Отправка данных из S3-хранилища в векторное хранилище Vector DB с помощью LangChain#
Загрузка данных в векторное хранилище является ключевым элементом при построении эффективных алгоритмов поиска и извлечения информации, особенно учитывая тот факт, что почти 80% данных являются неструктурированными и не имеют заранее определенного формата.
В этом руководстве будет создан оптимизированный конвейер загрузки данных, извлекая данные непосредственно из AWS S3-хранилища и отправляя их в Platform V Vector DB (далее - Vector DB). Произойдет погружение в мир векторных вложений, преобразовывая неструктурированные данные в формат, который позволяет выполнять семантический поиск документов. Приготовьтесь открыть новые способы выявления скрытых инсайтов внутри неструктурированных данных!
Архитектура рабочего процесса по загрузке данных#
Настройте мощный рабочий процесс загрузки и анализа документов, используя облачное хранилище, инструменты обработки естественного языка (NLP) и технологии встраивания. Начиная с сырых данных в корзине S3-хранилища предварительно обработав их с помощью LangChain, примените интерфейсы встраивания для текстов и изображений и сохраним результаты в Vector DB - векторной базе данных, оптимизированной для поиска сходства.
Архитектура рабочего процесса по загрузке данных:
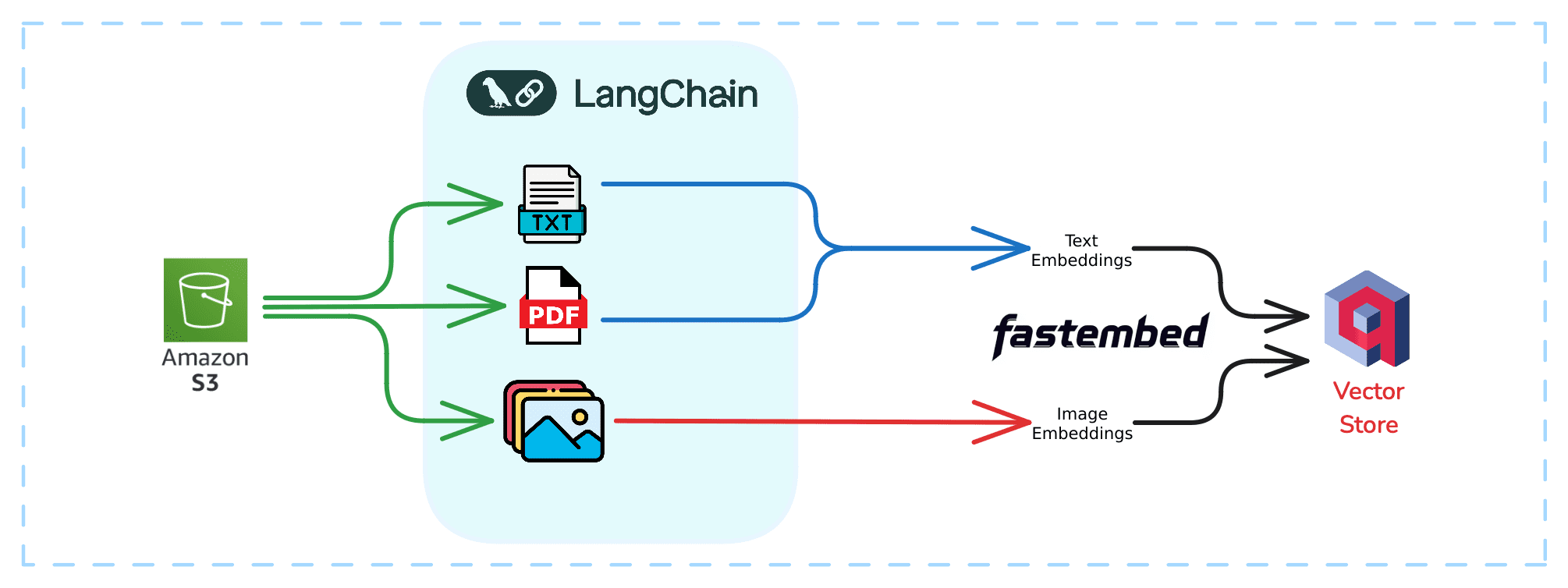
Корзина S3-хранилища: Это исходная точка, централизованное масштабируемое решение для хранения различных типов файлов, таких как PDF-документы, изображения и тексты.
