (задается в единицах времени);Отрицательные значения не допускаются, максимальное значение - 1 час. Если процесс продолжает выполняться после превышения лимита (реакция на превышение лимита - вывод сообщения в лог), то следующее сообщение о его превышении появится не раньше, чем через установленный таймаут. Если установлено нулевое значение, то сообщения выводятся на каждое превышение лимита. Значение по умолчанию - 1 секунда. При указании отрицательного значения или значения, превышающего 1 час, выводится предупреждение о невалидном параметре и используется значение по умолчанию.
check_interval- интервал контроля превышения.Задается во временных единицах. Отрицательные значения не допускаются, максимальное значение – 5 минут. Если задано нулевое значение, то контроль за потреблением оперативной памяти и CPU отключен. Значение по умолчанию – 30 с. Если задано значение отличное от нуля и включен контроль хотя бы за одним из ресурсов, то процесс будет периодически запускаться с заданным интервалом времени и проверять превышение лимитов.
Параметры можно изменять без перезапуска сервера.
Установка параметров для роли#
Параметры (кроме интервала контроля) могут быть заданы суперпользователем отдельно для каждой роли через ALTER ROLE ... SET name=value;. В этом случае реакция на их превышение и лимиты сессий в рамках данной роли будут проверяться с учетом этих параметров. Как и при определении соответствующих параметров в конфигурации сервера, ограничение будет применяться к каждой из сессий по отдельности. В каждой из сессий значение параметра для роли переопределяет общее значение. Контроль суммарного потребления ресурсов всеми пользовательскими сессиями не выполняется.
Примеры настройки параметров#
Сценарий 1 – потребление ресурсов ограничено для выбранных ролей, для остальных ролей потребление ресурсов не ограничено:
Задан нулевой параметр
mem_limit(илиcpu_limit) в конфигурации или с помощьюALTER SYSTEM SET(проверка для всех ролей отключена).Заданы ненулевые параметры mem_limit (или cpu_limit) для выбранных ролей с помощью ALTER ROLE … SET name=value; (проверка для отдельных ролей включена).
Сценарий 2 – потребление ресурсов не ограничено для выбранных ролей, для остальных ролей потребление ресурсов ограничено:
Задан ненулевой параметр
mem_limit(илиcpu_limit) в конфигурации или с помощьюALTER SYSTEM SET(проверка для всех ролей включена).Заданы нулевые параметры
mem_limit(илиcpu_limit) для выбранных ролей с помощьюALTER ROLE ... SET name=value;(проверка для отдельных ролей выключена).
Отключение функциональности#
Для отключения функциональности:
Выполните команду по удалению расширения:
DROP EXTENSION psql_resources_consumption_limits;Удалите имя библиотеки расширения из параметра
shared_preload_librariesконфигурационного файлаpostgresql.conf/postgres.yml:shared_preload_libraries = 'psql_resources_consumption_limits'Перезагрузите кластер:
restart --force && reload --force
Примечание:
Если требуется временное отключение функциональности для всех ролей, без удаления расширения, то это возможно сделать, установив параметр
check_intervalв нулевое значение.
Асинхронный поиск превышения лимитов#
Контроль превышения лимитов реализуется в отдельном процессе.
Процесс запускается всегда, не зависимо от того, включен ли контроль за ресурсами или нет. Если контроль ни за одним ресурсов не включен, то процесс находится в ожидании. По SIGHUP процесс перечитывает конфигурационные параметры и, если контроль хотя бы за одним из ресурсов был включен, то процесс начинает периодическую проверку превышения лимитов.
Внимание!
Если контролируемый процесс превысит лимит внутри интервала контроля, но на момент проверки лимиты превышены не будут, то это превышение пройдет незамеченным для контролирующего процесса
Параллельное выполнение запросов#
При порождении процессом сессии СУБД подпроцессов параллельного выполнения запросов или подпроцессов фонового выполнения (parallel worker или background worker) суммарное потребление ресурсов такой сессией и ее подпроцессами не может превысить заданное ограничение на сессию.
Потребление памяти одной сессией#
Лимит учитывает только RSS-память процесса.
Значение RSS для процесса вычисляется по полю resident [количество страниц памяти RSS] внутри файла /proc/<pid>/statm. Чтобы перевести значение в байты resident умножается на sysconf(_SC_PAGESIZE) [Кб].
Считывается потребление резидентной памяти для каждого процесса сессии по pid, затем вычисляется суммарное потребление для сессии.
Потребление CPU одним процессом сессии#
Потребление CPU процессом вычисляется по изменению полей utime, stime [clock ticks] внутри файла /proc/<pid>/stat со времени последнего измерения. Для этого на каждой итерации в памяти сохраняются поля utime, stime и время измерения, которые будут использоваться для вычисления процента потребления CPU на следующей итерации:
(((current utime + current stime) - (saved utime + saved stime)) / sysconf(_SC_CLK_TCK)) * 100 / (текущее время - время прошлого измерения)
Примечание:
sysconf(_SC_CLK_TCK) - функция, возвращающая количество тактов процессора в одной секунде.
Потребление ЦПУ считывается для каждого процесса сессии по pid, затем вычисляется суммарное потребление для сессии.
Остановка процессов сессии#
При превышении сессией установленных лимитов все ее процессы останавливаются сигналом SIGTERM.
Получение данных о потреблении ресурсов по процессам сессии#
Данные о потреблении ресурсов процессами отображаются в новом представлении psql_resources_consumption_limits.consumption.
Права доступа pg_read_all_stats.
Представление содержит поля:
session_id– идентификатор сессии;proc_id– идентификатор процесса;role_id– идентификатор роли;rolname– имя роли;log_level– уровень лога для сообщений о превышении лимитов;mem_current– текущее потребление памяти процессом;mem_current_session– текущее потребление памяти сессией;mem_max– максимальное потребление памяти процессом за все время контроля;mem_max_session– максимальное потребление памяти сессией за все время контроля;mem_limit– заданное для сессии ограничение по памяти;mem_reaction– заданная для сессии реакция на превышение ограничения по памяти;cpu_current– текущее потребление CPU процессом;cpu_current_session– текущее потребление CPU сессией;cpu_max– максимальное потребление CPU процессом за все время контроля;cpu_max_session– максимальное потребление CPU сессией за все время контроля;cpu_limit– заданное для сессии ограничение по CPU;cpu_reaction– заданная для сессии реакция на превышение ограничения по CPU.
Контроль системных процессов#
Контроль потребления ресурсов не производится для системных процессов Pangolin (в том числе для процессов потоковой и логической репликации).
Поддержка HTTP-клиента на уровне СУБД (расширение pgsql-http)#
Функциональность позволяет обращаться к REST-сервисам из SQL-запросов.
В Pangolin (в состав поставки Standard) включено расширение pgsql-http, которое является оберткой поверх библиотеки libcurl. Оно включает в себя функции для обращения к REST-сервисам и вспомогательных функций.
Установка расширения#
Подготовительные действия:
Разверните СУБД Pangolin в конфигурации с patroni (например,
cluster-patroni-etcd-pgbouncer).Измените настройки Patroni в
/etc/patroni/postgres.ymlтак, чтобы в секцииrestapiостались только следующие строки:
для работы по протоколу HTTP:
restapi: listen: <IP-адрес>:8008 connect_address: <hostname>:8008 allowlist: [] allowlist_include_members: trueдля работы по протоколу HTTPS (необходимо указать месторасположение сертификатов):
restapi: listen: <IP-адрес>:8008 connect_address: <hostname>:8008 allowlist: [] allowlist_include_members: true ciphers: DEFAULT:!SSLv1:!SSLv2:!SSLv3:!TLSv1:!TLSv1.1 verify_client: optional cafile: /pg_ssl/root.crt capath: /pg_ssl/root_dir certfile: /pg_ssl/server.crt keyfile: /pg_ssl/server.key crlpath: /pg_ssl/crl crlfile: /pg_ssl/crl/intermediate.crl
Разархивируйте папку расширения:
cd {путь к дистрибутиву pangolin}/3rdparty/pgsql-http
tar -C "/" -xzf pgsql-http.tar.gz
Перезапустите patroni:
sudo systemctl restart patroni
Для установки расширения необходимо подключиться к БД с правами суперпользователя:
CREATE EXTENSION http;
Описание#
Схема процесса «Выполнение HTTP запроса в рамках SQL-запроса»:
Табличное описание процесса «Выполнение HTTP запроса в рамках SQL-запроса»:
Наименование шага |
Входной документ |
Описание |
Исполнитель |
Выходной документ |
ИТ-система |
Переход к шагу |
|---|---|---|---|---|---|---|
010 Настроить CURL параметры |
Разработчик в рамках предварительного запроса вносит изменения в CURL параметры с помощью одной из http_XXX_curlopt функций |
Администратор АС / Администратор СУБД |
СУБД Pangolin |
020 |
||
020 Использовать http_METHOD функцию |
Разработчик использует одну из http_METHOD функций при написании SQL запроса, чтобы при выполнении запроса реализовывался HTTP запрос с указанными параметрами |
Администратор АС / Администратор СУБД |
СУБД Pangolin |
Выход |
В рамках расширения в продукт Pangolin добавлены новые типы данных:
http_header;http_request;http_response.
Каждый HTTP-вызов состоит из запроса (http_request) и ответа (http_response).
Параметры http_request:
Название параметра |
Тип |
Описание |
|---|---|---|
method |
varchar |
Название HTTP-метода |
uri |
varchar |
URI сервиса, к которому производится запрос |
headers |
http_header[] |
Массив HTTP-заголовков |
content_type |
varchar |
Тип содержимого |
content |
varchar |
Содержимое запроса |
Параметры http_response:
Название параметра |
Тип |
Описание |
|---|---|---|
status |
integer |
Код состояния HTTP-запроса |
content_type |
varchar |
Тип возвращаемых данных |
headers |
http_header[] |
Массив HTTP-заголовков |
content |
varchar |
Содержимое ответа сервиса на HTTP-запрос |
Служебные функции, http_get(), http_post(), http_put(), http_delete() и http_head() являются оболочками вокруг главной функции, http(http_request), которая возвращает http_response.
Поле headers для запросов и ответов представляет собой массив PostgreSQL типа http_header, который является кортежем.
Параметры http_header:
Название параметра |
Тип |
Описание |
|---|---|---|
field |
varchar |
Название HTTP-заголовка |
value |
varchar |
Значение HTTP-заголовка |
Можно распаковать массив http_header кортежей в результирующий набор, используя функцию PostgreSQL unnest() для массива. Затем оттуда выбрать конкретный интересующий вас заголовок (см. подробнее об этом в разделе «Примеры»).
Внимание!
Данное расширение может быть использовано для отсылки доступных для роли данных из СУБД во внешнюю систему. Чтобы минимизировать риски утечки данных следует:
Использовать версию
libcurl, скомпилированную с поддержкой минимально необходимого набора протоколов (HTTP/HTTPS/FTP). Как минимум следует отключать возможность использования протокола file (file://), чтобы исключить возможность чтения файлов на локальной файловой системе, доступных для чтения учетной записью ОСpostgres.Разрешать на уровне брандмауэра только сетевые взаимодействия из «белого списка», в который должны быть включены строго те маршруты передачи данных, которые необходимы для функционирования АС и их обслуживания.
