Руководство по ведению модели данных#
О документе#
DataSpace предусматривает возможность создания предметных моделей в XML-нотации. На основе файлов описания модели генерируется набор артефактов, необходимый для работы сервисов DataSpace. Правила формирования и структура создаваемых на основе модели артефактов описаны в документе "Структура артефактов DataSpace".
В данном документе освещены следующие вопросы:
Каким образом создавать и изменять файлы предметной модели DataSpace.
Каким образом генерировать рабочий артефакт из созданных файлов модели.
Каким образом поддерживать файлы модели и артефакт в рабочем состоянии после релиза приложения.
Расшифровку основных понятий см. в документе "Термины и определения".
О модели данных#
DataSpace позволяет моделировать объекты предметной области в формате XML. Модель может описывать объекты предметной области, статусы объектов, а также связи между ними.
Описание модели данных предоставляет следующие возможности:
задавать зависимости между классами для шардирования (центричность);
версионировать модель в случае ее дальнейшего изменения;
расширять возможность использования ключевого слова import в модели.
Основной подход к построению модели — разделение модели на DDD-агрегаты (объединение классов с использованием предметно-ориентированного подхода, англ. Domain-Driven Design aggregates). Для построения корректной и расширяемой модели необходимо правильно определять сущности, входящие в агрегаты. Поэтому перед описанием бизнес-модели фабрики необходимо определиться с ее структурой и требованиями к ней. Дополнительные сведения можно найти в разделе "DDD-агрегаты".
Разработка модели данных#
Для разработки предметной модели может потребоваться несколько файлов. Поэтому для данных файлов необходимо предусмотреть отдельную папку. Основным файлом предметной модели является файл model.xml, который должен быть расположен в корне данной папки.
Примечание
Базовый проект можно создать из maven-архетипа. Подробная инструкция по созданию проекта из архетипа имеется в документе "Быстрый страт".
Для создания предметной модели с помощью DataSpace необходимо выполнить следующие шаги:
Создать Maven-модуль и подключить в него плагин генерации модели.
Указать путь к созданным файлам в pom.xml.
Создать связи между классами модели и необходимые агрегаты.
Создание Maven-модуля#
Для использования DataSpace в проекте необходимо создать модуль Maven и подключить в него плагин генерации модели. В файл pom.xml модуля необходимо добавить зависимость на следующий артефакт DataSpace:
<dependencies>
<dependency>
<groupId>sbp.com.sbt.dataspace</groupId>
<artifactId>common-interfaces</artifactId>
</dependency>
</dependencies>
Создание файлов модели#
Чтобы создать файлы модели, необходимо выполнить следующие действия:
Создайте директорию
modelс удобным расположением внутри проекта.Внутри директории создайте требуемые подкаталоги.
Внутри директории создайте файл модели (model.xml) и при необходимости файл статусов (status.xml):
mkdir model сd model mkdir dictionary model touch model.xml touch status.xmlДобавьте в глобальный файл pom.xml путь к ресурсам предметной модели:
<properties> <model>deposits/src/main/resources/model</model> </properties>
Управление классами#
Файл модели включает в себя XML-элементы, заданные с помощью тегов. При разметке файла модели необходимо использовать следующие правила:
Все элементы модели заключаются между парой тегов
<model>.Для типов сущностей необходимо использовать теги
<class>(открывающие и закрывающие).Для свойств классов используются теги
<property/>(допустимы самозакрывающиеся).Индексируемые свойства дублируются между тегами
<index>.
Ниже показана упрощенная иерархия тегов в модели:
<model>
<class>
<property>
<index>
Редактирование файла model.xml можно начать со следующего шаблона:
<model>
<class label="Краткое описание сущности" name="ClassName">
<property label="Краткое описание свойств" name="propertyName" type="String"/>
<index unique="false">
<property name="propertyName"/>
</index>
</class>
</model>
Создание классов#
Для создания классов выполните следующие шаги:
В файле model.xml добавьте теги модели.
Добавьте атрибуты модели. Требования к атрибутам тега см. в разделе "Модель".
Внутри тегов модели добавьте теги для каждого из классов.
Укажите название каждого из классов (атрибут
name) и его краткое описание (атрибутlabel). Требования к атрибутам см. в разделе "Класс".Добавьте текст
<property label="" name="" type=""/>для каждого из свойств класса.Введите атрибуты свойств. Требования к атрибутам классов см. в разделе "Свойство". Обязательны следующие значения:
Имя свойства: атрибут
name.Отображаемое название свойства: атрибут
label.Тип свойства: атрибут
type.
Пример файла модели: файле model-simple.xml.
Добавление индекса#
Чтобы реализовать индексирование данных в базе, необходимо выполнить следующие действия:
Добавить пару тегов
<index></index>в определение класса.Ввести индексируемые параметры, как показано в примере ниже. При добавлении уникальных составных индексов необходимо учитывать их разное поведение на разных БД при наличии значений NULL в составе полей индекса. Допустим, для полей а1 и а2 класса А создан уникальный составной индекс, тогда вставка строк (а1=10,a2=NULL), (а1=10,a2=NULL) в БД Postgres не вызывает ошибку, т.к. данные строки не считаются уникальными в данной БД. А при вставке данных строк в БД Oracle будет вызвана ошибка нарушения уникальности индекса.
<model>
<class label="Краткое описание сущности" name="ClassName">
<property label="Краткое описание свойств" name="propertyName" type="String"/>
<index unique="false">
<property name="propertyName"/>
</index>
</class>
</model>
Моделирование свойств объектов#
При описании модели можно указать следующие типы свойств:
Примитивные типы (см. раздел "Использование примитивных типов").
Специализация примитивных типов (см. раздел "Использование специализированных типов").
Классы модели (см. раздел "Использование класса в свойстве").
Перечисления (тип
enum) (см. раздел "Использование перечисления в свойстве").
В дополнение к этому можно использовать значения по умолчанию.
Использование значений по умолчанию#
Для примитивных свойств, специализированных типов и перечислений можно указывать значения по умолчанию. Для этого необходимо использовать атрибут default-value:
<enum name="Size">
<value name="S"/>
<value name="M"/>
</enum>
<class name="Product">
<property name="size" type="Size" default-value="M"/>
<!-- ... -->
</class>
Помимо установки значений по умолчанию полей атрибут default-value используется еще в одном особом случае.
Если у выпущенной модели какое-нибудь поле становится обязательным для заполнения, то уже существующие записи в БД, где это поле может быть пустым, необходимо заполнить. В таком случае потребуется
указать default-value для этого поля. Значением, указанным в default-value, будут обновлены существующие записи.
Внимание
В случае, если у поля одновременно есть атрибут обязательности, то
default-valueбудет игнорироваться.При попытке выполнения транзакции с незаполненным обязательным полем будет появляться ошибка отсутствия такого поля, в том числе и при наличии атрибута
default-value.
Использование примитивных типов#
Большинство примитивных типов DataSpace схожи c типами Java: Boolean, Byte, Character (char), Short, Integer, Long, Float, Double, Date, LocalDate, LocalDateTime, OffsetDateTime, String, Text (строка неограниченной длины), BigDecimal (~java.math.BigDecimal) и Binary (~BLOB в БД Oracle).
Также предусмотрен строчный тип стандарта Юникод (Unicode String).
Подробные сведения о примитивах DataSpace и таблицу соответствия типов можно найти в разделе "Примитивные типы".
Использование специализированных типов#
В DataSpace можно использовать специализированные типы, производные от примитивов DataSpace.
Для использования специализированных типов в model.txt необходимо добавить блок <type-defs></type-defs>. Пользовательские новые типы необходимо использовать в значении поля type свойства (property) в классе (class).
Структура type-defs показана во фрагменте ниже:
<type-defs>
<type-def>
* name — имя производного типа (обязательно).
* type — оригинальный примитивный тип DataSpace (обязательно).
* length — длина (доступно для String и BigDecimal).
* scale — масштаб (доступно для BigDecimal).
Заданная длина и масштаб будет устанавливаться только в том случае, если пользователь явно не переопределил аналогичное свойство на классе:
Для типа
Stringимеется возможность задания length. По умолчанию: 254.Для типа
BigDecimalпомимоlengthвозможно задать значениеscale. По умолчанию:length = 38,scale= 10.Остальные типы не поддерживают
lengthиscale.
Пример использования для типа String и BigDecimal:
<type-defs>
<type-def length="6" name="ShortString" type="String"/>
</type-defs>
<class label="продукт" name="Product">
<property name="pinCode" type="ShortString"/> <!-- в итоге будет длина 6-->
<!--...-->
</class>
Использование класса в свойстве#
Классы можно использовать в качестве свойств других классов. Для этого имя класса необходимо указать в качестве типа свойства.
В случае использования связи OneToMany, необходимо дополнительно использовать параметр collection="set".
<class name="City" label="Город" is-dictionary="true">
<property name="code" type="String" label="Код" mandatory="true"/>
<property name="name" type="String" label="Наименование" mandatory="true"/>
<property name="offices" type="Office" label="Офисы" collection="set" mappedBy="city"/>
</class>
<class name="Office" label="Офис" is-dictionary="true">
<property name="city" type="City" label="Город" mandatory="true"/>
<property name="code" type="String" label="Код" mandatory="true"/>
<property name="name" type="String" label="Наименование" mandatory="true"/>
</class>
Использование перечисления в свойстве#
Перечисления можно использовать в качестве свойств объектов. Для этого необходимо указать имя перечисления в качества типа поля.
<enum name="Currency">
<value name="USD"/>
<value name="EUR"/>
<value name="RUB"/>
</enum>
<class name="DepositRequest" extends="Request" label="Запрос на открытие депозита">
<property name="sum" type="BigDecimal" label="Сумма"/>
<property name="currency" type="Currency" label="Валюта депозита"/>
</class>
Вычисляемые свойства#
Имеются свойства, вычисляемые на основе выражения, в которых могут участвовать другие не вычисляемые свойства этого же класса. Прямое изменение данных свойств не допустимо. Свойства класса в выражении могут указываться как с привязкой к классу "C1.firstName", так и без "firstName". Регистр не учитывается. Изменение выражения обратно несовместимо (в последующих версиях модели изменять не допустимо).
Вычисляемые свойства могут быть проиндексированы и участвовать в построении составных индексов.
Поддерживаемые операции и функции:
унарные операции: !, NOT;
операции сравнения: =, >, <, <=, >=, !=;
логические: AND, OR;
математические операции: *, /, +, -;
функции: ABS(X), ACOS(X), ASIN(X), ATAN(X), COS(X), SIN(X), TAN(X), LOG(X,Y), SQRT(X), ROUND(X,Y), CONCAT(X,Y), LOWER(X), UPPER(Y), COALESCE(X,Y,Z,…), SUBSTRING(X,Y,Z), TRIM(X FROM Y), TRANSLATE(string, from_string, to_string);
условия: IN, NOT IN, IS NULL, IS NOT NULL, BETWEEN … AND …, NOT BETWEEN … AND …, LIKE, NOT LIKE;
условные выражения:
CASE expression CASE WHEN X1 THEN Y1 WHEN expression THEN Y1 WHEN X2 THEN Y2 WHEN expression THEN Y2 ............. ............. [ELSE Y3] [ELSE Y3] END END * Y1, Y2, Y3 — допускается expression
<class name="C1" label="класс А">
<property name="stringField" type="String" label=""/>
<property name="integerField" type="Integer" label=""/>
<property name="byteField" type="Byte" label=""/>
<property name="code" type="String" label=""/>
<property name="c1" type="String" unique="true" >
COALESCE(stringField,'')
</property>
<property name="c2" type="Integer">
integerField+10+byteField
</property>
<property name="c3" type="string" >
CASE WHEN C1.stringField='Abc' and lower(stringField)!='cdf'
THEN null WHEN upper(stringField)='ABC' THEN upper(stringField)
ELSE lower(stringField) END
</property>
<property name="c4" type="String">
CASE WHEN code is not null THEN code
ELSE '' END
</property>
</class>
Пример, когда необходимо построить уникальный индекс по Имени и Фамилии без учета регистра:
<class name="C1" label="класс C1">
<property name="firstName" type="String" label="Имя" mandatory="true"/>
<property name="lastName" type="String" label="Фамилия" mandatory="true"/>
<property name="firstAndLastName" type="String" unique="true" >
CONCAT(UPPER(c1.firstName),CONCAT(' ',UPPER(c1.lastName)))
</property>
</class>
@Test
public void test() {
Packet packet1 = new Packet();
CreateC1Param createC1Param = CreateC1Param.create()
.setFirstName("Иван")
.setLastName("Иванов");
C1Ref c1Ref = packet1.c1.create(createC1Param);
C1Get c1Get = packet1.c1.get(c1Ref, p -> p
.withFirstAndLastName());
assertThatCode(() -> dataspaceCorePacketClient.execute(packet1)).doesNotThrowAnyException();
// Проверка, что в вычисляемой колонке данные сформированы согласно
// заданному правилу, описанному в модели
assertEquals("ИВАН ИВАНОВ", c1Get.getFirstAndLastName());
Packet packet2 = new Packet();
packet2.c1.create(p -> p
.setFirstName("ИВАН")
.setLastName("Иванов"));
// Попытка записать в вычисляемую колонку такое же значение и получить
// срабатывание уникального индекса
assertThatCode(() -> dataspaceCorePacketClient.execute(packet2))
.hasMessageFindingMatch(".*Нарушение уникального индекса.*FIRSTANDLASTNAME.*");
}
Пример, когда необходимо проверять на уникальность поле code если поле isDeleted==false:
<class name="C2" label="класс C2">
<property name="code" type="String" label="Коде" mandatory="true"/>
<property name="isDel" type="boolean" label="" mandatory="true"/>
<property name="codeForIndex" type="String" unique="true">
CASE
WHEN c2.isDel=TRUE THEN NULL
ELSE c2.code
END
</property>
</class>
@Test
public void test2() {
Packet packet1 = new Packet();
packet1.c2.create(p -> p
.setCode("ABC")
.setIsDel(false));
assertThatCode(() -> dataspaceCorePacketClient.execute(packet1)).doesNotThrowAnyException();
Packet packet2 = new Packet();
packet2.c2.create(p -> p
.setCode("ABC")
.setIsDel(true));
assertThatCode(() -> dataspaceCorePacketClient.execute(packet2)).doesNotThrowAnyException();
Packet packet3 = new Packet();
packet3.c2.create(p -> p
.setCode("ABC")
.setIsDel(true));
assertThatCode(() -> dataspaceCorePacketClient.execute(packet3)).doesNotThrowAnyException();
Packet packet4 = new Packet();
packet4.c2.create(p -> p
.setCode("ABC")
.setIsDel(false));
assertThatCode(() -> dataspaceCorePacketClient.execute(packet4))
.hasMessageFindingMatch(".*Нарушение уникального индекса.*");
}
Расширение модели#
Разрабатываемую модель можно расширить внешними файлами. Для этого необходимо выполнить следующие шаги:
В том же каталоге, где расположен файл model.xml создать каталог
import.Внутри каталога необходимо создать файл для дополнительных классов:
cd model mkdir import touch import/newClasses.xmlДобавить в созданный файл теги
<model name="myImportModelName">...</model>и требуемые классы:<model> <class></class> </model>
Импортируемые файлы должны оформляться аналогично model.xml, за исключением того, что в теге model нет необходимости указывать атрибуты.
Для импортируемых моделей необходимо задать идентифицирующие их имена.
По имени импортируемой модели через указание в плагине генерации SDK формируется частичные файлы работы с моделью, ограниченные именем модели.
Пример настройки плагина(см. параметр importModelName):
<plugin>
<groupId>sbp.com.sbt.dataspace</groupId>
<artifactId>model-api-generator-maven-plugin</artifactId>
<executions>
<execution>
<id>createSdk</id>
<goals>
<goal>createSdk</goal>
</goals>
<configuration>
<basePackage>${modelPackage}</basePackage>
<model>${model}</model>
<importModelName>myImportModelName</importModelName>
</configuration>
</execution>
</executions>
</plugin>
Функционал можно использовать и для простого разбиения модель на несколько xml файлов в случае ее сложности.
Если не нужно генерировать отдельные SDK по моделям — не передавайте параметр importModelName.
Для импорта будут доступны следующие элементы модели:
классы;
перечисления (enum);
интерфейсы.
Примечание
Папку для импорта можно переопределить. Для этого в основном файле model.xml необходимо прописать путь к папке, из которой будут импортироваться элементы модели:
<model ...=""> <import file="nameDir" type="IMPORT"/> ... </model>
Дробить модель рекомендуется на отдельные файлы для целых агрегатов.
Примечание
Чтобы в одной схеме базы данных использовать одну общую модель, которая будет обслуживать несколько модулей, к SDK этих модулей необходимо подключить отдельные файлы с описанием требуемых агрегатов. В этом случае разработчику SDK будет доступна только своя модель со принадлежащими ему агрегатами, и не будут доступны другие агрегаты.
Управление статусами#
Создание статусного файла#
Если поведение моделируемых объектов должно изменяться в зависимости от их состояния, необходимо реализовать статусы объектов модели. Статусы можно добавлять как в model.xml(рекомендуемый метод), так и в отдельный файл.
Для создания отдельного статусного файла необходимо выполнить следующие действия:
Создать файл status.xml в той же папке, что и файл model.xml.
Добавить инструкцию об импорте статусов в файл модели. Инструкция представляет собой следующий тег:
<import type="STATUS"/>.Добавить информацию о требуемых статусах в status.xml.
О влиянии статусов на классы модели#
При импорте статусов в модель произойдет следующее:
На объектах, указанных в теге
<status-classes>, автоматически добавятся поля для каждого описанного наблюдателя (тегstakeholder) со следующим именем:statusFor*StakeholderName.Добавится связь с таблицей истории статусов, имя свойства — statusHistory (при активации атрибута
historical).
О сохранении истории изменения статусов#
Продукт DataSpace может сохранять историю изменения статусов.
Для этого используется атрибут historical с возможными значениями true и false. Значение атрибута автоматически наследуется всеми классами-потомками. Значение по умолчанию: false.