LangChain: Выступая в роли оркестратора конвейера, LangChain управляет извлечением, предварительной обработкой и потоком данных для генерации вложений. Он упрощает обработку PDF-файлов, так что не придется беспокоиться о применении оптического распознавания символов (OCR).
Vector DB: В качестве векторной базы данных Vector DB хранит вложения и их полезную нагрузку, обеспечивая эффективный поиск сходств и выборки по всем типам контента.
Предварительные условия#
В данном разделе представлено пошаговое руководство по загрузке данных из корзины S3-хранилища. Но прежде чем приступить, убедитесь, что установлены все необходимые предварительные условия:
Условие |
Описание |
|---|---|
Образец данных |
Будет использован набор тестовых данных, где каждая папка включает отзывы о продуктах в текстовом формате наряду с соответствующими изображениями |
Аккаунт AWS |
Активный аккаунт AWS с доступом к сервисам S3-хранилища |
Облако Vector DB |
Аккаунт Vector DB Cloud с доступом к веб-интерфейсу пользователя (WebUI) для управления коллекциями и выполнения запросов |
LangChain |
Данный популярный фреймворк будет использоваться для объединения всех компонентов воедино |
Поддерживаемые типы документов#
Документы, используемые для загрузки, могут быть разных типов, например PDF-файлы, текстовые файлы или изображения. Необходимо организовать структурированную корзину S3-хранилища с папками поддерживаемых типов документов для тестирования и экспериментов.
Окружение Python#
Убедитесь, что установлено окружение Python (версия Python 3.9 или выше) со следующими установленными библиотеками:
boto3;langchain-community;langchain;python-dotenv;unstructured;unstructured[pdf];qdrant_client;fastembed.
Ключ доступа: Храните ключ доступа AWS, секретный ключ S3-хранилища и ключ API Vector DB в файле .env для удобного доступа.
Пример файла .env:
ACCESS_KEY = ""
SECRET_ACCESS_KEY = ""
QDRANT_KEY = ""
Хотя код поддерживает обработку PDF-файлов, текущий образец данных не содержит никаких PDF-файлов.
Шаг 1: загрузка данных из S3-хранилища#
Фреймворк LangChain облегчает загрузку данных из сервисов хранения, таких как AWS S3-хранилище, предоставляя встроенную поддержку для загрузки документов в форматах PDF, изображений и текстовых файлов.
Чтобы подключить LangChain к S3-хранилищу используется S3DirectoryLoader, который позволяет загружать файлы напрямую из корзины S3-хранилища в конвейер LangChain.
Пример: настройка LangChain для загрузки файлов из S3-хранилища#
Настройте LangChain для загрузки данных из корзины S3-хранилища:
from langchain_community.document_loaders import S3DirectoryLoader
# Initialize the S3 document loader
loader = S3DirectoryLoader(
"product-dataset", # S3 bucket name
"p_1", #S3 Folder name containing the data for the first product
aws_access_key_id=aws_access_key_id, # AWS Access Key
aws_secret_access_key=aws_secret_access_key # AWS Secret Access Key
)
# Load documents from the specified S3 bucket
docs = loader.load()
Шаг 2: преобразование документов во вложения#
Вложения здесь играют ключевую роль — это числовые представления данных (например, текста, изображений или аудио), которые захватывают «смысл» в форме, удобной для сравнения. Превращая текст и изображения во вложения станет возможно быстро и эффективно выполнять поиск похожих элементов. Представьте себе вложения как мост между сохранением и получением значимых выводов из данных в Vector DB.
Модели для создания вложений#
Для начала работы используются две мощные модели:
sentence-transformers/all-MiniLM-L6-v2Embeddings для преобразования текстовых данных.CLIP(Контрастное обучение языку изображения) для данных изображений.