SQL-функции#
Название функции |
Параметры |
Тип возвращаемых данных |
Описание |
|---|---|---|---|
http_header |
field VARCHAR, value VARCHAR |
http_header |
Конструктор HTTP-заголовков |
http |
request http_request |
http_response |
Основная функция, реализующая отправку HTTP-запроса и получение HTTP-ответа. По сути, функции, реализующие конкретные HTTP-методы, являются обертками данной функции |
http_get |
uri VARCHAR |
http_response |
Функция, реализующая отправку HTTP GET запроса |
http_get |
uri VARCHAR, data JSONB |
http_response |
Функция, реализующая отправку HTTP GET-запроса |
http_post |
uri VARCHAR, content VARCHAR, content_type VARCHAR |
http_response |
Функция, реализующая отправку HTTP POST-запроса |
http_post |
uri VARCHAR, data JSONB |
http_response |
Функция, реализующая отправку HTTP POST-запроса |
http_put |
uri VARCHAR, content VARCHAR, content_type VARCHAR |
http_response |
Функция, реализующая отправку HTTP PUT-запроса |
http_patch |
uri VARCHAR, content VARCHAR, content_type VARCHAR |
http_response |
Функция, реализующая отправку HTTP PATCH-запроса |
http_delete |
uri VARCHAR, content VARCHAR, content_type VARCHAR |
http_response |
Функция, реализующая отправку HTTP DELETE-запроса |
http_head |
uri VARCHAR |
http_response |
Функция, реализующая отправку HTTP HEAD-запроса |
http_set_curlopt |
curlopt VARCHAR, value varchar |
boolean |
Функция, позволяющая настроить параметры CURL, с которыми будут обрабатываться запросы. Настройки специфичны для сеанса СУБД и сохраняются до его завершения |
http_reset_curlopt |
boolean |
Функция для сброса параметров CURL к значениям по умолчанию |
|
http_list_curlopt |
setof(curlopt text, value text) |
Функция для получения списка текущих значений параметров CURL |
|
urlencode |
string VARCHAR |
text |
Функция для «URL кодирования» входящих строк. Все символы, подлежащие кодированию (не ASCII-символы, пробелы и т.д.), заменяются на «%» и две цифры в шестнадцатеричной системе |
urlencode |
data JSONB |
text |
Функция для «URL кодирования» входящих строк. Все символы, подлежащие кодированию (не ASCII-символы, пробелы и т.д.), заменяются на «%» и две цифры в шестнадцатеричной системе |
сURL-параметры#
сURL-параметры доступные для настройки с помощью функции http_set_curlopt(curlopt VARCHAR, value varchar):
Примечание:
Cписок CURL-опций, которые могут быть использованы в расширении, сильно зависит от версии
libcurl, используемой в ОС, от того, с какими опциямиlibcurlбыла скомпилирована, а также от самой ОС.
CURLOPT_DNS_SERVERS – список DNS-серверов, которые должны использоваться вместо того, что используется по умолчанию на уровне системы;
CURLOPT_PROXY – прокси-сервер, который следует использовать для последующих запросов. Указывается в формате (<IP-адрес> |
)[: ]; CURLOPT_PRE_PROXY – препрокси-сервер, который следует использовать для последующих запросов. Указывается в формате (<IP-адрес> |
)[: ]; CURLOPT_PROXYPORT – порт, который должен использоваться для подключения к прокси-серверу. Данная опция не рекомендована к использованию. При необходимости указания порта лучше использовать его в рамках параметра
CURLOPT_PROXY;CURLOPT_PROXYUSERPWD – имя пользователя и пароль для аутентификации на прокси-сервере. Указывается в формате <имя пользователя>:<пароль>;
CURLOPT_PROXYUSERNAME – имя пользователя для аутентификации на прокси-сервере;
CURLOPT_PROXYPASSWORD – пароль для аутентификации на прокси-сервере;
CURLOPT_PROXY_TLSAUTH_USERNAME – имя пользователя для аутентификации на прокси-сервере по протоколу TLS.;
CURLOPT_PROXY_TLSAUTH_PASSWORD – пароль для аутентификации на proxy сервере по протоколу TLS;
CURLOPT_PROXY_TLSAUTH_TYPE – метод аутентификации на proxy сервере по протоколу TLS. Допустимые значения: пустое (по умолчанию) и «SRP» для TLS-SRP-аутентификации;
CURLOPT_TLSAUTH_USERNAME – имя пользователя для аутентификации по протоколу TLS;
CURLOPT_TLSAUTH_PASSWORD – пароль для аутентификации по протоколу TLS;
CURLOPT_TLSAUTH_TYPE – метод аутентификации по протоколу TLS. Допустимые значения: пустое (по умолчанию) и «SRP» для TLS-SRP-аутентификации;
CURLOPT_SSL_VERIFYHOST – опция определяет, должна ли
libcurlпроверять, что серверный сертификат относится к данному серверу. Допустимые значения:2 (по умолчанию) – если сервер не совпадает с сервером, указанном в сертификате, соединение не будет установлено;
1 – поведение различается от версии к версии, не должно быть использовано в общем случае;
0 – соединение будет установлено успешно независимо от того, совпадает ли имя сервера с именем в сертификате;
CURLOPT_SSL_VERIFYPEER – данный параметр определяет, будет ли проводиться проверка, что серверный сертификат был подписан CA. Допустимые значения:
1 (по умолчанию) – проверка будет проводиться; в случае, если сертификат был подписан некорректно, соединение не будет установлено;
0 – проверка не будет проводиться;
Альтернативные CA сертификаты могут быть заданы с помощью параметров
CURLOPT_CAINFOиCURLOPT_CAPATH;CURLOPT_SSLCERT – имя файла с клиентским сертификатом. Формат по умолчанию: P12 (для Secure Transport) и PEM (для остальных случаев). Формат может быть изменен с помощью параметра
CURLOPT_SSLCERTTYPE;CURLOPT_SSLKEY – имя файла с частным ключом для клиентского TLS/SSL-сертификата. Формат по умолчанию: PEM (может быть изменен с помощью параметра
CURLOPT_SSLCERTTYPE);CURLOPT_SSLCERTTYPE – тип клиентского SSL-сертификата. Поддерживаемые форматы: PEM (по умолчанию) и DER (не поддерживается Secure Transport и Schannel). OpenSSL (версии старше 0.9.3), Secure Transport (iOS 5+, OS X 10.7+) и Schannel поддерживают P12 для PKCS#12 файлов;
CURLOPT_CAINFO – путь к Certificate Authority (CA) bundle;
CURLOPT_TIMEOUT – максимальное время (в секундах), за которое запрос должен быть завершен. Если указаны оба параметра
CURLOPT_TIMEOUTиCURLOPT_TIMEOUT_MS, то будет использовано значение, установленное последним;CURLOPT_TIMEOUT_MS – максимальное время (в миллисекундах), за которое запрос должен быть завершен. Если указаны оба параметра
CURLOPT_TIMEOUTиCURLOPT_TIMEOUT_MS, то будет использовано значение, установленное последним;CURLOPT_TCP_KEEPALIVE – если данный параметр включен (по умолчанию выключен), в периоды, когда соединение неактивно, будут посылаться TCP-пробы. Интервал между пробами определяется параметром
CURLOPT_TCP_KEEPIDLE;CURLOPT_TCP_KEEPIDLE – интервал между TCP-пробами в секундах;
CURLOPT_CONNECTTIMEOUT – таймаут для установки соединения в секундах. В случае, если проставлено нулевое значение, используется значение по умолчанию (300 секунд);
CURLOPT_USERAGENT – user-agent HTTP-заголовок.
Примеры#
Получение URL-кода строки:
SELECT urlencode('my special string''s & things?');
Пример ответа:
urlencode
-------------------------------------
my+special+string%27s+%26+things%3F
(1 row)
Получение URL-кода ассоциативного массива JSON:
SELECT urlencode(jsonb_build_object('name','Colin & James','rate','50%'));
Пример ответа:
urlencode
-------------------------------------
name=Colin+%26+James&rate=50%25
(1 row)
Выполнение GET-запроса с просмотром содержимого:
SELECT content
FROM http_get('http://httpbun.org/ip');
Пример ответа:
content
-----------------------------
{"origin":{IP-адрес}}
(1 row)
Выполнение GET-запроса с заголовком авторизации:
SELECT content::json->'headers'->>'Authorization'
FROM http((
'GET',
'http://httpbun.org/headers',
ARRAY[http_header('Authorization','Bearer {хеш}')],
NULL,
NULL
)::http_request);
Пример ответа:
content
----------------------------------------------
Bearer {хеш}
(1 row)
Считывание полей status и content_type из объекта http_response:
SELECT status, content_type
FROM http_get('http://httpbun.org/');
Пример ответа:
status | content_type
--------+--------------------------
200 | text/html; charset=utf-8
(1 row)
Отображение всех http_header в объекте http_response:
SELECT (unnest(headers)).*
FROM http_get('http://httpbun.org/');
Пример ответа:
field | value
------------------+--------------------------------------------------
Server | nginx
Date | Wed, 26 Jul 2023 19:52:51 GMT
Content-Type | text/html
Content-Length | 162
Connection | close
Location | https://httpbun.org
server | nginx
date | Wed, 26 Jul 2023 19:52:51 GMT
content-type | text/html
x-powered-by | httpbun/{хеш}
content-encoding | gzip
Отправка на сервер простого текстового документа с помощью команды PUT:
SELECT status, content_type, content::json->>'data' AS data
FROM http_put('http://httpbun.org/put', 'some text', 'text/plain');
status | content_type | data
--------+------------------+-----------
200 | application/json | some text
Отправка на сервер простого текстового JSON-документа с помощью команды PATCH:
SELECT status, content_type, content::json->>'data' AS data
FROM http_patch('http://httpbun.org/patch', '{"this":"that"}', 'application/json');
Пример ответа:
status | content_type | data
--------+------------------+------------------
200 | application/json | '{"this":"that"}'
Использование команды DELETE в запросе на удаление ресурса:
SELECT status, content_type, content::json->>'url' AS url
FROM http_delete('http://httpbun.org/delete');
Пример ответа:
status | content_type | url
--------+------------------+---------------------------
200 | application/json | http://httpbun.org/delete
Передача аргумента данных в формате JSONB в качестве сокращения для передачи данных в GET-запрос:
SELECT status, content::json->'args' AS args
FROM http_get('http://httpbun.org/get',
jsonb_build_object('myvar','myval','foo','bar'));
Кодирование данных в JSONB как полезной нагрузки данных, для выполнения POST на URL, используя полезную нагрузку данных вместо параметров, встроенных в URL:
SELECT status, content::json->'form' AS form
FROM http_post('http://httpbun.org/post',
jsonb_build_object('myvar','myval','foo','bar'));
Для доступа к двоичному содержимому необходимо преобразовать его из стандартного представления varchar в представление bytea с помощью функции text_to_bytea() или функции textsend(). Использование стандартного приведения varchar::bytea не будет работать, так как приведение остановится при первом же попадании на байт с нулевым значением (что часто встречается в двоичных данных):
WITH
http AS (
SELECT * FROM http_get('https://httpbingo.org/image/png')
),
headers AS (
SELECT (unnest(headers)).* FROM http
)
SELECT
http.content_type,
length(text_to_bytea(http.content)) AS length_binary
FROM http, headers
WHERE field ilike 'Content-Type';
Пример ответа:
content_type | length_binary
--------------+---------------
image/png | 8090
Аналогично, при использовании POST для отправки двоичного содержимого bytea в службу используйте функцию bytea_to_text для подготовки содержимого.