При необходимости сохранения информации о пользователе, внесшем изменения, можно воспользоваться функциональностью, описанной в разделе "Сохранение в историю пользователя, изменившего данные" документа "Руководство по системному администрированию".
При необходимости получения данных о переходе статуса можно воспользоваться функциональностью, описанной в разделе "Чтение истории изменения статусов" документа "Руководство прикладного разработчика".
Упрощенный пример файла модели:
<class name="A"></class>
<class extends="A" name="B"></class>
<class extends="B" name="C"></class>
<class extends="C" name="D"></class>
<class extends="D" name="E"></class>
Для этих классов указаны показанные ниже значения признака historical:
<statuses class="A"></statuses>
<statuses class="B" historical="true"></statuses>
<statuses class="D" historical="false"></statuses>
<statuses class="E" historical="true"></statuses>
На схеме показано, какие классы модели будут сохранять историю изменения статусов:
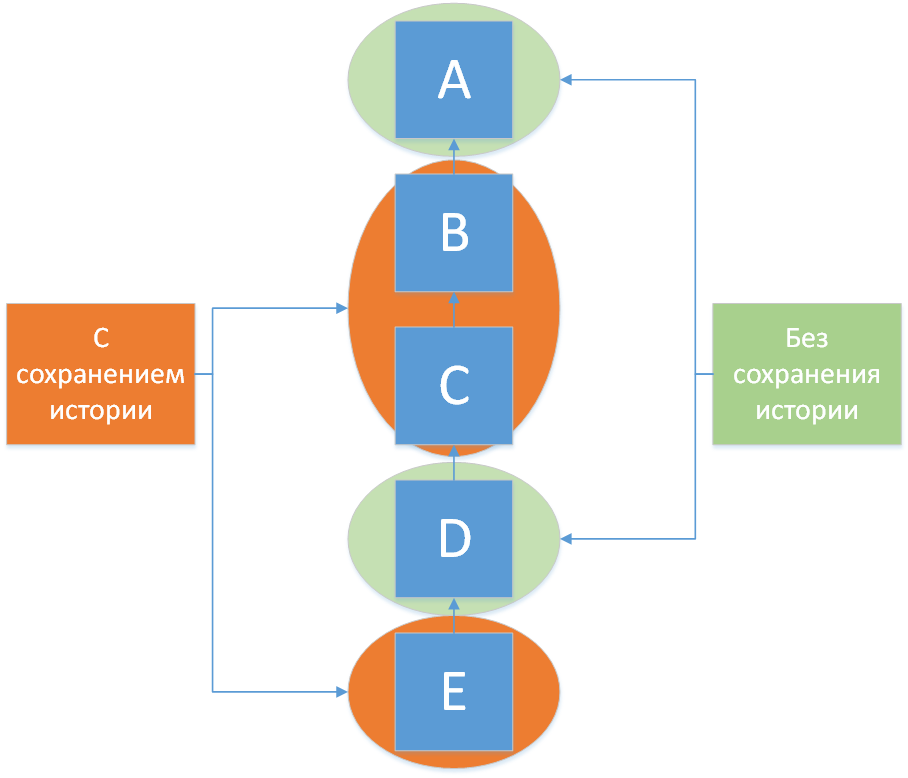
Пример получения истории статусов через поисковое API#
Возьмем некоторый продукт клиента:
<class name="ProductParty">
<property name="code" type="String" label="код"/>
...
</class>
Для продукта определены статусы с сохранением истории:
<statuses class="ProductParty" historical="true">
<stakeholder-link code="platform">
<status code="productCreated" description="Начальный статус продукта" name="Создание продукта"
initial="true">
<to status="productClosed"/>
<to status="productCheck"/>
</status>
<status code="productClosed" name="На закрытие"/>
<status code="productCheck" name="На рассмотрении">
<to status="productClosed"/>
</status>
</stakeholder-link>
<stakeholder-link code="service">
<status code="depositOpened" description="Начальный статус депозита ЮЛ" name="Начало открытия депозита"
initial="true">
<to status="depositCheck"/>
<to status="depositClosed"/>
</status>
<status code="depositCheck" name="На рассмотрении">
<to status="depositClosed"/>
</status>
<status code="depositClosed" name="Закрытие депозита"/>
</stakeholder-link>
<stakeholder-link code="serviceProductWatcher">
<status code="productCreatedProductWatcher" description="Начальный статус продукта"
name="Создание продукта" initial="true">
<to status="productClosedProductWatcher"/>
</status>
<status code="productClosedProductWatcher" name="На рассмотрении"/>
</stakeholder-link>
</statuses>
Создадим и проведем объект по жизненному циклу:
Packet createPacket = Packet.createPacket();
ProductPartyRef productPartyRef = createPacket.productParty.create(param -> param.setCode(myCode));
executePacket(createPacket);
Packet updatePacket1 = Packet.createPacket();
updatePacket1.productParty.update(productPartyRef, param ->
param.setStatusForPlatform(ProductPartyPlatformStatus.PRODUCTCHECK, "Передан на проверку УФК"));
executePacket(updatePacket1);
Packet updatePacket2 = Packet.createPacket();
updatePacket2.productParty.update(productPartyRef, param ->
param.setStatusForPlatform(ProductPartyPlatformStatus.PRODUCTCLOSED, "Клиент закрыл продукт"));
executePacket(updatePacket2);
При создании мы не указываем никаких статусов — значения статусов получат значения инициализирующих (initial="true") статусов. Затем обновим статус для наблюдателя platform с указанием причины изменения до productCheck, а затем еще раз — до productClosed.
Для того чтобы получить историю изменения жизненного цикла этого продукта можно написать следующий код (запрос получения истории изменения жизненного цикла задается указанием withStatusHistory, в котором можно описать детали возвращаемой информации):
GraphCollection<ProductPartyGet> productPartyGets = dataspaceCoreSearchClient().searchProductParty(product ->
product.withName()
.withStatusHistory(history -> history.withStatus(StatusWith::withCode).withChangeReason().withChangeTime()
.setWhere(it -> it.status().stakeholder().codeEq("platform")))
.setWhere(it -> it.codeEq(myCode)));
Assertions.assertEquals(1, productPartyGets.size());
ProductPartyGet productPartyGet = productPartyGets.get(0);
productPartyGet.getStatusHistory().forEach(it ->
System.out.println("Статус: " + it.getStatus().getCode() +
", Причина: " + it.getChangeReason() +
", Время изменения:" + it.getChangeTime()));
Мы отсекли жизненный цикл по не интересным нам наблюдателям service и serviceProductWatcher, ограничившись лишь platform.
Результат вывода будет следующим:
Статус: productCreated, причина: Установлен по умолчанию, Время изменения:Tue Nov 16 17:50:12 MSK 2021
Статус: productCheck, причина: Передан на проверку УФК, Время изменения:Tue Nov 16 17:50:13 MSK 2021
Статус: productClosed, причина: Клиент закрыл продукт, Время изменения:Tue Nov 16 17:50:13 MSK 2021
О наследовании статусов#
Наследование классов модели и назначенные классам статусы отражены в таблице ниже под примерами кода. Некоторые атрибуты удалены для лучшего понимания идеи процесса.
Пример реализации наследования в модели:
<class name="Product">
<property name="series" type="Date"/>
</class>
<class extends="Product" name="ProductExt">
<property name="name" type="String"/>
</class>
<class extends="ProductExt" name="ProductExt2">
<property name="code" type="String"/>
</class>
<class extends="ProductExt2" name="ProductExt3">
<property name="kind" type="String"/>
</class>
Описание заголовка статусов:
<status-classes class="Product">
<stakeholder code="platform"/>
</status-classes>
<status-classes class="ProductExt">
<stakeholder code="service"/>
</status-classes>
<status-classes class="ProductExt2">
<stakeholder code="party"/>
</status-classes>
Внимание!
Наблюдатели, указанные в теге
stakeholder, в процессе генерации станут новыми свойствами на сущностях. Таким образом, нет необходимости повторно определять наблюдателя на потомке внутри status-classes.
Далее рассмотрены следующие примеры:
Назначение каждому классу своего наблюдателя с переносом статусов потомку.
Переопределение статусов наблюдателя предка (по модели) в потомке.
Назначение классу наблюдателя с переносом статусов потомку#
Во фрагменте кода приведен пример содержимого файла status.xml для рассматриваемой ситуации:
<statuses class="Product">
<stakeholder-link code="platform">
<status code="productPl"/>
</stakeholder-link>
</statuses>
<statuses class="ProductExt">
<stakeholder-link code="service">
<status code="productExtSr"/>
</stakeholder-link>
</statuses>
<statuses class="ProductExt2">
<stakeholder-link code="party">
<status code="productExt2Pa"/>
</stakeholder-link>
</statuses>
В таблице показано, какие статусы из примера выше будут доступны наблюдателям с учетом порядка наследования классов:
Тип объекта, наблюдатель |
platform |
service |
party |
|---|---|---|---|
Product |
ProductPI |
— |
— |
ProductExt |
ProductPI |
productExtSr |
— |
ProductExt2 |
ProductPI |
productExtSr |
productExt2Pa |
ProductExt3 |
ProductPI |
productExtSr |
productExt2Pa |
ProductExt3 — класс, который автоматически получает статусы от предков.
Для данного примера важно, что каждый класс-потомок получает от предка статусы по наблюдателям.
Переопределение статусов наблюдателя предка в потомке#
Во фрагменте кода приведен пример содержимого файла status.xml для рассматриваемой ситуации:
<statuses class="Product">
<stakeholder-link code="platform">
<status code="productPl"/>
</stakeholder-link>
</statuses>
<statuses class="ProductExt">
<stakeholder-link code="service">
<status code="productSr"/>
</stakeholder-link>
</statuses>
<statuses class="ProductExt2">
<stakeholder-link code="platform">
<status code="productExt2tPl"/>
</stakeholder-link>
<stakeholder-link code="party">
<status code="productExt2Pa"/>
</stakeholder-link>
</statuses>
<statuses class="ProductExt3">
<stakeholder-link code="service">
<status code="productExt3Sr"/>
</stakeholder-link>
</statuses>
В таблице показано, какие статусы из вышеприведенного примера будут доступны наблюдателям:
Тип объекта\наблюдатель |
platform |
service |
party |
|---|---|---|---|
Product |
productPl |
* |
* |
ProductExt |
productPl |
productSr |
* |
ProductExt2 |
productExt2tPl |
productSr |
productExt2Pa |
ProductExt3 |
productExt2tPl |
productExt3Sr |
productExt2Pa |
Если переопределяемый наблюдатель в наследуемом классе определяет свои статусы, то статусы предков становятся недостижимыми.
Отключение проверки переходов#
Чтобы отключить контроль за переходами статусов, наблюдателю необходимо удалить теги <to status=".."/> внутри статусов. Указание начального статуса в этом случае становится обязательным к заполнению (initial).
Примечание
Наличие хотя бы одного перехода автоматически закрывает возможность беспорядочного движения статусов для конкретного наблюдателя.
Задание связей между классами#
В DataSpace предусмотрены следующие способы задания связей между классами:
Наследование классов#
Модель поддерживает наследование классов. Наследование реализуется за счет указания атрибута extends на классе-потомке.
<class name="Product">
</class>
<class name="Deposit" extends="Product">
</class>
<class name="LegalPersonDeposit" extends="Deposit">
</class>
Наследование с использованием абстрактных классов#
Внимание!
Наследовать можно и от абстрактных классов, но ссылки на абстрактные классы (например,
<property type="*AbstractClass*"/>) недопустимы. Ограничения связаны с невозможностью определения конкретной сущности на физическом уровне (абстрактный класс не является Entity и не имеет таблицы).
Таблица содержит возможные схемы наследования сущностей:
Без абстрактных классов |
Наследование от базового абстрактного класса |
Промежуточный абстрактный класс |
|---|---|---|
|
|
|
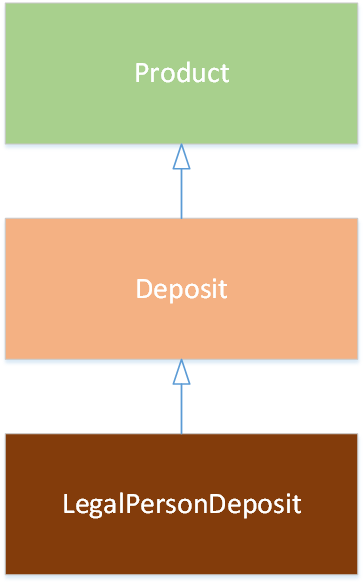
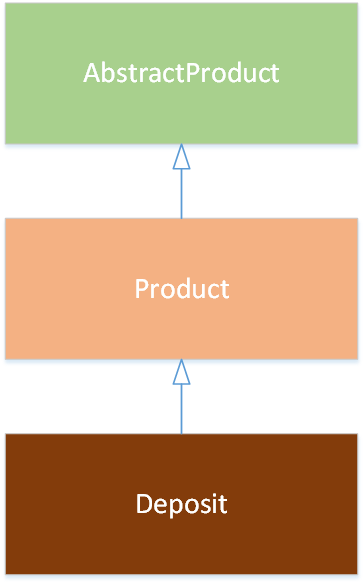
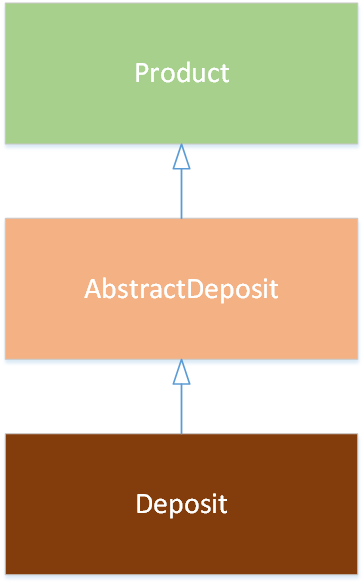
Пример кода для модели без абстрактных классов класса:
<class name="Product">
</class>
<class name="Deposit" extends="Product">
</class>
<class name="LegalPersonDeposit" extends="Deposit">
</class>
Пример наследования от базового абстрактного класса:
<class name="AbstractProduct" is-abstract="true">
</class>
<class name="Product" extends="AbstractProduct">
</class>
<class name="Deposit" extends="Product">
</class>
Пример промежуточного абстрактного класса:
<class name="Product">
</class>
<class name="AbstractDeposit" extends="Product" is-abstract="true">
</class>
<class name="Deposit" extends="AbstractDeposit">
</class>
Стратегии наследования#
Стратегия наследования описывается на первом неабстрактном классе, потомками которого являются все абстрактные классы или же потомков нет. Стратегию нельзя переопределять на классах-потомках. Данный атрибут влияет на физическое представление объектов в БД. Возможны следующие стратегии:
JOINED (по умолчанию).
Множественность связей#
В DataSpace поддерживаются следующие множественные связи между классами:
ManyToOne (многие к одному);
OneToMany (один ко многим);
OneToOne (один к одному).
Для создания связи ManyToMany (многие к многим) необходимо создать промежуточные сущности.
Связь OneToMany#
Связь является двунаправленной. Физически ссылка хранится на неколлекционном объекте.
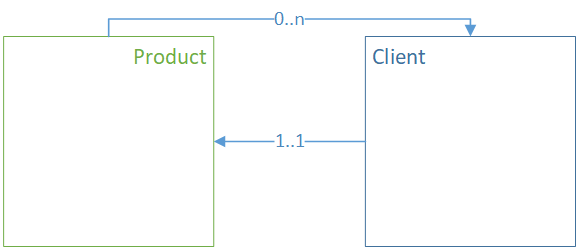
В терминах XML это может выглядеть следующим образом. Для рабочего варианта блока модели сущности должны быть частью одного агрегата. Дополнительные справочные сведения можно найти в разделе "DDD-агрегаты".
<class name="Product">
<property collection="set" mappedby="product" name="clients" type="Client"/>
</class>
<class name="Client">
<property name="product" type="Product"/>
</class>
Связь ManyToOne как ссылка#
Связь является однонаправленной.
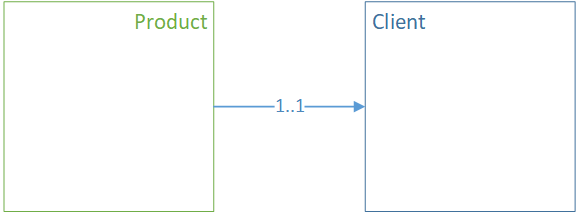
В терминах XML это выглядит следующим образом (для рабочего варианта блока модели сущности должны быть частью одного агрегата):
<class name="Product">
<property name="client" type="Client"/>
</class>
<class name="Client">
<property name="name" type="String"/>
</class>
Связь ManyToOne в связи с коллекцией#
Связь является двунаправленной. Физически ссылка хранится на неколлекционном объекте.
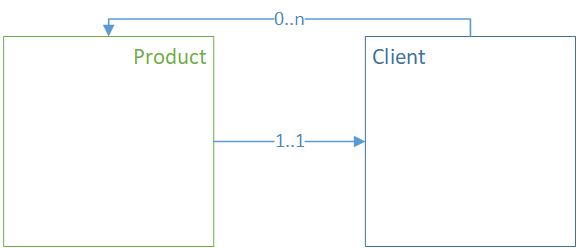
В терминах XML это выглядит следующим образом (для рабочего варианта блока модели сущности должны быть частью одного агрегата):
<class name="Product">
<property name="client" type="Client"/>
</class>
<class name="Client">
<property collection="set" mappedby="client" name="products" type="Product"/>
</class>
Связь OneToOne как уникальная ссылка#
Связь является однонаправленной.
В терминах XML это выглядит следующим образом:
<class name="Product">
<property name="client" type="Client" unique="true"/>
</class>
<class name="Client">
<property name="name" type="String"/>
</class>
Связь ManyToMany через сущность в модели#
Для создания связи ManyToMany необходимо создать промежуточный класс.
На диаграмме ниже между классами Product и Client создан промежуточный класс — ProductClientLink.
От Product к промежуточной сущности образована связь OneToMany, в обратную сторону — ManyToOne.
Промежуточный класс использует внешнюю ссылку к классу Client.
