Макет страницы базы данных#
Примечание
Эта страница переведена нейросетью GigaChat.
Этот раздел предоставляет обзор формата страниц, используемого в таблицах и индексах PostgreSQL. Последовательности и таблицы TOAST отформатированы так же, как обычная таблица.
В следующем объяснении предполагается, что байт содержит 8 бит. Кроме того, термин элемент относится к отдельному значению данных, которое хранится на странице. В таблице элемент представляет собой строку; в индексе элемент является записью индекса.
Каждая таблица и индекс хранятся в виде массива страниц фиксированного размера (обычно 8 КБ, хотя при компиляции сервера можно выбрать другой размер страницы). В таблице все страницы логически эквивалентны, поэтому конкретный элемент (строка) может храниться на любой странице. В индексах первая страница обычно зарезервирована для метастраницы, содержащей управляющую информацию, а внутри индекса могут быть разные типы страниц в зависимости от метода доступа к индексу.
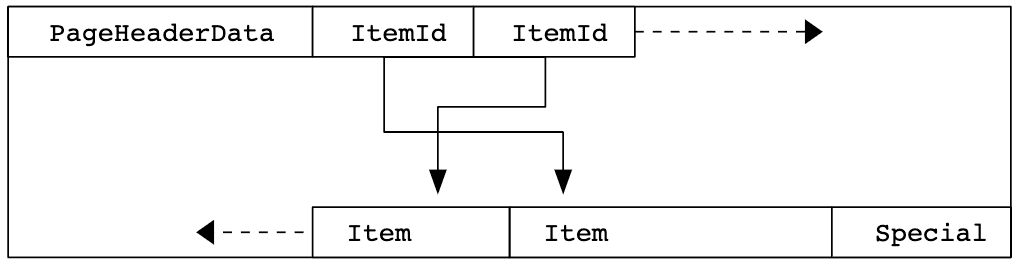
Таблица 73.2 показывает общую структуру страницы. На каждой странице есть пять частей.
Таблица 73.2. Общая компоновка страницы
Элемент |
Описание |
|---|---|
Заголовок страницы |
Длина 24 байта. Содержит общую информацию о странице, включая указатели свободного пространства. |
Данные элемента |
Массив идентификаторов элементов, указывающих на фактические элементы. Каждая запись представляет собой пару (смещение, длина). 4 байта на элемент. |
Свободное пространство |
Не распределенное пространство. Новые идентификаторы элементов распределяются с начала этой области, новые элементы - с конца. |
Элементы |
Фактические элементы сами по себе. |
Специальное пространство |
Метод доступа к индексу специфичен для конкретных данных. Разные методы хранят разные данные. Пусто в обычных таблицах. |
Первые 24 байта каждой страницы состоят из заголовка страницы (PageHeaderData). Первое поле отслеживает последнюю запись WAL, связанную с этой страницей. Второе поле содержит контрольную сумму страницы, если включены контрольные суммы данных. Далее следует двухбайтовое поле, содержащее флаговые биты. За этим следуют три двухбайтовых целых поля (pd_lower, pd_upper и pd_special). Они содержат смещения в байтах от начала страницы до начала неразмеченного пространства, до конца неразмеченного пространства и до начала специального пространства. Следующие два байта заголовка страницы, pd_pagesize_version, хранят как размер страницы, так и индикатор версии. Начиная с PostgreSQL 8.3 номер версии равен 4; PostgreSQL 8.1 и 8.2 использовали номер версии 3; PostgreSQL 8.0 использовал версию 2; PostgreSQL 7.3 и 7.4 использовали версию 1; предыдущие выпуски использовали версию 0. (Основная компоновка страниц и формат заголовков не изменились в большинстве этих версий, но изменилась компоновка заголовков строк кучи.) Размер страницы присутствует в основном только для перекрестной проверки; нет поддержки наличия более одного размера страницы в установке. Последнее поле - это подсказка, показывающая, вероятно ли, что обрезка страницы будет прибыльной: она отслеживает самый старый непрореженный XMAX на странице.
Макет PageHeaderData:
Поле |
Тип |
Длина |
Описание |
|---|---|---|---|
pd_lsn |
PageXLogRecPtr |
8 байт |
LSN: следующий байт после последнего байта записи WAL для последнего изменения этой страницы |
pd_checksum |
uint16 |
2 байта |
Контрольная сумма страницы |
pd_flags |
uint16 |
2 байта |
Флаги битов |
pd_lower |
Индекс местоположения |
2 байта |
Смещение начала свободного пространства |
pd_upper |
Индекс местоположения |
2 байта |
Смещение до конца свободного пространства |
pd_специальный |
Индекс местоположения |
2 байта |
Смещение начала специального пространства |
pd_размер_страницы_версия |
uint16 |
2 байта |
Информация о версии размера и макета страницы |
pd_prune_xid |
Идентификатор транзакции |
4 байта |
Самый старый непроходимый XMAX на странице или ноль, если его нет |
Все подробности можно найти в src/include/storage/bufpage.h.