Функция обработки документа#
Далее определите две функции - process_text и process_image для обработки различных типов файлов в рабочем процессе с документами. Функция process_text извлекает и возвращает необработанное содержимое из текстового документа, а функция process_image получает изображение из S3-хранилища и загружает его в память.
from PIL import Image
def process_text(doc):
source = doc.metadata['source'] # Extract document source (e.g., S3 URL)
text = doc.page_content # Extract the content from the text file
print(f"Processing text from {source}")
return source, text
def process_image(doc):
source = doc.metadata['source'] # Extract document source (e.g., S3 URL)
print(f"Processing image from {source}")
bucket_name, object_key = parse_s3_url(source) # Parse the S3 URL
response = s3.get_object(Bucket=bucket_name, Key=object_key) # Fetch image from S3
img_bytes = response['Body'].read()
img = Image.open(io.BytesIO(img_bytes))
return source, img
Вспомогательные функции для обработки документов#
Чтобы получить изображения из S3-хранилища, вспомогательная функция parse_s3_url разбивает URL-адрес S3-хранилища на составляющие части корзины и ключевые компоненты. Это необходимо для получения изображения из S3-хранилища.
def parse_s3_url(s3_url):
parts = s3_url.replace("s3://", "").split("/", 1)
bucket_name = parts[0]
object_key = parts[1]
return bucket_name, object_key
Шаг 3: загрузка вложений в Vector DB#
Теперь, когда документы были обработаны и преобразованы во вложения, следующий шаг — загрузить эти вложения в Vector DB.
Создание коллекции в Vector DB#
В Vector DB данные организованы в виде коллекций, каждая из которых представляет собой набор вложений (или точек) и связанных метаданных (полезной нагрузки). Чтобы сохранить ранее созданные вложения, сначала нужно создать коллекцию.
Вот как создать коллекцию в Vector DB для хранения вложений текста и изображений:
def create_collection(collection_name):
qdrant_client.create_collection(
collection_name,
vectors_config={
"text_embedding": models.VectorParams(
size=384, # Dimension of text embeddings
distance=models.Distance.COSINE, # Cosine similarity is used for comparison
),
"image_embedding": models.VectorParams(
size=512, # Dimension of image embeddings
distance=models.Distance.COSINE, # Cosine similarity is used for comparison
),
},
)
create_collection("products-data")
Эта функция создает коллекцию для хранения вложений текста (размерность 384) и изображений (размерность 512), используя косинусное подобие для сравнения вложений внутри коллекции.
После того как коллекция создана, можно загрузить вложения в Vector DB:
def ingest_data(points):
operation_info = qdrant_client.upsert(
collection_name="products-data", # Collection where data is being inserted
points=points
)
return operation_info
Объяснение процесса загрузки#
Добавление точки данных: Метод
upsertобъектаqdrant_clientвставляет каждую структуру PointStruct в заданную коллекцию. Если точка с таким же идентификатором уже существует, она будет обновлена новыми значениями.Информация о ходе операции: Функция возвращает объект
operation_info, содержащий сведения о выполнении операции upsert, включая статус успеха или возможные ошибки.
Запуск кода загрузки#
Вызов функции и выполнение загрузки данных:
from qdrant_client import models
if __name__ == "__main__":
collection_name = "products-data"
create_collection(collection_name)
for i in range(1,6): # Five documents
folder = f"p_{i}"
loader = S3DirectoryLoader(
"product-dataset",
folder,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
docs = loader.load()
points, text_review, product_image = [], "", ""
for idx, doc in enumerate(docs):
source = doc.metadata['source']
if source.endswith(".txt") or source.endswith(".pdf"):
_text_review_source, text_review = process_text(doc)
elif source.endswith(".png"):
product_image_source, product_image = process_image(doc)
if text_review:
point = models.PointStruct(
id=idx, # Unique identifier for each point
vector={
"text_embedding": models.Document(
text=text_review, model="sentence-transformers/all-MiniLM-L6-v2"
),
"image_embedding": models.Image(
image=product_image, model="Qdrant/clip-ViT-B-32-vision"
),
},
payload={"review": text_review, "product_image": product_image_source},
)
points.append(point)
operation_info = ingest_data(points)
print(operation_info)
Экземпляр PointStruct создается с этими ключевыми параметрами:
id: Уникальный идентификатор каждого вложения, обычно инкрементный индекс.
vector: Словарь, содержащий входные данные текста и изображения для встраивания. Под капотом
qdrant-clientиспользует FastEmbed для автоматического генерирования векторных представлений из этих входных данных локально.payload: Словарь, хранящий дополнительную мета-информацию, такую как обзоры продуктов и ссылки на изображения, которая незаменима для поиска и контекста во время поисковых операций.