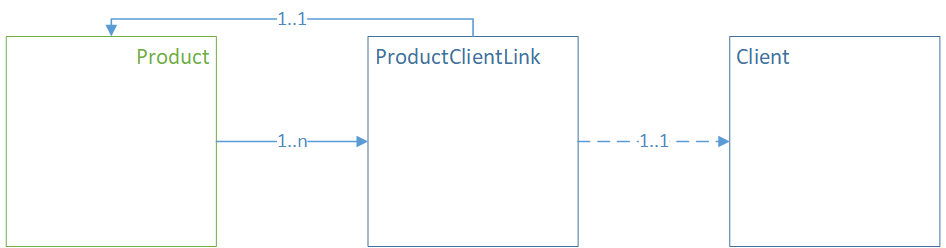
В терминах XML такая связь может выглядеть следующим образом:
<class name="Product">
<property name="clients" type="ProductClientLink" collection="set" mappedBy="product"/>
</class>
<class name="ProductClientLink">
<property name="product" type="Product" parent="true"/>
<reference name="client" type="Client"/> <!-- Создается внешняя ссылка, см. тему "Внешние ссылки" -->
</class>
<class name="Client"> <property name="name" type="String"/>
</class>
Embedded-классы#
При проектировании модели имеется возможность определить так называемые embedded-классы — классы, определяющие набор примитивных или enum-полей.
Ссылки и коллекционные атрибуты в embedded-классах запрещены.
Сам по себе embedded-класс (размеченный в модели данных свойством embeddable="true") не является отдельным объектом, но может выступать в качестве атрибута класса, не являющегося embedded.
В примере ниже представлен синтаксис определения таких классов и их использования в качестве атрибутов:
<class name="Address" label="Книга" embeddable="true">
<property name="city" type="String" label="Город"/>
<property name="street" type="String" label="Улица"/>
<property name="houseNumber" type="String" label="Номер дома"/>
</class>
<class name="BookStore" label="Книжный магазин">
<property name="name" type="String" label="Название"/>
<property name="addressReg" type="Address" label="Адрес регистрации"/>
<property name="addressFact" type="Address" label="Адрес фактический"/>
</class>
Внимание!
Если ключ имеет тип embeddable-класса, состоящего из нескольких полей, то будет сформирован составной индекс.
Пример model.xml:
<class name="MyKey" embeddable="true" label="">
<property name="a1" type="String" label=""/>
<property name="a2" type="String" label=""/>
</class>
<class name="CLassWithComplexPrimaryKey">
<id type="MyKey"/>
<property name="name" type="String"/>
</class>
Сформированный индекс:
<index index-name="PK_T_CLASSWITHCOMPLEXPRIMARYKEY" primary-key="true">
<property name="objectId.a1"/>
<property name="objectId.a2"/>
</index>
Управление пользовательскими SQL-запросами#
Пользовательские SQL-запросы необходимо воспринимать как параметризованное представление. В результате объявления пользовательского SQL-запроса будут созданы сущности, аналогичные классам, с возможностью применения к ним только поисковых методов.
Для объявления пользовательского SQL-запроса необходимо в файле модели model.xml внутри тега
<query name="Query1" label="searchPerformedServiceByCodeAndName" description="Поиск сервисов по коду и имени">
<params>
<param name="template" type="String" collection="true" label="" description=""/>
<param name="name" type="String" default-value="abc"/>
</params>
<implementations>
<sql dbms="h2">select t1.code code, t1.name name, t1.OBJECT_ID id from ${dspc.schemaPrefix}T_PERFORMEDSERVICE t1 where t1.code in (${template}) AND t1.name = ${name}</sql>
<sql dbms="postgresql">select t1.code code, t1.name name, t1.OBJECT_ID id from ${dspc.schemaPrefix}T_PERFORMEDSERVICE t1 where t1.code in (${template}) AND t1.name = ${name}</sql>
<sql dbms="oracle">select t1.code code, t1.name name, t1.OBJECT_ID id from ${dspc.schemaPrefix}T_PERFORMEDSERVICE t1 where t1.code in (${template}) AND t1.name = ${name}</sql>
</implementations>
<id name="id" label="id label" description="id description"/>
<property name="code" type="String" label="" description=""/>
<property name="name" type="String"/>
</query>
Примечание:
query— тег, открывающий объявление пользовательского SQL-запроса:name— атрибут, задающий имя запроса. С учетом данного имени будут созданы поисковые классы (включая классы для работы с результатом поиска) (обязательный атрибут).label— метка запроса, метаинформация, в алгоритмах не используется (необязательный атрибут).description— текстовое описание запроса, в алгоритмах не используется (необязательный атрибут).
params— тег, открывающий описание параметров, применяемых в запросе (необязательный раздел).param— тег, описывающий отдельный параметр запроса:name— атрибут, в котором указывается имя параметра в запросе (обязательный атрибут). Подстановка параметра в запрос осуществляется конструкцией вида:${paramName}.type— указывается тип параметра (параметры могут иметь только примитивные типы) (обязательный атрибут).collection— признак коллекционного параметра, допустимые значения: "true"/"false". Значение по умолчанию — "false" (необязательный атрибут).default-value— значение параметра по умолчанию, данное значение используется, если значение параметра не было передано (необязательный атрибут).label— метка параметра, метаинформация, в алгоритмах не используется (необязательный атрибут).description— текстовое описание параметра, в алгоритмах не используется (необязательный атрибут).
implementations— тег, открывающий раздел описания SQL-запроса (описаний запроса может быть несколько, если используется несколько БД с разными диалектами) (обязательный раздел).sql— тег, описывающий SQL-запрос в нативном для БД синтаксисе:dbms— атрибут указывающий диалект запроса. Допустимые значения: "h2", "postgresql", "oracle" (необязательный атрибут). Когда он задан, SQL-запрос будет выполняться только на БД, соответствующих указанному диалекту. Отсутствие атрибута означает, что SQL-запрос будет выполняться на тех БД, для которых явно не задан SQL-запрос с подходящим диалектом. Атрибут может содержать несколько значений, указанных через запятую, например: "h2,postgresql".
id— тег, задающий имя поля, содержащего идентификатор записи (всегда имеет тип String).name— атрибут в котором указывается имя поля результата, содержащее идентификатор записи (обязательный атрибут).label— метка, метаинформация, в алгоритмах не используется (необязательный атрибут).description— текстовое описание, в алгоритмах не используется (необязательный атрибут).
property— тег, описывающий отдельное поле результата:name— имя поля результата. Должно соответствовать имени поля в запросе.type— тип поля результата. Допускаются только примитивные типы.label— метка, метаинформация, в алгоритмах не используется (необязательный атрибут).description— текстовое описание, в алгоритмах не используется (необязательный атрибут).
Ограничения#
Пользовательские SQL-запросы не поддерживают наследование — нельзя унаследовать один запрос от другого.
Параметры и поля результата запроса могут быть только примитивных типов.
Пользовательский SQL-запрос не предоставляет возможности организации вложенного получения (запроса) связанных сущностей. При этом необходимые поля вложенной сущности могут быть получены путем указания (запроса) в самом SQL-запросе.
Указание имен таблиц в пользовательских запросах#
DataSpace требует указания имени схемы в наименованиях таблиц и представлений.
Для этого необходимо перед всеми именами таблиц и представлений, использованных в пользовательском SQL-запросе, добавить параметр ${dspc.schemaPrefix}.
Параметр ${dspc.schemaPrefix} необходимо добавлять непосредственно перед именем без пробелов и точек.
Пример:
<sql>select t1.object_id id, t1.code, t2.name, t2.object_id child_id from ${dspc.schemaPrefix}t_aggroot t1 left join ${dspc.schemaPrefix}t_aggchild t2 on t2.aggroot = t1.object_id where t1.code in ${template}</sql>
Использование DDD-агрегатов#
Деление модели на DDD-агрегаты — принцип построения деревьев модели, в каждом из которых данные сгруппированы вокруг центрального класса (корня). DataSpace поддерживает использование DDD-агрегатов.
Примечание
Связи между агрегатами отличаются от связей между простыми объектами использованием параметра
parent="true".
Для связей OneToMany и ManyToOne необходимо указать связанную сущность как параметр. В дополнение к этому необходимо указать множественную связь: collection="set" mappedBy="{имяОбратнойСсылки}".
<class name="Product">
<property name="client" type="Client" parent="true"/>
</class>
<class name="Client">
<property name="products" type="Product" collection="set" mappedBy="client"/>
</class>
Для связи OneToOne необходимо указать связанную сущность как параметр. Один из параметров необходимо указать, как родительский (parent="true"), для второго необходимо указать обратную ссылку (mappedBy="client").
<class name="Product">
<property name="client" type="Client" parent="true"/>
</class>
<class name="Client">
<property name="product" type="Product"
mappedBy="client"/>
</class>
Дополнительные сведения о способах использования DDD-агрегатов можно найти в справочном разделе "DDD-агрегаты".
Историцирование#
Предназначено для ведения истории изменения заданных атрибутов сущностей.
При работе функциональности имеются коллизии, которые необходимо учитывать. С информацией о коллизиях можно ознакомиться в разделе "Коллизии историцирования" документа "Руководство прикладного разработчика".
При необходимости сохранять информацию о пользователе, внесшем изменения, воспользоваться функциональностью, описанной в разделе "Сохранение пользователя, изменившего данные в историю" документа "Руководство по системному администрированию".
Минимальной единицей историцирования является атрибут сущности модели.
Для того чтобы пометить поле, как историцируемое, необходимо на модели добавить полю атрибут historical="true".
Внимание!
Нельзя историцировать поля
clobиblob, поля объектов embedded, поля обратных ссылок, а также поля-коллекции.
Внимание!
В плагин генерации модели и SDK (<artifactId>model-api-generator-maven-plugin</artifactId>) необходимо добавить настройку <enableHistoryGenerators>true</enableHistoryGenerators> (для целей: createSdk и createModel). В артефакте с моделью и SDK должна быть подключена зависимость sbp.com.sbt.dataspace:historical-changes-interfaces.
Внимание!
Ссылочные поля историцируются, как примитивные, т.е. историцируется само значение ссылки (идентификатор), а не расположенный по ней объект.
Пример класса с историцируемыми полями:
<class name="Product">
...
// историцруемое поле
<property name="code" type="String" historical="true"/>
// историцруемое поле
<property name="name" type="String" historical="true"/>
// не историцируемое поле
<property name="description" type="String"/>
// историцируемая ссылка
<property name="mainService" type="Service" historical="true"/>
</class>
<class name="Service">
...
</class>
Если на классе объявлены историцируемые поля, то для всех классов в цепочке наследования (как вверх, так и вниз) создаются классы историцирования. Имя класса историцирования формируется из имени класса с постфиксом History. Например, для класса Product имя класса историцирования будет ProductHistory.
Для всех классов в рамках одной цепочки наследования формируется одна таблица в БД для хранения исторических данных. Название таблицы формируется из префикса t_, имени первого неабстрактного класса в цепочке наследования и суффикса history. Для первого неабстрактного класса Product имя таблицы с историческими данными будет выглядеть следующим образом — t_producthistory.
Получение данных историцирования и детали работы механизма описаны в документе "Руководство прикладного разработчика" в разделе "Историцирование (получение данных)".
Генерация рабочих артефактов#
Для локальной сборки проекта необходимо использовать команду mvn clean install.
После выполнения команды Maven сформирует локальные классы, а также файлы с историей миграций данных (changelog.xml) и с текущей конфигурацией базы данных в терминах XML (pdm.xml).
Подробные сведения о способах генерации рабочих артефактов можно найти в документе "Руководство прикладного разработчика" в разделе "Генерация рабочего артефакта".
Поддержание моделей в рабочем состоянии#
Реализованные в промышленной среде модели необходимо версионировать.
О том, как происходит процесс проверки модели и ее выпуск, можно узнать в документе "Руководство по установке".
Если сборка пройдена и job настроен корректно, в ветку разработки будут добавлены файлы для версионирования модели. Эти файлы расположены по следующему пути: model/model.
Принцип: необходимые изменения необходимо проводить все в тех же файлах, что и ранее.
Внимание!
При первоначальном описании модели необходимо учитывать, что в последующих релизах изменять схему управления агрегатом (изменять свойство сущностей
parent) запрещено!
Проверка агрегатов и настройки#
Контроль ссылки в корне агрегата на агрегат того же типа#
До версии 1.7 DataSpace проверка модели допускает ссылку в корне агрегата на агрегат того же типа.
Несмотря на то, что модель остается в работоспособном состоянии, такая ссылка ограничивает более сложную функциональность сервиса. Пример такого описания:
<class name="Sample">
<property name="sample" type="Sample"/>
</class>
С версии 1.7 подобные ссылки запрещены и будут вызывать исключение при проверке модели. Однако в целях обратной совместимости для уже существующих ссылок проверка будет проходить.
Если необходимость в подобных ссылках есть, то предыдущую логику проверки, которая позволяла делать подобные ссылки, можно вернуть параметром плагина disableAggregateRootReferenceCheck со значением true.
Контроль принадлежности ссылок одному агрегату#
До версии 1.9 DataSpace сервис dataspace-core допускает заполнение ссылок на объектах одного агрегата объектами из других агрегатов. Начиная с версии 1.9 сервис dataspace-core выполняет проверку принадлежности объектов ссылок одному агрегату.
Пример такого описания:
<model>
<class name="Sample">
<property name="sampleElementSet" type="SampleElement" collection="set" mappedBy="owner"/>
<property name="sampleElement" type="SampleElement"/>
</class>
<class name="SampleElement">
<property name="owner" type="Sample" parent="true"/>
<property name="sample" type="Sample"/>
</class>
</model>
Проблемными свойствами являются sampleElement класса Sample и sample класса SampleElement.
Пример ошибочного заполнения элементов Sample:
id |
sampleElement |
|---|---|
1 |
2 |
2 |
1 |
Пример ошибочного заполнения элементов SampleElement:
id |
owner |
sample |
|---|---|---|
1 |
1 |
2 |
2 |
2 |
1 |
Объект SampleElement с id = 1 принадлежит агрегату Sample с id = 1, но содержит ссылку в sample на агрегат с id = 2.
Для объекта SampleElement с id = 2 ситуация аналогична.
Если модель содержит подобные варианты связей, то рекомендуется перед переходом на версию 1.9 выполнить проверку наличия расхождений в агрегатах базы данных.
Задав параметр <generateAggRefValidationInfo>true</generateAggRefValidationInfo> плагина model-api-generator-maven-plugin для цели createModel, можно получить файл agg-ref-validation.info в папке модели с SQL-запросами для проверки.
Если файл не сформирован, то модель не содержит требующих проверки связей.
Для примера модели файл имеет следующую структуру:
-- Sample.sampleElement
SELECT fo.OBJECT_ID, fo.TYPE, fo.SAMPLEELEMENT_ID FROM T_SAMPLE fo JOIN T_SAMPLEELEMENT fb ON fb.OBJECT_ID = fo.SAMPLEELEMENT_ID WHERE fo.SAMPLEELEMENT_ID IS NOT NULL AND fb.AGGREGATEROOT_ID <> fo.OBJECT_ID ORDER BY fo.OBJECT_ID;
-- SampleElement.sample
SELECT fo.OBJECT_ID, fo.TYPE, fo.SAMPLE_ID FROM T_SAMPLEELEMENT fo JOIN T_SAMPLE fb ON fb.OBJECT_ID = fo.SAMPLE_ID WHERE fo.SAMPLE_ID IS NOT NULL AND fb.OBJECT_ID <> fo.AGGREGATEROOT_ID ORDER BY fo.OBJECT_ID;
Структура файла:
комментарий
--отражает класс и свойство модели, для проверки которого в следующей строке составлен SQL;результат SQL-запроса содержит:
OBJECT_ID: идентификатор объекта содержащего ошибочную ссылку;
TYPE: имя типа объекта в модели (для работы с потомками);
имя третьей колонки зависит от имени свойства в модели, содержит идентификатор ошибочного объекта, то есть объекта, агрегат которого отличается от агрегата объекта-владельца ссылки.
Если запрос содержит пустой результат, то расхождений в данных нет. В противном случае переход на версию 1.9 может привести к ошибкам во время выполнения.
При необходимости использовать связи между агрегатами следует перейти на reference.
Для работы модуля dataspace-core в режиме без контроля ссылок (не рекомендуется) необходимо указать в параметре dataspace.useEntityReferenceAggregateValidation значение false.
Деление модели на части#
Предположим, команда Прикладной фабрики планирует разработать несколько модулей, работающих с DataSpace. Эти модули могут быть полностью независимы друг от друга, их разработкой могут заниматься разные группы разработчиков. Вместе с тем команда желает организовать для всех этих модулей общее хранилище — единую базу данных.
С одной стороны, на уровне работы с SDK каждого модуля необходимо обеспечить доступ только к своей модели и входящим в нее классам. С другой стороны, при развертывании и обновлении схемы в базе данных необходимо обеспечить общую модель, объединяющую модели всех модулей.
Решать задачу необходимо следующим образом:
Модель необходимо разбить на две части: общую и частичную.
Общая часть содержит классы, используемые в нескольких частичных моделях.
Частичная модель содержит независимые классы.
Создать модули для частичных моделей.
Внимание!
Разделение модели необходимо выполнять строго по агрегатам. Нельзя создавать корень агрегата в одной частичной модели, а зависимый класс в другой частичной модели. Также нельзя оформлять внешние ссылки из одной частичной модели на классы другой модели, которые не являются корнем агрегата! Допустимо оформлять внешние ссылки только на классы, являющиеся корнями агрегата.
Создание проекта раздельных моделей#
В рамках шага необходимо создать самостоятельный проект, который будет содержать в себе только модель и модули частичных моделей.
Структура проекта может выглядеть следующим образом:
На рисунке выше папки dictionaries, metal и notes являются модулями частичных моделей со своей бизнес-спецификой,
а файл model.xml, что в корне папки model содержит общие элементы модели.
Деление файла модели#
Главный файл описания общей модели должен находится внутри model/src/main/resources/model. Этот файл может выглядеть следующим образом:
<model model-name="commonmodel" version="1.0.0-SNAPSHOT">
<import type="IMPORT" file="import"/>
<class name="MyCommonClass" abstract="true">
<property name="code" type="String"/>
</class>
</model>
Рядом с этим файлом должна быть расположена папка import с подпапками dictionaries, metal и notes, содержащими файл с одинаковым именем model.xml, но разным содержимым согласно бизнес-правилам. Параметр file="import" в теге import можно опустить. По умолчанию папка с частичными моделями называется import. Если необходимо переопределить имя папки частичных моделей, то в параметре file можно указать необходимое имя.