После заголовка страницы следуют идентификаторы элементов (ItemIdData), каждый из которых требует четыре байта. Идентификатор элемента содержит смещение в байтах до начала элемента, его длину в байтах и несколько бит атрибутов, которые влияют на его интерпретацию. Новые идентификаторы элементов выделяются по мере необходимости с начала неразмеченного пространства. Количество присутствующих идентификаторов элементов может быть определено путем просмотра pd_lower, который увеличивается для выделения нового идентификатора. Поскольку идентификатор элемента никогда не перемещается до тех пор, пока он не будет освобожден, его индекс может использоваться в долгосрочной перспективе для ссылки на элемент, даже когда сам элемент перемещается по странице для компактного свободного места. Фактически, каждая ссылка на элемент (ItemPointer, также известная как CTID) создается PostgreSQL и состоит из номера страницы и индекса идентификатора элемента.
Сами элементы хранятся в пространстве, выделенном с конца неразмеченного пространства. Точная структура варьируется в зависимости от того, что должна содержать таблица. Таблицы и последовательности используют структуру под названием HeapTupleHeaderData, которая описана ниже.
Последний раздел - это «специальный раздел», который может содержать все, что метод доступа хочет сохранить. Например, индексы b-дерева хранят ссылки на левую и правую соседние страницы, а также некоторые другие данные, относящиеся к структуре индекса. Обычные таблицы вообще не используют специальный раздел (это указывается установкой pd_special равной размеру страницы).
На рисунке 73.1 показано, как эти части расположены на странице.
Рисунок 73.1. Макет страницы
Макет строки таблицы#
Все строки таблиц структурированы одинаково. Существует заголовок фиксированного размера (занимающий 23 байта на большинстве машин), за которым следует необязательная карта нулей, необязательное поле идентификатора объекта и пользовательские данные. Фактические пользовательские данные (столбцы строки) начинаются с смещения, указанного в t_hoff, которое всегда должно быть кратным расстоянию MAXALIGN для платформы. Карта нулей присутствует только в том случае, если бит HEAP_HASNULL установлен в t_infomask. Если она присутствует, то начинается сразу после фиксированного заголовка и занимает достаточно байтов, чтобы иметь один бит на каждый столбец данных (то есть количество битов, равное количеству атрибутов в t_infomask2). В этом списке битов бит 1 указывает не-нулевое значение, а бит 0 - нулевое. Когда карта нулей отсутствует, предполагается, что все столбцы не являются нулевыми. Идентификатор объекта присутствует только в том случае, если бит HEAP_HASOID_OLD установлен в t_infomask. Если он присутствует, он появляется прямо перед границей t_hoff. Любая необходимая подгонка для того, чтобы сделать t_hoff кратной MAXALIGN, появится между картой нулей и идентификатором объекта. (Это, в свою очередь, гарантирует, что идентификатор объекта правильно выровнен.)
Макет HeapTupleHeaderData:
Поле |
Тип |
Длина |
Описание |
|---|---|---|---|
t_xmin |
Идентификатор транзакции |
4 байта |
вставить штамп XID |
t_xmax |
Идентификатор транзакции |
4 байта |
удалить штамп XID |
t_cid |
Идентификатор команды |
4 байта |
вставка и/или удаление штампа CID (перекрывается с t_xvac) |
t_xvac |
Идентификатор транзакции |
4 байта |
XID для операции VACUUM перемещения версии строки |
t_ctid |
ItemPointerData |
6 байт |
текущий TID этой или более новой версии строки |
t_infomask2 |
uint16 |
2 байта |
количество атрибутов плюс различные флаги |
t_infomask |
uint16 |
2 байта |
различные флаги бит |
t_hoff |
uint8 |
1 байт |
смещение до пользовательских данных |
Все подробности можно найти в src/include/access/htup_details.h.
Интерпретация фактических данных может быть выполнена только с использованием информации, полученной из других таблиц, в основном pg_attribute. Ключевые значения, необходимые для идентификации расположения полей, это attlen и attalign. Нет прямого способа получить конкретный атрибут, за исключением случаев, когда используются поля фиксированной ширины и отсутствуют нулевые значения. Все эти уловки заключены в функции heap_getattr, fastgetattr и heap_getsysattr.
Чтобы прочитать данные, нужно проверить каждый атрибут по очереди. Сначала проверьте, является ли поле NULL согласно битовой карте нулевых значений. Если это так, перейдите к следующему. Затем убедитесь, что у вас правильное выравнивание. Если поле имеет фиксированную ширину, то все байты просто размещаются. Если это поле переменной длины (attlen = -1), то это немного сложнее. Все типы данных переменной длины имеют общую структуру заголовка struct varlena, которая включает общую длину хранимого значения и некоторые флаги. В зависимости от флагов данные могут находиться либо внутри, либо в таблице TOAST; они также могут быть сжаты (см. раздел «TOAST»).