Код динамически загружает папки из корзины S3-хранилища, отдельно обрабатывает текстовые и графические файлы и сохраняет их вложения и связанные данные в отдельных списках. Затем он создает экземпляр PointStruct для каждой записи данных и вызывает функцию загрузки для ее помещения в Vector DB.
Изучение панели инструментов WebUI Vector DB#
Как только вложения будут загружены в Vector DB, можно воспользоваться панелью инструментов WebUI для визуализации и управления коллекциями. Панель предоставляет четкий, структурированный интерфейс для просмотра коллекций и их данных.
Шаг 4: визуализация данных в WebUI Vector DB#
Чтобы начать визуализацию данных в WebUI Vector DB, перейдите в раздел Обзор и выберите пункт Доступ к базе данных.
Доступ к базе данных из пользовательского интерфейса Vector DB:
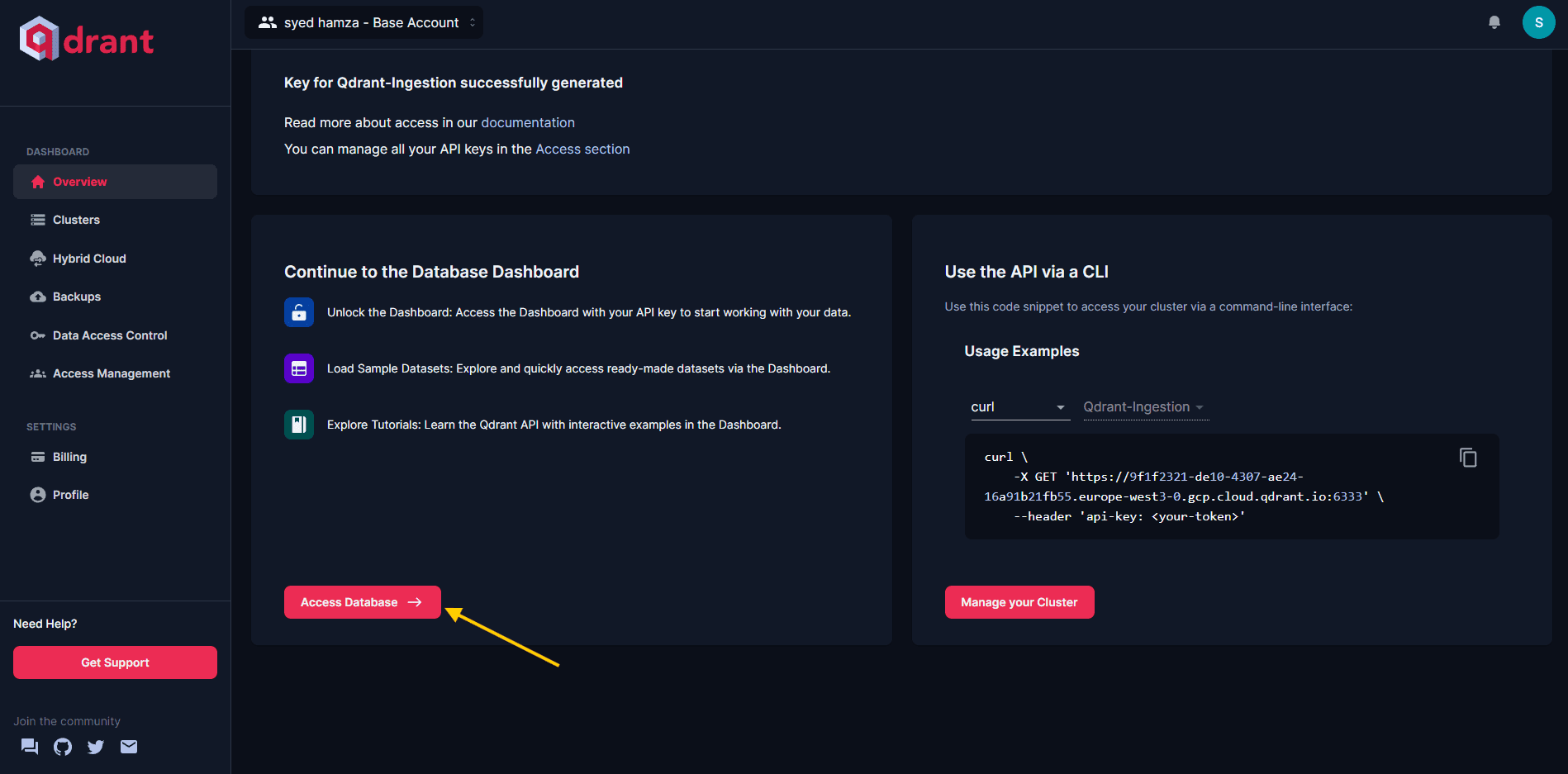
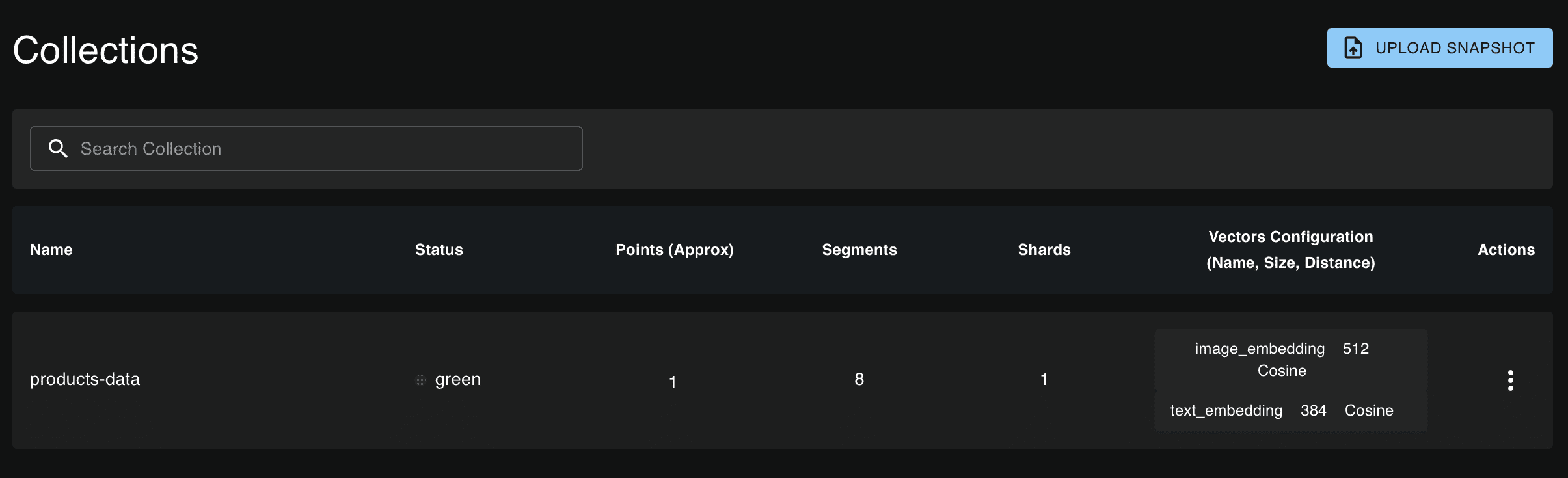