Чтобы получить доступ только к заголовкам, можно выполнить HEAD-запрос. Это не приведет к перенаправлениям:
SELECT
http.status,
headers.value AS location
FROM
http_head('http://google.com') AS http
LEFT OUTER JOIN LATERAL (SELECT value
FROM unnest(http.headers)
WHERE field = 'Location') AS headers
ON true;
Пример ответа:
status | location
--------+------------------------
301 | http://www.google.com/
Механизмы безопасности#
Журналирование и аудит#
Для журналирования и аудита событий безопасности используется модифицированное расширение pgAudit, интегрированное в ядро СУБД Pangolin. Оно обеспечивает детальное журналирование сессий и объектов для целей аудита. События подключения и события настройки механизма защиты данных выделены в отдельные классы регистрируемых событий для предоставления возможности гибкой настройки аудита. Расширение pgAudit заменяет стандартное средство журналирования СУБД Platform V Pangolin.
Авторизация и аутентификация#
СУБД Platform V Pangolin поддерживает несколько типов авторизации и аутентификации пользователей и сервисов:
trust— любой пользователь, подключающийся к серверу, авторизован для доступа;password— авторизация с помощью пароля, передаваемого в виде хеша MD5 или открытым текстом;GSSAPI— протокол авторизации по стандарту RFC 2743;SSPI— технология защищенной аутентификации Windows;ident— аутентификация с использованием сервераidentпо стандарту RFC 1413;peer— получение имени пользователя клиента из ядра и использование его в качестве авторизованного имени пользователя БД;LDAP— аналогичноpassword, но для подверждения пары «имя пользователя/пароль» используется метод LDAP;RADIUS— аналогичноpassword, но для подверждения пары «имя пользователя/пароль» используется метод RADIUS;аутентификация по сертификату — аутентификация с использованием клиентского сертификата SSL. Применимо только для SSL-подключений;
PAM— аналогичноpassword, но для подверждения пары «имя пользователя/пароль» используется метод PAM. Также поддерживается проверка имени и IP удаленного компьютера;BSD— аналогичноpassword, но для подверждения пары «имя пользователя/пароль» используется метод BSD;2f-scram-sha-256,2f-md5,2f-password или 2f-ldap— методы двухфакторной аутентификации (см. раздел «Двухфакторная аутентификация».
Авторизация#
Предоставление прав пользователям осуществляется в соответствии с ролевой системой и механизмом защиты данных от привилегированных пользователей.
Ролевая модель и права доступа#
Для обеспечения контроля доступа к защищаемым элементам системы применяется система разграничения доступа, основанная на ролях.
Права доступа пользователей устанавливаются парольными политиками в соответствии с ролевой моделью. Управление парольными политиками описано в подразделе «Интерфейс управления парольными политиками: PL/pgSQL API».
Матрица несовместимости ролей#
Н - не совместимо
Н/Ж - нежелательно
С - совместимо
sec_admin_role (администратор безопасности) |
superuser (администратор БД, включая |
Роли RBAC PostgreSQL |
|
|---|---|---|---|
sec_admin_role (администратор безопасности) |
Н |
Н |
|
superuser (администратор БД, включая |
Н |
С |
|
Роли RBAC PostgreSQL |
Н |
С |
Операции, которые не должны выполняться одним лицом#
Следующие операции имеют критическое значение для безопасности, поэтому не могут быть выполнены одним лицом:
Выполнение общих настроек, влияющих на возможность несанкционированного доступа к передаваемой или хранимой информации:
настройки защиты сетевых соединений;
настройки состава загружаемых модулей расширения;
настройки состава доверенных серверов аутентификации;
настройки включения прозрачного шифрования данных.
Управление доступом к объектам баз данных, содержащих конфиденциальную или секретную информацию.
Автоматическое завершение неактивных соединений#
Соединения, остающиеся неактивными определенное время, подлежат принудительному завершению.
Для завершения таких соединений используется фоновый процесс, осуществляющий мониторинг и завершение бездействующих клиентских сеансов. Этот процесс запускается при старте сервера Pangolin и завершается вместе с остановкой сервера.
Процесс регулируется двумя параметрами:
check_idle_time_delay— интервал мониторинга в миллисекундах;backend_idle_alive_time— допустимое время бездействия в секундах.
Если хотя бы один из этих параметров равен нулю, неактивные соединения завершаться не будут.
Идентификация и аутентификация#
Идентификация — определение имени пользователя базы данных. При работе в среде SQL по имени пользователя определяются права доступа к объектам базы данных для конкретного пользователя. Права доступа определяются парольными политиками (подробнее «Список PL/SQL функций продукта» раздел «Парольные политики»).
При аутентификации пользователя определяется логин пользователя, который далее идентифицирует его. Межсервисная идентификация осуществляется с помощью свойств сессии application_name (может быть задано аутентифицирующимся приложением, для того чтобы в логе СУБД отображалась данная информация), а также IP-адрес + клиентский порт.
Аутентификация — это процесс идентификации клиента сервером базы данных, а также определение того, может ли клиентское приложение (или пользователь запустивший приложение) подключиться с указанным именем пользователя.
В Pangolin реализовано несколько различных методов аутентификации клиентов. Метод аутентификации конкретного клиентского соединения может основываться на адресе компьютера клиента, имени базы данных, имени пользователя. Более детально описано в официальной документации на PostgreSQL 13 (https://www.postgresql.org/docs/13/client-authentication.html).
Файл pg_hba.conf#
Аутентификация клиентов управляется конфигурационным файлом pg_hba.conf, он расположен в каталоге с данными кластера базы данных. Файл pg_hba.conf со стандартным содержимым, создается командой initdb при инициализации каталога с данными. Располагается в каталоге PGDATA.
Общий формат файла pg_hba.conf — набор записей, по одной на строку. Пустые строки игнорируются, как и любой текст комментария после знака #. Запись может быть продолжена на следующей строке, для этого нужно завершить строку обратной косой чертой (обратная косая черта является спецсимволом только в конце строки). Запись состоит из нескольких полей, разделенных пробелами и/или табуляциями. Обратная косая черта обозначает перенос строки даже в тексте в кавычках или комментариях.
Каждая запись обозначает тип соединения, диапазон IP-адресов клиента (если он соотносится с типом соединения), имя базы данных, имя пользователя, и способ аутентификации, который будет использован для соединения в соответствии с этими параметрами.
Сквозная аутентификация pgBouncer — Pangolin#
В pgBouncer и Pangolin реализован механизм сквозной аутентификации. Программа pgBouncer выступает в режиме проксирования данных аутентификации от клиента к Pangolin и обратно, аутентификация пользователя выполняется только на Pangolin.
Количество итераций обмена данными аутентификации для конкретного пользователя зависит от установленных в файле pg_hba.conf методов аутентификации. Обмен данными аутентификации между pgBouncer и Pangolin выполняется по отдельным сетевым каналам. Количество сетевых каналов зависит от количества баз данных, к которым выполняется подключение пользователей.
Двухфакторная аутентификация#
Двухфакторная аутентификация представляет собой технологию, обеспечивающую идентификацию пользователей при помощи запроса аутентификационных данных двух разных типов, что обеспечивает двухслойную, а значит, более эффективную защиту БД от несанкционированного проникновения.
Пользователь может подключаться к БД:
непосредственно (или напрямую) к Pangolin;
через pgBouncer к Pangolin, используя сквозную аутентификацию;
через pgBouncer к Pangolin, используя базовые механизмы аутентификации.
Сертификат безопасности клиента должен содержать поле CN, содержащее логин клиента и, опционально, поле SubjectAltName, содержащее один или несколько IP-адресов (возможен вариант указания подсети) и (или) DNS-имен клиента.
Для подключения непосредственно к Pangolin, в файле pg_hba.conf необходимо указать метод аутентификации: 2f-scram-sha-256, 2f-md5, 2f-password или 2f-ldap.
Подробнее в документе «Руководство администратора», раздел «Сценарии администрирования», подраздел «Двухфакторная аутентификация».
Защита аутентификационной информации#
В Platform V Pangolin реализована защита аутентификационной информации в процессе ее ввода. При аутентификации через утилиту psql вводимые пользователем символы пароля не отображаются.
Внимание!
Не рекомендуется передавать или хранить пароль в открытом виде в:
файле
pgpass;строке параметров подключения (Connection string);
переменной окружения
PGPASSWORD.
Рекомендации по заданию стойких паролей#
Пароль считается стойким, если он удовлетворяет следующим условиям:
должен изменяться не менее 1 раза в 80 дней с момента последнего изменения;
должен быть сложен (обязательно использование строчных и прописных букв и цифр);
длина пароля — минимум 12 символов;
должен быть уникален, недопустимо использование одного и того же пароля для нескольких УЗ одного пользователя;
не должен содержать имя УЗ пользователя или какую-либо его часть;
в случае компрометации пароля необходимо незамедлительно его сменить;
должен храниться в зашифрованном виде.
В соответствии с написанным выше и Ролевой моделью Pangolin, парольные политики для Pangolin по умолчанию настроены следующим образом:
выключены для пользователей, проходящих внешнюю аутентификацию: LDAP;
для локальных УЗ включено использование библиотек: zxcvb и cracklib;
для специальных УЗ выключены проверки времени жизни пароля:
SELECT * FROM set_role_policies('masteromni', max_age('0 sec'), min_age('0 sec'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('zabbix_oasubd', max_age('0 sec'), min_age('0 sec'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('monitoring_php', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('auditor', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('pstgcmdb', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('as_TUZ', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('as_admin', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('db_admin', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3')); SELECT * FROM set_role_policies('postgres', max_age('0'), min_age('0'), check_syntax('1'), policy_enable('1'), lockout('0'), illegal_values('1'), use_password_strength_estimator('1'), password_strength_estimator_score('3'));
!!!
Защита аутентификационной информации#
В СУБД Platform V Pangolin реализована защита аутентификационной информации в процессе ее ввода. При аутентификации через утилиту psql вводимые пользователем символы пароля не отображаются.
Пароли хранятся в виде хешей для всех методов аутентификации, кроме PLAIN. Метод PLAIN не рекомендуется к использованию.
Не рекомендуется передавать или хранить пароль в открытом виде в:
файле
pgpass;строке параметров подключения (Connection string);
переменной окружения
PGPASSWORD.
Настроечные параметры, управляемые администраторами безопасности через KMS в режиме защищенного конфигурирования, находятся в таблице документа «Параметры, настраиваемые через KMS».
Двухфакторная аутентификация#
Также в Pangolin реализована двухфакторная аутентификация. Представляет собой технологию, обеспечивающую идентификацию пользователей при помощи запроса аутентификационных данных двух разных типов, что обеспечивает двухслойную, а значит, более эффективную защиту БД от несанкционированного проникновения.
Пользователь может подключаться к БД:
непосредственно (или напрямую) к Pangolin;
через pgBouncer к Pangolin, используя сквозную аутентификацию;
через pgBouncer к Pangolin, используя базовые механизмы аутентификации.
