Управление, мониторинг и обновление ядра#
Данный раздел содержит информацию о ядре SberLinux и его RPM-пакете. Неотъемлемой частью раздела является инструкция об обновлении ядра, гарантирующем наличие в операционной системе всех последних исправлений ошибок и уязвимостей, улучшений производительности, а также совместимость с новым оборудованием.
Ядро SberLinux#
Ядро — это основная часть операционной системы SberLinux, которая управляет системными ресурсами и обеспечивает взаимодействие между аппаратным и программным обеспечением. Ядра упакованы в формате RPM, поэтому они легко обновляются и проверяются менеджером пакетов dnf/yum.
RPM-пакет#
RPM-пакет - это файл, содержащий архив файлов и метаданные, используемые для установки и удаления этих файлов. RPM-пакет включает в себя:
подпись GPG - используется для проверки целостности пакета;
заголовок RPM (метаданные пакета) - используется диспетчером RPM-пакетов для определения зависимостей пакетов, места для установки файлов и др.;
cpio-архив - содержит файлы для установки в систему.
Существует два типа RPM-пакетов. Оба имеют общий формат файла и инструменты, но разное содержимое и служат разным целям:
RPM-пакеты с исходным кодом (Source RPM – SRPM) - содержат исходный код и файл спецификации, в котором описывается, как встроить исходный код в двоичный RPM. Могут также содержать исправления исходного кода;
бинарные RPM-пакеты – содержат бинарные файлы, созданные из исходников и исправлений.
Обзор kernel RPM-пакета ядра SberLinux#
Kernel RPM-пакет – это метапакет ядра, который не содержит в себе файлов, а обеспечивает правильную установку следующих необходимых подпакетов:
kernel-core– содержит бинарный образ ядра SberLinux;kernel-modules– содержит остальные модули ядра, которых нет вkernel-core.
Набор вышеперечисленных подпакетов призван облегчить обслуживание системным администраторам за счет уменьшения его области, особенно в виртуализированных и облачных средах.
Существуют также дополнительные пакеты ядра, например:
kernel-modules-extra- содержит модули ядра для редкого оборудования и модули, загрузка которых отключена по умолчанию;kernel-debug- содержит вариант ядра с многочисленными опциями отладки для диагностики ядра за счет снижения производительности;kernel-tools- содержит инструменты для работы с ядром SberLinux и сопроводительную документацию;kernel-devel- содержит заголовки ядра и make-файлы, достаточные для сборки модулей на основе пакетаkernel;kernel-abi-stablelists- содержит информацию, относящуюся к ABI ядра SberLinux, включая список символов ядра, необходимых внешним модулям ядра, и dnf/yum-плагин для обеспечения исполнения;kernel-headers- содержит заголовочные файлы C, определяющие взаимодействие между ядром SberLinux и библиотеками, а также программами пользовательского пространства; структуры и константы, необходимые для создания большинства стандартных программ.
Отображение содержимого пакета ядра#
Следующий сценарий описывает, как отобразить содержимое пакета ядра, список его файлов без загрузки или установки пакетов, запросив репозиторий с помощью команды.
Примечание
Обратите внимание, что пакет kernel представляет собой метапакет и не содержит в себе файлов.
Предварительные условия#
Получены RPM-пакеты kernel, kernel-core, kernel-modules, kernel-modules-extra для архитектуры ЦП.
Сценарии использования#
Для отображения доступных версий пакета используйте команду:
yum repoquery <имя_пакета>Например, для отображения доступных версий пакета
kernel-coreвведите команду:yum repoquery kernel-coreПример результата выполнения команды:
kernel-core-0:4.18.0-147.0.2.el8_1.x86_64 kernel-core-0:4.18.0-147.0.3.el8_1.x86_64 kernel-core-0:4.18.0-147.3.1.el8_1.x86_64 kernel-core-0:4.18.0-147.5.1.el8_1.x86_64 ...Для отображения списка файлов пакета используйте команду:
yum repoquery -l <имя_пакета>Например, для отображения списка файлов пакета
kernel-core-0:4.18.0-147.8.1.el8_1.x86_64введите команду:yum repoquery -l kernel-core-0:4.18.0-147.8.1.el8_1.x86_64Пример результата выполнения команды:
/boot/.vmlinuz-4.18.0-147.8.1.el8_1.x86_64.hmac /boot/System.map-4.18.0-147.8.1.el8_1.x86_64 /boot/config-4.18.0-147.8.1.el8_1.x86_64 /boot/initramfs-4.18.0-147.8.1.el8_1.x86_64.img /boot/symvers-4.18.0-147.8.1.el8_1.x86_64.gz /boot/vmlinuz-4.18.0-147.8.1.el8_1.x86_64 /etc/ld.so.conf.d/kernel-4.18.0-147.8.1.el8_1.x86_64.conf /lib/modules /lib/modules/4.18.0-147.8.1.el8_1.x86_64 ...
Установка определенных версий ядра#
Следующий сценарий описывает, как установить новые ядра с помощью менеджера пакетов dnf/yum.
Сценарий использования#
Для установки определенной версии ядра используйте команду:
yum install kernel-<версия>
Обновление ядра#
Следующий сценарий описывает, как обновить ядро с помощью менеджера пакетов dnf/yum.
Сценарий использования#
Для обновления ядра введите команду:
yum update kernelЭта команда обновляет ядро вместе со всеми зависимостями до последней доступной версии.
Перезагрузите систему, чтобы изменения вступили в силу.
Настройка ядра по умолчанию#
Настройте конкретное ядро по умолчанию, используя средство командной строки grubby и GRUB.
Сценарии использования#
Для настройки ядра по умолчанию при помощи
grubbyвведите команду:grubby --set-default $kernel_pathГде
$kernel_path- это абсолютный путь файла ядра.Данная команда использует ID машины без суффикса
.confв качестве аргумента. ID машины при этом находится в каталоге/boot/loader/entries/.Для настройки ядра по умолчанию с помощью аргумента
idвыполните следующие шаги:Для получения списка загрузочных записей с использованием аргумента
idвведите команду:grubby --info ALL | grep idДля настройки ядра по умолчанию используйте команду:
grubby --set-default /boot/vmlinuz-<версия>.<архитектура>
Примечание
Для получения списка загрузочных записей можно также использовать
titleаргумент, выполнив командуgrubby --info=ALL | grep title.Для настройки ядра по умолчанию только для следующей загрузки используйте команду:
grub2-reboot <index|title|id>Где
<index|title|id>- идентификационные данные записи в меню загрузчика GRUB2.Внимание
Настройку ядра по умолчанию только для следующей загрузки выполняйте с осторожностью - установка новых RPM-ядер, ядер собственной сборки и добавление записей вручную в каталог
/boot/loader/entries/могут изменить значения индекса.
Управление модулями ядра#
Данный раздел содержит информацию о модулях ядра, способах отображения информации о них и выполнении основных административных задач с ними.
Введение в модули ядра#
Ядро SberLinux может быть расширено дополнительными функциональными элементами, называемыми модулями ядра, без необходимости перезагрузки системы. В SberLinux модули ядра представляют собой дополнительный код ядра, встроенный в сжатые объектные файлы <имя_модуля_ядра>.ko.xz.
Наиболее распространенные функции, предоставляемые модулями ядра:
драйвер устройства, добавляющий поддержку нового оборудования;
поддержка файловой системы, такой как GFS2 или NFS;
системные вызовы.
В современных системах модули ядра загружаются автоматически по мере необходимости. Однако в некоторых случаях необходимо загружать или выгружать модули вручную.
Как и само ядро, модули могут принимать параметры, которые при необходимости настраивают их поведение.
В параграфах ниже описывается инструментарий для проверки: какие модули запущены в данный момент, какие модули доступны для загрузки в ядро и какие параметры принимает модуль. Также представлен механизм для загрузки и выгрузки модулей ядра в работающее ядро.
Зависимости модулей ядра#
Некоторые модули ядра иногда зависят от одного или нескольких других модулей. Файл зависимостей /lib/modules/<версия_ядра>/modules.dep содержит полный список зависимостей модулей для соответствующей версии ядра.
Утилита depmod#
Файл зависимостей генерируется утилитой depmod, входящей в состав пакета kmod. Многие из предоставляемых пакетом kmod утилит учитывают зависимости модулей при выполнении операций, поэтому ручное отслеживание зависимостей требуется редко.
Важно
Код модулей ядра выполняется в пространстве ядра в неограниченном режиме, поэтому помните о том, какие модули загружаете.
Скрипт weak-modules#
В дополнение к утилите depmod SberLinux предоставляет скрипт weak-modules, также поставляемый с пакетом kmod. weak-modules определяет, какие модули kABI-совместимы с установленными ядрами. При проверке совместимости модулей с ядром weak-modules обрабатывает зависимости спецификаций модулей от более высоких до более низких версий ядра, для которых они были созданы. Каждый модуль обрабатывается независимо от версий ядра.
Список установленных модулей ядра#
Для отображения списка установленных ядер и их индексов используйте команду grubby --info=ALL.
Сценарий использования#
Для отображения списка установленных ядер введите команду:
grubby --info=ALL | grep title
Результат выполнения команды:
title="SberLinux (<версия_ядра>) <версия_релиза> (Shkhara)"
title="SberLinux (0-rescue-<индекс_ядра>) <версия_релиза> (Shkhara)"
...
Результат выполнения команды содержит в себе версии всех установленных ядер из меню GRUB, а также путь к ним.
Список загруженных в данный момент модулей ядра#
Следующий сценарий описывает, как получить список загруженных в данный момент модулей ядра.
Предварительные условия#
Установлен пакет kmod.
Сценарий использования#
Для получения списка всех загруженных в данный момент модулей ядра введите команду lsmod.
Пример результата выполнения команды:
Module Size Used by
fuse 126976 3
uinput 20480 1
xt_CHECKSUM 16384 1
ipt_MASQUERADE 16384 1
xt_conntrack 16384 1
ipt_REJECT 16384 1
nft_counter 16384 16
nf_nat_tftp 16384 0
nf_conntrack_tftp 16384 1 nf_nat_tftp
tun 49152 1
bridge 192512 0
stp 16384 1 bridge
llc 16384 2 bridge,stp
nf_tables_set 32768 5
nft_fib_inet 16384 1
...
В приведенном выше примере:
первый столбец - имена загруженных в данный момент модулей;
второй столбец - объем памяти для каждого модуля в килобайтах;
третий столбец - количество и (необязательно) имена модулей, которые зависят от конкретного модуля.
Список всех установленных ядер#
Следующий сценарий описывает использование утилиты grubby для отображения списка всех установленных ядер в системе.
Сценарий использования#
Для отображения списка всех установленных ядер введите команду:
grubby --info=ALL | grep ^kernel
Пример результата выполнения команды:
kernel="/boot/vmlinuz-4.18.0-305.10.2.el8_4.x86_64"
kernel="/boot/vmlinuz-4.18.0-240.el8.x86_64"
kernel="/boot/vmlinuz-0-rescue-41eb2e172d7244698abda79a51778f1b"
Вывод отображает путь ко всем установленным ядрам, а также их версии.
Отображение информации о модулях ядра#
Следующий сценарий описывает использование команды modinfo для отображения дополнительной информации о модулях ядра.
Предварительные условия#
Установлен пакет kmod.
Сценарий использования#
Для отображения дополнительной информации о конкретном модуле ядра используйте команду:
modinfo <имя_модуля_ядра>
Например, для отображения подробной информации о модуле virtio_net введите команду:
modinfo virtio_net
Пример результата выполнения команды:
filename: /lib/modules/4.18.0-94.el8.x86_64/kernel/drivers/net/virtio_net.ko.xz
license: GPL
description: Virtio network driver
sloversion: 8.1
srcversion: 2E9345B281A898A91319773
alias: virtio:d00000001v*
depends: net_failover
intree: Y
name: virtio_net
vermagic: 4.18.0-94.el8.x86_64 SMP mod_unload modversions
...
parm: napi_weight:int
parm: csum:bool
parm: gso:bool
parm: napi_tx:bool
При помощи команды modinfo можно запросить информацию обо всех доступных модулях, независимо от того, загружены они или нет. Записи parm в выводе команды показывают параметры, которые можно установить для модуля, и их ожидаемые значения.