При запросе введите ключ API. Оказавшись внутри, станет доступна функция просмотра коллекций и соответствующих точек данных. Коллекция отобразится следующим образом:
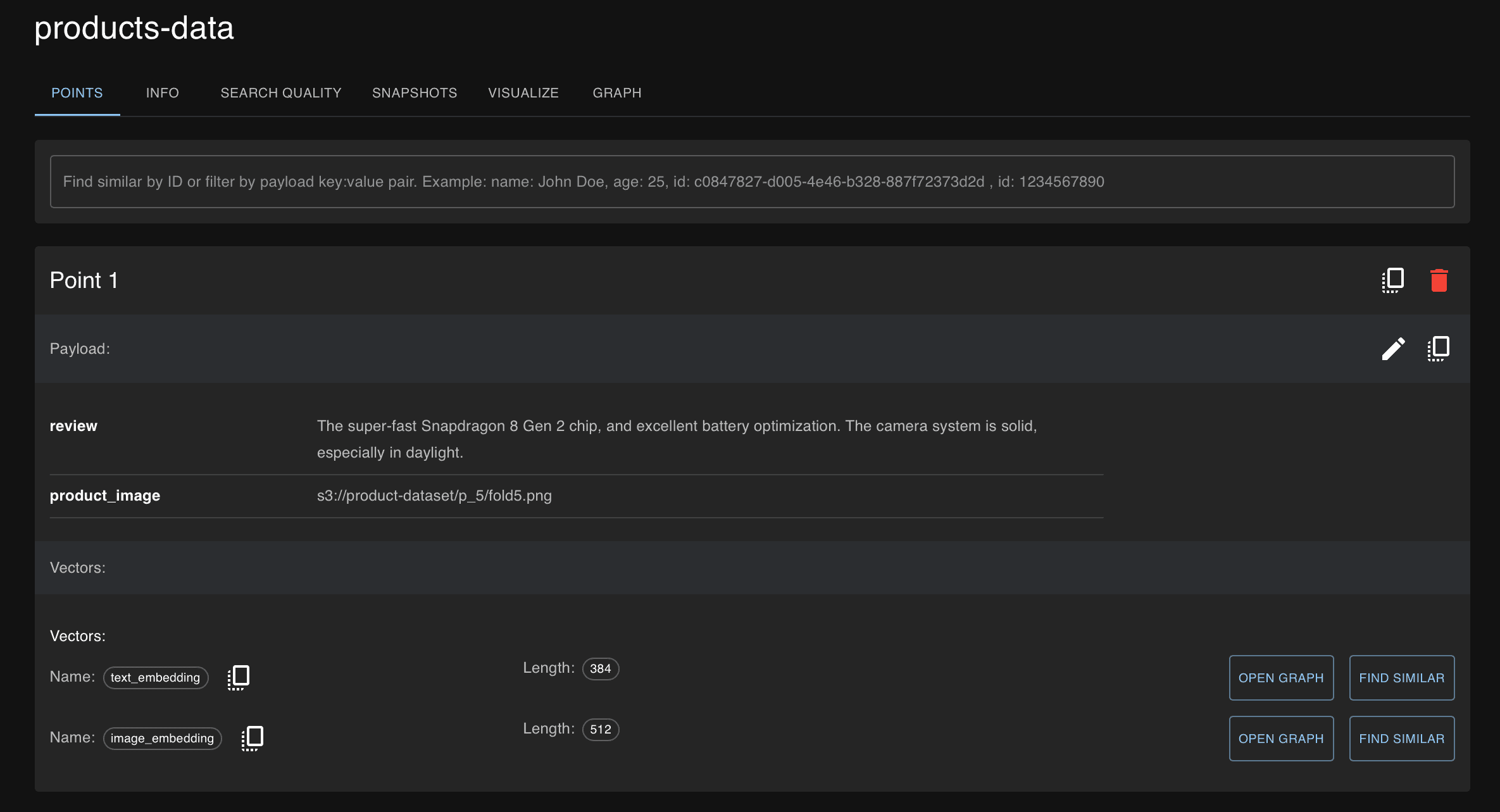
Последний элемент, добавленный в коллекцию product-data:
Функциональность поиска в WebUI Vector DB позволяет выполнять векторные запросы по коллекциям. С возможностью применения фильтров и параметров получение релевантных вложений и исследование взаимосвязей в данных