Руководство прикладного разработчика#
Основные понятия#
В таблице приведены основные аббревиатуры и сокращения:
Аббревиатура, сокращение |
Определение |
|---|---|
API |
Application Programming Interface. Интерфейс прикладного программирования |
CI |
Continuous Integration. Непрерывная интеграция |
UI |
User Interface. Пользовательский интерфейс |
В таблице приведены основные термины:
Термин |
Определение |
|---|---|
Платформа, Platform V |
Набор продуктов Platform V, правообладателем которых является АО «СберТех». Перечень таких продуктов обозначен в документации на конкретный продукт |
Компонент |
Компонент Сервис управления справочными данными (NSIX) продукта Platform V Dictionaries (SDT) |
Среда контейнеризации |
Kubernetes (рекомендуется), поддержана опциональная совместимость с OpenShift 4+ |
Системные требования#
Для локального развертывания приложения достаточным будет 4 CPU, 16 GB RAM, 100 GB HDD.
Для успешного функционирования в промышленной среде требуются:
сервер приложений 8 CPU, 28 GB RAM, 150 GB HDD;
сервер БД 8 CPU, 48 GB RAM, 360 GB HDD.
Детально с системными настройками можно ознакомиться в документе Руководстве по установке компонента Сервис управления справочными данными (NSIX) в разделе Системные требования.
Подготовка#
Backend-репозиторий компонента NSIX: мастер-система управления справочными данными организации.
Является модулем Platform V.
Содержит функциональность:
конструктор модели справочников;
ведение справочных данных через UI посредством бизнес-процессов;
импорт/экспорт данных;
версионирование данных.
Описание основных модулей Backend-репозитория компонента NSIX:
mdmp: корневой модуль с фиксацией версий зависимостей;
mdmp/core: модель, базовые сервисы и дополнительные сервисы типа безопасности, платформы и т.п.;
mdmp/core/model: сущности мета-модели и базовые классы модели;
mdmp/core/platform-services: реализация платформенных сервисов, все, что тянет зависимость на Platform V;
mdmp/core/security: сервисы безопасности, авторизация и аутентификация;
mdmp/core/services: сервисы работы с моделью;
mdmp/app: родительский модуль для модулей с развертыванием;
mdmp/app/ekpit: собственный прокси, с версии 30 будет удален;
mdmp/app/ivs-rest: ivs: интерфейс ведения справочников − бэк сервисы для основной работы по справочникам и записям справочников;
mdmp/app/jobs-rest: rest-сервисы по регламентным заданиям (spring-batch);
mdmp/app/kmd-rest: rest-сервисы kmd-конструктор модели данных;
mdmp/app/product: модель справочников и бизнес-валидаторы;
mdmp/app/rest-commons: общие rest-компоненты;
mdmp/app/rest-ui: модуль-обертка для фронта, фронтовые артефакты копируется сюда при сборке, фронт ведется в отдельном репозитории;
mdmp/app/version-rest: rest-сервисы управления версиями справочников;
mdmp/integration/jobmanager: обвязка над сервисами spring-batch;
mdmp/integration/jobs: регламентные задания.
Помимо данного репозитория используются также:
настройки релизов;
скрипты CI;
фронт;
утилиты;
настройка локального стенда;
функциональные тесты.
Для сборки необходим maven и настройка использования локального setting.xml.
Проект под java8.
Установка модуля#
Необходимо импортировать проект в интегрированную среду разработки (например, в IDEA). Корневой модуль – mdmp.
Подключение и конфигурирование#
Локальный запуск проекта#
Предварительные условия:
Проект клонирован из репозитория mdmp в интегрированную среду разработки (например, в IDEA).
Выполнена сборка из ветки develop-cloud командой mvn -DskipTests -Pcloud clean install.