Примечание
При вводе имени модуля ядра не добавляйте расширение .ko.xz в конец имени. Имена модулей ядра не имеют расширений, их имеют соответствующие файлы.
Загрузка модулей ядра во время работы системы#
Оптимальным способом расширения функциональности ядра SberLinux является загрузка дополнительных модулей. Следующий сценарий описывает использование команды modprobe для поиска и загрузки конкретного модуля в работающее в данный момент ядро.
Важно
Описываемые в данном сценарии изменения не сохранятся после перезагрузки системы. Для загрузки модулей ядра с сохранением после перезагрузки см. «Автоматическая загрузка модулей ядра во время загрузки системы».
Предварительные условия#
Установлен пакет
kmod.Соответствующий модуль ядра не загружен - для проверки можно посмотреть список загруженных модулей ядра (см. «Список загруженных в данный момент модулей ядра»).
Сценарий использования#
Для загрузки модулей ядра во время работы системы выполните следующие шаги:
Выберите модуль ядра, который необходимо загрузить. Модули находятся в каталоге
/lib/modules/$(uname -r)/kernel/<компонент_системы>/.Для загрузки соответствующего модуля ядра используйте команду:
modprobe <имя_модуля>Примечание
При вводе имени модуля ядра не добавляйте расширение
.ko.xzв конец имени. Имена модулей ядра не имеют расширений, их имеют соответствующие файлы.Для того, чтобы убедиться, что соответствующий модуль был загружен, используйте команду:
lsmod | grep <имя_модуля>Если модуль был загружен правильно, эта команда отобразит соответствующий модуль ядра.
Например, для проверки корректности загрузки модуля
serio_rawвведите команду:lsmod | grep serio_rawПример результата выполнения команды:
serio_raw 16384 0
Выгрузка модулей ядра во время работы системы#
Следующий сценарий описывает использование команды modprobe для поиска и выгрузки модуля ядра во время работы системы из загруженного в данный момент ядра.
Внимание
Не выгружайте модули ядра, используемые работающей системой. Это может привести к нестабильности или неработоспособности системы.
Важно
После завершения этого сценария модули ядра, определенные для автоматической загрузки при запуске системы, не останутся незагруженными после перезагрузки машины. Сценарий предотвращения автоматической загрузки модулей после перезагрузки см. в «Предотвращение автоматической загрузки модулей ядра во время загрузки системы».
Предварительные условия#
Установлен пакет kmod.
Сценарий использования#
Для выгрузки модулей ядра во время работы системы выполните следующие шаги:
Для отображения списка всех загруженных модулей ядра введите команду
lsmod.Выберите модуль ядра, который необходимо выгрузить.
Если модуль ядра имеет зависимости, выгрузите их перед выгрузкой модуля ядра. Подробнее об идентификации модулей с зависимостями см. в «Список загруженных в данный момент модулей ядра» и «Зависимости модулей ядра».
Для выгрузки выбранного модуля ядра используйте команду:
modprobe -r <имя_модуля>Примечание
При вводе имени модуля ядра не добавляйте расширение
.ko.xzв конец имени. Имена модулей ядра не имеют расширений, их имеют соответствующие файлы.Для того, чтобы убедиться, что соответствующий модуль был выгружен, используйте команду:
lsmod | grep <имя_модуля>Если модуль был успешно выгружен, эта команда ничего не выведет.
Выгрузка модулей ядра на ранних стадиях процесса загрузки#
Иногда возникает необходимость выгрузить модуль ядра в начале процесса загрузки. Например, если модуль ядра содержит код, приводящий к отказу системы отвечать на запросы, и пользователь не может перейти к этапу окончательного отключения вредоносного модуля ядра. В этом случае можно временно заблокировать загрузку модуля ядра с помощью загрузчика.
Важно
Изменения, описанные в этом сценарии, не сохранятся после перезагрузки. Информацию о добавлении модуля ядра в список запрещенных, чтобы он не загружался автоматически в процессе загрузки, см. в «Предотвращение автоматической загрузки модулей ядра во время загрузки системы».
Предварительные условия#
Имеется загружаемый модуль ядра, загрузку которого необходимо предотвратить.
Сценарий использования#
Для редактирования соответствующей записи загрузчика с целью выгрузки модуля ядра до продолжения загрузки системы выполните следующие шаги:
Для вызова меню GRUB при загрузке системы нажмите клавишу Esc.
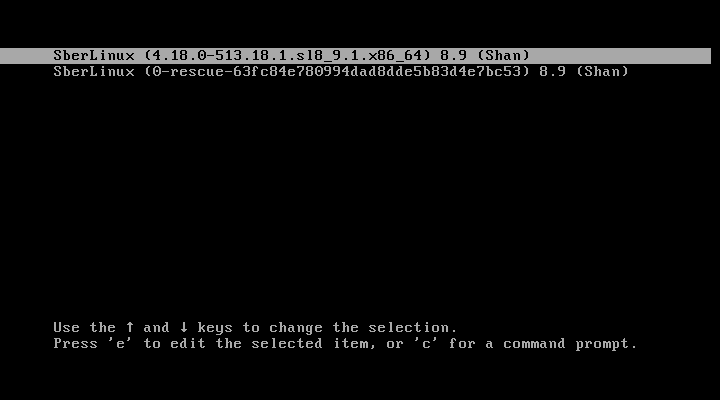
Рисунок. Пример меню GRUB
Для выделения соответствующей записи и выбора необходимого ядра используйте клавиши
↑и↓.Для редактирования выбранной записи нажмите клавишу e.
С помощью клавиш
↑,↓,←и→перейдите к строке, начинающейся сlinux ....В конце указанной строки добавьте
modprobe.blacklist=<имя_модуля>.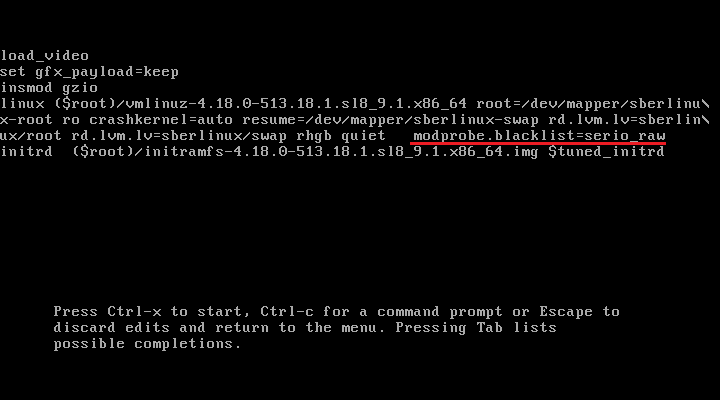
Рисунок. Пример редактирования записи
В качестве примера выгружаемого модуля использован модуль
serio_raw.Для загрузки с измененной конфигурацией нажмите Ctrl+x
Для проверки того, что соответствующий модуль ядра не загружен, используйте команду:
lsmod | grep <имя_модуля>Если модуль был успешно выгружен, эта команда ничего не выведет.
Автоматическая загрузка модулей ядра во время загрузки системы#
Следующий сценарий описывает, как настроить автоматическую загрузку модуля ядра во время загрузки системы.
Предварительные условия#
Установлен пакет kmod.
Сценарий использования#
Выберите модуль ядра, который необходимо загрузить в процессе загрузки системы.
Модули находятся в каталоге
/lib/modules/$(uname -r)/kernel/<компонент_системы>/.Для создания конфигурационного файла для выбранного модуля используйте команду:
echo <имя_модуля> > /etc/modules-load.d/<имя_модуля>.confПримечание
При вводе имени модуля ядра не добавляйте расширение
.ko.xzв конец имени. Имена модулей ядра не имеют расширений, их имеют соответствующие файлы.Для того, чтобы убедиться, что соответствующий модуль был загружен, используйте команду:
lsmod | grep <имя_модуля>Результатом успешного выполнения команды является отображение соответствующего модуля.
Важно
Изменения, описанные в данном сценарии, сохранятся после перезагрузки системы.
Предотвращение автоматической загрузки модулей ядра во время загрузки системы#
Следующий сценарий описывает, как добавить модуль ядра в список запрещенных, чтобы он не загружался автоматически в процессе загрузки системы.
Предварительные условия#
Установлен пакет
kmod.Соответствующий модуль ядра не требуется для текущей конфигурации системы.
Сценарий использования#
Для отображения списка модулей, загруженных в действующем ядре, введите команду
lsmod.Пример результата выполнения команды:
Module Size Used by fuse 126976 3 xt_CHECKSUM 16384 1 ipt_MASQUERADE 16384 1 uinput 20480 1 xt_conntrack 16384 1 ...Выберите модуль ядра, загрузку которого необходимо предотвратить.
Для определения незагруженного модуля ядра, который необходимо предотвратить от потенциальной загрузки, отобразите содержание каталога
/lib/modules/<версия_ядра>/kernel/<компонент_системы>/, выполнив командуlsс указанием соответствующего каталога.Для создания конфигурационного файла, выполняющего функции списка запрещенных модулей, введите команду:
touch /etc/modprobe.d/denylist.confВ текстовом редакторе (например,
vim) скомбинируйте имена модулей, которые необходимо исключить из автоматической загрузки в ядро, с помощью команды конфигурацииblacklist.Например:
# Prevents <модуль-ядра-1> from being loaded blacklist <имя_модуля_1> install <имя_модуля_1> /bin/false # Prevents <модуль-ядра-2> from being loaded blacklist <имя_модуля_2> install <имя_модуля_2> /bin/false ...Поскольку команда
blacklistне препятствует загрузке модуля в качестве зависимости для другого модуля ядра, не находящегося в списке запрещенных, необходимо также определить строкуinstall. В этом случае система запустится с использованием параметра/bin/falseвместо установки модуля. Строки, начинающиеся с#, являются комментариями, которые используются, чтобы сделать файл более читабельным.Примечание
При вводе имени модуля ядра не добавляйте расширение
.ko.xzв конец имени. Имена модулей ядра не имеют расширений, их имеют соответствующие файлы.Для создания резервной копии текущего исходного образа RAM-диска перед пересборкой введите команду:
cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).imgАльтернативный вариант - создайте резервную копию исходного образа RAM-диска, соответствующего версии ядра, для которой необходимо запретить автоматическую загрузку модулей ядра, введя команду:
cp /boot/initramfs-<версия>.img /boot/initramfs-<версия>.img.bak.$(date +%m-%d-%H%M%S)Для того, чтобы изменения вступили в силу, сгенерируйте новый исходный образ RAM-диска, выполнив команду:
dracut -f -vВ случае, если создается первоначальный образ RAM-диска для версии ядра, отличной от используемой системой в данный момент, укажите целевую версию
initramfsи версию ядра, выполнив команду:dracut -f -v /boot/initramfs-<целевая_версия>.img <соответствующая_целевая_версия_ядра>Для перезагрузки системы введите команду:
reboot
Важно
Изменения, описанные в этом сценарии, вступят в силу и сохранятся после перезагрузки системы. Если ключевой модуль ядра помещен в список запрещенных некорректно, то возможен перевод системы в нестабильное/неработоспособное состояние.
Компиляция пользовательских модулей ядра#
Следующий сценарий описывает, как собрать пробный модуль ядра в соответствии с требованиями различных конфигураций на аппаратном и программном уровне.
Предварительные условия#
Установлены пакеты
kernel-devel,gccиelfutils-libelf-devel.Создан каталог
/root/testmodule/, в котором компилируется пользовательский модуль ядра.