становится простым делом. Для начала перейдите в раздел Консоль на левой панели, где можно создавать запросы:
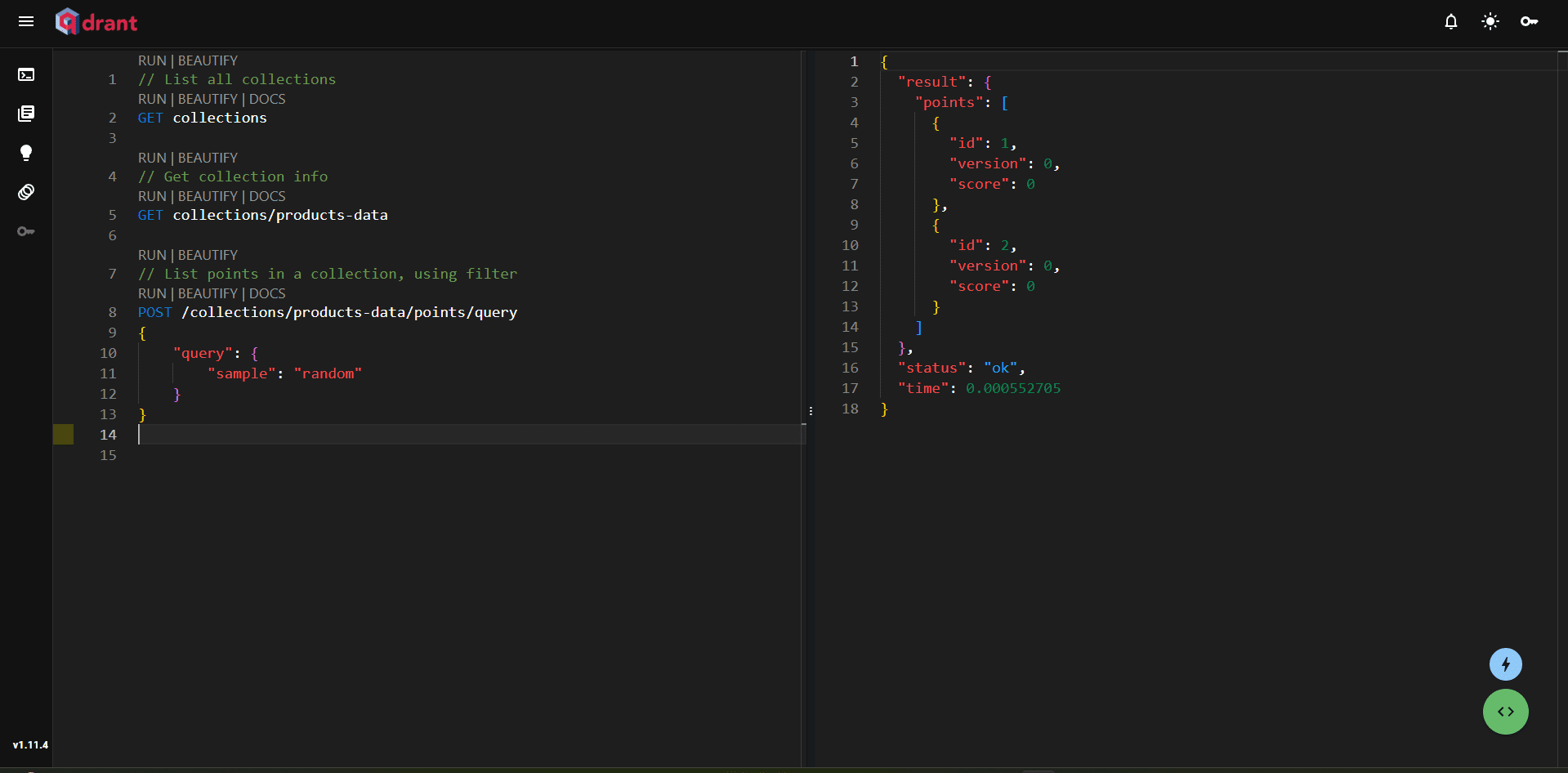
Первый запрос возвращает все коллекции, второй извлекает точки из коллекции product-data, третий выполняет пробный запрос. Это демонстрирует, насколько просто взаимодействовать с данными в интерфейсе Vector DB.
А теперь попробуйте извлечь некоторые документы из базы данных с использованием запроса!.