Частичные модели находятся в папке import рядом с главной моделью.
Разделение модулей#
Общая модель#
Для выпуска sdk артефакта с частичной моделью необходимо в параметр importModelName плагина model-api-generator-maven-plugin добавить наименование модели, для которой необходимо выпустить sdk. Имя модели берется из соответствующего файла model.xml атрибута model-name тега model:
<model model-name="notes">
...
</model>
Развертывание схемы и сборка модуля DataSpace Core (и всех других модулей DataSpace) должны выполняться с общей моделью. Для этого необходимо добавить модуль, который не будет содержать в настройках указания фильтра модели (importModelName).
Для общей модели необходимо создать только jpa-артефакт и Liquibase-скрипты. Настройка плагина для него может выглядеть так:
<plugin>
<groupId>sbp.com.sbt.dataspace</groupId>
<artifactId>model-api-generator-maven-plugin</artifactId>
<executions>
<execution>
<id>createModel</id>
<goals>
<goal>createModel</goal>
</goals>
<configuration>
<basePackage>ru.sberbank.gtp.notespm</basePackage>
<model>../models-module/src/main/resources/model</model>
</configuration>
</execution>
</executions>
</plugin>
Частичная модель#
В модулях с частичными моделями (например, в папке dictionaries-module) находится pom-файл, который в плагине model-api-generator-maven-plugin содержит параметр importModelName, который указывает для какой именно модели необходимо собрать sdk.
Возможная настройка плагина:
<plugins>
<plugin>
<groupId>sbp.com.sbt.dataspace</groupId>
<artifactId>model-api-generator-maven-plugin</artifactId>
<executions>
<execution>
<id>createSdk</id>
<goals>
<goal>createSdk</goal>
</goals>
<configuration>
<basePackage>ru.sberbank.gtp.notespm.dictionary</basePackage>
<model>../model/src/main/resources/model</model>
<importModelName>dictionary</importModelName>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
Обратите внимание, что путь всегда указывается к общей модели. Меняется лишь имя частичной модели.
Использование модели#
При подключении к SDK необходимо указывать артефакты частичных моделей. В проекте можно подключить более одного такого артефакта.
Пример подключения к внешней модели проекта, созданного с нуля#
В данном примере используется внешняя модель, описанная в тестовом проекте dataspace-merge-repo.
В качестве зависимостей при настройке SDK будут использованы такие:
<dependency>
<groupId>ru.sberbank.gtp.notespm</groupId>
<artifactId>notes-module</artifactId>
<version>1.2.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>ru.sberbank.gtp.notespm</groupId>
<artifactId>metal-module</artifactId>
<version>1.2.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>ru.sberbank.gtp.notespm</groupId>
<artifactId>dictionaries-module</artifactId>
<version>1.2.0-SNAPSHOT</version>
</dependency>
При настройке локального запуска Core необходимо указать артефакт с классами JPA общей модели:
<artifactItem>
<groupId>ru.sberbank.gtp.notespm</groupId>
<artifactId>common-model</artifactId>
<version>1.2.0-SNAPSHOT</version>
</artifactItem>
Создание проекта с нуля#
Для создания проекта с нуля в целевой папке выполните сборки проекта из архетипа версии не ниже 1.6.1-16 из Терминала (*Nix) или командной строки (Windows):
mvn -DgroupId=ru.test -DartifactId=test-metal -Dversion=DEV-SNAPSHOT -DmodelName=test_metal -DdataspaceBomVersion=4.3.20 -DarchetypeGroupId=sbp.com.sbt.dataspace -DarchetypeArtifactId=dataspace-model-archetype -DarchetypeVersion=4.3.23 -DarchetypeCatalog=local org.apache.maven.plugins:maven-archetype-plugin:RELEASE:generate
После выполнения команды в целевой папке будет создан подкаталог, содержащий полностью рабочий проект с одним тестом для той модели, которая входит в состав данного архетипа.
Запуск теста с временным поднятием локального сервера (Core)#
Для запуска тестов с временным поднятием локального сервера необходимо выполнить следующие шаги:
Выполнить сборку проекта clean-install с отключенными тестами.
Убедиться, что проект собирается успешно.
Запустить тест demoTest() из класса ModelTest.
Убедиться, что тест прошел успешно.
После прохождения тестов локальный экземпляр сервера и тестовые данные будут уничтожены.
Запуск теста вручную на поднятом локальном сервере (Core)#
В отличие от предыдущего способа, при тестировании на поднятом сервере тестовые данные не удаляются автоматически. Структуру и содержимое таблиц можно посмотреть по ссылке http://localhost:8080/h2-console/login.do. Также можно проверить работу GraphQL по ссылке http://localhost:8080/graphiql?.
Для проведения тестов на поднятом локальном сервере необходимо выполнить следующие шаги:
В классе BaseTest в строке 16 закомментировать весь текст, который отвечает за старт подъема окружения для теста в момент запуска теста:
@ExtendWith({JUnit5DataSpaceCoreLocalRunnerExtension.class}).В классе BaseTest в строке 19 установить явно порт 8080:
private static int servicePort = 8080.В терминале, Git CMD или Git Bash открыть каталог:
/model-local-test/local-run/.Поднять локальный сервер, запустив файл
local-run.sh. Следует убедиться, что значение параметра модуляdataspace-core.model.packagesToScanсоответствует пакету генерируемых классов jpa.Дождаться завершения подъема Core, примерный вид лога:
2021-08-17 17:15:36,795 [/] INFO [main] s.s.d.module.Runner$Companion — Started Runner.Companion in 137.522 seconds (JVM running for 140.759).Запустить тест
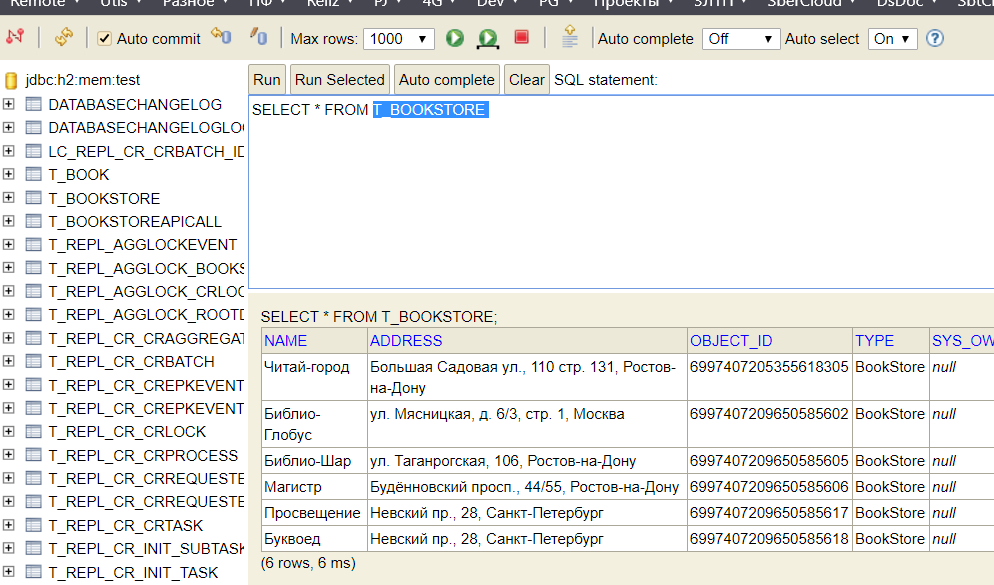
demoTest()из классаModelTest. Он должен теперь пройти гораздо быстрее, поскольку Core уже поднят.Зайти в БД H2 (http://localhost:8080/h2-console/login.do) и просмотреть содержимое таблицы T_BOOKSTORE.
Вставить текст двух запросов в редактор GraphQL (http://
:8080/graphiql или другой). mutation m2 { p2: packet(idempotencePacketId:"p2") { createBookStore(input: { name:"Книга Ростов" }) { id } } } query q2 { searchBookStore(cond: "it.name != '1'") { elems { name } } }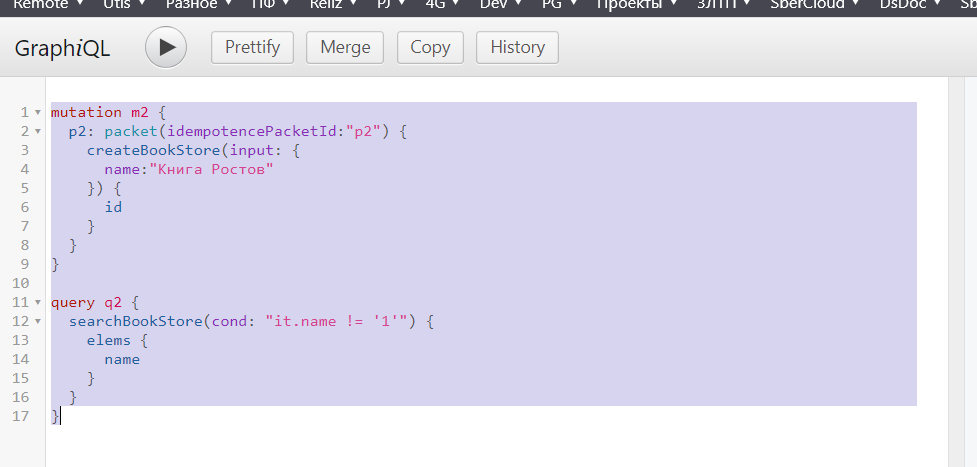
Выполнить запрос m2 и зафиксировать, что создана сущность (будет выведен id сущности).
Выполнить запрос q2 и зафиксировать, что вернулся список всех магазинов (в том числе и тот, что создан в m2).
Выполнить повторно m2 и сразу же q2 и зафиксировать, что новый магазин "Книга Ростов" не создан, поскольку был указан ключ идемпотентности:
idempotencePacketId:"p2".Исправить ключ идемпотентности на
= idempotencePacketId:"p3"и снова запустить m2, чтобы все-таки создать новый магазин с таким же именем.Выполнить запрос q2 и зафиксировать, что вывелось два магазина "Книга Ростов".
Переключение проекта на внешнюю модель#
Постановка задач:
Избавиться от всех артефактов, относящихся к модели, поставляемой в архетипе.
Подключиться к внешней модели так, чтобы в SDK были доступны классы только частичных моделей
metal-moduleиdictionary-module.
Для выполнения задач необходимо выполнить следующие шаги:
Удалить физически в проекте test-metal следующие модули и каталоги:
model,test-metal-model-jpaиtest-metal-model-sdk.Удалить в корневом pom-файле ссылки на эти модули (например,
<module>test_metal5-model-jpa</module>).Удалить в pom-файле модуля
model-local-testзависимости на удаленные артефактыtest_metal-model-sdkиtest_metal5-model-jpa.Вместо зависимостей в шаге 3 добавить зависимости на внешние модели: артефакты
metal-moduleиdictionary-module. Информацию о данных зависимостях можно найти по тексту выше.Удалить в pom-файле модуля
model-local-testартефакты в секции<artifactItem>с именами удаленных модулейtest_metal-model-sdkиtest_metal5-model-jpa, где описываются классы для организации локального старта Core.Вместо зависимостей в шаге 5 добавить зависимость на внешнюю модель, описывающую полный набор классов:
<artifactId>models-module</artifactId>. Полное описание дано выше.В файле
test-metal\config\standalone\dataspace-core-local-runner.propertiesзаменить значение параметраoverridden-spring-properties=--dataspace-core.model.packagesToScan=ru.test. Вместоru.testуказать пакет, где содержатся JPA-классы внешней модели:ru.sberbank.gtp.notespm.Удалить тестовый файл ModelTest и добавить тесты (ModelDictTest и ModelMetalTest), разработанные под новую модель (текст тестов см. ниже).
В классе BaseTest удалить устаревший импорт (
import ru.test.grasp.DataspaceCoreSearchClient;) и подгрузить новый (import ru.sberbank.gtp.notespm.grasp.DataspaceCoreSearchClient;).Пересобрать проект и запустить оба теста.
В результате выполнения шагов проект должен успешно скомпилироваться. При запуске тестов должен успешно стартовать DataSpace Core, оба теста должны успешно отработать.
Вывод: данный пример показывает, как подключить в SDK одновременно две частичные модели и как с ними работать.
Пример (тест ModelDictTest):
package ru.test;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import ru.sberbank.gtp.notespm.dictionary.graph.get.DictionaryContainerGet;
import ru.sberbank.gtp.notespm.dictionary.packet.DictionaryContainerRef;
import ru.sberbank.gtp.notespm.dictionary.packet.packet.Packet;
public class ModelDictTest extends BaseTest {
@Test
public void createDictionaryContainer() throws Throwable {
// Создание MetalTrade
Packet creatingPacket = new Packet();
DictionaryContainerRef metalTradeRef = creatingPacket.dictionaryContainer.create(param -> {
param.setName("998877");
});
dataspaceCorePacketClient.execute(creatingPacket);
// Чтение созданного MetalTrade
Packet readingPacket = new Packet();
DictionaryContainerGet dictionaryContainerGet = readingPacket.dictionaryContainer.get(metalTradeRef, param -> {
param.withName();
});
dataspaceCorePacketClient.execute(readingPacket);
Assertions.assertEquals("998877", dictionaryContainerGet.getName());
System.out.println("Name = " + dictionaryContainerGet.getName());
}
}
Пример (тест ModelMetalTest):
package ru.test;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import ru.sberbank.gtp.notespm.graph.get.MetalTradeGet;
import ru.sberbank.gtp.notespm.jpa.ExternalSource;
import ru.sberbank.gtp.notespm.jpa.MetalTradeDirection;
import ru.sberbank.gtp.notespm.jpa.MetalTradeStatus;
import ru.sberbank.gtp.notespm.jpa.MetalTradeType;
import ru.sberbank.gtp.notespm.packet.MetalTradeRef;
import ru.sberbank.gtp.notespm.packet.packet.Packet;
import java.time.LocalDate;
public class ModelMetalTest extends BaseTest {
@Test
public void createMetalTrade() throws Throwable {
// Создание MetalTrade
Packet creatingPacket = new Packet();
MetalTradeRef metalTradeRef = creatingPacket.metalTrade.create(param -> {
param.setTradeNumber("998877");
param.setTradeType(MetalTradeType.INOUT);
param.setMarket("Рынок РФ");
param.setCurrencyPair("CurrencyPair");
param.setDeliveryDate(LocalDate.now());
param.setExternalSourceSystem(ExternalSource.QUIK);
param.setIsEnabled(true);
param.setLastChangeInitiator("LastChangeInitiator");
param.setPaymentDate(LocalDate.now());
param.setPortfolio("Portfolio");
param.setStatus(MetalTradeStatus.CHANGED_BY_BO);
param.setTradeDate(LocalDate.now());
param.setTradeDirection(MetalTradeDirection.BUY);
param.setVersion(123);
});
dataspaceCorePacketClient.execute(creatingPacket);
// Чтение созданного MetalTrade
Packet readingPacket = new Packet();
MetalTradeGet metalTradeGet = readingPacket.metalTrade.get(metalTradeRef, param -> {
param.withTradeNumber();
param.withTradeType();
param.withMarket();
});
dataspaceCorePacketClient.execute(readingPacket);
Assertions.assertEquals("998877", metalTradeGet.getTradeNumber());
Assertions.assertEquals(MetalTradeType.INOUT, metalTradeGet.getTradeType());
Assertions.assertEquals("Рынок РФ", metalTradeGet.getMarket());
System.out.println("TradeNumber = " + metalTradeGet.getTradeNumber());
System.out.println("TradeType = " + metalTradeGet.getTradeType());
System.out.println("Market = " + metalTradeGet.getMarket());
}
}
Работа с локальными справочниками#
В DataSpace имеется возможность создавать локальные справочники и ссылаться на них из доменных сущностей. Таким образом можно иметь готовые данные, например, категории клиентов, города, офисы и другие.
Наполнение справочников в хранилище происходит на этапе применения Liquibase-скриптов изменения модели.
Разметка данных#
Для добавления справочников в проект необходимо пометить требуемые классы признаком is-dictionary и создать файлы справочников.
Для файлов справочников должна быть создана отдельная папка. По умолчанию используется подпапка model/dictionary, где model — папка с файлами модели и статусов. Папку для справочников можно переопределить с помощью свойства file: <import file="nameDir" type="IMPORT"/>.
Разметка справочников подчиняется следующим правилам:
Справочная сущность должна быть помечена свойством
is-dictionaryтега<class>. Этот признак должен стоять на корне наследования. Признак можно опустить на классах-потомках.Размечать на классе можно только поля, коллекции примитивов, индексы.
Ссылка на справочник может быть определена для любого агрегата.
Пример описания справочника:
<model model-name="myModel" version="1.0.0-SNAPSHOT">
<class name="City" label="Город" is-dictionary="true">
<property name="code" type="String" label="Код" mandatory="true"/>
<property name="name" type="String" label="Наименование" mandatory="true"/>
<property name="offices" type="Office" label="Офисы" collection="set" mappedBy="city"/>
<property name="identification" type="Identification"/>
</class>
<class name="Identification" embeddable="true">
<property name="ecs" type="String" label="Идентификатор в единой система"/>
<property name="kladr" type="String" label="Идентификатор в системе КЛАДР"/>
</class>
</model>
Для справочников не может быть иной стратегии заполнения идентификатора кроме ручной, то есть <id category="MANUAL"/>. Если вы не укажете категорию, то она заполнится этим значением по умолчанию.
Для справочников можно указать индексы. Разметка не отличается от общих правил.
Начиная с версии DataSpace 1.11.0 добавилась возможность указания тега parent для связи дочернего/родительского справочника. Указание
тега приведет к каскадному удалению дочерних справочных сущностей при удалении родительской.