Ниже представлена общая схема выполнения двухфакторной аутентификации:
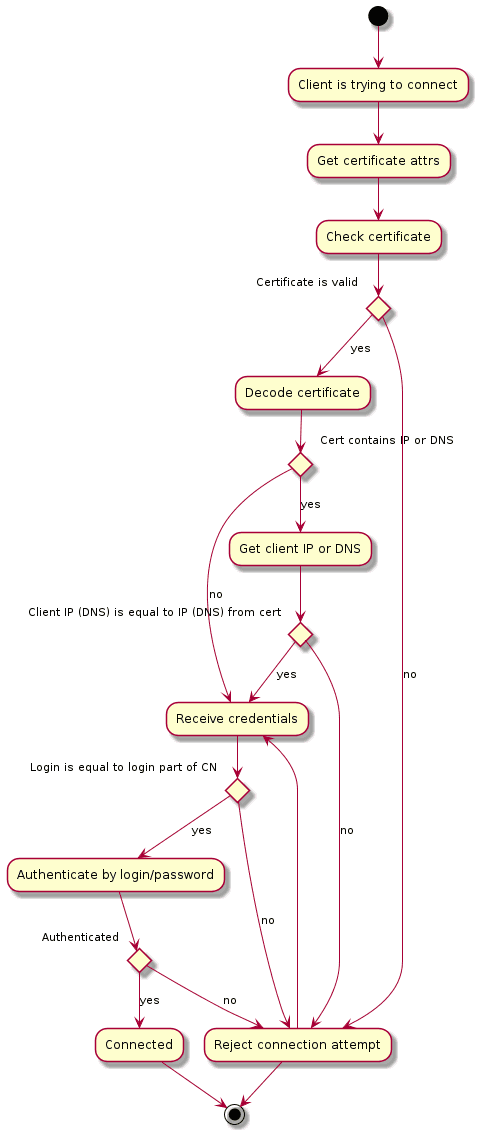
Реализация АРМ администратора#
Для администрирования системы используется утилита psql. Эта утилита представляет собой терминальный клиент для передачи запросов к СУБД и отображения результатов.
psql [параметр...] [имя_бд [имя_пользователя]]`
Архивирование и восстановление#
Для архивирования и восстановления используются утилиты:
pg_basebackup— утилита создания резервной копии кластера баз данных PostgreSQL;pg_probackup— утилита гибкого снятия и восстановления резервных копий баз данных PostgreSQL.
Система резервного копирования Pangolin позволяет защитить данные от потери в случае отказа оборудования, ошибок оператора, ошибок приложений, проблем сервисных служб, а также используется для целей аудита.
Функции системы:
резервное копирование и восстановление данных Pangolin;
создание полной резервной копии по расписанию;
снятие резервных копий с любого сервера кластера высокой доступности;
возможность хранения метаданных на отдельном служебном сервере;
дедупликация;
восстановление состояния на определенный момент времени (в соответствии с политиками хранения копий);
обеспечение соответствия нефункциональным требованиям к системам уровня Mission critical.
Подробнее в документе «Руководство администратора» раздел «Архивирование и восстановление».
Управление учетными записями#
Учетные записи пользователей и технические учетные записи создаются, удаляются и изменяются администраторами безопасности (в части политики доступа механизма защиты от привилегированных пользователей) и администраторами СУБД (в части управления УЗ и разрешениями RBAC и RLS) Platform V Pangolin.
Разрешения для учетных записей регулируются политиками, которые определяют права доступа той или иной роли к объектам базы данных.
Парольные политики описываются в «Список PL/SQL функций продукта», раздел «Парольные политики».
Проверки политик механизма защиты реализуются на базе обработчиков PostgreSQL на выполнение запросов:
set_role_hook;check_password_hook;object_access_hook;ExecutorCheckPerms_hook;ProcessUtility_hook.
Входными данными алгоритма являются:
роль пользователя, выполняющего запрос;
таблицы каталога безопасности, описанные в разделе «Модель данных каталога безопасности для механизма защиты данных»;
идентификатор базы данных, получаемый из переменной
MyDatabaseOidпроцесса бэкенда PostgreSQL;информация об объекте, участвующем в запросе.
Разграничение доступа к данным#
В СУБД Platform V Pangolin реализуется механизм защиты доступа к объектам, со следующими свойствами:
Механизм защиты функционирует параллельно RBAC и RLS СУБД Platform V Pangolin. RBAC управляется администраторами СУБД и авторизованными пользователями, RLS - администраторами СУБД и авторизованными пользователями с ролью администратора, защита - администраторами безопасности.
Механизм защиты реализуется как неотъемлемая часть ядра СУБД Platform V Pangolin и управляется дублируемыми параметрами в локальных конфигурационных файлах и защищенном хранилище.
Под защиту могут быть помещены следующие типы объектов:
таблицы — на действия DML чтения, вставки, изменения и удаления, DDL — изменения и удаления, создания или изменения триггера по таблице, создания или изменения правила по таблице;
партиции — на действия DML чтения, вставки, изменения и удаления, DDL — изменения и удаления;
материализованные представления — на действия DML чтения, DDL — изменения и удаления;
представления — на действия DML чтения, вставки, изменения и удаления, DDL — изменения и удаления, создания или изменения триггера по представлению, создания или изменения правила по представлению;
функции — на вызов, изменение, удаление;
роль — на действия удаления, изменения, выдачу роли-объекту, отзыв у роли-объекта, выдачу в качестве роли-объекта, отзыв в качестве роли-объекта, смену пароля, назначения текущей роли сессии.
Хранение информации для ограничения доступа выполняется в таблицах каталога безопасности.
Инициализация каталога безопасности и создание учетной записи администратора безопасности выполняется утилитой инициализации каталога безопасности.
Учетные записи администраторов безопасности также находятся под защитой и не могут быть изменены администратором БД СУБД Platform V Pangolin.
Наделение привилегиями администратора безопасности выполняется только администраторами безопасности.
Утилита инициализации каталога безопасности#
На вход утилите в качестве аргументов подаются следующие параметры:
путь к директории PGDATA базы данных;
логин администратора безопасности;
пароль администратора безопасности.
Предварительно администратором безопасности должна быть настроена загрузка расширения механизма защиты через параметр shared_preload_libraries.
Примечание:
Прием параметра пароля администратора безопасности в переменной окружения или параметрах вызова утилиты запрещен в целях безопасности.
Утилита выполняет следующие действия:
при запуске для экземпляра PostgreSQL с ранее инициализированным каталогом безопасности утилита выводит сообщение о том, что каталог безопасности находится не в ожидаемом состоянии;
запрашивает пароль создаваемого администратора безопасности для ввода пользователем с консоли;
заполняет таблицы каталога безопасности согласно п. "Модель данных каталога безопасности для механизма защиты данных";
создает роль пользователя администратора безопасности с указанными логином и паролем, выдает ему права на чтение из общего каталога и из каталогов баз данных;
создает функции интерфейса администратора безопасности;
включает в защищаемые объекты роль администратора безопасности;
включает в защищаемые объекты таблицы каталога безопасности;
включает в защищаемые объекты функции интерфейса администратора безопасности;
создает политику для доступа к роли администратора безопасности с именем adminPolicyOwner_<имя роли созданного администратор безопасности>, включающую права на смену пароля;
создает политику для доступа к таблицам каталога безопасности с именем securityCatalogAdmin, включающую права на вставку, чтение, изменение данных в таблице и удаление из таблицы;
создает политику доступа к функциям интерфейса администратора безопасности securityFunctionsAdmin, включающее права на вызов функций;
назначает все созданные политики созданной роли администратора безопасности;
Примечание:
После включения механизма защиты загрузка дополнительных расширений через команду LOAD становится недоступна. Также игнорируются параметры local_pleload_libraries и session_preload_libraries
Модель данных каталога безопасности для механизма защиты данных#
Включает следующие поля:
pr_object_kind- справочник типов защищаемых объектов;pr_action- справочник действий над защищаемыми типами объектов, регулируемых механизмом защиты;pr_object- реестр защищаемых объектов;pr_policy- реестр политик механизма защиты;pr_rule- реестр разрешений, включенных в политики;pr_grant- реестр политик, назначенных пользователям.
Управление доступом на уровне ролей (RBAC)#
Система ограничивает доступ пользователей к объектам БД в зависимости от их роли и привилегий, которые назначены для этой роли.
Подробнее в разделе «Ролевая модель и права доступа».
Row level security#
Механизм ограничения доступа пользователей к отдельным строкам в таблицах.
Защита от привилегированных пользователей#
В СУБД Platform V Pangolin используется механизм защиты данных от привилегированных пользователей, построенный на принципе разделения ролей.
В стандартном PostgreSQL привилегированные пользователи имеют доступ к объектам БД и настройкам подключения:
администраторы БД имеют произвольный доступ к любым пользовательским данным, что может привести к утечкам конфиденциальной информации;
администраторы ОС могут менять настройки БД таким образом, чтобы получать доступ к пользовательским данным, что тоже ведет к утечкам.
Администраторы БД и ОС в Platform V Pangolin теряют возможность самостоятельно управлять некоторыми параметрами и перестают иметь полный доступ ко всем объектам БД, в отличие от стандартного PostgreSQL.
В дополнение к роли суперпользователя, которая есть в стандартной версии PostgreSQL, в Pangolin можно создать специальную роль Администратора безопасности (АБ). Роль Администратора безопасности внутри БД недоступна для изменения суперпользователем (подробнее в документе «Руководство администратора» раздел «Защита от привилегированных пользователей»).
Подробнее о функциях в «Документации на публичные API», раздел «Защита от привилегированных пользователей».
Внимание!
Имеется опасность свободного использования расширения
pageinspectи схожих с ним на БД с включенной защитой от привилегированных пользователей, в связи с тем чтоpageinspectпозволяет посмотреть расшифрованные данные и не учитывает защиту от привилегированных пользователей.
Защита схемы#
Реализованная функциональность расширяет список типов защищаемых объектов возможностью защиты всех объектов в схеме, через защиту схемы.
В случае необходимости усилить защиту отдельного объекта схемы, он может быть поставлен под защиту индивидуально, тогда права доступа будут выданы именно на этот защищаемый объект. Таким образом, нахождение объекта под индвидуальной защитой аннулирует политики доступа к этому объекту, предоставляемые через схему.
Типы защищаемых объектов:
function;table;view;matview;partitioned;role;schema.
Аргументы функций настройки механизма защиты могут принимать следующие значения:
действия над объектами типа function:
alter,call,drop;действия над объектами типа table, view:
alter,alter_rule,alter_trigger,create_rule,create_trigger,delete,drop,drop_rule,drop_trigger,insert,select,update,move(только для типа table);действия над объектами типа matview:
alter,drop,select,move;действия над объектами типа partitioned:
alter,delete,drop,insert,select,update,move;действия над объектами типа role:
alter,be_granted,be_revoked,drop,grant_to,revoke_from,set_role;действия над объектами типа schema:
alter,drop.
Наименование объекта — это составное имя объекта: <имя схемы>.<имя объекта>. Так как поиск объектов по имени происходит только в базе подключения, то такой идентификатор в сочетании с типом объекта однозначно определяет объект.
Исключения из правил наименования объектов:
Для типа объектов типа schema в качестве имени объекта используется непосредственно имя схемы.
Для модификации правил доступа к типам объектов в защищенной схеме в качестве имени объекта используется конструкция со спецсимволом
<>.*.В наименование роли не входит имя схемы.