Сценарий использования#
Создайте файл
/root/testmodule/test.cсо следующим содержимым:#include <linux/module.h> #include <linux/kernel.h> int init_module(void) { printk("Hello World\n This is a test\n"); return 0; } void cleanup_module(void) { printk("Good Bye World"); }Файл
test.cявляется исходным файлом, обеспечивающим основную функциональность модуля ядра. Файл был создан в специальном каталоге/root/testmodule/для организационных целей. После компиляции модуля/root/testmodule/каталог будет содержать несколько файлов.Файл
test.cвключает в себя файлы из системных библиотек:заголовочный файл
linux/kernel.h- необходим для функцииprintk()в примере кода;файл
linux/module.h- содержит определения функций и макросов, которые будут совместно использоваться несколькими исходными файлами, написанными на языке программирования C.
Для запуска и завершения работы функции ведения журнала ядра
printk(), выводящей текст, используйте функцииinit_module()иcleanup_module().Создайте файл
/root/testmodule/Makefileсо следующим содержимым:obj-m := test.oВ результате файл
Makefileсодержит инструкцию, по которой компилятор должен создать объектный файл со специальным именемtest.o. Директиваobj-mуказывает, что результирующий файлtest.koбудет скомпилирован как загружаемый модуль ядра. Альтернативная директиваobj-yпредписывает сборкуtest.koв качестве встроенного модуля ядра.Для компиляции модуля ядра введите команду:
make -C /lib/modules/$(uname -r)/build M=/root/testmodule modulesПример результата выполнения команды:
make: Entering directory '/usr/src/kernels/4.18.0-305.el8.x86_64' CC [M] /root/testmodule/test.o Building modules, stage 2. MODPOST 1 modules WARNING: modpost: missing MODULE_LICENSE() in /root/testmodule/test.o see include/linux/module.h for more information CC /root/testmodule/test.mod.o LD [M] /root/testmodule/test.ko make: Leaving directory '/usr/src/kernels/4.18.0-305.el8.x86_64'Компилятор создает объектный файл (
test.o) для каждого исходного файла (test.c) в качестве промежуточного шага перед объединением их в окончательный модуль ядра (test.ko).В результате компиляции каталог
/root/testmodule/содержит дополнительные файлы скомпилированного пользовательского модуля ядра. Сам скомпилированный модуль представлен файломtest.ko.
Для осуществления проверки результатов исполнения сценария выполните следующие шаги:
Для отображения и проверки содержимого каталога
/root/testmodule/введите команду:ls -l /root/testmodule/Пример результата выполнения команды:
total 152 -rw-r—r--. 1 root root 16 Jul 26 08:19 Makefile -rw-r—r--. 1 root root 25 Jul 26 08:20 modules.order -rw-r—r--. 1 root root 0 Jul 26 08:20 Module.symvers -rw-r—r--. 1 root root 224 Jul 26 08:18 test.c -rw-r—r--. 1 root root 62176 Jul 26 08:20 test.ko -rw-r—r--. 1 root root 25 Jul 26 08:20 test.mod -rw-r—r--. 1 root root 849 Jul 26 08:20 test.mod.c -rw-r—r--. 1 root root 50936 Jul 26 08:20 test.mod.o -rw-r—r--. 1 root root 12912 Jul 26 08:20 test.oДля копирования модуля ядра в каталог
/lib/modules/$(uname -r)/введите команду:cp /root/testmodule/test.ko /lib/modules/$(uname -r)/Для обновления списка модульных зависимостей введите команду:
depmod -aДля загрузки модуля ядра введите команду:
modprobe -v testПример результата выполнения команды:
insmod /lib/modules/4.18.0-305.el8.x86_64/test.koДля того, чтобы убедиться, что модуль ядра был успешно загружен, введите команду:
lsmod | grep testПример результата выполнения команды:
test 16384 0Для вывода последних сообщений из кольцевого буфера ядра введите команду:
dmesgПример результата выполнения команды:
[74422.545004] Hello World This is a test
Настройка параметров командной строки ядра#
С помощью параметров командной строки ядра можно изменять поведение некоторых компонентов ядра SberLinux во время загрузки. Системный администратор имеет полный контроль над тем, какие параметры поведения ядра устанавливаются при загрузке; некоторые из них можно настроить только во время загрузки.
Важно
Изменение поведения системы посредством изменения параметров командной строки ядра может иметь негативные последствия для системы. Всегда тестируйте изменения перед их развертыванием в рабочей среде.
Введение в параметры командной строки ядра#
С помощью параметров командной строки ядра можно перезаписать значения по умолчанию и установить определенные аппаратные настройки.
Во время загрузки системы можно настроить:
ядро SberLinux;
начальный RAM-диск;
функции пользовательского пространства.
По умолчанию параметры командной строки ядра для систем, использующих загрузчик GRUB, определены переменной kernelopts в конфигурационном файле загрузочной записи /boot/grub2/grubenv для каждой загрузочной записи ядра.
Для изменения файлов конфигурации загрузчика можно использовать утилиту grubby. С помощью grubby возможно выполнение следующих действий:
изменение записи загрузки, установленной по умолчанию;
добавление/удаление аргументов из меню GRUB.
Загрузочные записи#
Загрузочная запись — это набор параметров, которые хранятся в файле конфигурации и привязаны к конкретной версии ядра. Количество загрузочных записей как минимум совпадает с количеством ядер, установленных в системе. Файл конфигурации загрузочной записи находится в каталоге /boot/loader/entries/ и может выглядеть, например, следующим образом:
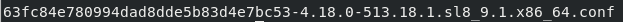
Рисунок. Пример файла конфигурации загрузочной записи
Приведенное выше имя файла состоит из идентификатора машины, хранящегося в файле /etc/machine-id, и версии ядра.
Файл конфигурации загрузочной записи содержит информацию о версии ядра, изначальном образе RAM-диска и переменной среды kernelopts, содержащей параметры командной строки ядра.
Пример содержимого конфигурации загрузочной записи:
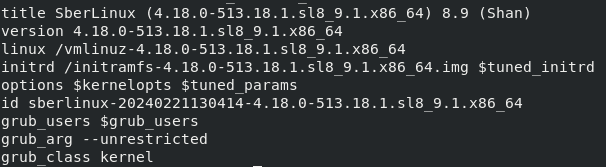
Рисунок. Пример содержимого конфигурации загрузочной записи
Изменение параметров командной строки ядра для всех загрузочных записей#
Следующий сценарий описывает, как изменить параметры командной строки ядра для всех загрузочных записей в системе.
Предварительные условия#
Установлена утилита grubby.
Сценарии использования#
Для добавления параметра используйте команду:
grubby --update-kernel=ALL --args="<новый_параметр>"Для систем, использующих загрузчик GRUB, данная команда обновляет файл
/boot/grub2/grubenv, добавляя новый параметр ядра в переменнуюkernelopts.Для удаления параметра используйте команду:
grubby --update-kernel=ALL --remove-args="<удаляемый_параметр>"
Примечание
Новые ядра наследуют параметры командной строки от ранее настроенных ядер.
Изменение параметров командной строки ядра для одной загрузочной записи#
Следующий сценарий описывает, как изменить параметры командной строки ядра для одной загрузочной записи в системе.
Предварительные условия#
Установлена утилита grubby.
Сценарии использования#
Для добавления параметра используйте команду:
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --args="<новый_параметр>"Для удаления параметра используйте команду:
grubby --update-kernel=/boot/vmlinuz-$(uname -r) --remove-args="<удаляемый_параметр>"
Примечание
В системах, использующих файл grub.cfg, по умолчанию для каждой загрузочной записи ядра используется параметр options, который присваивается переменной kernelopts. Данная переменная определена в файле конфигурации /boot/grub2/grubenv.
Важно
В системах GRUB2:
Если параметры командной строки ядра изменяются для всех загрузочных записей, то утилита
grubbyобновляет переменнуюkerneloptsв файле/boot/grub2/grubenv.Если параметры командной строки ядра изменяются для одной загрузочной записи, то переменная
kerneloptsрасширяется, изменяются параметры ядра, и результирующее значение сохраняется в файле соответствующей загрузочной записи/boot/loader/entries/<соответствующая_загрузочная_запись_ядра.conf>.
Временное изменение параметров командной строки ядра во время загрузки#
Следующий сценарий описывает, как внести временные изменения в запись меню ядра, изменив параметры на время одной загрузки.
Примечание
Данный сценарий применяется только для однократной загрузки и не вносит постоянных изменений.
Сценарий использования#
Войдите в меню загрузки GRUB2, нажав клавишу Esc при запуске системы.
Выберите ядро, которое необходимо запустить.
Нажмите клавишу e, чтобы отредактировать параметры ядра.
Найдите командную строку ядра, переместив курсор вниз. Командная строка ядра начинается с
linux....Переместите курсор в конец строки.
Примечание
Для перехода к началу строки нажмите Ctrl+a, для перехода к концу строки - Ctrl+e. В некоторых системах также могут работать Home и End.
Отредактируйте необходимые параметры ядра. Например:
Для запуска системы в аварийном режиме добавьте параметр
emergencyв конец строкиlinux...: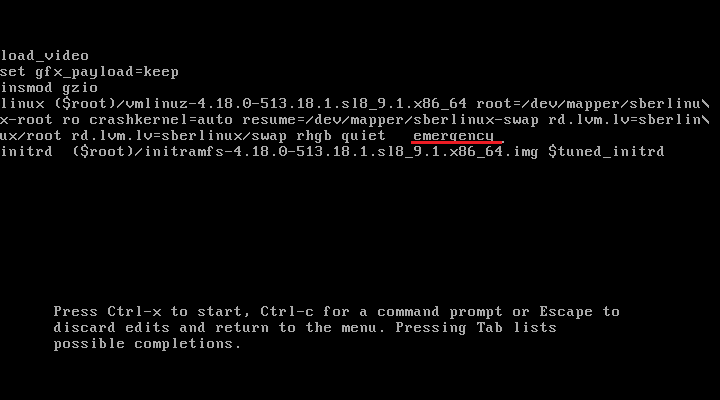
Рисунок. Пример корректировки параметра ядра
Для включения системных сообщений удалите параметры
rhgbиquiet.
Для загрузки системы с выбранным ядром и измененными параметрами командной строки нажмите Ctrl+x.
Важно
Для выхода из режима редактирования командной строки и отмены всех внесенных изменений нажмите клавишу Esc.
Настройка параметров GRUB для подключения последовательного консольного соединения#
Последовательная консоль полезна, когда нужно подключиться к headless-серверу или встроенной системе при неработающей сети. Или, например, в случае необходимости обхода правил безопасности и получения доступа для входа в другую систему.
Для использования последовательного консольного соединения необходимо настроить некоторые параметры GRUB, используемые по умолчанию.
Сценарий использования#
Добавьте следующие две строки в файл
/etc/default/grub:GRUB_TERMINAL="serial" GRUB_SERIAL_COMMAND="serial --speed=9600 --unit=0 --word=8 --parity=no --stop=1"Первая строка отключает графический терминал. Ключ
GRUB_TERMINALпереопределяет значения ключейGRUB_TERMINAL_INPUTиGRUB_TERMINAL_OUTPUT.Вторая строка настраивает скорость передачи данных в бодах
--speed, контроль четности--parityи другие значения в соответствии со средой и оборудованием.Примечание
Гораздо более высокая скорость передачи данных, например
115200, предпочтительнее для таких задач, как просмотр файлов журнала.Обновите файл конфигурации GRUB.
На машинах на базе BIOS:
grub2-mkconfig -o /boot/grub2/grub.cfgНа машинах на базе UEFI:
grub2-mkconfig -o /boot/efi/EFI/sberlinux/grub.cfg
Для того, чтобы изменения вступили в силу, перезагрузите систему.
Настройка параметров ядра во время выполнения#
Системный администратор может настраивать многие аспекты поведения ядра SberLinux во время выполнения. Настраивайте параметры ядра во время выполнения с помощью команды sysctl и путем изменения файлов конфигурации в каталогах /etc/sysctl.d/ и /proc/sys/.
Важно
Настройка параметров ядра в рабочей системе требует тщательного планирования. Незапланированные изменения могут привести к нестабильной работе ядра. Убедитесь, что используете допустимые параметры, прежде чем вносить изменения в настройки ядра.