Подготовка приложения#
Перейти в класс c аннотацией @SpringBootApplication (например для модуля ivs-rest-cloud это класс com.sbt.mdmp.app.ivs.cloud.IvsRestApplication) и выполнить действие, показанное на рисунке:

Появится диалоговое окно создания конфигурации запуска приложения:
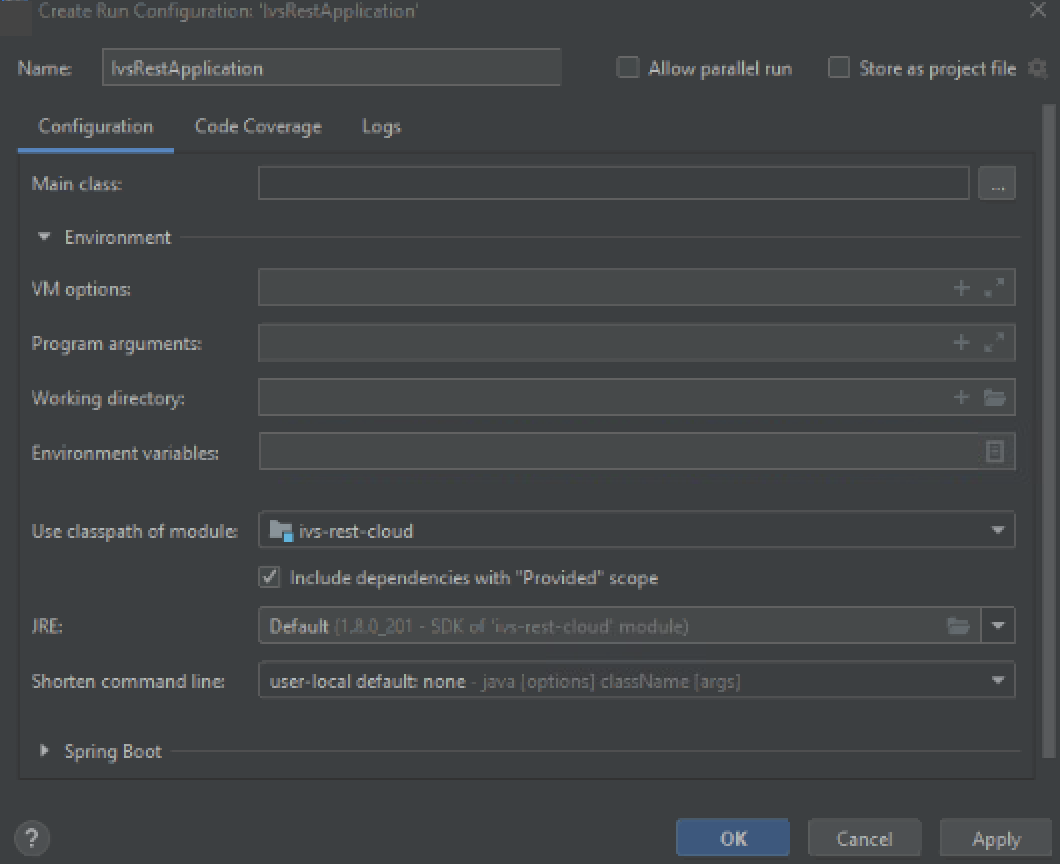
В поле Environment variables необходимо указать значения для обязательных параметров и сохранить изменения.
Список обязательных параметров:
DB_URL;
DB_SCHEMA;
JDBC.MDC_POSTGRES.USER;
JDBC.MDC_POSTGRES.PASSWORD.
Также можно переопределить значения, заданные по умолчанию и список доступных параметров см. в application.properties.
Запуск приложения и проверка API#
Выполнить запуск приложения можно с использованием панели инструментов интегрированной среды разработки (например, IDEA), для этого надо выбрать созданную конфиграцию запуска или непосредственно из класса c аннотацией @SpringBootApplication, вызовом метода main.
Приложение будет доступно по адресу http://localhost:0000.
В папке src/main/resources/samples/*.http находятся файлы с запросом для проверки API приложения.
Запуск на выполнение осуществляется соответствующей кнопкой напротив каждого запроса:
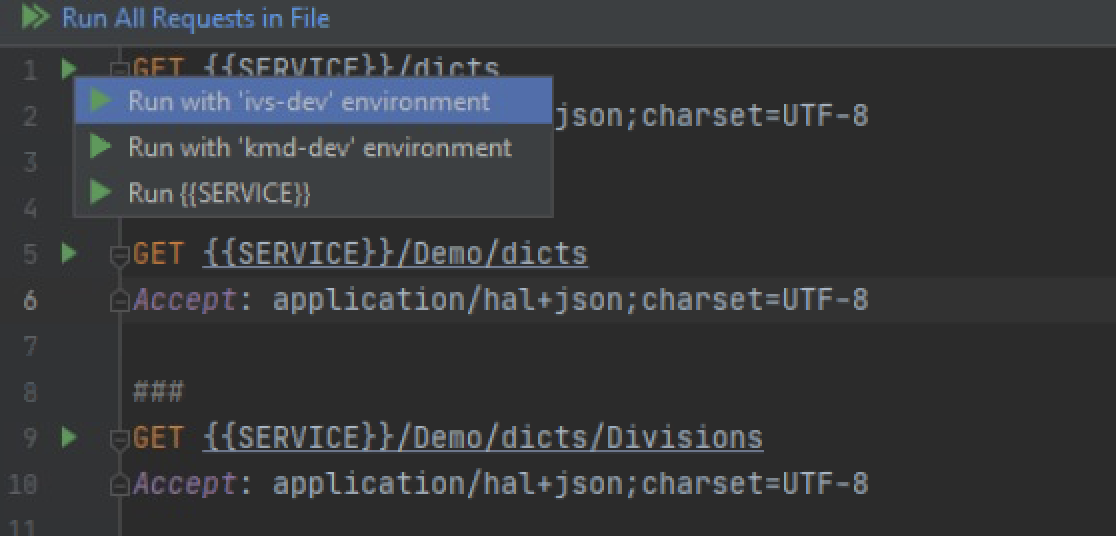
Миграция на текущую версию#
Для заполнения схемы данными из другой БД требуется произвести их миграцию.