Прозрачное шифрование данных#
В СУБД Platform V Pangolin используется прозрачное шифрование данных (TDE). С его помощью шифруются данные, хранящиеся в файлах данных, журналах изменений, резервных копиях и временных файлах баз данных, а также данные, передаваемые по каналам связи в ходе физической и логической репликации.
Для шифрования данных используется симметричный алгоритм блочного шифрования AES-256-CTR. Длина ключа механизма шифрования зависит от подключенного плагина шифрования. В Pangolin реализованы плагины для 128/192/256 бит. Ключи шифрования организуются в двухуровневую иерархию, корнем которой является регулярно изменяющийся мастер-ключ. Мастер-ключ используется для шифрования ключей второго уровня (ключей шифрования объектов баз данных).
Ключи шифрования второго уровня не ротируются, поэтому при смене мастер-ключа перешифровывать данные не требуется. Ротация мастер-ключа инициируется и выполняется на узле Active в кластере.
Концептуальная архитектура инфраструктуры шифрования и управления ключами:
Концептуальная архитектура Pangolin при реализации прозрачного шифрования представлена на схеме:
Для восстановления шифрования ключей при внезапном падении БД в процессе перешифрования ключей, реализуется функция восстановления шифрования.
Все серверы кластера периодически проверяют соответствие текущего мастер-ключа мастер-ключу из KMS. При обнаружении несоответствия выполняется процедура перешифрования: ключи второго уровня расшифровываются старым мастер-ключом и зашифровываются актуальным мастер-ключом, получаемым из KMS.
Двухуровневая система решает две задачи:
уменьшает объем данных в хранилище секретов;
позволяет не перешифровывать все данные при смене мастер-ключа.
Мастер-ключ#
Мастер-ключ является корневым ключом шифрования, регулярно изменяется. Мастер-ключ хранится в KMS (используется хранилище key-value в KMS).
Мастер-ключ устанавливается при первом запуске БД, также при необходимости сотрудник безопасности может установить его вручную в KMS. При смене мастер-ключа процесс установки нового мастер-ключа шифрования БД в KMS инициирует сотрудник безопасности, если новый мастер-ключ не был указан, то он генерируется автоматически.
В хранилище секретов KMS группа параметров и ключей шифрования кластера баз данных Pangolin размещена по пути postgresql/<id кластера>/keys (<id кластера> задается при установке):
ключ
actual_master_key— метка актуального мастер-ключа. При возможности, используется версионирование значений;ключ
prev_master_key— метка предыдущего мастер-ключа. При возможности, используется версионирование значений;ключ
wal_key— значение ключа шифрования WAL кластера. При возможности, используется версионирование значений;ключи
master_key_value_<timestamp>— значение мастер-ключа, где<timestamp>— дата и время в формате ГГГГММДД_ЧЧммСС (ГГГГ — год в формате 4 цифры, ММ — месяц с ведущим нулем при необходимости, ДД — день с ведущим нулем при необходимости, ЧЧ — часы в формате 24 часа, с ведущим нулем при необходимости, мм — минуты с ведущим нулем при необходимости, СС — секунды с ведущим нулем при необходимости).
Примечание:
id кластера можно уточнить на сервере:
в переменной окружения CLNAME;
в СУБД по значению параметра сервера
cluster_name:postgres=# SHOW cluster_name; cluster_name -------------- temp_install (1 row)
Ключи шифрования объектов БД#
Ключи шифрования объектов БД, а также параметры соединения с KMS, хранятся на сервере БД. Они относятся к ключам второго уровня и зашифрованы мастер-ключом. Ключи шифрования второго уровня не меняются, это позволяет не перешифровывать данные в случае смены мастер-ключа.
Файлы, хранящиеся на сервере БД:

Файл
enc_conn_settings.cfg(зашифрован) не включается в резервные копии БД, является настройкой экземпляра СУБД. Хранится в директории/etc/postgres, владелец (kmadmin_pg). Файлenc_conn_settings.cfgсоздается при настройке соединения с KMS путем запуска утилитыsetup_kms_credentialsадминистратором безопасности.Содержит:
параметры соединения с KMS;
зашифрованные credentials для соединения с KMS.
Файл
enc_settings.cfgвключается в резервные копии БД, хранится в директории$PGDATA/global, владелец (postgres). Файлenc_settings.cfgсоздается при первом старте БД.Содержит:
метку (ключ в KMS) актуального мастер-ключа шифрования;
метку (ключ в KMS) предыдущего мастер-ключа шифрования;
флаг необходимости шифрования WAL — по умолчанию включен.
Пример:
$PGDATA/global/ -rw------- 1 postgres postgres 84 Sep 28 10:59 enc_settings.cfg $ cat $PGDATA/global/enc_settings.cfg active_master_key_id = master_key_value_20220412_131233_249 kms_domain = postgresqlФайл
enc_keys.jsonвключается в резервные копии БД, содержит ключи шифрования табличных пространств, отношений и журналов WAL. Файл создается и хранится в директории$PGDATA/global, владелец (postgres), содержит следующие данные:controlBlock— контрольный блок, состоящий из: метки мастер-ключа, OID базы данных объекта, типа объекта и OID самого объекта, зашифрованный ключом шифрования;dataBaseId— oid базы данных объекта;encryptionKey— ключ шифрования объекта в зашифрованном виде.objectId— OID объекта, которому назначен соответствующий ключ шифрования. Для WAL должен бытьnull;pgObjectType— тип объекта, которому назначен соответствующий ключ шифрования.W— WAL,T— табличное пространство,R— отношение.
Пример:
$PGDATA/global/ -rw------- 1 postgres postgres 108916 Sep 28 10:59 enc_keys.json $ cat $PGDATA/global/enc_keys.json … { "controlBlock" : "OuxU2QLXJqOOUO2g/Sd83yGcSrbw43gMqMgTqo3v223M5m5kpBsxxY3nxGqL7RVq7QCPBIim93m5FBfFN6MaeaElz1KozXe6FeUINaFkK9aI3goAWRqfuV5FdXM6zox7iffoDWvaQfUhvkiP59Ut4g==", "dataBaseId" : 16403, "encryptionKey" : "FjbpCUKkMTgFmhtsVyW0qaGsfa4hovq0BTfuWR4sLeA=", "objectId" : 16774, "pgObjectType" : "R" }, { "controlBlock" : "zN+30qJjNZEY1KxEYVRAKor/e68meOYMLF6Zl334k8Enp68WQsCKlpB4baj3o3ezauEKlA+JSCe64bmBWV8DT9VO+BODlRkX06gB9g==", "encryptionKey" : "QXBAaVs952vYNGvje7Qy+DOcADi2lMNFQXv4DEe2sbw=", "pgObjectType" : "W" }
Средства криптографической защиты информации#
В качестве СКЗИ используется открытая криптографическая библиотека OpenSSL. Она обеспечивает шифрование трафика между сервером и клиентом, а также используется как провайдер алгоритмов шифрования для механизма прозрачного шифрования данных.
Автоматическое завершение неактивных соединений#
Соединения, остающиеся неактивными определенное время, подлежат принудительному завершению. Для завершения таких соединений используется фоновый процесс, осуществляющий мониторинг и завершение бездействующих клиентских сеансов. Этот процесс запускается при старте сервера СУБД Platform V Pangolin и завершается вместе с остановкой сервера.
Процесс регулируется двумя параметрами:
check_idle_time_delay— интервал мониторинга в миллисекундах;backend_idle_alive_time— допустимое время бездействия в секундах.
Если хотя бы один из этих параметров равен нулю, неактивные соединения завершаться не будут.
Функция генерации и установки постоянного пароля технологической УЗ#
Параметр rotate_password.valid_roles находится под защитой от привилегированных пользователей, и администратор безопасности участвует в его изменении. Более подробная информация приведена в документе «Руководство администратора», раздел «Генерация и установка постоянного пароля технологической УЗ»
Поддержка очередей сообщений#
Поддержка очередей сообщений в СУБД Pangolin реализуется взаимодействием следующих компонентов:
расширение pgq, предоставляющее реализацию монопольной очереди (включает в себя менеджер очереди
pgqd(версия 3.5);расширение pgq-coop, позволяющее организовывать кооперативные очереди сообщений.
Функциональность очередей сообщений позволяет:
определять очереди для передачи списка текстовых сообщений от генератора сообщений (producer) в сторону одного или нескольких подписчиков (subscriber) с использованием механизма монопольных или кооперативных очередей;
организовывать очереди сообщений между разными сущностями СУБД вне зависимости от версии СУБД и разрядности операционной системы;
накапливать сообщения от генератора и организовывать сеансы получения сообщений очереди (batch);
получить сообщение (event) повторно через определенное время без возможности приоритизации;
использовать менеджер сообщений средствами приложения, либо с использованием штатного менеджера сообщений;
управлять получением сообщений (event) в одном сеансе (batch), в том числе с фильтрацией по содержимому сообщений;
автоматически добавлять сообщения (event) в определенную очередь (queue) посредством триггеров.
Глобальные индексы и глобальные констрейнты на партиционированные таблицы#
В Pangolin реализован механизм глобальных индексов, способных физически покрывать сразу множество таблиц и обеспечивающих ограничение уникальности по набору атрибутов (не включающих ключ партиционирования).
Структура глобального индекса является комбинацией двух независимых структур данных - моноиндекса и эпииндекса.
Примечание:
Для высоконагруженных систем, выполняющих DML-операции без использования ключа секционирования, рекомендуется обратить внимание на количество создаваемых секций, так как для каждой секции, в момент выполнения операции, на уровне ядра СУБД выставляются дополнительные блокировки
RowExclusiveLockиAccessShareLockв представленииpg_locks, что потенциально может привести к исчерпанию ограниченияmax_locks_per_transactionи деградации производительности, связанной с ожиданиемLockManager.Оптимальное количество секций зависит от профиля нагрузки на систему.
Моноиндекс#
Моноиндекс - это логически и физически цельный индекс, покрывающий несколько таблиц одновременно. Поиск по ключу выдает кортежи, находящиеся в разных таблицах. В Pangolin моноиндекс реализован как B±Tree индекс, в листовых страницах которого хранятся не только CTID, но и OID таблицы. Это приводит к увеличению индексных кортежей листовых страниц на 4 байта.
Так как индексный кортеж в моноиндексе содержит информацию о таблице, в которую указывает CTID, все базовые операции, связанные с чтением кортежа из таблицы после сканирования, используют механизм подмены отношения:
Чтение
OID-атрибута из индексного кортежа.Обращение к кешу моноиндекса по заданному
OID:если кеш вернул
NULL, то обрабатывается индексный кортеж, ссылающийся на запись в таблице, которая не видна ни одной транзакции;если возвращено валидное состояние открытого отношения, то индексный кортеж является ссылкой на запись. В таком случае чтение и проверка видимости будут происходить непосредственно в этом отношении.
Кеш моноиндекса инициализируется в начале внешней операции, освобождается по ее завершении и состоит из:
хеш-таблицы
H = (OID, Relation), отображающейOIDв состояние открытого отношения;упорядоченного списка
S = \[OID\]идентификаторов таблиц, покрываемых моноиндексом.
Вместо вставки в пустой индекс всех кортрежей всех партиций для ускорения построения моноиндекса в СУБД Pangolin введен метод построения слиянием (метод доступа ambuildmerge).