Параметры ядра#
Параметры ядра — это настраиваемые значения, которые можно настроить во время работы системы. Для вступления изменений в силу нет необходимости перезагружать или перекомпилировать ядро.
К параметрам ядра можно обратиться через:
команду
sysctl;виртуальную файловую систему, скомпонованную в каталоге
/proc/sys/;файлы конфигурации в каталоге
/etc/sysctl.d/.
Настраиваемые объекты разделены подсистемой ядра на классы. SberLinux имеет следующие настраиваемые классы:
Таблица. Классы в sysctl
Настраиваемый класс |
Подсистема |
|---|---|
|
Домены исполнения и персонализации |
|
Криптографические интерфейсы |
|
Интерфейсы отладки ядра |
|
Информация о конкретном устройстве |
|
Глобальные и специальные настройки файловой системы |
|
Глобальные настройки ядра |
|
Сетевые настройки |
|
Удаленный вызов процедур Sun (NFS) |
|
Ограничения пользовательских namespace |
|
Настройка и управление памятью, буферами и кешем |
Временная настройка параметров ядра с помощью sysctl#
Следующий сценарий описывает, как использовать команду sysctl для временной установки параметров ядра во время выполнения. Команда также полезна для вывода списка и фильтрации настраиваемых параметров.
Сценарий использования#
Для перечисления всех параметров и их значений введите команду:
sysctl -aПримечание
Команда
sysctl -aотображает параметры ядра, настраиваемые во время выполнения и во время загрузки.Для временной настройки параметра используйте команду:
sysctl <настраиваемый_класс>.<параметр>=<целевое_значение>Приведенный выше пример команды изменяет значение параметра во время работы системы. Изменения вступают в силу немедленно, без перезагрузки.
Примечание
После перезагрузки системы внесенные изменения вернутся к значениям по умолчанию.
Постоянная настройка параметров ядра с помощью sysctl#
Следующий сценарий описывает, как использовать команду sysctl для постоянной установки параметров ядра.
Сценарий использования#
Для перечисления всех параметров и их значений введите команду:
sysctl -aКоманда отображает все параметры ядра, которые можно настроить во время выполнения и во время загрузки.
Для настройки параметра на постоянной основе используйте команду:
sysctl -w <настраиваемый_класс>.<параметр>=<целевое_значение> >> /etc/sysctl.confДанный пример команды изменяет настраиваемое значение и записывает его в файл
/etc/sysctl.conf, переопределяющий значения параметров ядра по умолчанию. Изменения вступают в силу немедленно и на постоянной основе, без необходимости перезагрузки.
Примечание
Для изменения параметров ядра на постоянной основе можно также вручную корректировать файлы конфигурации в каталоге /etc/sysctl.d/.
Использование файлов конфигурации в /etc/sysctl.d/ для настройки параметров ядра#
Следующий сценарий описывает, как вручную изменить файлы конфигурации в каталоге /etc/sysctl.d/ для установки постоянных параметров ядра.
Сценарий использования#
Для создания нового файла конфигурации в каталоге
/etc/sysctl.d/используйте команду:vim /etc/sysctl.d/<имя_файла.conf>Добавьте необходимые параметры ядра, по одному в строке, следующим образом:
<настраиваемый_класс>.<параметр>=<целевое_значение> <настраиваемый_класс>.<параметр>=<целевое_значение> ...Сохраните файл конфигурации.
Перезагрузите машину, чтобы изменения вступили в силу.
В качестве альтернативного способа применения изменений, без перезагрузки, можно использовать команду:
sysctl -p /etc/sysctl.d/<имя_файла.conf>Данная команда позволяет прочитать значения из файла конфигурации, созданного ранее.
Временная настройка параметров ядра с помощью /proc/sys/#
Следующий сценарий описывает, как временно установить параметры ядра с помощью файлов в каталоге виртуальной файловой системы /proc/sys/.
Сценарий использования#
Для определения параметра ядра, который необходимо настроить, используйте команду:
ls -l /proc/sys/<настраиваемый_класс>/Результат выполнения команды - доступные для записи файлы - можно использовать для настройки ядра. Файлы с правами только на чтение предоставляют информацию о текущих настройках.
Для присвоения целевого значения параметру ядра используйте команду:
echo <целевое_значение> > /proc/sys/<настраиваемый_класс>/<параметр>Команда вносит изменения в конфигурацию, которые исчезнут после перезапуска системы.
Опционально, для проверки значения вновь установленного параметра ядра используйте команду:
cat /proc/sys/<настраиваемый_класс>/<параметр>
Настройка алгоритма выделения портов#
Следующий сценарий описывает, как настроить улучшенный алгоритм выделения портов отправителя при установлении связи по протоколу TCP/IP v4 для частого открытия коротких соединений при взаимодействии с получателями, в том числе на базе ОС Windows, и избежать возникновения ошибок такого взаимодействия.
Регулировка алгоритма выделения портов относится к сетевым настройкам ядра и может быть осуществлена двумя вариантами:
командой
sysctlс использованием параметраnet.core.connect_rnd_src_port;либо изменением параметра в специальном файле
/proc/sys/net/core/connect_rnd_src_port.
Стандартный алгоритм выделения портов определен по умолчанию и соответствует значению 1, улучшенный алгоритм соответствует значению 0.
Улучшенный алгоритм реализует последовательное выделение портов отправителя по кругу (+1 следующий порт отправителя) для каждого соединения, если порт отправителя не задан явно при установлении соединения. Соединения при этом определяются адресом отправителя, получателя и портом получателя.
Сценарий использования#
Для настройки алгоритма выделения портов выполните следующие шаги:
Для запуска улучшенного алгоритма выделения портов выполните команду
sysctl -w net.core.connect_rnd_src_port=0, либо измените параметр в файле командойecho "0">/proc/sys/net/core/connect_rnd_src_port.Для возврата к стандартному алгоритму выполните команду
sysctl -w net.core.connect_rnd_src_port=1, либо измените параметр в файле командойecho "1">/proc/sys/net/core/connect_rnd_src_port.Для проверки режима настройки алгоритма и определения значения конкретного параметра выполните команду
sysctl net.core.connect_rnd_src_port, либо проверьте параметр в файле командойcat /proc/sys/net/core/connect_rnd_src_port.
Начало работы с ведением журнала ядра#
Файлы журналов (log-файлы) — это файлы, содержащие сообщения о системе, включая ядро, службы и приложения, запущенные в ней. Система ведения журналов в SberLinux основана на встроенном протоколе системного журнала syslog. Различные утилиты используют эту систему для записи событий и организации их в log-файлы. Эти файлы полезны при проверке операционной системы или устранении неполадок.
Кольцевой буфер ядра#
В процессе загрузки консоль предоставляет много важной информации о начальном этапе запуска системы. Чтобы избежать потери ранних сообщений, ядро использует так называемый кольцевой буфер. В этом буфере хранятся все сообщения, включая загрузочные, сгенерированные функцией printk() в коде ядра. Сообщения из кольцевого буфера ядра затем считываются и сохраняются в log-файлах на постоянном запоминающем устройстве (ПЗУ), например, службой syslog.
Кольцевой буфер ядра представляет собой циклическую структуру данных фиксированного размера, жестко запрограммированную в ядре. Пользователи могут отображать данные, хранящиеся в кольцевом буфере ядра, с помощью команды dmesg или файла /var/log/boot.log. Когда кольцевой буфер заполнен, новые данные перезаписывают старые.
Роль printk в ведении журнала ядра и его уровнях#
Каждое сообщение ядра связано с соответствующим уровнем журнала, определяющим важность сообщения. Кольцевой буфер ядра собирает сообщения всех уровней журнала. Параметр, определяющий, какие сообщения из буфера выводятся на консоль, - это kernel.printk.
Значения уровней журнала ядра:
0— Аварийная ситуация в ядре. Система непригодна для использования.1— Тревога. Необходимо немедленно принять меры.2— Состояние ядра считается критическим.3— Общая ошибка ядра.4— Общее предупреждение.5— Уведомление о нормальном, но требующем внимания состоянии.6— Информационное сообщение.7— Сообщение уровня отладки.
По умолчанию kernel.printk в SberLinux содержит четыре значения. Для отображения данных значений введите команду:
sysctl kernel.printk
Результат выполнения команды:
kernel.printk = 7 4 1 7
Приведенные четыре значения определяют следующее, в порядке перечисления:
Уровень журнала консоли - определяет самый низкий приоритет сообщений, выводимых на консоль.
Уровень журнала по умолчанию - для сообщений, за которыми явно не закреплен уровень журнала.
Устанавливает минимально возможную конфигурацию для уровня журнала консоли.
Устанавливает значение по умолчанию для уровня журнала консоли во время загрузки.
Каждое из данных значений определяет отдельное правило обработки сообщений об ошибках.
Важно
Значение printk по умолчанию 7 4 1 7 позволяет лучше отлаживать работу ядра. Однако в сочетании с последовательной консолью данный параметр printk может вызвать интенсивные сбои ввода-вывода, которые могут привести к временной потере работоспособности системы. Для избежания подобных ситуаций printk задаются значения 4 4 1 7 - это работает за счет потери дополнительной отладочной информации.
Также обратите внимание, что некоторые параметры командной строки ядра, такие как quiet или debug, изменяют значения kernel.printk по умолчанию.
Установка kdump#
Служба kdump устанавливается и активируется по умолчанию в новых установках SberLinux. В следующих разделах объясняется, что kdump такое и как установить, kdump если он не включен по умолчанию.
Служба kdump#
kdump — это служба, предоставляющая механизм аварийного dump для ядра. Сервис позволяет сохранять содержимое системной памяти для анализа. kdump использует системный вызов kexec для загрузки второго ядра (ядро захвата) без перезагрузки; а затем захватывает содержимое памяти сбойного ядра (аварийный dump или vmcore) и сохраняет его в файл. Второе ядро находится в зарезервированной части системной памяти.
Примечание: dump сбоя ядра может быть единственной доступной информацией в случае системного сбоя (критической ошибки). Поэтому оперативность kdump важна в критически важных средах. Рекомендуется, чтобы системные администраторы регулярно обновляли и тестировали kexec-tools обычный цикл обновления ядра. Это особенно важно, когда реализуются новые функции ядра.
Можно включить kdump для всех установленных ядер на машине или только для определенных ядер. Это полезно, когда на машине используется несколько ядер, некоторые из которых достаточно стабильны, чтобы не возникало опасений, что они могут выйти из строя.
При kdump установке создается /etc/kdump.conf файл по умолчанию. Файл включает минимальную kdump конфигурацию по умолчанию. Можно отредактировать этот файл, чтобы настроить kdump конфигурацию, но это не обязательно.
Установка kdump с помощью Anaconda#
Программа установки Anaconda предоставляет экран графического интерфейса для kdump настройки во время интерактивной установки. Экран установщика называется KDUMP и доступен на главном экране сводки установки. Можно включить kdump и зарезервировать необходимый объем памяти.
Процедура:
Перейдите в KDUMP поле.
Включите kdump, если еще не включено.
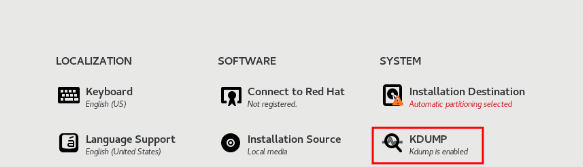
Рисунок. Включение kdump
Определите, сколько памяти должно быть зарезервировано для файлов kdump.

Рисунок. Память для файлов kdump
Установка kdump из командной строки#
Некоторые параметры установки, такие как выборочная установка Kickstart, в некоторых случаях не устанавливаются или не включаются kdump по умолчанию. В этом случае - выполните описанную ниже процедуру.
Предварительные условия:
Пакет kexec-tools установлен.
Выполнены требования к kdump конфигурациям и целям. Подробнее см. в разделе «Поддерживаемые конфигурации и цели kdump».
Процедура:
Проверьте, установлен ли kdump в системе:
# rpm -q kexec-tools
Вывод, если пакет установлен:
kexec-tools-2.0.17-11.el8.x86_64
Вывод, если пакет не установлен:
package kexec-tools is not installed
Установите kdump и другие необходимые пакеты:
# dnf install kexec-tools
Настройка kdump в командной строке#
В следующих разделах объясняется, как планировать и создавать kdump среду.