Пример:
<model>
<class name="Region" is-dictionary="true">
<property name="name" type="String"/>
<property name="city" type="City" collection="set" mappedBy="region"/>
</class>
<class name="City" is-dictionary="true">
<property name="name" type="String"/>
<property name="region" type="Region" parent="true"/>
</class>
</model>
В примере выше при удалении сущности Region все связанные с ней сущности City также будут удалены.
Структура справочника#
Структура данных задается в формате JSON. Для описания данных справочников необходимо выполнить следующие шаги:
В папке, в которой лежит описание модели (model.xml), создать папку
dictionary. Если это имя папки недопустимо, его необходимо переопределить, указав относительный путь к папке в файле model.xml:<import type="DICTIONARY_GENERATOR" file="./dictionaryFolder"/>Расположить в этой папке файлы справочников. Принадлежность файлов к справочным данным определяется по расширению файла. JSON-файлы должны называться *.json. Структурировать справочные данные можно по файлам и папкам, как показано на изображении ниже.
Описания данных в формате JSON должно включать в себя следующие поля:
type: имя типа. Это название справочника из атрибутаnameтегаclassфайла model.xml. Полеtype— опционально. Если его не указать, то тип определяется из названия файла <Имя справочника>.json.objects: массив с описанием данных. Объект в массиве objects подчиняется стандартным правилам json-описания объектов.
Пример описания данных для справочника "Область" из описания справочников выше:
{
"type": "City",
"objects": [
{
"id": "1",
"code": "RND",
"name": "Ростов-на-Дону",
"identification": {
"ecs": "22r",
"kladr": "32"
}
},
{
"id": "2",
"code": "MSK",
"name": "Москва",
"identification": {
"ecs": "23",
"kladr": "3"
}
},
{
"id": "3",
"code": "SPB",
"name": "Санкт-Петербург",
"identification": {
"ecs": "02pit",
"kladr": "320"
}
}
]
}
Спецификация формата#
При разработке справочников необходимо придерживаться следующих правил:
Для каждого справочника должен быть определен идентификатор, определенный через свойство
id. Если идентификатор не будет указан хотя бы на одном объекте, то будет сгенерирована ошибка типаObjectWithNoIdExceptionс указанием названия справочника с отсутствующим идентификатором.Из справочника можно ссылаться только на другой справочник и нельзя сослаться на сущность. Ссылка на другой справочник создается только через валидный идентификатор. Если указанный объект справочника не найден, будет сгенерирована ошибка
DictionaryConsistencyExceptionс уточнением того, справочник с какимidне удалось обнаружить.Можно использовать embedded-классы.
Для реализации связи между справочниками Справочник 1 должен включать в себя идентификаторы позиций из Справочника 2. В примере ниже это поле "город" (
city):{ "type": "Office", "objects": [ { "id": "1", "city": "2", "code": "Kosmonavtov27", "name": "Офис на Космонавтов 27" } ] }Ниже показан пример значения, на которое указывает ссылка:
{ "type": "City", "objects": [ { "id": "1", "code": "RND", "name": "Ростов-на-Дону" }, { "id": "2", "code": "MSK", "name": "Москва" } ] }Идентификаторы каждого справочника должны быть уникальны.
При создании справочника поля, имеющие null-значения, можно просто не описывать в данных. При обновлении поля значением "null" необходимо присвоить значению поля величину null. Значение указывается без кавычек. Пример:
{ "type": "City", "objects": [ { "id": "2", "code": "MSK", "name": null } ] }Поле
nameбудет иметь значение "null".Начиная с версии DataSpace 1.11.0 добавлена возможность указания максимального размера файла с данными справочников. Сделано это для предотвращения превышения размера вектора изменений данных при передаче через транспортную систему. Каждый файл обрабатывается отдельной транзакцией. Таким образом, регулируя размер файла, можно регулировать размер данных транзакции и размер вектора изменений. Размер файла регулируется параметром плагина сборки
maxDictionaryFileSize. По умолчанию значение параметра — 512 Кб.При возникновении ошибки с текстом В справочных данных присутствует объект, данные для обновления или для отката обновления которого целиком не могут быть размещены в файле заданного размера. Необходимо увеличить размер файла. Необходимо увеличить значение параметра
maxDictionaryFileSize, при этом проверив работоспособность StandIn с вектором изменения получающегося размера, при наличии интеграции со StandIn. При тестировании версии необходимо убедиться, что обновление справочника успешно выполняется на стенде, соответствующем промышленной конфигурации (включая настройки StandIn и Kafka).При задании связей между справочниками, образующих циклические ссылки между их записями, для исполнения их обновления в одной транзакции и отсутствию возможности поделить такие данные на независимые порции, все такие записи помещаются в один файл независимо от параметра максимального размера файла, что может привести к ошибкам при передаче вектора изменений. Следует учитывать это ограничение при формировании циклически связанных структур. В данной ситуации в логах сборки артефакта модели будет предупреждение с текстом "Файл части справочника не вписывается в размер, заданный параметром 'maxDictionaryFileSize', необходимо провести дополнительное тестирование загрузки справочника в условиях, приближенных к промышленной эксплуатации.
Алгоритм работы#
При первом формировании справочных данных происходит формирование скриптов Liquibase с наполнением хранилища данными справочников. Также произойдет сохранение текущих данных в папку model/dictionary.
Сохранение данных необходимо для расчета изменений справочников в дальнейшем. При дальнейшем развитии справочников анализируются новые объекты и сравниваются с сохраненной информацией от предыдущей итерации изменений. Очередные Liquibase-скрипты наполняются обновлением только той информации, которая изменилась. То есть будут вставлены только вновь появившиеся справочные данные и обновлены те, что изменились.
При формировании Liquibase скриптов осуществляется проверка справочных данных, заполненных в json файлах на валидность.
В случае, если данные не валидны, возникнет исключение с описанием проблемы.
Если необходимо отключить проверку, то можно воспользоваться параметром плагина enableDictionaryDataCheck. По умолчанию
параметр имеет значение true.
Внимание!
Удаление справочника недопустимо, ни один справочник из предыдущей итерации (анализируется id) не должен исчезнуть.
Обновление справочных данных#
Справочные данные можно обновить. Разрешается обновлять все поля кроме id. Изменение id равноценно удалению справочных данных, что запрещено (см. выше блок "Внимание"). Для обновления данных рассчитывается дельта изменений и обновлению подвергаются лишь изменившиеся данные. Обновление осуществляется простым изменением текущих данных справочников.
Справочные материалы#
Структура файла объектной модели#
Файл модели включает в себя XML-элементы, заданные с помощью тегов. При разметке файла модели необходимо использовать следующие правила:
Все элементы модели заключаются между парой тегов
<model>.Для каждого класса использовать теги
<class>...</class>.Для свойств классов использовать теги
<property/>(единые).Индексируемые свойства дублируются между парой тегов
<index>...</index>.
Пример разметки файла модели:
<model>
<class label="Международные реквизиты счета" name="InternationalRequisites">
<property label="Номер счета" name="number" type="String"/>
<property label="Международный номер счета" name="iban" type="String"/>
<index unique="false">
<property name="number"/>
</index>
</class>
</model>
Теги#
Модель#
Файл модель должен быть заключен между парой тегов <model></model>. Для этого тега предусмотрен ряд атрибутов.
Обязательный атрибут: model-name — название расширения модели (используется при генерации новых артефактов).
Необязательные атрибуты:
component-code— код фабрики в пространстве SberWorks.МЕТА;version— версия модели;table-prefix— назначить таблицам, индексам и т.п. фабричный префикс. По умолчанию — нет значения (пусто);versioned-entities— включение оптимистичной блокировки сущностей для всех классов модели (по умолчанию — "false").
Примечание
Оптимистичная блокировка не всегда ведет себя предсказуемо. Если принято решение о ее применении, необходимо дополнительно указать параметру плагина генерации модели
enableVersionedEntitiesзначение "true". Дополнительно можно ознакомиться с материалом об аннотации Version в JPA.
Внутри тега <model> предусмотрены следующие элементы:
Классы объектов. Процесс агрегации модели сходен с процессом построения деревьев.
Перечисления (тип Enum).
Интерфейсы — для обеспечения возможности построения union запросов.
Импорты.
Объявления внешних типов.
Класс#
Для классов предметной области используется пара тегов <class></class>, которая может содержать следующие атрибуты:
Обязательный атрибут —
name(имя класса).Необязательные атрибуты:
extends— имя расширяемого класса (см. описание в подразделе "Наследование классов").label— пользовательское описание класса.is-abstract— объявление типа абстрактным (см. описание в подразделе "Наследование классов"). По умолчанию —false.strategy— стратегия наследования JPA-классов относительно физической реализации. По умолчанию — JOINED. Допустимо: SINGLE_TABLE.lockable— признак того, что к объекту применим функционал прикладных (пессимистических) блокировок. Допустим к установке только на базовых классах. Использование прикладных блокировок описано в разделе "Прикладные блокировки" в документе "Руководство прикладного разработчика".id-prefixed— стратегия генерации ID с заданным строковым префиксом (см. раздел "Стратегия генерации ID с заданным строковым префиксом" в документе "Руководство прикладного разработчика").
К именам классов предъявляются следующие требования:
Имя класса должно начинаться с заглавной буквы. Символы — латинские. Длина — не более 40 символов CamelCase по умолчанию, но может быть изменена (см. раздел "Генерация артефактов серверного компонента" документа "Структура артефактов DataSpace").
Зарезервированные имена классов: Status, Stakeholder, StatusGraph, BaseEntity.
Имена системных элементов БД зарезервированы. В случае совпадения имен свойств в теге
<property/>с зарезервированными именами, названия целевых колонок будут изменены. Например, если в model.xml определено свойство с именем "clob", то в БД под это свойство будет создана колонка "CLOB_". Полный список изменяемых имен можно посмотреть во вложенном файле reservedwords.xml.
Внутри тега <class></class> могут находиться следующие теги:
Теги свойств объектов.
Теги ссылок на внешние объекты.
Тег категории установки (определяет способ формирования id объектов).
Свойство#
Свойства объекта задаются с помощью тега <property/>.
Следующие атрибуты тега <property/> обязательные:
name— название свойства;type— тип свойства.
В качестве типов можно использовать примитивы DataSpace, специализированные типы, разработанные классы и перечисления.
К числу необязательных атрибутов относятся следующие позиции:
label— описание свойства.collection— тип коллекции. Допустимо: set (множество). По умолчанию считается, что свойство коллекцией не является.mappedBy— имя атрибута обратной ссылки (для создания связи OneToMany, OneToOne).parent— является дочерним по отношению к типу свойства. Данное свойство описывает дерево сущностей. Данное свойство ставится только на свойствах типа "ссылка из модели". По умолчаниюparent= "false".length— длина. Необязательная уточняющая настройка для типа String (по умолчанию — 254, максимальная длина — 4000, иначе — использовать поле типаCLOB) и BigDecimal (по умолчанию — 38). Для BigDecimal означает не масштабируемое значение.scale— масштаб. Уточняющая настройка для типа BigDecimal (по умолчанию — 10).mandatory— признак обязательности. По умолчанию — "false".index— признак индексирования свойства. По умолчанию — "false". Имеется возможность создавать комбинированные индексы (см. раздел "Добавление индекса").unique— признак уникальности свойства. При значенииunique = false— индекс не уникален(значение по умолчанию), при значенииunique = true— индекс уникален. Необходимо учитывать разное поведение БД при наличии NULL-значений в составе поля индекса (возможна ошибка нарушения уникальности).default-value— значение по умолчанию.mask— Java-совместимое регулярное выражение проверки значения. Атрибут применим с типом String. Пример можно найти в файле объектной модели.
Идентификатор (Id)#
В DataSpace для идентификаторов объектов можно задать способ формирования id. Для этого необходимо использовать пару тегов <class></class> и указать способ назначения id объектов с помощью атрибута category (категория установки).
Доступны следующие стратегии формирования id:
SNOWFLAKE: Id задается через алгоритм snowflake. Передача пользовательского id запрещена. Является значением по умолчанию.MANUAL: Id передается исключительно пользователем.AUTO_ON_EMPTY: Id может передаваться пользователем. Если пользователь не передал id, то id формируется алгоритмом snowflake.
Пример использования тега <id/>:
<class label="Базовый продукт клиента" name="Product">
<id category="MANUAL"/>
<property name="name" type="String" />
</class>
Генерация идентификатора алгоритмом SNOWFLAKE#
SNOWFLAKE — внутренний алгоритм, используется для обеспечения генерации уникального идентификатора в распределенной (децентрализованной) среде.
Генерируемый идентификатор представляет собой Long-представление восьмибайтового значения (Longs.fromByteArray(byte[])), определяемого по следующему алгоритму:
0-3 байты |
4 байт |
5 байт |
6-7 байты |
|---|---|---|---|
Монотонно возрастающая временная составляющая, 4 первых байта от |
Случайное число от -128 до 127. Можно определить фиксированное значение параметром |
Четвертый (по умолчанию) байт (октет) IPv4-адреса сетевого интерфейса. В случае наличия нескольких соответствующих IPv4-адресов происходит сортировка по данным адресам и выбор первого из них. Используемый номер октета можно определить параметром |
Последний и первый байт двухбайтового счетчика, если генерация нескольких значений в JVM идет в рамках одного временного интервала (первые 4 байта генерируемого значения) |
Примечание
Для уникальности генерации идентификаторов в распределенной системе (кластере) необходимо обеспечивать уникальность 4-го октета IPv4-адресов в рамках всего кластера экземпляров сервиса DataSpace.
Индекс#
Индексы в модели реализуются путем установки атрибута index на свойстве или описанием в отдельном теге <index> со ссылками на индексируемые свойства.
Примечание
Указание индекса на поле через тег
indexилиuniqueприводит к созданию индекса. Явное добавление индекса с этим полем приведет к дублированию.Дублирование индексов запрещено.
Порядок свойств в индексе имеет значение. Свойства должны строиться в последовательности от высокоселективного к низкоселективному.
Следующий фрагмент кода содержит пример комбинированного индекса:
<class label="Международные реквизиты счета" name="InternationalRequisites">
<property label="Номер счета" name="number" type="String"/>
<property label="Международный номер счета" name="iban" type="String"/>
<property label="SWIFT банка-получателя" name="swift" type="SwiftCodes"/>
<index unique="false">
<property name="number"/>
<property name="swift"/>
</index>
</class>
Изначально логика создания индексов следующая: если имеется несколько индексов, и среди них есть индексы, которые содержат одинаковые поля с одинаковой последовательностью, но отличаются количеством полей, то индексы с меньшим количеством полей являются избыточными, поскольку запрос в состоянии использовать индекс с большим количеством полей. Пример:
<class label="Международные реквизиты счета" name="InternationalRequisites">
<property label="Номер счета" name="number" type="String"/>
<property label="Международный номер счета" name="iban" type="String"/>
<property label="SWIFT банка-получателя" name="swift" type="SwiftCodes"/>
<index unique="false">
<property name="number"/>
<property name="swift"/>
</index>
<index>
<property name="number"/>
</index>
</class>
В примере выше присутствуют два индекса, при этом индекс с одним полем number — избыточен, поскольку имеется индекс с большим количеством полей number, swift, и соблюдается последовательность полей (первый — number). В этом случае индекс, состоящий только из поля number, создан не будет.
Если индекс с меньшим количеством полей уникальный, то он будет создаваться.
Примечание
Возможно отключить игнорирование избыточных индексов включением настройки плагина
generateAllIndices. При значенииtrueсоздадутся все индексы, определенные пользователем.
Индексирование коллекций внешних ссылок#
Для оптимизации выборки сущностей, коллекция внешних ссылок (reference) которых содержит ссылку на определенный объект, может понадобиться создание дополнительного индекса по идентификатору сущности в коллекции.
Индекс можно указать как на элементе reference через атрибут index или создав отдельный элемент индекса.
Индекс будет создан на вспомогательной служебной таблице, связывающей ссылки и таблицу владельца коллекции, по полю entityId.
Поля коллекции внешних ссылок (reference) не могут участвовать в составном индексе.
Пример:
<class name="SomeClass">
<reference name="clients" type="Client" collection="set"/>
<reference name="documents" type="Document" collection="set" index="true"/>
<index>
<property name="clients"/>
</index>
</class>
Разметка приведет к созданию индексов на столбец REFERENCE_ENTITYID для служебных таблиц T_RCISOMECLASSDOCUMENTS и T_RCISOMECLASSCLIENTS.
Внешние ссылки#
Внешняя ссылка — ссылка на класс внешней системы или класс другого агрегата модели потребителя.
Типы внешних ссылок:
Ссылка на объект во внешней системе:
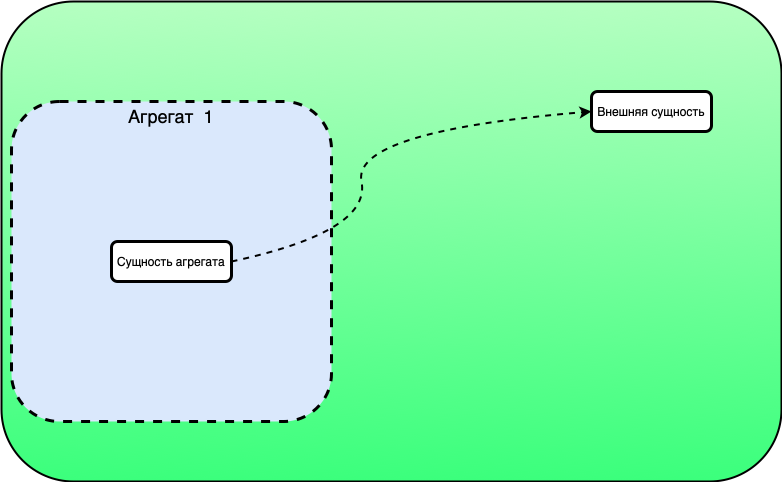
Типом ссылки является класс, не принадлежащий модели потребителя.