Слияние B±Tree
Листовой уровень страниц в B±Tree представляет собой упорядоченный связный список. Если для какого-то отношения имеется B±Tree индекс, необходимость в сортировке кортежей этого отношения по соответствующем набору атрибутов отсутствует. Метод построения слиянием использует этот факт для слияния множества B±Tree индексов с одинаковым определением в единый моноиндекс.
Алгоритм построения монодинекса слиянием:
Инициализация итераторов: для каждого индекса открывается, привязывается и блокируется на чтение буфер, соответствующий крайней левой странице. Итераторы предоставляют интерфейс последовательного чтения индексных кортежей.
Инициализация двоичной кучи, куда вставляются итераторы каждого индекса. Двоичная куча выдает итератор, указывающий на кортеж с минимальным ключом. Это аналог
k-way merge-алгоритма для объединенияkотсортированных массивов в один отсортированный.Bulk-loading кортежей в новый индекс, где двоичная куча предоставляет интерфейс отсортированного массива всех кортежей из всех индексов.
Ниже приведена схема слияния B±Tree:
Процесс построение моноиндекса для партиционированной таблицы:
последовательное построение временных локальных индексов для каждой партиции;
слияние всех индексов в моноиндекс;
удаление временных локальных индексов.
При отсоединении партиции, т.е. при вызове ALTER TABLE DETACH PARTITION, моноиндекс не изменяется, а все ссылки на кортежи отсоединенной партиции остаются в нем. При выполнении операций подмена отношения для индексных кортежей, ссылающихся на отсоединенные партиции, возвращает NULL.
При использовании VACUUM (не FULL) со страниц моноиндекса удаляются все индексные кортежи, подмена отношений для которых возвращает NULL.
Эпииндекс#
Эпииндекс представляет собой секционированный индекс, который реализует логический уровень для управления несколькими дочерними индексами с одинаковым определением как одним. Структура дочерних индексов может быть любой. В Pangolin добавлена поддержка эпииндекса над B+-Tree-индексами. Во избежание создания виртуальной структуры, эпииндекс - это реальный B+-Tree-индекс, у которого есть дочерние B+-Tree-индексы. В контексте глобальных индексов эпииндекс представляет из себя моноиндекс с дочерними локальными индексами. Моноиндекс должен содержать ссылки на кортежи всех партиций, для которых не существует дочернего локального индекса.
В общем случае глобальный индекс - это эпииндекс. Ниже приведена схема его структуры:
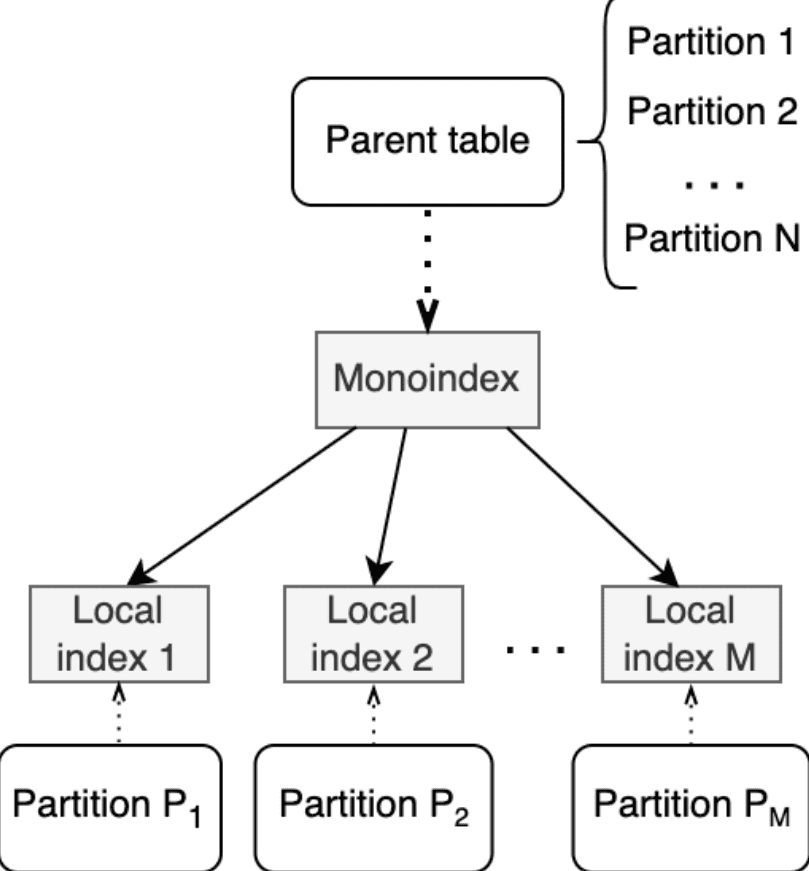
В зависимости от количества дочерних индексов в эпииндексе и их размера, в каких-то случаях эффективнее работать с моноиндексом без дочерних локальных индексов. В таких случаях команда ALTER INDEX UNITE производит объединение родительского моноиндекса и дочерних индексов в новый моноиндекс, при этом удаляя дочерние:
ALTER INDEX name UNITE;
Сканирование эпииндекса
Сканирование эпииндекса состоит из объединения результатов сканирования всех его сабиндексов.
Append:
Index Scan using monoindex
Index Scan using local index 1
...
Index Scan using local index M
Проверка уникальности в эпииндексе
При вставке в уникальный глобальный индекс проверка на уникальность проводится по всем индексам в эпииндексе. При этом на все части захватывается блокировка RowExclusiveLock.
ALTER TABLE ATTACH
В случае присоединения новой партиции происходит создание временного локального сабиндекса. В случае уникального глобального индекса во время построения локального индекса, после этапа сортировки кортежей, происходит последовательное сравнение массива отсортированных кортежей и части эпииндекса на пересечение. Для этого используется алгоритм, схожий с merge-этапом алгоритма merge-sort, который одновременно итерируется по листовым страницам индекса и отсортированным кортежам. В данном случае на все части эпииндекса устанавливается блокировка ShareRowExclusiveLock.
ALTER INDEX UNITE
В зависимости от количества дочерних индексов в эпииндексе и их размера в некоторых случаях эффективнее работать с моноиндексом без дочерних локальных индексов. Команда ALTER INDEX UNITE производит объединение родительского моноиндекса и дочерних индексов в новый моноиндекс, при этом удаляя дочерние:
ALTER INDEX name UNITE;
Эта команда конкурентная и состоит из следующих шагов:
захват блокировки
ShareUpdateExclusiveLockна родительскую таблицу и все части эпииндекса;создание пустой копии моноиндекса;
ambuildmerge- слияние всех частей моноиндекса. При этом параллельные транзакции могут модифировать данные в частях эпииндекса;ожидание завершения всех транзакций, для которых видны части эпииндекса;
взятие
ShareLockна части эпииндекса;валидация индекса: сравнение его кортежей с кортежами во всех частях эпииндекса, вставка недостающих кортежей;
замена старого моноиндекса;
удаление дочерних индексов.
Процесс автообъединения глобальных индексов#
Для обеспечения фонового объединения глобальных индексов в продукт добавлены процессы автообъединения. Процесс автообъединения может быть запускающим или выполняющим работу по автообъединению.
Запускающий процесс находится в памяти все время и через autounite_naptime запускает процесс, выполняющий работу по автообъединению в выбранной БД. Данный процесс запускается для одной базы данных и объединяет все глобальные индексы, имеющие потомков и соответствующие настройкам автообъединения. По умолчанию процесс автообъединения происходит для всех глобальных индексов, имеющих потомков.
Настройки автообъединения:
autounite- флаг запуска процесса автообъединения. Тип:bool. По умолчанию:true.autounite_naptime- задержка в секундах между выполнениями автобъединения на одной базе данных. Тип:int. По умолчанию:60секунд.autounite_parent_children_size_ratio- соотношение суммарного размера индексов потомков к размеру глобального индекса предка, при превышении которого будет выполняться автообъединение.0- автобъединение без анализа соотношения размеров;1- соотношение предка к потомкам1:1(объединение будет выполнено, как только суммарный размер индексов потомков превысит размер глобального индекса предка);2- соотношение предка к потомкам1:2(объединение будет выполнено, как только суммарный размер индексов потомков превысит 1/2 от размера глобального индекса предка). Тип:int. Диапазон:0 - 1024. По умолчанию:0.autounite_max_children_count: максимальное количество потомков глобального индекса, не вызывающее автообъединения.0- автобъединение без анализа количества потомков. Тип:int. Диапазон:0 - INT_MAX. По умолчанию:0.autounite_pause_period- период времени, в которыйautouniteне работает. Задается в 24-х часовом формате через дефис. ФорматЧЧ-ЧЧ, допускается писать одну цифру, если первая0(01и1читаются одинаково). Например,'11-13'задает период бездействия с11-00до12:59:59. Тип:string. По умолчанию:'', что значит, что период бездействия отсутствует.
Autovacuum глобальных индексов#
Сборщик статистики для партиционированной таблицы, у которой есть хотя бы один глобальный индекс, собирает информацию о количестве записей в партициях, отсоединенных в pg_stat_all_tables.n_dead_tuples. В процесс autovacuum launcher добавлена обработка партиционированных таблиц. Для них запускается очистка, если pg_stat_all_tables.n_dead_tuples >= autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * reltupes, где reltuples - это сумма pg_class.reltuples всех партиций. Очистка - специальный вид постраничной очистки B-Tree, не требующий сканирования таблиц и удаляющий все индексные кортежи, которые относятся к уже отсоединенным партициям. После очистки значение pg_stat_all_tables.n_dead_tuples для партиционированной таблицы обнуляется.
Параметры autovacuum на уровне таблицы:
autovacuum_vacuum_threshold- целое положительное число, свободный коэффициент в неравенствеautovacuum launcher;autovacuum_vacuum_scale_factor- коэффициент, определяющий суммарную долю записей в партициях;autovacuum_enabled- булевый параметр, для включения/отключенияautovacuumна уровне таблицы.
Создание глобального индекса#
Синтаксис для создания глобального индекса:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON [ ONLY ] table_name
[ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass [ ( opclass_parameter = value [, ... ] ) ] ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ INCLUDE ( column_name [, ...] ) ]
[ WITH ( storage_parameter [= value] [, ... ] ) ]
[ GLOBAL ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
Глобальные индексы реализуются как надстройка над механизмом B+-tree-индексов PostgreSQL. Объявление индекса как глобального выполняется через указание клаузы GLOBAL в запросе CREATE INDEX для партиционированной таблицы. Для индексов по другим видам отношений клауза GLOBAL смысла не имеет, а запрос создания глобального индекса будет завершаться с ошибкой. Уникальность глобального индекса, аналогично не глобальному индексу, определяется через клаузу UNIQUE в запросе CREATE INDEX.
Глобальный индекс поддерживает операции над партициями и партиционированными таблицами - ATTACH, DETACH, DROP, VACUUM, VACUUM FULL, REINDEX, а также DML-операции.
Статистическая информация о файле глобального индекса корректно отображается в представлениях pg_stat_all_indexes и pg_statio_all_indexes.
Команда psql \di+, выборки из каталогов pg_class и pg_index позволяют однозначно идентифицировать глобальный индекс как глобальный, а также получить информацию занимаемому им объему памяти. Выборка из каталога pg_inherits позволяет однозначно определить все дочерние индексы глобального индекса.