Оценка размера kdump#
При планировании и создании kdump среды важно знать, сколько места требуется для файла аварийного dump.
Команда makedumpfile --mem-usage оценивает, сколько места требуется для файла аварийного dump. Создает отчет об использовании памяти. Отчет поможет определить уровень dump и какие страницы можно безопасно исключить.
Процедура:
Выполните следующую команду, чтобы создать отчет об использовании памяти:
# makedumpfile --mem-usage /proc/kcore
TYPE PAGES EXCLUDABLE DESCRIPTION
-------------------------------------------------------------
ZERO 501635 yes Pages filled with zero
CACHE 51657 yes Cache pages
CACHE_PRIVATE 5442 yes Cache pages + private
USER 16301 yes User process pages
FREE 77738211 yes Free pages
KERN_DATA. 1333192 no Dumpable kernel data
Примечание: Команда makedumpfile --mem-usage сообщает требуемую память в страницах. Это означает, что нужно рассчитать размер используемой памяти в зависимости от размера страницы ядра.
Настройка использования памяти kdump#
Память для kdump резервируется во время загрузки системы. Размер памяти настраивается в системном файле конфигурации Grand Unified Bootloader (GRUB). Размер памяти зависит от значения crashkernel= параметра, указанного в файле конфигурации, и размера физической памяти системы.
Опция crashkernel= может быть определена несколькими способами. Можно указать crashkernel= значение или настроить auto параметр. Параметр crashkernel=auto резервирует память автоматически, исходя из общего объема физической памяти в системе. При настройке ядро автоматически резервирует соответствующий объем необходимой памяти для ядра захвата. Это помогает предотвратить ошибки нехватки памяти (OOM).
Предварительные условия:
root права;
Выполнены требования к kdump конфигурациям и целям. Подробнее см. в разделе "Поддерживаемые конфигурации и цели kdump".
Процедура:
Отредактируйте /etc/default/grub файл.
Установите crashkernel= параметр.
Например, чтобы зарезервировать 128 МБ памяти, используйте следующее:
crashkernel=128M
Кроме того, можно установить объем зарезервированной памяти переменной в зависимости от общего объема установленной памяти. Синтаксис резервирования памяти в переменную: crashkernel=<range1>:<size1>,<range2>:<size2>. Например:
crashkernel=512M-2G:64M,2G-:128M
В приведенном выше примере резервируется 64 МБ памяти, если общий объем системной памяти составляет от 512 МБ до 2 ГБ. Если общий объем памяти превышает 2 ГБ, резервируется 128 МБ.
Смещение зарезервированной памяти. Некоторым системам требуется резервировать память с определенным фиксированным смещением, поскольку crashkernelрезервирование происходит очень рано, и требуется зарезервировать некоторую область для специального использования. Если установлено смещение, зарезервированная память начинается там. Чтобы компенсировать зарезервированную память, используйте следующий синтаксис:
crashkernel=128M@16M
В приведенном выше примере kdump резервируется 128 МБ памяти, начиная с 16 МБ (физический адрес 0x01000000). Если параметр смещения установлен на 0 или полностью опущен, kdump автоматически смещается зарезервированная память. Также можно использовать этот синтаксис при настройке резервирования переменной памяти. В этом случае смещение всегда указывается последним (например, crashkernel=512M-2G:64M,2G-:128M@16M).
Используйте следующую команду для обновления файла конфигурации GRUB:
# grub2-mkconfig -o /boot/grub2/grub.cfg
Примечание: Альтернативный способ настроить память для kdump — добавить параметр crashkernel=<SOME_VALUE> к переменной kernelopts с помощью команды grub2-editenv, которая обновит все загрузочные записи. Или можно использовать утилиту grubbyдля обновления одной загрузочной записи, нескольких загрузочных записей или всех загрузочных записей.
Настройка цели kdump#
Аварийный dump обычно хранится в виде файла в локальной файловой системе и записывается непосредственно на устройство. Кроме того, можно настроить отправку аварийного dump по сети с использованием протоколов NFS или SSH. Одновременно можно установить только один из этих параметров для сохранения файла аварийного dump. Поведение по умолчанию — хранить его в /var/crash/ каталоге локальной файловой системы.
Предварительные условия:
Права root пользователя.
Выполнены требования к kdump конфигурациям и целям. Подробнее см. в разделе «Поддерживаемые конфигурации и цели kdump».
Процедура:
Чтобы сохранить файл аварийного dump в /var/crash/ каталоге локальной файловой системы, отредактируйте /etc/kdump.confфайл и укажите путь:
path /var/crash
Параметр path /var/crash представляет собой путь к файловой системе, в которой kdump сохраняется файл аварийного dump. Когда указана цель dump в /etc/kdump.conf файле, то path относится к указанной цели dump.
Если цель dump не указана в /etc/kdump.conf файле, то path представляет собой абсолютный путь от корневого каталога. В зависимости от того, что смонтировано в текущей системе, цель dump и скорректированный путь dump выбираются автоматически.
Предупреждение: kdump сохраняет файл аварийного dump в /var/crash/var/crash каталоге, когда цель dump смонтирована в /var/crash и параметр path установлен как /var/crash в /etc/kdump.conf файле. Например, в следующем примере ext4 файловая система уже смонтирована в /var/crash и path установлена как /var/crash:
# grep -v ^# /etc/kdump.conf | grep -v ^$
ext4 /dev/mapper/vg00-varcrashvol
path /var/crash
core_collector makedumpfile -c --message-level 1 -d 31
Эти результаты в /var/crash/var/crash пути. Чтобы решить эту проблему, используйте опцию path / вместо path /var/crash.
Чтобы изменить локальный каталог, в котором должен быть сохранен аварийный dump, от имени пользователя root отредактируйте файл конфигурации /etc/kdump.conf, как описано ниже.
Удалите знак решетки ("#") в начале #path /var/crash строки.
Замените значение предполагаемым путем к каталогу. Например:
path /usr/local/cores
Примечание: Каталог, определенный как цель kdump с помощью директивы пути, должен существовать при запуске службы kdump systemd, иначе служба не работает.
Чтобы записать файл в другой раздел, от имени пользователя root, отредактируйте файл конфигурации /etc/kdump.conf, как описано ниже.
Удалите знак решетки (" #") в начале #ext4 строки, в зависимости от выбора:
имени устройства ( #ext4 /dev/vg/lv_kdump строка)
метки файловой системы ( #ext4 LABEL=/boot строка)
UUID (#ext4 UUID=03138356-5e61-4ab3-b58e-27507ac41937 строка)
записи аварийного dump непосредственно на устройство, для этого отредактируйте /etc/kdump.conf файл конфигурации:
Удалите знак решетки (#) в начале #raw /dev/vg/lv_kdump строки.
Замените значение предполагаемым именем устройства. Например:
raw /dev/sdb1
Чтобы сохранить аварийный dump на удаленной машине с использованием NFS протокола, отредактируйте /etc/kdump.conf файл конфигурации:
Удалите знак решетки (#) в начале #nfs my.server.com:/export/tmp строки.
Замените значение допустимым именем хоста и путем к каталогу. Например:
nfs penguin.example.ru:/export/cores
Чтобы сохранить аварийный dump на удаленной машине с использованием SSH протокола, отредактируйте /etc/kdump.conf файл конфигурации:
Удалите знак решетки ("#") в начале строки #ssh user@my.server.com.
Замените значение допустимым именем пользователя и именем хоста.
Включите свой SSH ключ в конфигурацию.
Удалите знак решетки с начала #sshkey /root/.ssh/kdump_id_rsa строки.
Измените значение на расположение ключа, действительного на сервере, на который выполняется dump. Например:
ssh john@penguin.example.ru
sshkey /root/.ssh/mykey
Настройка сборщика ядер kdump#
Служба kdump использует core_collector программу для захвата образа аварийного dump. В SberLinux makedumpfile утилита является основным сборщиком по умолчанию. Это помогает уменьшить файл dump:
сжатие размера файла аварийного dump и копирование только необходимых страниц с использованием различных уровней dump;
исключение ненужных страниц аварийного dump;
фильтрация типов страниц для включения в аварийный dump.
Синтаксис:
core_collector makedumpfile -l --message-level 1 -d 31
Опции:
-c, -lили -p: укажите формат файла dump сжатия для каждой страницы, используя zlib для -c опции, lzo для -l опции или snappy для -p опции.
-d (dump_level): исключает страницы, чтобы они не копировались в файл dump.
–message-level: укажите типы сообщений. Можно ограничить вывод на печать, указав message_level эту опцию. Например, если указать 7 как, message_level будут напечатаны общие сообщения и сообщения об ошибках. Максимальное значение message_level- 31
Предварительные условия:
Права root пользователя.
Выполнены требования к kdump конфигурациям и целям.
Процедура:
Как пользователь root, отредактируйте /etc/kdump.conf файл конфигурации и удалите знак решетки (#) в начале файла #core_collector makedumpfile -l --message-level 1 -d 31.
Чтобы включить сжатие файла аварийного dump, выполните:
core_collector makedumpfile -l --message-level 1 -d 31
Параметр -l указывает dump формат сжатого файла. Параметр -d указывает уровень dump как 31. Параметр –message-level указывает уровень сообщения как 1.
Кроме того, рассмотрите следующие примеры с опциями -c и -p:
Чтобы сжать файл аварийного dump, используйте -c:
core_collector makedumpfile -c -d 31 --message-level 1
Чтобы сжать файл аварийного dump, используйте -p:
core_collector makedumpfile -p -d 31 --message-level 1
Настройка реакции kdump на сбой по умолчанию#
По умолчанию, если kdump не удается создать файл аварийного dump в настроенном целевом расположении, система перезагружается, и dump при этом теряется. Чтобы изменить это поведение, выполните описанную ниже процедуру.
Предварительные условия:
Права root пользователя.
Выполнены требования к kdump конфигурациям и целям.
Процедура:
Как пользователь root, удалите знак решетки (" #") в начале #failure_action строки в /etc/kdump.conf файле конфигурации.
Замените значение желаемым действием.
failure_action poweroff
Файл конфигурации для kdump#
Файл конфигурации для kdump ядра /etc/sysconfig/kdump. Этот файл управляет параметрами kdump командной строки ядра.
Для большинства конфигураций используйте параметры по умолчанию. Однако в некоторых сценариях может потребоваться изменить определенные параметры для управления kdump поведением ядра. Например, изменение для добавления kdump командной строки ядра для получения подробного вывода отладки.
В этом разделе содержится информация об изменении параметров KDUMP_COMMANDLINE_REMOVE и KDUMP_COMMANDLINE_APPEND для kdump. Информацию о дополнительных параметрах конфигурации см. в файле /etc/sysconfig/kdump.
KDUMP_COMMANDLINE_REMOVE
Эта опция удаляет аргументы из текущей kdump командной строки. Опция удаляет параметры, которые могут вызвать kdump ошибки или kdump сбои при загрузке ядра. Эти параметры могли быть проанализированы из предыдущего KDUMP_COMMANDLINE процесса или унаследованы от /proc/cmdline файла. Когда эта переменная не настроена, она наследует все значения из /proc/cmdline файла. Настройка этого параметра также предоставляет информацию, полезную при отладке проблемы.
Тестирование конфигурации kdump#
Можно проверить, что процесс аварийного dump работает и действителен.
Предупреждение: Приведенные ниже команды вызывают сбой ядра. Соблюдайте осторожность при выполнении этих шагов и никогда не применяйте их небрежно в активной производственной системе.
Процедура:
Перезагрузите систему с kdump включенным.
Убедитесь, что kdump запущен:
**# systemctl is-active kdump**
active
Принудительный сбой ядра Linux:
echo 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
Предупреждение: Приведенная выше команда приводит к сбою ядра, требуется перезагрузка.