Ссылка на корень агрегата:
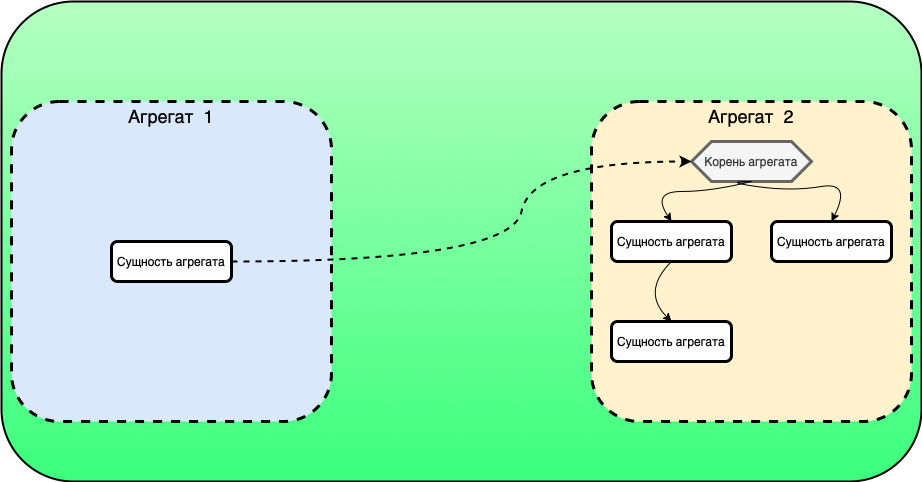
Типом ссылки является класс — корень агрегата
Ссылка на некорневую сущность агрегата:
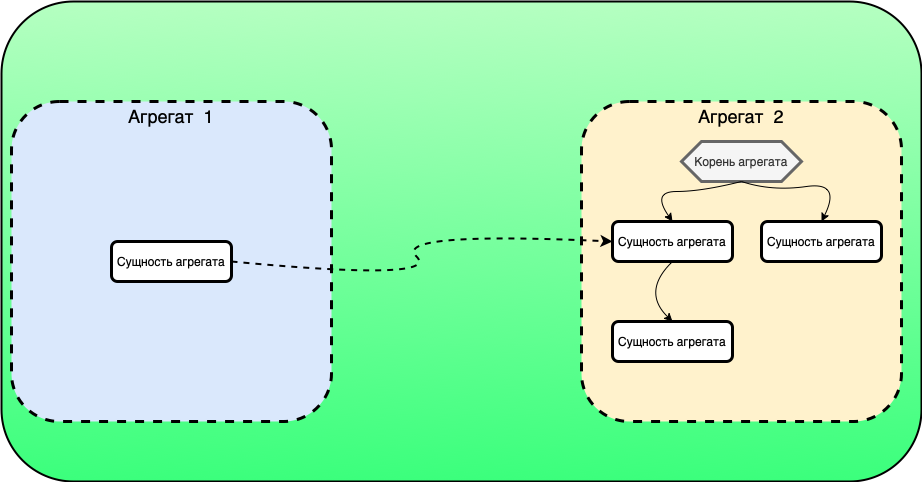
Типом ссылки является класс подчиненный корню агрегата.
Все типы ссылок на внешние объекты задаются с помощью тега <reference/>.
Следующие атрибуты тега <reference/> обязательны:
name— название свойства.type— тип ссылки (класс из модели или внешней системы).
К необязательным атрибутам тега относятся следующие позиции:
label— описание свойства.collection— тип коллекции. Допустимо:set(множество). По умолчанию считается, что свойство коллекцией не является.integrity-check— логический атрибут, определяющий необходимость проверки целостности ссылки. Атрибут применим только с типами модели. Проверка выполняется при заполнении объекта, содержащего внешнюю ссылку. Оба объекта должны быть расположены в одном шарде. При установке параметра dataspace-core.integrity-check.delete=true дополнительно выполняется проверка при удалении объекта ссылки. Важно отметить, что контроль на удаление является дополнительной нагрузкой на модуль.
Перечисления (enum)#
Перечисления (тип enum) можно использовать в качестве типы атрибута. Enum — набор зафиксированных статических переменных.
Перечисление можно расширить полями расширения.
Примечание
Все значения одного перечисления должны включать в себя единый набор расширений.
Пример типа enum показан в следующем фрагменте кода:
<enum name="Size">
<value name="S">
<extension name="rus" value="44"/>
<extension name="uk" value="small"/>
</value>
<value name="M">
<extension name="rus" value="46"/>
<extension name="uk" value="medium"/>
</value>
</enum>
Атрибуты тега <enum>:
name— имя класса-перечислителя (обязательное поле), в котором:символы — латинские;
длина не должна превышать 40 символов (по умолчанию, но может быть изменена, см. раздел "Генерация артефактов серверного компонента" документа "Структура артефактов DataSpace");
наименование — в стиле CamelCase;
label— описание enum-класса.
Атрибуты тега <value>:
name— имя перечисляемого значения (обязательное поле), в котором:имя свойства полностью заглавными буквами;
длина — не более 40 символов (по умолчанию, но может быть изменена, см. раздел "Генерация артефактов серверного компонента" документа "Структура артефактов DataSpace");
символы — латинские, цифры и нижнее подчеркивание;
label— краткое описание значения;description— полное описание значения.
Атрибуты тега <extension>:
name— имя расширения (обязательное поле);value— значение для расширения (обязательное поле, значение строковое).
Пример использования значений по умолчанию для enum показан во фрагменте кода ниже:
<enum name="size">
<value name="s"/>
<value name="m"/>
<value name="l"/>
<value name="xl"/>
</enum>
<class name="Product">
<property name="size" type="size" default-value="m"/>
...
</class>
Импорты#
Тег <import> позволяет менять конфигурацию ресурсов предметных моделей, задавать дополнительные опции их использования и импортировать ресурсы из сгенерированных Java-артефактов.
Тег необходимо включать в файл предметной модели (model.xml).
В примере ниже тег <import> подключает файл статусной модели с путем по умолчанию:
<model>
<import type="STATUS"/>
</model>
У тега имеется один обязательный атрибут: параметр "тип" (type="ТИП_ПАРАМЕТРА").
DataSpace поддерживает следующие типы импортируемых ресурсов предметной модели:
расширений модели;
статусной модели;
генератора словарей.
<import type="IMPORT"/>
Подробную информацию о способах дробления модели на файлы можно найти в разделе "Расширение модели".
<import type="STATUS"/>
Подробную информацию об использовании статусов можно найти в разделе "Управление статусами".
Если справочники расположены не в папке по умолчанию (model/dictionary), необходимо использовать выражение импорта с типом "DICTIONARY_GENERATOR" и путем к папке с файлами справочников.
<import type="DICTIONARY_GENERATOR" file="./dictionaryFolder"/>
Сведения о способах использования локальных справочников можно найти в разделе "Работа с локальными справочниками".
В дополнение к импорту ресурсов предметной модели продукт поддерживает импорт технических ресурсов (например, библиотек репликации).
<import type="CLOUD-RELOCATION"/>
Структура файла статусов#
Файл с описанием статусов должен называться status.xml и должен находиться в той же папке, что и файл с описанием модели.
Файл должен использовать следующую иерархию тегов:
<status>
<status-classes>
<stakeholder>
<statuses>
<stakeholder-link>
<status>
<to>
Теги перечислены в таблице:
Tег |
Описание |
|---|---|
|
Корневой тег, без атрибутов |
|
Тег с вложенным элементом для каждого класса со статусами |
|
Тег для наблюдателя за статусами. Одно значения для каждого класса |
|
Тег группы статусов, одна единица на каждый класс со статусами |
|
Код наблюдателя в теге |
|
Тег для каждого из статусов рассматриваемого класса |
Таблица ниже содержит описание тегов и атрибутов:
Тег |
Атрибут |
Описание |
Обязательность (Y/N) |
|---|---|---|---|
|
class |
Имя класса, для которого необходимо определить статусы |
Y |
|
code |
Код наблюдателя |
Y |
|
name |
Имя наблюдателя |
Y |
|
class |
Имя класса, для которого необходимо определить статусы |
Y |
|
historical |
Признак хранения истории изменения статусов (см. раздел "О сохранении истории изменения статусов") |
N |
|
code |
Код наблюдателя в теге |
Y |
|
code |
Код статуса |
Y |
|
name |
Название статуса |
Y |
|
initial |
Признак начального статуса |
N |
|
— |
Тег для каждого возможного перехода |
— |
|
status |
Статус после перехода |
Y |
Пример файла со статусами объектов включен в состав документации.
Примечание
При использовании DataSpace Java SDK коды статусов используются в upperCase, так как реализованы в виде enum. Исходное значение статуса, указанное в статусной модели, можно получить путем вызова метода
getValue(). Например:ProductPartyPlatformStatus.PRODUCTCREATED.getValue(). С подробной инструкцией по использованию DataSpace Java SDK можно ознакомиться в документе "Руководство прикладного разработчика".При использовании протоколов GraphQL или JSON-RPC коды используются в том формате, в котором заданы в статусной модели.
Примечание
Атрибут
initialявляется условно-опциональным, поскольку определяется автоматически.
Вычисление начального статуса происходит по следующей схеме:
Найти все статусы для конкретного наблюдателя (stakeholder-link) в классе (statuses/class), на которые никто не ссылается.
Начальный статус должен быть один, в противном случае возникнет исключение. Тогда необходимо определить начальный статус (пометить нужный статус атрибутом
initial="true").
Указанный вручную или вычисленный автоматически статус с признаком initial будет устанавливаться, если при создании сущности не указать статус. В противном случае будет установлен переданный статус. Статусная библиотека без начального статуса не может работать.
Примитивные типы#
Таблица содержит список примитивных типов, и их соответствие примитивам языка Java и размерностям полей БД:
Тип в xml (model.xml) |
Параметры типа |
Коллекционный |
Тип в терминах Java |
Тип в Liquibase |
Тип в БД Oracle |
Тип в БД PostgreSQL |
Совместимые изменения |
|---|---|---|---|---|---|---|---|
String, string |
length — максимальная длина строки в байтах. По умолчанию — 254. Допустимые значения — от 1 до 4000 включительно |
v |
|
|
|
|
Увеличение length. Перевод в UnicodeString (при условии ограничения length в 2000) |
UnicodeString, unicodestring |
length — максимальная длина строки в символах. По умолчанию — 254. Допустимые значения — от 1 до 2000 включительно |
v |
|
|
|
|
Увеличение length. Перевод в String (при увеличении length минимум в 2 раза) |
Text, text |
x |
|
|
|
|
||
BigDecimal, bigdecimal, Decimal, decimal |
length — количество отводимых под число символов (значащих цифр, включая знаки после запятой, при этом десятичный разделитель и знак минуса не учитываются). Допустимые значения length — от 1 до 38. По умолчанию — 38. scale — количество знаков после запятой. Допустимые значения scale — от 0 до (length — 1). По умолчанию — 10 |
v |
|
|
|
|
Увеличение length, scale |
Integer, int, integer |
v |
|
|
|
|
||
Short, short |
v |
|
|
|
|
||
Long, long |
v |
|
|
|
|
||
Byte, byte |
v |
|
|
|
|
||
Boolean, bool, boolean |
x |
|
|
|
|
||
Character, char, character |
v |
|
|
|
|
||
Date, date |
v |
|
|
|
|
||
LocalDate, localDate |
v |
|
|
|
|
||
LocalDateTime, localDateTime |
length — точность, определяющая, сколько знаков после запятой должно сохраняться в секундах. По умолчанию — 3. Допустимое значение — от 0 до 6 включительно |
v |
|
|
|
|
Увеличение length. Перевод из Date |
OffsetDateTime, offsetDateTime |
length — точность, определяющая, сколько знаков после запятой должно сохраняться в секундах. По умолчанию — 3. Допустимое значение — от 0 до 6 включительно |
v |
|
|
|
|
|
Float, float |
v |
|
|
|
|
||
Double, double |
v |
|
|
|
|
||
Binary, binary, byte[] |
x |
|
|
|
|
Примечание
Для типа OffsetDateTime время сохраняется в UTC для PostgeSQL и в локальной зоне для Oracle. Вычитывается время всегда в UTC.
Значение свойств по умолчанию#
Чтобы не дублировать начальные значения при создании объекта, необходимо определять значения по умолчанию. Для этого необходимо указывать атрибут default-value. Поддерживаются значения по умолчанию для примитивов и enum-классов, как показано в таблице:
Тип примитива |
Допустимые значения |
Пример |
|---|---|---|
BigDecimal |
Рациональные числа (дроби не допускаются) |
|
Boolean |
|
|
Byte |
Целые числа |
|
Date |
В формате |
|
Double |
Рациональные числа (дроби не допускаются) |
|
Float |
Рациональные числа (дроби не допускаются) |
|
Integer |
Целые числа |
|
LocalDate |
now |
|
LocalDateTime |
now |
|
Long |
Целые числа |
|
OffsetDateTime |
now |
|
Short |
Целые числа |
|
String |
Набор символов |
|
Text |
|
Примечание
При вставке пустых строк в качестве значения по умолчанию серверы БД ведут себя по-разному. Поэтому вне зависимости от БД, DataSpace интерпретирует вставку пустой строки в качестве значения по умолчанию как null-величину.
Примечание
При использовании значения
nowдля значения по умолчанию дат, конечное значение даты и времени зависит от времени окружения, на котором развернуто приложениеdataspace-core.
Примечание
При чтении поля типа OffsetDateTime время возвращается в UTC-формате.
Специализация примитивных полей#
В DataSpace можно использовать специализированные типы, производные из стандартных примитивов DataSpace.
Для использования специализированных типов в model.txt необходимо описать блок <type-defs></type-defs>. Пользовательские новые типы необходимо использовать в значении поля type свойства (property) в классе (class).
Структура type-defs показана во фрагменте ниже:
<type-defs>
<type-def>
* name — имя производного типа (обязательно).
* type — оригинальный примитивный тип DataSpace (обязательно).
* length — длина (доступно для String и BigDecimal).
* scale — масштаб (доступно для BigDecimal).
Заданная длина и масштаб будет устанавливаться только в том случае, если пользователь явно не переопределил аналогичное свойство на классе. При этом:
Для типа
Stringимеется возможность задания свойстваlength. По умолчанию — 254.Для типа
BigDecimalпомимоlengthможно указыватьscale. По умолчаниюlength = 38,scale= 10.Остальные типы не поддерживают
lengthиscale.
Пример использования для типа String и BigDecimal:
<type-defs>
<type-def length="12" name="ShortString" type="String"/>
<type-def length="12" name="ShortBigDecimal" scale="2" type="BigDecimal"/>
<type-def name="Position" type="Boolean"/>
</type-defs>
<class label="продукт" name="Product">
<property name="string" type="String"/> <!-- в итоге будет длина 254-->
<property name="shString" type="ShortString"/> <!-- в итоге будет длина 12-->
<property length="44" name="shString2" type="ShortString"/> <!-- в итоге будет длина 44-->
<property name="bigDecimal" type="BigDecimal"/> <!-- в итоге будет длина 38 масштаб 10-->
<property length="7" name="shortBigDecimal" type="ShortBigDecimal"/> <!-- в итоге будет длина 7 масштаб 2-->
<!-- Другие свойства... -->
</class>
Валидация значений строковых свойств при помощи регулярных выражений#
Для того чтобы наложить ограничение на формат значений для конкретного свойства, необходимо задать для него атрибут mask.
В качестве значения для атрибута mask выступает строка, содержащая регулярное выражение, формат которого должен соответствовать
спецификации, определенной языком Java.
<class name="MaskTesting">
<property name="ipAddress" type="String" mask="^[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$"/>
</class>
@Test
public void maskTest() {
Packet successPacket = new Packet();
successPacket.maskTesting.create(param ->
param.setIpAddress("192.168.0.1"));
org.assertj.core.api.Assertions.assertThatCode(() -> dataspaceCorePacketClient.execute(successPacket)).doesNotThrowAnyException();
Packet failedPacket = new Packet();
failedPacket.maskTesting.create(param ->
param.setIpAddress("192.2141.0.211"));
org.assertj.core.api.Assertions.assertThatCode(() -> dataspaceCorePacketClient.execute(failedPacket))
.isInstanceOf(MaskNotMatchException.class)
.hasMessageContaining(
"должно соответствовать \"^[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}$\"");
}
Типы классов#
Абстрактные классы#
С помощью DataSpace можно моделировать абстрактные классы. После обработки модели на основе модели абстрактного класса будет сформирован абстрактный класс Java, который может наследовать у других классов, и выступать предком, но не может инициализировать сущности.
Для добавления абстрактного класса в модель необходимо использовать тег <class></class> с признаком is-abstract="true". В примере ниже абстрактный класс AbstractDeposit наследует у класса Product и выступает предком класса Deposit.
<class name="Product">
</class>
<class name="AbstractDeposit" extends="Product" is-abstract="true">
</class>
<class name="Deposit" extends="AbstractDeposit">
</class>
Внимание!
Ссылки на абстрактные классы (типа
<property type="*AbstractClass*"/>) недопустимы! Ограничения связаны с невозможностью определения конкретной сущности на физическом уровне (абстрактный класс не может порождать сущности и таблицы баз данных).
Интерфейсы#
С помощью DataSpace можно моделировать Java-интерфейсы рабочих артефактов.
После обработки модели на основе созданного будет сформирован интерфейс Java, который можно реализовать в объектных классах Java.
Для моделирования интерфейса необходимо использовать тег <interface></interface>, как показано в примере ниже:
<interface name="WithCodeAndName">
<property name="code" type="String"/>
<property name="name" type="String"/>
</interface>
Для реализации интерфейса в классах необходимо использовать атрибут implements:
<class name="Product" label="Базовый продукт клиента" lockable="true" implements="WithCodeAndName">
<property name="code" type="String" label="код"/>
<property name="name" type="String" label="имя"/>
...
</class>
Перечисления (enum)#
С помощью DataSpace можно моделировать перечисления (тип enum), включающие в себя список значений. Перечисления можно использовать для моделирования справочников и некоторых других структур Java.
После обработки модели на основе созданного перечисления будет сформировано перечисление Java.
Для создания перечисления необходимо использовать тег <enum></enum>, как показано в примере ниже. Внутри тега <enum> необходимо указать возможные значения параметра (теги <value/>).
Перечисленные значения можно расширить с помощью тега <extension/>.