Настроечные параметры фонового процесса автоматического слияния глобальных индексов поддерживаются как валидатором компонента оркестратора кластера высокой доступности (Pangolin Manager), так и пользовательским конфигурационным файлом инсталлятора Pangolin.
Глобальный индекс поддерживает перемещение между табличными пространствами через команду ALTER INDEX SET TABLESPACE и перемещение партиций между табличными пространствами через команду ALTER TABLE SET TABLESPACE.
Создание глобального индекса успешно попадает в дамп схемы базы данных при использовании утилит pg_dump и pg_dumpall, в том числе в режиме --binary-upgrade для работы утилиты pg_upgrade.
Данные в глобальном индексе подпадают под шифрование TDE.
Функциональность глобального индекса входит в лицензию Platform V Pangolin Enterprise. Без данной лицензии создание новых глобальных индексов недоступно (при последующем понижении лицензии с Platform V Pangolin Enterprise функционирование ранее созданных глобальных индексов сохраняется).
Внимание!
Ограничения при использовании глобальных индексов:
Глобальный индекс реализуется только для типа
B+-tree.Операция кластеризации, исключения и предикаты на состав индекса, а также субпартиционирование не поддерживаются.
Глобальный индекс не может использоваться в качестве первичного ключа.
В текущей архитектуре ядра очистка страниц индекса не может выполняться параллельно двумя процессами. Так как операция
VACUUMдля партиции приводит к удалению ссылок на ее кортежи в глобальном индексе, может возникнуть ситуация одновременной попытки очистки глобального индекса несколькими процессами. Во избежание коллизий на уровне постраничной очистки процесс будет пытаться захватить блокировкуShareUpdateExclusiveLock,которая доступна только одной транзакции.
Глобальные констрейнты#
Для партиционированных таблиц поддерживаются два вида глобальных констрейнтов с использованием глобальных индексов:
глобальный первичный ключ;
глобальный уникальный ключ.
Особенности глобальных констрейнтов:
могут быть построены только по партиционированной таблице;
ссылаются на уникальный глобальный индекс, привязанный к партиционированной таблице, а не на его сабиндекс для соответствующей партиции. Таким образом, зависимость от констрейнта на партиционированной таблице и всех ее партициях имеет не сабиндекс, соответствующий партиции, а глобальный индекс, привязанный к партиционированной таблице;
могут быть построены по любому уникальному
NOT NULL-полю, имеющемуся в каждой из партиций таблицы, при этом включение полей ключа партиционирования не является обязательным;не могут быть построены по партиционированным таблицам с субпартициями в силу ограничений существующей реализации глобальных индексов;
на созданные глобальные констрейнты могут ссылаться внешние ключи с любых других таблиц, при этом ограничения целостности поддерживаются в полном объеме;
в системном каталоге
pg_constraintглобальным констрейнтам соответствуют новые значения поляcontype:'P'- для глобального первичного ключа,'U'- для глобального уникального ключа;под глобальными констрейнтами работает механизм глобальных индексов, поэтому для обслуживания физической структуры глобальных констрейнтов необходимо применять инструментарий глобальных индексов, включая конструкцию
ALTER TABLE .. UNITEпо соответствующему индексу, а также процесс автообъединения глобальных индексов.
Синтаксис создания глобальных констрейнтов базируется на синтаксисе создания констрейнтов партиционированных таблиц с добавлением клаузы GLOBAL.
Пример 1:
CREATE TABLE t1 (
id bigint PRIMARY KEY GLOBAL,
someint bigint
) PARTITION BY RANGE (someint);
Пример 2:
CREATE TABLE measurement_1 (
id int not null,
logdate date not null,
peaktemp int not null,
unitsales int,
CONSTRAINT m_ui UNIQUE(peaktemp) GLOBAL
) PARTITION BY RANGE (id, logdate);
Пример 3:
CREATE TABLE measurement_2 (
id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (id, logdate);
ALTER TABLE measurement_2 ADD PRIMARY KEY (logdate) GLOBAL;
Процесс резервного копирования и восстановления глобальных констрейнтов (dump/restore)#
Глобальные констрейнты выгружаются без параметра ONLY в конструкциях ALTER TABLE .. ADD CONSTRAINT. Это обусловлено тем, что в процессе создания глобального индекса требуется создание сабиндексов по партициям партиционированной таблицы, а добавление параметра ONLY блокирует такое построение.
В режиме восстановление логического дампа --binary-upgrade происходит отключение этого режима на время построения сабиндексов глобального индекса глобального констрейнта. Это связано тем, что задаваемый в дампе OID индекса относится только к самому глобальному индексу и не может быть спроецирован на строящиеся в процессе создания глобального индекса дочерние сабиндексы. При завершении построения глобального индекса режим --binary-upgrade возобновляется, а построенные сабиндексы удаляются и не должны препятствовать дальнейшему созданию отношений с OID, задействовавшимися в процессе построение глобального индекса.
Трассировка сессии#
СУБД Pangolin предоставляет механизм трассировки (включения/выключения отладочной печати) с различными уровнями детализации. Суперпользователь может использовать этот механизм для любой сессии, в рамках которой действие не запрещено правилами защиты от действий привилегированного пользователя.
Трассировка записывается на сервере СУБД в файл, путь к которому указывается в значении параметра сервера, а имя либо формируется по умолчанию из PID серверного процесса и уникального идентификатора, либо задается перед включением трассировки параметром на уровне сессии.
Содержание файла трассировки:
заголовок;
строка-описание для каждого из запросов;
строка-описание для каждой из фаз жизненного цикла запроса;
переменные привязки;
ожидания (по каждому из одиночных событий ожидания, в том числе блокировок);
предварительный план по операциям (переносится в файл во время полного закрытия курсора успехом или ошибкой);
реальный план выполнения по операциям (переносится в файл во время полного закрытия курсора успехом или ошибкой);
ошибка при разборе или выполнении запроса;
диагностика и стек вызовов для исключений PL/pgSQL.
По умолчанию файл трассировки имеет имя вида: <PID>_<YYYYMMDDHHMISS>, где PID - pid процесса сессии, YYYYMMDDHHMISS - временная метка начала формирования файла трассировки во временной зоне сервера СУБД (с точностью до секунд).
Файл трассировки параллельных процессов, порождаемых трассируемой сессией, имеет формат имени <SESSION_FILE_NAME>_parallel, где SESSION_FILE_NAME - имя файла родительской трассировки для данных процессов. Все трассировки параллельных процессов сохраняются в один файл, но в процессе их формирования для каждого из процессов будет создаваться свой файл с именем <SESSION_FILE_NAME>_<WORKER_PID>_<WORKER_YYYYMMDDHHMISS>, где SESSION_FILE_NAME - имя файла родительской трассировки, WORKER_PID - PID параллельного процесса, WORKER_YYYYMMDDHHMISS - временная метка начала формирования файла трассировки параллельного процесса во временной зоне сервера СУБД (с точностью до секунд).
Виды запросов, для которых фиксируется вышеуказанная информация:
одинарные запросы;
PL/pgSQL-запросы;многострочные запросы;
динамические запросы, выполняемые через
PL/pgSQL;подготовленные запросы, выполняемые через SQL-инструкции
PREPARE,EXECUTE,DECLARE CURSORиFETCH;подготовленные запросы, выполняемые через расширенный протокол;
запросы, выполняемые расширениями и триггерами через
SPI;многострочные запросы с конструкциями
SAVEPOINTиCOMMIT/ROLLBACK TO SAVEPOINT;иерархически организованные запросы (например, запросы, выполняемые функциями расширений в процессе выполнения запросов, или динамические запросы из
PL/pgSQL). Запросы организуются в иерархическую структуру, позволяющую определить их взаимное отношение.
Уровни трассировки#
Поддерживаются следующие уровни трассировки, комбинируемые через логическое ИЛИ:
NONE - значение 0, отсутствие трассировки сессии;
BASE - значение 1, базовая трассировка;
BIND - значение 2, добавляет вывод переменных привязки;
LOCK - значение 4, добавляет вывод информации о блокировках, как LWLock, так и Lock;
RESOURCE - значение 8, добавляет вывод информации о потребляемых всеми операциями ресурсах.
Примечание:
Изменить уровень трассировки для сессии с уже установленным уровнем трассировки возможно только через остановку трассировки сессии (то есть установить уровень трассировки
NONE)с последующим включением трассировки уже с обновленным уровнем. Это необходимо для явного разделения файлов трассировки по уровням. При указании того же имени файла, которое использовалось ранее, будет возвращено сообщение об ошибке, так как файл уже существует.
Параметры настройки#
Имя параметра |
Тип |
Значение по умолчанию |
Допустимые значения |
Комментарий |
|---|---|---|---|---|
|
bool |
|
|
При включении параметра начинается накопление информации по текущему выполняемому запросу в т.ч. при отсутствии включенной для сессии трассировки). Это необходимо для ее последующего сброса при включении трассировки в середине выполнения запроса. При выключении исключается влияние функциональности на производительность |
|
integer |
|
|
Уровень трассировки по умолчанию, работает в комбинации с параметром |
|
integer |
|
|
Максимальный размер файлов трассировки (в кБ). При значении |
|
string |
|
Любое |
Путь к директории по умолчанию для сохранения файлов трассировки. При значении |
|
string |
|
Любое |
Список имен пользователей, через запятую, для сессий которых автоматически должна устанавливаться трассировка с уровнем |
Примечание:
Изменять приведенные выше параметры может только роль с правами суперпользователя. После внесения изменения требуется перезапуск СУБД.
Включение функциональности выполняется только через изменение параметра
session_tracing_enable. Это обусловлено необходимостью выделения ресурсов общей памяти для обслуживания функциональности.
Внимание!
Включение функциональности трассировки сессий через установку настроечного параметра
session_tracing_enableв значениеonможет привести к снижению производительности запросов. Это связано с необходимостью предварительной подготовки и накопления трассировочной информации по выполняемым запросам при включении трассировки сессии в процесс их выполнения.
Функции API#
start_session_tracing#
Входные параметры:
pid;уровень трассировки;
имя файла трассировки (
NULLили пустая строка).
Выходной результат:
Успешное завершение / ошибка.
Возвращаемых значений нет.
Поведение функции:
Функция включает трассировку для сессии с указанным PID, уровнем трассировки, и, опционально, именем файла. Если имя файла будет задано как NULL или пустой строкой, то будет сгенерировано имя файла трассировки по умолчанию.
При успешном включении трассировки в лог будет выведено следующее сообщение:
"Process <PID> is signaled tracing to ON with level <уровень трассирвоки> for filename "<путь к файлу трассировки>""
При выключенной функции трассировки выводится ошибка:
"Session tracing isn't enabled"
При заданном уровне трассировки 0 выводится сообщение:
"Cannot start session tracing for process <PID> with level 0"
При попытке включения трассировки для сессии с уже включенной трассировкой будет получено сообщение:
"Session tracing for process <PID> already set"
При отсутствии процесса с указанным PID, в том числе, когда сессией управляет не суперпользователь (или владелец), будет получено сообщение вида:
"No process with PID <PID> for a session tracing"
stop_session_tracing#
Входные параметры:
pid.
Выходной результат:
Успешное завершение / ошибка.
Возвращаемых значений нет.
Поведение функции:
Функция выключает трассировку для сессии с указанным PID.