После повторной загрузки файл с адресом address-YYYY-MM-DD-HH:MM:SS/vmcore создается в месте, которое указано в файле /etc/kdump.conf(по умолчанию /var/crash/).
Примечание: Это действие подтверждает правильность конфигурации. Также это действие можно использовать для записи того, сколько времени требуется для создания аварийного dump с репрезентативной рабочей нагрузкой.
Включение kdump#
Можно включить и запустить kdump службу для всех ядер, установленных на машине.
Включение kdump для всех установленных ядер#
Предварительные условия:
Права администратора
Процедура:
Добавьте параметр командной строки crashkernel=auto ко всем установленным ядрам:
# grubby --update-kernel=ALL --args="crashkernel=auto"
Включите kdump службу.
# systemctl enable --now kdump.service
Проверка:
Убедитесь, что kdump служба запущена:
# systemctl status kdump.service
○ kdump.service - Crash recovery kernel arming
Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled)
Active: active (live)
Включение kdump для определенного установленного ядра#
Можно включить kdump службу для определенного ядра на машине.
Предварительные условия:
Права администратора
Процедура:
Перечислите ядра, установленные на машине.
# ls -a /boot/vmlinuz-
/boot/vmlinuz-0-rescue-2930657cd0dc43c2b75db480e5e5b4a9 /boot/vmlinuz-4.18.0-330.el8.x86_64 /boot/vmlinuz-4.18.0-330.rt7.111.el8 .x86_64
Добавьте конкретное kdump ядро в системный файл конфигурации Grand Unified Bootloader (GRUB). Например:
# grubby --update-kernel=vmlinuz-4.18.0-330.el8.x86_64 --args="crashkernel=auto"
Включите kdump службу.
# systemctl enable --now kdump.service
Проверка:
Убедитесь, что kdump служба запущена:
# systemctl status kdump.service
○ kdump.service - Crash recovery kernel arming
Loaded: loaded (/usr/lib/systemd/system/kdump.service; enabled; vendor preset: disabled)
Active: active (live)
Отключение службы kdump#
Чтобы отключить kdump службу во время загрузки, выполните описанную ниже процедуру.
Предварительные условия:
Выполнены требования к kdump конфигурациям и целям.
Все конфигурации для установки kdump настроены в соответствии с потребностями. Дополнительные сведения см. в разделе «Установка kdump».
Процедура:
Чтобы остановить kdump службу в текущем сеансе:
# systemctl stop kdump.service
Чтобы отключить kdump службу:
# systemctl disable kdump.service
Предупреждение: Рекомендуется установить kptr_restrict=1. В этом случае служба kdumpctl загружает аварийное ядро независимо от того, включено или нет расположение адресного пространства ядра (KASLR).
Устранение неполадок:
Когда для kptr_restrict не установлено значение (1) и если KASLR включен, содержимое файла /proc/kcore генерируется как все нули. Следовательно, служба kdumpctl не может получить доступ к /proc/kcore и загрузить аварийное ядро.
Чтобы обойти эту проблему, в файле /usr/share/doc/kexec-tools/kexec-kdump-howto.txt отображается предупреждающее сообщение, в котором рекомендуется параметр kptr_restrict=1.
Чтобы убедиться, что служба kdumpctl загружает аварийное ядро, убедитесь, что в файле sysctl.conf указано значение kernel.kptr_restrict = 1.
Поддерживаемые конфигурации и цели kdump#
Требования к памяти для kdump#
Чтобы kdump можно было захватить dump сбоя ядра и сохранить его для дальнейшего анализа, часть системной памяти должна быть постоянно зарезервирована для ядра захвата. Зарезервированная часть системной памяти недоступна основному ядру.
В следующей таблице перечислены минимальные требования к памяти для автоматического резервирования объема памяти kdump. Размер изменяется в зависимости от общего объема доступной физической памяти.
Таблица. Минимальный объем зарезервированной памяти, необходимый для kdump
Доступная память |
Минимальная зарезервированная память |
|---|---|
от 1 ГБ до 4 ГБ |
160 Мбайт оперативной памяти. |
от 4 ГБ до 64 ГБ |
192 Мбайт оперативной памяти. |
от 64 ГБ до 1 ТБ |
256 Мбайт оперативной памяти. |
1 ТБ и более |
512 Мбайт оперативной памяти |
На многих системах kdump умеет оценивать объем требуемой памяти и автоматически резервировать ее. Это поведение включено по умолчанию, но работает только в системах с более чем определенным объемом доступной памяти.
Примечание: Автоматическая конфигурация зарезервированной памяти на основе общего объема памяти в системе — это наилучшая оценка. Фактический требуемый объем памяти может варьироваться в зависимости от других факторов, таких как устройства ввода-вывода. Использование недостаточного количества памяти может привести к тому, что ядро отладки не сможет загрузиться как ядро захвата в случае Kernel panic (критической ошибки ядра). Чтобы избежать этой проблемы, достаточно увеличить память аварийного ядра.
Минимальный порог для автоматического резервирования памяти#
В некоторых системах возможно выделение памяти kdump автоматически, либо с помощью crashkernel=auto параметра в файле конфигурации загрузчика, либо путем включения этой опции в графической утилите настройки. Чтобы это автоматическое резервирование работало, в системе должен быть доступен определенный объем общей памяти.
Для x86_64 архитектуры пороговое значение для автоматического выделения памяти - 2 Гбайта. Если в системе имеется память меньше указанного порогового значения, необходимо настроить память вручную.
Поддерживаемые цели kdump#
Когда фиксируется сбой ядра, файл vmcore для dump может быть записан непосредственно на устройство, сохранен в виде файла в локальной файловой системе или отправлен по сети. В приведенной ниже таблице содержится полный список целей dump, которые в настоящее время поддерживаются или явно не поддерживаются kdump.
Тип |
Поддерживаемые цели |
Неподдерживаемые цели |
|---|---|---|
Необработанное устройство |
Все локально подключенные необработанные диски и разделы |
|
Локальная файловая система |
ext4 файловая система на напрямую подключенных дисках, аппаратных логических дисках RAID, устройствах LVM и mdraid массивах |
Любая локальная файловая система, явно не указанная в этой таблице как поддерживаемая, включая auto тип (автоматическое определение файловой системы) |
Удаленный каталог |
Удаленные каталоги, доступ к которым осуществляется по протоколу NFS или SSH через IPv4 |
Удаленные каталоги в rootfs файловой системе, доступ к которым осуществляется по NFS протоколу |
Доступ к удаленным каталогам осуществляется с использованием iSCSI протокола через аппаратные и программные инициаторы |
Доступ к удаленным каталогам осуществляется с использованием iSCSI протокола на be2iscsi оборудовании |
multipath-based хранилища |
Доступ к удаленным каталогам через IPv6 |
||
Удаленные каталоги, доступ к которым осуществляется с использованием протокола SMB или CIFS |
||
Доступ к удаленным каталогам осуществляется по протоколу FCoE (Fiber Channel over Ethernet) |
||
Удаленные каталоги, доступ к которым осуществляется через беспроводные сетевые интерфейсы |
Примечание: Использование встроенного dump (fadump) для захвата vmcore и его сохранения на удаленном компьютере с использованием протокола SSH или NFS приводит к переименованию сетевого интерфейса в kdump-<interface-name>. Переименование происходит, если <interface-name> является общим, например *eth#, net# и т. д. Эта проблема возникает из-за того, что сценарии захвата vmcore на начальном RAM-диске (initrd) добавляют префикс kdump- к имени сетевого интерфейса для обеспечения постоянного именования. Поскольку тот же самый initrd используется и для обычной загрузки, имя интерфейса изменено и для производственного ядра.
Поддерживаемые уровни фильтрации kdump#
Чтобы уменьшить размер файла dump, kdump использует основной сборщик makedumpfile для сжатия данных и, при необходимости, для исключения нежелательной информации. В приведенной ниже таблице содержится полный список уровней фильтрации, которые в настоящее время поддерживаются утилитой makedumpfile.
Вариант |
Описание |
|---|---|
1 |
Нулевые страницы |
2 |
кеш страниц |
4 |
кеш приватный |
8 |
Пользовательские страницы |
16 |
Свободные страницы |
Примечание: Команда makedumpfile поддерживает удаление прозрачных огромных страниц и страниц hugetlbfs. Рассмотрите типы пользовательских страниц огромных страниц и удалите их, используя уровень -8.
Поддерживаемые ответы на ошибки по умолчанию#
По умолчанию, когда kdump не может создать dump ядра, операционная система перезагружается. Однако можно настроить kdump на выполнение другой операции в случае, если ему не удастся сохранить dump ядра в первичную цель. В таблицах ниже перечислены все действия по умолчанию, которые в настоящее время поддерживаются.
Вариант |
Описание |
|---|---|
dump_to_rootfs |
Попытайтесь сохранить dump ядра в корневую файловую систему. Этот параметр особенно полезен в сочетании с сетевой целью: если сетевая цель недоступна, эта опция настраивает kdump для локального сохранения dump ядра. После этого система перезагружается. |
reboot |
Перезагрузите систему, потеряв при этом dump ядра. |
halt |
Остановите систему, потеряв при этом dump ядра. |
poweroff |
Выключите систему, потеряв при этом dump ядра. |
shell |
Запустите сеанс оболочки из initramfs, что позволит пользователю вручную записать dump ядра. |
final_action |
Включите дополнительные операции, такие как reboot, halt и poweroff питания после успешного выполнения kdump или после завершения действия shell или dump_to_rootfs. Параметр final_action по умолчанию — reboot. |
Использование параметра final_action#
Final_action параметр позволяет использовать некоторые дополнительные операции, такие как reboot, halt и poweroff после успешного kdump или после завершения вызванного механизма failure_response с использованием shell или dump_to_rootfs. Если final_action параметр не указан, по умолчанию используется reboot.
Процедура:
Отредактируйте `/etc/kdump.confфайл и добавьте final_action параметр.
final_action <reboot | halt | poweroff>
Перезапустите kdump службу:
kdumpctl restart
Установка лимитов для приложений#
Можно использовать функциональные возможности ядра групп управления (cgroups) для установки ограничений, определения приоритетов или изоляции аппаратных ресурсов процессов. Это позволяет детально контролировать использование ресурсов приложениями, чтобы использовать их более эффективно.
Общие сведения о контрольных группах#
Группы управления — это функция ядра Linux, которая позволяет организовывать процессы в иерархически упорядоченные группы — cgroups. Иерархия (дерево групп управления) определяется путем предоставления структуры виртуальной файловой системе cgroups, смонтированной по умолчанию в каталоге /sys/fs/cgroup/. Диспетчер систем и служб systemd использует cgroups для организации всех модулей и служб, которыми он управляет. Кроме того, можно вручную управлять иерархиями cgroups, создавая и удаляя подкаталоги в каталоге /sys/fs/cgroup/.
Контроллеры ресурсов (компонент ядра) затем изменяют поведение процессов в cgroups, ограничивая, расставляя приоритеты или распределяя системные ресурсы (такие, как процессорное время, память, пропускная способность сети или различные комбинации) этих процессов.
Дополнительным преимуществом cgroups является объединение процессов, позволяющее разделить аппаратные ресурсы между приложениями и пользователями. Тем самым может быть достигнуто повышение общей эффективности, стабильности и безопасности пользовательской среды.
Группы управления версия 1
Группы управления версии 1 (cgroups-v1) обеспечивают иерархию контроллеров для каждого ресурса. Это означает, что каждый ресурс, такой как ЦП, память, ввод-вывод и т. д., имеет свою собственную иерархию групп управления. Можно комбинировать различные иерархии групп управления таким образом, чтобы один контроллер мог координировать свои действия с другим при управлении соответствующими ресурсами. Однако два контроллера могут принадлежать к разным иерархиям процессов, что не позволяет обеспечить их надлежащую координацию.
Контроллеры cgroups-v1 разрабатывались в течение большого промежутка времени, и в результате поведение и имена их управляющих файлов неодинаковы.
Группы управления версия 2
Проблемы с координацией контроллеров, возникшие из-за гибкости иерархии, привели к разработке групп управления версии 2.