Запрос клиента Vector DB для извлечения релевантных документов:
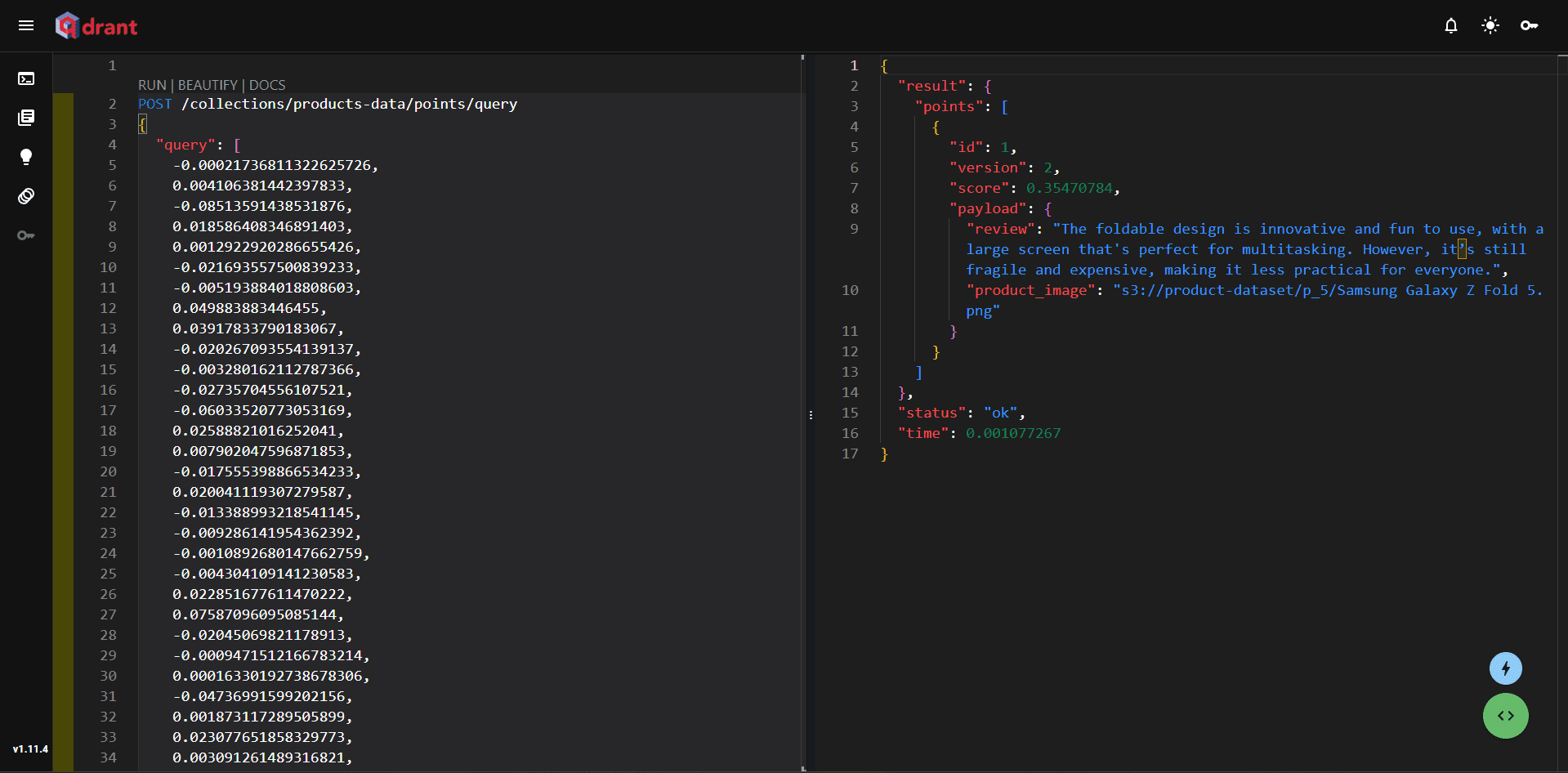
В этом примере осуществлен поиск Телефонов с улучшенным дизайном. Затем текст был преобразован в векторы с помощью OpenAI и получен соответствующий обзор телефона, выделяющий улучшения дизайна.
Заключение#
В этом руководстве была создана корзина S3-хранилища, загружены различные типы данных и сохранены вложения в Vector DB. Используя LangChain были динамически обработаны текстовые и графические файлы, упростив работу с каждым типом файлов.