При успешном выключении трассировки в лог выводится сообщение:
"Process <PID> is signaled tracing to OFF"
При выключенной функции трассировки будет получена следующая ошибка:
"Session tracing isn't enabled"
При попытке включения трассировки для сессии с уже включенной трассировкой будет получена ошибка:
"Session tracing for process <PID> not set"
При отсутствии процесса с указанным PID, в том числе когда сессией управляет не суперпользователь (или пользователь, не являющийся владельцем), будет получено сообщение вида:
"No process with PID <PID> for a session tracing"
Примечание:
Для обращения к функциям трассировки
start_session_tracingиstop_session_tracingпользователю необходимо иметь привилегии суперпользователя или иметь рольpg_tracing.Для включения и выключения трассировки через вызов функций
start_session_tracingиstop_session_tracingна процесс сессии требуется либо наличие привилегий суперпользователя, либо необходимо являться владельцем процесса (то есть быть тем пользователем, который запустил процесс), либо иметь рольpg_read_all_tracing.
psql_session_tracing#
Входные параметры:
pid(может бытьNULL).
Выходной результат:
Набор записей с полями:
pid;
перечисление текстовых представлений для уровней трассировки (например,
BASE | BIND | LOCK | RESOURCE);путь к файлу трассировки сессии.
Поведение функции:
Выводит список сессий с указанием их уровня трассировки и путей к файлам трассировки.
Выводятся только те сессии, для которых текущий пользователь имеет права на роль, запустившую сессию.
Пользователь с ролью pg_read_all_stats или суперпользователь видит все сессии.
При выключенной функции трассировки будет выведена ошибка:
"Session tracing isn't enabled"
Утилита генерации отчета trace_decode#
Утилита размещается в директории ${PGHOME}/bin/ и имеет следующие ключи запуска:
Ключ запуска |
Значения |
Комментарий |
|---|---|---|
-h, --help |
Без значений |
Вывод подсказки по работе утилиты |
-a |
Без значений |
Формирование агрегированного отчета |
-f |
TEXT или HTML |
Ключ может быть не указан, в таком случае будет использоваться формат HTML |
-p |
Путь к файлу трассировки |
Для корректного формирования отчета, при наличии соответствующего файла трассировки параллельных процессов сессии он должен размещаться в той же директории, что и файл трассировки сессии |
Отчет выводится в консоль. Для его вывода в файл необходимо перенаправить вывод stdout в файл с требуемым именем.
Структура отчета#
Основные блоки не агрегированного HTML-отчета:
Заголовок отчета c информацией о процессе (в том числе о
postmaster-процессе), временах запуска и версии продукта и СУБД.Уровень трассировки.
Значения всех GUC-переменных.
Блоки выполнения запросов.
Информация о незавершенном запросе (при его наличии).
Информация о незавершенном ожидании поступления запроса (при его наличии).
Суммарная информация о содержимом файла трассировки.
В агрегированном отчете каждый уникальный запрос указывается один раз. Блок запроса содержит обобщенную информацию о выполнении запроса и его потреблении ресурсов за все время трассировки. Сортировка запросов в агрегированном отчете выполняется в порядке убывания суммарной длительности выполнения запроса. При равной длительности - в порядке убывания количества выполнений запроса.
В не агрегированном отчете запросы указываются каждый раз, когда происходило их выполнение. Блок запроса содержит агрегированную информацию о выполнении запроса и о потреблении им ресурсов за одну команду. Сортировка запросов в не агрегированном отчете выполняется в порядке их выполнения.
Далее будет подробно рассмотрен состав каждого из блоков отчета.
Блок информации о запросе#
Подблоки:
Заголовок запроса, включая
queryId, текст запроса, значения параметровsession_user,current_role,search_pathиcurrent_schema. Также содержит временные метки начала и окончания выполнения запроса. При наличии в файле трассировки незавершенных запросов поле времени окончания запроса будет содержать значениеNot finished.Ошибка выполнения запроса. Опциональный, присутствует только при наличии ошибки. Содержит текст сообщения об ошибке и ее код.
Общая статистика выполнения запроса. Содержит информацию по количеству успешных выполнений запроса, откатов и ошибок. Также содержит информацию по количеству фаз выполнения запроса:
общее количество вызовов запроса извне;
обработка;
анализ;
перезапись;
планирование;
кеширование плана;
связывание переменных;
выполнение.
Информация о шагах выполнения. Для каждого шага приводится статистика по длительности его выполнения, и, при уровне трассировки
RESOURCE- о потреблении ресурсов. В агрегированном отчете приводится информация о минимальных, максимальных и суммарных временах выполнения фазы запроса, и потребленных ресурсах (при уровне трассировкиRESOURCE).Информация о легковесных блокировках (
LWLock). Отображается при уровне трассировкиLOCKи наличии таких блокировок во время выполнения запроса. Содержит агрегированную информацию о легковесных блокировках в порядке убывания суммарной длительности их ожидания и их количества. При уровне трассировкиRESOURCEпомимо длительности, содержит информацию о минимальном, максимальном и суммарном потреблении ресурсов процессом при ожидании блокировки.Информация о блокировках (
Locks). Отображается при уровне трассировкиLOCKи наличии таких блокировок во время выполнения запроса. Содержит агрегированную информацию о блокировках в порядке убывания суммарной длительности их ожидания и количества.Информация о порожденных запросах - содержит список всех запросов, для которых выполнялась хотя бы одна фаза в ходе выполнения текущего запроса. Формат идентичен формату описываемого блока запроса. Такие запросы могут возникать в ходе работы расширений, PL/pgSQL блоков, триггеров.
Информация о выполнении запроса. Детально описывает этап выполнения плана запроса.
Блок информации о потреблении ресурсов#
Раздел системных ресурсов включает в себя все показатели, которые выводятся только на уровне RESOURCE (кроме Duration):
Duration- длительность ожидания или операции (мс).Mem- память:ixrss- объем общей памяти;idrss- объем данных не в общей памяти;isrss- размер стека;minflt- ошибки программной страницы (soft page faults);majflt- ошибки страницы на диске (hard page faults).
IO- ввод/вывод:swap- не используется в Linux;inblock- количество операций ввода;outblock- количество операций вывода.
IPC- межпроцессные взаимодействия (не используются в Linux):msgsnd;msgrcv;nsignals.
CTX- переключения контекста:nvcsw- количество переключений контекста до истечения выделенного на процесс временного промежутка (например, при ожидании ресурса);nivcsw- количество переключений контекста по истечении процессного времени или количество переключений, осуществляемых процессом с более высоким приоритетом.
CPU- потребление CPU:user- в пользовательском режиме (мс);system- в режиме ядра (мс).
Раздел утилизации shared buffers:
shared buffer hits- число попаданий;shared disk blocks read- число прочитанных блоков;shared blocks dirtied- число измененных блоков;shared disk blocks written- число блоков, записанных изshared buffer;local buffer hits- число попаданий в локальный кеш блоков;local disk blocks read- число чтений локальных блоков;local blocks dirtied- число измененных локальных блоков;local disk blocks written- число записей локальных блоков;temp blocks read- число чтений временных блоков;temp blocks written- число записей временных блоков;time spent reading- время, потраченное на чтение блоков (мс);time spent writing- время, потраченное на запись блоков (мс).
Раздел утилизации WAL:
Records produced - количество созданных WAL-записей;
Full page images produced - количество
full page image-записей в WAL;Size of WAL records produced - общий объем памяти созданных WAL-записей.
Блок информации о легковесных блокировках#
Включает в себя подблок информации о последней легковесной блокировке (служит для определения длительности ожидания блокировки для незавершенного запроса):
Begin of latest lwlock- время начала ожидания;End of latest lwlock- время окончания ожидания;LWLock tranche Id- идентификатор потока, в состав которого входит блокировка (транш);LWLock tranche name- имя транша блокировки;LWLock mode- имя режима блокировки,LW_SHAREDилиLW_EXCLUSIVE.
Подблок, включающий в себе список всех легковесных блокировок в порядке убывания суммарной длительности ожидания:
LWLock tranche Id- идентификатор транша блокировки;LWLock tranche name- имя транша блокировки;LWLock mode- имя режима блокировки -LW_SHAREDилиLW_EXCLUSIVE;LWLock count- количество ожиданий блокировки;LWLock minimum resources- минимальные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL;LWLock maximum resources- максимальные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL;LWLock summary resources- суммарные ресурсы ожидания блокировки, не включают информацию поshared buffersи WAL.
Блок информации о блокировках#
Включает в себя подблок информации о последней легковесной блокировке (служит для определения длительности ожидания блокировки для незавершенного запроса):
Begin of latest lock- время начала ожидания;End of latest lock- время окончания ожидания;Lock type name- имя типа блокировки (соответствуют типам PostgreSQL);Lock mode- имя режима блокировки (соответствуют типам PostgreSQL);Описание объекта блокировки, в зависимости от типа (соответствуют типам PostgreSQL).
Подблок списка блокировок в порядке убывания суммарной длительности ожидания включает в себя информацию по каждой из блокировок:
Lock type name- имя типа блокировки (соответствуют типам PostgreSQL);Lock mode- имя режима блокировки (соответствуют типам PostgreSQL);Lock count- количество ожиданий блокировки;Описание объекта блокировки, в зависимости от типа (соответствуют типам PostgreSQL).
Блок выполнений запроса#
Включает в себя подблоки:
Query and environment- текст запроса, а также значения параметровsearch_path,current_schema,current_role,session_user.Error- сообщение об ошибке и код ошибки при ее возникновении в ходе выполнения плана запроса.Plan- план запроса. Может быть как предварительный, без детальной информации по шагам выполнения и их ресурсам (в случае незавершенного выполнения плана, то есть при длительном выполнении), так и окончательный, с детальной информацией по шагам выполнения и их ресурсам, в том числе при завершении с ошибкой.Common stats- статистика по количеству успешных, отмененных и завершенных с ошибкой выполнений.Binds- порядок, типы, флаги и значения связанных переменных. Только на уровне трассировкиBINDи при наличии связанных переменных. При включенномmasking_mode=fullна сервере все значения замаскированы.Resources- информация об утилизации ресурсов выполнения плана.LWLocks- информация о легковесных блокировках выполнения плана.Locks- информация о блокировках выполнения плана.Parallels- информация о параллельных процессах плана, включаяPIDпроцесса, блокировки и утилизацию ресурсов.
Блок информации об ожидании запроса#
Заголовок включает поля:
Times - количество ожиданий запросов;
Last started - время последнего начала ожидания поступления запроса;
Last finished - время последнего окончания ожидания поступления запроса (для незавершенных ожиданий будет отображаться
Not finished).
Также в блок включена информация об утилизированных ресурсах. Для агрегированного запроса - минимальных, максимальных и суммарных.
Блок сводной статистики#
Подблок статистики ожиданий запросов включает:
количество ожиданий запросов;
дату и время начала первого ожидания;
дату и время окончания последнего ожидания;
минимальные, максимальные и суммарные потребления времени, а при уровне трассировки
RESOURCE- и ресурсов на ожидание запросов (включая статистику по утилизации буферов и WAL).
Подблок статистики по запросам включает:
количество вызовов выполнения запросов;
количество подтвержденных транзакций;
количество отмененных транзакций;
количество ошибок;
минимальные, максимальные и суммарные потребления времени, а при уровне трассировки
RESOURCE- и ресурсов на выполнение запросов (включая статистику по утилизации буферов и WAL).
Также блок содержит информацию о порожденных параллельных процессах.