Группа управления версии 2 (cgroups-v2) обеспечивает единую иерархию группы управления, в которой монтируются все контроллеры ресурсов.
Поведение управляющего файла и его наименование одинаковы для разных контроллеров.
Формат вывода cgroups и irqs для обеспечения лучшей читаемости выводом команд tuna show_threads для утилиты cgroup структурирован в зависимости от размера терминала. Также можно настроить дополнительные интервалы между выводимыми данными cgroups, добавив в -z команду параметр new --spaced или show_threads. В результате можно просматривать выходные данные cgroups в удобочитаемом формате, который можно адаптировать к размеру терминала.
Контроллеры ресурсов ядра#
Функциональность контрольных групп обеспечивается контроллерами ресурсов ядра. SberLinux поддерживает различные контроллеры для контрольных групп версии 1 (cgroups-v1) и контрольных групп версии 2 (cgroups-v2).
Контроллер ресурсов, также называемый подсистемой группы управления, представляет собой подсистему ядра, представляющую один ресурс, такой как процессорное время, память, пропускная способность сети или дисковый ввод-вывод. Ядро Linux предоставляет ряд контроллеров ресурсов, которые автоматически монтируются системой systemd и диспетчером служб. Найдите список смонтированных в данный момент контроллеров ресурсов в /proc/cgroups файле.
Доступны следующие контроллеры cgroups-v1:
blkio - может устанавливать ограничения на доступ ввода/вывода к блочным устройствам и от них.
cpu- может настраивать параметры планировщика Completely Fair Scheduler (CFS) для задач контрольной группы. Монтируется вместе со cpuacct контроллером на одном креплении.
cpuacct - создает автоматические отчеты по ресурсам процессора, используемым задачами в контрольной группе. Монтируется вместе со cpu контроллером на одном креплении.
cpuset - может использоваться для ограничения задач группы управления только на указанном подмножестве ЦП и указания задачам использовать память только на указанных узлах памяти.
devices - может контролировать доступ к устройствам для задач в группе управления.
freezer - может использоваться для приостановки или возобновления задач в контрольной группе.
memory - может использоваться для установки ограничений на использование памяти задачами в контрольной группе и генерирует автоматические отчеты о ресурсах памяти, используемых этими задачами.
net_cls - может помечать сетевые пакеты идентификатором класса (classid), что позволяет контроллеру трафика Linux ( tc команде) идентифицировать пакеты, исходящие от конкретной задачи группы управления. Подсистема net_cls.
net_filter iptables - может использовать этот тег для выполнения действий с такими пакетами. Сетевые сокеты net_filter помечаются идентификатором межсетевого экрана (fwid), который позволяет межсетевому экрану Linux (через iptables команду) идентифицировать пакеты, исходящие от конкретной задачи группы управления.
net_prio - может устанавливать приоритет сетевого трафика.
pids - может устанавливать лимиты на количество процессов и их потомков в контрольной группе.
perf_event - может группировать задачи для мониторинга с помощью perf утилиты мониторинга производительности и создания отчетов.
rdma - может устанавливать ограничения на определенные ресурсы Remote Direct Memory Access/InfiniBand в контрольной группе.
hugetlb - может использоваться для ограничения использования страниц виртуальной памяти большого размера задачами в контрольной группе.
Доступны следующие контроллеры cgroups-v2:
io - Продолжение blkio из cgroups-v1;
memory - Продолжение memory из cgroups-v1;
pids - То же, что и pids из cgroups-v1;
rdma - То же, что и rdma из cgroups-v1;
cpu - Продолжение cpu и cpuacct из cgroups-v1;
cpuset - Поддерживает только основные функции(cpus{,.effective}, mems{,.effective}) с новой функцией разделов;
perf_event - Встроенная поддержка, нет явного управляющего файла. Можно указать v2 cgroupв качестве параметра perf команды, которая будет профилировать все задачи в этом файле cgroup.
Пространства имен#
Пространства имен — один из наиболее важных методов организации и идентификации программных объектов.
Пространство имен заключает глобальный системный ресурс (например, точку монтирования, сетевое устройство или имя хоста) в абстракцию, благодаря которой для процессов внутри пространства имен кажется, что у них есть собственный изолированный экземпляр глобального ресурса. Одной из наиболее распространенных технологий, использующих пространства имен, являются контейнеры.
Изменения конкретного глобального ресурса видны только процессам в этом пространстве имен и не влияют на остальную часть системы или другие пространства имен.
Чтобы проверить, членом каких пространств имен является процесс, Можно проверить символические ссылки в каталоге /proc/
В следующей таблице показаны поддерживаемые пространства имен и ресурсы, которые они изолируют:
Пространство имен |
Ресурсы |
|---|---|
Mount |
Точки монтирования |
UTS |
Имя хоста и доменное имя NIS |
IPC |
System V IPC, очереди сообщений POSIX |
PID |
Идентификаторы процессов |
Network |
Сетевые устройства, стеки, порты и т. д. |
User |
Идентификаторы пользователей и групп |
Control groups |
Корневой каталог группы управления |
Установка ограничений ЦП для приложений с помощью cgroups-v1#
Иногда приложение потребляет много процессорного времени, что может негативно сказаться на общем состоянии среды. Используйте виртуальную файловую систему /sys/fs/, чтобы настроить ограничения ЦП для приложения с помощью контрольных групп версии 1 (cgroups-v1).
Предварительные условия:
Права root пользователя.
Существует приложение, потребление ЦП которого нужно ограничить.
Контроллеры службы смонтированы.
# mount -l | grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
...
Процедура:
Определите идентификатор процесса (PID) приложения, которое необходимо ограничить потреблением ЦП:
# top
top - 12:28:42 up 1:06, 1 user, load average: 1.02, 1.02, 1.00
Tasks: 266 total, 6 running, 260 sleeping, 0 stopped, 0 zombie
%Cpu(s): 11.0 us, 1.2 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.2 st
MiB Mem : 1826.8 total, 287.1 free, 1054.4 used, 485.3 buff/cache
MiB Swap: 1536.0 total, 1396.7 free, 139.2 used. 608.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6955 root 20 0 228440 1752 1472 R 20.6 0.1 47:11.43 sha1sum
5760 jdoe 20 0 3604956 208832 65316 R 2.3 11.2 0:43.50 gnome-shell
6448 jdoe 20 0 743836 31736 19488 S 0.7 1.7 0:08.25 gnome-terminal-
505 root 20 0 0 0 0 I 0.3 0.0 0:03.39 kworker/u4:4-events_unbound
4217 root 20 0 74192 1612 1320 S 0.3 0.1 0:01.19 spice-vdagentd
...
Пример вывода top программы показывает, что PID 6955 (иллюстративное приложение sha1sum) потребляет много ресурсов ЦП.
Создайте подкаталог в каталоге cpu контроллера ресурсов:
# mkdir /sys/fs/cgroup/cpu/Example/
Вышеупомянутый каталог представляет собой группу управления, в которую нужно поместить определенные процессы и применить к ним определенные ограничения ЦП. В то же время в каталоге будут созданы некоторые файлы интерфейса cgroups-v1 и файлы, относящиеся к контроллеру cpu.
Настройте лимиты cpu для контрольной группы:
# ll /sys/fs/cgroup/cpu/Example/
-rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.clone_children
-rw-r—r--. 1 root root 0 Mar 11 11:42 cgroup.procs
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.stat
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_all
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_sys
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_percpu_user
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_sys
-r—r—r--. 1 root root 0 Mar 11 11:42 cpuacct.usage_user
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_period_us
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.cfs_quota_us
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_period_us
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.rt_runtime_us
-rw-r—r--. 1 root root 0 Mar 11 11:42 cpu.shares
-r—r—r--. 1 root root 0 Mar 11 11:42 cpu.stat
-rw-r—r--. 1 root root 0 Mar 11 11:42 notify_on_release
-rw-r—r--. 1 root root 0 Mar 11 11:42 tasks
Файл cpu.cfs_period_us представляет собой период времени в микросекундах (мкс, представленный здесь как нас) для того, как часто должен перераспределяться доступ контрольной группы к ресурсам ЦП. Верхний предел составляет 1 секунду, а нижний предел — 1000 микросекунд.
Файл cpu.cfs_quota_us представляет собой общее количество времени в микросекундах, в течение которого все процессы в группе управления могут выполняться в течение одного периода (как определено параметром cpu.cfs_period_us). Как только процессы в контрольной группе в течение одного периода израсходуют все время, указанное в квоте, они будут регулироваться на оставшуюся часть периода, и им не разрешается выполняться до следующего периода. Нижний предел составляет 1000 микросекунд.
Приведенные выше примеры команд устанавливают ограничения времени ЦП, чтобы все процессы в совокупности в Example группе управления могли работать только в течение 0,2 секунды (определяется cpu.cfs_quota_us) из каждой 1 секунды (определяется cpu.cfs_period_us).
Добавьте PID приложения в Example группу управления:
# echo "6955" > /sys/fs/cgroup/cpu/Example/cgroup.procs
или
# echo "6955" > /sys/fs/cgroup/cpu/Example/tasks
Предыдущая команда гарантирует, что желаемое приложение станет членом Example контрольной группы и, следовательно, не превысит ограничения ЦП, настроенные для Example контрольной группы. PID должен представлять существующий процесс в системе. Здесь PID 6955 был назначен процессу sha1sum /dev/zero &, используемый для иллюстрации варианта использования cpu контроллера.
Убедитесь, что приложение работает в указанной группе управления:
# cat /proc/6955/cgroup
12:cpuset:/
11:hugetlb:/
10:net_cls,net_prio:/
9:memory:/user.slice/user-1000.slice/user@1000.service
8:devices:/user.slice
7:blkio:/
6:freezer:/
5:rdma:/
4:pids:/user.slice/user-1000.slice/user@1000.service
3:perf_event:/
2:cpu,cpuacct:/Example
1:name=systemd:/user.slice/user-1000.slice/user@1000.service/terminal-server.service
В приведенном выше примере выходных данных показано, что процесс нужного приложения выполняется в группе управления Example, которая применяет ограничения cpu к процессу приложения.
Определите текущее потребление cpu регулируемым приложением:
# top
top - 12:28:42 up 1:06, 1 user, load average: 1.02, 1.02, 1.00
Tasks: 266 total, 6 running, 260 sleeping, 0 stopped, 0 zombie
%Cpu(s): 11.0 us, 1.2 sy, 0.0 ni, 87.5 id, 0.0 wa, 0.2 hi, 0.0 si, 0.2 st
MiB Mem : 1826.8 total, 287.1 free, 1054.4 used, 485.3 buff/cache
MiB Swap: 1536.0 total, 1396.7 free, 139.2 used. 608.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
6955 root 20 0 228440 1752 1472 R 20.6 0.1 47:11.43 sha1sum
5760 jdoe 20 0 3604956 208832 65316 R 2.3 11.2 0:43.50 gnome-shell
6448 jdoe 20 0 743836 31736 19488 S 0.7 1.7 0:08.25 gnome-terminal-
505 root 20 0 0 0 0 I 0.3 0.0 0:03.39 kworker/u4:4-events_unbound
4217 root 20 0 74192 1612 1320 S 0.3 0.1 0:01.19 spice-vdagentd
...
Обратите внимание, что потребление ЦП PID 6955уменьшилось с 99% до 20%.
Примечание: Аналогом cgroups-v2 для cpu.cfs_period_us и cpu.cfs_quota_us является cpu.max файл. Файл cpu.max доступен через cpu контроллер.
Команда rteval#
Команда rteval отображает сводный отчет с количеством загрузок программы, потоков измерения и соответствующим процессором, который запускал эти потоки. Эта информация помогает оценить производительность ядра реального времени под нагрузкой на определенных аппаратных платформах.
Отчет rteval записывается в XML-файл вместе с журналом загрузки системы и сохраняется в сжатом файле rteval-<date>-N-tar.bz2. Где date указывает дату создания отчета и N является счетчиком для N-го запуска.