<enum name="Size">
<value name="S">
<extension name="rus" value="44"/>
<extension name="uk" value="small"/>
</value>
<value name="M">
<extension name="rus" value="46"/>
<extension name="uk" value="medium"/>
</value>
</enum>
Финальные классы#
С помощью DataSpace можно создавать финальные классы. После обработки модели на основе созданного будет сформирован финальный класс Java.
Для моделирования финального класса необходимо использовать атрибут final-class, как показано в примере:
<class name="TestEntity" label="Тестовая сущность" final-class="true">
<!-- ... -->
</class>
DDD-агрегаты#
В первых версиях DataSpace единственным агрегатом выступал "Клиент". Сущность была жестко зафиксирована на уровне Корпоративной Модели Данных ("клиентоцентричная" модель). Такой подход порождал ограничения на разделение бизнес-сущностей.
В новом поколении Платформы это ограничение снято, предоставляя пользователю возможность самостоятельно определять границы агрегатов разрабатываемой модели: выделение продукта клиента в отдельный агрегат и т.п.
Общие сведения о способах использования агрегатов можно найти в следующих англоязычных статьях на сторонних ресурсах:
DDD_Aggregate (Мартин Фаулер).
Aggregates in Domain Driven Design (Chen Chen, Medium).
Концепция разделения модели на агрегаты накладывает следующее ограничение: транзакция (оптимистичные блокировки, выполнение пакета команд (UnitOfWork)) по умолчанию возможна только в рамках одного экземпляра агрегата. Имеется возможность разрешить исполнение транзакций, затрагивающих данные нескольких агрегатов. Описание правил транзакционности внутри пакета команд доступно в разделе "Транзакционная граница пакета" в документе "Руководство прикладного разработчика".
Правильное деление модели данных на агрегаты предоставляет следующие возможности:
Поддержка транзакции в рамках агрегата посредством оптимистичной блокировки. См. соответствующий раздел в документе "Руководство прикладного разработчика".
Поддержка согласованной репликации транзакций через Прикладной журнал: резервирование в StandIn, интеграция с Корпоративной Аналитической Платформой. Как следствие, возможность "быстрого" перехода на резервный контур достигается за счет обеспечения системных (скрытых от пользователя) блокировок на уровне агрегата.
После "быстрого" переключения на резервный источник допускается, что не все транзакции на изменение по агрегату реплицированы. В то же время система не даст осуществить транзакцию за счет скрытой от пользователя системной блокировки, ожидая, пока произойдет синхронизация состояния, актуального тому, которое имело место на первичном контуре до начала перехода.
Данный подход открывает большие возможности в достижении таких показателей системы, как "Надежность" (99.99…) и "Доступность" (24/7).Возможность переноса групп объектов между шардами (зонами). Это в свою очередь предоставляет следующие возможности:
горизонтальное масштабирование: распределение БД на несколько независимых физических серверов и ребалансировка данных между ними;
возможность выделения части прикладных объектов (агрегатов) в зону greenfield, возврат в промышленную зону.
Разделение/слияние агрегатов, обусловленные требованиями логики проектируемого приложения, например:
дедубликация клиентов: слияние клиентских данных, обусловленное нахождением дублей клиентов для нормализации;
передача части бизнес-объектов от одного владельца другому (продажа продукта в связи с банкротством, факторинг и т.п.).
Условия при разметке#
При разметке агрегатов необходимо учитывать следующие обстоятельства:
Агрегаты строятся (связываются) на базовых классах (класс, который не имеет предка или вся цепочка классов-предков — абстрактные классы).
"Корень" должен иметь коллекцию "листьев" или ссылку на "объект-листы" с атрибутом
mappedBy(связь OneToMany или OneToOne соответственно)."Лист" должен иметь свойство, имя которого указано в mappedBy "корня".
На "листе" необходимо добавить атрибут
parent="true". Этот маркер добавит объект в дерево агрегата.Добавление связи наследования (
extends="<SomeClassName>") к агрегату порождает еще один агрегат типа дочернего класса. Классы агрегата дочернего класса не являются членам агрегата класса предка. Связь между таким классами необходимо формировать внешними ссылками.
Пример перехода от клиентоцентричной модели к продуктоцентричной (на примере сущностей КМД)#
В примере на рисунке ниже мы видим, что все сущности принадлежат одному Клиенту(555), но поле AggregateRoot заполняется на основе идентификатора Агрегирующей сущности.
Каждый цвет — независимый агрегат, который может изменить клиента или находиться в другом шарде.
Ссылки из агрегатов других сущностей могут быть лишь в виде однонаправленных SoftReference (как показано в примере ContractProduct -> ProductPart), или в виде однонаправленных ComplexSoftReference для возможности ссылаться на дочерний объект агрегата. При этом в данной ссылке указывается и корневая сущность агрегата (как показано на примере TariffList -> ProductRegister).
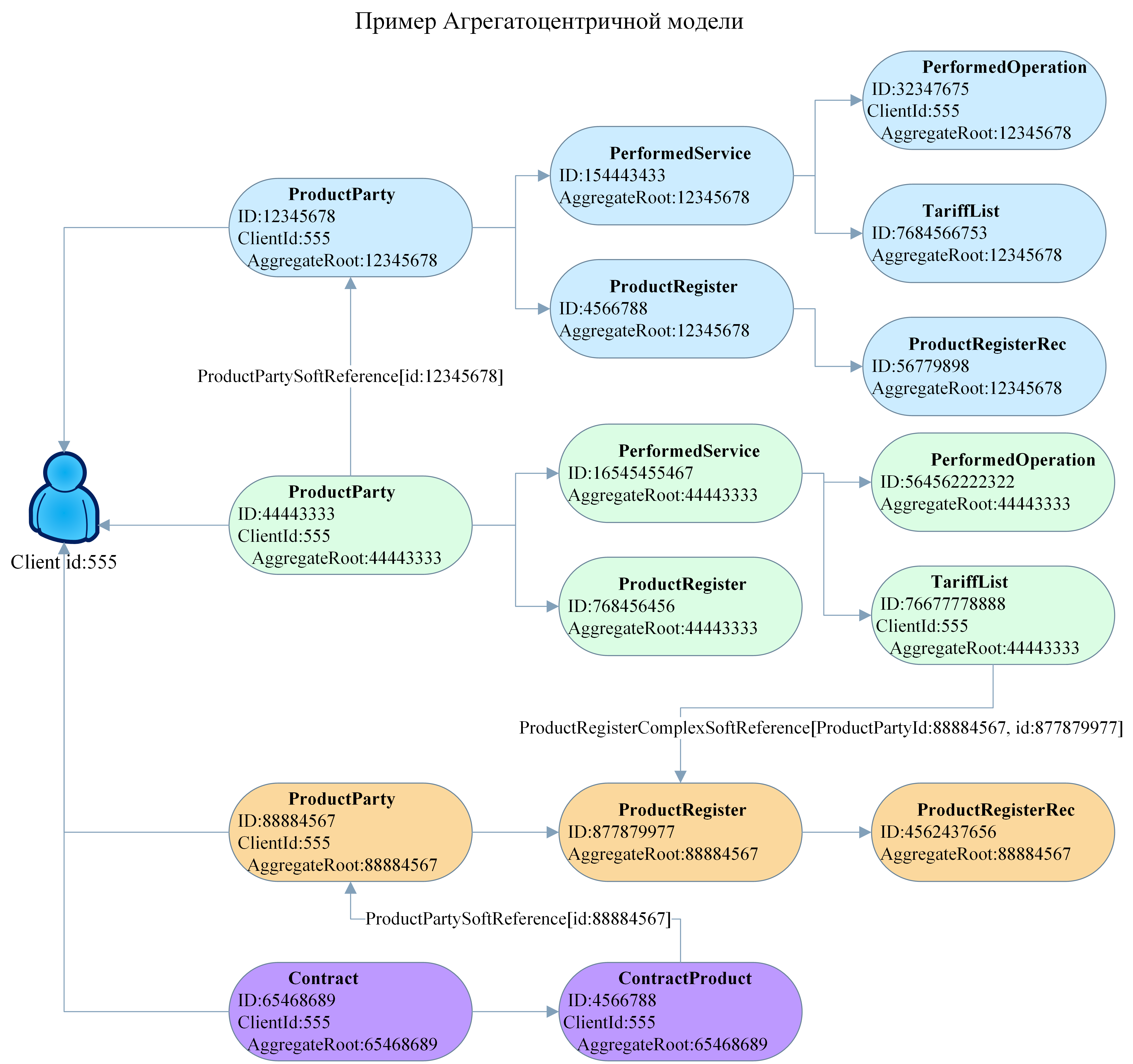
Связи OneToMany и ManyToOne#
Сущность 1 может иметь связь с неограниченным числом Сущностей 2, например, в случае связи Product: Client (1 — *).
Для обоих классов необходимо указать связанную сущность как параметр. В дополнение к этому, необходимо указать множественную связь: collection="set" mappedBy="{имяОбратнойСсылки}".
<class name="Product">
<property name="client" type="Client" parent="true"/>
</class>
<class name="Client">
<property name="products" type="Product"
collection="set" mappedBy="client"/>
</class>
Связь OneToOne#
Для обоих классов необходимо указать связанную сущность как параметр. Один из параметров необходимо указать как родительский (parent="true"), для второго необходимо указать обратную ссылку (mappedBy="client").
<class name="Product">
<property name="client" type="Client" parent="true"/>
</class>
<class name="Client">
<property name="product" type="Product"
mappedBy="client"/>
</class>
Пример центрирования агрегата#
Код ниже — пример задания отношений между сущностями. Код показывает, как и относительно каких классов возникает центрирование в обновленной версии DataSpace:
<class name="Product">
<property name="productLink" type="ProductLink" mappedBy="product"/>
<property name="service" type="Service" mappedBy="product"/>
</class>
<class name="ProductLink">
<property name="product" type="Product" parent="true"/>
</class>
<class name="Service">
<property name="product" type="Product" parent="true"/>
<property name="operation" type="Operation"
mappedBy="service"/>
</class>
<class name="Operation">
<property name="service" type="Service" parent="true"/>
</class>
<class name="Document">
<property name="subscriber" type="Subscriber"
mappedBy="document"/>
</class>
<class name="Subscriber">
<property name="document" type="Document" parent="true"/>
</class>
Диаграмма управления |
Центричность модели |
|---|---|
|
|
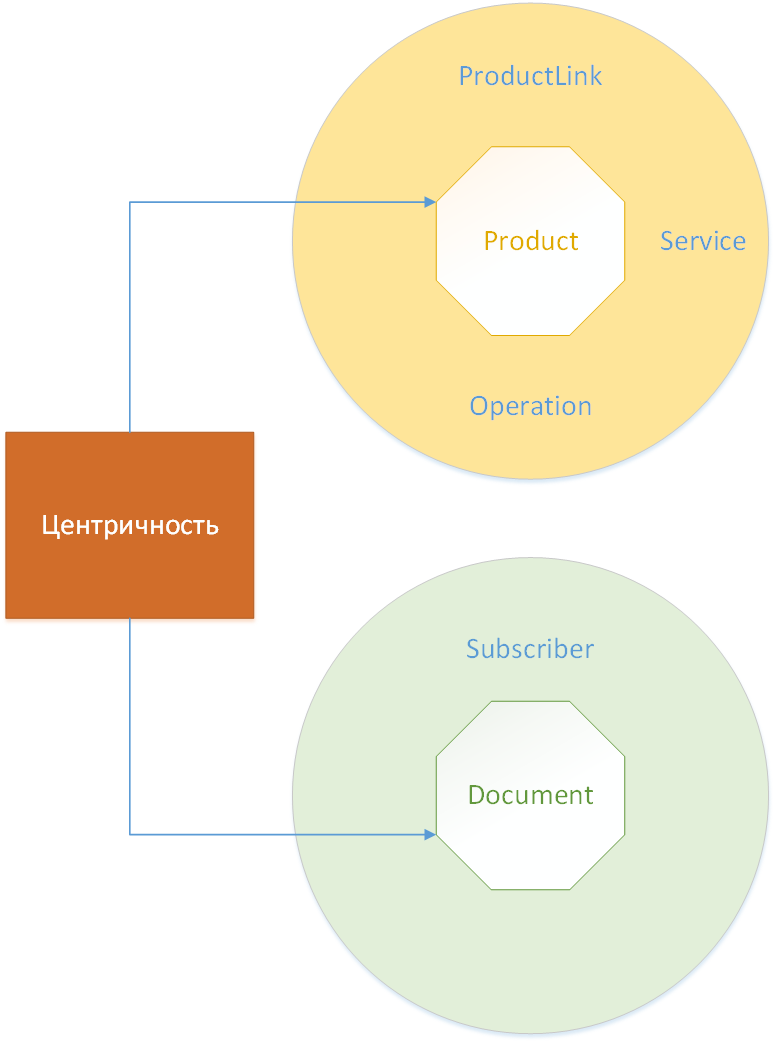
Пример клиентоцентричной модели агрегатов#
В коде ниже показан пример клиентоцентричной модели агрегата:
<class name="Client" label="клиент">
<property name="products" type="ProductParty" collection="set" mappedBy="client"
label="Коллекция продуктов"/>
<property name="contract" type="Contract" collection="set" mappedBy="client"
label="Коллекция контрактов"/>
</class>
<class name="Contract" label="Контракт">
<property name="client" type="Client" parent="true" label="клиент"/>
<property name="name" type="String" label="имя"/>
</class>
<class name="ProductParty" label="Базовый продукт клиента">
<property name="series" type="String" label="Серии"/>
<property name="client" type="Client" parent="true" label="клиент"/>
<property name="performedServices" type="PerformedService" collection="set"
mappedBy="product" label="Коллекция сервисов"/>
</class>
<class name="PerformedOperation" label="Фактическая операция">
<property name="service" type="PerformedService" parent="true" label="сервис"/>
<property name="name" type="String" label="имя"/>
</class>
<class name="PerformedService" label="Исполняемый сервис">
<property name="code" type="String" label="код"/>
<property name="performedOperations" type="PerformedOperation" collection="set"
mappedBy="service" label="операции"/>
<property name="product" type="ProductParty" label="продукт" parent="true"/>
<property name="states" type="String" collection="set" label="состояния"/>
</class>
Модель в виде дерева показана на изображении ниже:
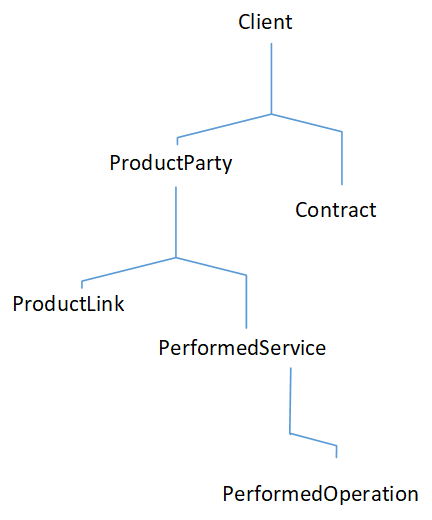
Использование внешних ссылок#
При описании модели с учетом агрегатов могут возникнуть следующие вопросы:
Как использовать ссылку на сущность из других агрегатов?
Каким образом получить ссылку на объект из внешней системы?
Для решения этих вопросов реализован тег <reference>, который позволяет хранить только ссылку на объект. Свойство внешней ссылки является индексируемым.
Примечание
Если объект не является корнем в агрегатной модели, то внешняя ссылка состоит из двух параметров: ссылка на корень агрегата и ссылка на сам объект.
Вне зависимости от выбранного способа представления внешних ссылок для коллекций создается новая сущность с суффиксом Reference для хранения внешней ссылки.
Таким образом, существуют следующие способы описания внешних ссылок:
Базовая модель из двух агрегатов.
Ссылка на корень агрегата.
Ссылка на дочерний объект агрегата.
Ссылка на внешний объект.
Базовая модель из двух агрегатов#
Базовая модель включает в себя два агрегата:
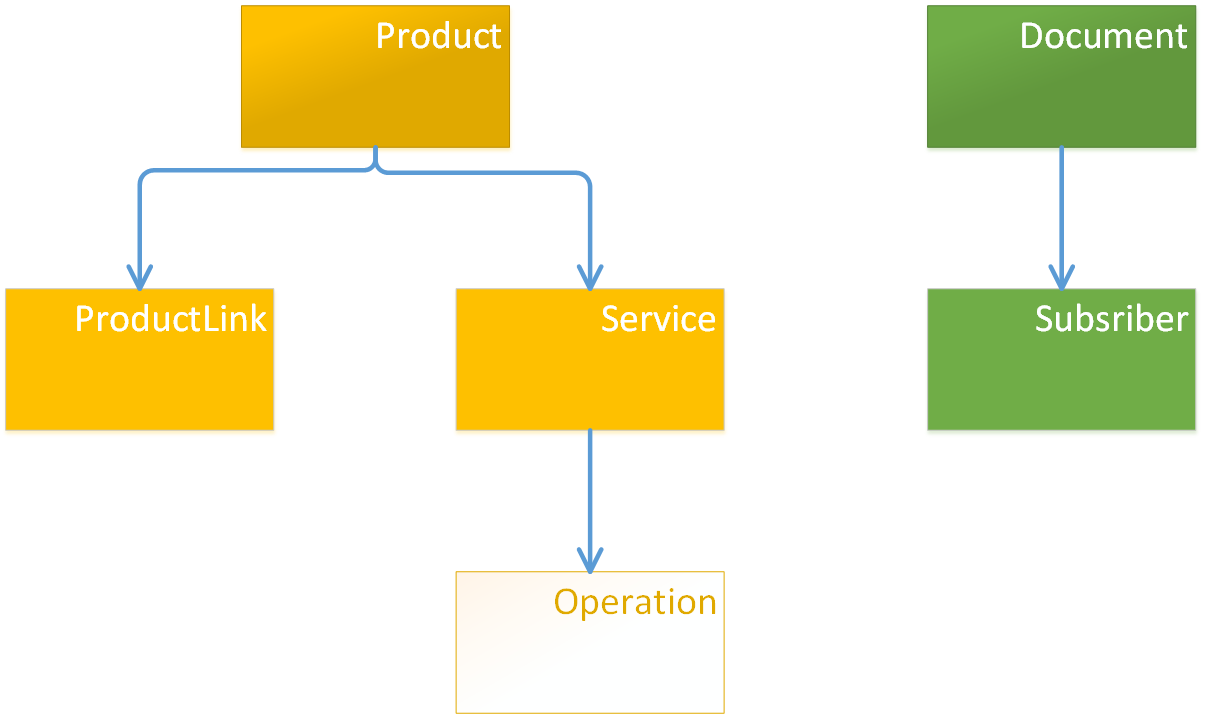
Ссылка на корень агрегата#
Пример кода со ссылкой на корень агрегата содержится во фрагменте кода ниже:
...