Миграция с другой БД на Platform V Pangolin SE провозится администраторами СУБД с помощью утилит pg_dump / pg_restore.
Разработка первого приложения с использованием программного компонента NSIX#
Написание тестов#
Создание тестового класса#
Для написания тестов в модулях желательно наследовать тестовый класс от абстрактного тестового класса в модуле, т. к. в нем прописан нужный application-context и листенеры. Например,
core/services→AbstractUnitilsTest;AbstractUnitilsTest;app/product→AbstractUnitilsTestBaseлибоAbstractUnitilsTestWithSecurity;
и т. д.
Настройки транзакционности в модулях различаются, например, в app/ivs-rest, app/kmd-rest, app/jobs-rest нет транзакционности. Если она нужна для теста, нужно добавить аннотацию @Transactional (+ @Commit если требуется комит по выполнении теста). Посмотреть настройки можно в абстрактном тестовом классе.
Загрузка данных в тестовую БД#
Загрузка данных в тестовую БД делается через датасет, с помощью аннотации @DataSet. Один датасет можно формировать из нескольких файлов. Если датасеты общие для всех тестовых методов в классе, разумно объявить один датасет на класс (он будете перезаписываться для каждого тестового метода), если различаются − то на каждый тестовый метод по отдельности. Объединение датасетов не работает, то есть если датасеты объявлены и на классе, и на методе, будет применен только датасет на методе.
Использование модельных датасетов#
При тестировании бизнес-логики и любой функциональности, привязанной к модели данных, обязательно использовать модельные датасеты из доменного пакета (app/product). Если модели еще нет, нужно завести в app/product аккуратные модельные датасеты, и использовать их. При создании модельных датасетов следить, чтобы ID в модельных таблицах не пересекались с другими. Общее правило такое − для типа записи выбирается неиспользованный 3-значный ID или группа (например: 330, 331…), а ID справочников, атрибутов и проч. назначаются как производные:
<RECORD_TYPE ID="330" ... />
<DICTIONARY ID="330" RECORD_TYPE_ID="330" ... />
<DICT_INST ID="330" MODEL_ID="330" ... />
<ATTRIBUTE ID=" 330 01" RECORD_TYPE_ID="330" ... />
<ATTRIBUTE ID=" 330 02" RECORD_TYPE_ID="330" ... />
...
При первом заведении модельных датасетов заводить только минимально необходимый набор атрибутов и связанных справочников. При развитии тестов дополнять файлы датасетов новыми атрибутами, таким образом, модель расширяется и поддерживается в актуальном состоянии.
Наполнение записей (значений атрибутов)#
Можно делать через датасет, в котором объявлены строки, соответствующие атрибут-инстансам (важно: не класть в один файл с модельным датасетом), но лучше загружать из yml-подобных датасетов. Для этого заводится переиспользуемый xml-датасет с набором «заготовок» версий справочников, версий записей и записей:
<DICT_VERSION ID="3301" DICT_INST_ID="330" ...>
<XXX_VERSION ID="33011" DICT_VERSION_ID="3301" RECORD_ID="33011" STATE="DRAFT" />
<XXX_RECORD ID="33011" MODEL_ID="330" INITIAL_VERSION_ID="33011" ... />
...
И отдельно, для каждого тест-кейса yml-датасеты, в которых заполняются значения атрибутов для этих записей:
XxxRecord#33011: # запись с ID=0000
Id: ... # атрибут "Id"
Name: ... # атрибут "Name"
ParentAttribute#1: # композитный множественный атрибут-инстанс "ParentAttribute#1"
ChildAttribute: ... # дочерний атрибут-инстанс "ParentAttribute#1/ChildAttribute"
AnotherChild#1: ... # "ParentAttribute#1/AnotherChild#1"
AnotherChild#2: ...
---
XxxRecord#33012: # еще одна запись
Id: ...
Name: ...
Кроме атрибут-инстансов, можно заполнять некоторые свойства самой записи/версии:
XxxRecord#000000:
_state: legacy # состояние версии записи (.initialVersion.states)
_version: 1 # номер записи (.version)
_beginDate: 2019-01-01 # дата начала действия версии (.initialVersion.beginDate)
_endDate: # дата окончания действия версии (.initialVersion.endDate)
Для чтения атрибутов в запись нужно вызвать RecordReader:
new RecordReader(ctx).readRecords("/path/to/dataset.yml");
Преимущества yml-датасетов:
имеют вид мапинга с имени атрибута на значение;
наглядная иерархическая структура записи;
произвольные комментарии (текст после # или // считается комментарием);
можно хранить в одном файле несколько записей, разделяя их символами —;
заготовки записей и версий записей переиспользуются, таким образом модель отделяется от данных.
Примеры#
Тестирование методов core-сервиса: core/serivces → VersionServiceGetTest.
Тестирование через REST-контроллер: app/ivs-rest → DictionaryControllerTest , app/kmd-rest → DomainControllerTest.
Использование программного Компонента#
Сценарии использования публичного API#
Запись справочников#
При необходимости создаем домен POST /mdc-api/domain (не обязательный шаг так как при импорте модели, если домена указанного в файле модели нет, то домен будет создан).
Импортируем модель справочника POST /mdc-api/dictionary/model.
Запускаем процесс импорта контента версии справочника POST /mdc-api/dictionaryVersion/content;
В запросе указываем callbackUrl на который придет POST запрос с результатами экспорта, по завершению процесса. Модель можно посмотреть в описании API в Models→ ImportProcess.
Допускается передача нескольких версий справочников в одном zip/rar архиве. Все связанные версии справочников должны импортироваться вместе, иначе возникнут ошибки импорта.
Чтение справочников#
Получаем справочник по идентификатору GET /mdc-api/dictionary/{dictionaryId}, либо перечень справочников по фильтру GET /mdc-api/dictionary (наименование, домен, …).
В составе данных о справочнике есть поле actualDictionaryVersion, которое содержит сведения об актуальной версии справочника.
По идентификатору актуальной версии справочника, запускаем процесс экспорта версии справочника GET /mdc-api/dictionaryVersion/content ;
В запросе указываем callbackUrl на который придет POST запрос с результатами экспорта, по завершению процесса. Модель можно посмотреть в описании API в Models→ExportProcess.Ищем версии справочника по фильтру GET /mdc-api/dictionaryVersion (наименование справочника, наименование домена).
По идентификатору имеющейся версии справочника получаем цепочку версий до актуальной версии справочника GET /mdc-api/dictionaryVersion/{dictionaryVersionId}/chain.
Форматы передаваемых файлов
Для импорта/экспорта модели справочников используются файлы формата xml. Несколько файлов с данными разных справочников могут быть запакованы в rar/zip архив.
Для импорта/экспорта данных используются xml файлы формата TransferReferenceRq. Файл может быть запакован в rar/zip архив. В файле может находится множество моделей справочников.
Часто встречающиеся проблемы и пути их устранения#
В компоненте NSIX есть возможность разграничения справочников на множества, объединенные доменом. Поддерживается возможность сборки приложения с сущностями только для определенных доменов. Одна из распространенных проблем − несоответствие сборки и схемы БД. Для успешного функционирования в схеме БД не должно быть справочников которые не были включены в сборку приложения.
В профилях сборки указываются домены справочников которые должны попасть в сборку (вместе с обязательным профилем cloud).
Пример: mvn -Pcloud,aml,cas,epk,other,pdl,sanctions,sfs -DskipTests clean install. Соответственно, если сборка была произведена только с профилем домена aml а в БД присутствуют справочники sfs, то возникнут ошибки вида: Caused by: org.hibernate.WrongClassException: Object [id=5001] was not of the specified subclass [com.sbt.mdmp.core.storage.DictionaryInstance] : Discriminator: txbcommenttemplate.