Чтобы сгенерировать отчет rteval, введите следующую команду:
# rteval --summarize rteval-<date>-N.tar.bz2
Настройка политик CPU Affinity и NUMA с помощью systemd#
Параметры управления ЦП, управления памятью и пропускной способности ввода-вывода связаны с разделением доступных ресурсов.
Настройка привязки ЦП с помощью systemd#
Настройки привязки ЦП помогают ограничить доступ определенного процесса к некоторым ЦП. По сути, планировщик ЦП никогда не планирует выполнение процесса на ЦП, который не находится в маске сходства процесса.
Маска привязки ЦП по умолчанию применяется ко всем службам, управляемым systemd.
Чтобы настроить маску соответствия ЦП для конкретной службы systemd, systemd предоставляет CPUAffinity= как параметр файла модуля, так и параметр конфигурации менеджера в файле /etc/systemd/system.conf.
Параметр файла модуля CPUAffinity= задает список ЦП или диапазонов ЦП, которые объединяются и используются в качестве маски сходства. Параметр CPUAffinity в файле /etc/systemd/system.conf определяет маску сходства для процесса с идентификационным номером (PID) 1 и всех процессов, ответвленных от PID1. Затем нужно переопределить CPUAffinity для каждой службы.
Примечание: После настройки маски соответствия ЦП для конкретной службы systemdнеобходимо перезапустить систему, чтобы изменения вступили в силу.
Процедура:
Чтобы установить маску привязки ЦП для конкретной службы systemd, используя параметр файла модуля CPUAffinity:
Проверьте значения параметра файла модуля CPUAffinity в выбранном сервисе:
$ systemctl show --property <CPU affinity configuration option> <service name>
В качестве пользователя root установите требуемое значение параметра файла модуля CPUAffinity для диапазонов ЦП, используемых в качестве маски сходства:
# systemctl set-property <service name> CPUAffinity=<value>
Перезапустите службу, чтобы применить изменения.
# systemctl restart <service name>
Чтобы установить маску соответствия ЦП для конкретной службы systemd, используя параметр конфигурации менеджера:
Отредактируйте файл /etc/systemd/system.conf:
# vi /etc/systemd/system.conf
Найдите параметр CPUAffinity= и установите номера процессоров.
Сохраните отредактированный файл и перезапустите сервер, чтобы изменения вступили в силу.
Настройка политик NUMA с помощью systemd#
Non-uniform memory access (NUMA) — это конструкция подсистемы памяти компьютера, в которой время доступа к памяти зависит от расположения физической памяти относительно процессора.
Память, близкая к ЦП, имеет меньшую задержку (локальная память), чем память, локальная для другого ЦП (внешняя память) или совместно используемая набором ЦП.
Что касается ядра Linux, политика NUMA определяет, где (например, на каких узлах NUMA) ядро выделяет страницы физической памяти для процесса.
systemd предоставляет параметры файла модуля NUMAPolicy и NUMAMask для управления политиками выделения памяти для служб.
Процедура:
Чтобы установить политику памяти NUMA с помощью параметра файла модуля NUMAPolicy:
Проверьте значения параметра файла модуля NUMAPolicy в выбранном сервисе:
$ systemctl show --property <NUMA policy configuration option> <service name>
В качестве пользователя root установите требуемый тип политики в параметре модуля NUMAPolicy:
# systemctl set-property <service name> NUMAPolicy=<value>
Перезапустите службу, чтобы применить изменения.
# systemctl restart <service name>
Чтобы установить глобальный параметр NUMAPolicy с помощью параметра конфигурации менеджера:
Найдите в файле /etc/systemd/system.conf параметр NUMAPolicy.
Измените тип политики, сохраните файл.
Перезагрузите конфигурацию systemd службы:
# systemd daemon-reload
Перезагрузите сервер.
Предупреждение: При настройке строгой политики NUMA, например bind, убедитесь, что также правильно установлен параметр файла модуля CPUAffinity=.
Параметры конфигурации политики NUMA для systemd#
Systemd предоставляет следующие параметры для настройки политики NUMA:
NUMAPolicy Управляет политикой памяти NUMA исполняемых процессов. Возможны следующие типы политик:
default;
preferred;
bind;
interleave;
local.
NUMAMask Управляет списком узлов NUMA, связанным с выбранной политикой NUMA.
Обратите внимание, что параметр NUMAMask не требуется указывать для следующих политик:
default;
local.
Для предпочтительной политики в списке указан только один узел NUMA.
Повышение безопасности с помощью подсистемы целостности ядра#
Можно усилить защиту своей системы, используя компоненты подсистемы целостности ядра. В следующих разделах представлены соответствующие компоненты и даны рекомендации по их настройке.
Подсистема целостности ядра#
Подсистема целостности — это часть ядра, отвечающая за поддержание целостности данных всей системы. Эта подсистема помогает сохранить состояние определенной системы неизменным с момента ее создания и, таким образом, предотвращает нежелательное изменение определенных системных файлов.
Подсистема целостности ядра может использовать доверенный платформенный модуль (TPM), чтобы повысить безопасность системы. TPM — это спецификация Trusted Computing Group (TCG) для важных криптографических функций. Модули TPM обычно представляют собой специальное аппаратное обеспечение, которое подключается к материнской плате платформы и предотвращает программные атаки, предоставляя криптографические функции из защищенной и защищенной от несанкционированного доступа области аппаратного чипа. Некоторые из функций TPM:
Генератор случайных чисел;
Генератор и безопасное хранилище криптографических ключей;
хеш-генератор;
Удаленная аттестация.
Надежные и зашифрованные ключи#
В следующем разделе представлены доверенные и зашифрованные ключи как важная часть повышения безопасности системы.
Надежные и зашифрованные ключи — это симметричные ключи переменной длины, сгенерированные ядром, которые используют службу набора ключей ядра. Тот факт, что этот тип ключей никогда не появляется в пользовательском пространстве в незашифрованном виде, означает, что их целостность может быть проверена. Программы пользовательского уровня могут получить доступ к ключам только в виде зашифрованных больших двоичных объектов.
Для доверенных ключей требуется аппаратный компонент: микросхема доверенного платформенного модуля (Trusted Platform Module (TPM)), которая используется как для создания, так и для шифрования (запечатывания) ключей. Доверенный платформенный модуль запечатывает ключи с помощью 2048-битного ключа RSA, называемого корневым ключом хранилища (storage root key (SRK)).
Примечание: Чтобы использовать спецификацию TPM 1.2, включите и активируйте ее с помощью параметра микропрограммы машины или с помощью команды tpm_setactive из пакета утилит tpm-tools. Кроме того, необходимо установить программный стек TrouSers и запустить демон tcsd для связи с TPM (выделенным оборудованием). Демон tcsd является частью пакета TrouSers, который доступен в пакете TrouSers. В более позднем и обратно несовместимом TPM 2.0 используется другой программный стек, в котором утилиты tpm2-tools или ibm-tss предоставляют доступ к выделенному оборудованию.
Кроме того, пользователь может запечатать доверенные ключи с помощью набора значений для регистра конфигурации платформы (platform configuration register (PCR)) TPM. PCR содержит набор значений управления целостностью, которые отражают встроенное ПО, загрузчик и операционную систему. Это означает, что ключи, запечатанные PCR, могут быть расшифрованы доверенным платформенным модулем только в той же системе, в которой они были зашифрованы. Однако, как только доверенный ключ, запечатанный PCR, загружен (добавлен в связку ключей) и, таким образом, проверены связанные с ним значения PCR, он может быть обновлен новыми (или будущими) значениями PCR, так что новое ядро, например, может быть загруженным. Один ключ также можно сохранить в виде нескольких больших двоичных объектов, каждый из которых имеет разные значения PCR.
Зашифрованные ключи не требуют доверенного платформенного модуля, поскольку они используют расширенный стандарт шифрования ядра (Advanced Encryption Standard (AES)), что делает их быстрее, чем доверенные ключи. Зашифрованные ключи создаются с использованием случайных чисел, сгенерированных ядром, и шифруются главным ключом при экспорте в большие двоичные объекты пользовательского пространства. Главный ключ — это либо доверенный ключ, либо пользовательский ключ. Если мастер-ключ не является доверенным, зашифрованный ключ безопасен настолько, насколько безопасен пользовательский ключ, используемый для его шифрования.
Работа с доверенными ключами#
В следующем разделе описывается, как создавать, экспортировать, загружать или обновлять доверенные ключи с помощью утилиты keyctl для повышения безопасности системы.
Предварительные условия:
Необходимо загрузить доверенный модуль ядра. Дополнительные сведения о загрузке модулей ядра см. в разделе «Управление модулями ядра».
Доверенный платформенный модуль (TPM) должен быть включен и активен. Дополнительные сведения о TPM см. в разделах "Подсистема целостности ядра" и «Доверенные и зашифрованные ключи».
Процедура:
Чтобы создать доверенный ключ с помощью TPM, выполните:
# keyctl **Add** trusted <name> "new <key_length> [options]" <key_ring>
На основе синтаксиса создайте пример команды следующим образом:
# keyctl **Add** trusted kmk "new 32" @u
642500861
Команда создает доверенный ключ kmk длиной 32 байта (256 бит) и помещает его в связку ключей пользователя (@u). Ключи могут иметь длину от 32 до 128 байт (от 256 до 1024 бит).
Чтобы просмотреть текущую структуру связок ключей ядра:
# keyctl show
Session Keyring
-3 --alswrv 500 500 keyring: ses 97833714 --alswrv 500 -1 \ keyring: uid.1000 642500861 --alswrv 500 500 \ trusted: kmk
Чтобы экспортировать ключ в большой двоичный объект пользовательского пространства, выполните:
# keyctl pipe 642500861 > kmk.blob
Команда использует pipe подкоманду и серийный номер файла kmk.
Чтобы загрузить доверенный ключ из большого двоичного объекта пользовательского пространства, используйте add подкоманду с большим двоичным объектом в качестве аргумента:
# keyctl **Add** trusted kmk "load `cat kmk.blob`" @u
268728824
Создайте безопасные зашифрованные ключи на основе доверенного ключа, запечатанного TPM:
# keyctl **Add** encrypted <pass:quotes[name]> "new [format] <pass:quotes[key_type]>:<pass:quotes[primary_key_name]> <pass:quotes[keylength]>" <pass:quotes[key_ring]>
На основе синтаксиса сгенерируйте зашифрованный ключ, используя уже созданный доверенный ключ:
# keyctl **Add** encrypted encr-key "new trusted:kmk 32" @u
159771175
Команда использует доверенный ключ, запечатанный TPM ( kmk), созданный на предыдущем шаге, в качестве первичного ключа для создания зашифрованных ключей.
Работа с зашифрованными ключами#
В следующем разделе описывается управление зашифрованными ключами для повышения безопасности в системах, в которых недоступен доверенный платформенный модуль (TPM).
Предварительные условия:
Необходимо загрузить encrypted-keys модуль ядра. Дополнительные сведения о загрузке модулей ядра см. в разделе «Управление модулями ядра».
Процедура:
Используйте случайную последовательность чисел для генерации пользовательского ключа:
# keyctl **Add** user kmk-user "$(dd if=/dev/urandom bs=1 count=32 2>/dev/null)" @u
427069434
Команда генерирует пользовательский ключ с именем kmk-user, который действует как первичный ключ и используется для запечатывания фактических зашифрованных ключей.
Сгенерируйте зашифрованный ключ, используя первичный ключ из предыдущего шага:
# keyctl **Add** encrypted encr-key "new user:kmk-user 32" @u
1012412758
При необходимости перечислите все ключи в указанной связке ключей пользователя:
# keyctl list @u
2 keys in keyring:
427069434: --alswrv 1000 1000 user: kmk-user
1012412758: --alswrv 1000 1000 encrypted: encr-key
Примечание: Имейте в виду, что зашифрованные ключи, которые не запечатаны доверенным первичным ключом, настолько же безопасны, как первичный ключ пользователя (ключ со случайным числом) для их шифрования. Следовательно, первичный пользовательский ключ следует загружать как можно более надежно и предпочтительно в самом начале процесса загрузки.