<class name="Service">
<reference name="document" type="Document"/>
...
</class>
...
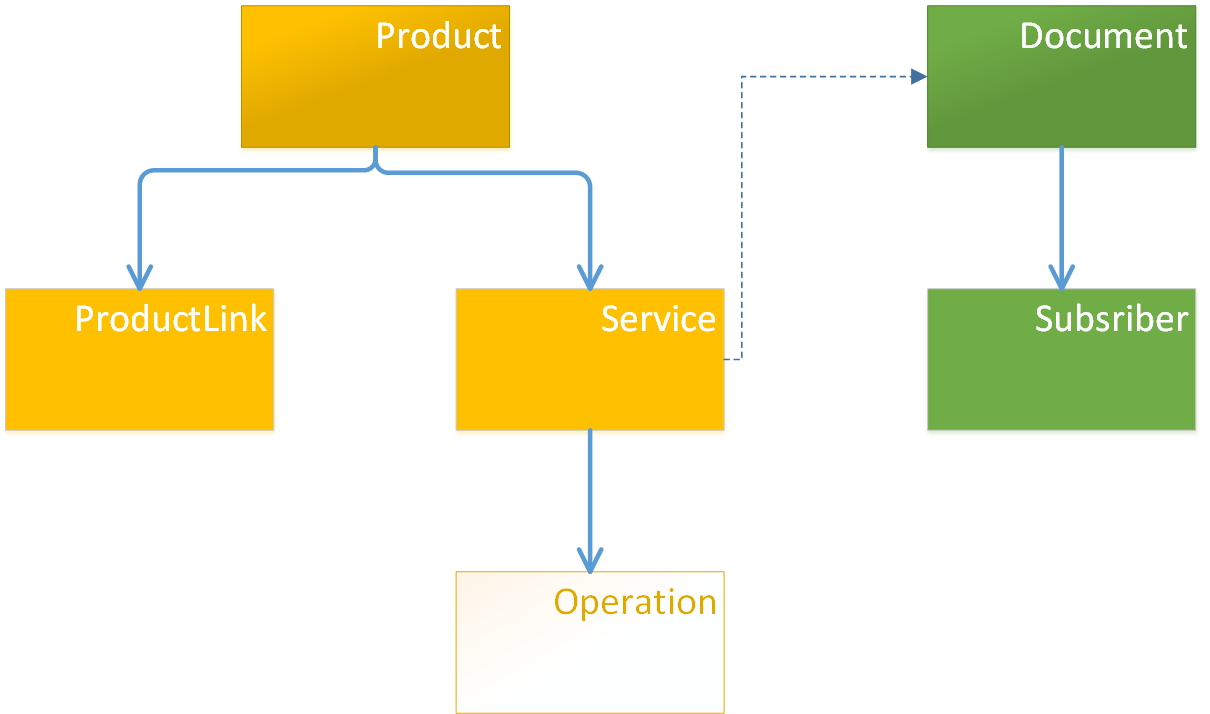
Ссылка на дочерний объект агрегата#
Пример ссылки на дочерний объект агрегата можно найти во фрагменте кода ниже:
...
<class name="Service">
<reference name="subscriber" type="Subscriber"/>
</class>
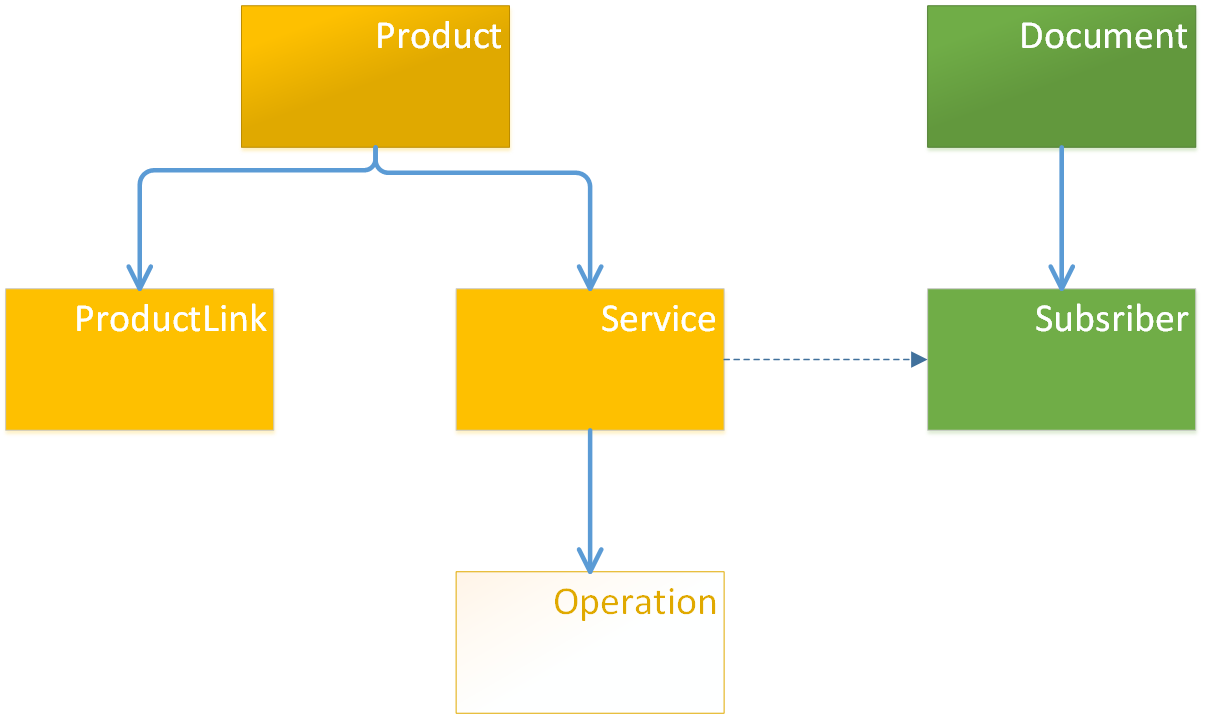
Ссылка на внешний объект#
Пример кода со ссылкой на внешний объект можно найти во фрагменте кода ниже:
...
<class name="Service">
<reference name="client" type="Client"/>
</class>
...
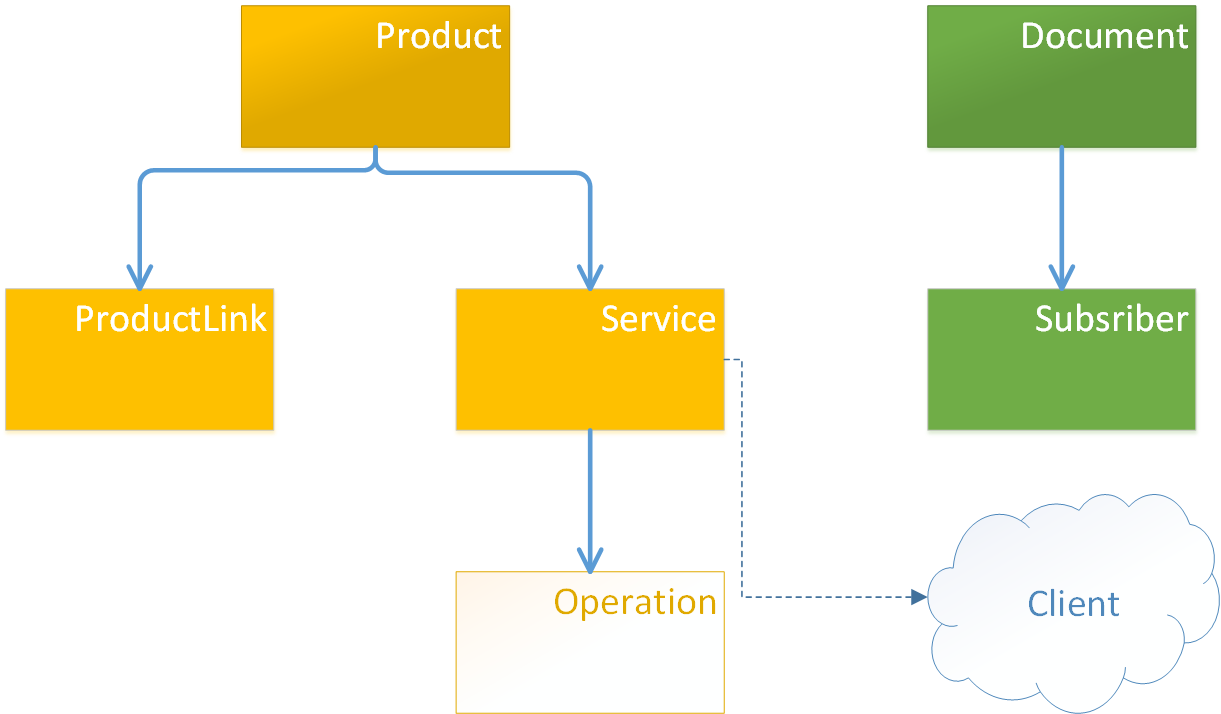
Процесс версионирования модели#
Внимание!
Версионирование модели построено на анализе содержимого каталога model. Поэтому содержимое данного каталога изменять не рекомендуется, в противном случае процесс версионирования нарушится!
Процесс версионирования модели отличается для выпуска релизных и тестовых (SNAPSHOT) версий модели.
Выпуск релизной версии модели#
После успешного релиза модели происходит фиксации версии.
В результате фиксации версии файлы changelog.xml, pdm.xml и ряд других системных файлов будут помещены в папку model рядом с файлом model.xml. Все последующие версии модели будут выпускаться с учетом обновленного содержания папки model. При генерации происходит сравнение моделей по содержимому файлов model.xml и pdm.xml.
В pdm.xml складывается из предыдущего состояния модели с учетом изменений в model.xml.
В changelog.xml попадает информация по изменению схемы объектов БД (добавляется в конец).
В случае удаления pdm.xml генератор будет считать, что модель не имеет предыдущего состояния. Соответственно, в changelog.xml будет добавлена информация о генерации всех объектов модели из model.xml, т.к. генератор не сможет посчитать разницу между релизами.
В случае удаления changelog.xml в changelog.xml добавится информация о генерации новых объектов БД. Информации об объектах из предыдущих релизов будет утрачена (changelog.xml будет содержать только разницу между текущим и предыдущим релизом).
В случае удаления и changelog.xml, и pdm.xml модель будет расцениваться как новая.
Выпуск тестовой (SNAPSHOT) версии модели#
В отличие от релизной версии версия SNAPSHOT не изменяет содержимое папки model. Соответственно, информация об изменениях, выполненных в текущем релизе, не сохраняется.
Если информация об изменениях в текущем релизе не сохранится, могут возникнуть проблемы версионирования.
Пример возможной проблемы и ее решения
Был выпущен снимок, в котором была добавлена таблица. Затем был произведен накат данных изменений на БД с помощью Liquibase.
Разработчик принимает решение добавить в эту таблицу еще одно поле, не фиксируя предыдущее состояние таблицы выпуском релизной версии, а выпуская еще один snapshot.
Так как генератор не знает, что таблица была выпущена ранее, он еще раз генерирует Liquibase-скрипт создания таблицы, который уже будет включать в себя новое поле.
При очередном накате этот скрипт не применится, т.к. у скрипта установлено условие — не выполняться, если такая таблица уже существует в БД.
Таким образом, поле добавлено не будет.
Для корректного добавления поля в этом примере необходимо либо очистить БД и выполнить полный скрипт наката еще раз, либо откатить изменения — сделать rollback последних изменений при помощи используемого pipeline или же вручную (см. раздел "Ручной откат с помощью Liquibase" в документе "Руководство по установке"). Чтобы такой проблемы не возникло, необходимо было зафиксировать первоначальное создание таблицы путем выпуска релизной версии модели, и затем добавить требуемое поле.
Требования к модели для ReferenceUpdater#
Для работы сервиса ReferenceUpdater требуется выделить ссылочные атрибуты (reference) в модели, которые будут обрабатываться при работе сервиса ReferenceUpdater.
Пример описания класса со ссылками на Клиента ЕПК:
<class name="Product" label="Продукт" lockable="true">
<property name="name" type="String" label="Наименование"/>
<!-- клиентская ссылка -->
<reference name="owner" type="Client" label="Ссылка на владельца — клиента"/>
<!-- так-же может обрабатывать и коллекции клиентских ссылок -->
<reference name="owners" type="Client" label="Ссылка на владельцев — клиентов" collection="set"/>
</class>
В классе Product (Продукт) указываем ссылку (reference) на Клиента ЕПК — владельца данного Продукта:
Поле — owner.
Тип — Client.
Аналогично можно добавить коллекцию ссылок на клиентов:
Поле — linkedClients.
Тип — Client.
Указываем тип коллекции — collection="set".
Внимание!
В модели для всех ссылочных типов на Клиента ЕПК необходимо указать одинаковый тип (например, Client). Именно эти поля и будет обрабатывать сервис ReferenceUpdater.
Для сопоставления с событиями ЕПК требуется привязать тип к событию следующим образом:
<external-types>
<external-type type="Client" merge-kind="organization"/>
<external-type type="Individual" merge-kind="individual"/>
<external-type type="ClientRB" merge-kind="client_rb"/>
</external-types>
Существует следующие типы событий ЕПК (merge-kind):
organization — событие слияния клиента от ЕПК корпоративного бизнеса;
individual — событие слияния связанного физического лица (СФЛ) от ЕПК корпоративного бизнеса;
client_rb — событие слияния клиента от ЕПК розничного бизнеса.
Пример модели, в которой данные по клиентам ведутся полностью в другой системе (ЕПК)#
Пример макета модели:
<model>
<external-types>
<external-type type="Client" merge-kind="organization"/>
</external-types>
<class name="Product">
<property name="name" type="STRING"/>
<reference name="epkId" type="Client" label="ЕПК Id"/>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkId"/>
</cci-index>
</class>
<class name="Request">
<property name="name" type="STRING"/>
<reference name="epkId" type="Client" label="ЕПК Id"/>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkId"/>
</cci-index>
</class>
</model>
В данном примере показано наличие двух агрегатов Product и Request, которые относятся к клиенту ЕПК.
Для отображения этой связи используется внешняя ссылка (reference) с типом Client, который указан в секции organization.
Шардирование осуществляется по ЕПК Id, и для этих целей добавлен CCI-индекс CCI_MYPRODUCTFACTORY_EPKID для обоих агрегатов.
В процессе дедубликации происходит простое изменение значений идентификатора ЕПК (epkId) с исходного на новое значение.
Пример модели, содержащий кроме продуктов Клиентов ЕПК самих клиентов ЕПК#
Особенность данной модели состоит в том, что разработчик желает организовать у себя копию данных по клиентам ЕПК, чтобы не совершать постоянно запросы в ЕПК для получения часто используемых данных из карточки клиента ЕПК (например, ИНН):
<model>
<external-types>
<external-type type="Client" merge-kind="organization"/>
</external-types>
<class name="ClientEpkCached" >
<property name="inn" type="STRING"/>
<property name="epkIdOriginal" type="STRING" length="100" label="Идентификатор ЕПК исходный" mandatory="true" unique="true" />
<reference name="epkId" type="Client" label="Идентификатор ЕПК с учетом дедубликации"/>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkId"/>
</cci-index>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkIdOriginal"/>
</cci-index>
</class>
<class name="ProductForClientEpk" >
<property name="name" type="STRING"/>
<reference name="epkId" type="Client" label="Идентификатор ЕПК с учетом дедубликации"/>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkId"/>
</cci-index>
</class>
<class name="Request">
<property name="name" type="STRING"/>
<reference name="epkId" type="Client" label="ЕПК Id"/>
<cci-index name="CCI_MYPRODUCTFACTORY_EPKID">
<property name="epkId"/>
</cci-index>
</class>
</model>
Отличие данной модели от модели в предыдущем разделе заключается в появлении нового агрегата — ClientEpkCached.
Очень важно не пытаться организовать дочерние сущности к агрегату ClientEpkCached: все связи этой сущности с Product и Request осуществляются только через ссылку (reference) типа Client, где находится идентификатор ЕПК (epkId).
Агрегат ClientEpkCached имеет не один, а два атрибута для хранения ЕПК Id:
epkIdOriginal— обычный атрибут строкового типа, который является обязательным, уникальным, и заполняется в момент создания агрегата, и далее никогда не изменяется. Процесс дедубликации никаким образом не затрагивает данный атрибут.epkId— ссылка типаClient, подлежащая дедубликации, однако на момент создания агрегата значение данного атрибута будет совпадать со значением атрибутаepkIdOriginal.
Процесс дедубликации по агрегатам Product и Request происходит обычным образом и был описан в предыдущем разделе.
Процесс дедубликации агрегата ClientEpkCached затрагивает только epkId и меняет его на новое значение. И как следствие, после дедубликации значения в epkIdOriginal и epkId будут различны, что является признаком выполнения дедубликации по данному клиенту ЕПК.
Шардирование осуществляется по идентификатору ЕПК (epkId), и для этих целей добавлен CCI-индекс CCI_MYPRODUCTFACTORY_EPKID для агрегата ClientEpkCached и для обоих агрегатов Product и Request, которые относятся к клиенту ЕПК.
Причем CCI-индекс CCI_MYPRODUCTFACTORY_EPKID для агрегата ClientEpkCached добавлен для двух разных атрибутов:
для
epkId— с целью поддержки шардирования;для
epkIdOriginal— с целью обеспечения уникальности не только в пределах одного шарда (там эту задачу выполняет уникальный индекс), но в пределах всех существующих шардов.
Пример описания модели#
В состав документации включены следующие артефакты: